Preface
Learning Programming Book!
Python基础
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python 本身也是由诸多其他语言发展而来的,这包括ABC、 Modula-3、 C、 C++、 Algol-68、 SmallTalk、 Unix shell 和其他的脚本语言等等。
环境配置
Python解释程序
运行Python程序
(1) 交互式编程
进入Python解释器环境,交互式执行命令语句。
$ python [options] # enter python environment
-q:进入交互式命令环境后,不输出提示信息。
安装pyreadline可以为终端启用tab命令自动补全功能。
(2) 脚本式编程
脚本是语句的集合,Python解释器会创建一个Python运行环境从而执行脚本中的语句。脚本执行完后,解释器退出运行环境。
python [options] -c "python_command" # 命令使用";"分隔
python [options] script.py [args] # execute python script
python [options] -m module_name [args] # 执行指定模块的内容(__main__)
当Python脚本首行指定了Python解释器路径,且该脚本具有可执行权限时,可直接运行该脚本。
#!/usr/bin/python # 指定执行该脚本的程序
#!/usr/bin/env python # 从路径中查找Python解释器以执行该脚本
python -m json.tool demo.json # 格式化JSON文本
python -m http.server 8080
python -m pydoc -p 8088 # python文档
python -m mimetypes filename
python -m tarfile -c demo.tar demo # tar
python -m gzip filename # => input only file, output filename.gz
python -m zipfile -c demo.zip demo
python -m telnetlib -d 192.168.56.200 22
运行环境
PYTHONPATH用于指定除系统的附加库搜索路径,程序启动后将加载到sys.path中。默认搜索顺序为当前路径、用户指定附加搜索路径、Python内置库路径、第三方Python库路径。PYTHONHOME指定Python标准库位置(prefix/lib/pythonversionandexec_prefix/lib/pythonversion);当PYTHONHOME为单个路径时,代替prefix和exec_prefix;反之,可以将PYTHONHOME设置为'prefix:exec_prefix'。PYTHONHOME==不是Python环境的安装目录==。PYTHONSTARTUP:启动Python Shell时需要执行的脚本路径。
如果使用虚拟环境,则通过激活命令(如
conda activate)可保证相关环境变量正确设置。
基本语法
标识符
所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头,区分大小写。
以下划线开头的标识符是有特殊意义的。
- 以单下划线开头(
_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用from xxx import *而导入; - 以双下划线开头(
__foo)代表类的私有成员; - 以双下划线开头和结尾的(
__foo__)代表 Python 里特殊方法专用的标识,如__init__()代表类的构造函数。
运算符
数值运算符参看数值计算。
逻辑运算符
逻辑运算符用于控制流程中的条件语句,包括and 、or 、not。
Python不支持
&&,||。
成员运算符
in, not in:在指定的容器(序列、元组、字典、集合等)中查找到值,返回值True或False;==也可用于判断一个字符串是否为另一个字符串的子串。==
list_str = ['--test', '-o output/test', '--debug']
if '--debug' in list_str:
print('find --debug in parameter list.')
if 'test' not in list_str:
print('not find test in parameter list.')
取决于容器类型,查询时间复杂度不同。
身份运算符
is, is not:判断两个标识符是否引用同一个对象,返回True或False。 ==用于判断引用变量的==值==是否相等。
id()函数返回一个整数表示变量的标识;CPython实现的id(x)返回x的内存地址。
hash(obj)返回基于对象内容的一个映射值,具有相同值的两个对象有相同hash值(不同于消息摘要是基于字节序列内容的)。
对象运算符
+ 运算符用于拼接序列对象;
* 用于重复序列对象:如果对象的元素为值类型,则复制该元素的值并将复制内容拼接;如果元素为引用类型,则仅复制引用(浅拷贝)。
print str*2 # 输出字符串两次
[]:下标运算符,取字符串、列表或元组元素。
运算符优先级
语句
同一行显示多条语句,方法是用分号“ ;” 分开。但是我们可以使用斜杠( \)将一行的语句分为多行显示。语句中包含[],{}或() 括号就不需要使用多行连接符。
用缩进(空格)长度来写语句块。缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
eval可以执行字符串表示的Python表达式(不支持复杂的代码逻辑,例如赋值操作、循环语句),并返回表达式的值。
x = eval('os.path.abspath(os.path.curdir)')
exec执行语句或代码块,不能做表达式求值并返回,但可以通过赋值表达定义新的变量并添加到当前上下文中。
exec('x = os.path.abspath(os.path.curdir)')
https://www.cnblogs.com/pythonista/p/10590682.html。
注释和文档
单行注释:“#”
文件开始的注释内容提供解释器与脚本的相关信息。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
脚本中包含中文时,需要指定文件的编码方式(UTF-8),默认编码方案是(ASCII)。Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。
位于类型定义之后的三引号文本(''',docstring)将自动生成为该类型的文档(type.__doc__)。
Package docstrings should be placed at the top of the package’s
__init__.pyfile. Module docstrings are placed at the top of the file even before any imports.
使用help()函数可查看当前环境已导入的模块的内容的文档。
文档生成
使用reStructuredText编写代码注释,可通过Sphinx自动转换为参考文档。
流程控制
条件
if expression1:
statements1……
elif expression2:
statements2……
else:
statements4……
c = a if <condition> else b
在Python中没有switch–case语句。
循环
while expression1:
statements……
else:
statements4……
for循环可以遍历任何序列的项目,例如字符串、列表;
for i = 1 to 10:
statements
for var in sequence: # 迭代过程不能更改迭代的对象
statements1(s)
break
continue
else:
statements2……
for idx,item in enumerate(lista): # enumerate构造(i, l(i))迭代元组
print('{idx} - {item}')
for idx,_ in enumerate(lista):
print('{idx} - {item}')
循环正常执行完之后,执行else语句。
sequence可以是索引集合:range(start,end, step=1)
pass语句
pass不做任何事情,一般用做占位语句。特殊变量...(Ellipse),可用于代替pass语句。
异常处理
触发异常
raise ExceptionObject, args, traceback
捕捉异常
try:
pass
except ExceptionName as e: # e为异常对象,如果不使用可省略as语句
statements1
except (Exception1, Exception2, ...) as e:
statements2
except:
statements3
else:
statements4
finally:
statementsN
Python 2.x语法:
try: statements except ExceptionType, Argument: statements
异常处理方法
处理异常时可使用traceback获取调用栈的信息。打印堆栈追踪信息:
traceback.print_exc() # 打印stacktrace
traceback.format_exc() # 返回stacktrace为字符串
traceback.print_tb(err.__traceback__) # stacktrace
对于捕获到的异常,如果没有合适处理方法可再次抛出异常。
异常类型
所有异常基于BaseException。Exception类用于定义用户异常。Warning也继承自Exception类,但通常不用于触发异常,而是用于产生警告信息。
Exception hierarchy:https://docs.python.org/3/library/exceptions.html#os-exceptions
内置异常类型:
ArithmeticError
BufferError
LookupError: IndexError, KeyError
AssertionError
EOFError
GeneratorExit
ImportError
ModuleNotFoundError
KeyboardInterrupt
MemoryError
NameError, TypeError, UnboundLocalError, ValueError, IOError, WindowsError
NotImplementedError
SystemError, SystemExit, EnvironmentError
OSError
https://docs.python.org/3/library/exceptions.html#os-exceptions
OverflowError, ZeroDivisionError
RecursionError
ReferenceError
RuntimeError
StopIteration, StopAsyncIteration
SyntaxError, IndentationError, TabError
UnicodeError, UnicodeEncodeError, UnicodeDecodeError, UnicodeTranslateError
with-as (Context Manager)
上下文管理协议:实现方法是为一个类定义__enter__和__exit__两个函数。
with open_resource(args) [as target(s)]:
do_something
with-as语句的执行过程是,首先执行__enter__函数,它的返回值会赋给as后面的变量。
然后开始执行with-block中的语句,在with-block执行完成或发生异常或退出,会执行__exit__函数(释放资源或处理可能产生的异常)。
支持上下文管理协议的类
class Resource():
def __enter__(self): # 实际分配资源的操作在该方法中,而不在__init__()中
print('===connect to resource===')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('===close resource connection===')
return True
contextlib.contextmanager装饰器
使用该装饰器可将构造资源的函数转换为支持上下文管理协议。
import contextlib
@contextlib.contextmanager
def open_func(file_name):
# __enter__ method
file_handler = open(file_name, 'r')
try:
yield file_handler
# __exit__ method
except Exception as exc: # 如果不需处理异常则无需使用try-except语句
pass
finally:
file_handler.close()
Exit handlers
atexit模块用于注册程序==正常退出==前的清理函数。可以注册多个函数,函数执行顺序与注册顺序相反。
atexit.register(func, *args, **kwargs)
atexit.unregister(func)
如果子进程由os.fork()创建,则继承父进程的退出处理函数;如果子进程由multiprocessing模块创建,则不会继承退出处理函数。
When used with C-API subinterpreters, registered functions are local to the interpreter they were registered in.
函数
定义函数
def function_name(arg1: int, arg2: float) -> float
"documentation"
statements
[return expr1, expr2, ...]
函数内部可访问全局脚本语句定义的变量。可以为输入输出参数添加类型提示。
参数
参数传递:不可变类型(数值、字符串、元组等)是值传递,可变类型(列表、字典、集合等)是引用传递;
关键字参数:使得调用函数时传入参数顺序可以与定义时不同,也可以为参数设置默认值(默认值在模块初始化时构造);关键字参数必须置于所有位置参数之后。
def func(arg1, age=50, name="miki")
不定长参数
*args用于传递任意数量的位置参数(列表或元组),**kwargs用于传递任意数量的关键字参数(字典)。
def functionname(formal_args, *args,**kwargs)
在函数调用时,也可以使用
*args将参数列表传递到函数中(需要与函数声明的参数个数或*args声明匹配),使用**kwargs将字典传入函数作为关键字参数(将值赋给与键名相同的参数,或与**kwargs声明匹配)。
返回值
通过return语句可以设置一个或多个返回值,或不返回值。
return不用于脚本退出,使用sys.exit()退出。
当返回多个值时,如果仅提供一个输出参数,则将返回值构造成元组。若提供多个参数存储返回值,则将从元组中一次读取元素给输出参数。
a, b, c = function_name(...) # 等效于 (a,b,c) = func_name(...)
d = function_name(...) # d = (a,b,c)
匿名函数 (Lambda表达式)
将函数作为对象保存和引用,也可以在使用函数的地方直接定义(而非使用def定义普通函数)。
add = lambda x, y : x+y
f = lambda x: 1 if x > 0 else -1
the_sum = add(1,2)
变量
Python的主要内置类型有数值、序列(string、list和tuple)、映射、类、实例和异常,方法也可以看作特殊的对象类型。每个变量(object)具有一个标识、类型和值。
创建和删除变量
定义变量不需要声明类型,根据赋值的类型确定变量类型。
a = b = c = 1
a, b, c = 1, 2, "john"
变量可重复赋值,赋值前后类型不需要一致(由赋值类型决定)。
删除变量:
del var_a, var_b
del list[i], dict[name]
变量作用域
在文件范围中定义的变量具有文件作用域,在文件其后的任意位置(包括调用的函数内部)都能访问。各文件中定义的变量属于不同的命名空间(模块名),互不影响。要引用其他模块中定义的全局变量,可使用import语句引入其他模块通过模块名访问或直接将该变量引入当前文件的命名空间。
import module
print(module.global_var)
from module import global_var
在文件中定义的函数引用全局变量时,总是引用该文件作用域中的全局变量,而不会使用调用该函数的文件中的全局变量。
可见性
当函数内部定义了与全局变量同名的局部变量,则全局变量将被隐藏(即使在定义局部变量之前也不能引用该同名全局变量)。使用global用于在函数内部对全部变量的声明和修改。
a = 'initialized'
def func()
global a
a = 'modified'
获取作用域中的变量信息:
dict_vars = locals() # 获取当前的局部作用域中的变量
dict_vars = globals() # 获取全局作用域中的变量
包括变量、函数、模块等信息。
在流程控制语句块中定义的变量在离开语句块后仍有效。
类型信息判断
type()返回变量的==类型信息可以和类型对象进行比较==。
type_info = type(var_name)
tf = type(x) == int # return True if x is int.
get_type_hints()可以查看模块、类、方法或函数的类型信息。
from typing import get_type_hints
Vector = list[float] # type alias
from typing import NewType
UserId = NewType('UserId', int) # New simple type
isinstance判断实例是否为某个类型(父类)的实例:
isinstance(obj, Type)
isinstance(obj, (Type1, Type2, ...)) # 任意一种类型
Type是在程序中使用的变量类型,不是字符串,例如pd.DataFrame,np.ndarray。
issubclass判断一种类型是否为某类型的子类:
isdubclass(subType, Type)
类型提示
age: int = 1 # 可不提供初始化值
容器类型需要使用专门定义的类型修饰变量。
from typing import List, Set, Dict, Tuple, Optional, Callable
x: Set[int] = {6, 7}
x: Dict[str, float] = {'field': 2.0}
x: Tuple[int, str, float] = (3, "yes", 7.5) # fixed size tuple
x: Tuple[int, ...] = (1, 2, 3) # variable size tuple
x: Optional[str] = some_function() # values that could be None
x: Callable[[int, float], float] = f # function
类型别名:
vector = List[float]
迭代器提示。
参数提示仅作为编写程序的辅助工具,在程序运行时并不会做相应的类型检查。
联合类型
可以为参数指定类型,且可使用typing.Union指定多种类型;
from typing import Union
def function_name(arg1:Union[str,int])
常量类型
from typing import Final # [Python 3.8]
Type hints cheat sheet (Python 3)。
类
类的定义:由成员,方法,数据属性组成。
class ClassName:
'''documentation''' #类文档字符串
static_var: Type = value
var1: Type # Annotate a member does not make it static.
# 构造函数
def __init__(self, value1, value2, ...) -> None:
self.var1 = value1 # 成员变量
self.var2 = value2
...
# 析构函数
def __del__(self):
release_unmanaged_resources
# 成员方法
def method_name(self, arg1, arg2, ...):
self.xxx # 调用类的成员变量或方法
# statements...
@staticmethod # 静态方法
def method_name(...)
statements
@property # read only property
def prop(self):
return self.xxx
@x.setter
def x(self, value):
self.__x = value
@x.deleter
def x(self):
del self.__x
静态变量
静态成员变量仅能通过类名或静态方法访问。实例可以定义与静态成员同名的成员变量(通过实例引用将隐藏静态变量)。子类可以定义与父类同名的静态变量(隐藏),通过子类名或实例将只能访问子类的静态变量。
==对实例成员的类型注释由于没有初始化,因此不会被视为静态变量==。
静态变量初始化:可在类外部对静态变量进行初始化,从而基于父类的静态变量对子类静态变量进行初始化。在子类内部使用父类静态变量初始化子类静态变量无效(得到None)。
构造
浅拷贝:很多类型(例如list、dict)提供copy()方法,支持对象的浅拷贝。这意味着对象中的成员变量如果是引用类型,则两个对象共享该引用类型成员。
析构函数__del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行。Python使用了引用计数这一简单技术来跟踪和回收垃圾。
obj = ClassName(args) # 创建对象
使用.运算符来访问对象的属性。
类的成员
类可以看作由元数据、用户定义数据和方法组成的字典,使用dir(x)(x.__dir__())返回类包含的属性和方法组成的字典。
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self(self不是Python关键字,换成其他标识符仍然有效)。self代表的是类的实例,代表当前对象的地址,而self.__class__是类的类型信息。
Python成员不存在访问控制,仅通过标识符在语义上区分。
-
__<private_member>:标记为私有属性/方法,其中形如__INNER_MEMBER__的成员为类的元数据。 -
_<protected_member>:标记为保护属性/方法。 -
<public_member>:标记为公开属性/方法。
类的元数据
通过类或对象均可访问类的元数据(所有对象共享)。
__class__:类型元信息(即type类型对象,等效于type(obj));
__name__:类名(字符串,==不包含类所在的包名==)。
__bases__ : 类的所有父类元信息构成的元素(包含了一个由所有父类组成的元组) 。
__dict__:所有成员变量名与对应的值组成的字典,等效于vars(obj);
__doc__:类的文档字符串 。
__module__: 类定义所在的模块(类的全名是__main__.className,如果类位于一个导入模块mymod中,那么className.__module__等于 mymod)
实例的元数据
obj.__str__(),:类成员信息的字符串表示,自动转换为字符串类型时调用该方法;
obj.__repr__():返回构造该对象的语句,repr(obj)会调用对象的该方法。调用eval(repr(obj))可重新构造该对象。
描述符协议
在类里实现了 __get__() 、__set__()、__delete__()其中至少一个方法。
class Score:
def __init__(self, default=0):
self._score = default
def __set__(self, instance, value): # 设置属性的值,进行验证
if not isinstance(value, int):
raise TypeError('Score must be integer')
if not 0 <= value <= 100:
raise ValueError('Valid value must be in [0, 100]')
self._score = value
def __get__(self, instance, owner): # 属性不存在、不合法等都可以抛出对应的异常
return self._score
def __delete__(self): # 删除内容
del self._score
class Student:
def __init__(math_score):
self.math = Score(math_score)
pass
数据类
dataclass(Python 3.7+)专门用于定义和存储数据的类型(更加适合序列化),封装了数据的初始化方法和基本运算方法(避免频繁编写这些基础代码)。dataclass继承自object类型,因此,开发者仍可基于dataclass编写自定义方法1。
定义数据
基于类型提示语法自动生成对应成员的定义,而无需重复在初始化方法中声明和初始化成员。
from dataclasses import dataclass
@dataclass
class Persion:
first_name: str
last_name: str = "Wang" # 支持默认值, 但必须在所有非默认值参数后
age: int
job: str
full_name: str = field(init=False, repr=False) # *
dataclass会自动生成__init__()、__eq__()(自动对比对象的所有成员)和__expr__()方法。由于dataclass的构造方法是自动生成的,也因此无法向父类传递初始化参数,所以通常自定义dataclass类型不再继承其他类。
*:当该成员的初始化依赖于其他成员变量时,不在自动生成的构造函数中初始化,而是在__post_init__方法中定义初始化方法。这种方式避免使用属性,在每次调用时需要重复计算值。
非可变对象
声明@dataclass(frozen=True),对象初始化后无法被更改。
数据转换
可轻易转换为元组或字典。
from dataclass import astuple,asdict
person:Tuple = astuple(Person(...))
person:Dict = asdict(Persion(...))
比较接口
@dataclass(order=True)将自动生成__lt__、__le__、__gt__、__ge__方法,从而支持排序比较。默认将对类中所有字段以此进行比较,在类定义中添加特殊的sort_index字段,该字段引用其他成员变量的值以定义排序参考值。
@dataclass(order=True)
class Persion:
# ...
sort_index: int = field(init=False, repr=False)
def __post_init__(self):
self.sort_index = self.age
继承语法
class ClassName (ParentClass1[, ParentClass2, ...]): # 支持多重继承
'Optional class documentation string'
def __init__(self, args):
super().__init__(...) # <=> super(ClassName, self).__init__(args)
# ...
在继承中基类的构造(__init__()方法)不会被自动调用,它需要在其派生类的构造中手动。需要通过基类名调用__init_()并且传递self变量。
方法重写(override)
当方法被重写后,==通过对象调用方法时将调用子类的方法==(即使是在父类中)。要通过super()以显式调用父类方法。
super().method(args) # <=> super(ClassName, self).method(args)
同名函数或成员调用:使用super().member()调用MRO搜索顺序上第一个存在该成员的类。如果要显式调用某一父类的方法,则使用super(SuperClass, self).method(args)。
在基于
pdb的调试环境下,如果在调试窗口调用父类方法,使用super().method(args)会报错(程序中正常执行)。
运算符重载
MRO(Method Resolution Order)
父类的初始化顺序:根据继承关系“深度优先—从左至右”搜索父类,确定初始化顺序(调用classname.__mro__查看类的搜索顺序)。
- 深度优先,按继承关系依次调用父类构造函数;
- 从左至右,当深度搜索到达顶端后,==如果顶层父类包含
super().__init__()调用==,则将调用第二条继承关系上的类型,并执行深度优先初始化; - 如果两条继承路线存在公共父类,则在第一条继承路线搜索到公共父类前会跳转到第二条继承路线,由第二条继承路线搜索到公共父类;多条继承路线具有公共父类的情况同理。
- 如果搜索过程中,某父类不存在
super().__init__(),则从该父类的代码开始,并按调用栈反向执行初始化。==在构造过程中已经被前面构造函数初始化过的属性会被后调用的构造方法再次初始化==。
如果在MRO搜索顺序中某个直接或间接父类未调用
super().__init__(),则==MRO初始化过程中断==(该类及MRO搜索顺序的后续类的构造方法不会被调用)。
参数传递:
-
==初始化过程中的参数传递与初始化顺序一致,而非子类分别传递给其各个直接父类==。因此在声明父类时,一定要将能通过
super().__init__()传递参数的父类声明在前,否则其后的父类无法获取参数。 -
传递给父类参数通常使用
*args和**kwargs代替(除非子类需要对相关参数进行处理)。def __init__(self, a,b,*args,c=1,b='hello',**kwargs)位置参数的顺序保持子类参数在前,父类参数在后(从而可以使用
*args来统一接收父类参数)。
Python Multiple Inheritance - JournalDev
mixin
抽取单一功能,提供给多个类继承,可视为带实现的接口;mixin模式适用于多个类各自有继承主线,但又共享部分功能。这部分功能即可通过mixin类型实现。
mixin类型不定义新的成员变量,仅定义关于目标混入对象的计算方法(可使用期望继承的类所包含的成员)。
https://stackoverflow.com/q/533631/6571140。
迭代器
迭代器Iterator提供__next__()方法以遍历所有元素;使用yield关键字的方法也可以实现简单迭代器。
def g(n: int) -> Iterator[int]:
i = 0
while i < n:
yield i
i += 1
可迭代对象Iterable提供两个方法:__iter__()和next()。通过iter(Iterable)可获取访问可迭代对象的迭代器。for语句实际需要传递迭代器对象,通过语法糖简化了对可迭代对象的访问语法。
python - What exactly are iterator, iterable, and iteration? - Stack Overflow
内存占用
import sys
s = sys.getsizeof(var)
所有内置类型均以对象封装,因此返回的为对象占用的内存(仅计算对象本身占用的内存,而不包括对象引用的内存)。第三方类型类型返回结果不一定准确。
程序结构
程序入口
模块中非类、函数定义的代码部分将在引用时被执行。
通过以下方式为程序设置一个入口,从而屏蔽引用模块中的非定义代码:
if __name__ == '__main__':
main_procedure
else:
module_initialization
注意:上述代码并非常规的主函数(
main(args)),只是一个普通的条件语句。可以自定义一个常规的主函数在上述结构中进行调用。
def main(args=None):
if args is None:
args = sys.argv
# main code
return value
if __name__ == '__main__':
sys.exit(main(sys.argv[1:]))
命令行参数处理
sys.argv[0]表示程序名,其他元素为传入参数。
for argi in sys.argv:
print(argi)
getopt
getopt采用Linux Shell的参数声明规则设置参数。读取参数的方法:
与UNIX类系统不同,非选项参数后的所有参数都不会被视为选项解析。
from getopt import getopt, GetoptError
options, args = getopt(cmd_args, short_opts, long_opts=[])
short_opts:代表短选项(命令行以-开头)的字母列表,如果一个选项还对应一个值,那么字母后添加:;
long_opts:代表长选项(命令行以--开头)的字符串列表,长选项如果需要一个值,则参数需要附加=。
命令行中,长选项的值可作为一个当都参数,或使用
=附加在选项名后。
返回值:options为选项列表,包括选项名(包括前缀)和对应的值(没有值则为空字符串);args为非选项参数。
典型用法:
def usage():
# print usage of the program, including options.
def main(sys_args):
try:
optlist, args = getopt(sys_args, short_opts, long_opts=[])
except GetoptError as err:
print(err) # will print something like "option -a not recognized"
usage()
return(2)
for option, value in optlist:
if option == '--test' or option == '-t':
# do something
...
ArgumentParser
ArgumentParser替代了OptionParser(从Python 3.2)。
创建参数转换实例:
from argparse import ArgumentParser
parser = ArgumentParser(
prog=None, # program name (default: sys.argv[0])
description=None, # information before argument help
usage=None, # usage syntax (default: auto generate)
epilog=None, # information after argument help
parent=[parent_parsers] # 继承父解析器实例的解析方法
)
parent:指定继承的参数解析实例。
添加参数规则:
parser.add_argument(
names_or_flags, # 可变参数列表:'--test', '-t', 'argname'
required=False,
dest='optname', # attribute name in return options
action='store',
nargs=1, # number of option arguments
const=0, #
default=None, # default value if not specified from command line
type=str, # type of option arguments
help=None, # option's usage information
metavar='NAME' # 帮助信息中作为选项值的标识(默认为长选项名大写)
)
ArgumentParser对参数控制更加严格,如果出现未配置的参数将产生异常。==参数名如果没有前缀,则代表位置参数==;而OptionParser将位置参数存储到一个单独的返回参数中。
参数解析规则说明:
dest:解析参数列表后存储参数值的变量名(参看parse_args()方法);如果没有指定字段,则会根据选项名生成合法的字段名;
nargs=N:选项所需要的参数个数,消耗N个参数构成列表。当需要获取位置参数而非选项时,nargs='?'消耗一个位置参数,nargs='*'消耗所有位置参数构成列表,此时names_or_flags作为存储位置参数的变量名。
type:值的类型,包括:string(默认)、int、float;整数值可以和短选项名组成一个参数,例如-n42等价于-n 42;bool类型参数使用store_true, store_false;
action:检测到选项后的处理方式
store:(默认处理方式)储存值,值的类型通过type指定;store_true|store_false:储存bool值True/False,对应的选项不需要另外参数设置值;store_const:'store_const'和'append_const'与const关键字结合使用,用于为选项保存一个常量。
default:选项的默认值(选项未出现在命令行的情况下设置默认值)。选项如果不是
bool类型,在命令行使用选项时必须提供值;
help:选项的帮助信息。当解析参数时,遇到-h或--help(程序退出)或调用parser.print_help()时会自动输出所有帮助信息。
%default可用于在帮助信息中表示输出变量的默认值。ArgumentParser自带-h,--help选项,命令行提供该选项时将输出帮助信息。参数解析器默认会添加帮助选项(
-h,--help),如果要禁用,设置parser.add_help=False。
转换命令行参数(默认为sys.argv[1:],==注意传入给args不要展开==):
options = parser.parse_args(args=None, namespace=None)
未在命令行提供的选项也会出现在options中,其值为默认值。返回值为NameSpace类型。
click
如果命令行嵌套子命令,可使用click进行命令转发。
程序运行信息
from inspect import currentframe, getframeinfo
frameinfo = getframeinfo(currentframe())
frameinfo.filename # 当前运行代码所在文件
frameinfo.lineno # 当前运行代码所在行号
frameinfo.function # 当前运行代码所在函数
模块(Module)
模块是一个文件,其中包含类,函数等的定义。==模块相当于一个命名空间,其中的定义与其他模块隔离==。
导入模块
import mod # modulename <- sys.modules['mod']
import mod as alias # aliasname <- sys.modules['mod']
from mod import name # objname <- sys.modules['mod'].name
from module import (name1,name2,...,namen,)
from module import * # 导入所有内容
from mod import name as alias # aliasname <- sys.modules['mod'].name
import importlib
path = importlib.import_module("os.path") # => import os.path as path
file, pathname, desc = importlib.find_module('os') # 查找模块
不能直接导入模块中的内容并设置别名。
从模块所在目录导入其他模块:
from . import module_name
相对路径是根据导入声明的包名
package.subpackage.module确定的,因此不可使用相对导入声明路径范围外的模块。由于__main__模块不包含任何路径信息,因此无法使用相对导入。
5. The import system — Python 3.9.5 documentation
引用模块
当导入整个模块时,使用模块名称访问其中的内容(类、函数等);也可以直接导入模块中的特定内容。
{module|alias}.name # use module contents via module name/alias
name # use name/alias to refer an imported class,funcion,...
alias
重载模块
检查模块是否导入:sys.modules记录了运行环境已导入的模块,从而防止模块被重复导入。
tf = 'modulename' in sys.modules # dict
tf = 'importedname' in dir() # 当前可见名称
tf = 'importedname' in globals() # 全局变量
重新加载修改过的包到当前正在运行的程序:
import importlib
importlib.reload(module) # <class module> not str
查看模块的文档
help(len) # doc for built-in functions
import pandas as pd
help(pd) # module doc
help(pd.DataFrame) # class doc
help(pd.DataFrame.to_csv)# function doc
相互引用
注意引用对象顺序,避免先引用未初始化的对象。
# in module A
from module B import b
def a()
# in module B
from module A import a
包(Package)
Package是特殊的模块(包含__path__属性的模块),包含subpackage和module。
常规package通常是一个文件夹中的所有模块以及子文件夹(sub-package)组成。__init__.py文件用于标识目录是一个package。当包被导入时,会自动执行__init__.py文件
my_package/
├── __init__.py
├── subpackage1/
│ ├── __init__.py
│ ├── module_x.py
│ └── module_y.py
├── subpackage2/
│ ├── __init__.py
│ └── module_z.py
└── module_a.py
Namespace packages
A namespace package is a composite of various portions, where each portion contributes a subpackage to the parent package. Portions may reside in different locations on the file system.
导入包中的模块
导入包名(相对搜索路径的目录路径)后,通过包名访问其中的内容;或将包名作为前缀导入其中的模块。
import pkg
import pkg.mod # packagename <- sys.modules['pkg']
import pkg.mod as alias # aliasname <- sys.modules['pkg.mod']
from pkg import mod # modulename <- sys.modules['pkg.mod']
from pkg import mod as alias # aliasname <- sys.modules['pkg.mod']
导入包名的时候会执行包目录下的__init__.py加载包中的模块。没有在__init__.py中指定加载的模块需要手动加载(import pkg.mod)。
查找路径
sys.path 是一个保存了查找包的路径的列表。Python解释器会自动将==Python程序所在目录==加入路径,从而方便导入同一目录下的其他文件。
==不要在包内部编写测试脚本==,运行该测试脚本时会将该脚本所在路径加入查找路径,从而破坏其所在包的结构。
程序的工作目录(
path.abspath(os.curdir))与程序所在目录可能不同,且不会加入搜索路径。语法检查的查找路径:在进行语法检查时(例如在VS Code中使用
pylint检查器),检查器的会将当前工作目录加入搜索路径,因此跟程序运行时的情形不同。为了保证程序运行时的路径也在检查器中,可在项目配置文件(settings.json)中配置"python.analysis.extraPaths": ["E:/Workspace/python"]
可以添加自定义搜索路径以导入第三方包:
sys.path.insert(0, '/lib/path') # 添加至头部
sys.path.append('/lib/path') # 添加至尾部
查询包是否在本地可加载:
import importlib
spec = importlib.util.find_spec("dask.dataframe") # None if not find
相对导入
from . import module # 导入同一包内同一层级的子包(或模块)
from .. import module # 导入同一包内上一层级的子包(或模块)
from .package import module
from ..package import module
不要将子包所在路径加入搜索路径,否则不能识别完整包结构,导致相对导入失败。
Python Modules and Packages – An Introduction。
标准库和应用
日期和时间
CGI
密码学
消息摘要
Python内置hashlib(消息摘要算法),包括 FIPS 的 SHA1, SHA224, SHA256, SHA384, and SHA512 (定义于 FIPS 180-2) 算法,以及 RSA 的 MD5 算法( 定义于 Internet RFC 1321)。消息摘要算法的输入为字节序列
在
zlib模块中包括adler32 或 crc32 哈希函数。
import hashlib
m = hashlib.sha256(b'init_data')
# m.update(a); m.update(b) => m.update(a+b)
m.update(b"Nobody inspects") # 向该对象追加消息(字节序列)
m.update(b" the spammish repetition")
m.digest() # 或hexdigest()
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
加密算法
cryptography包含加密、消息摘要以及密钥生成等方法。
The low-level cryptographic primitives are often dangerous and can be used incorrectly. They require making decisions and having an in-depth knowledge of the cryptographic concepts at work.
PyCryptodome (代替pycrypto):Python Cryptography Toolkit提供加密算法(AES, DES, RSA, ElGamal, ...),同时也提供安全哈希函数(SHA256,MD5等)。
from Crypto.Hash import SHA256
hash = SHA256.new() # update, digest, hexdigest
from Crypto.Cipher import AES
obj = AES.new('This is a key123', AES.MODE_CBC, 'This is an IV456')
message = "The answer is no"
ciphertext = obj.encrypt(message)
obj2 = AES.new('This is a key123', AES.MODE_CBC, 'This is an IV456')
obj2.decrypt(ciphertext)
from Crypto.PublicKey import RSA
from Crypto import Random
random_generator = Random.new().read
key = RSA.generate(1024, random_generator)
signature = key.sign(hash, '')
public_key=key.publickey()
public_key.verify(hash_ver,signature)
cryptography vs PyCrypto | LibHunt
HMAC
hmac — Keyed-Hashing for Message Authentication — Python 3.10.7 documentation
RFC 2104 - HMAC: Keyed-Hashing for Message Authentication (ietf.org):通信双方使用共享密钥对消息的摘要(如MD5、SHA-1等)进行完整性进行校验。
import hmac
h = hmac.new(key, message, digestmod='MD5')
常见问题
-
ModuleNotFoundError: No module named 'win32api'
安装
pypiwin32包。
参考文献
Python基础
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python 本身也是由诸多其他语言发展而来的,这包括ABC、 Modula-3、 C、 C++、 Algol-68、 SmallTalk、 Unix shell 和其他的脚本语言等等。
环境配置
Python解释程序
运行Python程序
(1) 交互式编程
进入Python解释器环境,交互式执行命令语句。
$ python [options] # enter python environment
-q:进入交互式命令环境后,不输出提示信息。
安装pyreadline可以为终端启用tab命令自动补全功能。
(2) 脚本式编程
脚本是语句的集合,Python解释器会创建一个Python运行环境从而执行脚本中的语句。脚本执行完后,解释器退出运行环境。
python [options] -c "python_command" # 命令使用";"分隔
python [options] script.py [args] # execute python script
python [options] -m module_name [args] # 执行指定模块的内容(__main__)
当Python脚本首行指定了Python解释器路径,且该脚本具有可执行权限时,可直接运行该脚本。
#!/usr/bin/python # 指定执行该脚本的程序
#!/usr/bin/env python # 从路径中查找Python解释器以执行该脚本
python -m json.tool demo.json # 格式化JSON文本
python -m http.server 8080
python -m pydoc -p 8088 # python文档
python -m mimetypes filename
python -m tarfile -c demo.tar demo # tar
python -m gzip filename # => input only file, output filename.gz
python -m zipfile -c demo.zip demo
python -m telnetlib -d 192.168.56.200 22
运行环境
PYTHONPATH用于指定除系统的附加库搜索路径,程序启动后将加载到sys.path中。默认搜索顺序为当前路径、用户指定附加搜索路径、Python内置库路径、第三方Python库路径。PYTHONHOME指定Python标准库位置(prefix/lib/pythonversionandexec_prefix/lib/pythonversion);当PYTHONHOME为单个路径时,代替prefix和exec_prefix;反之,可以将PYTHONHOME设置为'prefix:exec_prefix'。PYTHONHOME==不是Python环境的安装目录==。PYTHONSTARTUP:启动Python Shell时需要执行的脚本路径。
如果使用虚拟环境,则通过激活命令(如
conda activate)可保证相关环境变量正确设置。
基本语法
标识符
所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头,区分大小写。
以下划线开头的标识符是有特殊意义的。
- 以单下划线开头(
_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用from xxx import *而导入; - 以双下划线开头(
__foo)代表类的私有成员; - 以双下划线开头和结尾的(
__foo__)代表 Python 里特殊方法专用的标识,如__init__()代表类的构造函数。
运算符
数值运算符参看数值计算。
逻辑运算符
逻辑运算符用于控制流程中的条件语句,包括and 、or 、not。
Python不支持
&&,||。
成员运算符
in, not in:在指定的容器(序列、元组、字典、集合等)中查找到值,返回值True或False;==也可用于判断一个字符串是否为另一个字符串的子串。==
list_str = ['--test', '-o output/test', '--debug']
if '--debug' in list_str:
print('find --debug in parameter list.')
if 'test' not in list_str:
print('not find test in parameter list.')
取决于容器类型,查询时间复杂度不同。
身份运算符
is, is not:判断两个标识符是否引用同一个对象,返回True或False。 ==用于判断引用变量的==值==是否相等。
id()函数返回一个整数表示变量的标识;CPython实现的id(x)返回x的内存地址。
hash(obj)返回基于对象内容的一个映射值,具有相同值的两个对象有相同hash值(不同于消息摘要是基于字节序列内容的)。
对象运算符
+ 运算符用于拼接序列对象;
* 用于重复序列对象:如果对象的元素为值类型,则复制该元素的值并将复制内容拼接;如果元素为引用类型,则仅复制引用(浅拷贝)。
print str*2 # 输出字符串两次
[]:下标运算符,取字符串、列表或元组元素。
运算符优先级
语句
同一行显示多条语句,方法是用分号“ ;” 分开。但是我们可以使用斜杠( \)将一行的语句分为多行显示。语句中包含[],{}或() 括号就不需要使用多行连接符。
用缩进(空格)长度来写语句块。缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
eval可以执行字符串表示的Python表达式(不支持复杂的代码逻辑,例如赋值操作、循环语句),并返回表达式的值。
x = eval('os.path.abspath(os.path.curdir)')
exec执行语句或代码块,不能做表达式求值并返回,但可以通过赋值表达定义新的变量并添加到当前上下文中。
exec('x = os.path.abspath(os.path.curdir)')
https://www.cnblogs.com/pythonista/p/10590682.html。
注释和文档
单行注释:“#”
文件开始的注释内容提供解释器与脚本的相关信息。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
脚本中包含中文时,需要指定文件的编码方式(UTF-8),默认编码方案是(ASCII)。Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。
位于类型定义之后的三引号文本(''',docstring)将自动生成为该类型的文档(type.__doc__)。
Package docstrings should be placed at the top of the package’s
__init__.pyfile. Module docstrings are placed at the top of the file even before any imports.
使用help()函数可查看当前环境已导入的模块的内容的文档。
文档生成
使用reStructuredText编写代码注释,可通过Sphinx自动转换为参考文档。
流程控制
条件
if expression1:
statements1……
elif expression2:
statements2……
else:
statements4……
c = a if <condition> else b
在Python中没有switch–case语句。
循环
while expression1:
statements……
else:
statements4……
for循环可以遍历任何序列的项目,例如字符串、列表;
for i = 1 to 10:
statements
for var in sequence: # 迭代过程不能更改迭代的对象
statements1(s)
break
continue
else:
statements2……
for idx,item in enumerate(lista): # enumerate构造(i, l(i))迭代元组
print('{idx} - {item}')
for idx,_ in enumerate(lista):
print('{idx} - {item}')
循环正常执行完之后,执行else语句。
sequence可以是索引集合:range(start,end, step=1)
pass语句
pass不做任何事情,一般用做占位语句。特殊变量...(Ellipse),可用于代替pass语句。
异常处理
触发异常
raise ExceptionObject, args, traceback
捕捉异常
try:
pass
except ExceptionName as e: # e为异常对象,如果不使用可省略as语句
statements1
except (Exception1, Exception2, ...) as e:
statements2
except:
statements3
else:
statements4
finally:
statementsN
Python 2.x语法:
try: statements except ExceptionType, Argument: statements
异常处理方法
处理异常时可使用traceback获取调用栈的信息。打印堆栈追踪信息:
traceback.print_exc() # 打印stacktrace
traceback.format_exc() # 返回stacktrace为字符串
traceback.print_tb(err.__traceback__) # stacktrace
对于捕获到的异常,如果没有合适处理方法可再次抛出异常。
异常类型
所有异常基于BaseException。Exception类用于定义用户异常。Warning也继承自Exception类,但通常不用于触发异常,而是用于产生警告信息。
Exception hierarchy:https://docs.python.org/3/library/exceptions.html#os-exceptions
内置异常类型:
ArithmeticError
BufferError
LookupError: IndexError, KeyError
AssertionError
EOFError
GeneratorExit
ImportError
ModuleNotFoundError
KeyboardInterrupt
MemoryError
NameError, TypeError, UnboundLocalError, ValueError, IOError, WindowsError
NotImplementedError
SystemError, SystemExit, EnvironmentError
OSError
https://docs.python.org/3/library/exceptions.html#os-exceptions
OverflowError, ZeroDivisionError
RecursionError
ReferenceError
RuntimeError
StopIteration, StopAsyncIteration
SyntaxError, IndentationError, TabError
UnicodeError, UnicodeEncodeError, UnicodeDecodeError, UnicodeTranslateError
with-as (Context Manager)
上下文管理协议:实现方法是为一个类定义__enter__和__exit__两个函数。
with open_resource(args) [as target(s)]:
do_something
with-as语句的执行过程是,首先执行__enter__函数,它的返回值会赋给as后面的变量。
然后开始执行with-block中的语句,在with-block执行完成或发生异常或退出,会执行__exit__函数(释放资源或处理可能产生的异常)。
支持上下文管理协议的类
class Resource():
def __enter__(self): # 实际分配资源的操作在该方法中,而不在__init__()中
print('===connect to resource===')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('===close resource connection===')
return True
contextlib.contextmanager装饰器
使用该装饰器可将构造资源的函数转换为支持上下文管理协议。
import contextlib
@contextlib.contextmanager
def open_func(file_name):
# __enter__ method
file_handler = open(file_name, 'r')
try:
yield file_handler
# __exit__ method
except Exception as exc: # 如果不需处理异常则无需使用try-except语句
pass
finally:
file_handler.close()
Exit handlers
atexit模块用于注册程序==正常退出==前的清理函数。可以注册多个函数,函数执行顺序与注册顺序相反。
atexit.register(func, *args, **kwargs)
atexit.unregister(func)
如果子进程由os.fork()创建,则继承父进程的退出处理函数;如果子进程由multiprocessing模块创建,则不会继承退出处理函数。
When used with C-API subinterpreters, registered functions are local to the interpreter they were registered in.
函数
定义函数
def function_name(arg1: int, arg2: float) -> float
"documentation"
statements
[return expr1, expr2, ...]
函数内部可访问全局脚本语句定义的变量。可以为输入输出参数添加类型提示。
参数
参数传递:不可变类型(数值、字符串、元组等)是值传递,可变类型(列表、字典、集合等)是引用传递;
关键字参数:使得调用函数时传入参数顺序可以与定义时不同,也可以为参数设置默认值(默认值在模块初始化时构造);关键字参数必须置于所有位置参数之后。
def func(arg1, age=50, name="miki")
不定长参数
*args用于传递任意数量的位置参数(列表或元组),**kwargs用于传递任意数量的关键字参数(字典)。
def functionname(formal_args, *args,**kwargs)
在函数调用时,也可以使用
*args将参数列表传递到函数中(需要与函数声明的参数个数或*args声明匹配),使用**kwargs将字典传入函数作为关键字参数(将值赋给与键名相同的参数,或与**kwargs声明匹配)。
返回值
通过return语句可以设置一个或多个返回值,或不返回值。
return不用于脚本退出,使用sys.exit()退出。
当返回多个值时,如果仅提供一个输出参数,则将返回值构造成元组。若提供多个参数存储返回值,则将从元组中一次读取元素给输出参数。
a, b, c = function_name(...) # 等效于 (a,b,c) = func_name(...)
d = function_name(...) # d = (a,b,c)
匿名函数 (Lambda表达式)
将函数作为对象保存和引用,也可以在使用函数的地方直接定义(而非使用def定义普通函数)。
add = lambda x, y : x+y
f = lambda x: 1 if x > 0 else -1
the_sum = add(1,2)
变量
Python的主要内置类型有数值、序列(string、list和tuple)、映射、类、实例和异常,方法也可以看作特殊的对象类型。每个变量(object)具有一个标识、类型和值。
创建和删除变量
定义变量不需要声明类型,根据赋值的类型确定变量类型。
a = b = c = 1
a, b, c = 1, 2, "john"
变量可重复赋值,赋值前后类型不需要一致(由赋值类型决定)。
删除变量:
del var_a, var_b
del list[i], dict[name]
变量作用域
在文件范围中定义的变量具有文件作用域,在文件其后的任意位置(包括调用的函数内部)都能访问。各文件中定义的变量属于不同的命名空间(模块名),互不影响。要引用其他模块中定义的全局变量,可使用import语句引入其他模块通过模块名访问或直接将该变量引入当前文件的命名空间。
import module
print(module.global_var)
from module import global_var
在文件中定义的函数引用全局变量时,总是引用该文件作用域中的全局变量,而不会使用调用该函数的文件中的全局变量。
可见性
当函数内部定义了与全局变量同名的局部变量,则全局变量将被隐藏(即使在定义局部变量之前也不能引用该同名全局变量)。使用global用于在函数内部对全部变量的声明和修改。
a = 'initialized'
def func()
global a
a = 'modified'
获取作用域中的变量信息:
dict_vars = locals() # 获取当前的局部作用域中的变量
dict_vars = globals() # 获取全局作用域中的变量
包括变量、函数、模块等信息。
在流程控制语句块中定义的变量在离开语句块后仍有效。
类型信息判断
type()返回变量的==类型信息可以和类型对象进行比较==。
type_info = type(var_name)
tf = type(x) == int # return True if x is int.
get_type_hints()可以查看模块、类、方法或函数的类型信息。
from typing import get_type_hints
Vector = list[float] # type alias
from typing import NewType
UserId = NewType('UserId', int) # New simple type
isinstance判断实例是否为某个类型(父类)的实例:
isinstance(obj, Type)
isinstance(obj, (Type1, Type2, ...)) # 任意一种类型
Type是在程序中使用的变量类型,不是字符串,例如pd.DataFrame,np.ndarray。
issubclass判断一种类型是否为某类型的子类:
isdubclass(subType, Type)
类型提示
age: int = 1 # 可不提供初始化值
容器类型需要使用专门定义的类型修饰变量。
from typing import List, Set, Dict, Tuple, Optional, Callable
x: Set[int] = {6, 7}
x: Dict[str, float] = {'field': 2.0}
x: Tuple[int, str, float] = (3, "yes", 7.5) # fixed size tuple
x: Tuple[int, ...] = (1, 2, 3) # variable size tuple
x: Optional[str] = some_function() # values that could be None
x: Callable[[int, float], float] = f # function
类型别名:
vector = List[float]
迭代器提示。
参数提示仅作为编写程序的辅助工具,在程序运行时并不会做相应的类型检查。
联合类型
可以为参数指定类型,且可使用typing.Union指定多种类型;
from typing import Union
def function_name(arg1:Union[str,int])
常量类型
from typing import Final # [Python 3.8]
Type hints cheat sheet (Python 3)。
类
类的定义:由成员,方法,数据属性组成。
class ClassName:
'''documentation''' #类文档字符串
static_var: Type = value
var1: Type # Annotate a member does not make it static.
# 构造函数
def __init__(self, value1, value2, ...) -> None:
self.var1 = value1 # 成员变量
self.var2 = value2
...
# 析构函数
def __del__(self):
release_unmanaged_resources
# 成员方法
def method_name(self, arg1, arg2, ...):
self.xxx # 调用类的成员变量或方法
# statements...
@staticmethod # 静态方法
def method_name(...)
statements
@property # read only property
def prop(self):
return self.xxx
@x.setter
def x(self, value):
self.__x = value
@x.deleter
def x(self):
del self.__x
静态变量
静态成员变量仅能通过类名或静态方法访问。实例可以定义与静态成员同名的成员变量(通过实例引用将隐藏静态变量)。子类可以定义与父类同名的静态变量(隐藏),通过子类名或实例将只能访问子类的静态变量。
==对实例成员的类型注释由于没有初始化,因此不会被视为静态变量==。
静态变量初始化:可在类外部对静态变量进行初始化,从而基于父类的静态变量对子类静态变量进行初始化。在子类内部使用父类静态变量初始化子类静态变量无效(得到None)。
构造
浅拷贝:很多类型(例如list、dict)提供copy()方法,支持对象的浅拷贝。这意味着对象中的成员变量如果是引用类型,则两个对象共享该引用类型成员。
析构函数__del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行。Python使用了引用计数这一简单技术来跟踪和回收垃圾。
obj = ClassName(args) # 创建对象
使用.运算符来访问对象的属性。
类的成员
类可以看作由元数据、用户定义数据和方法组成的字典,使用dir(x)(x.__dir__())返回类包含的属性和方法组成的字典。
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self(self不是Python关键字,换成其他标识符仍然有效)。self代表的是类的实例,代表当前对象的地址,而self.__class__是类的类型信息。
Python成员不存在访问控制,仅通过标识符在语义上区分。
-
__<private_member>:标记为私有属性/方法,其中形如__INNER_MEMBER__的成员为类的元数据。 -
_<protected_member>:标记为保护属性/方法。 -
<public_member>:标记为公开属性/方法。
类的元数据
通过类或对象均可访问类的元数据(所有对象共享)。
__class__:类型元信息(即type类型对象,等效于type(obj));
__name__:类名(字符串,==不包含类所在的包名==)。
__bases__ : 类的所有父类元信息构成的元素(包含了一个由所有父类组成的元组) 。
__dict__:所有成员变量名与对应的值组成的字典,等效于vars(obj);
__doc__:类的文档字符串 。
__module__: 类定义所在的模块(类的全名是__main__.className,如果类位于一个导入模块mymod中,那么className.__module__等于 mymod)
实例的元数据
obj.__str__(),:类成员信息的字符串表示,自动转换为字符串类型时调用该方法;
obj.__repr__():返回构造该对象的语句,repr(obj)会调用对象的该方法。调用eval(repr(obj))可重新构造该对象。
描述符协议
在类里实现了 __get__() 、__set__()、__delete__()其中至少一个方法。
class Score:
def __init__(self, default=0):
self._score = default
def __set__(self, instance, value): # 设置属性的值,进行验证
if not isinstance(value, int):
raise TypeError('Score must be integer')
if not 0 <= value <= 100:
raise ValueError('Valid value must be in [0, 100]')
self._score = value
def __get__(self, instance, owner): # 属性不存在、不合法等都可以抛出对应的异常
return self._score
def __delete__(self): # 删除内容
del self._score
class Student:
def __init__(math_score):
self.math = Score(math_score)
pass
数据类
dataclass(Python 3.7+)专门用于定义和存储数据的类型(更加适合序列化),封装了数据的初始化方法和基本运算方法(避免频繁编写这些基础代码)。dataclass继承自object类型,因此,开发者仍可基于dataclass编写自定义方法1。
定义数据
基于类型提示语法自动生成对应成员的定义,而无需重复在初始化方法中声明和初始化成员。
from dataclasses import dataclass
@dataclass
class Persion:
first_name: str
last_name: str = "Wang" # 支持默认值, 但必须在所有非默认值参数后
age: int
job: str
full_name: str = field(init=False, repr=False) # *
dataclass会自动生成__init__()、__eq__()(自动对比对象的所有成员)和__expr__()方法。由于dataclass的构造方法是自动生成的,也因此无法向父类传递初始化参数,所以通常自定义dataclass类型不再继承其他类。
*:当该成员的初始化依赖于其他成员变量时,不在自动生成的构造函数中初始化,而是在__post_init__方法中定义初始化方法。这种方式避免使用属性,在每次调用时需要重复计算值。
非可变对象
声明@dataclass(frozen=True),对象初始化后无法被更改。
数据转换
可轻易转换为元组或字典。
from dataclass import astuple,asdict
person:Tuple = astuple(Person(...))
person:Dict = asdict(Persion(...))
比较接口
@dataclass(order=True)将自动生成__lt__、__le__、__gt__、__ge__方法,从而支持排序比较。默认将对类中所有字段以此进行比较,在类定义中添加特殊的sort_index字段,该字段引用其他成员变量的值以定义排序参考值。
@dataclass(order=True)
class Persion:
# ...
sort_index: int = field(init=False, repr=False)
def __post_init__(self):
self.sort_index = self.age
继承语法
class ClassName (ParentClass1[, ParentClass2, ...]): # 支持多重继承
'Optional class documentation string'
def __init__(self, args):
super().__init__(...) # <=> super(ClassName, self).__init__(args)
# ...
在继承中基类的构造(__init__()方法)不会被自动调用,它需要在其派生类的构造中手动。需要通过基类名调用__init_()并且传递self变量。
方法重写(override)
当方法被重写后,==通过对象调用方法时将调用子类的方法==(即使是在父类中)。要通过super()以显式调用父类方法。
super().method(args) # <=> super(ClassName, self).method(args)
同名函数或成员调用:使用super().member()调用MRO搜索顺序上第一个存在该成员的类。如果要显式调用某一父类的方法,则使用super(SuperClass, self).method(args)。
在基于
pdb的调试环境下,如果在调试窗口调用父类方法,使用super().method(args)会报错(程序中正常执行)。
运算符重载
MRO(Method Resolution Order)
父类的初始化顺序:根据继承关系“深度优先—从左至右”搜索父类,确定初始化顺序(调用classname.__mro__查看类的搜索顺序)。
- 深度优先,按继承关系依次调用父类构造函数;
- 从左至右,当深度搜索到达顶端后,==如果顶层父类包含
super().__init__()调用==,则将调用第二条继承关系上的类型,并执行深度优先初始化; - 如果两条继承路线存在公共父类,则在第一条继承路线搜索到公共父类前会跳转到第二条继承路线,由第二条继承路线搜索到公共父类;多条继承路线具有公共父类的情况同理。
- 如果搜索过程中,某父类不存在
super().__init__(),则从该父类的代码开始,并按调用栈反向执行初始化。==在构造过程中已经被前面构造函数初始化过的属性会被后调用的构造方法再次初始化==。
如果在MRO搜索顺序中某个直接或间接父类未调用
super().__init__(),则==MRO初始化过程中断==(该类及MRO搜索顺序的后续类的构造方法不会被调用)。
参数传递:
-
==初始化过程中的参数传递与初始化顺序一致,而非子类分别传递给其各个直接父类==。因此在声明父类时,一定要将能通过
super().__init__()传递参数的父类声明在前,否则其后的父类无法获取参数。 -
传递给父类参数通常使用
*args和**kwargs代替(除非子类需要对相关参数进行处理)。def __init__(self, a,b,*args,c=1,b='hello',**kwargs)位置参数的顺序保持子类参数在前,父类参数在后(从而可以使用
*args来统一接收父类参数)。
Python Multiple Inheritance - JournalDev
mixin
抽取单一功能,提供给多个类继承,可视为带实现的接口;mixin模式适用于多个类各自有继承主线,但又共享部分功能。这部分功能即可通过mixin类型实现。
mixin类型不定义新的成员变量,仅定义关于目标混入对象的计算方法(可使用期望继承的类所包含的成员)。
https://stackoverflow.com/q/533631/6571140。
迭代器
迭代器Iterator提供__next__()方法以遍历所有元素;使用yield关键字的方法也可以实现简单迭代器。
def g(n: int) -> Iterator[int]:
i = 0
while i < n:
yield i
i += 1
可迭代对象Iterable提供两个方法:__iter__()和next()。通过iter(Iterable)可获取访问可迭代对象的迭代器。for语句实际需要传递迭代器对象,通过语法糖简化了对可迭代对象的访问语法。
python - What exactly are iterator, iterable, and iteration? - Stack Overflow
内存占用
import sys
s = sys.getsizeof(var)
所有内置类型均以对象封装,因此返回的为对象占用的内存(仅计算对象本身占用的内存,而不包括对象引用的内存)。第三方类型类型返回结果不一定准确。
程序结构
程序入口
模块中非类、函数定义的代码部分将在引用时被执行。
通过以下方式为程序设置一个入口,从而屏蔽引用模块中的非定义代码:
if __name__ == '__main__':
main_procedure
else:
module_initialization
注意:上述代码并非常规的主函数(
main(args)),只是一个普通的条件语句。可以自定义一个常规的主函数在上述结构中进行调用。
def main(args=None):
if args is None:
args = sys.argv
# main code
return value
if __name__ == '__main__':
sys.exit(main(sys.argv[1:]))
命令行参数处理
sys.argv[0]表示程序名,其他元素为传入参数。
for argi in sys.argv:
print(argi)
getopt
getopt采用Linux Shell的参数声明规则设置参数。读取参数的方法:
与UNIX类系统不同,非选项参数后的所有参数都不会被视为选项解析。
from getopt import getopt, GetoptError
options, args = getopt(cmd_args, short_opts, long_opts=[])
short_opts:代表短选项(命令行以-开头)的字母列表,如果一个选项还对应一个值,那么字母后添加:;
long_opts:代表长选项(命令行以--开头)的字符串列表,长选项如果需要一个值,则参数需要附加=。
命令行中,长选项的值可作为一个当都参数,或使用
=附加在选项名后。
返回值:options为选项列表,包括选项名(包括前缀)和对应的值(没有值则为空字符串);args为非选项参数。
典型用法:
def usage():
# print usage of the program, including options.
def main(sys_args):
try:
optlist, args = getopt(sys_args, short_opts, long_opts=[])
except GetoptError as err:
print(err) # will print something like "option -a not recognized"
usage()
return(2)
for option, value in optlist:
if option == '--test' or option == '-t':
# do something
...
ArgumentParser
ArgumentParser替代了OptionParser(从Python 3.2)。
创建参数转换实例:
from argparse import ArgumentParser
parser = ArgumentParser(
prog=None, # program name (default: sys.argv[0])
description=None, # information before argument help
usage=None, # usage syntax (default: auto generate)
epilog=None, # information after argument help
parent=[parent_parsers] # 继承父解析器实例的解析方法
)
parent:指定继承的参数解析实例。
添加参数规则:
parser.add_argument(
names_or_flags, # 可变参数列表:'--test', '-t', 'argname'
required=False,
dest='optname', # attribute name in return options
action='store',
nargs=1, # number of option arguments
const=0, #
default=None, # default value if not specified from command line
type=str, # type of option arguments
help=None, # option's usage information
metavar='NAME' # 帮助信息中作为选项值的标识(默认为长选项名大写)
)
ArgumentParser对参数控制更加严格,如果出现未配置的参数将产生异常。==参数名如果没有前缀,则代表位置参数==;而OptionParser将位置参数存储到一个单独的返回参数中。
参数解析规则说明:
dest:解析参数列表后存储参数值的变量名(参看parse_args()方法);如果没有指定字段,则会根据选项名生成合法的字段名;
nargs=N:选项所需要的参数个数,消耗N个参数构成列表。当需要获取位置参数而非选项时,nargs='?'消耗一个位置参数,nargs='*'消耗所有位置参数构成列表,此时names_or_flags作为存储位置参数的变量名。
type:值的类型,包括:string(默认)、int、float;整数值可以和短选项名组成一个参数,例如-n42等价于-n 42;bool类型参数使用store_true, store_false;
action:检测到选项后的处理方式
store:(默认处理方式)储存值,值的类型通过type指定;store_true|store_false:储存bool值True/False,对应的选项不需要另外参数设置值;store_const:'store_const'和'append_const'与const关键字结合使用,用于为选项保存一个常量。
default:选项的默认值(选项未出现在命令行的情况下设置默认值)。选项如果不是
bool类型,在命令行使用选项时必须提供值;
help:选项的帮助信息。当解析参数时,遇到-h或--help(程序退出)或调用parser.print_help()时会自动输出所有帮助信息。
%default可用于在帮助信息中表示输出变量的默认值。ArgumentParser自带-h,--help选项,命令行提供该选项时将输出帮助信息。参数解析器默认会添加帮助选项(
-h,--help),如果要禁用,设置parser.add_help=False。
转换命令行参数(默认为sys.argv[1:],==注意传入给args不要展开==):
options = parser.parse_args(args=None, namespace=None)
未在命令行提供的选项也会出现在options中,其值为默认值。返回值为NameSpace类型。
click
如果命令行嵌套子命令,可使用click进行命令转发。
程序运行信息
from inspect import currentframe, getframeinfo
frameinfo = getframeinfo(currentframe())
frameinfo.filename # 当前运行代码所在文件
frameinfo.lineno # 当前运行代码所在行号
frameinfo.function # 当前运行代码所在函数
模块(Module)
模块是一个文件,其中包含类,函数等的定义。==模块相当于一个命名空间,其中的定义与其他模块隔离==。
导入模块
import mod # modulename <- sys.modules['mod']
import mod as alias # aliasname <- sys.modules['mod']
from mod import name # objname <- sys.modules['mod'].name
from module import (name1,name2,...,namen,)
from module import * # 导入所有内容
from mod import name as alias # aliasname <- sys.modules['mod'].name
import importlib
path = importlib.import_module("os.path") # => import os.path as path
file, pathname, desc = importlib.find_module('os') # 查找模块
不能直接导入模块中的内容并设置别名。
从模块所在目录导入其他模块:
from . import module_name
相对路径是根据导入声明的包名
package.subpackage.module确定的,因此不可使用相对导入声明路径范围外的模块。由于__main__模块不包含任何路径信息,因此无法使用相对导入。
5. The import system — Python 3.9.5 documentation
引用模块
当导入整个模块时,使用模块名称访问其中的内容(类、函数等);也可以直接导入模块中的特定内容。
{module|alias}.name # use module contents via module name/alias
name # use name/alias to refer an imported class,funcion,...
alias
重载模块
检查模块是否导入:sys.modules记录了运行环境已导入的模块,从而防止模块被重复导入。
tf = 'modulename' in sys.modules # dict
tf = 'importedname' in dir() # 当前可见名称
tf = 'importedname' in globals() # 全局变量
重新加载修改过的包到当前正在运行的程序:
import importlib
importlib.reload(module) # <class module> not str
查看模块的文档
help(len) # doc for built-in functions
import pandas as pd
help(pd) # module doc
help(pd.DataFrame) # class doc
help(pd.DataFrame.to_csv)# function doc
相互引用
注意引用对象顺序,避免先引用未初始化的对象。
# in module A
from module B import b
def a()
# in module B
from module A import a
包(Package)
Package是特殊的模块(包含__path__属性的模块),包含subpackage和module。
常规package通常是一个文件夹中的所有模块以及子文件夹(sub-package)组成。__init__.py文件用于标识目录是一个package。当包被导入时,会自动执行__init__.py文件
my_package/
├── __init__.py
├── subpackage1/
│ ├── __init__.py
│ ├── module_x.py
│ └── module_y.py
├── subpackage2/
│ ├── __init__.py
│ └── module_z.py
└── module_a.py
Namespace packages
A namespace package is a composite of various portions, where each portion contributes a subpackage to the parent package. Portions may reside in different locations on the file system.
导入包中的模块
导入包名(相对搜索路径的目录路径)后,通过包名访问其中的内容;或将包名作为前缀导入其中的模块。
import pkg
import pkg.mod # packagename <- sys.modules['pkg']
import pkg.mod as alias # aliasname <- sys.modules['pkg.mod']
from pkg import mod # modulename <- sys.modules['pkg.mod']
from pkg import mod as alias # aliasname <- sys.modules['pkg.mod']
导入包名的时候会执行包目录下的__init__.py加载包中的模块。没有在__init__.py中指定加载的模块需要手动加载(import pkg.mod)。
查找路径
sys.path 是一个保存了查找包的路径的列表。Python解释器会自动将==Python程序所在目录==加入路径,从而方便导入同一目录下的其他文件。
==不要在包内部编写测试脚本==,运行该测试脚本时会将该脚本所在路径加入查找路径,从而破坏其所在包的结构。
程序的工作目录(
path.abspath(os.curdir))与程序所在目录可能不同,且不会加入搜索路径。语法检查的查找路径:在进行语法检查时(例如在VS Code中使用
pylint检查器),检查器的会将当前工作目录加入搜索路径,因此跟程序运行时的情形不同。为了保证程序运行时的路径也在检查器中,可在项目配置文件(settings.json)中配置"python.analysis.extraPaths": ["E:/Workspace/python"]
可以添加自定义搜索路径以导入第三方包:
sys.path.insert(0, '/lib/path') # 添加至头部
sys.path.append('/lib/path') # 添加至尾部
查询包是否在本地可加载:
import importlib
spec = importlib.util.find_spec("dask.dataframe") # None if not find
相对导入
from . import module # 导入同一包内同一层级的子包(或模块)
from .. import module # 导入同一包内上一层级的子包(或模块)
from .package import module
from ..package import module
不要将子包所在路径加入搜索路径,否则不能识别完整包结构,导致相对导入失败。
Python Modules and Packages – An Introduction。
标准库和应用
日期和时间
CGI
密码学
消息摘要
Python内置hashlib(消息摘要算法),包括 FIPS 的 SHA1, SHA224, SHA256, SHA384, and SHA512 (定义于 FIPS 180-2) 算法,以及 RSA 的 MD5 算法( 定义于 Internet RFC 1321)。消息摘要算法的输入为字节序列
在
zlib模块中包括adler32 或 crc32 哈希函数。
import hashlib
m = hashlib.sha256(b'init_data')
# m.update(a); m.update(b) => m.update(a+b)
m.update(b"Nobody inspects") # 向该对象追加消息(字节序列)
m.update(b" the spammish repetition")
m.digest() # 或hexdigest()
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
加密算法
cryptography包含加密、消息摘要以及密钥生成等方法。
The low-level cryptographic primitives are often dangerous and can be used incorrectly. They require making decisions and having an in-depth knowledge of the cryptographic concepts at work.
PyCryptodome (代替pycrypto):Python Cryptography Toolkit提供加密算法(AES, DES, RSA, ElGamal, ...),同时也提供安全哈希函数(SHA256,MD5等)。
from Crypto.Hash import SHA256
hash = SHA256.new() # update, digest, hexdigest
from Crypto.Cipher import AES
obj = AES.new('This is a key123', AES.MODE_CBC, 'This is an IV456')
message = "The answer is no"
ciphertext = obj.encrypt(message)
obj2 = AES.new('This is a key123', AES.MODE_CBC, 'This is an IV456')
obj2.decrypt(ciphertext)
from Crypto.PublicKey import RSA
from Crypto import Random
random_generator = Random.new().read
key = RSA.generate(1024, random_generator)
signature = key.sign(hash, '')
public_key=key.publickey()
public_key.verify(hash_ver,signature)
cryptography vs PyCrypto | LibHunt
HMAC
hmac — Keyed-Hashing for Message Authentication — Python 3.10.7 documentation
RFC 2104 - HMAC: Keyed-Hashing for Message Authentication (ietf.org):通信双方使用共享密钥对消息的摘要(如MD5、SHA-1等)进行完整性进行校验。
import hmac
h = hmac.new(key, message, digestmod='MD5')
常见问题
-
ModuleNotFoundError: No module named 'win32api'
安装
pypiwin32包。
参考文献
Python开发环境配置
Python环境
系统集成Python环境
以Ubuntu为例,系统自带Python 3,用于支持相关系统组件工作。如果某些软件的运行需要依赖Python软件包而系统并未预装,则可以使用软件源管理工具(apt)安装。
使用相关python命令时需要注意:系统自带的
python3/pip3并没有创建符号链接python/pip,以便可以同时安装Python 2。
sudo apt install {python-package_name|python3-package_name}
sudo apt install python-is-python3 # 设置默认版本为Python3
如果软件源中找不到所需软件包,则可以通过pip工具从Python的软件仓库中下载软件包。系统的Python发行版默认未安装安装pip,需手动安装:
sudo apt install {python-pip|python3-pip} # Python package installer
python3-dev:Python软件开发依赖环境(header files and a static library for Python (default).),在Fedora/CentOS中命名为python3-devel。
查找软件包
pip list # list installed packages
pip show <package> # show information about installed packages
使用pip(pip3)安装和移除软件包:
pip install <pkgs> \
--user # 仅为当前用户安装,默认为系统范围安装
-r requirements.txt \ # 指定安装包声明文件
-i https://pypi.doubanio.com/simple/ \ # 强制使用镜像站点
--trusted-host 172.28.76.237 # 如果使用自建的代理站点,添加此选项
pip uninstall -r <requirements_file>
pip cache remove <pattern>|purge
使用
sudo在系统范围安装。Ubuntu等Linux发行版已经内置许多python模块,应该优先使用软件源管理工具而非
pip进行系统范围的Python软件包更新,否则可能导致系统功能出错。仅使用pip更新手动安装的软件包。如果不小心使用pip更新了pip,可以卸载更新后的版本并使用软件源管理工具重装。sudo python3 -m pip uninstall pip sudo apt install python3-pip --reinstall如果需要创建开发环境,使用虚拟Python环境(Virtualenv)
软件更新
pip list --outdated
pip install --upgrade package_name # 安装并更新依赖包(默认不更新)
pip-review # pip install pip-review
# pip install pipupgrade
使用较近的PyPi镜像站点可以加速软件包下载。
离线安装
下载(不安装)安装包,默认同时下载依赖包。
pip download [--python-version 3.7.4] package_name[==version]
-d,--dest <dir>: 下载目标文件夹(默认为当前工作目录)。指定
--python-version时,必须同时指定--no-deps或--only-binary=:all:。
安装离线包
pip install --no-index --find-links=/local_path package_name
--find-links:如果指定本地路径或file://url,则优先在本地目录中寻找安装文件。
--no-index:不使用在线仓库搜索依赖包;
Anaconda/Miniconda
Anaconda发行版打包了Python常用的软件包,可以从官网或镜像站点下载安装包。Miniconda是精简发行版,仅包含python语言环境和conda工具,其他软件包均需要在线下载。
Anaconda/Miniconda可以配置自定义的python环境屏蔽系统的Python,可以任意修改该环境而不会对系统产生影响。
在
Linux aarch64平台上,官方提供的安装包可能安装失败,可尝试使用conda-forge/miniforge: A conda-forge distribution. (github.com)。
version 'GLIBC_2.25' not found
Anaconda基础环境的Python版本参考发行注记:https://docs.anaconda.com/anaconda/reference/release-notes/。
安装conda运行环境
bash conda_installer.sh -b -f -p $INSTALL_PATH # 静默安装并指定安装路径
# -u更新已有安装;
静默安装模式不会执行初始化修改路径配置。如果安装期间未执行初始化,则Shell无法直接运行conda(不在路径中)。
eval "$($CONDAROOT/bin/conda shell.bash hook)" # 激活默认环境
conda init # [yes]
重新安装Anaconda/Miniconda
如果基础环境因为更新问题损坏(网络、杀毒软件拦截)需要重装,而不希望重装已配置的虚拟环境,可以将虚拟环境目录envs备份,在重装基础环境后还原。
卸载Anaconda/Miniconda
conda install anaconda-clean
anaconda-clean --yes # backup all files/directories in ~/.anaconda_backup
rm -rf $CONDA_HOME
最后清理~/.bashrc中的conda初始化代码。
conda配置
使用命令行修改配置项,
conda config --{system|env} SUB_COMMAND
conda配置文件包括三类:
--system:修改系统配置位于$CONDA_HOME/.condarc;--env:修改当前激活环境的配置,位于$CONDA_HOME/envs/$ENV/.condarc;- 如果未指定上述选项,则修改当前用户的配置,位于
$HOME/.condarc。
修改配置:
conda config --append KEY VALUE # 为配置项KEY追加一个值
--prepend/add KEY VALUE # 为配置项KEY前端插入一个值
--remove KEY VALUE # 从配置项KEY的值列表中删除匹配的VALUE
--set KEY VALUE # 更新配置项的值
--remove-key KEY # 移除配置项
列出当前的conda配置
conda config --show [CONFIG]
conda config --describe [CONFIG] # 显示配置项的说明
自动激活基础conda环境
是否在shell启动时启动Conda环境:
conda config --set auto_activate_base false # => auto_activate_base: false
使用conda进行包管理
conda info # infomation of conda installation (.condarc)
conda list [package_name] [-n envname]
conda search name --info
conda {update|upgrade} {--all | package_names}
conda [<cmd>] --help
Anaconda/Miniconda使用conda作为软件包管理工具。更新conda工具:
conda update -n base -c defaults conda
Anaconda发布的Python版本中,机器学习库
sklearn打包在scikit-learn中。
固定包的版本:在conda-meta目录中创建一个名为pinned的文件并加入不希望更新的包名以及版本信息(可以使用#注释行)。
numpy 1.7.* # stay on the 1.7 series
scipy==0.14.2 # fix to 0.14.2
conda update numpy --no-pin # 忽略pinned文件中的声明
每次执行更新时,conda会检查
pinned文件,因此使用--no-pin升级的包会恢复到pinned文件中声明的版本。
清理缓存
当软件包升级后,旧版本的软件包可能不再有用,因此可以从本地缓存删除。
conda clean \ # Remove unused packages and caches.
--all \ # index cache, lock files, unused packages and tarballs
-i,--index-cache \ # 清除索引缓存,保证用的是镜像站提供的索引。
-p,--packages \ # Remove unused packages
-t,--tarballs \ # remove cached package tarballs
-l,--logfiles
-d,--dry-run
安装软件包
conda {remove|uninstall} package_names
conda install -c conda-forge vaex=4.0.0 # --dry-run
conda install package_names \
--file requirements.txt \ # 安装文件给定的包
--freeze-installed \ # 避免已安装包升级
-n| --name ENVNAME \ # 目标环境名(未指定则为当前环境,默认为base)
-p,--prefix ENVPATH \ # 目标环境的目录
conda尝试安装最新的包,为此将升级其依赖的安装包。使用--freeze-installed避免已安装包自动升级。
指定仓库名:-c,--channel指定安装软件包优先使用的仓库;如果未指定该参数或指定仓库不包含相应的软件包,conda会检查.condarc中设定的channels中包含的其他仓库。
软件包声明文件格式:
channel::package_name=version=build_string # 使用指定使用*进行模糊匹配
声明
channel代替当前的默认通道;
常用声明格式:
pytorch # 安装最新的兼容版本
cudatoolkit>=11.3 # 限制最低版本 (命令行使用时需要使用""对><转义,避免解释为重定向)
cudatoolkit=11.3.* # 仅接受小版本更新(如果后续无build声明可省略.*)
cudatoolkit=11.3.1 # 安装固定版本
安装离线包
conda install --use-local /path/XXX.tar.bz
在Anaconda/Miniconda的Python环境中也可以使用pip进行软件包管理。
使用conda下载离线包:conda只能将软件包加载到本地仓库(缓存)中,而无法下载到指定文件夹。
conda本地仓库中的包无法用于pip安装。
安装Conda软件源中没有的包
pip install --upgrade-strategy "only-if-needed" packname
- 在使用conda安装尽可能多的包后,再使用
pip安装额外包;- 在单独虚拟环境中使用
pip(避免使用root环境);使用pip后,Conda无法识别相应的更改;- 如果后续还需要使用Conda进行更新或安装而外包,则使用基本环境再重新创建一个环境后再使用
pip;- 使用
-r, --requirements指定需要使用pip安装的包。
https://www.anaconda.com/using-pip-in-a-conda-environment/
虚拟Python环境
virtualenv
在指定目录ENV_DIR创建一个虚拟Python环境。
python3 -m venv ENV_DIR
创建虚拟环境,默认包含Python解释器(与系统中Python解释版本相同)、标准库等。可以使用
pip为虚拟环境安装额外的内容。在Debian/Ubuntu系统中需要首先安装
apt-get install python3-venv
Windows激活虚拟环境:
.\myenv\Scripts\activate.bat # windows cmd
.\myenv\Scripts\Activate.ps1 # windows powershell
Linux激活虚拟环境:
source myenv/bin/activate # on linux
which python # 查看python路径
pipenv
Pipenv: A Guide to the New Python Packaging Tool – Real Python
consolidate the pip & virtualenv into a single interface.
Conda虚拟环境
It makes your project more self-contained as everything, including the required software, is contained in a single project directory.
基于conda创建的虚拟环境并安装指定的软件包(和安装一样使用--file requirements.txt指定安装包)。Conda默认将虚拟环境置于envs目录下,并通过--names/-n选项指定要使用的环境名。使用--prefix可将虚拟环境置于任何路径下,但访问时也需要通过--prefix选项指定目录。
conda create -n pydev37 python=3.7 <pkgname=ver,...> \ # python=3*
--prefix ./envs ... # 指定虚拟环境的安装目录
conda create --name myclone --clone myenv # 复制已有环境
conda env remove --name myenv # <=> conda remove -n env_name --all
conda env list # <=> conda info --envs
*:如果创建环境时未指定Python版本,可能导致依赖解析很慢。支持创建Python 2.x环境。
虚拟环境中不会维护独立的软件包,而是由Conda维护一个统一的包目录(
pkgs)。通过conda-meta目录中的信息,可以定位到其引用的包路径,包的档案文件路径以及软件源路径。复制环境可直接将虚拟环境目录复制到
envs目录下(如果虚拟环境路径发生变化,需要使用conda-pack进行打包并在目标系统中解压并修复路径)
虚拟环境配置默认继承系统和用户配置,可以为虚拟环境添加设置覆盖默认配置。
查看conda环境更改历史:
conda list --revision[s]
conda install --revision=REVNUM # 恢复历史版本
虚拟环境信息文件:
conda env export [--from-history] > environment.yml
更新环境
conda env update --prefix | --name --file environment.yml --prune
复制环境
conda env create -f environment.yml #从配置文件创建虚拟环境
#=========================================
conda list --explicit > spec-file.txt
conda create --name myenv --file spec-file.txt
conda install --name myenv --file spec-file.txt
使用conda虚拟环境
conda activate env_name
conda deactivate
conda config --set env_prompt '({name})'
在脚本中尝试激活命令时会出现conda环境未初始化的错误,可在脚本中执行
source ~/.bashrc或将~/.bashrc中的conda初始化代码复制到用户脚本中。
Python - Activate conda env through shell script - Stack Overflow
Can't execute conda activate from bash script · Issue #7980 · conda/conda (github.com)
虚拟Python环境损坏
AttributeError: module 'brotli' has no attribute 'error'
解决方法:使用conda remove删除损坏的环境,并删除本地目录;
Pipeenv
虚拟环境打包部署
conda-pack可以将虚拟Python环境打包并部署到其他位置(操作系统相同)。可创建一个包含conda-pack的虚拟环境专门用于打包。
conda create -n pack -c conda-forge "conda-pack>=0.7" # pip install conda-pack=0.7
CondaPackError: Files managed by conda were found to have been deleted/overwritten...:
- Python升级到3.10后,其模块库目录下会创建一个
python3.1->python3.10的符号链接;这会导致旧版本的conda-pack无法正常工作,需要使用conda-pack>=0.7。- 如果虚拟环境中使用
pip安装了额外包,也可能导致上述错误。因此可将pip的安装包单独下载,再在目标环境中执行离线安装。
然后将目标环境打包环境为一个压缩档案文件(tar.gz):
conda-pack --name my_env \
--output out_name.tar.gz \ # 指定环境名
-d target_env_path \ #目标主机上虚拟环境的路径
--force
conda-pack -p /explicit/path/to/my_env # 指定环境路径
在目标位置解压文件,并激活虚拟环境(要求目标环境安装conda):
tar -xzf my_env.tar.gz -C conda_path/envs/my_env
source my_env/bin/activate # 激活环境 add `my_env/bin` to your path
conda-unpack # 修复库的路径(可在未激活环境情况下运行,指定路径)
conda-unpack是conda-pack打包到虚拟环境中的程序(envname/bin目录下),在解压后修复某些库的路径。==如果打包时指定-d选项,则不再打包unpack程序==。
Conda-Pack — conda-pack 0.6.0 documentation.
Arm64版本Python
支持aarch64 (arm64)的Conda环境:
- conda-forge/miniforge: A conda-forge distribution. (github.com)
- https://repo.anaconda.com/archive/Anaconda3-2021.04-Linux-aarch64.shell
需要使用conda-forge作为默认源(miniforge的默认设置),且不能使用国内镜像源(同步不完整)。
软件源配置
pip软件源
配置软件源和下载设置:
pip config set global.timeout 6000
pip config set global.index-url https://pypi.doubanio.com/simple/
pip config set install.use-mirrors true
pip config set install.mirrors https://pypi.doubanio.com/simple/
该配置文件位于$HOME/.pip/pip.conf(系统自带Python的配置文件位于$HOME/.config/pip/pip.conf)。也可以手动创建并编辑该文件(Windows下的配置文件位于%HOMEPATH%\AppData\Roming\pip\pip.ini),在文件中添加以下内容:
[global]
timeout = 6000
index-url = https://pypi.doubanio.com/simple
[install]
use-mirrors = true
mirrors = https://pypi.doubanio.com/simple
常用软件源包括:
https://pypi.doubanio.com:豆瓣;http://mirrors.aliyun.com/pypi:阿里;http://pypi.mirrors.ustc.edu.cn:中国科学技术大学;https://pypi.tuna.tsinghua.edu.cn:清华大学;
本地镜像可用Nexus配置。
conda软件源
添加默认仓库defaults的地址:
conda config --add default_channels \
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ # add default channel URL
conda config --set show_channel_urls yes # 显示下载内容的URL
添加自定义仓库名称和地址:
conda config --{prepend|append} channels <new_channel>
conda config --set custom_channels.conda-forge \
https://mirror.sjtu.edu.cn/anaconda/cloud/
直接编辑该文件:
channels:
- conda-forge
- defaults
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
配置文件中channels可包含多个源,优先级从上到下递减。默认从高优先级的源选择同名软件包(channel_priority=strict);反之优先选择高版本号的同名软件包。
conda config --set channel_priority strict
通过default_channels配置defaults仓库的实际地址;通过custom_channels配置其他仓库对应的地址;如果未设定相应的地址信息,则默认连接到Anaconda官方仓库。
列出当前的仓库配置
conda config --show channels
conda config --show-sources # show all sources
conda config --validate # 验证仓库源
仓库镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/:清华大学,包含pytorch、conda-forge等多个仓库,其中conda-forge包含linux-aarch64架构的仓库,可用于ARM平台;https://mirrors.bfsu.edu.cn/anaconda/cloud/:北京外国语大学(与清华大学镜像源一致);https://mirror.sjtu.edu.cn/anaconda/cloud/:上海交通大学(不包含conda-forge/linux-aarch64);https://mirrors.aliyun.com/anaconda/cloud/:阿里云(不包含conda-forge/linux-aarch64)。
使用Nexus可创建镜像代理
Nexus Conda代理不会获取
current_repodata.json,因此使用conda时总是会回退使用repodata.json,导致解析速度变慢(直接使用镜像源则不会有此问题)。mamba总是使用repodata.json不会受此影响。
多数镜像源仅包含最常用的仓库,如conda-forge、pytorch,而一些开源库在Anaconda官方仓库维护了独立的仓库(仅包含开源库相关包),因此要使用这些仓库需要使用Anaconda官方仓库作为代理源。
Name=anaconda-cloud
Remote=https://conda.anaconda.org/
URL=http://192.168.178.52:8081/repository/anaconda-cloud
软件包下载优化
安装mamba/libmamba加速依赖解析和下载
mambais a reimplementation of the conda package manager in C++.
mamba支持多线程并行下载仓库数据和包文件,使用libsolv以加速依赖解析(用于RPM包管理器)。
conda install -n base -c conda-forge mamba
安装完成后,使用mamba代替conda进行包管理,其语法与conda一致。
最新的
conda版本(22.9+)提供--experimental-solver libmamba选项(需要安装conda-libmamba-solver包),使用mamba进行依赖解析,但仍采用conda下载包。
mamba/libmamba虽然加速解析和下载,但不使用本地缓存导致重复下载(虽然检测到本地缓存包但似乎URL不匹配)。如果是通过本地镜像仓库下载,则重复下载没有多大影响;防止,如果通过远程仓库下载,这重复下载比较浪费时间。
配置HTTP代理
conda会自动检测系统代理配置,但不支持$no_proxy例外项。如果conda使用的代理配置与系统配置不同,可在.condarc中指定(同样不支持例外项)。
proxy_servers:
http: http://172.28.76.4:3128
https: http://172.28.76.4:3128
conda/mamba使用urllib3,会读取环境变量$http[s]_proxy;Windows中优先检测环境变量$env:HTTP[s]_PROXY,其次检测网络设置中的代理设置,可通过代理设置的例外项排除不需要通过代理访问的镜像源地址,例如本地仓库代理。)
网络超时设置
当使用nexus镜像代理时,新内容会首先下载到代理服务器,然后再下载到本地。因此,代理服务器如果下载速度较慢会导致本地conda下载超时。这种情况,可将网络读取的超时限制调大。
remote_read_timeout_secs: 180.0 # 60.0 by default
mamba忽略该选项,尝试设置export MAMBA_NO_LOW_SPEED_LIMIT=1。
开发环境
标准库
-
系统管理:
os, sys, shutil -
日期时间:
datetime, time, calendar -
高级数据结构:
collections, array, enum -
输入输出控制:
io, fcntl, logging, getpass, warnings -
数据处理:
re,struct -
文件解析:
csv, configparser, json, xml, htmlPython有三种方法解析XML,SAX,DOM,以及ElementTree。ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
**注:**因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
-
数据持久化:
pickle, marshal, sqlite3sqlite使用文件保存数据,因此无需运行任何服务。Python内置sqlite3提供sqlite数据库的操作。 -
数据库:
mysql-connector-python,psycopg2(PostgreSQL)DB-API 是一个规范. 它定义了一系列必须的对象和数据库存取方式, 以便为各种各样的底层数据库系统和多种多样的数据库接口程序提供一致的访问接口 。
-
网络通信:
socket,ipaddress,xmlrpc,email,smtpd,smtplib,imaplib,poplib,cgi,ftplib,uuid,base64,urllib.parse -
HTTP:
http,urllib.requesturllib是一个内置在Python标准库中的模块,并使用
http.client来实现HTTP和HTTPS协议的客户端。 -
密码学:
hashlib, hmac -
数据压缩归档:
zlib,gzip,bz2,lzma,zipfile,tarfile; -
任务调度:
asyncio, multiprocessing, threading, concurrent, signal, subprocess, queue, select, atexit:concurrent.futures -
程序管理:
importlib, inspect, typing, argparse, getopt, traceback; -
调试:
timeit, trace;
第三方库
-
语法格式:
autopep8,pylint; -
系统管理:
filelock, psutil -
数值计算:
numpy、scipy; -
数据可视化:
matplotlib, seaborn, bokeh, plotly, pyecharts; -
Web开发:
django, flask, tornado, requests, beatifulsoup, scrapy;urllib3,requests -
图形界面开发:
wxPython, PyQT, TKinter; -
命令行工具:
click、rich`。 -
机器学习。
数据处理
pandas、pandasql、pyarrow、dask;
使用conda安装时pyarrow,默认的仓库安装版本较旧(0.15),导致兼容问题,因此使用conda-forge通道。
conda install -c conda-forge pyarrow
conda install dask
pip install "dask[complete]" # Install everything
Pandas:
pd.show_versions() # 查看系统环境、pandas版本及其依赖包的版本
pd.io.parquet.get_engine('auto') # 获取parquet读写引擎
引入
pandas包后立即调用该方法,解决与matlab.engine的环境冲突。
Visual Studio
安装Python工作负载;
安装Python/Conda虚拟环境;
通过Python环境窗口,安装或卸载包或启动交互式Python命令环境;
Visual Studio Code(Python Extension Pack)
Conda环境未正确加载会导致某些包(例如numpy)无法被导入。解决方案:
-
为保证终端中Conda环境自动加载(终端启动时加载),执行
conda init cmd.exe|powershell # conda config --set auto_activate_base false初始化文件在
%USER%/Documents/WindowsPowerShell/profile.ps1。 -
在VS Code中配置Conda路径,从而使终端启动时自动激活Conda虚拟环境(
cmd)。"python.condaPath": "C:\\tools\\miniconda3\\Scripts\\conda.exe"
To ensure the environment is set up well from a shell perspective, one option is to use an Anaconda prompt with the activated environment to launch VS Code ==using the
code .command==. At that point you just need to select the interpreter using the Command Palette or by clicking on the status bar.Conda environments can't be automatically activated in the VS Code Integrated Terminal if the default shell is set to PowerShell.
忽略单行警告,在行末添加声明。如果要忽略同一文件,则将声明置于单独行。
import config.logging_settings # type: ignore => pylance
import config.logging_settings # pylint: disable=unused-import
pylint可以放在type标记后。
全局忽略警告:
"python.linting.pylintArgs": [
"--disable=unused-import",
"--disable=too-few-public-methods"
] // => pylint
"python.analysis.diagnosticSeverityOverrides": {
"reportUnusedImport": "information",
"reportMissingImports": "none"
} // ==> pylance
Pylance和pylint可同时启用,因此需要设置两项配置。
Better Comments插件:有5中类型的注释高亮,分别用符号* ? ! //todo来区分。
自动补全和语法分析配置
{
"python.autoComplete.extraPaths": [
"/home/gary/dataproc/dataproc/lib"
],
"python.analysis.extraPaths": [
"/home/gary/dataproc/dataproc/lib"
]
}
单元测试
可将项目目录下的一个文件夹设置为单元测试目录(如test);单元测试脚本需要位于该目录下,以test_*.py模式保存的文件将被自动发现为测试脚本1。单元测试环境会自动将测试目录和当前项目目录加入PYTHONPATH。
Tip: Sometimes tests placed in subfolders aren't discovered because such test files cannot be imported. To make them importable, create an empty file named
__init__.pyin that folder. (为每一级测试目录创建__init__.py测试路径可被识别为包)由于测试目录位于搜索路径的最前,因此应该避免测试目录中包含与系统模块或用户模块同名的文件或文件夹(导致其屏蔽系统/用户模块的导入)。
单元测试项自动发现
如果单元测试脚本中包含错误(无法捕获异常),则在发现阶段会将其分类的错误测试项一栏(完整错误日志可在Python输出窗口中查看);解决错误后会自动更新到对应的测试目录树下。
在VS Code中使用Jupyter Notebook
需要安装ipykernel以启动内核。
Jupyter
安装
conda create -n jupyterlab -c conda-forge {jupyterlab|jupyterhub}
conda install -c conda-forge ipywidgets jupyterhub-idle-culler
JupyterLab
路径信息
jupyter --path配置文件、数据等的默认路径(以下给出首选路径)。
config:
$HOME/.jupyter
data:
$HOME/.local/share/jupyter
runtime:
$HOME/.local/share/jupyter/runtime
生成配置文件:配置文件中包含默认值(可进行修改)
jupyter lab --generate-config # -> $HOME/.jupyter/jupyter_lab_config.py
网络配置
c.ServerApp.base_url='/analyze/jupyter'
c.ServerApp.ip = 'localhost' # --ip=0.0.0.0
c.ServerApp.port = 0 # --port=8888
如果使用代理出现403错误,尝试设置
c.ServerApp.disable_check_xsrf=True禁用cross-site-request-forgery检查。
NGINX反向代理JupyterLab服务,参考JupyterHub反向代理配置。
运行环境配置
c.ServerApp.root_dir='~/jupyter'
c.ServerApp.allow_root = False # --allow-root: Allow the server to be run from root.
c.ServerApp.autoreload = True # --autoreload
c.ServerApp.open_browser = False # --no-browser
安全配置
c.ServerApp.allow_origin = '*'
c.ServerApp.certfile = ''
c.ServerApp.keyfile = ''
c.ServerApp.cookie_secret = b''
c.ServerApp.cookie_secret_file = ''
c.ServerApp.password = '' # from jupyter_server.auth import passwd; passwd()
启动JupyterLab服务
以系统服务启动:
[Service]
Type=simple
Environment="WORKDIR=/home/ml/jupyterlab"
Environment="LOGDIR=/var/log/jupyterlab"
ExecStartPre=/usr/bin/mkdir -p /tmp/jupyter $WORKDIR
ExecStart=/usr/local/miniconda3/envs/jupyter/bin/jupyter lab $OPTIONS \
> ${LOGIDR}/server.log 2> ${LOGIDR}/server.error.log
TimeoutSec=10
ExecStop=/bin/kill -s TERM $MAINPID
User=ml
JupyterHub
系统架构
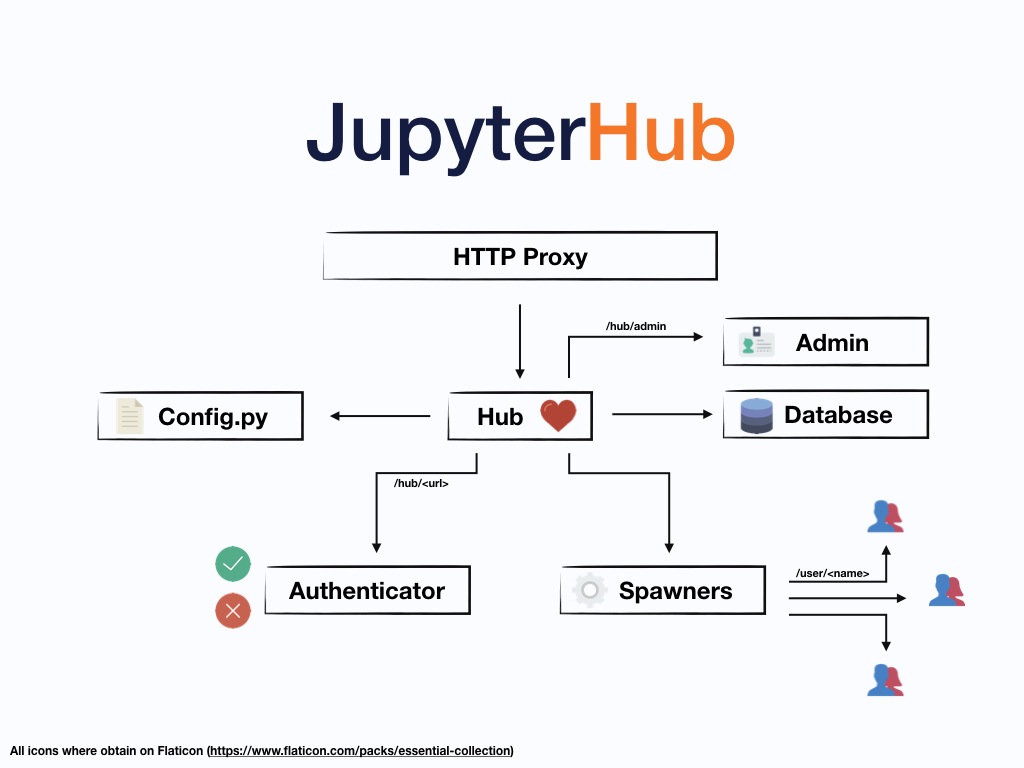
Jupyter系统组件包括:
- HTTP Proxy:代理用户请求,对外的唯一的Web接口;
- Hub:
- Spawners:管理用户服务;
- Authenticator:用户鉴权组件。
各个服务通过HTTP进行通信,因此可以分离部署。
Connections to user servers go through the proxy, and not the hub itself. If the proxy stays running when the hub restarts (for maintenance, re-configuration, etc.), then user connections are not interrupted. For simplicity, by default the hub starts the proxy automatically, so if the hub restarts, the proxy restarts, and user connections are interrupted. It is easy to run the proxy separately, for information see the separate proxy page.
jupyterhub token|upgrade-db -h
配置JupyterHub
推荐以下安装配置:
/srv/jupyterhubfor all security and runtime files/etc/jupyterhubfor all configuration files/var/logfor log files
生成并修改配置文件(默认输出到当前目录,使用-f选项指定输出目录)。
jupyterhub --generate-config -f /etc/jupyterhub/jupyterhub_config.py
jupyterhub -h,--help-all # 列出所有命令行配置项
configurable-http-proxy -h # 代理配置项
除了上述命令列出的配置项外,所有配置项均可通过命令行选项进行配置以覆盖配置文件中的对应配置项。
--Class.trait='value' # c.Class.trait in [jupyterhub_config.py]
验证配置:
jupyterhub --show-config -f config_file # 列出当前生效的配置(仅非默认值项)
数据存储配置
c.JupyterHub.data_files_path = '/usr/local/share/jupyterhub'
c.JupyterHub.db_url = 'sqlite:////var/lib/jupyterhub/jupyterhub.sqlite'
在读取配置文件时:
sqlite:///视为相对路径,绝对路径需要使用sqlite:////。
JupyterHub网络配置
bind_url配置JupyterHub代理服务(用户的Web访问地址,代替弃用的ip、port和base_url)。省略IP则监听所有地址接收的请求,默认URL根路径为/。
c.JupyterHub.bind_url='http://:8000/' # --url
api_url配置REST API接口的访问地址(Hub服务通过该接口与代理服务通信)。
c.ConfigurableHTTPProxy.api_url = 'http://localhost:8001'
hub_bind_url配置Hub服务的访问地址(代理与Spawners通过该地址与Hub通信,代替hub_ip和hub_port)。hub_connect_url用于分离部署时指定Hub服务的地址(代替hub_connect_ip/hub_connect_port)。
c.JupyterHub.hub_bind_url = 'http://localhost:8081'
c.JupyterHub.hub_connect_url = 'http://hub_ip:8081'
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
server {
location /jupyterhub {
proxy_pass http://127.0.0.1:8000;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host; # $http_host for http connection
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# websocket headers
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_set_header X-Scheme $scheme;
proxy_buffering off;
}
}
Spawner网络配置:
c.Spawner.ip = '127.0.0.1'
c.Spawner.port = 0
使用SSL:
--ssl-key my_ssl.key # c.JupyterHub.ssl_key = '/path/to/my.key'
--ssl-cert my_ssl.cert # c.JupyterHub.ssl_cert = '/path/to/my.cert'
使用
jupyterhub --generate-certs生成自签名证书和私钥。
用户访问控制
配置JupyterHub用户
c.Authenticator.allowed_users = {'mal', 'zoe', 'inara', 'kaylee'} # 初始化用户集合
c.Authenticator.admin_users = {'mal', 'zoe'}
if
allowed_usersis not set, then all authenticated users will be allowed into your hub.
可选:使用系统用户进行鉴权:creating that user via the system adduser command line tool.
c.LocalAuthenticator.create_system_users = True
# PAMAuthenticator -> LocalAuthenticator -> Authenticator
This approach is not recommended when running JupyterHub in situations where JupyterHub users map directly onto the system’s UNIX users.
自动创建用户可能会失败(CentOS7),可提前创建系统用户并进行初始化。
allowed_users=(mal zoe inara)
for u in "${users[@]}"; do
useradd -m -g ml $u; # 添加用户并添加到预定义的组
if [ $? -eq 0 ]; then # 为新用户设置默认密码(用于JupyterHub初始登录验证,登陆后修改密码)
passwd $u --stdin <<< '1234abcd'
fi
cat /etc/passwd | grep --color=always $u # 显示用户基本信息
done
Hub和Proxy(ConfigurableHTTPProxy )之间通过一个secret token来验证请求。此令牌可通过openssl生成,保存在配置文件或环境变量中。如果未设置,则Hub会自动随机生成一个,那么重启Hub的同时需要重启Proxy。
c.ConfigurableHTTPProxy.api_token = 'abc123...def'
export CONFIGPROXY_AUTH_TOKEN=$(openssl rand -hex 32)
cookie secret用于对浏览器中用于鉴权的Cookies信息进行加密,可通过openssl生成。
openssl rand -hex 32 > /srv/jupyterhub/jupyterhub_cookie_secret
chmod 600 /srv/jupyterhub/jupyterhub_cookie_secret
export JPY_COOKIE_SECRET=$(openssl rand -hex 32)
有三种指定方式:配置为环境变量,在配置文件中指定该信息所在的文件或在配置文件中指定该信息。
c.JupyterHub.cookie_secret_file = '/srv/jupyterhub/jupyterhub_cookie_secret'
c.JupyterHub.cookie_secret = bytes.fromhex('64 CHAR HEX STRING')
如果未配置上述任何方法,则
jupyterhub_cookie_secret默认创建在运行JupyterHub的用户的主目录下。该文件应该仅有该用户的读写权限,否则服务不会启动。使用环境变量配置的随机生成密码会在重启服务时重新生成,导致所有登录会话失效。
基于角色的访问控制:Scopes are specific permissions used to evaluate API requests. Roles are collections of scopes that specify the level of what a client is allowed to do.
c.JupyterHub.load_roles = [
{
'name': 'server-rights',
'description': 'Allows parties to start and stop user servers',
'scopes': ['servers'],
'users': ['alice', 'bob'],
'services': ['idle-culler'],
'groups': ['admin-group'],
}
]
Use Cases — Scopes in JupyterHub
配置用户后台服务
c.Spawner.cmd = ['jupyterhub-singleuser'] # 后台启动命令
# c.Spawner.cmd=["jupyter-labhub"]
c.Spawner.notebook_dir = '~/notebooks' # 工作目录路径(默认为~)
Since the single-user server extends the notebook server application, it still loads configuration from the jupyter_notebook_config.py config file. Each user may have one of these files in $HOME/.jupyter/. Jupyter also supports loading system-wide config files from /etc/jupyter/, which is the place to put configuration that you want to affect all of your users.
修改用户的工作目录为Jupyter服务独占目录,防止与用户的其他服务的文件冲突。如果为用户配置了非默认工作目录,则需要在用户服务初始化前进行检查确认该目录存在。JupyterHub配置文件中提供了初始化过程的接口。
def my_hook(spawner):
import os,pwd,shutil
username = spawner.user.name
path = f'/home/{username}/notebooks'
if not os.path.exists(path):
os.makedirs(path, mode=0o755, exist_ok=True)
passwd = pwd.getpwnam(username)
os.chown(path, passwd.pw_uid, passwd.pw_gid)
src = '/usr/local/share/jupyterhub/.bashrc'
if os.path.exists(src):
dest = f'/home/{username}/.bashrc'
shutil.copy(src, dest)
os.chown(dest, passwd.pw_uid, passwd.pw_gid)
c.Spawner.pre_spawn_hook = my_hook
除了工作目录外,这里也附带配置了用户的Shell初始化文件(
.bashrc中包含Python执行环境初始化,可将已有用户的Shell配置文件作为模板文件)。
资源分配控制
c.JupyterHub.active_server_limit = 0
c.JupyterHub.active_user_window = 1800
c.JupyterHub.activity_resolution = 30
c.Spawner.cpu_guarantee = None
c.Spawner.cpu_limit = None
c.Spawner.mem_guarantee = None
c.Spawner.mem_limit = None
启动JupyterHub
以系统服务运行JupyterHub:
[Service]
Type=simple
Environment="PATH=/usr/local/miniconda3/envs/jupyterhub/bin:..."
ExecStart=/usr/local/miniconda3/envs/jupyterhub/bin/jupyterhub -f \
/etc/jupyterhub/jupyterhub_config.py
TimeoutSec=10
ExecStop=/bin/kill -s TERM $MAINPID
StandardOutput=journal
StandardError=journal
SyslogIdentifier=JupyterHub
User=root
使用管理员权限运行JupyterHub可允许多用户登录。
Using sudo to run JupyterHub without root privileges · jupyterhub/jupyterhub Wiki (github.com)
Jupyter Docker Stack
https://jupyter-docker-stacks.readthedocs.io/en/latest/
Docker image for Core Stacks:https://jupyter-docker-stacks.readthedocs.io/en/latest/using/selecting.html#core-stacks
https://hub.docker.com/u/jupyter
Using Docker — JupyterHub 2.2.2 documentation
JupyterLab Documentation:https://jupyterlab.readthedocs.io/en/latest/
问题
-
终端启动配置问题,无法像登录终端一样初始化:jupyter - How to login to bash with current user, and the user's .bashrc file, in jupyterlab? - Stack Overflow
c.ServerApp.terminado_settings = {'shell_command': ['/bin/bash']}
PyCharm
支持Windows、Linux和mac。
辅助工具
pyreadline:命令行自动补全。在Windows平台中,如果命令记录中包含中文,那么pyreadline在读取历史记录时采用平台相关的编码(gbk)会出错。可以将其源码中默认的编码方式改为utf-8。
# xxx\envs\data\lib\site-packages\pyreadline\lineeditor\history.py
for line in open(filename, 'r', encoding='utf-8'):
参考文献
数据类型和数据结构
string、tuple、bytes和 number 是不可更改的对象(修改对象的方法返回新的对象),而 list、dict等则是可以修改的对象(可修改当前对象内容)。
特殊类型
None # null
NotImplemented
数值(Numbers)
数值类型
整数(int):
Python3不区分32bit/64bit整数,可以表现任意位数的整数。
Python预定义了一个小整数池[-5, 256],避免整数频繁申请和销毁内存空间。
x.bit_length() # 整数的位宽
字面值
- 二进制前缀:
0b; - 八进制前缀:
0o; - 十六进制前缀:
0x;
x = int('0xA2', base=16)
x = 281_028_344 # 数字分隔符
整数的字符串表示:hex(x),oct(x)。将字符转换为整数ord(ch)
浮点型(float):
有小数点或科学记数法表示
y = int(x,[base]) # x 为数值或字符串
y = float(x) # x 为数值或字符串
complex(real, imag)
nan和inf是特殊的浮点数:
x = float('nan')
y = float('inf') # -inf: -y 或 float('-inf')
numpy中对应的值为np.nan和np.inf。
逻辑(bool)
值为True或False。整数和浮点数可转换为bool类型(非零值为True);
复数(complex)
实部和虚部都是浮点型。
a + bj
complex(a,b)
判断是否为数值类型
from numbers import Number
isinstance(n, Number)
枚举类型
from enum import Enum, IntEnum, unqiue, auto
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec')) # auto-value
Enum类型成员不属于整数,IntEnum的成员可与整数进行比较(标准Enum枚举与整数比较返回False)。
虽然
Enum由class语法创建,但Enum并不是常规的Python 类。
如果需要更精确地控制枚举类型的值(可以是整数以外的值),可以使用IntEnum等派生类,或者从Enum派生出自定义类:
class Request(IntEnum):
POST = 1
GET = 2
pass
class Perm(IntFlag):
R = 4
W = 2
X = 1
@unique # 保证枚举值唯一
class Color(Enum):
RED = 1 # Color.RED.name = 'RED'
GREEN = 2 # Color.GREEN.value = 2
BLUE = 3
YELLOW = auto()
isinstance(Color.GREEN, Color) # True
使用自定义类行可以获得类型提示,而使用
Enum类则没有类型提示。
IntFlag类用于表示位类型的标识枚举,同时也继承整数类型。
访问枚举成员
m = Month.Jan # 显式成员引用
m = Month(1) # 按枚举成员的值(not index)引用: Month.Jan.value
m = Month['Jan'] # 按枚举成员的名称引用: Month.Jan.name
通过枚举成员的名称,可以==将字符串表示转换为枚举类型==。
获取枚举成员的属性
枚举类型的变量有一个字符串名称name以及值value(整数)。
for m in Month: # 按定义顺序,而非数值大小
print(m.name, m.value)
时间
时间类型
时间可以表示为字符串、时间戳、datetime(date,time)以及time_tuple(time_struct)。
时间戳
Python使用浮点数表示时间戳,单位为秒,精度为微秒($10^{-6}\mathrm{s}$)。
import time as tm
ts = tm.time() # return timestamp (seconds)
ts_ms = np.int64(ts*1000) # 毫秒表示的时间戳
时间元组(结构)
localtime()将时间戳转换为本地时间并返回时间元组struct_time;mktime()做逆向变换,tup_time为表示时间的九元组或time_struct。
import time
struct_time = time.localtime(ts)
ts = time.mktime(time_tuple|struct_time)
时间类型对象
时间对象封装了时间戳/时间字段。Python在datetime模块中提供多个类构造和修改时间:
datetime:完整的日期时间信息,精度为微秒(microseconds);date:仅包含日期部分;time:包含时间信息,精度为微秒;
import datetime as dt
t = dt.datetime(year, month, day, hour, ..., tzinfo) # datetime object
t = dt.datetime.combine(date, time)
d = dt.date(year, month, day) # date object
t = dt.time(hour, minute, second, microsecond, tzinfo)# time object
t = {datetime|date|time}.replace(...) # repalce fields with new value
构造函数的参数对应了对象中的成员变量。
获取当前日期/时间:
day = dt.date.today() # [date]
now = dt.datetime.today() # [datetime]=>dt.fromtimestamp(time.time())
now = dt.datetime.now(tz=None)# [datetime]
now.date()
now.time()
Pandas的Timestamp类的方法类似于标准库datetime类,其底层数据类型为np.datetime64。
import pandas as pd
pd_ts = pd.Timestamp(
ts, unit, # unit = 'h'|'m'|'s'|'ms'|... ==> pd.to_datetime()
year,month,day,hour,minute,second,microsecond,nanosecond, # =>dt.datetime
tz # e.g. Asia/Shanghai
)
nanosecond:其他时间类型精度达不到;获取
Timestamp对象的时间单位unit:np.datetime_data(t.to_datetime64())=>(unit,step);
时间类型转换
将时间日期对象转换为时间戳。
secs = dt.timestamp() # return timestamp as float
secs = pd_ts.timestamp() # return seconds
没有时区信息的时间日期对象转换为时间戳时视为UTC+00时间。
如果调用者将
UTC+NN:00的时间构造为时间对象,但未设置相应时区信息,则转换为时间戳会导致时间超前NN小时,即00:00(UTC+NN:00) != 00:00 UTC+00:00 <=> NN:00 UTC+NN:00。
将时间戳转换为为时间/日期对象
dt = datetime.fromtimestamp()
day = date.fromtimestamp()
将日期转换为时间结构:
dt.datetime.timetuple() # date.timetuple()
也可以从字符串表示构造时间日期对象。
时区设置和转换
datetime类构造的时间对象默认不包含时区信息(tzinfo=None,默认时区为计算机本地时区)。要设置时区,首先构造时区信息:
from datetime import timezone,timedelta
tz_local = timezone(timedelta(hours=8), name='Asia/Shanghai')
timezone.utc是内置的时区(UTC+00:00)。
切换时区信息:切换时区不影响时间对象底层的数据,只修改时区信息。
dt_local = t.replace(tzinfo=tz_local) # <== t.astimezone(tz_local)
获取时间对象中的时区信息:
delta = dt_local.utcoffset() # return offset to utc time.
tz_name = dt_local.tzname() # get timezone name
pandas.Timestamp类的时区
应尽可能显式设置构造方法中的时区参数,防止数据互操作时解析错误。如果ts中也同时包含时区信息,会将其转换至tz指定的时区(内部时间戳不变)。
如果Timestamp对象初始化时不包含信息或未设置时区参数:
- 从时间戳构造默认时区为
UTC+00:00(与datetime.fromtimestamp()不同),应该将其转换至本地时区使用; - 从(不包含时区信息的)时间对象或字符串构造默认时区为计算机本地时区,以==与字面值保持一致==(
UTC+08:00)。
pd_ts.tz_localize('UTC+08:00') # 导致时间戳减小8小时
pd_ts.tz_localize('UTC')\ # 设置时区信息 UTC+00:00,时间戳不变
.tz_convert('Asia/Shanghai') # 然后,转换为目标时区(时区名可使用UTC或区域名)
tz_localize()在时间字面值基础上添加了时区偏移,因此会==修改底层的时间数据(时间戳)==。tz_convert()则同时修改时间字面值和时区字面值,因此底层时间数据不变。
未设置时区信息的时间是不能转换时区的(Cannot convert tz-naive Timestamp),因此必须调用
tz_localize(类似于dt.replace(tzinfo=tz_local));已有时区信息的对象则不能再调用tz_localize。
时间段
表示由开始和结束时间确定的时间区间。
Time Interval
ti = pd.TimeInderval(pd.Timestamp('20210901'), pd.Timestamp('20210903'))
Time Period
pandas.Period表示给定周期的某个时间段,例如1月、1周、1天等;由于具有固定周期,因此可以与整数进行数值运算实现区间平移。
p = pd.Period(value, freq='M')
p = pd.Period(year=1971, month=1, day=1,..., freq='D')
p = p.asfreq(freq, how='end') # 改变周期,how决定原周期的起点或终点作为新周期的起点
至少指定
year(否则返回NaT), 参数day对于频率M无效。
传递给构造方法的参数可通过对象的属性访问,例如p.day。其他属性和方法包括:
p.start_time # p.strftime(), p.to_timestamp()
p.end_time
格式化时间
时间对象格式化
上述类型的时间对象提供strftime, strptime用于转换自定义格式的时间字符串,格式声明参考Linux规范(不支持 %q, %N)。isoformat()用于输出标准格式。
t = dt.datetime.strptime(time_str, '%Y%m%d')
t_str = t.strftime('%Y%m%d')
dt.isoformat(sep='T', timespec='milliseconds')
datetime.fromisoformat(fmt_str)
ISO格式:包括时区信息。
date类型未提供转换为datetime类型的方法。通过字符串方法可以方便地实现date类型到datetime类型的变换,或是使用datetime.combine()方法将date和time类型组合构造成datetime类型。
pd.Period也支持strftime方法,将start_time转换为字符串。
时间元组(结构)
time模块提供的格式化函数在字符串和时间元组之间相互转换。
import time
str_time = time.asctime(st_time) # 格式化输出时间。
str_time = time.strftime(format, st_time)
st_time = time.strptime(str_time, format)
Pandas Period
除Python默认的格式声明外,还支持 %f, %F, %q。
对象集合
集合类型包括序列类型(列表、元组、字符串)、映射类型(字典)、集合类型等。
统计函数
可应用于所有内置容器类型(包括字典)。
x = max(a) # built-in max/min in Python, min
l = len(a) # length of container
序列类型
字符串(String)
s = 'ilovepython'
Python可以使用引号(')、双引号(")、三引号('''或 """)来表示字符串,引号的开始与结束必须的相同类型的。其中三引号可以由多行组成,可以直接包含换行、制表等特殊字符(而无需使用转义字符);常用于文档字符串,在文件的特定地点,被当做注释。
Python使用了字符串驻留技术来提高字符串效率,即同样的字符串对象仅仅会保存一份(长度不超过20),这也决定了字符串必须是不可变对象。
转义序列
| 转义序列 | 实际字符 | 转义序列 | 实际字符 |
|---|---|---|---|
\\ | \ | ||
\" | " | \' | ' |
\n | 换行 | \t | 横向制表符 |
无效的转义序列(例如
'\.')不会被处理和丢弃,保持原始输入。
八进制编码:\0xx,例如\000=>NULL;
十六进制编码:\xFF,对应latin-1编码字符;
Unicode编码:\uFFFF,\UFFFFEEEE(Python3中文本被解析为字符串后都是UTF-8编码);
Unicode 字符串:u'Hello 世界!'可直接在字符串字面值输入非ASCII字符。
字符编码:
chr(i)返回Unicode编码(整数0<=i<=0x10ffff)对应的字符;ord(x)返回字符的Unicode编码。
原始字符串:不解释转义序列:r'Hello\nWorld!'(或R前缀)。使用repr(str)可恢复字符串的原始文本表示(将特殊字符转换为转义序列)。
变量替换:s = f'{arg1}, {arg2}'
可以采用对象运算符对字符串进行拼接、重复和截取等操作。
查找统计
idx=str.find(sub_str, beg=0, end=len(str)):rfind、index、rindex,以及序列类型公共方法(index);in和not in运算符可用于判断字符串是否包含子串。
import operator # operator模块是用c实现的,所以执行速度比python代码快。
tf = operator.contains("hello, python", "llo")
tf=str.startWith(suffix, beg=0,end=len(str)):endWith:suffix可以是单个字符串或多个字符串构成的元组(只要其中一个满足即返回True)。
正则表达式匹配查找使用
re模块。
n=str.count(sub_str, beg=0,end=len(str)):查找字串:返回字串出现的次数。
使用正则表达式。
is*()方法:
变换
sep.join(list_str):将字符串拼接起来,并适用字符串sep作为分隔符。
new_str = str.replace(old, new, max_count=-1):替换子串。
new_str=center(width, fillchar):类似地ljust、rjust、zfill(width)。
new_str=str.expandtabs(tabsize=8):将tab符号替换为空格。
new_str=str.strip(chars=''):移除字符串两端chars中指定的任意字符,默认为空白字符。lstrip、rstrip。
list_strs=split(sep=None):默认分隔符为==所有连续==空字符,包括空格、换行、制表符等。sep指定的==字符串被视为一个分隔符==,而非将其中单个字符视为分隔符(若需要提供多个分隔符,使用re.split)。两个连续sep字符串之间会形成一个空的字串。
list_strs=str.splitlines(keepends=False)
new_str=str.title():每个单词首字母大写,capitalize()、swapcase()、lower()、upper()。
字符串格式化
C-style格式化: 仅在字符串后缀%参数时,字符串中的%序列才会执行变量替换,否则只是普通字符。
"... %s ... %04d ..."%(args...)
Python-style格式化:其中,idx代表参数位置,从0开始,没有指定则使用默认参数顺序;位置及关键字参数可以任意的结合。format代表格式化参数;args为需要被代入字符串的参数;
"... {} ... {:format} ...".format(args...)
"... {idx} ... {idx.member} ... {idx:format} ...".format(args...)
"... {idx.member} ... {idx[0]} ...".format(args...)
"... {var_name} ...".format(var_name=value)
格式化声明:
[[fill]align][sign][#][0][width][,][.precision][type]
fill = <any character>
align = {< | ^ | >}[=]
sign = +| - | "" # +表示始终显示符号,-和""表示仅显示负号
width = integer
precision = integer
type = b|c|d|e|E|f|F|g|G|n|o|s|x|X|%
对齐方式:“
=”不能在字符串中使用,在符号位后添加填充(反之在符号位前);如果需要指定填充,则必须指定对齐方式;位宽前如果存在0,则0作为默认的填充字符。
#:为二进制、八进制和十六进制添加前缀0b,0o,0x;
,:千位分隔符;
e/E:科学计数法,precision表示小数位数;
f/F:定点计数法,固定小数位数(precision默认6位),位宽width不限制整数部分范围;
g/G:使用位宽width(包括符号位)、固定有效数字位数precision表示。首先按有效数字位数丢弃末尾小数,当在小数部分无法显示足够位数有效数字时,切换为科学计数法(.precision表示有效数字位数)。https://docs.python.org/3/library/string.html#format-specification-mini-language。
正则表达式
正则表达式匹配可用于字符串和字节序列。
re.match:尝试从字符串的起始位置匹配一个模式(等效于^pattern),否则返回None。
re.fullmatch:将模式与整个字符串匹配,相当于使用^pattern$。
re.search:扫描整个字符串并返回第一个成功的匹配。
import re
m=re.match(pattern, string, flags=0) # startswith(pattern)
m=re.search(pattern, string, flags=0) # include(pattern)
m.span() # 匹配位置(m.start(),m.end()) m.pos和m.endpos是原字符串的开始和结束位置
m.group() # 匹配内容=>m.group(0)
m.groups() # 捕获组:(m.groups()[i]=>m.group(i+1),...)
m.groups() 数量与表达式中声明的捕获组"(pattern)"对应。未成功匹配的捕获组,其捕获内容返回Null。
text=r'试图打印下列文档:D:\Users\gary\Documents\Python数据类型.md' pattern=r'(文档:)(.*)(\.\w*)|(文档:)(.*)' m = re.search(pattern, text)
re.findall():查找并返回所有匹配结果。如果模式中不包含捕获,则每个结果括整个匹配内容;反之,返回子串构成的元组。re.finditer()返回一个子串匹配对象Match的迭代器。
all_matches = re.findall(pattern, string[, pos[, endpos]]) # -> List[str]|List[Tuple[str]]
for m in re.finditer(pattern, text):
print(m.group(0))
re.sub:从最左至右替换字符串中的匹配项(最大匹配次数count)。
newstr = re.sub(pattern, replace, count=0, flags=0)
newstr,n = re.subn(pattern, replace, count=0, flags=0)
replace可以是一个函数,可基于匹配内容生成替换内容def repl(matched: re.Match): return '\\' + matched.group(0) # group(0)未整个匹配内容,group(1)为第一个捕获组
字符串分割:
list_strs = re.split('.|,|:|;| ', string)
re.compile编译正则表达式并检查语法,生成一个正则表达式re.Pattern对象,提供match、search等方法(与静态方法相同)。
pat=re.compile(pattern[,flag])
https://www.runoob.com/python3/python3-reg-expressions.html.
JSON
编码和解码:
json.dumps(obj) # 将Python类型转换为JSON字符串
json.loads(string) # 将JSON字符串转换为Python对象
提供
dump,load直接与文件进行输入输出。
URL编码
将非ASCII按给定的编码方案进行编码,并将编码结果以十六进制字符表示。
from urllib.parse import quote,unquote,quote_plus,unquote_plus
text = "丽江@2020//"
url_code_str = quote(text,'utf-8') # => '%E4%B8%BD%E6%B1%9F%402020%2F%2F'
text_orgin = unquote(url_code_str,'utf-8')
urllib.request.pathname2url(path) # url2pathname
quote_plus,unquote_plus额外将' '(空格)替换为+。
字节序列类型
==字节序列类型bytes和字符串类型有相同的操作方法==;bytearray可以修改对象内容。
[
memoryview](https://docs.python.org/zh-cn/3.7/library/stdtypes.html?highlight=list append#memoryview) 对象允许 Python 代码访问一个对象的内部数据,只要该对象支持 缓冲区协议 而无需进行拷贝。
字符串编码和解码
字符串底层对应了某种编码方案(例如gbk, utf-8),因此可以使用对应的编码方案实现字符串与字节序列间的相互转换。
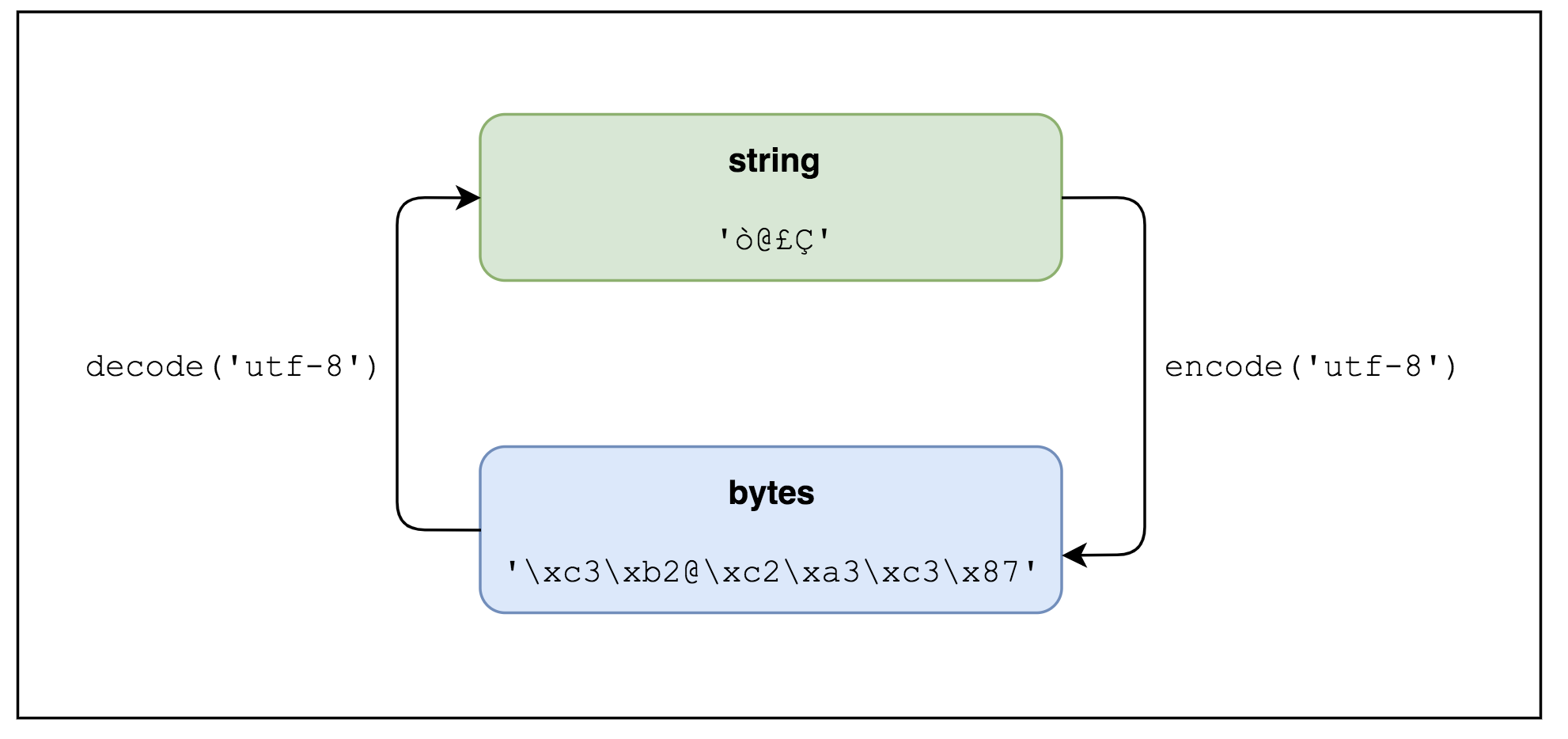
s_encoded = s.encode(encoding='utf-8', errors='strict')
b_decoded = b.decode(encoding='utf-8', errors='strict')
乱码:显示界面与字符串采用的编解码方式不一致。当输出文本到显示界面,实际是将对应的编码序列发送过去,而显示界面需要解码然后进行显示。当显示界面不能成功解码时,可能随机选择某系符号代替错误码字(或者丢弃码字),从而产生乱码。
产生乱码的常见情形:
- 单字节编码方案(如
latin-1)与utf-8不匹配; - 本地化编码方案(如
gbk)与utf-8不匹配。
在严格模式errors=strict下编码生成的字符串对象,只要采用对应的编码方案即可逆变换得到字节序列,并尝试使用其他编码方案以获得正确解码文本。
In Python 3, reading files in
rmode means decoding the data into Unicode and getting astrobject. Reading files inrbmode means reading the data as is, with no implicit decoding, and saving it asbytes.https://docs.python.org/3/library/codecs.html#standard-encodings
Codec Meaning raw_unicode_escape编码:将字符串按 latin_1方案(单字节)编码。如果字符串中包含其他非latin_1范围的码字,则使用转义表示"\\uXXXX"和"\\UXXXXXXXX"Unicode码点;unicode_escapeDecode from Latin-1 ==source code==.
解码会处理所有以\字符开始的序列,并吸收无效序列。
推断未知编码类型
chardet可根据编码序列特征推断文本最可能的编码类型。
import chardet
chardet.detect(text_bytes)
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
十六进字符串转换
bytes_array = bytes.fromhex('FEF0ABC12')
hex_str = bytes_array.hex() # str.upper() to uppercase
二进制数据的字符编解码
Base64 将6bit数据映射为8bit,对应于将3字节数据编码为4个码字(合法码字共64个包含
A~Za~z0~9以及符号+/,此外=用于填充不在合法码字范围内)1。
import base64
x = 'this is a string'
x_bytes = x.encode('utf-8')
x_b64:bytes = base64.b64encode(x_bytes:bytes)
x_bytes = base64.b64decode(x_b64) # 输入为bytes或ASCII str
x = str(x_bytes, 'utf-8') # x_bytes.decode(encoding='utf-8')
命令行调用:
echo "hell world" | python -m base64 echo "aGVsbG8sIHdvcmxkCg==" | python3 -m base64 -d
struct
struct - 廖雪峰的官方网站 (liaoxuefeng.com)
元组(Tuple)
tup = ( 'runoob', 786 , 2.23, 'john', 70.2 )
定义元组所用的括号可省略。
元组的元素不能二次赋值(tup[i]=value),相当于只读列表。多个元组可以进行拼接(+)生成新的元组。
如果元素是可变对象,可以对对象内容修改。
(x,)表示只有一个元素的元组,使用,区分元组与普通括号运算符。
展开元组:将元组元素返回到变量中。
x,y,z = (1,2,3)
x,y,*rest = (1,2,...) # 使用rest接收其他元素
x,y,*_ = (1,2,...) # 使用*_代替其他任意多的元素
_用于替代返回值中不需要接收的数据。
zip
使用zip将多个序列中的相应元素合并到一个元组中:
l1 = ['bar', 'bar', 'baz', 'baz', 'foo']
l2 = ['one', 'two', 'one', 'two', 'one']
tuples = list(zip(l1, l2))
# [('bar', 'one'), ('bar', 'two'), ..., ('foo', 'one')]
zip生成一个元组的迭代器,需要进行类型转换。
列表(List)
列表可以动态添加和删除元素。
li = [ 'runoob', 786 , 2.23, 'john', 70.2 ]
li = [ func(x) for x in iterable if cond(x) ] # cond(x) is optional
li = [ func1(x) if cond1(x) else func2(x) for x in iterable ]
使用
[]构造列表性能更好。
range类型表示不可变的数字序列,通常用于在 for循环中循环指定的次数。
class range(start, stop[, step])
包含
start,不包含stop。
修改列表
l.append(e) # 追加元素。
l.insert(index,e) # 在当前index位置前插入元素
l.remove(e) # 删除第一个值为e的元素(必须在列表中,否则产生ValueError)。
v = l.pop(i=-1) # => del l[i]
合并序列
l.extend(l1) # 拼接另一个序列
“
+”运算符将返回新的对象,且只能支持列表合并;extend()支持当前对象与任意iterable对象合并(等价于+=)。
合并多个序列的方法。
列表排序
list.sort(key=None, reverse=False)为列表类型特有的(升序)排序函数,对原列表进行稳定排序操作(in-place and stable)。key为比较参考值,基于基于排序元素的计算函数。
Python的排序规则不是通过显式指定比较函数,而是指定排序所使用的参考值。使用以下方法可实现自定义比较函数进行排序。
import functools def cmp_func(a,b): if a.value > b.value: return 1 elif a.value < b.value: return -1 else: return 0 li.sort(key=functools.cmp_to_key(cmp_func))
为了支持多个字段的排序,可对序列进行多次排序,即按优先级最低到最高的字段分别进行排序(list.sort是稳定排序算法,对较高优先级字段的排序时如果值相同不会改变顺序,因此也就不会影响低优先级字段的排序结果):
from operator import attrgetter
def multisort(xs, specs):
for key, reverse in reversed(specs):
xs.sort(key=attrgetter(key), reverse=reverse)
return xs
multisort(list(objects), (('field1', True), ('Field2', False)))
Get unique values from a list
https://www.geeksforgeeks.org/python-get-unique-values-list/
- Traversal of list
if x not in unique_list; - Using
set:unique_list = list(set(list1)); - Using
numpy.unique(); - Using
Series.unique()。
序列类型公共方法
序列类型的索引
访问元素:
s[idx]
不能使用列表或元组访问多个元素。
切片:从左到右索引默认0开始(zero-based)的,最大范围是字符串长度少1;从右到左索引默认-1开始的,最大范围是数组开头。(包含开始不包含结束位置的值)
a[start:end+1] # 读取从第start到第end的元素
a[start:end+1:step]# i缺省为0 j缺省为L s缺省为1
a[-j:-i]# 读取从倒数第(j-1)到倒数第i的元素: a[-i:-j:1]
a[-i:-j:-s] # 步长为负,逆序读取
a[:] # all
a[:-1] # 从位置0到位置-1之前的数 a[-L:-1:-1]
a[::-1] # 反转操作:-n 读取倒数第n个元素之前的内容
超出范围的下标自动被忽略。
序列类型不能通过整数序列或
bool序列选取元素(numpy.ndarray支持)。
对象操作
使用对象运算符*复制序列,使用+进行序列拼接。
li = [None]*5 # 构造长度为的序列
s = 'xyz'*5 # 通过复制扩展字符串
查找(find)
idx = list.index(value) # retrun the first occurence
==运算符不能用于序列与元素的比较,返回bool掩码;==直接比较两个对象。如果元素不存在,返回异常
ValueError。
查找多个元素:
L = [1,2,3,2,1,4,5]
R = [1,3]
indices = [i for i in range(len(L)) if L[i] in R]
排序
排序结果作为新的对象返回(适用于元组等不能修改的对象)。
sorted(iterable, key=None, reverse=False)
key = lambda x: x[0]
key = lambda x: x.prop
from operator import attrgetter
key = attrgetter('prop') # 使用对象的"prop"属性进行排序
key是一个(升序)排序元素的函数,使用迭代器的元素计算排序的比较参考值。sorted不支持自定义比较函数(Python3)。
过滤
iterable = filter(func, iterable) # 过滤序列中func(item)为False的元素
iterable = [item if func(item)==True for item in iterable]
如果
func=None,则过滤item=False的元素。
迭代
import itertools
构造可迭代对象 。
合并多个序列
-
:按序依次拼接。
# Method1: def concat function with for-loop and concat operator (+) def concat(nest_list): li = [] for l in nest_list: li.extend(l) # 合并两个列表 return li l_nest = [[1,2,3], ['a', 'b'], [4]] ll = concat(l_nest) # Method3: Substitute concat() with reduce() from functools import reduce ll = reduce(list.__add__, l_nest) # => lambda x,y: x+y # Method2: List constructor, append by elements ll = [y for l in l_nest for y in l] # Method 6 yield from [Python编程基础.md#迭代器] def merge(*lists): for l in lists: yield from l # return one element one time from l list(merge(list01, list02, list03)) # Method4: import itertools # use itertools flat = itertools.chain.from_iterable(l_nest) iterable = itertools.chain(list01, list02, list03) # 可转换为序列类型 -
合并且排序
# Method 5 from heapq import merge li = list(merge(li1,li2,li3,...)) # 堆排序算法合并序列,保持序列有序
映射类型
字典(Dictionary)
字典当中的元素是通过键来存取的,而不是通过偏移存取。
定义字典
从元素构造字典,或基于已有字典进行构造(合并)。
d = {'name': 'john','code':6734, 'dept': 'sales'}
# ==> d = {**d, **d2}
d = dict(key1=val1, key2=val2, ...) # => d = dict(**d1, **d2)
d = dict([(key1, val1), (key2,val2), ...]) # <- zip(keys, values)
# ==> d = {k:v for k,v in kv_tuples}
# ==> d = dict(itertools.chain(d.items(), d2.items()))
d = dict.fromkeys(keys, value) # 初始化所有keys的值为同一个value
d.update(d2:dict) # inplace
Python 3.9支持使用
|和|=运算符进行字典合并。
复制字典对象:
d2 = d.copy() # 浅拷贝
from copy import deepcopy
d2 = deepcopy(d) # 深拷贝
增删字典元素:
d['key'] = value
value=d.setdefault(key, default)
d.update([(k1,v1), ...], k1=v1,...)
del(d['key']) # 删除字典元素 => del d['key']
value=d.pop(key, default) # 移除元素,如果key不存在则返回default;
# 如果未提供default则产生KeyError
key_val=d.popitem() #移除末尾元素
dict.clear() #清空字典元素。
遍历字典元素:
for key in dict: # => for key in dict.keys()
print(key, dict[keys])
for key,value in dict.items(): # iter on (key,value)
print(key, value)
键是不可变数据类型,包括数值、字符串、元组、datetime等; 值可以是任意类型。
keys = d.keys() # return Type <dict_keys>
vals = d.values() # return type <dict_values>
keys()和values()无法通过下标访问,但可通过迭代访问。
查询字典
字典的key是唯一标识,相当于集合类型。可查询key是否存在字典中。
tf = key in dc # => key in dc.keys()
字典排序
Python 3.7+的字典保持其元素加入的顺序。可通过重新构造对象实现对字典的排序或使用有序容器。
dict(sorted(x.items(), key=lambda item: item[0])) # sorted by key
dict(sorted(x.items(), key=lambda item: item[1])) # sorted by value
NameSpace
A namespace is essentially a collection of names bound to values. They are sometimes implemented by a dict "under the hood", but not always, and the implementation detail is really irrelevant, and they're not the same thing.
from types import SimpleNamespace
from argparse import Namespace
ns = SimpleNamespace(**kwargs)
ns.varname # 访问命名空间中的变量
ns.__dict__ # 将命名空间的成员转换为字典
命名空间中的变量类似于字典的值或类的成员变量(具有类作用域)。
集合
set对象是由具有唯一性的 hashable 对象所组成的无序多项集。 常见的用途包括成员检测、从序列中去除重复项以及数学中的集合类计算,例如交集、并集、差集与对称差集等等。
s = {'xyz', 123, True} # 空集合为set(),{}创建的是空字典
s = set('abcdefg') # 将字符串的字符转换为集合元素。
集合类型是无序的,其元素顺序与构造时提供的顺序不一定一致。
使用
in/not in判断集合元素是否存在。第三方包
orderedset和ordered-set实现了保持元素顺序的集合OrderedSet:from orderedset import OrderedSet # or from ordered_set
修改集合
s.add(x)
s.update(x) # 参数可以是列表,元组,字典等
s.remove(x) # 不存在会发生错误
s.discard(x)
s.pop() # 设置随机删除集合中的一个元素
s.clear()
frozenset为对应的不可变类型。
集合运算
s = s1.intersection(s2) # 交集:s = s1&s2
s = s1.union(s2) # 并集:s = s1|s2
s = s1.difference(s2) # 差集:s = s1-s2, 在s1中但不在s2中的元素
s = s1^s2 # 等效:s1.union(s2)-s1.intersection(s2)
s.isdisjoint() # 集合是否有没有交集
s.issubset(A) # 判断s是否为A的子集
s.issubset(A) # 判断s是否为A的子集
集合不支持
+运算符。
容器类型转换
元组:tuple(s);列表:list(s);集合:set(s), frozenset(s)。
有序容器
sortedcontainers包含SortedList、SortedSet、SortedDict等维持元素大小顺序的容器(默认升序)。
sd = SortedDict(func_key, *kv_tuples, **dict_kwargs) # func_key将key映射为比较值
sd.__reversed__() <==> reversed(sd)
sortedcollections(基于sortedcontainers实现)除包含上述类型外,还包含保持元素加入顺序的类型:OrderedSet、OrderedDict。
矩阵
存储同类型元素的类型,区别于list、tuple等序列类型。
多维矩阵
ndarray(array)类型可表示多维同构(homogeneous)矩阵。
属性
| 名称 | 用途 |
|---|---|
ndim | 数组的维数,例如向量为1,矩阵为2矩阵。 |
shape | 数组的形状。使用矩阵表示向量:列向量$N\times 1$,行向量默认为$1\times N$,与仅有一个维度的向量类型不同。 |
size | 数组的元素总数。 |
dtype | 数据类型,矩阵元素不仅可以使数值类型,也可以是字符串等类型,但所有元素类型相同。 |
itemsize | 单个元素的内存占用量。 |
data | 数据的==内存地址==。 |
base | If the array is a view into another array, that array is its base |
len(array)返回数组第一维的长度。
数组维度判断
可以ndarray以外的类型进行判断:对象维度为0,序列维度为1。
n = np.ndim(x)
shape = np.shape(x)
标量:(内置)数值对象、字符串、字节序列等(np.ndim(x)==0);
tf = np.isscalar(x)
只有一个元素的序列类型、数组类型等返回
False。非数值对象返回False。
np.isscalar(None)==False。
元素数据类型
Python defines only one type of a particular data class (there is only one integer type, one floating-point type, etc.).
NumPy defines 24 new fundamental scalar types, mostly based on the types available in the C language that CPython is written in.
内置数据类型定义包括:平台相关类型(np.int,np.float,...,np.ubyte,...,弃用)以及定长类型(np.int8, np.int16 , np.int32, np.int64, np.float32, np.float64, ..., np.bool,无符号类型:np.uint8,...)。
数据类型元信息
在创建矩阵时,dtype参数可以为矩阵统一或的每列指定一个名称和类型。dtype声明了数据的类型(整数i/u、浮点数f、对象O等)、占用字节数、字节序(little-endian或big-endian)、结构以及子数组大小类型等信息。上述信息封装在np.dtype对象中(类似于Python内置的type类)。
Several kinds of strings can be converted. Recognized strings can be prepended with
'>'(big-endian),'<'(little-endian), or'='(hardware-native, the default), to specify the byte order.
dtype.aligment # 占用字节数
t.kind # 数据类型(整数/浮点数/...)
t.name # 类型名(int64)
t.str # 数据类型规则声明('<i8') -> t.descr
dtype.byteorder # 字节序
数据类型判断
可以将数据类型对象与字符串表示进行比较(Pandas数据表的底层类型为ndarray,也遵循该规则)。
isinstance(x[0], np.int32)
x.dtype # dtype('int32')
x.dtype == 'int32' # return True
x.dtype == np.int32 # return True >> type(x) == np.int32
x.dtype == int # return True
x.dtype == '<i4'
创建数组
numpy.full(shape, fill_value, dtype=None, order='C')
创建指定形状shape的数组,并指定初始值fill_value和元素类型dtype(例如bool)。shape指定数组的维度,可以是整数标量、列表或元组([m,n,p,...])。
- 标量:为
0表示空数组;为1相当于标量组成的数组,其他值则为向量; - 长度为
2的列表或元组:生成矩阵; - 大于2的列表或元组:生成高阶数组。
order指定数据存储方式: row-major (C-style) or column-major (Fortran-style)。
np.ones(shape, dtype=None, order='C')
np.zeros(...)
当采用C-style时,最后的维度([m,n,p]中的p)索引的元素在内存中是连续存储的;反之,采用Fortran-style时,最前的维度索引的元素是连续存储的。==元素在内存中的存储方式对于新创建的数组以及按索引访问数组而言没有影响,但影响数组变形(reshape)后元素的排列方式以及切片赋值的效率。==
np.empty(shape, dtype=Float, order='C')
创建数组,不执行初始化。
等差序列
np.arange(start=0, stop, step=1, dtype=None)
np.linspace(start, stop, num=50, endpoint=True, ...)
arange创建序列不包含stop,使用step指定步长;linspace包含stop,使用num指定序列元素个数。
等比序列
np.logspace(start, stop, num=50, endpoint=True, base=10.0)
该等比序列可以表示为指数形式:$\mathrm{base}^\mathrm{idx}$,其中指数$\mathrm{idx}$对应于等差序列np.linspace(start, stop, num)中的元素。如果要生成(s,t)之间的等比序列,则先取其对数的等差序列:
nums = np.logspace(np.log10(s), np.log10(t), int(n))
# 等价于
# exps = np.linspace(np.log10(s), np.log10(s), n)
# nums = np.power(10, exps)
np.meshgrid(x,y,...,sparse=False,...)
对角矩阵
identity,eye,diag|diagonal,diag_flat、
三角矩阵
tri,tril,triu。
从已有数据对象构造
np.array(array_like, dtype=None, ndmin=0,...)
从已有矩阵或序列对象创建矩阵,==矩阵元素类型默认根据序列对象的兼容类型推导,并对元素进行强制类型转换==。嵌套序列对象可初始化为多维矩阵。
np.array([(1,2,3), (4,5,6)], dtype='i4')
当数据中包含混合类型(如字符串与整数),Numpy将自动将数值转换为统一的兼容类型(将整数转换为字符串)。如果要保持原类型,应该声明dtype=object。
另有其他采用固定选项对
array方法的封装方法:
asarray:避免兼容类型复制(copy=False);asanyarray:避免兼容类型及其子类的复制(copy=False,subok=True);copy:总是复制;- ...
从数据源创建
读取缓存数据
numpy.frombuffer(buffer, dtype=float, count=-1, offset=0)
从字节数组读取数据并创建一维数组。count为读取的字节数,offset为跳过起始字节数。
读取文件数据
使用loadtxt、genfromtxt。
其他特殊数组
随机数:np.random.randn(m, n,...)
数组对象操作
复制对象
-
不复制,直接引用
a = b a = b[:,idx]通过切片方式获得的数组子集仍然直接引用原数组。
-
浅拷贝/视图
对象之间共享底层存储数据的内存,两个对象可对底层数据有不同的表达。
y = x.view(dtype=np.int16, type=np.matrix) # reinterpret b = a.reshape(shape)多数数组操作函数,不必要情况下都不会复制数组内容,而是使用浅拷贝。
-
深拷贝
a = b.copy() # list.copy()是浅拷贝
初始化
a.fill(value)
数组变形
a.reshape((m,n,...), order='C') # => np.reshape(a,...)
参数为-1表示该维度的长度由其他维度和数组元素数量决定(只能有一个维度设置为-1)。a.reshape(-1)将数组变换为向量,等效方法包括:
a.ravel(order='C') # => np.ravel(a,...)
a.flatten(order='C')
a.squeeze():降维,移除数组中长度为1的维度。
a.resize((m,n,...))
根据新的形状重新分配存储空间,如果数组空间减小则舍弃靠后的元素,反之将新增元素置为0。根据底层存储方式(C或F)决定元素在内存中的位置。
np.repeat(a, n_repeat, axis)
在给定方向axis,对矩阵a进行重复。
转置:
a.transpose
拼接
将多个数组进行垂直/水平拼接。
np.concatenate((a1,a2,...),axis=0)
np.vstack(list_array) # vertical concatenate
np.hstack(list_array) # horizontal concatenate (沿行方向拼接,对于1D数组直接拼接)
np.stack(list_array, axis=0) # 在新的维度上拼接数据(维度+1)
list_array是多个数组组成的序列(列表或元组),这里的数组可以是标量、Python序列以及ndarray。
拼接方向上各数组长度应该相同。一维数组(向量)与向量/标量只能进行水平拼接。
分割
np.hsplit
访问数组
索引
访问数组时的下标个数应与声明时的维数(ndim)一致。
a[i] # vector
a[i,j], a[i][j] # matrix
a[(i,j)] # matrix
元组作为下标将被展开至每个维度,因此长度需要与矩阵维数相同。
切片
对高维数组(例如3d)切片时,得到的子数组元素按最低维度连续排列(C-style,反之如果是Fortran-style,则按最高维度连续排列)。
a[I] # sub-array, equals to a[i,;] for 2d array or a[i,:,:] for 3d array
A[I,:]
A[:,J]
A[I,J] # I/J is a sequece or ndarray-vector
下标可以是单个元素,也可以是列表,或
ndarray向量。
迭代
for row in array: # iterate by rows
print(row)
for col in array.T: # iterate by columns
print(col)
for a in array1d: # iterate by elements
print(a)
更新
a[m:n]=x # 修改数组内容
a[:]=a+1 # a=a+1 将使a指向新的对象
结构数组
结构数组是特殊的ndarray,其每个元素是由不同简单类型构成的元组,元素类型具有统一的复合类型声明。
x = np.array([('Rex', 9, 81.0), ('Fido', 3, 27.0)],
dtype=[('name', 'U10'), ('age', 'i4'), ('weight', 'f4')])
其中,
dtype声明了每个元素的各个字段名称及其类型。
与普通数组一样,可以声明高维数组,但此时元组作为整体不再展开为ndarray的元素。
可以使用声明的字段名称访问各元素:
x['age'] = 10 # set all elements' age to 10
结构数组可以支持pandas.DataFrame的构造。
稀疏矩阵
scipy.sparse提供稀疏矩阵。
As = lil_matrix(D) # construct from 2D ndarray
As = lil_matrix(As) # construct from a sparse matrix
As = lil_matrix((M,N), dtype=None) # construct empty matrix with size and type
稀疏矩阵类型:
| 类型 | 说明 |
|---|---|
lil_matrix | Row-based linked list sparse matrix。 用于==高效地逐步构建稀疏矩阵==,但数值运算效率低,在数值运算前转换为其他类型。 |
dok_matrix | Dictionary Of Keys based sparse matrix. 用于==高效地逐步构建稀疏矩阵==,但数值运算效率低,在数值运算前转换为其他类型。 支持$O(1)$复杂度访问元素,可以高效转换为 coo_matrix。支持矩阵元素运算。 |
coo_matrix | ijv三元组表示稀疏矩阵,==不支持算术运算==,用于稀疏矩阵类型间的快速转换。 |
csr_matrix | 同类型矩阵高效地数值运算;高效地行切片。 |
csc_matrix | 同类型矩阵高效地数值运算;高效地列切片。 |
Compressed Sparse Row matrix
表示方法(其中一种构造方法):
csr_matrix((data, indices, indptr), [shape=(M, N)])
data/indices是一个1D向量,分别按序储存所有行非零元素的值及其列索引;同时,indptr[i:i+1]则表示第i行非零元素的值与索引在data/indices中的位置。由于元素可按行快速索引,因此方便进行高效切片以及按行运算(运算结果需重新构造三个存储结构)。
其他构造方法:
csr_matrix((data, (row_ind, col_ind)), [shape=(M, N)]) # 基于ijk三元组构造
csr_matrix((M, N), [dtype]) # empty matrix
csr_matrix(D) # from dense/sparse matrix
Compressed Sparse Column matrix
类似于csr_matrix。
数组类型转换
ndarray转换为其他类型
ndarray.astype(dtype, ...)
复制数组并作元素类型转换。
list(a)
a.tolist()
将矩阵转换为嵌套的列表。
稀疏矩阵转换
稀疏矩阵可以在各类型间相互转换,根据面向的运算类型,选择合适的稀疏矩阵类型。
稀疏矩阵可以转换为常规矩阵。
A = As.todense() # A=As.toarray(oder=None,out=None)
表格
构造对象
DataFrame
df = pd.DataFrame(data=array, dtype=single_type,
index=index_label, columns=label_list)
df = pd.DataFrame.from_records(data, columns)
DataFrame封装的数据类型
data可以是list、tuple、Series及其复合类型(如list_of_list、list_of_tuple、tuple_of_list等)以及ndarray(支持结构数组)。
- 当数据表示向量时,构造的表格为
Nx1类型的。 - 当复合类型为字典时,等效于
pd.DataFrame.from_dict(*, orient='columns'); - 当字典元素的值为标量时,应为构造函数指定
index=[0];
pd.DataFrame的dtype参数只能为整个表格指定一种数据类型,可在创建后调用astype分别设置各列的数据类型。pd.DataFrame.from_records(...)可以指定每列的类型。
DataFrame内部的数据存储类型为numpy数组,其基本数值类型为numpy内置类型以及str类型。
以字典或列表初始化
df = pd.DataFrame({'col1':values1, 'col2':values2, ...})
df = pd.DataFrame.from_dict(
{'col1': values1, 'col2': values2, ...},
orient='columns'
)
字典的键作为表格的行/列索引名,值可以是序列类型(list、tuple、Series等),作为表格对应列的数据。from_dict(...)将字典的值(序列类型)转换为表格的行(orient='columns',默认)或列(orient='index')。
当字典的值为标量,可使用
from_dict(d, orient='index')得到单列的表格(不支持orient='columns')。
如果字典的值为
Series,则无法指定orient=index,可在按列构造后转置。
df = pd.DataFrame.from_records(
[
{'col1': v1, 'col2': v2},
{'col1': v1, 'col2': v2}
]
)
每个记录的字段类型可以不同,缺少的字段值未
NaN。
Pandas也提供将DataFrame转换为字典或序列的方法to_dict(orient='records')(根据orient参数的值决定转换后的对象类型为字典或对象,以及具体的数据结构)。
创建空对象
构造函数不传入数据,但设置行列索引(将行或列索引设置为空)。
index=pd.MultiIndex.from_tuples([],names=['Name', 'IP'])
df = pd.DataFrame(columns=['A', 'B', 'C'], index=index)
或将列设置为索引(数据为空,因此索引也为空,但设置了索引名)。
df = pd.DataFrame(columns=['A', 'B', 'C']).set_index(['A', 'C'], drop=False)
可向空对象按索引添加新的行。
读取数据源
表格通常通过从数据源导入数据的方式初始化,例如read_csv、read_parquet等。
read_parquet需要pyarrow或fastparquet支持。
Series
ss = pd.Series(data=None, index=None, dtype=None, name=None, copy=False)
ss = pd.Series(values, index=arrays)
一维序列。copy表示是否复制输入数据。
迭代
Series对象返回每个元素。Series没有列索引,因此不需要传入字典进行初始化。ss = pd.Series([1, 3, 5, np.nan, 6, 8])
pd.Series不能进行自动hash,因此无法与同样长度的元组进行比较,需要将其转换为元组再比较。
数据属性
shape:行列数。
size:元素总数。
empty:==数据表是否为空==。
values:推荐使用.array()or.to_numpy()
df.info(memory_usage='deep', show_counts=True)
df.memory_usage(index=True, deep=False) # sys.getsizeof(df)
Series属性
ss.shape # 行数
ss.is_monotonic # => is_monotonic_increasing
ss.is_unique
ss.hasnans
列数据类型
df.dtypes:每列的数据类型。
y = df.astype(dtype, copy=True) # 转换整个数据表
# 转换指定列的类型
y = df.astype({col1:dtype1,col2:dtype2,...}, copy=True, errors='raise')
copy和其他方法的inplace意义不同,此处总是返回新的表格。如果列名和类型分别为序列,首先将其转换为字典。
将数据类型转换为支持pd.NA的最可能类型。
df.convert_dtypes(
infer_objects=True, # 将object类型转换为最合适类型
convert_string=True, # 将object类型转换为StringDtype
convert_integer=True, # 尽可能转为为pandas整数类型
convert_boolean=True, # 尽可能转为为BooleanDtype
convert_floating=True # 尽可能转为为pandas浮点数类型(优先转换为整数)
)
df.infer_objects() # 推断最合适的列数据类型
时间日期序列类型
pd.Timestamp使用NumPy datetime64 and timedelta64 dtypes。Time series / date functionality — pandas 1.3.0 documentation (pydata.org)
当对时间类型的列复制为非时间类型数据,如时间文本或时间戳数值,==其结果会自动转换为时间类型==。时间类型字段也可以和时间文本或时间戳数值自动比较。
概览数据
可以直接打印(print),Pandas根据窗口控件对部分内容进行省略(可以控制终端显示内容)。
df.head(n=5) # return the first n rows
df.tail()
print(df.to_string(index=True, header=True)) # remove dtype/header/index info
终端会自动回显方法返回的值,在脚本中必须使用
索引
Index
表示(行/列)索引的数据类型。
index = pd.Index(['e', 'd', 'a', 'b'])
index = pd.Index(list(range(5)), name='rows')
columns = pd.Index(['A', 'B', 'C'], name='cols')
Index可以被视为特殊类型的Series,因此Series多数属性、方法也适用于Index。
df.index # 获取DataFrame的索引
index.name # 索引的名称
index.has_duplicates
index.is_all_dates
loc = index.get_loc(key)
Return int if unique index, slice if monotonic index, else mask.
nan不影响unique index的统计(包含多个nan的索引调用get_loc()时仍返回的是标量)。
- 更方便的数据查询(
df.loc[index]); - 使用index可以获得性能提升:对于唯一的index使用hash表查找,对于有序index使用二分法查找;
- 自动的数据对齐功能(进行序列或表格运算时,非公共的index对应的数据计算结果为
Nan); - 更多更强大的数据结构支持,包括
Categoricallndex、Multilndex、Datetimeindex等;
索引类型
数值索引
类别索引
时间索引
DatetimeIndex以时间点为数据点。可从时间数据、周期索引转换构造、或者按规则构造。从时间数据(文本表示或时间戳表示)构造索引:
dt_index = pd.to_datetime(
ts_data,
utc=False, # True=>为时间添加时区信息(UTC+00:00)
unit='s', # unit='s'|'ms'|'ns'转换数值类型
format=None, # strftime格式转换字符类型
exact=True,
dayfirst=False, yearfirst=False, # 推测格式
infer_datetime_format=False, # True->format优先级比自动推测更高
) # 返回值与输入对应:
# -> list-like: DatetimeIndex
# -> Series: Series of datetime64 dtype
# -> scalar: Timestamp (pd.Timestamp)
dt_index = pd.DatetimeIndex(datetime_data)
ts_data为datetime类型的数据或表示时间的字符串构成的序列类型。如果原数据未包含时区信息,则采用默认时区,但无法转换为其他时区(需要调用tz_localize)。DatetimeIndex和PeriodIndex可直接调用tz_localize和tz_convert,但元素类型为Timestamp或Period的序列无法直接调用(需要使用apply方法对每个元素分别转换时区)。
构造周期性时间索引:
datetime_index = pd.date_range(
start=None, end=None, periods=None, freq=None,
tz=None, normalize, name, closed)
start, end:起始和结束时间(str|datetime);
periods:生成的点数;
freq:时间间隔,如5H。==以上四个参数仅需指定三个==(剩余一个可推测)。
单位标识如下:
年 季 月 周 日 时 分 秒 毫秒 YQMWDHTSL前缀
B:仅计算工作时间,默认单位为天(+MQY);CB:自定义工作时间; 后缀S:以周期开始作为记录点(无后缀代表以结束为记录点,+MQY); 前缀S(semi):以半周期为记录点(只用于M,可与其他前后缀组合使用)。
tz:时区,缺少时区设置则采用计算机本地时区。
normalize=True|False:将起点和终点对齐当天午夜零点。
name:索引的列名。
closed=None|'left'|'right':索引区间的开闭,默认为全闭。
区间索引
pd.IntervalIndex.from_arrays(left, right, closed='left|right|both|neither')
pd.IntervalIndex.from_breaks([0, 1, 2, 3], ...)
pd.IntervalIndex.from_tuples([(0, 1), (1, 2)], ...)
pandas.Interval(left, right, colsed='right')表示区间,left和right表示可比较大小的数值类型、pd.Timestamp以及pd.Timedelta(不支持dt.datetime和dt.timedelta)。
时间区间索引:PeriodIndex以==固定周期==的时间段索引数据。pandas.IntervalIndex也可使用datetime作为元素表示时间区间。
pi_index = pd.period_range(start, end, periods, freq, name) # ==> date_range
pi_index = pd.PeriodIndex(period_list, freq="M")
部分索引
对于DatetimeIndex和PeriodIndex,可传入datetime或str表示时间日期的高位部分以索引相应时间的数据。
ss.loc['2020-01']
ss.loc[dt.datetime(2011, 12, 25):]
ss["10/31/2011":"12/31/2011"]
时间索引和区间索引的相互转换:
dt_index.to_period() # <==> pi_index.to_timestamp()
MultiIndex
通常使用辅助函数创建MultiIndex。
from pandas import MultiIndex
MultiIndex.from_arrays(list_of_arrays) # 每个数组为一级索引
MultiIndex.from_tuples(list_of_tuples) # 每个元组为一行索引
MultiIndex.from_product([('a','b'),(1,2),...]) # cross product
MultiIndex.from_frame(...) # from DataFrame
from_product适用于多个索引具有层级关系的情况(先给出的索引为高层级,在生成的索引中是连续相同的)。
以上方法的其他参数:
names=['first', 'second']多级索引的名称;使用index.names查看索引名称;多级索引的index.name为None。sortorder=i|None:指定用于排序的索引级别。
创建DataFrame时,可通过index参数提供原始数据直接创建MultiIndex,或通过set_index来创建。
表格索引操作方法
df.columns:类型为Index,获取或设置列索引名称,Series不存在列索引。
df.index:获取或设置行索引名。
df.columns = ['A', 'B', 'C', ...] # 整体修改
df.rename(columns={"A": "a", "B": "c"},
errors='raise'|'ignore', inplace=False) # 替换修改
df.rename(index={0: "x", 1: "y", 2: "z"})
ss.rename(index='name') # ss.name='Name', 使用标量或hashable序列(元组)修改名称
ss.rename(index = dict_map_func) # 修改序列索引
设置行列索引的名称(index.name或index.names):
df.rename_axis(index='index_axis_name', columns='col_axis_name')
当存在多个行列标签时,以字典给出新旧名称的映射。
当打印表格时,行列索引名如果不为空将显示在左上角单元格。
设置索引
使用指定的一列/或多列数据设置为索引。
df.index = data
df.set_index(keys, drop=True, inplace=False) # 添加新的索引项
keys:如果为列名,则使用对应列移至索引列,索引列名称为对应列名;如果为与表格长度相同的列(包括Series、Index、np.ndarray、Iterator),则设置默认的索引列(无索引列名);也可以是以上两者组合的列表(设置多重索引)。
drop:默认移除作为索引的列,反之移保留为索引的列;
重置索引
设置为数字索引。
df.reset_index(drop=False, inplace=False)
drop:默认将原有索引设置为新的列(首列),反之移除原有索引;
inplace:默认返回新的对象,反之对源对象进行修改。
修改多级索引
移除数据表指定级的索引:
df=df.droplevel(level:Union[int,str,list], axis=0)
MultiIndex.droplevel功能相同,返回修改后的索引。
The swaplevel() method can switch the order of two levels。
访问数据
下标运算符[]和成员运算符.:接受标签或切片对象作为参数。
使用
.时,标签/列名需要是合法的Python标识符。
ss = df[colname] # return Series corresponding to colname
ss = df.<column_name> # column_name必须是合法标识符。
可以使用列表传递多个列的名称
df_sub = df[names],返回表格的子集。
Series的参数为行索引,而非列名(Series无列名)。
x = ss[index_labels] # return sca lar/Series value via index labels
x = ss.<index_name>
访问数据切片
s1 = ss[i:j:s] # s not included
d1 = df[i:j:s] # slicing rows
仅支持
:操作符构造的参数(与Python规则一致),不支持列表作为参数(会被视为列标签)
loc属性
参数为标签,或boolean向量。
提供的参数与数据表标签类型不一致会导致报错。
s.loc[index_labels] # Series
df.loc[row_labels,column_names] # DataFrame
标签表示方法包括:
-
单个标签:例如
5、a等; -
序列:
['a', 'b', 'c']; -
切片对象:
'a':'f'、'd':等,与下标不同,==end包含在内==; -
boolean向量可以使用
query(expr)代替boolean表达式(不能使用1和0分别代表True和False,前者会直接被当作索引处理)。
loc属性和[]运算符可以增大数据表,方便增添数据。
df.loc[row_labels,:]等价于df.loc[row_labels]。返回值为单个元素时,如果参数为标量对象则返回标量,如果参数包含列表类型(即使仅有一个元素),则返回值为
Series。返回值为向量时,如果参数为标量,则返回值构成
Series,反之(即使仅有一列)构成DataFrame。
以切片索引访问表格时总是返回表格类型,而当行列索引为标量时,返回值类型会转换为Series;以当给定的切片索引范围不在表格内时,对应索引会被忽略;给定单个索引不在表格内则会报错。
x = df.loc[i:j] # x always be DataFrame
x = df.loc[i] # x becomes Series if i is scalar
iloc属性
参数基于整数位置(下标,和Python,Numpy的语法一致),或boolean向量。
参数表示方式对返回值的类型影响与
.loc一致。
s0 = s.iloc[indices]
df.iloc[row_indices, col_indices]
下标表达方式包括:
-
标量整数;
-
整数列表;
-
切片对象;
-
boolean向量:查询数据表返回的表达式(例如df['A']>0)为Series,不能直接用于iloc的下标参数,代替方法可以先将返回值转换为矩阵:df['A'].to_numpy()>0 # or ((df['A'])>0).to_numpy()
ixis deprecated.
访问单个元素
通过简化下标的判断和处理,访问速度比通过切片接口loc和iloc更快,仅限访问一行一列的单个元素。
df.at[label, column_name] # s.at[label] # label based
df.iat[row_idx, col_idx] # s.iat[index] # integer based
多级访问
当传入单个索引时,可仅指定条目的部分索引(编号最小的索引)。
df.loc[l1_key, cols] # access data with only level-1 index labels
df.loc[(l1_key, l2_key)] # access data with both 2-level index labels
df.loc[(l1_key, l2_key), cols] # with column labels
df.loc[index, :] # 使用索引对象访问数据
# .loc does not accept access directly via level-2 index labels
df.xs(idx, level=idx_name) # direct "read" any index level
indexing past lexsort depth may impact performance:当索引未排序时可能产生以上警告。
当传入单个索引时,取回内容会自动去掉传入层级的索引,因此可以使用链式访问方式:
df.loc[l1_key][cols]
df.loc[l1_key].loc[l2_key] # chaining access
如果要同时访问多个条目,则必须提供每个层级完整的索引。可将索引封装为元组序列,或者将每一级索引单独提供:
df.loc[[(id1,id2,...),(id1,id2,...),...],cols] # list of tuple index
df.loc[l1_idx, l2_idx, :, ...][cols] # separate index
当单独提供每一级索引时,不能同时包含列名,因此需要链式访问方式提供列名。
https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html
获取部分索引:
idx = df.index.get_level_values(level_name) # get index of specified level
idx = df.index.droplevel(level_name) # drop index of specified level
获取某一级索引对应的下标:
df.index.get_loc_level(idx) # return (tf_values, loc)
赋值
可以将Series对象赋值给DataFrame的行或列,无需保证两者的索引一致。
- 仅
Series对象和DataFrame对象的公共索引元素被赋值; - 未包含在
DataFrame的索引所对应的元素被忽略; DataFrame中存在而Series对象中不存在的索引赋值为NaN。
当赋值使表格新增行列时,可以使用字典对表格进行赋值(不能使用字典对已有行赋值,会将字典的键名而非值传递给表格),字典的字段必须与表格行/列匹配。
索引赋值
直接将表格对象赋值给另一个变量是浅拷贝(引用类型默认行为)。
SettingWithCopyWarning
pandas/core/indexing.py/_LocationIndexer/__setitem__ pandas/core/indexing.py/_iLocIndexer/__setitem_with_single_block pandas/core/generic.py/NDFrame/_check_is_chain_assignment pandas/core/generic.py/NDFrame/_check_set_item_copy
对DataFrame进行索引时返回视图或新对象的情况比较复杂。pandas使用内部变量记录下表格(_is_view和_is_copy)生成的方式,从而在对新对象赋值时给出相应的警告SettingWithCopyWarning,从而避免用户对数据进行误操作。
显式链式索引赋值 (Chained assignment)
链式索引赋值的首个索引运算符可能会返回新对象,导致后续的索引赋值运算不会作用在原对象上,这可能与用户的意图不符,因此Pandas会给出警告。
df[row_indices][cols]=value
df.loc[row_indices[,col_indices]][cols]=value
避免这种警告的方式就是将链式索引更改为.loc索引,从而实现一次索引赋值运算:
df.loc[row_slice, cols] = value
隐式链式索引赋值
被索引的对象可能是先前代码(或方法传入参数)中通过索引得到的子表格,子表格的构造方式(视图/实例)对于当前代码而言未知(即使用户自己生成的子表格,也难以判断其构造方式)。因此后续的索引赋值也难以判断其是更改的新对象或原始对象,因此Pandas会根据内部变量状态给出警告。
传入函数的表格对象通常不要对其进行修改,如果有修改应该利用返回值返回,以提示该对象做了修改。
df1 = df[row_indices] # df2 = df.loc[row_indices]
df1.loc[idx] = value
消除警告的方式是用户主动断开隐式的索引链,即在先前代码生成子表格(或传入参数)时进行拷贝。==即如果预计到要对某个子表格做更改,则使用copy()方法复制得到子表格,反之则使用索引得到的对象。==
df1 = df[row_indices].copy() # df2 = df.loc[row_indices]
df1.loc[idx] = value
索引总是浅拷贝,因为索引为不可变对象,更新索引时总是创建新的对象,所以浅拷贝是安全的。
迭代
按列/行以此访问表格。
for col_name in df: # iterate column names
print(df[col_name])
for label, series_column in df.iteriterms(): # df.iterms(), df.iterrows()
print(label)
print(series_column)
查询筛选
查找
isin()查询Series或DataFrame每个元素是否在指定集合中。
df_tf = df.isin(values:[iterable,Series,DataFrame,dict])
in运算符返回前置运算数是否在后置运算数(集合)中。
==要求运算对象的维度兼容,而isin不限制参数类型。
查找Series或DataFrame是否包含某个索引:
tf = idx in ss # => idx in ss.index
tf = idx in df # => idx in df.columns
查找满足条件的行列:
tf_mask = df[col_name]==value # return Series
idx = df.index[tf_mask] # return index as Index
idx = np.where(tf_mask)[0] # as ndarray-vector
idx = np.argwhere(tf_mask.to_numpy()).reshape(2)
ss.argmin() # ss.argmax() 仅适用于数值, see also np.argmin(a)
获取满足条件的子表格:
s = df.loc[tf_mask,'colname'] # return filtered value:
s = df.loc[idx, 'colname']
基于标签查找对应元素。
a = df.lookup(row_labels, col_labels) # -> array([df.loc[row_label,col_label]])
表达式查找
df.query(expr)根据表达式的值筛选表格。表达式语法格式:
- 普通标识符表示数据中的列名,特殊列名使用
`First Name`表示; - 全局空间中的变量名使用
@var引用; - 字面值与Python语法一致;
s = df.query('col_name=="gary" & value == 10')
Boolean Reduction
df.all(axis=[0,1,None]) # see also df.any()
df.isna().all(axis=0) # 判断列是否全为Nan
编辑
替换
df.where(df_mask, new_value=nan)# replace with new_value where df_mask is true
不像
np.where()返回下标。
df.replace(to_replace=None, value=None, regex=False, inplace=False, limit=None)
to_replace:数值类型、字符串、正则表达式(regex=True)以及
- 列表类型:与
value类型长度==兼容==; - 字典类型:
to_replace.key()==限定查找的列==,.value()为查找的值,value参数对应替换内容(字典类型提供其他参数表达方式,但与分参数传递重复)。
value:除了普通值外,接受正则表达式中的替换命令。
新增行列
新增行列开销较大,不适合大型数据表格。
新增列
df = df.assign(colname=values,...) # 添加一个或多个新列(colname)
df[new_cols] = values # scalar|vector|array => df.loc[:, newcols]
插入列
df.insert(col_loc, colname:str, value:Union[int,ndarray,Series])
loc为插入列的位置,colname为插入列的名称,value为插入列的值。==插入操作更新当前对象==。
==插入操作一次只能插入一列==,如果要插入多列可逐次插入或使用拼接方式。
for col in reversed(new_frame.columns):
df.insert(insert_loc, col, new_frame[col])
df = pd.concat([df.iloc[:,:insert_loc], new_frame, df.iloc[:,insert_loc]], axis=1)
追加行
df.loc[index]=values # values可为标量或规格相同的向量
df.loc[index, cols] = values # 未指定的列值为NaN
当指定的index不存在于表格时,新增一行;==只能一次新增一行==,尝试提供多个不存在的索引会提示KeyError: 'Non of [label] are in the index'。
当索引为连续整数,令
index=df.shape[0]可使==增加的行索引保持连续==;使用index=-1将添加-1作为索引(而不是在表格末尾自动增加索引编号)。
如果是MultiIndex,则不能省略列索引参数(可使用:代替列名),否则无法正确识别索引。注意:df.loc[index,:]=values默认会自动将数值类型转换为float64,当新增数据后需要使用astype将数据类型转换为预期类型。
df.loc在原数据表上修改,df.append()返回新的数据表。
df = df.append(other_df_ss_dict, ignore_index=False) #追加表格、行或字典表示的行
当ignore_index=True时(重置索引为RangeIndex),可以追加一个Series或dict作为新的行,或追加一个序列的上述对象以追加多行记录。
扩展表格
df.at[row_idx,col_idx] = value # scalar
可同时扩展多列,但类似于
loc,一次只能增加一行(即只提供单个行索引)。
iloc、iat无法新增数据(out-of-bounds)。
Explode
指定列的元素如果为序列类型,将其展开为多行,同一行其他列的值复制原有值。
df.explode(column:str, ignore_index=False) # simliar for Series
# A B A B
# 0 [1, 2, 3] a => 0 1 a # 将序列元素转换为多行
# 0 2 a
# 0 3 a
# 1 foo b => 1 foo b # 标量元素不变
# 2 [] c => 2 NaN c # 空序列变换为np.nan
移除行列
按索引移除行列
pd.drop(labels=None, axis=0, index=None, columns=None,inplace=False)
labels和axis组合使用,以确定labels代表的是行/列索引;或者可以同时指定index和columns以删除指定行列。
labels、index、columns是标量或列表类似结构(不能是元组)。
按索引保留行列
按照给定的索引标签顺序重排表格内容。未给出的索引对应的表格行列将被丢弃,新增的索引对应的行列将填充指定的值fill_value。
df_new = df.reindex(labels, axis={'index'|'columns'}, fill_value=nan, ...) # axis选择行/列索引
df_new = df.reindex(index=idx_labels, columns=colnames, copy=True, ...) # 直接以关键字给出行列索引
copy=True将返回新的表格对象。
移除重复行列
重复行:
tf = df.duplicated(subset=cols, keep='first')
df.drop_duplicates(...,inplace=False,ignore_index=False)
tf = ss.duplicated(keep)
keep='first'|'last'|False:first将第一行以外的重复项标记为True。
移除重复列:将底层数据转职并检查其中的重复行。
df.loc[:,~df.T.duplicated(keep='first')]
表格排序
索引排序
按照索引标签对表格的行/列排序:
df.sort_index(axis=0, ascending=True, inplace=False)
axis指定按行/列排序,ascending指定升序/降序。
数值排序
按照行/列的值对表格排序:
df.sort_values(by, axis=0, ascending=True, inplace=False)
ss.sort_values(...) # 无需指定排序的列,使用数据列排序
DataFrame的排序参考为表格的一个或多个列,由by指定。
判断数据是否有序:
pd.Index(data).is_monotonic // or Series
表格对象操作
表格操作只能返回新的对象。
df_t = df.T # 返回表格的转置
拼接
拼接数据表或序列。
df_new = pd.concat([df1, df2, s1, ...], axis=0, join='outer', ignore_index=False,...)
axis:0表示沿行索引方向拼接,1表示按列索引方向拼接;==当指定axis=1时,DataFrame与Series可按列拼接==。
join:'inner'表示取非拼接方向索引的交集,‘outer表示取索引的并集(缺失数据填充为NaN)(==只支持两种方式==,其他合并方式使用merge或join);
ignore_index:如果为True则忽略在==拼接方向==上原有的索引,以0,1,2,...代替;
keys:追加最外层的索引(每个组成表格对应相同的索引元素)。当沿列索引方向拼接时,keys将替换相应数据表的列标签。
性能问题:创建新的数据表对象设计大量数据复制,因此在进行拼接多个数据表时,首先将数据表组成列表。
frames = [ process_your_file(f) for f in files ] result = pd.concat(frames)
DataFrame.append方法仅用于在行索引方向进行拼接。
df = df1.append(df2, ignore_index=True)
DataFrame.append仍返回拼接后的新对象,而不像Python列表的append方法对原对象进行修改。
python - Concat DataFrame Reindexing only valid with uniquely valued Index objects - Stack Overflow
问题:存在列名相同的列。
数据库方式合并
merge
根据指定列或索引进行表格合并。
result = pd.merge(left_df, right_df, how='inner', on=None, sort=True,
suffixes=('_x', '_y'))
result_df = pd.DataFram.merge(self, right, ...)
on:拼接参考列或索引名,需要在两个表中均存在;可以使用多个标签的组合(on=['key1','key2'])作为参考。如果未指定参考标签,则两个表的公共列将被作为合并参考关键字。
left_on=None, right_on=None:可以分别指定两个表格的参考列或索引名;left_index: bool, right_index: bool:使用索引作为参考列。
how:合并方法
'left':使用左侧表的参考列作为合并索引。如果合并索引的值与右侧对应参考列的一行或多行相等,则进行一对多合并;如果右侧表的参考列不存在对应的值,则合并后右表其他列填充NaN;右表未被匹配的行被丢弃。'right':使用右侧表的参考列作为合并索引;'outer':使用两侧表的参考列的并集作为合并索引,若索引未在某个表格中匹配到行,则合并结果中该表格对应的列填充Nan;'inner':使用两侧表的参考列的交集作为合并索引。左右表格中未被索引匹配的行被丢弃。'cross': ==cartesian product==。
sort:按参考标签值进行字典序排序;
suffixes:同名的非参考列都会添加到合并结果中。suffixes为同名列添加后缀,其中一个可以为None,即使用原列名。如果未指定后缀而存在相同列,则自动添加_x,_y作为后缀。
join
将表格的列或索引与==另一个表格的索引==(column-on-index)作为合并的参考。
df_new = df.join(other, on=None, how='left', ...)
join不能指定另一个表格的参考列,只能使用索引作为另一个表格的参考列。可已将另一个表格的列首先设置为索引。
表格数据类型转换
序列数据转换
Pandas提供方法将标量、列表、元组一维数组或Series的数据类型转换,返回ndarray或Series(输入为Series时)
pd.to_numeric(data)
index.to_series()
转换为矩阵
DataFrame对象如果保存的是同一类型数据,则to_numpy()将返回对象的底层数据对象,可通过底层数据对象修改DataFrame对象。对于异构的数据类型,则返回矩阵的数据类型将适当调整(例如包括整数和string类型则返回类型为object,如果包含浮点数和整数,则返回类型为浮点型),返回的数据不是DataFrame的底层数据对象。
a = df.to_numpy(copy=False) # -> np.ndarray
a = df.values # ss.values, idx.values, recommend using to_numpy()
将数据对象转换为矩阵。
copy=False只在必要的时候复制数据。
Index
index类型可转换为set。
Graph
networkx
创建图
从空图开始
import networkx as nx
G = nx.Graph(**prop_kwargs) # nx.DiGraph有向图
prop_kwargs为图对象添加属性。
添加节点:nodes can be any hashable object。
G.add_node(node_obj, prop=value)
G.add_nodes_from([v2, v3], prop=value)
G.add_nodes_from([(node_obj, node_attrs_dict),...])
当字符串作为
add_nodes_from的参数时,每个字符将被视为一个节点。
可在添加节点的同时,设置节点的属性(dict)。
添加边:添加边的同时也会自动添加节点。
G.add_edge(v1, v2, object=x, weight=1)
G.add_edges_from([(v1, v2), (v1, v3),...])
G.add_edges_from([(v1, v2, edge_attr_dict),...])
G = nx.Graph(edgelist)
weight必须是数值类型,提供给需要权重的算法。
移除元素:
G.remove_node(v2)
G.remove_nodes_from([v2, v3])
G.remove_edge(1, 3) # remove_edge_from()
从数据表构造图
如果数据中包含节点和边的属性,可通过以下方式构造。
df_nodes=pd.DataFrame.from_records(data_nodes) # 节点编号和属性数据
df_edges=pd.DataFrame.form_records(data_edges) # 连接编号和属性数据
for idx,n in df_nodes.set_index('id',drop=True).iterrows():
G.add_node(idx, **n.to_dict())
for idx,e in df_edges.set_index(['head','tail'],drop=True).iterrows():
G.add_node(*idx, **e.to_dict())
如果节点无属性信息,可以通过以下方法从连接表直接构造和导出。
df = nx.to_pandas_edgelist(G, source='source', target='target') # source,target,weight,...
G = nx.from_pandas_edgelist(df)
从邻接矩阵构造图
对于只有权重的图,可以使用以下方法通过邻接矩阵构造和导出。
df = nx.to_pandas_adjacency(G, weight='weight', nonedge=0.0) # 邻接矩阵
G = nx.from_pandas_adjacency(df)
array = nx.to_numpy_array(G, weight='weight', nonedge=0) # 邻接矩阵
G = nx.from_numpy_array(array)
array = nx.to_scipy_sparse_matrix(G, weight='weight', format='csr')
G = nx.from_scipy_sparse_matrix(A, edge_attribute='weight')
基于已有图构造
G.add_nodes_from(H) # 从另一个图中添加节点
G.add_edges_from(H.edges)
G = nx.Graph(H)
文本数据导入导出
from networkx import json_graph
data = json_graph.node_link_data(G) # return nodes and links as dict
G = json_graph.node_link_graph(data)
data = json_graph.adjacency_data(G) # return nodes and adjacent neighbors
G = json_graph.adjcency_graph(data)
除了直接按上述方法从JSON数据构造图外,还可将导出的JSON数据转换为DataFrame,从而得到规范完整的节点和链路信息,可进一步编辑并构造图对象。
图的信息
节点信息
节点属性集合是一个字典,可动态修改。
G.nodes # -> NodeView:Iterable
for n in G.nodes: # n 是节点的索引,即初始化时传入的节点编号
print(G.nodes[n])
边信息
G.edges # EdgeView:Iterable,
for e in G.edges: # e为边的索引,即首尾节点编号二元组
print(e, G.edges[e]) # => G.edges[v1,v2] => G[v1][v2] 边
G.edges([subset_nodes]) # -> EdgeDataView:获取包含给定节点的边集合
遍历元素属性:
for (u, v, wt) in FG.edges.data('weight'):
if wt < 0.5:
print(f"({u}, {v}, {wt:.3})")
邻居信息
G.adj # -> AdjacencyView: {node:{adj_node:link_attrs,...},...}
G.adj[v] # <=> G[v] -> AtlasView: {node:link_attrs,...}
G.adjacency() # -> dict_itemiterator: [(node:{adj_node:link_attrs,...}),...]
G.neighbors(v) # ->Iterator 邻接表:节点v的邻居列表
G.degree()
G.degree[v] # <=> G.degree(v) or G.degree()[v]
G.degree([subset_nodes])
遍历图的信息:
for n, nbrs in G.adj.items():
for nbr, eattr in nbrs.items():
wt = eattr['weight']
if wt < 0.5: print(f"({n}, {nbr}, {wt:.3})")
设置图属性
除了构造图时设置属性,也可采用类似字典的方式为图或元素设置属性。
G.graph['day'] = "Monday"
设置元素属性
设置节点属性:
nx.set_node_attributes(G, values, name=AttributeName) # 设置节点属性
nx.set_edge_attributes(...) # 设置边属性
如果values为字典({node:value,...}),则仅设置其中指定的节点为对应的值;否则values应该为标量并设置全部节点。也可直接通过访问节点或边设置某一个具体节点或边的属性。
G.nodes[1]['room'] = 714
G.nodes[1]['pos'] = (1,2)
G[1][3]['color'] = "blue"
节点位置pos属性通常在图可视化中使用,除了已知位置(如地理位置),可利用布局引擎生成节点位置(如Graphviz)。
有向图
Dask分布式数据结构
提供基于Numpy数组和Pandas DataFrame对象等的分布式数据结构,支持本地化分布式并行计算。
分布式数据
Dask DataFrame
 https://docs.dask.org/en/latest/dataframe.html
https://docs.dask.org/en/latest/dataframe.html
https://docs.dask.org/en/latest/dataframe-api.html
import dask.dataframe as dd
df = dd.read_parquet("/path/sub*/file*.parquet") # read_csv()
df = dd.from_pandas(
df_or_ss,
npartitions=None,
chunksize=None, # number of rows per partition
sort=True, # 首先对数据按索引排序,以获得divisions
name=None # 为分布式数据命名(默认名为Hash值)
)
dask的读取函数可以使用通配符匹配文件夹和文件。如果数据是从HDFS导出的分片数据,则传入父文件夹将以子文件夹名重建分片参考列。
df.to_parquet(path,
write_index=True, # 写入索引
partition_on=None, # 对每个分区按指定列拆分为多个文件
write_metadata_file=True # 导出元数据(_metadata)到文件
)
将每个分区单独写入一个文件。
Dask Array
数据表操作
多数可执行操作为Pandas API的子集,但行为有所不同。
df.reset_index:与Pandas不同,索引在每个分区中单独设置,因此非单调。df.set_index:该操作会首先对要设置的索引列进行排序(开销较大;如果指定列已经有序可通过sorted参数告知方法避免重新排序);- 不支持为行赋值(
df.loc[i,col]=a出错);iloc仅支持取整列:df.iloc[:,col_idx] head(n=5, npartitions=1, compute=True):groupby仅支持对分组后的数据进行汇聚统计,不支持获取分组子表格,不支持以列索引级别分组(level=)。to_datetime:仅支持表格类型的数据转换(需要包含index),如Pandas/Dask的DataFrame和Series等。df.any(axis=None).compute():如果df是列为1的表,返回的是长度为1的Series,而非标量(pd.DataFrame:axis=None计算所有元素返回标量);代替方法转换为pandas.DataFrame或转换为Series。dask.dataframe不支持排序操作(分布式运行耗时)。
判断是否缺失数据:Dask仅提供notnull()和isnull()方法,未实现isna()和notna()。
数据源
- 不支持限定读取行数(例如
read_csv不支持n_rows参数); read_csv不支持设置数据中的列为索引列(设置索引开销较大且会改变数据顺序,可显式调用set_index);
赋值
不支持df.loc[:,cols]=values赋值,使用df.loc[idx]=values为行赋值。支持行索引和真值访问数据表的一行或多行。
df1 = df.loc[df[col]<10] # truth value必须为dask类型
数据分区
df = df.partitions[start:end:step]
n = df.npartitions
df.get_partition(n)
汇总
df = result.compute()
最佳实践
使用Pandas
在内存能够容纳数据的情况下,优先使用Pandas,避免并行计算开销。
筛选汇聚数据后使用Pandas
利用条件筛选行列,利用分组统计(groupby)进行汇聚后,可大幅减少数据量。
使用索引
可以为DataFrame设置一列索引(set_index),针对索引列的某些操作将会很快,例如通过排序过的索引查找内容,执行groupby.apply等操作。可通过df.known_divisions判断数据是否是经过排序的。
df2 = df.set_index(d.timestamp,
drop=True,
sorted=False,
npartitions='auto')
为
dask.DataFrame设置索引开销较大(Data Shuffling),因此应避免频繁使用(使用persist),或者将设置索引后的数据表存储到磁盘上供后续使用。如果指定列本身为有序的,则设置索引可以快速完成。
避免数据交换(Data Shuffling)
排序、分区(repartition)、去重(drop_duplicates)、设置索引(set_index)等操作需要各分区间进行数据交换。
shuffling operations that rearrange data become much more communication intensive.
将结算结果缓存(persist)在内存中,从而避免重复读取和交换数据等操作。
在单机集群上,由于所有工作节点共存,因此为避免数据缓存占用过多内存,应该首先对数据进行筛选。
ddf = dd.read_parquet(filepath) # Load data from files
ddf = ddf.loc[ddf[colA]==value, cols] # Filter data to a subset
ddf = ddf.set_index('date_time') # set an intelligent index (shuffle)
df = client.persist(df) # persist data in memory
在单机上,如果数据量过大导致无法将内容缓存在内存中,则可以将中间运算结果存储到外部存储。由于Dask采取并行懒加载方式处理数据,后续再重新从外部存储读取并处理数据仍比较快。
Repartition to Reduce Overhead
分区大小影响数据交换和Pandas向量化计算的效率。每个分区大小控制在100MB左右,而少于100个分区则有利于数据交换。应该控制分区数量(df.repartition),使得分区适应内存(小于1G),并减少调度节点的处理开销。
df = df.repartition(divisions=None, npartitions=None, partition_size='5MB')
当数据有索引时,
df.divisions为分区的索引边界。
partition_size为内存占用量,大约为磁盘占用量的2倍。
repartition会根据指定参数合并或拆分已有分区。在未指定divisions的情况下,并不能保证各分区大小均匀。
使用Parquet格式存储数据
https://docs.dask.org/en/latest/dataframe-best-practices.html
https://docs.dask.org/en/latest/dataframe-joins.html
dask.DataFrame类型转换
df.to_dask_array()
dd.to_datetime()
Vaex
| Vaex | Dask | Pandas | |
|---|---|---|---|
| Performance | $>{10}^9$ RPS | ||
| Lazy Compute | √ | ||
| Memory | memory mapping | ||
vaex-core: DataFrame and core algorithms, takes numpy arrays as input columns.
vaex-hdf5: Provides memory mapped numpy arrays to a DataFrame.
vaex-arrow: Arrow support for cross language data sharing.
vaex-viz: Visualization based on matplotlib.
vaex-ml: Machine learning
vaex-jupyter: interactive visualization and selection in the Jupyter notebook and Jupyter lab.
Vaex依赖Dask。
Instead of making copies, Vaex internally keeps track which rows are selected.
df.select(df.x < 0)
df.evaluate(df.x, selection=True)
you can also create filtered datasets. This is similar to using Pandas, except that Vaex does not copy the data.
df_negative = df[df.x < 0]
df_negative[['x', 'y', 'z', 'r']]
group-and-compute
counts_x = df.count(binby=df.x, limits=[-10, 10], shape=64)
二维分组:
xycounts = df.count(binby=[df.x, df.y], limits=[[-10, 10], [-10, 20]], shape=(64, 128))
import data
df = vaex.from_arrays(col_x=x, col_y=y)
vaex.from_pandas(df, name='pandas', copy_index=False, index_name='index')
# Read a CSV file as a DataFrame, and optionally convert to an hdf5 file.
vaex.from_csv(file, chunk_size=None,
convert:Union[bool, str]=False,
**pd_kwargs)
vaex.from_ascii(path, seperator=None, names=True, skip_lines=0)
vaex.open(path,...)
to_pandas_df(column_names=None, selection=None, strings=True, virtual=True, index_name=None, parallel=True, chunk_size=None, array_type=None)
to_records(index=None, selection=None, column_names=None, strings=True, virtual=True, parallel=True, chunk_size=None, array_type='python')
export(path, progress=None, chunk_size=1048576, parallel=True, fs_options=None, fs=None)
export_hdf5(path, byteorder='=', progress=None, chunk_size=1048576, parallel=True, column_count=1, writer_threads=0, group='/table', mode='w')
export_arrow(to, progress=None, chunk_size=1048576, parallel=True, reduce_large=True, fs_options=None, fs=None, as_stream=True) # support parquet
export_parquet(path, progress=None, chunk_size=1048576, parallel=True, fs_options=None, fs=None, **kwargs)
export_partitioned(path, by, directory_format='{key}={value}', progress=None, chunk_size=1048576, parallel=True, fs_options={}, fs=None)
export_csv(path, progress=None, chunk_size=1048576, parallel=True, **kwargs)[source]
Introduction to HDF5 (mit.edu)
可视化
df.plot1d(df.x, limits='99.7%');
参考文献
输入输出
文件读写
创建文件对象:
fp = open(file_name, mode='r|b', encoding=None, buffering) # === io.open
# os.open底层IO接口
access_mode:访问模式。文件打开模式决定读写内容是文本(默认)或字节序列。
a:追加模式,如果文件不存在将自动创建。
close:可使用with语句实现自动管理文件资源。
文件对象
| 属性 | 描述 |
|---|---|
file.closed | 如果文件已被关闭返回true,否则返回false。 |
file.mode | 返回被打开文件的访问模式。 |
file.name | 返回文件的名称。 |
file.softspace | 如果用print输出后必须跟一个空格符,则返回false。 |
文件读写
readreadlineswritewritelinesseektell;
fp.readline()返回结果包含换行符“\n”;
fileinput基于行读取文件:
import fileinput
with fileinput.input(files=('data.txt',)) as file:
for line in file: print(line)
内置库filecache,你可以用它来指定读取具体某一行,或者某几行,不指定就读取全部行。
import linecache
content = linecache.getline(filename, lineno) # 行号从1开始,0返回空行
content = linecache.getlines(filename)
输入输出对象
提供类似文件读写的接口读写内存缓存空间的数据,包括基于文本io.StringIO和基于字节io.BytesIO的输入输出对象。
str_buffer = io.StringIO(initial_value='')
bytes_buffer = io.BytesIO(initial_bytes=b'')
文件类型支持
gzip
gzip模块提供 GzipFile 类和 open()、compress()、decompress() 几个便利的函数。
GzipFile 类可以读写gzip格式的文件,还能自动压缩和解压缩数据,这让操作压缩文件如同操作普通的文件对象一样方便。
gzip.open(filename, mode='rb', ...)
对于二进制模式,这个函数等价于
GzipFile构造器:GzipFile(filename, mode, compresslevel)。
gzip.compress(data, compresslevel=9)
gzip.decompress(data)
XML
import xml.etree.ElementTree as xml
root = xml.Element("users")
标准输入输出
读取一行输入字符串。
line = input("Press [enter] to continue.")
输入密码:
import getpass
p=getpass.getpass(prompt='Password: ')
使用print打印对象的文本表示 str(x)(__str__())。如果要格式化输出,通过str.format将输出格式化为字符串,再通过print输出字符串。
print(value, ..., sep=' ', end ='\n', file=sys.stdout) # 支持多个参数连续输出
print("... %{0:s} ... %{1:d} ...".format('Zara',21))
Python 2.x:
print "... %s ... %d ..." % ('Zara', 21)。
警告信息
生成警告信息
import warnings
warnings.warn(message,category=UserWarning,stacklevel=1,source=None)
stacklevel用于指定显示触发告警语句的层级,1表示warn语句所在行,2表示warn语句的上一级调用。
source:*if supplied, is the destroyed object which emitted aResourceWarning.*通常没用。
warn告警信息给出的行号总是在调用warn的位置,因此不能准确反映代码中触发告警的位置。使用warn_explicit()可以指定代码行号。
warnings.warn_explicit(message, category, filename, lineno, module=None, registry=None, module_globals=None, source=None)
警告类型
Warning:所有警告类型的基类,继承自Exception。UserWarning是warn()产生警告的默认类型。DeprecationWarning和FutureWarning分别用于告知开发者和最终用户相关特性将被弃用。
SyntaxWarning/RuntimeWarning/ImportWarning/UnicodeWarning/BytesWarning/ResourceWarning...。
警告信息筛选
每条告警信息按尝试依次匹配筛选规则,当匹配到规则,则按该规则的处理方式处理告警1。告警筛选规则包括:
action:警告的处理方式;"always":总是打印警告;"default":打印首次出现的匹配警告(不同的module+lineno);"module"打印模块内首次出现的匹配警告(不同的module);"once":仅打印一次匹配的警告;"error":将警告转换为异常;"ignore":从不打印警告;
message:匹配警告信息的正则表达式(大小写不敏感);category:匹配警告类型的类名(Warning的子类);module:匹配触发警告信息的模块名的正则表达式(大小写不敏感);lineno:匹配触发警告的行号(默认0匹配任意行)。
如果一条警告信息未匹配到筛选规则,则按默认处理方式处理。
设置警告规则列表
使用环境变量PYTHONWARNINGS(使用,分隔规则)、Python解释器-W选项(多次提供设置多个规则)设置,首次导入warnings模块时加载这些设置。一条规则的声明语法为
action:message:category:module:line
如果某个参数未提供,则:之间为空;如果字段数不足则对应参数值为空。Python内置了部分告警过滤规则,通过上述方法可覆盖这些预置规则。
warnings.filterwarnings(action,message='',category=Warning,module='',lineno=0,append=False)
warnings.simplefilter(action,category=Warning,lineno=0,append=False) # 不匹配message和module
append=False:默认将规则置于最前端。
临时设置警告规则
with warnings.catch_warnings():
warnings.simplefilter("ignore")
states_contains_warning()
日志
产生日志
产生日志的方法:debug(), info(), warning(), error(), critical(),对应了相应的日志等级DEBUG, INFO, WARNING, ERROR, CRITICAL,默认等级为WARNING。
全局日志生成器
import logging
logging.warning('Watch out!') # print to console
root_logger = logging.getLogger()
Logger
日志生成器(Logger)包含一名称用于区分日志来源,推荐基于模块级别构造日志生成器(使用.命名区分层级)。
logger = logging.getLogger(name=__name__) # default is root
logger.setLevel(level) # effective level
logger.warning(msg) # error/exception/warning/info/debug/trace
属性:level(日志级别)、name(日志器名称)。日志生成器会默认将消息传递给全局生成器(意味着会在生成两次日志并发送到相应目标),如果这一行为并非期望的方式,令logger.propagate=False禁止传递消息。
处理日志
日志处理方法包括:打印至控制台(StreamHandler,默认输出流为标准错误输出sys.stderr),存储到磁盘文件FileHandler。
配置全局日志处理方法
logging.basicConfig(filename='example.log', encoding='utf-8', level=...)
basicConfig()需要在产生日志的方法前调用。
自定义配置日志处理方法
Handlers类型将日志发送到指定的目标。可以为一个日志生成器添加多个日志处理器,从而将日志送至不同目标(默认添加了全局的日志处理方法,即输出到stderr)。常用处方法类型:FileHandler、RotatingFileHandler、TimedRotatingFileHandler、SocketHandler、DatagramHandler、SysLogHandler、NTEventLogHandler、QueueHandler
handler = logging.FileHandler(filename,mode='a',encoding=...) # mode可为追加(a)或清空(w)
from logging import handlers # 更多的处理方法在handlers模块中
handlers.TimedRotatingFileHandler(filename, when='h', interval=1,...)
# TimedRotatingFileHandler按时间区间轮换
# RotatingFileHandler按文件大小轮换,适用于多个进程向文件写数据。
when:时间单位包括S秒;M分;H时;D天;W0-W6周(大小写不敏感)。
logger.hasHandlers()可查看日志生成器是否配置了处理方法;使用logger.handlers查看其直接处理方法。如果日志生成器的属性propagate=True,则该日志生成器还会将日志传递上级日志生成器(logger.parent,默认为root)。
handler.setLevel(level) # handler需要处理的最低日志级别
logger.addHandler(handler) # logger.removeHandler() => logger.handlers
logger.addFilter(filter) # and Logger.removeFilter() => logger.filters
# addFilter() and removeFilter()
日志格式
logging.basicConfig(format='[%(asctime)s] - %(levelname)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S')
%(name)s:日志发生器名称;%(asctime)s:输出日期时间(格式参考time.strftime());%(message)s:日志消息;%(levelname)s,%(lineno)d,%(funcName)s,%(process)d……
Formatter
handler.setFormatter(
logging.Formatter(fmt=None, datefmt=None, style='%|{|$')
) # 设置格式化方法
配置日志
- 分别创建并配置日志处理流程的各个对象;
- 读取日志配置文件
fileConfig('log.conf'); - 读取包含配置信息的字典
dictConfig(),可从JSON或YAML文件读取配置信息。
Logging HOWTO — Python 3.9.5 documentation
Logging Cookbook — Python 3.9.5 documentation
How to Collect, Customize, and Centralize Python Logs | Datadog (datadoghq.com)
logging — Logging facility for Python — Python 3.9.5 documentation
对象输出
格式化对象输出
Python内置pprint模块,支持将对象的数据成员序列化为JSON对象并格式化输出(提供缩进),默认输出到标准输出(stream=None)。
from pprint import pprint
pprint(object, stream=None, indent=1, width=80, depth=None, *, compact=False)
使用rich模块能够利用现代终端特性,提供输出内容的风格设置(斜体、加粗、颜色、高亮等)。
from rich import print # as rprint
print("[italic red] Hello[/italic red] World!", locals()) # 替换系统print函数
from rich import pretty
pretty.install() # 自动格式化Python命令行回显的对象。
from rich import inspect
inspect(obj, methods=Ture) # 格式化输出对象成员信息
在notebook中首先执行
%load_ext rich,在Jupyter Notebook中通过display方法使用rich。
数组输出
设置打印选项:
np.set_printoptions(
precision=8, # number of digits after "."
linewidth=75,
nanstr=None, infstr=None,
suppress=False, formatter=None, sign=None, floatmode=None)
表格输出
Pandas设置打印宽度等参数:
pd.set_option('display.width', 80) # 每行显示字符数
pd.set_option('display.max_columns', 40) # 最多显示的数据列数
pd.set_option('display.max_rows', 60) # 也适用于Jupyter Notebook
width和max_columns需要同时设置才有效。
设置数值显示精度:
with pd.option_context('display.precision', 2):
print(df)
进度条
click.progressbar
tqdm
安装:
conda install -c conda-forge tqdm # pip install tqdm
用法:
from tqdm import tqdm, trange
for char in tqdm(iterable):
sleep(0.25)
for i in trange(100): sleep(0.01)
with tqdm(total=10, desc='TaskName',unit='it') as pbar: # => pbar.close()
for i in range(10):
tqdm.write("task in progress ...")
sleep(1)
_ = pbar.update(n=1) # True if a `display()` was triggered.
desc值当进度条左侧显示的信息;unit指定在进度条右侧显示的速率单位。tqbar.set_description(desc=None, refresh=True)
防止进度条重绘
直接在进度条循环中添加输出语句(print)会导致进度条重复绘制(内容会粘连到之前绘制的进度条后面),可使用tqdm.write来输出信息(清除之前的进度条并输出信息,然后在下一行重绘进度条)。如果迭代过程中调用第三方库输出内容,可以首先将标准输出和错误输出重定向到tqdm。
import sys, contextlib, tqdm, time
from tqdm.contrib import DummyTqdmFile
@contextlib.contextmanager
def std_out_err_redirect_tqdm():
orig_out_err = sys.stdout, sys.stderr
try:
sys.stdout, sys.stderr = map(DummyTqdmFile, orig_out_err)
yield orig_out_err[0]
except Exception as exc:
raise exc
finally:
sys.stdout, sys.stderr = orig_out_err
with std_out_err_redirect_tqdm() as orig_stdout:
pbar = tqdm(total=100, file=orig_stdout, dynamic_ncols=True)
for i in range(100):
time.sleep(1) # internal messages
print(f'progress to {i}')
print(f'progress to {i*10}')
_ = pbar.update(n=1)
pbar.close()
图形界面
import tqdm.gui
tqdm.gui.tqdm(total=100, desc='Progress')
用于Apply|Map操作
tqdm.pandas(desc)
df.progress_apply(...) # similar to apply()
df.progress_applymap(...) # similar to applymap()
alive-progress
安装:pip install alive-progress。
from alive_progress import alive_bar
with alive_bar(total=100, title='Task') as bar:
for i in range(100): # iterate as usual
sleep(1)
bar() # call after consuming one item
title:显示在进度条左侧。
数据交换
对象序列化
JSON对象序列化
将Python对象转为为JSON描述的字符串形式,并写入文件;或从文件读取JSON字符串并转换为Python对象。
json.dump(obj, fp,..., ensure_ascii=True,indent=None,
default=default_func, cls=custom_encoder)
obj = json.load(fp,...)
ensure_ascii=True则将非ASCII字符传唤为Unicode转义序列,如\u9ed8\u8ba4;反之则使用UTF-8编码文本,文件也应该使用UTF-8编码打开。
indent:如果为None,则不会换行;反之,按给定数量缩进各层级内容;
dumps和loads在对象和字符串之间转换。
默认编码类JSONEncoder支持转换的Python类型包括:
| Python | JSON |
|---|---|
dict | object |
list/ tuple | array |
str | string |
numeric(int,float) | number |
True | true |
False | false |
None | null |
对于JSONEncoder不支持的类型,可通过自定义default方法或继承JSONEncoder并重写default方法。例如,将任意迭代类型转换为list,或者将np.int64转换为int。
def default(o):
try:
iterable = iter(o)
return list(iterable)
except TypeError as e:
raise e
def MyEncoder(JSONEncoder):
def default(self, o):
pass
不完整的JSON对象解析
YAML
安装
pip install pyyaml
python setup.py --with-libyaml install # install with lib
使用
import yaml
try: # use LibYAML based parser and emitter
from yaml import CLoader as Loader, CDumper as Dumper
except ImportError:
from yaml import Loader, Dumper
data = yaml.load(stream, Loader=Loader)
output = yaml.dump(data, Dumper=Dumper)
marshmallow
marshmallow: simplified object serialization, converting complex datatypes to and from native Python datatypes.
marshmallow使用Schema约束对象的序列化和反序列化时的==数据类型==(相比json无类型验证)。Schema定义的字段对应于对象的成员变量/属性或是字典的元素。
from marshmallow import Schema, fields
class ArtistSchema(Schema): # 使用静态成员来定义Schema
name = fields.Str()
class AlbumSchema(Schema):
title = fields.Str()
release_date = fields.Date()
artist = fields.Nested(ArtistSchema()) # 嵌套定义
album = dict( # 要序列化的对象可以是字典或是对象(特别地,数据类对象)
artist=dict(name="David Bowie"),
title="Hunky Dory",
release_date=date(1971, 12, 17)
)
schema = AlbumSchema()
result = schema.dump(album) # -> Python字典
result = schema.dumps(album) # -> JSON文本
Quickstart — marshmallow 3.11.1 documentation
pickle
The
picklemodule implements binary protocols for serializing and de-serializing a Python object structure.The
picklemodule is not secure. Only unpickle data you trust.
pickle.dump(obj, file, ...) # write an object to file stream
obj_bytes = pickle.dumps(...) # return bytes array instead of writing to file
file:打开的文件对象。
a = pickle.load(file, ...)
a = pickle.loads(bytes_buffer, ...)
pickle编码的数据与代码相关,不同Python版本间可能存在兼容性问题。
pickle编码速度较慢。
cloudpicke
cloudpickle支持序列化pickle模块不支持的Python数据结构,尤其是支持==函数对象==,因此可以将代码保存并传递到本地或远程的其他进程。cloudpickle提供与pickle相同的接口。
marshal
marshal不能用于序列化用户自定义类型对象。
The
marshalmodule exists mainly to support reading and writing the “pseudo-compiled” code for Python modules of.pycfiles. Therefore, the Python maintainers reserve the right to modify the marshal format in ==backward incompatible== ways should the need arise. If you’re serializing and de-serializing Python objects, use thepicklemodule instead – the performance is comparable, version independence is guaranteed, and pickle supports a substantially wider range of objects than marshal.
How to pickle a python function with its dependencies?
shelve
A “shelf” is a persistent, dictionary-like object, where the values in a shelf can be essentially arbitrary Python objects that the
picklemodule can handle. including most class instances, recursive data types, and objects containing lots of shared sub-objects. The keys are ordinary strings.shelve — Python object persistence — Python 3.10.7 documentation
导入导出数据
使用NumPy/SciPy
保存数组数据为二进制文件(默认以.npy作为扩展名)。
np.save(file_name, array, allow_pickle=True, fix_imports=True)
array = np.load(file_name) # 加载数组或pickle对象。
序列类型也可以进行保存,Numpy会自动将其转换为
ndarray。
保存多个数组
np.savez(file, arrays, kw_arrays) # save as '.npz' format
使用关键字参数可以关键字作为数组名一并保存;反之,数组将按'arr_0', 'arr_1'的方式依次命名。
npz文件格式是一个由数组对象对应的npy文件组成的档案文件。使用savez_compressed将档案文件进行压缩。
同样使用np.load读取npz文件并返回一个NpzFile对象,可访问其中包括的数组对象。
arrays = np.load(file)
var_names = arrays.files # 获取包含的数组名
arr = arrays[var_name] # 读取数组
保存数组为文本文件
==仅适用于1D或2D数组==。
np.savetxt(fname, array, fmt='%.18e', delimiter=' ', newline='\n', header='', ...)
array = np.loadtxt(fname, dtype=<class 'float'>, delimiter=None,...)
array = np.genfromtxt(fname, dtype=<class 'float'>, delimiter=None,...)
fmt中可以添加固定字符,例如添加\n以强制换行。
newline为插入到两行之间的分隔符(默认\n);
genfromtxt增加了处理缺失数据的选项。
保存稀疏数组
from scipy import sparse
sparse.save_npz(file_path, matrix)
matrix = sparse.load_npz(file_path)
使用Pandas
Pandas提供读取多种格式的数据的方法:包括CSV、EXCEL、JSON、数据库等。pd.read_csv/read_json()和pd.DataFrame.to_csv/to_json()可读取文件或IO文本缓存对象。
# 适用于转换命令行输出的表格型数据
df=pd.read_csv(io.StringIO(output))
CSV
data = pd.read_csv(
"D:/DataSets/NSL-KDD/KDDTrain+.txt", header='infer', index_col=None, escapechar="\\")
header:默认将第一行作为表头header=0,没有头部的CSV文件应该设置header=None(将生成默认数组编号表头);names:代替从文件中读取的表头;index_col:设置作为行索引的列名,设置多个列名以生成MultiIndex;usecols:指定要读取的列;dtype:指定数据类型,使用字典单独指定某列类型;skipinitialspace:==跳过分隔符后的空白字符==。quotechar:引号字符用于包含字符串,对字符串中的分隔符转移;doublequote将两个连续引号字符视为一个引号元素。escapechar:转义字符,可以消除任何字符可能具有的特殊含义(\n、\t等代表特殊控制序列,直接转换为字母),主要用于消除引号的特殊意义。不仅限于使用引号字符的字符串,任何字段中包含转移字符都有效。 分隔符sep|delimiter:sep=','(默认);\s+空白,==用于处理以空格或\t分隔的数据==;长于1个字符将被视为正则表达式(强制使用Python解析引擎);delim_whitespace=True用于指定空白作为分隔符。lineterminator:只有选择'C'解析引擎才可用。encoding=utf-8:文件的编码方案,其他包括:gb18030。skiprows=N|[i,j,...]|func:跳过文件中的行,先于读取表头(即跳过的行包含表头)。如果参数为列表,则跳过指定行,如果为整数则跳过相应行数。如果为函数,则函数根据输入行号计算是否跳过对应行,如:
lambda i: i>0 and i<=100(跳过除第一行之后的100行)。lambda j: i%2==0(跳过奇数行)。
error_bad_lines:warn_bad_lines:comment:注释行开始符号。
日期解析选项:
parse_dates:bool|List[str]|List[int]|dict{'name': List}:指定是否解析日期以及解析日期的列名/编号;使用字典表示使用多列的值拼接后进行解析,并将解析后的值以字典键名作为列名输出。infer_datetime_format=False:自动推测日期格式。keep_date_col=False:如果是使用原数据的多列拼接解析,是否保留原数据。date_parser=dateutil.parser.parser:解析日期的函数。day_first=False:日期格式为DD/MM。
读取excel文件需要openpyxl库支持。
输出:
df.to_csv("path/to/file.csv", header=True, index=True, columns=None, float_format='%.2f', sep=',', na_rep='', )
使用
columns参数指定导出的列。
quotechar(默认为")、doublequote=True、escapechar=None
JSON
pd.read_json(path_or_none, orient='records', dtype=True,
convert_dates=True, keep_default_dates=True, date_unit=None,
encoding='utf-8', encoding_errors='strict',
compression='infer', # 'infer', 'gzip', 'bz2', 'zip', 'xz', None for no compression
lines=False, chunksize=None, nrows=None, # refer to pd.read_csv()
storage_options=None # e.g. http://user:passwd@host/path/file.json
)
orient:导出数据格式。
-
'split':=>{'index':[...],'columns':[...],'data':[...]},分别存储索引、列名和数据(矩阵); -
'values':仅存储数据矩阵(split的数据矩阵); -
'index':=>{'index':{'column':value,...},...},按==行索引==存储记录,每条记录都包含列名;-
'columns':=>{'column':{'index':value,...},...},按==列存储==,每列都包含索引名; -
'records':=>[{'col1':val1,...},...,{'col2':val2,...}],使用列表存储记录,不存储索引; -
'table':{'schema': schema, 'data': data}。data结构和records输出结构相同(包含index);{ "fields": [{"name": name, "type": type},...], "primaryKey": ["index"] }
-
dtype:默认自动推导数据类型,如果为字典则使用指定类型;
convert_dates:默认将类似日期的列转换为日期类型数据(datetime64[ns]);如果为列表,则只对指定列进行转换;
keep_default_dates:默认尝试转换以'_at','_time'结尾,以'timestamp'开头,或为'modified, date'的字段;
date_unit:默认尝试检测日期的单位;如果自动检测不正确,则可以指定单位为's','ms','us','ns';此处指定的时间单位仅影响读取数据,==不影响转换后日期类型的单位==。
chunksize:分块大小,返回一个迭代对象,每次获取指定数量的记录;
nrows:仅返回指定数量的记录(默认返回全部)。
df.to_json(path_or_none, orient='records',
date_format='epoch', date_unit='ms', double_precision=10,
force_ascii=True, # 不强制保存为ASCII(可使用UTF-8打开文件)
lines=False, # for orient='records':输出去掉外层[],每行一条记录
index=True, # for orient='split'| 'table'
indent=4,
default_handler=str,
compression='infer', # infer from filename
storage_options,
)
date_format:'epoch'表示date_unit单位的时间戳(除orient='table'外的默认值),iso表示ISO8601文本格式(2017-09-30T09:00:00,orient='table'的默认值)。
date_unit:转换后的数值单位('s','ms','us','ns')。
default_handler:对于无法转换的数据结构的默认转换方法。与
to_json()类似的方法是to_dict(),后者仅将数据表转换为Python字典,因此不需要考虑数据序列化的问题,因此没有序列化相关参数。
Parquet
df.to_parqeut(filepath=None, index=None, partition_cols=None)
index=False:不保存索引信息。如果为True则索引被保存为数据列,如果为None,则索引被保存为元数据。==如果未指定分区,则路径为文件;反之,路径为目录名==;如果未指定路径则返回一个bytes对象。Pandas使用
pyarrow库作为读写Parquet文件的接口,使用以下方法可以读取文件的元信息:import pyarrow.parquet as pq pq.read_metadata(file) # 汇总信息 schema = pq.read_schema(file) # 表格字段类型定义 types = [str(t) for t in schema.types] df = pd.DataFrame({'Field': schema.names, 'Type': types})
读取分片数据时可能遇到类型不匹配问题(null schema)。
数据库
Pandas使用SQLAlchemy读取数据库。
sql_engine = sqlalchemy.create_engine(db_url, **kwargs)
df = pd.read_sql(table_or_query, sql_engine, **kwargs)
如果参数为表名则调用read_sql_table,反之调用read_sql_query。
index_col:用作索引的列(str或list);
coerce_float:尝试将非数值(如decimal.Decimal)转换为浮点数类型;
parse_dates:针对源数据为字符串或时间戳,转为日期时间的列名(list)或:
{column_name: format_string}):列名及其对应的变换格式;{column_name: arg_dict}:列名及传递给pandas.to_datetime的选项参数(用于数据库不支持Datetime的情况)
columns:从表中读取的列(仅用于读取表格);
chunksize:如果指定该参数,则返回一个迭代器Iterator[DataFrame]包含指定的行数;
写入数据库(如果表格不存在将自动创建):
df.to_sql(
table_name,
con=sql_engine, # created by SQLalchemy
if_exists='fail', # 如果表格存在, "replace" or "append"
dtype=dict_or_scalar, # 指定某些列的类型,使用SQLAlchemy定义的类型
index=True, # 是否将索引保存为数据库表的列
index_label=str_or_list, # 指定保存的索引列名称
chunksize=None # 每次写入的行数(默认一次全部写入)
)
覆盖表格内容:使用if_exists='replace'将删除并重新创建数据库表。为了==确保数据库表的定义不变==(to_sql生成的表定义可能与人工配置的定义不同),可在写入前先执行TRUNCATE TABLE命令,再使用if_exists='append'进行==追加写入==。
df.to_sql()不支持更新已有数据库表中的记录(因为涉及查找匹配记录的具体逻辑)。
读写配置文件
configparser:Tips and Tricks for Handling Configuration Files in Python | by Ng Wai Foong | Better Programming
python - Pros and cons for different configuration formats? - Stack Overflow
Config Files: INI, XML, JSON, YAML, TOML | BareNakedCoder.com
声音
产生蜂鸣音:
import winsound
frequency = 2500 # Set Frequency To 2500 Hertz
duration = 1000 # Set Duration To 1000 ms == 1 second
winsound.Beep(frequency, duration)
os.system("beep -f 555 -l 460") # on linux
图形
Matplotlib
matplotlib中,frontend就是我们写的python代码,而backend就是负责显示我们代码所写图形的底层代码。backend分为两类:
interface backend(interactive backend):跟显示到屏幕相关的UI库(需要额外安装);hardcopy backend(non-interactive backend):写入到文件相关的库。
import matplotlib
matplotlib.rcsetup.interactive_bk # 获取 interactive backend
# GTK4Agg, Qt5Agg, TkAgg, WXAgg, GTX4Cario, Qt5Cario, TkCario, WXCario ......
matplotlib.rcsetup.non_interactive_bk # 获取 non-interactive backend
# agg, cario, pdf, pgf, ps, svg, template
matplotlib.rcsetup.all_backends # 获取所有 backend
plt.get_backend() # 获取正在使用的后端
plt.switch_backend('name') # 切换后端
matplotlib.use('Qt5Agg') # 切换后端, use before import pyplot
不同的后端提供的图形接口可能不同。
绘图窗口(figure)
import matplotlib.pyplot as plt
fig = plt.figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True, clear=False)
figsize:图形尺寸(英寸)[width, height]。
clear:激活图形时是否清除已有内容。
num:可以为整数(fig.number)或字符串(作为图形标签以及窗口标题)。如果没有指定,则自动编号。如果为整数,则窗口编号默认为Figure <num>。==如果指定编号切片对应图形窗口存在,则激活该窗口,反之创建对应该编号的窗口。==可以在相关绘图函数中指定编号以操作对应的图形窗口。
图形窗口创建后默认为隐藏状态,需要调用fig.show()(非阻塞)/show()来显示窗口。
利用各种绘图函数也可以自动创建图形窗口。
绘制子图
在当前图形窗口中创建子图。如果当前没有图形窗口则创建一个。
ax = plt.subplot(nrows, ncols, index, ...,**kwargs)
ax = plt.subplot(pos, ..., **kwargs)
nrows, ncols指定网格大小,index为按行索引的子图序号。index也可以设置为二元组(first,last)表示子图跨列。==当指定的网格大小超出当前图形窗口的网格范围,会清除此前已经创建的子图网格并重新创建;反之,则切换当前子图。==如果只是添加子图,则使用add_subplot()方法。
pos使用三位数字代替nrows, ncols, index(少于9幅子图);
sharex, sharey:所有子图共享坐标轴设置(limits, ticks, scale);
label:子图坐标系的标签;当指定指定坐标子图时默认返回已有子图(如果没有则新创建一个),==如果提供不同标签,则会返回新的子图==。
**kwargs:subplot()方法还接受坐标轴的属性对应的关键字参数。
封装了
Figure.add_subplot(nrows, ncols, index, ...,**kwargs)。
创建一个包含子图网格的窗口:==当所有子图的属性一致时,以及设置窗口属性==,使用该函数更加方便。
fig,ax = plt.subplots(nrows=1, ncols=1,
**subplot_kw, **gridspec_kw, **fig_kw)
当只生成一幅子图时,返回的坐标对象ax;当生成1xN或Nx1幅子图时,返回1维坐标对象向量;其他返回MxN坐标对象矩阵。
当不提供行列数(即
nrows=1, ncols=1),subplots等效于先创建图形窗口,再调用fig.add_subplot()。
subplots()不接受pos参数。
获取当前窗口
获取当前窗口,如果不存在图形窗口,则创建一个。
fig = plt.gcf()
部件
显示绘图
plt.show(block=True) # show current figure
block=True:在交互式终端中,显示绘图后阻塞程序,直到绘图窗口关闭。fig.show()不能阻塞程序,当程序退出时,图形窗口将关闭(在图形显示后执行sleep会使图形窗口无响应)。
在非交互模式(ion()/ioff())下,修改图形数据后重绘当前图形窗口。
plt.draw() # ==> fig.canvas.draw_idle()
plt.clf() # Clear the current figure
清除图形内容
fig.clear() # fig.clf() 清除图形内容
ax.cla() # 清除坐标轴内容
关闭图形窗口
plt.close()
坐标系
除了绘图返回坐标系以外,也可以首先手动创建坐标系。
from matplotlib.pyplot import axes, gca
ax = plt.axes(**kwargs) # creat an axes and make it current axes.
plt.axes(ax) # add an axes and make it the current axes.
获取当前坐标系,如果不存在,则创建一个新的坐标系。
ax = plt.gca(**kwargs) # 参数用于必要情况下创建坐标系
ax.get_figure() # 获取坐标系所属图片
ax.axis('off') # hide the axes: ax.set_axis_off()
ax.set(**kwargs)
ax.set_title(label, fontdict=None, loc={'center|left|right'},y)
ax.set_xlabel() # set_ylabel
ax.set_xlim() # set_ylim
kwargs中的属性都对应了相应的set_property()方法。plt.property(...)快捷方法等效于调用或ax.set_property(...)使用$\LaTeX$为标签添加数学公式:
bbplt.rcParams.update({ "text.usetex": True, "font.family": "sans-serif", # serif "font.sans-serif": ["Helvetica"]}) # "Times New Roman"在标签文本中添加行内公式(inline),$\LaTeX$命令需要使用转义字符
$\\beta=0.1$。
设置坐标刻度
默认以图形数据的x,y值作为刻度数值和刻度的标签。当数据点数较多时,可人工设置刻度值和标签,从而减少坐标轴上标记的数量(刻度数值和刻度标签是一一对应的,刻度标签需要在设置刻度后设置(调用ax.set_xticks,ax.set_xticklabels或者plt.xticks等效调用),否则可能会导致标签与刻度错位)。
ax.set_xticks(x, minors=False) # => set_yticks,
ax.set_xticklabels(labels, minors=False, rotation=50) # set_yticklabels
plt.xticks(ticks=None,labels=None,**kwargs) # 同时设置刻度值和刻度标签(Text properties)
kwargs为标签文本的属性,包括rotation(逆时针旋转角度)。plt.xticks在未提供刻度和标签参数,但提供属性参数时,更新当前坐标轴刻度的属性。
坐标轴对象提供了刻度常用属性的设置:
ax.tick_params(axis='both|x|y', which='major|minor', labelrotation=...) # 设置刻度及标签属性
ax.ticklabel_format(axis='both|x|y', style='sci', scilimits=(0,3)) # 设置标签格式(科学计数法)
tick_params常用属性包括:
color, labelsize, labelcolor,labelrotation,bottom,top,left,right(是显示某个方向的刻度),labelbottom,labeltop,labelleft,labelright(是否显示某个方向的标签)。
设置网格
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
设置图例
ax.legend(fontsize='small', loc='upper left', ncol=2) # 自动设置(plt.legend)
ax.legend(lines, labels, ...) # 指定对应图例
自动设置:1) 在调用相应绘图函数时指定标签(label='line_label');2)通过已绘制的图形部件设置标签(set_label('line_label'));
以下划线开头的标签,将不会自动显示在图例中。
图形部件
折线图
lines = plt.plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)
lines = ax.plot(...)
使用fmt定义折线格式的颜色、标记和线形,例如--ro;或使用曲线(Line2D)属性作为kwargs(应用于此次绘制的所有曲线),其中:
-
color='green'(或c): -
marker='o':标记类型,常用类型包括:+(加号)、o(实心圆)、*(星号)、.(点)、|_(短划线)、1|2|3|4(三分符号)、x(斜十字)、^|v|<|>(三角形)、s(正方形)、D|d(菱形)、p(五边形)、h|H(六边形),(仅为一个像素点)、8(八边形)、P(加粗十字)、X(加粗斜十字)。 -
markersize=12:标记尺寸; -
markevery=(start,N):当绘图点数较多时,通过该选项减少标记的点数。每N个点标记,从start开始标记(Line2D.set_markevery())。 -
fillstyle:标记填充方式,'full'使用markerfacecolor填充、none不填充; -
linestyle='-'(或ls):线形'-','--','-.',':','',...; -
linewidth=2(或lw): -
label='Line1':折线关联的标签,用于显示图例(ax.legend)。
对数尺度绘图
手动绘图:将坐标值进行对数转换(np.log10);坐标轴刻度值设置为相应的对数转换后的值,坐标轴刻度标签设置为原始数值的表示。
ax = np.plot(np.log10(x), y)
ax.set(
xticks = np.log10(sub_x), # 选取部分值作为坐标轴刻度
xticklabels = ['format'.(x) for x in sub_x]
)
使用库函数绘制对数尺度折线图:自动设置刻度和标签格式(默认为指数表示)。
plt.semilogx(x,y,...) # plt.semilogy(...), ax.semilogx(...), ...
plt.loglog(x,y,...) # 横纵坐标均使用对数尺度绘图。
如果需要手动设置刻度标签,为了使刻度均匀分布,刻度值应该是等比数列,标签与刻度值保持一致。
plt.axvline(x) # 垂直线, 水平线 plt.axhline(x)
柱状图
from matplotlib.axes import Axes
bars = ax.bar(x, height, align='center', tick_label=...,
width=0.8, label=...)
x:柱状图的横坐标;如果x为数值则表示实际位置;如果x为字符串,则位置按序号确定。x的值为默认横坐标标签,使用tick_label自定义横坐标标签。width表示柱形占x两个点之间的间距的比例,align='center'|'edge'为柱形相对x点的对齐方式(默认为中心对齐,edge为靠左边缘对齐)。
xerr,yerr:横纵坐标的值与误差。误差的设置方式:
- 标量:每个柱形的
+/-误差相同; - 向量:每个柱形对应
+/-误差,+/-误差相同; - 矩阵(
2,N):每个柱形具有独立的+/-误差。 None:没有误差线。
使用
barh绘制水平柱形图。此时x为纵轴,y为横轴,但``xerr,yerr`的含义不变。
label:为一个系列数据的标签,用于显示图例(legend)。
颜色选项:color、edgecolor;
线条选项:linewidth、``
堆栈式柱状图
每个条形分为多段,每一段代表一个系列的数据。
通过指定bottom参数来指定各个系列的相对位置。
ax.bar(x,y1,...)
ax.bar(x,y2,...,bottom=y1)
分组柱状图
 多个系列数据的每个点并列展示。绘图时需要设置每个系列的
多个系列数据的每个点并列展示。绘图时需要设置每个系列的x值偏移量,使各系列同一点的柱形并排显示(pandas封装了分组柱状图的快捷绘图方式)。
频数直方图
plt.hist(x, bins, range, density)
如果x是多个序列组成列表,则分别统计并绘制多个直方图。
bins:如果为整数,则指定分组个数,按均匀间隔分组;如果为序列,则指定分组的边界($N+1$);如果为字符串,则应该为:'auto', 'fd', 'doane','scott', 'stone', 'rice', 'sturges', or 'sqrt'(np.histogram_bin_edges)。
density=True:显示频率而非频数。
饼图
ax.pie(sizes, explode=None,
labels=None, labeldistance, # 标签及其离中心距离
autopct='%1.1f%%', pctdistance=None, # 百分比及其离中心距离
shadow=False, startangle=0)
explode控制饼图组成部分与中心分离的程度;
autopct:在饼图中显示百分比,并设置百分数格式;
shadow:饼图的立体阴影;
startangle:起始部分的角度(默认为0,即右侧水平位置);
boxplot
hexbin
 统计二维数据的分布信息。
统计二维数据的分布信息。
形状
from matplotlib.patches import Ellipse, Polygon
文本
文本对象在图中的标题、坐标轴标题、图例、刻度标签等使用,需要设置其属性。标签文本的常用属性包括:
text:color:fontfamily={FONTNAME,'serif','sans-serif','monospace'}:math_fontfamily:fontsize|size:fontstyle|style={'normal'|'italic'|'oblique'}:fontweight|weight={VALUE|'normal'|'regular'|'light'|'bold'...}:horizontalalignment|ha={'center'|'right'|'left'}:verticalalignment|va={'center'|'top'|'bottom'|'baseline'|'center_baseline'};parse_math:bool:usetex:bool:None使用rcParams["text.usetex"];rotation={FLOAT|'vertical'|'horizontal'}:url:str
标注
plt.annotate('msg', point)
默认绘图属性
默认绘图属性通过matplotlibrc配置文件、样式表(style sheets)和运行时配置参数rcParams(runtime configuration)确定,优先级按载入顺序依次由低到高。所有运行时配置参数储存在字典结构matplotlib.rcParams中(可通过matplotlib或pyplot来访问)。
plt.rcParams.update({'group.prop': value}) # 单独设置各项属性
plt.rc(group, **kwargs) # by group: plt.rc('font', size=20)
plt.rc按属性分组(font,lines,axes,figure等)设置当前的绘图属性。
通过
plt.rcParams()获取所有绘图属性的当前值,默认值可通过plt.rcParamsDefault获取;matplotlib.rcdefaults。
临时修改默认属性:
with mpl.rc_context(prop_value_pairs): # 使用上下文管理器
plt.plot(data)
@mpl.rc_context(prop_value_pairs) # 使用装饰器
def plotting_function():
plt.plot(data)
使用样式表设置默认绘图属性
print(plt.style.available)
plt.style.use('ggplot') # 使用内置或自定义样式表。
plt.style.use(['dark_background', 'presentation'])
with plt.style.context('dark_background'): # 临时修改绘图属性
plt.plot(np.sin(np.linspace(0, 2 * np.pi)), 'r-o')
plt.show()
自定义样式表格式与matplotlibrc格式相同,忽略与实际样式无关的rcParams参数。多个样式表(定义不同方面的样式)可进行叠加。
axes.titlesize : 24
axes.labelsize : 20
lines.linewidth : 3
lines.markersize : 10
xtick.labelsize : 16
ytick.labelsize : 16
标题
fig.canvas.set_window_title('title') # Window Title
# fig.canvas.setWindowTitle('title') 无效
尺寸
fig.set_size_inches(w, h=None, forward=True)
fig.set_figwidth(val, forward=True) # set_figheigth()
forward=True自动更新画布。长度单位转换:$1\mathrm{cm}\approx0.39\mathrm{in}$。
窗口状态:最大/最小化
fig_manager = plt.get_current_fig_manager()
# TkAgg backend
fig_manager.window.state('zoomed')
# Qt5Agg: showMinimized, showNormal, showFullScreen
fig_manager.window.showMaximized()
# wxAgg
fig_manager.frame.Maximize(True)
颜色
colormap
Matplotlib具有一系列内置colormap。
cmap = plt.get_cmap(name) # => matplotlib.cm.get_cmap(name)
A perceptually uniform colormap: equal steps in data are perceived as equal steps in the color space. Human brain perceives changes in the lightness much better than changes in hue(颜色).
gist_earth, ocean, and terrain all seem to be created for plotting topography (green/brown) and water depths (blue) together.
获取颜色系列:
colors = pl.cm.jet(np.linspace(a,b,n)) # a,b in [0,1]
matplotlib.cm内置颜色表(colormaps)和处理程序。
Pandas
使用表格数据绘图。类型包括:line、bar、barh(水平柱状图)、hist、box(boxplot)、kde|density (Kernel Density Estimation)、area、pie、scatter、hexbin。plot()方法统一封装了上述类型的绘图方法。
ax = df.plot(x=xname, y=y_names,
kind='line',
..,
ax=None,
subplots=False, # separate subplots for each y-column,
layout=(rows, columns), # subplot layout
figsize, # 单独使用Pandas创建窗口使用
title, # title (list) for (sub)plot
grid=False, # 显示网格
legend=False, # place legend
style:[list,dict], # matplotlib linestyle for column
logx=False, # log-scale x axis, => logy, loglog
xticks, # => yticks, xlim, ylim, xlabel, ylabel,
use_index, # index as x-ticks
fontsize,
colormap,
rot, # *rot=0水平显示横坐标
sort_columns=False,
**kwargs # 传递给绘图方法
)
ax = df.plot.bar(...,stacked=False,color[list,dict],**kwargs) # => barh
ax = df.plot.hexbin(x='x', y='y', gridsize=20)
ax = df.plot.hist(by=cols, bins=10, **kwargs)
ax = df.plot.scatter(...,c=colors)
x|y:指定DataFrame中用于绘图x轴和y轴数据的列名;同时,x用作坐标轴名称,y用做默认图例名;某些类型的图形可能不需要指定横坐标值(如hist和pie);x轴的值可以是非数值类型,x的值作为刻度均匀分布于坐标轴上,==其位置与数值大小无关==。当未指定x时,适用数据的index作为x值;未指定y时,适用所有数据列绘图。
默认后端:plotting.backend=matplotlib。可以与matplotlib的方法混合使用,例如绘制子图(需要==指定已有的坐标系对象ax==,否则创建新的图形窗口)。
Seaborn
https://stackoverflow.com/questions/62115464/sns-pairplot-shows-density-curve-instead-of-histogram
sns.pairplot(df, vars, hue='class', diag_kind='hist', kind='scatter')
diag_kind='auto'|'hist'|'kde'|None,If ‘auto’, choose based on whether or not hue is used.
kind='scatter'|'kde'|'hist’|'reg'
绘图数据太多会导致内存开销过大,执行缓慢;可随机抽样数据的一个子集绘图。
Plotly
创建图形窗口:
fig = go.Figure(data,layout=None) # data is a single trace or a tuple of traces.
fig.update_layout(**kwargs)
fig.show()
layout是布局对象或创建对象所需的参数字典。创建图形的显示布局对象:
layout=go.Layout(
title='Network graph made with Python',
titlefont_size=16, # layout.title.font
showlegend=False,
hovermode='closest',
margin={'b':20,'l':5,'r':5,'t':40}, # 图形外部填充的空白
annotations=[{
'text':"a", 'showarrow':False, 'xref':"paper", 'yref':"paper",
x=0.005, y=-0.002 }],
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False)
)
布局参数:
width,height:图形的绝对尺寸;margin:图形的边缘空白填充,需要保留填充空间才能显示标题等图形外的内容。
图片
im_ax = plt.imshow(X, cmap=None, norm=None, aspect=None, origin)
X:图像数据矩阵,支持的格式包括:
- $(M,N)$:使用colormap(
cmap)可视化数据。 - $(M,N,3)$:RGB值
- $(M,N,4)$:RGBA值。
aspect:图像纵横比,可设置为equal、auto或任意浮点数值。
origin:指定图像[0,0]像素点位于左上角(upper)或左下角(lower)。
读取图像:
plt.imread(fname, format=None)
fname表示文件名、URL或可读文件对象;format如果未给出则从文件扩展名推测,如果无法推测,则默认为PNG格式。
显示矩阵数据:原点为左上角,图形的比例与矩阵维度比例一致。
plt.matshow(A, fignum=None, **kwargs)
如果fignum=None则创建一个新图形窗口;如果fignum=0则在当前坐标系绘图。
保存图像
plt.savefig(fname, format=None,
bbox_inches='tight', transparent = False)
fname:文件路径、文件对象等。如果未设置format则从文件名中推测保存格式。该方法不会尝试将格式类型追加为扩展名。format包括'png'、'pdf'、'svg'、……
保存图片:
plt.imsave(fname, X, format=None, ...)
绘制网络图
使用NetworkX绘图
NetworkX提供基于Matplotlib的基本的图可视化方法(其主要是用于图分析),推荐使用专门的图可视化工具如Graphviz。
nx.draw(G)
使用Graphviz绘制网络图
from graphviz import Digraph,Graph
G = Digraph(name=None,
comment='The Round Table',
filename='hello.gv',
directory=None,
format='svg', # jpg|png|pdf|svg...
engine='neato', # 布局
encoding='utf-8',
graph_attr={'rankdir': 'LR'},
node_attr={'shape': 'plaintext'},
edge_attr={}
)
G.source生成图形源代码。
engine参数设置布局引擎,在绘图时自动计算节点位置以及边的形状。
图数据源
添加节点和边的方法。添加边会自动添加不存在的节点。
G.node('A', label='King Arthur', **attr_dict) # add node
G.edge(tail_name, head_name, label=label_str, **attr_dict)
G.edges(['AB', ('A','L')]) # add edges
节点和边添加后,不能修改指定节点或边的属性,只能修改某类型对象的默认属性。如动态更新图数据,可维护一个外部数据结构,如:NetworkX的图对象或Pandas表格存储的节点和边数据,且提供更加灵活的方法来访问边和节点并修改其属性。最后,在进行绘图前,可首先将图数据表示为上述数据结构,再转换为Graphviz对象。
NetworkX图(G.nodes,G.edges)转换为Graphviz图:
for n in G.nodes: # G is NetworkX Graph
g.node(str(n), **G.nodes[n]) # 如果节点索引非字符串,需要首先将其转换为字符串
for e in G.edges:
g.edge(str(e[0]), str(e[1]), **G.edges[e])
Pandas表格图数据(节点和边数据)转换为Graphviz图。节点数据包含节点索引列和节点属性,边数据包含边首尾节点编号和边的属性。
for idx, n in df_nodes.set_index('id',drop=True).iterrows():
g.node(str(idx), **n.to_dict())
for idx, e in df_edges.set_index(['head','tail'],drop=True).iterrows():
g.edge(str(idx[0]),str(idx[1]),**e.to_dict())
导入外部数据时注意:仅通过接口(如nx.set_node_attributes)设置取值有区别的属性,节点或边的公共属性可通Graphviz提供的attr等方统一设置,因此数据转换时没必要传递给每一个节点或边。
此外,可利用NetworkX提供的pydot接口将NetworkX图对象直接转换为Graphviz的源码,并用于构造Graphviz图对象。
dot: pydot.Dot = nx.nx_pydot.to_pydot(G)
g = gv.Graph(name="Reconstruct from source", strict=True,
body=dot.to_string().split('\n')[1:-2],...)
body:源码中的正文部分的行构成的==序列==,不包括"[strict] graph <NAME> {"和"}",因此需要根据源码格式去除开始和结尾行。
图的属性
图形元素的默认属性
修改组件的默认属性,后续添加元素如果未声明相应属性则使用默认属性。属性的值均使用字符串表示。
g.attr(kw=None, attrs=value, **kwargs)
kw表示要设置属性的对象类别,包括None,'graph','node','edge',None表示通用属性。attrs表示属性声明文本,例如:"fixedsize=shape shape=circle width=0.5"。kwargs为单独的属性项。也可通过图对象提供的成员(字典类型,g.graph_attr,edge_attr,node_attr)修改对应类别的默认属性。
g.graph_attr['rankdir'] = 'LR' # graph类
全局属性
对于图、节点和边通用的属性。
| 属性 | 说明 | 参数值(字符串) |
|---|---|---|
color | 填充或边框颜色 | `aqua |
style | 图形填充和边框样式 | `filled |
图形属性
| 属性 | 说明 | 参数值(字符串) |
|---|---|---|
engine | 图形布局 | `dot |
rankdir | 图形的流向 | `LR |
size | 图形尺寸 | |
节点属性
| 属性 | 说明 | 参数值说明 |
|---|---|---|
label | 节点标签 | 支持HTML标记<tag></tag>。 |
shape | 节点形状 | box/rect/rectangle/square/:矩形/正方形invtriangle/triangle:三角形diamond/parallelogram:菱形/平行四边形circle/doublecircle/ellipse/oval:圆/椭圆plaintext/plain/none:纯文本tab/folder/note:标签页/文件夹/笔记图标 |
fixedsize | false:由包含内容和边距决定最小长宽,且不小于width,height;true:仅由width,height决定,不会自适应内容;shape:类似于true,但根据内容调整节点距离避免重叠。 | |
width | 节点宽度 | 宽度或最小宽度 |
height | 节点高度 | 高度或最小高度 |
连接属性
| 属性 | 说明 | 参数值 |
|---|---|---|
weight | ||
label | 连线标签 | |
len | 边长度(dot引擎下无效) | 1.00 |
arrowhead | 箭头形状(Digraph) | `normal |
arrowsize | 箭头大小(Digraph) | 2 |
fontsize | 边标签字号 | 10 |
布局
u = w.unflatten(stagger=3)
渲染和保存
将图对象转换为源码并生成图像文件。
G.render('test-output/round-table.gv', view=True, cleanup=False)
gv.render(...,) # gv.render(filepath,...)
gv.Source.render(...) #直接从DOT源码渲染对象
To render the generated DOT source code, you also need to install [Graphviz](https://www.graphviz.org/ ).
从字符串读取DOT源码:
G.save() # 保存图形的DOT源码
dot_src = gv.Source(dot_str, ...)
gv.Source.from_file(...)
dot_src.save(...)
相关模块
pydot
PyGraphviz requires [Graphviz](https://www.graphviz.org/ ).
dot = nx.nx_agraph.to_agraph(G) # pygraphviz.AGraph()
使用Plotly绘制网络图
如果图的节点没有位置信息,需要使用布局引擎来计算节点位置以及边的形状。networkx提供多个布局方法以及基于Graphviz的布局方法生成位置数据。
pos=nx.bipartite_layout(G, nodes, align='vertical',...,aspect_ratio=4/3)
pos=nx.circular_layout(G, scale=1, center=None, dim=2)
pos=nx.nx_agraph.graphviz_layout(G, prog='neato', root=None, args='') # => pygraphviz_layout
pos=nx.nx_pydot.graphviz_layout(G, prog='neato', root=None) # => pydot_layout(...)
root是某些布局算法需要确定的根节点,args为传递给布局程序的额外参数。
pos是关于节点名的字典,元素值为(x,y)。因此,可直接将生成的节位置添加到图的节点属性中:
nx.set_node_attributes(G, pos, name='pos')
生成Plotly绘图数据,即节点和边的绘图数据:
def get_edge_trace(graph, linewidth=3):
edge_x, edge_y = [],[]
for edge in graph.edges():
x0, y0 = graph.nodes[edge[0]]['pos']
x1, y1 = graph.nodes[edge[1]]['pos']
edge_x.extend((x0, x1, None))
edge_y.extend((y0, y1, None))
edge_trace = go.Scatter(
x=edge_x, y=edge_y,
line=dict(width=linewidth, color='#888'),
hoverinfo='none',
mode='lines')
return edge_trace
def get_node_trace(graph, nodesize=20):
node_x,node_y = [],[]
for node in graph.nodes():
x, y = graph.nodes[node]['pos']
node_x.append(x)
node_y.append(y)
marker_specs = {
'size':nodesize,
'line_width':2,
'reversescale':True,
'showscale':True,
'colorscale':'Jet', # Greys,Rainbow,Jet,...
'color':[],
'colorbar':{title='ColorMeaning',titleside='right',xanchor='left',thickness=15}
}
node_trace = go.Scatter(x=node_x, y=node_y,
mode='markers', hoverinfo='text', marker=marker_specs)
num_neighbor = np.zeros(len(graph.nodes))
node_text = []
for i, adj in enumerate(graph.adjacency()):
num_neighbor[i] = len(adj[1])
node_text.append(f'Number of connections: {num_neighbor[i]}')
node_trace.marker.color = list(num_neighbor)
node_trace.text = node_text
return node_trace
使用Plotly绘制生成的绘图数据(生成的绘图对象可调用show()方法显示)。
layout = go.Layout(...)
fig = go.Figure(data=[edge_trace, node_trace], layout=layout)
绘制表格
使用Plotly绘制表格
plotly_table = go.Table(
columnwidth = [60]*len(df.columns), # 宽度比例,绝对宽度由图形宽度决定.
header=dict(
values=list(df.columns),
line_color='darkslategray',
fill_color='paleturquoise',
align='center',
font=dict(color='blue', size=16),
height=30
),
cells=dict(
values=[df[col] for col in df.columns], # values given by columns
#fill_color='lavender', # cell fill color
line_color='darkslategray', # default is None, scalar or list
fill=dict(color=['lavender', 'white']), # missing column use the last specified color
align='center',
format= ['d'] + [ '.3f']*(len(df.columns)-1),
font_size=16,
height=30
)
)
fig = go.Figure(data=plotly_table)
使用HTML渲染Pandas表格输出
pd.DataFrame.style是Style类型对象,使用生成表格数据的显示格式(CSS)。
https://mp.weixin.qq.com/s/uaYAQj69BCx5EqcxL4uqoA
颜色
def color_negative_red(val):
color = 'red' if val < 0 else 'black'
return f'color: {color}'
s = df.style.applymap(color_negative_red)
def highlight_max(s):
is_max = s == s.max()
return ['background-color: yellow' if v else '' for v in is_max]
s = df.style.apply(highlight_max, axis=0, subset=['B', 'C'])
需要在支持HTML的输出环境中(例如Notebook或Streamlit)才能显示指定的效果。
Style类型支持链式调用,因此可以将多种格式叠加到一个表格。
数值格式
df.style.format("{:.2%}", na_rep="-")
df.style.format("B": "{:.2%}") # 设置指定列的格式
df.style.format({"B": lambda x: "±{:.2f}".format(abs(x))}) # 格式化函数
df.style.set_precision(2)
字符串的对齐声明符在HTML输出中无效,使用CSS
text-align属性声明。
内置风格
df.style.highlight_null(null_color='red')
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
s = df.style.background_gradient(cmap=cm)
df.style.hide_index()
df.style.hide_columns(['C','D'])
全局风格
使用全局风格声明表格的默认字体、字号、对齐等风格。
list_style = [
dict(selector="th", props=[("font-size", "4pt")]), # header
dict(selector="td", props=[('padding', "0em 0em")]), # cell
dict(selector="tr:hover",
props=[("background-color", "%s" % hover_color)]# row
]
df.style.set_table_styles(list_style)
props由一个或多个属性的键值对组成。
设置一个数据切片的的属性:
df.style.set_properties(subset=None, **kwargs)
subset表示表格的子集,例如列名的列表;kwargs为CSS属性。
在列数据背景上绘制柱状图:
df.style.bar(subset=['A', 'B'], color='#d65f5f')
标题:
df.style.set_caption('Colormaps, with a caption.')
共享格式
style2.use(style1.export())
DTale
流程图
diagrams
conda create -n diagram -c conda-forge diagrams # pip install diagrams
Diagrams · Diagrams (mingrammer.com)
图形用户界面
Jupyter Notebook
常用控件
可用控件:
import ipywidgets as widgets
l = pd.Series([x for x in dir(widgets) if not x.startswith('_')])
df_widgets = l.loc[l.apply(lambda x: x[0].isupper())]
display(pd.DataFrame(df_widgets.to_numpy()[:60].reshape(10,6))) # 超过60个内置控件
[Widget List — Jupyter Widgets 8.0.0rc0 documentation (ipywidgets.readthedocs.io)](https://ipywidgets.readthedocs.io/en/latest/examples/Widget List.html)
输入控件
widgets.IntSlider(min=0, max=10, step=1, description='Slider:', value=3)
输出控件
from IPython.display import display
slider = widgets.IntSlider()
text = widgets.IntText()
display(slider, text, ...)
slider.value
IPython.display可根据对象类型采用合适的展示方式,而不仅是print对象。
from IPython.display import display
display(obj_value)
Matplotlib绘图对象会自动显示(无论命令执行位置,显示在单元输出的结尾位置),不需要使用display。
UI属性
description='Int Slider:' # 空间标签
布局和数据交互
连接控件:上一控件的输出更新下一控件的输入。
widgets.jslink((slider, 'value'), (text, 'value'))
UI事件
btn = widgets.Button(description='Medium')
display(btn)
def btn_eventhandler(obj):
print('Hello from the {} button!'.format(obj.description))
btn.on_click(btn_eventhandler)
刷新输出:使用Output控件捕获cell输出。
output_year = widgets.Output()
def dropdown_year_eventhandler(change):
output_year.clear_output()
with output_year:
display(output_info)
dropdown_year.observe(dropdown_year_eventhandler, names='value')
display(output_year)
Streamlit
安装:
pip install streamlit # conda install streamlit -c conda-forge
启动:
streamlit run app.py
编辑程序:运行中的程序可感知代码发生变换,并重新执行。
import streamlit as st
版本信息:
st.__version__
UI组件
key:默认以UI的标签区分UI对象,如果标签相同,则需要提供额外的key参数区分UI对象。
标签
标题:
st.title('Title')
st.header('Header1')
st.subheader('Header2')
选择
按钮/开关:
tf_press = st.button("Button")
tf_check = st.checkbox("Check", value=False)
单选组:
genre = st.radio(
"What's your favorite movie genre",
('Comedy', 'Drama', 'Documentary'),
index=1
)
单选下拉列表:
option = st.selectbox(
'How would you like to be contacted?',
('Email', 'Home phone', 'Mobile phone'),
index = 2
)
数值选择器:
age = st.slider(
'How old are you?',
value=25,
min_value=0, max_value=130)
类型选择器:
color = st.select_slider(
'Select a color of the rainbow',
options=[
'red', 'orange', 'yellow', 'green', 'blue', 'indigo', 'violet']
)
颜色选择:
color = st.color_picker('Pick A Color', '#00f900')
多选:
options = st.multiselect(
'What are your favorite colors',
['Green', 'Yellow', 'Red', 'Blue'],
['Yellow', 'Red']
)
输入
单行文本输入:
title = st.text_input('Movie title', value = 'Life of Brian', type='default')
type=password:设置为密码输入框。
文本区(多行文本输入):
txt = st.text_area('Text to analyze',
'''It was the best of times, it was the worst of times, it was
the age of wisdom, it was the age of foolishness, it was
the epoch of belief, it was the epoch of incredulity, it
was the season of Light, it was the season of Darkness, it
was the spring of hope, it was the winter of despair, (...)''',
height=200
)
数值输入:
number = st.number_input('Insert a number',
value=50,
min_value=0, max_value=100,step=1,
format='%.2f')
日期输入:
d = st.date_input(
"When's your birthday",
datetime.date(2019, 7, 6)
)
时间输入:
t = st.time_input('Set an alarm for', datetime.time(8, 45))
文件上传
uploaded_file = st.file_uploader("Choose a CSV file", type="csv")
文本输出
st.write根据对象类型选择相应的输出格式。
st.write(object)
全局作用域中的多行注释内容将被视为Markdown格式内容添加到输出结果中(等效于st.write),因此可以利用该性质添加段落输出。
文字格式输出:
st.text(text) # 等宽字体
st.caption(text) # 小号字体
数字指标输出:
st.metric(label="Streamlit version", value=0.87, delta=0.01)
表格输出
st.dataframe(data:Union[pd.DataFrame,pd.Styler,np.ndarray,Iterable,dict])
支持df.style的高亮语法,不支持宽度和对齐等设置。高度固定,自动生成水平/垂直滑动块;
Streamlit不能输出超过50MB的表格,此时可以仅截取部分内容输出。
Streamlit目前不能显示
category类型的数据。
table = st.table(df):支持自动调整列宽,在页面上显示全部内容。当页面宽度足够时,设置宽度有效。
信息块
st.success('This is a success message!')
st.info('This is a purely informational message')
st.warning('This is a warning')
st.error('This is an error')
e = RuntimeError('This is an exception of type RuntimeError')
st.exception(e) # display an exception
动画
进度条:
# placeholder = st.empty() # 进度条占位符
my_bar = st.progress(0) # placeholder.progress(0)
for percent_complete in range(10):
time.sleep(0.1)
my_bar.progress(percent_complete * 10)
# placeholder.empty() # 移除进度条
可将进度条置于st.empty()中,可以在进度完成后手动移除进度条。
进度指示器:
with st.spinner('Wait for it...'):
time.sleep(5)
下载
st.download_button
布局
st.set_page_config(page_title='动态服务管理', page_icon=None,
layout='wide', initial_sidebar_state='auto')
在其他命令使用前运行。
容器
在一个容器中添加多个UI组件。
with st.container():
st.write("This is inside the container")
st.bar_chart(np.random.randn(50, 3))
group = st.container()
group.write("This is inside another container")
与主页中直接组件的效果添加相同,和empty()不同不能更新已添加的组件。可以将empty()置于容器内部。
简单容器
空占位符st.empty():可在后续代码中向其中添加==一个==UI组件。空占位符引用该组件对象,因此可以多次调用该组件以更新其内容。
普通方式调用组件函数未返回组件对象的引用,因此无法对其更新,重复调用组件函数将创建多个UI组件。
placeholder = st.empty()
for i in range (1,100):
placeholder.text(f'Progress is: {i}') # update text
删除占位容器中的UI组件:
placeholder.empty()
可使用placeholder多次创建UI组件并替换现有内容。==通常不使用包含key参数的UI组件==(通常是输出组件,例如st.progress, st.write, st.text等),如果再次通过placeholder替换该类型组件,需要提供不同的key。
在with语句块中调用组件函数不会重复创建UI,with语句块结束后其中创建的组件不会消失。
with st.empty():
for seconds in range(60):
st.write(f"⏳ {seconds} seconds have passed")
time.sleep(1)
st.write("✔️ 1 minute over!")
可在st.empty()中设置一个container,从而构造可刷新的仪表板。
placeholder = st.empty()
with placeholder.container():
# place components here!
折叠内容
with st.expander(title, expanded=True):
add_components
表单
with streamlit.form(key:str):
# add_components
slider_val = st.slider("Form slider")
submitted = st.form_submit_button("Submit") # 提交按钮位于表单环境中
pass
if submitted:
handle_form_data
UI响应:未使用表单时,更改UI组件状态将自动触发代码重新执行(更新组件后台状态);使用表单后,更改表单内部组件的状态不会自动触发代码重新执行,内部组件的状态由表单UI组件缓存,直到点击提交按钮才会向后台发送状态变更并触发代码执行。
状态缓存:代码执行时,总是使用上次点击“提交”按钮后的各组件的后台状态。
水平线性布局
col1,co2,... = st.columns(n_or_portion)
with col1:
add_components_to_col1
co2.add_components
当参数为整数n时表示创建n个等宽列;如果为列表portion,则根据列表元素值确定每列的宽度占比。
水平多标签页
tab1, tab2, tab3 = st.tabs(['页面1', '页面2', '页面3'])
with tab1:
pass
tab2.dataframe(df)
侧边栏
在主页面上可使用的组件也可以添加到侧边栏(侧边栏可看组是一个特殊容器)。
add_selectbox = st.sidebar.selectbox(
"How would you like to be contacted?",
("Email", "Home phone", "Mobile phone")
)
多页面App
多页面App将单页面应用的代码按功能分解到多个文件中,代码组织结构如下。
multipage-app
├── 01_⏱_demo_app.py
└── pages
├── 02_🍕_output_demo.py
├── 03_🥗_input_demo.py
└── 04_🥩_plots_demo.py
streamlit run 01_⏱_demo_app.py
页面可根据文件名编号指定顺序展示。
绘图
内置绘图
chart = st.line_chart(data=None, width=0, height=0)
chart = st.area_chart(data=None, width=0, height=0)
chart = st.bar_chart(data=None, width=0, height=0)
use_container_width=True:与页面宽度一致。
可以向图形对象添加数据,从而更新返回结果。
chart.add_rows(data2)
显示图像
from PIL import Image
image = Image.open('sunrise.jpg')
st.image(image,caption='Sunrise',width=None,use_column_width='auto',output_format='png')
Matplotlib绘图
fig,ax = plt.subplots(figsize=(width_inch,height_inch),...)
ax.bar(x1,y1)
st.pyplot(fig=fig, **kwargs_savefig)
matplotlib的绘图后端:
matplotlib.rcsetup.all_backends # supported backends
matplotlib.pyplot.get_backend() # current use backend
==图形占用的宽度总是与页面宽度一致,图形的尺寸只影响显示的分辨率==。
-
可以使用
st.columns将页面划分为多个部分,而只在其中一列中放置图形。 -
将绘图转换为图片,使用
st.image显示。from io import BytesIO buf = BytesIO() fig.savefig(buf, format="png") st.image(buf, caption=None, width=600, output_format='png')
graphviz绘图
import graphviz
graph = graphviz.Digraph()
st.graphviz_chart(graph)
bokeh(*无法显示图像)
Visualizing network graphs — Bokeh 2.3.1 Documentation
from bokeh.plotting import figure
p = figure(
title='simple line example',
x_axis_label='x',
y_axis_label='y')
st.bokeh_chart(p, use_container_width=True)
Plotly
API reference — Streamlit 0.81.1 documentation
Tutorial: Network Visualization Basics with Networkx and Plotly in Python | Towards Data Science
import plotly.figure_factory as ff
fig = ff.create_distplot(
hist_data, group_labels, bin_size=[.1, .25, .5])
st.plotly_chart(fig, use_container_width=True)
代码执行
UI与程序执行流程
UI状态变更后,程序将从头重新执行。
当执行到UI创建代码后,UI创建代码会根据输入使用缓存UI或重绘UI,相应地返回的值为上一次UI状态变更时的数据,或本次重绘UI后的初始值。
UI缓存
UI内置了缓存机制,以保存UI状态更改。UI初始化应该使用常量(每次运行用户程序不变的量),从而保证UI对象始终缓存。不需要尝试手动保存UI的最新状态,并随后再次使用最新状态初始化UI。
实际上,由于界面状态更新后,用户代码才开始执行,当执行到相应UI代码时,会使用上一次的缓存状态再次初始化UI并返回初始化值(即上一次的缓存状态),导致用户获取不到更新的界面状态。一般情况下,==如果界面初始化参数发生变化都将导致用户上一次的UI更改无效==。
下图以
selectbox为例,初始化index=0(初次执行代码后用户缓存该值cache=0),如果用户选择index=2将刷新页面并再次执行代码,UI对象的初始化输入不变(cache=0-->index),因此返回给程序用户记录的选择(2);当用户再次选择(index=1)并触发界面刷新和代码执行,UI对象的初始化输入从index=0变为index=2,会导致UI对象的重新初始化,并返回再次初始化的结果(index=2),与用户的目标选择不一致。这时用户获取的结果和界面显示一致,继续操作会导致上述行为会反复出现。如下图所示:
graph LR
A[index=0]-->X1(get_ui)-->B(sel=0)-->|user select|D[index=2]-->X2[get_ui]
B-->C(cache=0)-->|缓存一致|X2-->E(sel=2)-->|user select|D2[index=1]-->F
E-->C1(cache=2)-->|缓存落后|F[update_ui]
A_[index=0]-->X1_(get_ui)-->B_(sel=0)-->|user select|D_[index=2]-->X2_[get_ui]-->E_(sel=2)-->|user select|D2_[index=1]-->F_[get_ui]
实际上,用户可以缓存数据,但无需将其应用于更新UI。用户利用缓存数据与最新数据的对比以确定某个UI的状态变化从而执行相应操作。
回调函数
状态变更后,代码从头开始执行。回调函数将先于其他代码首先被执行。回调函数仅知道UI状态变化,无法获取变更后的值。
缓存
Streamlit可以缓存函数的返回对象,从而优化性能。
Streamlit在调用函数时记录函数名、函数参数、外部变量、函数体内容、调用的用户自定义函数内容,当再次调用函数时检测上述内容(基于Hash函数)是否被修改。如果未发生修改,则直接返回缓存对象;反之,重新执行函数并缓存新的对象。
streamlit.cache(
func=None, # 调用的函数对象
persist=False, # 是否缓存到磁盘
allow_output_mutation=False, # 允许返回对象在外部被修改,不计算返回对象的Hash
hash_funcs={Type:hash_func}, # 自定指定类型对象的Hash函数
max_entries=None, # 最大缓存条目数
ttl=None # 缓存有效期(秒)
) -> object
@st.cache(**kwargs)
func(*args, **kwargs):
pass
Hash函数
- 返回对象的基础类型成员,Streamlit可以使用内置Hash函数对其再进行Hash;
id()函数:用于传入参数,计算全局唯一对象(指向外部资源)的内存地址,例如会话连接;lambda _: None:已知对应类型对象不会在程序运行期间发生变化(避免对大型数据结构的计算开销);hash()函数:使用Python内置的hash方法代替Streamlit的hash方法,以解决某些类型无法计算hash值得问题;- 自定义
变量显式缓存
全局缓存:用户可以定义缓存函数创建缓存的数据容器(如字典),以显式缓存程序运行过程中产生的变量。
@st.cache(allow_output_mutation=True)
def namespace(name:str):
return {}
ns = namespace('streamlit')
ns['x'] = 100
@st.experimental_memo
@st.experimental_singleton
会话状态缓存
st.session_state:与每个Web会话(WebSocket)相关的缓存变量,同一应用的不同页面其会话缓存变量相互独立。
多线程执行
每开启一个Web页面,Streamlit应用会启动一个子线程执行该应用的用户代码并在Web页面进行展示。多个线程共享全局缓存空间,具有独立的会话状态空间。
基于Streamlit的服务
利用Streamlit应用运行的规则,可以在用户代码中封装一个服务(持续执行不退出),当首次开启应用时启动该服务,并在全局缓存中记录服务的运行状态;后续再启动应用时,检测该服务的状态,并与该服务进行交互。
问题
inotify watch limit reached,该问题会导致无法监控到后台文件更新,以及streamlit无法刷新Web页面(创建连接Streamlith后台服务的WebSocket失败)。
机器学习可视化
性能评估可视化
混淆矩阵
Confusion Matrix
from sklearn.metrics import ConfusionMatrixDisplay as cm_disp
disp = cm_disp.from_predictions(y_test, y_pred)
disp = cm_disp.from_estimator(clf, X_test, y_test) # 直接从分类器获取预测
plt.show()
# 自动生成混淆矩阵并创建图形对象
# cm = confusion_matrix(y_test, y_pred) # from sklearn.metrics import confusion_matrix
# disp = cm_disp(confusion_matrix=cm, display_labels=clf.classes_)
# disp.plot()
问题
中文乱码
原因:Linux系统缺少中文字体;
解决方法:
-
下载中文字体(从Windows系统中复制),黑体(
simhei.ttf)、华文宋体(STSONG.TTF)、楷体(simkai.ttf)...... -
将字体==安装==到
/usr/share/fonts目录下,并链接到matplotlib的字体目录下。cd $CONDA_HOME/envs/$ENV/lib/python3.7/site-packages/matplotlib ln -s /usr/share/fonts/simhei.ttf mpl-data/fonts/ttf/simhei.ttf -
修改
matplotlib配置文件:vim mpl-data/matplotlibrc font.family: sans-serif # uncomment font.sans-serif: simhei,... # uncomment and add fonts at head -
删除缓存文件:
rm ~/.cache/matplotlib/fontlist-v###.json -
重启Python程序。
中文字体测试代码
from matplotlib.font_manager import FontManager import subprocess fm = FontManager() mat_fonts = set(f.name for f in fm.ttflist) print( '*' * 10, 'Matplotlib可用字体', '*' * 10) for f in mat_fonts: print(f) output = subprocess.check_output( 'fc-list :lang=zh -f "%{family}\n"', shell=True, encoding='utf-8') print( '*' * 10, '系统可用的中文字体', '*' * 10) zh_fonts = set(f.split(',', 1)[0] for f in output.split('\n')) for f in zh_fonts: print(f)
参考文献
Python编程应用
Python应用框架和编程接口。
命令行工具
click
Command Line Interface Creation Kit (click)
- 命令嵌套
- 自动生成帮助文档
- 支持运行时懒加载子命令
- Unix/POSIX命令行约定
https://click.palletsprojects.com/en/7.x/quickstart/
pip install click
应用模板
import click
@click.group(help="group info.") # 创建命令组,可以添加子命令
def cli():
pass
@click.command(name='init', help='command info.', eplilog)
def initdb():
click.echo('Initialized the database')
cli.add_command(initdb) # 添加子命令
@cli.command(name='drop') # 添加子命令
@click.option('-c','--count', default=1, help='number of greetings') # 添加选项
@click.argument('name') # 添加位置参数
def dropdb(count, name):
click.echo('Dropped the database')
if __name__ == '__main__':
cli() # 调用定义的任意命令或分组
分组和子命令
使用@click.command()定义程序所需处理的命令行参数及其对应的处理函数;如果程序具有多个子命令,则需要使用@click.group()定义统一入口,以访问子命令。此外,通过@Group.group()可以嵌套定义子命令集合。
主程序只能调用一个
click对象(返回后程序结束),因此必须将子命令的处理方法组织到一个分组中。否则主程序只能调用其中一个子命令的处理方法。
除了根分组外,子命令和子分组的名称默认为对应处理函数名,也可通过name参数指定。
参数分类
-
位置参数:使用
@click.argument()定义,第一个参数为参数名,并对应作为Python变量名。 -
选项参数:使用
@click.option()定义,参数列表*args用于定义多个长/短选项名(例如"-n","--name","name")。-
其中如果包含没有短划线前缀的名称,则作为该选项的变量名传递给修饰的函数;反之,
-
第一个长选项用于推导选项变量名(移除前缀并将名称中出现的短划线转换为
_以构成合法变量名); -
没有长选项时,使用第一个短选项作为变量名。
-
通过装饰器声明的参数,必须在对应的处理函数的输入参数中声明。
参数数据类型
str(默认类型),int,float,bool
click.DateTime
如果未指定类型,则根据默认值default推导(如果未提供default,则默认为str)。
选项参数
@click.option('-c', '--count', default=1, help='number of greetings')
help:设置文档的帮助信息;metavar:帮助文档中用于表示选项的值。
强制选项
选项通常时可选的,如果需要强制某选项提供,则令required=True;
标识选项
-
真值标识选项:
is_flag=True:如果选项名称中包含/,则定义真值开关的两个选项(变量名为前者)。@click.option('--shout/--no-shout', default=False) -
切换标识选项:
flag_value=value,多个选项定义一个变量,其中一个设置为True。@click.option('--upper', 'transformation', flag_value='upper', default=True) @click.option('--lower', 'transformation', flag_value='lower')
多值选项
- 一个选项如果要接受多个参数,使用
nargs=k声明,该选项变量将保存为tuple;也可以通过直接定义多个参数的类型type=(str,int)表明选项接受的参数个数。 - 可重复使用的选项
multiple=True:每次使用选项指定的值都被添加到序列对象; - 计数选项:
count=True:选项的值为选项声明的次数。
取值受限的选项
根据选项配置,对输入值进行校验。
-
单选选项:
@click.option('--hash-type', type=click.Choice(['MD5', 'SHA1'], case_sensitive=False)) -
数值范围选项:
IntRange/FloatRange(默认为闭区间,可通过min_open/max_open设置开区间)。@click.option('--count', type=click.IntRange(0, 20, clamp=True)) #* @click.option('--digit', type=click.IntRange(0, 10))*:clamp=True对于超出范围的输入参数,将其修改为设定的边界。 -
密码选项:
@click.password_option() # equivalent password @click.option('--password', prompt=True, hide_input=True, confirmation_prompt=True)
交互式选项与回调函数
prompt=Ture|message:当命令行未提供该选项的值,弹出消息提示用户输入该选项的值。
根据用户输入决定程序的后续处理流程:
@click.confirmation_option(prompt='Are you want to continue?')
等价实现方式:
def abort_if_flase(ctx, param, value): if not value: # value of 'yes' ctx.abort() @click.option('--yes','-y', is_flag=True, callback=abort_if_false, expose_value=False, # 不向处理流函数传递该参数 prompt='Are you want to continue?')
选项默认值
通过default参数设置选项默认值。默认值可以是固定编码值,可以从配置文件或系统环境变量读取。
@option('username',
default=lambda: os.environ.get('USER',''),
show_default='current user', prompt=True)
default如果为函数,则可同时与prompt结合使用;反之,如果设置了default则不会再弹出交互信息。使用show_default在文档中显示默认值信息。
auto_envvar_prefix='PREFIX':自动读取指定前缀环境变量PREFIX_COMMAND_OPTION(命令名中的-使用_替换);
手动指定环境变量:
@click.option('username', envvar='USERNAME')
从一个环境变量中读取多个值。在命令行利用multiple=True可重复使用一个选项以读入多个值;对于从环境变量读取,则尝试将环境变量分割为多个部分(默认使用空白分割,对于File和Path类型的选项值,则使用平台相关分隔符)。
default_map:
优先处理选项
@click.version_option()
实现方式:使用
eager选项以优先处理该参数。def print_version(ctx, param, value): if not value or ctx.resilient_parsing: # value of 'version' return ctx.echo('version 1.0') ctx.exit() @click.option('--version','-V', is_flag=True, callback=print_version, expose_value=False, eager=True)
Multiple Values from Environment Values
位置参数
参数接受的值的个数:
@click.argument('src', nargs=-1) # 接受任意数量的值(只能由一个此类型)
@click.argument('dst', nargs=1)
required=True,可变数量参数至少包括一个参数(不能为空)。
click.File
click.Path
命令嵌套
https://click.palletsprojects.com/en/7.x/commands/
子命令的方法运行时父命令的方法也被执行。
Group Invocation Without Command
生成文档
https://click.palletsprojects.com/en/7.x/documentation/
自动补全
Completion is only available if a script is installed and invoked through an entry point, not through the
pythoncommand. See Setuptools Integration.
交互式程序中的应用
在Python脚本主模块中,调用click定义的任意命令或分组,即可实现相应命令的自动解析处理。
通过上述方式,执行命令后程序将自动退出。对于不自动退出的交互式程序,需要在程序中显式调用该命令行框架并将所需处理的命令行参数传入。
cli.main(['add', '--help'], standalone_mode=False)
standalone_mode=False:在命令执行完成后继续执行程序,反之直接退出程序。
问题:
click捕获SystemExit,使得注册的退出处理函数不会被触发。
next:https://click.palletsprojects.com/en/7.x/complex/。
Typer
HTTP
HTTP客户端
Python http.client模块
http.client is a low-level HTTP protocol client; implement the client side of the HTTP and HTTPS protocols. It is normally not used directly — the module urllib.request uses it to handle URLs that use HTTP and HTTPS.
httpis a package that collects several modules for working with the HyperText Transfer Protocol:
http.client;http.servercontains basic HTTP server classes based onsocketserverhttp.cookieshas utilities for implementing state management with cookieshttp.cookiejarprovides persistence of cookies
http.client.HTTPConnection(host, port=None, timeout=None)
HTTPConnection.request(method, url, body=None, headers={})
HTTPConnection.getresponse()
# HTTPSConnection
Python urllib.request模块
Extensible library of high level API for opening URLs.
r = urllib.request.urlopen(url_or_request, data=None, timeout=None)
urllib.request.Request(url, data=None, headers={}, method=None)
r.url
r.headers
r.response
r.read(length) # read response body
This function always returns an object which can work as a context manager and has the properties url, headers, and status.
The default method is 'GET' if data is None or 'POST' otherwise.
urllib3
Home - urllib3 2.0.0.dev0 documentation
请求
response = urllib3.request(METHOD, url)
http = urllib3.PoolManager()
response = http.request(METHOD, url,headers=hdr_dict, fields=query_dict)
resp = http.request(
"POST", url,
fields={"hello": "world"}, # form data
body=encoded_data # JSON string or something else
)
响应
response.status
response.headers
response.data
requests
Requests: HTTP for Humans™ — Requests 2.25.1 documentation (python-requests.org)
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your POST data. Keep-alive and HTTP connection pooling are 100% automatic, thanks to urllib3.
请求
response = requests.get(
url,
params=query_dict,
headers=hdr_dict,
cookies=cookie_dict_or_jar, # jar = requests.cookies.RequestsCookieJar(),
allow_redirects=True, # HEAD默认为False
timeout=0.001
)
response = requests.post(
url,
data = payload_str_or_dict, # data/files优先级高于json
files = file_dict,
json = payload_dict # Content-Type: application/json
)
files = {
'file': (
'report.xls',
open('report.xls', 'rb'),
'application/vnd.ms-excel',
{'Expires': '0'}
)
}
其他HTTP方法:
put, delete, head, options, ...
响应
response.status_code
response.raise_for_status() # 抛出异常
response.headers # HTTP headers (Header names are case-insensitive)
response.request.headers
response.cookies #
response.text # 响应体
response.encoding # 响应体编码,设置编码以获得正确解码的text
response.content # 原始响应体(binary,已解压缩),用于接收非文本数据
response.json # 将JSON响应体解码为JSON对象
response.raw # HTTP原始响应(未经处理的接收数据)
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
重定向
response.history
异常
ConnectionError:网络问题;
HttpError:HTTP返回非成功响应码;
Timeout:响应的超时;
TooManyRedirects:重定向次数超过限制;
RequestException:所有引发的异常的基类。
会话对象
HTTP持久连接,重用TCP连接。
session = requests.Session() # 通过session使用requests接口
Flask
The “micro” in microframework means Flask aims to keep the core simple but extensible.
Flask has many configuration values, with sensible defaults, and a few conventions when getting started. By convention, templates and static files are stored in subdirectories within the application’s Python source tree, with the names templates and static respectively.
Flask itself just bridges to Werkzeug to implement a proper WSGI application and to Jinja2 to handle templating. It also binds to a few common standard library packages such as logging. Everything else is up for extensions.
Flask supports Python 3.6 and newer. async support in Flask requires Python 3.7+ for contextvars.ContextVar.
conda create -n flask python=3.7 flask
Quickstart — Flask Documentation (2.0.x) (palletsprojects.com)
Flask App
Project Layout
flaskproject/
├── flaskproject/
│ ├── __init__.py
│ ├── db.py
│ ├── schema.sql
│ ├── auth.py
│ ├── blog.py
│ ├── templates/
│ │ ├── base.html
│ │ ├── auth/
│ │ │ ├── login.html
│ │ │ └── register.html
│ │ └── blog/
│ │ ├── create.html
│ │ ├── index.html
│ │ └── update.html
│ └── static/
│ └── style.css
├── tests/
│ ├── conftest.py
│ ├── data.sql
│ ├── test_factory.py
│ ├── test_db.py
│ ├── test_auth.py
│ └── test_blog.py
├── venv/
├── .gitignore
├── setup.py
└── MANIFEST.in
Project Layout — Flask Documentation (2.1.x) (palletsprojects.com)
Application Setup — Flask Documentation (2.1.x) (palletsprojects.com)
Deployment Options — Flask Documentation (2.1.x) (palletsprojects.com)
Template Designer Documentation — Jinja Documentation (3.0.x) (palletsprojects.com)
App Layout
from flask import Flask, request
app = Flask(__name__)
app.config['JSON_SORT_KEYS'] = False # 响应JSON数据不对字段排序
@app.route("/url_path/<name>", methods=['GET', 'POST'])
def route_process(name="test"):
req = request.get_data(as_text=True)
return "success"
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5000, debug=False,load_dotenv=True,**wsgi_options)
load_dotenv=True:加载.env或.flaskenv中定义的环境变量。
调试运行Flask App
如果Python代码中包含__main__代码块,且其中调用了app.run()方法,则可以直接运行该代码文件或模块启动Flask程序。反之,通过flask run命令自动调用指定Python模块$FLASK_APP(默认为app)中的Flask实例(通常是app=Flask(__name__))的run()方法。
export FLASK_APP=hello
export FLASK_ENV=development
flask run --host=0.0.0.0 --port=5000 --cert=PATH --key=FILE # => python -m flask run
这种方式不会执行Flask程序中的
__main__代码块,因此不能将额外参数传递给要执行的程序。
调试模式:如果配置环境变量FLASK_ENV=development或运行时参数debug=True,将启用调式模式,在代码发生变化时服务器会自动加载且在发生异常时在终端显示交互式的调试器(使用use_evalex=False禁用调试器,使用use_reloader=False禁用自动加载),并在前端显示异常的追踪信息页面。未启用调试模式时,Flask会忽略任意处理过程产生的错误,仅返回通用的错误页面。==不推荐在启用自动加载的情况下通过代码调用run()方法(支持不好),而是使用flask run的方式==。大规模生产环境部署需要使用专门的WSGI服务器。
处理请求
路由绑定
@app.route("PATH", methods=['POST','GET',...],)
路径:客户端请求通过装饰器声明的路径规则进行分发,路径规则:
/path:路径以“/”结尾代表目录,请求省略/会被自动重定向到对应目录;反之,代表文件,如果请求包含“/”则无法找到相应资源(返回404 Not Found)。/path/<ARGUMENT>:ARGUMENT作为响应函数的参数。/path/<int:ARGUMENT>:限定参数数据类型。
一个响应方法可添加多个路径声明。
url_for()方法用于测试当前已声明的处理方法对应的URL。
with app.test_request_context():
print(url_for('index'))
print(url_for('login')) # "index" and "login" 是已定义的处理方法
获取请求信息
from flask import request # context local object
request.url # request.base_url, request.host_url, request.root_url
request.args # -> dict: URL查询参数 -> request.query_string
request.method
data = request.data # binary data
request.get_data(as_text=True) # text data
request.get_json() # json object -> request.is_json
为了避免用户请求数据中包含的注入攻击脚本被执行,使用escape将请求数据转换为纯文本。
from markupsafe import escape
@app.route("/<name>")
def hello(name):
return f"Hello, {escape(name)}!"
构造响应消息
处理方法必须提供返回值(不能返回None),响应消息可以是纯文本、JSON对象、HTML文本等类型。
重定向和错误处理
from flask import abort, redirect, url_for
redirect(url_for('static', filename=subpath))
abort(404)
会话
除了处理单次请求外,Flask为每个会话提供了会话上下文session。处理方法可在会话上下文中记录用户的登录状态,从而连续处理用户的不同请求。
日志
app.logger.warning('A warning occurred (%d apples)', 42) # logging.Logger
静态文件
静态文件位于Flask程序的工作目录下static/目录中。这些文件可以根据用户请求的URL(如/static/style.css)被自动响应。
HTML模板
利用指定模板(Jinja2)和输入参数自动生成HTML响应。模板文件位于程序目录下的templates/目录下。
from flask import render_template
return render_template('hello.html', name=name)
文件上传
Cookies
部署Flask应用
While lightweight and easy to use, Flask’s built-in server is not suitable for production as it doesn’t scale well. You can deploy your Flask application to a WSGI server, where your
Flaskapplication object is the actual WSGI application.
Flask实现了一个简易的HTTP WSGI服务器,方便开发者调试运行Flask程序而无须安装专门的WSGI服务器。但内置WSGI服务器功能简单,性能扩展能力差,因此可能无法胜任生产环境大规模服务请求。
花了两个星期,我终于把 WSGI 给搞明白了 - 知乎用户的文章 - 知乎
WSGI服务器包括:Gunicorn、uWSGI、
Run Flask with Gunicorn
gunicorn -w 4 -b 0.0.0.0:5000 your_project:app # serve your app with 4 workers on port 5000
app是模块中可调用的Flask应用实例,或者提供创建实例的函数myproject:create_app()。
使用gevent(-k gevent)或eventlet(-k eventlet)提供工作线程的异步支持。
gevent is a coroutine -based Python networking library that uses greenlet to provide a high-level synchronous API on top of the libev or libuv event loop.
Nginx代理WSGI服务器
server {
location /flask {
proxy_pass http://127.0.0.1:8000/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
FastAPI
conda create --name fastapi python=3.7
pip install fastapi uvicorn[standard]
数据库
SQLAlchemy由Core和ORM两套API组成,其中ORM基于Core构建。
-
Core:数据库工具集的基础架构,包括管理数据库连接、处理查询和响应、构建SQL查询语句。
-
ORM:提供Python对象到数据库表的映射以及对象持久化机制。
对象关系映射(Object Relational Mapping,ORM)模式使用描述对象和数据库之间映射的元数据,实现程序中的对象与数据库中的记录的同步与持久化存储。
import sqlalchemy as sqa
print(sqa.__version__) # -> 1.4.20
数据库连接管理
db_url='dialect[+driver]://user:password@[host]/dbname[?key=value..],'
engine = sqa.create_engine(db_url, encoding='utf-8', echo=False, future=True)
-
echo:回显执行的SQL命令(如果为"debug",还将输出返回结果);也可通过logging模块调整输出信息的级别。 -
future=True:完全使用2.0风格API。
数据库连接:需要首先安装相应数据的驱动包(DBAPI)。
- SQLite:
"sqlite+pysqlite:///:memory:"- PostgreSQL:
"postgresql+psycopg2://user:passwd@/dbname?host=/var/run/postgresql"- MySQL:
"mysql+pymysql://root:gang2019wsl@/test?unix_socket=/var/run/mysqld/mysqld.sock"
连接
Engine对象用于管理数据库连接Connection,从而实现对数据库的并发访问。当连接关闭时,连接的资源实际返回给Engine所管理的连接池,同时调用.rollback()释放未完成的事务以及锁从而使之能够被再次使用。
with engine.connect() as connection:
result = connection.execute(sql_command)
事务
事务用于保证数据操作过程的正确性和完整性,如果在事务执行过程中发生异常,则可以回退到初始状态,防止对数据库产生非预期操作。Engine.begin()或Connection.begin()会创建一个事务Transaction对象,使用上下文管理器来自动提交事务.commit()和处理异常回退·.rollback()(不使用上下文则需要手动提交和进行异常回退)。
with engine.begin() as conn: # -> Transaction
result = conn.execute(sql_command)
# equals to =>
# with engine.connect() as connection:
# with connection.begin():
# result = connection.execute(sql_command)
数据库元数据
SQLAlchemy的查询和对象映射需要数据库元数据(database metadata)支持。元数据以Python对象的形式描述表格和其他Schema层次的对象(SQLAlchemy使用schema name来区分表格所属命令空间)。
PostgreSQL的默认命名空间为
public。
构造数据库元数据
元数据存储对象MetaData用于保存一个数据相关的元数据。
from sqlalchemy import MetaData
metadata_obj = MetaData(bind=engine, schema="default_schema")
engine可不提供,在实际执行操作时通过相关接口传入覆盖初始配置。当指定schema时,表格将显式通过schema来引用。如果需要通过元数据对数据执行实际操作,则==数据库中必须已经存在相应的命名空间==。
向元数据存储中添加表格定义(描述数据类型及其他属性):
from sqlalchemy.schema import Table,Column,ForeignKey,Sequence
from sqlalchemy import Integer, String
user = Table('user',metadata_obj,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False),
schema='user'
)
访问元数据存储的表格定义:
for n in metadata_obj.tables: # <-> metadata_obj.sorted_tables
table:Table = metadata_obj.tables[n]
print(n) # -> print(table) -> print(table.name)
table.metadata # a runtime property of MetaData
table.bind # bound Engine/Connection
访问表格列信息:
col = user.columns.id # -> user.c.id -> user['id']
col.name # col.{type,nullable,primary_key,foreign_keys}
col.table # 反向引用列所属的表
for col in user.c:
print(col)
for primary_key in employees.primary_key:
print(primary_key)
for fkey in employees.foreign_keys:
print(fkey)
获取数据库元数据
使用SQLAlchemy提供的反射机制(reflection)从数据库自动加载元数据。
使用MetaData
MetaData可自动返回连接数据库的所有数据表的元数据对象。
from sqlalchemy import MetaData
metadata_obj = MetaData()
metadata_obj.reflect(bind=engine,**kwargs)
metadata_obj.tables # 所有表组成的字典
使用Table可返回指定数据表(及其外键引用的数据表)的元数据。
user = Table('user', metadata_obj, autoload_with=engine)
使用Inspector
Inspector提供更加底层的接口获取数据库表的元数据。
from sqlalchemy import inspect
from sqlalchemy.engine.reflection import Inspector
inspector:Inspector = inspect(engine)
for table in inspector.get_table_names(): # 获取表名
for column in inspector.get_columns(table): # 获取列定义(字典)*
print(column['name'])
*:列定义包含name、type、nullable、default、autoincrement、comment等属性。
检查表格是否存在:
tf = sqa.inspect(sql_engine).has_table(table_name)
使用SQL命令
使用SQL语句从数据库的元数据表中获取,具体命令与数据库类型相关。不支持PostgreSQL的pgsql命令行工具的快捷命令,如\dt。
创建和删除数据表
使用元数据定义(批量)创建表。
metadata_obj.create_all(engine, checkfirst=True)
metadata_obj.drop_all(bind=engine)
table.create(bind=engine, checkfirst=True)
table.drop(bind=engine)
checkfirst=True:如果表格存在则不执行操作。
SQL查询API
API用法
查询语句的构造方式分为两类:1) 构造SQL命令的文本对象;2) 通过API调用构造命令;
from sqlalchemy.sql import column, select, table #*
sql_query = text("select x, y from some_table where y > :y") # 文本模式
t = table("some_table", column('x'), column('y'))
sql_query = select(column('x'), column('y'))\
.select_from(t)\
.where(t.c.y > bindparam('y')) # API构造模式
result = conn.execute(sql_query, {'y':'100'})
result.rowcount # 查看查询/修改记录的行数
虽然SQL命令文本更加简洁,但是通过API调用可在程序更加灵活地参数化构造SQL查询命令(无需关注SQL语法细节)。
查询对象构建
查询过程中的列和表都需要构造为语句对象而不能使用字符串文本直接表示,可用文本模式或API模式构建对象。
col_a, table_x = text('col_a'), text('table_x') # 文本模式
col_a, table_x = column('col_a'), table('table_x', schema='public') # API模式
API模式支持对列或表做更多参数配置(如为表指定所属的schema)。column,table分别是ColumnClause和TableClause类型构造方法的封装。区别于元数据定义中使用的Column和Table类,后者不仅继承前者,还扩展了与数据类型、属性和数据库后端相关的接口。
文本模式如果指定
schema_name.table_name作为表名无法工作,因为该形式会被整体视为默认schema中的表名public."schema_name.table_name"。
参数传递
在执行execute()方法时,SQL语句中的绑定参数通过execute()方法的*multiparams, **params参数传递。对于单次执行的命令,使用execute()方法的**params参数传递SQL语句中对应的绑定参数:
conn.execute(sql, key1=value1, key2=value2)
对于无返回值的SQL命令(如INSERT、UPDATE等,即未添加RETURNING表达式),可以批量执行SQL命令,则需要使用*multiparams参数(可以==合并为一个字典对象的序列传递==,方便从pandas.DataFrame传递数据),批量接收绑定参数对应的参数数据。SQL命令将根据每个字典对象中的参数执行一次查询(底层数据库API也可能对批量查询提供优化)。
conn.execute(
table.insert(),
{'key1': value1, 'key2': value2},
{'key1': value3, 'key2': value4},
# ...
) # [{'key1': v1, 'key2': v2}, {'key1': v3, 'key2': v4},...]
输出SQL命令
可将通过API构造的SQL命令编译为文本形式并输出,从而方便验证是否正确调用相关API。
stmt: ClauseElement = select(t).where(t.c.id == 5)
print(stmt)
sql: Compiled = stmt.compile(literal_binds=True)
print(sql)
literal_binds=True:将构造命令中的字面值嵌入表达式(反之在表达式中将以自动生成的绑定参数代替,执行时再使用字面值代替绑定参数)。
表达式参数绑定
文本命令模式:使用:arg_name在SQL命令中嵌入运行时参数。
API构造模式:使用bindparam()设置运行时参数,其构造结果与文本造模式一致。对于参数为常量的表达式,SQLAlchemy也会将其转换为自动命名参数(基于列名和数字编号),并将常量作为参数的默认值在运行时传递给SQL语句。
条件语句
逻辑连接:and_(*exprs)、or_(*exprs)和not_(expr)。支持使用相应的Python运算符&、|和~,但注意使用()限定每个表达式的范围。
比较运算符
column('x').is_(None) # [is_/is_not] -> x IS NULL
column('x').in_([1, 2, 3]) # [in_/not_in]
# any_()/all_()
# between
column('x').like('word') # like/ilike/notlike/notilike*
column('x').startswith('word') # startswith/endswith/contains
# match
column('name').regexp_match('word') # dialect specific
*:需要添加通配符%以模糊匹配。
读取数据
通过SELECT命令或select()API调用读取数据。
from sqlalchemy import select
select(table).where(cond_expr)
select(table.c.name, table.c.fullname)
select(name, fullname).select_from(table)
table.select().where(expr) #*
*:此方式不再支持传入列名以选择数据表中的列;同时,仅返回已定义的表对象中的列(SELECT命令会自动包含所定义的列)。
选择数据源的所有列
sql = select(text('*')).select_from(table)
排序和分组统计
from sqlalchemy import asc,desc,func
select(user).order_by(asc(user.c.name)) # -> user.c.name.asc()
select(user.name, func.count(user.id).label("count"))\
.group_by(user.name)\
.having(func.count(user.id) > 10) # HIVAING是对分组结果进行过滤
SQL函数
提取字段:extract("YEAR", t.c.date_created);
SQL统计函数:func.FUNCNAME():将对应的函数调用FUNCNAME()转换为SQL函数表达式。
连接
连接两个表并返回查询结果。默认根据两个表的外键字段进行连接;可通过join_from的第三个参数(join的第二个参数)指定连接条件,如user.c.id == address.c.user_id。
select(user.c.name, address.c.email_address)\
.join_from(user, address, isouter=False, full=False) #*
select(user.c.name, address.c.email_address).join_from(address,**kwargs) #**
*:指定OUTER和FULL连接方式。
**:join()方法只指定连接运算的右侧表(左侧根据查询推测)。
获取执行结果
result:CursorResult = connection.execute(sql_query)
for row in result: # -> CursorResult: DBAPI cursor
print(f"x: {row.x} y: {row.y}")
for row in result: # 将行数据返回为对象: 可通过下标或属性访问数据
x = row[0]
y = row.y
for x, y in result: # 直接将序列对象展开为列元素
# ...
for dict_row in result.mappings(): # 将行数据返回为字典
x = dict_row['x']
y = dict_row['y']
当返回的CursorResult被读取完后,DBAPI游标将被自动关闭(因此无法重复读取一个返回结果)。
Selecting Rows with Core or ORM — SQLAlchemy 1.4 Documentation
修改记录
插入
from sqlalchemy import insert
stmt = insert(user_table)\ # -> user_table.insert()
.values(name='name', fullname='Full Name')\
result = conn.execute(sql_query, records_data) # 数据包含name,fullname字段
Insert.values()方法对绑定参数进行了简化,如果未显式调用bindparam()方法,则==SQL命令的参数名称与values方法的关键字参数名称相同==。
需要注意:
values()关键字参数中定义的列必须包含在操作的数据表的列定义中(适用于insert()和update()方法),否则出错*CompileError: Unconsumed column names: xxx*。
更新
根据匹配条件更新数据。如果未发生匹配则不会更改任何数据,如果未指定任何条件,则对所有数据都进行更新。
update(user_table)\ # -> user_table.update()
.where(user_table.c.name == 'patrick')\
.values(fullname='Patrick the Star') # values类似于insert()
where()和values()方法中的列名不能重复,否则出错*CompileError: Bind parameter 'xxx' conflicts with unique bind parameter of the same name.*。已经出现在where()语句中的列是不需要执行更新操作的,因此无须再出现在values()中。
删除记录
delete(user_table)\ # -> user_table.delete()
.where(user_table.c.name == 'patrick')
返回修改记录的信息
stmt.returning(user.c.id, user.c.name)
在上述修改数据记录的相关命令后,调用returning将返回修改数据的指定字段(==调用returning后,执行命令时将不支持批量传递数据==)。根据这些字段可判断对应的数据是否按预期完成操作(某些插入操作可能存在主键重复,或是更新和删除操作存在多个匹配项或未发现匹配项等)。
ORM API
ORM Quick Start — SQLAlchemy 1.4 Documentation
定义数据模型
ORM Mapped Class Overview — SQLAlchemy 1.4 Documentation
声明式定义:
from sqlalchemy import Column,ForeignKey,Integer,String
from sqlalchemy.orm import declarative_base,relationship
Base = declarative_base() # 创建ORM对象存储
class User(Base):
__tablename__ = "user_account"
id = Column(Integer, primary_key=True)
name = Column(String(30))
fullname = Column(String)
addresses = relationship(
"Address", back_populates="user", cascade="all, delete-orphan"
)
def __repr__(self):
return f"User(id={self.id!r}, name={self.name!r}, fullname={self.fullname!r})"
class Address(Base):
__tablename__ = "address"
id = Column(Integer, primary_key=True)
email_address = Column(String, nullable=False)
user_id = Column(Integer, ForeignKey("user_account.id"), nullable=False)
user = relationship("User", back_populates="addresses")
def __repr__(self):
return f"Address(id={self.id!r}, email_address={self.email_address!r})"
命令式定义:类的字段可动态设置。
from sqlalchemy import Table, Column, Integer, String, ForeignKey
from sqlalchemy.orm import registry
mapper_registry = registry()
user_table = Table(
'user',
mapper_registry.metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('nickname', String(12))
)
class User:
pass
mapper_registry.map_imperatively(User, user_table)
数据模型可用于创建数据对象。
squidward = User(name="squidward", fullname="Squidward Tentacles")
krabs = User(name="ehkrabs", fullname="Eugene H. Krabs")
ORM会话
会话用于记录数据库与程序对象间的映射实例。通过上下文管理器实现数据的自动同步。
with Session(engine) as session, session.begin():
session.execute(select(User)) # 获取数据
session.add(squidward) # 修改数据
session.add(krabs)
# equals to =>
# with Session(engine) as session:
# with session.begin():
# session.add(some_object)
# session.add(some_other_object)
Session Basics — SQLAlchemy 1.4 Documentation
常见问题
查询语句中存在特殊字符
-
URL字段中如果存在特殊字符,使用urllib.parse.quote_plus进行转义;或者使用sqa.engine.url.URL.create()创建URL对象。 -
%序列在SQL查询语句中会由SQLAlchemy再次执行变量替换,为了防止替换,使用%%代替%或将查询语句置于sqlalchemy.text()避免变量替换。可能出现错误提示:
ValueError: unsupported format character (...) at index ...
$\LaTeX$文档
生成$\LaTeX$代码
文档对象
Document
doc=Document(
default_filepath='default_filepath',
documentclass='article',
document_options=["12pt"], # 文档类的选项列表
fontenc='T1', inputenc='utf8',
font_size="normalsize",
lmodern=True, textcomp=True, page_numbers=True, indent=None,
geometry_options={"margin": "2.5cm"},
data=None
)
doc.preamble.append(Command('title', 'Awesome Title'))
doc.preamble.append(Command('author', 'Gary Wang'))
doc.preamble.append(Command('date', NoEscape(r'\today')))
doc.append(NoEscape(r'\maketitle')) # from pylatex.utils import NoEscape
NoEscape将字符串直接添加到文档内容中,不会对其进行转义解释。
generate_pdf
章节
使用doc.append(item)向章节中添加内容,添加内容不会自动包含切换换段落。
from pylatex import Section,Subsection,Subsubsection
with doc.create(Section('A section')):
doc.append('Some regular text and some ') # 添加段落
doc.append(italic('italic text. ')) # from pylatex.utils import italic
with doc.create(Subsection('A subsection')):
doc.append('Also some crazy characters: $&#{}')
文本内容
文本中的特殊字符会在生成的$\LaTeX$文档中被还原未转义序列(例如,"\"->"\textbackslash")。如果不需要转换使用NoEscape(text)。
图表
with doc.create(Table(position='!htbp')):
with doc.create(Center()):
with doc.create(Tabular('rccl')) as table:
table.add_hline()
table.add_row((1, 2, 3, 4))
table.add_hline(1, 2)
table.add_empty_row()
table.add_row((4, 5, 6, 7))
table.add_hline()
数学环境
数学公式内容需要放在数学环境对象中。
doc.append(Math(data=[r'2\times\alpha=9'], escape=False))
Alignat封装align环境,支持多行公式、编号等功能。
with doc.create(Alignat(aligns=2, escape=False)):
doc.append(r'c^2&=a^2+b^2\\')
doc.append(r'x&=\frac{a}{b}')
矩阵对象Matrix可以基于numpy==二维数组==构造,可作为公式环境中的内容:
a = np.array([[100, 10, 20]]).T
M = np.matrix([[2, 3, 4], [0, 0, 1], [0, 0, 2]])
with doc.create(Alignat(aligns=2, numbering=False)):
doc.append(Matrix(M))
doc.append(Matrix(a))
doc.append('=')
doc.append(Matrix(M*a))
列表
with doc.create(Itemize()) as itemize:
itemize.add_item("the first item")
itemize.append(Command("ldots"))
with doc.create(Enumerate(enumeration_symbol=r"\arabic*)",
options={'start': 20})) as enum:
enum.add_item("the first item")
格式
对齐
Center对象定义居中对齐环境(\begin{center}...\end{center})。
命令对象
Command(command=None, arguments=None, options=None, packages=None)
# \usepackage{packages}
# \command[options]{arguments}
doc.append(Command("maketitle"))
doc.append(NoEscape(r'\maketitle'))
生成源码
doc.generate_tex(filepath=None) # 将源码保存未tex文件
tex = doc.dumps() # 将源码输出为字符串
编译文档
doc.generate_pdf(
filepath=None,
clean=True, # 是否删除编译生成的辅助文件
clean_tex=True, # 是否删除生成的tex文件
compiler=None, # 编译引擎名,默认依次尝试latexmk和pdflatex
compiler_args=None, # 编译引擎选项
silent=True # 是否输出编译日志
)
如果要使用
latexmk/xelatex编译,需要指定编译选项-xelatex(检测到latexmkrc配置没有生效)。
数学运算
Python内置运算符和计算库
运算符
算术运算符
+、-、*:
/:在python 2.x中对于整数除法,只返回整数部分;在python 3.x都返回浮点数;
x**y :幂运算,返回$x^y$;
//:取整除 - 返回商的整数部分;% :取模 - 返回除法的余数。
比较运算符
| 运算符 | 描述 | 运算符 | 描 述 |
|---|---|---|---|
== | ==比较对象的值是否相等== | != : | 不等于,比较对象的值 |
> | < | ||
>= | <= |
<>在Python3中不是合法的“不等于”运算符。
使用is运算符确定是否引用相同对象。==和!=运算符的默认行为与is一致,但多数==内置类型覆盖了默认行为,提供值比较功能==,包括:内置数值类型、字符串、序列类型(同类型)、字典、集合。
由同一字面值构造的字符串引用同一对象,某些字符串运算(如切片)得到的字串将产生新的对象(即使具有相同值)。因此比较字符串是否相等应该使用
==/!=。
bool值在系统中为常量,因此引用True/False的变量为相同对象(使用is和==等价)。较小的整数值(测试256以内)在系统也为常量,但大整数不是常量,因此应该同一使用==进行比较。
None在程序中具有唯一引用,可使用is或==与之进行比较,但某些符合数据类型(如pd.DataFrame)重载了比较运算符用于比较元素而非对象,使用==时需要注意场景。
"
x < y <= z" is equivalent to "x < y and y <= z"
赋值运算符
| 运算符 | 描述 | 运算符 | 描述 | 运算符 | 描述 |
|---|---|---|---|---|---|
= | += | -= | |||
*= | /= | %= | 取模赋值 | ||
**= | 幂运算赋值 | //= | 整除赋值 |
二进制数值运算符
整数位运算按bit进行,bool类型按逻辑关系运算。注意运算符优先级。
| 运算符 | 描述 | 运算符 | 描述 | 运算符 | 描述 |
| ------ | ---- | ------ | ------ | ------ | ------ |
| & | | | | | ~ | 非 |
| ^ | 异或 | << | 左移位 | >> | 右移位 |
整数的二进制表示(补码)有符号前缀位(0表示整数,1表示负数)。前缀也会参与执行位运算。
|的优先级比==高,因此使用|连接两个比较表达式时应该使用()保证优先计算比较表达式。
数学函数
math包集成了常用的数学函数,包括三角函数、双曲函数、近似运算、指数、对数等。
cmath
时间日期
时间差
timedelta:时间增量,可与datetime或date类型进行运算(与date类型运算时时,时间字段无效);timedelta自身也可以与数值进行运算,内部存储转换为按天、秒和微妙计数。
date对象仅与timedelta对象的日期部分运算。
delta = dt.timedelta(days=1,hours=0,...) # 构造时间差
delta = day2 - day1 # 计算时间差
day = day + delta # 和时间对象运算
y = delta2/delta1 # 时间差对象可进行除法,结果为实数
delta = delta2%delta1 # 求余数运算,结果仍为时间差
pd.Timedelta具有类似功能。
Offset:时间偏移量,具有固定单位;不同于timedelta,==支持年、月等非固定周期==。
offset = pd.offsets.Day(5) # offset.delta is <Timedelta>
offset.n # => number of unit e.g., 5
offset.name # => name of unit, e.g., 'D'
day = day + offset # python时间对象也可以和pandas.Offset进行计算
MonthBegin/MonthEnd偏移指定月份,并定位起始日期到月初/月末;YearBegin/YearEnd等同理。
时间周期
Period可与数值、时间增量、时间偏移进行运算,实现周期平移。
p = pd.Period(...)
p = p + 1 # 起始时间增加一个周期
p = p + dt.timedelta(days=1) # => pd.Timedelta
p = p + offset # 起始时间增加一定偏移量
时间周期与时间偏移计算时,时间偏移的单位
offset.name应该不小于时间周期的单位p.freq.name;类似地,timedelta的最小增量单位应该不小于时间周期的单位。
比较大小:
tf = p2 > p1 # MUST have the same freq
计算偏移:
offset = p2 - p1 # => pd.Offset
p1.freq # => pd.Offset
对齐时间周期:调整其中一个时间周期对象,使两个时间周期相差整数倍的周期偏移:
offset = p_align - p_base
n_offset = offset.n - offset.n % p_align.freq.n
offset = pd.offsets.Day(n_offset) # 假设周期单位为Day
p_align = p_base + p_align
矩阵
查找筛选
indices = np.where(bool_expr[, x, y])
返回表达式boo_expr(例如x==b)的值为真的元素的下标,按行评估元素的值。返回类型为tuple,indices[i]为所有值为真的元素的第i维下标构成的1D向量。==当提供三个参数时,根据bool_expr的真值决定返回x或y的元素==(三个参数的维度需要兼容)。
# 将返回值转换为每个元素对应的坐标对 idx_pair = np.array(indices).transpose()
查找非零元素:
idx_pair = np.argwhere(a) # 即使a是一维向量,仍返回二维矩阵
返回一个二维矩阵,矩阵的每一行对应一个元素的坐标。
idx_pair = np.argmax() # see argwhere() idx_pair = np.argmin() # see argwhere()返回元素的坐标分量单独保存:
indices = np.where(a!=0) # 各维度坐标分别返回为一维向量 indices = a.nonzero() # => np.where(a!=0)
从矩阵中查找指定元素:
indices = np.where(x==a0)
idx_pair = np.argwhere(x==a0)
对于一维向量,可以转换为Python序列(
list),使用index()方法查找。
从矩阵中筛选满足条件的元素:
a0 = np.extract(bool_expr,a) # b = a[bool_expr]
计算
矩阵计算方法通常通过np模块访问,矩阵对象主要提供面向矩阵元素的数值计算方法。
运算符
按元素计算:+(add),-(substract),*(multiply),/(divide),**(pow)(幂),%(余数),//(向下取整整除),+=,-=,...(自运算符),-(negative)(一元取反运算符),>,<,>=,<=,==,~=;执行按元素计算时,如果运算数的维度不同,则会尝试自动扩展为维度相同的矩阵后进行计算(如行向量与列向量运算)。
y=x**a # => y=np.pow(x,a)
位运算符及其函数形式:&(bitwise_and), |(bitwise_or), ^(bitwise_xor), ~(invert), >>(leftshift) <<(right_shift)。
广播机制:矩阵/表格可以和维度兼容的序列类型进行运算(此时重载的是矩阵/表格的运算符而非序列类型运算符)。
矩阵运算规则(如矩阵乘法)计算。注意:matrix和稀疏矩阵的运算符*代表矩阵乘法,而非元素乘法。
X=A@B # 矩阵乘法 A.dot(B)
计算函数
np.absolute(a) # fabs(a)
np.divmod(a,b) # 返回商和余数
np.pow(a,x) # exp(a), sqrt(a), square(a)
np.exp(x) # e^x, exp2: 2^x, expm1: (e^x)-1
np.log(x) # log2 log10
np.log1p(x) # log(1+x)
np.logaddexp() # log(sum(exp()))
复数运算
np.angle(c)
np.real(c)
np.imag(c)
np.conj(c) # conjugate(x), complex conjugate
比较运算
<,<=,>,>=,==,!=
np.maximum(a,b) # minimum(a,b), find max/min among a,b; preserve nan
np.fmax(a,b) # fmin(a,b), drop nan
上述方法用于比较两个对象,返回两者之中较大(小)的元素组成的对象。
NaN(float('nan')和np.nan)与任何数值计算都返回np.nan;且NaN!=NaN,要比较两个NaN值,可以首先使用np.isnan(x)判断数值(矩阵)是否为NaN。
np.isnan()不能用于非数值类型(如字符串)的矩阵。
近似
round(decimal)
floor
fix
ceil
trunc
三角和双曲线函数
np.sin(a)
特征值
e,v = np.linalg.eig(array)
scipy.linalg.eig(array,...)
e,v = scipy.linalg.eigh(array, subset_by_index=[n-3,n-1])
返回特征值以升序排列。
稀疏矩阵运算
为了防止运算破坏矩阵的稀疏性,稀疏矩阵运输算不支持:
- 广播机制,因此必须保证参与运算的矩阵维数相同(广播机制容易)。
- 与标量进行加/减运算。
稀疏矩阵与普通矩阵运算结果为普通矩阵(matrix)。
统计
np.sum(a, axis, keepdims=None)
np.cumsum(a)
np.max(a, axis) # a.min(), find max/min in a
np.mean(a)
np.var(a)
np.std(a)
np.prod(a)
np.cumprod(a)
np.all(a, axis) # return true if all is true
np.any(a, axis) # return true if any is true
np.count_nonzero(a, axis)
数值计算函数通常不仅能用于ndarray,也支持list等序列类型以及==表格类型==pd.DataFrame,因此使用np.func(obj)的调用方式比array.func()更加通用。
axis=None:默认对数组所有元素执行运算;如果设置为数值$i$,则对第$i$个维度方向的所有元素执行运算。对于矩阵,0代表行索引方向(即对一列数据进行运算),1代表列索引方向(对一行数据进行运算)。==axis对应数组的维度顺序(即0总是代表最前维度),与数组元素存储方式(order='C'|'F')无关。==
keepdims=True:将保持计算结果维数不变(计算方向上长度为1)。
Python自带
max、min等函数是对序列类型元素或参数列表进行比较。
如果返回值为True|False,其类型为numpy.bool_而非Python内置bool类型,因此需要使用==而非is进行比较。
向量矩阵差分
np.diff(a, n=1, axis=-1, prepend=None, append=None)
n:每n个点进行差分,如果n=0则返回原数据;
axis:默认沿最后一个坐标轴进行差分;
prepend|append:添加默认元素,以保证所有输入数据完成差分。如果未指定,==则输出结果将根据差分距离n减少==(默认不会包含NaN);反之,指定值的维度需要与除差坐标轴外的其他维度一致,坐标轴方向长度至少为n;特别地,如果输入为向量,且n=1,则可以指定输入为标量。
频数和概率密度
hist, bin_edges = np.histogram(data, bins=10, range=None, weights=None, density=None)
range手动指定数据的边界(默认为data.min(), data.max())。density=True计算概率密度函数(在指定区间上积分为1)。bin_edges为每个分区的边界(分组数+1)。
不分维度,计算所有数据的统计信息。
排序
沿指定坐标轴排序,修改当前矩阵。
a.sort(axis=-1,kind='quicksort')
若
axis=-1,则沿最后一维坐标轴排序;kind表示排序算法,包括'quicksort', 'mergesort', 'heapsort', 'stable'。
==该方法对所有行或列分别进行排序==。若要基于某一行/列对矩阵整体排序,将其转换为Pandas.DataFrame的排序方法。
线性代数
其他
convolve(a,b) # 卷积
a.clip(min,max) #将取值裁剪到[min,max]之间
随机数
随机数发生器由BitGenerator和Generator两部分组成:BitGenerator负责生成随机字节序列,而Generator负责将字节序列转换为服从相应分布的随机数。
推荐使用随机数生成器提供的方法代替
np.random模块中方法。
获取随机数发生器:
from numpy.random import default_rng
rng = default_rng() # 使用默认BitGenerator(PCG64)
rng = default_rng(seed)
rng = Generator(PCG64(12345)) #指定并初始化序列发生器
产生随机数:
rng.random(size=[m,n],dtype=np.float64) # [0.0, 1.0)均匀分布浮点随机数
rng.integers(low,high,dtype,endpoint=True) #整数随机数
rng.standard_normal(10) # 标准正态分布
支持的分布包括:
exponential、logistic、lognormal、normal、poisson等分布。
随机置换:
array = rng.permutaiton(x, axis=0)
rng.shuffle(x, axis=0) # 置换输入数组
如果
x为整数,则随机置换(range(x)),axis指定随机置换的方向。
随机排列一个序列,或range对象(如果x是整数)。
随机采样:
rng.choice(a, size, replace,...) #从a中随机抽样并组成新数组
rng.bytes(length) #返回随机序列
数据表运算
缺失数据
Pandas读取数据源时,默认使用np.nan代替缺失数据。
判断数据是否为有效数据( 数值矩阵中NaN , 对象矩阵中None 或 NaN,日期中NaT):
df_tf = pd.isna(df) # ==> df.isna()
df_tf = pd.notna(df) # ==> df.notna()
静态方法还支持除Panda内置数据以外的类型,例如
ndarray、list等,且返回类型与输入类型。==按元素比较,实例类型返回值类型与实例一致==。
isnull是isna的别名;notnull是notna的别名。
丢弃缺失数据的行:
df1.dropna(how='any')
填充缺失数据:
df1.fillna(value=5)
如果某一列数据为category,则需要将填充的值添加到类别中。
df.col_name = df.col_name.cat.add_categories("D")
df.col_name.fillna("D")
比较大小
按元素比较,类似与np.ndarray:
df.gt(df2) # eq, ne, lt, gt, le, and ge
df == val # => df.eq(val) 比较维度兼容的标量、序列、数组、Series/DataFrame
当两个表格比较时,其行列标签必须相等(否则出错)。
整体比较:判断两个表格的数据是否完全相等。
tf_equal = df.equals(df2)
tf_equal = (df1==df2).all(axis=None) # 此处axis用法与np.ndarray一致
equals()比较两个对象是否具有完全相同的元素(对象类型相同,即同为DataFrame/Series,数据类型相同,表头的数据类型不需要相同);与按元素比较不同的是,对应的NaN元素被视为相等。
==和!=是DataFrame的元素比较,df.equals是元素比较后的汇总结果,而is和is not运算符则是判断是否引用为同一对象。x1=np.array(['dos', 'normal']) x2 = pd.Series(x1) x1 == x2 # 0 True # 1 True x2.equals(x1) # False
矩阵计算
表格兼容numpy的矩阵运算方式,函数名称与numpy保持一致。在元素处理规则方面:1) 由于表格每一列数据类型可能不同,因此沿axis=1方向的运算可能不可用。2) numpy默认对所有元素执行计算,pandas默认对列执行计算。
df.add(other, fill_value=None) # element-wise add, sub, mul, div, mod, pow
other:标量、矩阵、序列等数值运算规则兼容的类型。
==对于索引不同的表格,默认将索引对齐进行运算,计算结果的索引将按序排列==,可能产生非预料的结果(为对齐索引产生缺失元素,其参与运算使结果变为NaN)。如果要忽略索引可以使用reset_index或将其中至少一个转换为ndarray(to_numpy())。
差分
df.diff仅包含默认的差分设置,使==运算前后表格维度不变==,可使用np.diff进行自定义。
df.diff(periods=1, axis=0) # ss.diff
前
peirods行/列对应的差分值为NaN。
统计
总体统计信息:
df.describe(percentiles=None, include=None, exclude=None)
获取数据表中的统计特征:sum、mean、median、 cumsum 、cumprod、max、min、idmax、idmin、any、all等。
df.max(axis=0, skipna=True, level=None, numeric_only=only)
ss.max(...)
axis:仅支持行/列统计(axis=0|1),不支持全局统计。
执行数值运算时(求和、均值等),缺失数据默认按
0处理;skipna=True跳过NaN元素。如果指定了
level,则分别对不同索引值对应的数据进行统计,等效于df.groupby(level,sort=False).max();如果
numeric_only=True,则只返回数值列的统计结果。字符串运算:可以比较大小,求和与累加为字符串拼接,其他运算未定义。==字符串与数值混合的列默认不会包含在统计结果中==。
累计运算:计算结果的第一个值为原数据的第一个元素。
按列/行统计有效数值(non-NA)的数量:
ss = df.count(axis=0)
统计非零值:可直接比较后求和,或使用np.count_nonzero()(返回标量或ndarray)。
Boolean Reduction
df.all(axis=[0,1,None]) # see also df.any()
df.isna().all(axis=0) # 判断列是否全为Nan
查找唯一项
Series可以判断序列是否唯一,或返回唯一元素组成的矩阵(nx1 np.ndarray)。
tf = ss.is_unique
array = df[col_name].unique() # return ndarray
DataFrame的groupby方法可以通过分组后的组名确定唯一项(参考列的值),同时确定唯一项对应的行索引/下标。
统计频数:
df.value_counts(subset=None,normalize=False,sort=True,ascending=False)
ss.value_counts(normalize=False,sort=True,ascending=False,bins=None,dropna=True)
normalize:将结果归一化为比例;bins:分区间计数而非按值计数(仅适用于数值类型)。
df.value_counts可统计多列联合的频数(等效于使用groupby(by=cols).size())。pd.value_counts用法与ss.value_counts相同,且支持非Pandas序列类型。
直方图
hist = df.hist(bins=3)
DataFrame和Series提供hist()方法绘制直方图,但不会返回直方图的数据。使用np.histogram计算统计信息。
相关系数
计算特征列间的相关系数:
df.corr(method='pearson')
method='pearson'|'kendall'|'spearman'|callable:相关系数计算方法:
计算离散类型的相关性。
https://blog.csdn.net/sky88088/article/details/51737136
采样
随机抽样
df.sample(n=None, frac=None, random_state=None, axis=None, replace=False)
n和frac:采样个数或比列,两者不能同时设置。当frac未设置时,n=1。
自定义数值计算
Apply/Map
x=df.apply(func, axis=0, raw=False, args=(), **kwds)
x=df.apply(np.sqrt)
x=df.apply(np.sum, axis=0) # 将执作为计算单元
def f(x,a,b=0):
return x + a + b
x=df.apply(lambda x: f(x, a, b), axis=1) # 将行作为计算单元
x=df.apply(f, axis=1, args=(a,), b=10) # 将行作为计算单元
将数据表的==每一行(axis=1)/每一列(axis=0,默认)==提供给func执行计算(对于Series则直接按元素计算)并返回结果。
- 如果
func的计算结果为标量,则apply返回值为Series(索引与axis遍历方向一致); - 计算结果为
Series,则apply返回值为DataFrame(索引与axis遍历方向一致);
利用
apply可以实现1->n行变换,特别地,将Series扩展为DataFrame,或将DataFrame汇总为一列Series。
args和kwds可分别向计算函数传递除计算对象以外的位置参数和键值参数。
apply/applymap会对第一行/列调用函数两次,以确定是否能快速执行代码。通常存在向量化的函数,因此应该优先调用向量化函数,而非
apply/applymap。
applymap和transform保持源数据维度不变。applymap专门用于按元素计算(Series不提供applymap,其与使用apply效果一致)。transform仍传递行或列给func,可以进行行列内变换,但返回值需要与输入DataFrame保持一致,即func不改变输入行列的维度。可为不同列指定不同的变换方法
applymap(self, func, na_action = 'ignore')
df.transform(func, axis=0, *args, **kwargs) #DataFrame
Aggregate(Reduce)
Aggregate方法将数据进行统计汇总,使数据的维度降低。
- 计算对象为
Series且聚合函数只有一个,则返回标量; - 对象为
Series且汇聚函数有多个,返回以函数名索引的Series; - 对象为
DataFrame且汇聚函数只有一个,则返回以列名索引的Series; - 对象为
DataFrame且而汇聚函数有多个,返回DataFrame,函数名作为行索引index,列名作为列索引。
df = df.aggregate(func:[func|list_func|dict_func], axis=0,...) # agg
使用给定的聚合函数func对每个分组进行汇总计算,并将计算结果汇聚到同一个表格。支持的函数参数:
- 函数,函数名或函数和函数名的列表(混合):将函数应用到数据的每一列,返回各个函数的计算结果(==组成函数名和列名索引的表格==)。
- 列名和函数/函数名/列表组成的字典,对==不同列应用不同的函数==,返回结果中没有应用某函数的列的值设置为
nan。 - 如果计算对象为
Series,输入多个聚合函数,则默认输出列名为函数名;如果输入字典,则以字典的key作为输出列名。
分组计算
离散值分组
根据列的值(或多列值的组合)进行分组:
grouped = df.groupby(by=col_names) # -> <DataFrameGroupBy> object
grouped = ss.groupby(by=sequence) # -> <SeriesGroupBy> object
grouped = df.groupby(level=[l1,l2,...]) # by index (number or )
参数说明
by=func|dict|series|ndarray|label|[labels,...]:
- 函数,则作用于对象的索引,计算结果作为分组参考;
dict或Series,将其值作为对应数据行的分组依据;ndarray,将每行作为对应数据行的分组依据;- 标签或标签列表,使用待分组对象的对应==数据列或索引列==的数值作为分组依据;数据和索引不能存在同名。
对
Series分组时,根据传入sequence的值进行分组,并应用到Series上。因此,对自身的值进行分组:ss.groupby(by=ss)。
level={0,1,...}|name:指定级别的索引作为分组依据;
sort=True:对返回分组排序按分组列进行==排序==(==关闭该选项可提高性能==);
dropna=True:默认将分组列值为Nan的丢弃,如果希望分组后的计算返回结果与原表格一一对应,应将该参数设置为False。
通过遍历分组对象迭代器,可迅速获得分组中的数据条目:
for group_label, subframe in gs:
group_idx = gs.groups[group_label] # group_label -> index *
sub_group = df.loc[group_idx] # == group_frame
group_iloc = gs.indices[group_label] # group_label -> location
sub_group = df.iloc[group_iloc] # == group_frame
subframe是分组对象内部数据,对其进行修改不会影响原数据。
分组的组名由参考列的值或参考列的值构成的tuple,分组对象的属性包括:
-
groups:组名和**组内记录的行索引Index**组成的字典; -
indices:组名和分组所属元素的行下标Array组成的字典;如果基于
MultiIndex进行分组且其中包含NaN值,则indices中不包含NaN值索引(==待测试==)。 -
size():返回各组的记录数量(等效于对任意一列使用count()运算。)
对分组的计算
通过groupby返回的分组结果grouped,可以同时对各个分组的每列进行统计聚合(max, min, hist...)自定义聚合运算 或自定义映射运算(apply)。应优先调用用aggregate/transform等内置函数。
grouped.mean() # count, max, avg, min, sum, ... on each column
grouped.aggregate({
{'A': 'max', 'B': 'count', ...} # customied func on specified columns
}) # customized reduce computation
grouped.apply(func, axis=0) # customized map computation
grouped.transform(func, *args, engine=None) # return a same size DataFrame
如果运算规约到标量(
reduce),则返回结果以分组名作为索引;如果运算不改变规模(map),则返回结果与原数据表的索引结构一致。在
transform中,如果func返回值==降维,则将返回值复制到组内每一行记录==;反之,输出与输入对应。
或单独对某列进行统计:
grouped.col_name.count()
grouped['colname'].count()
grouped.aggregate({'col_name': 'count'})
注意:==如果使用索引进行分组==,即使在分组时添加dropna=False,如果直接调用聚合函数,结果仍会忽略包含NaN的组。通过grouped.groups查看分组信息发现分组结果包含NaN组,因此仍可显式对各分组进行汇聚计算。
二维分组
将指定列数据映射到二维表格(pivot table):指定为index的列的值作为新表格的行名,指定为columns的列的值作为新表格的列名,指定为values的列的值作为新表格中对应行列的值。
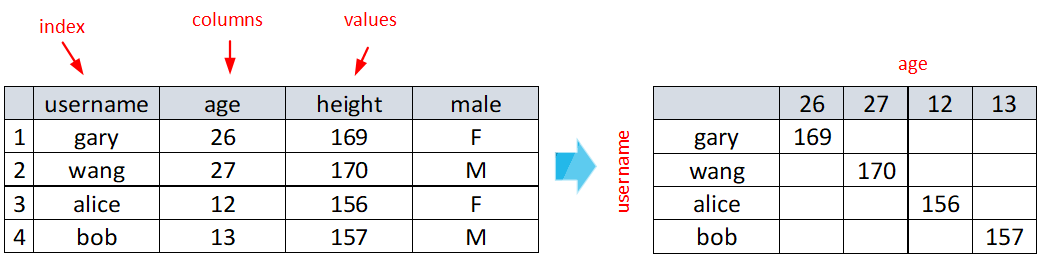
类似于:$\mathrm{df}(m, [i,j,k]) \rightarrow \mathrm{df}_{pivot}(\mathrm{df}(m,i),\mathrm{df}(m,j))=\mathrm{df}(m,k)$。
df_pivote = df.pivot(index=cols1, columns=cols2, values=cols3)
可以为
index/columns/values指定多个列,从而生成表格的索引为MultiIndex。
当行列索引值对应多条表格行时,将产生ValueError。此时,应选择pivot_table,都重复记录进行聚合。
df.pivot_table(index='name', columns='ctg', values=None, aggfunc='mean',
fill_value=None, dropna=True)
fill_value为结果中不存在的元素填充值;dropna丢弃输入数据中NaN。如果columns=None,可为aggfunc单独指定每列的聚合函数(等效于aggregate())。
时序分组
对以时间(DatetimeIndex,PeriodIndex以及TimedeltaIndex)为索引的数据按时间维度进行分组。基于分组结果可进行统计等运算,从而生成时序特征数据。
rs = df.resample(rule, axis=0, closed='left', label='left', kind=None,
on, level, origin='start_day', offset = None) -> Resampler
rule:DateOffset,Timedelta或==使用字符串类型表示采样周期==;根据指定的周期以及数据的时间粒度,采样方式可能是下采样或上采样。origin:调整分组起始时间点,可在此基础上再增加offset。可设置为:
epoch:1970-01-01 00:00:00;start|end:数据第一个/最后一个点的时间;start_day|end_day:数据第一个(最后一个)点当天(次日)的零点(1.3新增,end_day用于反向采样);str|timestamp:表示时间的字符串或时间戳。
closed={'left|right'}:指定==下采样==的闭合边界;closed='right'相当于逆时间轴==反向采样==。label={'left'|'right'}:指定==下采样==后的数据标签为原始数据的左/右边界;on:指定采样的列代替索引(构造方法参考时间索引);level:指定采样使用的索引列;kind={'timestamp'|'period'}:timestamp将采样指定列转换为DateTimeIndex;period将采样指定列转换为PeriodIndex。
下采样
每个周期分组内包含多个原始数据的样本(参考groupby对每个分组进行迭代)。
-
对采样后的各个区间数据的各列进行汇总(不含缺失数据):
rs.sum/count/nunique/first/last/max/min/mean/median/ohlc/prod/size() rs.sem() # standard error rs.std/var() # standard deviation of groups也可仅对给定的列汇总:
rs[['A','B']].sum() -
自定义采样后的计算(参考
groupby, aggregate):df.resample('3T').apply(func) rs["A"].agg([np.sum, np.mean, np.std]) # => aggregate
上采样
如果输入时序数据的数据点间的周期要高于采样周期,则发生上采样。
df.resample('3T', convention='start')
 上采样后,原数据的一个点映射到新数据的多个点,
上采样后,原数据的一个点映射到新数据的多个点,convention指定原数据如何映射到新数据中(分配给起点或终点'start'|'end')。convention仅用于采样指定的时间序列为PeriodIndex的情况。
上采样后的聚合不能直接采用
rs.func的方式;需要调用rs[cols].aggregate(func_list|func_dict)(注意:调用单个函数的形式.agg(func)等效于rs.func)。
使用非零点的值填充上采样后缺失信息,可限制每个周期填充的点数:
rs.fillna(method, limit=None) # method=ffill|bfill|nearest...
rs.ffill(limit=None) # 前向填充缺失值,limit限制填充点数===rs.pad()
rs.bfill(limit=None) # === backfill()
rs.nearest(limit=None)# 使用最近有效数据填充缺失值
也可采用插值函数进行填充:
rs.interpolate(method='linear',...)
反向采样(R1.3)
将origin设置为end|end_day,则默认以结束时间/结束日期的次日零点为原点,反向计算分组区间(默认左开右闭,即closed=right)。
图运算
NetworkX
Tutorial — NetworkX 2.5 documentation
加速运算
向量运算
安装numexpr和bottleneck库:
numexpr库使用smart chunking, caching, and multiple cores ;
bottleneck库使用cpython库的方法加速具有nan值的矩阵。
支持整数/boolean类型数据的某些二元运算加速。
dask
应用场景
简单并行运算
-
按元素算术运算
map_partitions(func, *args, **kwargs):以分区为计算单元输入执行map操作,再将返回结果合并。 -
按行运算:
df[df.x>0] -
切片:
df.loc[1:10] -
统计聚合:
df.max() -
查找:
df[df.x.isin([1,2,3])] -
时间日期:
df.timestamp.month
智能并行运算
-
groupby-aggregate:
df.groupby('x').y.max()apply-concat-apply -
groupby-apply on index:
common groupby operations like
df.groupby(columns).reduction()for known reductions likemean, sum, std, var, count, nuniqueare all quite fast and efficient. -
统计计数:
df.x.value_counts() -
去重:
df.x.drop_duplicates()对整个表格去重会很慢,因为需要交换大量数据以及进行比较。
-
Join on index, join with small Pandas DataFrames/single partition Dask DataFrame
# Large join small small = small.repartition(npartitions=1) result = big.merge(small) # Join on index left = left.set_index('id').persist() left.merge(right_one, left_index=True, ...) -
分区/列之间的按元素计算:
df.x+df.y -
相关系数:
df[['col1', 'col2']].corr()
需要shuffle的运算(除非在index上,否则较慢)
- groupby-apply not on index:需要设置索引
- Join not on the index:需要设置索引
https://docs.dask.org/en/latest/dataframe-groupby.html
方法
汇聚
df.apply(func, axis=1, meta=('name', type))
返回值类型推断:需要通过meta关键字提供输出的元信息:根据返回对象类型,提供相应的空对象进行类型推断;快捷设置方式,==如果计算对象是DataFrame,则meta可以是字典或元组列表;如果是Series,则meta是元组==。如果没有声明meta,则Dask将尝试根据数据推断类型(可能导致非预期结果)。
DataFrame仅支持axis=1(按行计算)。
系统编程
Python封装与系统底层交互的接口。
-
shutil:封装Shell命令; -
os:封装NT/Posix系统底层接口(部分是跨平台通用接口);sys模块主要封装Python程序的运行环境,非系统接口; -
socket:封装系统底层的套接字通信接口; -
fcntl:封装Unix的fcntl和ioctl接口; -
multiprocessing和subprocess:对多进程接口的高层封装; -
psutil:process and system utilities,封装了系统监控功能(==非内置库==);
运行环境
硬件信息
CPU
获取CPU数量:
os.cpu_count()
psutil.cpu_count() # CPU逻辑数量
multiprocessing.cpu_count()
统计CPU的用户/系统/空闲时间:
psutil.cpu_times()
内存
获取内存容量:
vmem = psutil.virtual_memory() # return total, available, percent, used, free,...
swap = psutil.swap_memory()
磁盘
psutil.disk_partition()
psutil.disk_usage('/') # total, used, free, percent
psutil.disk_io_counters()
网络
psutil.net_io_counters() # 获取网络读写字节/包的个数
psutil.net_if_addrs() # 获取网络接口信息
psutil.net_if_stats() # 获取网络接口状态
psutil.net_connections() # 获取网络连接信息
用户信息
用户家目录
路径字符串中的"~"不会像Shell自动替换为用户家目录路径。
from pathlib import Path # python 3.5+
home = str(Path.home())
realpath = os.path.expanduser("~/subpath")
Python运行环境
sys.path:Python库的搜索路径构成的序列;
使用
python -m site|sysconfig可输出路径等信息。
sys.modules 是一个字典对象,表示程序当前已加载的模块信息(包括模块所在路径)。
sys.version_info:Python版本信息(major, minor, micro)。
sys.args:命令行参数。
系统信息
os.uname()
# posix.uname_result(sysname='Linux', nodename='WS-GARY', release='5.4.72-microsoft-standard-WSL2', version='#1 SMP Wed Oct 28 23:40:43 UTC 2020', machine='x86_64')
封装系统
uname方法并将输出信息抽取到多个字段中。
sys.platform :获取操作系统平台,包括win32,linux。
系统环境变量
os.environ:环境变量字典。
os.getenv('USER') # os.environ['USER'] -> os.path.expanduser
os.path.expandvars(path) # 展开字符串中环境变量,未知变量不会被展开
Windows下的用户名变量为
USERNAME。
工作目录
os.getcwd():直接返回工作目录的绝对路径;os.curdir是当前目录的相对[路径标识](# 跨平台路径标识)。
os.chdir(path):切换工作目录。
文件系统
路径
import os.path as path
p=path.dirname()
p=path.basename()
p = path.abspath(p) # 绝对路径 (=>realpath)
p = path.relpath(p) # 相对路径
tf = path.isabs() # 检查是否为绝对路径
拼接路径:
path.join(parent, child)
如果
parent为空,则结果为child;如果parent='.',则结果为./child。如果
parent于child之间没有路径分隔符,则添加路径分隔符。
跨平台路径标识
os.curdir:当前路径标识,即.;使用path.abspath返回当前路径的绝对路径;
os.pardir:父路径标识,即..;
os.sep:路径分隔符,Linux中为/,Windows中为\\;
os.pathsep:环境变量分隔符,Linux中为:,Windows中为;;
os.linesep:换行符,Linux为\n,Windows为\r\n;输出换行符时总是使用\n,底层会根据系统自动转换。
os.devnull:Linux为/dev/null;Windows为nul。
检查文件/文件夹
from os import path
tf = path.isfile(filename) # test regular file
tf = path.isdir(dirname) # test existing dir
tf = path.islink(filename) # test symbolic link
tf = path.exists(filename)
tf = path.ismount(path) # test mount point(or driver/share root)
isdir等效于exists and not isfile。
pathlib将路径封装为Path对象。import pathlib my_file = pathlib.Path("/path/to/file") tf = my_file.is_file() tf = my_file.is_dir() tf = my_file.exists()
文件信息
s = path.getsize(filename) # get file size
管理文件夹
创建文件夹
os.mkdir(dir_path) # 父目录必须存在
os.makedirs(dir_path, exist_ok=False) # 父目录不存在则创建父目录,exist_ok防止抛出异常
删除文件夹
os.rmdir(path):仅当这文件夹是空的才可以,否则抛出OSError。
os.removedirs(path):删除文件夹树(同样也只能删除空目录)。
shutil.rmtree(path, ignore_errors=True):==可删除非空目录==。
列举文件夹内容
列出文件夹中所有内容的名称,不保证文件的列举顺序(对返回列表进行排序)。
contents = [f for f in os.listdir(dirname)]
files = [for f in contents if path.isfile(path.join(dirname, f))]
os.listdir返回内容仅包含名称(basename),==不包含路径==。
递归遍历目录:
for dirpath, dirnames, filenames in os.walk():
for d in dirnames:
print(os.path.join(dirname, d))
for f in filenames:
print(os.path.join(dirname, f))
dirpath是当前遍历的目录路径;dirnames为当前目录下子目录的集合(不包括.和..);filenames为当前目录下文件的集合。
管理文件
rename重命名文件
remove删除文件
os.remove(filepath)
移动/复制文件:
shutil.copyfile(src, dst) # only file
shutil.copy(src, dst) # dst can be a folder; use shutil.copy2() to preserve timestamp
shutil.move(src, dst) # 内部使用copy2进行复制
文件权限
os.chmod(path,mode)
os.chown(path,mode)
os.access(path,mode):使用real uid/gid 测试文件是否具有访问权限(mode=os.F_OK测试文件存在;R_OK|W_OK|X_OK测试文件的读写执行权限);
监控文件系统变化
使用watchdog模块可对文件系统变化进行监控并执行相应处理。
class MyEventHandler(watchdog.events.FileEventHandler):
def on_any_event(self, event: FileSystemEvent):
pass
event_handler = MyEventHandler()
observer = watchdog.observers.Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(3)
finally:
observer.stop()
observer.join()
输入输出
文件描述符
os.open(file, flags, mode):底层open函数;
os.close(fd):
os.dup2()方法用于将一个文件描述符复制到另一个文件描述符(必要时先关闭后一个文件描述符)。
os.dup2(se.fileno(), sys.stderr.fileno())
标准输入输出
sys.stdout/stdin/stderr 分别表示标准输入、输出和错误输出的文件对象。
stdin.readline()从标准输入读一行;stdout.write("a")屏幕输出;
日志
套接字接口
s = socket.socket(family=AF_INET, type=SOCK_STREAM, proto=0)
s = socket.create_connection(...) # => s.connect()
s = socket.create_server(...)
socket.close(s) # s.close()
socket对象
conn = s.accept()
s.bind(address)
s.listen(address)
s.connect(address)
s.fileno() # for select()
s.recv/recvfrom/recvmsg/recv_into/recvmsg_into/recvfrom_into()
s.send/sendall/sendto/sendmsg/sendfile(...)
s.shutdown()
s.close()
IO多路复用
Python select库封装了LinuxIO多路复用接口,使用select、poll和epoll方法来监听文件描述符状态。
select
select方法返回就绪的每类文件描述符,用户需要对描述符的状态进行查询(sock_poll)。
r,w,x = select.select(rlist, wlist, xlist, timeout=None, /)
Windows仅支持select方法监听socket。
rlist:读取准备就绪的文件描述符列表;
文件描述符是
socket、文件对象或文件对象的fileno()方法返回的整数值。
wlist:写入准备就绪的文件描述符列表;
三类文件描述符中不需要监听的将对应参数设置为空列表([])。
epoll
使用epoll的程序通常会执行以下步骤:
-
创建一个
epoll类型对象epl -
让对象监听指定文件描述符上的上的指定事件
epl.register(fd, select.EPOLLIN) -
轮询所有监听的文件描述符
events = epl.poll(timeout=None, maxevents=-1)timeout=None则等待直到其中某个文件发生监听事件,maxevents表示最大返回事件数,默认无限制。 -
基于轮询结果确定发生事件的文件及其对应的事件,从而执行相应的文件读写操作,然后修改相关文件的监听状态
-
重复上述过程,直到程序推出前销毁
epoll对象。
以下给出了使用套接字的示例:
import select
EOF = b'\n\r\n' # End of Request
epl = select.epoll() #: 创建一个epoll对象
epl.register(serversocket.fileno(), select.EPOLLIN) # 注册socket读事件
while True:
events = epl.poll(0.1) # 等待0.1s进行轮询
for fn, event in events:
if fn == serversocket.fileno(): # accept new connection
connection, address = socket.accept()
connection.setblocking(0) # 将新的socket设为非阻塞并注册读事件
epl.register(connection.fileno(), select.EPOLLIN)
# 记录连接对象和文件描述符的映射
connections[connection.fileno()] = connection # dict
elif event & select.EPOLLIN:
# 对发生读事件的socket读取数据
requests[fn] += connections[fn].recv(1024)
if EOR in requests[fn]:
print(requests[fn]) # 处理客户请求
# 注册写事件(EPOLLOUT),响应客户端请求;
# 如果用户还有后续输入,则使用epl.register()
epl.register(fn, select.EPOLLOUT)
# 反之将注册时间修改为EPOLLOUT
eplmodify(fn, select.EPOLLOUT)
elif event & select.EPOLLOUT:
# 当套接字准备好发送新数据(可能之前有数据还未发送完成需要等待)
# 每次向客户端发送一定长度的响应内容,每次都更新余下待发送的响应内容
byteswritten = connections[fn].send(responses[fn])
responses[fn] = responses[fn][byteswritten:]
if len(responses[fn]) == 0:
epl.modify(fn, 0) # 单次响应:完成服务,不再监听事件,关闭连接
close_connection(fn, socket.SHUT_RDWR);
# 如果是多次响应的服务,则使用epl.unregister()暂时取消输出就绪查询,
# 直到再次接收到数据或用户发送EOF指令或用户断开连接。
if requests[fn].endswith(EOF):
close_connection(fn, socket.SHUT_RDWR)
else:
el.unregister(fn, select.EPOLLOUT)
elif event & select.EPOLLHUP: # HUP(挂起)表明客户端断开了连接
epl.unregister(fn)
close_connection(fn)
epl.unregister(serversocket.fileno())
epl.close()
serversocket.close()
当一个连接中由多个请求需要处理时,需要在输入流中添加分隔各请求的序列EOF(例如非文本的特殊字符\n\r\n);从而在服务器接收信息后检查请求接收完成并注册EPOLLOUT事件进行响应输出。EOF不应在请求内容中出现。
等待输出准备完成:当并发数量较大时,多个输出Sockets将共享网络输出,使得输出数据消耗较慢,一个Sockets在完成输出并就绪之前可能收到新的输出请求,此时该Sockets将等待输出准备完成。
def close_connection(fn, socket_opt=None): # 服务端关闭连接,释放资源 if socket_opt is socket.SHUT_RDWR: connections[fn].shutdown(socket.SHUT_RDWR) else: connections[fn].close(socket_opt) del connections[fn], recv_buffer[fn], send_buffer[fn]
Edge Triggered只在文件状态变化时通知应用。
管道IO:假设需要从输入流fd_read读取数据并写入输出流fd_write,其中一个没准备好都不能完成读写。如果使用LT模式(Level Triggered),则在两者全部准备好之前会持续收到其中已准备好的文件的通知,从而浪费资源。在ET(Edge Triggered)模式下,在收到某个文件准备好的通知时,记录其状态,当所有相关文件状态都就绪时,进行读写操作直到返回EAGAIN,然后重置状态进入下一次读写准备阶段。
select、poll、epoll之间的区别总结 - Rabbit_Dale - 博客园 (cnblogs.com)。
非阻塞IO
设置非阻塞IO:read()方法仅读取流中已有数据,并立即返回。为文件描述符添加os.O_NONBLOCK标识。
import fcntl
old_flags = fcntl.fcntl(f.fileno(), fcntl.F_GETFL)
fcntl.fcntl(f.fileno(), fcntl.F_SETFL, old_flags | os.O_NONBLOCK)
fcntl仅支持Linux。Windows上仅支持套接字的非阻塞模式(系统调用socket.ioctl(control, option))。
非阻塞方式通常与IO多路复用或异步接口结合使用,从而保证相应文件准备好读写内容。
socket.SOCK_NONBLOCK=>s.setblocking(False)=>s.settimeout(0.0)
多任务执行
多线程共享代码、内存数据,用于输入输出密集型(IO-bound)任务并行;多进程具有独立的代码、内存空间,用于计算密集型(CPU-bound)任务的并行。
线程
threading将线程封装为threading.Thread类。
th = threading.Thread(traget=func_my_thread, args=(args,))
class myThread(threading.Thread): # 支持继承`threading.Thread`类:
def __init__(self, target, *args, **kwargs):
threading.Thread.__init__(self, target, *args, **kwargs)
# do customized init
pass
def run(self):
# thread code
pass
th = myThread(args) # 创建线程
CPython(Python解释器)设置了全局解释器锁GIL(Global Interpreter Lock ),导致多线程中仅有一个线程获取到互斥锁,因此==无法实现真正地多线程并行执行。但多线程能够切换,因此能应用于I/O密集型任务避免IO阻塞==。基于C扩展的模块,例如numpy、pandas在调用内部C代码时不受GIL限制,因此能够实现并行。
thread提供了低级别的、原始的线程以及一个简单的锁。thread模块已被废弃。用户可以使用threading模块代替。为了兼容性,Python3将thread重命名为"_thread"。import _thread as thread thread.start_new_thread(func_thread, args)
线程信息
threading.currentThread():返回当前的线程变量(同current_thread())。
threading.main_thread():返回主线程信息。
threading.enumerate():返回当前进程包含正在运行的线程的列表。
threading.active_count():活动线程数量(activeCount)。
th.setName(name):设置线程名。th.getName()获取线程名。
th.name。
th.ident:线程ID;th.native_id:内核返回的线程编号,与ident不同。
th.daemon:是否为守护线程(th.isDaemon(),仅当守护线程退出时整个程序才完全退出),新线程继承父线程的守护属性(默认为False)。
线程调度
th.start() # 启动线程
th.join(time) # 等待线程结束或超时
根据
th.is_alive()判断线程是否已结束运行或超时。
可在全局空间中声明一个对应线程的停止标识,当目标线程检测到该标识后,主动退出(从线程函数返回),而非从其他线程强制停止该线程。
强制停止线程可能导致线程申请的资源未正确释放。
线程同步
互斥锁
互斥锁变量可作为全局变量或作为参数传递给线程,多个线程可尝试申请互斥锁的使用权避免共享资源竞争。
lock = threading.Lock()
lock.aqcuire()
lock.release()
参考进程同步原语。
Python的queue模块中提供了同步的、线程安全的队列类,包括Queue(FIFO),LifoQueue(LIFO),和优先级队列 PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
https://harveyqing.gitbooks.io/python-read-and-write/content/python_advance/python_thread_sync.html
创建进程
在Unix系统中,创建进程包括两种方式:
- 复制进程并共享代码空间,子进程与父进程执行不同的代码块;
- 替换(复制)进程,子进程执行其他文件内容。
Python提供上述两种方式的系统接口封装,并提供了抽象的类型封装。父进程可选择阻塞等待子进程执行结束或启动子进程后立即返回。
系统接口
os.fork()复制当前进程创建新进程(Unix-Only)。
os.system()封装了标准C函数system(),启动一个shell环境(子进程)执行命令,并返回命令的完成状态。命令的输出将合并到当前进程。
n = os.system('ls -l /home/user')
# >>> sh -c ls -l /home/user # -c read argumments as commands
Python封装了许多系统程序接口(
os库),可直接访问这些Python接口函数,而无需使用system()函数调用shell命令。
进程信息和控制接口
os.getpid()
os.getppid()
os.kill(pid, signal.SIGTERM)
(repid, status) = os.waitpid(pid, options=0) # 等待任意一个子进程结束
(repid, status) = os.wait() # 等待任意一个子进程结束
(repid, status, resinfo) = os.wait3()
(repid, status, resinfo) = os.wait4(pid,options)
siginfo = os.waitid(os.P_PID|os.P_PGID|os.P_ALL, id, options)
如果
pid=0,获取当前进程所在进程组的任意子进程的状态;如果pid=-1,则等效于wait();*如果pid<-1,则获取进程组|pid|中任意进程的状态(可能应该是当前进程所在进程组)。*在Windows上pid只能是正数,且不需要是一个子进程。
options:os.WNOHANG(Unix):立即返回,如果没有子进程终止,则返回(0,0);
status:16位整数,低字节为终止进程的信号,高字节为返回值(信号为0)。如果产生core dump,则信号字节的最高位被设置(waitstatus_to_exitcode())。
通过psutil可以获取到所有进程的详细信息:
psutil.pids()
psutil.test() # 模拟shell的ps命令
p = psutil.Process(3776) # 获取指定进程ID=3776的信息
通过psutil.Process可访问进程相关的信息。
共享代码的进程类型
multiprocessing库提供Process类创建子进程并运行指定代码(使用Pool创建进程池)。
p = Process(target=func, name='ProcName', args=(), kwargs={}, daemon=None)
p.start() # 启动进程
p.join() # 等待并清理进程
调用p.start()启动子进程,子进程的运行函数为p.run(),其默认调用初始化的target()。父进程记录子进程信息后从start()方法返回(非阻塞模式)。
可继承
Process并重载Process.run()方法,添加子进程初始化以及清理代码。
阻塞模式:父进程在启动子进程后可调用p.join()阻塞等待子进程结束。
使用
Process创建的进程在子进程退出前不会主动退出(等效于退出前调用了join())。==如果子进程是不会退出的服务,则主进程会阻塞而无法结束。==
进程启动方法
import multiprocessing as mp
if __name__ == '__main__':
mp.set_start_method('spawn') # 在main中设置默认进程创建方法,不能调用多次
mp.set_executable(PYTHON_PATH) # 设置运行子进程的Python解释器路径
-
spawn:父进程启动一个全新的Python解释器进程。子进程只会继承那些运行进程对象的run()方法所需的资源,不必要的文件描述符等不会从父进程继承。使用此方法相对其他两种方法较慢但最可靠,Windows的默认设置。 -
fork:使用os.fork()复制Python解释器,因此子进程启动时与父进程相同,父进程的所有资源都由子进程继承。Unix中的默认值(仅UNIX可用)。==为了减少进程创建开销,应该使父进程尽量轻量,即避免在父进程中创建不必要的资源==。避免对具有多线程的进程执行复制操作,
fork系统调用是面向单线程进程的,只有地址空间被复制,线程不能被继承。 -
forkserver:首先启动一个轻量的server进程(通过spawn方法创建),当需要创建进程时,复制server进程而不是当前进程。可在Unix平台上使用。使用context.set_forkserver_preload([modules])为server进程预加载部分模块(modules将会在主进程和server进程分别被导入一次,后续复制server进程是直接复制内存空间所以不会再加载模块)。server进程为单线程,因此使用os.fork()时是安全的。
在
Unix上使用spawn或forkserver方法还会启动一个资源追踪进程(resource tracker process),以追踪由进程创建的未连接的命名系统资源(例如命名信号量或共享内存对象)。当所有进程退出后,该追踪进程释放追踪的资源对象。如果一个进程被信号终止而未及时释放上述资源,可能导致资源泄漏。
可以在同一个程序中建立多个上下文(Context),以使用不同的进程启动方法。get_context()返回Context对象并提供与multiprocessing模块相同的接口。
ctx = mp.get_context('spawn')
q = ctx.Queue()
p = ctx.Process(target=foo, args=(q,))
p.start()
- Python forkserver and set_forkserver_preload():http://www.bnikolic.co.uk/blog/python/parallelism/2019/11/13/python-forkserver-preload.html
进程属性
-
ident和pid:进程ID。 -
authkey:当multiprocessing初始化时,主进程被分配的一个随机字符串;当进程被创建时继承父进程的authkey(可以手动修改该字符串); -
Process.name -
Process.exitcode:进程退出代码; -
Process.daemon:必须在调用start()前设置(该值继承自父进程,并可以通过构造函数设置)。注意:daemon=True的进程不是UNIX守护程序或服务,其不再被允许创建子进程,父进程退出前会主动结束并清理此类进程。 -
mp.current_process():返回当前进程。 -
mp.active_children():返回活动子进程列表。 -
mp.parent_process():获取父进程。 -
is_alive():进程是否存活;
start,join,is_alive,terminate和exitcode仅应该再父进程中被调用。
进程控制
terminate():中止进程,发送SIGTERM信号(Linux)或使用TerminateProcess()(Windows);进程立即退出,不会调用退出处理程序和finally语句块。kill()与terminate()一样,但发送SIGKILL信号;
p.join(timeout=None):合并子进程并清理子进程资源;
进程不能在自己的进程中调用
join(会形成死锁,不允许这样调用会产生错误);
join()不会返回进程退出状态,检查exitcode确定子进程的退出状态;已结束但还未合并的进程变为僵尸进程。每次新建子进程,调用
active_children()或调用已完成进程的is_alive()方法时,所有已完成的子进程会被自动清理;仍然建议尽可能手动合并子进程。==如果父进程可能先于子进程退出,则应该在父进程中调用
join()等待子进程退出,防止子进程变成僵尸进程后不会再被合并==。当一个子进程需要持续运行时,父进程调用join()来合并该子进程会导致阻塞而无法继续工作,令daemon=True可自动在主进程结束前尝试结束所有daemonic子进程防止其变为僵尸进程。
执行文件的进程类型
subprocess库提供方法在子进程中运行文件,用于替代os.system(), os.spawn*()。最常用的模式为接口为run():给定执行命令与参数,在给定时间内等待子进程执行完成并获取其输出内容和返回值。(如果子进程需要脱离前台进程运行,则需要调用Popen()方法自定义与子进程的交互过程)。
run()等效于调用Popen()、communicate()和wait()。
timeout,input传递给communicate();check, 和capture_output外,其他参数都传递给Popen()。
import subprocess as sp
sp.run(args, *,
input=None, # True => stdin=sp.PIPE
capture_output=False, # True => stdout=sp.PIPE, stderr=sp.PIPE
timeout=None,
check=False, # True => can raiseCalledProcessError
stdin,sdtout,stderr,
shell=False,
cwd=None
text, # True => 文本模式
encoding, # 使用文本模式并指定文本编码
errors,
env, # 环境变量字典
**popen_kwargs) -> sp.CompletedProcess # 返回进程结束状态
args:命令行参数为字符串或参数序列。在Windows上,参数序列将被转换为字符串传递给底层进程创建函数;在Linux上,==如果为字符串则整体视为执行的命令(不含参数);如果为参数序列,则首个参数为可执行命令,其他为该命令的参数==。
shell=True:创建并使用Shell解释执行命令。在Linux上,如果传递的是参数序列,则首个参数作为Shell的命令输入(类似于命令行上输入的所有内容),其他参数作为Shell环境的参数;
在Linux上需要设置
shell=True的情况,
- 需要对执行命令的Shell设置参数;
- 命令中包含非命令参数的字符,例如==通配符、管道和重定向==运算符。
在Windows上,参数表示方式对执行方式没有影响。但某些命令内置于shell中(如
dir),因此需要设置shell=True使用Shell来解释命令以及参数,以免产生FileNotFoundError。
进程间输入输出
默认子进程与父进程使用相同的标准输入输出流,无法捕获输出内容。可以将子进程的标准输入输出重定向到文件或者管道。
- 管道:
sp.PIPE表示创建一个连接到子进程的管道;stdin=sp.PIPE:父进程可以输入信息到子进程的标准输入;stdout=sp.PIPE:父进程可以从子进程的标准输出读取信息;- 合并标准输出和标准错误输出:
stdout=sp.PIPE和stderr=sp.STDOUT;
sp.DEVNULL将输出内容丢弃。- 其他合法的文件描述符。
如果使用文本模式,则 stdin、stdout和 stderr传递字符串;反之为字节流模式,使用bytes.decode('utf-8')方法将输出的字节数组转换为字符串,以及str.encode()将字符串转换为输入的字节数组。
Windows终端默认编码是GBK/GB2312。
返回值:包含了命令行参数args(传递给run()方法的)、返回值returncode、捕获的标准/错误输出数据stdout/stderr(capture_output=True)等。
proc = sp.run(['ps', '-ef'], capture_output=True, text=True)
print(proc.returncode)
print(proc.stdout)
os.popen()由sp.Popen()实现,执行命令并捕获输出内容(相比于sp.run(),==不会返回命令的返回值==,捕获的标准输出和错误输出合并)。stream = os.popen('echo ps -ef') # 返回标准输出的错误输出的流 output = stream.read() for r in stream.readlines(): print(r)
使用Popen创建子进程
proc = sp.Popen(args, *, bufsize, executable, ...) -> sp.Popen
Linux上使用类似
os.execvp()的方式创建子进程;Windows上使用CreateProcess()函数。
executable指定命令以代替args中的命令(如果shell=True,则代替shell;原来的命令作为进程的名称)。返回值封装子进程相关信息(参数、输入输出流、pid、返回值),后续调用可更新该对象。
非阻塞执行:子进程创建后立即返回,使用proc.poll()查询命令执行状态(储存在proc.returncode),程序执行完成前返回None;
阻塞执行:调用wait()方法等待子进程结束并清理子进程。
process.wait(timeout=10) # [except TimeoutExpired] 等待和回收子进程
子进程结束后,需要在父进程中回收资源,避免子进程成为僵尸进程,浪费系统资源。
终止进程:
proc.terminate() # SIGTERM / TerminateProcess()
proc.kill() # SIGKILL / TerminateProcess()
proc.send_signal(sig)
自定义输入输出交互流程
使用communicate()向子进程发送数据作为输入,并从标准输出流读取数据直到流结束(子进程退出),同时也执行wait()的功能清理子进程。
try:
outs, errs = proc.communicate(input='input content', timeout=None)
except TimeoutExpired: # 异常不会导致接收的数据丢失
proc.kill() # 强制终止进程
outs, errs = proc.communicate()
使用
communicate的前提是子进程与父进程已经建立管道连接。输入内容的类型(字节序列或字符串)与编码输入输出流的编码对应。
父进程从子进程读到的数据缓存在内存中,因此
commucate()不适合与子进程交换过大的数据。
如果子进程与父进程建立了对应的管道,那么在主进程中proc.stdin可写入子进程的输入流,proc.stdout,proc.stderr可读取子进程的输出。
readlines()方法将读取子进程的所有输出,直到进程结束。readline或readlines将阻塞进程,如果在终端中强制终止该方法,将导致管道损坏,无法继续读写数据。
使用管道将两个或多个子进程的输入输出连接:
child1 = Popen(args1, stdout=subprocess.PIPE) # 将子进程1的输出提供给父进程
child2 = Popen(args2, stdin=child1.stdout) # 子进程2将子进程1的输出作为输入
创建ssh连接进程:
如果输入输出缓存bufsize不为0,可能导致子进程不能及时接收到父进程发送的数据,可以使用flush强制刷新输入缓存。
如果要向子进程发送多次信息,并且在每次发送后获取输出,需要在父进程中将读取proc.stdout设置为非阻塞模式,使用异步方式读取输出内容。同时,添加特殊序列EOF以识别响应内容结束,从而进入下一条命令的发送。
在文本模式下(
encoding='UTF-8')使用特殊字符作为EOF时注意,Linux终端会将输出内容中的\r转换为\n,从而可能导致未检测到EOF。如果子进程连续输出内容,为保证获取足够多的输出内容,可以在每次查询(
select、epoll)输出是否可用前休眠一段时间。注意:如果使用阻塞模式读取内容,则只能每次读取1个字节,以避免在读取到
EOF之前发生阻塞。这种方式效率太低。
proc_ssh = subprocess.Popen(["ssh", "-T", "gary@myserver"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
EOF = b'\r\n\r'
proc_ssh.stdin.write(b"uname -a; echo -n {0}\n".format(EOF))
proc_ssh.stdin.flush() # 刷新缓冲区,使输入立即送到子进程
# Fetch output
for line in proc_ssh.stdout:
print(line.strip())
proc_ssh.stdin.close() # 关闭输入将使ssh退出
proc_ssh.wait()
stderr=subprocess.STDOUT导致输出提示Pseudo-terminal will not be allocated because stdin is not a terminal。使用ssh -T禁用伪终端分配可消除该信息。
subprocess提供的其他方法
sp.call(args, *, stdin, stdout, stderr, shell)
sp.check_call() # 退出值非0抛出异常CalledProcessError
sp.check_output() # 输出子进程的输出,退出值非0抛出异常
How to Execute Shell Commands with Python。
spawn
os.spawn*()系列函数使用可执行文件创建新进程(fork and exec on Linux)。
pid = os.spawnl(mode, file, *args) # see also: spawnle
os.spawnlpe(os.P_NOWAIT, 'python', 'python', 'ff.py', env)
# l: 传递可变参数列表;v: 将参数列表封装为一个序列传递
# p:使用环境变量中的PATH搜索可执行文件
# e:传递自定义环境变量(默认不传递)
mode={P_NOWAIT|P_WAIT}:非阻塞模式下返回进程ID,反之返回进程的退出值。
需要将首个参数指定为命令名。In either case, the arguments to the child process must start with the name of the command being run.
无法重定向输入输出(使用subprocess)。
守护进程
使新进程脱离父进程(double-fork):
import os
from multiprocessing import Process
def daemonize(func):
def wrapper(*args, **kwargs):
pid = os.fork()
if pid == 0:
# setsid()
ppid = os.fork()
if ppid == 0:
func(*args, **kwargs)
elif ppid > 0:
sys.exit(0) # intermediate process exit
else:
warnings.warn('create daemon process error.')
elif pid > 0: # parent process
if waitpid(pid) != pid:
warnings.warn(f'wait sub-process [{pid}] error.')
else: # sub-process
warnings.warn('create sub-process error.')
return wrapper
def daemonize(func):
def subsubproc(*args, **kwargs):
# setsid()
# 让first child成为session leader并与控制终端脱离,
# 这样second child就无法再获得控制终端了(非session leader)
proc_daemon = Process(target=func, *args, **kwargs)
proc_daemon.start()
# >>> proc_temp exit here <<<
# >>> proc_daemon becomes daemon (managed by init) <<<
def subproc(*args, **kwargs):
proc_temp = Process(target=subsubproc, *args, **kwargs)
proc_temp.start()
proc_temp.join() # waitpid,防止proc_temp成为僵尸进程
return subproc
daemonize(f)('Async and detached!!!')
@daemonize
def func_daemon(message):
while True:
time.sleep(5)
log(message)
func_daemon('Async and detached!!!')
class DaemonProcess(Process):
def __init__(self, target=None, name=None, args=(), kwargs={}, daemon=None):
Process.__init__(self, target=target, name=name, args=args, kwargs=kwargs)
def run(self):
setsid()
proc = Process(target=func, *args, **kwargs)
proc.start()
==在守护进程中创建Manager,以管理共享对象==。
进程同步
==multiprocessing包含来自threading的所有同步原语的等价物。==multiprocessing具有多种锁类型,根据使用情况自行选择:
-
非递归锁
multiprocessing.synchronize.Lockfrom multiprocessing import Process, Lock def f(l, i): l.acquire(block=True, timeout=None) # 防止各子进程输出内容混杂 try: print('hello world', i) finally: l.release() if __name__ == '__main__': lock = Lock() procs = [Process(target=f, args=(lock, num)) for num in range 10] for p in procs: p.start() for p in procs: p.join() -
递归锁:
RLock(); -
信号量:
Semaphore(value=1)计数器锁(信号量锁),value为初始计数; -
BoundedSemaphore(value=1)带上限的计数器锁(信号量锁),value即是初始计数,同时也是允许的计数上限; -
Barrier -
Condition(lock=None) -
Event
进程间通信
- 避免在进程间传递大量数据。
- 尽可能使用进程间共享对象类型(例如队列或管道),避免直接使用低层次的同步原语。
- 避免调用
terminate()方法,防止共享资源(例如锁、信号量、管道和队列)被损坏或不可用;
参数传递
创建进程时将需要共享的对象通过参数传递给子进程,例如管道对象、Queue对象、同步锁、信号量等。
文件锁
锁定文件描述符:
fcntl.flock(fd, operation) # man flock(2), emulated using fcntl()
fcntl.lockf(fd, cmd, len=0, start=0, whence=0)
cmd=LOCK_UN, LOCK_SH, LOCK_EX:分别代表解锁、共享锁和互斥锁。可以与LOCK_NB共同使用以避免阻塞(产生OSError,异常属性包括EACCESS或EAGAIN)。lockf可通过len, start, whence来控制锁定文件的部分内容。
filelock是一个跨平台的库。
from filelock import FileLock
import logging
logging.getLogger("filelock").setLevel(logging.ERROR)
with FileLock('filename.lock', timeout=10): #=> with FileLock(...).acquire():
open('filename', "a").write(msg)
==加锁文件与需要读写的文件需要分开==。加锁文件所在的目录必须存在,加锁文件不存在将自动创建。
共享内存
可以使用 Value 或 Array 将数据存储在共享内存映射中。在调用顺序不确定的情况下,应该结合同步机制访问共享内存中的数据。
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0) # double type value
arr = Array('i', range(10)) # singed integer array
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
管道和消息队列
管道和消息队列内部实现了同步机制,因此用户无需管理同步。
管道
管道用于连接两个进程:
from multiprocessing import Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe() # 返回Connection对象
p = Process(target=f, args=(child_conn,)) # 将管道对端传递给子进程
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
管道对端连接描述符(
child_conn)传递给子进程时会进行复制(连接计数+1),使得父进程和子进程都可以从管道对端读写数据。为了使父进程能够感知子进程已经关闭连接(或已经无数据可接收),父进程必须首先关闭管道对端。
Connection对象:用于传递可序列化的(picklable)对象或字节序列。
conn.send(obj):obj = conn.recv():阻塞直到有数据收到,如果对端关闭或无数据可接收,返回EOFError(==实际运行发现未返回错误并一直阻塞==)。close():关闭连接(垃圾回收时自动关闭,但发送方主动关闭可让接收方感知到发送数据结束而不必持续等待)。poll(timeout);查询是否有数据可接收。如果未指定参数则立即返回,如果timeout=None则持续等待。send_bytes(buffer, offset=0, size=None):buffer类型为字节序列类型,例如bytes。recv_bytes(maxlength=None):阻塞模式参考recv;recv_bytes_into(buffer, offset=0):
mp.connection.wait(conn_list, timeout=None):等待Connection、socket、Process.sentinel等对象就绪(==有数据可读,或对端已经关闭==);如果当前进程要同时接收其他多个进程的数据,则可以使用该方法实现IO复用。
Unix:与
select.select(object_list, [], [], timeout)几乎相同。
conn.close():关闭连接并释放资源,支持with语法。
消息队列
消息队列允许连接多个进程(生产者和消费者)。
from multiprocessing import Queue,SimpleQueue,JoinableQueue
def f(q):
q.put(obj, block, timeout) # block控制阻塞,timeout控制阻塞时长
if __name__ == '__main__':
q = Queue(maxsize) # qisze(), empty(), full()
p = Process(target=f, args=(q,))
p.start()
obj = q.get(block, timeout)
print(obj) # "[42, None, 'hello']"
p.join()
Queue使用标准库的queue.Queue,并基于管道、锁和信号量。
https://docs.python.org/3/library/multiprocessing.html?highlight=process#pipes-and-queues
信号
信号处理函数:
def on_terminate(signum, frame):
print('Terminated by signal.', file=sys.stderr)
sys.exit(0)
signal.signal(signal.SIGTERM, on_terminate)
应用程序不能处理:
SIGKILL、SIGSTOP信号。
frame
time.sleep(s)
套接字连接
from multiprocessing.connection import Client, Listener
client_conn = Client(address, family=, authkey=)
listener = Listener(address, family=, backlog=, authkey=)
with listener.accept() as conn: # 建立连接
conn.send(data)
conn.recv(data)
地址格式:
- TCP/IP套接字
AF_INET:(hostname, port); - Unix域套接字
AF_UNIX:文件路径名; - 命名管道
AF_PIPE(Windows):r'\.\pipe{PipeName}'或r'\ServerName\pipe{PipeName}'(远程)。
建立连接后与管道读写数据的方法一致。*但如果Listener要持续接受新的连接,则可能在读取连接的数据前阻塞在Listener处。*此时应该使用socket模块提供的套接字接口。
Manager
Manager创建一个服务进程并管理共享对象,其他进程通过代理访问共享对象。
SyncManager
使用SyncManager自动生成子进程,已经注册了常用的数据类型以及用于进程同步数据类型,因此用户可直接创建这些类型变量进行共享。如果SyncManager对象被垃圾回收或者父进程退出,则SyncManager对应的进程也随之退出。
from multiprocessing import Manager
manager = Manager() # Returns a started SyncManager object
manager.shutdown()
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l)) # 传递Manager管理的数据对象给子进程
# ...
SyncManager不能直接传递给其他进程,而是应该传递其管理的数据(Proxy)。SyncManager没有公开的地址(内部使用Unix域套接字地址),无法通过地址远程访问(进程重新启动后无法再次访问原来的管理对象)。每个进程有自己独立的
SyncManager。
特殊数据类型:
-
Namespace:在该命名空间中可创建变量,并通过空间名称引用;with Manager() as manager: ns = manager.Namespace() ns.x = 10 ns.y = 'hello' print(ns) # => Namespace(x=10, y='hello')
BaseManager
BaseManager支持远程进程访问共享对象(使用套接字)。
from multiprocessing.managers import BaseManager
manager = BaseManager(address=('', 50000), authkey=b'abc')
manager.get_server().serve_forever() # 前台阻塞执行
manager.start() # 启动后台进程,类似于SyncManager
使用Manager管理共享队列,需要手动注册共享对象。
from multiprocessing.managers import BaseManager
from queue import Queue
queue = Queue() # 创建一个队列
BaseManager.register('get_queue', callable=lambda:queue)
m = BaseManager(address=('', 50000), authkey=b'abc')
queue = m.get_queue()
queue.put('hello')
m = BaseManager(address=('127.0.0.1', 50000), authkey=b'abc')
BaseManager.register('get_queue')
m.connect() # connect to a manager server
queue = m.get_queue()
queue.get()
BaseManager.register:
Proxy对象
使用Manager创建的共享数据类型基于BaseProxy类型,通过该类型对象可访问被引用的共享对象。Proxy类型可以被序列化,因此能在进程间传递。
Proxy对象包含弱引用回调函数,当其被垃圾回收时,会向Manager注销其对共享对象的引用。当共享对象的引用数量减少为0时,Manager将删除共享对象。
服务框架
使用Flask等服务模型,简化请求响应式的多进程/线程的程序编写。开发人员只需编写对应请求的处理逻辑。
并行任务调度

并发模型
由于GIL限制,Python多线程模型并非正真的并发,因此需要靠多进程实现并发。
进程池
multiprocessing.Pool类表示一个工作进程池,它允许以几种不同方式将任务分配到工作进程。适用于大并发短任务场景,无需反复创建销毁进程从而减小开销
import multiprocessing
def some_work(args):
pass
pool = multiprocessing.Pool(processes=nproc) # start in __main__
# 将任务发送给到进程池,可以反复调用发送任务
async_result = pool.apply_async(some_work, (args))
pool.close()
with multiprocessing.Pool(processes=nproc): # 使用上下文管理器
pool.apply_async(some_work, (args,))
apply方法是阻塞的,不能实现并行。apply_async方法返回运算结果指示器AsyncResult,主程序后续可以通过适当方式查询AsyncResult的状态然后获取计算结果。
批量提交
map/map_async:将一批计算的参数构造成序列,序列的每个元素分别对应一个计算任务的输入,返回计算结果构成的序列。
map(func, [args1,args2,...], chunksize) # => starmap, starmap_async
multiprocessing — Process-based parallelism — Python 3.9.6 documentation
pathos
pathos是一个较为综合性的模块,既能多进程,也能多线程。其主要采用进程池/线程池方法。pathos本身有一套进程池方法,同时也集成了multiprocess、pp模块的进程池方法。
concurrent.futures
concurrent.futures模块的接口与multiprocessing差异比较大,要理解如何用它,需要搞清楚executor和future两个概念:
Executor
executor可以类比为multiprocessing的进程池、threading的线程池,相当于一个多进程或多线程的环境。
with ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(pow, 323, 1235)
executor.submit(shutil.copy, 'src1.txt', 'dest1.txt')
print(future.result())
或:
executor = ThreadPoolExecutor(max_workers=2)
a = executor.submit(wait_on_b)
b = executor.submit(wait_on_a)
Future
future对象可以类比为添加到进程池或线程池的一条条具体任务。
future.result(timeout=None)
等待直到完成任务或超时,返回计算结果或concurrent.future.TimeoutError。默认无时间限制。
add_done_callback(fn)
当future完成或取消时会调用fn。使用cancelled()、done()和running()判断future的状态。
Parallel Python
pp模块(也即parallel python模块)是用纯Python编写的开源、跨平台、轻巧并行模块。
pp模块实现并行的方式与multiprocessing等不同,他是通过修改Python的GIL机制突破这个限制,而非开启多个解释器(未详细确认)。可能也是因为以上原因,pp模块调用子进程中的print函数可以正常输出到主进程标准输出,不像在multiprocessing、multiprocess、pathos.multiprocessing.ProcessPool、concurrent.futures等模块中还必须通过进程间通信传递给主进程操作。
要建立多进程,首先需通过Server类创建进程服务器(类似于进程池);然后,在这个服务中,创建具体的子进程任务Task。
终端
获取终端的行列数:
rc = os.get_terminal_size()
# os.terminal_size(columns=80, lines=24)
Python高级编程
Python语言的高级特性。
协程和任务
asynciois used as a foundation for multiple Python asynchronous frameworks that provide high-performance network and web-servers, database connection libraries, distributed task queues, etc.
asyncio适用于IO密集型任务,提供high-level APIs:
- run Python coroutines concurrently and have full control over their execution;
- perform network IO and IPC;
- control subprocesses;
- distribute tasks via queues;
- synchronize concurrent code;
以及底层API用于开发库和框架。
异步方法
基于async/await语法定义异步函数:异步方法中可嵌套调用异步方法,也可仅是普通耗时IO操作。
import asyncio
async say_after(length, msg):
await asyncio.sleep(length)
print(msg*length)
async def main():
print('start')
await asyncio.sleep(1)
task1 = asyncio.create_task(say_after(1, 'hello'))
task2 = asyncio.create_task(say_after(2, 'hello'))
await task1
await task2
print('end')
运行异步方法
入口函数
执行异步方法,管理异步事件循环和线程池。
asyncio.run(main())
嵌套调用异步方法
直接访问异步方法返回的是coroutines对象,需要通过await关键字来启用协程。
await async_method()
await function_that_returns_a_future_object() # await Future object
awaitable objects: coroutines, Tasks, and Futures.
并发调用异步方法
使用asyncio.create_task创建并调度多个协程并返回Task对象,可在后续等待一批协程执行完成。
https://docs.python.org/3/library/asyncio-task.html
https://docs.python.org/3/library/asyncio.html
反射
获取动态属性
value = getattr(obj, name) # exception if not exist
tf = hasattr(obj, name)
动态增删属性
setattr(obj, name, value) # obj.attr = value
delattr(obj, name) # del obj.attr
object.__set_attr__():子类内部可覆盖该方法,以改变设置属性时的行为。只有在没有找到属性的情况下,才调用__getattr__,已有的属性,比如name,不会在__getattr__中查找。注意:如果存在成员函数名
name,则不能设置同名属性,否则产生(AttributeError)。
定制类 - 廖雪峰的官方网站 (liaoxuefeng.com)
装饰器
装饰器(Decorator)可以基于函数的闭包构建,为已有函数some_func增加前置/后置处理。
def decorator(some_func):
def wrapper(*args,**kwargs): # warpper for some_func
print "before some_func"
ret = some_func(*args,**kwargs)
return ret + 1
return wrapper
# 等效于回调函数
def decorator(some_func, *args, **kwargs):
print "before some_func"
ret = some_func(*args,**kwargs)
return ret + 1
使用装饰器:
@decorator
def some_func(*args,**kwargs):
pass
# equivalent form
some_func = decorator(som_func)(*args,**kwargs)
向装饰器传递参数需要再定义一层装饰器:
def decorator_with_args(deco_args):
def decorator(some_func):
def wrapper(*args,**kwargs):
# use deco_args in the the wrapper function.
return some_func(*args,**kwargs)
return wrapper
return decorator
# define function with decorator
@decorator_with_args(deco_args)
def some_func(*args, **kwargs)
基于类的装饰器
装饰器实际是callable对象。除函数外,实现__call__方法的类也是callable对象(等效于将基于函数定义的内容放到了__call__方法中)。带参数的基于类的装饰器定义(在构造函数中定义传递给装饰器的参数,装饰目标传递给__call__方法):
class logger(object):
def __init__(self, level='INFO'):
self.level = level
def __call__(self, func): # 实现callable接口
def wrapper(*args, **kwargs):
print("[{level}]: the function {func}() is running..."\
.format(level=self.level, func=func.__name__))
func(*args, **kwargs)
return wrapper # 返回包装后的函数对象
@logger(level='WARN')
def somefunc(*args, **kwargs): # => logger(level='WARN')(somefunc,...)
pass
如果装饰器不带参数(类比于基于函数的装饰器,比带参数的少了一层函数定义;装饰目标传递给装饰器的构造方法):
class logger(object):
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs): # 实现callable接口
print("[INFO]: the function {func}() is running..."\
.format(func=self.func.__name__))
return self.func(*args, **kwargs)
@logger
def somefunc(*args,**kwargs): # => logger(somefunc)(...)
pass
装饰类的装饰器
装饰器的参数由函数名变为类。
class singleton: # <== 基于类的装饰器,用于装饰Singleton Class
_instances = {} # <== 记录所有Singleton实例
def __init__(self, cls):
self._cls = cls
def __call__(self, *args,**kwargs):
if self._cls.__name__ not in singleton._instances:
singleton._instances[self._cls.__name__] = cls(*args, **kwargs)
return singleton._instances[self._cls.__name__]
@singleton
class User:
def __init__(self, name):
self.name = name
user = User('gary') # => singleton(User)('gary')
跨语言编程
Matlab
Python调用Matlab
cd "matlabroot\extern\engines\python"
python setup.py install # conda activate
import matlab.engine
eng = matlab.engine.start_matlab()
eng.addpath(r'path\to\work\dir')
在Python程序中创建Matlab矩阵类型
matlab.type(initializer=None,size=None,is_complex=False)
type包括:double、single、intXX、uintXX、logical。
matlab.int64在Matlab中转换为int32;matlab.uint64在Matlab中转换为uint32;logical类型不能用于构造复数(无is_complex参数)。
initializer为矩阵初始值,即Python序列类型(list和tuple);size为矩阵维度,需要与初始化值的维度匹配。未指定size时,矩阵维度默认为$1\times N$;如果初始化数据中元素为序列类型,矩阵维度为$m\times N$。未指定初始化值时,元素值设为默认值(0)。
matlab.type.size:获取矩阵的维度;
matlab.type.reshape(size):修改矩阵维度;
pyarray[i]:索引矩阵的行。Matlab矩阵默认为二维矩阵。
pyarray[i][j]:索引矩阵元素。Matlab中索引起始为1,在Python代码中索引起始为0;
pyarray[i][j:k]:切片;
如果使用Matlab矩阵自身元素更新自身可能得到造成非预期结果。
mlarray[0] = mlarray[0][::-1]
将数据从Python程序传递至Matlab程序:
| Python Input Argument Type | Resulting MATLAB Data Type |
|---|---|
matlab.type (数值矩阵) | 数值矩阵 |
float | double |
complex | Complex double |
int | int32(Windows)int64(Linux/Mac) |
float('nan'\|'inf') | |
bool | logical |
str | char |
bytearray/bytes | uint8 array |
dict | 结构体(key必须为字符串) |
list/set/tuple/range | Cell array |
memoryview/None | Not supported |
从Matlab程序返回至Python的数据:
| MATLAB Output Argument Type | Resulting Python Data Type |
|---|---|
| 数值矩阵 | matlab 数值矩阵 |
double single | float |
| 复数(any numeric type) | complex |
int8 uint8 int16 uint16 int32 | int |
uint32 int64 uint64 | int long |
NaN | inf |
logical | bool |
char array (1-by-N, N-by-1) | str |
| 结构体 | dict |
| 1D cell array | list |
在Matlab中调用Python
在Matlab会话中启用Python环境:
pe = pyenv('Version','C:/tools/miniconda3/envs/data/python.exe')
pe = pyenv # read curent python environment
在整个会话中只能导入一次Python环境,可根据
pe.Status来判断是否已经导入。
调用python的包无需使用import语句
syspath = py.sys.path
syspath.append(pwd)
import py.textwrap.wrap
S2 = wrap('another string');
mm = py.importlib.import_module('mymod');
% Use mm as an alias to access functionality in mymod
py.help('object')
Java
Python项目
Basic Layout
projectname/
├── .gitignore
├── projectname.py
├── LICENSE # if you’re distributing code.
├── README.md
├── requirements.txt # Python dependencies and versions
├── setup.py # installation
└── tests.py
modulized layout
helloworld/
├── bin/ # 可编写脚本调用模块的主程序
├── docs/
│ ├── hello.md
│ └── world.md
├── helloworld/ # package contains sub-modules
│ ├── __init__.py # indicator of package
│ ├── helloworld.py # 可包括多层内部package进行功能划分
│ └── helpers.py
├── tests/ # 对应功能模块结构编写测试
│ ├── helloworld_tests.py
│ └── helpers_tests.py
└── ... # other files in basic layout
测试
性能测试
代码片段的运行时间统计。
from timeit import timeit
print(timeit('[n**2 for n in range(10) if n%2==0]', number=10000))
单元测试
A unit is a specific piece of code to be tested, such as a function or a class. Unit tests are then other pieces of code that specifically exercise the code unit with a full range of different inputs, including boundary and edge cases.
unittest用于单元测试。setUp(由__init__()调用)和tearDown用于为每个测试用例初始化和回收资源,与test_case()组成一个测试配置。unittest.main()为测试类中的每个测试用例构造一个测试类实例,并调用该测试用例方法(因此在一个测试类中setUp等方法调用次数与测试样例数一致)。
import unittest
class MyTestCases(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_case(self): # 测试项
self.assertTrue(True, msg='Test Pass.') # 使用assert语句判断并记录测试结果
if __name__ == '__main__':
unittest.main() # 使用Python运行该脚本自动执行所有测试
执行测试。测试项的执行顺序依据测试方法名称排序。
python test/components/test_operators.py
python -m unittest test.components.test_operators
python -m unittest test/components/test_operators.py
# 需要相应目录下有__init__.py,否则无法将对应文件夹视为模块
构造测试组
if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTests([
TestCases('test_scalar_operator'), # 参数为测试类中的测试方法名
])
runner = unittest.TextTestRunner()
runner.run(suite)
TextTestRunner以文本形式显示测试结果,包括:
- 测试名称;
- 测试过程中的错误信息;
- 测试结果汇总。
编译打包
python -m compileall pysrc.py # compile to .pyc file
python -m zipfile \
-c demo.zip demo/* # 将源文件打包为zip => 执行:python demo.zip
python3 -m zipapp demo -m "main:main"
分发和安装
from setuptools import setup, find_packages
setup(
name="mytest",
version="1.0",
author="wangbm",
author_email="wongbingming@163.com",
description="Learn to Pack Python Module",
url="http://iswbm.com/",
packages=find_packages(),
python_requires='>=2.7, <=3',
install_requires=['docutils>=0.3'], # 自动下载安装依赖包
setup_requires=['pbr'], # 当前环境必须存在依赖包
entry_points={
'console_scripts': [
'foo = foo.main:main' # 生成/usr/bin/foo -> foo.main模块中的main函数
]
},
scripts=['bin/foo.sh', 'bar.py'] # 将脚本复制到系统路径中
)
花了两天,终于把 Python 的 setup.py 给整明白了 - 知乎 (zhihu.com)
setuptools Quickstart - setuptools 60.5.2 documentation (pypa.io)
JAVA编程
Java语言不使用指针,而是引用。
Java程序
编写
代码结构
一个*.java文件可以包含多个类的定义:
- 只能有一个
public类/接口,源文件名与public类名相同;
打包声明
包用于描述代码的逻辑组织结构(类似于C#的命名空间):
-
把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用
-
并防止命名冲突。
如果一个public类要包含在某个包内,需要在代码的第一行使用package关键字进行声明。
package org.develop.app;
在指定的源代码根目录下,层级的打包声明也对应源代码(编译输出字节码)文件树目录结构。
不同类型项目的源文件根目录设置可能不同,例如Maven项目的源代码根目录为
src/main/java,则上述源代码对应的路径为src\main\java\org\develop\App.java。
导入包声明
为了使用外部代码(例如Java库),源文件文件中可以导入(import)外部依赖包的内容。
导入语句位于打包语句之后。
import java.io.*; // import all
import java.io.File; // import single class
包具有层级嵌套结构,导入声明仅能引用当前层级包中的类,而不能引用下一层级的包中的类(需要单独声明)。
模块系统(Java 9)
同一个jar文件中的.class文件并没有依赖关系限制;模块则附加依赖关系,还可包含二进制代码。
oop-module
├── bin # 存放编译后的class文件
├── build.sh
└── src # 源码:按包名的目录结构存放
├── com
│ └── hello
│ └── world
│ ├── Greeting.java
│ └── Main.java
└── module-info.java # 模块的描述文件,包含依赖声明
在Java代码中仅能引用模块描述文件中声明的依赖库。
module hello.world {
requires java.base; // 可不写,任何模块都会自动引入java.base
requires java.xml;
exports com.hello.world; // 只有声明导出的包,外部代码才能问。(进一步隔离了代码的访问权限)
}
java --list-modules显示JDK自带模块。java -d,describe-module module_name显示模块的描述信息。
执行Java程序
编译
Java程序被编译为字节码格式(*.class文件)。在运行时,Java平台中的Java解释器对这些字节码进行解释执行,执行过程中需要的类在联接阶段被载入到运行环境中。
运行
Java应用程序是由若干类定义组成的独立的解释型程序,其中必须有一个包含Main方法的主类;执行Java应用程序时,需要使用Java解释器(java.exe)来执行这个主类的字节码文件(.class)。
java App.java # 直接编译执行源文件
java [options] -jar package-name.jar [args...] # 执行jar包中包含Main方法的class文件
java [options] -cp <classpath> package.ClassName [args...] # 指定搜索路径下的class
package.ClassName:程序执行时应该执行入口函数所在的类,解释器在搜索路径下寻找指定类。Java应用程序的入口函数为类中的名为Main的静态方法。使用-jar选项执行时,jar包中需要在manifest中声明主类。
--dry-run:创建VM并加载主类,但不执行主方法。用于验证命令行参数是否有效。Java小程序(Java Applet)的源代码编辑与字节码编译生成过程与Java应用程序相同,但它不是一类可独立运行的程序。Applet程序的字节码文件必须嵌入到HTML文件中并由负责解释HTML文件的浏览器充当其解释器。将Java Applet引入HTML中,使得网页能够提供动态信息。Java小程序与Java应用程序最大不同在于Applet不需要
Main方法,而要求程序中必须有且只有一个类是Applet类的子类。系统类Applet类中已经定义了许多成员,它们规定了Applet如何与执行它的解释器——浏览器配合工作。
Java环境变量
-D<name>=<value> # 系统属性(system.Properties),传递应用程序
-X # 输出所有`-X`(extra)虚拟机选项的名称;
Java虚拟机选项
-Xms:Java虚拟机的初始堆内存分配量,例如-Xms256m;单位包括:k,m,g,...。
-Xmx:JVM最大堆内存分配量,例如-Xmx2048m,通常默认值为256m;如果超过最大内存分配限制,程序将触发java.lang.OutOfMemoryError异常。
Java系统属性
路径
当前路径
执行Java程序时所在的工作目录。
类搜索路径
Java解释器需要在搜索路径CLASSPATH中寻找.class文件进行执行。==类文件(*.class)可能位于文件夹、jar文件或zip文件==,使用以下选项添加搜索路径。
-{cp,class-path,classpath} libpath1:libpath2/*:lib3.jar:...
特别地,==如果文件夹以/*结尾,那么该文件夹下的所有jar/zip文件都会被加入搜索路径==。
JVM自带的标准库
rt.jar不要写到CLASSPATH中,写了反而会干扰JVM的正常运行。*不能视为通配符,因此*.jar的写法将无效且造成错误。
连接动态库
如果程序依赖共享库(JNI),而不能定位,则会引发java.lang.UnsatisfiedLinkError。
使用-Djava.library.path=/your/lib/path选项指定。
另一种方法是在执行程序之前(或加入/etc/profit)设置环境变量 LD_LIBRARY_PATH。
不建议修改共享库搜索路径。如果使用的共享库在系统中存在其他版本,可能影响程序使用的共享库版本,使程序出错(
ImportError: tensorflow/python/_pywrap_tensorflow_internal.so: undefined symbol)。
export LD_LIBRARY_PATH=:~/Workspace/lib/java/tensorflow/
模块搜索路径
-p,--module-path <module path> path1:path2:...
语法
标识符大小写敏感。命名规则:
- 类名:单词首字母大写;
- 方法名:首字母小写,其余单词首字母大写;
注释和文档
注释:
- 使用
//或/*...*/添加单行注释; - 使用
/*...*/添加多行注释。
文档化注释
/**
* <h1>Find average of three numbers!</h1>
* <p>The FindAvg program implements an application that
* simply calculates average of three integers and Prints
* the output on the screen. </p>
*
* @param parameter_name description [Parameters” section]
* @return description [“Returns” section]
* @exception ExceptionClass [Throws subheading]
* @author Author Name
* @version version [“Version” subheading]
* @since release-date [“Since” subheading]
* @see reference [See Also” heading]
* @deprecated Indicating Deprecated components
* {@link package.class#member label}
* {@code text}
*/
使用javadoc生成格式化文档。
javadoc Program.java
https://www.geeksforgeeks.org/comments-in-java/
https://www.oracle.com/technetwork/java/javase/documentation/index-137868.html
标注(Annotation)
标注以@开始,用于辅助程序元素与元信息的关联,并控制编译器的行为,但对编译后的程序不起作用。
@MarkerAnnotation
@SingleValueAnnotation("info")
@FullAnnotation(key1="value1",key2="value2")
预定义标注:
import java.lang.annotations.*;
@Deprecated // indicate an oboslated declaration
@Override // must override a method from superclass
@SuppressWarnings({"checked", "deprecation"}) // 参数可为空
@FunctionalInterface
@SafeVarargs // 标注的方法不会对可变参数执行不安全操作
标注可用于类、方法、语句等的开头(上一行),for语句等的条件语句的开头。
自定义标注,类似于定义接口(使用@interface关键字),自定义标注本身还可添加标注信息(meta annotations):
@Documented // 添加所定义标注的元素信息文档化(javadoc etc.)
@Target(ElementType.METHOD) // 标注的目标TYPE, METHOD, FIELD...
@Inherited // 子类是否继承父类元素的该标注
@Retention(RetentionPolicy.RUNTIME) // === SOURCE,CLASS, RUNTIME
@Repeatable // 该标注是否可重复声明
public @interface MethodInfo{
String author() default "gary"; // 方法不能包含参数
int revision() default 1; // 方法返回值仅限基本类型
}
https://www.geeksforgeeks.org/annotations-in-java/
变量声明
变量在使用前必须声明:
type var_name[ = value, var_name2[ = value]...];
变量根据作用域可分为:类变量(静态字段)、实列变量(字段)和局部变量。
局部变量是在栈上分配的,在所在作用域(方法、代码块)被执行时创建,执行完即被销毁。
局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
流程控制
条件
if(condition){
}else if (condition){
}else{
}
循环
while
while (condition){
do_something;
}
赋值语句的返回值可作为条件语句,例如:(line = reader.readLine()) != null(null本身不能直接作为条件语句)。
do-while
do{
do_something;
}while(true);
for
for(int i=0; i<len; ++i){
do_something;
}
增强for循环,结合迭代器。
for(String name : names){
do_something;
}
Stream API
定义对元素的计算函数,由Stream框架执行内部迭代,从而实现并行计算、过滤、映射等功能特性。
Java 8 Stream - Java Stream - JournalDev
return list.stream().filter(x -> x > 10).mapToInt(x -> x).sum();
switch-case
switch(expr){
case const_val1:
statements;
break;
case const_val2:
case const_val3:
statements;
break;
default:
statements;
}
说明:
- 变量类型可以是:
byte、short、int、char以及string(Java 7); case语句的值为常量或字面值常量;
try-catch-finally
用于处理程序异常的控制结构。
try {
do_something;
} catch (ExceptionTypeA | ExceptionTypeB e) {
handle_exception;
} finally {
clean_work;
}
try-with-resource
简化资源关闭与异常处理流程(Java 7)。
try (open_resources){
do_something;
}
catch(exception e){
handle_exception;
}
为了能够配合try-with-resource,资源必须实现AutoClosable接口。
运算符
instanceof
检查该对象是否是一个特定类型(类类型或接口类型)
Object instanceof ClassName
函数
Lambda表达式(匿名函数)
使用Lambda表达式:可减少代码量,传递函数作为参数,在使用时定义函数。
(args)->{statements} // 参数和方法内容均可省略,单语句可省略"{}"
无返回值的方法体以最后语句的返回值作为方法的返回值。
参数类型可==同时==省略(自动推断)。
方法引用(Java 8)
面向对象的编程
Java中所有内容均包含在类的定义中。
类与对象
[public] [modifier] class ClassName [extends BaseClass][implements Interfaces,...]{
[protected] [modifier] int PropertyName [= value];
[public] ClassName(int param,...) throw exceptions{
super(param,...)
do_initialization;
}
[private] [modifer] void methodName(int param,...)throw exceptions{
statements;
this.another_method(param,...);
super.base_method(param,...);
}
public int static main(String[] args){
ClassName c = new ClassName(...);
}
protected class InternalClass{
class_definitions;
}
}
使用new关键字创建对象。创建对象时将调用类的构造方法。
注意:类的实例都是通过引用来使用的,使用new创建的对象都会在内存中开辟独立的空间,两个对象即使内容相同,但是在内存中的地址不同,所以如果使用==进行比较,会得到false;但是使用类的方法equals比较两个实例的内容。使用对象相互赋值的方法,则只是复制了对象的引用,并没有开辟新空间,所以两者指向同样的区域。==对于字符串来说,如果直接将带引号的字符串赋值给两个字符串对象,则由于Java处理字符串的特性,两个对象将指向内存中的同一位置(内存中的特殊区域String Pool),使用======也会返回true==。
类的成员包括方法和字段。在类内部可直接通过名称访问成员。当成员名称与参数名或局部变量重名时,使用this关键字访问成员。this还可用于在构造方法内部引用该类的其他构造方法(只能出现在构造方法内部的第一行,即只能调用一次)。
修饰符
访问控制
-
public:这个类可以被其他所有类访问和引用,只能被定义在同名文件中。 -
default:即没有访问控制符修饰,这样的类只能被同一个包内的类引用,而对其他包内的类不可见。
-
protected: -
private:只用于内部类。
其他
abstract:抽象类,不能直接被实例化的类,但是可以声明对象的引用,只是声明的对象引用默认值都是null,必须使用可实例化的子类的构造函数对其赋值。抽象类内部可以包含任意个抽象方法,也可以包含构造方法、字段和实体方法。final:不能被继承的类。
字段
字段(Fields,属性Attributes)是类内部定义的变量。
访问控制修饰符
public: 允许任何位置对字段的访问。由于具有默认访问权限的类本身只能被同一包内的成员所访问,所以这种类中的成员即使具有public权限也只能被同一包内的其他类访问。- default:同一个包内的位置可对字段进行访问。
protected:允许该类及其子类中对该字段进行访问。private:允许在该类内部对该字段进行访问。访问控制是针对类而言的,而并非针对具体实例而言,即同一个类的不同实例可以互相访问它们的私有成员。而通过继承关系生成的子类,其新定义的方法则不能访问父类的私有成员,但继承自父类的成员函数因为本来可以访问父类成员,所以在子类中仍然可以访问父类成员。
其他修饰符
-
static:同一个类所有的实例共享静态字段。静态成员不属于对象,所以推荐使用类名来访问静态成员(在类内部可直接使用字段名)。
ClassName.StaticProperty;由于静态字段从属于类,而不属于实例,所以不能用构造函数进行初始化。同时由于除了通过在声明字段时对字段赋初值,还可以通过静态代码块对静态字段进行初始化。
static{ initialize-statements; } -
final:常量字段,通常用大写字母作为常量标识符。 -
transient:序列化对象时,跳过该类变量。 -
volatile:在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
方法
方法的访问控制与字段一致。
修饰符
-
abstract:只有函数声明(declaration/signature),而没有函数体。具有抽象方法的类即抽象类。抽象类的类必须重载这些抽象方法才能实例化,否则子类也必须声明为抽象类。 -
final:不能被类的子类重写。 -
static:静态方法,只能访问和修改类的静态成员,通过类名调用。ClassName.StaticMethod(args);名为
main的静态方法可作为Java程序的入口函数。public static void main(String[] args) // args not contain program name主函数无须返回值(
return)。由于程序由java解释器执行,因此从主函数返回值并不能被shell接收。java解释器将获取由System.exit(value)返回的值,并返回给shell。 -
synchronized:方法同一时间只能被一个线程访问。
方法重载(Overload)
重载的方法必须拥有不同的参数列表。不能仅依据修饰符或者返回类型的不同来重载方法。
可变参数
一个方法中只能指定一个可变参数,它必须是方法的最后一个参数,在参数类型后加一个省略号(...)。
public static void printMax( double... numbers)
命令行参数解析
picocli
可以通过外部依赖或源代码(CommandLine.java)的方式使用。以下为通过Maven配置依赖项。
<dependency>
<groupId>info.picocli</groupId>
<artifactId>picocli</artifactId>
<version>4.2.0</version>
</dependency>
启用Annotation Processor:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.0</version> <!-- 3.5 or higher -->
<configuration>
<annotationProcessorPaths>
<path>
<groupId>info.picocli</groupId>
<artifactId>picocli-codegen</artifactId>
<version>4.2.0</version>
</path>
</annotationProcessorPaths>
<compilerArgs>
<arg>-Aproject=${project.groupId}/${project.artifactId}</arg>
</compilerArgs>
</configuration>
</plugin>
示例代码:
@Command(name="App", version="v1.0.0", header="Example App.")
class Tar {
@Option(names="-c", description="create a new archive")
boolean create;
@Option(names={"-f","--file"}, paramLabel="ARCHIVE", ...)
File archive;
@Parameters(paramLabel="FILES", description = "one ore more files...")
File[] files; // all positional arguments
@Option(names = { "-h", "--help" }, usageHelp = true, ...)
private boolean helpRequested = false;
@Parameters(index = "0") // index="2-4", index="3-*"
String command = "save"; // first positional arguments
public static void main(String args){
Tar tar = new Tar();
new CommandLine(tar).parseArgs(args);
if (tar.helpRequested){
CommandLine.usage(app, System.out);
System.exit(0);
}
}
}
CommonCLI
Commons CLI https://commons.apache.org/proper/commons-cli/usage.html
picocli - a mighty tiny command line interface
How do I parse command line arguments in Java?
构造方法
用于对类的成员变量进行初始化。
构造方法的特点:方法名与类名相同;没有返回值。
构造方法同一般方法一样,可以重载;如果一个类没有声明构造方法,则系统会为类添加一个默认构造方法,其方法体为空,访问权限与类相同;如果自己声明了构造方法,则系统就不再添加默认构造方法。
finalize
finalize()方法在对象被垃圾收集器析构(回收)之前调用,用来清除回收对象,确保一个对象打开的文件被关闭了。
内部类
在某个类内部定义的类称为内部类。一个类如同使用其它类一样使用自己的内部类,包括创建内部类的对象并调用其方法。而内部类拥有对外层类所有字段和方法成员的访问权。
内部类的访问权限除了默认权限和public外,还可以是protected和private。如果为private,则该内部只能在本类中使用;如果为protected,则外层类、处于同一包中的类及外层类的子类可以访问它。
内部类还可以定义在方法内部,其作用域仅限于该方法内部。内部类可以在使用的地方,声明的同时使用。
继承
所有的类都是继承于java.lang.Object。当一个类没有声明继承,则默认继承Object。
Java只能进行单继承。
子类可以从父类那里继承非private成员:即子类可以直接访问父类的非private成员,private成员在子类中不可见,仅能通过父类提供的非private成员作为接口间接访问。
子类不继承父类的构造方法。子类在构造方法中使用super关键字调用父类的构造方法对父类的成员进行初始化:
super(args); //出现在构造方法内部的第一行
如果子类的构造方法中不调用父类的构造方法,则系统会自动调用父类的默认构造方法(如果父类已经声明了构造方法,则需要显式添加默认构造方法,否则不能实现自动调用)。
类成员的初始化过程:
-
分配内存空间,并将字段单元初始化;
-
使用字段在声明时赋的值,对字段初始化;
-
调用构造函数,在构造函数中,首先对父类进行初始化,再初始化子类字段。
重写/覆盖/隐藏(Override)
在子类中声明的成员与父类的成员完全一致,则父类的成员称为被子类成员隐藏。
一般不推荐对父类的字段进行隐藏,这样会导致类的结构混乱。
进行方法隐藏时,子类声明的方法必须和父类的方法原型一致,而且子类方法的访问限制不能比父类严格(否则就直接访问父类方法了)。
子类不能直接访问到父类的同名方法,通过super关键字访问父类方法。
规则:
- 如果不能继承一个方法,则不能重写这个方法。
- 访问权限不能比父类中被重写的方法的访问权限更低。
- 回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类。
- 声明为
final、static的方法不能被重写
抽象类
使用abstract关键字声明的类(可能并不包含抽象方法)。
如果一个类包含未实现方法,则该类必须被声明为抽象类:
-
继承的接口未实现的类;
-
包含使用
abstract关键字声明的抽象方法的类;
不能被继承的方法,如构造方法,静态方法,不能声明为抽象方法。
接口
接口是包含若干抽象方法和常量的一个集合,提供对某一种功能的抽象,使实现接口的类具有统一的外部访问方式。
public interface 接口名 [extends 父接口名列表]{
public static final int CONST_VAR = const_value;
public abstract [native] int methodName(params)[throw exceptions];
}
实现接口:首先在类的声明中使用implements添加要实现的接口名,如类的声明格式所示;如果声明继承某接口的类,则接口的所有方法都必须实现,否则该类为抽象类;类在实现接口的方法时,必须保证方法原型与接口中声明的原型一致,否则就成了方法的重载。
接口的方法的访问限制符都限定为public,所以类在实现方法时,也必须使用public修饰符。
与抽象类相似,不能声明不能被继承的方法,如静态方法;
接口不能包含成员变量,除了static final变量。
标记接口
标记接口是没有任何方法和字段的接口。
- 向一个类添加数据类型:通过引用多态使该类对象可以作为接口类型引用,供其他代码来测试类型。
- 建立公共的父接口。
函数接口
An interface with exactly one abstract method is called Functional Interface(可使用@FunctionInterface对接口进行标注,以避免在该接口中声明多个方法)。
java.util.function
对象引用多态
对象引用的多态是指:声明对象的类型不由对象的引用类型(类似于指针)决定,而是由创建对象时调用的构造方法决定。虽然对象本身是确定的,但是因为子类对象可以作为父类对象来引用,所以可以实现对象引用的多态。
引用多态的三个必要条件:继承、重写、父类引用子类对象。
示例:
SuperClass sc = new SuperClass(); //父类的引用实际表示父类对象
SuperClass sc1 = new SubClass(); //父类的引用实际表示子类对象
动态绑定
==通过父类/接口引用子类对象的方法时,总是调用子类方法,而非父类同名方法==。区别于C++,C++中只有虚函数才具有此性质,否则使用父类指针将访问父类同名函数。也就是说Java中的成员方法具有C++虚函数的性质。如果 Java 中不希望某个方法具有虚函数特性,可以加上final关键字变成非虚函数。
判断一个引用究竟指向那种类的对象可以使用instanceof运算符来进行判断。
if (object instanceof ClassName){
do_something
}
对象引用多态的使用情形:
-
参数传递。当一个函数需要接收的参数可能是某个类的多个子类时,就可将参数声明为父类的引用,实际传参时,则传递实际的子类对象引用。
-
存储。在存储一系列不同子类的对象时,可以声明一个父类对象的数组进行存储,每个数组元素可以是具体的子类对象。
-
强制类型转换。虽然将各种子类统一使用父类引用进行管理非常方便,但使用父类的引用就只能访问到子类中父类的成员。如果要访问子类的成员,就需要将父类引用强制转换为子类引用,强制类型转换的前提是引用对象本身必须是转换目标所属的类,这时可以先使用
instanceof先判断,再转换。Object [] list = {"abc", "def", "ghi"}; for (String str : list){ // String str = (String)list[i]; do_some_things; }
反射
https://www.journaldev.com/1789/java-reflection-example-tutorial#invoke-public-method
Poor Performance:动态解析类型
java.lang.Class:类的元数据,用于查找类的属性以及创建新的实例。
泛型(Generic)
泛型提供了编译时类型安全检测机制。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。Java编译器使用类型擦除将泛型类型替换为通用类型(例如Object, Comparable)并适当添加类型转换。
不同于C++模板,编译器不会将泛型类型替换为具体类型,从而不会产生新的类型。
泛型方法
public [static] <T1,T2> void methodName(T1[] data, GenericsType<T2> info)
- 类型参数声明:在在方法返回类型之前;
- 类型参数声明可以包含多个类型参数,
- 类型参数只能代表引用型类型,不能是基本类型。
有界类型参数
限制被允许传递到一个类型参数的类型种类。
public <T extends Type[,...]> void methodName(T[] data)
泛型类
在声明的类名后面添加了类型参数声明部分:
[modifier] class ClassName <T [extends Type][,...]>{
public void methodName(T data)
}
在类的定义中可以使用声明的类型参数来定义字段,或作为方法的参数类型。
类型通配符
类型通配符一般是使用?代替泛型类的具体类型参数,?不需要放在类型参数声明列表中。
public static void getData(List<?> data)
public static void getUperNumber(List<? extends Number> data)
public static void getUperNumber(List<? super Number> data)
extends定义类型参数的上限(该类及其子类);super定义类型的下限(该类及其父类)。
在使用类型通配符具体化类型作为参数的方法中,仅使用泛型类提供的公共方法,而不使用具体类型相关的方法。
https://docs.oracle.com/javase/tutorial/extra/generics/index.html.
Java Generics Example Tutorial - Generic Method, Class, Interface - JournalDev
Java包简介
| 类库 | 简介 |
|---|---|
java.io | 提供系统的输入输出,包括各类输入输出流。 |
java.lang | Java语言的基础,包括对基本数据类型的封装,以及Math、Process、Thread等类。java.lang包默认加载到所有的Java程序的。 |
java.net | 提供Java访问网络的功能,包括对TCP/UDP套接字的封装以及对应用层协议的封装。 |
java.util | 包括了容器框架的接口和类,日期和时间的处理,事件模型以及其他功能(随机数发生、字符串格式化等)。 |
java.applet | 提供创建Java Applet程序所必要的类。 |
java.awt | 提供图形界面编程的类和接口。 |
异常处理
异常分类
所有的异常类是从java.lang.Exception类继承的子类。Exception类是Throwable类的子类。除了Exception类外,Throwable还有一个子类Error。
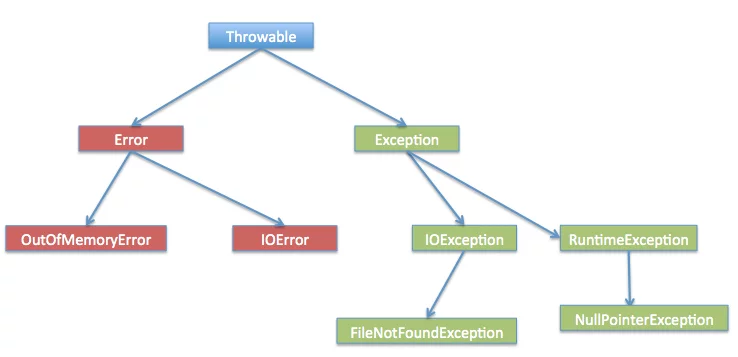
Exception Handling in Java - JournalDev
处理异常
使用try-catch语句捕获异常。
使用捕获的异常对象,获取异常信息:
String getMessage() // 关于发生的异常的详细信息
String toString() // 返回异常类的名字
Throwable getCause() // 异常原因
void printStackTrace() //
抛出异常:
如果一个方法存在未捕获的异常,则方法的声明需要使用throws关键字来给出未处理异常列表。
public void method(···) throws XxxException, YyyException
在方法内部可以使用throw关键字抛出一个捕获到的异常或新实例化的异常。
自定义异常
所有异常都必须是 Throwable 的子类。
如果希望写一个检查性异常类,则需要继承 Exception 类。
如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
设计模式
==Java Design Patterns== - Example Tutorial - JournalDev
参考文献
JAVA编程
Java语言不使用指针,而是引用。
Java程序
编写
代码结构
一个*.java文件可以包含多个类的定义:
- 只能有一个
public类/接口,源文件名与public类名相同;
打包声明
包用于描述代码的逻辑组织结构(类似于C#的命名空间):
-
把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用
-
并防止命名冲突。
如果一个public类要包含在某个包内,需要在代码的第一行使用package关键字进行声明。
package org.develop.app;
在指定的源代码根目录下,层级的打包声明也对应源代码(编译输出字节码)文件树目录结构。
不同类型项目的源文件根目录设置可能不同,例如Maven项目的源代码根目录为
src/main/java,则上述源代码对应的路径为src\main\java\org\develop\App.java。
导入包声明
为了使用外部代码(例如Java库),源文件文件中可以导入(import)外部依赖包的内容。
导入语句位于打包语句之后。
import java.io.*; // import all
import java.io.File; // import single class
包具有层级嵌套结构,导入声明仅能引用当前层级包中的类,而不能引用下一层级的包中的类(需要单独声明)。
模块系统(Java 9)
同一个jar文件中的.class文件并没有依赖关系限制;模块则附加依赖关系,还可包含二进制代码。
oop-module
├── bin # 存放编译后的class文件
├── build.sh
└── src # 源码:按包名的目录结构存放
├── com
│ └── hello
│ └── world
│ ├── Greeting.java
│ └── Main.java
└── module-info.java # 模块的描述文件,包含依赖声明
在Java代码中仅能引用模块描述文件中声明的依赖库。
module hello.world {
requires java.base; // 可不写,任何模块都会自动引入java.base
requires java.xml;
exports com.hello.world; // 只有声明导出的包,外部代码才能问。(进一步隔离了代码的访问权限)
}
java --list-modules显示JDK自带模块。java -d,describe-module module_name显示模块的描述信息。
执行Java程序
编译
Java程序被编译为字节码格式(*.class文件)。在运行时,Java平台中的Java解释器对这些字节码进行解释执行,执行过程中需要的类在联接阶段被载入到运行环境中。
运行
Java应用程序是由若干类定义组成的独立的解释型程序,其中必须有一个包含Main方法的主类;执行Java应用程序时,需要使用Java解释器(java.exe)来执行这个主类的字节码文件(.class)。
java App.java # 直接编译执行源文件
java [options] -jar package-name.jar [args...] # 执行jar包中包含Main方法的class文件
java [options] -cp <classpath> package.ClassName [args...] # 指定搜索路径下的class
package.ClassName:程序执行时应该执行入口函数所在的类,解释器在搜索路径下寻找指定类。Java应用程序的入口函数为类中的名为Main的静态方法。使用-jar选项执行时,jar包中需要在manifest中声明主类。
--dry-run:创建VM并加载主类,但不执行主方法。用于验证命令行参数是否有效。Java小程序(Java Applet)的源代码编辑与字节码编译生成过程与Java应用程序相同,但它不是一类可独立运行的程序。Applet程序的字节码文件必须嵌入到HTML文件中并由负责解释HTML文件的浏览器充当其解释器。将Java Applet引入HTML中,使得网页能够提供动态信息。Java小程序与Java应用程序最大不同在于Applet不需要
Main方法,而要求程序中必须有且只有一个类是Applet类的子类。系统类Applet类中已经定义了许多成员,它们规定了Applet如何与执行它的解释器——浏览器配合工作。
Java环境变量
-D<name>=<value> # 系统属性(system.Properties),传递应用程序
-X # 输出所有`-X`(extra)虚拟机选项的名称;
Java虚拟机选项
-Xms:Java虚拟机的初始堆内存分配量,例如-Xms256m;单位包括:k,m,g,...。
-Xmx:JVM最大堆内存分配量,例如-Xmx2048m,通常默认值为256m;如果超过最大内存分配限制,程序将触发java.lang.OutOfMemoryError异常。
Java系统属性
路径
当前路径
执行Java程序时所在的工作目录。
类搜索路径
Java解释器需要在搜索路径CLASSPATH中寻找.class文件进行执行。==类文件(*.class)可能位于文件夹、jar文件或zip文件==,使用以下选项添加搜索路径。
-{cp,class-path,classpath} libpath1:libpath2/*:lib3.jar:...
特别地,==如果文件夹以/*结尾,那么该文件夹下的所有jar/zip文件都会被加入搜索路径==。
JVM自带的标准库
rt.jar不要写到CLASSPATH中,写了反而会干扰JVM的正常运行。*不能视为通配符,因此*.jar的写法将无效且造成错误。
连接动态库
如果程序依赖共享库(JNI),而不能定位,则会引发java.lang.UnsatisfiedLinkError。
使用-Djava.library.path=/your/lib/path选项指定。
另一种方法是在执行程序之前(或加入/etc/profit)设置环境变量 LD_LIBRARY_PATH。
不建议修改共享库搜索路径。如果使用的共享库在系统中存在其他版本,可能影响程序使用的共享库版本,使程序出错(
ImportError: tensorflow/python/_pywrap_tensorflow_internal.so: undefined symbol)。
export LD_LIBRARY_PATH=:~/Workspace/lib/java/tensorflow/
模块搜索路径
-p,--module-path <module path> path1:path2:...
语法
标识符大小写敏感。命名规则:
- 类名:单词首字母大写;
- 方法名:首字母小写,其余单词首字母大写;
注释和文档
注释:
- 使用
//或/*...*/添加单行注释; - 使用
/*...*/添加多行注释。
文档化注释
/**
* <h1>Find average of three numbers!</h1>
* <p>The FindAvg program implements an application that
* simply calculates average of three integers and Prints
* the output on the screen. </p>
*
* @param parameter_name description [Parameters” section]
* @return description [“Returns” section]
* @exception ExceptionClass [Throws subheading]
* @author Author Name
* @version version [“Version” subheading]
* @since release-date [“Since” subheading]
* @see reference [See Also” heading]
* @deprecated Indicating Deprecated components
* {@link package.class#member label}
* {@code text}
*/
使用javadoc生成格式化文档。
javadoc Program.java
https://www.geeksforgeeks.org/comments-in-java/
https://www.oracle.com/technetwork/java/javase/documentation/index-137868.html
标注(Annotation)
标注以@开始,用于辅助程序元素与元信息的关联,并控制编译器的行为,但对编译后的程序不起作用。
@MarkerAnnotation
@SingleValueAnnotation("info")
@FullAnnotation(key1="value1",key2="value2")
预定义标注:
import java.lang.annotations.*;
@Deprecated // indicate an oboslated declaration
@Override // must override a method from superclass
@SuppressWarnings({"checked", "deprecation"}) // 参数可为空
@FunctionalInterface
@SafeVarargs // 标注的方法不会对可变参数执行不安全操作
标注可用于类、方法、语句等的开头(上一行),for语句等的条件语句的开头。
自定义标注,类似于定义接口(使用@interface关键字),自定义标注本身还可添加标注信息(meta annotations):
@Documented // 添加所定义标注的元素信息文档化(javadoc etc.)
@Target(ElementType.METHOD) // 标注的目标TYPE, METHOD, FIELD...
@Inherited // 子类是否继承父类元素的该标注
@Retention(RetentionPolicy.RUNTIME) // === SOURCE,CLASS, RUNTIME
@Repeatable // 该标注是否可重复声明
public @interface MethodInfo{
String author() default "gary"; // 方法不能包含参数
int revision() default 1; // 方法返回值仅限基本类型
}
https://www.geeksforgeeks.org/annotations-in-java/
变量声明
变量在使用前必须声明:
type var_name[ = value, var_name2[ = value]...];
变量根据作用域可分为:类变量(静态字段)、实列变量(字段)和局部变量。
局部变量是在栈上分配的,在所在作用域(方法、代码块)被执行时创建,执行完即被销毁。
局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
流程控制
条件
if(condition){
}else if (condition){
}else{
}
循环
while
while (condition){
do_something;
}
赋值语句的返回值可作为条件语句,例如:(line = reader.readLine()) != null(null本身不能直接作为条件语句)。
do-while
do{
do_something;
}while(true);
for
for(int i=0; i<len; ++i){
do_something;
}
增强for循环,结合迭代器。
for(String name : names){
do_something;
}
Stream API
定义对元素的计算函数,由Stream框架执行内部迭代,从而实现并行计算、过滤、映射等功能特性。
Java 8 Stream - Java Stream - JournalDev
return list.stream().filter(x -> x > 10).mapToInt(x -> x).sum();
switch-case
switch(expr){
case const_val1:
statements;
break;
case const_val2:
case const_val3:
statements;
break;
default:
statements;
}
说明:
- 变量类型可以是:
byte、short、int、char以及string(Java 7); case语句的值为常量或字面值常量;
try-catch-finally
用于处理程序异常的控制结构。
try {
do_something;
} catch (ExceptionTypeA | ExceptionTypeB e) {
handle_exception;
} finally {
clean_work;
}
try-with-resource
简化资源关闭与异常处理流程(Java 7)。
try (open_resources){
do_something;
}
catch(exception e){
handle_exception;
}
为了能够配合try-with-resource,资源必须实现AutoClosable接口。
运算符
instanceof
检查该对象是否是一个特定类型(类类型或接口类型)
Object instanceof ClassName
函数
Lambda表达式(匿名函数)
使用Lambda表达式:可减少代码量,传递函数作为参数,在使用时定义函数。
(args)->{statements} // 参数和方法内容均可省略,单语句可省略"{}"
无返回值的方法体以最后语句的返回值作为方法的返回值。
参数类型可==同时==省略(自动推断)。
方法引用(Java 8)
面向对象的编程
Java中所有内容均包含在类的定义中。
类与对象
[public] [modifier] class ClassName [extends BaseClass][implements Interfaces,...]{
[protected] [modifier] int PropertyName [= value];
[public] ClassName(int param,...) throw exceptions{
super(param,...)
do_initialization;
}
[private] [modifer] void methodName(int param,...)throw exceptions{
statements;
this.another_method(param,...);
super.base_method(param,...);
}
public int static main(String[] args){
ClassName c = new ClassName(...);
}
protected class InternalClass{
class_definitions;
}
}
使用new关键字创建对象。创建对象时将调用类的构造方法。
注意:类的实例都是通过引用来使用的,使用new创建的对象都会在内存中开辟独立的空间,两个对象即使内容相同,但是在内存中的地址不同,所以如果使用==进行比较,会得到false;但是使用类的方法equals比较两个实例的内容。使用对象相互赋值的方法,则只是复制了对象的引用,并没有开辟新空间,所以两者指向同样的区域。==对于字符串来说,如果直接将带引号的字符串赋值给两个字符串对象,则由于Java处理字符串的特性,两个对象将指向内存中的同一位置(内存中的特殊区域String Pool),使用======也会返回true==。
类的成员包括方法和字段。在类内部可直接通过名称访问成员。当成员名称与参数名或局部变量重名时,使用this关键字访问成员。this还可用于在构造方法内部引用该类的其他构造方法(只能出现在构造方法内部的第一行,即只能调用一次)。
修饰符
访问控制
-
public:这个类可以被其他所有类访问和引用,只能被定义在同名文件中。 -
default:即没有访问控制符修饰,这样的类只能被同一个包内的类引用,而对其他包内的类不可见。
-
protected: -
private:只用于内部类。
其他
abstract:抽象类,不能直接被实例化的类,但是可以声明对象的引用,只是声明的对象引用默认值都是null,必须使用可实例化的子类的构造函数对其赋值。抽象类内部可以包含任意个抽象方法,也可以包含构造方法、字段和实体方法。final:不能被继承的类。
字段
字段(Fields,属性Attributes)是类内部定义的变量。
访问控制修饰符
public: 允许任何位置对字段的访问。由于具有默认访问权限的类本身只能被同一包内的成员所访问,所以这种类中的成员即使具有public权限也只能被同一包内的其他类访问。- default:同一个包内的位置可对字段进行访问。
protected:允许该类及其子类中对该字段进行访问。private:允许在该类内部对该字段进行访问。访问控制是针对类而言的,而并非针对具体实例而言,即同一个类的不同实例可以互相访问它们的私有成员。而通过继承关系生成的子类,其新定义的方法则不能访问父类的私有成员,但继承自父类的成员函数因为本来可以访问父类成员,所以在子类中仍然可以访问父类成员。
其他修饰符
-
static:同一个类所有的实例共享静态字段。静态成员不属于对象,所以推荐使用类名来访问静态成员(在类内部可直接使用字段名)。
ClassName.StaticProperty;由于静态字段从属于类,而不属于实例,所以不能用构造函数进行初始化。同时由于除了通过在声明字段时对字段赋初值,还可以通过静态代码块对静态字段进行初始化。
static{ initialize-statements; } -
final:常量字段,通常用大写字母作为常量标识符。 -
transient:序列化对象时,跳过该类变量。 -
volatile:在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
方法
方法的访问控制与字段一致。
修饰符
-
abstract:只有函数声明(declaration/signature),而没有函数体。具有抽象方法的类即抽象类。抽象类的类必须重载这些抽象方法才能实例化,否则子类也必须声明为抽象类。 -
final:不能被类的子类重写。 -
static:静态方法,只能访问和修改类的静态成员,通过类名调用。ClassName.StaticMethod(args);名为
main的静态方法可作为Java程序的入口函数。public static void main(String[] args) // args not contain program name主函数无须返回值(
return)。由于程序由java解释器执行,因此从主函数返回值并不能被shell接收。java解释器将获取由System.exit(value)返回的值,并返回给shell。 -
synchronized:方法同一时间只能被一个线程访问。
方法重载(Overload)
重载的方法必须拥有不同的参数列表。不能仅依据修饰符或者返回类型的不同来重载方法。
可变参数
一个方法中只能指定一个可变参数,它必须是方法的最后一个参数,在参数类型后加一个省略号(...)。
public static void printMax( double... numbers)
命令行参数解析
picocli
可以通过外部依赖或源代码(CommandLine.java)的方式使用。以下为通过Maven配置依赖项。
<dependency>
<groupId>info.picocli</groupId>
<artifactId>picocli</artifactId>
<version>4.2.0</version>
</dependency>
启用Annotation Processor:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.0</version> <!-- 3.5 or higher -->
<configuration>
<annotationProcessorPaths>
<path>
<groupId>info.picocli</groupId>
<artifactId>picocli-codegen</artifactId>
<version>4.2.0</version>
</path>
</annotationProcessorPaths>
<compilerArgs>
<arg>-Aproject=${project.groupId}/${project.artifactId}</arg>
</compilerArgs>
</configuration>
</plugin>
示例代码:
@Command(name="App", version="v1.0.0", header="Example App.")
class Tar {
@Option(names="-c", description="create a new archive")
boolean create;
@Option(names={"-f","--file"}, paramLabel="ARCHIVE", ...)
File archive;
@Parameters(paramLabel="FILES", description = "one ore more files...")
File[] files; // all positional arguments
@Option(names = { "-h", "--help" }, usageHelp = true, ...)
private boolean helpRequested = false;
@Parameters(index = "0") // index="2-4", index="3-*"
String command = "save"; // first positional arguments
public static void main(String args){
Tar tar = new Tar();
new CommandLine(tar).parseArgs(args);
if (tar.helpRequested){
CommandLine.usage(app, System.out);
System.exit(0);
}
}
}
CommonCLI
Commons CLI https://commons.apache.org/proper/commons-cli/usage.html
picocli - a mighty tiny command line interface
How do I parse command line arguments in Java?
构造方法
用于对类的成员变量进行初始化。
构造方法的特点:方法名与类名相同;没有返回值。
构造方法同一般方法一样,可以重载;如果一个类没有声明构造方法,则系统会为类添加一个默认构造方法,其方法体为空,访问权限与类相同;如果自己声明了构造方法,则系统就不再添加默认构造方法。
finalize
finalize()方法在对象被垃圾收集器析构(回收)之前调用,用来清除回收对象,确保一个对象打开的文件被关闭了。
内部类
在某个类内部定义的类称为内部类。一个类如同使用其它类一样使用自己的内部类,包括创建内部类的对象并调用其方法。而内部类拥有对外层类所有字段和方法成员的访问权。
内部类的访问权限除了默认权限和public外,还可以是protected和private。如果为private,则该内部只能在本类中使用;如果为protected,则外层类、处于同一包中的类及外层类的子类可以访问它。
内部类还可以定义在方法内部,其作用域仅限于该方法内部。内部类可以在使用的地方,声明的同时使用。
继承
所有的类都是继承于java.lang.Object。当一个类没有声明继承,则默认继承Object。
Java只能进行单继承。
子类可以从父类那里继承非private成员:即子类可以直接访问父类的非private成员,private成员在子类中不可见,仅能通过父类提供的非private成员作为接口间接访问。
子类不继承父类的构造方法。子类在构造方法中使用super关键字调用父类的构造方法对父类的成员进行初始化:
super(args); //出现在构造方法内部的第一行
如果子类的构造方法中不调用父类的构造方法,则系统会自动调用父类的默认构造方法(如果父类已经声明了构造方法,则需要显式添加默认构造方法,否则不能实现自动调用)。
类成员的初始化过程:
-
分配内存空间,并将字段单元初始化;
-
使用字段在声明时赋的值,对字段初始化;
-
调用构造函数,在构造函数中,首先对父类进行初始化,再初始化子类字段。
重写/覆盖/隐藏(Override)
在子类中声明的成员与父类的成员完全一致,则父类的成员称为被子类成员隐藏。
一般不推荐对父类的字段进行隐藏,这样会导致类的结构混乱。
进行方法隐藏时,子类声明的方法必须和父类的方法原型一致,而且子类方法的访问限制不能比父类严格(否则就直接访问父类方法了)。
子类不能直接访问到父类的同名方法,通过super关键字访问父类方法。
规则:
- 如果不能继承一个方法,则不能重写这个方法。
- 访问权限不能比父类中被重写的方法的访问权限更低。
- 回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类。
- 声明为
final、static的方法不能被重写
抽象类
使用abstract关键字声明的类(可能并不包含抽象方法)。
如果一个类包含未实现方法,则该类必须被声明为抽象类:
-
继承的接口未实现的类;
-
包含使用
abstract关键字声明的抽象方法的类;
不能被继承的方法,如构造方法,静态方法,不能声明为抽象方法。
接口
接口是包含若干抽象方法和常量的一个集合,提供对某一种功能的抽象,使实现接口的类具有统一的外部访问方式。
public interface 接口名 [extends 父接口名列表]{
public static final int CONST_VAR = const_value;
public abstract [native] int methodName(params)[throw exceptions];
}
实现接口:首先在类的声明中使用implements添加要实现的接口名,如类的声明格式所示;如果声明继承某接口的类,则接口的所有方法都必须实现,否则该类为抽象类;类在实现接口的方法时,必须保证方法原型与接口中声明的原型一致,否则就成了方法的重载。
接口的方法的访问限制符都限定为public,所以类在实现方法时,也必须使用public修饰符。
与抽象类相似,不能声明不能被继承的方法,如静态方法;
接口不能包含成员变量,除了static final变量。
标记接口
标记接口是没有任何方法和字段的接口。
- 向一个类添加数据类型:通过引用多态使该类对象可以作为接口类型引用,供其他代码来测试类型。
- 建立公共的父接口。
函数接口
An interface with exactly one abstract method is called Functional Interface(可使用@FunctionInterface对接口进行标注,以避免在该接口中声明多个方法)。
java.util.function
对象引用多态
对象引用的多态是指:声明对象的类型不由对象的引用类型(类似于指针)决定,而是由创建对象时调用的构造方法决定。虽然对象本身是确定的,但是因为子类对象可以作为父类对象来引用,所以可以实现对象引用的多态。
引用多态的三个必要条件:继承、重写、父类引用子类对象。
示例:
SuperClass sc = new SuperClass(); //父类的引用实际表示父类对象
SuperClass sc1 = new SubClass(); //父类的引用实际表示子类对象
动态绑定
==通过父类/接口引用子类对象的方法时,总是调用子类方法,而非父类同名方法==。区别于C++,C++中只有虚函数才具有此性质,否则使用父类指针将访问父类同名函数。也就是说Java中的成员方法具有C++虚函数的性质。如果 Java 中不希望某个方法具有虚函数特性,可以加上final关键字变成非虚函数。
判断一个引用究竟指向那种类的对象可以使用instanceof运算符来进行判断。
if (object instanceof ClassName){
do_something
}
对象引用多态的使用情形:
-
参数传递。当一个函数需要接收的参数可能是某个类的多个子类时,就可将参数声明为父类的引用,实际传参时,则传递实际的子类对象引用。
-
存储。在存储一系列不同子类的对象时,可以声明一个父类对象的数组进行存储,每个数组元素可以是具体的子类对象。
-
强制类型转换。虽然将各种子类统一使用父类引用进行管理非常方便,但使用父类的引用就只能访问到子类中父类的成员。如果要访问子类的成员,就需要将父类引用强制转换为子类引用,强制类型转换的前提是引用对象本身必须是转换目标所属的类,这时可以先使用
instanceof先判断,再转换。Object [] list = {"abc", "def", "ghi"}; for (String str : list){ // String str = (String)list[i]; do_some_things; }
反射
https://www.journaldev.com/1789/java-reflection-example-tutorial#invoke-public-method
Poor Performance:动态解析类型
java.lang.Class:类的元数据,用于查找类的属性以及创建新的实例。
泛型(Generic)
泛型提供了编译时类型安全检测机制。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。Java编译器使用类型擦除将泛型类型替换为通用类型(例如Object, Comparable)并适当添加类型转换。
不同于C++模板,编译器不会将泛型类型替换为具体类型,从而不会产生新的类型。
泛型方法
public [static] <T1,T2> void methodName(T1[] data, GenericsType<T2> info)
- 类型参数声明:在在方法返回类型之前;
- 类型参数声明可以包含多个类型参数,
- 类型参数只能代表引用型类型,不能是基本类型。
有界类型参数
限制被允许传递到一个类型参数的类型种类。
public <T extends Type[,...]> void methodName(T[] data)
泛型类
在声明的类名后面添加了类型参数声明部分:
[modifier] class ClassName <T [extends Type][,...]>{
public void methodName(T data)
}
在类的定义中可以使用声明的类型参数来定义字段,或作为方法的参数类型。
类型通配符
类型通配符一般是使用?代替泛型类的具体类型参数,?不需要放在类型参数声明列表中。
public static void getData(List<?> data)
public static void getUperNumber(List<? extends Number> data)
public static void getUperNumber(List<? super Number> data)
extends定义类型参数的上限(该类及其子类);super定义类型的下限(该类及其父类)。
在使用类型通配符具体化类型作为参数的方法中,仅使用泛型类提供的公共方法,而不使用具体类型相关的方法。
https://docs.oracle.com/javase/tutorial/extra/generics/index.html.
Java Generics Example Tutorial - Generic Method, Class, Interface - JournalDev
Java包简介
| 类库 | 简介 |
|---|---|
java.io | 提供系统的输入输出,包括各类输入输出流。 |
java.lang | Java语言的基础,包括对基本数据类型的封装,以及Math、Process、Thread等类。java.lang包默认加载到所有的Java程序的。 |
java.net | 提供Java访问网络的功能,包括对TCP/UDP套接字的封装以及对应用层协议的封装。 |
java.util | 包括了容器框架的接口和类,日期和时间的处理,事件模型以及其他功能(随机数发生、字符串格式化等)。 |
java.applet | 提供创建Java Applet程序所必要的类。 |
java.awt | 提供图形界面编程的类和接口。 |
异常处理
异常分类
所有的异常类是从java.lang.Exception类继承的子类。Exception类是Throwable类的子类。除了Exception类外,Throwable还有一个子类Error。
Exception Handling in Java - JournalDev
处理异常
使用try-catch语句捕获异常。
使用捕获的异常对象,获取异常信息:
String getMessage() // 关于发生的异常的详细信息
String toString() // 返回异常类的名字
Throwable getCause() // 异常原因
void printStackTrace() //
抛出异常:
如果一个方法存在未捕获的异常,则方法的声明需要使用throws关键字来给出未处理异常列表。
public void method(···) throws XxxException, YyyException
在方法内部可以使用throw关键字抛出一个捕获到的异常或新实例化的异常。
自定义异常
所有异常都必须是 Throwable 的子类。
如果希望写一个检查性异常类,则需要继承 Exception 类。
如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
设计模式
==Java Design Patterns== - Example Tutorial - JournalDev
参考文献
Java开发环境
Java Development Kit
choco install jdk8 # Windows: choco install jdk11, ojdkbuild11...
sudo apt install openjdk-8-jdk # => yum install java-1.8.0-openjdk
apt:openjdk-11-jdk安装JDK;openjdk-11-jre仅安装JRE。
yum:java-11-openjdk-devel安装JDK;java-11-openjdk:仅安装JRE。
迁移到 Java 11 的原因 - Azure | Microsoft Docs
从 Java 8 转换到 Java 11 - Azure | Microsoft Docs(ClassLoader 注意事项)。
Optimized to run Java™ applications cost-effectively in the cloud, Eclipse OpenJ9 is a fast and efficient JVM that delivers power and performance when you need it most.
环境变量
通过软件包管理器安装的开发环境通常已经设置环境变量,如果是直接下载的软件包则需要手动设置。基于Java的软件依赖Java相关的环境变量来定位Java的可执行文件和库文件。其中:
PATH:可执行文件(Java编译器、解释器),位于JDK安装目录下的bin目录;JAVA_HOME:Java安装目录;CLASSPATH:外部库搜索路径,JVM通过CLASSPATH来寻找类。LD_LIBRARY_PATH:shared native libraries like.DLLor.sonotJARSor classes.
在Linux中,通过系统安装的JDK会将可执行文件的符号链接(例如/etc/alternatives/java$\rightarrow$
/usr/lib/jvm/java-6-openjdk-i386/jre/bin/java)放在/usr/bin目录下,所以在终端中可以直接运行,而无需修改PATH变量。如果是手动安装的JDK,则不会有这些符号链接。要设置上述变量,则编辑~/.bashrc文件,添加以下内容:
export PATH=$PATH:java_home/bin # echo $PATH
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 # echo $JAVA_HOME
export CLASSPATH=.:java_home/lib/dt.jar:java_home/lib/tools.jar
全局设置:在/etc/profile.d/java.sh 中添加
export JAVA_HOME=/path/to/java_installation
或/etc/environment中添加
JAVA_HOME=/path/to/java_installation
在Windows中则通过系统中的环境变量编辑窗口设置(如果是安装版软件,通常会设置上述变量)。
确定JAVA_HOME
update-alternatives --display java
返回值为java可执行文件的路径,其父目录为xxxjdk/jre/bin。
JDK目前会在
jre的上层目录创建一个bin目录,其中部分可执行文件链接到jre/bin中的对应文件,但jdk/bin目录下包含更多可执行文件。因此两个位置都可以作为JAVA_HOME。
如果安装了JDK,可以使用jrunscript程序查找JAVA_HOME:
jrunscript -e 'java.lang.System.out.println(java.lang.System.getProperty("java.home"));'
JDK/JRE headless: 没有键盘、鼠标和显示系统支持,更适合服务器应用。
JavaFX
Java 11开始JavaFX从JDK拆分出来,独立发布。因此对于需要使用JavaFX的程序,需要在系统中单独进行安装。
Ubuntu 18.04 (LTS) 提供openjfx作为openjdk的JavaFX版本。在软件仓库中可以选择安装openjdk-8-jdk(JDK8)或openjdk-11-jdk(JDK11),但是默认提供最新版openjfx(JavaFX11),而JavaFX11与JDK8不兼容。因此如果使用JDK8,需要指定安装的JavaFX版本,并阻止其升级。
sudo apt install \
openjfx=8u161-b12-1ubuntu2 \
libopenjfx-java=8u161-b12-1ubuntu2 \
libopenjfx-jni=8u161-b12-1ubuntu2
# list all available openjfx version in the repository
# sudo apt show openjfx -a
sudo apt-mark hold openjfx libopenjfx-java libopenjfx-jni
Java编译器
将java源文件编译为字节码文件。
javac -d <dir> \
--{class-path,classpath,cp} <path> \ # 依赖库搜索目录
--{boot-class-path,bootclasspath} <path> \ # 启动类的路径
-encoding <encoding> \ # 指定源文件使用的字符编码
-sourcepath <project_path> \ # 代码查找路径 => 项目根目录
src/main/java/.../src.java
源代码默认位于项目根目录下的src/main/java目录(Maven约定),往下为包结构对应的目录。
-d:指定编译输出的目录(默认为源代码所在目录),在该目录下,输出字节码的存储路径与源代码中声明的包名对应(不包含src/main/java)。
依赖库搜索路径用于寻找源代码中导入的外部类*.class,可以为目录、jar文件和zip文件;path/*将包含该目录下的所有jar文件。
反编译
使用javap可进行反编译代码(将字节码转换为可读格式),jd-gui是一个图形化反编译工具,可根据字节码还原源代码。
javap -c -verbose ... App.class
# -classpath 指定搜索路径
# -l 输出行号和本地变量表
# -public/protected/package/private: 要输出的成员访问级别,private输出所有成员
归档
查看档案文件内容
jar tvf jarfile.jar
工具链
Make
target:
javac ./package1/A.java -d ../classes
javac ./package1/B.java -d ../classes
javac ./package2/C.java -d ../classes
javac ./main/Test.java -d ../classes/main/ -classpath ../classes
run:
java -classpath ../classes/main;../classes Test
clean:
rm -rf ../classes/package1/*.class
rm -rf ../classes/package2/*.class
rm -rf ../classes/main/*.class
Maven
Apache Maven是软件项目管理和分析工具,基于项目对象模型(Project Object Model,POM),Maven可以管理项目的构建、报告和文档。
Maven程序仓库:查找插件、项目的相关信息(例如版本)。
安装和配置Maven
IDEA和Eclipse等IDE通常已集成Maven。独立安装方式:
choco install maven # Windows
sudo apt install maven # Linux
配置文件settings.xml:
- 全局:
${maven.home}/conf或/etc/maven/settings.xml; - 用户:
${user.home}/.m2/settings.xml(默认无此文件,可将全局文件复制过来修改);
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<mirror>
<id>central-mirror</id>
<url>https://maven.aliyun.com/repository/central</url>
<mirrorOf>*</mirrorOf>
</mirror>
</mirrors>
</settings>
使用-s选项切换默认用户配置文件,使用-f选项切换默认项目文件:
mvn commands [...] -s settings.xml -f pom.xml
全局配置
<profiles>
<profile>
<id>nexus</id>
<activation><!--激活条件-->
<activeByDefault>false</activeByDefault>
<jdk>1.5</jdk> <!-- JDK版本 -->
<os>...</os> <!-- 操作系统版本 -->
<property></property> <!-- POM中定义的属性是否满足条件:$${name}=value -->
<file></file> <!-- 判断文件是否存在exists/missing -->
</activation>
<properties></properties> <!-- POM属性定义:覆盖全局定义 -->
<repositories>...</repositories>
<pluginRepositories>...</pluginRepositories>
</profile>
</profiles>
<activeProfiles> <!-- 无论activation是否有效 -->
<activeProfile>nexus</activeProfile>
</activeProfiles>
设置仓库
local and remote (public and internal)
Downloading in Maven is triggered by a project declaring a dependency that is not present in the local repository (or for a SNAPSHOT, when the remote repository contains one that is newer).
为提升下载速度,可使用距离较近的镜像仓库或本地仓库。修改settings.xml文件。依赖仓库的选择方式:依赖优先级关系
Maven执行构建时,由近(本地仓库)及远(远程仓库)获取依赖库,具体地:
-
首先查找本地仓库,默认位于
$HOME/$.m2/repository。本地仓库路径配置项位于settings.xml中。<settings> <localRepository>$PATH/.m2/repository</localRepository> </settings> -
其次,根据全局配置文件
settings.xml以及项目配置文件pom.xml中关于仓库的配置信息,从已配置仓库中依次尝试下载依赖库,直到下载成功或尝试完所有仓库后失败。
Maven[默认使用中央仓库](Maven POM.md#默认仓库),如果上述配置文件中配置了任何仓库,将不再请求默认仓库。
Note: The official Maven repository is at https://repo.maven.apache.org/maven2 hosted by the Sonatype Company and is distributed worldwide via CDN.
阿里云公共仓库:线上可搜索包名、获取其Maven依赖配置语句以及直接下载包。将其仓库地址通过以下方式设置为项目使用的仓库地址。
仓库名称 仓库地址 central https://maven.aliyun.com/repository/central不包含spring库 spring https://maven.aliyun.com/repository/springpublic https://maven.aliyun.com/repository/publiccentral和jcenter的聚合
仓库的配置方式包括:
-
通过项目的
pom.xml中project.repositories/pluginRepositories声明一个或多个repository配置;<repositories> <repository> <id>central</id> <url>http://127.0.0.1:8081/repository/maven-central/</url> </repository> <reposirtory>...</reposirtory> </repositories> <pluginRepositories>...</pluginRepositories> -
可将上述声明置于项目的
project.profiles声明的一个profile中;<profiles> <profile> <id>nexus</id> <repositories>...</repositories> </profile> </profiles> -
也可将较为固定的仓库配置以
profile写在全局配置文件中,根据环境激活相应配置或手动激活;<profiles> <profile> <id>nexus</id> <activation>...</activation> <repositories>...</repositories> </profile> </profiles> <activeProfiles> <!-- 无论activation是否有效 --> <activeProfile>nexus</activeProfile> </activeProfiles>
设置仓库镜像
此外,Maven支持配置仓库镜像转发,用于将对上述配置仓库的下载请求转发到第三方或本地仓库或代理。通过settings.xml中的settings.mirrors.mirror配置基于仓库ID匹配的转发规则,可以为不同仓库指定不同的镜像源。匹配从上向下进行,如果未匹配到任何项,则尝试使用第一条规则,然后使用匹配到的规则的URL进行请求下载。
<mirrors>
<mirror>
<id>nexus-central</id> <!-- mirror-rule-id -->
<url>http://127.0.0.1:8081/repository/maven-central/</url> <!--forward URL-->
<mirrorOf>*,!dev</mirrorOf> <!-- 匹配要转发的仓库请求:默认响应central仓库请求 -->
</mirror>
<mirror>
<id>nexus-dev</id> <!-- mirror-rule-id: self-hosted repo -->
<url>http://127.0.0.1:8081/repository/maven-dev/</url>
<mirrorOf>dev</mirrorOf> <!-- 仅响应dev仓库的请求 -->
</mirror>
</mirrors>
匹配规则:
*:匹配所有仓库请求;*,!repo:除repo以外的所有仓库;
通过仓库管理器(如Nexus)可将不同仓库合并统一对外提供服务接口。仓库管理接收到请求后,将逐次尝试合并仓库中的每个仓库是否有请求的内容,并对外服务。通过这种方式可将上述mirrors或repositroies的配置简化为一项。
声明依赖包
在项目的pom.xml文件中添加依赖包声明。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
声明项目使用的插件
应指定插件的groupId,artifactId和version。
发布声明
在项目pom.xml的project块下声明distributionManagement,用于声明输出包的发布服务器信息(包括releases和snapshot版本)。
<distributionManagement>
<repository> <!-- snapshotRepository -->
<id>nexus</id>
<url>http://127.0.0.1:8081/repository/maven-releases/</url>
</repository>
</distributionManagement>
Maven工作流
编译
mvn [clean] compile -s settings.xml -f pom.xml # 指定配置文件
mvn verify
编译过程会自动从Maven程序仓库下载依赖包,默认的本地存储路径为$HOME/.m2/repository。
编译时,在resources目录下的文件也将被复制到目标(target/classes)目录下,在打包时也一同输出至包。
源代码文本编码
在Windows下,Maven传递给编译器的默认编码方式为GBK,而代码通常为UTF-8编码,如果代码中存在中文字符,则会出现编码GBK的不可映射字符。解决方法:1)在项目pom.xml的project/properties块中设置project.build.sourceEncoding=UTF-8;2) 如果上述设置无效或需要使用项目特定的编码方式,则在项目/project/build/plugins下的资源插件配置项中设置encoding=UTF-8。3) 在编译插件maven-compiler-plugin配置中指定编码方式。
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
打包
mvn [clean] package
如果程序依赖其他软件包,则打包的文件需要声明依赖软件包的路径,或者将依赖软件包同时打包至输出文件。如果无法引用相应的依赖包,将造成NoClassDefFoundError等错误。
-
指定程序的入口和依赖包的位置,在运行java程序时,查找依赖包的根目录为java程序包所在目录,而非Java解释器的当前工作目录。
在Linux下使用
*.jar文件的符号链接,仍然会以符号链接的目标文件路径作为查找根目录;而在Windows下的符号链接则以符号链接所在目录为根目录。<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.1.0</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>package.MainClass</mainClass> </manifest> </archive> </configuration> </plugin>如果项目的多个类包含
Main函数,则需使用具体的类名package.MainClass指定程序入口函数所在类 。将
${project.build.finalName}作为classpathPrefix的前缀,导致搜索不到某些类(例如picocli)。 -
将依赖软件包作为库输出。在执行打包时,利用
maven-dependency-plugin工具将依赖软件包输出至指定位置:<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <executions> <execution> <id>copy-dependencies</id> <phase>prepare-package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <outputDirectory> ${project.build.directory}/lib </outputDirectory> </configuration> </execution> </executions> </plugin>依赖软件包应该与输出的包同时分发,避免无法引用。
-
将依赖包同时打包至输出软件包
在执行打包期间,利用
maven-shade-plugin将依赖包添加至目标包。<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin>此方法将造成目标包体积过大。类似地,
maven-assembly-plugin也可以完成此功能。<plugin> <artifactId>maven-assembly-plugin</artifactId> <version>3.2.0</version> <configuration> <archive> <manifest> <mainClass>fully.qualified.MainClass</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>signle</goal> </goals> </execution> </executions> </plugin>完成打包后,还需执行
mvn assembly:assembly将依赖包添加进目标包。mvn clean package assembly:singleIf your project wants to package your artifact in an uber-jar, the assembly plugin provides only basic support. For more control, use the Maven Shade Plugin.
Gradle vs. Maven: Performance, Compatibility, Builds, & More – Stackify
Maven常见问题
- 下载依赖包的过程中出现
Checksum failed on download:...的错误。有可能是因为下载过程为多线程,依赖包先于其校验文件被下载到本地无法完成校验。这种情况可尝试重新执行编译命令看是否依赖包已下载完成,或设置-Dmaven.artifact.threads=1使用单线程下载依赖包。
集成开发环境
Visual Studio Code
安装Java Extension Pack,其中的扩展包括: Language Support for Java™ by Red Hat,Debugger for Java,Java Test Runner,Maven Project Explorer,Java Dependency Viewer,Visual Studio IntelliCode。
Java开发环境配置
配置系统中可用的Java运行环境及其版本信息(name的值为内置用于识别Java版本,可进行选择)。
"java.configuration.runtimes": [
{
"name": "JavaSE-11",
"path": "C:/Program Files/AdoptOpenJDK/jdk-11.0.11.9-hotspot",
"default": true
},{
"name": "JavaSE-1.8",
"path": "C:/tools/jdk8u275-b01"
}
]
调试环境配置
设置环境变量,以及程序的传入参数等。
"configurations": [
{
"args": "tfapi", # input arguments
"env":{ "LD_LIBRARY_PATH": "your/path" } # environment variables
}
]
基于Maven的Java项目
安装Maven,使用maven插件,快速创建项目maven-archtype-quickstart。
maven.compiler.source和maven.compiler.target如果与默认JDK版本不同,将产生警告,需要首先配置相应的JDK版本。
Eclipse
Maven支持:Eclipse内置Maven支持(m2e)。
IntelliJ IDEA
IDEA内置maven插件,支持直接创建基于maven的项目(自动生成pom.xml)。
项目配置
入口:菜单项File/Project Structure...(项目管理器没有配置入口)。
配置项目使用的JDK等信息。
加载依赖项
在pom.xml中添加依赖项定义(dependency)后,不会自动下载依赖项,需要重新加载Maven项目。
常见问题
-
依赖项冲突
出现
NoSuchMethodError或UndefinedClassError:引用的依赖库版本不正确,API不兼容导致找不到调用的类或方法。
Maven Project Object Model
https://maven.apache.org/pom.html
项目对象模型
采用xml描述项目的所有配置信息。
Super POM
Super POM是Maven项目的默认设置,Maven项目的POM文件继承自Super POM,项目文件中的设置将覆盖默认设置。
默认仓库
<repositories> <!-- <pluginRepositories> 也是同一地址 -->
<repository>
<id>central</id>
<name>Central Repository</name>
<url>https://repo.maven.apache.org/maven2</url>
<layout>default</layout>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
Maven – Settings Reference (apache.org): certain settings such as username and password should not be distributed along with the pom.xml. This type of information should exist on the build server in the settings.xml.
变量
Any field of the model that is a single value element can be referenced as a variable.
特殊变量
| 变量 | 含义 |
|---|---|
元素说明
Maven Model – Maven (apache.org)
项目信息
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--unique id: groupId-artifactId-version-->
<groupId>gary.deeplearning4j</groupId> <!--unique org ID-->
<artifactId>dl4j-start-app</artifactId> <!--project name-->
<version>1.0.0.0</version>
<packaging>jar</packaging> <!--pom for parent project-->
<!--Information of project-->
<name>DeepLearning4j Start</name>
<url>http://deaplearning.gary.net</url>
<description>
The start application for learning the Deeplearnig4J project.
</description >
<properties>...</properties>
<dependency>...</dependency>
<build>....</build>
</project>
POM信息
| 标签 | 说明 |
|---|---|
project | 根元素:声明POM的XML命名空间。 |
modelVersion | POM版本,通常为4.0.0,不常变化 |
项目信息
| 标签 | 说明 |
|---|---|
groupId | 创建项目的组织名称,通常基于有效的组织域名。 |
artifactId | 输出文件名称。 |
packaging | 输出文件打包格式(默认为*.jar)。 |
version | 输出文件版本。 |
name | 项目的显示名称。 |
url | 项目的网站。 |
description | 项目的描述信息。 |
modules | 多项目管理。 |
parent | 多项目的父项目信息。 |
licences | |
organization | |
developers | |
contributors |
环境变量
获取环境变量:
env.PATH:返回系统环境变量;
project.X.Y:返回POM.xml中对应元素的值;
settings.xxx:获取settings.xml中元素的值;
Java环境变量,例如${java.home};
xxx.yyy.zzz:在properties标签中设置的元素。
| 标签 | 说明 |
|---|---|
properties | 声明环境变量用于在文件其他部分进行替换(${dl4j.version})。作为过滤器。 |
maven.compiler.source maven.compiler.target | 为Maven的编译任务指定Java版本(例如1.8,11)。 |
<!--Define enviromnment variables for Maven-->
<properties>
<nd4j.version>1.0.0-beta4</nd4j.version>
<dl4j.version>1.0.0-beta4</dl4j.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
特殊变量:${project.basedir} 项目根目录。
依赖库
| 标签 | 说明 |
|---|---|
dependencies | 依赖库列表,其子元素为dependency。 |
dependency | 依赖库声明,其子元素包括:groupId、artifactId和version。依赖库的信息可以在Maven软件仓库中查询。 |
dependencyManagement | 用于父项目管理依赖项配置。 |
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>${nd4j.backend}</artifactId>
<version>${nd4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-nlp</artifactId>
<version>${dl4j.version}</version>
</dependency>
</dependencies>
构建工具配置
| 标签 | 说明 |
|---|---|
build | 构建工具配置。 |
plugins | 位于build子节点,构建工具列表。 |
pluginManagement | 位于build子节点,其子节点plugins/plugin声明全局的插件配置信息,任何子项目要使用其中的插件还需要在build/plugins子节点中声明。 |
plugin | 构建工具声明,包括工具的groupId、artifactId、version以及相关配置信息。 |
configuration | 构建工具配置信息,其包含的子元素取决于具体工具。 |
executions | 指定构建工具的执行方式。 |
resources | specifying where resources exist within your project. |
<build>
<sourceDirectory>${basedir}/src/main/java</sourceDirectory>
<scriptSourceDirectory>${basedir}/src/main/scripts</scriptSourceDirectory>
<testSourceDirectory>${basedir}/src/test/java</testSourceDirectory>
<outputDirectory>${basedir}/target/classes</outputDirectory>
<testOutputDirectory>${basedir}/target/test-classes</testOutputDirectory>
<defaultGoal>install</defaultGoal> <!--default goal/phase to execute-->
<directory>${basedir}/target</directory> <!--output dir-->
<finalName>${artifactId}-${version}</finalName> <!--output name-->
...
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>gary.App</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
数据类型
数据类型分为基本类型(值类型)和引用类型(类似于指针)。==基本类型默认初始化值为0,引用类型默认初始化值为null==。
基本类型
数值类型:byte(8bit)、short(16bit)、int、long、float(32bit)、double(64bit)、boolean;
字符类型:char(16bit Unicode)。
基本类型作为类成员,
字面值
前缀0表示八进制,而前缀0x代表十六进制。
字符串字面值(常量)包含在双引号间:“Hello World”。
字符常量和字符串常量可以包含转义字符以及Unicode字符编号:‘\u0001’。
类型转换
进行运算时,低精度自动向高精度转换(例如short到int,float到double),使用强制转换从高精度向低精度转换(可能损失数据)。
long y = 1234;
int x = (int) y; //强制类型转换
包装类
当内置数据类型被当作对象使用的时候,编译器会把内置类型装箱为包装类,例如:Integer, Long, Char等。
数值类型包装类基于Number类,提供常用的静态方法:
计算值
返回字符串所表示的对应类型的字面值。
static Type valueOf(String s[, int radix])
static int parseInt(String s[, int radix])
数值转换为文本
static String toString(int i) // for all basic types
字符类型对应的包装类为Character。
字符串
由于字符串是常用的一类数据类型,因此将String也归为基本类型,默认值为null。String 类是不可改变的,对字符串的修改方法都会返回新的字符串对象。如果需要对字符串做修改,应该选择使用 StringBuffer & StringBuilder 类。
str = "This is a string";
str = new String(byte[] buffer,int offset, int length);
格式化字符串
String format("%d %f %s", args);
String valueOf(Type x); // == toString
查找和索引
char charAt(int index);
int indexOf(int ch[, int fromIndex]);
int indexOf(String str[, int fromIndex]);
int lastIndexOf(int ch[, int fromIndex]);
int lastIndexOf(String str[, int fromIndex]);
boolean startWith(String prefix);
boolean endsWith(String suffix);
boolean matches(String regex);
String substring(int beginIndex[, int endIndex]);
修改
替换:
String replace(char oldChar, char newChar); // replace all
String replaceAll(String regex, String replacement);
String replaceFirst(String regex, String replacement);
根据正则表达式拆分字符串,注意转义字符。
String[] split(String regex[, int limit])
使用正则表达式支持更加灵活地分割:
" ?, ?"、" ?= ?"、" ?: ?"。
字符串拼接:
String concat(String str)
String String.join(delimiters, Iterable); // since 1.8
使用+操作符等效。
修剪
String trim(); // remove blank space
StringBuffer/StringBuilder
StringBuilder 相较于 StringBuffer 有速度优势,但是StringBuilder的方法不是线程安全的(不能同步访问)。
正则表达式
检测是否匹配模式:
import java.util.regex.Pattern
String text = "this is a string";
String pattern = ".*\\w{4}.*";
boolean matches = Pattern.matches(regex, text);
String.matches也可以执行匹配任务。
返回匹配内容:
Pattern regex = Pattern.compile(pattern);
Matches matches = regex.match(text);
while(matches.find()){
println(matches.group(0))
}
n = matches.groupCount(); // 捕获组数量(不包括匹配)
String sub = matches.group(i); //返回捕获内容
Java字符串会解释转义字符“
\”,因此当正则表达式中包含“\”时,需要使用“\\”。
match方法尝试匹配整个字符串,而find方法尝试匹配子串。find一次仅匹配一个字串,并记录匹配位置,可重复在同一Matches对象上调用find以返回后续匹配字串。
替换匹配内容:replaceAll,replaceFirst(等效于String.replaceAll和String.replaceFirst)。
Regular Expression in Java - Java Regex Example - JournalDev
容器框架
容器在java.util包中提供,java.util.concurrent提供线程安全容器类型。
数组
一维数组
数组是包装对象,封装了连续的同类型变量。对于基本类型,数据储存于连续的内存空间中;对于对象,则连续存储的为对象的引用,而实际对象储存于堆分段。
声明数组(的引用):
type[] array_name; // preferred java ctyle
type array_name[]; // c/c++ style
数组在声明之后,具有默认值(null),必须经过初始化才能使用(可以和声明结合)。
静态初始化
在声明数组时,使用“{...}”为数组的整体赋值,必须紧接在声明之后。
type array_name[] = {value1,value2,...,valuen};
动态初始化
使用new创建具有指定长度的数组。动态初始化不用和声明语句写在一起,也可以将新创建的数组赋值给已定义的数组引用。
array_name = new type[array_size];
访问数组元素
x = array_name[index];
通过下标访问数组元素,下标起始值为0,数组长度可通过字段array_name.length获得。提供的索引不应超过数组长度,否则引起ArrayIndexOutOfBoundsException 异常。
多维数组
多维数组又称为数组的数组,即数组元素储存了另一个数组的引用。
int[][] intArray = new int[10][20]; //a 2D array or matrix
int[][][] intArray = new int[10][20][10]; //a 3D array
锯齿数组
根据多维数组的定义,我们其实可以先声明数组的最高维,然后为最高维的每一个元素初始化一个子数组。由于子数组长度可能不一样,因此称这样的数组为**锯齿数组**。
int[][] array_name = new int[len1][];
for(int i = 0; i < len1; ++i){
array_name[i] = new int[len_i];
}
由于多维数组的构造方式,其底层数据的内存空间将不再是连续的。
Arrays类
提供静态方法操作数组,包括排序、比较、查找、赋值等操作。
提供数组与容器类型转换的接口。
容器接口
容器框架是一个用来代表和操纵集合的统一架构,包含如下内容:
- 接口:是代表集合的抽象数据类型。例如
Collection、List、Set、Map等。之所以定义多个接口,是为了以不同的方式操作集合对象。 - 实现(类):是集合接口的具体实现,例如:
ArrayList、LinkedList、HashSet、HashMap。 - 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。相同的方法可以在相似的接口上有着不同的实现。
Java 容器框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合;另一种是图(Map),存储键/值对映射。
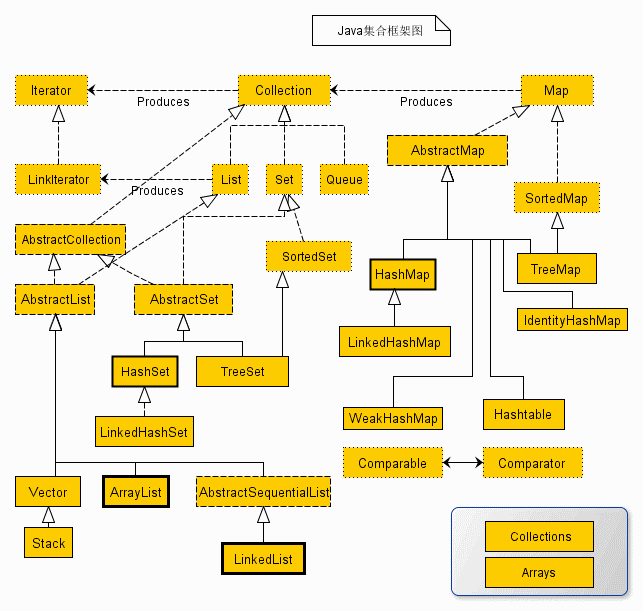
Collection接口存储一组不唯一,无序的对象。
List接口存储一组不唯一,有序(插入顺序)的对象。Set接口存储一组唯一,无序的对象。SortedSet接口有序的集合
Queue:在容器首端取出元素。通常实现包括FIFO队列(在容器末端插入元素)与优先队列(PriorityQueue,插入位置与元素大小相关)。Dequeue(double-ended queue):支持在容器的两端插入和删除元素。
Map接口存储一组键值对象(字典)。
abstract interface Map<KeyType,ValueType>
SortedMap接口使Key保持在升序排列。
容器包装
同步容器
每类容器提供了静态包装方法,返回线程安全的容器类型。
public static Collection synchronizedCollection(Collection c);
不可修改
检查所有容器操作,如有修改容器的操作则抛出异常。
public static Collection unmodifiableCollection(Collection<? extends T> c);
容器类型
Note that all the core collection interfaces are generic.
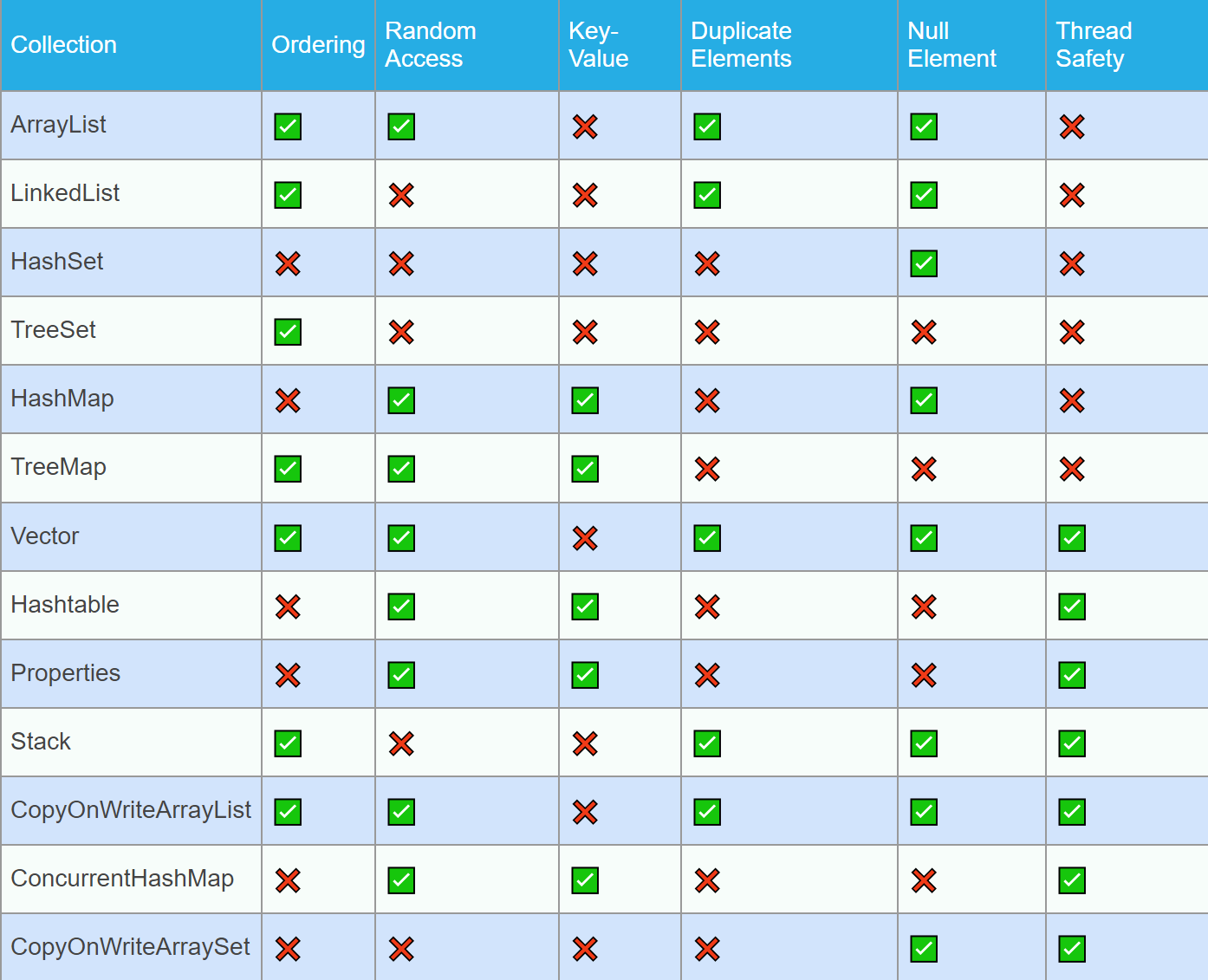
容器类型公共方法
collection.size();
collection.clear();
List
可变长度数组:
ArrayList在内部维护常规数组;如果数组容量不足,则需要重新分配数组;适用于频繁随机访问元素。LinkedList在内部维护链表;适用于频繁增删元素。
ArrayList<Integer> list = new ArrayList<Integer>();
// new ArrayList<Type>(Collection c);
// new ArrayList<Type>(int capacity);
list.add(element);
list.set(0, 100); // => list.get(0); // 不能使用[]运算符
list.remove(0); // => list.clear();
list.sort((x,y)->x-y) // => Collections.sort(list);
n = list.size();
tf = list.contains(object);
元素类型必须是引用类型,基本类型需要用包装类代替。
LinkedList提供额外方法(比普通方法更加高效):addFirst/addLast、removeFirst/removeLast、getFirst/getLast。
序列和数组相互转换
Integer[] intArray = list.toArray(new Integer[5]); // cast to array
ArrayList<Integer> list = new Arrays.asList({2,3,0,-1});
Set
操作方法类似于ArrayList。由于元素是无序存储的,没有基于索引的方法。
HashSet and LinkedHashSet
HashSet为无序集合(backed by HashMap,迭代顺序是随机的);
LinkedHashSet通过双向链表维持元素的插入顺序。
TreeSet(SortedSet)
A
NavigableSetimplementation based on aTreeMap. The elements are ordered using their natural ordering, or by aComparatorprovided at set creation time.
Map
存储key-value映射(即字典)。
HashMap
public class HashMap<K,V> extends java.util.AbstractMap
implements Map, Cloneable, Serializable;
TreeMap(SortedMap)
A Red-Black tree based
NavigableMapimplementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time.
用法
import java.util.HashMap;
HashMap<String,Object> map = new HashMap<>();
map.put(key ,value); // => value = map.get(key)
map.remove(key); // => map.clear()
tf = map.containsKey(key);
tf = map.containsValue(value);
for (Map.Entry<String, Object> entry : map.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
}
for (String key : map.keySet()) {...}
for (Object value : map.values()) {...}
https://stackoverflow.com/a/1066607
https://stackoverflow.com/questions/46898/how-do-i-efficiently-iterate-over-each-entry-in-a-java-map
Queue
PriorityQueueis an unbounded queue based on a priority heap.
旧式数据结构
枚举
可以枚举(一次获得一个)对象集合中的元素。这种传统接口已被迭代器取代,虽然Enumeration 还未被遗弃,但在现代代码中已经被很少使用了。尽管如此,它还是使用在诸如Vector和Properties这些传统类所定义的方法中。
区别于C/C++等的枚举类型,其元素是通过其他类型(如Vector.elements),无法定义或直接访问其中的枚举元素。
向量
Vector类实现了一个动态数组,和ArrayList很相似,但是两者是不同的:
Vector是同步访问的。Vector包含了许多传统的方法,这些方法不属于集合框架。
Vector支持泛型,如果构造时未给出初始化类型,编译器会给出警告。
栈
Stack是Vector的一个子类,它实现了一个标准的后进先出的栈。
注意:Vector/Stack对象无法使用下标运算符[]访问其对象。
位集合
一个Bitset类创建一种特殊类型的数组来保存位值。BitSet中数组大小会随需要增加
字典
Dictionary类是一个抽象类,用来存储键/值对,作用和Map类相似。Dictionary类已经过时了。在实际开发中,你可以实现Map接口来获取键/值的存储功能。
哈希表
Hashtable原本是Dictionary的一个具体实现 。
Java 2 重构的Hashtable实现了Map接口,因此,Hashtable现在集成到了集合框架中。它和HashMap类很相似,但是它支持同步。键经过哈希处理,所得到的散列码被用作存储在该表中值的索引。
属性
Properties继承于Hashtable,表示了一个持久的属性集。属性列表中每个键及其对应值都是一个字符串。
Properties类被许多Java类使用。例如在获取环境变量时它就作为System.getProperties()方法的返回值。
输入输出
文件读写(File IO)
open:当程序需要从文件(例如数据文件、网络等)读取数据时,创建一个适当类型的输入流对象,建立与数据源的连接,然后调用该输入流对象的方法(read),来读取外设的数据。当程序需要输出数据时,应该创建一个输出流对象来完成对文件的连接,然后利用输出流对象的write方法将数据顺序写入到目标。
close:完成读写后关闭对应的流,释放占用的资源。
输入输出流
流的类型
Java提供两类基本输入输出方式,即基于字节的(InputStream/OutputStream)和基于字符的(Reader/Writer对应了C的文件打开方式b和t)。
根据数据源的区别,可以将流分为:
- 节点流:直接与输入输出目标相连的流;
- 过滤流(基于
FilterInputStream/FilterOutputStream):与另一个流相连的流。使用过滤流需要注意,当关闭过滤流时,其所连接的源输入流会被自动关闭,变得不能再使用。而在使用过滤流时,也不能提前关闭其所依赖的源输入流。
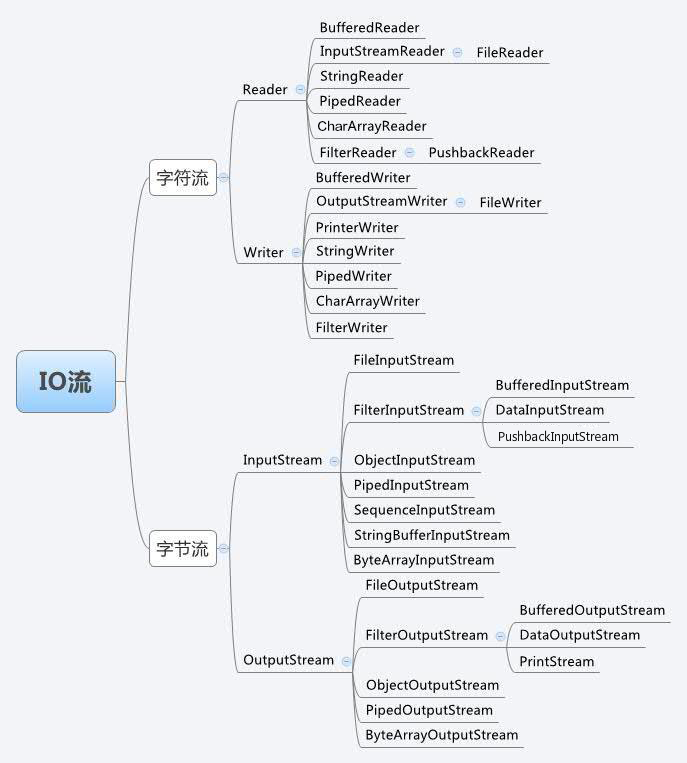
字节流输入输出
InputStream
数据作为字节流输入,其提供的读取方法包括:
int read()
int read(byte[] b)
int read(byte[] b,int off,int len)
(1)读取1byte数据并返回读取数据值;如果读取到流的末端则返回-1;该方法发生阻塞直到流的数据可用、检测到已经到达流的结束或抛出异常。 (2) 将数据读入字节数组,返回实际读取的字节数(阻塞); (3) 从数组off下标开始的位置写入,并指定最大读取的字节数
len。
定位:
long skip(long n)
void mark(int readlimit)
void reset()
skip使位置指针从当前位置向后跳过n个字节,返回实际跳过的字节数。mark标记当前位置,以备reset方法使用,标记以最后一次调用mark为准。reset将位置指针移动到标记的位置处。
基于InputStream实现的类型包括:
-
ByteArrayInputStream:以字节数组作为输入的数据源; -
FileInputStream:以数据文件作为数据源。InputStream f = new FileInputStream(path); // path string InputStream f = new FileInputStream(file); // file object
基于InputStream的过滤流类型包括:
BufferedInputStream:增加了输入缓冲区功能,支持mark和reset,显著提高了输入效率。DataInputStream:实现了DataInput接口中定义的独立于具体机器的带格式的读操作,从而实现了针对不同类型数据的字节读取,例如:readByte、readBoolean、readShort、readChar、readInt、readLong、readFloat、readDouble、readLine、readUTF等。注意:这种读取方式适合读取二进制文件、而不适合读取控制台的标准输入和文本文件后者应该使用Reader类。
OutputStream
void write(int b)
void write(byte[] b)
void write(byte[] b,int off,int len)
(1) 向输出流写入一个字节,该字节为参数
b的低8位,其余24位忽略。 (2) 将字节数组b的内容按字节写入流。 (3) 将字节数组从下标off开始的数据逐字节写入流,并指定要写入流的字节数。如果len+off大于数组的长度,则会引起IndexOutOfBoundsException。
void flush()
将输出流缓冲区的数据立即输出到目标文件。
基于OutputStream的子类:
-
ByteArrayOutputStream:将数据输出到内存中的一个无名数组中。如果想获取无名数组中的数据,可以利用该输出流的以下方法byte[] toByteArray() String toString() -
FileOutputStream:输出至文件。OutputStream f = new FileOutputStream(path) // path string OutputStream f = new FileOutputStream(new File(path));
基于OutputStream的过滤流类:
-
DataOutputStream:提供了针对不同类型数据的写方法,如:writeByte、writeBoolean、writeShort、WriteChar、WriteInt、WriteLong、WriteFloat、WriteDouble、WriteChars等。需要注意写入目的地的数据是数据的二进制形式而非字符形式。 -
PrintStream:即可作为过滤流,也可以作为节点流(直接以文件作为输出)。该输出流不产生IOException、具有自动刷新功能等特点。PrintStream(String fileName) // option-args: encoding PrintStream(File file) PrintStream(OutputStream out) // out is an underlay output stream该输出流提供了类似于一般高级语言的输出语句,例如:
print(int i); println(String x);在标准输出和文件输出,都输出数据的字符形式,适合于写文本文档。
直接从File或文件名创建输出流默认未覆盖模式,需要使用底层输出流支持追加模式。
字符流输入输出
Reader
数据作为编码后的字符流输入,Java使用Unicode字符编码。
-
读取
int read() int read(char[] cbuf)(1) 从输入流读取并返回一个字符。 (2) 从输入流中读取字符,并写入字符数组,返回实际读取的字符数。
-
定位
long skip(long n) void mark(int readAheadLimit) void reset()以字符为单位进行定位。
mark标记当前位置,并规定能返回当前位置的最大读取字符数readAheadLimit,当从当前位置读取的字符数超过这个上限,使用reset函数将不能返回标记位置。并不是所有输入字符流都支持标记功能。
基于Reader的子类:
CharArrayReader:StringReader:FileReader:
基于Reader的过滤流类型:
-
BufferedReader:以一个Reader类对象为数据源,加入了缓冲功能,提供了读字符、数组和行的功能。 -
InputStreamReader:该类型提供从字节流到字符流的桥梁。它可以从字节输入流获得数据,然后转换为字符数据交给程序。InputStreamReader虽然将字节流转换为字符流,但是没有提供更多的read方法,不方便文本的读取,例如:将FileInputStream和InputStreamReader联合使用,其效果相当于FileReader。如果要实现更方便的读功能,就要在字符流的基础上增加BufferedReader,即:br = new BufferedReader(new InputStreamReader(new FileInputStream(...))) br = new BufferedReader(new FileReader(...))
Writer
-
写入
void write(char[] cbuf) void write(String str) void write(String str, int off,int len) -
刷新缓冲区
void flush()
基于Writer的子类:
-
CharArrayWriter:该字符输出流的目的地是内存中的无名数组,其方式类似于ByteArrayOutputStream。 -
FileWriter:FileWriter(String fileName, ...) FileWriter(File file, boolean append) // [append=False] FileWriter(File file, Charset charset, boolean append)如果文件不存在,自动创建;默认为覆盖模式。
基于Writer的过滤流子类:
-
BufferedWriter:参看BufferedReader。 -
OutputStreamWriter:参看InputStreamReader。 -
PrintWriter:类似于PrintStream。PrintWriter(String fileName) // auto-create and overwrite PrintWriter(File file) PrintWriter(OutputStream out) PrintWriter(Writer out)
标准输入输出
标准输入/输出是System类中的两个静态成员字段(System类中所有字段和方法都是静态的)System.in和System.out。
System.in是InputStream类的子类对象。使用read方法需要注意一下几点:
-
System.in.read()语句必须包含在try语句块中,且其后必须有一个可接收IOException的catch语句块; -
执行该语句虽然只读取一个字节的数据,但返回的是16bit的整型量,只有低8位的数据是真正的输入数据,高8位为0。
-
作为
InputStream类的对象,System.in只能从键盘读取字节数据,要实现复杂输入,可以将System.in作为源,使用上述的过滤流(BufferedReader)来实现。java.util.Scanner 是 Java5 的新特征,我们可以通过 Scanner 类来获取用户的输入。
Scanner s = new Scanner(System.in); -
标准输入时,无论是字节流或字符流,若将数据输入到数组中,会将
Enter键也算入输入,并且相当于"回车(13,\r)"和"换行(\n,10)",所以在使用输入数据时应该去掉这两个字节(字符)的数据。当使用记事本等程序打开文件时,\r\n,\r,\n出现时,识别为一个换行。 -
当键盘缓冲区没有数据时,执行
System.in.read()会引起阻塞。
System.out是PrintStream类的对象。
日志
Logger in Java - Java Logging Example - JournalDev
网络编程
基本元素
IP地址和端口号
InetAddress封装了IP地址,端口号使用整数表示。
InetAddress.getByName("127.0.0.1"); // or domain.name
InetAddress.getLocalHost();
InetAddress.getHostAddress(); // return IP text
SocketAddress封装了IP地址和端口号。
UDP通信
DatagramSocket类封装了UDP通信的服务端和客户端。
udp_conn = new DatagramSocket(); // client
udp_conn = new DatagramSocket(port[, inet_addr]); //server
udp_conn.send(packet); // DatagramPacket
udp_conn.receive(packet);
sql_conn.getInetAddress();
ip_addr = udp_conn.getLocalAddress();
sql_conn.getPort()
port = udp_conn.getLocalPort();
sock_addr = sql_conn.getLocalSocketAddress();
sql_conn.getRemoteSocketAddress(); # return null if not connected
数据报分组
DatagramPacket封装了UDP协议分组,该类型包含一个数据缓存(byte[])的引用,可通过构造函数或setData设置分组的数据缓存。
send_packet = new DatagramPacket(msg.getBytes(), msg.length(), server_addr, server_port); // msg (String) convert to byte array.
send_packet = new DatagramPacket(msg.getBytes(), msg.length(), socket_addr);
send_packet.setData(msg.getBytes(), offset, msg.length());
byte[] recv_buffer = new byte[128];
recv_packet = new DatagramPacket(recv_buffer, recv_buffer.length);
待发送的分组需要设置目标套接字地址,接收到的分组可以读取远端的套接字地址。
send_packet.setAddress(inet_addr);
send_packet.setPort(port);
send_packet.setSocketAddress(inet_addr);
client_addr = recv_packet.getAddress();
client_port = recv_packet.getPort();
client_addr = recv_packet.getSocketAddress();
TCP通信
ServerSocket类代表服务器端。
ServerSocket([int port[, int backlog[, InetAddress address]]])
throws IOException
Socket accept() throws IOException
void bind(SocketAddress host, int backlog)
Socket类代表TCP客户端。
Socket()
Socket(String host, int port) throws UnknownHostException, IOException
Socket(InetAddress host, int port) throws IOException
Socket(String host, int port, InetAddress localAddress, int localPort) throws IOException
Socket(InetAddress host, int port, InetAddress localAddress, int localPort) throws IOException
void connect(SocketAddress host, int timeout) throws IOException
InputStream getInputStream() throws IOException
OutputStream getOutputStream() throws IOException
void close() throws IOException
数据序列化
对象序列化
一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化。
当序列化一个对象到文件时, 按照 Java 的标准约定是给文件一个
.ser扩展名。
类ObjectInputStream和ObjectOutputStream是高层次的数据流,它们包含反序列化和序列化对象的方法。
final void writeObject(Object x) throws IOException // ObjectOutputStream
final Object readObject() throws IOException, // ObjectInputStream
ClassNotFoundException
对于 JVM 可以反序列化对象,它必须是能够找到字节码的类。
一个类的对象要实现序列化功能,必须:
- 实现
java.io.Serializable对象。 - 所有字段是可序列化的或
transient的。
JSON
org.json提供处理JSON数据的方法。
<!-- https://mvnrepository.com/artifact/org.json/json -->
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20190722</version>
</dependency>
JSON的数据类型主要分为两类,即
-
对象
JSONObject:包含一个或多个key-value(可以是JSONArray)的字典;import org.json.JSONObject; JSONObject jo = new JSONObject(); // creating empty JSONObject JSONObject jo = new JSONObject(JSON_String); // Parse from string jo.put(key, value); // add or modify elements jo.getString(key); // throw exception if key not exist jo.optString(key); // return empty string if key not exist jo.optString(key,default_value); // return default if key not exist jo.getLong(key); // get Numerical type jo.optLong(key);jo.toString(); // convert to string转换为字符串时,特殊字符将使用转义字符执行逆向转换。
-
数组
JSONArray:包含value(可以是JSONObject)一个序列。JSONArray的方法与JSONObject类似,但没有key参数。
https://www.geeksforgeeks.org/parse-json-java/
https://stackoverflow.com/questions/2591098/how-to-parse-json-in-java
XML
系统接口
系统信息
String os_name = System.getProperty("os.name")
日期和时间
import java.time.*;
LocalDate封装日期,LocalTime封装时间,LocalDateTime封装日期和时间的组合。
按使用场景选择相应的类型,不能访问类型未封装的时间字段。
获取当前日期时间:
LocalDateTime datetime = LocalDateTime.now();
设定一个日期时间:
LocalDate date_set = LocalDate.of(2020, 2, 19);
修改日期时间对象:
datetime = datetime.withYear(2077).withDayOfMonth(1).withMonth(10);
datetime.plusYears(1); // plus() method series
datetime.minusSeconds(seconds); // minus() method series
获取日期时间中的字段:
get(TemporalField field)
datetime.getYear(); // get() method series
格式和解析
DateTimeFormatter设置日期时间的格式:
formatter = DateTimeFormatter.ofPattern("dd-MM-yyyy HH:mm:ss");
System.out.println(datetime.format(formatter));
设定的格式也可以用于时间字符串的解析:
date_parse = LocalDateTime.parse("12-03-2010 11:22:33", formatter);
时间间隔
Duration:
Duration.between(datetime1, datetime2);
时间戳(Timestamp)
Instant
Instant timestamp = Instant.parse(date.toString());
System.out.println("Timestamp: " + timestamp.toString());
旧式API
Date表示一个时间点,精确到毫秒,相当于存储一个整数值。
import java.util.Date;
Date d = new Date(); // 获取当前日期和时间
Date d = new Date(long millisec); //指定从1970年1月1日00:00:00开始的毫秒数
Date的初始化可以通过指定年月日获字符串表达式等的方式设置,但是这些设置方式已被废弃,这些设置方式可以用在Calender或DateFormat类中。
int compareTo(Date anotherDate)
使本对象与另一个时间比较。
long getTime()
void setTime(long time)
获取/设置时间。
Calendar按照日历的表示形式来设置和获取日期。 Calendar是抽象类,不能用构造函数初始化;Calendar的表达与地区有关,使用getInstance()来获取合适的子类实例作为Calendar引用的对象。
import java.util.Calendar;
Calendar c = Calendar.getInstance();
year = c.get(Calendar.YEAR) // MONTH, DAY_OF_MONTH, HOUR_OF_DAY, MINUTE, ...
使用set(),add(),roll()可以改变字段的值。
-
set(f, value)设置指定字段f的值。 -
add(f, delta)增加指定字段f的值,如果超过了该字段的最大值,则会发生进位。 -
roll(f, delta)与add一样,只是不会改变上一级字段的值。
利用Time获取:唯一不足是取出时间只有24小时模式。
import java.util.Time;
Time t=new Time(); // or Time t=new Time("GMT+8"); 加上Time Zone资料。
t.setToNow(); // 取得系统时间。
int year = t.year; // month, monthDay, hour, minute, second
DateFormat表示日期或时间格式的抽象类。
import java.text.SimpleDateFormat;
SimpleDateFormat formatter = new SimpleDateFormat ("yyyy年MM月dd日 HH:mm:ss ");
String str = formatter.format(Date());
当然还有就是可以指定时区的时间:
df=DateFormat.getDateTimeInstance(DateFormat.FULL,Locale.CHINA);
System.out.println(df.format(new Date()));
文件管理
目录和文件管理由File类实现。
package java.io;
public class File implements java.io.Serializable, java.lang.Comparable
每个File对象对应与一个磁盘文件或目录(以下统称文件),通过其字段可以查询对应文件的相关信息,调用它的方法可完成对文件或目录的常用操作,如创建、删除等。
创建File对象
File(String pathname) //使用文件或目录名创建对象
File(String parent,String child)//使用父目录+子目录创建对象
File(File parent,String child)//使用父目录对象+子目录创建对象
File(URI uri) //使用URI(同一资源标识符)创建对象
由于Windows系统中使用
\作为分隔符,容易与转义字符发生混淆,所以在路径名中使用\\代替\,而在UNIX等系统中则使用/。当书写路径名或以驱动器名开头时,代表绝对路径;以\\或/开头,也代表绝对路径,此时驱动器默认为当前工作目录所在驱动器;若以.、..或其他单词开头则代表相对路径。
获取文件的属性
boolean exists()
boolean isDirectory()
boolean isFile()
exists()判断文件是否存在;isDirectory()判断文件目录是否为目录;isFile()判断文件是否为普通文件。
String getName()
String getPath()
String getAbsolutePath()
String getParent()
getName()返回文件名;getPath()返回文件路径(根据构造函数给的是相对路径还是绝对路径决定),等效于toString();getAbsolutePath()返回绝对路径;getParent()返回父目录的路径。
String[] list()
File[] listFiles()
list()列出目录下的所有文件和目录;listFiles()列出目录下的所有普通文件。如果对像不是目录或是空目录则返回
null。
boolean canRead()
boolean canWrite()
获取文件的读写权限。
long length()
获取文件的长度(对与目录则返回值无意义)。
文件操作
boolean renameTo(File dest)
将文件或目录的名称改为指定的名称(移动文件或目录),该操作是平台相关的,可能造成文件不能从一个文件系统移动到另一个文件系统,另外如果目标路径已经存在,则不能完成移动。根据返回值确定移动操作是否成功进行。
boolean delete()
删除文件或目录,如果是目录,则目录必须为空才能执行删除。
boolean mkdir()
boolean mkdirs()
创建目录,返回是否创建成功。
mkdir()要求文件的父目录存在;mkdirs()在父目录不存在的情况下先创建父目录。
boolean createNewFile() // return true if file not exist and created.
仅在文件不存在时创建新文件,文件的父目录必须存在。
注意:
File对象本身只是对磁盘文件/目录的映射,并不代表相应的文件实际存在或已被打开。
进程和线程
创建进程
执行系统命令
使用Runtime
Runtime rt = Runtime.getRuntime();
Process ps = rt.exec(cmd_string);
int exitCode = ps.waitFor();
https://www.javaworld.com/article/2071275/when-runtime-exec---won-t.html
使用ProcessBuilder
ProcessBuilder builder = new ProcessBuilder();
builder.command("cmd.exe", "/c", "dir"); // "sh" for linux
builder.directory(new File(System.getProperty("user.home")));
Process process = builder.start();
int exitCode = process.waitFor();
命令的输出
the output must be consumed – otherwise the process doesn't return successfully, instead it will hang.
StreamGobbler streamGobbler =
new StreamGobbler(process.getInputStream(), System.out::println);
// process.getErrorStream()
Executors.newSingleThreadExecutor().submit(streamGobbler);
创建线程
Multithreading in Java - Everything You MUST Know - JournalDev
Java Thread Example - JournalDev
Java 提供了三种创建线程的方法:
-
继承
Thread类,实现run()方法:class MyThread extends Thread{ public void run(){ while(true){ System.out.println("MyThread类的run()方法在运行"); } } } MyThread myThread=new MyThread(); myThread.start(); -
继承
Runnable接口并实现run()方法的类。可以使用Lambda表达式定义函数接口。Runnable runnable = () -> { while(true){ System.out.println("MyThread类的run()方法在运行"); } } runnable.start(); // => thread.start(new Thread(runnable)); -
通过
Callable和Future创建线程。Callable一般是和ExecutorService配合来使用的<T> Future<T> submit(Callable<T> task); <T> Future<T> submit(Runnable task, T result); Future<?> submit(Runnable task);Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。public interface RunnableFuture<V> extends Runnable, Future<V> { void run(); } public class FutureTask<V> implements RunnableFuture<V>
Scala
The name Scala comes from the word scalable, and true to that name, the Scala language is used to power busy websites and analyze huge data sets.
Scala特性:
-
高级语言:无需处理底层概念,如指针和内存管理;
-
面向对象和函数式编程:函数也能当成值来使用,定义匿名函数,支持高阶函数,允许嵌套多层函数;支持函数式和面向对象混合编程。
- Functions for the logic
- Objects for the modularity
-
静态类型(编译时检查),具有表达性强的类型系统(可自动推测类型,而无需为变量声明固定类型);
-
Scala源代码被编译成Java字节码运行在Java虚拟机上,可以无缝与现有的Java类库交互。
-
并发性:Scala使用Actor作为其并发模型,Actor是类似线程的实体,通过邮箱发收消息。
-
应用:服务、大数据应用、浏览器(Scala.js)。
安装
使用Coursier
使用系统软件仓库或安装包
不推荐:不能一次性安装所有工具。
Ubuntu (scala-2.11)
apt install scala # 包括scalac、scala、fsc、scaladoc
安装sbt
echo "deb https://repo.scala-sbt.org/scalasbt/debian all main" | sudo tee /etc/apt/sources.list.d/sbt.list
echo "deb https://repo.scala-sbt.org/scalasbt/debian /" | sudo tee /etc/apt/sources.list.d/sbt_old.list
curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add
sudo apt update && sudo apt install sbt
Windows
winget install scala
winget install sbt
Scala程序
交互式编程
脚本
// class definition similar to JAVA
object ExampleClass { // object is singleton class
def main(args: Array[String]) {
println("Hello, world!") // 输出 Hello World
}
}
@main def main(args:Array[String]) = {...} // scala3
基本语法
语句可以用分号(;)结束或换行符。
包
package com.runoob // java package style
class HelloWorld
package com.runoob{ // c# Namespace style
class HelloWorld
}
导入依赖包:使用_代表包中所有可导入内容。
import java.util.*
import org.apache.spark.sla._
import scala.jdk.CollectionConverters.*
val scalaList: Seq[Integer] = JavaClass.getJavaList().asScala.toSeq
流行的Scala库
- Play Framework:Web应用服务;
- Lagom:微服务架构;
- Apache Spark:分布式大数据处理。
- Scala.js:Web前端应用。
- 其他Scala应用。
数据类型
Scala与Java有着相同的数据类型,scala没有java中的原生类型。空值是 scala.Null 类型。
变量
变量声明
var myVar [: String] = "Foo" // 变量
val myVal [: String] = "Foo" // 常量
类型推断:根据初始化值推断变量类型,而无需指定变量类型。
类型转换
Int和Long不能自动类型转换(ClassCastException),需要使用强制类型转换:
v.asInstanceOf[Type]
Any类型只向其实际类型转换,不能直接转换为其他类型;必须还原实际类型后执行强制转换。
运算符
- 算术运算符:
+,-,*,/,% - 比较运算符:
==,!=,>,<,>=,<= - 逻辑运算符:
&&,||,! - 位运算符:
&,|,^,~,<<,>>,>>>(>>>右移补零) - 赋值运算符:
=,+=,-=,...
类
Scala中的类不声明为public,一个Scala源文件中可以有多个类。
class Point(xc: Int, yc: Int) extends baseclass(args) {
var x: Int = xc
var y: Int = yc
def move(dx: Int, dy: Int) { }
}
所有类继承自Any,其子类包括AnyVal(值类型)和AnyRef(引用类型,类似于Java)。
Traits
Traits(特征) 相当于Java的接口。与接口不同的是,它还可以定义属性和方法的实现。
使用
new关键字创建对象。
数组(Array)
import Array._
var array:Array[String] = new Array[String](3)
var array = new Array[String](3)
var myMatrix = ofDim[Int](3,3) // 二维数组
var x = range(1,10,2) //start stop step Range
下标访问符为
(),而非[]。泛型类型声明符为
[],而非<>(容器类型)。
容器(Collection)
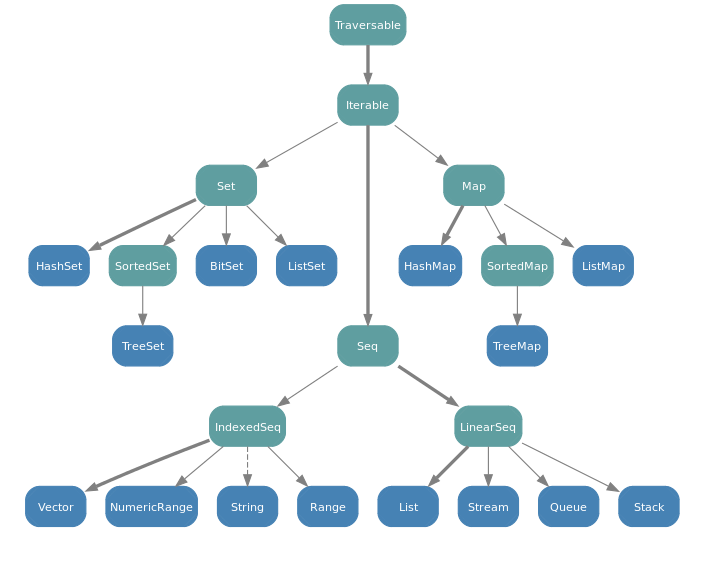
不可变对象
Scala默认使用不可变对象(scala.collection.immutable)。可以导入collection.mutable包使用可变对象版本。
import scala.collection.mutable
var s = mutable.Set()
修改对象的操作返回新对象。
List
Nil表示空列表。
Seq是List继承的特征(trait)。
Set
set(val)判断值是否在集合中。无法按下标返回元素。
Map
var A:Map[Char,Int] = Map()
A += ('I' -> 1) // add key-value
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF")
println(colors("red"))
for (c <- colors){
println(c) // iterate c is (key,value) tuple
}
Tuple
使用
t._idx访问元组的元素(idx 1-based);目前 Scala 支持的元组最大长度为 22。
Option
Iterator
运算符
:用于声明运算符与相邻对象的结合关系。
var a = List(1,2,3), c = List(4,5,6), item = 10
val b = a:+item // append a with item
val b = item+:a // prepend a with item: item::a
val b = a++c // appended c to a
val b = a++:c // prepend a to c: also a:::c
+运算符用于字符串(String)拼接。
:++error.
Java容器
访问修饰符
方法和函数
Scala 方法是类的一部分,而函数是一个对象可以赋值给一个变量。
方法定义语法
方法声明中,可以选择指定参数类型、参数默认值、返回值类型。
def sum(x: Int, y: Int = 0)[: Int]= x + y // expression style
@Transaction
@throws(classOf[IOException])
def methodName ([arg1:Int, arg2 Double])[: Double] = // method style
{
statements
return [expr]
}
def matchState(x): Int=x match{...} // methods with single match
公开方法需要声明返回类型,局部或私有方法可以省略返回类型声明(
: Int)。无返回值,则声明
: Unit(类似于void)。类似于Java,可以声明标注(Annotations),包括抛出异常(Java使用关键字
throws抛出异常)。
method style
与多数编程语言类似,使用{}代码块表示函数体。
expression style
使用=运算符连接单句表达式作为函数体(类似于Lambda表达式)。
match表达式
函数对象
函数对象保存一个匿名函数定义,=>运算符用于分隔参数列表和函数体。
val f1 = (a: Int, b: Int) => a + b
val f2 = { (a: Int, b: Int) =>
val sum = a + b
sum // return sum
}
闭包
匿名函数及其引用的外部作用域中的对象组成闭包。
factor = 5
val multiplier = (i:Int) => i * factor
注意函数返回值使用
=,方法返回值使用=>。
Map and Reduce
传递(匿名)函数对象作为map和reduce的参数。
val l = List(2, 5, 3, 6, 4, 7)
val sum = l.reduce((x, y) => x+y)
val sqrt = l.map(x => x*x)
模式匹配(switch-case)
def matchTest(x: Any): Any = x match {
case 1 => "one"
case "two" => 2
case y: Int => "scala.Int"
case _ => "many"
}
正则表达式
import scala.util.matching.Regex
流程控制
条件
y = x match {
case hd :: tail => hd + sum(tail)
case Nil => 0
}
循环
for ( x <- iterable ){
println(x)
}
异常处理
try {
val f = new FileReader("input.txt")
} catch {
case ex: FileNotFoundException =>{
println("Missing file exception")
}
case ex: IOException => {
println("IO Exception")
}
} finally {
println("Exiting finally...")
}
输入输出
Scala 进行文件写操作,直接用的都是 java中 的 I/O 类 (java.io.File)。
Java的标准输入输出已经导入运行环境,可以直接调用函数如print、println,无需添加包名(System.out)。
Scala项目
sbt是首选的Scala项目管理工具,其他工具包括ant、gradle、maven……
sbt项目
创建项目
sbt new scala/hello-world.g8 # Scala 3 project
sbt new scala/scala3.g8 # Scala 2 project
需要下载运行环境(包括从Maven仓库下载依赖库,视网络环境可能占用一定时间)。
项目结构
project-name
├── build.sbt # sbt项目配置
├── project
│ └── build.properties
└── src
└── main
└── scala
└── Main.scala # 入口程序
项目配置
build.sbt:
name := "HelloWorld"
version := "1.0"
scalaVersion := "2.13.8" # *
*:项目可指定Scala版本而无需使用全局Scala版本。
开发环境
Coursier管理工具
Coursier命令行工具用于安装Scala应用程序和设置开发环境1。
安装Coursier
==如果安装过程无法下载数据,首先检查网络状况,可能需要设置代理。==
Linux
CS_URL=https://github.com/coursier/launchers/raw/master/cs-x86_64-pc-linux.gz
curl -fL $CS_URL | gzip -d > cs && chmod +x cs && ./cs [options] setup [options]
将安装coursier(cs)到默认位置,以及安装以下全局命令行工具和JVM(安装过程会提示是否更新用户配置文件(.profile)中的环境变量,从而使相应工具全局可用):
scala-cli, a convenient tool to compile / run / package Scala codescala, the Scala REPLscalac, the Scala compilersbtandsbtn, the sbt build toolsammonite, an enhanced REPL for Scalascalafmt, the Scala code formatter
安装完成后可移除下载的cs文件,使用安装版本的couriser/cs进行管理。
cs setup \
--apps sbt-launcher,ammonite \ # 安装额外的命令行工具
--install-dir ~/.local/scala \ # 修改安装目录*
--yes # 使用默认选项,取消交互
*:--install-dir仅适用于cs以及scala工具,不适用于JVM安装路径。
Windows
$Uri="https://github.com/coursier/launchers/raw/master/cs-x86_64-pc-win32.zip"
Invoke-WebRequest -Uri $Uri -OutFile "cs-x86_64-pc-win32.zip"
Expand-Archive -Path "cs-x86_64-pc-win32.zip"
.\cs-x86_64-pc-win32.exe setup
get-command cs # 重新打开终端执行
安装完成后,将自动添加Coursier目录C:\Users\USER\AppData\Local\Coursier\data\bin到路径环境变量中(如果未添加,可手动添加;如果不需要全局启用,可通过PowerShell $Profile设置)。
$env:JAVA_HOME="C:\Users\gary\AppData\Local\Coursier\cache\arc\https\github.com\AdoptOpenJDK\openjdk8-binaries\releases\download\jdk8u292-b10\OpenJDK8U-jdk_x64_windows_hotspot_8u292b10.zip\jdk8u292-b10"
$env:PATH="$env:JAVA_HOME\bin;C:\tools\scala;$env:PATH"
配置Coursier
coursier网络代理配置
Coursier的JVM不会自动使用系统的代理配置,需要将代理配置通过Java选项传递给JVM。
coursier '-J-Dhttps.proxyHost=127.0.0.1' '-J-Dhttps.proxyPort=7890' [args] #*
sbt '-Dhttps.proxyHost=…' '-Dhttps.proxyPort=…' [args] #**
传递给
java.net.HttpURLConnection的代理属性,HTTP同理。
*:PowerShell会将-XX解释为PowerShell命令的选项,需要使用''将其视为普通参数传递。
**:在环境变量JAVA_OPTS中配置(仅适用于sbt,不适用于coursier):export JAVA_OPTS="$JAVA_OPTS -Dhttp.proxyHost= -Dhttp.proxyPort= ..."
仓库配置
仓库列表:~/.sbt/repositories文件(不存在则手动创建)记录所有可用仓库列表。
[repositories]
local
maven-central
模板配置文件:delta/repositories at master · delta-io/delta (github.com)
默认仓库为:
ivy2local:Ivy2本地仓库,位于~/.ivy2/local;central:Maven中央仓库,即https://repo1.maven.org/maven2;
上述默认配置可通过环境变量COURSIER_REPOSITORIES修改(使用镜像仓库代替Maven中央仓库central)。或通过命令行选项-r,--repository指定额外仓库(可指定多次以包含多个仓库)。提供--no-default将不使用默认或通过环境变量配置的仓库。
export COURSIER_REPOSITORIES="ivy2Local|central|sonatype:releases|jitpack|http://"
sbt Reference Manual — Proxy Repositories sbt Configuration
sbt Reference Manual — sbt Launcher Configuration 3. Repositories Section
相应地,可在项目配置文件(优先级更高)中添加:
resolvers += "central" at "http://maven.aliyun.com/nexus/content/groups/public/"
externalResolvers :=
Resolver.withDefaultResolvers(resolvers.value, mavenCentral = false)
镜像配置:sbt默认使用Maven中央仓库下载依赖,因此速度很慢。~/.config/coursier/mirror.properties(Linux)中配置代理转发规则(类似于Maven配置的mirrorOf)。
central.from=https://repo1.maven.org/maven2
central.to=https://mirrors.huaweicloud.com/repository/maven #*
*:阿里云/163中央仓库镜像缺少部分Scala插件包,腾讯云下载文件可能校验和不一致,实测华为云镜像更新安装时不会报错。该配置文件路径可通过
COURSIER_MIRRORS环境变量或命令行选项-Dcoursier.mirrors=指定。
缓存路径
缓存用于存放不经常发生变化的依赖库,默认路径为~/.cache/coursier/v1(Linux),配置COURSIER_CACHE环境变量或coursier.cacheJava选项覆盖默认路径。
coursier使用的缓存路径:传递--cache选项覆盖上述配置;sbt使用的缓存路径:其位置可在sbt交互环境中使用show csrCacheDirectory查看。通过或传递-Dsbt.coursier.home选项来更改缓存路径。
缓存声明周期:以-SNAPSHOT结尾的包、Maven元数据等具有缓存周期(TTL,默认为24小时)。
管理Scala命令行应用程序
cs install <app:version> --install-dir DIR # -> cs setup --apps <app:version>
cs list|update|uninstall|search <app:version>
默认安装位置:~/.local/share/coursier/bin,可通过配置修改;需要将安装位置加入PATH以便通过命令名启动应用。环境变量COURSIER_BIN_DIR|COURSIER_INSTALL_DIR以及Java属性coursier.install.dir可覆盖上述默认位置(优先级由高到低)。==命令行选项--dir,--install-dir具有最高优先级==。
管理JVM
cs java --available # 列出可用Java版本
cs java --installed # 列出已安装Java版本
cs setup --jvm 11 # 安装Java环境*
cs java --jvm 11 --env # 输出设置Java环境变量的语句,可调用eval执行
cs java --jvm 11 [options] args... # 使用指定Java(不存在则自动下载安装)**
cs java --jvm VER --setup # 设置默认Java版本
cs java-home [--jvm ver]... # 显示指定环境的JAVA_HOME
cs会首先检查系统是否自带Java并尝试使用该版本;如果没有,则自动安装AdoptOpenJDK 1.8。通过--jvm指定的Java即使与自带版本相同(如1.8)还是会额外下载安装,如果版本仅指定数字,默认安装Adoptium发布的JDK(adoptium,与AdoptOpenJDK标识adopt不同)。安装后会提示是否更新环境变量,环境变量决定命令行工具依赖的Java版本。如果使用指定版本Java执行命令时,该版本不存在,则
cs会自动下载安装相应版本Java。Adoptium OpenJDK是从GitHub下载,可能需要使用代理。
*:--jvm-dir(指定Java安装路径)不可用。JVM安装路径可通过COURSIER_JVM_CACHE或coursier.jvm.cacheJava系统属性设置。
启动Scala应用
install命令会将安装的应用存放在上述路径下,因此通过命令名启动应用程序则是最近安装的版本。
app [options] args... # 启动默认版本
如果要启动其他版本,使用cs launch命令。
cs launch <app:version> [cs_options] -- [app_args...] # app未经安装则直接从仓库源拉取
# cs launch scala:2.12.15
cs launch org.scalameta::scalafmt-cli:2.4.2
-M,--main-class # 如果指定的库找不到主类,可通过该选项指定
-java-opt -Dfoo=bar --java-opt -Xmx2g # 传递Java参数给应用
应用程序支持接收Java运行时参数,如
"-J-Xmx2g";或通过环境变量设置,两种可混合使用。export JAVA_OPTS="-Xmx2g -Dfoo=bar"
bootstrap将从指定的依赖库构造可执行的应用程序文件。
cs bootstrap org.scalameta::scalafmt-cli:2.4.2 -o scalafmt
配置应用程序通道
默认使用主通道,即io.get-coursier:apps。
cs install --contrib app # io.get-coursier:apps-contrib*
--channel <custom-channel>
*:app和io.get-coursier:apps-contrib是官方维护的仓库通道。
管理Maven依赖项
解析依赖项
cs resolve io.circe::circe-generic:0.12.3
下载依赖项
cs fetch io.circe::circe-generic:0.12.3
--classpath # 输出依赖包的CLASSPATH,而不是仅列出下载路径
--source # 下载源码包而非标准包
--javadoc # 下载文档而非标准包
--default=true # 同时下载标准包
Scala依赖库和应用程序
命令行工具
编译工具
sbt # 进入sbt交互环境
[~]run # 使用"~"可在文件发生更改时自动重新执行, 输入exit退出
sbt run # 直接编译运行
集成开发环境
集成开发环境可使用IntelliJ或VSCode。
VSCode+Metals
开发环境设置
设置下Metals语言服务器依赖库的仓库源。
{
"metals.customRepositories": [
"https://maven.aliyun.com/repository/central"
]
}
Metal项目设置
bloop
Scala3
新特性
New in Scala 3 | Scala Documentation (scala-lang.org)
参考资料
Introduction | Scala 3 — Book | Scala Documentation (scala-lang.org) 3: Scala 3 Reference (scala-lang.org) 4: Scala 3 Features | Scala 3 — Book | Scala Documentation (scala-lang.org)
开发框架
Play Framework
Play框架简介
- Model-View-Controller (MVC) architecture
- hot reloading:在接收请求时检查当前是否存在内容需要重新加载。
Play项目
sbt '-Dhttps.proxyHost=127.0.0.1' '-Dhttps.proxyPort=10809' new playframework/play-scala-seed.g8
将自动在当前目录下创建项目目录(目录名通过交互命令提供)。项目结构:
D:\USERS\GARY\ONEDRIVE\WORKSPACE\SCALA\LEARN-PLAY-FRAMEWORK
├─.g8
│ └─form
│ ├─app # MVC
│ │ ├─controllers
│ │ └─views
│ └─test
│ └─controllers
├─app
│ ├─controllers
│ └─views
├─conf
├─project
├─public # 静态资源
│ ├─images
│ ├─javascripts
│ └─stylesheets
└─test
└─controllers
routes
conf/routes定义了URL的处理路径。
# An example controller showing a sample home page
GET / controllers.HomeController.index()
GET /hello controllers.HomeController.hello(name: String)
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
MVC架构
使用MVC架构处理并响应URL。
视图及模板
app/views中定义了Web应用的视图,支持使用模板(Twirl+HTML)。
@(name:String)
@main("Hello") {
<section id="top">
<div class="wrapper">
<h1>Hello World, @name!</h1>
</div>
</section>
}
Twirl模板语法:
-
@开始的内容通过模板引擎生成内容。 -
@(var:Type)定义从控制器调用页面时传入的参数,在模板中使用@var引用参数。 -
@main("Hello", assetsFinder)引用其他模板内容,并传入参数。 -
{}中的内容将被插入生成的HTMLbody。
控制器
以下定义控制器app/controllers及其包含的URL处理方法。通过在routes文件中添加声明,以调用该控制器中的URL处理方法。
class HomeController extends BaseController {
/* "/"根URL处理 */
def index() = Action { implicit request: Request[AnyContent] =>
Ok(views.html.index()) // 对应app/views目录下的页面
}
/* URL参数处理和传递至视图 */
def hello(name:String) = Action {
Ok(views.html.hello(name))
}
}
示例教程
Play’s documentation shows the available features and how to use them, but the documentation will not show how to create an application from start to finish. This is where tutorials and examples come in. Tutorials and examples are useful for showing a single application at work, especially when it comes to integrating with other systems such as databases or Javascript frameworks.
Play Tutorials - 2.8.x (playframework.com)
C# Programming
C#是面向对象的编程语言,支持面向组件的编程,通过属性、方法和事件来提供编程模型。
C# 特性:垃圾回收 (Garbage collection);异常处理 (exception handling);类型安全 (type-safe) 的语言设计。
基本语法
应用程序 (application)以名为Main的静态方法作为程序执行的起点。Main方法中可书写表达式语句或调用类库或自定义的其他方法。
namespace NameSpace{
class Program{
static void Main(string[] args){
/* statements ... */
} // return void or int
static async Task Main() { }
static async Task<int> Main(string[] args) { } // (C# 7.1)
}
} // Libraries and services do not require a Main method.
Main方法:必须为static方法,不需要是public。
args为除了程序名称以外的参数。
一个类中最多包含一个名为Main的方法。在一个程序的多个类或结构中,可能都定义了Main方法。这样的情况下,必须利用某种外部机制(如命令行编译器的选项-main)来选择其中一个Main方法用作入口点。
应用程序入口点方法不能位于泛型类声明中。
从C#9开始,可以省略Main方法,将位于全局命名空间的语句作为主函数内容。
变量
变量表示数据的存储位置。
定义变量
<type> varname = value;
变量名称约定
-
使用驼峰式,即第一个单词以小写字母开始,后续每个单词的首字母采用大写形式。
-
变量名称不应包含变量的数据类型(在实际代码中可能不能代表实际类型)。
隐式类型本地变量使用 var 关键字进行创建,该关键字指示 C# 编译器去推断类型。
var age = 10;
变量名应使用骆驼式命名法。
常量
对于数学常量,在System.Math类中有比较精确的定义,可以直接使用,例如pi和e。
字面值
在数字后加上后缀,可以将字面值表示成不同类型的数值。
整形
- 没有后缀:解析成
int、uint、long、ulong; - 具有
u后缀:解析成uint、ulong; - 具有
l后缀:解析成long、ulong; - 具有
ul或lu后缀:解析成ulong; - 十六进制表示:添加前缀“
0x”
bool类型的字面值:true、false。
浮点型
- 具有
D/d后缀:解析成double; - 具有
M/m后缀:解析成decimal; - 具有
F/f后缀:解析成float。
指数记法:
- 使用后缀
e,在后缀后面添加一个整数,并在最后加一个后缀,表示整个数的类型。 - 后缀是不区分大小写的。
字符串
转义字符:C# 将反斜杠固定用于转义序列,如果出现非法转义序列将产生错误。
使用
\uFFFF转义序列在文本字符串中添加Unicode编码(UTF-16)字符。
字符串的前面使用 @ 指令避免转义。原始字符串:@“this is \ a string.”
当字符串中含有“\”时,后面的字符以及“\”就会被编译程序解析为转义字符。如果要使用带“\”的字符串而屏蔽掉其转义字符的性质,可以在字符串(双引号)前添加字符“@”。
运算符
复合赋值运算符:如 +=、-=、*=、++ 和 --;
定位增量和减量运算符:++,--;
同时
System.Threading.Interlocked类提供了线程安全的方法Increment()和Decrement()。
比较运算符:==、>、<、>=、<=、!=;继承自Object的类可以重写Equals方法,实现值比较(例如String类型的==比较的是字符串的值)。
逻辑运算符:&&、||、``;
赋值运算符:对变量进行一次赋值会返回一个值,所以可以一次对多个变量进行赋值。
string req,max;
req=max="It would take a miracle."
位运算符:&,|,^,~
移位运算符:>>, <<
op1st >> op2nd如果第一个操作数为
int或uint(32 位),则移位数由第二个操作数的低五位给出(op2nd&0x1f,即最多移32位)。 如果第一个操作数为long或ulong(64位数),则移位数由第二个操作数的低六位给出(op2nd&0x3f,即最多移64位)。 如果第一个操作数为int或long,则右移位是算术移位(高序空位设置为符号位)。如果第一个操作数为uint或ulong类型,则右移位是逻辑移位(高位填充0)。
op1st << op2nd如果第一个操作数是
int或uint(32 位),第二个参数给出移动位数。 移位操作不会导致溢出:不在移位后第一个操作数类型范围内的任意高序位均不会使用,低序空位用零填充。
优先级
- 圆括号 (括号内的内容首先执行)
- 指数 (
System.Math.Pow()) - 乘法和除法(从左至右)
- 加法和减法(从左至右)
代码
标识符:
By convention, C# programs use
PascalCasefor type names, namespaces, and all public members.
表达式:由多个字面值和运算符可以构成常量表达式。
代码块:使用{}定义的一行或多行代码的集合。代码块可以包含其他代码块。
“空格”:指的是由 space bar 生成的单个空格、由 tab 键生成的制表符以及由 enter 键生成的新行。C# 编译器会忽略空格。
注释和文档
注释的作用
-
记下一段代码的意图,有助于描述用途或思考过程;
勿添加关于单个代码行如何工作的注释,相关信息可通过文档获取;
不要完全相信注释。 在进行许多更改之后,它们可能不会反映代码的当前状态。
-
暂时删除应用程序中的代码,以尝试其他方法;
-
添加类似于
TODO的消息。
单行注释以字符 // 开头并延续到源行的结尾。
带分隔符的注释 以字符 /* 开头,以字符 */ 结束。带分隔符的注释可以跨多行。
具有特殊格式的注释可用于指导某个工具根据这些注释 和它们后面的源代码元素生成 XML。这类注释是以三个斜杠 (///) 开始的单行注释,或者是以一个斜杠和两个星号 /**) 开始的分隔注释。
流程控制
选择
if-else
if (condition1){ statements }
else if (condition2) { statements }
else {statements}
if-else可以嵌套使用。
switch-case
switch (condition) {
case value1:
statements;
break;
case value2:
statements;
break;
default:
statements;
break;
}
}
每一个非空的分支必须使用跳转语句(break,return等)。
condition不仅可以是整数,还可以是字符串等类型。而判断条件也不仅包括值类型,还包括模式匹配(例如判断是否为整数/常量)。
循环迭代
do-while
while (condition){
statements;
}
do {
statements
} while (consition);
for
for (int i = 0; i < args.Length; i++) {
statements;
}
foreach
foreach语句用于访问数组的所有元素或实现了接口IEnumeralbe或IEnumerable<T>的集合对象的所有元素。
foreach(collection_type element in CollectionObject)
{ statements; }
foreach用于迭代遍历集合查找信息,但是不能对源集合增加或删除元素以避免不可预知的后果。如果需要增加或删除元素,使用for循环。
在foreach语句块的任何点,都可以使用break跳出循环,或使用continue进入下一步迭代。foreach循环也可以使用goto、return或throw语句退出。
yield语句:使用yield语句的方法、操作符或get访问器相当于是一个建议的迭代器。
class MyIterator {
public IEnumerable MyEnumerator(int start, int end){
for (int i = start; i < end; i++){
yield return i;
} // 当使用foreach语句访问迭代器时,每次执行到yield语句则直接返回,并记录下当前位置
} // 下一次迭代则从上次中断位置继续运行。
} // 可使用一系列yield语句构造迭代器的元素,或使用循环(本示例)实时构造迭代器元素
// 或通过循环返回迭代器类型的内部成员变量。
跳转
break、continue、goto、throw、return和
异常处理
try {
statements;
} catch (Exception e) {
statements;
} finally {
statements;
}
using语句
当fianlly语句块仅存在单个语句用于释放try语句块中申请的资源,则可用using语句代替。
using(File f = File.Open(name)){
system.WriteLine(f.Readline())
}
类型系统
变量大致具有7种用途,即静态变量、实例变量、数组元素、值参数、引用参数、输出参数和局部变量。
每个变量都具有一个类型,用于确定哪些值可以存储在该变量中。C#具有统一类型系统 (unified type system),所有C#类型(包括int和double 等基本类型)都继承于单个根类型object(System.Object)。
根据变量在内存中的存储方式以及操作方式,可以分为值类型(value-type)和引用类型(class-type)两大类:
- 值类型存储在堆栈中,一般都是直接访问;将一个变量值赋给另一个变量,会在内存中重新开辟一段空间,函数传递参数也会在内存中另外生成一个副本。
- 引用类型必须在托管堆中为引用类型变量的值分配内存,而引用类型对象的引用(地址)存储在栈中;引用类型是由垃圾回收机制来管理的;
所有值类型均从类
System.ValueType隐式继承,后者又从类object继承。System.ValueType本身不是值类型,而是引用类型。(可以看成根类型object中不包含任何数据,因此该类型既可以视为值类型也可以视为引用类型。System.ValueType则定义了数据及其值类型操作规则,从而覆盖了引用类型的规则。其他继承自object的类型因为不包含这一套操作规则,因此具有引用类型的操作规则。)
五种类型是用户可定义的:类 (class type)、结构类(struct type)、接口(interface type)、枚举(enum type) 和委托(delegate type)。
值类型

布尔类型不能与其它类型进行转换;
简单数值类型定义了该类型的取值范围:MaxValue和MinValue,可通过GetTypeCode获得类型名。
浮点数float和double类型,当一个数除0时,不会出现错误,而是产生“非零”结果,当打印结果时会得到“NaN”;当数值溢出时,也不会产生异常,而是记为“Inf”。当一个数,非常接近与0时,就会被近似为0,根据数的正负,近似后的数可能为“+0”,也可能为“-0”。
字符类型(char):定义了一系列判断字符类型的方法和转换大小写方法。
值相等关系
==运算符比较基本值类型的值是否相等。
结构体
结构类型与类类型相似,结构类型除了是值类型以外,还不支持用户指定的继承,并且所有结构类型都隐式地从类型object继承。结构类型的成员默认访问权限为private,且不能为成员指定初始值,而必须通过构造方法进行初始化(不支持无参数构造方法)。
枚举
每个枚举类型都有一个相应的整型类型,称为该枚举类型的基础类型 (underlying type)。没有显式声明基础类型的枚举类型所对应的基础类型是 int。枚举类型的存储格式和取值范围由其基础类型确定。
enum Alignment: sbyte{
Left = -1,
Center = 0,
Right = 1
}
获取枚举类型的字符串表示:(1)ToString();(2)Enum.GetName()。
引用类型
构建C#应用程序的主要对象类型数据。引用类型在默认值都是null。
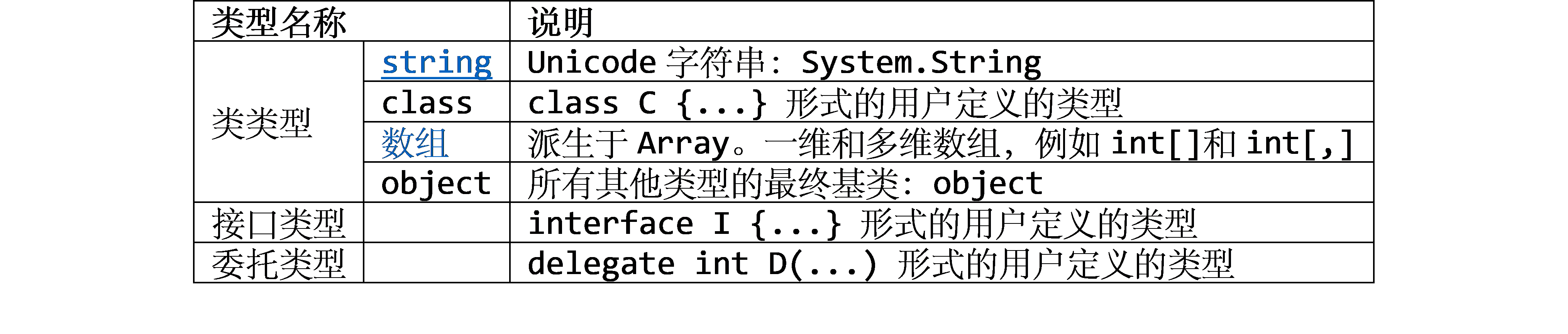
引用相等关系
引用类型在使用“==”或“~=”操作符时,默认比较的是其引用的地址,Object.Equals()等价于“==”。
使用“=”操作符只使得多个引用类型引用同一个对象,即将一个引用类型变量赋值给另一个同类型变量,赋值的是这个类型对象的地址,所以两个引用都指向同一对象;通过任意一个引用修改该对象,都使得对象发生改变。
必须使用new关键字来创建引用类型变量(实际创建了对象),运算结果也会产生新的对象(运算结果也是通过new生成的);
变量引用:variable-reference 表示一个存储位置,访问它可以获取当前值以及存储新值,在 C 和 C++ 中,variable-reference称为
lvalue。
字符串
数组
委托
委托类型 (delegate type)表示具有特定参数列表和返回类型的方法,即方法视为对象,==委托即方法的类型==。委托是用来处理其他语言(如 C++)需用函数指针来处理的情况的。与 C++ 函数指针不同,C++ 指针仅指向成员函数,而委托同时封装了对象实例和方法。
函数对象(闭包)。
委托声明定义一个从 System.Delegate类派生的类,与方法声明语法一致(除了使用delegate关键字):
[modifier] delegate <type> delegateName(param_list);
委托类型使用函数或匿名函数进行初始化。
public delegate double Calculator(double x, double y);
public double Add(double x, double y);
public double Sub(double x, double y);
Calculator CalAdd = new Calculator(Add); // 完整初始化写法
Calculator CalSub = Sub; // 简洁写法
委托运算
委托实例封装了列表包括一个或多个函数对象。委托对象可使用 "+" 运算符进行合并。一个合并委托调用它所合并的两个委托。只有相同类型的委托可被合并。"-" 运算符可用于从合并的委托中移除组件委托。在执行委托时,调用列表中的方法被依次执行。
Calulator MultiCal = CalAdd + CalSub;
MultiCal(10, 5); // invoke two Calculator methods
**对于实例方法,可调用实体由该方法和一个相关联的实例组成,若该方法会修改实例,则委托中的可调用实体也会修改对应实例。对于静态方法,可调用实体仅由一个方法组成。**用一个适当的参数集来调用一个委托实例,就是用此给定的参数集来调用该委托实例的每个可调用实体。
Lambda表达式
Lambda表达式是一个匿名函数(anonymous function),可以用于创建委托;可以当作局部函数作为某些函数的参数。
(input parameters) => expression;
(input parameters) => {statement;}
"=>"操作符左边为输入参数列表,右侧为表达式或语句块。参数个数为1时,括号可以省略。可以没有输入参数。
类型转换
类型判断
is关键字判断对象是否为给定类型。
语法:obj is type
当type是一个类,而obj也是该类、或继承该类、或封箱到该类中的实例,结果为true;
当type是接口,而obj也是该接口类型、或继承该接口的类,结果为true。
转换
自动转换:子类可以自动向父类转换
强制转换:父类转换为子类需要强制转换
int first = 7, second = 5;
decimal quotient = (decimal)first / (decimal)second;
as关键字:在类型兼容的引用类型之间进行类型转换。
语法:type obj_type = obj as type
当能够进行转换时,执行转换;当不能转换时,返回null。
字符串与数值之间转换:使用Parse()方法、System.Convert()、ToString()方法。另外TryParse()方法和Parse()方法的区别在于如果转换不成功,不会引起异常而是返回false。
装箱和拆箱
引用类型和值类型的相互转换。
char ch = 'c';
Object obj_ch = ch; // obj_ch boxing the value type ch
char ch2 = (char) obj_ch; // unboxing from ref-type obj_ch
装箱:隐式将值类型转换为 object 类型。
取消装箱:显式地将一个对象类型转换为值类型,使用强制转换方法。这种转换方式必须类型兼容,否则出现异常。
面向对象编程
类
类的定义语法:
public class ClassName<TypeName,...>: baseClass, Interfaces
{
private int fieldName;
protected static int StaticField;
public int propertyName {get{};set{}};
public void methodName(args){statements;}
// constructor
public ClassName(args){statements}
// indexer
public TypeName this[int index]
{statements; return items[index]}
// event
public event DelegateType ThingsChanged;
}
class修饰符:new、public、protected、internal、private、abstract、sealed、static。
当使用
new关键字创建对象时,如果使用该对象的位置(函数参数)类型已知,则可省略对象名直接提供参数。new(0, "Squeaky Bone", 20.99m)
声明了类型参数(TypeName)的类型成为泛型类型。结构类型、接口类型和委托类型也可以是泛型。
如果类型定义时没有指定父类,则类继承于System.Object(object)。
字段
如果需要一个具有常量值的符号名称,但该值的类型不允许在 const声明中使用,或者无法在编译时计算出该值,则static readonly 字段就可以发挥作用了。
方法
type functionName(args) { /*body*/}
type functionName(args) => single_expr; // 方法表达式(C# 6)
Lambda表达式是没有函数名的函数表达式。
通常,为了保持程序的简洁,函数仅返回一个值。但如有必要从函数返回多个值,可以采用的方法:(1)创建一个包含多个值的类,并返回该类的对象;(2)将参数声明为ref/out类型。
方法名后的
()为函数调用运算符。
参数
值参数:是实际参数的副本。
引用参数(ref)引用参数与实际参数为同一个变量。
输出参数(out)输出参数可引用函数内部的局部变量,当函数返回时变量不会被释放。ref参数必须在传入前进行初始化,而out参数则不必。
参数数组允许向方法传递可变数量的实参。
静态方法
静态方法的操作不需要引用特定对象。
构造函数和析构函数
==静态构造函数==用于初始化类的静态成员。
子类构造函数调用基类构造函数(类似于C++构造方法),使用“:”操作符,base关键字(由于C#是单继承的,因此不需要使用基类名称)。
public ClassName(param_list): base(base_params){
// 构造函数
}
public ClassName(arg) => Member = arg; // (C# 7)
如果需要将参数传给基类构造器之前进行修改,可以在base_params中调用相关的函数并返回修改后的值。
析构函数不能带参数,不能具有可访问性修饰符,也不能被显式调用。垃圾回收期间会自动调用所涉及实例的析构函数。
~Destroyer() { /*release resources*/ }
~Destroyer() => expr; // (c# 7)
对象初始化
除调用构造函数外,可直接提供成员变量初始化列表进行初始化。
var instance3 = new ExampleClass(){
Name="Desktop", ID=37414, Location="Redmond", Age=2.3 };
等效于调用默认构造函数后,再对相应成员赋值。
属性
属性 (property) 提供对私有成员进行读写、计算的方法,可被视为公共的数据成员,实际上则是特殊的方法(访问器)。属性与字段的声明方法区别在于属性声明了访问器,因此对类的数据实现间接访问,而字段则是对类的数据的直接访问。
modifiers int PropertyName{
get{ return this.x; }
set{ this.x = value; }
}
type PropertyName => expr; // Read-only properties (C# 6)
type PropertyName { // (C# 7)
get => member;
set => member = value;
}
get访问器相当于有返回值的无形参方法。当在表达式中引用属性时,将调用该属性的get访问器以计算该属性的值。没有get访问器的属性是只写的。set访问器相当于具有单个形参(以关键字value作为隐形参)和void返回类型的方法。没有实现set访问器的属性是只读的。
属性的访问限定符可以是五种中的任意一种。
属性不是变量,因此不能传递作为ref或out修饰的参数。
使用属性并不一定比直接公开字段效率低。当属性是非虚的且只包含少量代码时,执行环境可能会用访问器的实际代码替换对访问器进行的调用。此过程称为内联 (inlining),它使属性访问与字段访问一样高效,而且仍保留了属性的更高灵活性。
当属性不需要添加额外的读写逻辑时,声明属性的同时,编译器将自动为该属性创建对应的匿名字段,该字段只能被属性的get和set访问器所访问。这时属性等效于一个字段。
public type PropertyName { get; set; }
当属性声明包含static修饰符时,称该属性为静态属性 (static property);反之,该属性为实例属性 (instance property)。静态属性不与特定实例相关联,因此在静态属性的访问器内引用 this会导致编译时错误。静态属性需要通过类名进行访问,而实例属性需要通过实例名称进行访问。
属性的访问器可以是虚的。当属性声明包括 virtual、abstract 或 override修饰符时,修饰符应用于该属性的访问器。
索引器(Indexer)
索引器的定义方式类似属性。
private string[] types = { "Baseball", "Basketball", "Football"};
public string this[int i]{
get => types[i];
set => types[i] = value;
}
事件
事件 (event) 是一种使类或对象能够提供通知的成员。事件的声明与字段类似,不同的是,事件的声明使用event关键字修飾,值类型必须是委托类型,表示事件的处理方法。
public event DelegateType SampleEvent;
使用?.运算符发起事件。
SampleEvent?.Invoke(sender, event_args);
SampleEvent(sender, event_args)
事件参数:根据发起事件所对应的委托类型的参数数量和类型决定。
可使用任意类型和数量的参数作为事件参数。
EventArgs类是表示事件参数的基类,不包含任何数据。可从该类导出自定义类型将所有参数作为成员变量包括其中。使用单一类型作为事件处理方法的参数,便于代码自动生成。
事件处理函数(event handler)
委托类型可以进行加减操作,因此可以为事件添加一个或多个处理方法。事件处理方法签名与事件的委托类型一致。
void event_handler(object sender, EventArgs e){}
sender.SampleEvent += listener.event_handler;
事件处理方法可以是发布事件的类(sender)中的成员函数,也可以是其他类的成员函数。在其他类中订阅发布者的事件必须能够获取发布者类的引用(sender)。
委托实际还封装了成员函数及其所属类型的实例,因此事件发布和订阅在实例对象之间进行。
解除订阅:使用-=运算符从事件委托中删除事件处理函数。
异步事件处理
事件的发送和接收是同步的,即事件委托中所有事件处理函数被执行。为了实现异步,应该在将事件处理函数实现为异步方法。
运算符
可以定义三类运算符:一元运算符、二元运算符和转换运算符。
所有运算符都必须声明为public static。
访问限定符
访问限定符用于声明类成员的访问能力。访问限定符包括以下四类:
publicprotectedinternalprivate
使用以上访问限定符可以声明以下五类访问级别:
public:访问不受限制。protected:访问限制在本类型,或由本类派生的类型。internal:访问限制在当前程序集。protected internal:访问限制在当前程序集,或由本类派生的类型。private:访问限制于包含类型。
多态
类支持单一继承和多态,这些是派生类可用来扩展和专用化基类的机制。
虚方法
使用“virtual”关键字修饰的方法,用于实现多态。当调用虚方法时,运行时将确定调用对象是哪一个子类的实例,并调用适当的覆盖方法。
通过override关键字在子类中声明覆盖父类的虚方法。使用override关键字时不能同时使用new、static和virtual关键字修饰方法;使用override修饰符时,父类必须具有同名虚函数或抽象方法。(另一种覆盖父类方法的关键字是new,使用new关键字时,父类和基类中需要有同名的函数。这个过程叫做方法的隐藏。重写虚方法可以使用override或new,重写抽象方法只能用override。)
抽象方法
用于抽象表示公共的方法,将具体的实现交给具体的类。
抽象 (abstract) 方法是没有实现的虚方法。用“abstract”关键字修饰的方法,只有函数原型,不能添加函数体。声明抽象方法的类必须被声明为抽象类(以“abstract”关键字修饰的类)。
在子类中,使用overide关键字重写父类中的抽象方法,同时该函数在父类中不能是私有成员。
不能用 “sealed”修饰符修饰抽象类,因为这两个修饰符的含义是相反的。
方法重载
同一类中的多个方法具有相同名称,条件是这些方法具有唯一的签名(signature)。
接口
接口 (interface) 定义了一个可由类和结构实现的协定,可以包含方法、属性、事件和索引器。
一个接口可以从多个基接口继承,而一个类或结构可以实现多个接口。
当类或结构实现某个特定接口时,该类或结构的实例可以隐式地转换为该接口类型。
反射
Function
obtain information about loaded assemblies and the types defined within them, such as classes, interfaces, and value types.
Classes, Assembly, Module, ConstructorInfo, MethodInfo, FieldInfo, EventInfo, PropertyInfo, ParameterInfo, CustomAttributeData.
create type instances at run time, and to invoke and access them.
nameof(identifier):生成变量、类型、成员的字符串表示名称。
using System.Reflection;
using System.Type;
运行时中的泛型
https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/generics/generics-in-the-run-time
泛型和反射
https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/generics/generics-and-reflection
特性(Attributes)
特性将元数据、声明性信息与代码(例如程序集、类型、方法、属性等)关联。可通过反射在程序运行时获取这些信息。
在代码声明前添加特性标签:
[Serializable]
public class SampleClass{
// Objects of this type can be serialized.
}
[System.Runtime.InteropServices.DllImport("user32.dll")]
extern static void SampleMethod();
https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/attributes/
内置属性
using System.Attribute;
[Required] string Name; // 该属性非空
[Range(0.01, 9999.99)] decimal Price; // 数值范围
程序结构
C#程序由一个或多个源文件(编译单元)组成,在逻辑上按命名空间进行组织。命名空间中定义类,类的定义中包含各类型成员。
命名空间
命名空间(namespace)中定义以下内容:
- 嵌套命名空间
- 类
- 接口
- 结构
- 枚举
- 委托
定义命名空间
namespace identifier {……}
命名空间隐式地具有公开(public)访问属性且不可被修改,在声明时不允许使用任何访问修饰符。它要么出现在编译单元第一行,要么作为成员出现在其他名字空间的声明中。
命名空间的声明空间是“开放式的”,两个具有相同的完全限定名的命名空间声明共同构成同一个声明空间,因此命名空间可以跨文件进行组织。
无论你是否在源代码中声明一个命名空间,编译器都会添加一个默认的命名空间。该命名空间有时称为全局命名空间,在每个文件中都出现。全局命名空间中的任何标识符在有名的命名空间中都可访问。
引用命名空间中的内容
程序可以直接使用自身所在的命名空间内的名称。如果在程序中使用其他命名空间中的内容,可以将该命名空间引入当前程序。
using Namespace;
可使用该空间中的所有内容。
或者通过命名空间名称索引要使用的内容
space1.space2.class1
命名空间之间的层次结构只是一种组织上的形式:当引用父空间时,子空间对于引用程序来说是透明的,如果还要使用子空间需要另外声明引用。同时注意:如果在父空间和子空间都声明了同名的类,则同时引用两个空间,会导致引用混乱,编译器无法确定程序究竟是要使用哪一级的类。这是只能通过指明类的命名空间来进行访问。
定义命名空间别名:
using co = Company.Proj.Nested;
.NET Framework的命名空间包括:System、System.Windows.Forms、System.Drawing ……
Partial Class
将类、结构或接口的定义分离为多个部分到多个文件中。每个部分都必须使用partial关键字。每个部分必须在编译时可用,每个部分具有相同的访问权限,例如public、private等。
如果某个部分定义为abstract,则整个类被认为是abstract。如果某个部分定义为sealed,则整个类被认为是sealed。如果某个部分声明了基类,则整个类继承该基类(所有部分必须声明一致的基类,但是省略基类声明的部分仍然继承该基类。)。
每个部分可以声明不同的基类接口,且最终类型必须实现所有由每个部分声明的接口。任何类、结构、接口成员在每一个部分中都可用。最终类型是所有部分的组合。
以下几种情况应该将类的定义分离为多个部分:
-
大型项目,将类分为几个文件允许多个程序员同时工作。
-
自动生成源代码的情况。
Partial Methods
局部类可以包含局部方法。类的一个部分可以包含方法的原型,可选的方法实现可以在同一个部分或其他部分。如果没有提供方法的实现,则该方法和该方法的所有调用在编译时被移除。
局部方法必须以partial修饰,并且返回void。
局部方法可以具有ref但是不能有out参数。
局部方法是隐式的私有方法,因此不能是抽象方法(virtual)。
局部方法不能被extern修饰,因为方法体的出现与否决定该方法是否被定义或实现。
局部方法可以具有static或unsafe修饰符。
嵌套类型
在类或结构声明内部声明的类型称为嵌套类型 (nested type)。在命名空间内声明的类型称为非嵌套类型 (non-nested type)。
异步编程
https://docs.microsoft.com/en-us/dotnet/csharp/async
Task-based Asynchronous Pattern (TAP)
The async keyword turns a method into an async method, which allows you to use the await keyword in its body. The await keyword ==yields control== to the caller of the method that performed await, and it ultimately allows a UI to be responsive or a service to be elastic.
The compiler transforms your code into a state machine that keeps track of things like yielding execution when an
awaitis reached and resuming execution when a background job has finished.
IO密集型任务:await an operation that returns a Task or Task<T> inside of an async method.
your code be "waiting" for something
public async Task<int> GetDotNetCountAsync(){
var html = await client.GetStringAsync("https://dotnetfoundation.org");
return Regex.Matches(html, @"\.NET").Count;
} // await GetDotNetCountAsync() at somewhere
public async Task<string> GetHtmlAsync(){
var client = new HttpClient(); // Execution is synchronous here
return client.GetStringAsync("https://www.dotnetfoundation.org");
}
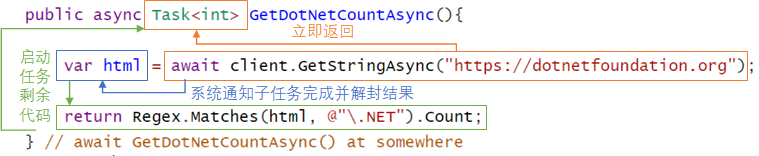
在一个方法中如果有后续计算依赖于异步方法的返回结果,应当使用await关键字。此时,await将创建并返回一个新的Task<T>对象,表示一个可能尚未完成的任务。await关键字之后的代码将封装到Task<T>对象中,稍后由系统调度并通过Task的方法和属性进行监视。此任务稍后完成时,将计算结果返回更新之前无计算结果的Task<T>对象。
此处的返回机制类似于
fork方法,即进程在此处分支,父进程立即返回Task<T>,子进程的代码则是await语句之后的内容。但是子进程不是立即启动执行,而是由系统管理。当系统收到await的任务执行完成时,将该任务的返回结果解封,并传递给子进程继续执行。==一个方法如果使用了
await关键字,则必须在方法声明上添加async修饰==;一个方法如果调用了异步方法,但没有
await获取结果,则该方法应该直接在异步方法处返回(后续代码依赖于异步方法返回的结果,否则也无需写在异步方法之后);该方法中没有后续需要执行的代码,因此无需使用await创建一个新的Task<T>对象。
异步方法的起点:Task<T>的返回方式使得异步方法层层嵌套,并最终由系统调用进入内核启动真正的异步过程。例如系统与网络设备的交互,设备在收到系统指令后,准备通过网络发送数据,并向系统返回该过程的状态为挂起(pending),系统因此可以暂时从该任务返回执行其他任务。当请求完成且收到来自设备驱动的数据后,设备通过中断信号(interrupt)通知系统(CPU),系统的中断处理器将接收数据并向上传递到注册的任务(通过system interop call),这些结果将缓存在队列中直到将其解封并交给空闲线程执行任务中的剩余代码。
异步过程实现的基本原理,仍然是并行处理模型。系统(CPU)和设备是并行运行的,两者间通过总线等方式进行通信。系统(CPU)内部内核进程和用户进程也是并行的,通过系统调用进行数据交换。
共享线程池:异步方法在await之后将返回,从而释放占用的线程,可以由其他任务调用。而当异步任务完成后,系统将从线程池中分配线程以运行Task<T>对象中的剩余代码。当一个Task<T>执行完成时,将更新其上层Task<T>的状态,将其加入缓存队列,从而使得上层任务在未来某个时刻被空余线程执行。由此,层层向上经过一系列离散时间片段完成异步任务,直到顶层异步方法。==因此,异步方法真正占用线程的时间被大幅减少,从而提高系统的服务能力。==对于客户端而言,为了增加UI的响应能力,需要将耗时的计算或IO任务分配给额外线程。使用共享线程池可大幅减少手动创建专用线程的开销。对于IO任务而言,由于其并不消耗CPU资源,因此分配其单独的线程将严重浪费CPU资源。
异步方法的终点:在await之后输出结果(终端、屏幕或文件等),而非再返回到上一层调用者。这意味者该方法的返回类型为Task<void>,这通常是事件处理器(event handler)。
async Task<void>should only be used for event handlers.事件处理器的调用者(事件队列管理器)无需等待事件处理器执行完成并查看其结果。
CPU密集型任务:await an operation that is started on a background thread with the Task.Run method.
your code be performing an expensive computation
spawn off the work on another thread with
Task.Runconcurrency and parallelism: Task Parallel Library
calculateButton.Clicked += async (o, e) => {
var damageResult = await Task.Run(() => CalculateDamageDone());
DisplayDamage(damageResult);
}
Wait for multiple tasks to complete
可以首先构造多个异步任务,再等待其执行完成。由于每个异步任务会在wait语句处立即返回,因此启动多个任务的延迟不会太大。待所有任务启动后,再等待最先结束的任务。
var eggsTask = FryEggsAsync(2); // => Task<Egg>
var baconTask = FryBaconAsync(3);
var toastTask = MakeToastWithButterAndJamAsync(2);
var eggs = await eggsTask;
var bacon = await baconTask;
var toast = await toastTask;
这些任务可同时被分发执行,可以首先等待预计最先完成的任务。
Task.WhenAll and Task.WhenAny
public static async Task<List<User>> GetUsersAsync(List<int> userIds){
var getUserTasks = new List<Task<User>>();
foreach (int userId in userIds){
getUserTasks.Add(GetUserAsync(userId));
}
return Task.WhenAll(getUserTasks); // similar for `Task.WhenAny`
}
await Task.WhenAny类似于Linux的select或epoll。
Tips
-
You should add "Async" as the suffix of every async method name you write.
-
Consider using
ValueTaskwhere possible
Task and Task<T>
Task and Task<T> objects supported by the async and await keywords.
Taskrepresents a single operation which does not return a value.Task<T>represents a single operation which returns a value of typeT.
By default, tasks execute on the current thread and ==delegate work to the Operating System==, as appropriate. Optionally, tasks can be explicitly requested to ==run on a separate thread== via the Task.Run API.
构造Task
预处理指令
自动内存管理
不安全代码
指针
附录
关键字
const:如果变量是const,则该变量也是static的。
using:声明语句块,用于保证具有Idisposable接口的对象(非托管资源)的正确使用。
using (declare DisposableObjects){
statements;
}
在语句块中,定义的对象为只读,不能修改或重新赋值。
C# Programming
C#是面向对象的编程语言,支持面向组件的编程,通过属性、方法和事件来提供编程模型。
C# 特性:垃圾回收 (Garbage collection);异常处理 (exception handling);类型安全 (type-safe) 的语言设计。
基本语法
应用程序 (application)以名为Main的静态方法作为程序执行的起点。Main方法中可书写表达式语句或调用类库或自定义的其他方法。
namespace NameSpace{
class Program{
static void Main(string[] args){
/* statements ... */
} // return void or int
static async Task Main() { }
static async Task<int> Main(string[] args) { } // (C# 7.1)
}
} // Libraries and services do not require a Main method.
Main方法:必须为static方法,不需要是public。
args为除了程序名称以外的参数。
一个类中最多包含一个名为Main的方法。在一个程序的多个类或结构中,可能都定义了Main方法。这样的情况下,必须利用某种外部机制(如命令行编译器的选项-main)来选择其中一个Main方法用作入口点。
应用程序入口点方法不能位于泛型类声明中。
从C#9开始,可以省略Main方法,将位于全局命名空间的语句作为主函数内容。
变量
变量表示数据的存储位置。
定义变量
<type> varname = value;
变量名称约定
-
使用驼峰式,即第一个单词以小写字母开始,后续每个单词的首字母采用大写形式。
-
变量名称不应包含变量的数据类型(在实际代码中可能不能代表实际类型)。
隐式类型本地变量使用 var 关键字进行创建,该关键字指示 C# 编译器去推断类型。
var age = 10;
变量名应使用骆驼式命名法。
常量
对于数学常量,在System.Math类中有比较精确的定义,可以直接使用,例如pi和e。
字面值
在数字后加上后缀,可以将字面值表示成不同类型的数值。
整形
- 没有后缀:解析成
int、uint、long、ulong; - 具有
u后缀:解析成uint、ulong; - 具有
l后缀:解析成long、ulong; - 具有
ul或lu后缀:解析成ulong; - 十六进制表示:添加前缀“
0x”
bool类型的字面值:true、false。
浮点型
- 具有
D/d后缀:解析成double; - 具有
M/m后缀:解析成decimal; - 具有
F/f后缀:解析成float。
指数记法:
- 使用后缀
e,在后缀后面添加一个整数,并在最后加一个后缀,表示整个数的类型。 - 后缀是不区分大小写的。
字符串
转义字符:C# 将反斜杠固定用于转义序列,如果出现非法转义序列将产生错误。
使用
\uFFFF转义序列在文本字符串中添加Unicode编码(UTF-16)字符。
字符串的前面使用 @ 指令避免转义。原始字符串:@“this is \ a string.”
当字符串中含有“\”时,后面的字符以及“\”就会被编译程序解析为转义字符。如果要使用带“\”的字符串而屏蔽掉其转义字符的性质,可以在字符串(双引号)前添加字符“@”。
运算符
复合赋值运算符:如 +=、-=、*=、++ 和 --;
定位增量和减量运算符:++,--;
同时
System.Threading.Interlocked类提供了线程安全的方法Increment()和Decrement()。
比较运算符:==、>、<、>=、<=、!=;继承自Object的类可以重写Equals方法,实现值比较(例如String类型的==比较的是字符串的值)。
逻辑运算符:&&、||、``;
赋值运算符:对变量进行一次赋值会返回一个值,所以可以一次对多个变量进行赋值。
string req,max;
req=max="It would take a miracle."
位运算符:&,|,^,~
移位运算符:>>, <<
op1st >> op2nd如果第一个操作数为
int或uint(32 位),则移位数由第二个操作数的低五位给出(op2nd&0x1f,即最多移32位)。 如果第一个操作数为long或ulong(64位数),则移位数由第二个操作数的低六位给出(op2nd&0x3f,即最多移64位)。 如果第一个操作数为int或long,则右移位是算术移位(高序空位设置为符号位)。如果第一个操作数为uint或ulong类型,则右移位是逻辑移位(高位填充0)。
op1st << op2nd如果第一个操作数是
int或uint(32 位),第二个参数给出移动位数。 移位操作不会导致溢出:不在移位后第一个操作数类型范围内的任意高序位均不会使用,低序空位用零填充。
优先级
- 圆括号 (括号内的内容首先执行)
- 指数 (
System.Math.Pow()) - 乘法和除法(从左至右)
- 加法和减法(从左至右)
代码
标识符:
By convention, C# programs use
PascalCasefor type names, namespaces, and all public members.
表达式:由多个字面值和运算符可以构成常量表达式。
代码块:使用{}定义的一行或多行代码的集合。代码块可以包含其他代码块。
“空格”:指的是由 space bar 生成的单个空格、由 tab 键生成的制表符以及由 enter 键生成的新行。C# 编译器会忽略空格。
注释和文档
注释的作用
-
记下一段代码的意图,有助于描述用途或思考过程;
勿添加关于单个代码行如何工作的注释,相关信息可通过文档获取;
不要完全相信注释。 在进行许多更改之后,它们可能不会反映代码的当前状态。
-
暂时删除应用程序中的代码,以尝试其他方法;
-
添加类似于
TODO的消息。
单行注释以字符 // 开头并延续到源行的结尾。
带分隔符的注释 以字符 /* 开头,以字符 */ 结束。带分隔符的注释可以跨多行。
具有特殊格式的注释可用于指导某个工具根据这些注释 和它们后面的源代码元素生成 XML。这类注释是以三个斜杠 (///) 开始的单行注释,或者是以一个斜杠和两个星号 /**) 开始的分隔注释。
流程控制
选择
if-else
if (condition1){ statements }
else if (condition2) { statements }
else {statements}
if-else可以嵌套使用。
switch-case
switch (condition) {
case value1:
statements;
break;
case value2:
statements;
break;
default:
statements;
break;
}
}
每一个非空的分支必须使用跳转语句(break,return等)。
condition不仅可以是整数,还可以是字符串等类型。而判断条件也不仅包括值类型,还包括模式匹配(例如判断是否为整数/常量)。
循环迭代
do-while
while (condition){
statements;
}
do {
statements
} while (consition);
for
for (int i = 0; i < args.Length; i++) {
statements;
}
foreach
foreach语句用于访问数组的所有元素或实现了接口IEnumeralbe或IEnumerable<T>的集合对象的所有元素。
foreach(collection_type element in CollectionObject)
{ statements; }
foreach用于迭代遍历集合查找信息,但是不能对源集合增加或删除元素以避免不可预知的后果。如果需要增加或删除元素,使用for循环。
在foreach语句块的任何点,都可以使用break跳出循环,或使用continue进入下一步迭代。foreach循环也可以使用goto、return或throw语句退出。
yield语句:使用yield语句的方法、操作符或get访问器相当于是一个建议的迭代器。
class MyIterator {
public IEnumerable MyEnumerator(int start, int end){
for (int i = start; i < end; i++){
yield return i;
} // 当使用foreach语句访问迭代器时,每次执行到yield语句则直接返回,并记录下当前位置
} // 下一次迭代则从上次中断位置继续运行。
} // 可使用一系列yield语句构造迭代器的元素,或使用循环(本示例)实时构造迭代器元素
// 或通过循环返回迭代器类型的内部成员变量。
跳转
break、continue、goto、throw、return和
异常处理
try {
statements;
} catch (Exception e) {
statements;
} finally {
statements;
}
using语句
当fianlly语句块仅存在单个语句用于释放try语句块中申请的资源,则可用using语句代替。
using(File f = File.Open(name)){
system.WriteLine(f.Readline())
}
类型系统
变量大致具有7种用途,即静态变量、实例变量、数组元素、值参数、引用参数、输出参数和局部变量。
每个变量都具有一个类型,用于确定哪些值可以存储在该变量中。C#具有统一类型系统 (unified type system),所有C#类型(包括int和double 等基本类型)都继承于单个根类型object(System.Object)。
根据变量在内存中的存储方式以及操作方式,可以分为值类型(value-type)和引用类型(class-type)两大类:
- 值类型存储在堆栈中,一般都是直接访问;将一个变量值赋给另一个变量,会在内存中重新开辟一段空间,函数传递参数也会在内存中另外生成一个副本。
- 引用类型必须在托管堆中为引用类型变量的值分配内存,而引用类型对象的引用(地址)存储在栈中;引用类型是由垃圾回收机制来管理的;
所有值类型均从类
System.ValueType隐式继承,后者又从类object继承。System.ValueType本身不是值类型,而是引用类型。(可以看成根类型object中不包含任何数据,因此该类型既可以视为值类型也可以视为引用类型。System.ValueType则定义了数据及其值类型操作规则,从而覆盖了引用类型的规则。其他继承自object的类型因为不包含这一套操作规则,因此具有引用类型的操作规则。)
五种类型是用户可定义的:类 (class type)、结构类(struct type)、接口(interface type)、枚举(enum type) 和委托(delegate type)。
值类型
布尔类型不能与其它类型进行转换;
简单数值类型定义了该类型的取值范围:MaxValue和MinValue,可通过GetTypeCode获得类型名。
浮点数float和double类型,当一个数除0时,不会出现错误,而是产生“非零”结果,当打印结果时会得到“NaN”;当数值溢出时,也不会产生异常,而是记为“Inf”。当一个数,非常接近与0时,就会被近似为0,根据数的正负,近似后的数可能为“+0”,也可能为“-0”。
字符类型(char):定义了一系列判断字符类型的方法和转换大小写方法。
值相等关系
==运算符比较基本值类型的值是否相等。
结构体
结构类型与类类型相似,结构类型除了是值类型以外,还不支持用户指定的继承,并且所有结构类型都隐式地从类型object继承。结构类型的成员默认访问权限为private,且不能为成员指定初始值,而必须通过构造方法进行初始化(不支持无参数构造方法)。
枚举
每个枚举类型都有一个相应的整型类型,称为该枚举类型的基础类型 (underlying type)。没有显式声明基础类型的枚举类型所对应的基础类型是 int。枚举类型的存储格式和取值范围由其基础类型确定。
enum Alignment: sbyte{
Left = -1,
Center = 0,
Right = 1
}
获取枚举类型的字符串表示:(1)ToString();(2)Enum.GetName()。
引用类型
构建C#应用程序的主要对象类型数据。引用类型在默认值都是null。
引用相等关系
引用类型在使用“==”或“~=”操作符时,默认比较的是其引用的地址,Object.Equals()等价于“==”。
使用“=”操作符只使得多个引用类型引用同一个对象,即将一个引用类型变量赋值给另一个同类型变量,赋值的是这个类型对象的地址,所以两个引用都指向同一对象;通过任意一个引用修改该对象,都使得对象发生改变。
必须使用new关键字来创建引用类型变量(实际创建了对象),运算结果也会产生新的对象(运算结果也是通过new生成的);
变量引用:variable-reference 表示一个存储位置,访问它可以获取当前值以及存储新值,在 C 和 C++ 中,variable-reference称为
lvalue。
字符串
数组
委托
委托类型 (delegate type)表示具有特定参数列表和返回类型的方法,即方法视为对象,==委托即方法的类型==。委托是用来处理其他语言(如 C++)需用函数指针来处理的情况的。与 C++ 函数指针不同,C++ 指针仅指向成员函数,而委托同时封装了对象实例和方法。
函数对象(闭包)。
委托声明定义一个从 System.Delegate类派生的类,与方法声明语法一致(除了使用delegate关键字):
[modifier] delegate <type> delegateName(param_list);
委托类型使用函数或匿名函数进行初始化。
public delegate double Calculator(double x, double y);
public double Add(double x, double y);
public double Sub(double x, double y);
Calculator CalAdd = new Calculator(Add); // 完整初始化写法
Calculator CalSub = Sub; // 简洁写法
委托运算
委托实例封装了列表包括一个或多个函数对象。委托对象可使用 "+" 运算符进行合并。一个合并委托调用它所合并的两个委托。只有相同类型的委托可被合并。"-" 运算符可用于从合并的委托中移除组件委托。在执行委托时,调用列表中的方法被依次执行。
Calulator MultiCal = CalAdd + CalSub;
MultiCal(10, 5); // invoke two Calculator methods
**对于实例方法,可调用实体由该方法和一个相关联的实例组成,若该方法会修改实例,则委托中的可调用实体也会修改对应实例。对于静态方法,可调用实体仅由一个方法组成。**用一个适当的参数集来调用一个委托实例,就是用此给定的参数集来调用该委托实例的每个可调用实体。
Lambda表达式
Lambda表达式是一个匿名函数(anonymous function),可以用于创建委托;可以当作局部函数作为某些函数的参数。
(input parameters) => expression;
(input parameters) => {statement;}
"=>"操作符左边为输入参数列表,右侧为表达式或语句块。参数个数为1时,括号可以省略。可以没有输入参数。
类型转换
类型判断
is关键字判断对象是否为给定类型。
语法:obj is type
当type是一个类,而obj也是该类、或继承该类、或封箱到该类中的实例,结果为true;
当type是接口,而obj也是该接口类型、或继承该接口的类,结果为true。
转换
自动转换:子类可以自动向父类转换
强制转换:父类转换为子类需要强制转换
int first = 7, second = 5;
decimal quotient = (decimal)first / (decimal)second;
as关键字:在类型兼容的引用类型之间进行类型转换。
语法:type obj_type = obj as type
当能够进行转换时,执行转换;当不能转换时,返回null。
字符串与数值之间转换:使用Parse()方法、System.Convert()、ToString()方法。另外TryParse()方法和Parse()方法的区别在于如果转换不成功,不会引起异常而是返回false。
装箱和拆箱
引用类型和值类型的相互转换。
char ch = 'c';
Object obj_ch = ch; // obj_ch boxing the value type ch
char ch2 = (char) obj_ch; // unboxing from ref-type obj_ch
装箱:隐式将值类型转换为 object 类型。
取消装箱:显式地将一个对象类型转换为值类型,使用强制转换方法。这种转换方式必须类型兼容,否则出现异常。
面向对象编程
类
类的定义语法:
public class ClassName<TypeName,...>: baseClass, Interfaces
{
private int fieldName;
protected static int StaticField;
public int propertyName {get{};set{}};
public void methodName(args){statements;}
// constructor
public ClassName(args){statements}
// indexer
public TypeName this[int index]
{statements; return items[index]}
// event
public event DelegateType ThingsChanged;
}
class修饰符:new、public、protected、internal、private、abstract、sealed、static。
当使用
new关键字创建对象时,如果使用该对象的位置(函数参数)类型已知,则可省略对象名直接提供参数。new(0, "Squeaky Bone", 20.99m)
声明了类型参数(TypeName)的类型成为泛型类型。结构类型、接口类型和委托类型也可以是泛型。
如果类型定义时没有指定父类,则类继承于System.Object(object)。
字段
如果需要一个具有常量值的符号名称,但该值的类型不允许在 const声明中使用,或者无法在编译时计算出该值,则static readonly 字段就可以发挥作用了。
方法
type functionName(args) { /*body*/}
type functionName(args) => single_expr; // 方法表达式(C# 6)
Lambda表达式是没有函数名的函数表达式。
通常,为了保持程序的简洁,函数仅返回一个值。但如有必要从函数返回多个值,可以采用的方法:(1)创建一个包含多个值的类,并返回该类的对象;(2)将参数声明为ref/out类型。
方法名后的
()为函数调用运算符。
参数
值参数:是实际参数的副本。
引用参数(ref)引用参数与实际参数为同一个变量。
输出参数(out)输出参数可引用函数内部的局部变量,当函数返回时变量不会被释放。ref参数必须在传入前进行初始化,而out参数则不必。
参数数组允许向方法传递可变数量的实参。
静态方法
静态方法的操作不需要引用特定对象。
构造函数和析构函数
==静态构造函数==用于初始化类的静态成员。
子类构造函数调用基类构造函数(类似于C++构造方法),使用“:”操作符,base关键字(由于C#是单继承的,因此不需要使用基类名称)。
public ClassName(param_list): base(base_params){
// 构造函数
}
public ClassName(arg) => Member = arg; // (C# 7)
如果需要将参数传给基类构造器之前进行修改,可以在base_params中调用相关的函数并返回修改后的值。
析构函数不能带参数,不能具有可访问性修饰符,也不能被显式调用。垃圾回收期间会自动调用所涉及实例的析构函数。
~Destroyer() { /*release resources*/ }
~Destroyer() => expr; // (c# 7)
对象初始化
除调用构造函数外,可直接提供成员变量初始化列表进行初始化。
var instance3 = new ExampleClass(){
Name="Desktop", ID=37414, Location="Redmond", Age=2.3 };
等效于调用默认构造函数后,再对相应成员赋值。
属性
属性 (property) 提供对私有成员进行读写、计算的方法,可被视为公共的数据成员,实际上则是特殊的方法(访问器)。属性与字段的声明方法区别在于属性声明了访问器,因此对类的数据实现间接访问,而字段则是对类的数据的直接访问。
modifiers int PropertyName{
get{ return this.x; }
set{ this.x = value; }
}
type PropertyName => expr; // Read-only properties (C# 6)
type PropertyName { // (C# 7)
get => member;
set => member = value;
}
get访问器相当于有返回值的无形参方法。当在表达式中引用属性时,将调用该属性的get访问器以计算该属性的值。没有get访问器的属性是只写的。set访问器相当于具有单个形参(以关键字value作为隐形参)和void返回类型的方法。没有实现set访问器的属性是只读的。
属性的访问限定符可以是五种中的任意一种。
属性不是变量,因此不能传递作为ref或out修饰的参数。
使用属性并不一定比直接公开字段效率低。当属性是非虚的且只包含少量代码时,执行环境可能会用访问器的实际代码替换对访问器进行的调用。此过程称为内联 (inlining),它使属性访问与字段访问一样高效,而且仍保留了属性的更高灵活性。
当属性不需要添加额外的读写逻辑时,声明属性的同时,编译器将自动为该属性创建对应的匿名字段,该字段只能被属性的get和set访问器所访问。这时属性等效于一个字段。
public type PropertyName { get; set; }
当属性声明包含static修饰符时,称该属性为静态属性 (static property);反之,该属性为实例属性 (instance property)。静态属性不与特定实例相关联,因此在静态属性的访问器内引用 this会导致编译时错误。静态属性需要通过类名进行访问,而实例属性需要通过实例名称进行访问。
属性的访问器可以是虚的。当属性声明包括 virtual、abstract 或 override修饰符时,修饰符应用于该属性的访问器。
索引器(Indexer)
索引器的定义方式类似属性。
private string[] types = { "Baseball", "Basketball", "Football"};
public string this[int i]{
get => types[i];
set => types[i] = value;
}
事件
事件 (event) 是一种使类或对象能够提供通知的成员。事件的声明与字段类似,不同的是,事件的声明使用event关键字修飾,值类型必须是委托类型,表示事件的处理方法。
public event DelegateType SampleEvent;
使用?.运算符发起事件。
SampleEvent?.Invoke(sender, event_args);
SampleEvent(sender, event_args)
事件参数:根据发起事件所对应的委托类型的参数数量和类型决定。
可使用任意类型和数量的参数作为事件参数。
EventArgs类是表示事件参数的基类,不包含任何数据。可从该类导出自定义类型将所有参数作为成员变量包括其中。使用单一类型作为事件处理方法的参数,便于代码自动生成。
事件处理函数(event handler)
委托类型可以进行加减操作,因此可以为事件添加一个或多个处理方法。事件处理方法签名与事件的委托类型一致。
void event_handler(object sender, EventArgs e){}
sender.SampleEvent += listener.event_handler;
事件处理方法可以是发布事件的类(sender)中的成员函数,也可以是其他类的成员函数。在其他类中订阅发布者的事件必须能够获取发布者类的引用(sender)。
委托实际还封装了成员函数及其所属类型的实例,因此事件发布和订阅在实例对象之间进行。
解除订阅:使用-=运算符从事件委托中删除事件处理函数。
异步事件处理
事件的发送和接收是同步的,即事件委托中所有事件处理函数被执行。为了实现异步,应该在将事件处理函数实现为异步方法。
运算符
可以定义三类运算符:一元运算符、二元运算符和转换运算符。
所有运算符都必须声明为public static。
访问限定符
访问限定符用于声明类成员的访问能力。访问限定符包括以下四类:
publicprotectedinternalprivate
使用以上访问限定符可以声明以下五类访问级别:
public:访问不受限制。protected:访问限制在本类型,或由本类派生的类型。internal:访问限制在当前程序集。protected internal:访问限制在当前程序集,或由本类派生的类型。private:访问限制于包含类型。
多态
类支持单一继承和多态,这些是派生类可用来扩展和专用化基类的机制。
虚方法
使用“virtual”关键字修饰的方法,用于实现多态。当调用虚方法时,运行时将确定调用对象是哪一个子类的实例,并调用适当的覆盖方法。
通过override关键字在子类中声明覆盖父类的虚方法。使用override关键字时不能同时使用new、static和virtual关键字修饰方法;使用override修饰符时,父类必须具有同名虚函数或抽象方法。(另一种覆盖父类方法的关键字是new,使用new关键字时,父类和基类中需要有同名的函数。这个过程叫做方法的隐藏。重写虚方法可以使用override或new,重写抽象方法只能用override。)
抽象方法
用于抽象表示公共的方法,将具体的实现交给具体的类。
抽象 (abstract) 方法是没有实现的虚方法。用“abstract”关键字修饰的方法,只有函数原型,不能添加函数体。声明抽象方法的类必须被声明为抽象类(以“abstract”关键字修饰的类)。
在子类中,使用overide关键字重写父类中的抽象方法,同时该函数在父类中不能是私有成员。
不能用 “sealed”修饰符修饰抽象类,因为这两个修饰符的含义是相反的。
方法重载
同一类中的多个方法具有相同名称,条件是这些方法具有唯一的签名(signature)。
接口
接口 (interface) 定义了一个可由类和结构实现的协定,可以包含方法、属性、事件和索引器。
一个接口可以从多个基接口继承,而一个类或结构可以实现多个接口。
当类或结构实现某个特定接口时,该类或结构的实例可以隐式地转换为该接口类型。
反射
Function
obtain information about loaded assemblies and the types defined within them, such as classes, interfaces, and value types.
Classes, Assembly, Module, ConstructorInfo, MethodInfo, FieldInfo, EventInfo, PropertyInfo, ParameterInfo, CustomAttributeData.
create type instances at run time, and to invoke and access them.
nameof(identifier):生成变量、类型、成员的字符串表示名称。
using System.Reflection;
using System.Type;
运行时中的泛型
https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/generics/generics-in-the-run-time
泛型和反射
https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/generics/generics-and-reflection
特性(Attributes)
特性将元数据、声明性信息与代码(例如程序集、类型、方法、属性等)关联。可通过反射在程序运行时获取这些信息。
在代码声明前添加特性标签:
[Serializable]
public class SampleClass{
// Objects of this type can be serialized.
}
[System.Runtime.InteropServices.DllImport("user32.dll")]
extern static void SampleMethod();
https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/attributes/
内置属性
using System.Attribute;
[Required] string Name; // 该属性非空
[Range(0.01, 9999.99)] decimal Price; // 数值范围
程序结构
C#程序由一个或多个源文件(编译单元)组成,在逻辑上按命名空间进行组织。命名空间中定义类,类的定义中包含各类型成员。
命名空间
命名空间(namespace)中定义以下内容:
- 嵌套命名空间
- 类
- 接口
- 结构
- 枚举
- 委托
定义命名空间
namespace identifier {……}
命名空间隐式地具有公开(public)访问属性且不可被修改,在声明时不允许使用任何访问修饰符。它要么出现在编译单元第一行,要么作为成员出现在其他名字空间的声明中。
命名空间的声明空间是“开放式的”,两个具有相同的完全限定名的命名空间声明共同构成同一个声明空间,因此命名空间可以跨文件进行组织。
无论你是否在源代码中声明一个命名空间,编译器都会添加一个默认的命名空间。该命名空间有时称为全局命名空间,在每个文件中都出现。全局命名空间中的任何标识符在有名的命名空间中都可访问。
引用命名空间中的内容
程序可以直接使用自身所在的命名空间内的名称。如果在程序中使用其他命名空间中的内容,可以将该命名空间引入当前程序。
using Namespace;
可使用该空间中的所有内容。
或者通过命名空间名称索引要使用的内容
space1.space2.class1
命名空间之间的层次结构只是一种组织上的形式:当引用父空间时,子空间对于引用程序来说是透明的,如果还要使用子空间需要另外声明引用。同时注意:如果在父空间和子空间都声明了同名的类,则同时引用两个空间,会导致引用混乱,编译器无法确定程序究竟是要使用哪一级的类。这是只能通过指明类的命名空间来进行访问。
定义命名空间别名:
using co = Company.Proj.Nested;
.NET Framework的命名空间包括:System、System.Windows.Forms、System.Drawing ……
Partial Class
将类、结构或接口的定义分离为多个部分到多个文件中。每个部分都必须使用partial关键字。每个部分必须在编译时可用,每个部分具有相同的访问权限,例如public、private等。
如果某个部分定义为abstract,则整个类被认为是abstract。如果某个部分定义为sealed,则整个类被认为是sealed。如果某个部分声明了基类,则整个类继承该基类(所有部分必须声明一致的基类,但是省略基类声明的部分仍然继承该基类。)。
每个部分可以声明不同的基类接口,且最终类型必须实现所有由每个部分声明的接口。任何类、结构、接口成员在每一个部分中都可用。最终类型是所有部分的组合。
以下几种情况应该将类的定义分离为多个部分:
-
大型项目,将类分为几个文件允许多个程序员同时工作。
-
自动生成源代码的情况。
Partial Methods
局部类可以包含局部方法。类的一个部分可以包含方法的原型,可选的方法实现可以在同一个部分或其他部分。如果没有提供方法的实现,则该方法和该方法的所有调用在编译时被移除。
局部方法必须以partial修饰,并且返回void。
局部方法可以具有ref但是不能有out参数。
局部方法是隐式的私有方法,因此不能是抽象方法(virtual)。
局部方法不能被extern修饰,因为方法体的出现与否决定该方法是否被定义或实现。
局部方法可以具有static或unsafe修饰符。
嵌套类型
在类或结构声明内部声明的类型称为嵌套类型 (nested type)。在命名空间内声明的类型称为非嵌套类型 (non-nested type)。
异步编程
https://docs.microsoft.com/en-us/dotnet/csharp/async
Task-based Asynchronous Pattern (TAP)
The async keyword turns a method into an async method, which allows you to use the await keyword in its body. The await keyword ==yields control== to the caller of the method that performed await, and it ultimately allows a UI to be responsive or a service to be elastic.
The compiler transforms your code into a state machine that keeps track of things like yielding execution when an
awaitis reached and resuming execution when a background job has finished.
IO密集型任务:await an operation that returns a Task or Task<T> inside of an async method.
your code be "waiting" for something
public async Task<int> GetDotNetCountAsync(){
var html = await client.GetStringAsync("https://dotnetfoundation.org");
return Regex.Matches(html, @"\.NET").Count;
} // await GetDotNetCountAsync() at somewhere
public async Task<string> GetHtmlAsync(){
var client = new HttpClient(); // Execution is synchronous here
return client.GetStringAsync("https://www.dotnetfoundation.org");
}
在一个方法中如果有后续计算依赖于异步方法的返回结果,应当使用await关键字。此时,await将创建并返回一个新的Task<T>对象,表示一个可能尚未完成的任务。await关键字之后的代码将封装到Task<T>对象中,稍后由系统调度并通过Task的方法和属性进行监视。此任务稍后完成时,将计算结果返回更新之前无计算结果的Task<T>对象。
此处的返回机制类似于
fork方法,即进程在此处分支,父进程立即返回Task<T>,子进程的代码则是await语句之后的内容。但是子进程不是立即启动执行,而是由系统管理。当系统收到await的任务执行完成时,将该任务的返回结果解封,并传递给子进程继续执行。==一个方法如果使用了
await关键字,则必须在方法声明上添加async修饰==;一个方法如果调用了异步方法,但没有
await获取结果,则该方法应该直接在异步方法处返回(后续代码依赖于异步方法返回的结果,否则也无需写在异步方法之后);该方法中没有后续需要执行的代码,因此无需使用await创建一个新的Task<T>对象。
异步方法的起点:Task<T>的返回方式使得异步方法层层嵌套,并最终由系统调用进入内核启动真正的异步过程。例如系统与网络设备的交互,设备在收到系统指令后,准备通过网络发送数据,并向系统返回该过程的状态为挂起(pending),系统因此可以暂时从该任务返回执行其他任务。当请求完成且收到来自设备驱动的数据后,设备通过中断信号(interrupt)通知系统(CPU),系统的中断处理器将接收数据并向上传递到注册的任务(通过system interop call),这些结果将缓存在队列中直到将其解封并交给空闲线程执行任务中的剩余代码。
异步过程实现的基本原理,仍然是并行处理模型。系统(CPU)和设备是并行运行的,两者间通过总线等方式进行通信。系统(CPU)内部内核进程和用户进程也是并行的,通过系统调用进行数据交换。
共享线程池:异步方法在await之后将返回,从而释放占用的线程,可以由其他任务调用。而当异步任务完成后,系统将从线程池中分配线程以运行Task<T>对象中的剩余代码。当一个Task<T>执行完成时,将更新其上层Task<T>的状态,将其加入缓存队列,从而使得上层任务在未来某个时刻被空余线程执行。由此,层层向上经过一系列离散时间片段完成异步任务,直到顶层异步方法。==因此,异步方法真正占用线程的时间被大幅减少,从而提高系统的服务能力。==对于客户端而言,为了增加UI的响应能力,需要将耗时的计算或IO任务分配给额外线程。使用共享线程池可大幅减少手动创建专用线程的开销。对于IO任务而言,由于其并不消耗CPU资源,因此分配其单独的线程将严重浪费CPU资源。
异步方法的终点:在await之后输出结果(终端、屏幕或文件等),而非再返回到上一层调用者。这意味者该方法的返回类型为Task<void>,这通常是事件处理器(event handler)。
async Task<void>should only be used for event handlers.事件处理器的调用者(事件队列管理器)无需等待事件处理器执行完成并查看其结果。
CPU密集型任务:await an operation that is started on a background thread with the Task.Run method.
your code be performing an expensive computation
spawn off the work on another thread with
Task.Runconcurrency and parallelism: Task Parallel Library
calculateButton.Clicked += async (o, e) => {
var damageResult = await Task.Run(() => CalculateDamageDone());
DisplayDamage(damageResult);
}
Wait for multiple tasks to complete
可以首先构造多个异步任务,再等待其执行完成。由于每个异步任务会在wait语句处立即返回,因此启动多个任务的延迟不会太大。待所有任务启动后,再等待最先结束的任务。
var eggsTask = FryEggsAsync(2); // => Task<Egg>
var baconTask = FryBaconAsync(3);
var toastTask = MakeToastWithButterAndJamAsync(2);
var eggs = await eggsTask;
var bacon = await baconTask;
var toast = await toastTask;
这些任务可同时被分发执行,可以首先等待预计最先完成的任务。
Task.WhenAll and Task.WhenAny
public static async Task<List<User>> GetUsersAsync(List<int> userIds){
var getUserTasks = new List<Task<User>>();
foreach (int userId in userIds){
getUserTasks.Add(GetUserAsync(userId));
}
return Task.WhenAll(getUserTasks); // similar for `Task.WhenAny`
}
await Task.WhenAny类似于Linux的select或epoll。
Tips
-
You should add "Async" as the suffix of every async method name you write.
-
Consider using
ValueTaskwhere possible
Task and Task<T>
Task and Task<T> objects supported by the async and await keywords.
Taskrepresents a single operation which does not return a value.Task<T>represents a single operation which returns a value of typeT.
By default, tasks execute on the current thread and ==delegate work to the Operating System==, as appropriate. Optionally, tasks can be explicitly requested to ==run on a separate thread== via the Task.Run API.
构造Task
预处理指令
自动内存管理
不安全代码
指针
附录
关键字
const:如果变量是const,则该变量也是static的。
using:声明语句块,用于保证具有Idisposable接口的对象(非托管资源)的正确使用。
using (declare DisposableObjects){
statements;
}
在语句块中,定义的对象为只读,不能修改或重新赋值。
输入输出
标准输入输出
System.Console提供终端的标准输入输出方法。
Console.Write(value);
Console.Write(string Format, args)
Format参考字符串格式化。
Console.WriteLine额外输出换行。
文件系统
System.IO 命名空间包含与文件和目录进行交互的类型、对数据流和文件进行同步和异步读取和写入。
路径
Path类并不关心内容是否确实存在。 路径是概念上的路径,而不是物理路径。
分隔符:Path.DirectorySeparatorChar。
连接路径:
var p = Path.Combine("stores","201")
var ext = Path.GetExtension("sales.json")
目录
目录信息
目录属性
DirecotryInfo
列出目录包含的文件夹和文件。
using System.IO;
IEnumerable<string> dirs = Directory.EnumerateDirectories("stores");
IEnumerable<string> files = Directory.EnumerateFiles("stores", '*.txt', SearchOption.AllDirectories);
接受用于指定搜索模式文件和目录名称匹配模式,以及是否递归方式遍历指定的文件夹及其所有子文件夹。
返回路径基于给定的路径。
bool tf = Directory.Exists(path) // 判断目录是否存在
特殊目录
当前目录
string curdir = Directory.GetCurrentDirectory() // 绝对路径
System.Environment.SpecialFolder 枚举指定用于检索特殊系统文件夹路径的常量。
文件属性
FileInfo
创建文件和目录
Directory.CreateDirectory(path);
目录管理
文件输出输出
使用静态方法读写:
File.WriteAllText(path, txt);
File.AppendAllText(path, txt);
string txt = File.ReadAllText(path);
使用File类读写。
JSON
dotnet add package Newtonsoft.Json
class SalesTotal
{
public double Total { get; set; }
}
// 反序列化构造
var data = JsonConvert.DeserializeObject<SalesTotal>(str_data);
CSV
CsvHelper
C#数据容器
字符串(String)
构造
string str = "this is a string"; //使用字面值初始化;
str = new string(charr_array); //使用字符数组初始化;
str = new string(ch, n); // 重复字符n次;
查找
tf = name.StartsWith("B")
正则表达式
Regex in System.Text.RegularExpressions
Regex.Match()
运算
String类有很多字符串修改方法,但是String对象本身是不会改变的;修改的结果由返回值返回,只能对变量进行重新复制,让它指向内存中的另一块区域。
要在源字符串直接做修改,则改用StringBuilder类。
拼接
使用+或Concat方法,将对象的字符串表示(ToString())拼接形成一个字符串。
String.Concat(obj1,obj2,...);
String.Concat({obj1,obj2,....})
+运算符作用对象包含字符串时,作为拼接运算符。
字符串内插
string greeting = 'Hello', firstName = 'Bob';
string message = $"{greeting} {firstName}!";
可以同时使用逐字文本前缀符号
@和字符串内插$符号。
格式化
使用格式声明对参数进行格式化并输出字符串。
String.Format("{0}...{1}...", arg1, arg2, ...)
支持格式化语法的类似方法包括:
StringBuilder.AppendFormat、Console.WriteLine、TextWriter.WriteLine、Debug.WriteLine等。
复合格式声明
复合格式由参数索引,对齐声明和格式声明组成)。
{ index[,[+-]alignment][:formatString]}
多个格式项可以引用同一个参数,索引顺序与参数顺序无关。
对齐方式:alignment的绝对值代表了字符串的最小长度(字符串长度超过该值,则alignment无效);正值代表右对齐,负值代表左对齐,如果需要则填充空白。
不同类型的对象有不同的格式声明(格式声明在不同国家/语言有不同输出),其中: 标准数字格式包括:
| 格式 | 名称 | 说明 |
|---|---|---|
| `C | c[n]` | 货币格式 |
| `D | d[n]` | 整型数字 |
| `E | e[n]` | 指数计数法 |
| `F | f[n]` | 定点计数法 |
| `G | g[n]` | 科学计数法 |
| `P | p[n]` | 百分比 |
| `X | x` | 十六进制整型 |
自定义数值格式:
标准日期和时间:
| 格式 | 说明 | 示例 |
|---|---|---|
d | 短日期 | 6/15/2009 |
D | 长日期 | Monday, June 15, 2009 |
g | 短日期时间 | 6/15/2009 1:45 PM |
G | 长日期时间 | 6/15/2009 1:45:30 PM |
自定义日期和时间类型:获取日期时间中的字段
| 格式 | 说明 | 格式 | 说明 |
|---|---|---|---|
y/yy | year(0-99/00-99) | yyyy | year(0000-9999) |
M/MM | month(1-12/01-12) | MMM/MMMM | month name (short/long) |
d/dd | day-of-month | ||
ddd | day-of-week, short (Mon) | dddd | day-of-week, long (Monday) |
h/hh | hour(1-12/01~12) | H/HH | hour(0-23/01-23) |
m/mm | minute(0-59/00-59) | ||
s/ss | second(0-59/00-59) | ||
t/tt | AM/PM | ||
g/gg | A.D. or B.C. | f/ff/fff/... | .x/.xx/.xxx/... seconds |
K | time zone | z/zz | timezone hour offset |
: | 时间分隔符 | / | 日期分隔符 |
TimeSpan类型
枚举类型
比较
bool Equals(string value, StringComparison comparisonType);
bool EndsWith(string value, comparisonType)
comparisonType:比较规则包括{Ordinal, OrdinalIgnoreCase }。当调用字符串比较函数如String.Compare、String.Equals、String.IndexOf,应该总是使用带有comparisonType的函数指定比较规则。省略comparisonType,则该方法按照Ordinal规则(case-sensitive和culture-insensitive)进行比较。
StringBuilder
StringBuilder str = new StringBuilder();
str.Append(value);
编码
Encoding
数组
数组是用于存储多个同一类型变量的数据结构。数组是引用类型,派生于抽象基类Array类,所以数组也能当做类来使用。
声明
声明数组:
type[] arrayname; // 1-D
type[,,,...] arrayname; // multi-dimension array
数组的类型由值类型type和“[]”指定的维数决定。数组元素的类型可以是基本类型也可以是引用类型(甚至可以是数组类型)。数组的维数根据“[]”中的“,”的个数确定,维数=逗号个数+1。
数组初始化时的维度应该与数组声明一致,也可以将数组的声明和初始化放到一起。
type[] arrayname = new type[size];// initialize as default
数组在初始化时确定其维数和长度,且不能在实例存在期间修改。
数组的每个维度的长度或初始化列表可以省略,但两者不能同时省略:如果省略初始化列表则使用元素类型的默认值初始化数组;如果省略长度,则根据初始化列表元素的长度确定数组的长度;如果两者同时给出,则必须保证维数和长度声明与初始化列表一致。
arrayname = new type[size]{initialize_list};
arrayname = new type[m,n]{{list1},{list2},...{listm}};
arrayname = new type[,]{{list1},{list2},...{listm}};
arrayname = {{list1},{list2},...{listm}};
锯齿数组
锯齿数组(或称为交错数组)的每个元素是数组。
type [,...][,...] arrayname;
声明中,第一个[,...]是锯齿数组的维度声明,第二个是锯齿数组元素的维度声明。虽然每个子数组的维数由声明确定,但是在初始化时,子数组之间各相应维度的长度可以各不相同,因此称为锯齿/交错数组。使用初始化列表赋值:
int[][,] jag_array = { // 使用初始化列表
new int[,]{{1,2,3},{2,4,1}},
new int[,]{{2,1},{4,2}},
new int[,]{{1,3,5},{2,1,3},{3,4,5}}
...
};
int[][,] jag_array = new int[M][,]{...}
先使用new初始化交替数组本身,再初始化数组的每个元素:
int[][] jag_array = new int[M][];
for(int i=0; i<M; ++i){ //对每个元素逐个赋值
jag_array[i] = new int[len_i];
}
可以定义高维的锯齿数组::
int[,][] multi_array = {
{new int[]{1,2,3}, new int[]{2,1}},
{new int[]{1,3}, new int[]{2,1,3}}
};
数组访问
下标
普通数组的访问方法是array[i,j,...]。
交错数组的访问方法是array[i][j,k,...]。
迭代
使用循环语句for。
// 普通数组
for(int i = 0; i<M; ++i){
for(int j=0; j<M; ++j){
Console.Write("{0:G} ", array2d[i,j])
}
}
使用foreach语句,高维数组视为一维数组迭代。
foreach(int x in array2d){
Console.Write("{0:G} ", x)
}
foreach只能读元素,而不能修改数组。
数组维数和长度
array.Length; // 数组的元素总数
array.GetLength(dim); //数组的一个维度的长度;
容器
容器类型
泛型和非泛型容器
泛型容器(System.Collections.Generic)用于储存同一类型的元素,具有强类型要求,从而提供更好的类型安全以及更好的性能。
非泛型容器(System.Collections)存储的元素不要求特定的类型,所有元素都当作Object对象。非泛型集合(如 ArrayList)不建议使用,并且保留用于兼容性目的。大多数非泛型版本容器都不支持应用商店应用。
| 容器名 | 泛型 | 非泛型 | 说明 |
|---|---|---|---|
| 列表 | List<T> | ArrayList | 容器的大小可以增加或减小。提供查找、排序和修改等等方法。 |
| 链表 | LinkedList<T> | ||
| 有序列表 | SortedList<Tk, Tv> | SortedList | 使用ICompare接口根据对元素进行排序。 |
| 队列 | Queue<T> | Queue | 具有先进先出(FIFO)操作规则。 |
| 栈 | Stack<T> | Stack | |
| 映射 | Dictionary<Tk,Tv> | HashTable | 基于键值或Hash值索引元素。 |
| 有序映射 | SortedDictionary<Tk, Tv> | ||
| 集合 | HashSet<T> | ||
| 有序集合 | SortedSet<T> |
专用容器
System.Collections.Specialized
包含专用的强类型的结合。例如:链表字典,位向量,字符串容器。
并发容器
System.Collections.Concurrent
提供高效地线程安全的容器访问操作。当从多线程访问容器时,应该使用本空间中的对应容器类型代替System.Collections.Generic和System.Collections中的类型。
容器公共特性
容器基于ICollection、IList和IDictionary接口及其泛型版本。IList和IDictionary派生自ICollection。
容器接口包括:
-
ICollection<T> -
IList<T> -
IDictionary<T> -
IComparer<T> -
IEqualityComparer<T> -
IEnumerator<T> -
ISet<T>
枚举元素
容器类型继承IEnumerable/IEnumerable<T>,因此可以通过foreach语句进行枚举。继承自IEnumerable<T>的容器还可以通过LINQ进行查询。LINQ通常更简洁且可读性更强,提供筛选、排序以及分组能力,且能提高性能。
复制到数组
通过CopyTo方法将元素按照枚举顺序复制到一维数组中。
容量和计数
-
Capacity在不重新分配空间前,容器的容量。
Capacity不应该设置为比Count小的值,否则引发异常(ArgumentOutOfRangeException)。 -
Count容器包含元素的数量。
一致的下界
元素从0起索引。Array可以自定义起始索引。
比较
Contains, IndexOf,
LastIndexOf以及Remove等方法使用等式比较。泛型容器的比较方案:如果类型T继承了IEquatable\<T\>接口,则使用接口的Equals函数;否则使用Object.Equals。
排序顺序
BinarySearch和Sort使用一个顺序比较器,用于比较容器的元素或与给定的值比较。
default comparer:依赖参与比较的对象至少有一个实现了IComparable接口。泛型类型的比较器方案:如果T实现了IComparable<T>接口,则默认比较器为IComparable<T>.CompareTo(T);如果T实现了IComparable接口,则默认比较器为IComparable.CompareTo(T);如果T没有实现以上接口,则必须显示提供比较器。
元素排序
SortedList/SortedList<TKey, TValue>、SortedDictionary<TKey, TValue>
实现
IDictionary/``IDictionary<TKey, TValue>`接口,每个元素是key/value对。元素根据
ICompare/ICompare<T>接口排序。每个类提供仅返回key或value的属性。
HashTable/Dictionary<TKey,TValue>
按key排序。
迭代器
迭代器用于容器的迭代访问操作。
使用foreach语句来调用迭代器。
访问容器的接口
容器相关操作
Queue
- Dequeue/Enqueue
Stack
-
Push/Pop
Peek
LINQ
You can write LINQ queries in C# with SQL Server databases, XML documents, ADO.NET Datasets, and any collection of objects that supports IEnumerable or the generic IEnumerable<T> interface.
All LINQ query operations consist of three distinct actions:
-
Obtain the data source.
-
Create the query.
-
Execute the query.
数据源(Data Source)
LINQ数据源可以是支持IEnumerable<T>接口以及继承该接口的任何实例。支持IEnumerable<T>及其派生接口(如IQueryable<T>)的类型被称为可查询类型。
Enumerable类提供一组用于查询实现IEnumerable<T>的对象的静态方法。
XElement
Northwnd
查询
查询语法:从对象序列中查询满足条件的对象,并返回筛选结果。
var seattleCustomers = from customer in customers
where customer.City == "Seattle"
[orderby customer.ID]
select customer.Name; // or select customer
from指定数据源;where应用过滤条件;select语句指定返回元素的类型。
var localDistributors =
from customer in customers
join distributor in distributors on customer.City equals distributor.City
select new { Customer = customer, Distributor = distributor.ID };
return a new type
var scoreQuery = from student in students
from score in student.Scores
where score > 90
select new { Last = student.LastName, score };
执行查询
延迟执行
查询变量本身只储存查询命令,当通过foreach语句对查询变量进行迭代时,才真正执行查询。
强制立即执行
统计函数:Count、Max、Average、First
强制执行:ToList()或ToArray();
在查询语句之后,立即使用foreach语句。
List
List实现的接口
IndexOf、LastIndexOf和Remove方法使用类型T的默认比较函数(EqualityComparer<T>.Default属性)判断相等。如果T实现了System.IEquatable<T>接口,则返回包含该接口的EqualityComparer,否则返回包含由T提供的Objects.Equals和Objects.GetHashCode的EqualityComparer。
Contains方法使用默认的相等比较函数判断相等。如果T实现了IEquatable<T>接口,则调用IEquatabale.Equals方法,否则使用Object.Equals。
Sort、BinarySearch使用类型T的默认的比较函数(Comparer<T>.Default属性)。如果T实现了IComparable<T>接口,则默认比较函数为IComparable<T>.CompareTo(T);否则如果实现了IComparable接口,则默认比较函数是IComparable.CompareTo();如果T没有实现比较接口,则必须显式提供比较委托。
List允许引用类型取值为null,以及重复元素。
ArrayList
ArrayList的容量是自动扩充的(类似于字符串,与一般数组不同);
ArrayList只能是一维的;
构造函数
List<T>() //with default capacity
List<T>(Int32 Capacity)
属性
T this[int index] { get; set; }
按序号访问指定的元素。
方法
插入
void Add( T item );
void Insert( int index, T item )
Add添加元素到列表末尾。
Insert在指定序号处插入元素,指定的序号小于0或大于Count会引发异常(ArgumentOutOfRangeException)。
删除
bool Remove( T item );
int RemoveAll( Predicate<T> match );
void RemoveAt( int index )
void Clear();
void TrimExcess()
Remove移除出现的第一个指定元素,如果成功移除返回true;如果指定元素不在列表中或移除失败,返回false。
RemoveAll移除满足条件的所有元素,并返回移除元素的数量。
RemoveAt移除指定位置的元素,指定的序号小于0或大于Count会引发异常(ArgumentOutOfRangeException)。
Clear移除列表中的所有元素。
TrimExcess将列表的容量缩小至元素实际数量。
查找
bool Contains( T item );
bool Exists( Predicate<T> match );
T Find( Predicate\<T\> match ); // FindLast
int FindIndex( Predicate\<T\> match ); // FindLastIndex
int IndexOf( T item ); // LastIndexOf
List<T> FindAll( Predicate<T> match );
Contains判断一个元素是否包含在列表中。(This method determines equality by using
the default equality comparer, as defined by the object's
implementation of the IEquatable<T>.Equals method forT (the type of
values in the list).)
Exists判断是否存在匹配给定条件的元素。match定义了查找元素的条件。列表的元素分别被传递给match函数,当找到匹配元素时停止操作。
Find查找满足条件的元素并返回第一个元素。
FindAll查找所有满足条件的元素并返回。
FindIndex查找满足条件的元素并返回第一个元素序号。
IndexOf查找指定的元素,并返回第一个元素的序号。
排序
void Reverse()
反转整个列表的元素排列顺序。
void Sort()
void Sort( Comparison<T> comparison )
void Sort( IComparer<T> comparer )
使用comparison对列表排序。
使用comparer进行排序。
Dictionary
System.Collections in mscorlib
代表非一般性的键值对(key/value)的容器。每一个键值对储存在一个DictionaryEntry对象中。
每个键值对必须具有唯一的键名,实现类型可以决定是否允许键名为null。值可以是null且不要求唯一性。
IDictionary的实现类型分为三类:只读、固定长度、可变长度。
属性
按键名key访问元素:
Object this[ Object key] { get; set; }
键名和值
ICollection Keys { get; }
ICollection Values { get; }
值的顺序与Keys返回的键名的顺序对应。
DictionaryEntry定义字典的键值对。
Object Key { get; set; }
Object Value { get; set; }
.NET开发
C# 和 .NET 是截然不同的。 C# 是一种编程语言语法。 作为语法的一部分,你可以引用和调用 .NET 代码库或程序集中定义的方法。 此外,还可以使用随 .NET SDK 一起安装的 C# 编译器从 C# 代码创建程序集。
应用程序框架合并了几个相关的库,以及初学者项目、文件模板、代码生成器和其他工具。 你可以使用这些资源为特定目的生成整个应用程序。 这些应用程序框架称为“应用模型”。 例如,常用的 .NET 应用程序框架可用于 Web 开发、桌面和移动开发,以及游戏开发等应用模型。
开发环境
可以选择 Visual Studio 2019 或 Visual Studio Code和.NET 软件开发工具包 (SDK)。
.NET SDK
.NET CLI
.NET CLI 概述:https://docs.microsoft.com/zh-cn/dotnet/core/tools/。
dotnet --info # .NET install information
create app
dotnet new console -o myApp # creat project with templates
-o:创建指定目录以存储项目文件;
可创建的项目类型可通过以下命令查看。
dotnet new -l [<name>]
# Templates Short Name Language Tags
# -------------------- ------------ ------------ --------------
# Console Application console [C#], F#, VB Common/Console
# Class library classlib [C#], F#, VB Common/Library
# ......
运行应用:
cd myApp
dotnet run
NuGet 包管理器
NuGet 是适用于 .NET 的包管理器。 它使开发人员能够创建、共享和使用有用的 .NET 库。 NuGet 客户端工具可生成这些库并将其作为“包”。
访问https://www.nuget.org/packages/查看包的详情。
NuGet 文档:https://docs.microsoft.com/zh-cn/nuget/。
- 若面向.NET Core或.NET Standard,请使用
dotnetCLI(是SDK项目格式所必需的)。- 要面向.NET Framework(仅限非SDK样式项目),请使用
nuget.exeCLI。
NU1202: Package is not compatible with net50-windows:dotnet工具版本太低,升级dotnetSDK。
配置Nuget仓库
Nuget官方仓库未默认配置(导致无法添加包),通过以下命令配置仓库源。
dotnet nuget add source https://api.nuget.org/v3/index.json -n nuget.org
dotnet nuget list source # 查看注册的软件源
其他软件源相关命令:enable,disable,remove,update
向项目添加包
Visual Studio 和 Visual Studio for Mac 中有一个内置的包管理器命令行和图形用户界面。 可手动向项目文件添加包引用。 也可通过命令行接口 (CLI) 工具(如 Paket 或 .NET Core CLI)进行安装。
运行 dotnet add package <package name> 命令时将抓取和下载所有依赖项。安装的包在项目文件(.csproj )中列出。
<ItemGroup>
<PackageReference Include="Humanizer" Version="2.8.26" />
</ItemGroup>
如果需要查看项目中的包,可以输入
dotnet list package [--include-transitive]
.NET命令行工具
使用 dotnet tool install <package name> 命令安装工具。
A .NET tool is a special NuGet package that contains a console application.
- global tool: The tool binaries are installed in a default directory that is added to the PATH environment variable.
- global tool in a custom location
- local tool: The .NET CLI uses manifest files to keep track of which tools are installed as local to a directory.
https://docs.microsoft.com/en-us/dotnet/core/tools/global-tools
使用 dotnet new -i <package name> 命令安装模板。
版本控制
语义化版本控制的工作原理是确保包具有版本号,并且该版本号划分为以下部分:
- 主版本。 最左边的数字。 例如 1.0.0 中的 1。 此数字发生更改意味着代码可能出现中断性变更。 可能需要重写部分代码。
- 次要版本。 中间的数字。 例如 1.2.0 中的 2。 此数字发生更改意味着添加了新功能。 你的代码仍可正常工作。 接受更新通常是安全的。
- 修补程序版本。 最右边的数字。 例如 1.2.3 中的 3。 此数字发生更改意味着应用了一个更改,修复了代码中应正常工作的内容。 接受更新应是安全的。
查找和更新过时的包
dotnet list package --outdated [--include-prerelease]
运行 dotnet add package <package name> [--prerelease],它将尝试更新到最新版本,可选择传入 --version=<version number/range>。
生成项目
dotnet build
调试运行
dotnet App.dll >App.log &
可以直接启动动态链接库文件
调试器所具有的两个最重要的功能是:
- 控制程序执行。 你可以暂停程序并逐步运行它,以便查看执行了哪些代码及其对程序状态的影响。
- 观察程序的状态。 例如,你可以在代码执行期间随时查看变量的值和函数参数。
日志记录
-
传统的调试器可能难以调试长期存在的问题。 通过日志,可以对较长的时间跨度进行详细的事后剖析。 与此相反,调试器限制为只能进行实时分析。
-
多线程应用程序和分布式应用程序通常难以调试。 附加调试器往往会修改行为。 可以根据需要分析详细日志,以了解复杂的系统。
-
分布式应用程序中的问题可能是由许多组件之间的复杂交互导致的。 将调试器连接到系统的每个部分可能并不合理。
-
许多服务不应停止。 附加调试器往往会导致超时失败。
-
问题并非总是可预见的。 日志记录和跟踪旨在降低开销,以便在出现问题的情况下可以始终记录程序。
-
System.Console- 始终启用,并始终写入控制台。
- 适用于客户可能需要在发行版中看到的信息。
- 由于这是最简单的方法,所以常常用于临时调试。 此调试代码通常不会签入到源代码管理中。
- 在非控制台应用程序中使用
System.Console.WriteLine时,应慎重考虑。
-
System.Diagnostics.Trace- 仅在定义
TRACE时启用。 - 写入附加侦听器,默认情况下为 DefaultTraceListener。
- 创建将在大多数生成中启用的日志时,请使用此 API。
- 仅在定义
-
System.Diagnostics.Debug- 仅在定义
DEBUG时才启用(处于调试模式时)。 - 写入附加调试器。
- 创建仅在调试生成中启用的日志时,请使用此 API。
- 仅在定义
定义 TRACE 和 DEBUG 常数
在项目文件中添加PropertyGroup:
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Debug|AnyCPU'">
<DefineConstants>DEBUG;TRACE</DefineConstants>
</PropertyGroup>
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Release|AnyCPU'">
<DefineConstants>TRACE</DefineConstants>
</PropertyGroup>
Debug.Assert(n2 == 5, "The return value is not 5 and it should be.");
ASP.NET Core
RESTful API: adding, viewing, modifying, and removing;
HTTP action verbs : Create, Read, Update, Delete (CRUD).
Entity Framework (EF) Core
概览

API Specification
| API | Description | Request body | Response body |
|---|---|---|---|
GET /api/Items | Get all items | None | Array of items |
GET /api/Items/{id} | Get item by ID | None | item |
POST /api/Items | Add a new item | To-do item | item |
PUT /api/Items/{id} | Update existing item | To-do item | None |
DELETE /api/Items/{id} | Delete an item | None | None |
创建项目
dotnet new webapi -o dotnet-webapi
cd dotnet-webapi
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
dotnet add package Microsoft.EntityFrameworkCore.InMemory
dotnet dev-certs https --trust # Trust the HTTPS deve certificate
code .
https://docs.microsoft.com/en-us/aspnet/core/tutorials/first-web-api?view=aspnetcore-5.0&tabs=visual-studio-code
编程模型
MVC
Model
Model classes can go anywhere in the project, but the Models folder is used by convention.
The database context is the main class that coordinates Entity Framework functionality for a data model.
public class ContosoPetsContext : DbContext { /*...*/ }
Controllers (HTTP endpoints)
自动生成代码:
-
Marks the class with the ApiController attribute. This attribute indicates that the controller responds to web API requests.
-
Uses DI to inject the database context (
TodoContext) into the controller. The database context is used in each of the CRUD methods in the controller.
dotnet add package Microsoft.VisualStudio.Web.CodeGeneration.Design
dotnet add package Microsoft.EntityFrameworkCore.Design
dotnet tool install -g dotnet-aspnet-codegenerator
dotnet aspnet-codegenerator controller -name TodoItemsController -async -api -m TodoItem -dc TodoContext -outDir Controllers
-m TodoItem -dc TodoContext:指定了创建的Controller对象关联的数据模型和数据库上下文对象。
Routing and URL Path
[Route("api/[controller]")]
[ApiController]
public class TodoItemsController : ControllerBase{}
Routing to controller actions in ASP.NET Core.
// GET: api/TodoItems/5
[HttpGet("{id}")]
public async Task<ActionResult<TodoItem>> GetTodoItem(long id){}
When
GetTodoItemis invoked, the value of"{id}"in the URL is provided to the method in itsidparameter.
返回值:The return type of the GetTodoItems and GetTodoItem methods is ActionResult type. ASP.NET Core automatically serializes the object to JSON and writes the JSON into the body of the response message.
POST API处理
从HTTP请求中读取数据。
配置服务
注册服务
Registers the custom DbContext class
// Startup.cs
public void ConfigureServices(IServiceCollection services)
{
services.AddDbContext<ContosoPetsContext>(options =>
options.UseInMemoryDatabase("ContosoPets"));
services.AddControllers();
// code omitted for brevity
}
测试
Postman
https://www.postman.com/downloads/
Entity Framework Core
The Microsoft.EntityFrameworkCore.InMemory package is required to use an EF Core in-memory database.
第三方库
Terminal.GUI
dotnet add package Terminal.GUI
模块
应用实例
Application.Init();
Application.Shutdown ();
视图
应用程序中添加的UI元素组成视图(Views),视图负责处理显示、接收输入事件和参与聚焦机制。
视图可包含任意数量的子视图(Subviews),View.SuperView是当前视图的容器。
TopLevels
Toplevel视图占用整个屏幕,不含可见的UI元素,通常需要在程序中向其中添加子视图或组件(如文本标签Label、菜单MenuBar、工作窗口Window等)。
TopLevel top = Application.Top; // 默认的视图
top.add(label);
Application.Run(); // 渲染顶层界面
自定义其他视图:
var top = new Toplevel(){ X=0, Y=0, Width=Dim.Fill(), Height = Dim.Fill() }; Application.Run(top);
Windows
Window(窗口)视图扩展Toplevel,将视图划为标题栏和画框(frame),屏幕上可同时存在多个窗口。
Dialogs
Dialog是位于屏幕中央的一类窗口,以模态方式运行。通过AddButtion可在底部增加按钮。
bool ok_pressed = false;
var ok = new Button("Ok"){
Clicked = () => { Application.RequestStop (); ok_pressed = true; }
};
var cancel = new Button("Cancel"){
Clicked = () => Application.RequestStop();
};
var dialog = new Dialog("Quit", 60, 7, ok, cancel);
Application.Run(dialog);
if (ok_pressed){
Console.WriteLine ("xxx");
}
布局
UI元素的布局通过指定左上角位置和组件的尺寸确定。布局方案View.LayoutStyle包括绝对布局和动态布局。
var label2 = new Label (new Rect (1, 2, 20, 1), "World"); // 使用Rect定义绝对尺寸
var label = new Label ("Hello") {
X = 1, //绝对值
Y = Pos.Center(), //动态计算
Width = Dim.Fill(), //动态计算
Height = 1 //绝对值
};
绝对布局
View.Frame
动态布局
位置计算方法:
view.X = Pos.Center () - 10;
view.Y = Pos.Percent (20); //按比例布局
//相对边界布局
view.X = AnchorEnd(10);
//相对其他组件布局
view.X = Pos.X(super_view);
view.Y = Pos.Bottom(another_view);
尺寸计算方法:
view.Width = Dim.Fill () - 10;
view.Height = Dim.Percent(20) - 1;
anotherView.Height = Dim.Height(view)+1;
色彩样式
UI组件
工具栏
窗口
事件处理
Event Processing and the Application Main Loop (gui-cs.github.io)
参考文献
Introducing .NET Standard - .NET Blog (microsoft.com) 2: The future of .NET Standard - .NET Blog (microsoft.com)
Modern C++
Introducing Modern C++
C++标准
-
C++98 -
C++03 -
C++11 -
c++14 -
C++17 -
C++20Support in
gccis highly experimental, and will almost certainly change in incompatible ways in future releases.
C++特性
C++ v.s. C
| C++ | C |
|---|---|
| not a strict subset of C++ | |
| stronger type system | weak type system |
| high-level abstractions | only low-level memory abstraction |
powerful custom types (classes) | only data aggregation (struct) |
| use compiler as correctness checker | get the code to compile quickly |
| if it compiles, it should be correct | debugging is the real work |
C++ v.s. Java
| C++ | Java |
|---|---|
| ==value semantics for all types== | ==value semantics only for primitives (int, float,… )== |
| optional reference semantics for all types | baked-in reference semantics for class types |
| full control over memory (de-)allocation; no garbage collection | garbage collector; can degrade performance |
| deterministic & controllable object lifetime | no predictable object lifetime control |
| ⇒ memory frugal | ⇒ high memory consumption |
| aggressive inline can eliminate slow function calls | performance degradation due to un-devirtualizable, non-inlinable methods |
C++ v.s. Python
| C++ | Python |
|---|---|
| almost always faster | almost always slower (in practice around 25-50 times) |
| complex syntax and tons of features can be intimidating to newcomers | simple syntax; usually easy to comprehend |
| statically typed | dynamically typed |
| many types of bugs can be caught at compile time | many types of bugs will only manifest at runtime |
| suited for safety-critical large-scale systems | hard to build reliable large-scale systems |
| even simple, small-scope tasks can quickly require an expert knowledge of various arcane corner cases & quirks | tends to be more beginner-friendly and small scripts are usually quickly written |
| fairly small standard library but extensive ecosystem with libraries for nearly everything | ==batteries included philosophy== with tons of libraries only one import away |
https://isocpp.org/wiki/faq
数据类型
基础数据类型
0is alwaysfalse;everything else istrue。
字符类型:char型(1字节),wchar_t型(长度与平台相关可能是2或4字节),char16_t(2字节), char32_t(4字节)。
字面值
字面值类型包括:整数常量、字符常量、浮点数常量、字符串常量。此处的常量均是指字面值常量。
整数常量
整数常量可以声明为十进制、八进制、十六进制,有无符号,长或短整型。十进制数以非零数字开始,八进制以数字“0”为前导,十六进制以“0x”为前导。
后缀“u”或“U”用于声明该数值为无符号数,未添加该后缀则表示有符号数。
后缀“L”或“l”用于声明长整形。
后缀“i64”或“ll”或“LL”用于声明64位整形。
浮点常量
浮点常量中是必须包含小数点的定点数,还可以包含指数,还可以附加后缀用于声明类型。浮点数默认类型为double,当添加后缀“F”或“f”表示浮点型,“L”或“l”表示long double(long double和double的长度都是一样的,但是类型不相同)。
定点数的表示方法:
double x = 18.46, y = 38. ;
指数表示方法:
double x = 18.46e0, y = 18.46E1 ;
指数部分可以是负数。当浮点数包含指数时,定点数部分可以不包含小数点。
数值范围:
#include <limits>
std::numeric_limits<double>::max() // largest positive value
std::numeric_limits<double>::min() // smallest value > 0
std::numeric_limits<double>::lowest() // smallest negative value
std::numeric_limits<double>::epsilon() // smallest difference
一个整型类型可以转换成更宽位数的整型类型,这种转换称为整型提升。进行这种转换不改变数据的值。
字符常量
字符常量是使用“'”包围的一个或多个字符。
如果整型使用普通字符常量或宽字符常量声明,则不足位补零;如果普通字符或宽字符用多字符常量声明,则将丢弃高位(左边的)字符。超过四个字符的字符常量声明将出错。
在字符声明中,具有特殊意义的字符(\、'、"等)需要使用转义字符“\”消除特殊意义。转义序列有三种类型:
-
简单类型:
\' \" \? \\ \a \b \f \n \r \t \v; -
八进制转义序列(转移字符之后最长三位八进制数,超过三位则第二个字符开始,或者从第一非八进制数字结束):
\012; -
十六进制转义字符:转义字符后接“
x”,其后接十六进制数字,后接数字位数无限制,只能以非十六进制数字结束。十六进制转义字符首先去除多余的高位,然后将剩余的8位数字转换为整型,再将整型转换为字符,如果整形的无符号值大于255,则转换不能完成,编译时会出错。转移字符之后的字符如果不是特殊字符,则结果由具体的实现决定。
双引号在字符常量中可以不使用转义字符。
Microsoft Specification:通常只能是ASCII字符,包括96个字符:空格、水平制表符、垂直制表符、换行符、Formfeed和26个大小写字符、10个数字、以及下列字符:
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '对于转义字符之后的非特殊意义字符,非特殊字符将正常显示,而转义字符不会显示;编译时会出现警告“不可识别的字符转移序列”。
字符串常量
一个字符串常量由0个或多个字符构成,有双引号所包围,字符串代表一个由“null”结尾的字符序列。字符串中可以包含所有字符常量允许使用的字符,以及使用转义字符。C++字符串包含两种类型:char[],wchar_t[]。
wchar_t w[] = L"wide string";
声明
wchar_t字符或字符串常量需要添加一个前缀“L”,类似地u用于char16_t类型字面值,U用于char32_t类型字面值。通过指向常量字符串的指针修改常量字符串是不允许的,结果未知。
以空格分隔的字符串会被自动拼接为单个字符串(也可以在行末使用“\”连接两行。)。
const char* b = "first" "second" // ⇒ "first second"
原始字符转字面值:
char const * ch_array = R"(raw "C"-string c:\users\joe )"; // c++11
Microsoft Specification:在一些情况下,声明的相同的字符串将被合并为一个字符串,在内存中使用同一段内存。
字符串的字面值最大长度为2048字节,对于
char和wchar_t都一样。如果定义了UNICODE,则
_T()等效于前缀L。
枚举
限定作用域枚举,使用枚举类型名访问枚举成员。
enum class day:short { mon, tue, wed, thu, fri, sat, sun };
day d = day::mon;
非限定作用域枚举,不同的枚举类型不能包含相同名字的成员。
enum day { mon, tue, wed, thu, fri, sat, sun };
day d = mon;
可以为枚举指定底层整数类型(char, short, long,...,默认为int)。可以将枚举强制转换为其底层类型。
引用
引用声明以后就是绑定到变量的别名,对引用名再赋值等效于修改绑定变量的值,因此无法再修改引用本身(赋值)使之绑定到其他变量。由于引用是变量的别名,因此通过引用总是能访问有效的变量。
[const] ValueType [const] & ref_name = VarName;
const声明符可以位于类型的前面或后面,但后者与指针类型声明风格保持一致。references cannot be "null", i.e., they must always refer to an object
int i = 2, k = 3;
int& ri = i; // reference to i
ri = k; // assign new value to ri(i)
如果引用声明为常量,则无法通过该引用修改变量的值。
引用的应用
-
作为函数、“
[]”和“=”操作符的返回值,满足左操作数可以被赋值的要求(L-value)。Dangling Reference:
不要返回局部变量的引用;
引用容器元素在修改容器后可能失效;
-
作为函数参数,等价于使用指针进行参数传递,而无须复制实际参数。
-
在迭代循环中使用
for(std::string & s : v) { cin >> s; } // modify vector elements for(std::string const& s : v) { cout << s; } // read-only access for(auto & s : v) { cin >> s; } for(auto const& s : v) { cout << s; } -
Avoid Output Parameters! 难以确定参数是否发生变化,参数是否仅作为输出或还作为输入。
-
Just take returned objects by value. This does not involve expensive copies for most functions and types in modern C++, especially in C++17 and above.
使用引用绑定函数返回值将导致临时变量的生命周期变长。
引用绑定规则
Rvalues and Lvalues
左值(Lvalues):expressions of which we can get memory address
- 内存中可引用的对象
- 具有名字的对象 (variables, function parameters, …)
右值(Rvalues):expressions of which we can't get memory address
- 字面值(
123,"string literal", …)(位于代码区); - 运算的零时结果;
- 函数返回的零时变量;
左值引用:type&,仅能绑定到左值;type const&可绑定到const左值和右值;
右值引用:type&&,仅能绑定到右值(涉及类型推断的除外);
万能引用(转发引用):根据类型推断的结果,可能为左值或右值引用。
auto&& ref = var;
template<typename T> void f(T&& param);
类型推导是必要条件,被推导类型必须为
T&&,其中T是模板类型参数。
类型语法
类型别名
using NewType = OldType; // C++11
typedef OldType NewType; // C++98
类型推断
auto variable = expression; // c++11
类型转换
static_cast(v):强制类型转换,编译器允许执行(但不一定是自动执行的)的任何转换都可以完成。避免发生精度损失时的警告。类似于C语法type(var)。
const_cast(v):去除常量性质,是变量能够被修改。
dynamic_cast(v):运行时动态识别类型。将基类类型的指针或引用安全地转换为派生类型的指针或引用。
reinterpret_cast(v):对于编译器不允许的转换类型(如指针类型转换),可以使用reinterpret_cast进行强制转换而不产生编译期错误。
std:move(T&&)将参数强制转换为右值;
std:forward<T>(param):仅当实参为右值时,将形参转换为右值;
指针
指针可以用于访问对象,且可以在运行期间改变其引用的对象(引用则不能修改)。指针的一个重要用途是函数参数传递,使用指针可以进行地址传递,则主函数和子函数可以访问同一段内存的变量。
原始指针
指针存储内存地址的整数变量。通过取地址运算符&获取变量地址。
int a = 1;
int* ptr = &a;
或通过动态内存分配获取堆上创建的变量的地址。
指针运算
指针可以进行赋值运算、算数运算、关系运算和解引用运算。
*:对象引用运算符;
->:对象成员引用运算符;
point *p = new point{1,2};
cout << p->x << p->y << *(p).x;
优先使用引用,语法更加简洁。
智能指针(C++11)

unique_ptr
不能复制指针,但可以移动指针指向的对象到新的指针,原指针被置为nullptr。
#include <memory>
auto p = make_unique<Type>(init_list); // c++14, more safe
std::unique_ptr<Type> p1(new Type(args)); // c++14
auto p2 = move(p); // 不能复制unique_ptr
仍然使用
->运算符访问类型的成员。
shared_ptr
#include <memory>
auto p = make_shared<Type>(init_list); // c++14
std::shared_ptr<Type> p1(new Type(args)); // c++14
auto p2 = p;
引用计数:当最后引用对象的指针被销毁时,对象被销毁。
weak_ptr可以复制shared_ptr但不影响引用计数。
数组
type array[N];
type array[N] = {1,2,3,...};
当初始化列表给定时,可省略数组长度参数。==数组长度?==
动态创建数组:
type* ptr_array = new type[size];
type* ptr_array = new type[size]{1,2,...};
多维数组:创建$M\times N\times\cdots$维数组。
type array[M][N]...[];
type (*ptr)[N]... = new type[size][N]...;
仅有数组的最高维度是可以动态分配的,将其他维度整体看作一个整体(子数组)。
K维数组可以看成由size个维度为K-1的子数组构成的。分配一维数组,实际上是分配连续的size个基本变量;分配二维数组,实际上是连续分配size个一维数组,以此类推……动态创建数组时只有
size是变量,其他参数必须是编译期确定的常量(字面值或constexpr)。指向数组的指针进行“加减”运算,指针加减1实际对应的内存地址偏移量为对应子数组的内存占用长度。
指针数组
即数组元素是指针类型。指针数组的声明:
type* ptr_array[L1][L2]...;
type(*ptr_array[L1][L2]...)[M][N]...[P];
其中[L1][L2]...是指针数组本身的维度,而type(*)[M][N]...[P]代表最终指向的数据类型。如果带参数[M][N]...[P],则代表指向的是数组(的维度);如果没有该参数则为指向变量的指针(此时不省略()会生成警告)。
数组索引
array_name[index];
*(array_name+index);
数组名相当于指针常量。
高维数组在内存中实际上是按照线性方式存储数据的,所以实质上等效于是一个一维数组,所以仍然可以定义一维数组指针来访问数组元素。则指向第一个元素的一维数组指针的值应该是:
type *ptr = array[M][N]...; // 省略最后一维
type *ptr = &array[M][N]...[P]; // 或直接取元素地址
类型修饰符
静态变量
static int x = 1; // 定义静态(文件作用域)变量
extern int x; // 引用全局(非静态)变量,不推荐使用全局变量
可以在头文件中定义静态变量,引用该头文件的源文件将分别生成独立的文件作用域静态变量。
局部静态变量:静态变量定义在非全局作用域(如函数内部)。该变量的生命周期为程序生命周期,但仅能在定义该变量的作用域中访问。==局部静态变量只会在定义位置被初始化一次==。
全局变量构造器:在静态函数中返回静态变量的引用。
常量
Type const variable_name = value;
const Type variable_name = value;
用const关键字可以代替#define宏,使用const关键字声明的常量在编译时可以进行类型检查,而使用#define宏定义的常量则不能。
常量表达式
表达式的值在编译期间是确定的,其组成部分都是常量表达式。
constexpr int i = 2; // OK '2' is a literal
constexpr int cxf(int i) { return i*2; }
constexpr int j = cxf(5); // OK, cxf is constexpr
constexpr int k = cxf(i); // OK, cxf and i are constexpr
c++14:常量表达式函数内部可以包含多条语句;
常量相关指针
常量指针:指针本身是常量,即不能更改指针本身(所存储的内存位置),但可以更改指针指向的内容。
指向常量的指针:指针所指的内容必须是常量,不能修改指针所指的内容,但可以修改指针本身(所存储的内存地址)。可以用于函数参数,防止函数改变通过指针传入的参数。
type *const ptr; // const pointer to variable of Type <type>
type const *ptr; // pointer to const variable of Type <type>
type const *const:指针本身不能改变,指针所指的值也不允许改变。
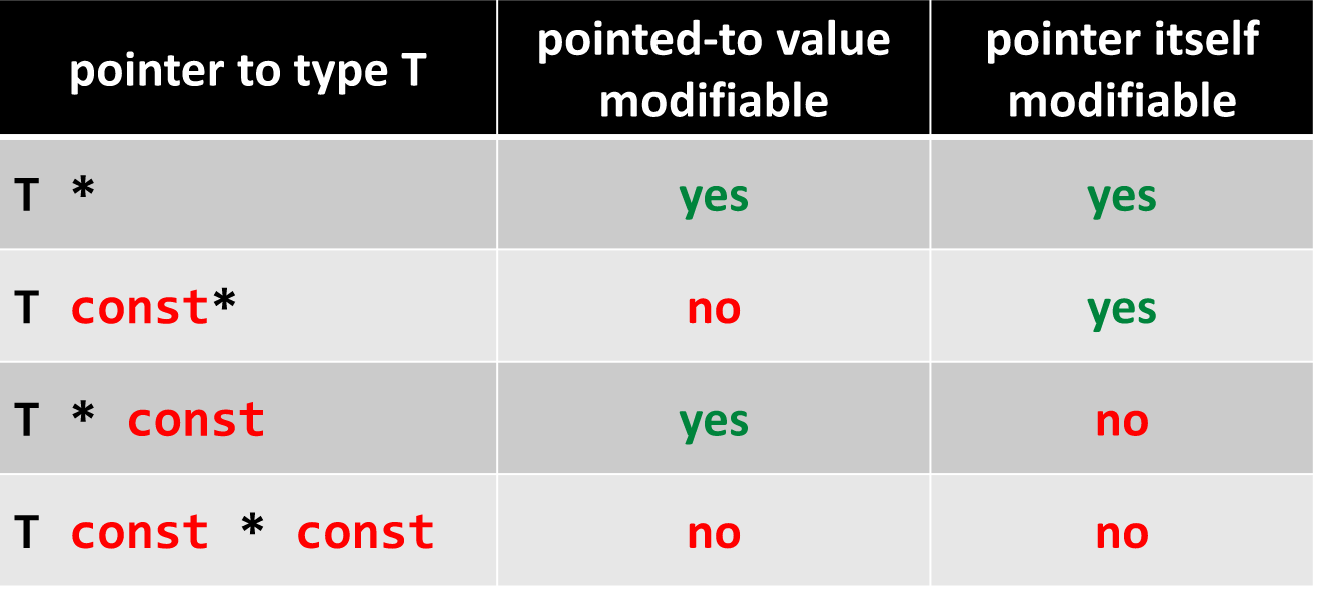
从右到左解释类型声明。
内存模型
heap: used for objects of dynamic storage duration;
空闲内存块列表。
stack: used for objects of automatic storage duration: local variables, function parameters, etc.
栈分配通常从高地址到低地址。

内存占用
基本数据类型的区别主要在于内存占用量。
sizeof(char); // 操作符: auto x = sizeof char
Integer Size Guarantees C++11
#include <cstdint>exact size:
int8_t,int16_t,int32_t,int64_t,unt8_t, …
动态内存分配
C++使用new和delete关键字进行动态内存管理。当使用new关键字为变量在堆上分配内存并返回内存地址,并自动调用构造函数进行初始化。如果分配内存失败,new返回nullptr或抛出异常。
nullptr为指针默认值(转换为false,可以用于逻辑判断)。
type *ptr = new type(args); // type *ptr = new type{args};
type *ptr = new type[const_num]{init_list};
delete ptr; // delete variable
delete [] ptr; // delete array
无法从指针类型判断其是只想单个变量或数组。
使用delete关键字对值为nullptr的指针进行操作不会出错;但使用delete对不是用new分配的内存块(栈)的指针进行操作将会出现不可知的结果;在使用delete释放内存后,再使用指针将会出现未知结果或导致程序崩溃。
In modern C++, manual allocation is actually only really necessary if you want to implement your own dynamic data structures / containers.
语法
定义变量
type varname;
定义可以与初始化结合。
type varname = value;
type varname = {value};
type varname{value}; // C++11: narrowing conversion ⇒ compiler warning
==基本数值类型变量在声明时不会被赋予默认值,其值是随机的。==
ClassName varname = ClassName(args); // 调用构造函数初始化变量
ClassName varname(args); // 简洁写法
ClassName varname = ClassName{args}; // c++11: narrow conversion
ClassName varname{args}; // 简洁写法
动态分配的变量返回变量的地址。
赋值
赋值运算默认具有值语义,即显式复制对象的数据成员,避免在非期望情况下修改数据;
-
避免将聚合类型变量的定义和初始化分开,否则则首先会调用默认构造函数执行初始化再随后执行赋值操作,造成额外开销。
-
==具有指针成员变量的类==应该重写赋值运算符和复制/移动构造函数,以处理动态分配对象的复制问题。否则,对已定义变量使用新构造对象赋值应注意,新构造对象仅具有临时生命周期,因此可能导致赋值后的变量中指针成员引用无效对象。
LinkedList l1; // LinkedList.header是指针成员变量 vector<int> v = {1, 2, 3, 4}; l1 = LinkedList(v); // 如果没有适当的赋值拷贝,由于临时创建对象释放,l1可能包含无效指针
引用语义
值语义(value semantics):赋值运算默认为值传递方式(包括函数输入输出参数)。
更接近数学记法:输入参数不会被函数改变;
we do not run into any memory management issues. No dangling references to nonexistent objects, no expensive and unnecessary free store allocation, no memory leaks, no smart or dumb pointers.
引用语义(reference semantics)
where you want to create an object, and let it live for a significant amount of time, and want different parties to modify the object, you need to pass by reference.
This is the case for globals like
std::coutthat need to be accessible from different places in the code, and it always has to be this very object at this very address.
指针:
they are objects that store values which are addresses in memory referring to objects.
at the higher level of abstraction passing and returning pointers to and from functions is usually considered passing by reference (reference semantics), even though technically you are passing values.
the reason people often resort to allocating objects in free store (on the heap) and returning a (more or less) smart pointer to it, is that value semantics does not play well with OO techniques that require access to objects via references or pointers to enable virtual function calls.
运算符
自增/自减
- prefix expressions
++x/--xreturns new (incremented/decremented) value; - postfix expression
x++/x--increments/decrements value, but returns old value;
逻辑运算
bool c = a && b; // false logical AND
bool d = a || b; // true logical OR
bool e = !a; // false logical NOT
Short-circuit Evaluation: The second operand of a boolean comparison is not evaluated if the result is already known after evaluating the first operand.
移位运算
只有整数类型能进行移位操作:
result = op1 >> op2 // 右移
result = op1 << op2 // 左移
其中op1是要进行移位的整数,op2是要偏移的位数。op1的值不会改变,移位的结果作为返回值,返回结果的类型与op1的类型相同(准确的说,返回类型应该是长整型,赋值的过程可以强制转换)。
如果op2=0,则实际不对op1移位;如果op2为负数或达到整数类型的bit长度,则结果未定义。实际测试(Windows/Linux)可以发现,移位运算会先对op2进行求余处理,使移位范围不超过整数的bit长度,再进行移位。
左移运算是逻辑移位,即右侧空出的位补零;如果op1是有符号数,则右移运算是算数移位,即左边空出的位填充符号位,如果op1是无符号数,则右移运算是逻辑移位,即左边空出的位补0。
控制流程
表达式(Expressions): series of computations (operators + operands); may produce a result.
Statements: sequence of expressions; do not produce a result; delimited by
;and grouped by{ }.
条件分支
if-else
if (condition1) {
// do this if condition1 is true
}
else {
// otherwise do this
}
// if(statement; condition) { … } C++17
else if是if嵌套在else语句块的结果。三元运算符:
condition ? true_statement : false_statement。
switch
switch (m) {
case 0: // do this if m is 0
break;
case 1:
case 3: // do this if m is 1 or 3
break;
default: // do this if m is not 0, 1 or 3
}
// switch (statement; variable) { … } C++17
Ternary Condition Operator
Result = Condition ? If-Expression : Else-Expression
循环
for (int i = 0; i < 5; ++i) {
cout << i << ' ';
}
std::vector<int> v {1,2,3,4,5};
for(auto i = begin(v); i != end(v); ++i) { cout << *i; }
for (int x : v) { cout << x << '\n'; } // c++11
while (j < 10) {
cout << j << ' ';
++j;
}
do {
cout << j << ' ';
--j;
} while (j > 0);
异常
try {...}
catch(std::invalid_argument&e){
throw; //re-throw exception
}catch(...){
// catch all exceptions
}
void funcname(...) noexcept {...} // throw exception not allowed
预处理命令
头文件
头文件用于集中存放函数原型声明和类型定义。
#include <filename>
按照标准方式搜索要包含的文件(将文件内容添加到当前处理的源文件中),该文件位于C++系统目录的include子目录下,一般要包含系统提供的标准文件时这样使用。
#include "filename"
首先在当前目录下搜索要包含的文件,如果没有,再按照标准方式搜索,*对用户自己编辑的文件,采用这种方式*。
宏
#define MACRO // 定义宏
#undef MACRO // 删除由define定义的宏
特殊宏
__LINE__; // 行号
__FILE__; // 文件名
__DATE__;
__TIME__;
__cplusplus; // 值为最新支持的c++标准发布时间
带参数的宏
#define LOG(x) std::cout << x << std::endl
条件编译指令
#if constant_expression
statements;
#elif constant_expression
statements;
#else
statements;
#endif
#ifdef identifier
statements;
#elif defined(identfier2)
statements;
#else
statements;
#endif
#ifndef identifier
statements;
#else
statements;
#endif
#ifdef和#ifndef用于判断一个宏是否已经定义,这两个命令常组合起来使用,在头文件中加入以下结构,用于防止头文件的重复包含。
#ifndef identifier
#define identifier
header_file_contents
#endif
#pragma once:保证在源文件中只会包含该头文件一次,避免类型的重复定义。
**注意:**不要在头文件中添加定义,因为该头文件如果被包含到不同源文件,在链接阶段会产生重复符号定义。
- 将函数声明为
static,但没有必要为每个源文件定义功能相同的函数; - ==将函数声明为
inline,则编译时函数体被替换为代码块==。
兼容C语言
使C++在编译C语言函数保持对C语言的兼容,在头文件中添加以下结构。
#ifdef __cplusplus
#if __cplusplus
extern "C"{
#endif
#endif
function-declare;
#ifdef __cplusplus
#if __cplusplus
}
#endif
#endif
注释
文档
C++ Docstrings
/**
* Create a new Triangle object of side lengths 1, 1, and 1.
* @brief Triangle class used for triangle manipulations.
* @details 细节
* @param a The Length of triangle side a.
* @return The length of side a.
* @see Triangle(const double a, const double b, const double c)
* @file 文件名
* @todo todo things
*/
/**
* @mainpage Triangle Library Documentation
* @author 作者
* @version 版本号
* @date 年-月-日
* @section intro_sec Introduction
* Do somethings ...
* @subsection install_dependencies Installing Dependencies
*/
doxygen
运行doxygen生成文档。
doxygen –g Doxyfile
Lei Mao's Log Book – C/C++ Documentation Using Doxygen
Doxygen Documentation Generator - Visual Studio Marketplace
函数
- encapsulation of implementation details
- easier reasoning about correctness and testing by breaking down problems into separate functions
- avoids repeating code for common tasks
返回类型推断:在编译期间可以确定返回类型。
auto foo (int i, double d) {
…
return i;
}
默认参数:
double f (double a, double b = 1.5) {
return (a * b);
}
函数声明(declaration):
- 告知编译器一个函数存在于某个源文件中。函数声明通常放置在头文件中,便于导入。
- 作为函数参数,接受声明类型的函数对象
int cmp(int &, int &);
参数传递
传入参数

Read from cheaply copyable object (all fundamental types) ⇒ pass by value;
Read from object with larger (> 64bit) memory footprint ⇒ pass by
type const &;Write to function-external object ⇒ pass by
type &.
可变参数列表
可变参数函数(如printf)的最后一个参数以“...”代替。
return_type func_name (param,...){...}
使用在“stdarg.h”中定义的类型(va_list指针类型)和宏(va_start、va_arg、va_end和va_copy)访问参数列表。
-
va_start:返回参数列表存储区的指针。使用可变参数列表必须至少提供一个占位的固定参数,这个参数可以不被函数使用。这样va_start才可以定位到参数列表的首地址。va_list ptr_args = va_start(param, param1); for(;ptr_args!=nullptr; ++ptr_args){ var_name = va_arg(ptr_args, type); } -
va_arg:返回一个参数。 -
va_end:将参数列表指针设为nullptr,等效标记为end。 -
va_copy: 将参数列表指针,赋值给另一个指针。
参数列表并没有显式的结束标识,因此在传递参数时,需要使用固定参数指定可变参数个数,或者使用特殊参数值标识参数列表结束。
传递数组作为参数
通过以上两种指针的定义及赋值,可以得知数组指针是有类型的,即数组指针的类型为:指明数组低维度长度的指针型变量,表示为:
type (*ptr_name)[N]...;
数组指针类型用于定义数组对象或==传递数组参数==。
数组也可通过引用类型传递,但必须显式指定数组长度,传递的参数必须与声明长度相同(否则产生编译错误)。
void print_array_ref(int (&array)[5]);
由于长度固定,难以通用。因此传递数组参数通常还是通过指针或容器对象(如std::vector和std::array)。
传递函数作为参数
函数指针:函数是特殊类型的对象,函数名是该对象的地址。可定义该函数类型的指针以引用该函数,并作为参数传递:
return_type (*ptr_func)(arg_types,...); // 定义函数类型时不需要形参名
ptr_func(arg_list); // => (*ptr_func)(arg_list);
函数指针可自动解引用,因此可以不添加
*运算符。
为了在定义函数参数时简化语法,可以预先定义函数类型:
typedef return_type (* FunctionType)(arg_types);
using FunctionType = return_type (*)(arg_types); // [c++11]
call_func(FunctionType call_func); // 传递函数参数
函数对象:
std::function<return_type (arg_types)> func_obj; // [c++11]
using func_type = std::function<return_type (arg_types)>;
返回值

返回多值:
==使用结构体来构造多返回值结构==。
使用
tuple和自动展开;std::make_pair(); // return tuple使用数组
std::array或向量std::vector(类型相同);==使用引用或指针类型输入参数作为输出参数==(可能产生歧义)。
可选参数
optional<int> x;
if (x) {} // x若未经初始化,则判断条件为false;代替传统使用空指针判断值是否可用。
函数重载
functions with the same name but different parameter lists.
如果一组函数具有相同的名称,但具有不同的输入参数模式(参数类型,参数个数,参数顺序),则这些参数可以同时存在于同一命名空间。重载(overload)就是在编译时通过传入参数的类型,来选择相应的函数。
不能通过访问权限、返回类型、抛出的异常进行重载。
对于继承来说,如果某一方法在父类中是访问权限是
private,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
运算符重载
运算符重载是对已有运算符赋予多重含义,使同一个运算符作用于不同类型的数据时导致不同的行为。运算符重载的实质是函数重载。
运算符可重载为独立函数或类的成员函数。运算符声明可能需要在相应操作数类定义中使用friend声明以访问操作数的非公开成员。
[friend] type operator op (params) { /*statements*/ }
op => +,-,*,/,[],++,--,...
重载为成员函数时:
- 对于单目运算符,则不需要参数;对于“++”和“--”,为了区分前置运算符和后置运算符,当重载为后置运算符是,增加一个整形参数,但该参数只用于区分,没有其它用途。
- 对于双目运算符,还需要将另一个操作数作为参数传入函数;
输出运算符
ostream& operator << (ostream& os, type T)
{ os << T.x << T.y; return os; }
比较运算符
C++使用值语义,因此比较运算符==,!=是比较对象的值。编译器不会自动为自定义类型生成比较运算符,需要自定义。
bool operator==(T1 const&, T2 const&)const=default; // c++20
=default:自动生成默认比较运算符(递归比较所有成员变量),无需给出函数原型;不用重载
!=运算符,编译器会自动根据==的定义生成!=运算符的定义。
c++20:compiler rewrites a calla == basb == aif necessary。
双目运算符的交换问题:双目运算符的运算数类型如果不同,需要声明不同的操作符重载,以满足定义的交换律。
优化
Return Value Optimization (RVO):在返回语句中构造对象时,将不会为返回值创建临时对象。
Type create_object(){
// ...
return Type(...) // Performing RVO
}
Type a = create_object();
由于类型在Stack上占用的空间在编译期间是确定的,因此编译器预先为返回值
a在Stack上分配空间(==相当于调用一个空的默认构造函数==)。通过修改函数原型以及函数行为,将该空间地址通过指针传递给调用函数,在返回语句构造对象时使用传入地址指定的空间,而非重新在Stack上分配一段内存空间。当函数执行完成时,将上述预分配空间的地址绑定到返回值。整个过程仅执行一次对象构造,而为执行优化时,将执行一次构造函数和两次复制构造函数(从局部对象到临时对象,从临时对象到返回值,临时对象实际也是在调用对象前通过指针传入函数)。
Named Return Value Optimization (NRVO):在返回语句中返回局部对象,将不会为返回值创建临时对象。
类似地,NRVO则是在要返回的局部变量在构造时,使用上层传入的Stack空间。
内联(inlining):Calls to small/short functions are replaced with the code of the function.
Inlining is a lot harder or sometimes impossible in many other languages like Java, C#, etc. with always-on polymorphism which means that all/most function/method calls can only be resolved at runtime.
主函数
#include <iostream>
int main (int argc, char* argv[]) {
for(int i = 0; i < argc; ++i) {
std::cout << argv[i] << '\n';
}
} // return 0 by default only for main function
- names
argcandargvare only a conventionargv[0]contains the program call
匿名函数
lambda class
编译器自动生成的函数对象,用于需要提供函数作为参数的位置。
[](P const& x, P const& y){ return x.c < y.c; }
[](auto x){ ... } // c++14
[](auto const & x){ ... }
[](auto &x){ ... }
输入参数为空则可以省略
()。
closure
instance of lambda class。
保存外部作用域的变量:
[=](...){...} // captures all by value
[&](...){...} // captures all by reference
[=x,&y](...){...} // captures x by value and y by reference
[= ,&y](...){...} // captures all by value except y by reference
保存闭包:闭包类型由编译器确定,因此使用auto表示结果。
auto f = [...](...){...}
聚合类型
将多个基本类型变量组合成一个聚合类型,相当于一个简单类型,成员变量根据声明顺序在内存中连续存储。
聚合类型是对逻辑上相关的函数和数据的封装,是对问题的抽象描述。提供成员访问限制,自定义初始化、解构、复制和赋值,成员函数;保证类行为的不变性、清晰性和正确性。
结构体
struct point {
int x; // ← "member variable"
int y;
};
point p1 = {10, 5};
point p2 {5, 10}; // c++11
- semantic data grouping:
point,date, …- avoids many function parameters and thus, confusion
- can return multiple values from function with one dedicated type instead of multiple non-const reference output parameters
类
class ClassName: public classA,…, protected classB,…, private classC,…
{
public: //外部接口
//构造函数
ClassName()=default;
[explicit]ClassName(args1, arg2,...){ /*initialization;*/}
virtual ~ClassName();//(虚)析构函数
//数据成员;
using value_type = std::uint64_t; //类型接口
//函数成员;
type func_name(params){}
private:
protected://保护成员
};
在C++中,
class和struct关键字都可用于定义类,不同之处在于两者的默认访问权限不同(class是private,struct是public)。Do not use leading underscores or double underscores in names of types, variables, functions, private data members.
继承语法:访问修饰符指明基类成员的访问方式,如果不显式给出,则默认为私有继承。
组合类:一个类的成员不仅包含基本数据类型,还包含其它类的对象。
成员变量
常量成员变量
==如果对象被声明成常量,那么限定只能调用对象的常成员函数以防止对象被修改。==
一般常量必须在声明时进行初始化,在C++的类中,常数据成员的初始化,在构造函数的初始化列表中完成,而不能在声明时初始化(C++11支持声明时初始化),或在构造函数的函数体中进行初始化。
静态成员变量
如果某个属性为整个类所共有,不属于任何一个具体对象,则采用static关键字声明为静态成员变量。静态成员在每个类中只有一个实例,实现同一类的不同对象之间的数据共享。
类内部只是静态成员的声明,静态成员(包括常量)需要在程序的全局作用域的某个位置对其进行定义和初始化。
由于类的静态成员变量在头文件中声明,其作用域为全局作用域而非文件作用域。因此需要将初始化放在某个源文件中,而不能放在头文件中;否则当头文件被多个源文件引用时,会分别执行多次定义产生符号冲突。
type class_name::static_var = value;
整数静态常量比较特别,可以在声明时进行初始化。
资源管理
构造函数
构造函数的函数名与类名相同,且没有返回值,被声明为公有函数。如果类中没有声明构造函数,或给出了无参构造函数的声明但没有给出实现,则编译器会自动生成一个默认的构造函数,不做任何事情;如果用户自定义了构造函数,则不会再自动生成默认构造函数,如果没有另外声明无参构造函数,则必须在声明对象时,提供必要的参数完成初始化。
尽可能避免书写特殊成员函数,除非需要资源分配。使用成员初始化器可以执行默认初始化,使用智能指针、容器等可以尽量减少人工管理内存分配,从而避免自定义析构函数。
初始化列表构造函数
初始化列表initializer_list是一种特殊可迭代容器,用于序列类型的初始化。
#include <initializer_list> // c++11
ClassA{ ClassA(std::initializer_list<int> li){...} }
ClassA a {1,3,4,5}; // {}调用初始化列表构造函数,而()调用其他构造函数
复制构造函数
复制构造函数是一种特殊的构造函数,具有一般构造函数的所有特性,其形参是本类对象的引用,其作用是使用一个已经存在的对象,去初始化一个同类型的新对象。如果没有在类中定义复制构造函数,则编译器会生成默认的复制构造函数,其功能是:把参数对象的每个数据成员的复制到新建立的对象中(如果声明了复制构造函数,则复制功能由复制构造函数完成,类将不会自动复制相应的变量)。
ClassName(const ClassName & obj); //复制构造函数
ClassName(const ClassName & obj)=delete; //禁用复制构造函数
浅拷贝:C++默认是值语义,因此进行赋值运算时,会复制类的所有成员,但使用原始指针引用的对象不会被复制(弱引用关系,不属于该类的成员)。==自定义复制构造函数和赋值运算符可以定义是否为指针引用的对象创建副本==。
Object(const Object& other){ // 默认复制类的成员
memcpy(this, &other, sizeof(Object))
}
复制构造函数的调用情况:
-
当用类的一个对象去初始化该类的另一个对象。
-
如果函数的形参是类的对象,调用函数时,用实参初始化形参。
-
如果函数的返回值是类的对象,函数执行完返回时,为了完成从子函数到主函数的值传递,创建一个临时对象,初始化该对象。
如果类不包含动态分配的资源,则一般使用默认的构造函数就足够了。 一般情况,每个对象所拥有的资源应该是相互独立的,这样一个对象的操作才不会影响到另一个对象。 但是使用默认复制构造函数,只能完成成员变量即相关资源的标识符的复制,而不能自动完成动态资源的分配。 这时候就需要程序定义复制构造函数,来完成动态分配资源的分配和值的复制。
“=”操作符的意义在于使用一个对象向另一个同类型对象赋值,这和初始化时使用一个对象对同类型对象进行初始化的原理基本相同。
“=”操作符的处理==可能还需要先释放对象已分配的资源==,再申请新的资源。
如果没有定义“=”操作符,则会自动生成一个与默认复制构造函数具有相同功能的操作符定义,因此,默认的“=”操作符并不能完成具有动态资源的对象的复制。
通常,定义了复制构造函数也就意味着需要定义“=”操作符。
ClassName& ClassName::operator = (ClassName const&);
https://en.cppreference.com/w/cpp/language/copy_constructor
移动语义
将对象在堆上的空间与新对象进行交换(新对象可能并未分配堆空间)。
std::swap(a,b);
移动构造函数和移动赋值函数
ClassName(const ClassName && obj); //移动构造函数
ClassName& ClassName::operator = (ClassName const&&); //移动赋值运算符
https://hackingcpp.com/cpp/lang/move_semantics.html
初始化
Resource Acquisition Is Initialization (RAII)
- acquire some resource (memory, file handle, connection, …) when object is constructed
- release/clean up resource when object is destroyed (de-allocate memory, close connection, …)
对象所占据的内存空间只是用于存放数据成员,函数成员不在每个对象中存储副本。但是如果该类包含虚函数,则虚函数地址存放在虚函数表中,将占用内存空间。
成员初始化列表
通过构造函数的初始化列表对成员变量进行初始化(构造)。==初始值可以来自构造函数的参数。====初始化列表也可以调用本类的其他构造函数代替单独变量初始化。==
class Foo {
int i_; // 1st
double x_; // 2nd
public:
Foo(): i_{10}, x_{3.14} { } // same order: i_ , x_
Foo(int i, double x): i_(i), x_(x) {}
};
成员初始化列表:使用
()或{}(C++11: narrowing conversion)传递参数。
初始化列表应首先给出父类的初始化声明,再给出当前类中成员变量的初始值(初始化顺序与成员的声明顺序保持一致)。构造函数执行的次序:
-
调用父类的构造函数初始化父类成员,顺序与继承声明一致(从左到右);
-
初始化基本类型或调用成员的构造函数,调用顺序与内嵌对象在类中声明的次序一致;
当未在初始化列表给出成员的初始化声明,则会调用该类型的默认构造函数(此时该类型需要具有默认构造函数)。而如果在构造函数体内对该成员通过赋值进行初始化,则会重复执行构造,造成性能开销。==因此应该优先使用成员初始化列表。==
-
执行构造函数体的内容。
隐式类型转换
只有一个参数的构造函数,其调用形式与强制类型转换的语法相同,因此,等效于同时重载了由指定类型到当前类型的(隐式)类型转换运算符。
type y;
ClassName x = y; // => 隐式转换:className x = ClassName(y);
当构造函数被
explicit关键字修饰时,则不会同时重载该运算符,因此上述代码不会进行隐式转换,从而赋值语句类型不兼容。
初始化器
C++11支持在声明成员变量时给出默认初始值。
class Foo {
int i_ = 10;
double x_ = 3.14;
};
析构函数
析构函数与构造函数的作用基本相反,用来完成对象被删除前的一些清理工作,在对象的生命期即将结束时被自动调用。和构造函数不同的是,析构函数不接受任何参数,但可以是虚函数。声明虚析构函数必须给出实现(参考虚函数)。
析构函数调用顺序由类的继承关系决定,与构造函数的调用顺序相反:即类本身的析构函数,类成员对象的析构函数,基类的析构函数。由于析构函数是自动调用的,因此无需显示调用父类析构函数。
成员函数
成员函数可以在类的声明之外单独定义(使用作用域限定符),在类声明中仅给出声明。
type ClassName::func_name(params){}
代码量较小的函数应该尽量放置于类定义中,以方便“内联”优化。
How to implement a feature / add new functionality?
- only need to access public data (e.g. via member functions) ⇒ implement as free standing function
- need to access private data ⇒ implement as member function
==use "action" functions instead of just "setters"==:usually models problems better; more fine-grained control; better code readability / expression of intent
在成员函数中访问成员变量/函数:
this指针
非静态成员函数的参数隐含了当前实例的指针this。
如果在Class的成员函数中没有可见的同名局部作用域标识符,那么在该函数内可以直接访问成员Member。反之,非静态成员需要通过this指针进行访问this->Member。
也可以使用作用域限定符
::访问类成员,通常作用域限定符用于访问静态成员,而实例成员通过this指针访问。
此外,this指针还可以用于在类内部调用需要该类指针的函数。
成员运算符
当运算符的第一个参数是自定义类型,可将该运算符定义/重载为自定义类的成员。
当第一个参数不是自定义类类型,则重载为独立运算符。也可将独立运算符在类内部以
friends修饰以确保其能访问类的内部数据。
类型转换运算符
类型转换函数用于自动==将类对象转换成其他兼容类型的对象==,从而实现类似基本数据类型隐式转换的功能。类型转换函数通过重载“(...)”操作符实现:
public operator type(); // 定义方法将当前类型转换为type
该函数原型比较特别,没有返回值,也不需要提供参数。但是函数结束前必须返回type类型的值。
指针转换运算符是为了方便对自定义模板类的指针进行强制类型转换而重载的,因为系统不能直接把自定义类的指针强制转换成基本类型的指针。指针转换运算符的重载函数比较特殊,它没有返回值(连void也没有)。
函数对象
重载()运算符的类。 ==函数对象可以通过私有变量保存内部状态==。
public type operator (args); // 注意函数原型与类型转换运算符的区别
obj(args); // 调用()重载的函数。
成员引用运算符*
当一个类封装另一个类对象或指针时(例如智能指针),如果要透明访问被封装类的成员,可以重载->运算符(普通版本以及常量版本):
InternalObject* operator->(){ return prt_obj;}
ExternalObject* m = new ExternalObject();
m->some_interal_member;
“=”和“[]”运算符
这两种运算符的适用场合,有可能作为表达式的左值出现,如
A[5]=2;
(a=b)++;
作为左值的量都必须是变量,否则无法进行赋值或自加等操作,这就要求在重载“=”和“[]”运算符时返回变量;由于函数的返回值是一个右值(临时变量),所以不满足要求。
所以在重载这两个操作符时,返回值应该是引用类型。当然,由于局部变量在函数结束时就消失了,所以不能返回局部变量的引用,否则对引用的操作将出现错误。
“=”返回左操组数(上面例子中a)的引用;
“[]”返回左操作数(上面例子的A)的索引对应项的引用。只能重载一维数组下标操作符(如何重载多维下标http://blog.sina.com.cn/s/blog_66ec4d660100mxq5.html)。
静态成员函数
static type static_function_declare();
class_name::static_function(); // 调用静态成员函数
静态成员函数只能访问类的静态成员函数/变量。
常量成员函数
type member_function_declare() const;
const可以用于修饰函数的返回值,表示对函数的返回值不可以做修改。
使用const关键字修饰成员函数,意味着成员函数具有“只读”属性,而不能修改对象(实例成员变量)或者调用任何非常成员函数。
使用
mutable修饰的成员是例外,可以被const方法修改。
const可以用于成员函数的重载(在声明和定义处都需要使用const修饰),当对象被声明成常量时,则该实例只能访问使用const成员函数,因为只有这样才能保证类的成员变量不会被修改。
对于一般对象,则常函数成员和非常函数成员都可以被调用。
当对象是变量时,优先调用同名非常成员函数(当没有声明非常成员函数时,调用同名常成员函数)。
const-qualify all non-modifying member functions。
访问静态成员
静态成员不与类的实例绑定,需要通过作用域限定符和类名进行访问。
ClassName::StaticMember;
ClassName::StaticMemberFunction(args);
访问限制
在类内部,所有的数据成员的为其成员函数所共享;通过静态数据成员,实现同一类的不同对象之间的数据共享。
访问关系是针对于类而言的,并不是针对类的实例。即对象的成员函数可以访问同一类型对象的所有成员变量。
访问控制的主要作用是限定代码的组织方式,对程序运行没有影响;实际上可以通过操纵指针绕过访问控制限制。

Friends
class A{…… friend class B; …… } // friend class
class A{…… type function(args); …… } // friend function
友元函数是在类中用关键字friend修饰的非成员函数,可以是普通函数也可以是其他类的成员函数,虽然它不是本类的成员函数,但是可以访问本类的私有和保护成员。
**友元关系是不能传递的:**A是B的友元,B是C的友元,如果没有声明,A和C是没有友元关系的;
**友元关系是单向的:**A是B的友元,如果没有声明,则B不是A的友元;
**友元关系是不被继承的:**如果A是B的友元,但A的派生类,如果没有声明,则不是B的友元。
自定义类型
https://hackingcpp.com/cpp/design/arithmetic_types.html
https://hackingcpp.com/cpp/design/node_based_data_structures.html
程序结构
命名空间
- 避免命名冲突;
- 将内容分为不同的部分。
命名空间仅用于防止命名冲突,不具有访问控制作用(访问控制修饰符修饰命名空间无效)。
定义
namespace my{
class vector {...};
namespace time{...}
}
一个文件中可以定义多个命名空间;同时,一个命名空间也可以出现在多个文件中。
命名空间可嵌套定义。
引入命名空间
my::vector v1;
using my::vector; // 单独引入命名空间中的定义
vector v2;
using my; // 引入命名空间中的所有定义
namespace mt = my::time; // 定义命名空间别名简化书写
避免在头文件中引入命名空间:引入命名空间会导入其中所有的声明到头文件中。该头文件再被其他文件引用时,可能造成命名冲突。
标识符作用域
-
局部作用域:在代码块中声明的标识符,其作用域从声明处开始,一直到块结束的大括号为止。**具有局部作用域的变量也称为局部变量。**函数体、控制语句块,空语句块等都是局部作用域。
-
类作用域:类
Class的成员Member具有类作用域,其范围为类的定义。 -
文件作用域:具有文件作用域的标识符其作用域开始于声明点,结束于文件尾。具有文件作用域的变量也称为全局变量。
命名空间将文件作用域进行了逻辑划分;
可见性
程序运行到某一点在,能够引用到的标识符就是该处可见的标识符。作用域可见性的规则:
- 标识符声明在前,引用在后;
- 在同一作用域中不能定义同名标识符;
- 在没有互相包含关系的不同作用域中定义的同名标识符,互不影响;
- 如果在两个或多个具有包含关系的作用域中声明了同名标识符,则外层标识符在内层不可见。
作用域限定符
用于在默认规则不可见的位置访问某些标识符。
- 访问命名空间中的成员(例如
std::cout); - 在类定义外部,定义函原型和初始化静态变量;
- 访问静态成员;
- 在类内部,识别多继承的同名成员;
对于静态成员,则通过作用域分辨符::进行访问:ClassName::M。
多继承的父类成员可见性。
前向声明
两个类不能相互引用作为其定义的一部分,因为这样无法确定任何一个类的类型。但是两个类可以相互引用其指针作为定义的一部分。
如果出现以上相互引用的情况下,一般地,应该互相包含其头文件,但这样又会造成头文件内容无法确定。为了解决这一问题,C++引入了前向声明,即==在定义类之前对类名进行声明==,则无需包含该类定义所在的头文件,即可定义该类的指针。
class c_a;
class c_b{
c_a *p_a;
}
多态
继承
类的继承,是新类从已有类那里得到已有的特性。同时,从已有类产生新类的过程就是派生。由原有类产生新类时,新类便包含了原有类的特性,同时也可以加入自己所有的新特性。
从对象的数据存储来看,组合类和派生的作用一样:如果把派生类的父类的实例都添加到一个新类的定义中,则派生类的这个新类有相同的数据成员,只是组织形式不同。但是组合类只能利用现有类提供的功能并在新类中定义新功能,而派生类在此基础上可以提供多态行为,即子类可以通过虚函数覆盖父类的同名函数。反之,如果不需要更改父类行为,使用组合类更简洁。
构造/析构函数
根据构造函数调用规则,应该在子类的初始化列表中调用父类构造函数。
虚继承
成员函数重载
运算符重载
覆盖
具有相同函数原型(即相同的函数名与输入参数列表)的函数不满足重载的条件,不能存在于同一命名空间。但具有相同原型的函数可存在于父类(接口)与子类(实现)中。子类(实现)提供的具有相同原型的函数是对父类(接口)的相应函数进行重定义,以替换原有的功能,这种方式称为覆盖(override)。
隐藏
当子类中定义与父类同名函数时,将无法直接访问父类的同名函数(即使非重载形式)。此时需要使用父类指针(在类外部)或作用域限定符(类内部)访问父类函数。
多继承情况下,如果继承多个父类的同名函数,也会导致父类同名函数的隐藏。
虚函数
对于从同一父类派生出的不同类的对象,如果使用==父类的指针==统一进行管理与访问,可以明显的简化程序。但使用父类指针引用子类对象只能访问到父类中定义的成员,而不能访问子类中的成员。如果需要使用父类的指针访问子类中的成员函数,就需要首先在父类中将该函数声明为虚函数(不能通过父类指针访问子类数据成员)。
虚函数是动态绑定的基础,虚函数必须是非静态的成员函数,虚函数经过派生后,在类族中就可以实现运行过程中的多态。虚函数的声明语法:
virtual type function_name(arg_list); // in parent class
type function_name(arg_list)override {statements} // in child class
[1] C++ 虚函数表解析. http://blog.csdn.net/haoel/article/details/1948051/。
虚函数的修饰符只能出现在类中函数声明处,而不能在函数实现处。在子类中不需要显式地给出虚函数的声明,当子类的成员函数满足重载条件时就会自动确定为虚函数。被覆盖的父类函数,任然可以通过作用域标识符来访问。
虚函数的适用条件
当子类需要修改父类的行为时,就应该将父类的相应函数声明为虚函数。而父类中声明的非虚函数,通常代表那些不希望被子类改变的功能,也是不能实现多态的。因此一般不要重写继承而来的非虚函数(虽然语法没有限制)。
在重写继承来的虚函数时,不能改变函数的默认形参值,因为:虽然虚函数是动态绑定的,但是默认形参值是静态绑定的。
虚函数必须给出实现,否则应该声明为纯虚函数。
虚析构函数
使用父类指针访问子类对象完成后,如果子类对象是动态分配的,这时存在的一个问题是:能否直接delete父类指针,完成子类对象的删除。在动态分配内存时,系统会记录下所分配的内存的首地址和分配长度,因此在执行删除操作时,无论指针指向的是父类对象还是子类对象,都能够正确的释放对象所占用的内存。
但是如果动态创建的对象中还有指向动态分配的内存空间的指针成员,则这样的删除就是不完全的,因为这些指针成员指向的动态分配的内存空间并不能得到释放(如同深拷贝与浅拷贝的原理一样,在构造函数中,浅拷贝只会复制指针,而不会另外增加一份指针指向的内容,这时需要深拷贝手动完成内容的赋值)。
动态空间的释放显然应该由析构函数来完成,其中父类的构造函数释放父类对象动态申请的内存空间,子类的构造函数释放子类对象动态申请的内存空间。当使用父类指针来实现多态时,由于通过父类指针只能直接访问父类成员,析构函数也是一样,这种情况下访问不到子类的析构函数(对象通过delete销毁获声明周期结束时,只会调用父类的构造函数),则不能完成子类动态分配空间的释放,因此要将父类的析构函数声明为虚函数。
抽象类
抽象类用于抽象和设计接口。一个抽象类无法实例化,只能通过继承将抽象类改写为非抽象类,然后再实例化。可以定义抽象类的指针和引用,通过指针和引用,就可以访问子类的对象,实现多态性。
纯虚函数
抽象类是带有纯虚函数的类。抽象方法、接口。
virtual tpye function_name(args...) = 0;
抽象类派生出新类后,如果子类中给出了所有纯虚函数的函数实现,这个子类就不再是抽象类,而可以实例化;反之,如果子类中没有完全给出所有纯虚函数的实现,那么这个子类就仍然是抽象类。
模板
模板定义语法
template <typename T,..., args> declaration;
其中,declaration可以表示函数或类的声明语法。模板参数包括:
-
类型参数,使用类型定义关键字(
class或typename)或者嵌套定义的类模板类型(template <typename T,...>ClassName); -
非类型参数,参数类型可以是整数,枚举,指针,引用或指向成员的指针,且==在编译时可以确定为常量==(类似于数组长度)。
模板参数可设置默认值。
编译器根据模板生成实际代码:定义模板并不定义实际类型或函数,只有在使用模板并传递相应的参数时,编译器才真正添加一个类型或函数。
函数模板
函数模板的声明语法:
template <typename T1, typename T2,...>
T2 function_name(T param,...){statements}
类型参数用来指定函数模板的参数类型和返回值类型,以及声明函数中的变量类型等。
实例化
fucntion_name<T>(args); // 可省略类型参数,当类型可由参数推导出
类模板
使用类模板使用户可以为类声明一种模式,使得类中的某些数据成员,某些成员函数的参数、返回值能取任意类型(包括系统预定义的和用户自定义的)。类模板的定义语法:
template <typename T1, typename T2, ..., int n,...>
class ClassName{member_declaration}
在类模板内部定义成员的方法与普通类成员的定义语法一样,可能用到模板参数表中定义的类型或数值参数。模板类成员可以是静态或非静态,数据或函数成员。
如果要在类模板定义范围以外定义其成员函数,则必须指定其所属的模板类,且模板类要指定相应的模板参数,即采用以下定义形式
template < class T1,class T2, ..., int n,...> T2 ClassName<T1,T2,...,n...>::functionname(arg_list){statements}静态数据成员的定义方法也类似。
类模板的成员函数也可作为函数模板来定义,即增加额外的模板参数,其声明和定义语法如下所示。
template <typename A1,...>
class ClassName(args_list){
template<typename T1,...>
T1 function_identifer(A1 param1, ...){statements}
}
==(在类中的声明形式与一般函数一致),而不能如普通类一样,将成员函数的实现放到源文件中(否则或出现链接错误,LINK2019/2001)==。
类模板实例化
使用一个模板类建立对象时,应该按以下形式声明:
ClassTemplate<T1,T2,...,n,...>obj1;
完美转发
Modern C++
Introducing Modern C++
C++标准
-
C++98 -
C++03 -
C++11 -
c++14 -
C++17 -
C++20Support in
gccis highly experimental, and will almost certainly change in incompatible ways in future releases.
C++特性
C++ v.s. C
| C++ | C |
|---|---|
| not a strict subset of C++ | |
| stronger type system | weak type system |
| high-level abstractions | only low-level memory abstraction |
powerful custom types (classes) | only data aggregation (struct) |
| use compiler as correctness checker | get the code to compile quickly |
| if it compiles, it should be correct | debugging is the real work |
C++ v.s. Java
| C++ | Java |
|---|---|
| ==value semantics for all types== | ==value semantics only for primitives (int, float,… )== |
| optional reference semantics for all types | baked-in reference semantics for class types |
| full control over memory (de-)allocation; no garbage collection | garbage collector; can degrade performance |
| deterministic & controllable object lifetime | no predictable object lifetime control |
| ⇒ memory frugal | ⇒ high memory consumption |
| aggressive inline can eliminate slow function calls | performance degradation due to un-devirtualizable, non-inlinable methods |
C++ v.s. Python
| C++ | Python |
|---|---|
| almost always faster | almost always slower (in practice around 25-50 times) |
| complex syntax and tons of features can be intimidating to newcomers | simple syntax; usually easy to comprehend |
| statically typed | dynamically typed |
| many types of bugs can be caught at compile time | many types of bugs will only manifest at runtime |
| suited for safety-critical large-scale systems | hard to build reliable large-scale systems |
| even simple, small-scope tasks can quickly require an expert knowledge of various arcane corner cases & quirks | tends to be more beginner-friendly and small scripts are usually quickly written |
| fairly small standard library but extensive ecosystem with libraries for nearly everything | ==batteries included philosophy== with tons of libraries only one import away |
https://isocpp.org/wiki/faq
数据类型
基础数据类型
0is alwaysfalse;everything else istrue。
字符类型:char型(1字节),wchar_t型(长度与平台相关可能是2或4字节),char16_t(2字节), char32_t(4字节)。
字面值
字面值类型包括:整数常量、字符常量、浮点数常量、字符串常量。此处的常量均是指字面值常量。
整数常量
整数常量可以声明为十进制、八进制、十六进制,有无符号,长或短整型。十进制数以非零数字开始,八进制以数字“0”为前导,十六进制以“0x”为前导。
后缀“u”或“U”用于声明该数值为无符号数,未添加该后缀则表示有符号数。
后缀“L”或“l”用于声明长整形。
后缀“i64”或“ll”或“LL”用于声明64位整形。
浮点常量
浮点常量中是必须包含小数点的定点数,还可以包含指数,还可以附加后缀用于声明类型。浮点数默认类型为double,当添加后缀“F”或“f”表示浮点型,“L”或“l”表示long double(long double和double的长度都是一样的,但是类型不相同)。
定点数的表示方法:
double x = 18.46, y = 38. ;
指数表示方法:
double x = 18.46e0, y = 18.46E1 ;
指数部分可以是负数。当浮点数包含指数时,定点数部分可以不包含小数点。
数值范围:
#include <limits>
std::numeric_limits<double>::max() // largest positive value
std::numeric_limits<double>::min() // smallest value > 0
std::numeric_limits<double>::lowest() // smallest negative value
std::numeric_limits<double>::epsilon() // smallest difference
一个整型类型可以转换成更宽位数的整型类型,这种转换称为整型提升。进行这种转换不改变数据的值。
字符常量
字符常量是使用“'”包围的一个或多个字符。
如果整型使用普通字符常量或宽字符常量声明,则不足位补零;如果普通字符或宽字符用多字符常量声明,则将丢弃高位(左边的)字符。超过四个字符的字符常量声明将出错。
在字符声明中,具有特殊意义的字符(\、'、"等)需要使用转义字符“\”消除特殊意义。转义序列有三种类型:
-
简单类型:
\' \" \? \\ \a \b \f \n \r \t \v; -
八进制转义序列(转移字符之后最长三位八进制数,超过三位则第二个字符开始,或者从第一非八进制数字结束):
\012; -
十六进制转义字符:转义字符后接“
x”,其后接十六进制数字,后接数字位数无限制,只能以非十六进制数字结束。十六进制转义字符首先去除多余的高位,然后将剩余的8位数字转换为整型,再将整型转换为字符,如果整形的无符号值大于255,则转换不能完成,编译时会出错。转移字符之后的字符如果不是特殊字符,则结果由具体的实现决定。
双引号在字符常量中可以不使用转义字符。
Microsoft Specification:通常只能是ASCII字符,包括96个字符:空格、水平制表符、垂直制表符、换行符、Formfeed和26个大小写字符、10个数字、以及下列字符:
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '对于转义字符之后的非特殊意义字符,非特殊字符将正常显示,而转义字符不会显示;编译时会出现警告“不可识别的字符转移序列”。
字符串常量
一个字符串常量由0个或多个字符构成,有双引号所包围,字符串代表一个由“null”结尾的字符序列。字符串中可以包含所有字符常量允许使用的字符,以及使用转义字符。C++字符串包含两种类型:char[],wchar_t[]。
wchar_t w[] = L"wide string";
声明
wchar_t字符或字符串常量需要添加一个前缀“L”,类似地u用于char16_t类型字面值,U用于char32_t类型字面值。通过指向常量字符串的指针修改常量字符串是不允许的,结果未知。
以空格分隔的字符串会被自动拼接为单个字符串(也可以在行末使用“\”连接两行。)。
const char* b = "first" "second" // ⇒ "first second"
原始字符转字面值:
char const * ch_array = R"(raw "C"-string c:\users\joe )"; // c++11
Microsoft Specification:在一些情况下,声明的相同的字符串将被合并为一个字符串,在内存中使用同一段内存。
字符串的字面值最大长度为2048字节,对于
char和wchar_t都一样。如果定义了UNICODE,则
_T()等效于前缀L。
枚举
限定作用域枚举,使用枚举类型名访问枚举成员。
enum class day:short { mon, tue, wed, thu, fri, sat, sun };
day d = day::mon;
非限定作用域枚举,不同的枚举类型不能包含相同名字的成员。
enum day { mon, tue, wed, thu, fri, sat, sun };
day d = mon;
可以为枚举指定底层整数类型(char, short, long,...,默认为int)。可以将枚举强制转换为其底层类型。
引用
引用声明以后就是绑定到变量的别名,对引用名再赋值等效于修改绑定变量的值,因此无法再修改引用本身(赋值)使之绑定到其他变量。由于引用是变量的别名,因此通过引用总是能访问有效的变量。
[const] ValueType [const] & ref_name = VarName;
const声明符可以位于类型的前面或后面,但后者与指针类型声明风格保持一致。references cannot be "null", i.e., they must always refer to an object
int i = 2, k = 3;
int& ri = i; // reference to i
ri = k; // assign new value to ri(i)
如果引用声明为常量,则无法通过该引用修改变量的值。
引用的应用
-
作为函数、“
[]”和“=”操作符的返回值,满足左操作数可以被赋值的要求(L-value)。Dangling Reference:
不要返回局部变量的引用;
引用容器元素在修改容器后可能失效;
-
作为函数参数,等价于使用指针进行参数传递,而无须复制实际参数。
-
在迭代循环中使用
for(std::string & s : v) { cin >> s; } // modify vector elements for(std::string const& s : v) { cout << s; } // read-only access for(auto & s : v) { cin >> s; } for(auto const& s : v) { cout << s; } -
Avoid Output Parameters! 难以确定参数是否发生变化,参数是否仅作为输出或还作为输入。
-
Just take returned objects by value. This does not involve expensive copies for most functions and types in modern C++, especially in C++17 and above.
使用引用绑定函数返回值将导致临时变量的生命周期变长。
引用绑定规则
Rvalues and Lvalues
左值(Lvalues):expressions of which we can get memory address
- 内存中可引用的对象
- 具有名字的对象 (variables, function parameters, …)
右值(Rvalues):expressions of which we can't get memory address
- 字面值(
123,"string literal", …)(位于代码区); - 运算的零时结果;
- 函数返回的零时变量;
左值引用:type&,仅能绑定到左值;type const&可绑定到const左值和右值;
右值引用:type&&,仅能绑定到右值(涉及类型推断的除外);
万能引用(转发引用):根据类型推断的结果,可能为左值或右值引用。
auto&& ref = var;
template<typename T> void f(T&& param);
类型推导是必要条件,被推导类型必须为
T&&,其中T是模板类型参数。
类型语法
类型别名
using NewType = OldType; // C++11
typedef OldType NewType; // C++98
类型推断
auto variable = expression; // c++11
类型转换
static_cast(v):强制类型转换,编译器允许执行(但不一定是自动执行的)的任何转换都可以完成。避免发生精度损失时的警告。类似于C语法type(var)。
const_cast(v):去除常量性质,是变量能够被修改。
dynamic_cast(v):运行时动态识别类型。将基类类型的指针或引用安全地转换为派生类型的指针或引用。
reinterpret_cast(v):对于编译器不允许的转换类型(如指针类型转换),可以使用reinterpret_cast进行强制转换而不产生编译期错误。
std:move(T&&)将参数强制转换为右值;
std:forward<T>(param):仅当实参为右值时,将形参转换为右值;
指针
指针可以用于访问对象,且可以在运行期间改变其引用的对象(引用则不能修改)。指针的一个重要用途是函数参数传递,使用指针可以进行地址传递,则主函数和子函数可以访问同一段内存的变量。
原始指针
指针存储内存地址的整数变量。通过取地址运算符&获取变量地址。
int a = 1;
int* ptr = &a;
或通过动态内存分配获取堆上创建的变量的地址。
指针运算
指针可以进行赋值运算、算数运算、关系运算和解引用运算。
*:对象引用运算符;
->:对象成员引用运算符;
point *p = new point{1,2};
cout << p->x << p->y << *(p).x;
优先使用引用,语法更加简洁。
智能指针(C++11)
unique_ptr
不能复制指针,但可以移动指针指向的对象到新的指针,原指针被置为nullptr。
#include <memory>
auto p = make_unique<Type>(init_list); // c++14, more safe
std::unique_ptr<Type> p1(new Type(args)); // c++14
auto p2 = move(p); // 不能复制unique_ptr
仍然使用
->运算符访问类型的成员。
shared_ptr
#include <memory>
auto p = make_shared<Type>(init_list); // c++14
std::shared_ptr<Type> p1(new Type(args)); // c++14
auto p2 = p;
引用计数:当最后引用对象的指针被销毁时,对象被销毁。
weak_ptr可以复制shared_ptr但不影响引用计数。
数组
type array[N];
type array[N] = {1,2,3,...};
当初始化列表给定时,可省略数组长度参数。==数组长度?==
动态创建数组:
type* ptr_array = new type[size];
type* ptr_array = new type[size]{1,2,...};
多维数组:创建$M\times N\times\cdots$维数组。
type array[M][N]...[];
type (*ptr)[N]... = new type[size][N]...;
仅有数组的最高维度是可以动态分配的,将其他维度整体看作一个整体(子数组)。
K维数组可以看成由size个维度为K-1的子数组构成的。分配一维数组,实际上是分配连续的size个基本变量;分配二维数组,实际上是连续分配size个一维数组,以此类推……动态创建数组时只有
size是变量,其他参数必须是编译期确定的常量(字面值或constexpr)。指向数组的指针进行“加减”运算,指针加减1实际对应的内存地址偏移量为对应子数组的内存占用长度。
指针数组
即数组元素是指针类型。指针数组的声明:
type* ptr_array[L1][L2]...;
type(*ptr_array[L1][L2]...)[M][N]...[P];
其中[L1][L2]...是指针数组本身的维度,而type(*)[M][N]...[P]代表最终指向的数据类型。如果带参数[M][N]...[P],则代表指向的是数组(的维度);如果没有该参数则为指向变量的指针(此时不省略()会生成警告)。
数组索引
array_name[index];
*(array_name+index);
数组名相当于指针常量。
高维数组在内存中实际上是按照线性方式存储数据的,所以实质上等效于是一个一维数组,所以仍然可以定义一维数组指针来访问数组元素。则指向第一个元素的一维数组指针的值应该是:
type *ptr = array[M][N]...; // 省略最后一维
type *ptr = &array[M][N]...[P]; // 或直接取元素地址
类型修饰符
静态变量
static int x = 1; // 定义静态(文件作用域)变量
extern int x; // 引用全局(非静态)变量,不推荐使用全局变量
可以在头文件中定义静态变量,引用该头文件的源文件将分别生成独立的文件作用域静态变量。
局部静态变量:静态变量定义在非全局作用域(如函数内部)。该变量的生命周期为程序生命周期,但仅能在定义该变量的作用域中访问。==局部静态变量只会在定义位置被初始化一次==。
全局变量构造器:在静态函数中返回静态变量的引用。
常量
Type const variable_name = value;
const Type variable_name = value;
用const关键字可以代替#define宏,使用const关键字声明的常量在编译时可以进行类型检查,而使用#define宏定义的常量则不能。
常量表达式
表达式的值在编译期间是确定的,其组成部分都是常量表达式。
constexpr int i = 2; // OK '2' is a literal
constexpr int cxf(int i) { return i*2; }
constexpr int j = cxf(5); // OK, cxf is constexpr
constexpr int k = cxf(i); // OK, cxf and i are constexpr
c++14:常量表达式函数内部可以包含多条语句;
常量相关指针
常量指针:指针本身是常量,即不能更改指针本身(所存储的内存位置),但可以更改指针指向的内容。
指向常量的指针:指针所指的内容必须是常量,不能修改指针所指的内容,但可以修改指针本身(所存储的内存地址)。可以用于函数参数,防止函数改变通过指针传入的参数。
type *const ptr; // const pointer to variable of Type <type>
type const *ptr; // pointer to const variable of Type <type>
type const *const:指针本身不能改变,指针所指的值也不允许改变。
从右到左解释类型声明。
内存模型
heap: used for objects of dynamic storage duration;
空闲内存块列表。
stack: used for objects of automatic storage duration: local variables, function parameters, etc.
栈分配通常从高地址到低地址。
内存占用
基本数据类型的区别主要在于内存占用量。
sizeof(char); // 操作符: auto x = sizeof char
Integer Size Guarantees C++11
#include <cstdint>exact size:
int8_t,int16_t,int32_t,int64_t,unt8_t, …
动态内存分配
C++使用new和delete关键字进行动态内存管理。当使用new关键字为变量在堆上分配内存并返回内存地址,并自动调用构造函数进行初始化。如果分配内存失败,new返回nullptr或抛出异常。
nullptr为指针默认值(转换为false,可以用于逻辑判断)。
type *ptr = new type(args); // type *ptr = new type{args};
type *ptr = new type[const_num]{init_list};
delete ptr; // delete variable
delete [] ptr; // delete array
无法从指针类型判断其是只想单个变量或数组。
使用delete关键字对值为nullptr的指针进行操作不会出错;但使用delete对不是用new分配的内存块(栈)的指针进行操作将会出现不可知的结果;在使用delete释放内存后,再使用指针将会出现未知结果或导致程序崩溃。
In modern C++, manual allocation is actually only really necessary if you want to implement your own dynamic data structures / containers.
语法
定义变量
type varname;
定义可以与初始化结合。
type varname = value;
type varname = {value};
type varname{value}; // C++11: narrowing conversion ⇒ compiler warning
==基本数值类型变量在声明时不会被赋予默认值,其值是随机的。==
ClassName varname = ClassName(args); // 调用构造函数初始化变量
ClassName varname(args); // 简洁写法
ClassName varname = ClassName{args}; // c++11: narrow conversion
ClassName varname{args}; // 简洁写法
动态分配的变量返回变量的地址。
赋值
赋值运算默认具有值语义,即显式复制对象的数据成员,避免在非期望情况下修改数据;
-
避免将聚合类型变量的定义和初始化分开,否则则首先会调用默认构造函数执行初始化再随后执行赋值操作,造成额外开销。
-
==具有指针成员变量的类==应该重写赋值运算符和复制/移动构造函数,以处理动态分配对象的复制问题。否则,对已定义变量使用新构造对象赋值应注意,新构造对象仅具有临时生命周期,因此可能导致赋值后的变量中指针成员引用无效对象。
LinkedList l1; // LinkedList.header是指针成员变量 vector<int> v = {1, 2, 3, 4}; l1 = LinkedList(v); // 如果没有适当的赋值拷贝,由于临时创建对象释放,l1可能包含无效指针
引用语义
值语义(value semantics):赋值运算默认为值传递方式(包括函数输入输出参数)。
更接近数学记法:输入参数不会被函数改变;
we do not run into any memory management issues. No dangling references to nonexistent objects, no expensive and unnecessary free store allocation, no memory leaks, no smart or dumb pointers.
引用语义(reference semantics)
where you want to create an object, and let it live for a significant amount of time, and want different parties to modify the object, you need to pass by reference.
This is the case for globals like
std::coutthat need to be accessible from different places in the code, and it always has to be this very object at this very address.
指针:
they are objects that store values which are addresses in memory referring to objects.
at the higher level of abstraction passing and returning pointers to and from functions is usually considered passing by reference (reference semantics), even though technically you are passing values.
the reason people often resort to allocating objects in free store (on the heap) and returning a (more or less) smart pointer to it, is that value semantics does not play well with OO techniques that require access to objects via references or pointers to enable virtual function calls.
运算符
自增/自减
- prefix expressions
++x/--xreturns new (incremented/decremented) value; - postfix expression
x++/x--increments/decrements value, but returns old value;
逻辑运算
bool c = a && b; // false logical AND
bool d = a || b; // true logical OR
bool e = !a; // false logical NOT
Short-circuit Evaluation: The second operand of a boolean comparison is not evaluated if the result is already known after evaluating the first operand.
移位运算
只有整数类型能进行移位操作:
result = op1 >> op2 // 右移
result = op1 << op2 // 左移
其中op1是要进行移位的整数,op2是要偏移的位数。op1的值不会改变,移位的结果作为返回值,返回结果的类型与op1的类型相同(准确的说,返回类型应该是长整型,赋值的过程可以强制转换)。
如果op2=0,则实际不对op1移位;如果op2为负数或达到整数类型的bit长度,则结果未定义。实际测试(Windows/Linux)可以发现,移位运算会先对op2进行求余处理,使移位范围不超过整数的bit长度,再进行移位。
左移运算是逻辑移位,即右侧空出的位补零;如果op1是有符号数,则右移运算是算数移位,即左边空出的位填充符号位,如果op1是无符号数,则右移运算是逻辑移位,即左边空出的位补0。
控制流程
表达式(Expressions): series of computations (operators + operands); may produce a result.
Statements: sequence of expressions; do not produce a result; delimited by
;and grouped by{ }.
条件分支
if-else
if (condition1) {
// do this if condition1 is true
}
else {
// otherwise do this
}
// if(statement; condition) { … } C++17
else if是if嵌套在else语句块的结果。三元运算符:
condition ? true_statement : false_statement。
switch
switch (m) {
case 0: // do this if m is 0
break;
case 1:
case 3: // do this if m is 1 or 3
break;
default: // do this if m is not 0, 1 or 3
}
// switch (statement; variable) { … } C++17
Ternary Condition Operator
Result = Condition ? If-Expression : Else-Expression
循环
for (int i = 0; i < 5; ++i) {
cout << i << ' ';
}
std::vector<int> v {1,2,3,4,5};
for(auto i = begin(v); i != end(v); ++i) { cout << *i; }
for (int x : v) { cout << x << '\n'; } // c++11
while (j < 10) {
cout << j << ' ';
++j;
}
do {
cout << j << ' ';
--j;
} while (j > 0);
异常
try {...}
catch(std::invalid_argument&e){
throw; //re-throw exception
}catch(...){
// catch all exceptions
}
void funcname(...) noexcept {...} // throw exception not allowed
预处理命令
头文件
头文件用于集中存放函数原型声明和类型定义。
#include <filename>
按照标准方式搜索要包含的文件(将文件内容添加到当前处理的源文件中),该文件位于C++系统目录的include子目录下,一般要包含系统提供的标准文件时这样使用。
#include "filename"
首先在当前目录下搜索要包含的文件,如果没有,再按照标准方式搜索,*对用户自己编辑的文件,采用这种方式*。
宏
#define MACRO // 定义宏
#undef MACRO // 删除由define定义的宏
特殊宏
__LINE__; // 行号
__FILE__; // 文件名
__DATE__;
__TIME__;
__cplusplus; // 值为最新支持的c++标准发布时间
带参数的宏
#define LOG(x) std::cout << x << std::endl
条件编译指令
#if constant_expression
statements;
#elif constant_expression
statements;
#else
statements;
#endif
#ifdef identifier
statements;
#elif defined(identfier2)
statements;
#else
statements;
#endif
#ifndef identifier
statements;
#else
statements;
#endif
#ifdef和#ifndef用于判断一个宏是否已经定义,这两个命令常组合起来使用,在头文件中加入以下结构,用于防止头文件的重复包含。
#ifndef identifier
#define identifier
header_file_contents
#endif
#pragma once:保证在源文件中只会包含该头文件一次,避免类型的重复定义。
**注意:**不要在头文件中添加定义,因为该头文件如果被包含到不同源文件,在链接阶段会产生重复符号定义。
- 将函数声明为
static,但没有必要为每个源文件定义功能相同的函数; - ==将函数声明为
inline,则编译时函数体被替换为代码块==。
兼容C语言
使C++在编译C语言函数保持对C语言的兼容,在头文件中添加以下结构。
#ifdef __cplusplus
#if __cplusplus
extern "C"{
#endif
#endif
function-declare;
#ifdef __cplusplus
#if __cplusplus
}
#endif
#endif
注释
文档
C++ Docstrings
/**
* Create a new Triangle object of side lengths 1, 1, and 1.
* @brief Triangle class used for triangle manipulations.
* @details 细节
* @param a The Length of triangle side a.
* @return The length of side a.
* @see Triangle(const double a, const double b, const double c)
* @file 文件名
* @todo todo things
*/
/**
* @mainpage Triangle Library Documentation
* @author 作者
* @version 版本号
* @date 年-月-日
* @section intro_sec Introduction
* Do somethings ...
* @subsection install_dependencies Installing Dependencies
*/
doxygen
运行doxygen生成文档。
doxygen –g Doxyfile
Lei Mao's Log Book – C/C++ Documentation Using Doxygen
Doxygen Documentation Generator - Visual Studio Marketplace
函数
- encapsulation of implementation details
- easier reasoning about correctness and testing by breaking down problems into separate functions
- avoids repeating code for common tasks
返回类型推断:在编译期间可以确定返回类型。
auto foo (int i, double d) {
…
return i;
}
默认参数:
double f (double a, double b = 1.5) {
return (a * b);
}
函数声明(declaration):
- 告知编译器一个函数存在于某个源文件中。函数声明通常放置在头文件中,便于导入。
- 作为函数参数,接受声明类型的函数对象
int cmp(int &, int &);
参数传递
传入参数
Read from cheaply copyable object (all fundamental types) ⇒ pass by value;
Read from object with larger (> 64bit) memory footprint ⇒ pass by
type const &;Write to function-external object ⇒ pass by
type &.
可变参数列表
可变参数函数(如printf)的最后一个参数以“...”代替。
return_type func_name (param,...){...}
使用在“stdarg.h”中定义的类型(va_list指针类型)和宏(va_start、va_arg、va_end和va_copy)访问参数列表。
-
va_start:返回参数列表存储区的指针。使用可变参数列表必须至少提供一个占位的固定参数,这个参数可以不被函数使用。这样va_start才可以定位到参数列表的首地址。va_list ptr_args = va_start(param, param1); for(;ptr_args!=nullptr; ++ptr_args){ var_name = va_arg(ptr_args, type); } -
va_arg:返回一个参数。 -
va_end:将参数列表指针设为nullptr,等效标记为end。 -
va_copy: 将参数列表指针,赋值给另一个指针。
参数列表并没有显式的结束标识,因此在传递参数时,需要使用固定参数指定可变参数个数,或者使用特殊参数值标识参数列表结束。
传递数组作为参数
通过以上两种指针的定义及赋值,可以得知数组指针是有类型的,即数组指针的类型为:指明数组低维度长度的指针型变量,表示为:
type (*ptr_name)[N]...;
数组指针类型用于定义数组对象或==传递数组参数==。
数组也可通过引用类型传递,但必须显式指定数组长度,传递的参数必须与声明长度相同(否则产生编译错误)。
void print_array_ref(int (&array)[5]);
由于长度固定,难以通用。因此传递数组参数通常还是通过指针或容器对象(如std::vector和std::array)。
传递函数作为参数
函数指针:函数是特殊类型的对象,函数名是该对象的地址。可定义该函数类型的指针以引用该函数,并作为参数传递:
return_type (*ptr_func)(arg_types,...); // 定义函数类型时不需要形参名
ptr_func(arg_list); // => (*ptr_func)(arg_list);
函数指针可自动解引用,因此可以不添加
*运算符。
为了在定义函数参数时简化语法,可以预先定义函数类型:
typedef return_type (* FunctionType)(arg_types);
using FunctionType = return_type (*)(arg_types); // [c++11]
call_func(FunctionType call_func); // 传递函数参数
函数对象:
std::function<return_type (arg_types)> func_obj; // [c++11]
using func_type = std::function<return_type (arg_types)>;
返回值
返回多值:
==使用结构体来构造多返回值结构==。
使用
tuple和自动展开;std::make_pair(); // return tuple使用数组
std::array或向量std::vector(类型相同);==使用引用或指针类型输入参数作为输出参数==(可能产生歧义)。
可选参数
optional<int> x;
if (x) {} // x若未经初始化,则判断条件为false;代替传统使用空指针判断值是否可用。
函数重载
functions with the same name but different parameter lists.
如果一组函数具有相同的名称,但具有不同的输入参数模式(参数类型,参数个数,参数顺序),则这些参数可以同时存在于同一命名空间。重载(overload)就是在编译时通过传入参数的类型,来选择相应的函数。
不能通过访问权限、返回类型、抛出的异常进行重载。
对于继承来说,如果某一方法在父类中是访问权限是
private,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
运算符重载
运算符重载是对已有运算符赋予多重含义,使同一个运算符作用于不同类型的数据时导致不同的行为。运算符重载的实质是函数重载。
运算符可重载为独立函数或类的成员函数。运算符声明可能需要在相应操作数类定义中使用friend声明以访问操作数的非公开成员。
[friend] type operator op (params) { /*statements*/ }
op => +,-,*,/,[],++,--,...
重载为成员函数时:
- 对于单目运算符,则不需要参数;对于“++”和“--”,为了区分前置运算符和后置运算符,当重载为后置运算符是,增加一个整形参数,但该参数只用于区分,没有其它用途。
- 对于双目运算符,还需要将另一个操作数作为参数传入函数;
输出运算符
ostream& operator << (ostream& os, type T)
{ os << T.x << T.y; return os; }
比较运算符
C++使用值语义,因此比较运算符==,!=是比较对象的值。编译器不会自动为自定义类型生成比较运算符,需要自定义。
bool operator==(T1 const&, T2 const&)const=default; // c++20
=default:自动生成默认比较运算符(递归比较所有成员变量),无需给出函数原型;不用重载
!=运算符,编译器会自动根据==的定义生成!=运算符的定义。
c++20:compiler rewrites a calla == basb == aif necessary。
双目运算符的交换问题:双目运算符的运算数类型如果不同,需要声明不同的操作符重载,以满足定义的交换律。
优化
Return Value Optimization (RVO):在返回语句中构造对象时,将不会为返回值创建临时对象。
Type create_object(){
// ...
return Type(...) // Performing RVO
}
Type a = create_object();
由于类型在Stack上占用的空间在编译期间是确定的,因此编译器预先为返回值
a在Stack上分配空间(==相当于调用一个空的默认构造函数==)。通过修改函数原型以及函数行为,将该空间地址通过指针传递给调用函数,在返回语句构造对象时使用传入地址指定的空间,而非重新在Stack上分配一段内存空间。当函数执行完成时,将上述预分配空间的地址绑定到返回值。整个过程仅执行一次对象构造,而为执行优化时,将执行一次构造函数和两次复制构造函数(从局部对象到临时对象,从临时对象到返回值,临时对象实际也是在调用对象前通过指针传入函数)。
Named Return Value Optimization (NRVO):在返回语句中返回局部对象,将不会为返回值创建临时对象。
类似地,NRVO则是在要返回的局部变量在构造时,使用上层传入的Stack空间。
内联(inlining):Calls to small/short functions are replaced with the code of the function.
Inlining is a lot harder or sometimes impossible in many other languages like Java, C#, etc. with always-on polymorphism which means that all/most function/method calls can only be resolved at runtime.
主函数
#include <iostream>
int main (int argc, char* argv[]) {
for(int i = 0; i < argc; ++i) {
std::cout << argv[i] << '\n';
}
} // return 0 by default only for main function
- names
argcandargvare only a conventionargv[0]contains the program call
匿名函数
lambda class
编译器自动生成的函数对象,用于需要提供函数作为参数的位置。
[](P const& x, P const& y){ return x.c < y.c; }
[](auto x){ ... } // c++14
[](auto const & x){ ... }
[](auto &x){ ... }
输入参数为空则可以省略
()。
closure
instance of lambda class。
保存外部作用域的变量:
[=](...){...} // captures all by value
[&](...){...} // captures all by reference
[=x,&y](...){...} // captures x by value and y by reference
[= ,&y](...){...} // captures all by value except y by reference
保存闭包:闭包类型由编译器确定,因此使用auto表示结果。
auto f = [...](...){...}
聚合类型
将多个基本类型变量组合成一个聚合类型,相当于一个简单类型,成员变量根据声明顺序在内存中连续存储。
聚合类型是对逻辑上相关的函数和数据的封装,是对问题的抽象描述。提供成员访问限制,自定义初始化、解构、复制和赋值,成员函数;保证类行为的不变性、清晰性和正确性。
结构体
struct point {
int x; // ← "member variable"
int y;
};
point p1 = {10, 5};
point p2 {5, 10}; // c++11
- semantic data grouping:
point,date, …- avoids many function parameters and thus, confusion
- can return multiple values from function with one dedicated type instead of multiple non-const reference output parameters
类
class ClassName: public classA,…, protected classB,…, private classC,…
{
public: //外部接口
//构造函数
ClassName()=default;
[explicit]ClassName(args1, arg2,...){ /*initialization;*/}
virtual ~ClassName();//(虚)析构函数
//数据成员;
using value_type = std::uint64_t; //类型接口
//函数成员;
type func_name(params){}
private:
protected://保护成员
};
在C++中,
class和struct关键字都可用于定义类,不同之处在于两者的默认访问权限不同(class是private,struct是public)。Do not use leading underscores or double underscores in names of types, variables, functions, private data members.
继承语法:访问修饰符指明基类成员的访问方式,如果不显式给出,则默认为私有继承。
组合类:一个类的成员不仅包含基本数据类型,还包含其它类的对象。
成员变量
常量成员变量
==如果对象被声明成常量,那么限定只能调用对象的常成员函数以防止对象被修改。==
一般常量必须在声明时进行初始化,在C++的类中,常数据成员的初始化,在构造函数的初始化列表中完成,而不能在声明时初始化(C++11支持声明时初始化),或在构造函数的函数体中进行初始化。
静态成员变量
如果某个属性为整个类所共有,不属于任何一个具体对象,则采用static关键字声明为静态成员变量。静态成员在每个类中只有一个实例,实现同一类的不同对象之间的数据共享。
类内部只是静态成员的声明,静态成员(包括常量)需要在程序的全局作用域的某个位置对其进行定义和初始化。
由于类的静态成员变量在头文件中声明,其作用域为全局作用域而非文件作用域。因此需要将初始化放在某个源文件中,而不能放在头文件中;否则当头文件被多个源文件引用时,会分别执行多次定义产生符号冲突。
type class_name::static_var = value;
整数静态常量比较特别,可以在声明时进行初始化。
资源管理
构造函数
构造函数的函数名与类名相同,且没有返回值,被声明为公有函数。如果类中没有声明构造函数,或给出了无参构造函数的声明但没有给出实现,则编译器会自动生成一个默认的构造函数,不做任何事情;如果用户自定义了构造函数,则不会再自动生成默认构造函数,如果没有另外声明无参构造函数,则必须在声明对象时,提供必要的参数完成初始化。
尽可能避免书写特殊成员函数,除非需要资源分配。使用成员初始化器可以执行默认初始化,使用智能指针、容器等可以尽量减少人工管理内存分配,从而避免自定义析构函数。
初始化列表构造函数
初始化列表initializer_list是一种特殊可迭代容器,用于序列类型的初始化。
#include <initializer_list> // c++11
ClassA{ ClassA(std::initializer_list<int> li){...} }
ClassA a {1,3,4,5}; // {}调用初始化列表构造函数,而()调用其他构造函数
复制构造函数
复制构造函数是一种特殊的构造函数,具有一般构造函数的所有特性,其形参是本类对象的引用,其作用是使用一个已经存在的对象,去初始化一个同类型的新对象。如果没有在类中定义复制构造函数,则编译器会生成默认的复制构造函数,其功能是:把参数对象的每个数据成员的复制到新建立的对象中(如果声明了复制构造函数,则复制功能由复制构造函数完成,类将不会自动复制相应的变量)。
ClassName(const ClassName & obj); //复制构造函数
ClassName(const ClassName & obj)=delete; //禁用复制构造函数
浅拷贝:C++默认是值语义,因此进行赋值运算时,会复制类的所有成员,但使用原始指针引用的对象不会被复制(弱引用关系,不属于该类的成员)。==自定义复制构造函数和赋值运算符可以定义是否为指针引用的对象创建副本==。
Object(const Object& other){ // 默认复制类的成员
memcpy(this, &other, sizeof(Object))
}
复制构造函数的调用情况:
-
当用类的一个对象去初始化该类的另一个对象。
-
如果函数的形参是类的对象,调用函数时,用实参初始化形参。
-
如果函数的返回值是类的对象,函数执行完返回时,为了完成从子函数到主函数的值传递,创建一个临时对象,初始化该对象。
如果类不包含动态分配的资源,则一般使用默认的构造函数就足够了。 一般情况,每个对象所拥有的资源应该是相互独立的,这样一个对象的操作才不会影响到另一个对象。 但是使用默认复制构造函数,只能完成成员变量即相关资源的标识符的复制,而不能自动完成动态资源的分配。 这时候就需要程序定义复制构造函数,来完成动态分配资源的分配和值的复制。
“=”操作符的意义在于使用一个对象向另一个同类型对象赋值,这和初始化时使用一个对象对同类型对象进行初始化的原理基本相同。
“=”操作符的处理==可能还需要先释放对象已分配的资源==,再申请新的资源。
如果没有定义“=”操作符,则会自动生成一个与默认复制构造函数具有相同功能的操作符定义,因此,默认的“=”操作符并不能完成具有动态资源的对象的复制。
通常,定义了复制构造函数也就意味着需要定义“=”操作符。
ClassName& ClassName::operator = (ClassName const&);
https://en.cppreference.com/w/cpp/language/copy_constructor
移动语义
将对象在堆上的空间与新对象进行交换(新对象可能并未分配堆空间)。
std::swap(a,b);
移动构造函数和移动赋值函数
ClassName(const ClassName && obj); //移动构造函数
ClassName& ClassName::operator = (ClassName const&&); //移动赋值运算符
https://hackingcpp.com/cpp/lang/move_semantics.html
初始化
Resource Acquisition Is Initialization (RAII)
- acquire some resource (memory, file handle, connection, …) when object is constructed
- release/clean up resource when object is destroyed (de-allocate memory, close connection, …)
对象所占据的内存空间只是用于存放数据成员,函数成员不在每个对象中存储副本。但是如果该类包含虚函数,则虚函数地址存放在虚函数表中,将占用内存空间。
成员初始化列表
通过构造函数的初始化列表对成员变量进行初始化(构造)。==初始值可以来自构造函数的参数。====初始化列表也可以调用本类的其他构造函数代替单独变量初始化。==
class Foo {
int i_; // 1st
double x_; // 2nd
public:
Foo(): i_{10}, x_{3.14} { } // same order: i_ , x_
Foo(int i, double x): i_(i), x_(x) {}
};
成员初始化列表:使用
()或{}(C++11: narrowing conversion)传递参数。
初始化列表应首先给出父类的初始化声明,再给出当前类中成员变量的初始值(初始化顺序与成员的声明顺序保持一致)。构造函数执行的次序:
-
调用父类的构造函数初始化父类成员,顺序与继承声明一致(从左到右);
-
初始化基本类型或调用成员的构造函数,调用顺序与内嵌对象在类中声明的次序一致;
当未在初始化列表给出成员的初始化声明,则会调用该类型的默认构造函数(此时该类型需要具有默认构造函数)。而如果在构造函数体内对该成员通过赋值进行初始化,则会重复执行构造,造成性能开销。==因此应该优先使用成员初始化列表。==
-
执行构造函数体的内容。
隐式类型转换
只有一个参数的构造函数,其调用形式与强制类型转换的语法相同,因此,等效于同时重载了由指定类型到当前类型的(隐式)类型转换运算符。
type y;
ClassName x = y; // => 隐式转换:className x = ClassName(y);
当构造函数被
explicit关键字修饰时,则不会同时重载该运算符,因此上述代码不会进行隐式转换,从而赋值语句类型不兼容。
初始化器
C++11支持在声明成员变量时给出默认初始值。
class Foo {
int i_ = 10;
double x_ = 3.14;
};
析构函数
析构函数与构造函数的作用基本相反,用来完成对象被删除前的一些清理工作,在对象的生命期即将结束时被自动调用。和构造函数不同的是,析构函数不接受任何参数,但可以是虚函数。声明虚析构函数必须给出实现(参考虚函数)。
析构函数调用顺序由类的继承关系决定,与构造函数的调用顺序相反:即类本身的析构函数,类成员对象的析构函数,基类的析构函数。由于析构函数是自动调用的,因此无需显示调用父类析构函数。
成员函数
成员函数可以在类的声明之外单独定义(使用作用域限定符),在类声明中仅给出声明。
type ClassName::func_name(params){}
代码量较小的函数应该尽量放置于类定义中,以方便“内联”优化。
How to implement a feature / add new functionality?
- only need to access public data (e.g. via member functions) ⇒ implement as free standing function
- need to access private data ⇒ implement as member function
==use "action" functions instead of just "setters"==:usually models problems better; more fine-grained control; better code readability / expression of intent
在成员函数中访问成员变量/函数:
this指针
非静态成员函数的参数隐含了当前实例的指针this。
如果在Class的成员函数中没有可见的同名局部作用域标识符,那么在该函数内可以直接访问成员Member。反之,非静态成员需要通过this指针进行访问this->Member。
也可以使用作用域限定符
::访问类成员,通常作用域限定符用于访问静态成员,而实例成员通过this指针访问。
此外,this指针还可以用于在类内部调用需要该类指针的函数。
成员运算符
当运算符的第一个参数是自定义类型,可将该运算符定义/重载为自定义类的成员。
当第一个参数不是自定义类类型,则重载为独立运算符。也可将独立运算符在类内部以
friends修饰以确保其能访问类的内部数据。
类型转换运算符
类型转换函数用于自动==将类对象转换成其他兼容类型的对象==,从而实现类似基本数据类型隐式转换的功能。类型转换函数通过重载“(...)”操作符实现:
public operator type(); // 定义方法将当前类型转换为type
该函数原型比较特别,没有返回值,也不需要提供参数。但是函数结束前必须返回type类型的值。
指针转换运算符是为了方便对自定义模板类的指针进行强制类型转换而重载的,因为系统不能直接把自定义类的指针强制转换成基本类型的指针。指针转换运算符的重载函数比较特殊,它没有返回值(连void也没有)。
函数对象
重载()运算符的类。 ==函数对象可以通过私有变量保存内部状态==。
public type operator (args); // 注意函数原型与类型转换运算符的区别
obj(args); // 调用()重载的函数。
成员引用运算符*
当一个类封装另一个类对象或指针时(例如智能指针),如果要透明访问被封装类的成员,可以重载->运算符(普通版本以及常量版本):
InternalObject* operator->(){ return prt_obj;}
ExternalObject* m = new ExternalObject();
m->some_interal_member;
“=”和“[]”运算符
这两种运算符的适用场合,有可能作为表达式的左值出现,如
A[5]=2;
(a=b)++;
作为左值的量都必须是变量,否则无法进行赋值或自加等操作,这就要求在重载“=”和“[]”运算符时返回变量;由于函数的返回值是一个右值(临时变量),所以不满足要求。
所以在重载这两个操作符时,返回值应该是引用类型。当然,由于局部变量在函数结束时就消失了,所以不能返回局部变量的引用,否则对引用的操作将出现错误。
“=”返回左操组数(上面例子中a)的引用;
“[]”返回左操作数(上面例子的A)的索引对应项的引用。只能重载一维数组下标操作符(如何重载多维下标http://blog.sina.com.cn/s/blog_66ec4d660100mxq5.html)。
静态成员函数
static type static_function_declare();
class_name::static_function(); // 调用静态成员函数
静态成员函数只能访问类的静态成员函数/变量。
常量成员函数
type member_function_declare() const;
const可以用于修饰函数的返回值,表示对函数的返回值不可以做修改。
使用const关键字修饰成员函数,意味着成员函数具有“只读”属性,而不能修改对象(实例成员变量)或者调用任何非常成员函数。
使用
mutable修饰的成员是例外,可以被const方法修改。
const可以用于成员函数的重载(在声明和定义处都需要使用const修饰),当对象被声明成常量时,则该实例只能访问使用const成员函数,因为只有这样才能保证类的成员变量不会被修改。
对于一般对象,则常函数成员和非常函数成员都可以被调用。
当对象是变量时,优先调用同名非常成员函数(当没有声明非常成员函数时,调用同名常成员函数)。
const-qualify all non-modifying member functions。
访问静态成员
静态成员不与类的实例绑定,需要通过作用域限定符和类名进行访问。
ClassName::StaticMember;
ClassName::StaticMemberFunction(args);
访问限制
在类内部,所有的数据成员的为其成员函数所共享;通过静态数据成员,实现同一类的不同对象之间的数据共享。
访问关系是针对于类而言的,并不是针对类的实例。即对象的成员函数可以访问同一类型对象的所有成员变量。
访问控制的主要作用是限定代码的组织方式,对程序运行没有影响;实际上可以通过操纵指针绕过访问控制限制。
Friends
class A{…… friend class B; …… } // friend class
class A{…… type function(args); …… } // friend function
友元函数是在类中用关键字friend修饰的非成员函数,可以是普通函数也可以是其他类的成员函数,虽然它不是本类的成员函数,但是可以访问本类的私有和保护成员。
**友元关系是不能传递的:**A是B的友元,B是C的友元,如果没有声明,A和C是没有友元关系的;
**友元关系是单向的:**A是B的友元,如果没有声明,则B不是A的友元;
**友元关系是不被继承的:**如果A是B的友元,但A的派生类,如果没有声明,则不是B的友元。
自定义类型
https://hackingcpp.com/cpp/design/arithmetic_types.html
https://hackingcpp.com/cpp/design/node_based_data_structures.html
程序结构
命名空间
- 避免命名冲突;
- 将内容分为不同的部分。
命名空间仅用于防止命名冲突,不具有访问控制作用(访问控制修饰符修饰命名空间无效)。
定义
namespace my{
class vector {...};
namespace time{...}
}
一个文件中可以定义多个命名空间;同时,一个命名空间也可以出现在多个文件中。
命名空间可嵌套定义。
引入命名空间
my::vector v1;
using my::vector; // 单独引入命名空间中的定义
vector v2;
using my; // 引入命名空间中的所有定义
namespace mt = my::time; // 定义命名空间别名简化书写
避免在头文件中引入命名空间:引入命名空间会导入其中所有的声明到头文件中。该头文件再被其他文件引用时,可能造成命名冲突。
标识符作用域
-
局部作用域:在代码块中声明的标识符,其作用域从声明处开始,一直到块结束的大括号为止。**具有局部作用域的变量也称为局部变量。**函数体、控制语句块,空语句块等都是局部作用域。
-
类作用域:类
Class的成员Member具有类作用域,其范围为类的定义。 -
文件作用域:具有文件作用域的标识符其作用域开始于声明点,结束于文件尾。具有文件作用域的变量也称为全局变量。
命名空间将文件作用域进行了逻辑划分;
可见性
程序运行到某一点在,能够引用到的标识符就是该处可见的标识符。作用域可见性的规则:
- 标识符声明在前,引用在后;
- 在同一作用域中不能定义同名标识符;
- 在没有互相包含关系的不同作用域中定义的同名标识符,互不影响;
- 如果在两个或多个具有包含关系的作用域中声明了同名标识符,则外层标识符在内层不可见。
作用域限定符
用于在默认规则不可见的位置访问某些标识符。
- 访问命名空间中的成员(例如
std::cout); - 在类定义外部,定义函原型和初始化静态变量;
- 访问静态成员;
- 在类内部,识别多继承的同名成员;
对于静态成员,则通过作用域分辨符::进行访问:ClassName::M。
多继承的父类成员可见性。
前向声明
两个类不能相互引用作为其定义的一部分,因为这样无法确定任何一个类的类型。但是两个类可以相互引用其指针作为定义的一部分。
如果出现以上相互引用的情况下,一般地,应该互相包含其头文件,但这样又会造成头文件内容无法确定。为了解决这一问题,C++引入了前向声明,即==在定义类之前对类名进行声明==,则无需包含该类定义所在的头文件,即可定义该类的指针。
class c_a;
class c_b{
c_a *p_a;
}
多态
继承
类的继承,是新类从已有类那里得到已有的特性。同时,从已有类产生新类的过程就是派生。由原有类产生新类时,新类便包含了原有类的特性,同时也可以加入自己所有的新特性。
从对象的数据存储来看,组合类和派生的作用一样:如果把派生类的父类的实例都添加到一个新类的定义中,则派生类的这个新类有相同的数据成员,只是组织形式不同。但是组合类只能利用现有类提供的功能并在新类中定义新功能,而派生类在此基础上可以提供多态行为,即子类可以通过虚函数覆盖父类的同名函数。反之,如果不需要更改父类行为,使用组合类更简洁。
构造/析构函数
根据构造函数调用规则,应该在子类的初始化列表中调用父类构造函数。
虚继承
成员函数重载
运算符重载
覆盖
具有相同函数原型(即相同的函数名与输入参数列表)的函数不满足重载的条件,不能存在于同一命名空间。但具有相同原型的函数可存在于父类(接口)与子类(实现)中。子类(实现)提供的具有相同原型的函数是对父类(接口)的相应函数进行重定义,以替换原有的功能,这种方式称为覆盖(override)。
隐藏
当子类中定义与父类同名函数时,将无法直接访问父类的同名函数(即使非重载形式)。此时需要使用父类指针(在类外部)或作用域限定符(类内部)访问父类函数。
多继承情况下,如果继承多个父类的同名函数,也会导致父类同名函数的隐藏。
虚函数
对于从同一父类派生出的不同类的对象,如果使用==父类的指针==统一进行管理与访问,可以明显的简化程序。但使用父类指针引用子类对象只能访问到父类中定义的成员,而不能访问子类中的成员。如果需要使用父类的指针访问子类中的成员函数,就需要首先在父类中将该函数声明为虚函数(不能通过父类指针访问子类数据成员)。
虚函数是动态绑定的基础,虚函数必须是非静态的成员函数,虚函数经过派生后,在类族中就可以实现运行过程中的多态。虚函数的声明语法:
virtual type function_name(arg_list); // in parent class
type function_name(arg_list)override {statements} // in child class
[1] C++ 虚函数表解析. http://blog.csdn.net/haoel/article/details/1948051/。
虚函数的修饰符只能出现在类中函数声明处,而不能在函数实现处。在子类中不需要显式地给出虚函数的声明,当子类的成员函数满足重载条件时就会自动确定为虚函数。被覆盖的父类函数,任然可以通过作用域标识符来访问。
虚函数的适用条件
当子类需要修改父类的行为时,就应该将父类的相应函数声明为虚函数。而父类中声明的非虚函数,通常代表那些不希望被子类改变的功能,也是不能实现多态的。因此一般不要重写继承而来的非虚函数(虽然语法没有限制)。
在重写继承来的虚函数时,不能改变函数的默认形参值,因为:虽然虚函数是动态绑定的,但是默认形参值是静态绑定的。
虚函数必须给出实现,否则应该声明为纯虚函数。
虚析构函数
使用父类指针访问子类对象完成后,如果子类对象是动态分配的,这时存在的一个问题是:能否直接delete父类指针,完成子类对象的删除。在动态分配内存时,系统会记录下所分配的内存的首地址和分配长度,因此在执行删除操作时,无论指针指向的是父类对象还是子类对象,都能够正确的释放对象所占用的内存。
但是如果动态创建的对象中还有指向动态分配的内存空间的指针成员,则这样的删除就是不完全的,因为这些指针成员指向的动态分配的内存空间并不能得到释放(如同深拷贝与浅拷贝的原理一样,在构造函数中,浅拷贝只会复制指针,而不会另外增加一份指针指向的内容,这时需要深拷贝手动完成内容的赋值)。
动态空间的释放显然应该由析构函数来完成,其中父类的构造函数释放父类对象动态申请的内存空间,子类的构造函数释放子类对象动态申请的内存空间。当使用父类指针来实现多态时,由于通过父类指针只能直接访问父类成员,析构函数也是一样,这种情况下访问不到子类的析构函数(对象通过delete销毁获声明周期结束时,只会调用父类的构造函数),则不能完成子类动态分配空间的释放,因此要将父类的析构函数声明为虚函数。
抽象类
抽象类用于抽象和设计接口。一个抽象类无法实例化,只能通过继承将抽象类改写为非抽象类,然后再实例化。可以定义抽象类的指针和引用,通过指针和引用,就可以访问子类的对象,实现多态性。
纯虚函数
抽象类是带有纯虚函数的类。抽象方法、接口。
virtual tpye function_name(args...) = 0;
抽象类派生出新类后,如果子类中给出了所有纯虚函数的函数实现,这个子类就不再是抽象类,而可以实例化;反之,如果子类中没有完全给出所有纯虚函数的实现,那么这个子类就仍然是抽象类。
模板
模板定义语法
template <typename T,..., args> declaration;
其中,declaration可以表示函数或类的声明语法。模板参数包括:
-
类型参数,使用类型定义关键字(
class或typename)或者嵌套定义的类模板类型(template <typename T,...>ClassName); -
非类型参数,参数类型可以是整数,枚举,指针,引用或指向成员的指针,且==在编译时可以确定为常量==(类似于数组长度)。
模板参数可设置默认值。
编译器根据模板生成实际代码:定义模板并不定义实际类型或函数,只有在使用模板并传递相应的参数时,编译器才真正添加一个类型或函数。
函数模板
函数模板的声明语法:
template <typename T1, typename T2,...>
T2 function_name(T param,...){statements}
类型参数用来指定函数模板的参数类型和返回值类型,以及声明函数中的变量类型等。
实例化
fucntion_name<T>(args); // 可省略类型参数,当类型可由参数推导出
类模板
使用类模板使用户可以为类声明一种模式,使得类中的某些数据成员,某些成员函数的参数、返回值能取任意类型(包括系统预定义的和用户自定义的)。类模板的定义语法:
template <typename T1, typename T2, ..., int n,...>
class ClassName{member_declaration}
在类模板内部定义成员的方法与普通类成员的定义语法一样,可能用到模板参数表中定义的类型或数值参数。模板类成员可以是静态或非静态,数据或函数成员。
如果要在类模板定义范围以外定义其成员函数,则必须指定其所属的模板类,且模板类要指定相应的模板参数,即采用以下定义形式
template < class T1,class T2, ..., int n,...> T2 ClassName<T1,T2,...,n...>::functionname(arg_list){statements}静态数据成员的定义方法也类似。
类模板的成员函数也可作为函数模板来定义,即增加额外的模板参数,其声明和定义语法如下所示。
template <typename A1,...>
class ClassName(args_list){
template<typename T1,...>
T1 function_identifer(A1 param1, ...){statements}
}
==(在类中的声明形式与一般函数一致),而不能如普通类一样,将成员函数的实现放到源文件中(否则或出现链接错误,LINK2019/2001)==。
类模板实例化
使用一个模板类建立对象时,应该按以下形式声明:
ClassTemplate<T1,T2,...,n,...>obj1;
完美转发
开发环境
编辑器
VIM
编译
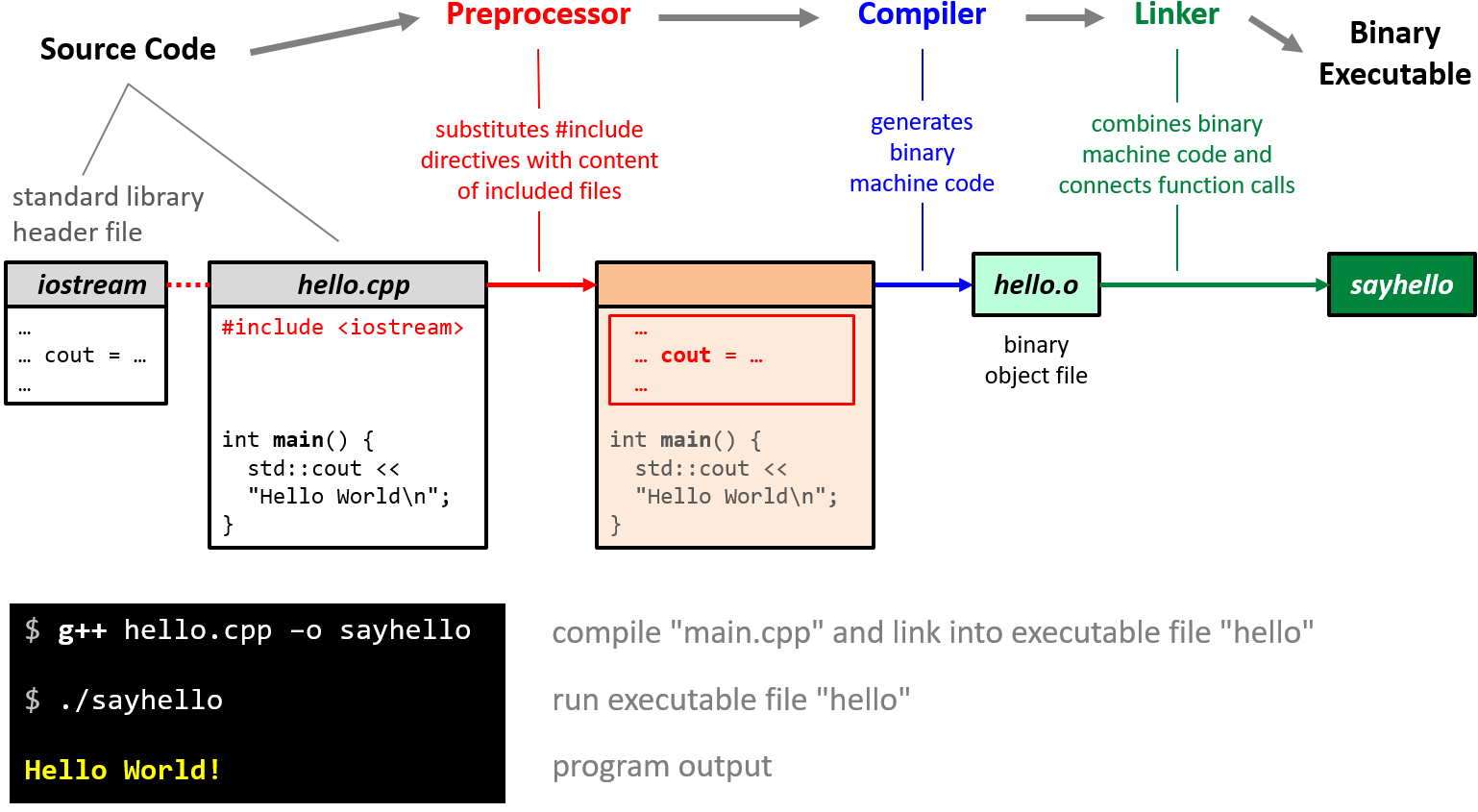
编译器
gcc/g++
sudo apt-get install -y g++
sudo apt-get install -y build-essential
g++ -std=c++17 -Wall -Wextra -Wpedantic input.cpp -o output
-g:compile for debugging; avoid optimization level -O1,-O2,-O3, use -O0, -Og instead.
-D MACRO: 定义宏;
-I path:添加搜索路径;
-l lib:添加外部库;
-L path:外部库目录;
The use of
gccdoes not add the C++ library.g++is a program that callsgccand automatically specifies linking against the C++ library.
clang/clang++
sudo apt-get install -y clang
sudo apt-get install -y build-essential
在规模较大的项目中,往往需要多个源程序文件,每个源程序文件称为一个编译单元。一个类的声明必须出现在所有使用该类的编译单元中。
链接
跨目标文件查找符号(变量、函数)并进行关联。
默认的程序入口函数为main,可通过连接器选项指定。
static声明的函数只会在当前文件作用域被调用,因此当此函数未在该文件中被调用时,链接器不会尝试去链接该函数内部调用的其他函数。
静态链接
外部库的路径
包含目录$INCLUDE:头文件的搜索路径;
库目录$LIB:库文件的搜索路径;
Visual Studio: 在
c++项目属性中配置Visual C++目录。
链接到外部库
为连接器指定库文件。
Visual Studio:在
c++项目属性中配置“连接器/附加依赖项”,在给定库目录路径后,只需给出文件名即可。在同一解决方案下的库,可使用“添加/引用”的方式导入依赖库。
静态链接可以执行链接优化。
动态链接
xxxdll.lib
将xxx.dll文件放置在可执行文件所在目录(或设置库目录)。
工具链
make
先声明最后的输出文件(可执行文件)的构建命令,然后分别声明依赖文件的构建命令。make根据依赖关系决定是否继续查找后续目标,然后反向执行命令。
prog: main.o dbl.o
g++ main.o dbl.o -o prog
main.o : main.cpp
g++ -c main.cpp
dbl.o : dbl.cpp
g++ -c dbl.cpp # tab for indentation
clean:
rm -rf *.o prog
install:
install prog /usr/local/bin/
仅编译更新过的源文件、目标文件。
设置编译器选项(CFLAGS)
./configure CFLAGS='-g -O2 -w' CXXFLAGS='-g -O2 -w'
make CFLAGS='-g -O2 -w' CXXFLAGS='-g -O2 -w'
编译项目
make & make install # building project and install the software
make clean # cleaning the building output
make uninstall # uninstall the software from the configured location
cmake
https://cliutils.gitlab.io/modern-cmake。
sudo apt install cmake
https://https//github.com/lefticus/cpp_starter_project。
# Makefile
camke_minimum_required(VERSION 3.5)
project (HelloWorld)
set (CMAKE_CXX_FLAGS "$CMAKE_CXX_FLAGS -Wall -Werror -std=c++11")
set (source_dir "$PROJECT_SOURCE_DIR/src/")
file (GLOB source_files "$source_dir/*.cpp")
add_executable (HelloWorld $(source_files))
Cmake -G "Codelite - Unix Makefiles" -DCMKAE_BUILD_TYPE=Debug
MSBuild
build2
QMake
IDE
Visual Studio
-
Visual Studio Free Community Edition
VisualAssist
VC++项目属性配置
目录配置:使用宏(
例如$(SolutionDir))配置输出目录。配置类型:可执行文件(
.exe)、静态库(.lib)、动态库(.dll)……。语言标准:
C++/CLI属性
-
Code Completion
- C++ code completion: powerful and amazingly fast code completion based on our in-house parser (supports C++11 auto keyword, templates, inheritance etc)
- clang based code completion for C++ projects - based on the CLANG/LLVM project - this feature provides a compiler level code completion
- Parse and display doxygen comments in the code completion box (as a separated floating window)
Compilers
- Generic support for compilers with built-in support for GCC/clang/VC++
- Display errors as code annotations or as tooltip in the editor window
- Errors are clickable via the Build tab
LLDB Support
GDB Support
- Watches table - add persistent watches with a single click
- Quick Watch - right click on a variable to expand it
- Locals tree - automatically displays the current stack variables (also displays *this if available)
- Threads view - contains a list of currently-running threads; switch between them with a single click
- Breakpoint management - disable, enable, conditional, temporary
- Automatic tree like tooltips
- Memory view
- Tree View tooltips (auto de-references pointers)
- Allow modifying tooltips
Refactoring
- Rename symbol, local symbol
- Rename file (will also change all
#includein the code) - Generate setters / getters
- Implement inherited virtual functions
- Implement inherited pure-virtual functions
- Easily change function signature to match its header / implementation counterpart
- Move functions implementation to another source file
- Implement all unimplemented methods
- Implement method
Source Control Plugins
标准库
标准模板库(STL)。
Microsoft 基础类 (MFC) 通过 Win32 提供面向 C++ 对象的包装,以便实现本机桌面应用程序的快速开发。 活动模板库 (ATL, ActiveX Template Library) 是一个包装库,它简化了 COM 开发,广泛用于创建 ActiveX 控件。
工具集
命令行工具:
| 工具 | 命令 | 说明 |
|---|---|---|
hexdump | hexdump -C file | 查看文件的十六进制编码 |
readelf | readelf -aW file | 查看ELF二进制文件结构 |
Red Hat Developer Toolset
Red Hat Developer Toolset does not replace the default system tools.
Enable Red Hat Developer Toolset by using Red Hat Subscription Management.
yum install devtoolset-10 # all development, debugging, and performance monitoring tools
# devtoolset-10-toolchain
# devtoolset-10-perftools
使用指定的工具
scl enable devtoolset-10 'gcc -o output_file source_file...'
scl enable devtoolset-10 'bash' # 使开发工具集中的执行程序成为默认
Developing C and C++ applications in RHEL 8 Red Hat Enterprise Linux 8 | Red Hat Customer Portal
C++容器
概述
标准容器都是模板类型,可以指定自定义的数据类型。
容器分为三类:序列容器、关联容器、容器适配器。
序列容器保持元素添加的顺序,允许指定插入元素的位置。序列容器类型包括,vector、list和deque(双端队列)。string类具有与序列容器相同的基本操作。
关联容器的元素以预先给定的顺序插入,例如排序顺序,分为两个子类:map(dictionary)和set。map(dictionary)由key/value组成,其中key用于排序。set中的元素按升序排列。
容器适配器包括:stack,queue,priority_queue。容器适配器不支持迭代,不能用于STL算法。
迭代器
标准库为每一种标准容器定义了迭代器类型container<type>::iterator(常量迭代器类型container<type>::const_iterator)。
container.begin(); // → @first_element
container.end(); // → @one_behind_last_element
std::begin(container); // → @first_element
std::end(container); // → @one_behind_last_element
使用
@pos代表迭代器。
rbegin(),rend()用于反向迭代。
const_iterator类型只能用于读取容器内元素,但不能改变其值,返回迭代器的函数以c开头,与iterator类型的返回函数对应。
迭代器运算
vector<int> v {1,2,3,4,5,6,7}
auto i = begin(v); // 获取迭代器
auto e = end(v);
cout << *i; // 访问容器元素
++i; // => pos=std::next(pos); // move to end() by 1 element
--i; // => pos=std::prev(pos); // move to begin() by 1 element
i+=2; // => pos=std::next(pos,2); // move forward
i-=3; // => pos=std::next(pos, -3); // move backward
end()返回的迭代器不指向任何元素。迭代器的移动运算结果只有在begin()到end()之间才是有效的。
同指针一样,可以使用解引用操作符(*, ->)来访问容器中的元素。
用==或!=运算符来比较两个迭代器,如果两个迭代器对象指向同一个元素,则它们相等,否则就不相等。
迭代区间
容器的部分操作支持以迭代区间作为参数。
vector<int> v (begin(u)+i, begin(u)+j); // [i,j)
w.assign(begin(u)+i, end(u)+j);
容器初始化类型推断 C++17
std::vector v {1, 2, 3, 4}; // std::vector<int>
容器属性
size,获取容器的长度(元素数量);empty,判断容器是否为空。
size_type n = v.size();
bool tf = v.empty(); // [c++17] std::empty(container)
容器方法
赋值
assign,为容器重新赋值;“=”操作符。
v.assign(@First, @Last);
比较
同类型容器间比较,对于==,元素数量相同且对应值相等返回true。其他运算符包括!=,<,>,>=,<=。
bool values_same = s1 == s2; // true
删除
c.erase(@pos) // → @behind_deleted
c.erase(@begin,@end) // → @behind_last_deleted
clear,删除容器中的所有元素,等价于调用erase(begin(),end())。
void clear( );
遍历访问
适用于所有序列容器和关联容器。
for(type variable : container){}// no out-of-bounds access possible
迭代变量声明:
type variable:read-only, type cheap to copy;type const & variable:read-only, type expensive to copy;type & variable:modify values;auto:支持自动类型推导。
range::for_each(v, func); // c++20: no out-of-bounds access possible
range::for_each(@begin, @end, func);
range::for_each_n(@begin, n, func); // c++17: only for n elements
在循环中使用迭代器。
反向遍历
for(type variable : container | std::views::reverse){} // c++20
#include <ranges> // std::ranges::for_each
namespace ranges = std::ranges; // alias
namespace views = std::ranges::views; // alias
ranges::for_each(views::reverse(v), [](auto x){ cout << x; });
works for all bidirectional containers.
使用反向迭代器rbegin(), rend()。
简单容器
#include <utility>
pair<int, double> p {4, 2.0};
tuple<int, double, vector<int>> t = {4,2.0, vector<int>{1,2,3}} //c++11
c++17支持类型自动推导。std::tie(i,j,k) = func_return_tuple(); // 展开返回参数 auto [i,j,k] = func_return_tuple_or_struct(); //c++17
序列容器
array

array类型不支持更改容器的容量。
#include <array>
std::array<int,6> a {4,8,15,16,23,42}; // array长度必须在编译期间确定(常量)
序列容器支持的操作
赋值
v.assign(count, value);
属性
max_size,在不断分配内存情况下,允许存储的元素最大数量;。
size_type n = v.max_size();
resize:更改容器的长度,如果没有指定初始值,新增加的值被设为默认初始值。
v.resize(size_type n);
v.resize(size_type n, value);
将容器长度设置为0等价于
v.clear()。
访问
返回容器中最后一个/第一个元素。
[const_]reference back( ) [const];
[const_]reference front( ) [const];
如果容器为空,则返回结果不确定。如果将返回值赋值给常量引用,则返回值不能被修改,如果赋值给普通引用,则返回值可以修改。
插入
insert,emplace*,在迭代器指定位置插入单个,多个值或连续的一列值;
v.insert(@pos, value); // return
v.insert(@pos, T&&value);
v.insert(@pos, count, value);
v.insert(@pos, @first, @Last);
v.insert(@pos, list);
v.emplace(@pos, Args&&...args); //[c++11]
返回插入的首个元素的迭代器,如果未插入任何元素,返回@pos。emplace直接用参数构造的对象插入容器(完美转发)。
- 引用容器的位置参数
@pos从普通迭代器变为常量迭代器c++11;- 插入容器的值支持移动语义
c++11;- 返回值类型从迭代器变为常量迭代器
c++20。
push_back,emplace_back,在容器末端插入元素;
void push_back(value);
void emplace_back(Args&&...args);
emplace_back提供可变参数列表适配构造函数,当参数是容器元素引用时,调用移动构造函数,和其他容器的调用方法一致。
删除
pop_back,从容器末端删除一个元素;
void pop_back( );
其他操作:交换,释放额外存储空间,保留最小存储空间。
序列容器的特殊操作
随机访问
vector和deque支持随机访问,因此可以使用at()、操作符“[]”返回指定位置的元素,如果索引值大于容器的大小,则at抛出异常,而运算符“[]”的返回值是不确定的。如果将返回值赋值给常量引用,则返回值不能被修改,如果赋值给普通引用,则返回值可以修改。
[const_]reference at(size_type _Pos) [const];
[const_]reference operator[](size_type _Pos) [const];
利用随机访问特性,可以使用序号遍历容器元素。
for (int i = 0; i < v.size(); ++i){cout << v[i];}
插入和删除
push_front,pop_front,emplace_front,由于list支持在任意位置快速插入/删除元素,deque支持在首尾快速插入,因此这两个插入函数为list和deque提供更高效的插入方式。
vector

vector是序列容器(Array/List),元素按照线性方式存储,允许快速地随机访问。vector不提供查找功能。
#include <vector>
using namespace std;
template <
class Type, //元素数据类型
class Allocator = allocator<Type>
> class vector;
vector<int> v {2, 7, 9};
在vector末端进行插入和删除只需花费常数时间,在中间插入或删除需要线性时间。
dequeue容器优先用于在队列的首尾插入以及随机访问,list容器优先用于在任意位置插入或删除。
当vector中的元素数目达到其容量时,vector就会重新分配存储空间,插入和删除也会造成元素存储地址的改变,这种情况下==先前创建的迭代器可能会失效==。
构造函数
vector<int> v2; // vector(); => vector<int> v2{}; 空向量
vector<int> v2(v1); // vector(const vector& v); 拷贝构造函数
Copies Are Always Deep! Most types in the C++ standard library and ecosystem are regular.
vector<int> v2(5); // explicit vector(count);
vector<int> v2(5,2); // vector(count, value);
创建一个空的vector或创建大小为count的向量,指定vector的元素,如果没有指定元素的值,则元素值为类型的默认值。
vector<int> v2 (@start, @end); // vector(@First, @Last);
用指定的vector的一段来初始化新的vector。First是指向被拷贝段的第一个元素的迭代器,Last指向被拷贝元素后的一个元素。
成员函数
int n = v.capacity();
在目前不增加分配内存时,容器可储存的最大元素数量。
预留容量:与构造函数初始化指定数量的元素不同,预留的容量未被使用,而是用于后续添加的元素。
v.reserve(new_capacity);
缩小容量:
shrink_to_fit v = vector<int>(v); // C++11-20
deque

deque类(Double Ended Queue)以线性方式组织数据元素,与vector一样允许快速的随机访问以及高效地在末端插入和删除元素。但与vector不一样的,deque也支持==高效地在首端插入和删除元素==。
#include <deque>
using namespace std;
template <
class Type,
class Allocator=allocator<Type>
> class deque
当成员函数需要插入或删除元素时,deque将会重新分配内存:
- 如果向空容器中插入元素,或将元素移除后容器为空,则先前返回的begin()或end()迭代器都会变成无效的。
- 如果在首端插入一个元素,则指向元素的所有迭代器(并非引用)将变成无效的。
- 如果在末端插入一个元素,则指向元素的所有迭代器(并非引用)将编程无效的。
- 如果
deque容器首端的元素被移除,则只有被移除元素的引用和指针变为无效。- 如果
deque容器末端的元素被移除,则只有被移除元素的引用和指针变为无效。- 其他情况,插入或删除将会导致所有迭代器和指针都变为无效的。
构造函数
deque(); // 空的deque容器
explicit deque(count); // 大小为count的deque容器(默认值)
deque(count, value); // 大小为count值为value的deque容器
deque(const deque& d); // 拷贝构造
deque(@first, @last);
成员函数
在容器前端插入/删除元素:
d.push_front(2);
d.pop_front();
list

list使用双向链表存储,支持高效的插入和删除。
#include <list>
using namespace std;
template<class Type, class Allocator=allocator<Type>> class list
构造函数
list(); // 创建空列表
explicit list(count); // 创建大小为count的列表
list(count, value); // 创建的元素都被初始化为value。
list(const list& li); // 使用已有列表创建新的列表
list(@first, @last);
成员函数
删除
删除所有匹配值对应的元素或满足条件的元素。
li.remove(value);
template<class UnaryPredicate> // [](int n){return n>10;}
void remove_if(UnaryPredicate pred);
C++20:返回移除的元素数量。
删除重复或满足条件的连续元素。
li.unique();
template<class BinaryPredicate> void unique(BinaryPredicate _Pred);
unique假设列表经过了排序,所以重复元素都可以被检测到,而不连续的重复元素不能被检测到。在
<functional>和<xfunctional>中定义了部分比较条件,也可以自己定义比较条件。
排序
li.sort(); // 默认升序
template<class Compare> void sort(Compare comp);
comp:比较函数对象。可以是一个返回bool值的二元比较函数,或者是一个重载了“()”运算符作为比较函数。class compare{ public: bool operator()(left, right)const{ return left.val>_Right.val; } };
将队列反向排列:
void reverse();
合并操作
从一个列表将元素转移到另一个列表(移除另一个列表中的元素)。
li.splice(@where, list& other); //移动所有元素,other!=*this
li.splice(@where, list& other, @first); //仅移动迭代器指向的元素
li.splice(@where, list& other, @first, @last); //移动一个区间的元素(@where不应该位于区间内)
将转移的元素插入到@where引用的元素之前。
不会复制或移动任何元素,仅修改内部指针;迭代器不会失效,但指向当前容器中的元素。
The behavior is undefined if:
get_allocator() != other.get_allocator().
C++11列表参数支持移动语义(list &&other)
merge合并两个有序列表。
li.merge(list& other);
template<class Compare>
void merge(list& other, Compare comp);
合并规则:根据比较规则comp(默认为<运算符,即升序),取出两个队列队首较小的元素放入新的队列(实际上不需要改变*this,而是将other的元素插入到*this中)。
merge适用于已经排序的列表(li.sort())的合并,合并后的结果仍然有序;反之,元素排列结果不确定(根据合并规则与实际值有关)。
forward_list
单向链表(只能前向遍历)。

somewhat cumbersome interface due to forward-only links
- no:
size(),back(),push_back(),pop_back(),insert()- instead:
insert_after(),splice_after(),before_begin()
string
字符串动态数组,基本元素为char的basic_string具体类(类似于vector<char>)。wstring是基本元素为wchar_t的basic_string具体类。
#include <string>
using namespace std;
typedef basic_string
<char,char_traits<char>,allocator<char>> string;
typedef basic_string
<wchar_t,char_traits<wchar_t>,allocator<wchar_t>> wstring;
初始化
使用[字符串数组](Modern C++.md#字符串常量)初始化:没有指定字符数的函数则表示用整个字符串来初始化string。
string s0; // string(); empty string
string s1 = "xyz"; // string(char const* ptr_cstr);
string(char const* ptr_cstr, count);
使用字符初始化。
string(size_type count, char ch);
使用string类型字面值(后缀s)初始化:
using namespace std::string_literals;
string s2 = "std string literal"s; // string类型字面值[c++14]
string(str, @first, count);
string(@first, @last);
string s = R"(raw "std"-string c:\users\moe )"s; // raw string literal[C++14]
访问
除了size()之外,还有length()函数可返回string的元素总数(底层字符串的字节长度size=length)。
char ch = str[index];
底层数据
C-style字符串可以通过string的构造函数自动转换为string,但是string不能自动转换为C-style的字符串,需要使用以下函数。
const char *c_str( ) const;
const char *data( ) const;
由于返回的是常量指针,所以不能通过返回的指针修改字符串。
返回指向string的字符内容的C-style字符串常量指针,当调用string的非const函数时,会导致指针变为无效。string的数据不会以“\0”结尾,“\0”在string对象中只是一个普通字符,但是返回的C-style字符串是以“\0”结尾的。
复制字符串的内容:拷贝字符到字符数组,返回实际拷贝的字符数,不会在拷贝结果后面自动添加null字符,所以在拷贝前最好将源数组先初始化为全0。
size_type copy(char* _Ptr, size_type _Count, size_type _Off = 0) const;
size_type _Copy_s(value_type *_Dest, size_type _Dest_size,
size_type _Count, size_type _Off = 0) const;
查找
find:指向查找指定字符或字符串,返回首个符合条件的子串的首字符位置,如果没找到则返回string::npos(=-1)。
s.find("r");
s.rfind("r");
find_first_of:寻找首个属于制指定字符串的字符,找到返回其索引,否则返回npos。
find_first_not_of:返回首个不属于指定子串的字符的位置,没找到则返回npos。
find_last_not_of:寻找最后一个不在字串中的字符。
find_last_of:寻找最后一个在字串中的字符。
查找子串:
s.substr(idx, len)
修改
==直接在目标字符串上作修改==。
拼接
运算符+、+=:将字符、C-style字符串或string的部分或全部内容追加到目标字符串,返回目标字符串的引用。
string& append(const char* ptr);
string& append(const char* ptr, count);
string& append(other);
string& append(other, offset, count);
string& append(count, char ch);
string& append(&First, &Last);
string& append(@First, @Last);
参数意义参考构造函数。
这里的迭代器或指针“
_Last”是指要插入的最后一个元素的后一个位置,如果是整个插入一个string,则_Last=string.end(),如果插入整个C-style字符串,则_Last=&cstring[strlen(cstring)]。
插入
在指定位置插入内容。
str.insert(int idx, "new content");
str.insert(@pos, &first, &last);
str.insert(@pos, @first, @last);
删除
erase(参考容器方法):从字符串的指定位置删除一个元素或一部分元素。
s.erase(index, count)
替换
s.replace(idx, len, "contents")
转换为数值
#include <string> C++11
int stoi (s);
long stol (s);
float stof (s);
double stod (s);
序列类型视图
试图不负责资源的管理,仅是资源的一种表示方式。
- 视图主要用于函数参数(轻量级复制),易于获取序列类型的子序列,总是引用有效内存,且使用
view的对象不会破坏对象所有者的内存。 - 避免返回视图,容易产生无效视图,且不清楚该视图引用的是什么对象/内存。
string_view
==只读==访问:常量引用(C++98/11/14);视图(c++17/20);
#include <string_view> //c++17
std::string_view sv1 { str };
std::string_view sv2 {@pos, count}; //从@pos起连续count个字符
std::string_view sv3 {@start, @end};
注意避免
string_view比其初始化的字符串生命周期更长(例如在其初始化列表中构造的字符串对象);
span
连续的内存区块(如vector,array)。
span<type> s {v}; // c++20
span<type const> s {v}; // read-only access
span<type> s {@pos, count}; //从@pos起连续count个元素
span<type> s {@start, @end};
支持自动类型推导,可省略模板类型。
tf = s.empty();
int n = s.size();
x = s[i]; //indexed access
s.begin(), s.end(); // iterator access
内存数据比较:
bool memory_same = s1.data() == s2.data(); // false
容器元素比较
s1==s2。
subspan
auto first3elements = s.first(3);
auto last3elements = s.last(3);
auto subs = s.subspan(offset, count);
std::span<std::byte const> b = s.as_bytes();
std::span<std::byte> wb = s.as_writable_bytes();
其他容器
queue类
为底层的容器类型提供访问限制,元素只能从末端插入,从首端移除(FIFO),元素可以从queue的两端查看。
template <
class Type, //元素类型
class Container = deque<Type> //容器类型
> class queue
合适的底层容器包括deque和list或其他支持front, back, push_back, and pop_front操作的线性容器。容器的元素类型必须与第一个参数一致。底层容器被封装在容器适配器中,容器适配器只提供了有限的线性容器成员函数。
stack类
为底层的容器类型提供访问限制,使的只能对底层容器进行栈操作(后进先出,LIFO)。
template <class Type, class Container=deque<Type> > class stack;
合适的底层容器包括deque、list和vector或其他支持back, push_back, and pop_back操作的线性容器。底层容器被封装在容器适配器中,容器适配器只提供了有限的线性容器成员函数。
priority_queue类
为底层的容器类型提供访问限制,使底层容器具有priority queue的性质。容器中的元素是按值的性质排序的,即具有某种优先级。该类只支持在顶端插入、删除或查看元素。
template <
class Type,
class Container=vector<Type>,
class Compare=less<typename Container::value_type>
> class priority_queue
关联容器
关联容器分为集合(set)和映射(map),每种类型包括有序和无序两种类型。
有序关联容器的数据结构是平衡二叉树(balanced binary tree)。

无序关联容器的数据结构是哈希表(hash table,默认使用std::hash<Key>计算哈希值)。

节点之间通过指针链接,集合类型节点(container::node_type)仅包含key,映射类型的每个节点包含key和value(std::pair)。
#include <set> // #include <unordered_set>
#include <map> // #include <unordered_map>
关联类型构造
空容器
std::set<int> s1; // => std::set<int> s2 {};
std::map<int> m1; // => std::map<int> m2 {};
从数据构造集合
std::set<int> s2 {3,2,1,4,5};
std::set<int> s {s1}; // set(other)
std::set<int> s (s1); // set(other)
std::set<int> s (@start,@end); // set(@start, @end)
c++17支持自动类型推导。
关联类型支持的操作
查找
pos = s.find(7); // return end() if not found
tf = s.contains(7); // c++20
删除
s.erase(key);
移动节点
node = m.extract(key); //→ node
node = m.extract(@position); //→ node
node.key() = "new key"; // change key
m.insert(node); // transfer node
合并
s.merge(t); // 将t的元素转移至s中,t成为空容器。
集合类型操作
迭代
迭代器:begin(s)、end(s)、rbegin(s)、rend(s)。
pair = s.insert(const Type& value); //return std::pair<iterator, bool>
pair = s.insert(Type&& value);
it = s.insert(@hint, const value_type& value );
s.insert(@first, @last);
s.insert(ilist);
插入值位置
hint从普通迭代器变为常量迭代器c++11;
pair = s.emplace(Args&&... args);
s.emplace_hint(@hint, Args&&... args)
set.emplace(args):使用参数直接构造集合元素并加入集合,避免不必要的复制操作。
映射类型操作
迭代
for(auto const& keyValuePair : myMap) {/*...*/}
for(auto const& [key,value] : myMap) {/*...*/} // c++17
迭代器:begin(m)、end(m)、rbegin(m)、rend(m)。
插入
pair = m.insert({key, value}); // return pair<@pos,insert_success>
pair = m.insert(@hint, {key,value});
m.insert(@kv_pairs_begin,@kv_pairs_end);
pair = m.emplace(key, value); // c++11
pair = m.emplace_hint(@hint,key,value); // c++11
pair = m.try_emplace(key,Arg1,Arg2,...); // c++17
m[key] = value; // insert key if not found
m.at(key) = value; // throws out_of_range if key not found
m.insert_or_assign(key,value); // c++17
emplace使用参数直接构造要插入的节点,try_emplace使用参数列表直接构造要插入的节点的值value。
输入输出
标准输入输出
c语言使用printf和wprintf作为标准输出函数;
int wprintf(const wchar_t *format, ...);
用wprintf()时,要用%ls表示wchar_t的字符串,用%s表示char的字符串; Windows 的实现用%ls、%s都可以正确输出wchar_t字符串。
C++使用cout和wcout作为标准输出函数;
在输出Unicode编码的宽字符时,使用带前缀“w”的函数;在使用之前需要设置程序的区域,即调用setlocale函数(C语言),或使用locale类和流对象的imbue(C++)。
char * setlocale ( int category, const char * locale );
在Linux下,可以使用 locale -a 命令查看系统中所有已配置的 locale。用不带选项的 locale命令查看当前 Shell 中活动的 locale。用locale -m 命令查看locale系统支持的所有可用的字符集编码。
Linux下wcout可以输出char型字符串和wchar_t型字符串。运行环境的locale设置要和程序中setlocale()设定的locale一致,比如:终端的活动字符集、环境变量(一般用LANG),要设置为*.UTF-8,才能显示setlocale(LC_ALL, "zh_CN.UTF-8") 设定的wchar_t的中文字符。
不要混用char和 wchar_t 版本的流操作函数,否则会导致这些函数运行异常。
fscanf 在Linux下,只能正常读取UTF-8(ASCII)编码的文本,不能对其他编码格式进行自动解码。 如果是其他编码,则需要以字节方式读入,手动转换为UTF-8编码,才能正常使用。
| I/O Streams | IO desc | Details | Operators |
|---|---|---|---|
std::cin | stdin | reads from buffer. | cin >> var |
std::cout | stdout | output to console when buffer full. | cout << var |
std::clog | stderr | output to console when buffer full. | clog << var |
std::cerr | stderr | immediately writes to console. | cerr << var |
using namespace std;
getline(cin, s); // read entire line
getline(cin, s, ch); // read until next character ch
数据流
C++输入输出通过输入输出流类来完成,在头文件“iostream”中定义了这些类的基类:
• istream:从流中读取数数据。
• ostream:写入数据到流中。
• iostream:对流进行读和写操作,继承自istream和ostream。
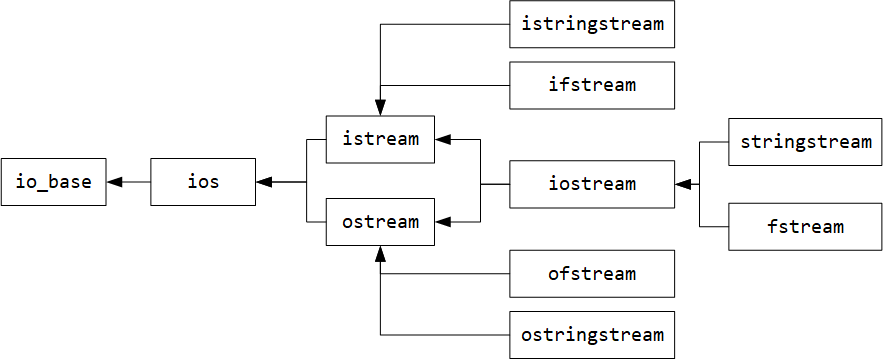
所有输入输出流类,还有其宽字符版本,以支持国际化。宽字符版本在普通版本前增加“w”前缀。所有类型均由basic_xxxstream通过模板参数(charT, traits)实例化(类似于string类型)。
std::cin是istream类型对象;std::cout是ostream类型对象
格式化
所有设置函数未接收参数时,返回当前的设置。
标识
old_flags = cout.flags(ios::right|ios::hex); // set all flags
old_flags = cout.setf(flags, mask); //only set specified flags
void unsetf(fmtflags mask); // clear specified flags
flags()设置流的所有标识(未给出的清空),而setf仅设置给出的标识(未给出的不变)。
标识为两种:1) 独立标识;2) 选择性标识:一组包括多个标识,但同时只能设置一个。mask用于设置选择性标识,用以清空非当前设置的同组其他标识。
标识定义在
ios类中,类型为fmtflags(bitmask)。
独立标识
| 独立标识 | 说明 |
|---|---|
boolalpha | 以字符串格式读写bool值 (true and false) |
showbase | 输出前缀(0x,o) |
showpoint | 浮点数总是输出小数点 |
showpos | 整数输出+号 |
skipws | 跳过输入内容前面的空白 |
unitbuf | flush output after each inserting operation. |
uppercase | 替换未大写字母 in certain insertion operations. |
选择性标识
| 选择性标识位 | 掩码 | 说明 |
|---|---|---|
left, right or internal | adjustfield | 对齐方式 |
dec, oct or hex | basefield | 计数进制 |
scientific or fixed | floatfield | 浮点数表示法 |
使用操作符格式化:
cout << fixed;
cout << scientific;
cout << boolalpha; // booleans as string
宽度
ios.width(int n); // cout << std::setw() #include <iomanip>
ios.fill(char ch); // 填充字符
显示数据的最小宽度,数据内容少于该宽度将填充字符,填充字符位置更具对齐方式决定(adjustfield)。
精度
精度的具体定义取决于使用定点法或科学计数法。
ios.precision(int n) // cout << std::setprecision(n)
locale
locale loc = ios.getloc()
状态
iostate s = ios.rdstate(); // 返回内部错误状态标识
bool tf = ios.good();// goodbit: True if no errors
bool tf = ios.eof(); // eofbit:
bool tf = ios.fail();// failbit|badbit: IO逻辑错误(在输入模式下执行输出,识别内容失败)
bool tf = ios.bad(); // badbit: IO操作读写错误
badbit:标志着系统级的故障,如无法恢复的读写错误。如果出现了这类错误,则该流通常就不能再继续使用了。
failbit:出现的是可恢复的错误,如在希望获得数值型数据时输入了字符,此时则设置 failbit 标志,这种导致设置 failbit的问题通常是可以修正的。
eofbit:遇到文件结束符时设置。
当流出现错误时,缓存中的错误内容不会自动被丢弃,再该流上继续执行操作还会产生错误。
cin.clear(state=goodbit) // 重置状态
cin.ignore(numeric_limits<streamsize>::max(), '\n'); // 清除缓存
设置异常触发:根据设置的状态触发异常。
ios.exceptions(iostate except);
读写操作符
“<<”操作符(print()):将数据格式化输出到输出流。
“>>”操作符:从输入流扫描并格式化读入数据。
重载运算符
std::ostream& operator << (std::ostream& os, point const& p) {
return os << '(' << p.x << ',' << p.y << ')';
}
std::istream& operator >> (std::istream& is, point& p) {
return is >> p.x >> p.y;
}
https://hackingcpp.com/cpp/std/istream_recover_from_errors.html
读写方法
std::getline(istream&, string&, stopat='\n')
std::istream.ignore(n, c) // skip n chars, or until char 'c'.
流式字符串读写
ostringstream,istringstream。
流式文件读写
用于普通文件读写的输入输出流类在头文件“fstream”中声明,包含以下类型:
#include <fstream>
using namespace std;
ifstream; // 继承`istream`,用于读文件。
ofstream; // 继承`ostream`,用于写文件。
fstream; // 继承`iostream`,用于读写文件。
fstream中声明的类除了继承下来的行为外,还定义了两个新操作——open和close,以及形参为要打开的文件名的构造函数。
std::ofstream os {"squares.txt", ios::in}; // ios::binary
os.open("squares.txt");
os.good();
os.close(); // file can be automatically closed
标准函数库
数组
拷贝数据
void *memcpy(void *dest, const void *src, size_t count); // => wmemcpy
memcpy从src拷贝count字节数据到dest;wmemcpy则拷贝count个宽字符的数据。如果源和目的区域有重叠,则该函数的行为未定义。
注意:应该保证目的缓存应该大于或等于源缓存。
void *memmove(void *dest,const void *src, size_t count);
// => wmemmove、memmove_s、wmemmove_s
从src到dest拷贝count字节(memmove)或字符(wmemmove)。如果源和目的区域有重叠,则该函数能保证覆盖区域的数据被覆盖之前被正确拷贝。
注意:应该保证目的缓存应该大于或等于源缓存。
设置数据
memset
比较
memcmp
C字符串
char型字符串==存储变长字符编码==(Linux平台为UTF-8,Windows平台为GBK),以单字节“null”结尾;wchar_t存储定长字符编码(UTF-16),以两个“null”结尾。
wchar_t字符串的处理函数以wcs开头,对应char字符串以str开头的函数。
char str[5] = {'T', 'h', 'i', 's', 0}; // string as array
当使用字符串字面值初始化时,对应的字符串是不能修改的,因此将其声明为常量。
const char str[] = "this is a string";
const char* ptr = "this is a string";
属性
size_t strlen(const char *s); // => wcslen
计算字符串长度,遇到'\0'结束,==长度以字节计数==;如果是中文,则一般一个中文字符占3字节。
拼接
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
将字符串src连接到dest的尾部。从dest的\0开始。strncat与strcat的区别在:strncat最多使用src的n个字节;如果src的长度大于或等于n,则strncat的src字符串不需要是null结尾。
strlen()和strcat()是两个比较耗时的操作。在程序中应该少使用。
比较
int strcmp(const *s1,const *s2);
int strncmp(const char *s1, const char *s2, size_t n);
int strcasecmp(const char *s1, const char *s2);
int strncasecmp(const char *s1, const char *s2, size_t n);
比较s1和s2。strncmp只比较最多n个字符。strcasecmp忽略大小写。
s1 = s2的时候返回值 =0;s1 < s2的时候返回至 <0;s1 > s2的时候返回值 >0;
查找
char *strchr(const char *s, char c);
char *strrchr(const char *s, int c);
char *strchrnul(const char *s, int c);
strchr返回s中首次出现c的位置的指针,strrchr返回最后出现c的位置的指针。如果s中不存在c则返回NULL。
strchrnul与strchr类似,只是在找不到c的时候,返回字符串的null位置指针,而不是NULL。
char *strstr(const char *haystack, const char *needle);
char *strcasestr(const char *haystack, const char *needle);
返回haystack中needle字符串首次出现的位置的指针(不比较结束符null)。若果没找到则返回NULL。strcasestr在查找时忽略字符串的大小写。
复制
char *strcpy(char *dest, const char *src); // => wcscpy,wcscpy_s
char *strncpy(char *dest, const char *src, size_t n); // => wcscat,wcscat_s
拷贝src指向的字符串到dest指向的缓冲区。strncpy则最多拷贝n个字符,如果前n个字符没有以null结束,则目标字符串也不会以null结束。
类型转换
#include <cstdlib>
int atoi(const char *nptr);
long atol(const char *nptr);
long long atoll(const char *nptr);
将字符串转换成int,long和long long型整数。atoi()会扫描参数nptr字符串,跳过前面的空格,直到遇上数字或者正负号才开始装换,而再遇到非数字或者字符串结束时停止转换。atoi不会检测错误。
double atof(const char *nptr);
将字符串转换为浮点数。atof不会检测错误。
long int strtol(const char *nptr, char **endptr, int base);
long long int strtoll(const char *nptr, char **endptr, int base);
strtol根据base的值就将nptr指向的字符串转换为整数。base的取值范围为2~36,或为0。 字符串可以在开头包含任意数量的空格,空格之后可以包含“+”或“-”。如果base = 0,若字符串包含前缀“0x”,字符串字符串将按照16进制解析;若字符串包含前缀“0”,字符串字符串将按照8进制解析;其他情况则按10进制解析。解析停止于首个非法字符。
如果endptr不是NULL,则strtol将把首个非法字符的地址存储在*endptr中。如果nptr中没有数字,则*endptr=nptr并返回0,如果nptr!=NULL且*endnptr=NULL,则全部是合法字符。
strtoll与strtol类似,只是返回值的类型为long long int。如果发生下溢出,则strtol返回LONG_MIN;如果发生上溢出,则strtol返回LONG_MAX。两种情况下,errno被设置为ERANGE。strtoll也是类似,只是返回值为LLONG_MIN和LLONG_MAX。
unsigned long int strtoul(const char *nptr, char **endptr, int base);
unsigned long long int strtoull(const char *nptr, char **endptr, int base);
strtoul根据base的值将nptr指向的字符串转换为无符号整数,转换规则与strtol类似。
double strtod(const char *nptr, char **endptr);
float strtof(const char *nptr, char **endptr);
long double strtold(const char *nptr, char **endptr);
将nptr指向的字符串转换为浮点数。
格式化
int sprintf(char *buf, char *format,arg_list);
int snprintf(char *restrict buf, size_t n, const char *restrict format,...);
sprintf()是一个功能强大的函数。跟printf(char *format,arg_list)的功能类似。不过,printf()是将格式化的字符输出到屏幕,而sprintf()则是将格式化的字符放入到buf中。这个函数对操作缓冲区buf,并对其内容加以格式带来了极大的方便。
snprintf()最多从源串format中拷贝n-1个字符到目标串buf中,然后再在后面加一个'\0'.如果目标串的大小为n的话,将不会溢出。snprintf()如果成功则返回存入数组的字符数,若错误则返回负值。
int sscanf(string str, string fmt, mixed var1, mixed var2 ... );
int scanf(const char *format [,argument]... );
从一个字符串中读进与指定格式相符的数据。sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。其中,format可以是一个或多个
{%[*][width][{h|l|I64|L}]type|' '|'\t'|'\n'|非%符号}
格式化输入
char buf[512];
sscanf("123456 ", "%s", buf);
sscanf("123456 ", "%4s", buf); // 取最大长度为4字节的字符串
正则匹配:sscanf的%[]类似于一个正则表达式,但却没有正则表达式强大,所以如果对于比较复杂的字符串处理,建议使用正则表达式。
sscanf("123456 abcdedf", "%[^ ]", buf); // 取遇到空格为止字符串
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf); //仅包含指定字符集的字符串
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
给定一个字符串iios/12DDWDFF@122,获取 / 和 @ 之间的字符串,先将 "iios/"过滤掉,再将非'@'的一串内容送到buf中
sscanf("iios/12DDWDFF@122", "%*[^/]/%[^@]", buf);
sscanf(“hello, world”, "%*s%s", buf);
%*s表示第一个匹配到的%s被过滤掉,即'hello'被过滤了;如果没有空格则结果为NULL。
其他方法
strace strcspn strings strdup strip strpbrk
strdupa strtok strtouq strerror strtok_r strverscmp
strerror_r strsep strxfrm strchrnul strfmon strsignal
strfry strspn strcoll strndup string strndupa
时间
时间格式化
size_t strftime(
char *strDest,
size_t maxsize,
const char *format,
const struct tm *timeptr
);
format用于声明格式化字符串。
时间字符串解析
strptime
系统调用
文件系统
#include <stdio.h>
int rename( const char *oldfname, const char *newfname ); // 更改文件名
系统接口
system解释执行一条命令。函数将命令传递给命令环境(Shell),如果输入命令为空,则system函数检查命令环境是否存在。在使用system函数前,必须显式调用刷新流(调用fflush或_flushall)或者关闭流。
#include <stdlib.h>
int system(const char *command );
int _wsystem(const wchar_t *command);
_wsystem是宽字符版本的system函数。_tsystem则根据程序中是否定义了_UNICODE来确定使用的函数。如果输入命令为空,而命令解释器为找到,则返回0并且将
errno设为``ENOENT,否则返回一个非零值;如果输入命令不为空,而命令解释器可以找到,则函数返回值就是命令解释器返回的值。如果返回-1,表明发生了错误,errno`设置为以下值:
E2BIGENOENT未能找到解释器ENOEXEC解释器的格式无效,不能执行ENOMEM内存不足。
数学函数
基本数值计算
#include <cmath>
double sqrt(double x) // √x square root
double pow(double a, double b) // a^b power
double abs(double x) // |x| absolute value
double sin(double x) // sin(x) sine
double cos(double x) // cos(x) cosine
double exp(double x) // ex exponential
double log(double x) // log(x) logarithm
double floor(double x) // ⌊x⌋ next smaller integer
double ceil(double x) // ⌈x⌉ next larger integer
double fmod(double x, double y)// remainder of x/y
随机数
随机数生成器
随机数生成器:分布+发生器。
#include <random>
auto urng = std:mt19937{}; // Mersenne Twister
urng.seed(1001);
auto dist = std:uniform_int_distribution<int>{1,6};
int x = dist(urng); // 生成随机数
dist = std:uniform_real_distribution<float>{1.0,6.0};
rand, srand, rand_r
#include <stdlib.h> int rand(void); void srand(unsigned int seed); int rand_r(unsigned int * seedp);
rand()返回一个[0,RAND_MAX]之间的伪随机数。RAND_MAX的值可能是平台相关的,在Linux下RAND_MAX=0x7FFFFFFF,Windows下RAND_MAX=0x7FFF。srand()用于设置rand()产生随机数的种子。如果没有调用srand()函数,则默认的随机数种子为1。因为rand()使用隐藏的state来连续产生随机数,因此每次调用rand()获得的结果都是不相同,除非调用srand()重置了随机数种子,而rand()也不是线程安全的,同一进程的多个线程应该是共享同一个随机数state的。
rand_r()使用独立的变量(seedp指向的变量)存储随机数的状态。因此可以并发调用rand_r(),而互不影响各自序列的生成。但由于seedp所指变量只能提供很小的状态数,因此产生的序列的随机性可能较差。(drand48_r)
rand()使用的状态和rand_r()使用的状态是无关的。random, srandom,initstate,setstate
#include <stdlib.h> long int random(void); void srandom(unsigned int seed); char *initstate(unsigned int seed, char *state, size_t n); char *setstate(char *state);
random()产生[0,RAND_MAX]之间的随机数,random()使用的随机数发生器的周期非常长。srandom()用于设置random()产生随机数的种子。相同的种子将产生相同的随机数(序列),默认的随机数种子是1。
initstate()用于初始化random()函数用于保存状态的空间。state是保存状态的数组的首地址,n则表示数组的长度,n越大,则保存的状态越复杂,产生的序列随机性也越好,n的取值至少应该为8,少于8字节的空间会导致函数调用错误,当前“最优的”取值包括8、32、64、128和256,其他值将会被缩小为之前述的几个值。setstate()用于改变random()所使用的保存状态的空间,state必须是经过initstate()初始化过的,或先前调用setstate()的返回值。如果调用成功,则initstate()和setstate()都返回先前使用的存储状态的空间的指针。如果失败,setstate()函数返回NULL。为了保证产生的结果互不影响,
random()同样是不能用于多线程的。reentrant random generator
#include <stdio.h> int random_r(struct random_data * buf, int32_t *result); int srandom_r(unsigned int seed, struct random_data * buf); int initstate_r(unsigned int seed, char * statebuf, size_t statelen, struct random_data * buf); int setstate_r(char * statebuf, struct random_data * buf);这些函数是适合于多线程程序使用的可再入的函数,可在多个线程中产生相同的随机序列。这些函数与1.2的区别在于,使用指定的
buf存储随机数发生器的状态,而非存储在原来的一个全局变量中。
random_r()将生成的随机数通过参数result返回。所有函数在成功执行后返回0,否则返回-1。this functions are nonstandard glib extensions
算法
C++'s Standard Algorithms are
- operating on (iterator) ranges of elements and implemented as free-standing functions: allows algorithms to be implemented independent from container types (generic).
- functions as parameters: many are customizable with function(object)s / lambdas
- well-tested and efficient
#include <algorithm>
#include <memory>
Non-Modifying Queries
-
finding elements / existence queries
using namespace std; tf = all_of(@begin, @end, tf_func_check); tf = any_of(@begin, @end, tf_func_check); tf = none_of(@begin, @end, tf_func_check);==
c++20在ranges中封装了支持容器作为参数的同名函数,下同。==tf = ranges::all_of(container, check);tf = count(@begin, @end, value); tf = count_if(@begin, @end, tf_func_check);@pos = find(@begin, @end, value); // return end() if not find @pos = find_if(@begin, @end, tf_check); // return end() if not findfind_if_not()。从备选集合中查找元素:
@pos = find_first_of(@sbegin, @send, @wbegin, @wend); @pos = find_first_of(container, candidates); // c++20,下同查找子序列:
@pos = search(@sbegin, @send, @wbegin, @wend); // find 1st occurance @pos = find_end(@sbegin, @send, @wbegin, @wend); // find last occurance查找连续出现元素:
@pos = adjacent_find(@begin, @end, cmp=<); @pos = search_n(@begin, @end, n, tf_func_equal); // 连续出现n个相同元素 -
minimum / maximum
using namespace std; x = min(a,b, cmp=<); // same for max,minmax x = min({x1,x2,...}, cmp=<); // C++11 @min = min_element(@first, @last, cmp=<);// also max_element, minmax_elementminmax:返回包括最小值和最大值的元组(pair)。minmax_element返回对应迭代器组成的元组。 -
comparing ranges of elements
tf = equal(@begin1, @end1, @begin2, @end2, tf_func_equal); pair = mismatch(@begin1, @end1, @begin2, @end2, tf_func_equal);mismatch返回两个序列中不匹配位置的迭代器组成的元组。 -
binary search of sorted ranges
Modifying Operations
-
copying / moving elements
copy:目标必须具有足够空间容纳源数据。@cp_end = copy(@begin, @end, @tgt_begin); // .resize(n) @cp_end = copy_n(@begin, n, @tgt_begin); @cp_first = copy_backward(@begin, @end, @tgt_end); // 向目标容器中反向复制 @cp_end = copy_if(@begin, @end, @tgt_begin, tf_func_check);ranges::copy(src, begin(tgt))。reverse(@begin, @end); @cp_end = reverse_copy(@begin, @end, @tgt_begin); // 将源数据反向复制到目标容器移位:


移位后原位置上的元素值不改变。
循环移位:将开始区间移至末尾。

rotate_copy(@begin, @new_first, @end, @target);随机采样:
#include <random> auto rgen = std::mt19937{}; // 32 bit mersenne twister engine sample(@begin, @end, @tgt, n, rgen);随机打乱:
shuffle(@begin, @end, random_engine);排列:
next_permutation(begin(v),end(v)); prev_permutation(begin(v),end(v)); is_permutation(begin(v1), end(v1), begin(v2)); // c++11排序:
sort(@begin, @end, cmp=<); stable_sort(@begin, @end, cmp=<); tf = is_sorted(@begin, @end, cmp=<);分割:根据条件将区间元素分为两个部分。分割后区间前半部分
tf_func=true,后半部分tf_func=false。@true_end = partition(@begin, @end, tf_func); partition_copy(@begin, @end, @out1, @out2, tf_func); @true_end = stable_partition(@begin, @end, tf_func); tf = is_partitioned(@begin, @end, tf_func); @true_end = partition_point(@begin, @end, tf_func); -
replacing / transforming elements
fill(@begin, @end, value); fill_n(@begin, n, value);auto generator = [i=0]() mutable { i += 2; return i; }; generate(@begin, @end, generator); generate_n(@begin, n, generator); #include <numeric> iota(@begin, @end, value); // 使用递增数列填充区间,起始值为value
replace(@begin, @end, old_value, new_value); replace_if(@begin, @end, f_condition, new_value);replace_copy,replace_copy_if。remove(@begin, @end, value); remove_if(@begin, @end, f_condition);remove_copy,remove_copy_if。@new_end = unique(@begin, @end);仅清除连续的重复值,并将后续值向前移动,不会重新分配内存。可以在移除前首先对数据排序,以保证最终结果唯一。(
unique_copy) -
removing elements
erase(container, value); // c++20 erase(container, f_condition); // c++20 -
union/intersection/etc. of sorted ranges
#include <iterator>
n = distance(@first, @last);
数值计算
#include <numeric>
序列构造
iota(@begin, @end, Type start_value=1); // iota stants for greek letter ι
map-reduce
reduce(begin(v), end(v));
reduce(begin(v), end(v), w0);
reduce(begin(v), end(v), w0, func); // 默认运算为+
未提供初始值
w0时,将区间的第一个值作为初始值。
差分
adjacent_difference(@begin, @end, @out, diff_func=-); //C++17: custom operator
inclusive_scan(@begin, @end, @out, operator=+);
inclusive_scan,transform_inclusive_scan:输入的第一个元素为输出结果的第一个元素(c++17)。
exclusive_scan,transform_exclusive_scan:输出第一个元素为0,最后一个输入元素不会参与运算。
有序序列
查找有序序列:
tf = binary_search(@begin, @end, value, comp=<);
@pos=lower_bound(upper_bound):查找不小(大)于指定值的第一个元素;
<@start,@end>=equal_range():查找等于指定值的子序列;
tf=includes(...):查找子序列;
合并有序序列:
merge(@begin1, @end1, @begin2, @end2, @out);

集合运算
@end=set_union(@begin1, @end1, @begin2, @end2, @out, compare=<);
set_intersection、set_difference(在s1中而不在s2中)、set_symmtric_difference(仅在s1或s2中)。
函数对象
比较运算
#include <functional>
-
std::equal_to -
std::not_equal_to -
std::greater -
std::less -
std::greater_equal -
std::less_equal -
C++11 must specify operand type explicitly:
std::greater<Type>{} -
C++14 no need for specifying operand type:
std::greater<>{}
算术运算
std::plusstd::minusstd::multipliesstd::dividesstd::modulusstd::negate
JavaScript
... for the 6th major edition of the standard, published in June 2015. Since then a yearly edition has been published. For example, the 13th edition was published in June 20221.
Unlike most programming languages, the JavaScript language has ==no concept of input or output==. It is designed to run as a scripting language in a ==host environment==, and it is up to the host environment to provide mechanisms for communicating with the outside world. The most common host environment is the ==browser==, but JavaScript interpreters can also be found in other places, including Adobe Acrobat/Photoshop, SVG images, server-side environments such as ==Node.js==, NoSQL databases like Apache CouchDB, desktop environments like GNOME , and others.
JavaScript is a multi-paradigm, dynamic language with types and operators, standard built-in objects, and methods. Its syntax is based on the Java and C languages.
***HTML**, **CSS**, and **JavaScript** are **front-end** (or **client-side**) languages, which means they are run by the browser to produce a website front-end that your users can use[^web-basic]. There are **back-end** (or **server-side**) languages, running on the server to get some data out of a database and generate some HTML to contain the data, before the result is then sent to the browser to be displayed. Example server-side languages include **ASP.NET**, **Python**, **PHP**, and **NodeJS**.*
JavaScript First Steps - Learn web development | MDN (mozilla.org)
JavaScript building blocks - Learn web development | MDN (mozilla.org)
JavaScript object basics - Learn web development | MDN (mozilla.org)
变量
变量类型
-
Number:双精度64位浮点数/整数(整数也按浮点数处理);
parseInt('123', 10) // 将字符串转换为整数 parseInt('123.45') // 将字符串转换为浮点数NaN、Infinity和-InfinityNumber.isNaN(NaN) isFinite(1 / 0); // false -
BigInt
-
String:UTF-16编码。
'hello'.length; // 字符串长度(编码单位*)*:一个字符由一个或两个UTF-16编码单位组成,一个编码单位占用2字节。 -
Boolean
-
Function
-
Object
FunctionArrayDateRegExpMath:提供数学计算方法和常量。Error
-
Symbol (ES2015)
-
undefined和null:null表示故意设置的空值,undefined表示变量未初始化。 -
boolean:表示true或false。false、0、空字符串("")、NaN、null和undefined都可转换为false;其他值则转换为true。if等语句块的判断条件可执行自动转换。Boolean(1) // trueboolean类型支持&&、||和!逻辑运算。
变量声明
let a = 1; // block-scope variable
const c = 3.14 // block-scope constant
var b = "hello"; // function-scope variable
变量类型由初始化的值决定,如果未赋值,其类型为undefined。
运算符
数值运算符
+, -, *, / and % 。
+可用于字符串拼接。
赋值运算符
=、+=、……、++、--(可前缀/后缀)
比较运算符
<, >, <= and >=.
==进行比较时会对不同类型尝试强制转换;===,!==则直接比较。
没有!=运算符,使用逻辑!转换比较结果。
逻辑运算符
&&和||支持短路。
字符串
str[i]//.charAt(5);
.indexOf/lastIndexOf(substr)
.slice(i[,j]);
.length
toUpperCase() and toLowerCase()
.split(" ");
.trim();
.replace("How", "Where");
.replace(/javascript/gi, "JavaScript"):正则表达式替换;
字符串插值
const poem = "The Wide Ocean", author = "Pablo Neruda";
const favePoem = `My favorite poem is ${poem} by ${author}.`; //支持换行, 支持包含引号
引号转义
交替使用''和"";
使用\'或\"进行转义;
使用"``"。
对象类型
构造对象实例
JavaScript对象可以看作name-value组成的集合,类似于Python字典、C/C++散列表或JavaHashMap等。
构造空对象:
const obj = new Object();
const obj = {}; // prefered JSON format*
*:JSON - JavaScript Object Notation。
构造包含属性和方法的对象。
const obj = {
name: 'Carrot',
details: { color: 'orange', size: 12 },
var, //*
func_name(){/*...*/} //定义函数
func_name: function(){/*...*/} //使用匿名函数语法
};
*:简写,使用变量名和变量的值。
使用函数定义构造对象(函数对象)。函数既是对象类型也作为对象的构造函数。
function Person(name, age) {
this.name = name;
this.age = age;
this.fullName = function(){/**/}
}
使用对象原型构造对象
上述使用函数构造对象的方法在实例化对象时会重复定义函数成员,使用对象原型ClassName.prototype定义所有实例共享的函数对象与静态成员。
Person.prototype.fullName = function() {/*...*/};
const you = new Person('You', 24);
new创建一个空对象,并将其赋值给Person函数的this。未使用new,则this表示的是全局变量空间。
访问属性
obj.details.color
obj['details']['color']
对象内部可使用this引用当前对象的属性。
数组
数组是一类特殊的JavaScript对象。
const a = new Array();
a[0] = 'dog'; a[1] = 'cat'; a[2] = 'hen'; //*
a.push(item); // 追加元素
a.length; // -> 3
const a = ['dog', 'cat', 'hen'];
*:数组可动态扩展,对应下标未赋值的元素的值为undefined(类似于Shell脚本)。
数组迭代
-
使用循环进行迭代。
-
使用
forEach方法进行迭代。array.forEach(iter_func)
数组方法
Array - JavaScript | MDN (mozilla.org)
语法
换行:
注释:单行// coments;多行/*comments*/。
流程控制
条件选择
if (name === 'puppies') {}
else if (name === 'kittens') {}
else {} // 与C语言结构相同
switch (action) {
case 'draw':
break; // 如果不添加break, 则会继续执行后续分支
case 'eat';
break;
default:
doNothing();
} // 比较总是使用"==="
循环
while (n > 0) {}
do {
input = get_input();
} while (!(input === 'exit'));
for (let i = 0; i < 5; ++i){}
for (const v of array) {} // 迭代数组元素
for (const prop in object) {} // 迭代对象属性
函数
function add(x, y,...args) {
const total = x + y;
return total; // 如果未指定返回值, 返回undefined
}
参数列表
函数参数列表仅具有声明意义,实际调用时可传入少于或多于声明的参数个数。缺少的参数将被视为undefined,多余的参数被忽略
变长参数列表
- 使用
...args捕获所有未声明的传入参数。 - 可在函数内部,通过
arguments访问传入的所有参数。 - 参数展开:调用时
func(...args)。
函数对象
函数也是一类特殊对象,可用于变量赋值或参数传递赋值。
匿名函数
let avg = function(){};
closures
Whenever JavaScript executes a function, a 'scope' object is created to hold the local variables created within that function.
A closure is the combination of a function and the scope object in which it was created.
嵌套函数
可访问其上级函数作用域中的变量。
异步
✨Introducing asynchronous JavaScript - Learn web development | MDN (mozilla.org)
标准库
输入输出
console是封装控制台的对象,可向控制台(浏览器控制台/Node.js终端)输出日志:
console.log(obj) // trace/debug/info/warn/error
log系列函数可直接输出对象。
时间日期
Date();
浏览器应用
HTML文件中通过<script>标签引用JavaScript脚本(可位于<head>或<body>,相对HTML文件路径),默认情况下脚本执行顺序与引用顺序一致。脚本执行环境由浏览器解释器构建,通过运行环境中的document对象(Document)对HTML页面进行修改(页面元素内容、CSS等)。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>JavaScript Tutorial</title>
<script src="scripts/main.js" defer></script> <!--*-->
<script>/*inline script*/</script>
</head>
<body>
<h1></h1>
</body>
</html>
*:defer在HTML文档解析完成后再执行脚本程序(按出现顺序执行),async:异步获取脚本内容而不阻塞页面加载,当脚本下载完后会立即开始执行(仅用于独立执行的脚本)。
对于与页面内容紧密相关的脚本,可将其置于对应的HTML元素之后。
使用独立的脚本文件的优点:1)分离HTML和Javascript代码,使两者更易于书写、理解和维护;2)独立的脚本文件可在本地缓存,从而加快页面的加载速度。

const myHeading = document.querySelector('h1'); //*
myHeading.textContent = 'Hello world!';
*:Returns the first element that is a descendant of node that matches selectors.
JavaScript的作用:
- 动态更新HTML和CSS文件;
- 处理用户交互。
✨Introduction to web APIs - Learn web development | MDN (mozilla.org)
事件处理
document.querySelector('html') // 获取页面对象
.addEventListener( // 为对象增加事件处理方法
'click',
function () {
alert('Ouch! Stop poking me!');
}
);
交互组件
alert(msg);
let value = prompt(msg);
存储
localStorage API
localStorage.setItem('name', 'gary');
const stored_name = localStorage.getItem('name');
优化
program.min.js是program.js优化后的文件,减少网络传输以加快网页加载:将长变量转换为短名。
just-in-time compiling:
The JavaScript source code gets compiled into a faster, binary format while the script is being used, so that it can be run as quickly as possible.
Node.js
Node.js项目
模块
在Node.js中,一般将代码合理拆分到不同的文件中,每一个文件就是一个模块,而文件路径就是模块名。在编写每个模块时,
-
require函数用于加载和使用模块(执行模块代码并返回导出内容,一个模块中的代码仅在模块第一次被使用时执行一次)。另外,可以require加载一个JSON文件。let data = require('./data/two-nodes.json') console.log(data); -
exports对象用于保存当前模块要导出的公有对象。通过require函数引用的就是模块的exports对象。exports.hello = function () { console.log('Hello World!'); }; -
module对象可以访问到当前模块包括exports在内的信息,主要用途是替换当前模块的exports对象。
***:import的用法。import defaultExport from "module-name"; import * as name from "module-name"; import { export } from "module-name"; import { export as alias } from "module-name";
模块路径解析规则
通过文件路径:模块名可使用相对路径(./开头)或绝对路径(以/或X:开头);
通过搜索路径:模块名按搜索路径下的层级索引(类似于foo/bar),搜索顺序:
- 内置模块
node_modules目录$NODE_PATH
模块名中的.js扩展名可以省略。
主模块
通过命令行参数传递给NodeJS以启动程序的模块被称为主模块。主模块通过引用程序的其它模块完成工作。
入口程序
function main(argv) {
copy(argv[2], argv[3]); //argv[0]是node路径, argv[1]是主模块文件路径。
}
main(process.argv);
process是Node.js执行环境中的全局变量。
包
把由多个子模块组成的大模块称做包,并把所有子模块放在同一个目录里。其中一个模块作为入口模块,其导出对象将引用其他模块的导出对象,作为整个包的导出对象。当入口模块的文件名是index.js,加载模块时可以使用模块所在目录的路径代替模块文件路径。
可通过包目录下的package.json修改默认的入口模块名和位置。
{
"name": "cat",
"main": "./lib/main.js"
}
工程目录
- /home/user/workspace/node-echo/ # 工程目录
- bin/ # 存放命令行相关代码
node-echo
+ doc/ # 存放文档
- lib/ # 存放API相关代码
echo.js
- node_modules/ # 存放三方包
+ argv/
+ tests/ # 存放测试用例
package.json # 元数据文件
README.md # 说明文件
执行Node.js程序
启动Node.js程序:
-
直接在命令行通过
node解释执行脚本;node src/index.js -
在Linux系统下,通过脚本首行
#! /usr/bin/env node指定当前脚本的解释器,并为该脚本添加可执行权限; -
在Windows系统下,通过一个cmd或PowerShell脚本封装
node命令;@node "./node-echo.js" %*
输入输出
标准输入输出
process.stdin、process.stdout和process.stderr。
process.stdout.write(util.format.apply(util, arguments) + '\n');
文件读写
var fs = require('fs')
function copy(src, dst) {
fs.writeFileSync(dst, fs.readFileSync(src));
}
异步读写
通过回调函数处理数据或错误。
fs.readFile(pathname, function (err, data) {
if (err) {
// Deal with error.
} else {
// Deal with data.
}
});
命名约定:默认为异步方法,带
Sync的方法为同步方法。
流式读写
function copy(src, dst) {
fs.createReadStream(src).pipe(fs.createWriteStream(dst));
}
Stream基于事件机制工作。
var rs = fs.createReadStream(pathname);
rs.on('data', function (chunk) {
rs.puase();
doSomething(chunk, function(){rs.resume()});
});
rs.on('end', function () { cleanUp(); });
Buffer
http://nodejs.org/api/buffer.html
文本编码
iconv-lite转码。
文件系统
路径操作
http://nodejs.org/api/path.html
path.normalize(pathname)
path.join(name1, name2)
path.extname('foo/bar.js'); // => ".js"
访问目录信息
fs.readdirSync(pathname)
fs.statSync(pathname)
网络操作
http服务
var http = require('http');
http_server = http.createServer(http_handler);
http_server.listen(8124);
let http_handler = function (request, response) {
/*接收请求数据*/
var body[];
request.on('data', function (chunk) {
body.push(chunk);
// response.write(chunk); // 将请求数据原样返回
});
request.on('end', function () {
body = Buffer.concat(body);
console.log(body.toString());
// response.end();
});
/*发送响应*/
response.writeHead(200, { 'Content-Type': 'text-plain' });
response.end('Hello World\n');
}
request是一个对象,可以访问request.url。
http客户端
var options = {
hostname: 'www.example.com',
port: 80,
path: '/upload',
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
}
};
var request = http.request(options, function (response) {});
request.write('Hello World');
request.end();
// => http.get('http://www.example.com/', function (response) {});
https
http://nodejs.org/api/https.html
URL
url.parse('http://user:pass@host.com:8080/p/a/t/h?query=string#hash');
// 返回数据:
{ protocol: 'http:',
auth: 'user:pass',
host: 'host.com:8080',
port: '8080',
hostname: 'host.com',
hash: '#hash',
search: '?query=string',
query: 'query=string',
pathname: '/p/a/t/h',
path: '/p/a/t/h?query=string',
href: 'http://user:pass@host.com:8080/p/a/t/h?query=string#hash'
}
请求参数
http://nodejs.org/api/querystring.html
进程管理
process对象用于管理控制当前进程。
创建进程
var child = child_process.spawn('node', [ 'xxx.js' ],
stdio:[0,1,2,'ipc']);
// 获取子进程的输出
child.stdout.on('data', function (data) {
console.log('stdout: ' + data);
});
child.stderr.on('data', function (data) {
console.log('stderr: ' + data);
});
child.on('close', function (code) {
console.log('child process exited with code ' + code);
});
同步调用
var child_process = require('child_process');
var util = require('util');
function copy(source, target, callback) {
child_process.exec(
util.format('cp -r %s/* %s', source, target), callback);
}
cluster
cluster模块是对child_process模块的进一步封装,用于解决单进程服务无法充分利用多核CPU的问题。使用该模块可以让每个核上运行一个工作进程,并统一通过主进程监听端口和分发请求。
降低进程权限
http.createServer(callback).listen(80, function () {
var env = process.env,
uid = parseInt(env['SUDO_UID'] || process.getuid(), 10),
gid = parseInt(env['SUDO_GID'] || process.getgid(), 10);
process.setgid(gid);
process.setuid(uid);
});
退出进程
try {
// ...
} catch (err) {
// ...
process.exit(1);
}
进程间通信
信号
child.kill('SIGTERM')
IPC
/* parent.js: 收发数据 */
child.on('message', function (msg) {
console.log(msg);
});
child.send({ hello: 'hello' });
/* child.js: 接收数据 */
process.on('message', function (msg) {
msg.hello = msg.hello.toUpperCase();
process.send(msg);
});
数据格式为序列化JSON文本。
守护进程
异步编程
异步方式下,函数执行结果不是通过返回值,而是通过回调函数的参数传递。
JS自身提供的异常捕获和处理机制try..catch..,只能用于同步执行的代码。由于异步函数会打断代码执行路径,异步函数执行过程中以及执行之后产生的异常抛出到执行路径被打断的位置过程中,如果没有遇到try语句,就作为一个全局异常抛出。
使用域简化异步代码的异常处理
在域(就是运行环境)中,如果一个异常没有被捕获,将作为一个全局异常被抛出。Node.js通过process对象提供了捕获全局异常的方法。
process.on('uncaughtException', function (err) {
console.log('Error: %s', err.message);
});
创建子域以尽早捕获异常。
http.createServer(function (request, response) {
var d = domain.create();
d.on('error', function () {/*error handler*/ });
d.run(function () {
asyncMethod(request, function (data) {/*processing*/});
});
});
使用
uncaughtException或domain捕获异常,代码执行路径里涉及到了C/C++部分的代码时,如果不能确定是否会导致内存泄漏等问题,最好在处理完异常后重启程序比较妥当。而使用try语句捕获异常时一般捕获到的都是JS本身的异常,不用担心上诉问题。
http://nodejs.org/api/domain.html
参考资料
What is JavaScript? A Brief History 1: A re-introduction to JavaScript (JS tutorial) - JavaScript | MDN (mozilla.org) 3:How the web works - Learn web development | MDN (mozilla.org) 4: The web and web standards - Learn web development | MDN (mozilla.org) 5: JavaScript documentation — DevDocs 6: micromata/awesome-javascript-learning: A tiny list limited to the best JavaScript Learning Resources (github.com)
TypeScript
A Typed Superset of JavaScript.
- TypeScript is a language that is a superset of JavaScript: JS syntax is therefore legal TS.
- TypeScript is a typed superset, meaning that it adds rules about how different kinds of values can be used.
- TypeScript never changes the runtime behavior of JavaScript code, even if TypeScript thinks that the code has type errors.
对象类型声明
JavaScript的变量具有类型,但使用前无需声明。TypeScript增加了类型声明,从而支持静态类型检查。
基础类型
string, number, and boolean
let myName: string = "Alice";
bigint [ES2020]
null and undefined with strictNullChecks on:必须处理变量为null或undefined的情形。
Non-null Assertion Operator
function liveDangerously(x?: number | null) {
console.log(x!.toFixed()); // ! add assertion for null/undefined
}
数组
string[], number[], boolean[] or Array<number>
any
表示任意类型,避免类型检查错误。任何无法自动推测的对象会被视为any类型导致跳过类型检查,在项目配置中设置noImplicitAny将无法推测的类型视为错误。
对象类型
let pt: {x: number; y: number} = {x:3, y:7};
let name: {first: string; last?: string};
name.last !== undefined // check optional property existence
函数
// Parameter type annotation
function greet(name: string): number {
console.log("Hello, " + name.toUpperCase() + "!!");
return 0;
}
匿名函数参数类型可根据其调用==上下文推断==,因此无需声明其参数类型。
函数类型变量声明
函数也是一种变量类型,因此可以用于类型声明。
function func(fn: (a: string)=>void)
type GreetFunction = (a: string) => void; // 为函数类型定义别名*
*:函数类型声明中必须同时给出参数名和参数类型名;如果省略参数名,则会将参数类型名视为参数名,而将对应的参数类型视为Any。
带属性的函数类型
type DescribableFunction = {
description: string; // 属性
(someArg: number): boolean; // 函数原型
};
构造函数类型
使用此类声明的函数函数类型标识new方法调用以创建某类对象。构造函数类型可与普通调用方法并列声明(根据参数类型决定调用对象)。
type SomeConstructor = {
new (s: string): SomeObject;
};
interface CallOrConstruct {
new (s: string): Date;
(n?: number): number;
}
函数泛型参数声明
function firstElement<Type>(arr: Type[]): Type | undefined {}
function map<Input, Output>(arr: Input[], func: (arg: Input) => Output): Output[] {}
泛型类型限制
限制类型应具有的接口(包含的属性)。
function longest<Type extends { length: number }>(a: Type, b: Type) {}
联合类型
let id: number | string;
function print(obj: number|string){/*...*/}
其他判断条件:Array.isArray(x)
字面值枚举
let alignment: "left" | "right" | "center" = "center";
字面值可以和其他类型组合成联合类型。
类型限制(Narrowing)
联合类型默认仅能调用类型的公共方法,可通过类型判断typeof在分支中调用类型特有的方法。
if (typeof id === "string") { // [type guard]
// In this branch, id is of type 'string'
console.log(id.toUpperCase());
} else {
// Here, id is of type 'number'
console.log(id);
}
typeof支持返回以下类型:"string"、"number"、"bigint"、"boolean"、"symbol"、"undefined"、"object"、"function"。
TypeScript: Documentation - Narrowing (typescriptlang.org)
类型别名
type Point = {
x: number;
y: number;
};
let pt: Point = {x:3, y:7};
type ID = number | string;
let id: ID = 1001;
接口
接口类似于类型别名,但支持继承语法(类型别名也可以不同语法实现),并可以动态添加属性(类型别名不支持)。
interface Animal {
name: string
}
interface Animal {
weight: number // Animal: {name, weight}
}
interface Bear extends Animal {
honey: boolean
}
类型断言
根据代码运行的实际情况,将对象显式转换为已知的类型。
const myCanvas = document.getElementById("main_canvas") as HTMLCanvasElement;
const myCanvas = <HTMLCanvasElement>document.getElementById("main_canvas");
仅允许具有继承关系的类型进行相互转换。对于未知关系的类型,确实需要转换的情况,可先转换为any或unknown,再转换为目标类型。
const a = (expr as any) as T;
开发环境
Web开发环境
客户侧开发工具
✨Understanding client-side web development tools - Learn web development | MDN (mozilla.org)
客户侧框架
✨Introduction to client-side frameworks - Learn web development | MDN (mozilla.org)
| Framework | Browser support | Preferred DSL | Supported DSLs |
|---|---|---|---|
| Angular | IE9+ | TypeScript | HTML-based; TypeScript |
| React | Modern (IE9+ with Polyfills) | JSX | JSX; TypeScript |
| Vue | IE9+ | HTML-based | HTML-based, JSX, Pug |
| Ember | Modern (IE9+ in Ember version 2.18) | Handlebars | Handlebars, TypeScript |
服务侧框架
Server-side website programming - Learn web development | MDN (mozilla.org)
✨Express/Node introduction - Learn web development | MDN (mozilla.org)
Node.js
安装Node.js
Node.js® 是一个基于 Chrome V8引擎 的 JavaScript 运行时环境。
The runtime is intended for running directly on a computer or server OS. As such, the environment omits browser-specific JavaScript APIs and adds support for more traditional OS APIs including HTTP and file system libraries. ✨maxogden/art-of-node: a short introduction to node.js (github.com)
Linux
# Using Ubuntu
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash -
apt-get install -y nodejs
# CentOS/Fedora
curl -fsSL https://rpm.nodesource.com/setup_lts.x | bash -
yum install -y nodejs
yum install gcc-c++ make # to compile&install native addons from npm*
*:或者执行yum groupinstall 'Development Tools'。Latest LTS Version: 16.17.0 (includes
npm8.15)。Linux版本:https://github.com/nodesource/distributions/blob/master/README.md。
Windows版本:https://nodejs.org/en/download/。
Windows
winget install OpenJS.NodeJS.LTS # v16 *
winget安装包无法自动安装Python和C++编译工具,需要从官网下载安装包并修改安装。MSBUILD : error MSB4132: 无法识别工具版本“2.0”。可用的工具版本为 "4.0"。
包管理器
NPM
NPM (Node package manager)包含在Node.js中。
npm -l # display usage info for all commands
npm <command> -h # quick help on <command>
npm help <command> # show help in browser
初始化项目
为项目创建配置文件package.json(交互式):
cd progdir && npm {init|create} # create<->init
# package name: (test-api)
# version: (1.0.0)
# description: coding a fun API using Express, a NodeJS minimalist web framework.
# entry point: (index.js)
# test command:
# git repository:
# keywords: express, api, nodejs
# author: Gary Wang
# license: (ISC)
mkdir src && touch src/index.js
配置文件内容包括:项目基本信息、执行脚本、依赖库声明。
{
"name": "node-echo",
"main": "./lib/echo.js", // 包的主模块
"dependencies": {
"argv": "0.0.2" // 依赖库名称和版本
}
}
包管理
也可在npm (npmjs.com)搜索包。
安装/更新依赖库:
npm install # 安装当前项目所需依赖(package.json)
--location=global,user,project #*
--global
npm install <foo> <bar@version> # 安装指定模块**
--save # 将安装的模块加入package.json
npm update # 更新满足条件的依赖库并更新(package-lock.json)
npm run <script> # 运行package.json中定义的脚本
npm start|restart|stop --if-present # => npm run start
相应脚本需要在配置文件中定义,
--if-present仅在相应命令存在的情况下执行而不产生错误。
*:安装位置:
global:~\AppData\Roaming\npm\node_modules(Windows)或/usr/local/nodejs/lib/node_modules/(Linux);user:~\node_modules;project:PROJECT_HOME\node_modules;
**:如果当前目录下没有项目配置文件(package.json),执行命令时会自动生成包含所安装包的配置文件。
仓库镜像配置
默认仓库为https://registry.npmjs.org/,可修改为国内镜像源(阿里云:https://registry.npmmirror.com)
npm config set registry https://registry.npmmirror.com
npm config get registry
包管理
Java Script包采用语义化版本控制,以在项目中使用依赖包时保证良好的兼容性。项目使用的依赖包声明方式:
- 仅允许
patch版本升级:1.0, 1.0.x, ~1.0.4; - 允许
minor和patch版本升级:1, 1.x, ^1.0.4; - 允许
major版本升级:*, x。 - 版本范围:
>2.1,1.0.0 - 1.2.0(可使用>,<,>=,<=,=或-表示范围)。 - 组合:
^2 <2.2 || >2.3。
安装全局工具
npm install --global,-g <module-name>
yarn
curl -sL https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo
yum install yarn
NODE_ENV=prodution yarn start --production
pnpm
模块编译
node-gyp:MSBuild.exe failed with exit code: 1,解决方法:
npm install --ignore-scripts
npm rebuild node-sass --force --ignore-scripts
Node运行环境管理
nvm version # 查看nvm版本
nvm arch # 查看node运行的系统架构
nvm current # 当前激活的node版本
nvm list [available] # 列出已安装/可安装版本
nvm install <version> [32|64] # 安装指定版本node*
nvm use [version] [32|64] # 切换版本(全局生效)**
nvm uninstall <version> # 必须指定具体版本
*:具体版本号、lts或latest;
**:需要管理员权限创建符号链接。
下载镜像
nvm proxy [URL]
nvm node_mirror [URL] # -> 下载node地址:https://nodejs.org/dist/
nvm npm_mirror [URL] # -> 下载NPM地址:https://github.com/npm/cli/archive/
nvm root [PATH] # -> 环境安装目录:~\AppData\Roaming\nvm
Node交互式环境
在终端执行node进入交互命令行。
console.log('hello world!')
Node.js库
HTTP服务
const http = require("http");
const hostname = "127.0.0.1", port = 5000;
const server = http.createServer(function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello World\n');
});
server.listen(port, hostname, function () { // start server
console.log(`Server running at http://${hostname}:${port}/`);
})
Node.js应用程序
npx <package> # -> x, npm exec
http-server
http-serveris a simple, zero-configuration command-line static HTTP server. It is powerful enough for production usage, but it's simple and hackable enough to be used for testing, local development and learning.
用法
http-server [./public] # 如果"./public"不存在则默认为"./"
-p,--port=8080
-a 0.0.0.0
--cors=false
-o [path] # 在浏览器中打开指定路径
--username USER
--password
-S,--tls,--ssl -C,--cert=cert.pem -K,--key=key.pem
Web前端打包
将HTML文件引用的NPM包及其依赖库打包到单一文件,方便引用。
browserify
npm install -g browserify
browserify/browserify: browser-side require() the node.js way (github.com)
browserify.cmd .\index.js --outfile .\bundle.js
--outfile:在Windows终端中执行命令,如果将输出定向到文件可能导致编码不匹配的问题(输出内容为UTF-8,而终端编码为UTF-16)从而导致乱码。使用该选项打开文件进行输出可避免该问题。
webpack
internally builds a dependency graph from one or more entry points and then combines every module your project needs into one or more bundles, which are static assets to serve your content from.
打包配置webpack.config.js:
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
},
};
引用打包后的文件:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
...
</head>
<body>
...
<script src="dist/bundle.js"></script>
</body>
</html>
esbuild
npm install -g esbuild
esbuild app.jsx --bundle --outfile=out.js
TypeScript
TypeScript is available as a package on the npm registry available as
"typescript".
npm install typescript --save-dev # install for current project
npm install -g typescript # Globally Installing TypeScript
codebases should prefer a project-wide installation over a global install so that they can benefit from reproducible builds across different machines.
TypeScript: Bootstrapping tools for TypeScript projects (typescriptlang.org)
编译
将TypeScript源码转换为JavaScript。
- Erased Types
- Downleveling
- Strictness
编译项目
npx tsc --init # 初始化项目,生成tsconfig.json
npx tsc # 编译项目
tsc -p ./path/to/tsconfig.json # 编译指定路径下的项目
npx tsc program.ts utils.ts # 编译源码,忽略项目配置
Express
Fast, unopinionated, minimalist web framework for Node.js.
Express封装了Node.js的http和https库,并提供高层次的HTTP处理接口,如处理不同的HTTP方法、API路由、服务静态文件和基于模板创建动态响应。
Express middleware
While Express itself is fairly minimalist, developers have created compatible middleware packages to address almost any web development problem, related to cookies, sessions, user logins, URL parameters, POST data, security headers, ......
- Robust routing
- Focus on high performance
- Super-high test coverage
- HTTP helpers (redirection, caching, etc)
- View system supporting 14+ template engines
- Content negotiation
- Executable for generating applications quickly
Express项目
使用模板快速开始构建App。
npm install -g express-generator@4
express /project/folder # "npx express-generator" for Node.js 8.2+
npm install
npm start # -> http://localhost:3000
项目目录结构如下:
/project/folder
├─bin
├─public
│ ├─images
│ ├─javascripts
│ └─stylesheets
├─routes
└─views
创建新项目并添加express库。
npm init && npm install express
代码结构
const express = require('express') // 导入express库
const app = express() // 创建应用实例
const port = 5000
// 定义API和处理方法
app.get('/', (req, res) => {
res.send('hello world!');
})
// 启动服务
app.listen(port, () => {
console.log(`Example app listening on port ${port}.`);
})
监听多个端口与协议:
const http = require('http'),
https = require('https'),
express = require('express'),
app = express();
http.createServer(app).listen(80);
https.createServer({options}, app).listen(443);
Express examples (expressjs.com)
Express Tutorial: The Local Library website - Learn web development | MDN (mozilla.org)
Express/Node introduction - Learn web development | MDN (mozilla.org)
URL处理函数
一个URL可定义多个匹配的处理函数。
app.METHOD(PATH, HANDLER)
METHOD是HTTP方法;PATH是服务器的URL;HANDLER是处理函数。
req
res
服务静态文件
express.static(root, [options])
app.use(express.static('public')) // 添加多个静态文件目录
app.use(express.static('files')) // 按顺序查找静态资源
app.use('/static', express.static('public')) // 为静态资源URL添加前缀
root指定服务器上存放静态文件的根目录(可为绝对或相对路径,该目录名称不是URL的一部分)。
使用反向代理提高静态资源的服务效率。
API路由
app.use('BASE_URL', Router)
服务静态文件
错误处理
使用数据库
Angular
Angular是一个用HTML和TypeScript构建客户端应用的平台与框架。
- 模块
NgModule;根模块AppModule提供了用来启动应用的引导机制。 - 组件
@Component():每个应用至少有一个组件(根组件),它会把组件树和页面中的DOM连接起来。每个组件都会定义一个类,其中包含应用的数据和逻辑,并与一个HTML模板相关联,该模板定义了一个供目标环境下显示的视图。 - 模板:模板中的指令会提供程序逻辑,而绑定标记会把你应用中的数据和 DOM 连接在一起。
- 服务类:与特定视图无关并希望跨组件共享的数据或逻辑,通过
@Injectable()让服务作为依赖被注入到客户组件中。 - 路由:
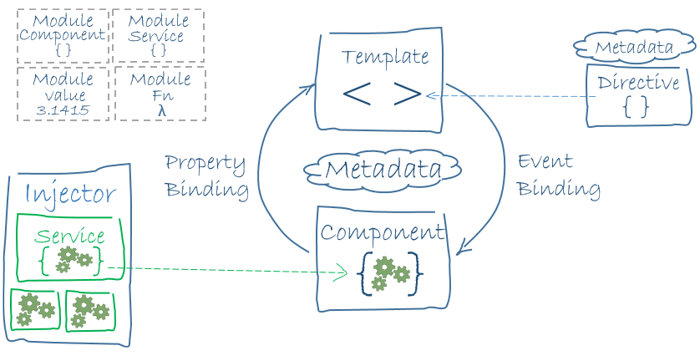
Angular命令行工具
安装和卸载命令行工具
npm install -g @angular/cli # sudo on Ubuntu
npm uninstall -g @angular/cli
npm cache clean --force
Windows上使用PowerShell需要修改脚本执行策略:
Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy RemoteSigned
创建新项目
ng new my-app
npm install --legacy-peer-deps # 如果安装依赖出错使用该命令
编译项目
ng build
启动应用
ng serve --host=ws-gary --port port --ssl [--disableHostCheck]
项目结构
package.json:包含了项目的配置文件,包括项目名称、描述、源代码仓库、版本、许可证、项目构建、测试、启动命令、依赖包等信息。
angular.json:Angular框架配置文件。
tsconfig.json:TypeScript配置文件。
编译
ng update # shou packages can be updated
ng update --all [--allow-dirty] [--force]
ng update @angular/core @angular/cli
Electron
Electron is a framework for building desktop applications using JavaScript, HTML, and CSS. By embedding Chromium and Node.js into its binary, Electron allows you to maintain one JavaScript codebase and create cross-platform apps that work on Windows, macOS, and Linux — no native development experience required.
git clone https://github.com/electron/electron-quick-start
cd electron-quick-start
npm install && npm start
开发工具
VS Code
调试
VS Code支持在浏览器中启动服务并调试Javascript程序,或通过Node.js执行环境进行调试。
 --fast-version-control
--fast-version-control
Concept
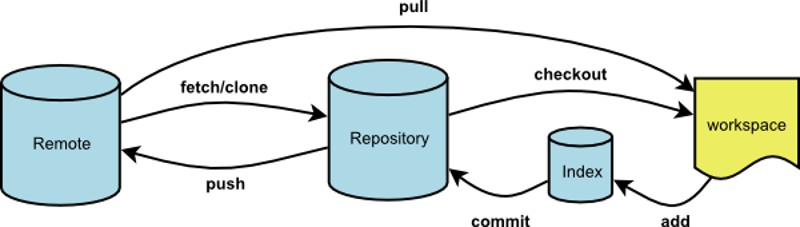
仓库结构
git仓库信息包含本地仓库(Repository)和远程仓库(remote),两者具有相同结构。
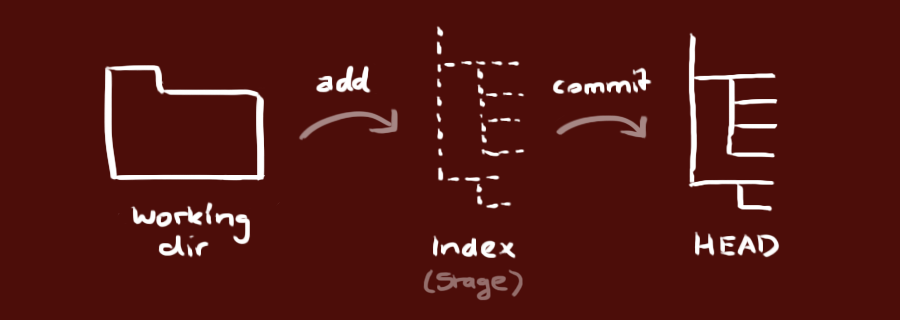
Your local repository consists of three "trees" maintained by git:
-
Working Directory: which holds the actual files (file system);
-
Index: which acts as a staging area;
Git uses its hash algorithm to index everything in your repo. Each file has a SHA that reflects the contents of that file. Each directory, in turn, is hashed. If a file in that directory changes, then the SHA of the directory changes too.
-
HEAD: which points to the last commit you've made.
Each commit contains the SHA of the top-level directory in your repo along with some other info.
由于远程仓库可能由多人参与维护,因此其版本与本地仓库版本(HEAD)可能不同。因此,将本地仓库推送到远程之前,需要首先将远程仓库拉取(fetch)到本地,并保证本地提交版本未落后于远程版本。否则,需要暂存本地更改,并使用远程版本更新本地版本,再恢复本地更改后提交。强制提交本地落后的版本可能会产生文件内容冲突。
repository
alias
bookmark
Workflow
Operations
stage
commit
使用git的原则
-
Only put source files into version control, never generated files.
-
Commit binary files with caution and strongly avoid committing large files.
-
never put confidential information into a repo, especially one you might share publicly.
Status
tracked/un-tracked
modified
staged/un-staged
committed
安装git
git配置
git config --global init.defaultBranch <name>
git config --global --edit # 打开git配置文件并编辑
添加--global将设置应用于当前系统用户下的所有仓库的默认配置。
配置文件位置
| 选项 | 说明 | 配置文件路径 |
|---|---|---|
--system | 默认配置 | /etc/gitconfig |
--global | 用户全局配置 | ~/.gitconfig or ~/.config/git/config |
--local | 仓库配置 | .git/config |
列出所有配置:
git config -l,--list
.gitignore:声明忽略仓库目录下的未追踪文件。
git用户配置
使用git提交代码前需要配置git用户信息(用户名和邮箱)。
git config user.name "John Doe"
git config user.email "you@emal.com"
输出格式配置
git config color.ui true # 使用彩色输出
git config color.ui auto
git图形界面
gitk
管理仓库
创建仓库
git init [project-name] # 默认在当前目录下创建仓库
git clone [url] [local_path]
在远程服务器创建仓库:
git remote add origin <server>
查看状态
列出仓库目录下的待提交的已更改文件以及未加入仓库的新文件。
git status [-s | --short]
-s:输出简洁信息。
对比文件的更改:
git diff [--staged | --cached] [file]
图形用户界面。
git difftool [--tool-help]
记录
查看当前分支的历史记录
git log --author=bob --pretty=oneline
git log --name-status # 显示修改过的文件名
git log --graph --oneline --decorate --all # 查看分支树
git show [commit]
管理仓库内容
添加文件
将未加入仓库的文件加入仓库以追踪更改;或者将已加入仓库的文件暂存(stage)等待提交(commit)。
git add -i [file/dir] # 'git add .' adding the current directory
-i:交互式添加文件。
Marking merge-conflicted files as resolved.
编辑文件
直接使用文件系统命令移动文件,git可能无法检测重命到移动行为(可能任务先删除一个文件并创建另一个文件)。使用git mv更改文件名(移动文件):
git mv [file-original] [file-renamed]
如果被改名的文件已经做了修改,则修改和重命名记录都能被保留。
优先提交(commit)文件名修改。
移除文件
从仓库中移除文件。
git rm [-rf][--cached][file]
-f:如果一个文件被修改过,则需要-f选项强制移除。该选项避免了意外数据丢失。
--cached:保留本地文件。
提交更改
将本地仓库的更改保存为本地的最新版本(HEAD)。
git commit [options] [files]
==默认提交暂存的文件==,如果命令列出文件,则忽略现阶段暂存的文件,直接提交列出的文件。
-m 'message':提交信息。未提供选项则默认会弹出文本编辑器保存提交信息。--dry-run:列出提交的概览信息而不执行提交。--amend:追加内容,替换之前的提交(而不产生新的commit ID)。-a: 直接将所有修改过的已追踪的(包括未暂存的)文件提交,删除所有从工作树移除的文件。--interactive: 交互式决定每个文件是否要提交。
最小化提交代码原则:每次提交包含单一的问题修复、功能更新,从而便与按主题追踪代码更改。
提交信息书写规范
推送更改
git push origin <branch> # 默认分支为master
如果本地仓库并非从远程复制过来,则需要首先连接到远程服务器:
git remote add origin <server>
替换本地修改
用最近提交版本还原工作目录下修改过的文件:
git checkout -- <filename>
其他文件的修改不会受影响。
用服务器的版本替代本地的==修改和提交==:
git fetch origin
git reset --hard origin/master
--hard:删除所有比加载版本新的版本。
过滤仓库内容
忽略已经提交到仓库的文件的最新更改:
git update-index --assume-unchanged <file>
停止忽略:
git update-index --no-assume-unchanged <file>
https://docs.microsoft.com/en-us/vsts/git/tutorial/ignore-files?view=vsts&tabs=visual-studio
显示忽略的文件:
git ls-files --other --ignored --exclude-standard
分支(Branching)
如果有多项功能需要并行开发,可以使用分支来管理代码的多个版本。当功能开发测试完成,再将该分支合并回主线版本(master)。
Branches are used to develop features isolated from each other. The
masterbranch is the "default" branch when you create a repository. Use other branches for development and merge them back to the master branch upon completion.新增或修改功能在分支进行,待测试完成后合并到主线版本;Bug修复在主线版本进行。
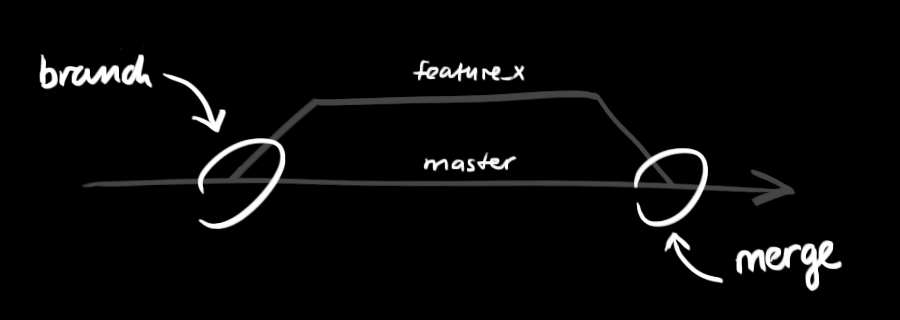
创建分支
从当前状态创建并切换到一个新的分支feature_x:
git checkout -b feature_x
do commit before checkout to avoid data loss.
仅创建分支:
git branch [old_branch] new_branch # 默认从当前分支创建分支
仅切换分支:
git checkout <branch_name> # e.g. master
为了使分支在远程仓库可用,需要将分支推送到远程仓库。
分支信息
列出分支:
git branch [--list]
删除分支
删除一个分支。
git branch -d,--delete feature_x
更新与合并
获取远程仓库内容(稍后手动合并):
git fetch # 仅更新本地HEAD,不合并工作目录
获取远程仓库内容,并与本地分支/工作目录合并:
git pull [url] [branch] # fetch + merge
当前目录下有更改而未保存时,不能使用远程目录覆盖当前内容,否则当前内容被远程覆盖导致数据丢失。如果直接尝试执行git merge或直接执行git pull将产生错误。为了将远程更新与本地更改合并:
- 使用
git stash [push]命令暂存本地更改,使本地index状态最新; - 然后使用
git pull或git merge将远程与本地仓库合并; - 然后
git stash pop恢复本地更改,待本地工作完成后再将本地更改提交到仓库。
暂存最近更改:
git stash push -m,--message <message>
需要预先配置用户身份。
git stash list # 列出暂存的更改版本
git stash show [id] # 列出对应版本和当前状态的变更信息
git stash pop # 恢复最近更改
git stash drop # 丢弃最近更改(需要先暂存)
如果本地提交和远程提交本版不同:
hint: You have divergent branches and need to specify how to reconcile them.
hint: You can do so by running one of the following commands sometime before
hint: your next pull:
hint:
hint: git config pull.rebase false # merge (the default strategy)
hint: git config pull.rebase true # rebase
hint: git config pull.ff only # fast-forward only
分支合并
将当前分支与另一个分支合并:
git merge <branch>
合并工具:
git mergetool
冲突与消除
git尝试自动合并,当通常会产生冲突。用户需要手动编辑冲突文件来消除冲突。手动编辑完成后,使用:
git add <conflicted_file>
以确认完成合并。在开始合并前,可以对比两个分支:
git diff <source_branch> <target_branch>
https://git-scm.com/docs/git-mergetool
https://git-scm.com/docs/git-merge
发布
tagging
git tag 1.0.0 <short_commit_id> # commit id 前10位
GitHub
GitLab
Squash and merge (FREE)
As you work on a feature branch, you often create small, self-contained commits. These small commits help describe the process of building a feature, but can clutter your Git history after the feature is finished. As you finish features, you can combine these commits and ensure a cleaner merge history in your Git repository by using the squash and merge strategy.
- Small commits are joined together, making it simpler to revert all parts of a change.
- When the single commit merges into the target branch, it retains the full commit history.
- Your base branch remains clean, and contains meaningful commit messages.
Each time a branch merges into your base branch, up to two commits are added:
- The single commit created by squashing the commits from the branch.
- A merge commit, unless you have enabled fast-forward merges in your project. Fast-forward merges disable merge commits.
By default, squashed commits contain the following metadata:
- Message: Description of the squash commit, or a customized message
- Author: User that created the merge request
- Committer: User who initiated the squash
Project owners can create new default messages for all squash commits and merge commits.
角色与权限管理
分支合标签保护
设置参与人员修改分支的权限。
[Branch]
branch="master*"
allow to merge="Maintainers"
allow to push="Developers+Maintainers"
[Tag]
tag="v-*"
allow to create="Maintainers"
参考资料
- git Reference.
- Git - Book (git-scm.com)
- workspace :: Git Cheatsheet :: NDP Software
- Introduction to Git and GitHub for Python Developers – Real Python
文本查找
Wildcard (Glob)
In computer programming, glob patterns specify sets of filenames with wildcard characters.
*:匹配任意数量字符;
?:匹配单个字符;
[abc]:匹配集合中的单个字符;[!...]反向匹配。
[a-z]:匹配范围内的单个字符。
SQL通配符
SQL LIKE语句:_对应?;%对应*;不支持[...]。
glob (programming) - Wikipedia
正则表达式(Regular Expression)
正则表达式定义了字符串的模式,可以用来搜索、编辑或处理文本。
正则表达式并不仅限于某一种编程语言,但是在每种语言中有细微的差别。
表达式语法
正则表达式是一个字符串,其中包含:
- 普通字符、转义字符;
- 字符集合;
- 匹配位置,位于匹配内容之前;
- 匹配次数,位于匹配内容之后。
- 运算符:
():优先级运算符,产生捕获组;x|y|z:匹配其中一项,从左至右依次尝试;使用(...|...|...)将选择内容括起来以免产生歧义。
正则表达式类型
基本正则表达式(BRE)与扩展正则表达式(ERE)的主要区别是对特殊字符的解释:BRE需要使用\表示特殊字符,而ERE则恰好相反(使用\将特殊字符转为普通字符)。
- BRE:
\+、\?、\{...\}、\(...\)、\|; - ERE:
+、?、{...}、(...)、|;
BRE和ERE对其他转义字符的处理方式一致,即\CHAR。
PRE在ERE基础上定义了许多扩展功能,如预定义的匹配集合、非捕获元等。
匹配位置
^:扫描行的开始 如:^word匹配所有以word开头的行。
$:扫描行的结束 如:word$匹配所有以word结尾的行。
当未指定匹配位置时,可在文本任何位置进行匹配。注意某些编程语言(例如Python)中提供的
match方法限制了从开始位置匹配。文本行的开始和结束可能包含空白字符,执行边界匹配时需要考虑。
匹配次数
| 表达式 | 说明 |
|---|---|
(...){n} | 表达式重复n次 |
(...){m,n}(...){m,} | 表达式至少重复m次(最多重复n次) |
(...)? | 匹配表达式0或者1次,相当于{0,1}(通配符) |
(...)+ | 前面的表达式至少出现1次,相当于{1,} |
(...)* | 表达式不出现或出现任意次,相当于{0,}(正则表达式中不代表匹配任意字符) |
(...)*?(...)+? | 匹配尽可能多的文本(非贪婪模式)。 |
(...)?? | 匹配尽可能少的文本(非贪婪模式)*。 |
非捕获选择
用圆括号将所有选择项括起来,相邻的选择项之间用|分隔。但用圆括号会有一个副作用,使相关的匹配会被捕获(group),此时可用(?:A|B|...)(非捕获元)放在第一个选项前来消除这种副作用(仅PRE支持)。
捕获组的内容可在表达式后续内容中进行引用:([0-9]{3}),(\w{4})\1\2(\1和\2分别代表之前出现过的捕获组内容)。捕获组的==索引顺序:从左至右,由外至内==;
?=和?!:正向/反向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
消费
当字符串的内容与模式匹配成功后,匹配内容及之前的内容将被消耗,后续匹配将从剩余字串继续匹配。
字符
字符集合
| 预定义集合表达式 | 说明 |
|---|---|
\d/\D | 0~9之间的任意数字;\D为补集* |
\w/\W | 字母(包括非英语文字)、数字或下划线,\W为\w的补集; |
\s/\S | ==空白字符==:包括空格、制表符、换行符 |
\b | 文字字符边界(boundary between a \w and a \W character)。注意:两个非文字字符之间没有边界。 |
. | 除换行符之外的任意一个字符 |
*:\d,\D是PRE扩展,对于grep/sed等程序,如果使用ERE/BRE,可使用[:digit:]代替。
各实现还定义了扩展的字符集合。
自定义字符集合
[...]用于自定义匹配范围,其中可以包括:
-
普通字符:
[ab5@],[a-z],[0-9],[a-zA-z0-9]; -
预定义集合:
[\d.+],[[:digit:]a-z]; -
排除运算:
[^abc],除a,b,c以外的任意字符; -
范围运算:
[f-k],f~k之间的任意字符; -
排除范围:
[^A-F0~3],A~F以及0~3以外的任意字符。
正则表达式的特殊符号(如.+*),被包含到中括号中,则失去特殊意义,除了^,-之外。
:是普通字符。
转义字符
| 序列 | 代表字符 | 序列 | 代表字符 |
|---|---|---|---|
\n | 换行符 | \\ | 反斜线 |
\t | 制表符* | \r | 回车符 |
\f | 换页符 | \v | 垂直制表符 |
\^,\$,\.,\*,,\[,\], \- | 特殊字符 | \xn | 匹配十六进制码n表示的字符 |
*:\n和\\是通用的,其他特殊序列如\t则可能被解释为字符t。
注意:部分转移字符(例如\n、\\等)在编程语言的字符串中首先会被作为转义字符处理,因此在正则表达式中要额外使用\消除编程语言中的转义处理。在Python中可以使用原始字符串类型,以避免对字符串中的\的解释。
regexp_str = r'hello\.world\\'
regexp_str = 'hello\\.world\\\\'
应用
IP地址
Simple regex to check for an IP address:
'^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$'
Accurate regex to check for an IP address:
'^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$'
Simple regex to extract IP addresses from longer text:
'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b' # \b for word space
Accurate regex to extract IP addresses from longer text:
'(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)'
(?:xxx)在grep中导致无匹配输出,在Pythonre中可以正常输出匹配。
URL
re.sub('https://.*?/', '', data, count=1) # 获取URI
实现
预定义字符集
grep and sed
| 集合表达式 | 说明 | 集合表达式 | 说明 |
|---|---|---|---|
[:ascii:] | ASCII字符 | [:cntrl:] | ASCII控制字符 |
[:graph:] | 非控制/空格字符 | [:blank:] | 空格或制表符 |
[:space:] | 空白字符(包括垂直制表符) | [:punct:] | 标点符号 |
[:digit:] | 数字 | [:xdigit:] | 十六进制数字 |
[:alpha:] | 字母 | [:alnum:] | 英语字母与数字 |
[:lower:] | 小写字母 | [:print:] | 可打印字符(包括非ASCII字符) |
[:upper:] | 大写字母 |
python
| 集合表达式 | 说明 |
|---|---|
\NNN | 匹配第$N$个捕获组内容([...]中无效) |
\A/\Z | 匹配文本开始(^)和结束($); |
Regular Expression Language - Quick Reference
Linux配置和管理
文件管理
在Linux/UNIX中,所有的对象都被视为文件,包括普通文件、目录、设备、套接字。
目录路径
pwd # Print Working Directory
dirname filename # parent directory
basename filename #
pwd列出正在工作的目录,用于显示你当前所处的目录名。pwd命令总是返回你当前所处的目录的完全路径名。dirname返回查询路径的父目录(从文件路径中截取)。basename仅返回文件的名称。
readlink和realpath解析文件的绝对路径,跟踪解析所有符号链接。
readlink -e \ # 解析过程中的所有目标必须存在 => realpath -e filename
-f \ # 除最终目标外所有目标必须存在 => realpath filename
-m \ # 允许目标不存在 => realpath -m filename
FILENAME
切换目录
cd [dir_name] # 切换工作目录(Change Directory)
chroot [OPTION] NEWROOT [COMMAND [ARG]...] # 切换命令运行的根目录
不带任何参数时,将把你送回自己的用户主目录中(等效于
cd ~)。..表示父目录。登录完成后,工作目录为用户主目录。
创建目录
在每一个新的子目录中,均包含两个标准的项目:.代表当前目录和..代表父目录。
mkdir -m,--mode=MODE -p dir_name
install [OPTIONS] -d dir1 dir2 ... # 创建目录并设置权限
-m:可用来创建一个带有特定权限的子目录(chmod声明方式)。-p:父目录不存在的情况下首先创建父目录,忽略已存在目录(默认报错)。
删除目录
rmdir -p dir_name ... # -p 一次删除多个目录
dir_name不能为当前工作目录(即要在父目录中删除子目录)。应该拥有被删除目录的写该目录必须为空目录(即只包含.和..,否则使用rm -rf dir_name)。
显示目录中的项目
列表显示
ls [options] [dir_name]
文件过滤选项
-a:显示所有文件(包括以.开头的文件(夹)),-A仅忽略.和..;
-R:递归显示所有子目录的内容;
-d:只显示目录条目的信息;
文件信息选项
-l:列表显示目录中文件的详细信息,与其他排序方式组合使用时则显示相应的排序字段;-g与-l相似但不显示文件所有者,-o不显示用户组;
文件类型信息:
-表示普通文件(f);d目录文件;b块设备文件例如磁盘;c字符设备文件,p命名管道(FIFO) ;l符号链接;s套接字(socket);
--author:显示文件创建者;
-n:显示数字形式的用户和用户组ID;
-i:inode序号将列在第一列;
--time-STYLE:时间显示格式,包括:full-iso(2020-03-07 15:07:15.542112573 +0800)、long-iso(2020-03-07 17:34)、iso(03-07 15:07)、locale(Mar 7 15:07)或+FORMAT;
--full-time:显示完整时间,等价于-l --time-style=full-iso;
-h:显示更加友好的文件长度信息(1K 234M 2G,等价--human-readable);
-s:显示文件占用的磁盘容量;
--block-size=SIZE:K,M,G,T,P,E,Z,Y (powers of 1024)或 KB,MB,... (powers of 1000)
排序选项
--sort=WORD:WORD=none(-U),size(-S),time(-t),version(-v),extension(-X),未声明排序选项时,默认按文件名排序。-c:按ctime(指文件的inode信息被改变的时间)排序;-u:按访问时间排序;-t:按修改时间排序,优先级低于-c和-u;
-r:反向排序;
查看目录树
tree -L <n> path # not built-in
-L <n>:搜索深度;-l:跟踪符号链接;
文件信息
获取文件的信息:
stat <path/to/file> -c,--format,--printf=FORMAT \
-f,--file-system # 显示文件所在文件系统信息而非文件信息
格式参数FORMAT可包含多个格式声明以及普通字符,--printf还可使用"\"转义字符;
| 格式 | 内容 | 格式 | 内容 | 格式 | 内容 | 格式 | 内容 | 格式 | 内容 |
|---|---|---|---|---|---|---|---|---|---|
%n | 文件名 | %F | 文件类型 | %g | group id | %y | 修改时间 | %a | 八进制访问权限 |
%N | "文件名" | %s | file bytes | %G | group name | %Y | 修改时间戳 | %A | 字母访问权限 |
%h | 硬链接数 | %m | 挂载点 | %u | owner id | %w | 创建时间 | %x | 访问时间 |
%i | inode数 | %C | SELinux | %U | owner name | %W | 创建时间戳 | %X | 访问时间戳 |
除stat外,还可以使用date获取文件修改时间:
date -r <filename> [+"%Y%m%d"]
获取文件类型:
file <path/to/file> \
-i,--mime \ # => --mime-type + --mime encoding
-z,--uncompress \ # 尝试解压压缩文件并查看其中内容
修改文件属性
touch可以用于修改文件访问时间。
touch filename
touch -d "2 hours ago" filename
普通文件
移动
如果源文件/目录与目标文件/目录同名,则用源文件/目录替换同名目标文件/目录的内容;否则,将源文件/目录移动到目标目录中;此时,目标目录必须存在,不会首先创建目录。
mv [-f] file_path /path/newname
如果源与目标所在路径相同,
mv等效于重命名。
批量重命名
将文件名中已知的部分内容替换为新的内容,其余部分(使用通配符表示)不变。
rename 's/pattern/replace/' FILES # sed style
rename pattern replace FILES
pattern为Perl正则表达式,文件名FILES支持通配符(?*.txt)。
使用需注意,原始的
rename不会检查已有文件而直接覆盖。
复制
cp [-raf] file_path /path/filecopy # -a 保留原属性
cp的文件创建行为与mv相同。
安装
install支持设置目标文件的权限和属性(==不支持文件夹(递归)复制==):
-
-m,--mode=MODE:设置访问权限; -
-g,--group=GROUP,-o,--owner=OWNER:设置所属关系(chgrp,chown),代替当前进程的默认值; -
-p, --preserve-timestamps:保留文件的访问/修改时间;
install [OPTION] -D [-T] SOURCE DEST # single-file to file
-D:(递归)创建目标文件的父目录(mkdir -p),未指定该选项则不会自动创建目录;
install [OPTION] SOURCE... DIRECTORY # single to dir
install [OPTION] -t DIRECTORY SOURCE...# multiple to dir (--target-directory)
-b,--suffix=BACKUP:备份选项以及备份目标文件夹;
删除文件
rm [-rf] file # can use wildcard
使用
-rf递归删除非空文件夹。
文件链接
硬链接(hard link):是对原文件的引用(引用同一个inode,在inode中计数),与原文件等价(即拥有相同访问权限)。删除硬链接将减小inode计数,到inode计数为0时删除文件。
符号链接(symbolic/soft link):保存到目标文件(夹)的路径(或相对路径),访问符号链接将跳转到目标文件(夹)。符号链接是一个独立的文件(具有相应的inode节点),因此具有独立的文件权限。删除原文件后,符号链接失效。
创建链接
ln -s /file/path /symbol/path # symbolic link
ln /file/path /symbol/path # hard link file
ln -d /dir/path /symbol/path # hard link 目录(不一定支持)
# -f,--force 移除已有文件链接
符号链接的目标可以是任意内容(创建的时候不做检查合法性),符号链接支持跨文件系统。硬链接的目标必须存在且仅支持在同一设备的同一文件系统。
访问链接
==文件链接解引用时,相对路径的父目录为文件链接所在目录==,解析符号链接目标时是递归式解析。
工作目录路径:如果切换工作目录到符号链接指向的目录,则工作目录路径为符号链接的路径而非目标目录的真实路径(比较pwd和realpath的输出结果),向上跳转(..)会返回符号链接所在目录。
在Linux中创建的符号链接在Windows中仍然能访问(WSL),但Windows不做递归解析,仅以当前工作目录路径为参考解析符号链接,因此使用相对路径的多级符号链接解析会出错。
临时文件
在指定目录下(默认为/tmp)创建临时文件并输出文件路径。
tempfile --directory PATH # [Debian]
mktemp -p PATH # [Fedora-coreutils]
--directory # 创建目录而非文件
查找文件
which <command>
command -V <command>
从系统环境变量中查找文件并返回绝对路径。
查找目录中的文件
find [-HLP][-D debugopts][-Olevel][start_dir...][expression]
start_dir表示查找路径,可以使用绝对路径,也可以使用相对路径,可以同时指定多个目录;如果没有指定,则默认为当前目录。==默认输出信息为查找到的文件夹和文件信息,并包含从查找目录开始的完整路径信息。==
选项(Option)
选项控制find访问文件系统的行为。
-H,-L和-P(默认)控制处理符号链接的行为。
-P表示不解析任何符号链接;-H表示除了命令行提供的文件名外,不解析其他符号链接。如果符号链接不能被解析,则返回符号连接本身的信息;-L表示在可能的情况下解析符号链接,反之返回符号链接自身的信息。(-followdeprecated)
-D debugopts:输出诊断信息。
-Olevel:查询优化。默认首先执行基于文件名的表达式(-name,-regex等);其次执行-type或-xtype的表达式(通过readdir()读取文件类型)。
读取上述选项之后,检查后续参数是否为文件/路径,直到以-、(、!开始的参数(也可以使用--声明选项参数的结束)。剩余参数为控制搜索行为的表达式。
表达式(Expression)
表达式用于控制如何匹配文件以及对匹配文件的操作。表达式可以包含以下内容:
Tests:测试文件属性,返回true|false;Actions:对匹配结果执行操作,根据操作结果返回true|false;如果表达式没有包含操作,则默认为-print;Global options:全局选项,总是返回true;Positional options:仅影响其后的测试或操作,总是返回true;Operator:将表达式中多个内容连接起来:-o(逻辑OR)、-a(逻辑AND);表达式内容之间默认使用-a连接;可以使用()声明优先级。
全局选项
-d,-depth:先处理文件夹中的内容,再处理文件夹本身;-maxdepth,-mindepth LEVEL:指定搜索的层级,0表示起始点本身;-mount, -xdev:不搜索挂载的其他文件系统目录;-help,--help,--version:帮助、版本信息。
位置选项
-
-daystart:计算时间时从今天开始,而非24小时前算起。影响其后的测试条件-amin,-cmin,-mmin,-atime,-ctime和-mtime。 -
-regextype TYPE:默认为emacs,包括:awk,egrep,grep,sed等。-regextype egrep在CentOS 7 上不支持{}。
测试条件
| 表达式 | 说明 |
|---|---|
-name PATTERN | 查找==文件名==匹配PATTERN的文件,可以使用通配符*,?,[]。 |
-path PATTERN | ==从搜索路径开始的完整文件名(非绝对路径)==与PATTERN进行匹配( -wholename)。 |
-regex PATTERN | 使用正则表达式匹配文件。文件名以./开头的==完整相对路径==,注意在正则表达式前添加 .*以匹配前缀; |
-atime [+-]N -ctime [+-]N -mtime [+-]N | 判断最近访问(-a),状态变化(-c),修改(-m)时间:如果参数为 N,表示时间在N天之内(0表示0~24小时,1表示24~48小时,…) |
-amin [+-]N | 时间单位为min(类似地-cmin,-mmin) |
-anewer FILE | 测试最近访问时间是否比FILE更近(-cnewer,-newer)。 |
-used [+-]N | 在文件状态改变N天(+N,-N)之内文件被访问过。 |
-empty | 测试文件或文件夹是否为空。 |
-size n[u] | 文件大小:单位u=cwbkMG: |
-fstype TYPE | 测试文件所在的文件系统的类型是否为TYPE。 |
-uid [+-]N | 文件的用户ID(组ID-gid)是否为N(或+N,-N)。 |
-user NAME | 文件的用户名(组名-group)是否为NAME(允许使用ID)。 |
-nouser | 文件的用户ID(组ID-nogroup)没有对应的用户(组)。 |
-lname PATTERN | 符号链接所指向的文件的文件名是否与PATTERN匹配。 |
-perm pmode | 文件的权限是否与pmode匹配,pmode可以是符号或数字模式,例如:-perm 664。直接指定单项权限 -readable、-writable、-executable。 |
-type <c> | 文件类型: bcdpfls |
-xtype c | 除符号链接以外,与-type作用一致; |
-inum [+-]N | rarely useful. |
-samefile NAME | 文件与NAME为同一个文件。 |
-links [+-]N | File has n hard links. |
匹配文件名的测试命令前添加
i(例如-iname)为忽略大小写版本。 通配符需要使用引号包围以防被shell展开。 参数如果为+N,则表示大于N,如果为-N则表示小于N。
运算符
| 运算符 | 表达式 |
|---|---|
() | (EXPR) |
! -not | !EXPR –not EXPR |
-a -and | EXPR1 –a EXPR2 EXPR1 –and EXPR2 |
-o -or | EXPR1 –o EXPR2 EXPR1 –or EXPR2 |
, | EXPR1, EXPR2 |
动作
| 命令 | 说明 |
|---|---|
-print, -print0 | print0会在文件名结尾追加“null”。 |
-fprint FILE-fprint0 FILE | 打印完整文件名到FILE。如果文件不存在则创建文件; 如果存在,则文件内容被删除; 即使没有输出内容,该文件仍然会被创建。 |
-ls-fls FILE | 以ls -dils格式打印到标准输出。-fls输出到文件。 |
-printf FORMAT-fprintf FILE FORMAT | 位宽和精度说明类似于C语言的printf(man find)。 |
-execdir command-exec command | -execdir将其后直到;的所有内容视为command,同时将其中的“ {}”替换为查找结果的文件名。command中的特殊字符需要使用“\”或“'”以防被shell展开。 |
-execdir command {}+-exec command {}+ | 命令末尾的“{}”展开为匹配文件名称的列表; |
-okdir command-ok command | 询问用户是否执行命令 |
-delete | 删除成功返回真;如果失败,生成错误信息; |
查找文件示例
高亮find查找结果:
find ./ -name '*.tar.gz' | grep --color '.tar.gz'
打印查找到文件的详细信息。
find ./ -name '*.tar.gz' -exec ls -lh {} ';'
删除文件:
find . -maxdepth 1 -newer archive.tar.gz -execdir rm -rf {} ';'
在过滤文件中查找内容:
find ./ –name '*.cpp' –exec grep -Hn 'main' {} ';'
find ./ -name "*.log" | xargs grep –Hn 'ERROR'
grep与find同时使用时,默认不会输出文件名(添加-H选项),也不会高亮文本(使用--color选项)。
查找文件内容
使用grep查找具有给定内容和文件名的文件:
grep -rl 'main' --include='*.cpp' ./ # 输出匹配文件的文件名
grep -rn 'main' --include='*.cpp' ./ # 输出匹配行的行号和内容
硬件管理
查看硬件信息
sudo dmidecode -t,--type type_code|type_keyword
sudo dmidecode [options] | grep -A16 'System Information$' # 系统和主板信息
硬件类型(type_keyword)包括:bios, system, baseboard, chassis, processor, memory, cache, connector, slot。每种类型可能包括多个子类型(type_code)。
sudo lshw \ # list hardware [yum install lshw]
-class <hw_class> \ # class can be found using lshw -short
-{html|xml|json} \ # 输出格式
-short \ # device tree: 优先级高于输出格式
-businfo # showing bus information
硬件类型可通过lshw -short的输出获取,包括:system,bus,memory,processor,storage,input,display,disk,volume,network,power等。
其他工具:
hwinfo(默认未安装到系统);hardinfo(图形界面)。
CPU
lscpu # CPU信息概述
nproc # number of process unit
sudo lshw -C processor
cat /proc/cpuinfo # CPU details
sudo dmidecode --type processor # details
cpuid获取详细信息(未安装)。
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
# 8 Intel(R) Xeon(R) CPU E5410 @ 2.33GHz
## (CPU with 8 logical core)
cat /proc/cpuinfo | grep 'physical id' | uniq -c
# 4 physical id : 0
# 4 physical id : 1
### (2 physical CPU with 4-core)
内存
free -h -w # summary
cat /proc/meminfo # details
vmstat -s
sudo dmidecode -t memory # Memory Device
all tmpfs pages will be shown as “
Shmem” in/proc/meminfoand “Shared” infree(1).
磁盘信息
列出存储设备信息:
sudo fdisk -l [device_name] # 查看磁盘设备 => sudo parted /dev/sda print
lsblk # 列出块设备
sudo blkid /dev/sda
# /dev/sda: UUID="3255683f-53a2-4fdf-91cf-b4c1041e2a62" TYPE="ext4"
查看序列号:
udevadm info --query=all --name=/dev/sda | grep ID_SERIAL
hdparm -I /dev/sda # install hdparm
lshw -class disk # install lshw
smartctl -i /dev/sda # install smartmontools
位于磁盘阵列中的磁盘序列号不可见(系统读取的是RAID分配的ID)。
文件系统信息
列出系统支持的文件系统:
cat /proc/filesystems
exfat格式支持需要安装exfat-fuse和exfat-utils包;NTFS格式需要安装ntfs-3g包(CentOS)。
列出挂载的(文件或目录所在)文件系统信息。
df [-ahHkT] [目录或文件名]
# Filesystem Size Used Avail Use% Mounted on
# /dev/sdd 251G 1.6G 237G 1% /
# tmpfs 13G 252M 13G 2% /mnt/wsl
-hH:以合适的单位显示数据(1024进制,-H为1000进制),提高可读性;-i,--inodes:显示inode信息而非磁盘容量信息;-T,--print-type:==打印文件系统类型==,例如ext4、tmpfs等;-t,--type=TYPE:仅显示指定类型文件系统;-x,--exclude-type=TYPE排除指定类型;
列出文件或目录的磁盘占用量(disk usage):
du [-ahskm] 文件或目录名称
-c, --total;
-h, --human-readable;
-s, --summarize;
-d,--max-depth=N:显示最大路径深度;
磁盘管理
磁盘分区与格式化
注意:以下操作可能导致数据丢失,应事先做好数据备份!!!
使用fdisk或parted操作文件分区表(fdisk -l查看磁盘信息):
sudo fdisk device_name # 操作分区表
# fdisk命令
# [F] 列出未分区的空闲空间 n 新增分区
# l 列出已知分区类型 t 更改分区类型
# p 打印分区表 d 删除分区
# [i] 打印选择的分区信息 v 验证分区表
# m 打印命令列表 g 创建GPT分区表
# o 创建DOS(MBR)分区表
# q 放弃更改并退出 w 保存分区更改
未添加
device_name时,列出系统内所有存储设备(/dev)的分区(partition)信息。GParted -- Live CD/USB/PXE/HD:With GParted you can resize, copy, and move partitions without data loss.
gparted是一款图形界面的分区工具。
更改正在使用的分区:首先删除分区(记录下分区表的起止位置),然后重新创建分区,并指定新的起止位置(注意不要和已有分区重叠)和分区类型,保存并退出(使用工具cloud-utils.growpart)。分区表更改不会立即生效,因此可以修改正在使用的分区,重启机器或使用partprobe [/dev/sda]或kpartx [/dev/sda]命令重新载入新的分区表。如果是普通卷,则需要使用resize2fs更新文件系统容量,如果是LVM物理卷,则使用pvresize更新(resize2fs无法操作LVM物理卷)。
磁盘格式化
新建分区后,需要对分区进行格式化设置文件系统才能进行挂载使用。整个磁盘也可以不进行分区直接格式化。
mkfs -t <fstype> /dev/sda
mkfs.<fstype> options /dev/sda # 格式化分区/dev/sda1
fstype文件系统类型,例如 ext4, xfs, btrfs , ZFS等(系统有支持才会生效)。在选择文件系统类型时,如无特殊要求,选择系统中已有分区类型(默认类型),确保兼容和稳定性。
mke2fs:创建ext2/ext3/ext4文件系统,对应命令:mkfs.ext2|3|4。ext文件系统的i-node节点总数在文件系统创建后不能改变,调整文件系统容量将按比例调整inode数量(bytes-per-inode)。
Linux File System Types Explained, Which One Should You Use (linuxiac.com)
数据恢复
TestDisk Step By Step - CGSecurity
How to recover partitions and data using Linux - Tutorial (dedoimedo.com)
How to recover lost partition using Linux (simplified.guide)
TestDisk is powerful free data recovery software! It was primarily designed to help recover lost partitions and/or make non-booting disks bootable again when these symptoms are caused by faulty software: certain types of viruses or human error (such as accidentally deleting a Partition Table).
==Even though the old partition table was destroyed, it was just a pointer to the start and end addresses of the actual data, so to speak.==
The new and definite CloneZilla tutorial (dedoimedo.com)
磁盘检验
fsck [-t <fstype>] [-ACay] /dev/sda
用来检查和维护不一致的文件系统。若系统掉电或磁盘发生问题,可利用
fsck命令对文件系统进行检查。
磁盘挂载与卸除
mount -t <fstype> -L <label> -o <opts> -n /dev/dev_name /mnt/mnt_name
mount --move /mnt/userdirs /home # move mount point of a filesystem
umount [-fn] [/dev/dev_name | /mnt/mnt_name]
findmnt --types <fstype> # 查看已挂载的文件系统
如果挂载的目标路径下有数据,则数据会被隐藏;卸载磁盘后可恢复访问原有数据1。
挂载NTFS文件系统:
yum install fuse ntfs-3g # centos
mount -t ntfs-3g /dev/sdb1 /mnt/win
如果卸除设备时出现设备忙的错误,可查看正在使用该设备的进程有哪些并尝试关闭进程。
挂载CD
mount -t auto [-r] /dev/cdrom /mnt/cdrom # 挂载CD
挂载可移动介质
挂载磁盘的目标文件夹必须存在,挂载的磁盘应该已经使用支持的文件系统格式化。可移动磁盘设备标识类似于内置磁盘(使用fdisk -l或parted -l查看)。
自动挂载
-
将挂载命令写入开机启动脚本;
-
配置
systemd.mount单元文件;[Mount] What=/dev/sda Where=/data Type=ext4 Options= -
使用
/etc/fstab配置,systemd会将其中的内容转换为单元文件;# DevicePath MountPoint FS Type Mount Options Dump CheckOrder /dev/sdba /data ext4 - 0 1 LABEL=t-home2 /home ext4 defaults,auto_da_alloc 0 2 SERVER:PATH
逻辑卷管理LVM
Logical Volume Management, gives users the power to pool and abstract the physical layout of component storage devices, to gather existing storage devices into groups and allocate logical units from the combined space as needed.
LVM存储信息
显示系统中的LVM兼容卷,包括可转换为LVM物理卷(Physical Volumns)的存储设备:
sudo lvmdiskscan \
-l # 仅显示LVM物理卷, ==> pvscan, pvs, pvdisplay
显示系统中的物理卷组(Virtual Group)信息:
sudo vgscan # => vgs, vgdisplay
显示系统中的逻辑卷(Logical Volumn):(逻辑卷设备路径、VG Name、PV)
sudo lvscan # lvs, lvdisplay [-m]
管理LVM存储
从原始磁盘创建LVM物理卷,注意将磁盘上原有数据备份,加入LVM管理后将覆盖原有数据。
A header is written to storage devices to mark them as free to use as LVM components.
sudo pvcreate /dev/sda /dev/sdb ...
pvresize /dev/sda1
pvresize --setphysicalvolumesize 40G /dev/sda1 # shrink
如果物理磁盘分区通过
fdisk进行了扩展,可以通过pvresize更新LVM物理卷的容量。也可以将空余磁盘空间创建为一个新的物理分区,设置为LVM PV并加入LVM虚拟卷组。
将物理卷创建为卷组,通常只需要一个卷组并在此之上创建虚拟卷。
sudo vgcreate volume_group_name /dev/sda /dev/sdb ...
向卷组中增加物理卷:
sudo vgextend volume_group_name /dev/sdb
创建虚拟卷,创建后需要对虚拟卷进行格式化。
sudo lvcreate -L 10G -n VolumnName LVMVolGroup # 绝对容量
sudo lvcreate -l 100%FREE -n VolumnName2 LVMVolGroup # 相对容量
虚拟卷的底层物理磁盘分配方案支持线性(
linear,默认)、striped(RAID 0)、raid1等。
虚拟卷容量调整,使用-L选项增加/减少绝对容量,或用-l选项增加相对容量。
sudo lvresize -L +5G --resizefs LVMVolGroup/vol_name
sudo lvresize -l +100%FREE --resizefs LVMVolGroup/vol_name
XFS filesystem shrinking is unsupported.
resize2fsis for ext filesystems.
RAID
Hardware RAID
在BIOS中配置磁盘的RAID选项,参考产品用户手册。
Software RAID
- How To Use LVM To Manage Storage Devices on Ubuntu 18.04.
- How To Create RAID Arrays with mdadm on Ubuntu 18.04 | DigitalOcean.
显示设备
查看显示设备:
lspci | grep -i vga # <== install pciutils
sudo lshow [-short] -c CLASS # list hardware, CLASS for class/description
sudo lspci -v -s 03:00.0
安装Nvidia显卡驱动
rl=$(uname -r)
yum install gcc gcc-c++ make kernel-devel-$rl kernel-headers-$rl
apt install gcc make linux-headers-$rl [libglvnd]
注意内核开发包的版本需要于系统内核版本完全一致,否则无法成功安装驱动程序。
检查nouveau模块是否加载,已加载则先禁用
lsmod | grep nouveau
# edit: /usr/lib/modprobe.d/blacklist-nouveau.conf # [Ubuntu]/etc/modprobe.d/*
blacklist nouveau
options nouveau modeset=0
dracut -force # 重启系统,使内核模块配置生效 [Ubuntu]update-initramfs -u
安装驱动程序:
./NVIDIA-Linux-x86_64-390.46.run --no-opengl-files --ui=none --no-questions --accept-license
# edit: /etc/rc.d/rc.local
nvidia-smi -pm 1 # GPU驱动模式设置为常驻内存
nvidia-smi # nvidia proprietary driver => watch -n 1 nvidia-smi
Ubuntu桌面版显卡驱动
ubuntu-drivers devices # 列出可用驱动
sudo ubuntu-drivers autoinstall # 安装推荐驱动
sudo apt install nvidia-driver-440 # 安装指定名称驱动
安装完成后重启。
网络设备配置管理
系统配置
系统信息
操作系统
uname [options]
| 选项 | 说明 |
|---|---|
-a, --all | 包括以下系统信息: |
-s, --kernel-name | 内核名称(Linux) |
-n, --nodename | 网络主机名称(使用hostnamectl设置) |
-r, --kernel-release | 内核发行版本(3.10.0-1160.24.1.el7.x86_64) |
-v, --kernel-version | 内核版本(#1 SMP Thu Apr 8 19:51:47 UTC 2021) |
-m, --machine | 机器的硬件架构名称(x86_64) |
-o, --operating-system | 操作系统(GNU/Linux) |
-i,--hardware-platform和-p, --processor(不可移植),通常与-m输出一致。
系统版本信息
cat /etc/issue # [Ubuntu]
cat /etc/lsb-release # [Ubuntu]
cat /etc/os-release # [Ubuntu|CentOS]
lsb_release -crid # 包含版本号详细信息,CentOS需要安装redhat-lsb-core
rpm -qa centos-release # [Fedora/CentOS]
rpm -qi basesystem # [Fedora/CentOS](包含安装日期)
操作系统安装时间
通过文件系统创建时间判断操作系统安装时间:
tune2fs -l $(df / | awk '$6 ~ /\// {print $1}') | grep 'Filesystem created:' # -> dumpe2fs
rpm -qi setup|setuptool|basesystem # [Fedora/CentOS]
tune2fs是设置ext2/ext3/ext4文件系统参数的工具。
主机名
hostnamectl # 显示主机信息(主机名、系统名、架构...)
hostnamectl set-hostname 'gfs.server.03.net' # 设置主机名
sysctl -n kernel.hostname
某些服务(例如Cloudera)需要检测主机名与域名(FQDN)的一致性,为了避免产生警告,将主机名设置为域名。
WSL-Ubuntu中
hostnamectl不可用。
域名映射
sudo vi /etc/hosts
# change <hosts> file
192.168.137.11 new-host-name
可能需要重启。
日期时间
显示时间
date # Sun May 16 13:07:15 CST 2021
date +'%H' # %T %c %F
date -d,--date='7:00:00' +'%s' # parse a date and display it
date --date='@2147483647' # parse a timestamp (seconds)
date -r,--reference=FILE # 显示文件最近修改时间
默认显示当前时间,使用
-d,--date指定要显示的时间的字符串;字符串缺少的部分设为当前时间。空字符串表示当天开始时间。
A list of date command field descriptors
获取日期字段
| 格式声明 | 含义 | 格式声明 | 含义 | 格式声明 | 含义 |
|---|---|---|---|---|---|
%Y | YYYY | %m | mm | %d | dd |
%H | HH(00-23) | %M | MM(00-59) | %S | SS |
%s | 时间戳(秒) | %3N | 毫秒 | %N | 纳秒 |
%f | 微秒 |
格式化日期字段
%后可额外设置表示填充的字符:-不填充;_填充空格;0填充0(默认);^使用大写字母;#(尽可能)改变字符大小写。
| 格式 | 含义 | 格式 | 含义 | 格式 | 含义 |
|---|---|---|---|---|---|
%c | locale's datetime | %x | locale' date | %X | locale's time |
%D | %m/%d/%y | %F | %Y-%m-%d | ||
%T | %H:%M:%S | %r | 12:11:04 PM | %X | 23:13:48(locale) |
%y | yy | %e | %_d | ||
%I | hh(01-12) | %k | _H(0-23) | %l | _h |
%j | ddd: day of year | %w | day of week(0-6) 0 is Sunday | %u | day of week(1-7) 1 is Monday |
%W | week of year(00-53), Monday first | %U | week of year(00-53), Sunday first | %V | week of year(01-53), Monday first |
%p | AM/PM | %P | am/pm | %q | quater 00-04 |
%z | 时区-0400 | %:z | -04:00 | %::z | -04:00:00 |
%Z | 时区类型EDT/CST |
设置时间:
timedatectl [status] # 显示系统的日期、时间和时区等信息
timedatectl set-time "2012-10-30 18:17:16" # <== timedatectl set-ntp no
date -u,--utc=MMDDhhmmCCYY.ss # print or set datetime
date -s,--set=STRING
timedatectl set-timezone <Asia/Shanghai>
timedatectl list-timezones # 列出已知时区
系统启动时间:
uptime
系统引导配置
引导配置文件:
/etc/default/grub
/etc/grub/grub.cfg # auto-generated by grub-update
选择默认用户界面:
sudo systemctl set-default multiuser.target # terminal shell
sudo systemctl set-default graphical.target # GUI
添加开机启动项
-
编辑
/etc/rc.local脚本(兼容性目的),并设定可执行权限(sudo chmod 755)适合较短的命令
-
将启动项的脚本添加到
/etc/init.d目录下,并设置可执行权限ln -s task.sh /etc/init.d/task sudo chmod +x /etc/init.d/taskcd /etc/init.d sudo update-rc.d task defaults 95 # execute order sudo update-rc.d -f task remove # remove the task如果使用需要开机通过
chkconfig设置开机启动的服务,则脚本开头应该包含以下信息:#!/bin/bash # chkconfig: 2345 20 80 # description: Saves and restores system entropy pool \ # for higher quality random number generation.chkconfig: 2345 20 80表示这个服务在运行级别2345下运行,20表示开机启动优先权重,80表示关闭优先权重。也可以手动调用
chkconfig添加开机启动服务chkconfig --add my-service实际上
chkconfig --add命令是将/etc/init.d中的启动脚本软连接到/etc/rc.d/rcx.d(rc0.d ... rc6.d)0-6个运行级别对应相应的目录,都是位于/etc/init.d中脚本的软连接。/etc/init.d/中的脚本,可以通过命令:service service_name [start/stop]启动或者关闭(添加到启动脚本中实现自启动,见方法1或)。
-
将启动任务的脚本放到目录
/etc/profile.d下,系统启动后将自动执行其中的shell脚本。 -
注册为
systemd托管的服务,在系统启动时运行。
内核配置
内核配置项对应文件系统中/proc/sys目录。
读取内核配置项:配置项具有分级结构(对应上述目录树),名称以.或/分隔。
sysctl -n variable # 输出value, 默认输出 variable = value
sysctl -a -pattern PATTERN # 打印所有配置项(某些配置项需要管理员权限才可访问)
-n,--values:仅打印配置项的值;-N,--names:仅打印配置项的名称;
sysctl -q,--quiet \ # 不将设置的值回显到屏幕
-w variable=value ...
加载内核配置:
sysctl -p,--load [FILE] # 默认加载/etc/sysctl.conf
sysctl --system # 加载系统中所有配置文件
文件系统
最大打开文件数量限制
ulimit -n 8192 # 默认1024, 临时修改
编辑/etc/security/limits.conf,永久修改:
# domain type item value
* soft nofile 16384 # soft limits of Number of Open file
* hard nofile 16384 # hard limits
linux - Fix with ulimit -n 8192 - Stack Overflow
inotify文件监控数量限制
文件监控数量限制如果设置太小,容易触发inotify watch limit reached错误。临时设置运行时参数:
sudo sysctl fs.inotify.max_user_watches=524288 # 8192 default
永久修改配置(/etc/sysctl.conf)并运行sysctl -p重新加载。
fs.inotify.max_user_watches=524288
字体
用户可将字体安装在/usr/share/fonts目录下,使用fc-list(需要安装fontconfig)可查看系统中可用字体。
fc-list # "FONT_PATH: FONT_FAMILY:style=STYLE"
fc-list : family # 仅输出字体名
fc-list :lang=zh family style file spacing # "PATH: FAMILY:style=STYLE:spacing=SPACE"
日志
大部分的发行版都内置使用syslog系统日志,常见的日志一般存放在 /var/log 中。
常见的系统日志
| 日志名称 | 记录信息 |
|---|---|
alternatives.log | 系统的一些更新替代信息记录 |
apport.log | 应用程序崩溃信息记录 |
apt/history.log | 使用apt安装卸载软件的信息记录 |
apt/term.log | 使用apt时的具体操作,如package的下载、打开等 |
auth.log | 登录认证的信息记录 |
boot.log | 系统启动时的程序服务的日志信息 |
Consolekit/history | 控制台的信息记录 |
dist-upgrade | dist-upgrade 这种更新方式的信息记录 |
dmesg | 启动时,显示屏幕上内核缓冲信息,与硬件有关的信息 |
dpkg.log | dpkg 命令管理包的日志 |
faillog | 用户登录失败详细信息记录 |
fontconfig.log | 与字体配置有关的信息记录 |
kern.log | 内核产生的信息记录,在自己修改内核时有很大帮助 |
lastlog | 用户的最近一次信息记录。 |
wtmp | 登录信息的记录。 |
btmp | 远程登录信息记录。 |
syslog | 系统信息记录 |
日志一般都是文本文件,可使用 less、cat、more 等工具查看。 wtmp、lastlog 是二进制文件,需要使用last和lastlog工具来提取其中的信息。
rsyslog
systemd-journal
查看日志
筛选日志:
journalctl --system|user # 查看系统/当前用户日志
journalctl -u,--unit=UNIT
-t,--identifier=STRING # 查看指定syslog标识的日志
-S,--since=DATE # '2022-05-01 [12:00:00]'
-U,--until=DATE
追踪日志更新:
journalctl -f,--follow
-n,--lines=NUM # 显示日志数量
日志存储设置
journalctl --disk-usage
journalctl --rotate
journalctl --vacuum-time=2d # 清理超过2天的日志
journalctl --vacuum-size=100M # 清理超过100M的日志
journalctl --vacuum-files=5 # 清理超过数量的日志
systemctl kill --kill-who=main --signal=SIGUSR2 systemd-journald.service
rm -rf /run/log/journal/*
rm -rf /var/log/journal/*
systemctl restart systemd-journald.service
journalctl --verify
终端命令记录
histroy # 显示历史记录: cat ~/.bash_history
history -c # 删除历史记录:rm ~/.bash_history
用户登录信息
who /var/log/wtmp # 查看用户登录历史记录
last [username] [-f /var/log/btmp] # 默认读取/var/log/wtmp
lastlog [-u username] [-t 5] [-b 60]
浏览器(桌面环境)
ls -l ~/.opera/cach4
ls -l ~/.mozilla/firefox/*.default/cache
日志清理
logrotate是Linux自带的文本日志处理工具,可进行切割、打包、压缩等处理。其配置文件位于/etc/logrotate.conf以及/etc/logrotate.d/。
/tmp/dask/*log {
rotate 7 # 指定日志文件删除之前转储的次数,0直接删除,-1不删除
daily # 指定转储周期:hourly,daily,weekly,monthly, yearly
minsize 1M # 文件大于1M时才会进行轮转
maxsize 100M # 文件大于100M时强制进行轮转(即使还未到轮换周期)
size 100M # 指定轮转大小: k/M/G (与轮转周期互斥)
minage 10 # 文件创建超过10天才进行轮转
maxage 100 # 移除创建超过100天的已轮转的文件
missingok # 忽略不存在的日志文件/nomissingok
ifempty # 即使日志文件为空文件也做轮转/noifempty
dateext # 使用当期日期作为命名格式,默认值取决于轮换周期
dateformat -%Y%m%d%H #
nocompress #
create [[mode] owner group] # 新日志文件的权限, 默认和原来的文件相同的权限
copytruncate # 复制并清空日志文件(override create)*
prerotate
script
endscript
postrotate # postrotate脚本
/sbin/nginx -s reload
endscript # postrotate脚本结束
}
*:适用于日志输出程序无法获取日志文件打开状态的情况;但可能造成少量日志丢失。
logrotate通过ctrontab调度,默认每天运行一次(除非任务指定更小的周期)。可手动立即执行:
logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf
软件管理
各发行版提供的软件仓库与软件管理方案。本章介绍,当前主要的跨发行版软件管理解决方案。
Snap
Snap将软件及其依赖打包到独立环境,它的运行环境是容器化的沙箱,从而避免各发行版兼容性问题并保证一定的安全性。
安装snap
Ubuntu/Debian系统预装snapd,使用snap version查看。
sudo yum install snapd # [epel-release]
sudo systemctl enable snapd # 安装后需要手动启动
snapd无需持续在后台运行,仅在执行snap命令时被调用运行。
安装和升级snap软件
snap find "media player"
sudo snapd install 'appname'
sudo snap refresh 'appname' # update
snap list # 列出已安装的软件的简要信息
snap info 'pkgname'| 'pkgname.snap' # 查看[已安装]软件包信息
--color=auto|always|never
--verbose
安装classic类型的软件,此类软件不受沙盒限制:
sudo ln -s /var/lib/snapd/snap /snap
sudo snap install julia --classic
下载snap包和离线安装:
snap donwload 'package name'
--target-directory=.
--channel=5.x/stable
snap ack path/to/package_name.assert
snap install path/to/package_name.snap
--dangerous # 如果没有执行ack,则需要该选项才可以安装
snap安装目录
/snap # -> Debian based
#/snap/bin - Symlinks to snap applications.
#/snap/<snapname>/<revision> - Mountpoint for snap content.
#/snap/<snapname>/current - Symlink to current revision, if enabled.
/var/lib/snapd/snap # -> RHEL based
snapying用的配置文件/数据目录
/var/snap/"snap_name"
移除snap软件
snap remove "snap_name"
--purge # 不保存软件的数据
软件的所有数据将自动备份(automatic snapshopt)以便后续恢复。
备份和恢复
snap save 'appname' --users "all" # 创建用户、系统和配置数据的快照。
snap saved --id ID
snap forget "id" "appname"
snap restore "id" "snap_name" --users "all" # 使用指定快照恢复其中的用户、系统和配置数据。
snap export-snapshot "id" /path/to/export
snap import-snapshot /path/to/import
不同版本(
epoch)之间不能恢复数据。
回退到上个版本并恢复数据(不包括共享数据):
sudo snap revert 'appname' --revision ID
snap配置
snap get "appname"
snap set "appname" key1=value1 key2.subkey=value2
snap unset "appname" key1 key2
管理snap应用的运行状态
查看服务运行状态和日志:
snap services <appaname> # 查看APP提供的服务的运行状态
# => systemctl status snap.<appname>.<appserivce>
snap logs -f <appname>.<servicename>
启动应用软件
如果安装未生成启动软件的快捷方式,可通过命令启动。
snap run <appcommand> # 命令可通过snap info查看
管理软件服务
可使用snap或systemctl来控制服务运行。snap服务默认会在失效后自动重启。
sudo snap start/restart/stop <appname>
sudo snap restart <appname>.<servicename>
sudo systemctl restart snap.<appname>.<servicename>
AppImage
AppImage比较简单易用,不需要安装额外的工具,整个软件都在一个文件里,下载后可以直接运行。里面有个SquashFS的文件系统,运行的时候会挂在到一个临时的地方,里面有所有只读的文件,包括可执行文件、库文件、静态数据等。除此之外都和普通的软件运行环境是一样的。
Similar projects · AppImage/AppImageKit Wiki (github.com)
Flatpak
linuxbrew
安装发行版软件仓库缺失的软件。
安装linuxbrew
SRC_URL='https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh'
/bin/bash -c "$(curl -fsSL $SRC_URL)"
官方安装脚本下载以及官方源(github)的速度都比较慢,推荐使用代理进行安装。或者使用国内镜像进行安装和后续软件安装,配置镜像源相关环境变量:
MIRROR="https://mirrors.tuna.tsinghua.edu.cn"
export HOMEBREW_BREW_GIT_REMOTE="$MIRROR/git/homebrew/brew.git"
export HOMEBREW_CORE_GIT_REMOTE="$MIRROR/git/homebrew/homebrew-core.git"
export HOMEBREW_BOTTLE_DOMAIN="$MIRROR/homebrew-bottles"
执行以下命令下载安装脚本并执行安装:
git clone --depth=1 $MIRROR/git/homebrew/install.git brew-install
bash brew-install/install.sh
rm -rf brew-install
安装完成后根据输出提示,将初始化命令加入shell配置文件。然后,根据输出信息,安装建议的编译环境,用于brew进行本地编译打包。
brew的默认安装位置为/home/linuxbrew/.linuxbrew/。
安装软件
brew install pkgname
查找软件可在brew.sh查找,或通过命令查找:
brew search pkgname
进程管理
查看进程
jobs [-lnprs] [jobspec ...] or jobs -x command [args]
# Display status of jobs.
查看并过滤进程
ps -e|-A \ # 查看所有进程
-T|t \ # 当前终端上的所有进程
-x \ # 没有关联控制终端(tty)的进程
-r \ # 正在运行的进程
-a \ # 排除关联tty的所有进程或session leader
-d \ # 除了session leader外的所有进程
-N \ # --deselect 反选
H # 将线程视作进程显示
查找进程
ps -C cmd1,cmd2,... \ # 根据命令名comm筛选
-p 123,124,... \ # --pid,-q 根据进程号筛选
-ppid 10 \ # 根据父进程号筛选
-U EUID \ # effective user ID (EUID) or name
-u RUID \ # real user ID (RUID) or name
-C匹配进程命令起始子串,不包括路径与特殊字符'/-';无法匹配到僵尸进程。
pgrep -f PATTERN \ # --full 匹配完整进程名
-x \ # --exact 完整匹配命令行
-v \ # --inverse 反向匹配
-g PGID,... \ # --pgroup 匹配进程组ID
-G GID,... \ # --group 匹配real group IDs
-i \ # --ignore-case
-n \ # --newest 选择最近启动的进程
-o \ # --oldest
-P PPID,... \ # --parent 匹配父进程ID
-s SID,... \ # --sessioin 匹配会话ID
-u ID,... \ # --euid 匹配effective user ID
-U ID,... \ # --uid 匹配real user ID
-t TTY,... \ # --terminal 匹配终端
--ns PID --nslist ns,...
pgrep -l \ # --list-name 列出PID和进程名
-a \ # --list-full 列出PID和命令行
-c \ # --count 输出匹配计数
ps -C和pgrep无法匹配到僵尸进程<defunct>,可以利用ps -ef的输出内容进行匹配。
ps -ef | grep defunct | grep -v grep
输出进程信息
ps -f|-F \ # 完全信息,包括命令行(-F包括附加信息)
-l \ # 显示更多信息,可以与-f|-F组合使用
ps -o pid,tid,... \ # 指定输出的字段
-o '%cpu %mem' \ # 在单个参数中指定输出的字段
-o class \ # 可指定多个输出选项
-o wchan:14 \ # 指定输出字段的位宽
-o comm= \ # 该字段不输出字段名(当所有字段都不输出字段名,省略表头)
pid | ==进程编号== | ppid | 父进程编号 |
| `lwp | spid | tid` | 轻量线程ID |
| `pgid | prp` | 进程组编号 | tgid |
| `%cpu | pcpu` | CPU占用率(小数) | c |
| `cputime | time` | ==累计CPU占用时长== | pri |
start_time | ==进程启动时间/日期== | start | 进程启动时间 |
etime | ==进程启动后经过的时间== | etimes | 单位为秒 |
| `%mem | pmem` | 内存占用比例 | `vsz |
sz | 进程镜像大小 | size | 需要的交换空间大小 |
| `args | cmd | command` | 命令行参数 |
| `sess | session | sid` | 会话编号 |
| `tty | tt | tname` | 控制终端 |
| `fgid | fsgid` | 文件访问组编号 | `fgroup |
| `state | s` | stat |
进程关联用户信息:
| real | effective | saved | ||
|---|---|---|---|---|
| 用户ID | uid | ruid | `euid | uid` |
| 用户标识 | user | ruser | `euser | user |
| 组 | gid | rgid | `egid | gid` |
| 组标识 | group | rgroup | `group | egroup` |
需要systemd支持的字段:
machine:进程分配到的VM或容器名;ouid:进程会话所有者;lsession:进程的登录会话标识;其他:
psr:为进程分配的处理器,sgi_p:进程当前运行的处理器;
cgroup:控制组;
class|cls|policy:进程调度类型;sched;
blocked|sig_block|sigmask:阻止的信号(32或64位掩码);caught|sig_catch|sigcatch:捕获的信号(32或64位掩码);ignored|sig_ignore, sigignore:忽略的信号(32或64位掩码);pending|sig:挂起的信号(32或64位掩码);
f|flag|flags:进程标识。
进程树
ps f \ # 显示为进程树
-H \ # 显示进程层级(缩进)
pstree -U \ # --unicode 使用UTF-8画线符号(默认)表示树
-A \ # --ascii 使用ASCII画线符号
-h \ # --highlight-all 重点显示当前进程及其祖先进程
-H PID \ # --highlight-pid 重点显示给定进程及其祖先进程
-g \ # --show-pgids 显示进程组标识
-p \ # --show-pids 显示进程标识
-s \ # --show-parents 显示父进程标识
-n \ # --numeric-sort 根据PID对输出排序
-l \ # --long 不截断长行
PID \ # 进程树根节点的PID,默认为1(init/systemd)
USER \ # 显示指定用户的进程树
任务状态
top -b -n N \ # 非交互模式,刷新N次
-o FIELD[-+] \ # 按字段排序:"+"=>DESC; "-"=>ASC
-O # 不执行命令,仅输出可用的排序字段
top命令显示的是你的程序占用的cpu的总数,也就是说如果你是4核cpu那么cpu最高占用率可达400%,top里显示的是把所有使用率加起来。在
top的运行环境中按下键盘的1,显示每个cpu核的状态。
交互环境命令
排序:M->Mem, N->PID, P->%cpu, T->TIME+。
watch
watch "ps -ef | grep nginx | grep -v grep" \
-d,--difference \ # 高亮两次更新的差别
-n,--interval seconds \ # 更新周期
watch的命令参数可包含多条命令,输出结果包含每条命令的输出内容。
查看进程打开资源
打开的文件可能是常规文件、文件夹、库、流、网络文件(套接字、NFS文件)等。
lsof # list open files
lsof /bin/bash
#COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
#mysqld_sa 1597 mysql txt REG 253,0 960472 738200678 /usr/bin/bash
#sh 11503 es txt REG 253,0 960472 738200678 /usr/bin/bash
#bash 16538 yarn txt REG 253,0 960472 738200678 /usr/bin/bash
#bash 63028 yarn txt REG 253,0 960472 738200678 /usr/bin/bash
需要安装
lsof。
fuser [options] file/fs # identify processes using files or sockets
fuser /bin/bash # 返回使用文件的进程号与使用方式(后缀)
# /usr/bin/bash: 1597e 11503e 13039e 63028e 63030e 64836e
进程控制
创建进程
nohup &
终止进程
如果父进程在子进程之后终止,但子进程终止时父进程没有进行最后的回收工作,子进程残留的数据结构称为僵尸进程。
终止单个进程
kill向进程发送信号使进程终止,默认信号是-TERM。
kill [-s sigspec | -n signum | -sigspec] pid ...
kill -l [sigspec]
sigspec表示信号名,signum表示信号值。
| 选项 | 说明 |
|---|---|
-l, --list [sigspec] | 列出可发送的信号,如果给出信号名(值), 则将信号名(值)转换为信号值(名) |
-s sigspec -n signum -sigspec | 指定发送的信号,例如:-ABRT,-ALRM,-HUP,-KILL,-STOP,-SEGV, -TERM,-TRAP。 |
终止匹配名称的进程
killall [-s sigspec | -sigspec] [-e] [-I] [-g] [-i] [-u user] [-v] [-w] name ...
killall –l
选项
| 选项 | 说明 |
|---|---|
-l, --list | 列出可发送的信号 |
-s,--signal sigspec -sigspec | 指定发送的信号 |
-e, --exact | 匹配名称 |
-I, --ignore--case | 匹配名称时忽略大小写 |
-g, --process-group | 向进程所属的进程组发送信号 |
-i, --interactive | 在杀死进程前交互式确认 |
-q, --quiet | 如果没有进程被杀死,不输出信息 |
-u, --user | 仅杀死属于给定用户的进程 |
-v, --verbose | 报告信号是否成功发送 |
-w, --wait | 等待所有被杀死的进程结束 |
终止匹配的进程
pkill [options] --signal SIGNAL PATTERN
终止图形进程
xkill
出现“x”标志的鼠标,点击需要中止的程序即可。
清理进程
wait -f -n [CH_PID,,,] # 清理子进程
服务
systemd
systemd(system and service manager),init system (PID=12, started by the kernel, to bring up userspace) managing userspace services. (fast and efficient boot-up)
sysvinit
/sbin/init -> ../lib/systemd/systemd
system instance: system.conf and the files in system.conf.d
user instance: user.conf and the files in user.conf.d
"units" of 11 different types. states: active/inactive/activating/decativating/failed;
Units are named as their configuration files
Processes systemd spawns are placed in individual Linux control groups named after the unit which they belong to in the private systemd hierarchy. /sys/fs/cgroup/systemd/
transaction system: before executing a requested operation, systemd will verify that it makes sense, fixing it if possible, and only failing if it really cannot work.
-
Service:管理控制守护进程及其相关进程;
-
Socket:用于提前创建套接字资源。
-
Target:group units(使用
Requires,After)。default.target whose job is to activate on-boot services and other on-boot units by pulling them in via dependencies.
graphical.target/multi-user.target -
Device:expose kernel devices
-
Mount/Swap:mount points/memory swap(类似于
mount命令) -
Automount
-
Timer:定时触发其他单元;
-
Path:
-
Slice:分组资源管理;
-
Scope:管理外部进程
信号处理:
SIGTERM:重启systemd system manager;
SIGINT(Ctrl+Alt+Del):If this signal is received more than 7 times per 2s, an immediate reboot is triggered.
SIGHUP:systemctl daemon-reload
管理器交互命令可以用于管理服务。systemctl are used to give commands to the manager.
systemctl --version # 查看版本和加载模块
systemctl {start|stop|reload|restart|kill} <service>
systemctl {enable|unmask} --now <service> # 启用并立即启动服务
systemctl {disable|mask} <service> # 禁用/屏蔽服务
systemctl status <service>
systemctl show <service>
systemctl list-unit-files --type {service|target} # 列出已安装单元
systemctl list-units --type {...} # 列出已加载单元
systemctl daemon-reload # 重新加载服务单元配置(不影响现有服务)
此外,
systemdctl还可用于控制系统systemctl {poweroff|reboot[arg]|suspend|hibernate}
service命令也用用管理服务,在Ubuntu中其实际调用的是systemctl。
Systemd 入门教程:命令篇 - 阮一峰的网络日志 (ruanyifeng.com)
管理配置文件
A unit file is a plain text ini-style file that encodes information about a service, socket, device, mount point, automount point, swap file or partition, start-up target, watched file system path, timer controlled and supervised by
systemd, resource management slice or group of externally created processes.
服务配置文件(.ini格式)位于/lib/systemd/system(/lib->/usr/lib);systemctl enable会在/etc/systemd/system目录(某些服务也直接置于*.target子目录下)创建一个指向服务单元的链接(也可直接在该目录下储存配置文件或链接其他位置的配置文件,但无法使用enable/disable命令)。
pkg-config systemd --variable=systemdsystemunitdir:系统服务配置文件路径;
pkg-config systemd --variable=systemduserunitdir;不同于其他
systemctl命令,==必须以管理员权限执行==systemctl enable|disable以创建或删除服务配置文件的链接。
配置文件名由管理单元名和类型名组成,如unit-name[@instance-name].service(服务模板:在配置文件中通过"%i"引用实例名称)。文件格式:key=value,=前后空格被忽略;#或;为注释行;\用于换行拼接(连接时添加空格,换行符后的注释行被忽略,随后的内容将继续被拼接);
boolean:1,yes,true,on,0,no,false,off
time:默认为秒,"2min 200ms", s", "min", "h", "d", "w", "ms", "us".
multiple settings form a list, empty value "resets"
[Unit]
Description=The descript of the service
Documentation=http://,https://,file:,info:,man:,
Wants/Requires/Requisite/BindsTo/PartOf/Upholds=
Conflicts=
Before/After=
After=network.target ... nginx.service mongod.service
[Install]
Alias=sshd.service # create symlinks
WantedBy/RequiredBy=multi-user.target
Unit和Install是所有单元类型配置文件共有的部分。
foo.service.d/*.conf:在该目录下添加配置文件覆盖该服务的默认配置。
单元参数说明:
- 依赖声明:==不影响启动顺序(可并行启动)==
Wants=:one-time effect=> [Install] WantedBy=:foo.service.wants/Requires=:=> [Install] RequiredBy=Requisite=:=> RequisiteOf=BindsTo=:=> BoundBy=PartOf=:=> ConsistsOf=
UpHolds=:continuous effect,
Conflicts=:=> ConflictedBy=
- 启动顺序
Before=, After=OnFailure=,OnSuccess=
Specifiers available in unit files: https://www.freedesktop.org/software/systemd/man/systemd.unit.html#Specifiers
服务单元参数说明:
[Service]
Type=simple/exec/forking/oneshot/dbus/notify/idle
ExecStartPre=/usr/local/nginx/sbin/nginx -t -c conf/nginx.conf # 启动前的检测
ExecStart=/usr/local/nginx/sbin/nginx -c conf/nginx.conf # 启动服务的命令
ExecStartPost=/bin/sleep 1 # 启动服务后的命令
ExecReload=/usr/local/nginx/sbin/nginx -s reload # reload命令
ExecStop=/bin/kill -s TERM $MAINPID # stop命令
StandardOutput=syslog
User=service_user
Environment="VAR=VALUE" "VAR2=VALUE2"
Environment="VAR3=VALUE3" # 可声明多行环境变量
KillMode=control-group, mixed, process, none
KillSignal=SIGTERM
-
Type=:服务类型simple(默认):认为ExecStart=配置的进程为服务主进程;当服务主进程被创建后(服务执行程序还未运行)即认为服务启动(即使随后服务启动过程出错,systemctl start仍然报告启动成功)并继续启动后续服务。exec:等待服务进程被执行后才认为服务启动(systemd219版本不支持,245版本支持该类型);notify:类似于exec,但服务启动后需要发送一个通知消息,服务管理在收到通知消息后,认为服务启动完成并继续启动后续服务;设置NotifyAccess=以访问systemd提供的通知套接字。
oneshot:类似于simple,服务主进程退出后即认为服务启动完成,通常用于设置==开机启动任务==;RemainAfterExit=yes用于表示服务在启动完成后进入active状态,否则,由于没有配置持续运行的进程,服务状态将变为deactivating或dead状态。dbus:类似于simple,服务获得一个D-Bus总线名(BusName=)后,即认为完成启动;默认依赖dbus.socket;idle:类似于simple,但会延迟服务程序的执行时间(最多5s),直到活动任务被执行。
forking:ExecStart=配置的进程会调用fork()来启动后台服务(Unix服务启动协议)。父进程在后台进程启动完成后退出,服务管理认为服务启动完成。==如果服务自身可以输出主进程ID到文件,则推荐使用PIDFile=选项==,使得systemd能够可靠地识别服务主进程从而判断服务状态 。如果未设置PIDFile,则默认GuessMainPID=yes以尝试获取服务主进程ID,但如果服务存在多个守护进程,则不一定准确。
对于长期运行服务,首先推荐使用简单且快速的
Type=simlpe。但如果需要获取服务启动状态,或其他服务依赖此服务,则推荐使用notify或dbus;如果服务程序并不支持notify或dbus,则使用forking。对于==仅启动时执行一次==的服务,则可以使用oneshot。 -
-
RootDirectory=(chroot) -
WorkingDirectory= -
User=, Group= -
进程资源限制
ulimit:LimitCPU/LimitFSIZE/LimitNOFILE...; -
CPU调度策略:
CPUSchedulingPolicy/CPUAffinity... -
Environment=,EnvironmentFile=:定义传递给服务的环境变量(定义不支持Shell变量替换,重复定义将替换之前的定义);$PATH:默认值/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin;$MAINPID:服务主进程ID,用于管理服务控制进程的关闭和重载;$PIDFILE:通过PIDFile=传递,用于服务守护进程写入进程ID;
-
StandardInput=,StandardOutput=,StandardError=:inherit, null, tty, kmsg, journal+console, kmsg+console, socket or fd:name.journal:发送到journal,输出日志通过journalctl查看syslog:发送到系统的syslog服务和journal。file:path(v236+),append:path(v240+),truncate:path:输出到指定文件(219版本不支持,对于不支持的版本使用文件重定向标准输出)。
systemd管理的服务产生的日志可通过journalctl查看。journalctl [FIELD=VALUE...] \ # 未添加匹配条件则返回所有日志 systemd.journal-fields --options -
SyslogIdentifier=,SyslogFacility=,SyslogLevel=
-
-
ExecStart=:服务启动命令。==除非是oneshot类型==,否则仅能给定一条命令。==命令必须以可执行程序的绝对路径开头==(对于其他Exec命令也一样)。systemd-path search-binaries-default:如果返回路径,则表示支持直接使用位于路径的命令名。命令参数支持环境变量替换:
${VARIABLE}始终解释为一个参数,$VARIABLE必须与命令行==其他内容使用空格分开==(否则不会展开),展开后会按空白分割为多个参数;支持Systemd定义的
%特殊变量。--opt1 $VARIABLE1 --opt2=${VARIABLE2} # --opt2=$VARIABLE3 无法完成变量替换命令中不能包含重定向(
<,<<,>,>>)、管道(|)和后台执行(&)等Shell语法。显式使用bash命令ExecStart=bash -c 'dmesg | tac'命令前缀:
-:记非零错误返回,但处理行为等效于命令成功执行;::不替换命令行环境变量;- "
+"以完整权限执行,不受用户和分组设置限制;
-
ExecStartPre=, ExecStartPost=:类似于ExecStart=:,分别在ExecStart=:前后执行,并可指定多条命令。ExecStart=仅在ExecStartPre=执行成功的情况下执行,否则服务启动失败(ExecStartPost=类似)。ExecStartPre=不应用于启动长期运行程序(ExecStartPre=启动进程所创建的子进程会在服务程序执行前被终止)。任何Exec*=命令执行失败或超时,则会跳转到执行ExecStopPost(跳过ExecStop=)。 -
ExecReload=:服务重新加载配置的一条或多条命令(语法类似于ExecStart=)。 -
ExecStop=,ExecStopPost=:停止服务的一条或多条命令。如果未指定,则向服务发送``KillSignal=或RestartKillSignal=`指定的信号以终止服务进程。 -
TimeoutSec=,RestartSec=,TimeoutStartSec=,TimeoutStopSec=服务启动/停止超时期限。 -
Restart=no|on-success|on-failure|on-abnormal|on-watchdog|on-abort|always -
SuccessExitStatus=TEMPFAIL 250 SIGKILL:成功退出状态,默认包括0,SIGHUP,SIGINT,SIGTERM和SIGPIPE。
systemd.service (www.freedesktop.org)
服务沙盒
以下选项用于屏蔽向服务进程暴露的系统资源(需要底层安全机制支持才开启,如ProtectSystem需要包含文件系统命名空间的内核)。
ProtectSystem=false|true|full|strict*
ProtectHome=false|true|read-only|tmpfs
PrivateTmp=false|true
*:strict,tmpfs在219版本(CentOS 7)不可用。
- [Mastering systemd: Securing and sandboxing applications and services | Enable Sysadmin (redhat.com)](https://www.redhat.com/sysadmin/mastering-systemd#:~:text=Systemd provides a significant number of security features,this option to full also makes %2Fetc read-only.)
- systemd.exec Sandboxing(www.freedesktop.org)
问题:
-
开启
ProtectSystem后无法对用户家目录进行写操作。如果使用普通用户运行服务,则不用担心该服务修改系统资源(无权限)。因此,可以关闭
ProctectSystem选项。也可尝试将服务的写入目录修改为其他位置,例如/tmp或/var(适用于以root运行的服务)。
挂载单元配置
[Mount]
What=/dev/DEVNAME
Where=/mnt/MOUNT_PATH
Type=fs_type
Options=
DirectoryMode=0755 # 自动创建挂载点
TimeoutSec=
# Check systemd.exec(5) and systemd.kill(5) for more settings.
定时单元器配置
[Timer]
OnActiveSec/OnUnitActiveSec= # 相对定时器(执行单元)上次触发时间设置定时器
OnUnitInactiveSec= # 相对定时器执行单元上次休眠时间设置定时器
OnCalendar= # systemd.time(7)
Unit= # 定时器超时后触发的单元名称
supervisor
Introduction — Supervisor 4.2.2 documentation (supervisord.org)
Supervisor is a client/server system that allows its users to control a number of processes on UNIX-like operating systems. It is not meant to be run as a substitute for
initas “process id 1”. Instead it is meant to be used to ==control processes related to a project or a customer==,
supervisordstarts processes as its subprocesses viafork/execand subprocesses don’t daemonize. It always knows the true up/down status of its children. If supervisord is started as root, it is possible to allow “normal” users to control (“stop”, “start”, and “restart” ) such processes.
client/server system
delegation: Supervisorctl allows a very limited form of access to the machine, essentially allowing users to see process status and control supervisord-controlled subprocesses by emitting “stop”, “start”, and “restart” commands from a simple shell or web UI.
/etc/supervisord.conf
supervisord -c conf_file
-n, --nodaemon
-q ,--childlogdir=PATH # must exist, for auto-mode child proocess
-k, --nocleanup # prevent removal of old AUTO process log files
supervisorctl -c conf_file
-i,--interactive # 启动交互式命令
-r,--history-file # 记录输入命令(realine模块可用)
ACTION args...
ACTION:
add/update NAME[:*]... # activate/update process/group config
remove NAME ... # deactivate process config
clear NAME ... # clear process log
pid [NAME] # get pid of supervisord/subprocess
reload # restart remote supervisord
reread # reload daemon's config without restart
start NAME[:*]... # start process/group (not reread configs)
restart NAME[:*]... # restart process/group (not reread configs)
status [NAME[:*]...] # 返回进程(组)状态
tail [-f] NAME [stdout|stderr] # 输出日志的最后部分
all用于参数中表示所有进程和分组。
supervisord as a system service
# supervisord service for systemd (CentOS 7.0+)
[Unit]
Description=Supervisor daemon
[Service]
Type=forking
ExecStart=/usr/bin/supervisord
ExecStop=/usr/bin/supervisorctl $OPTIONS shutdown
ExecReload=/usr/bin/supervisorctl $OPTIONS reload
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
supervisord
[supervisord]
logfile=$CWD/supervisord.log # (-l,--logfile=FILE)
logfile_maxbytes=50MB # rotate limit (-y,--logfile_maxbytes=BYTES)
logfile_backups=10 # number of rotates (-z,--logfile_backups=NUM)
loglevel=info # (-e,--loglevel=LEVEL)
pidfile=$CWD/supervisord.pid # (-j,--pidfile=FILE)
directory=$PWD # workdir of supervisord daemon (-d,--directory=PATH)
environment=KEY="val",KEY2="val2" # for all subprocess
信号处理:
SIGTERM/SIGINT/SIGQUIT:supervisord及其管理的子进程将会关闭。SIGHUP:关闭所有进程,重新加载配置,并重启所有进程。SIGUSR2:关闭并重新打开主日志以及子进程日志。
服务进程配置
[program:SERVICE_NAME]
command=/path/to/programname # relative is OK
user=gary # 启动进程的用户
numprocs=1
priority=999 # Lower priorities indicate programs that start first
autostart=true # start with supervisord
autorestart=unexpected # false, unexpected, or true
startsecs=1 # 0不检查是否进程在运行
startretries=3
exitcodes=0 # 正常退出代码(,分隔)
stopwaitsecs=10 # 进程停止等待时间(超时使用SIGKILL强制停止)
stopasgroup=false # 用于停止具有子进程的进程(如Flask调试模式)
stdout_logfile=AUTO # 进程的标准输出文件
stdout_logfile_maxbytes=50MB # 日志文件轮转大小
stdout_logfile_backups=10 # 日志轮转数量限制
stderr_logfile=AUTO # stderr_logfile_maxbytes/stderr_logfile_backups
stdout_syslog=10 # 使用进程名输出到syslog / stderr_syslog
redirect_stderr=false # 将进程的错误输出重定向到supervisord的输出
environment= # 传递给进程的环境变量
directory= # 进程运行的工作目录
服务进程本身不应该以守护进程模式运行。
自动重启:如果
autorestart=unexpected,则在非手动停止进程的情况下,如果进程退出代码非exitcodes列出的,则重启该进程。
AUTOlog files and their backups will be deleted when supervisord restarts.输出文件名为可包含变量
group_name,host_node_name,process_num,program_name和here的Python字符串表达式。
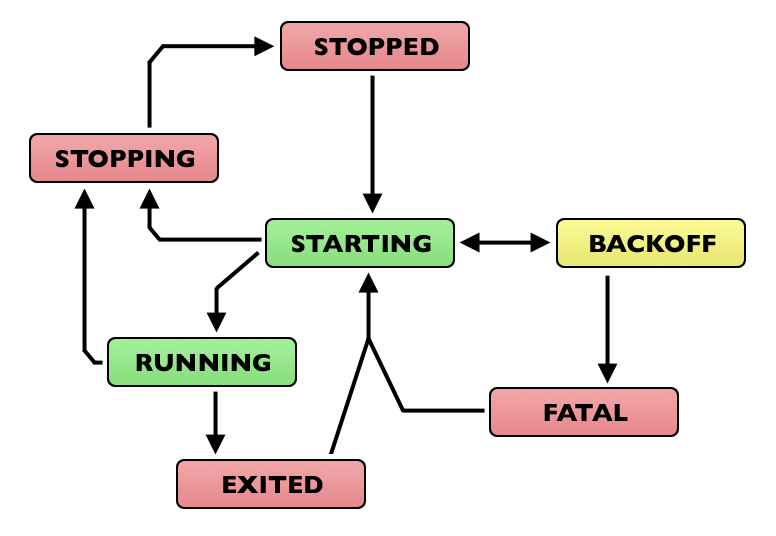
服务分组:同类型服务;
[group:foo]
programs=bar,baz
priority=999
supervisorctl访问supervisord
supervisorctl可访问本地(UNIX套接字)或远程的supervisord服务(TCP/IP套接字)。
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock # (-s,--serverurl URL)
# serverurl=http://127.0.0.1:9001
username=gary # (-u,--username NAME)
password=gang2019 # (-p,--password)
prompt=mysupervisor # 命令行提示符
使用Web访问supervisord
[inet_http_server]
port=0.0.0.0:9001
username=gary
password=gang2019 # or passord hash: {SHA}82ab876d1387bfafe46cc1c8a2ef074eae50cb1d
重启
supervisor(使用systemctl)。
XML-RPC接口
from xmlrpc.client import ServerProxy
server = ServerProxy('http://localhost:9001/RPC2')
server.supervisor.getState()
server.system.listMethods()
server.system.methodHelp('supervisor.shutdown')
子配置文件
[include]
files=/path/filename.conf /path/*.conf foo.conf config??.conf
XML-RPC API Documentation — Supervisor 4.2.2 documentation (supervisord.org)
Supervisor: A Process Control System — Supervisor 4.2.4 documentation (supervisord.org)
Process Monitoring and Events
Supervisor continually emits event notifications, and the subscribed listener will be notified.
provide a mechanism for code to be run (e.g. send an email, make an HTTP request, etc) when some condition related to subprocess state is met.
The event notification protocol is based on communication via a subprocess’ stdin and stdout.
Example Event Listener Implementation
服务管理程序对比
supervisord主要用于管理用户服务进程,systemd处理服务管理外,还支持系统中其他对象如外部设备、套接字、定时器等的管理。
systemd具有启动依赖管理控制功能,可以实现有依赖关系的一组对象的正确启动和运行管理;supervisord仅支持进程分组,无依赖解析功能。systemd具有完善的进程资源控制和系统调度策略设置,supervisor可实现较为简单的资源控制。
supervisord提供网络访问接口并有可用的Web访问UI,可方便普通用户实现进程管理;systemd需要管理权限执行管理控制功能。
superivord发布于2004年,systemd发布于2010年。systemd现在为多数Linux发行版的init程序,因此开箱即用。supervisord需要以Python库或发行版软件仓库软件的方式进行安装。
对于较为简单的服务进程配置管理,supervisord和systemd都能有效实现;对于有远程管理需求的场景,supervisord提供网络访问接口更适合。对于复杂的服务配置管控需求以及supervisor不支持的管控对象,使用systemd更加合适。
网络管理
网络管理工具
net-tools:包含arp, ifconfig, netstat, rarp, nameif and route。
ip:show/manipulate routing, network devices, interfaces and tunnels,代替net-tools。
NetworkManager:包含NetworkManager服务和命令行工具nmcli、nmtui等。
与使用
ip的功能相同,使用nmcli+NetworkManager将管理功能与用户交互分离。
networkd
NetworkManager
NetworkManager用于代替已有的配置工具ifconfig及其配置文件。NetworkManager作为systemd服务运行(服务的配置文件为/etc/NetworkManager/NetworkManager.conf)。
udev设备管理器发现系统新加入设备,通知NetworkManager通过D-Bus来检测和初始化配置网络设备实现即插即用(配置信息动态生成并存储于内存中)。
永久配置文件检查(如果未找到配置文件,则尝试从DHCP服务器获取配置信息):
-
etc/sysconfig/network-scripts/ifcfg-*:后向兼容ifconfig配置文件; -
/etc/NetworkManager/system-connections/:NetworkManager配置文件。
nmcli是NetworkManger的命令行工具(客户端),nmtui是对应的终端图形界面工具。
yum install NetworkManaget-tui # nmcli随NetworkManager安装
图形化配置接口:
nmtui edit <ifname> # in CentOS
在修改配置时,不要修改设备(
00:0C:29:BD:83:63 (ens32))
网络状态
主机名和域名
hostname可以读取主机的主机名、域名和对应的IP地址(/etc/hostname)。
-A:所有主机名;-s返回一个短主机名;-f返回长主机名;-I:所有IP地址;-i还首先读取IPv6地址;-d:DNS域名;
使用
hostnamectl设置主机名。
域名地址映射*
dig [@dns_server] domain_name
dig -x ip_addr # reverse lookup
nslookup <domain>
支持反向查询
nslookup <ipaddr>,但查询到的域名不是通常使用的域名,也可能查不到结果。
whois <ipaddr|domain> # sudo apt install whois
查询IP地址/域名==所有者==。
网络接口信息
nmcli # 代替ifconfig
netstat -i # 输出网络接口设备的统计信息;
-ie # => ifconfig
使用ip工具列出设备参数(type,mtu,qdisc,state,mode,qlen,mac):
ip link [show] [up|down] [dev eth0] [type bridge] [master br0] # 显示链路信息
ip address ... # 显示链路层以及网络地址信息
使用nmcli查看网络接口连接:
nmcli c[onnection] [show] --active # summary table
# NAME UUID TYPE DEVICE
# eth0 cb149a11-edae-3f8f-9af1-7dc541e1ac5d ethernet ens32
nmcli connection show <name/id> # interface details
设备未知的接口通常是由于配置文件存在错误。
查看网络设备信息:
nmcli d[evice] [show] # summary table
# DEVICE TYPE STATE CONNECTION
# ens33 ethernet connected ens33
# lo loopback unmanaged --
nmcli device show <device> # device details
网络通信状态信息
netstat -a # 列出tcp,udp和unix协议套接字连接(默认仅显示unix套接字连接) *
-{t|u} # 只列出TCP/UDP连接
-l # 只列出监听中的连接
-p # 列出进程ID和命令名
-e # 列出进程用户和进程文件的Inode编号
-n # 禁用对IP地址/端口的反向域名解析,加快查询速度
*:需要安装net-tools包。
示例:
sudo netstat -anp | grep ESTABLISHED # 打印active状态的连接
sudo netstat -anp | grep apache2 # 查看指定服务是否正常运行
通过访问套接字获取连接信息:
ss -n # 禁止解析服务名称
-r # 尝试解析地址端口信息
-a/l # 显示所有/监听套接字信息
-m # 显示套接字内存占用
-p # 显示使用套接字的进程
-e # 显示扩展信息
-i # 显示TCP内部信息
-s # 打印汇总信息
-N,--net=NSNAME # 切换网络命名空间
-f,--family=unix/inet/inet6/link/netlink/vsock
由于网络连接(套接字)是特殊文件,因此可以使用lsof查看(lsof用于列举进程打开的文件)。
lsof -i -P -n
-i [addr]:列出使用互联网地址的文件(套接字);地址格式
[46][protocol][@hostname|hostaddr][:service|port]
-U筛选使用UNIX套接字的进程。
-P:禁止将端口号解析为服务名;
-n:禁止将IP地址解析为主机名或域名。
网络协议统计信息
netstat -s
监控网络通信状态
iftop # apt|yum install iftop => 主机间通信速率
nload # apt|yum install nload => 网络接口通信统计
bmon # apt|yum install bmon => 系统带宽监控
nethogs # yum install nethogs => 进程通信统计
系统监控工具也可以监控网络通信状态的基本参数。
网络可达性检测
ping:is part of iputils package。
ping \ # ICMP ECHO_REQUEST
-4|6 \ # IPv4/IPv6
-c count \
-D # print timestamp before each line
-I interface # 设置源地址或源接口名称
tracepath:is part of iputils package.
tracepath -4|6 -n|b # n|b 仅打印IP地址/打印主机名和IP地址
网络设备链路管理
网络配置数据
系统中可能存在的网络设备和接口配置文件:
-
ifup/ifdown(/etc/network/interfaces) -
networkd[connection] id=br0_eno1 uuid=ccfcb8fa-5f16-4407-ae6c-1af6c9117265 type=bridge autoconnect=false interface-name=br0_eno1 permissions= timestamp=1650420144 [bridge] stp=false [ipv4] address1=172.28.76.22/24,172.28.76.234 dns=172.28.28.28;223.5.5.5; dns-priority=100 dns-search= method=manual [ipv6] addr-gen-mode=stable-privacy dns-priority=100 dns-search= method=link-local [proxy] -
ifconfig(etc/sysconfig/network-scripts/ifcfg-*)TYPE=Ethernet NAME=eth0 # 应该和配置文件后缀匹配 DEVICE=ens33 # 绑定的设备名 UUID=a016f249-6703-42eb-a207-e40f80de212f # 绑定的设备UUID HWADDR=84:16:f9:03:fd:85 # 绑定的设备MAC(old) IPADDR=192.168.2.203 PREFIX=24 # <-> NETMASK GATEWAY=192.168.178.2 DNS1=223.5.5.5 DNS2=8.8.8.8 ONBOOT=yes BOOTPROTO=static # dhcp|bootp|none|static -
NetworkManager(/etc/NetworkManager/system-connections)
netplan
netplan在系统启动早期将配置信息解析并提供给系统的网络管理服务(如NetworkManager)。
- 默认由
systemd-networkd管理网络设备,其他服务如NetworkManager可替代其功能。
netplan配置文件位于 /{lib,etc,run}/netplan/*.yaml:
- 对于不同目录下的同名配置文件,仅读取最高优先级目录下的文件(
/run>/etc>/lib); - 对于不同名文件,将按文件名字典顺序读取配置文件,并将新内容追加/覆盖已读取内容。
配置文件格式(YAML):
network: # 网络配置的根节点
renderer: networkd|NetworkManager # networking backend,
ethernets: # 设备分组, 如: ethernet, modem, wifi
ens33: # 设备ID
dhcp4: false
dhcp6: true
addresses:
- 192.168.0.200/24 # IPv4
lifetime: 0
label: "maas"
- "2001:1::1/64" # IPv6
gateway4: 192.168.0.1 #! deprecated
gateway6: "2001:4::1" #! deprecated
routes: # 静态路由*
- to: default # could be 0/0 or 0.0.0.0/0 optionally 默认路由
via: 192.168.0.1 # 默认网关
metric: 100
on-link: true
- to: default # could be ::/0 optionally
via: cf02:de:ad:be:ef::2
nameservers: # 手动地址配置时设置
addresses: [ 223.5.5.5, "FEDC::1" ]
search: [lab, home] #**
match:
macaddress: 52:54:00:6b:3c:58
macaddress: 52:54:00:6b:3c:59 # 修改匹配设备的MAC地址
mtu: 1500 # 修改匹配设备的MAC地址
version: 2
应用配置文件:
sudo netplan generate # 生成后端配置文件
sudo netplan apply # 直接应用配置
sudo netplan try # validate the config and then apply
物理链路管理
创建和删除链路
ip link add \ # 添加虚拟链路
link DEVICE \ # 指定物理设备(某些链路类型无物理设备,如IP-over-IP)
name NAME \ # 默认为物理设备名称
type TYPE \ # 链路类型:bridge,veth,vlan,macvlan,mactap,ip6tnl,gre,...
index ID # 链路编号
其他参数包括:
mtu,address,broadcast,txqueuelen,numtxqueues,numrxqueues,...。不同类型链路采用不同的数据链路层协议。
ip link delete {dev NAME|group GROUP} type TYPE
nmcli connection add type <type> ifname <ifname> ... # 创建链路
nmcli connection delete <ifname>
配置链路参数
ip link set [dev NAME] [group GROUP] prop VALUE
ip address {add|change|replace} IFADDR dev NAME # 配置IP地址
如果指定了group则修改设备所属分组,如果未指定设备,则修改分组中所有设备的属性。配置了IP地址的链路能够使用IP协议进行通信。
nmcli connection modify <ifname> [+-]ipv4.addresses 192.168.0.58[/24]
nmcli connection modify <ifname> [+-]ipv4.dns 114.114.114.114
nmcli connection modify <ifname> [-]ipv4.gateway 192.168.0.2
# ipv4.method manual must be supplied with address
nmcli connection modify <ifname> ipv4.method manual \
ipv4.addresses 192.168.0.58/24
nmcli edit <ifname/id> # 交互式编辑模式,查看和编辑配置项
启用和停用链路
nmcli c reload
nmcli c up <interface> # if interface exist
虚拟网桥管理
创建和配置虚拟网桥
ip link add BRIDGE_NAME type bridge
brctl addbr BRIDGE_NAME
nmcli connection add type bridge CONN_NAME BRIDGE_NAME ifname BRIDGE_NAME
Chapter 12. Configuring a network bridge Red Hat Enterprise Linux 8 | Red Hat Customer Portal
将网卡绑定至网桥
ip link set dev IFNAME master BRIDGE_NAME
nmcli connection modify DEVICE_NAME master BRIDGE_NAME
nmcli connection add type ethernet slave-type bridge CONN_NAME DEVICE_NAME ifname IF_NAME master bridge0
虚拟网卡管理
tap网卡
ip tuntap add dev tap1 mode tap
Tap网卡创建是临时的,如果要永久生效,可将上述命令添加到开机启动命令(如rc.local)。
linux - How to make tap interfaces persistent after reboot? - Super User
防火墙
Linux内核使用Netfilter/iptables过滤包,其中iptables为用户交互接口(iptable-services)。
防火墙规则管理
iptables -t,--table TABLE -OP CHAIN rule_spec # 链名为大写,表名为小写
-t TABLE:指定访问的表(省略则查看filter表);
-OP CHAIN:指定访问的链(省略链名则查看所有链)及其操作(例如-L FORWARD);
查询规则
iptables -t TABLE -L,--list CHAIN -v -n --line-number -x # 列出所有规则
iptables -t TABLE -C,--check CHAIN RULE_SPEC # 检查指定规则是否存在
-n:不反向解析IP地址(显示IP地址而非域名,加快速度);
--line,--line-number:显示规则编号;
-v:显示更多信息(分组数、字节数等);
-x:显示精确的计数,而非经过单位转换的数据。
管理规则
iptables -I,--insert CHAIN [NUM] RULE -j TARGET # 在表首部插入一条规则
iptables -A,--append CHAIN RULE -j TARGET # 在表尾部插入一条规则
iptables -R,--replace CHAIN NUM RULE -j TARGET # 替换指定编号的规则
iptables -D,--delete CHAIN RULE -j TARGET # 删除匹配条件的规则
iptables -D CHAIN NUM # 删除指定编号的规则
iptables -F,--flush CHAIN # 清空表中的规则
默认的表为
-t filter。
添加相同的规则不会覆盖已有规则,可用以下命令修改已有规则的动作:
iptables -t filter -R INPUT 2 <rules> -j <traget> # 修改指定规则的动作
必须指定要修改规则的条件,否则该规则的条件将变为默认值(例如IP将变为
anywhere)。
修改默认策略
iptables -t filter -P FORWARD DROP
黑白名单机制
黑名单:将默认策略设置为ACCEPT;在规则中添加阻止策略。
白名单:将默认策略设置为DROP,在规则中添加允许策略。
默认策略设置为
DROP的缺点:在对应的链中没有设置任何规则时,管理员也会把自己拒之门外;即使对应的链中存在放行规则,当不小心使用"iptables -F"清空规则时,放行规则被删除,则所有数据包都无法进入。所以,如果想要使用"白名单"的机制,最好将链的默认策略保持为"ACCEPT",然后将"拒绝所有请求"这条规则放在链的尾部,将"放行规则"放在前面,这样做,既能实现"白名单"机制,又能保证在规则被清空时,管理员还有机会连接到主机。
自定义链
自定义链仅对应一种类型的表,自定义链中规则配置方式与默认链相同。
iptables -t filter -N,--new-chain IN_WEB # 创建用于filter表的自定义链
iptables -E,--rename-chain IN_WEB WEB # 重命名
iptables -X,--delete-chain WEB # 删除自定义链,需未被引用且不包含任何规则
iptables -t filter -I INPUT RULE -j IN_WEB # 引用自定义链
保存规则
通过iptables对规则的修改并非永久生效,当重启iptables服务或者重启服务器以后规则便失效了。如果想要修改永久生效,必须使用service iptables save保存规则,如果误操作了规则但是并没有保存,那么使用service iptables restart命令重启iptables以后即恢复修改前的状态。
目前的发现版多数已用防火墙软件(如
CentOS/firewall、Ubuntu/ufw)代替了iptable-services了,因此使用上述方法需要安装该服务。
iptables-save # 将防火墙规则导出到标准输出
iptables-restore # 从标准输入导入防火墙规则
包匹配条件
多个条件之间具有AND关系,使用!对条件取反。
基本匹配条件:
# IP地址
-s sip1,sip2 -d dip1
-s ip/mask
# 协议类型
-p tcp # all, tcp, udp, udplite, icmp, icmpv6,esp, ah, sctp, mh
# 网卡接口
-i eth0 -o eth1
-i选项只能用于上图中的PREROUTING链、INPUT链、FORWARD链;-o选项只能用于FORWARD链、OUTPUT链、POSTROUTING链。
扩展匹配条件:由netfilter的扩展模块处理的条件。
# 端口
-m tcp --sport 1:1024 --dport 22 # 需要指定扩展模块tcp, udp, icmp
-m tcp --sport :1024 --dport 10000: # 可省略一个端口边界参数
-m multiport --dports 22,36,80:100
# IP范围
-m iprange --src-range 192.168.1.127-192.168.1.146 # --dst-range
# 字符串:匹配报文中包含的字符串
-m string --algo bm --string xyz
# time
-m time --datestart 2017-12-24 --datestop 2017-12-27
-m time --timestart 09:00:00 --timestop 18:00:00
-m time --weekdays 6,7 --monthdays 22,23
当扩展模块的名称与协议名称相同的情况下,如果已经指定了协议,则可以省略模块选项。
--algo指定字符串匹配算法,可选算法有bm与kmp。
# connlimit 限制连接数量
-m connlimit --connlimit-above 2 --connlimit-mask 24 -j DROP
--connlimit-mask表示对一个网段施加连接数限制(未指定时为对每个IP的连接数进行限制)
# limit 使用令牌桶限制报文速率
-p icmp -m limit --limit 10/minute -j ACCEPT
-p icmp -m limit --limit-burst 3 --limit 10/minute -j ACCEPT
--limit:报文允许的速率(令牌的生成速率,单位可以是second,minute,hour,day);--limit-burst:允许的突发流量(令牌桶的容量,默认值为5);需要添加一条默认
DROP/REJECT的规则,以丢弃超过速率限制的包。
其他扩展条件:tcp-flags、state
http://www.zsythink.net/archives/1578
动作
REJECT可以附加发送一个ICMP响应报文。
-j REJCT --reject-with icmp-host-unreachable
-j LOG --log-prefix "logname" --log-level alert
LOG动作默认将报文的相关信息记录在/var/log/message文件中,通过修改/etc/rsyslog.conf(或/etc/syslog.conf),kern.warning /var/log/iptables.log
--log-level:emerg,alert,crit,error,warning,notice,info,debug。
端口管理
sudo vi /etc/sysconfig/iptables
端口权限
小于1024的端口号(特权端口)不允许非root用户打开,以防恶意程序占用这些端口建立恶意服务。
如果用户需要使用这些端口,解决方法包括:
-
使用Apache或nginx作为代理服务器;
-
使用iptables设置防火墙规则,使得低端口在内部自动转发至高端口;
-
jsvc
-
authbind
-
sudo setcap CAP_NET_BIND_SERVICE=+eip /path/to/binary
路由配置
转发功能
开启防火墙的转发功能。
echo 1 > /proc/sys/net/ipv4/ip_forward # 设置为1开启转发,0关闭转发
sysctl -w net.ipv4.ip_foward=1
上述方式为设置系统运行时变量,要永久生效需要修改系统配置。
Ubuntu使用
ufw管理防火墙规则,其配置文件在/etc/ufw/sysctl.conf,其中对应的配置项为:net/ipv4/ip_forward=1 net/ipv6/conf/default/forwarding=1 net/ipv6/conf/all/forwarding=1CentOS7中配置
/usr/lib/sysctl.d/00-system.conf,并设置net.ipv4.ip_forward=1。
设置防火墙转发规则:
iptables -I FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
NAT
# SNAT: 将源内网地址映射到公网地址
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -o eth0 -j SNAT --to-source 192.168.1.146
# 动态SNAT: 动态将源内网地址映射到动态变化的公网地址
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -o eth0 -j MASQUERADE
# DNAT: 将目的公网地址+端口映射到内网地址+端口
iptables -t nat -I PREROUTING \
-d 192.168.1.146 -p tcp --dport 3389 -j DNAT --to-destination 10.1.0.6:3389
DNAT在理论上只配置DNAT规则即可,但是如果在测试时无法正常DNAT,可以尝试增加对应的SNAT,此处按照配置SNAT的流程进行。
如果没有动态SNAT的需求,没有必要使用
MASQUERADE,因为SNAT更加高效。
本机端口转发
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080 # INPUT
iptables -t nat -A OUTPUT -p tcp --dport 80 -j REDIRECT --to-port 8080 # LOCAL
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 1186 -j DNAT --to-destination 127.0.0.1:1186
将访问本机80端口的请求重定向到本机的8080端口(修改目标端口)。
如果要从外部访问本机localhost监听的端口,可使用DNAT将地址和端口映射到本机换回地址和相应端口(需要开启本地换回路由:sysctl -w net.ipv4.conf.<ifname>.route_localnet=1 ,ifname为输入网络接口)。
路由表
获取路由信息
ip {r|route}
#default via 192.168.178.2 dev ens32 proto static
#default via 172.28.76.234 dev ens33 scope link metric 1
#172.28.76.0/24 dev ens33 proto kernel scope link src 172.28.76.234
#192.168.178.0/24 dev ens32 proto kernel scope link src 192.168.178.40
表格形式:
route [-nee]
#Destination Gateway Genmask Flags Metric ... Iface
#0.0.0.0 192.168.178.2 0.0.0.0 UG 0 ... ens32
#0.0.0.0 172.28.76.234 0.0.0.0 UG 1 ... ens33
#172.28.76.0 0.0.0.0 255.255.255.0 U 0 ... ens33
#192.168.178.0 0.0.0.0 255.255.255.0 U 0 ... ens32
netstat -r -n
#Kernel IP routing table
#Destination Gateway Genmask Flags MSS Window irtt Iface
#0.0.0.0 172.28.76.234 0.0.0.0 UG 0 0 0 ens33
#172.28.76.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
ee:显示更多信息。
-
路由类型
主机路由:掩码为32位; 网络路由: 默认路由:目标为
0.0.0.0/0.0.0.0。当主机不能在路由表中查找到目标主机的IP地址或网络路由时,数据包就被发送到默认路由(默认网关)上。 -
Flags说明:
U(route is up):活动路由;H(target is host):目的地址是主机;G(use gateway): 需要网关转发; -
Metric:路由距离,到达指定网络所需的中转数。 -
Iface: 当前路由会使用哪个接口来发送数据
配置静态路由
route [add|del] [-net | -host] target [netmask Nm] [gw Gw] [[dev] If]
route add default gw 192.168.1.1
route add -net 5.0.0.0 netmask 255.0.0.0 reject # 设置到指定网络为不可达
没有修改已有路由的命令(例如修改metric),需要先删除再添加一条。
上述命令仅在当前运行环境中有效,要永久保存需要将其添加至文件中。可直接在在/etc/rc.local中添加上述命令,则开机会自动添加静态路由,但如果开机状态下重启网络服务则不会再次执行/etc/rc.local,导致静态路由失效。
另一种方式是编辑/etc/sysconfig/static-routes(CentOS/Fedora),该文件由网络服务自动加载。
any -net 192.56.76.0 netmask 255.255.255.0 dev eth0
由
any开头的行将被解释为静态路由项。Ubuntu静态路由配置?
ip工具包用于替换route等管理工具:
ip route {add|del|change|append|replace} ROUTE
# ROUTE= [TYPE] NETWORK/MASK [via [FAMILY] GW_IP] [dev DEVICE] [weight NUM]
ip route add default via 192.168.1.1 dev eth0 # 设置默认路由
TYPE:路由类型,包括unicast,mulitcast,broadcast,nat,local,...;
FAMILY:协议族: inet,inet6,mpls,bridge,link;
本地网络代理
可配置系统范围(/etc/environment)或用户范围(~/.bashrc或~/.profile)。
export http_proxy="http://USERNAME:PASSWORD@proxy.server.net:port/"
export https_proxy="http://proxy.server.net:port/"
export ftp_proxy="http://proxy.server.net:port/"
export no_proxy="localhost, 127.0.0.1, 192.168.178.4" #*
*:no_proxy不支持通配符,如果要写一个网段,只能逐个地址列出。no_proxy主要用于匹配域名后缀,而非IP地址(前缀)。
如果是系统范围代理,还需设置/etc/sudoers.d/proxy,避免环境变量被覆盖。
Defaults env_keep+="http_proxy https_proxy no_proxy"
网络服务
systemctl restart networking
常用网络服务
远程访问
X-Window
https://wiki.ubuntu.org.cn/%E7%90%86%E8%A7%A3_Xwindow
安全
内核强制访问控制
Both SELinux and AppArmor supports the Type Enforcement security model, which is a type of mandatory access control, based on rules where subjects (processes or users) are allowed to access objects (files, directories, sockets, etc.).
Implementing Mandatory Access Control with SELinux or AppArmor in Linux (tecmint.com)
Security Enhanced Linux
SELinux支持更强的访问控制。
查看SELinux状态:
getenforce
sestatus -v
临时关闭(设置成permissive模式,仅产生日志不进行控制):
sudo setenforce 0 # setenforce 1 => enforcing mode
永久关闭:
# sudo vi /etc/selinux/config
SELINUX=disabled # SELINUX=enforcing|permissive|disabled
SELinux策略
查看boolean策略状态:
getsebool -a [se_boolean_entry]
设置boolean策略:
setsebool -PV se_bool_entry value # (1|true|on,0|false|off)
Apparmor
AppArmor是与SELinux类似的一个访问控制系统,通过它你可以指定程序可以读、写或运行哪些文件,是否可以打开网络端口等。
linux内核强制访问控制--Apparmor - 运维之路 (361way.com)
AppArmor与SELinux - 运维之路 (361way.com)
数字证书
安装证书
系统信任证书目录位于/usr/local/share/ca-certificates。将证书文件置于该目录下,并将权限设置为644。
sudo apt install ca-certificates
sudo update ca-certificates # needs super user privilege
生成证书和私钥
OpenSSL是一个非常有用的开源命令行工具包,可用于 X.509 证书,证书签名请求(CSRs)和加密密钥。
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365
openssl x509 -in cert.pem -text -noout # 查看证书结构信息
key.pem为私钥;cert.pem为证书(包含公钥);生成签名过程设置的密码是在使用密钥的时候使用。使用私钥和证书需要输入制作时设置的密码。
详细步骤
Create an RSA Keypair:
sudo apt install openssl
openssl genrsa -des3 -passout pass:PASSWORD -out keypair.key 2048
Extract the Private Key:
openssl rsa -passin pass:PASSWORD -in keypair.key -out private.key
Creating a “Certificate Signing Request” or CSR File:
openssl req -new -key private.key -out service.csr
Creating the Certificate “.crt” File:
openssl x509 -req -days 365 -in service.csr -signkey private.key -out service.crt
https://www.rosehosting.com/blog/how-to-generate-a-self-signed-ssl-certificate-on-linux/
https://www.linux.com/tutorials/creating-self-signed-ssl-certificates-apache-linux/
SSL/TLS
权限管理
用户管理
创建用户
useradd -m -c "FULL NAME" -g GROUP USERNAME # [lowlevel]
adduser --home DIR --shell SHELL --ingroup GROUP USERNAME
adduser在Debian系发行版上重新封装了底层useradd命令,其他发行版上是useradd的别名。以下均为useradd选项。有效用户名模式:
[a-z_][a-z0-9_-]*[$]?,长度不超过32。
-c "COMMENT":通常用于设置用户名全称;
-s,--shell SHELL用户的登录shell程序,/etc/default/useradd#SHELL(chsh)。
用户目录
-b,--base-dir BASE_DIR:用户主目录的根目录路径,默认值为/etc/default/useradd#HOME=/home;-d,--home-dir HOME_DIR:用户主目录路径,默认值为$BASE_DIR/USERNAME;- 使用
-m,--create-home保证创建用户目录;-M,--no-create-home不创建用户目录(通常用于运行系统服务的非登录用户);
用户组
-g,--gid GROUP:用户的初始登录组(primary group:ID或名称,必须存在)。 如果未指定该选项,默认(/etc/login.defs#USERGROUPS_ENAB=yes)会自动创建与用户名同名的组(等效于指定-U,--create-user-group选项);如果USERGROUPS_ENAB=no,则新用户的主要组设置为/etc/default/useradd#GROUP=100。-G,--groups groupname[,...]:将用户添加至组(supplementary groups);
账户和密码有效性
-f,--inactive DAYS:密码过期后账户被禁用前的天数。-e,--expiredate YYYY-MM-DD:账户失效(禁用)日期,默认值为/etc/default/useradd#EXPIRE=''(不失效);
修改用户
使用usermod修改用户属性(多数属性对应的选项与useradd相同)。
usermod -a,--append -G GROUPNAME # 将用户添加到supplementary groups
usermod -l,--login NAME # 修改登录名
usermod -m,--move-home -d,--home HOME # (移动)修改用户主目录
设置账户有效期限
usermod -e,--expiredate YYYY-MM-DD/N/-1 USER # 设置失效日期*
chage -E,--expiredate YYYY-MM-DD/N/-1 USER
*:N表示自1970年1月1日的天数。
此外,账户密码失效后账户也会处于失效状态。
设置和更新密码
创建用户时默认禁用密码。使用passwd设置和更新密码(root账号可修改普通用户的密码,用户忘记密码可通过root帐号使用passwd指令来处理即可)。
passwd username
usermod -p,--password ENCRYPT_PASSWORD
passwd -d,--delete # 删除(置空)用户密码
如果
root帐号忘记了,可以进入单人维护模式,此时系统会给予提供root权限的bash接口,再用passwd修改密码;或者利用Live CD开机后挂载根目录去修改/etc/shadow,将root的密码删除,重新开机后再用passwd设置新密码。
密码有效期配置
passwd -e,--expire # 立即使用户密码失效, 用户必须在下次登录时重设密码
passwd -x,--maxdays DAYS USER #->chage -M 密码有效期天数(99999/-1)*
passwd -i,--inactive DAYS USER #->chage -I 密码失效后禁用账户前的天数(never)
passwd -n,--mindays DAYS USER #->chage -m 两次修改密码之间至少相隔的天数(0)
passwd -w,--warndays DAYS USER #->chage -W 需要修改密码前向发送警告的天数(7)
*:chage的长选项与passwd对应长选项一致。
显示密码状态:
passwd -S <user> # 使用-a代替<user>查看所有用户的密码状态。
# gary P 06/02/2022 0 99999 7 -1
chage -l <user>
# Last password change : Jun 02, 2022
# Password expires : never
# Password inactive : never
# Account expires : never
# Minimum number of days between password change : 0
# Maximum number of days between password change : 99999
# Number of days of warning before password expires : 7
删除用户
userdel -f $USER # deluser [Debian]
rm -rf /home/$USER
查看用户信息
查系统中的用户信息:
/etc/passwd # User account information.
/etc/shadow # Secure user account information. [read by root only]
查看当前登录的所有用户:
w
# 09:42:35 up 26 min, 3 users, load average: 0.18, 0.12, 0.09
#USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
#root pts/0 172.28.76.41 09:17 3.00s 0.13s 0.03s w
#root pts/1 172.28.76.239 09:19 22:45 0.02s 0.02s -bash
who显示的信息没有w完整。who可以显示系统引导终端(tty1)。
查看指定用户信息:
id $USER
# uid=1000(gary) gid=1000(gary) groups=1000(gary),...(secondary groups)
groups $USER # 查看用户所属组
username=$(whoami) # return user name
sudo whoami # -> root
组管理
groupadd groupname
groupdel groupname
addgroup [options] [--gid ID] group
sudo usermod -g groupname username # change user's primary group
sudo usermod -a -G group[,...] username # add user to a secondary group
adduser user group # add user to grpup
If you omit the
-aoption, the user will be removed from any groups not listed after the-Goption.
sudo gpasswd -d username groupname # Remove a User From a Group
查看组信息
/etc/group # Group account information.
/etc/gshadow # Secure group account information.
访问权限控制
访问权限
修改用户访问文件的权限:
chmod [ugoa][+-=][rwxXstugo],... FILE ...
chmod OCTAL-MODE FILE ...
ugoa分别代表文件所有用户,文件同组用户,其他用户和所有用户(省略则默认为a,umask?);+-=表示增加、删除和设置权限。
权限模式:rwxXst中的一个或多个,或ugo中的一个
| 标识 | 说明 | 标识 | 说明 | 标识 | 说明 |
|---|---|---|---|---|---|
r | 读文件 | w | 写文件 | x | 访问/执行 |
s | 设置用户或组 | t | 限制删除 | X | * |
u | 授予所有者权限 | g | 授予组用户权限 | o | 授予其他组权限 |
*:X表示仅当目标为目录或已经具有其他用户执行权限时,才设置该目标的访问/执行权限。
OCTAL-MODE为1~4数字(取值范围0~7,3bit),第一位代表(设置用户ID,设置组ID和限制删除),其余三位数字分别代表ugo对应的rwx权限。
Ownership
获取对象的所有者信息:
ls -l /opt/360es/ | awk '{print $3,$4}' # 根据字段位置确定
ls -l /opt/360es/ | sed -n '2,$p' | awk '{printf "user=%s,group=%s\n",$3,$4}'
stat /path/file --format="user=%U group=%G"
从外部(互联网)获取的文件(档案),其所有者信息非本机用户,因此导致本机用户无法正常访问文件,所以需要修改文件的所有者/组。
chown -hR owner[:group] FILE
chgrp
--dereference:影响符号链接指向的文件而非符号链接;-h,--no-dereference相反;--from=CURRENT_OWNER:CURRENT_GROUP:仅当文件的当前属性匹配才进行修改;--reference=RFILE:使用RFILE的属性作为修改后的属性;-R:递归修改。符号链接指向的文件夹的遍历规则根据以下选项决定:
-H:遍历命令行参数为符号链接锁指向的文件夹;-L:遍历所有符号链接指向的文件夹;-P:步遍历符号链接指向的文件夹(默认)。
提升权限
切换登录用户
su - username # switch user
不支持切换到非登录用户。
以管理员身份运行
sudo \
-u, --user=user \ # 指定用户执行输入的命令
-i,--login \ # 使用指定用户登录shell
[command] # 运行命令(未指定则切换终端用户)
当前多数发行版默认禁用root账户,并以安装系统期间创建的账户作为管理员。管理员需要使用sudo命令并提供密码以暂时获得root账户权限(使用sudo命令创建的文件其所属用户和组为root)。将其他用户加入sudo用户组使其具有运行sudo的权限。如果要恢复root账户(不推荐),为其设置密码:
sudo passwd root
帮助文档
Linux Manual
- 可执行程序和Shell命令;
- 系统调用函数文档;
- 库函数文档;
- 特殊设备文件(通常位于
/dev); - 系统内置文件格式和规范(如
/etc/passwd); - 游戏;
- 其他,如
man(7); - 系统管理命令(管理员使用);
- 内核过程(非标准)。
急救模式
emergency mode
进入急救模式
-
GRUB系统选择界面按
e进入启动配置项编辑模式;linux16 /vmlinuz-.... # 添加rd.break -
按
Ctrl+X进入急救模式。
修复磁盘
修复XFS文件系统
由于突然断电,导致XFS文件系统数据损坏。
ls -l /dev/mapper # 找到dm-0对应的挂载点并卸载设备
umount /dev/mapper/centos-root
xfs_repair -L /dev/mapper/centos-root # 修复该设备
init 6 # 成功修复后重启设备
参考资料
Linux配置和管理
文件管理
在Linux/UNIX中,所有的对象都被视为文件,包括普通文件、目录、设备、套接字。
目录路径
pwd # Print Working Directory
dirname filename # parent directory
basename filename #
pwd列出正在工作的目录,用于显示你当前所处的目录名。pwd命令总是返回你当前所处的目录的完全路径名。dirname返回查询路径的父目录(从文件路径中截取)。basename仅返回文件的名称。
readlink和realpath解析文件的绝对路径,跟踪解析所有符号链接。
readlink -e \ # 解析过程中的所有目标必须存在 => realpath -e filename
-f \ # 除最终目标外所有目标必须存在 => realpath filename
-m \ # 允许目标不存在 => realpath -m filename
FILENAME
切换目录
cd [dir_name] # 切换工作目录(Change Directory)
chroot [OPTION] NEWROOT [COMMAND [ARG]...] # 切换命令运行的根目录
不带任何参数时,将把你送回自己的用户主目录中(等效于
cd ~)。..表示父目录。登录完成后,工作目录为用户主目录。
创建目录
在每一个新的子目录中,均包含两个标准的项目:.代表当前目录和..代表父目录。
mkdir -m,--mode=MODE -p dir_name
install [OPTIONS] -d dir1 dir2 ... # 创建目录并设置权限
-m:可用来创建一个带有特定权限的子目录(chmod声明方式)。-p:父目录不存在的情况下首先创建父目录,忽略已存在目录(默认报错)。
删除目录
rmdir -p dir_name ... # -p 一次删除多个目录
dir_name不能为当前工作目录(即要在父目录中删除子目录)。应该拥有被删除目录的写该目录必须为空目录(即只包含.和..,否则使用rm -rf dir_name)。
显示目录中的项目
列表显示
ls [options] [dir_name]
文件过滤选项
-a:显示所有文件(包括以.开头的文件(夹)),-A仅忽略.和..;
-R:递归显示所有子目录的内容;
-d:只显示目录条目的信息;
文件信息选项
-l:列表显示目录中文件的详细信息,与其他排序方式组合使用时则显示相应的排序字段;-g与-l相似但不显示文件所有者,-o不显示用户组;
文件类型信息:
-表示普通文件(f);d目录文件;b块设备文件例如磁盘;c字符设备文件,p命名管道(FIFO) ;l符号链接;s套接字(socket);
--author:显示文件创建者;
-n:显示数字形式的用户和用户组ID;
-i:inode序号将列在第一列;
--time-STYLE:时间显示格式,包括:full-iso(2020-03-07 15:07:15.542112573 +0800)、long-iso(2020-03-07 17:34)、iso(03-07 15:07)、locale(Mar 7 15:07)或+FORMAT;
--full-time:显示完整时间,等价于-l --time-style=full-iso;
-h:显示更加友好的文件长度信息(1K 234M 2G,等价--human-readable);
-s:显示文件占用的磁盘容量;
--block-size=SIZE:K,M,G,T,P,E,Z,Y (powers of 1024)或 KB,MB,... (powers of 1000)
排序选项
--sort=WORD:WORD=none(-U),size(-S),time(-t),version(-v),extension(-X),未声明排序选项时,默认按文件名排序。-c:按ctime(指文件的inode信息被改变的时间)排序;-u:按访问时间排序;-t:按修改时间排序,优先级低于-c和-u;
-r:反向排序;
查看目录树
tree -L <n> path # not built-in
-L <n>:搜索深度;-l:跟踪符号链接;
文件信息
获取文件的信息:
stat <path/to/file> -c,--format,--printf=FORMAT \
-f,--file-system # 显示文件所在文件系统信息而非文件信息
格式参数FORMAT可包含多个格式声明以及普通字符,--printf还可使用"\"转义字符;
| 格式 | 内容 | 格式 | 内容 | 格式 | 内容 | 格式 | 内容 | 格式 | 内容 |
|---|---|---|---|---|---|---|---|---|---|
%n | 文件名 | %F | 文件类型 | %g | group id | %y | 修改时间 | %a | 八进制访问权限 |
%N | "文件名" | %s | file bytes | %G | group name | %Y | 修改时间戳 | %A | 字母访问权限 |
%h | 硬链接数 | %m | 挂载点 | %u | owner id | %w | 创建时间 | %x | 访问时间 |
%i | inode数 | %C | SELinux | %U | owner name | %W | 创建时间戳 | %X | 访问时间戳 |
除stat外,还可以使用date获取文件修改时间:
date -r <filename> [+"%Y%m%d"]
获取文件类型:
file <path/to/file> \
-i,--mime \ # => --mime-type + --mime encoding
-z,--uncompress \ # 尝试解压压缩文件并查看其中内容
修改文件属性
touch可以用于修改文件访问时间。
touch filename
touch -d "2 hours ago" filename
普通文件
移动
如果源文件/目录与目标文件/目录同名,则用源文件/目录替换同名目标文件/目录的内容;否则,将源文件/目录移动到目标目录中;此时,目标目录必须存在,不会首先创建目录。
mv [-f] file_path /path/newname
如果源与目标所在路径相同,
mv等效于重命名。
批量重命名
将文件名中已知的部分内容替换为新的内容,其余部分(使用通配符表示)不变。
rename 's/pattern/replace/' FILES # sed style
rename pattern replace FILES
pattern为Perl正则表达式,文件名FILES支持通配符(?*.txt)。
使用需注意,原始的
rename不会检查已有文件而直接覆盖。
复制
cp [-raf] file_path /path/filecopy # -a 保留原属性
cp的文件创建行为与mv相同。
安装
install支持设置目标文件的权限和属性(==不支持文件夹(递归)复制==):
-
-m,--mode=MODE:设置访问权限; -
-g,--group=GROUP,-o,--owner=OWNER:设置所属关系(chgrp,chown),代替当前进程的默认值; -
-p, --preserve-timestamps:保留文件的访问/修改时间;
install [OPTION] -D [-T] SOURCE DEST # single-file to file
-D:(递归)创建目标文件的父目录(mkdir -p),未指定该选项则不会自动创建目录;
install [OPTION] SOURCE... DIRECTORY # single to dir
install [OPTION] -t DIRECTORY SOURCE...# multiple to dir (--target-directory)
-b,--suffix=BACKUP:备份选项以及备份目标文件夹;
删除文件
rm [-rf] file # can use wildcard
使用
-rf递归删除非空文件夹。
文件链接
硬链接(hard link):是对原文件的引用(引用同一个inode,在inode中计数),与原文件等价(即拥有相同访问权限)。删除硬链接将减小inode计数,到inode计数为0时删除文件。
符号链接(symbolic/soft link):保存到目标文件(夹)的路径(或相对路径),访问符号链接将跳转到目标文件(夹)。符号链接是一个独立的文件(具有相应的inode节点),因此具有独立的文件权限。删除原文件后,符号链接失效。
创建链接
ln -s /file/path /symbol/path # symbolic link
ln /file/path /symbol/path # hard link file
ln -d /dir/path /symbol/path # hard link 目录(不一定支持)
# -f,--force 移除已有文件链接
符号链接的目标可以是任意内容(创建的时候不做检查合法性),符号链接支持跨文件系统。硬链接的目标必须存在且仅支持在同一设备的同一文件系统。
访问链接
==文件链接解引用时,相对路径的父目录为文件链接所在目录==,解析符号链接目标时是递归式解析。
工作目录路径:如果切换工作目录到符号链接指向的目录,则工作目录路径为符号链接的路径而非目标目录的真实路径(比较pwd和realpath的输出结果),向上跳转(..)会返回符号链接所在目录。
在Linux中创建的符号链接在Windows中仍然能访问(WSL),但Windows不做递归解析,仅以当前工作目录路径为参考解析符号链接,因此使用相对路径的多级符号链接解析会出错。
临时文件
在指定目录下(默认为/tmp)创建临时文件并输出文件路径。
tempfile --directory PATH # [Debian]
mktemp -p PATH # [Fedora-coreutils]
--directory # 创建目录而非文件
查找文件
which <command>
command -V <command>
从系统环境变量中查找文件并返回绝对路径。
查找目录中的文件
find [-HLP][-D debugopts][-Olevel][start_dir...][expression]
start_dir表示查找路径,可以使用绝对路径,也可以使用相对路径,可以同时指定多个目录;如果没有指定,则默认为当前目录。==默认输出信息为查找到的文件夹和文件信息,并包含从查找目录开始的完整路径信息。==
选项(Option)
选项控制find访问文件系统的行为。
-H,-L和-P(默认)控制处理符号链接的行为。
-P表示不解析任何符号链接;-H表示除了命令行提供的文件名外,不解析其他符号链接。如果符号链接不能被解析,则返回符号连接本身的信息;-L表示在可能的情况下解析符号链接,反之返回符号链接自身的信息。(-followdeprecated)
-D debugopts:输出诊断信息。
-Olevel:查询优化。默认首先执行基于文件名的表达式(-name,-regex等);其次执行-type或-xtype的表达式(通过readdir()读取文件类型)。
读取上述选项之后,检查后续参数是否为文件/路径,直到以-、(、!开始的参数(也可以使用--声明选项参数的结束)。剩余参数为控制搜索行为的表达式。
表达式(Expression)
表达式用于控制如何匹配文件以及对匹配文件的操作。表达式可以包含以下内容:
Tests:测试文件属性,返回true|false;Actions:对匹配结果执行操作,根据操作结果返回true|false;如果表达式没有包含操作,则默认为-print;Global options:全局选项,总是返回true;Positional options:仅影响其后的测试或操作,总是返回true;Operator:将表达式中多个内容连接起来:-o(逻辑OR)、-a(逻辑AND);表达式内容之间默认使用-a连接;可以使用()声明优先级。
全局选项
-d,-depth:先处理文件夹中的内容,再处理文件夹本身;-maxdepth,-mindepth LEVEL:指定搜索的层级,0表示起始点本身;-mount, -xdev:不搜索挂载的其他文件系统目录;-help,--help,--version:帮助、版本信息。
位置选项
-
-daystart:计算时间时从今天开始,而非24小时前算起。影响其后的测试条件-amin,-cmin,-mmin,-atime,-ctime和-mtime。 -
-regextype TYPE:默认为emacs,包括:awk,egrep,grep,sed等。-regextype egrep在CentOS 7 上不支持{}。
测试条件
| 表达式 | 说明 |
|---|---|
-name PATTERN | 查找==文件名==匹配PATTERN的文件,可以使用通配符*,?,[]。 |
-path PATTERN | ==从搜索路径开始的完整文件名(非绝对路径)==与PATTERN进行匹配( -wholename)。 |
-regex PATTERN | 使用正则表达式匹配文件。文件名以./开头的==完整相对路径==,注意在正则表达式前添加 .*以匹配前缀; |
-atime [+-]N -ctime [+-]N -mtime [+-]N | 判断最近访问(-a),状态变化(-c),修改(-m)时间:如果参数为 N,表示时间在N天之内(0表示0~24小时,1表示24~48小时,…) |
-amin [+-]N | 时间单位为min(类似地-cmin,-mmin) |
-anewer FILE | 测试最近访问时间是否比FILE更近(-cnewer,-newer)。 |
-used [+-]N | 在文件状态改变N天(+N,-N)之内文件被访问过。 |
-empty | 测试文件或文件夹是否为空。 |
-size n[u] | 文件大小:单位u=cwbkMG: |
-fstype TYPE | 测试文件所在的文件系统的类型是否为TYPE。 |
-uid [+-]N | 文件的用户ID(组ID-gid)是否为N(或+N,-N)。 |
-user NAME | 文件的用户名(组名-group)是否为NAME(允许使用ID)。 |
-nouser | 文件的用户ID(组ID-nogroup)没有对应的用户(组)。 |
-lname PATTERN | 符号链接所指向的文件的文件名是否与PATTERN匹配。 |
-perm pmode | 文件的权限是否与pmode匹配,pmode可以是符号或数字模式,例如:-perm 664。直接指定单项权限 -readable、-writable、-executable。 |
-type <c> | 文件类型: bcdpfls |
-xtype c | 除符号链接以外,与-type作用一致; |
-inum [+-]N | rarely useful. |
-samefile NAME | 文件与NAME为同一个文件。 |
-links [+-]N | File has n hard links. |
匹配文件名的测试命令前添加
i(例如-iname)为忽略大小写版本。 通配符需要使用引号包围以防被shell展开。 参数如果为+N,则表示大于N,如果为-N则表示小于N。
运算符
| 运算符 | 表达式 |
|---|---|
() | (EXPR) |
! -not | !EXPR –not EXPR |
-a -and | EXPR1 –a EXPR2 EXPR1 –and EXPR2 |
-o -or | EXPR1 –o EXPR2 EXPR1 –or EXPR2 |
, | EXPR1, EXPR2 |
动作
| 命令 | 说明 |
|---|---|
-print, -print0 | print0会在文件名结尾追加“null”。 |
-fprint FILE-fprint0 FILE | 打印完整文件名到FILE。如果文件不存在则创建文件; 如果存在,则文件内容被删除; 即使没有输出内容,该文件仍然会被创建。 |
-ls-fls FILE | 以ls -dils格式打印到标准输出。-fls输出到文件。 |
-printf FORMAT-fprintf FILE FORMAT | 位宽和精度说明类似于C语言的printf(man find)。 |
-execdir command-exec command | -execdir将其后直到;的所有内容视为command,同时将其中的“ {}”替换为查找结果的文件名。command中的特殊字符需要使用“\”或“'”以防被shell展开。 |
-execdir command {}+-exec command {}+ | 命令末尾的“{}”展开为匹配文件名称的列表; |
-okdir command-ok command | 询问用户是否执行命令 |
-delete | 删除成功返回真;如果失败,生成错误信息; |
查找文件示例
高亮find查找结果:
find ./ -name '*.tar.gz' | grep --color '.tar.gz'
打印查找到文件的详细信息。
find ./ -name '*.tar.gz' -exec ls -lh {} ';'
删除文件:
find . -maxdepth 1 -newer archive.tar.gz -execdir rm -rf {} ';'
在过滤文件中查找内容:
find ./ –name '*.cpp' –exec grep -Hn 'main' {} ';'
find ./ -name "*.log" | xargs grep –Hn 'ERROR'
grep与find同时使用时,默认不会输出文件名(添加-H选项),也不会高亮文本(使用--color选项)。
查找文件内容
使用grep查找具有给定内容和文件名的文件:
grep -rl 'main' --include='*.cpp' ./ # 输出匹配文件的文件名
grep -rn 'main' --include='*.cpp' ./ # 输出匹配行的行号和内容
硬件管理
查看硬件信息
sudo dmidecode -t,--type type_code|type_keyword
sudo dmidecode [options] | grep -A16 'System Information$' # 系统和主板信息
硬件类型(type_keyword)包括:bios, system, baseboard, chassis, processor, memory, cache, connector, slot。每种类型可能包括多个子类型(type_code)。
sudo lshw \ # list hardware [yum install lshw]
-class <hw_class> \ # class can be found using lshw -short
-{html|xml|json} \ # 输出格式
-short \ # device tree: 优先级高于输出格式
-businfo # showing bus information
硬件类型可通过lshw -short的输出获取,包括:system,bus,memory,processor,storage,input,display,disk,volume,network,power等。
其他工具:
hwinfo(默认未安装到系统);hardinfo(图形界面)。
CPU
lscpu # CPU信息概述
nproc # number of process unit
sudo lshw -C processor
cat /proc/cpuinfo # CPU details
sudo dmidecode --type processor # details
cpuid获取详细信息(未安装)。
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
# 8 Intel(R) Xeon(R) CPU E5410 @ 2.33GHz
## (CPU with 8 logical core)
cat /proc/cpuinfo | grep 'physical id' | uniq -c
# 4 physical id : 0
# 4 physical id : 1
### (2 physical CPU with 4-core)
内存
free -h -w # summary
cat /proc/meminfo # details
vmstat -s
sudo dmidecode -t memory # Memory Device
all tmpfs pages will be shown as “
Shmem” in/proc/meminfoand “Shared” infree(1).
磁盘信息
列出存储设备信息:
sudo fdisk -l [device_name] # 查看磁盘设备 => sudo parted /dev/sda print
lsblk # 列出块设备
sudo blkid /dev/sda
# /dev/sda: UUID="3255683f-53a2-4fdf-91cf-b4c1041e2a62" TYPE="ext4"
查看序列号:
udevadm info --query=all --name=/dev/sda | grep ID_SERIAL
hdparm -I /dev/sda # install hdparm
lshw -class disk # install lshw
smartctl -i /dev/sda # install smartmontools
位于磁盘阵列中的磁盘序列号不可见(系统读取的是RAID分配的ID)。
文件系统信息
列出系统支持的文件系统:
cat /proc/filesystems
exfat格式支持需要安装exfat-fuse和exfat-utils包;NTFS格式需要安装ntfs-3g包(CentOS)。
列出挂载的(文件或目录所在)文件系统信息。
df [-ahHkT] [目录或文件名]
# Filesystem Size Used Avail Use% Mounted on
# /dev/sdd 251G 1.6G 237G 1% /
# tmpfs 13G 252M 13G 2% /mnt/wsl
-hH:以合适的单位显示数据(1024进制,-H为1000进制),提高可读性;-i,--inodes:显示inode信息而非磁盘容量信息;-T,--print-type:==打印文件系统类型==,例如ext4、tmpfs等;-t,--type=TYPE:仅显示指定类型文件系统;-x,--exclude-type=TYPE排除指定类型;
列出文件或目录的磁盘占用量(disk usage):
du [-ahskm] 文件或目录名称
-c, --total;
-h, --human-readable;
-s, --summarize;
-d,--max-depth=N:显示最大路径深度;
磁盘管理
磁盘分区与格式化
注意:以下操作可能导致数据丢失,应事先做好数据备份!!!
使用fdisk或parted操作文件分区表(fdisk -l查看磁盘信息):
sudo fdisk device_name # 操作分区表
# fdisk命令
# [F] 列出未分区的空闲空间 n 新增分区
# l 列出已知分区类型 t 更改分区类型
# p 打印分区表 d 删除分区
# [i] 打印选择的分区信息 v 验证分区表
# m 打印命令列表 g 创建GPT分区表
# o 创建DOS(MBR)分区表
# q 放弃更改并退出 w 保存分区更改
未添加
device_name时,列出系统内所有存储设备(/dev)的分区(partition)信息。GParted -- Live CD/USB/PXE/HD:With GParted you can resize, copy, and move partitions without data loss.
gparted是一款图形界面的分区工具。
更改正在使用的分区:首先删除分区(记录下分区表的起止位置),然后重新创建分区,并指定新的起止位置(注意不要和已有分区重叠)和分区类型,保存并退出(使用工具cloud-utils.growpart)。分区表更改不会立即生效,因此可以修改正在使用的分区,重启机器或使用partprobe [/dev/sda]或kpartx [/dev/sda]命令重新载入新的分区表。如果是普通卷,则需要使用resize2fs更新文件系统容量,如果是LVM物理卷,则使用pvresize更新(resize2fs无法操作LVM物理卷)。
磁盘格式化
新建分区后,需要对分区进行格式化设置文件系统才能进行挂载使用。整个磁盘也可以不进行分区直接格式化。
mkfs -t <fstype> /dev/sda
mkfs.<fstype> options /dev/sda # 格式化分区/dev/sda1
fstype文件系统类型,例如 ext4, xfs, btrfs , ZFS等(系统有支持才会生效)。在选择文件系统类型时,如无特殊要求,选择系统中已有分区类型(默认类型),确保兼容和稳定性。
mke2fs:创建ext2/ext3/ext4文件系统,对应命令:mkfs.ext2|3|4。ext文件系统的i-node节点总数在文件系统创建后不能改变,调整文件系统容量将按比例调整inode数量(bytes-per-inode)。
Linux File System Types Explained, Which One Should You Use (linuxiac.com)
数据恢复
TestDisk Step By Step - CGSecurity
How to recover partitions and data using Linux - Tutorial (dedoimedo.com)
How to recover lost partition using Linux (simplified.guide)
TestDisk is powerful free data recovery software! It was primarily designed to help recover lost partitions and/or make non-booting disks bootable again when these symptoms are caused by faulty software: certain types of viruses or human error (such as accidentally deleting a Partition Table).
==Even though the old partition table was destroyed, it was just a pointer to the start and end addresses of the actual data, so to speak.==
The new and definite CloneZilla tutorial (dedoimedo.com)
磁盘检验
fsck [-t <fstype>] [-ACay] /dev/sda
用来检查和维护不一致的文件系统。若系统掉电或磁盘发生问题,可利用
fsck命令对文件系统进行检查。
磁盘挂载与卸除
mount -t <fstype> -L <label> -o <opts> -n /dev/dev_name /mnt/mnt_name
mount --move /mnt/userdirs /home # move mount point of a filesystem
umount [-fn] [/dev/dev_name | /mnt/mnt_name]
findmnt --types <fstype> # 查看已挂载的文件系统
如果挂载的目标路径下有数据,则数据会被隐藏;卸载磁盘后可恢复访问原有数据1。
挂载NTFS文件系统:
yum install fuse ntfs-3g # centos
mount -t ntfs-3g /dev/sdb1 /mnt/win
如果卸除设备时出现设备忙的错误,可查看正在使用该设备的进程有哪些并尝试关闭进程。
挂载CD
mount -t auto [-r] /dev/cdrom /mnt/cdrom # 挂载CD
挂载可移动介质
挂载磁盘的目标文件夹必须存在,挂载的磁盘应该已经使用支持的文件系统格式化。可移动磁盘设备标识类似于内置磁盘(使用fdisk -l或parted -l查看)。
自动挂载
-
将挂载命令写入开机启动脚本;
-
配置
systemd.mount单元文件;[Mount] What=/dev/sda Where=/data Type=ext4 Options= -
使用
/etc/fstab配置,systemd会将其中的内容转换为单元文件;# DevicePath MountPoint FS Type Mount Options Dump CheckOrder /dev/sdba /data ext4 - 0 1 LABEL=t-home2 /home ext4 defaults,auto_da_alloc 0 2 SERVER:PATH
逻辑卷管理LVM
Logical Volume Management, gives users the power to pool and abstract the physical layout of component storage devices, to gather existing storage devices into groups and allocate logical units from the combined space as needed.
LVM存储信息
显示系统中的LVM兼容卷,包括可转换为LVM物理卷(Physical Volumns)的存储设备:
sudo lvmdiskscan \
-l # 仅显示LVM物理卷, ==> pvscan, pvs, pvdisplay
显示系统中的物理卷组(Virtual Group)信息:
sudo vgscan # => vgs, vgdisplay
显示系统中的逻辑卷(Logical Volumn):(逻辑卷设备路径、VG Name、PV)
sudo lvscan # lvs, lvdisplay [-m]
管理LVM存储
从原始磁盘创建LVM物理卷,注意将磁盘上原有数据备份,加入LVM管理后将覆盖原有数据。
A header is written to storage devices to mark them as free to use as LVM components.
sudo pvcreate /dev/sda /dev/sdb ...
pvresize /dev/sda1
pvresize --setphysicalvolumesize 40G /dev/sda1 # shrink
如果物理磁盘分区通过
fdisk进行了扩展,可以通过pvresize更新LVM物理卷的容量。也可以将空余磁盘空间创建为一个新的物理分区,设置为LVM PV并加入LVM虚拟卷组。
将物理卷创建为卷组,通常只需要一个卷组并在此之上创建虚拟卷。
sudo vgcreate volume_group_name /dev/sda /dev/sdb ...
向卷组中增加物理卷:
sudo vgextend volume_group_name /dev/sdb
创建虚拟卷,创建后需要对虚拟卷进行格式化。
sudo lvcreate -L 10G -n VolumnName LVMVolGroup # 绝对容量
sudo lvcreate -l 100%FREE -n VolumnName2 LVMVolGroup # 相对容量
虚拟卷的底层物理磁盘分配方案支持线性(
linear,默认)、striped(RAID 0)、raid1等。
虚拟卷容量调整,使用-L选项增加/减少绝对容量,或用-l选项增加相对容量。
sudo lvresize -L +5G --resizefs LVMVolGroup/vol_name
sudo lvresize -l +100%FREE --resizefs LVMVolGroup/vol_name
XFS filesystem shrinking is unsupported.
resize2fsis for ext filesystems.
RAID
Hardware RAID
在BIOS中配置磁盘的RAID选项,参考产品用户手册。
Software RAID
- How To Use LVM To Manage Storage Devices on Ubuntu 18.04.
- How To Create RAID Arrays with mdadm on Ubuntu 18.04 | DigitalOcean.
显示设备
查看显示设备:
lspci | grep -i vga # <== install pciutils
sudo lshow [-short] -c CLASS # list hardware, CLASS for class/description
sudo lspci -v -s 03:00.0
安装Nvidia显卡驱动
rl=$(uname -r)
yum install gcc gcc-c++ make kernel-devel-$rl kernel-headers-$rl
apt install gcc make linux-headers-$rl [libglvnd]
注意内核开发包的版本需要于系统内核版本完全一致,否则无法成功安装驱动程序。
检查nouveau模块是否加载,已加载则先禁用
lsmod | grep nouveau
# edit: /usr/lib/modprobe.d/blacklist-nouveau.conf # [Ubuntu]/etc/modprobe.d/*
blacklist nouveau
options nouveau modeset=0
dracut -force # 重启系统,使内核模块配置生效 [Ubuntu]update-initramfs -u
安装驱动程序:
./NVIDIA-Linux-x86_64-390.46.run --no-opengl-files --ui=none --no-questions --accept-license
# edit: /etc/rc.d/rc.local
nvidia-smi -pm 1 # GPU驱动模式设置为常驻内存
nvidia-smi # nvidia proprietary driver => watch -n 1 nvidia-smi
Ubuntu桌面版显卡驱动
ubuntu-drivers devices # 列出可用驱动
sudo ubuntu-drivers autoinstall # 安装推荐驱动
sudo apt install nvidia-driver-440 # 安装指定名称驱动
安装完成后重启。
网络设备配置管理
系统配置
系统信息
操作系统
uname [options]
| 选项 | 说明 |
|---|---|
-a, --all | 包括以下系统信息: |
-s, --kernel-name | 内核名称(Linux) |
-n, --nodename | 网络主机名称(使用hostnamectl设置) |
-r, --kernel-release | 内核发行版本(3.10.0-1160.24.1.el7.x86_64) |
-v, --kernel-version | 内核版本(#1 SMP Thu Apr 8 19:51:47 UTC 2021) |
-m, --machine | 机器的硬件架构名称(x86_64) |
-o, --operating-system | 操作系统(GNU/Linux) |
-i,--hardware-platform和-p, --processor(不可移植),通常与-m输出一致。
系统版本信息
cat /etc/issue # [Ubuntu]
cat /etc/lsb-release # [Ubuntu]
cat /etc/os-release # [Ubuntu|CentOS]
lsb_release -crid # 包含版本号详细信息,CentOS需要安装redhat-lsb-core
rpm -qa centos-release # [Fedora/CentOS]
rpm -qi basesystem # [Fedora/CentOS](包含安装日期)
操作系统安装时间
通过文件系统创建时间判断操作系统安装时间:
tune2fs -l $(df / | awk '$6 ~ /\// {print $1}') | grep 'Filesystem created:' # -> dumpe2fs
rpm -qi setup|setuptool|basesystem # [Fedora/CentOS]
tune2fs是设置ext2/ext3/ext4文件系统参数的工具。
主机名
hostnamectl # 显示主机信息(主机名、系统名、架构...)
hostnamectl set-hostname 'gfs.server.03.net' # 设置主机名
sysctl -n kernel.hostname
某些服务(例如Cloudera)需要检测主机名与域名(FQDN)的一致性,为了避免产生警告,将主机名设置为域名。
WSL-Ubuntu中
hostnamectl不可用。
域名映射
sudo vi /etc/hosts
# change <hosts> file
192.168.137.11 new-host-name
可能需要重启。
日期时间
显示时间
date # Sun May 16 13:07:15 CST 2021
date +'%H' # %T %c %F
date -d,--date='7:00:00' +'%s' # parse a date and display it
date --date='@2147483647' # parse a timestamp (seconds)
date -r,--reference=FILE # 显示文件最近修改时间
默认显示当前时间,使用
-d,--date指定要显示的时间的字符串;字符串缺少的部分设为当前时间。空字符串表示当天开始时间。
A list of date command field descriptors
获取日期字段
| 格式声明 | 含义 | 格式声明 | 含义 | 格式声明 | 含义 |
|---|---|---|---|---|---|
%Y | YYYY | %m | mm | %d | dd |
%H | HH(00-23) | %M | MM(00-59) | %S | SS |
%s | 时间戳(秒) | %3N | 毫秒 | %N | 纳秒 |
%f | 微秒 |
格式化日期字段
%后可额外设置表示填充的字符:-不填充;_填充空格;0填充0(默认);^使用大写字母;#(尽可能)改变字符大小写。
| 格式 | 含义 | 格式 | 含义 | 格式 | 含义 |
|---|---|---|---|---|---|
%c | locale's datetime | %x | locale' date | %X | locale's time |
%D | %m/%d/%y | %F | %Y-%m-%d | ||
%T | %H:%M:%S | %r | 12:11:04 PM | %X | 23:13:48(locale) |
%y | yy | %e | %_d | ||
%I | hh(01-12) | %k | _H(0-23) | %l | _h |
%j | ddd: day of year | %w | day of week(0-6) 0 is Sunday | %u | day of week(1-7) 1 is Monday |
%W | week of year(00-53), Monday first | %U | week of year(00-53), Sunday first | %V | week of year(01-53), Monday first |
%p | AM/PM | %P | am/pm | %q | quater 00-04 |
%z | 时区-0400 | %:z | -04:00 | %::z | -04:00:00 |
%Z | 时区类型EDT/CST |
设置时间:
timedatectl [status] # 显示系统的日期、时间和时区等信息
timedatectl set-time "2012-10-30 18:17:16" # <== timedatectl set-ntp no
date -u,--utc=MMDDhhmmCCYY.ss # print or set datetime
date -s,--set=STRING
timedatectl set-timezone <Asia/Shanghai>
timedatectl list-timezones # 列出已知时区
系统启动时间:
uptime
系统引导配置
引导配置文件:
/etc/default/grub
/etc/grub/grub.cfg # auto-generated by grub-update
选择默认用户界面:
sudo systemctl set-default multiuser.target # terminal shell
sudo systemctl set-default graphical.target # GUI
添加开机启动项
-
编辑
/etc/rc.local脚本(兼容性目的),并设定可执行权限(sudo chmod 755)适合较短的命令
-
将启动项的脚本添加到
/etc/init.d目录下,并设置可执行权限ln -s task.sh /etc/init.d/task sudo chmod +x /etc/init.d/taskcd /etc/init.d sudo update-rc.d task defaults 95 # execute order sudo update-rc.d -f task remove # remove the task如果使用需要开机通过
chkconfig设置开机启动的服务,则脚本开头应该包含以下信息:#!/bin/bash # chkconfig: 2345 20 80 # description: Saves and restores system entropy pool \ # for higher quality random number generation.chkconfig: 2345 20 80表示这个服务在运行级别2345下运行,20表示开机启动优先权重,80表示关闭优先权重。也可以手动调用
chkconfig添加开机启动服务chkconfig --add my-service实际上
chkconfig --add命令是将/etc/init.d中的启动脚本软连接到/etc/rc.d/rcx.d(rc0.d ... rc6.d)0-6个运行级别对应相应的目录,都是位于/etc/init.d中脚本的软连接。/etc/init.d/中的脚本,可以通过命令:service service_name [start/stop]启动或者关闭(添加到启动脚本中实现自启动,见方法1或)。
-
将启动任务的脚本放到目录
/etc/profile.d下,系统启动后将自动执行其中的shell脚本。 -
注册为
systemd托管的服务,在系统启动时运行。
内核配置
内核配置项对应文件系统中/proc/sys目录。
读取内核配置项:配置项具有分级结构(对应上述目录树),名称以.或/分隔。
sysctl -n variable # 输出value, 默认输出 variable = value
sysctl -a -pattern PATTERN # 打印所有配置项(某些配置项需要管理员权限才可访问)
-n,--values:仅打印配置项的值;-N,--names:仅打印配置项的名称;
sysctl -q,--quiet \ # 不将设置的值回显到屏幕
-w variable=value ...
加载内核配置:
sysctl -p,--load [FILE] # 默认加载/etc/sysctl.conf
sysctl --system # 加载系统中所有配置文件
文件系统
最大打开文件数量限制
ulimit -n 8192 # 默认1024, 临时修改
编辑/etc/security/limits.conf,永久修改:
# domain type item value
* soft nofile 16384 # soft limits of Number of Open file
* hard nofile 16384 # hard limits
linux - Fix with ulimit -n 8192 - Stack Overflow
inotify文件监控数量限制
文件监控数量限制如果设置太小,容易触发inotify watch limit reached错误。临时设置运行时参数:
sudo sysctl fs.inotify.max_user_watches=524288 # 8192 default
永久修改配置(/etc/sysctl.conf)并运行sysctl -p重新加载。
fs.inotify.max_user_watches=524288
字体
用户可将字体安装在/usr/share/fonts目录下,使用fc-list(需要安装fontconfig)可查看系统中可用字体。
fc-list # "FONT_PATH: FONT_FAMILY:style=STYLE"
fc-list : family # 仅输出字体名
fc-list :lang=zh family style file spacing # "PATH: FAMILY:style=STYLE:spacing=SPACE"
日志
大部分的发行版都内置使用syslog系统日志,常见的日志一般存放在 /var/log 中。
常见的系统日志
| 日志名称 | 记录信息 |
|---|---|
alternatives.log | 系统的一些更新替代信息记录 |
apport.log | 应用程序崩溃信息记录 |
apt/history.log | 使用apt安装卸载软件的信息记录 |
apt/term.log | 使用apt时的具体操作,如package的下载、打开等 |
auth.log | 登录认证的信息记录 |
boot.log | 系统启动时的程序服务的日志信息 |
Consolekit/history | 控制台的信息记录 |
dist-upgrade | dist-upgrade 这种更新方式的信息记录 |
dmesg | 启动时,显示屏幕上内核缓冲信息,与硬件有关的信息 |
dpkg.log | dpkg 命令管理包的日志 |
faillog | 用户登录失败详细信息记录 |
fontconfig.log | 与字体配置有关的信息记录 |
kern.log | 内核产生的信息记录,在自己修改内核时有很大帮助 |
lastlog | 用户的最近一次信息记录。 |
wtmp | 登录信息的记录。 |
btmp | 远程登录信息记录。 |
syslog | 系统信息记录 |
日志一般都是文本文件,可使用 less、cat、more 等工具查看。 wtmp、lastlog 是二进制文件,需要使用last和lastlog工具来提取其中的信息。
rsyslog
systemd-journal
查看日志
筛选日志:
journalctl --system|user # 查看系统/当前用户日志
journalctl -u,--unit=UNIT
-t,--identifier=STRING # 查看指定syslog标识的日志
-S,--since=DATE # '2022-05-01 [12:00:00]'
-U,--until=DATE
追踪日志更新:
journalctl -f,--follow
-n,--lines=NUM # 显示日志数量
日志存储设置
journalctl --disk-usage
journalctl --rotate
journalctl --vacuum-time=2d # 清理超过2天的日志
journalctl --vacuum-size=100M # 清理超过100M的日志
journalctl --vacuum-files=5 # 清理超过数量的日志
systemctl kill --kill-who=main --signal=SIGUSR2 systemd-journald.service
rm -rf /run/log/journal/*
rm -rf /var/log/journal/*
systemctl restart systemd-journald.service
journalctl --verify
终端命令记录
histroy # 显示历史记录: cat ~/.bash_history
history -c # 删除历史记录:rm ~/.bash_history
用户登录信息
who /var/log/wtmp # 查看用户登录历史记录
last [username] [-f /var/log/btmp] # 默认读取/var/log/wtmp
lastlog [-u username] [-t 5] [-b 60]
浏览器(桌面环境)
ls -l ~/.opera/cach4
ls -l ~/.mozilla/firefox/*.default/cache
日志清理
logrotate是Linux自带的文本日志处理工具,可进行切割、打包、压缩等处理。其配置文件位于/etc/logrotate.conf以及/etc/logrotate.d/。
/tmp/dask/*log {
rotate 7 # 指定日志文件删除之前转储的次数,0直接删除,-1不删除
daily # 指定转储周期:hourly,daily,weekly,monthly, yearly
minsize 1M # 文件大于1M时才会进行轮转
maxsize 100M # 文件大于100M时强制进行轮转(即使还未到轮换周期)
size 100M # 指定轮转大小: k/M/G (与轮转周期互斥)
minage 10 # 文件创建超过10天才进行轮转
maxage 100 # 移除创建超过100天的已轮转的文件
missingok # 忽略不存在的日志文件/nomissingok
ifempty # 即使日志文件为空文件也做轮转/noifempty
dateext # 使用当期日期作为命名格式,默认值取决于轮换周期
dateformat -%Y%m%d%H #
nocompress #
create [[mode] owner group] # 新日志文件的权限, 默认和原来的文件相同的权限
copytruncate # 复制并清空日志文件(override create)*
prerotate
script
endscript
postrotate # postrotate脚本
/sbin/nginx -s reload
endscript # postrotate脚本结束
}
*:适用于日志输出程序无法获取日志文件打开状态的情况;但可能造成少量日志丢失。
logrotate通过ctrontab调度,默认每天运行一次(除非任务指定更小的周期)。可手动立即执行:
logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf
软件管理
各发行版提供的软件仓库与软件管理方案。本章介绍,当前主要的跨发行版软件管理解决方案。
Snap
Snap将软件及其依赖打包到独立环境,它的运行环境是容器化的沙箱,从而避免各发行版兼容性问题并保证一定的安全性。
安装snap
Ubuntu/Debian系统预装snapd,使用snap version查看。
sudo yum install snapd # [epel-release]
sudo systemctl enable snapd # 安装后需要手动启动
snapd无需持续在后台运行,仅在执行snap命令时被调用运行。
安装和升级snap软件
snap find "media player"
sudo snapd install 'appname'
sudo snap refresh 'appname' # update
snap list # 列出已安装的软件的简要信息
snap info 'pkgname'| 'pkgname.snap' # 查看[已安装]软件包信息
--color=auto|always|never
--verbose
安装classic类型的软件,此类软件不受沙盒限制:
sudo ln -s /var/lib/snapd/snap /snap
sudo snap install julia --classic
下载snap包和离线安装:
snap donwload 'package name'
--target-directory=.
--channel=5.x/stable
snap ack path/to/package_name.assert
snap install path/to/package_name.snap
--dangerous # 如果没有执行ack,则需要该选项才可以安装
snap安装目录
/snap # -> Debian based
#/snap/bin - Symlinks to snap applications.
#/snap/<snapname>/<revision> - Mountpoint for snap content.
#/snap/<snapname>/current - Symlink to current revision, if enabled.
/var/lib/snapd/snap # -> RHEL based
snapying用的配置文件/数据目录
/var/snap/"snap_name"
移除snap软件
snap remove "snap_name"
--purge # 不保存软件的数据
软件的所有数据将自动备份(automatic snapshopt)以便后续恢复。
备份和恢复
snap save 'appname' --users "all" # 创建用户、系统和配置数据的快照。
snap saved --id ID
snap forget "id" "appname"
snap restore "id" "snap_name" --users "all" # 使用指定快照恢复其中的用户、系统和配置数据。
snap export-snapshot "id" /path/to/export
snap import-snapshot /path/to/import
不同版本(
epoch)之间不能恢复数据。
回退到上个版本并恢复数据(不包括共享数据):
sudo snap revert 'appname' --revision ID
snap配置
snap get "appname"
snap set "appname" key1=value1 key2.subkey=value2
snap unset "appname" key1 key2
管理snap应用的运行状态
查看服务运行状态和日志:
snap services <appaname> # 查看APP提供的服务的运行状态
# => systemctl status snap.<appname>.<appserivce>
snap logs -f <appname>.<servicename>
启动应用软件
如果安装未生成启动软件的快捷方式,可通过命令启动。
snap run <appcommand> # 命令可通过snap info查看
管理软件服务
可使用snap或systemctl来控制服务运行。snap服务默认会在失效后自动重启。
sudo snap start/restart/stop <appname>
sudo snap restart <appname>.<servicename>
sudo systemctl restart snap.<appname>.<servicename>
AppImage
AppImage比较简单易用,不需要安装额外的工具,整个软件都在一个文件里,下载后可以直接运行。里面有个SquashFS的文件系统,运行的时候会挂在到一个临时的地方,里面有所有只读的文件,包括可执行文件、库文件、静态数据等。除此之外都和普通的软件运行环境是一样的。
Similar projects · AppImage/AppImageKit Wiki (github.com)
Flatpak
linuxbrew
安装发行版软件仓库缺失的软件。
安装linuxbrew
SRC_URL='https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh'
/bin/bash -c "$(curl -fsSL $SRC_URL)"
官方安装脚本下载以及官方源(github)的速度都比较慢,推荐使用代理进行安装。或者使用国内镜像进行安装和后续软件安装,配置镜像源相关环境变量:
MIRROR="https://mirrors.tuna.tsinghua.edu.cn"
export HOMEBREW_BREW_GIT_REMOTE="$MIRROR/git/homebrew/brew.git"
export HOMEBREW_CORE_GIT_REMOTE="$MIRROR/git/homebrew/homebrew-core.git"
export HOMEBREW_BOTTLE_DOMAIN="$MIRROR/homebrew-bottles"
执行以下命令下载安装脚本并执行安装:
git clone --depth=1 $MIRROR/git/homebrew/install.git brew-install
bash brew-install/install.sh
rm -rf brew-install
安装完成后根据输出提示,将初始化命令加入shell配置文件。然后,根据输出信息,安装建议的编译环境,用于brew进行本地编译打包。
brew的默认安装位置为/home/linuxbrew/.linuxbrew/。
安装软件
brew install pkgname
查找软件可在brew.sh查找,或通过命令查找:
brew search pkgname
进程管理
查看进程
jobs [-lnprs] [jobspec ...] or jobs -x command [args]
# Display status of jobs.
查看并过滤进程
ps -e|-A \ # 查看所有进程
-T|t \ # 当前终端上的所有进程
-x \ # 没有关联控制终端(tty)的进程
-r \ # 正在运行的进程
-a \ # 排除关联tty的所有进程或session leader
-d \ # 除了session leader外的所有进程
-N \ # --deselect 反选
H # 将线程视作进程显示
查找进程
ps -C cmd1,cmd2,... \ # 根据命令名comm筛选
-p 123,124,... \ # --pid,-q 根据进程号筛选
-ppid 10 \ # 根据父进程号筛选
-U EUID \ # effective user ID (EUID) or name
-u RUID \ # real user ID (RUID) or name
-C匹配进程命令起始子串,不包括路径与特殊字符'/-';无法匹配到僵尸进程。
pgrep -f PATTERN \ # --full 匹配完整进程名
-x \ # --exact 完整匹配命令行
-v \ # --inverse 反向匹配
-g PGID,... \ # --pgroup 匹配进程组ID
-G GID,... \ # --group 匹配real group IDs
-i \ # --ignore-case
-n \ # --newest 选择最近启动的进程
-o \ # --oldest
-P PPID,... \ # --parent 匹配父进程ID
-s SID,... \ # --sessioin 匹配会话ID
-u ID,... \ # --euid 匹配effective user ID
-U ID,... \ # --uid 匹配real user ID
-t TTY,... \ # --terminal 匹配终端
--ns PID --nslist ns,...
pgrep -l \ # --list-name 列出PID和进程名
-a \ # --list-full 列出PID和命令行
-c \ # --count 输出匹配计数
ps -C和pgrep无法匹配到僵尸进程<defunct>,可以利用ps -ef的输出内容进行匹配。
ps -ef | grep defunct | grep -v grep
输出进程信息
ps -f|-F \ # 完全信息,包括命令行(-F包括附加信息)
-l \ # 显示更多信息,可以与-f|-F组合使用
ps -o pid,tid,... \ # 指定输出的字段
-o '%cpu %mem' \ # 在单个参数中指定输出的字段
-o class \ # 可指定多个输出选项
-o wchan:14 \ # 指定输出字段的位宽
-o comm= \ # 该字段不输出字段名(当所有字段都不输出字段名,省略表头)
pid | ==进程编号== | ppid | 父进程编号 |
| `lwp | spid | tid` | 轻量线程ID |
| `pgid | prp` | 进程组编号 | tgid |
| `%cpu | pcpu` | CPU占用率(小数) | c |
| `cputime | time` | ==累计CPU占用时长== | pri |
start_time | ==进程启动时间/日期== | start | 进程启动时间 |
etime | ==进程启动后经过的时间== | etimes | 单位为秒 |
| `%mem | pmem` | 内存占用比例 | `vsz |
sz | 进程镜像大小 | size | 需要的交换空间大小 |
| `args | cmd | command` | 命令行参数 |
| `sess | session | sid` | 会话编号 |
| `tty | tt | tname` | 控制终端 |
| `fgid | fsgid` | 文件访问组编号 | `fgroup |
| `state | s` | stat |
进程关联用户信息:
| real | effective | saved | ||
|---|---|---|---|---|
| 用户ID | uid | ruid | `euid | uid` |
| 用户标识 | user | ruser | `euser | user |
| 组 | gid | rgid | `egid | gid` |
| 组标识 | group | rgroup | `group | egroup` |
需要systemd支持的字段:
machine:进程分配到的VM或容器名;ouid:进程会话所有者;lsession:进程的登录会话标识;其他:
psr:为进程分配的处理器,sgi_p:进程当前运行的处理器;
cgroup:控制组;
class|cls|policy:进程调度类型;sched;
blocked|sig_block|sigmask:阻止的信号(32或64位掩码);caught|sig_catch|sigcatch:捕获的信号(32或64位掩码);ignored|sig_ignore, sigignore:忽略的信号(32或64位掩码);pending|sig:挂起的信号(32或64位掩码);
f|flag|flags:进程标识。
进程树
ps f \ # 显示为进程树
-H \ # 显示进程层级(缩进)
pstree -U \ # --unicode 使用UTF-8画线符号(默认)表示树
-A \ # --ascii 使用ASCII画线符号
-h \ # --highlight-all 重点显示当前进程及其祖先进程
-H PID \ # --highlight-pid 重点显示给定进程及其祖先进程
-g \ # --show-pgids 显示进程组标识
-p \ # --show-pids 显示进程标识
-s \ # --show-parents 显示父进程标识
-n \ # --numeric-sort 根据PID对输出排序
-l \ # --long 不截断长行
PID \ # 进程树根节点的PID,默认为1(init/systemd)
USER \ # 显示指定用户的进程树
任务状态
top -b -n N \ # 非交互模式,刷新N次
-o FIELD[-+] \ # 按字段排序:"+"=>DESC; "-"=>ASC
-O # 不执行命令,仅输出可用的排序字段
top命令显示的是你的程序占用的cpu的总数,也就是说如果你是4核cpu那么cpu最高占用率可达400%,top里显示的是把所有使用率加起来。在
top的运行环境中按下键盘的1,显示每个cpu核的状态。
交互环境命令
排序:M->Mem, N->PID, P->%cpu, T->TIME+。
watch
watch "ps -ef | grep nginx | grep -v grep" \
-d,--difference \ # 高亮两次更新的差别
-n,--interval seconds \ # 更新周期
watch的命令参数可包含多条命令,输出结果包含每条命令的输出内容。
查看进程打开资源
打开的文件可能是常规文件、文件夹、库、流、网络文件(套接字、NFS文件)等。
lsof # list open files
lsof /bin/bash
#COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
#mysqld_sa 1597 mysql txt REG 253,0 960472 738200678 /usr/bin/bash
#sh 11503 es txt REG 253,0 960472 738200678 /usr/bin/bash
#bash 16538 yarn txt REG 253,0 960472 738200678 /usr/bin/bash
#bash 63028 yarn txt REG 253,0 960472 738200678 /usr/bin/bash
需要安装
lsof。
fuser [options] file/fs # identify processes using files or sockets
fuser /bin/bash # 返回使用文件的进程号与使用方式(后缀)
# /usr/bin/bash: 1597e 11503e 13039e 63028e 63030e 64836e
进程控制
创建进程
nohup &
终止进程
如果父进程在子进程之后终止,但子进程终止时父进程没有进行最后的回收工作,子进程残留的数据结构称为僵尸进程。
终止单个进程
kill向进程发送信号使进程终止,默认信号是-TERM。
kill [-s sigspec | -n signum | -sigspec] pid ...
kill -l [sigspec]
sigspec表示信号名,signum表示信号值。
| 选项 | 说明 |
|---|---|
-l, --list [sigspec] | 列出可发送的信号,如果给出信号名(值), 则将信号名(值)转换为信号值(名) |
-s sigspec -n signum -sigspec | 指定发送的信号,例如:-ABRT,-ALRM,-HUP,-KILL,-STOP,-SEGV, -TERM,-TRAP。 |
终止匹配名称的进程
killall [-s sigspec | -sigspec] [-e] [-I] [-g] [-i] [-u user] [-v] [-w] name ...
killall –l
选项
| 选项 | 说明 |
|---|---|
-l, --list | 列出可发送的信号 |
-s,--signal sigspec -sigspec | 指定发送的信号 |
-e, --exact | 匹配名称 |
-I, --ignore--case | 匹配名称时忽略大小写 |
-g, --process-group | 向进程所属的进程组发送信号 |
-i, --interactive | 在杀死进程前交互式确认 |
-q, --quiet | 如果没有进程被杀死,不输出信息 |
-u, --user | 仅杀死属于给定用户的进程 |
-v, --verbose | 报告信号是否成功发送 |
-w, --wait | 等待所有被杀死的进程结束 |
终止匹配的进程
pkill [options] --signal SIGNAL PATTERN
终止图形进程
xkill
出现“x”标志的鼠标,点击需要中止的程序即可。
清理进程
wait -f -n [CH_PID,,,] # 清理子进程
服务
systemd
systemd(system and service manager),init system (PID=12, started by the kernel, to bring up userspace) managing userspace services. (fast and efficient boot-up)
sysvinit
/sbin/init -> ../lib/systemd/systemd
system instance: system.conf and the files in system.conf.d
user instance: user.conf and the files in user.conf.d
"units" of 11 different types. states: active/inactive/activating/decativating/failed;
Units are named as their configuration files
Processes systemd spawns are placed in individual Linux control groups named after the unit which they belong to in the private systemd hierarchy. /sys/fs/cgroup/systemd/
transaction system: before executing a requested operation, systemd will verify that it makes sense, fixing it if possible, and only failing if it really cannot work.
-
Service:管理控制守护进程及其相关进程;
-
Socket:用于提前创建套接字资源。
-
Target:group units(使用
Requires,After)。default.target whose job is to activate on-boot services and other on-boot units by pulling them in via dependencies.
graphical.target/multi-user.target -
Device:expose kernel devices
-
Mount/Swap:mount points/memory swap(类似于
mount命令) -
Automount
-
Timer:定时触发其他单元;
-
Path:
-
Slice:分组资源管理;
-
Scope:管理外部进程
信号处理:
SIGTERM:重启systemd system manager;
SIGINT(Ctrl+Alt+Del):If this signal is received more than 7 times per 2s, an immediate reboot is triggered.
SIGHUP:systemctl daemon-reload
管理器交互命令可以用于管理服务。systemctl are used to give commands to the manager.
systemctl --version # 查看版本和加载模块
systemctl {start|stop|reload|restart|kill} <service>
systemctl {enable|unmask} --now <service> # 启用并立即启动服务
systemctl {disable|mask} <service> # 禁用/屏蔽服务
systemctl status <service>
systemctl show <service>
systemctl list-unit-files --type {service|target} # 列出已安装单元
systemctl list-units --type {...} # 列出已加载单元
systemctl daemon-reload # 重新加载服务单元配置(不影响现有服务)
此外,
systemdctl还可用于控制系统systemctl {poweroff|reboot[arg]|suspend|hibernate}
service命令也用用管理服务,在Ubuntu中其实际调用的是systemctl。
Systemd 入门教程:命令篇 - 阮一峰的网络日志 (ruanyifeng.com)
管理配置文件
A unit file is a plain text ini-style file that encodes information about a service, socket, device, mount point, automount point, swap file or partition, start-up target, watched file system path, timer controlled and supervised by
systemd, resource management slice or group of externally created processes.
服务配置文件(.ini格式)位于/lib/systemd/system(/lib->/usr/lib);systemctl enable会在/etc/systemd/system目录(某些服务也直接置于*.target子目录下)创建一个指向服务单元的链接(也可直接在该目录下储存配置文件或链接其他位置的配置文件,但无法使用enable/disable命令)。
pkg-config systemd --variable=systemdsystemunitdir:系统服务配置文件路径;
pkg-config systemd --variable=systemduserunitdir;不同于其他
systemctl命令,==必须以管理员权限执行==systemctl enable|disable以创建或删除服务配置文件的链接。
配置文件名由管理单元名和类型名组成,如unit-name[@instance-name].service(服务模板:在配置文件中通过"%i"引用实例名称)。文件格式:key=value,=前后空格被忽略;#或;为注释行;\用于换行拼接(连接时添加空格,换行符后的注释行被忽略,随后的内容将继续被拼接);
boolean:1,yes,true,on,0,no,false,off
time:默认为秒,"2min 200ms", s", "min", "h", "d", "w", "ms", "us".
multiple settings form a list, empty value "resets"
[Unit]
Description=The descript of the service
Documentation=http://,https://,file:,info:,man:,
Wants/Requires/Requisite/BindsTo/PartOf/Upholds=
Conflicts=
Before/After=
After=network.target ... nginx.service mongod.service
[Install]
Alias=sshd.service # create symlinks
WantedBy/RequiredBy=multi-user.target
Unit和Install是所有单元类型配置文件共有的部分。
foo.service.d/*.conf:在该目录下添加配置文件覆盖该服务的默认配置。
单元参数说明:
- 依赖声明:==不影响启动顺序(可并行启动)==
Wants=:one-time effect=> [Install] WantedBy=:foo.service.wants/Requires=:=> [Install] RequiredBy=Requisite=:=> RequisiteOf=BindsTo=:=> BoundBy=PartOf=:=> ConsistsOf=
UpHolds=:continuous effect,
Conflicts=:=> ConflictedBy=
- 启动顺序
Before=, After=OnFailure=,OnSuccess=
Specifiers available in unit files: https://www.freedesktop.org/software/systemd/man/systemd.unit.html#Specifiers
服务单元参数说明:
[Service]
Type=simple/exec/forking/oneshot/dbus/notify/idle
ExecStartPre=/usr/local/nginx/sbin/nginx -t -c conf/nginx.conf # 启动前的检测
ExecStart=/usr/local/nginx/sbin/nginx -c conf/nginx.conf # 启动服务的命令
ExecStartPost=/bin/sleep 1 # 启动服务后的命令
ExecReload=/usr/local/nginx/sbin/nginx -s reload # reload命令
ExecStop=/bin/kill -s TERM $MAINPID # stop命令
StandardOutput=syslog
User=service_user
Environment="VAR=VALUE" "VAR2=VALUE2"
Environment="VAR3=VALUE3" # 可声明多行环境变量
KillMode=control-group, mixed, process, none
KillSignal=SIGTERM
-
Type=:服务类型simple(默认):认为ExecStart=配置的进程为服务主进程;当服务主进程被创建后(服务执行程序还未运行)即认为服务启动(即使随后服务启动过程出错,systemctl start仍然报告启动成功)并继续启动后续服务。exec:等待服务进程被执行后才认为服务启动(systemd219版本不支持,245版本支持该类型);notify:类似于exec,但服务启动后需要发送一个通知消息,服务管理在收到通知消息后,认为服务启动完成并继续启动后续服务;设置NotifyAccess=以访问systemd提供的通知套接字。
oneshot:类似于simple,服务主进程退出后即认为服务启动完成,通常用于设置==开机启动任务==;RemainAfterExit=yes用于表示服务在启动完成后进入active状态,否则,由于没有配置持续运行的进程,服务状态将变为deactivating或dead状态。dbus:类似于simple,服务获得一个D-Bus总线名(BusName=)后,即认为完成启动;默认依赖dbus.socket;idle:类似于simple,但会延迟服务程序的执行时间(最多5s),直到活动任务被执行。
forking:ExecStart=配置的进程会调用fork()来启动后台服务(Unix服务启动协议)。父进程在后台进程启动完成后退出,服务管理认为服务启动完成。==如果服务自身可以输出主进程ID到文件,则推荐使用PIDFile=选项==,使得systemd能够可靠地识别服务主进程从而判断服务状态 。如果未设置PIDFile,则默认GuessMainPID=yes以尝试获取服务主进程ID,但如果服务存在多个守护进程,则不一定准确。
对于长期运行服务,首先推荐使用简单且快速的
Type=simlpe。但如果需要获取服务启动状态,或其他服务依赖此服务,则推荐使用notify或dbus;如果服务程序并不支持notify或dbus,则使用forking。对于==仅启动时执行一次==的服务,则可以使用oneshot。 -
-
RootDirectory=(chroot) -
WorkingDirectory= -
User=, Group= -
进程资源限制
ulimit:LimitCPU/LimitFSIZE/LimitNOFILE...; -
CPU调度策略:
CPUSchedulingPolicy/CPUAffinity... -
Environment=,EnvironmentFile=:定义传递给服务的环境变量(定义不支持Shell变量替换,重复定义将替换之前的定义);$PATH:默认值/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin;$MAINPID:服务主进程ID,用于管理服务控制进程的关闭和重载;$PIDFILE:通过PIDFile=传递,用于服务守护进程写入进程ID;
-
StandardInput=,StandardOutput=,StandardError=:inherit, null, tty, kmsg, journal+console, kmsg+console, socket or fd:name.journal:发送到journal,输出日志通过journalctl查看syslog:发送到系统的syslog服务和journal。file:path(v236+),append:path(v240+),truncate:path:输出到指定文件(219版本不支持,对于不支持的版本使用文件重定向标准输出)。
systemd管理的服务产生的日志可通过journalctl查看。journalctl [FIELD=VALUE...] \ # 未添加匹配条件则返回所有日志 systemd.journal-fields --options -
SyslogIdentifier=,SyslogFacility=,SyslogLevel=
-
-
ExecStart=:服务启动命令。==除非是oneshot类型==,否则仅能给定一条命令。==命令必须以可执行程序的绝对路径开头==(对于其他Exec命令也一样)。systemd-path search-binaries-default:如果返回路径,则表示支持直接使用位于路径的命令名。命令参数支持环境变量替换:
${VARIABLE}始终解释为一个参数,$VARIABLE必须与命令行==其他内容使用空格分开==(否则不会展开),展开后会按空白分割为多个参数;支持Systemd定义的
%特殊变量。--opt1 $VARIABLE1 --opt2=${VARIABLE2} # --opt2=$VARIABLE3 无法完成变量替换命令中不能包含重定向(
<,<<,>,>>)、管道(|)和后台执行(&)等Shell语法。显式使用bash命令ExecStart=bash -c 'dmesg | tac'命令前缀:
-:记非零错误返回,但处理行为等效于命令成功执行;::不替换命令行环境变量;- "
+"以完整权限执行,不受用户和分组设置限制;
-
ExecStartPre=, ExecStartPost=:类似于ExecStart=:,分别在ExecStart=:前后执行,并可指定多条命令。ExecStart=仅在ExecStartPre=执行成功的情况下执行,否则服务启动失败(ExecStartPost=类似)。ExecStartPre=不应用于启动长期运行程序(ExecStartPre=启动进程所创建的子进程会在服务程序执行前被终止)。任何Exec*=命令执行失败或超时,则会跳转到执行ExecStopPost(跳过ExecStop=)。 -
ExecReload=:服务重新加载配置的一条或多条命令(语法类似于ExecStart=)。 -
ExecStop=,ExecStopPost=:停止服务的一条或多条命令。如果未指定,则向服务发送``KillSignal=或RestartKillSignal=`指定的信号以终止服务进程。 -
TimeoutSec=,RestartSec=,TimeoutStartSec=,TimeoutStopSec=服务启动/停止超时期限。 -
Restart=no|on-success|on-failure|on-abnormal|on-watchdog|on-abort|always -
SuccessExitStatus=TEMPFAIL 250 SIGKILL:成功退出状态,默认包括0,SIGHUP,SIGINT,SIGTERM和SIGPIPE。
systemd.service (www.freedesktop.org)
服务沙盒
以下选项用于屏蔽向服务进程暴露的系统资源(需要底层安全机制支持才开启,如ProtectSystem需要包含文件系统命名空间的内核)。
ProtectSystem=false|true|full|strict*
ProtectHome=false|true|read-only|tmpfs
PrivateTmp=false|true
*:strict,tmpfs在219版本(CentOS 7)不可用。
- [Mastering systemd: Securing and sandboxing applications and services | Enable Sysadmin (redhat.com)](https://www.redhat.com/sysadmin/mastering-systemd#:~:text=Systemd provides a significant number of security features,this option to full also makes %2Fetc read-only.)
- systemd.exec Sandboxing(www.freedesktop.org)
问题:
-
开启
ProtectSystem后无法对用户家目录进行写操作。如果使用普通用户运行服务,则不用担心该服务修改系统资源(无权限)。因此,可以关闭
ProctectSystem选项。也可尝试将服务的写入目录修改为其他位置,例如/tmp或/var(适用于以root运行的服务)。
挂载单元配置
[Mount]
What=/dev/DEVNAME
Where=/mnt/MOUNT_PATH
Type=fs_type
Options=
DirectoryMode=0755 # 自动创建挂载点
TimeoutSec=
# Check systemd.exec(5) and systemd.kill(5) for more settings.
定时单元器配置
[Timer]
OnActiveSec/OnUnitActiveSec= # 相对定时器(执行单元)上次触发时间设置定时器
OnUnitInactiveSec= # 相对定时器执行单元上次休眠时间设置定时器
OnCalendar= # systemd.time(7)
Unit= # 定时器超时后触发的单元名称
supervisor
Introduction — Supervisor 4.2.2 documentation (supervisord.org)
Supervisor is a client/server system that allows its users to control a number of processes on UNIX-like operating systems. It is not meant to be run as a substitute for
initas “process id 1”. Instead it is meant to be used to ==control processes related to a project or a customer==,
supervisordstarts processes as its subprocesses viafork/execand subprocesses don’t daemonize. It always knows the true up/down status of its children. If supervisord is started as root, it is possible to allow “normal” users to control (“stop”, “start”, and “restart” ) such processes.
client/server system
delegation: Supervisorctl allows a very limited form of access to the machine, essentially allowing users to see process status and control supervisord-controlled subprocesses by emitting “stop”, “start”, and “restart” commands from a simple shell or web UI.
/etc/supervisord.conf
supervisord -c conf_file
-n, --nodaemon
-q ,--childlogdir=PATH # must exist, for auto-mode child proocess
-k, --nocleanup # prevent removal of old AUTO process log files
supervisorctl -c conf_file
-i,--interactive # 启动交互式命令
-r,--history-file # 记录输入命令(realine模块可用)
ACTION args...
ACTION:
add/update NAME[:*]... # activate/update process/group config
remove NAME ... # deactivate process config
clear NAME ... # clear process log
pid [NAME] # get pid of supervisord/subprocess
reload # restart remote supervisord
reread # reload daemon's config without restart
start NAME[:*]... # start process/group (not reread configs)
restart NAME[:*]... # restart process/group (not reread configs)
status [NAME[:*]...] # 返回进程(组)状态
tail [-f] NAME [stdout|stderr] # 输出日志的最后部分
all用于参数中表示所有进程和分组。
supervisord as a system service
# supervisord service for systemd (CentOS 7.0+)
[Unit]
Description=Supervisor daemon
[Service]
Type=forking
ExecStart=/usr/bin/supervisord
ExecStop=/usr/bin/supervisorctl $OPTIONS shutdown
ExecReload=/usr/bin/supervisorctl $OPTIONS reload
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
supervisord
[supervisord]
logfile=$CWD/supervisord.log # (-l,--logfile=FILE)
logfile_maxbytes=50MB # rotate limit (-y,--logfile_maxbytes=BYTES)
logfile_backups=10 # number of rotates (-z,--logfile_backups=NUM)
loglevel=info # (-e,--loglevel=LEVEL)
pidfile=$CWD/supervisord.pid # (-j,--pidfile=FILE)
directory=$PWD # workdir of supervisord daemon (-d,--directory=PATH)
environment=KEY="val",KEY2="val2" # for all subprocess
信号处理:
SIGTERM/SIGINT/SIGQUIT:supervisord及其管理的子进程将会关闭。SIGHUP:关闭所有进程,重新加载配置,并重启所有进程。SIGUSR2:关闭并重新打开主日志以及子进程日志。
服务进程配置
[program:SERVICE_NAME]
command=/path/to/programname # relative is OK
user=gary # 启动进程的用户
numprocs=1
priority=999 # Lower priorities indicate programs that start first
autostart=true # start with supervisord
autorestart=unexpected # false, unexpected, or true
startsecs=1 # 0不检查是否进程在运行
startretries=3
exitcodes=0 # 正常退出代码(,分隔)
stopwaitsecs=10 # 进程停止等待时间(超时使用SIGKILL强制停止)
stopasgroup=false # 用于停止具有子进程的进程(如Flask调试模式)
stdout_logfile=AUTO # 进程的标准输出文件
stdout_logfile_maxbytes=50MB # 日志文件轮转大小
stdout_logfile_backups=10 # 日志轮转数量限制
stderr_logfile=AUTO # stderr_logfile_maxbytes/stderr_logfile_backups
stdout_syslog=10 # 使用进程名输出到syslog / stderr_syslog
redirect_stderr=false # 将进程的错误输出重定向到supervisord的输出
environment= # 传递给进程的环境变量
directory= # 进程运行的工作目录
服务进程本身不应该以守护进程模式运行。
自动重启:如果
autorestart=unexpected,则在非手动停止进程的情况下,如果进程退出代码非exitcodes列出的,则重启该进程。
AUTOlog files and their backups will be deleted when supervisord restarts.输出文件名为可包含变量
group_name,host_node_name,process_num,program_name和here的Python字符串表达式。
服务分组:同类型服务;
[group:foo]
programs=bar,baz
priority=999
supervisorctl访问supervisord
supervisorctl可访问本地(UNIX套接字)或远程的supervisord服务(TCP/IP套接字)。
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock # (-s,--serverurl URL)
# serverurl=http://127.0.0.1:9001
username=gary # (-u,--username NAME)
password=gang2019 # (-p,--password)
prompt=mysupervisor # 命令行提示符
使用Web访问supervisord
[inet_http_server]
port=0.0.0.0:9001
username=gary
password=gang2019 # or passord hash: {SHA}82ab876d1387bfafe46cc1c8a2ef074eae50cb1d
重启
supervisor(使用systemctl)。
XML-RPC接口
from xmlrpc.client import ServerProxy
server = ServerProxy('http://localhost:9001/RPC2')
server.supervisor.getState()
server.system.listMethods()
server.system.methodHelp('supervisor.shutdown')
子配置文件
[include]
files=/path/filename.conf /path/*.conf foo.conf config??.conf
XML-RPC API Documentation — Supervisor 4.2.2 documentation (supervisord.org)
Supervisor: A Process Control System — Supervisor 4.2.4 documentation (supervisord.org)
Process Monitoring and Events
Supervisor continually emits event notifications, and the subscribed listener will be notified.
provide a mechanism for code to be run (e.g. send an email, make an HTTP request, etc) when some condition related to subprocess state is met.
The event notification protocol is based on communication via a subprocess’ stdin and stdout.
Example Event Listener Implementation
服务管理程序对比
supervisord主要用于管理用户服务进程,systemd处理服务管理外,还支持系统中其他对象如外部设备、套接字、定时器等的管理。
systemd具有启动依赖管理控制功能,可以实现有依赖关系的一组对象的正确启动和运行管理;supervisord仅支持进程分组,无依赖解析功能。systemd具有完善的进程资源控制和系统调度策略设置,supervisor可实现较为简单的资源控制。
supervisord提供网络访问接口并有可用的Web访问UI,可方便普通用户实现进程管理;systemd需要管理权限执行管理控制功能。
superivord发布于2004年,systemd发布于2010年。systemd现在为多数Linux发行版的init程序,因此开箱即用。supervisord需要以Python库或发行版软件仓库软件的方式进行安装。
对于较为简单的服务进程配置管理,supervisord和systemd都能有效实现;对于有远程管理需求的场景,supervisord提供网络访问接口更适合。对于复杂的服务配置管控需求以及supervisor不支持的管控对象,使用systemd更加合适。
网络管理
网络管理工具
net-tools:包含arp, ifconfig, netstat, rarp, nameif and route。
ip:show/manipulate routing, network devices, interfaces and tunnels,代替net-tools。
NetworkManager:包含NetworkManager服务和命令行工具nmcli、nmtui等。
与使用
ip的功能相同,使用nmcli+NetworkManager将管理功能与用户交互分离。
networkd
NetworkManager
NetworkManager用于代替已有的配置工具ifconfig及其配置文件。NetworkManager作为systemd服务运行(服务的配置文件为/etc/NetworkManager/NetworkManager.conf)。
udev设备管理器发现系统新加入设备,通知NetworkManager通过D-Bus来检测和初始化配置网络设备实现即插即用(配置信息动态生成并存储于内存中)。
永久配置文件检查(如果未找到配置文件,则尝试从DHCP服务器获取配置信息):
-
etc/sysconfig/network-scripts/ifcfg-*:后向兼容ifconfig配置文件; -
/etc/NetworkManager/system-connections/:NetworkManager配置文件。
nmcli是NetworkManger的命令行工具(客户端),nmtui是对应的终端图形界面工具。
yum install NetworkManaget-tui # nmcli随NetworkManager安装
图形化配置接口:
nmtui edit <ifname> # in CentOS
在修改配置时,不要修改设备(
00:0C:29:BD:83:63 (ens32))
网络状态
主机名和域名
hostname可以读取主机的主机名、域名和对应的IP地址(/etc/hostname)。
-A:所有主机名;-s返回一个短主机名;-f返回长主机名;-I:所有IP地址;-i还首先读取IPv6地址;-d:DNS域名;
使用
hostnamectl设置主机名。
域名地址映射*
dig [@dns_server] domain_name
dig -x ip_addr # reverse lookup
nslookup <domain>
支持反向查询
nslookup <ipaddr>,但查询到的域名不是通常使用的域名,也可能查不到结果。
whois <ipaddr|domain> # sudo apt install whois
查询IP地址/域名==所有者==。
网络接口信息
nmcli # 代替ifconfig
netstat -i # 输出网络接口设备的统计信息;
-ie # => ifconfig
使用ip工具列出设备参数(type,mtu,qdisc,state,mode,qlen,mac):
ip link [show] [up|down] [dev eth0] [type bridge] [master br0] # 显示链路信息
ip address ... # 显示链路层以及网络地址信息
使用nmcli查看网络接口连接:
nmcli c[onnection] [show] --active # summary table
# NAME UUID TYPE DEVICE
# eth0 cb149a11-edae-3f8f-9af1-7dc541e1ac5d ethernet ens32
nmcli connection show <name/id> # interface details
设备未知的接口通常是由于配置文件存在错误。
查看网络设备信息:
nmcli d[evice] [show] # summary table
# DEVICE TYPE STATE CONNECTION
# ens33 ethernet connected ens33
# lo loopback unmanaged --
nmcli device show <device> # device details
网络通信状态信息
netstat -a # 列出tcp,udp和unix协议套接字连接(默认仅显示unix套接字连接) *
-{t|u} # 只列出TCP/UDP连接
-l # 只列出监听中的连接
-p # 列出进程ID和命令名
-e # 列出进程用户和进程文件的Inode编号
-n # 禁用对IP地址/端口的反向域名解析,加快查询速度
*:需要安装net-tools包。
示例:
sudo netstat -anp | grep ESTABLISHED # 打印active状态的连接
sudo netstat -anp | grep apache2 # 查看指定服务是否正常运行
通过访问套接字获取连接信息:
ss -n # 禁止解析服务名称
-r # 尝试解析地址端口信息
-a/l # 显示所有/监听套接字信息
-m # 显示套接字内存占用
-p # 显示使用套接字的进程
-e # 显示扩展信息
-i # 显示TCP内部信息
-s # 打印汇总信息
-N,--net=NSNAME # 切换网络命名空间
-f,--family=unix/inet/inet6/link/netlink/vsock
由于网络连接(套接字)是特殊文件,因此可以使用lsof查看(lsof用于列举进程打开的文件)。
lsof -i -P -n
-i [addr]:列出使用互联网地址的文件(套接字);地址格式
[46][protocol][@hostname|hostaddr][:service|port]
-U筛选使用UNIX套接字的进程。
-P:禁止将端口号解析为服务名;
-n:禁止将IP地址解析为主机名或域名。
网络协议统计信息
netstat -s
监控网络通信状态
iftop # apt|yum install iftop => 主机间通信速率
nload # apt|yum install nload => 网络接口通信统计
bmon # apt|yum install bmon => 系统带宽监控
nethogs # yum install nethogs => 进程通信统计
系统监控工具也可以监控网络通信状态的基本参数。
网络可达性检测
ping:is part of iputils package。
ping \ # ICMP ECHO_REQUEST
-4|6 \ # IPv4/IPv6
-c count \
-D # print timestamp before each line
-I interface # 设置源地址或源接口名称
tracepath:is part of iputils package.
tracepath -4|6 -n|b # n|b 仅打印IP地址/打印主机名和IP地址
网络设备链路管理
网络配置数据
系统中可能存在的网络设备和接口配置文件:
-
ifup/ifdown(/etc/network/interfaces) -
networkd[connection] id=br0_eno1 uuid=ccfcb8fa-5f16-4407-ae6c-1af6c9117265 type=bridge autoconnect=false interface-name=br0_eno1 permissions= timestamp=1650420144 [bridge] stp=false [ipv4] address1=172.28.76.22/24,172.28.76.234 dns=172.28.28.28;223.5.5.5; dns-priority=100 dns-search= method=manual [ipv6] addr-gen-mode=stable-privacy dns-priority=100 dns-search= method=link-local [proxy] -
ifconfig(etc/sysconfig/network-scripts/ifcfg-*)TYPE=Ethernet NAME=eth0 # 应该和配置文件后缀匹配 DEVICE=ens33 # 绑定的设备名 UUID=a016f249-6703-42eb-a207-e40f80de212f # 绑定的设备UUID HWADDR=84:16:f9:03:fd:85 # 绑定的设备MAC(old) IPADDR=192.168.2.203 PREFIX=24 # <-> NETMASK GATEWAY=192.168.178.2 DNS1=223.5.5.5 DNS2=8.8.8.8 ONBOOT=yes BOOTPROTO=static # dhcp|bootp|none|static -
NetworkManager(/etc/NetworkManager/system-connections)
netplan
netplan在系统启动早期将配置信息解析并提供给系统的网络管理服务(如NetworkManager)。
- 默认由
systemd-networkd管理网络设备,其他服务如NetworkManager可替代其功能。
netplan配置文件位于 /{lib,etc,run}/netplan/*.yaml:
- 对于不同目录下的同名配置文件,仅读取最高优先级目录下的文件(
/run>/etc>/lib); - 对于不同名文件,将按文件名字典顺序读取配置文件,并将新内容追加/覆盖已读取内容。
配置文件格式(YAML):
network: # 网络配置的根节点
renderer: networkd|NetworkManager # networking backend,
ethernets: # 设备分组, 如: ethernet, modem, wifi
ens33: # 设备ID
dhcp4: false
dhcp6: true
addresses:
- 192.168.0.200/24 # IPv4
lifetime: 0
label: "maas"
- "2001:1::1/64" # IPv6
gateway4: 192.168.0.1 #! deprecated
gateway6: "2001:4::1" #! deprecated
routes: # 静态路由*
- to: default # could be 0/0 or 0.0.0.0/0 optionally 默认路由
via: 192.168.0.1 # 默认网关
metric: 100
on-link: true
- to: default # could be ::/0 optionally
via: cf02:de:ad:be:ef::2
nameservers: # 手动地址配置时设置
addresses: [ 223.5.5.5, "FEDC::1" ]
search: [lab, home] #**
match:
macaddress: 52:54:00:6b:3c:58
macaddress: 52:54:00:6b:3c:59 # 修改匹配设备的MAC地址
mtu: 1500 # 修改匹配设备的MAC地址
version: 2
应用配置文件:
sudo netplan generate # 生成后端配置文件
sudo netplan apply # 直接应用配置
sudo netplan try # validate the config and then apply
物理链路管理
创建和删除链路
ip link add \ # 添加虚拟链路
link DEVICE \ # 指定物理设备(某些链路类型无物理设备,如IP-over-IP)
name NAME \ # 默认为物理设备名称
type TYPE \ # 链路类型:bridge,veth,vlan,macvlan,mactap,ip6tnl,gre,...
index ID # 链路编号
其他参数包括:
mtu,address,broadcast,txqueuelen,numtxqueues,numrxqueues,...。不同类型链路采用不同的数据链路层协议。
ip link delete {dev NAME|group GROUP} type TYPE
nmcli connection add type <type> ifname <ifname> ... # 创建链路
nmcli connection delete <ifname>
配置链路参数
ip link set [dev NAME] [group GROUP] prop VALUE
ip address {add|change|replace} IFADDR dev NAME # 配置IP地址
如果指定了group则修改设备所属分组,如果未指定设备,则修改分组中所有设备的属性。配置了IP地址的链路能够使用IP协议进行通信。
nmcli connection modify <ifname> [+-]ipv4.addresses 192.168.0.58[/24]
nmcli connection modify <ifname> [+-]ipv4.dns 114.114.114.114
nmcli connection modify <ifname> [-]ipv4.gateway 192.168.0.2
# ipv4.method manual must be supplied with address
nmcli connection modify <ifname> ipv4.method manual \
ipv4.addresses 192.168.0.58/24
nmcli edit <ifname/id> # 交互式编辑模式,查看和编辑配置项
启用和停用链路
nmcli c reload
nmcli c up <interface> # if interface exist
虚拟网桥管理
创建和配置虚拟网桥
ip link add BRIDGE_NAME type bridge
brctl addbr BRIDGE_NAME
nmcli connection add type bridge CONN_NAME BRIDGE_NAME ifname BRIDGE_NAME
Chapter 12. Configuring a network bridge Red Hat Enterprise Linux 8 | Red Hat Customer Portal
将网卡绑定至网桥
ip link set dev IFNAME master BRIDGE_NAME
nmcli connection modify DEVICE_NAME master BRIDGE_NAME
nmcli connection add type ethernet slave-type bridge CONN_NAME DEVICE_NAME ifname IF_NAME master bridge0
虚拟网卡管理
tap网卡
ip tuntap add dev tap1 mode tap
Tap网卡创建是临时的,如果要永久生效,可将上述命令添加到开机启动命令(如rc.local)。
linux - How to make tap interfaces persistent after reboot? - Super User
防火墙
Linux内核使用Netfilter/iptables过滤包,其中iptables为用户交互接口(iptable-services)。
防火墙规则管理
iptables -t,--table TABLE -OP CHAIN rule_spec # 链名为大写,表名为小写
-t TABLE:指定访问的表(省略则查看filter表);
-OP CHAIN:指定访问的链(省略链名则查看所有链)及其操作(例如-L FORWARD);
查询规则
iptables -t TABLE -L,--list CHAIN -v -n --line-number -x # 列出所有规则
iptables -t TABLE -C,--check CHAIN RULE_SPEC # 检查指定规则是否存在
-n:不反向解析IP地址(显示IP地址而非域名,加快速度);
--line,--line-number:显示规则编号;
-v:显示更多信息(分组数、字节数等);
-x:显示精确的计数,而非经过单位转换的数据。
管理规则
iptables -I,--insert CHAIN [NUM] RULE -j TARGET # 在表首部插入一条规则
iptables -A,--append CHAIN RULE -j TARGET # 在表尾部插入一条规则
iptables -R,--replace CHAIN NUM RULE -j TARGET # 替换指定编号的规则
iptables -D,--delete CHAIN RULE -j TARGET # 删除匹配条件的规则
iptables -D CHAIN NUM # 删除指定编号的规则
iptables -F,--flush CHAIN # 清空表中的规则
默认的表为
-t filter。
添加相同的规则不会覆盖已有规则,可用以下命令修改已有规则的动作:
iptables -t filter -R INPUT 2 <rules> -j <traget> # 修改指定规则的动作
必须指定要修改规则的条件,否则该规则的条件将变为默认值(例如IP将变为
anywhere)。
修改默认策略
iptables -t filter -P FORWARD DROP
黑白名单机制
黑名单:将默认策略设置为ACCEPT;在规则中添加阻止策略。
白名单:将默认策略设置为DROP,在规则中添加允许策略。
默认策略设置为
DROP的缺点:在对应的链中没有设置任何规则时,管理员也会把自己拒之门外;即使对应的链中存在放行规则,当不小心使用"iptables -F"清空规则时,放行规则被删除,则所有数据包都无法进入。所以,如果想要使用"白名单"的机制,最好将链的默认策略保持为"ACCEPT",然后将"拒绝所有请求"这条规则放在链的尾部,将"放行规则"放在前面,这样做,既能实现"白名单"机制,又能保证在规则被清空时,管理员还有机会连接到主机。
自定义链
自定义链仅对应一种类型的表,自定义链中规则配置方式与默认链相同。
iptables -t filter -N,--new-chain IN_WEB # 创建用于filter表的自定义链
iptables -E,--rename-chain IN_WEB WEB # 重命名
iptables -X,--delete-chain WEB # 删除自定义链,需未被引用且不包含任何规则
iptables -t filter -I INPUT RULE -j IN_WEB # 引用自定义链
保存规则
通过iptables对规则的修改并非永久生效,当重启iptables服务或者重启服务器以后规则便失效了。如果想要修改永久生效,必须使用service iptables save保存规则,如果误操作了规则但是并没有保存,那么使用service iptables restart命令重启iptables以后即恢复修改前的状态。
目前的发现版多数已用防火墙软件(如
CentOS/firewall、Ubuntu/ufw)代替了iptable-services了,因此使用上述方法需要安装该服务。
iptables-save # 将防火墙规则导出到标准输出
iptables-restore # 从标准输入导入防火墙规则
包匹配条件
多个条件之间具有AND关系,使用!对条件取反。
基本匹配条件:
# IP地址
-s sip1,sip2 -d dip1
-s ip/mask
# 协议类型
-p tcp # all, tcp, udp, udplite, icmp, icmpv6,esp, ah, sctp, mh
# 网卡接口
-i eth0 -o eth1
-i选项只能用于上图中的PREROUTING链、INPUT链、FORWARD链;-o选项只能用于FORWARD链、OUTPUT链、POSTROUTING链。
扩展匹配条件:由netfilter的扩展模块处理的条件。
# 端口
-m tcp --sport 1:1024 --dport 22 # 需要指定扩展模块tcp, udp, icmp
-m tcp --sport :1024 --dport 10000: # 可省略一个端口边界参数
-m multiport --dports 22,36,80:100
# IP范围
-m iprange --src-range 192.168.1.127-192.168.1.146 # --dst-range
# 字符串:匹配报文中包含的字符串
-m string --algo bm --string xyz
# time
-m time --datestart 2017-12-24 --datestop 2017-12-27
-m time --timestart 09:00:00 --timestop 18:00:00
-m time --weekdays 6,7 --monthdays 22,23
当扩展模块的名称与协议名称相同的情况下,如果已经指定了协议,则可以省略模块选项。
--algo指定字符串匹配算法,可选算法有bm与kmp。
# connlimit 限制连接数量
-m connlimit --connlimit-above 2 --connlimit-mask 24 -j DROP
--connlimit-mask表示对一个网段施加连接数限制(未指定时为对每个IP的连接数进行限制)
# limit 使用令牌桶限制报文速率
-p icmp -m limit --limit 10/minute -j ACCEPT
-p icmp -m limit --limit-burst 3 --limit 10/minute -j ACCEPT
--limit:报文允许的速率(令牌的生成速率,单位可以是second,minute,hour,day);--limit-burst:允许的突发流量(令牌桶的容量,默认值为5);需要添加一条默认
DROP/REJECT的规则,以丢弃超过速率限制的包。
其他扩展条件:tcp-flags、state
http://www.zsythink.net/archives/1578
动作
REJECT可以附加发送一个ICMP响应报文。
-j REJCT --reject-with icmp-host-unreachable
-j LOG --log-prefix "logname" --log-level alert
LOG动作默认将报文的相关信息记录在/var/log/message文件中,通过修改/etc/rsyslog.conf(或/etc/syslog.conf),kern.warning /var/log/iptables.log
--log-level:emerg,alert,crit,error,warning,notice,info,debug。
端口管理
sudo vi /etc/sysconfig/iptables
端口权限
小于1024的端口号(特权端口)不允许非root用户打开,以防恶意程序占用这些端口建立恶意服务。
如果用户需要使用这些端口,解决方法包括:
-
使用Apache或nginx作为代理服务器;
-
使用iptables设置防火墙规则,使得低端口在内部自动转发至高端口;
-
jsvc
-
authbind
-
sudo setcap CAP_NET_BIND_SERVICE=+eip /path/to/binary
路由配置
转发功能
开启防火墙的转发功能。
echo 1 > /proc/sys/net/ipv4/ip_forward # 设置为1开启转发,0关闭转发
sysctl -w net.ipv4.ip_foward=1
上述方式为设置系统运行时变量,要永久生效需要修改系统配置。
Ubuntu使用
ufw管理防火墙规则,其配置文件在/etc/ufw/sysctl.conf,其中对应的配置项为:net/ipv4/ip_forward=1 net/ipv6/conf/default/forwarding=1 net/ipv6/conf/all/forwarding=1CentOS7中配置
/usr/lib/sysctl.d/00-system.conf,并设置net.ipv4.ip_forward=1。
设置防火墙转发规则:
iptables -I FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
NAT
# SNAT: 将源内网地址映射到公网地址
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -o eth0 -j SNAT --to-source 192.168.1.146
# 动态SNAT: 动态将源内网地址映射到动态变化的公网地址
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -o eth0 -j MASQUERADE
# DNAT: 将目的公网地址+端口映射到内网地址+端口
iptables -t nat -I PREROUTING \
-d 192.168.1.146 -p tcp --dport 3389 -j DNAT --to-destination 10.1.0.6:3389
DNAT在理论上只配置DNAT规则即可,但是如果在测试时无法正常DNAT,可以尝试增加对应的SNAT,此处按照配置SNAT的流程进行。
如果没有动态SNAT的需求,没有必要使用
MASQUERADE,因为SNAT更加高效。
本机端口转发
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080 # INPUT
iptables -t nat -A OUTPUT -p tcp --dport 80 -j REDIRECT --to-port 8080 # LOCAL
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 1186 -j DNAT --to-destination 127.0.0.1:1186
将访问本机80端口的请求重定向到本机的8080端口(修改目标端口)。
如果要从外部访问本机localhost监听的端口,可使用DNAT将地址和端口映射到本机换回地址和相应端口(需要开启本地换回路由:sysctl -w net.ipv4.conf.<ifname>.route_localnet=1 ,ifname为输入网络接口)。
路由表
获取路由信息
ip {r|route}
#default via 192.168.178.2 dev ens32 proto static
#default via 172.28.76.234 dev ens33 scope link metric 1
#172.28.76.0/24 dev ens33 proto kernel scope link src 172.28.76.234
#192.168.178.0/24 dev ens32 proto kernel scope link src 192.168.178.40
表格形式:
route [-nee]
#Destination Gateway Genmask Flags Metric ... Iface
#0.0.0.0 192.168.178.2 0.0.0.0 UG 0 ... ens32
#0.0.0.0 172.28.76.234 0.0.0.0 UG 1 ... ens33
#172.28.76.0 0.0.0.0 255.255.255.0 U 0 ... ens33
#192.168.178.0 0.0.0.0 255.255.255.0 U 0 ... ens32
netstat -r -n
#Kernel IP routing table
#Destination Gateway Genmask Flags MSS Window irtt Iface
#0.0.0.0 172.28.76.234 0.0.0.0 UG 0 0 0 ens33
#172.28.76.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
ee:显示更多信息。
-
路由类型
主机路由:掩码为32位; 网络路由: 默认路由:目标为
0.0.0.0/0.0.0.0。当主机不能在路由表中查找到目标主机的IP地址或网络路由时,数据包就被发送到默认路由(默认网关)上。 -
Flags说明:
U(route is up):活动路由;H(target is host):目的地址是主机;G(use gateway): 需要网关转发; -
Metric:路由距离,到达指定网络所需的中转数。 -
Iface: 当前路由会使用哪个接口来发送数据
配置静态路由
route [add|del] [-net | -host] target [netmask Nm] [gw Gw] [[dev] If]
route add default gw 192.168.1.1
route add -net 5.0.0.0 netmask 255.0.0.0 reject # 设置到指定网络为不可达
没有修改已有路由的命令(例如修改metric),需要先删除再添加一条。
上述命令仅在当前运行环境中有效,要永久保存需要将其添加至文件中。可直接在在/etc/rc.local中添加上述命令,则开机会自动添加静态路由,但如果开机状态下重启网络服务则不会再次执行/etc/rc.local,导致静态路由失效。
另一种方式是编辑/etc/sysconfig/static-routes(CentOS/Fedora),该文件由网络服务自动加载。
any -net 192.56.76.0 netmask 255.255.255.0 dev eth0
由
any开头的行将被解释为静态路由项。Ubuntu静态路由配置?
ip工具包用于替换route等管理工具:
ip route {add|del|change|append|replace} ROUTE
# ROUTE= [TYPE] NETWORK/MASK [via [FAMILY] GW_IP] [dev DEVICE] [weight NUM]
ip route add default via 192.168.1.1 dev eth0 # 设置默认路由
TYPE:路由类型,包括unicast,mulitcast,broadcast,nat,local,...;
FAMILY:协议族: inet,inet6,mpls,bridge,link;
本地网络代理
可配置系统范围(/etc/environment)或用户范围(~/.bashrc或~/.profile)。
export http_proxy="http://USERNAME:PASSWORD@proxy.server.net:port/"
export https_proxy="http://proxy.server.net:port/"
export ftp_proxy="http://proxy.server.net:port/"
export no_proxy="localhost, 127.0.0.1, 192.168.178.4" #*
*:no_proxy不支持通配符,如果要写一个网段,只能逐个地址列出。no_proxy主要用于匹配域名后缀,而非IP地址(前缀)。
如果是系统范围代理,还需设置/etc/sudoers.d/proxy,避免环境变量被覆盖。
Defaults env_keep+="http_proxy https_proxy no_proxy"
网络服务
systemctl restart networking
常用网络服务
远程访问
X-Window
https://wiki.ubuntu.org.cn/%E7%90%86%E8%A7%A3_Xwindow
安全
内核强制访问控制
Both SELinux and AppArmor supports the Type Enforcement security model, which is a type of mandatory access control, based on rules where subjects (processes or users) are allowed to access objects (files, directories, sockets, etc.).
Implementing Mandatory Access Control with SELinux or AppArmor in Linux (tecmint.com)
Security Enhanced Linux
SELinux支持更强的访问控制。
查看SELinux状态:
getenforce
sestatus -v
临时关闭(设置成permissive模式,仅产生日志不进行控制):
sudo setenforce 0 # setenforce 1 => enforcing mode
永久关闭:
# sudo vi /etc/selinux/config
SELINUX=disabled # SELINUX=enforcing|permissive|disabled
SELinux策略
查看boolean策略状态:
getsebool -a [se_boolean_entry]
设置boolean策略:
setsebool -PV se_bool_entry value # (1|true|on,0|false|off)
Apparmor
AppArmor是与SELinux类似的一个访问控制系统,通过它你可以指定程序可以读、写或运行哪些文件,是否可以打开网络端口等。
linux内核强制访问控制--Apparmor - 运维之路 (361way.com)
AppArmor与SELinux - 运维之路 (361way.com)
数字证书
安装证书
系统信任证书目录位于/usr/local/share/ca-certificates。将证书文件置于该目录下,并将权限设置为644。
sudo apt install ca-certificates
sudo update ca-certificates # needs super user privilege
生成证书和私钥
OpenSSL是一个非常有用的开源命令行工具包,可用于 X.509 证书,证书签名请求(CSRs)和加密密钥。
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365
openssl x509 -in cert.pem -text -noout # 查看证书结构信息
key.pem为私钥;cert.pem为证书(包含公钥);生成签名过程设置的密码是在使用密钥的时候使用。使用私钥和证书需要输入制作时设置的密码。
详细步骤
Create an RSA Keypair:
sudo apt install openssl
openssl genrsa -des3 -passout pass:PASSWORD -out keypair.key 2048
Extract the Private Key:
openssl rsa -passin pass:PASSWORD -in keypair.key -out private.key
Creating a “Certificate Signing Request” or CSR File:
openssl req -new -key private.key -out service.csr
Creating the Certificate “.crt” File:
openssl x509 -req -days 365 -in service.csr -signkey private.key -out service.crt
https://www.rosehosting.com/blog/how-to-generate-a-self-signed-ssl-certificate-on-linux/
https://www.linux.com/tutorials/creating-self-signed-ssl-certificates-apache-linux/
SSL/TLS
权限管理
用户管理
创建用户
useradd -m -c "FULL NAME" -g GROUP USERNAME # [lowlevel]
adduser --home DIR --shell SHELL --ingroup GROUP USERNAME
adduser在Debian系发行版上重新封装了底层useradd命令,其他发行版上是useradd的别名。以下均为useradd选项。有效用户名模式:
[a-z_][a-z0-9_-]*[$]?,长度不超过32。
-c "COMMENT":通常用于设置用户名全称;
-s,--shell SHELL用户的登录shell程序,/etc/default/useradd#SHELL(chsh)。
用户目录
-b,--base-dir BASE_DIR:用户主目录的根目录路径,默认值为/etc/default/useradd#HOME=/home;-d,--home-dir HOME_DIR:用户主目录路径,默认值为$BASE_DIR/USERNAME;- 使用
-m,--create-home保证创建用户目录;-M,--no-create-home不创建用户目录(通常用于运行系统服务的非登录用户);
用户组
-g,--gid GROUP:用户的初始登录组(primary group:ID或名称,必须存在)。 如果未指定该选项,默认(/etc/login.defs#USERGROUPS_ENAB=yes)会自动创建与用户名同名的组(等效于指定-U,--create-user-group选项);如果USERGROUPS_ENAB=no,则新用户的主要组设置为/etc/default/useradd#GROUP=100。-G,--groups groupname[,...]:将用户添加至组(supplementary groups);
账户和密码有效性
-f,--inactive DAYS:密码过期后账户被禁用前的天数。-e,--expiredate YYYY-MM-DD:账户失效(禁用)日期,默认值为/etc/default/useradd#EXPIRE=''(不失效);
修改用户
使用usermod修改用户属性(多数属性对应的选项与useradd相同)。
usermod -a,--append -G GROUPNAME # 将用户添加到supplementary groups
usermod -l,--login NAME # 修改登录名
usermod -m,--move-home -d,--home HOME # (移动)修改用户主目录
设置账户有效期限
usermod -e,--expiredate YYYY-MM-DD/N/-1 USER # 设置失效日期*
chage -E,--expiredate YYYY-MM-DD/N/-1 USER
*:N表示自1970年1月1日的天数。
此外,账户密码失效后账户也会处于失效状态。
设置和更新密码
创建用户时默认禁用密码。使用passwd设置和更新密码(root账号可修改普通用户的密码,用户忘记密码可通过root帐号使用passwd指令来处理即可)。
passwd username
usermod -p,--password ENCRYPT_PASSWORD
passwd -d,--delete # 删除(置空)用户密码
如果
root帐号忘记了,可以进入单人维护模式,此时系统会给予提供root权限的bash接口,再用passwd修改密码;或者利用Live CD开机后挂载根目录去修改/etc/shadow,将root的密码删除,重新开机后再用passwd设置新密码。
密码有效期配置
passwd -e,--expire # 立即使用户密码失效, 用户必须在下次登录时重设密码
passwd -x,--maxdays DAYS USER #->chage -M 密码有效期天数(99999/-1)*
passwd -i,--inactive DAYS USER #->chage -I 密码失效后禁用账户前的天数(never)
passwd -n,--mindays DAYS USER #->chage -m 两次修改密码之间至少相隔的天数(0)
passwd -w,--warndays DAYS USER #->chage -W 需要修改密码前向发送警告的天数(7)
*:chage的长选项与passwd对应长选项一致。
显示密码状态:
passwd -S <user> # 使用-a代替<user>查看所有用户的密码状态。
# gary P 06/02/2022 0 99999 7 -1
chage -l <user>
# Last password change : Jun 02, 2022
# Password expires : never
# Password inactive : never
# Account expires : never
# Minimum number of days between password change : 0
# Maximum number of days between password change : 99999
# Number of days of warning before password expires : 7
删除用户
userdel -f $USER # deluser [Debian]
rm -rf /home/$USER
查看用户信息
查系统中的用户信息:
/etc/passwd # User account information.
/etc/shadow # Secure user account information. [read by root only]
查看当前登录的所有用户:
w
# 09:42:35 up 26 min, 3 users, load average: 0.18, 0.12, 0.09
#USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
#root pts/0 172.28.76.41 09:17 3.00s 0.13s 0.03s w
#root pts/1 172.28.76.239 09:19 22:45 0.02s 0.02s -bash
who显示的信息没有w完整。who可以显示系统引导终端(tty1)。
查看指定用户信息:
id $USER
# uid=1000(gary) gid=1000(gary) groups=1000(gary),...(secondary groups)
groups $USER # 查看用户所属组
username=$(whoami) # return user name
sudo whoami # -> root
组管理
groupadd groupname
groupdel groupname
addgroup [options] [--gid ID] group
sudo usermod -g groupname username # change user's primary group
sudo usermod -a -G group[,...] username # add user to a secondary group
adduser user group # add user to grpup
If you omit the
-aoption, the user will be removed from any groups not listed after the-Goption.
sudo gpasswd -d username groupname # Remove a User From a Group
查看组信息
/etc/group # Group account information.
/etc/gshadow # Secure group account information.
访问权限控制
访问权限
修改用户访问文件的权限:
chmod [ugoa][+-=][rwxXstugo],... FILE ...
chmod OCTAL-MODE FILE ...
ugoa分别代表文件所有用户,文件同组用户,其他用户和所有用户(省略则默认为a,umask?);+-=表示增加、删除和设置权限。
权限模式:rwxXst中的一个或多个,或ugo中的一个
| 标识 | 说明 | 标识 | 说明 | 标识 | 说明 |
|---|---|---|---|---|---|
r | 读文件 | w | 写文件 | x | 访问/执行 |
s | 设置用户或组 | t | 限制删除 | X | * |
u | 授予所有者权限 | g | 授予组用户权限 | o | 授予其他组权限 |
*:X表示仅当目标为目录或已经具有其他用户执行权限时,才设置该目标的访问/执行权限。
OCTAL-MODE为1~4数字(取值范围0~7,3bit),第一位代表(设置用户ID,设置组ID和限制删除),其余三位数字分别代表ugo对应的rwx权限。
Ownership
获取对象的所有者信息:
ls -l /opt/360es/ | awk '{print $3,$4}' # 根据字段位置确定
ls -l /opt/360es/ | sed -n '2,$p' | awk '{printf "user=%s,group=%s\n",$3,$4}'
stat /path/file --format="user=%U group=%G"
从外部(互联网)获取的文件(档案),其所有者信息非本机用户,因此导致本机用户无法正常访问文件,所以需要修改文件的所有者/组。
chown -hR owner[:group] FILE
chgrp
--dereference:影响符号链接指向的文件而非符号链接;-h,--no-dereference相反;--from=CURRENT_OWNER:CURRENT_GROUP:仅当文件的当前属性匹配才进行修改;--reference=RFILE:使用RFILE的属性作为修改后的属性;-R:递归修改。符号链接指向的文件夹的遍历规则根据以下选项决定:
-H:遍历命令行参数为符号链接锁指向的文件夹;-L:遍历所有符号链接指向的文件夹;-P:步遍历符号链接指向的文件夹(默认)。
提升权限
切换登录用户
su - username # switch user
不支持切换到非登录用户。
以管理员身份运行
sudo \
-u, --user=user \ # 指定用户执行输入的命令
-i,--login \ # 使用指定用户登录shell
[command] # 运行命令(未指定则切换终端用户)
当前多数发行版默认禁用root账户,并以安装系统期间创建的账户作为管理员。管理员需要使用sudo命令并提供密码以暂时获得root账户权限(使用sudo命令创建的文件其所属用户和组为root)。将其他用户加入sudo用户组使其具有运行sudo的权限。如果要恢复root账户(不推荐),为其设置密码:
sudo passwd root
帮助文档
Linux Manual
- 可执行程序和Shell命令;
- 系统调用函数文档;
- 库函数文档;
- 特殊设备文件(通常位于
/dev); - 系统内置文件格式和规范(如
/etc/passwd); - 游戏;
- 其他,如
man(7); - 系统管理命令(管理员使用);
- 内核过程(非标准)。
急救模式
emergency mode
进入急救模式
-
GRUB系统选择界面按
e进入启动配置项编辑模式;linux16 /vmlinuz-.... # 添加rd.break -
按
Ctrl+X进入急救模式。
修复磁盘
修复XFS文件系统
由于突然断电,导致XFS文件系统数据损坏。
ls -l /dev/mapper # 找到dm-0对应的挂载点并卸载设备
umount /dev/mapper/centos-root
xfs_repair -L /dev/mapper/centos-root # 修复该设备
init 6 # 成功修复后重启设备
参考资料
Linux Shell
Shell
Shell包括命令行Shell和图形Shell,Linux中使用的命令行Shell包括:
- Bourne Shell(
/usr/bin/sh或/bin/sh) - Bourne Again Shell(
/bin/bash,常用) - C Shell(
/usr/bin/csh) - K Shell(
/usr/bin/ksh) - Shell for Root(
/sbin/sh) - ……
如今Debian和Ubuntu中,
/bin/sh默认已经指向dash,这是一个不同于bash的shell,它主要是为了==执行脚本==而出现,而不是交互环境,它速度更快,但功能相比bash要少很多,语法严格遵守POSIX标准。
chsh -s /usr/bin/bash # 切换用户默认的登录环境
Shell将用户输入的命令进行解释并提交系统执行,从而实现用户与系统间的交互。为了避免不必要的用户操作,Shell支持从文件自动读取命令并执行,即执行Shell Script/Shell Program。
A shell is a command language interpreter which provide an interface to user to use operating system services.
Shell脚本文件
注释:“#”用于注释。第一行#!/bin/bash声明执行这个脚本所使用的shell程序的名称。在较为特殊的程序代码部分,务必要加上批注说明。
保持良好的编程风格,应该在每个脚本文件的头部记录文件相关信息:功能、版本信息、作者与联络方式、版权宣告方式、
主要代码部分:如果读到一个换行符号(CR),就尝试开始执行该行(或该串)指令。指令、选项与参数之间的多个空白(空格、制表符、空白行)会被忽略掉。如果一行内容太多,可使用“\”来延伸至下一行(\之后不==能有包括空白在内的任何内容==);
Windows换行规则
CR LF不能被正确识别。
语句块:使用花括号“{}”可以将多条语句放在一起,一个语句块相当于一条语句。
变量
变量名大小写敏感,有效字符包括字母、下划线和数字,但首字母不能是数字。变量的值为字符串。
变量属性
declare [option] [name=[value]]
-i:使变量具有整数性质,对变量赋值时将评估赋值表达式的数值结果;
-a/-A:将一个变量声明为数组/字典;
-l/-u:将赋给变量的值自动转换为小写/大写;
-r:使变量只读;
-x:使变量成为环境变量(export);
使用
+关闭相应的属性;
输出控制:
-
-p:显示==变量的值和属性==;如果未指定名称,则显示所有变量的信息;declare -p # 输出所有变量的信息 y=0; declare -p y # 输出: declare -- y="0" declare -p array # 输出: declare -a array='([0]="1" [1]="2" [2]="3")' -
-f/-F:仅显示函数,-F仅显示函数名和属性;
赋值
未赋值的变量也可以使用,其值为空字符串。==字符串可以跨行表示,两行内容之间会添加空白分隔(使用“\”连接两行消除换行符)==。
var_name="value"
readonly var_name # 将变量设置为只读。
等号两边不能有空格。
当value中包含空白字符时,需要使用引号'或"将其包围起来,否则只能识别空白之前的内容。引号内容可以换行(两行间的空白内容以及换行符被自动替换为一个空格)。两个相邻字符串(无空分隔)视为一个字符串。
-
==变量如果不带引号,则能触发通配符
*和?匹配文件名;会消耗转移字符,\a实际内容为a。== -
单引号中的内容不做额外解释,即双引号
"、取值运算符$、历史记录运算符!、以及转义字符\等都视为普通字符。 -
双引号中可使用特殊字符,并使用
\$、\"和\\分别来取消$、"和\的特殊含义,单引号视为普通字符。双引号中非转义字符前出现的
\无特殊作用,例如\a,不会消耗转义字符,内容为"\a"。
读取
获取变量的值,使用大括号用于帮助解释器识别变量名的边界。
$var_name
${var_name}abc
echo "$str_name"
获取变量的值时,一定要带上
$,否则只是使用变量名字符串。
输出当前Shell环境中的所有变量和函数:
set/declare
命令行展开
Shell解释器执行语句时,会首先对语句中的变量$var进行值替换,然后对其中的特殊字符(如*,~)进行替换,最后根据空白将语句内容解析为命令和参数序列。
-
避免特殊字符展开:将特殊字符或包含特殊字符的变量置于引号中
"$var",其中的所有字符都被视为普通字符(除转义序列外); -
避免包含空白的变量被展开为多个参数:同样将该变量的引用置于
""中。如"hello world"或"$var_with_spaces"; -
如果变量的内容已经显示指定了参数边界,如
'arg 1' 'arg2',则命令行不要为其添加""(否则仅相当于一个参数);但如果该变量受上述两项限制需要"",则使用eval对命令行内容执行两遍解释,从而对该变量进行两次解释(第一次执行变量替换,第二次执行参数解析)。消除参数中成对的双引号(字符),并将引号之间的内容作为一个参数。
eval echo '"abc' 'def"' 'ghi' # => echo "abc def" ghi => abc def ghi变量值中自带的引号只是普通字符(区别与命令行或脚本上书写的引号边界),其不能避免变量在空白处被展开。带空格的变量与其他变量拼接后再作为参数传递给其他脚本,则无法避免该变量在空格处被展开。应该单独将该变量置于引号中传递给脚本,或者使用
eval命令对参数中包含的引号做第二次解释。x="x 'y z'" y="\"a b c\"" z="$y $x" # => z = ["a b c" x 'y z'] ./script.sh $z # ./script.sh '"a' 'b' 'c"' 'x' 'y' 'z' eval./script.sh $z # ./script.sh 'a b c' 'x' 'y z' ./script.sh "$y" "$x" # ./script.sh '"a b c"' 'x 'y z'
删除变量
unset TEST_VAR # clear a shell/env variable
数据结构
数组
序列由()包含多个元素
array=('abc' 123 4.56 ...) # declare -a array=(1 2 3)
名为
@的数组:脚本的所有输入参数组成的特殊的数组。
使用从0开始的下标访问数组元素:
ai="${array[i]}" # ${array}=>${array[0]}
数组与字符串转换
使用“@”或“*”获取数组所有元素,其返回结果为字符串。
x="${array[@]}" # 所有元素拼接成的字符串*
cmd "${array[@]}" # 将数组展开到命令行,每个元素成为单独参数**
*:表达式添加""后,数组元素中可以包含空白,解释器视整个数组元素内容为一个参数(类似于命令行输入'abc d');
**:用于命令行时(如作为for循环的迭代序列或命令参数序列),Shell会首先对"${array[@]}"进行解释展开为多个参数,而赋值时则不会(否则如x=1 2 3这样的语句会报错);
将字符串转换为数组:根据展开表达式中的空格分隔数组元素
array=($cat_array)
eval array=("$cat_array") #*
*:如果字符串中人为定义了元素边界'',则使用eval对字符串内容再解释一次。
数组元素迭代
for a in "${array[@]}"; do #*
echo $a
done
# => 也可根据子串长度,按编号顺序迭代
for ((i=0;i<${#array[@]};i++)); do echo ${array[$i]}; done
查找序列中的元素:
function arrayfind(){
local value=$1; shift; local array=("$@"); #*
local index=-1
for (( i=0; i<${#array[@]}; i++ )); do
if [[ "$value" == ${array[$i]} ]]; then
index=$i
break
fi
done
echo $index
}
*:函数无法接受数组对象作为参数,传入数组首先被扩展为多个参数,再在函数中重新拼装为数组。
子数组
获取子数组,第二个参数省略则获取到结束。
sub_array=(${array[@]:i[:j]})
如果数组元素包含空格,则应该使用"${array[@]:i[:j]}"防止数组元素边界丢失,否则上述表达式将按空格为边界重新构造数组。
序列长度:
${#array[@]} # <=> ${#array[*]}
注意:
${#array}返回数组第一个元素(字符串)的长度。
扩展序列,序列元素可动态增加,跳过赋值的序列元素为空。
a+=(1 2) # 不支持 (1 2)+(3 4)
array[5]=v2 # echo $array[4] ==> 输出为空
字典
declare -A dict # decalre dict as a dictonary
dict[x]=1
declare -A dict=([x]=1 [y]=2 ...)
echo dict[x]
运行
脚本文件如果具有可读可执行权限 (rx),可将其视为命令在Shell中执行:
/home/gary/work.sh # 绝对路径
./work.sh # 相对路径(不能省略./)
work.sh # 文件位于系统路径PATH
对于不具有执行权限的脚本文件,则可由解释器(bash)读取执行:
bash /path/to/file.sh arg1, arg2,...
可以为运行脚本提供多个参数。通过以上各方法执行Shell脚本将会创建一个新Shell实例(进程),脚本将由新的Shell实例解释执行。==环境变量将由原有的Shell实例传递给新的Shell实例,而普通变量将不会传递==。在脚本执行过程中,新Shell中任何变量的修改都不会传递回原有的Shell。
利用 source 来执行脚本:在当前Shell进程中执行脚本中的语句,而不创建新的Shell进程。如果提供额外参数,则脚本的运行的参数变量会被更新,脚本执行完后恢复原有的参数变量。==脚本执行过程中对原Shell中的变量更新有效==。
source script [args] # . script
source ~/.bashrc # Ubuntu必须在交互式Shell中运行=> bash -i script.sh
Ubuntu环境下运行
.bashrc必须在交互式Shell中进行(运行的Shell脚本非交互环境),否则脚本直接返回。如果不屏蔽.bashrc中判断交互式逻辑,可将初始化内容移至其他脚本文件中并在用户脚本中使用source调用。注意:
.bashrc中如果有输出语句(例如echo),可能导致从远端执行scp无法正常工作(启动SSH会话会自动加载.bashrc,输出语句可能中断后续传输命令)。
执行符号链接的脚本时,当前工作目录为符号链接所在目录。
运行环境
Shell配置文件通常定义了环境变量以及初始化脚本。配置文件根据作用范围分为系统配置文件和用户配置文件。
系统配置脚本
/etc/profile为系统默认配置,在系统启动时加载。不推荐用户修改此文件,以免系统升级时造成配置丢失,应该在/etc/profile.d目录下创建appxxx.sh定义环境变量。
系统环境变量
/etc/environment保存了系统环境变量(如PATH)的赋值表达式,在==用户登录==时读取。
用户配置文件
用户登录时,Shell会自动按序尝试加载~/.bash_profile、~/.bash_login和~/.profile(如果发现一个文件则不再加载后续文件)。系统默认创建的~/.bash_profile还会加载~/.bashrc,而~/.bashrc则会加载/etc/bashrc1。如果希望配置仅对当前用户有效,应修改用户目录下的上述配置文件。
当使用SSH远程登录时,上述与Shell相关配置文件不会被加载,而是直接加载~/.bashrc(Ubuntu中会在~/.bashrc中判断Shell是否为交互式,如果非交互式跳过后续配置加载)。
设置运行时选项
set命令可以对Shell进行设置。
set -x # [-o xtrace] 按执行内容回显命令
set -e # [-o errexit] 命令返回非0时退出程序
set -u # [-o nonset] 引用未设置的变量产生错误
set -v # [-o verbose] 按输入内容回显命令
set -n cmdline # [-o noexec] 读取命令输入但不执行
set -o posix # config to print variables only
set -o history # enable command history
使用
set +opt关闭选项。
环境变量
Environmental Variable:可以被子进程或Shell继承的变量。
| 变量 | 描述 |
|---|---|
$PATH | 可执行文件的搜索路径 |
$LANG | 操作系统的语言和编码方案(例如en_US.UTF-8) |
$LD_LIBRARY_PATH | 非标准共享库的搜索路径 |
$HOME | 用户家目录 |
共享库的寻找和加载是由
/lib/ld.so实现的。ld.so在标准路经(/lib,/usr/lib) 中寻找共享库。Linux通用的做法是将非标准路径加入/etc/ld.so.conf,然后运行ldconfig生成/etc/ld.so.cache。
Shell Variable:独立为每个Shell定义的变量。
| 变量 | 描述 |
|---|---|
$$ | 当前进程的进程号,通常用它来生成唯一的临时文件。 |
$! | 最后运行的==后台==进程的进程标识(pid)。 |
$? | 上个命令的退出状态,或函数的返回值(可获取ssh远程执行命令的返回值)。 |
$LINENO | 当前的行号(sh中无效,使用bash) |
$- | ==启用的Shell环境选项==。 |
env NAME=VALUE
[-u,--unset=NAME]
修改(删除)环境变量。
查看环境变量:
env
printenv [ | grep PATH]
printenv NAME
转换普通变量为环境变量:
export [-n] SHELL_VAR # turn into env-variable / turn normal
export var=value # define a new env-variable
set -a # [-o allexport] export all defined variables
参数变量
执行程序(脚本、二进制文件)时,可以传入多个参数。
./shfile.sh [arg1 arg2 ...]
传入程序的参数变量为字符串值而非脚本中书写的字面值,变量中的转义字符不会被再被解释。
在脚本文件内部,按以下方式获取参数信息:
| 变量 | 描述 |
|---|---|
$0, $1,$2,... | 按序号访问传入参数($0为脚本名) |
$*、$@ | 输入参数(不包含$0)组成的序列,使用""避免参数展开。 |
"$*" | 结果为一个字符串'arg 1 arg 2 arg 3' |
"$@" | 保留原参数结构'arg 1' 'arg 2' 'arg 3' |
${@:m:n} | 获取输入参数序列部分内容,使用""避免原参数展开。==使用 ()使返回结果仍以数组存储,否则结果会转换为字符串==。 |
$# | 传递给脚本的参数个数,不包括脚本名称($0) |
命令行参数展开测试:
for arg in "$@" ; do # <-> $* "$*" echo $arg done
shift n:移动输入参数起始下标,向右移动$i和$@等参数读取位置(默认n=1,不影响$0)。
设置参数:更新当前Shell环境得输入参数(覆盖调用时传入值):
set -- args...
eval set -- "arg1 'arg 2' 'arg 3'" #*
set - # -x and -v options are off **
*:如果参数通过字符串提供且其中带字符串边界('),则需使用eval避免错误空白位置参数展开。
**:如果未提供参数,则将当前状态下的"$@"(如经过shift移位后)设置为输入参数。
隔离运行
使用chroot命令切换待执行程序的根目录,运行的程序不能访问指定根目录以外的文件,适用于做为测试环境。要在指定根目录下和真正根目录下一样运行相应的程序,需要:
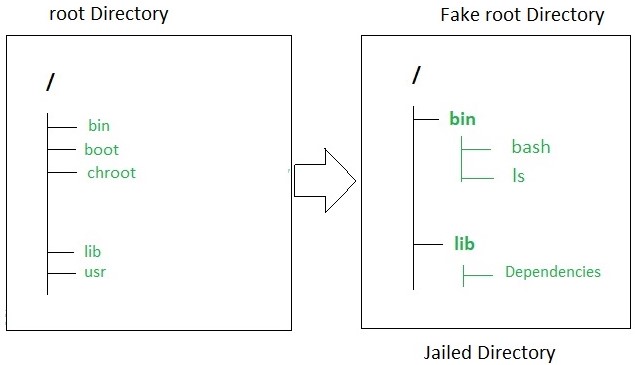
- 在该根目录下安装对应的程序,该方法将自动安装程序及其依赖包。
- 手动复制系统根目录下已可执行文件及其依赖项,需要自行确定依赖项。
chroot --userspec=USER:GROUP --groups=G_LIST NEWROOT [COMMAND [ARG]...]
如果未指定命令,则默认运行:'${SHELL} -i'。
历史记录
ctrl + r # 在终端反向搜索历史命令
!! # 执行上一条命令
!* # 上一条命令的所有参数 (!:1-$)
!$ # 上一条命令的最后一个参数 (!:N,第N个参数; !-n:$, last-but-n)
历史记录中最常用的命令:
history | awk 'BEGIN {FS="[ \t]+|\\|"} {print $3}' | \
sort | uniq -c | sort -nr | head -n N
清空屏幕:ctrl+l。
复制/粘贴:ctrl+shift+c/v。
运算
字符串操作
${#str} # 字符串的长度,注意数组长度${#array[@]}
查找
使用grep和正则表达式可以自定义查找方式,包括startswith,endswith等,在程序中可根据返回值判断是否成功匹配。
grep 'hive' <<< 'apache-hive-3.1.2-bin'
#> apache-hive-3.1.2-bin
grep -Po '^(\w)+' <<< 'spark-3.0.1-bin-hadoop3.2.tgz' # startswith
#> spark
grep -Eo '(tar.gz|tgz)$' <<< 'hadoop-3.2.1.tar.gz' # endswith
#> tar.gz
在条件表达式中,通过字符串比较测试也可进行查找匹配,但仅能判断是否匹配,而不能获取匹配结果;另一方面,grep的返回值可用于条件表达式判断是否成功匹配。
替换
${param:-DEFAULT} # 如果param为空,则返回为默认值
${param-DEFAULT} # 如果param未定义,则返回为默认值
${param:=DEFAULT} # 如果param为空,则把它设置为默认值,并返回param的值
${param=DEFAULT} # 如果param未定义,则把它设置为默认值,并返回param的值
# ":"限定判断条件变量为空,"=/-"决定是否为变量赋值
${param%PATERRN} # 从param尾部删除与PATERRN最小匹配
${param%%PATERRN} # 从param尾部删除与PATERRN最长匹配
${param#PATERRN} # 从param头部删除与PATERRN最小匹配
${param##PATERRN} # 从param头部删除与PATERRN最长匹配
shell 编程:冒号 后面跟 等号,加号,减号,问号的意义 - 笨鸟教程的博客 | BY BenderFly (handerfly.github.io)
使用sed和正则表达式可以很容易实现字符串内容的修改:
sed -n 's/ /\*/p' <<< 'hello world' # 替换匹配内容
#> hello*world
sed -E 's/.(tar.gz|tgz)$//' <<< 'hadoop-3.2.1.tar.gz' # 删除后缀
#> hadoop-3.2.1
拼接
str3=$str1$str2
拼接变量的值,由于变量的值为字符串,因此实际等效于字符串拼接。
拼接文件内容:
STR=''
for line in $(cat filename); do
line=$(sed -E 's/#.*//' <<< $line) # edit the line
STR="$STR $line"
done
获取子串
按索引(0-based index)获取:
sub_str=${str:START:LENGTH} # ${string:start=0:length=${#str}}
使用正则表达式(捕获组)获取匹配子串:
ps -ef | sed -nE '100s/^[a-zA-Z0-9\+]+ +([0-9]+).*/\1/p' # 获取pid
#> 184289
使用分隔符拆分字符串并获取子串:
read -a cmd_args <<< "sudo apt update" # 将拆分结果存入数组(分隔符$IFS,默认为空白)
仅获取拆分后的某个子串:
ps -ef | sed -n '10p' | awk '{print $2}' # use awk
cut -d ";" -f 1 <<< "bla@some.com;john@home.com" # use cut
awk将连续多个分隔符视为一个分隔符;cut将连续分隔符之间视为空字符串。
xargs将管道或标准输入(stdin)数据转换成命令行参数。
xargs # https://www.runoob.com/linux/linux-comm-xargs.html
local_home=${local_home%'/'} # trim the trailing '/'
整数运算
declare
declare -i n
n=7/3 # echo $n => 2 : 非四舍五入(舍去小数)
n=n+1 # 计算表达式中无须使用$对变量求值
expr
expr将参数解释为表达式并进行评估,输出计算结果。表达式中操作符和操作数需要使用空白分开,可以包含简单四则==整数==运算(+、-、*、/)、求余(%)、逻辑运算(|、&、=、>、>=、<、<=、!=)。乘号(*)前边必须加反斜杠(\)避免通配符展开。
R=$(expr $a + $b – 20 \* $c / $d + $e % 10)
==let==
let表达式中不能包含空格,且变量名无需添加$,let会对表达式进行解释和计算。
let z=5
let z=z+1 # <=> let z=$z+1
bash算术运算
((a = $b + 10)) # 对空格没有要求
日期和时间
date命令可以对表示时间的变量进行增加(+)/减少(-)操作。
iter_date=$(date +%Y%m%d -d "$iter_date + 1 year")
输入
$iter_date为空时,默认为当前日期时间
计算时间差
利用时间戳计算时间差。
let DIFF=($(date +%s -d 20210131)-$(date +%s -d 20210101)) # diff of seconds
let t_minutes=t_elapse/60
let t_seconds=t_elapse%60
条件表达式
语法:使用[ expr ]定义条件表达式。表达式返回值0表示true,1表示false。
注意在中括号内的变量,最好都以双引号括号起来(避免空字符串以及带空白的字符串展开造成语法错误);常数也最好都以单或双引号括号起来。
[是条件表达式的命令名,其后的内容作为其参数展开,因此[]、运算符、变量之间必须以空格分隔,而展开后带空格的变量也需要使用引号保证参数的完整性。<、>、&&、||、()等特殊字符作为Shell的命令,是不能作为参数的,因此不能直接出现在条件表达式中(使用转义字符\)。
表达式中仅允许使用以下定义的运算符对变量进行测试,而使用其他命令将会出错。
数值比较
-eq(==)、-ne(!=)、-gt(>)、-lt(<)、-ge(>=)、-le(<=),只支持数值比较。
[ $a -eq $b ]
由于
>、<为特殊字符不能作为关系运算符,使用命令选项表示关系运算符。
逻辑运算
[ ! expr1 ] # logical not
[ $a -o $b ] # logical or
[ $a -a $b ] # logical and
[ -r $1 ] && [ -s $1 ]
字符串比较
字符串运算符:=、!=;
[ $str1 != $str2 ] # 字符串比较
[ -z "$str" ] # true(0) if str is zero-length
[ -n "$str" ] # true(0) if str is non-zero-length
-n参数需要使用""括起来,否则对空字符串的计算结果不正确。
文件测试
[ -dfrwxse file ]
-e:文件是否存在;-d:目录;-f:普通文件;-r:读权限;-w:写权限;-x:访问/执行权限;-s:文件是否为空。
Robust Condition Expression
相比于[],[[]]提高了条件语句的健壮性和可用性,具体地,[[]]可以==处理空字符串以及带空格的字符串==,因此不用对变量取值($var)增加额外的引号。
需要在
bash环境中使用[[]]。
-
使用
&&、||作为逻辑运算符[[ expr1 && expr2 ]] # logical and [[ expr1 || expr2 ]] # logical or -
支持使用
<,>,==,>,<,!=做字符串比较; -
=~运算符,用于正则表达式匹配(==正则表达式模式不能加引号==);[[ $answer =~ ^y(es)?$ ]]; echo $? #* -
通配符
*、?匹配(模式表达式不能带引号,否则视为普通字符串);[[ $ANSWER = y* ]]; echo $? # start with
优先级
在[[]]表达式中,使用()保证优先级。
流程控制
不存在块作用域:语句块中定义的变量在语句块结束后仍有效(因为不存在变量声明语句)。
==流程控制语句块可以嵌套==。
==语句块内容不能为空,否则有语法错误==。
函数
在脚本中可将一组常用操作定义为函数。函数的定义必须出现在调用之前,不存在前向声明。
function fun_name(){ # function keyword is optional
statements;
return n; # optional
}
函数输入参数
函数没有显式定义参数,参数传入规则与脚本一致,即在函数内部参数变量$1,...将被更新未调用函数时传递的参数,其中$0==仍为调用脚本名==。函数执行完返回调用程序后,参数变量将恢复到调用程序之前的状态。
函数返回值
返回值代表函数的执行状态,不表示函数的输出内容。因此,使用 return返回整数值(通常<128);如果不加return语句,将以最后一条命令的返回值作为函数的返回值。
函数输出
函数应该向标准输出发送输出数据(如echo "output"),从而使调用程序可通过$(func args)捕获到输出内容。同时,应该向标准错误输出(command >&2)发送预计行为外的输出(如错误信息、日志信息等),以保证调用程序获得预期的输出内容(或在出现异常的情况下获得空内容)。调用程序如果未捕获输出结果且未做重定向,则标准输出和标准错误输出通常都会打印到控制台。
函数内的变量作用域
函数中的变量作用域与source script.sh(当前Shell执行)相似:
-
==函数可以访问被执行脚本所在Shell环境中的变量==。
-
==函数中声明的变量默认为
global作用域,即在函数调用返回后仍然有效==。- ==如果函数调用是在
$(...)中而非当前Shell,则函数中定义的变量离开$(...)语句后无效==。
- ==如果函数调用是在
-
使用
local关键字在函数内部声明局部变量。如果局部变量与全局变量名字相同,则在局部变量的作用域内,局部变量将覆盖全局变量。==局部变量仅具有函数范围生命周期==。
语句连接和语句块
&&:如果第一条命令执行成功(返回0)则执行&&后续命令;
;:用于连接两条命令,无论第一条是否执行成功,都继续执行后续命令。在交互环境下执行命令时,前一条命令中的==赋值语句==设置的变量仅限当前命令使用,当前命令执行完后恢复设置前的值;在脚本中编写同样的命令则不会被重置。这个特性方便临时设置分隔符等变量。
IFS=:; read host path <<< 'user@host:downloads/'; echo IFS=$IFS;
上述命令在交互终端中运行时,打印
IFS为空;在脚本中执行(bash -c)则打印:。仅对赋值语句有效,通过read赋值的变量的值在下一语句执行后仍然保留。
条件
if cond_expr1 ; then
statements
elif cond_expr2 ; then # elif 可选
statements
else # else 可选
statements
fi
cond_expr1为条件表达式。then可以和condition置于一行,但需要在condition和then之间添加“;”。
case $variable in # swith-case
pattern1 [|pattern11...] )
statements
;;
pattern2 [|pattern22...] )
statements
;;
......
*)
;;
esac
pattern表示匹配模式字符串,不需要添加引号。多种模式可以使用“|”合并为一类。使用“)”表示模式说明的结束,使用“;;(双分号)”表示一个模式行的结束。
只执行一个匹配行,即使其后有更精确的匹配。
模式语句支持正则表达式。
模式可使用通配符,因此可以使用“*”作为默认模式。当所有的匹配都不成功时,才执行“*”对应的命令。通配符扩展在引号中不起作用。
循环
迭代
基于数值的迭代:
for ((i=0;i<len;i++)); do # 控制语句不需要使用$i和$len, 但过程语句需要$i
echo $i
done
遍历基于空格分割的字符串序列:
for v in v1 v2 v3 ...; do
statements
done
==v1 v2 v3...是由空格分隔的字符串==。
序列展开迭代
可由序列转换v in ${array[@]}得到迭代元素。如果序列元素本身包含空白,则要使用v in "${array[@]}",防止元素被分割。
命令行参数展开(*),将被替换为所有匹配文件名构成的可迭代对象。
for s in ./*.sh; do echo $s; done # 文件名包含空格不会被中断
条件循环
while condition ; do
statements
done
until condition ; do
statements
done
其他
break:跳出循环(case语句使用;;终止分支,不需要使用break);
continue:跳过本次循环的剩余内容;
return:用于函数的返回(或使用source/shell调用的脚本的返回),并提供返回值。
exit:用于脚本提前退出并提供返回值。
输入输出
标准输入输出
输出
echo -n -e $var
echo `expr`
echo $var1 $var2
-n:不输出换行;-e:确保输出内容启用==转义字符==(例如\n, \t);
C语言风格输出函数:
printf "%10s %08d %-10.2f\n" hello 8 9.9
printf '%s\n' A-{1..5} # 自动展开并迭代1到5的序列
printf -v outstr FORMAT ARGS # 将格式化输出存储到变量中。
获取命令的==标准输出==(非返回值,返回值为$?)。错误输出不会被$()捕获,仍正常输出(到终端)。
result=$(cmd.sh args) # assign the output string to result
result=`cmd.sh args`
输入
read从标准输入==读取一行==内容。可将文件或标准输出重定向至read。
read -a array -d delim prompt -r ... [vars ...]
如果提供了一个或多个位置参数变量,则==使用分隔符$IFS分割读取内容==,并将分隔后的内容依次存入位置参数;如果没有位置参数变量,则将读取内容存入$REPLY中。
read如何从子shell中返回变量到父进程?
参数:
-a array:将分割后的内容按顺序存入数组;
-d delim:将行结束符设置为delim的第一个字符(后续字符无效)而不是以换行结束;将行结束符置空将读取整个文件的内容。
-e:使用readline读取一行内容(可自动补全文件名等);
-n nchars:读取最多nchars个字符后结束(不用等到换行),仍支持分隔符;-N忽略分隔符;
-p prompt:输入内容前的提示信息;
-r:忽略字符串中的转义字符(\);
-s:不在终端上显示输入内容(用于==输入密码==);Enter结束输入但不会产生换行作用;需要在程序中执行换行。
-t timeout:设置读取超时时间(用于交互式界面);
从标准输入读取多行内容:直到输入一行内容为"EOF"终止,也可以使用ctrl+D结束输入标准输入流。
text=$(cat << EOF)
重定向
Linux程序通常使用标准输入/输出与用户或系统交互。
- 编写程序时,默认仅需要处理标准输入输出,在不必要的情况下不额外打开文件,以简化程序逻辑。
- 调用程序时,通过重定向命令使用文件数据流代替标准输入输出;
重定向语法
| 语法 | 说明 |
|---|---|
command < filename | 使用文件代替标准输入。 |
command >&2 | 将命令的输出定向到错误输出。 |
command <<[-] end_word | 从标准输入读取内容,直到一行仅包含end_word;-去除内容开始前的tab制表符。 |
command <<< args | 使用命令行参数代替标准输入。 |
command > filename | 使用文件代替标准输出(>>追加模式)。 |
command 2> filename | 使用文件代替标准错误输出(2>>追加模式)。 |
command > filename 2>&1command 2> filename 1>&2 | 将标准输出和标准错误输出都定向到指定文件。 ( >>或2>>追加模式) |
2>&1表示将标准错误输出再定向到标准输出。
https://www.gnu.org/software/bash/manual/html_node/Redirections.html
示例:
command > /dev/null 2>&1 # 将标准输出和错误输出丢弃
清空文件
> FILENAME # => > FILENAME => true > FILENAME
cat /dev/null > FILENAME # => cp /dev/null FILENAME
truncate -s 0 FILENAME
不要尝试将一个文件读出的同时再写回当前文件(cat file > file),因为此命令在执行前会为输出流清空当前文件。
管道
管道用于连接两个命令,将上一个命令的标准输出作为下一个命令的标准输入。示例如下:
ps -ef | grep 'apache' | grep -v grep
将错误输出流传入管道:
command | 2>&1 grep 'something'
文件输入输出
text=$(cat txtfile)
除了使用文件名读取文件内容外,使用重定向语法也可以使程序读取文件内容代替默认的标准输入。
head/tail用于过滤部分数据:
head -n,--lines=[-]N FILE # 输出前N行内容,-表示除去最后N行的内容
tail -f,--follow FILE
-n,--lines=[+]N # 输出文件最后N行,+表示从第N行开始输出
--pid=PID # with -f, terminate after process PID dies
more:键入用〈space〉键显示后续内容,显示当前查看的百分比。
pg:分屏显示文件的内容,按<enter>键显示下一屏的内容。
按行读写和处理文件
使用循环读取文件中每一行的内容:将while语句块视为一条语句,可使用“|”接收前置命令的输出或使用“<,>”等 来重定向标准输入/输出输入到文件,那么while语句块中的所有命令将使用重定向后的输入输出。
# read name=value pairs from file
lines=()
while IFS='=' read name ...; do # 如果读整行则指定一个变量(IFS='')
echo $name $value;
# process line
lines+=($name) # 将文件内容保存到数组
done < src_file # default: from stand input
IFS=默认以空白为分隔符(将自动截断输入的前后空白内容)。需要注意,如果使用文件重定向,但循环过程中存在交互输入,则交互输入内容也会从文件中获取,这可能是不希望的行为。因此需要首先==将文件内容读取序列==中,然后再使用
for循环迭代并获取用户的输入。如果需要对读入的每一行分别进行处理输出(如替换修改等,可使用
grep/sed/awk等工具)。当如果需要处理的内容与上下文相关,则需要自定义处理逻辑。
将文件内容构造为序列
mapfile和readarray可简化上述读取操作。
mapfile -t lines < file.txt # ==> readarray
# 默认分隔符为所有空白,这里将分隔符设置为换行,因此按行拆分为序列
IFS=$'\r\n' GLOBIGNORE='*' command eval 'XYZ=($(cat /etc/passwd))'
IFS=$'\n' read -d '' -r -a lines < /etc/passwd
如果使用
for语句读取文件输入(使用cat, sed等),需要注意==文件内容将会被拼接为一个整体,并按空格分离进行迭代==。for pkg in $(sed -E 's/#.*//' all_conda.pkgs); do echo $pkg; done
将序列内容写入文件
将整个命令的标准输出定向到文件,避免重复打开文件。
for line in "${text_array[@]}"; do
echo $line
done > text.txt
for ((i=0;i<${#text_array[@]};i++)); do
echo "$i: ${text_array[i]}"
done > text.txt
进程
创建进程
Shell执行命令时创建子进程(子Shell,进程号$!),并等待子进程结束。如果要立即返回则使用&使子进程与Shell分离。
./script.sh args > tmp.log 2>&1 &
子进程分离后,其标准输入输出仍然绑定在原Shell,因此需要进行重定向。也可以使用nohup自动进行重定向,输出内容到nohup.out中。
nohup ./script.sh args &
信号处理
通常,当子进程在执行时,bash会忽略所有信号。
#!/bin/bash
term_handler() {
echo "Caught SIGTERM signal!"
kill -TERM "$child" 2>/dev/null
}
trap term_handler SIGTERM
echo "Doing some initial work...";
/bin/start/main/server --nodaemon &
child=$! # get Process ID
wait "$child" # wait child to end or any signals
term_handler='-'默认处理方式;term_handler=''忽略信号。
调度
休眠
sleep 100 # seconds
调试程序
Fix bugs in Bash scripts by printing a stack trace | Opensource.com
set -E # the error trap is inherited throughout the script
trap 'ERRO_LINENO=$LINENO' ERR # traps commands that exit with a non-zero code
trap '_failure' EXIT
_failure() {
ERR_CODE=$? # capture last command exit code
set +xv # turns off debug logging, just in case
if [[ $- =~ e && ${ERR_CODE} != 0 ]]
then
# only log stack trace if requested (set -e)
# and last command failed
echo
echo "========= CATASTROPHIC COMMAND FAIL ========="
echo
echo "SCRIPT EXITED ON ERROR CODE: ${ERR_CODE}"
echo
LEN=${#BASH_LINENO[@]}
for (( INDEX=0; INDEX<$LEN-1; INDEX++ ))
do
echo '---'
echo "FILE: $(basename ${BASH_SOURCE[${INDEX}+1]})"
echo " FUNCTION: ${FUNCNAME[${INDEX}+1]}"
if [[ ${INDEX} > 0 ]]
then
# commands in stack trace
echo " COMMAND: ${FUNCNAME[${INDEX}]}"
echo " LINE: ${BASH_LINENO[${INDEX}]}"
else
# command that failed
echo " COMMAND: ${BASH_COMMAND}"
echo " LINE: ${ERRO_LINENO}"
fi
done
echo
echo "======= END CATASTROPHIC COMMAND FAIL ======="
echo
fi
}
The following built-in shell values are used to build the stack trace:
BASH_SOURCE: Array of filenames where each command was called back to the main script.FUNCNAME: Array of function names matching each file inBASH_SOURCE.BASH_LINENO: Array of line numbers per file matchingBASH_SOURCE.BASH_COMMAND: Last command executed with flags and arguments.
应用
选项参数设置
选项参数解析:getopt是标准的参数处理程序,可以处理长、短选项参数以及位置参数。将arguments中的选项参数和位置参数使用"--"分离开,任意位置的非选项参数全部移至"--"之后。
getopt --longoptions longopts \ # 长选项
--options shortopts \ # 短选项
--name progname \ # 解析参数出错时显示的程序名(通常为当前脚本名"$0")
arguments... # 带解析的参数列表(通常为$@)
OPTIONS和LONGOPTS不能包含空格。==如果某类选项为空,仍需要传递空字符串""作为相应的参数==,否则解析选项参数不正确。
参数处理程序
将命令行输入参数中的选项参数与位置参数分离并处理,提供给后续程序使用。
SHORT=dfo:v
LONGS=debug,force,output:,verbose
! PARSED=$(getopt --options=$SHORT --longoptions=$LONGS --name "$0" -- "$@") #*
if [ ${PIPESTATUS[0]} -ne 0 ]; then # [ $? -ne 0 ]
exit 2
fi
eval set -- "$PARSED" #**
while true; do
case "$1" in
-d|--debug)
OPT_DEBUG='--debug'
;;
-o|--output)
OUTPUT=$2
shift
;;
--)
shift
break # break the while loop
;;
*)
echo "Programming error"
exit 3
;;
esac
shift
done
*:"$@"防止包含空格的原有参数被展开为多个参数,!忽略命令执行错误并继续执行(如果未设置set -o errexit则无需添加,直接检查$0而非$PIPESTATUS)。
**:正确处理解析后带空格的参数,如-d --source 'test 1' -- 'test 2'。其中的'是字符串中的普通字符而非参数边界,如果直接书写$PARSED,则会导致命令行按其值的空白展开得到'test,1'这样的参数,破坏原有参数结构。通过添加""以及使用eval可将解析后的参数中的'重新解释为参数边界。
执行脚本:如果选项的值带有空格,可使用引号将选项括起来,防止空格后内容被展开解释为独立参数。
./script.sh --option="sip REGEXP 10.12.20.4[5-9]"
如果脚本还具有子命令,则在调用上述处理参数前首先处理并消耗固定的子命令参数。
if [[ $1 == "command" ]]; then
shift
set - #*
sub_process "$@" #**
fi
*:消耗子命令参数后,重设参数变量。
**:可以将该子命令的参数处理程序及功能代码写在当前if语句块中,或者将其封装为单独函数(函数支持参数传递)。
固定参数检测逻辑
以下命令不做替换,仅检测参数是否为空已决定程序是否继续执行,适用于处理固定参数。
param=${param:?MESSAGE}
如果param为空,则向标准错误输出信息,并退出脚本。
文本处理
文本处理工具grep,sed,awk对比:
- 三者均可以通过正则表达式对输入行进行筛选;
grep仅用于查找匹配模式,并返回匹配行(或匹配模式部分);sed还可以对匹配行进行编辑(替换),并进行上下文相关的修改,==通过替换操作可提取文本中的正则表达式捕获内容==;awk更适合格式化文本,对文本进行较复杂格式处理(如分割字段并格式化)。
grep
从文件读取行并执行正则表达式匹配。返回值:0匹配到模式;1未匹配到模式。
grep [option] PATTERN [file1 file2 …]
-作为文件名代表标准输入;使用管道输入则无需提供文件输入参数。
正则表达式类型:-G,--basic-regexp,-E,--extended-regexp ,-P,--perl-regexp。-P支持\d,\w等字符集合;此外,grep支持预定义的命名字符集合(这些与实现相关,仅在grep中可用)。
匹配模式(pattern)
| 选项 | 说明 |
|---|---|
-e,--regexp=PATTERN | 使用PATTERN进行匹配。由于 PATTERN直接提供在命令行,该选项可以省略。该选项可以用于提供多个匹配模式,而命令行中只能提供一个。 |
-f,--file=FILE | 从文件FILE中读取PATTERN。 |
-i,--ignore-case | 忽略大小写 |
-w,--word-regexp | 匹配整个单词 |
-x,--line-regexp | 匹配整行 |
执行控制
| 选项 | 说明 |
|---|---|
-m,--max-count=NUM | 在NUM次匹配之后停止 |
--binary-files=TYPE | 文件类型:binary,text或without-match |
-a, --text--binary-file=text | |
-I--binary-file=without-match | 表示不查找二进制文件。 |
-d,--directories=ACTION | 如何处理文件夹:read,recurse,skip |
-r, --recursive | --directories=recurse |
-R | 递归,但不追踪符号链接。 |
-D,-devices=ACTION | 如何处devices,FIFOs和socket:read,skip |
--include=FILE_PATTERN | 搜索文件的文件名需要匹配FILE_PATTERN,FILE_PATTERN可以包括通配符“*”“?”。 |
--exclude=FILE_PATTERN | 排除文件名与FILE_PATTERN匹配的文件。 |
--exclude-from=FILE | 跳过与FILE中的模式匹配的文件 |
--exclude-dir=PATTERN | 跳过与PATTERN匹配的文件夹 |
-v, --inver-match | 选择没有匹配的行 |
输出控制
| 选项 | 说明 |
|---|---|
-b,--byte-offset | 在输出的匹配行前添加匹配行相对文件起始位置的字节数。 |
-n,--line-number | 在输出的匹配行前添加行号 |
-H,--with-filename -h,--no-filename | 在输出的匹配行前添加文件名 (从起始位置开始的相对路径,默认)。 -h不输出文件名。 |
-o, --only-matching | ==只输出匹配部分== |
-q, --quiet, --silent | 不输出普通消息 |
-s, --no-message | 不输出错误消息(要输出其他消息) |
-L,--files-without-match | 仅输出没有发生匹配的文件的文件名。 |
-l,--files-with-matches | 仅输出发生匹配的文件的文件名 (从起始位置开始的相对路径)。 |
-c, --count | 仅输出一个文件中匹配的行数。 |
-B, --before-context=N | 输出匹配行及其之前的N行内容 |
-A, --after-context=N | 输出匹配行及其之后的N行内容 |
-C, --context=<NUM>-<NUM> | 输出匹配行及其前后的NUM行内容 |
--color[=WHEN] --colour[=WHEN] | 使用颜色高亮匹配内容,WHEN='always','never', 'auto'。 |
sed
stream editor for filtering and transforming text. (
info sed)
sed一次处理一行内容,把当前行存储在称为“模式空间”(pattern space)临时缓冲区中,接着用sed命令处理模式空间中的内容;处理完成后将结果发送到输出流并清空模式空间,再继续处理下一行内容直到文件输入结束。保持空间(hold space)用于保存一些内容,在整个循环执行过程中不会被自动清空。
sed [options] [script] input-files
-E,-r,--regexp-extended:在脚本中==使用扩展的正则表达式==(ERE)而非基本正则表达式(BRE),由于/在sed表达式中用于脚本命令的分隔符,因此是特殊字符,对于普通的/字符需要添加转义\,或使用\%REGEXP%设置分隔符(%可以为任意字符)。
不支持字符集合
\d、\w等。
脚本script:处理一行内容sed脚本语句。如果没有指定-e,-f选项,则sed使用第一个非选项参数作为脚本,其他参数作为输入文件;-e,-f选项可组合使用也可出现多次,最终的命令脚本是所有选项提供的脚本的组合;
-e,--expression=script:要执行的命令;-f,--file=script-file:从文件中读取命令;
script参数中使用;分隔多个命令;文件中的命令使用换行分隔;
输入输出:如果未指定输入文件,或输入文件为-,则sed使用标准输入流作为输入,也可以接收管道作为输入;sed使用标准输出流输出,可将输出重定向到文件(注意不要将输出重定向到输入文件,这样会先清空输入文件内容,应该使用--in-place[=BACKUP_SUFFIX]选项更新源文件)。
sed 's/hello/world/' input.txt > output.txt
cat input.txt | sed 's/hello/world' - > output.txt
sed默认输出所有输入内容(除了被d命令删除的内容)。使用-n抑制输出后,仅输出命令指定的内容(例如使用p命令输出指定的行)。
ps -ef | sed -n '1p;10p;$p' file.txt # 仅输出第1、10行和最后一行
-s,--separate:将多个文件视为独立的流,而非一个单独的长输入流;
-i,--inplace[=SUFFIX]:修改原始文件(inplace);具体操作是先将输出保存到一个临时文件,结束处理时用临时替换原始文件。如果提供SUFFIX则将原始文件重命名为以SUFFIX结尾的备份文件。如果SUFFIX包含*,则将*替换为原始文件名,从而实现添加前缀(或路径名)。==由于-i是对原文修改,因此慎用-n选项,否则导致原文内容被误删除==;
--follow-symlinks:仅在-i指定时有效,修改符号链接最终指向的文件;
-n,--silent,--quiet:抑制自动输出;
-l,--line-length=N:指定输出自动换行的长度,默认值为70;
返回值:0成功;1无效命令;2某个文件无法打开;4输入输出错误;使用命令q或Q自定义返回值Q42。
sed脚本语句
sed脚本语句的语法:[addr]{X[/options/];Y[/opts/];...}。
X,Y,...代表单字符的sed命令;addr为行地址;options为某些命令的选项。
一条语句中包含一个行地址,但可包含多条命令构成命令组。如果只有一条命令则可以省略{}。
如果没有使用
{},则;后的命令属于下一条语句(没有行地址,默认匹配全部文本)。
行地址
使用数值表示单独的行(从1开始,$表示最后一行),使用N1,N2指定连续的行区间;使用start~step来指定每隔若干行取一行执行;==未指定行地址则默认对所有行执行命令==;可以使用正则表达式/pattern/来匹配目标行:
ps -ef | sed -n '2,$/p' # 跳过第一行
sed '/apple/s/hello/world/' input > output # edit on line contain 'apple'
无论是数字或正则表达式表示的行地址,取补集即:
'/REGEXP/!cmd'。
| 命令 | 说明 |
|---|---|
aTEXT, a TEXT | 在一行后插入文本 |
cTEXT, c TEXT | 替换文本 |
iTEXT, i TEXT | 在一行前插入文本 |
p,P,l | 打印模式空间(一行),-P打印到出现换行符; |
d | 删除模式空间,进入下一次循环;-D删除换行符之前内容,并重新开始当前循环(没有换行符则进入下一循环); |
n | 非安静模式下,输出当前模式空间内容, 在任何情况下,用下一行内容替换当前模式空间内容 (下一行内容被消耗不会再被下一个循环读取) |
z | 清空模式空间(空字符串,仍占一行) |
F | 将前行所属的文件名作为一行插入当前行之前 |
g,G | 用保持空间的内容替换模式空间的内容;G为追加模式 |
h,H | 使用模式空间内容替换保持空间的内容;H为追加模式 |
x | 交换模式空间和保持空间的内容 |
s/REGEXP/REPLACE/[FLAGS] | ==替换匹配行的匹配内容== |
y/src/dst/ | 将模式空间中属于src集合中的字符用dst集合中的相应字符代替 |
'a', 'c', 'i'命令之后内容为插入的文本,因此不能在其后使用;连接其他命令。这些命令只能放在脚本最后或使用换行符分隔其他命令(命令行输入一条命令后换行继续输入另一条命令)。$ seq 2 | sed '1a Hello > 2d'替换模式:使用源空间内容替换目标空间内容;
追加模式:在目标空间的内容基础上拼接一个换行符(
newline)以及源空间的内容;
-n命令常用于处理每隔N行执行的操作;
seq 6 | sed '0~3s/./x/' # 等效于 sed 'n;n;s/./x'
s命令(substitute)
s命令可添加的选项(FLAG):
g:==替换所有匹配,而不仅是首个匹配==;
p:如果发生替换,则输出替换后的模式空间;未发生替换则不输出内容;未添加该选项时,根据-n选项(抑制自动输出)确定是否输出当前行(可能发生替换)的内容。
w FILENAME:如果发生替换,则将结果输出到文件,使用/dev/stderr和/dev/stdout表示标准输出流;
i,I:大小写不敏感的匹配;
当使用==扩展正则表达式==(-E)时,REPLACE中的特殊字符需要添加\转义为普通字符。
\、&、空格和换行(换行为\n)。对于非转义字符,使用\c等效于直接使用该字符。
使用\N(N=1~9)表示第N个捕获(位于正则表达式中(和)之间的内容),用&表示整个匹配(即实现在原文内容前后插入内容);
\L:将替换内容变换为小写字母直到\U或\E;\l将后续第一个字符变为小写;
\U:将替换内容变换为大写字母直到\L或\E;\u将后续第一个字符变为大写;
大小写替换范围作用在一个匹配结果之内,每个匹配结果独立执行大小写替换;
awk/gawk
gawk - pattern scanning and processing language.
基本用法
awk '{[pattern] action}' {filenames}
awk的命令语句只能用单引号'',避免shell展开其中的参数(例如$1)。
输出:
awk '{print $1,$4}' <<< 'this is a string' # 每行按空格或TAB分割,输出文本中的1、4项
awk '{printf "%-8s %-10s\n",$1,$4}' <<< 'this is a string' # 格式化输出
printf的格式声明和参数之间使用,分隔(可包含空格)。
设置分隔符:
awk -F, '{print $1,$2}' log.txt # 使用","分割
awk 'BEGIN{FS=","} {print $1,$2}' log.txt
# 使用多个分隔符:先使用空格分割,然后对分割结果再使用","分割,[]不是分隔符的一部分
awk -F '[ ,]' '{print $1,$2,$5}' log.txt
设置变量:
awk -va=1 '{print $1,$1+a}' log.txt # set a=1
调用脚本:
awk [options] -f program-file [--] file ...
awk [options] [--] program-text file ...
运算符
内置变量
$NF:字符串的最后一列;
https://www.runoob.com/linux/linux-comm-awk.html
过滤
过滤:
awk '$1>2' log.txt
awk '$1==2 {print $1,$3}' log.txt
awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt
可使用正则表达式过滤行。对整行进行过滤,/REGEXP/是模式。
awk '/re/ ' log.txt # 输出包含 "re" 的行 ==> grep 're' < log.txt
awk '!/th/ {print $2,$4}' log.txt # 取反匹配
awk 'BEGIN{IGNORECASE=1} /this/' log.txt # 忽略大小写
或根据分割后的字段进行过滤,~表示模式开始:
awk '$2 ~ /th/ {print $2,$4}' log.txt # 第二列包含 "th"
awk '$2 !~ /th/ {print $2,$4}' log.txt # 取反匹配
awk脚本
#!/bin/awk -f
BEGIN{} #运行前
{} #运行中:处理每一行
END{} #运行后
awk参考资料
全文处理
按行排序
sort [OPTIONS] FILES...
sort << EOF # 对键入内容按行进行排序
cmd_output | sort # 对命令输出内容按行排序 <==
-b, --ignore-leading-blanks:忽略起始空白;-f, --ignore-case:忽略大小写;-r, --reverse:反向排序;-o, --output=FILE:输出文件。
去重
检测连续的重复记录(可能需要先进行排序),默认输出去除重复记录的结果。
uniq INPUT
cmd_output | unique
以标准输入或文件作为输入,并输出到标准输出或文件。选项:
-c, --count:在每一行前添加出现次数;-d, --repeated:仅打印重复行(只保留一条记录);-u, --unique:仅打印不重复的行;
参考文献
Math in Shell Scripts, http://faculty.salina.k-state.edu/tim/unix_sg/bash/math.html
Linux 发行版
Ubuntu
安装系统
系统版本:
- Server:默认无桌面环境;在编译时优化了某些选项;支持多处理器对称技术和NUMA;服务器版本的内核时钟频率由桌面的100hz转为1khz(参考)。
Ubuntu默认采用的文件系统格式为ext4,默认除根目录和/boot外,不会为其他目录挂载分区。
软件管理
软件源配置
添加镜像站点加速。国内的站点包括:
- 阿里云:https://developer.aliyun.com/mirror/ubuntu
- 清华:https://mirrors.tuna.tsinghua.edu.cn/ubuntu(
Certificate verification failed) - 中科大:https://mirrors.ustc.edu.cn/ubuntu
- 网易:http://mirrors.163.com/ubuntu
安装服务器版本过程中,可以设置镜像站点。
编辑软件源配置文件:
sudo vi /etc/apt/sources.list
修改配置文件中的站点为镜像站点。
更新软件源信息:
sudo apt update
如果需要使用代理访问网络,则设置/etc/apt/apt.conf.d/00aptproxy(apt不适用系统代理环境变量):
Acquire::http::proxy "http://[<domain\user>:<password>@]<yourproxyserver>:<Port>";
Acquire::https::proxy "http://[<domain\user>:<password>@]<yourproxyserver>:<Port>";
Acquire::ftp::proxy "http://[<domain\user>:<password>@]<yourproxyserver>:<Port>";
如果代理需要认证,则需要配置用户名和密码
[<domain\user>:<password>@]。
常见问题
-
Certificate verification failed:(容器)使用https协议需要ca-certificates。使用基于
http的镜像源。或者手动下载安装ca-certificates及其依赖文件。
软件管理工具
apt-get
apt-get是其他APT工具的后端,如aptitude,synaptic和wajig。
apt-get update # 从软件源同步软件包索引
upgrade # 升级软件包到最新版本
dist-upgrade # 系统重大升级(可能移除某些软件包)
install|reinstall PKG[=version] --download-only
remove|purge PKG # purge还移除配置文件
autoremove # 移除系统中不需要的软件包
download PKG[=version] # 下载软件包到当前目录
# 不能指定下载位置
clean|autoclean # 清理本地仓库,autoclean清理不再使用的缓存文件
apt-get changelog # 获取软件包的改动历史
remove将保留用户做过修改的配置文件(以防以外卸载导致用户配置丢失),而purge将移除所有相关文件(包括之前卸载过的软件,用户主目录下的文件除外)。==手动删除remove保留的配置文件可能导致重装软件出现问题。==
install --reinstall => reinstall;remove --purge => purge
选项:
-a,--host-architecture=architecture:
apt-cache
查询APT缓存。
apt-cahce gencaches # 生成缓存,其他命令如需要会调用
stats # 显示缓存统计信息
search REGEX
-f,--full # 列出所有版本的信息
-n,--names-only # 仅搜索包名
pkgnames PREFIX # 显示匹配前缀的包名
showpkg PKG # 显示软件包信息
show PKG # 显示软件包信息(更多详情)
-a,--all-versions # 显示所有可用版本
showsrc PKG # 显示软件源码包(必须source.list中配置源码源)
depends PKG # 显示依赖信息(包括冲突包)
--recurse # 递归解析依赖
apt
apt封装了apt-get、apt-cache等后端工具的常用命令,并对选项默认值做了部分改动。
查找软件
sudo apt search PACKAGE # -> apt-cache search
sudo apt list PACKAGE [--installed] # 列出(已安装)软件包信息*
sudo apt show PACKAGE # 列出软件包详细信息(list --full)
PACKAGE支持POSIX正则表达式(不支持\d等)。
安装/卸载软件
sudo apt install PACKAGE # 安装软件包
sudo apt remove|purge PACKAGE # 移除软件包
sudo apt autoremove
安装桌面环境的交互命令:
sudo apt install tasksel -y
sudo tasksel
sudo apt install ./<file>.deb
软件升级
安装操作系统后首先对系统进行升级。
sudo apt list --upgradable # 列出所有可升级软件包的信息
sudo apt upgrade # 升级软件包,更新系统
sudo apt full-upgrade
长期支持版升级
sudo apt update && sudo apt upgrade && sudo apt dist-upgrade
sudo apt install update-manager-core
# edit /etc/update-manager/release-upgrades
Prompt=lts # normal
sudo do-release-upgrade
# -d upgrade to development release*
*:The new LTS release isn’t made available todo-release-upgradeuntil its first point release (e.g.,22.04.1, usually comes a few months after the initial release date). If you don’t see an available release, add the-doption to upgrade to the development release.
离线安装软件包
下载离线安装包到指定位置:apt-get可以将包下载到当前目录。
app=mysql-server
depends=$(apt-cache depends --recurse --no-recommends --no-suggests --no-conflicts --no-breaks --no-replaces --no-enhances $app| grep "^\w" | sort -u)
apt-get download $depends
dpkg-scanpackages扫描目录(包括子目录)并创建包索引文件Packages.gz(给apt等工具查找和安装包使用)。
# sudo apt install dpkg-dev # <== dpkg-scanpackages
cd /path/to/repository
dpkg-scanpackages [--OPTS] . [OVERRIDE_FILE PATH_PREFIX] > Packages
gzip -9c Packages > Packages.gz #*
*:如果通过file://访问仓库,则使用Packages,如果通过http://等方式,则使用的文件需要压缩为*.xz,*.bz2,*.gz。
-m:输出内容中包括包的所有版本(包括重复内容);
path-prefix:添加到输出内容的Filename字段;等效于PACKAGE_APTH前添加前缀;OVERRIDE_FILE包含包的附加信息(可选,或设置为/dev/null)。
创建本地源
vi /etc/apt/sources.list.d/local.list
deb [trusted=yes] file:/home/user/download/packages/ ./ # 本地文件*
deb [trusted=yes] http://local-server/debs/amd64/ ./ # HTTP服务=> /var/www/debs/amd64
sudo apt-get update
源声明中,第一列为包类型(软件包或源代码包),第二列固定参数为仓库URL,第三列为发行版名称(通常本地源使用
./代替),后两者组成索引文件Packages或Packages.gz所在目录。索引文件声明了软件包相对于索引文件的位置,因此进行迁移部署时,应该保持扫描包时软件包与索引文件的相对位置不变。
使用apt等工具搜索安装软件。
sudo dpkg -i * # 不推荐直接安装目录下的所有包,可能有兼容性问题 sudo dpkg --configure -a
软件文件缺损
软件中心
遇到软件中心安装程序长时间不能完成或无响应
-
使用以下命令找到root的
dpkg进程ps -af | grep dpkg -
使用以下命令杀死该进程
sudo kill -9 PID -
然后可以继续安装软件
PPA
从软件源移除PPA:
sudo ls /etc/apt/sources.list.d #列出PPA名称
sudo rm -i /etc/apt/sources.list.d/PPA_Name.list #移除指定的PPA
网络接口配置
Ubuntu使用netplan,其配置文件:/etc/netplan/50-cloud-init.yaml(或00-installer-config.yaml)
示例:
network:
renderer: networkd # NetworkManager for desktop system
ethernets:
eth0: # WAN interface
dhcp4: true
eth1: # LAN interface
addresses: # static IP configuration
- 192.168.1.100/24
dhcp4: false
gateway4: 192.168.1.1
nameservers: # DNS servers
addresses:
- 223.5.5.5
- 223.6.6.6
search: []
version: 2
将dhcp4设置为true时,也可以人工设置部分参数,DHCP服务仅更新未设置的网络参数,如默认网关(影响路由表中默认路由信息生成)。
使用静态配置时,如果更新了网关,可能路由表中的条目没有及时更新,导致网络不可用。此时可使用DHCP动态刷新默认路由。
dhcp=true时,如果设置了IP地址,则此时接口同时具有动态和静态IP地址。
网络配置:https://ubuntu.com/server/docs/network-configuration。
防火墙ufw
ufw(Uncomplicated Firewall)为Ubuntu中的防火墙用户程序,其简化了iptables直接操作表链的命令。
ufw enable|disable|reload # enable重载防火墙并开机自启
ufw reset --force # 重置防火墙到安装状态,--force不确认直接执行
ufw logging on|off|LEVEL # 日志级别:off,low,medium,high,full(默认"low")
ufw需要管理员权限(sudo)运行。使用--dry-run查看命令产生的修改,但不应用修改;即使不提供该选项,ufw默认也会在应用规则前提示用户要执行的操作。输出信息中
Anywhere表示any和0.0.0.0/0;。
ufw在启用时会首先清空防火墙规则表(以保证状态一致性),这可能导致已有连接中断(如果默认策略为拒绝)。ufw支持在启用前添加规则,即sudo ufw allow 22/tcp && ufw enable。该规则仍然会在启用防火墙时被清空,但防火墙在启用后相应端口的连接会保持。防火墙启用后,添加或删除规则不会再次清空规则表。
防火墙状态
ufw status [numbered|verbose] # 查看防火墙状态及ufw管理的规则
查看防火墙统计信息:
ufw show raw|builtins|before-rules|user-rules|after-rules|logging-rules|listening|added
规则配置
设置默认规则
ufw default allow|deny|reject [incoming|outgoing|routed] # 默认规则
设置收发规则
ufw allow|deny|reject|limit [in|out] [PORT[/PROTO]|APPNAME] [comment COMMENT] # 简洁模式
ufw allow|deny|reject|limit \ # 完整命令模式
[in|out] [on INTERFACE] \ # 方向和接口
[from SRC] [TO DEST] \ # IP地址:any表示所有地址,10.0.0.0/8表示网段
[PORT[/PROTO]|APPNAME] \ # 端口协议(默认tcp和udp)|服务,80,443,8080:8090指定多个(连续)端口
[comment COMMENT] # 规则说明
# ufw allow 53; ufw allow 25/tcp; ufw allow smtp; ufw allow in http comment "web service"
IPv6地址
2001:db8::/32(在/etc/default/ufw中启用IPv6防火墙);如果设置规则时未指定IP地址且启用IPv6,则添加规则时将同时添加两条规则。其他协议包括:
ah/esp/gre(未指定端口时有效);ipv6/igmp(未指定端口且指定IPv4地址)。
limit用于限制会话速率(防止暴力破解登录攻击,ufw limit ssh/tcp)。
上述命令默认将规则添加到规则列表末尾。
ufw insert NUM RULE # 插入规则到指定编号位置(原有规则编号自动更新)
ufw prepend RULE # 将已添加的规则置顶
NUM的值不能比现有规则编号大,因此要在规则列表末端添加规则就不提供insert NUM命令。==IPv6规则默认在所有IPv4规则之后==(虽然编号是连续的,但实际是两张独立的表),因此指定NUM时,其值必须在对应的IP协议规则编号范围内。
删除规则:
ufw delete RULE|NUM # 删除指定规则或对应编号规则
RULE同时匹配IPv4和IPv6规则时,将同时删除两条规则;删除规则时可不指定规则的说明。
设置路由规则
路由规则在收发规则语句前增加route关键字,以处理目的地址非本机的数据包。路由规则可同时指定in/out及其接口。
ufw route ACTION RULE
启用路由功能需开启IP转发功能,然后重启
ufw。
应用配置
在配置规则时,可使用应用名称代替端口协议配置。应用配置文件位于/etc/ufw/applications.d (/etc/services)。
[SomeService]
title=Some title
description=Some description
ports=12/udp|34|56,78:90/tcp
ufw app list # 列出已配置的应用名称,应用名为配置文件中节标题(SomeService)
ufw app update <name>|all # 更新应用相关的防火墙规则
桌面环境
字体
安装中文字体
sudo apt-get install ttf-wqy-microhei #文泉驿-微米黑
sudo apt-get install ttf-wqy-zenhei #文泉驿-正黑
sudo apt-get install xfonts-wqy #文泉驿-点阵宋体
列出系统字体
fc-list: lang=zh # list fonts
Elementary OS
Elementary OS基于Ubuntu。
常见问题
-
启动黑屏/花屏
更新显卡驱动程序(NVIDIA/ASPEED/...)。
-
欢迎屏幕之前有字符界面
更新grub设置。
sudo vi /boot/grub/grub.cfg # add quiet splash nomodeset sudo update-grub问题:系统无法在初始化阶段获得屏幕信息,导致进入欢迎界面以及登陆后的分辨率过低。
-
中文乱码
-
没有安装中文支持
-
没有中文字体
-
控制台不支持中文
-
Kali Linux
# edit /etc/apt/sources.list
deb https://mirrors.tuna.tsinghua.edu.cn/kali kali-rolling main non-free contrib
sudo apt install kali-linux-default
https://www.kali.org/docs/general-use/metapackages/
Kaili on WSL2*
Win-KeX provides a Kali Desktop Experience for WSL.
sudo apt install -y kali-win-kex
# Run in Kali
kex --win -s # start in Window mode with sound support
kex --esm --ip -s # start in Enhanced Session Mode
kex --sl -s # start in Seamless mode with sound support
Fedora/CentOS/RHEL
安装
CentOS/RHEL采用图形界面配置安装过程,在安装界面可配置工作站、服务器和带图形界面的服务器等多种安装方案(VMWare中选择简易安装将进入无人值守安装,默认安装带图形界面的服务器版本,无法进行自定义。可通过鼠标键盘选择界面中的配置项以中断自动安装过程)。
软件环境配置:
CentOS支持远程Web管理(Cockpit,默认端口9090(websm))。
磁盘分区
CentOS自动分区得到的根目录空间较小(/目录最多分配50GiB),默认文件系统类型为LVM/XFS。XFS不支持文件系统扩容/缩容,因此若选择XFS,必须在安装系统时根据需求规划好分区方案。
软件管理
所有发行版可使用命令工具dnf/yum从软件源下载安装软件,桌面版可使用软件中心检查和安装更新。使用dnf/yum/rpm可以从本地软件包安装软件。
软件包管理器yum(dnf)
dnf(Dandified YUM)是yum(Yellow dog Updater, Modified)的下一个版本。
yum clean # 清除本地仓库缓存数据
dnf history
查找
yum repolist [all] # 列出可用仓库, all包括未启用仓库
yum-config-manager --enable <repo-name>
yum search <keyword> # 按关键字搜索软件包
yum list [installed] [PACKAGE] # 列出(已安装)软件包信息:包名|版本|源
yum info [installed] PACKAGE # 查看(已安装)软件包的信息
yum --showduplicates list httpd # 列出软件包的不同版本
软件安装源对应
*.repo文件的节名称,其中以@anaconda开头的为系统预装软件,软件源为installed为安装系统后手动安装的软件(通过软件源或RPM包)。
安装和更新
yum --installroot NEWROOT --releasever=/ install PACKAGE[-ver]
--enablerepo=<reponame> # 即时启用软件仓库(支持通配符)
--disablerepo=<reponame>
yum reinstall # 重新安装
yum check-update # 检查可用更新
yum update [PACKAGE]
如果未指定installroot选项,则默认安装根目录为/,否则使用指定的根目录(需要同时指定--releasever=/,否则报错),yum会==在指定位置创建完整的根文件树==并安装指定软件及其依赖项。每个根目录下安装的软件是相互独立的,即检查依赖项时在当前根目录下查找依赖项的安装记录(查找已安装软件时也可指定installroot选项,从而查找指定安装根目录下的软件)。
创建基本的运行环境:
yum --installroot=/root/tmproot/ --releasever=/ install bash coreutils grep创建新的根目录时使用的是真实系统的软件仓库设置;在已创建的根目录下继续安装软件将使用该根目录下的仓库配置
/NEWROOT/etc/yum.repos.d。如果要使用真实系统中的仓库源配置,将相应文件复制到上述目录。
卸载
yum remove <package>
yum autoremove [<package>] # 移除不再使用的依赖包
清理不再维护的软件
dnf install remove-retired-packages
remove-retired-packages
清理过时的软件,以下命令列出的软件可能不再需要,可检查并移除相应软件。
PKGS=$(dnf repoquery --unsatisfied) # 不满足依赖的软件(通常为空)
PKGS=$(dnf repoquery --duplicates) # 具有重复版本的软件
PKGS=$(dnf list extras) # 不在仓库中的软件
使用以下脚本清理旧版本内核
old_kernels=($(dnf repoquery --installonly --latest-limit=-1 -q))
dnf remove "${old_kernels[@]}"
Fedora系统升级
dnf upgrade --refresh
dnf install dnf-plugin-system-upgrade
dnf system-upgrade download --releasever=36 # 官方仅支持跨两个版本升级
dnf system-upgrade reboot
合并配置文件
dnf install rpmconf
rpmconf -a #
清理失效的符号连接:
dnf install symlinks
symlinks -r /usr | grep dangling # 检查列出的失效链接文件
symlinks -r -d /usr # 删除失效链接文件
安装
中文字体
yum groupinstall Fonts
软件源配置
Fedora
Fedora/CentOS 默认使用 Metalink 给出推荐的镜像列表,保证用户使用的镜像仓库足够新,并且能够尽快拿到安全更新,从而提供更好的安全性。所以通常情况下使用默认配置即可,无需更改配置文件。
由于 Metalink 需要从国外的 Fedora 项目服务器上获取元信息,所以对于校园内网、无国外访问等特殊情况,metalink 并不适用,此时可以将
/etc/yum.repos.d目录下的文件fedora.repo、fedora-updates.repo、fedora-modular.repo和fedora-updates-modular.repo中的metalink注释掉,并将baseurl的域名改为国内镜像站点。
https://mirrors.aliyun.com/fedora/https://mirrors.tuna.tsinghua.edu.cn/fedorabaseurl=MIRROR_SITE/releases/$releasever/Everything/$basearch/os/由于Fedora发行节奏较快,部分镜像源通常仅保留最近若干个版本的仓库数据(由于主站点对旧版本进行归档)。如果进行软件安装或升级时,发现无法获取仓库元数据(
repodata.xml),则需要更换为Metalink自动寻找仍支持当前系统版本的软件源,稍后尝试对系统进行升级。
CentOS
默认启用的软件源包括:Base、AppStream、Extras。
sudo cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
编辑/etc/yum.repos.d/CentOS-Base.repo文件,在mirrorlist=开头行前面加#注释掉;并将baseurl=开头行取消注释,把该行内的域名(例如mirror.centos.org)替换为 ``https://mirrors.tuna.tsinghua.edu.cn/`。
sudo yum makecache # 生成缓存软件包元数据
epel
EPEL(Extra Packages for Enterprise Linux)是由Fedora Special Interest Group维护的Enterprise Linux(RHEL/CentOS)中经常用到的包。首先安装epel-release,生成epel.repo。
yum install epel-release
EPEL不适用于Fedora,Fedora源中已经包含了大部分EPEL中的包。
如果需要使用epel镜像源,在安装上述包后,修改其中的baseurl。
redhat
RHEL安装后系统中没有配置仓库,需要通过subscription-manager将系统注册到RedHat的订阅(需要现在RedHat开发者网站注册开发者账号并更新订阅)。
subscription-manager register # 在当前系统登录,输入开发者网站用户名和密码
subscription-manager attach # 将当前系统绑定到账户的订阅
subscription-manager list|status # 列出当前系统信息和订阅信息
subscription-manager repos # 列出系统使用的仓库=>yum repolist
subscription-manager repos --enable rhel-xxx-rpms # 启用仓库(yum-config-manage)
subscription-manager-gui是图形界面版本。由于网络原因,
subscription.rhsm.redhat.com的IP可能无法获取,尝试更改DNS配置并通过ping获取正确IP,手动更新/etc/hosts文件。
使用nexus代理
[CentOS]
name=centos
baseurl=http://localhost:8081/repository/proxy-centos/7/os/x86_64
enabled=1
gpgcheck=0
# baseurl=http://localhost:8081/repository/proxy-centos/7/extras/x86_64
# baseurl=http://localhost:8081/repository/proxy-centos/7/updates/x86_64
# baseurl=http://localhost:8081/repository/proxy-epel/7/x86_64
注意:通常镜像站点包含一系列repo,baseurl路径是可以找到repodata的目录。
离线安装软件
软件包:使用浏览器从软件官网或从使用dnf/yum从软件源下载rpm软件包。alien可以将deb包转换为rpm包,但不一定成功。
yum whatprovides */lspci # 查看命令所在的包
yum install yum-utils # provide yumdownloader, repoquery, repotrack
yum install --installroot /tmproot --releasever=/ \
--downloadonly --downloaddir=DLDIR <package> # 已安装的依赖包不会下载
yumdownloader [yum_options] \ # 与yum download等效
--resolve \ # 解析并下载依赖包(已安装的包不会下载)
--destdir=prefix \ # defaults to current directory
--archlist=x86_64,noarch -x '*i686' \ # 系统架构, 排除兼容包
#--urls \ # 仅列出要下载包的URL而不下载
package_name # 要下载的软件包
由于已安装的依赖包不会被下载,因此我们可以使用全新系统进行下载,或者使用yum制作一个只包括预装软件的操作系统环境。如果没有基础环境,也可以通过以下方式解析和下载软件及其依赖包。
如果目标系统版本低于下载包的系统版本,则需要使用repoquery/repotrack下载所有依赖项(包括系统库)进行升级。
repoquery --archlist=x86_64,noarch \
-f \ # 查询提供当前文件的包*
--requires \ # 列出依赖项 <=> -R
--resolve \ # 将依赖项解析为对应的包名
--recursive \ # 递归解析依赖项
#--list \ # 列出包中包含的文件
#--installed \ # 仅查询已安装的包
package_name | xargs -r yumdownloader [options]
*:根据帮助文档,该选项的值为指定包中应该包含的文件名;实际上,如果缺少该选项,会导致命令行提供的包名对应的包不会被返回(仅返回依赖项),因此需要添加该选项(无需提供值)。
repotrack --arch=x86_64 \ # 默认当前架构*
-p,--download_path=DIR \
-u,--url \ # 列举要下载的内容
packages... # 递归下载软件及其依赖安装包(包括系统预装库)
*:x_86架构会自动下载兼容i686和noarch包。为了排除i686包,可先列举下载内容并过滤,再使用yumdownloader进行下载(类似于上述使用repoquery下载方法)。1045871 – yumdownloader --archlist=x86_64 downloads i686 on x86_64 (redhat.com)
通常
repotrack用于下载包及其依赖项,repoquery用于查询相关信息(类似于rpm -q*)。
使用软件包安装/移除软件:
yum install <package>.rpm # 兼容localinstall命令,可自动检查安装本地依赖包
rpm -ivh --force --upgrade <package>.rpm # -i => --install, --force=>强制重新安装, --upgrade升级安装
rpm -e,--erase <package>.rpm # remove installation
rpm -q <package> # print Name.Version.Release
rpm -qa # query all packages
rpm -ql[p][v] <package> # contents at install location/oackage file
RPM选项:
-q,--queryto specify it as a query command-l,--listto list the files in the package,-p,--package查询/验证包文件中的内容,未提供则查询/验证以安装内容;-v(verbose) provides additional information (permissions, owner, etc.)
构建本地软件仓库
安装带依赖项的软件包:配置本地软件源,将软件包放置于本地目录。
-
首先安装在系统中安装
createrepo; -
在软件包所在目录下执行。
createrepo --update --output=repodir path/to/packages默认输出到软件包所在目录,软件包路径相对
repodir指定,保证下载软件时路径正确。 -
在
/etc/yum.repos.d创建一个本地源的配置文件:[local] name=My Awesome Repo baseurl=file:///path/to/repodir enabled=1 # "enabled" not "enable" gpgcheck=0
将系统内置的在线软件源禁用或将配置移到备份位置。
-
使用
yum install命令安装相应软件包。yum clean all # package-cleanup --cleandupes <== yum-utils yum makecache # 载入本地源的元数据如果系统中存在卸载残留的依赖包,可能导致新安装的包产生依赖冲突,因此需要执行
clean命令。
yum install alien
alien -r <package>.deb
桌面软件
中文输入法
应用程序/系统工具/设置/区域和语言/输入源/(+号,汉语(中国))/添加 “汉语(Intelligent Pinyin)”
坚果云
需要使用管理员权限从终端安装。
rpm -ivh nutstore.rpm
构建RPM软件包
安装RPM构建工具:
yum install rpmdevtools
创建和编辑打包声明文件:
rpmdev-setuptree # mkdir -pv ~/rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS}
cd ~/rpmbuild/SPECS
rpmdev-newspec <appname> # 生成<appname>.spec
编写打包声明文件
打包声明文件通过头部定义了包的元数据,并按阶段定义了打包、部署等过程。每个阶段以%STAGE声明开始,如果某个阶段无操作,则可省略该阶段的声明。
声明元数据
| 字段名称 | 说明 |
|---|---|
Name | 软件包名,也是打包声明文件名 |
Version | 版本号:与上游源文件版本对应 |
Release | 发行号:与系统发行号保持一致1%{?dist}根据需要==调整== |
Summary | 软件包的简要描述信息,详细信息在%description中 |
License | 许可类型,如:GPLv3+, Apache, BSD, MIT,... |
URL | 开发者的网站地址 |
Packager | 软件包维护者信息 |
Group | 软件分类,如Development/IDE |
Source0 | 源归档文件路径:位于编译目录SOURCES下或网络资源;可声明多个源 Source1,Source2,... |
BuildArch | 编译和打包输出的架构,如:noarch, x86_64, aarch64,... |
Provides | 软件安装后在目标系统中提供的项 |
AutoReqProvAutoReqAutoProv | yes:自动发现软件包内容所需依赖和软件包提供内容;no禁用。如果开启自动发现,还可设置过滤规则。 |
Requires | 软件安装时检查目标系统依赖项,可进一步指定安装和卸载阶段的脚本依赖, 例如: Requires(pre) |
BuildRequires | 打包时检查当前系统的依赖项 |
Conflicts | 软件安装时检查目标系统冲突项 |
RPM包的名称由Name-Version-Release构成。
依赖和提供内容发现过滤规则(使用正则表达式):
%global __requires_exclude_from PATH_PATTERN # 排除扫描文件
%global __provides_exclude_from PATH_PATTERN
%global __provides_exclude PATH_PATTERN # 排除发现的结果
%global __requires_exclude PATH_PATTERN
%description
由于rpmbuild和正则表达式都会处理\转义序列,因此文件中对特殊符号转义需要使用\\(特别地,对\转义需要使用\\\\)。
条件语句块
条件语句块可使用的命令包括:%ifarch/ifnarch,%elifarch、%ifos/ifnos,%elifos、%if,%elif,所有条件命令可附加%else,所有语句块以%endif结束。%else, %endif后不可包含其他文本。
%ifarch s390 s390x
BuildRequires: s390utils-devel
%endif
%if %{defined with_foo} && %{undefined with_bar}
%if "%{optimize_flags}" != "none"
%if 0%{?fedora} > 10 || 0%{?rhel} > 7
打包
打包过程包括准备(%prep)、编译(%build)、封装(%install)、清理(%clean)和测试。
-
%prep:将Source0等定义的源归档文件(格式.tar、.tar.gz或.tgz等)释放到编译工作目录%{_builddir}(rpmbuild/BUILD),用于编译和封装。该过程主要使用
%setup指令定义源归档文件的释放行为,默认过程为:进入编译根目录,删除已有的软件包编译工作目录,释放源归档文件Source0,切换到软件包编译工作目录。cd /root/rpmbuild/BUILD # %{_builddir} rm -rf package-name-1.7.0 /usr/bin/tar -xvvf /root/rpmbuild/SOURCES/package-name-1.7.0.tar cd package-name-1.7.0该过程假定软件包编译工作目录(默认为
%{name}-%{version})和归档文件的根目录一致,否则上述释放过程完成后将无法切换到编译工作目录。解决该问题的两个途径:1) 打包源文件时保证根目录为上述默认值;2) 修改编译工作目录名%setup -n build-name,与归档文件根目录一致。如果
Source0没有唯一根目录,则首先使用%setup -c创建编译工作目录并切换到该目录下,使得Source0的所有内容释放到该目录下;-c可以和-n共同使用以创建指定的编译工作目录。cd /root/rpmbuild/BUILD # %setup -c -n build-name rm -rf build-name /usr/bin/mkdir -p build-name cd build-name /usr/bin/tar -xvvf /root/rpmbuild/SOURCES/package-name-1.7.0.tar对于有多个源档案文件存在的情况下,声明了
%setup指令则默认自动根据指令释放Source0(添加-T选项禁止自动释放,除了第一条%setup指令外,其他都应该添加-T防止重复释放),其他源档案文件则需要添加额外%setup指令。-
如果
SourceN的根目录与编译工作目录相同或者需要将SourceN置于编译工作目录同级(例如外部依赖项),则应该在进入编译工作目录前释放,因此指令为:%setup -D -T -b N。其中,-D防止删除前面已经释放的文件。cd /root/rpmbuild/BUILD # rm -rf package-name-1.7.0 # %setup -D -
如果
SourceN是编译工作目录下的部分内容,则应该在进入编译工作目录后释放,因此指令为:%setup -D -T -a N。
-
-
%build:执行编译命令并输出编译结果到编译目录下。对于已经在外部编译完成的软件则跳过此阶段。 -
%install:将准备和编译阶段生成的文件,根据需要添加到RPM包的根目录%{buildroot}(该目录模拟目标系统的根目录)。这些文件将在部署阶段被安装到目标系统中。 -
%clean:编写命令,清理rpmbuild工作目录下释放的源文件以及编译输出文件(默认不清理,可为构建命令指定--clean选项,在完成打包后自动清理工作目录); -
%check:编写命令测试RPM包。
部署软件包
%files:从RPM包的根目录下,复制指定文件/目录到目标系统上的相同位置并设置相应文件的属性;
%attr(0744,root,root) /usr/local/bin/*:安装并设置指定内容的属性(744对于用户具有读写和执行/访问权限,对于用户组或其他用户仅有读权限);defattr(644,apache,apache[,755]):设置安装文件和目录的默认权限(无需设置则使用-代替)和所有者;相比于attr增加了目录权限设置参数(文件的执行劝降和目录的访问权限不相同)。%license LICENSE:安装并声明指定内容为许可文件;%doc doc/*.html:安装并声明指定内容为软件的文档;%config(noreplace) %{_sysconfdir}/%{name}/%{name}.conf:安装并声明指定内容为配置文件。如果配置文件在本地被修改过,且新旧版软件包中配置文件发生变更,则声明noreplace会将新版本的配置文件另存为.rpmnew;反之将修改过的本地文件另存为.rpmsave。如果新旧版软件包中配置文件未发生变更,则不会更新配置文件。对于未被%config声明的文件,将直接被覆盖。/opt/appname:将RPM中的其他指定内容安装到目标系统;注意RPM包提供的内容都需要通过%files声明(否则打包过程认为安装与打包不一致)。%exlcude /path/file:从已声明内容中排除文件,支持使用通配符。==即使后面再添加相应的文件声明,被排除内容也不会被安装==。
推荐:**RPM仅包含普通文件构成的树形结构。**RPM包的安装过程经过%files声明的文件,能够被包管理器记录并实现自动卸载,RPM包也能检测到用户是否对这些文件进行过修改。
如果RPM在安装过程中释放的文件未经声明(例如通过
%post脚本释放压缩包或执行其中的程序产生新文件),那么包管理器在卸载软件时无法处理这些文件。除非能够由%post和%postun流程管理这些文件的清理,否则不应该包含这些内容。由于第三方安装包的释放内容往往难以确定,如果这些包没有相应的卸载方法,则不应该在安装过程中调用,否则无法在卸载阶段完成该包的清理工作。
问题:
rpmbuild warning file listed twice:通常需要声明整个目录作为安装内容,并且详细指定其中部分内容的权限、类型等,因此导致部分内容被重复声明。此告警信息只是提示作用,对打包结果无影响。
安装和卸载脚本
安装和卸载脚本用于对系统进行配置和清理,按过程按顺序分为以下阶段,每个阶段包含一段Shell脚本1。
安装软件包前(几乎没有软件包安装需要在安装前进行配置):%pretrans、%triggerprein、%pre2。
安装软件包后:
%post:RPM包中数据复制完成后执行的命令(例如启动服务、动态生成配置文件等);该环境下仅加载系统基本的环境变量,需要手动定义环境变量或导入相应的脚本。通常%postun与之成对出现,以保证清理安装内容,恢复安装前的系统配置和状态。%triggerin:如果该软件包触发安装依赖包,则首先执行依赖包的对应脚本。
卸载软件包前:
%triggerun:如果卸载旧版本软件包触发卸载依赖包,则首先执行当前软件包的对应脚本。%preun:卸载旧版本软件包前的处理。
卸载软件包后:
%postun:卸载旧版本软件时清理%post阶段产生的文件,%files阶段安装的文件将在卸载时自动删除。%triggerpostun:如果卸载旧版本软件包触发卸载依赖包,则首先执行当前软件包的对应脚本。%postrans:
脚本通过传入参数$1判断是安装、升级或卸载:
| stage | install | upgrade | uninstall |
|---|---|---|---|
%pretrans | $1 == 1 | $1 -gt 1 | (N/A) |
%pre | $1 == 1 | $1 -gt 1 | (N/A) |
%post | $1 == 1 | $1 -gt 1 | (N/A) |
%preun | (N/A) | $1 == 1 | $1 == 0 |
%postun | (N/A) | $1 == 1 | $1 == 0 |
%posttrans | $1 == 1 | $1 == 1 | (N/A) |
脚本的最后命令退出状态如果非0,则后续阶段不会执行。因此除非是严重错误导致安装无法继续,应该在每个脚本最后添加exit 0。
其他
-
%description:完整的RPM包描述信息文本。 -
%changelog:RPM包的变更记录。每条记录第一行(以*开头)为变更记录的元数据,包括日期、作者、邮箱、和版本号,后续为变更信息列表(以-开头)。%changelog * Tue May 31 2016 Adam Miller <maxamillion@fedoraproject.org> - 0.1-1 - First bello package - Example second item in the changelog for version-release 0.1-1
在声明文件中使用宏变量
使用宏变量可替代声明文件中的配置信息,从而保证文件中使用配置的一致性。
宏变量包括:
-
预定义:使用
rpm或rpmbuild命令时,通过--define选项定义宏变量。rpm --define "MACRO some_value" --eval %{MACRO}rpmbuild命令在解析声明文件时会使用宏变量进行替换。 -
基于配置文件元数据:声明文件中的元数据,如
Name, Version, Release等,会生成对应元数据名的小写形式(name,version,release...)的宏变量及对应的环境变量(RPM_PACKAGE_NAME, RPM_PACKAGE_VERSION, RPM_PACKAGE_RELEASE),可在后续声明中使用。 -
内置宏变量:关于打包过程的环境变量:
macro env definition %{_buildrootdir}%{_topdir}/BUILDROOT%{buildroot}$RPM_BUILD_ROOT$RPM_ROOT_DIR%{_buildrootdir}/%{name}-%{version}-%{release}.%{_arch}%{_topdir}%{getenv:HOME}/rpmbuild%{_builddir}$RPM_BUILD_DIR%{_topdir}/BUILD%{_rpmdir}%{_topdir}/RPMS%{_sourcedir}$RPM_SOURCE_DIR%{_topdir}/SOURCES%{_specdir}%{_topdir}/SPECS%{_srcrpmdir}%{_topdir}/SRPMS关于路径的宏变量:
macro definition default %{_sysconfdir}/etc%{_prefix}/usr/appfor flatpak builds%{_exec_prefix}%{_prefix}/usr%{_includedir}%{_prefix}/include/usr/include%{_bindir}%{_exec_prefix}/bin/usr/bin%{_libdir}%{_exec_prefix}/%{_lib}/usr/%{_lib}%{_libexecdir}%{_exec_prefix}/libexec/usr/libexec%{_sbindir}%{_exec_prefix}/sbin/usr/sbin%{_datarootdir}%{_prefix}/share/usr/share%{_datadir}%{_datarootdir}/usr/share%{_infodir}%{_datarootdir}/info/usr/share/info%{_mandir}%{_datarootdir}/man/usr/share/man%{_docdir}%{_datadir}/doc/usr/share/doc%{_rundir}/run%{_localstatedir}/var%{_sharedstatedir}/var/lib%{_lib}/lib64/libon 32bit platforms%{_tmppath}%{_var}/tmp/var/tmp
打包方法
rpmbuild -b[bas] \
--clean \ # 清理构建路径
--sign \ # 添加数字签名using PGP
--buildroot <buildroot> \ # 在<buildroot>执行%install定义的命令
--buildarch <arch> \ # override BuildArch
--define "_topdir $(pwd)/rpmbuild" \ # 指定工作目录
<appname>.spec
# Output => {Name}-{Version}-{Release}.rpm
rpmdev-setuptree在用户主目录下创建工作目录,如果要在其他位置进行打包,将创建的目录移动到其他位置,同时在打包命令中指定"_topdir"或在打包声明文件中指定%_topdir 的值。
-b选项的值限定打包过程所执行的阶段,在编写声明文件时,可根据情况选择执行阶段,从而加快测试打包过程。
-
p:%prep; -
c:%prep, %build;仅显示执行过程,移除命令输出,方便调试打包过程:
rpmbuild -bc --define "_topdir $(pwd)/rpmbuild" \ rpmbuild/SPECS/package-name.spec | grep -E "^(\+|E)" -
i:%prep, %build, %install, %check,不打包; -
b:%prep, %build, %install, %check,打包可执行程序; -
a:%prep, %build, %install, %check,打包可执行程序和源代码;
打包过程中的自动编译
在%install结束阶段,打包工具会检查安装内容,对于某些可编译内容(如Python脚本),打包工具默认会自动调用编译工具进行编译。可在该阶段的定义中显式声明exit 0以结束该阶段从而禁用后续的自动检查和编译。如果开启该功能,则需要设置正确的编译工具(防止利用系统默认工具或找不到相应工具)。
/usr/bin/rpmbuild -bb --define "_python_override ${PYTHON_PATH}" # build commmand
%define __python %{_python_override}/python # in sepcfile
软件包内容
RPM package consists of the
cpioarchive. The files inbuildrootare later put into acpioarchive, which becomes the main part of the RPM. When RPM is installed on the end user’s system, these files are extracted in therootdirectory, preserving the correct hierarchy.
查看软件包内容:
rpm -qlpv <pakagename>.rpm # contents of package file
v列出文件属性,不指定则只列出文件名。
提取软件包内容:
rpm2cpio ./<packagename>.rpm | cpio -idmv
-iextract the files from the archive,-dcreate the leading directories where needed,-mpreserve the file modification times when creating files.-v(verbose) list the files processed.
Inspecting and extracting RPM package contents - Packagecloud Blog
跨平台打包
问题:Why building RPMs for a different architecture is a hard problem。
防火墙配置
Fedora/CentOS使用firewalld/firewall-cmd作为防火墙应用程序,其中firewall-cmd为用户接口,firewalld与内核(netfilter)交互。
防火墙运行管理
firewalld作为系统服务,由systemd托管,使用systemctl进行管理。
firewall-cmd --state # firewalld的状态==>systemctl status firewalld
firewall-cmd --reload # 不中断服务的重新加载,更新防火墙规则
firewall-cmd --complete-reload # 中断所有连接的重新加载
firewall-cmd --runtime-to-permanent # 将当前防火墙的规则永久保存
firewall-cmd --check-config # 检查配置正确性
选项:
--permanent:使规则永久生效(当前并未生效,须适用--reload命令重新加载规则);反之,防火墙重新加载后规则失效(适用--runtime-to-permanent命令保存)。某些非定义规则的命令必须使用--permanent。
预定义信息
区域
区域是==防火墙控制范围的逻辑划分==,可将本机的网络接口、远程的IP地址等绑定到区域(--add-interface, --add-source),==其相关流量控制由相应区域的规则决定==。未绑定区域的网络实体的控制逻辑由默认(active)区域中的规则确定。区域信息由NetworkManager 管理,而非firewalld。
==Zones are predefined sets of rules==. Network interfaces and sources can be assigned to a zone.
firewall-cmd --get-zones # 查看支持的区域
firewall-cmd --get-active-zones # 查看区域信息
预定义的区域(存储于/usr/lib/firewalld/zones/)及其默认配置:
drop:拒绝所有外来请求,没有通知消息;block:拒绝所有外部链接请求并发送ICMP消息,仅允许系统内部发起的连接;dmz:Only selected incoming connections are accepted.external:do not trust others on the network. external networks with masquerading enabled, especially for routers. Only selected incoming connections are accepted.public:do not trust others on the network. Only selected incoming connections are accepted.home,internal,work:mostly trust the others on the network. Only selected incoming connections are accepted.trusted:允许所有连接。
其他区域:
FedoraServer, FedoraWorkstation,nm-shared, libvirt。可使用--new-zone,--new-zone-from-file,--delete-zone自定义区域。
区域设置和地址绑定:
firewall-cmd --set-default-zone=<ZoneName> # 设置默认区域=>get-default-zone
firewall-cmd --zone=<ZoneName> --add-interface=eth0 # 绑定本机网络接口
firewall-cmd --zone=<ZoneName> --change-interface=enp03s # 修改接口所属区域
firewall-cmd --zone=<ZoneName> \ # 绑定源地址到区域=>--remove-source
--add-source=<source>[/<mask>]|<MAC>|ipset:<ipset>
firewall-cmd --get-zone-of-interface=enp1s0 # 查看指定接口所属区域
未指定区域则命令的目标为默认区域。
地址集合(IPSet)
获取地址集合以及预定义的类型:
firewall-cmd --get-ipsets
sudo firewall-cmd --get-ipset-types
定义地址集合(必须重启才能生效):
firewall-cmd --permanent --new-ipset=local --type=hash:net # MUST --permanent
firewall-cmd --permanent --ipset=local --add-entry=172.28.76.41 # => 192.168.1.0/24
# --add-entries-from-file, --remove-entries-from-file, --remove-entry
firewall-cmd --reload # 需重新加载才生效
--add-entry:如果定义的ipset还未加载,则必须添加--permanent选项,否则无法在当前加载信息中找到相应的ipset。
获取IP地址集合的信息:
firewall-cmd --info-ipset=local
firewall-cmd --ipset=local --get-entries # 仅返回地址
服务
自定义服务:
firewall-cmd --new-service=ssh # 创建新的服务/--new-service-from-file
firewall-cmd --delete-service=ssh # 删除定义的服务
firewall-cmd --service=<service> \
--set-short \ # 设置服务信息/--get-short
--set-description \
--add-port=1024[-10000]/tcp # --query-port, --remove-port
firewall-cmd --get-services # 显示已定义的服务,已内置标准服务。
firewall-cmd --info-service=ssh
firewall-cmd --path-service=ssh # 显示ssh配置文件的路径
防火墙规则
查看防火墙规则:防火墙规则是关联到区域的。
firewall-cmd --zone=public \ # 默认为active的区域
--list-ports \ # 查看打开的端口
--list-all # 所有信息
firewall-cmd --list-all-zones
基于端口的规则
firewall-cmd --permanent --zone=<zone> \
--add-port=8080/tcp \ # protocl=<tcp|udp|sctp|dccp>
--remove-port=8080/tcp \
--add-source-port=10000-65535 \ # --remove-source-port
--set-target=<target> # 防火墙动作(默认为accept)
--timeout=600:临时设置规则,时限到后规则失效。target表示匹配规则后防火墙的动作。
基于服务的规则:
firewall-cmd --add-service=smtp # 将服务添加到允许列表
--remove-service=smtp
firewall-cmd --list-services # 显示允许访问的服务
复杂规则
规则中的条件包含了:协议族、地址、端口和传输层协议等。
firewall-cmd --add-rich-rule='rule family=ipv4 source ipset=local port port=8501-9000 protocol=tcp accept'
firewall-cmd --direct -add-rule \ # 直接模式:使用iptables语法
ipv4 filter INPUT 0 -p tcp --dport 9000 -j ACCEPT
端口转发
firewall-cmd --add-forward-port=\ # --query-forward
port=80:proto=tcp[:toaddr=192.168.0.1][:toport=8080] # --remove-forward
默认规则:
firewall-cmd --panic-on # 拒绝所有包
firewall-cmd --panic-off # 取消拒绝状态
firewall-cmd --query-panic # 查看是否默认拒绝
防火墙日志
firewall-cmd --get-log-denied # 获取记录被拒绝的日志
https://www.tecmint.com/start-stop-disable-enable-firewalld-iptables-firewall/
Firewalld Cheat Sheet | Liquid Web Knowledge Base
WSL
WSL是基于Windows Hype-V虚拟化技术的Linux发行版。
参考资料
Ubuntu release cycle | Ubuntu 1: Epoch, Scriptlets and Triggers, Red Hat Enterprise Linux 7 RPM Packaging Guide. 2: Scripts: RPM's Workhorse, Maximum RPM: Taking the RPM Package Manager to the Limit, Chapter 13. Inside the Spec File.
操作系统原理
存储设备
磁盘分区
MBR最多有四个主分区,使用扩展分区和逻辑分区最多可以划分15个分区,单个分区最大2TB。
GPT是UEFI标准的一部分,最多提供128个分区,使用GUID来识别每个磁盘和分区。与MBR存在单一故障 点不同,GPT 提供分区表信息的冗余。主GPT位于磁盘头部,而备份副本(次要GPT)位于磁盘尾部。GPT 使用校验和来检测GPT头和分区表中的错误与损坏。
磁盘阵列
RAID 0:breaking up data into chunks and striping it across the available disks. This means that each disk contains a portion of the data and that multiple disks will be referenced when retrieving information.
RAID 1:mirroring data across all available disks.
RAID 5:N strips + 1 parity
RAID 6:N strips + 2 parity
RAID10:RAID 0 + RAID 1
文件系统
文件系统类型
vfat
ext4
btrfs
xfs
无法调整已有分区。
tmpfs
https://www.kernel.org/doc/html/latest/filesystems/tmpfs.html
devtmpfs
Linux目录树
| 目录 | 简介 | 用途 |
|---|---|---|
/home | 用户主目录 | 用户个人文件、用户配置文件 |
/root | 超级管理员目录 | 保留 |
/usr | 系统资源 | Unix System Resources |
/usr/bin | binary | 可执行程序(/bin) |
/usr/sbin | system binary | 系统配置、维护和管理相关可执行程序 ( /sbin) |
/usr/lib[xx] | library | 库文件(/lib[xx]),/bin和/sbin中的可执行程序共享的库文件 |
/usr/local | ==自编译或第三方程序== | |
/usr/src | 内核源代码、头文件和文档 | |
/usr/include | 用于编译用户空间源代码的头文件 | |
/usr/share | 与系统架构无关的共享文件 | |
/opt | optional | ==第三方系统软件== |
/etc | 系统范围配置文件 | |
/media | 自动挂载的外部可移动设备(取代/cdrom) | |
/mnt | mount | 手动挂载外部设备的位置 |
/dev | device | 通过其中的文件访问设备 |
/dev/sda | 硬盘 | |
/dev/sda1 | 硬盘分区 | |
/dev/lp0 | 打印机 | |
/dev/mem | 内存 | |
/dev/tty | 终端 | |
/boot | boot loader | vmlinuz, grub |
/sys | 与内核交互的虚拟文件系统;系统与组件信息 | |
/proc | process | 虚拟文件系统:系统进程和资源信息 |
/run | 系统启动早期守护进程的运行数据 | |
/srv | service | 服务数据 |
/var | variables | 系统运行时可变数据,例如系统日志、缓存、临时文件 |
/var/log | 系统和应用日志 | |
/tmp | temporary | 临时文件(重启系统时清空) |
/snap | snap packages* |
*:snap packages do not depend on any other packages, dependencies, or libraries. They are bundled with everything they need for proper functioning, and completely isolated from the rest of the system.
单独挂载分区到某些目录:linux - Why put things other than /home to a separate partition? - Unix & Linux Stack Exchange
权限
文件可以设置三种权限:
-
读(
r)权限:可读取文件的内容;对于目录则是列举其中的内容; -
写(
w)权限:可修改文件的内容;对于目录则是创建或删除其中的文件; -
执行(
x)权限:对普通文件,文件内容可被装入内存直接运行或逐条解释执行;对于目录,则是可以读其中文件。
文件的用户分为三组:owner(所有者)、group(文件所在的用户组中的其他用户)、其他用户。文件在创建时被给定所有者(通常是当前用户)和用户组(文件所在的目录的用户组);每组中都包含了rwx三种权限声明。不同的文件系统还可能具有其他一些权限,例如ACL,可压缩,可修改等。
权限描述
新创建的文件及目录的缺省权限umask分别为:
-
文件:
-rw-r--r-- 644; -
目录:
drwxr-xr-x 755;
操作系统的启动
操作系统的启动分为两个阶段:
- 引导阶段开始于打开电源开关,结束于内核初始化完成和
systemd进程成功运行。 - 启动阶段接管剩余工作,直到操作系统进入可操作状态。
引导(boot)
-
BIOS上电自检:检验电脑硬件基本功能是否正常。
自检成功后,BIOS产生一个中断
INT 13H,指向某个接入的可引导设备的引导扇区。它所找到的包含有效的引导记录(主引导记录,MBR)的第一个引导扇区将被装载到内存中,并且控制权也将从BIOS转移到引导扇区代码。引导扇区是引导加载器的第一阶段。大多数 Linux 发行版本使用的引导加载器有三种:GRUB、GRUB2 和 LILO。GRUB2 是最新的,也是相对于其他老的同类程序使用最广泛的。
-
GRUB2(GRand Unified BootLoader,Version 2)
寻找操作系统内核并加载其到内存的程序。
-
阶段1:执行引导代码(引导镜像,
boot.img)。引导代码必须非常小,因为它必须连同分区表放到硬盘的第一个 512 字节的扇区中,其中不包含设备的分区信息。由于引导记录必须非常的小,不能理解文件系统结构,因此阶段 1 的唯一功能就是定位并加载阶段1.5的代码,且该段代码必须位于引导记录与设备第一个分区之间的位置。
-
阶段1.5:执行文件系统驱动程序
在第一个分区的开始位置(扇区63)和MBR(扇区 0)之间有 62 个 512 字节的扇区(共 31744 字节),用于存储阶段1.5的代码镜像
core.img文件。该空间足够容纳一些通用的文件系统驱动程序,如EXT、FAT、NTFS等。因此GRUB2的阶段2能够放在EXT文件系统内(
/boot/grub,但不能放在逻辑卷内)。 -
阶段2:定位和加载 Linux 内核到内存,并转移控制权到内核
内核的相关文件位于
/boot目录下(其文件名均带有前缀 vmlinuz),以一种自解压的压缩格式存储以节省空间。ls -la vmlinuz*
GRUB2 通过
/boot/grub/grub.cfg进行配置。该配置文件通常是利用工具自动生成的( 例如在Ubuntu中,grub-update基于/etc/default/grub生成配置文件)。 -
-
内核
内核加载到内存后,首先必须从压缩格式解压自身。
内核自解压完成后,则加载
systemd进程,并转移控制权到systemd,结束引导过程。
启动(startup)
引导过程结束后,Linux 内核和 systemd 处于运行状态,但是由于没有其他任何程序在执行,故其不能执行任何有关用户的功能性任务。
systemd是所有进程的父进程(代替旧式init程序),其功能包括:
-
挂载文件系统
systemd挂载在/etc/fstab中配置的文件系统,包括内存交换文件或分区。 -
决定系统启动的目标态
目标态(target)对应旧式的运行级别(runlevel),包括
graphical.target(桌面系统,对应runlevel 5)、multi-user.target(服务器系统,对应runlevel 3)。根据配置文件
/etc/systemd/system/default.target决定系统应该进入的目标态,default.target是一个链接文件,通常链接到描述文件graphical.target或multi-user.target。每个目标态有一个在其配置文件中描述的依赖集,
systemd需要首先启动其所需依赖。systemd也会查看老式的systemV init目录中是否存在相关启动文件,若存在,则systemd根据这些配置文件的内容启动对应的服务。
用户管理
用户
群组
The Primary group – When a user creates a file, the file’s group is set to the user’s primary group.
Secondary or supplementary group - Useful when you want to grant certain file permissions to a set of users who are members of the group.
Each user can belong to exactly one primary group and zero or more secondary groups.
Only root or users with sudo access can add a user to a group.
用户信息存储
群组ID(Group ID,GID)
帐号信息存储在/etc/passwd 文件中,每一行代表一个帐号,每行包含7部分内容:
用户名:密码(x):UID:GID:用户信息说明:家目录:shell
UID为用户编号(User ID),其分配规则为:
-
0:系统管理员;
-
1~499:系统帐号;
-
500~65535:一般用户。
账户信息中的密码使用“x”代替,没有任何密码。
密码信息储存在/etc/shadow文件中,密码以加密后的密文存储。
用户名:经过加密的密码:密码改动的日期:密码不可被改动的天数:密码需要重新更改的天数:密码更改前进行提示的天数:密码过期后的宽限时间:帐号失效时间:保留
群组信息存储在/etc/group中,每一行代表一个群组,分为4个字段:
组名:群组密码(x):GID:此群组包含的用户名称
用户名用","隔开,不能有额外的空格。
在/etc/passwd中的GID是用户的初始群组,当用户登入系统后,就拥有了这个群组的权限。使用groups命令查看用户支持的群组,第一个输出的群组即为有效群组,在创建新文件时,档案的群组属性就是有效群组。使用newfrp切换有效群组,这时会在原本的shell中重新启动一个shell,其中用户的有效群组就是切换后的。当退出新的shell后,有效群组就恢复了。
群组管理员信息保存在/etc/shadow中,
组名:密码:群管理员帐号:群包含的用户帐号
密码栏开头为“!”表示无合法密码,所以无群组管理员。
群组管理员可以将帐号加入自己管理的群组中,而不许要root来进行管理,减少了root的工作量。现在由于有sudo命令,所以群管理员已经很少使用了。
有效身份与真实身份
用户登录过程
用户输入用户名和密码后,系统在/etc/passwd里面寻找帐号。如果没有则跳出;如果有,则将对应的UID和GID一起读出来,另外该帐号的家目录和shell设定也一并读出。
核对密码,系统进入/etc/shadow找到对应帐号与UID,然后核对输入的密码和里面的(加密)密码是否相同。
如果密码正确,那么就启动用户的shell环境。
进程
每个会话(session)拥有一个或者多个进程组(process group),每个进程组拥有一个或多个进程(process)。会话中的第一个进程就是这个会话的领导(session leader),会话标识(session id)就用它的进程标识(process id)。
用户态和内核态
同步原语
非递归锁
non-recursive lock:当一个进程获取到一个非递归锁后,尝试获取该锁的其他进程将阻塞直到该锁被释放。
Locks are associated with processes. A process can only have one kind of lock set for each byte of a given file. When any file descriptor for that file is closed by the process, all of the locks that process holds on that file are released, even if the locks were made using other descriptors that remain open. Likewise, ==locks are released when a process exits==, and are ==not inherited by child processes== created using fork (see Creating a Process).
递归锁
recursive lock:同一个进程可多次获取一个递归锁,但也需要释放同样多次数。
信号量
semaphore:
网络
内核防火墙
netfilter/iptables组成Linux中的包过滤防火墙,完成数据包过滤、修改、重定向和网络地址转换等功能。netfilter位于内核空间,iptables位于用户空间。iptables将用户的安全设定执行到安全框架netfilter中。

By Jan Engelhardt - Own work, Origin SVG PNG, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=8575254
处理位置-链
网络层对分组处理可分为五个模块(Chain,链)。每个链上设置了一系列规则,匹配规则的数据包按对应的处理方式进行处理。
PREROUTING:FORWARD:POSTROUTING:INPUT:OUTPUT:
处理方式-表
每个链按对分组的处理方式将相应地规则归入表中,按处理优先级由高到低依次为:
raw:mangle:解析并修改报文;nat:网络地址转换;filter:过滤数据包;security*(SELinux)。
每个表由默认策略(policy)和若干条规则(rule)组成,如果没有任何规则与数据包匹配,则按默认策略处理数据包。
根据数据包的转递场景,某些链中不完全包含四类表,具体情况如下:
PREROUTING | FORWARD | POSTROUTING | INPUT | OUTPUT | |
|---|---|---|---|---|---|
raw | √ | √ | |||
mangle | √ | √ | √ | √ | √ |
nat | √ | 〇 | √ | ||
filter | √ | √ | √ | √ | |
security | √ | √ | √ |
匹配条件
根据指定的匹配条件来尝试匹配每个流经此处的包,并由指定的动作进行处理。
动作(target)
-
ACCEPT:允许数据包通过。 -
DROP:直接丢弃数据包,不给任何回应信息。 -
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。 -
SNAT:源地址转换,解决内网用户用同一个公网地址访问外部服务的问题。 -
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的IP地址上。 -
DNAT:目标地址转换,外部请求或响应进入内网时执行。 -
REDIRECT:在本机做端口映射。 -
LOG:在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配。
匹配顺序
一个表格中的规则,如果一条规则被匹配上,则后续规则不再匹配;反之,继续匹配剩下的规则。
在没有顺序要求的情况下(匹配范围有包含关系的情况),匹配频率高的规则应该放在前面,以减少规则检查次数。
自定义链
将符合同一规则的所有规则合并写入自定义链中,由默认链根据规则引用自定义链进行处理。自定义链还可以进一步引用其他自定义链。
使用自定义链等效于将原来的一级规则匹配变换成了多级匹配。同时,将具有公共部分的规则合并到自定义链中有助于简化规则管理。
NAT
当网络内部主机的报文经过路由器时,路由器会维护一张NAT表,表中记录了报文来自于哪个内部主机的哪个进程(内部主机IP+端口)。

SNAT:当报文经过路由器时,路由器会将报文的内部主机源IP替换为路由器的IP地址,把源端口也映射为某个端口,NAT表会把这种对应关系记录下来。外部主机收到报文时,源IP与源端口显示的都是路由的IP与端口。当外部网络中的主机进行回应时,外部主机将响应报文发送给路由器,路由器根据NAT表中的映射,将响应报文中的目标IP与目标端口再改为内部主机的IP与端口号,然后再将响应报文发送给内部网络中的主机。整个过程中,外部主机都不知道内部主机的IP地址,内部主机还能与外部主机通讯,于是起到了隐藏网络内主机IP的作用。还能够让局域网内的主机共享公网IP,让使用私网IP的主机能够访问互联网。
DNAT:会话开始时使用DNAT,如公网中的客户端通过路由器向内网中的服务器发起请求,路由器将“目标IP+端口”映射到“内网IP+端口”。
LVS
Linux Virtual Server
LVS由两部分组成,ipvs与ipvsadm。
-
ipvsadm:LVS管理工具,管理员通过ipvsadm定义或管理集群规则。 -
ipvs:LVS核心实现,根据定义好的集群规则进行工作。ipvs作为netfilter的模块存在。
LVS-NAT
LVS主机作为内网中服务器集群的代理,通过NAT将来自客户端的请求转发给服务器集群。LVS通过调度模块ipvs来调节转发给集群各服务器的负载。
VIP:公网IP,客户端实际访问的IP;
RIP:集群中服务器的内网IP;
DIP:LVS主机链接集群的接口分配的内网IP。
输入输出
TCP Socket
Connect and Accept
The connect and accept function the three-hand-shake procedure.
accept will peak one connection request from the backlog queue, which has finished three-hand-shake procedure.
三次握手的过程是由内核完成,不是
connect/connect完成.https://www.cnblogs.com/pengyusong/p/6434788.html
调用*listen*系统调用时,socket状态会变为LISTEN,此时需要为这个socket指定一个backlog。backlog通常被用来指定队列能容下的链接的个数。
在TCP建立连接的三路握手过程中,连接需要先经历SYN RECEIVED状态才能到达最终的ESTABLISHED状态,处于ESTABLISHED状态的连接才能被*accept*系统调用返回给应用。正因为如此,TCP/IP协议栈通常有两种实现backlog queue的策略:
- 使用一个队列,其大小由listen系统调用的backlog参数决定。当服务器收到SYN数据包后,会发送SYN/ACK数据包给客户端并将该连接入队列;当服务器收到客户端的ACK确认数据包后,连接状态变为ESTABLISHED,该连接可以被应用程序使用。这意味着这个队列会包含SYN RECEIVED和ESTABLISHED两种状态的连接,只是只有处于ESTABLISHED状态的连接才会返回给用户程序中的accept系统调用。
- 使用两个队列,一个SYN 队列(或者说是未完成连接队列)和一个accept 队列(或者说是连接完成队列)。处于SYN RECEIVED状态的连接会被添加到SYN队列,然后,当这一连接状态变为ESTABLISHED后,其被移至accept队列。
accept系统调用只会从accept队列中消耗连接。在这种策略中,listen系统调用的backlog参数决定的是accept 队列的大小。https://harveyqing.gitbooks.io/python-read-and-write/content/python_advance/how_to_use_linux_epoll.html
任务调度模式
IO密集型和CPU密集型任务
同步和异步
根据用户程序与内核的交互方式,进程的运行方式可分为同步和异步:
- 同步:用户程序向内核发起操作请求,并从内核空间中获取数据;
- 异步:用户程序向内核发起操作请求,内核完成请求后将数据写入用户空间(通过信号处理函数或回调函数写入用户空间提前分配的内存)。
阻塞和非阻塞
阻塞:用户程序等待内核操作结束;以输入为例,read系列方法将尝试读取指定字节数据、或读取直到指定字符(例如换行\n或文件结束EOF)。默认模式下,如果输入流还未满足返回条件,则方法将被阻塞。
非阻塞:用户不等待内核操作结束,而是立即返回内核操作的状态。
同步阻塞模式
The application blocks until the system call is complete. The calling application consumes no CPU and simply awaits the response, so it is efficient from a processing perspective.
the read/write task is multiplexed with other work in the kernel.
同步非阻塞模式
可读取的数据量不确定,可能会频繁从内核读取少量数据,增加上下文切换开销。
low data throughput due to frequent system call with context switch.
异步阻塞通知模式
IO多路复用:non-blocking I/O with asynchronous blocking notifications。
==不存在“异步阻塞IO”的模式==:如果用户程序阻塞等待内核操作完成,则“异步阻塞IO”与同步阻塞IO对于计算任务调度是相同效果,区别仅在于读取数据的方式。
在同步IO模式下,若用户程序阻塞于一个IO操作,而此时其它文件已经准备好操作,则进程无法转去操作其他文件,导致进程的运行效率降低(CPU的利用率)。因此,应该将所有进行IO操作的文件进行统一管理,通过查询文件读写状态获取可操作的文件,并执行相应的操作。只要存在可执行的IO操作,则进程不会出现空闲状态,从而提高进程运行效率。
Linux提供了select、poll、epoll接口监听文件描述符状态变化信息。select需要用户程序对发生状态变化的文件查询其发生的事件,而poll、epoll则由内核来设置文件描述符发生的事件。
监听接口是异步阻塞模式(依赖于内核事件通知),直到存在文件描述符准备就绪。在该模式下,任何内核操作都应该立即返回结果而非发生阻塞(非阻塞IO模式),否则令监听机制失效(阻塞在内核操作处,而非阻塞在监听接口处)。
selectcall can provide notification for many descriptors. A convenient model for asynchronous notification, not advised for high-performance I/O.
异步非阻塞模式
多线程模型
线程池模型
事件驱动模型
参考文献
- Boost application performance using asynchronous I/O, Learn when and how to use the POSIX AIO API. https://developer.ibm.com/technologies/linux/articles/l-async/
套接字
对于套接字而言,accept()函数会一直阻塞,直到有来自客户端的连接;recv()函数会一直阻塞,直到接收到了客户端的数据(或者没有更多的可接收数据);send()函数也会一直阻塞,直到发送给客户端的数据已经准备好了。
多线程(进程)阻塞模型:程序主线程包含了监听socket,这个监听socket接受来自众多客户端的连接;每当一个客户端连接进来时,将新创建的socket交给另外一个线程,由这个线程与客户端进行通信。因为每个线程只会与一个客户端通信,因此一个线程的阻塞并不会影响其它工作线程。使用多线程的阻塞socket写的代码逻辑上很简单直接,但这种模型有一些缺点,比如多线程的数据同步和单CPU多线程的低效。
异步套接字:对异步socket的操作会立即返回成功或失败,程序可以通过返回来决定后续操作。因为异步socket是非阻塞的,所以不需要用多线程,所有任务可能都在一个线程中完成。
异步多线程模型:主线程负责网络,其它线程处理阻塞任务;
安全
数字证书
PEM (originally “Privacy Enhanced Mail”) is the most common format for X.509 certificates, CSRs, and cryptographic keys. A PEM file is a text file containing one or more items in Base64 ASCII encoding, each with plain-text headers and footers (e.g. -----BEGIN CERTIFICATE----- and -----END CERTIFICATE-----). A single PEM file could contain an end-entity certificate, a private key, or multiple certificates forming a complete chain of trust. Most certificate files downloaded from SSL.com will be in PEM format.
PEM files are usually seen with the extensions .crt, .pem, .cer, and .key (for private keys), but you may also see them with different extensions. For example, the SSL.com CA bundle file available from the download table in a certificate order has the extension .ca-bundle.
Binary文件
All ELF binaries need to have a few things in place in order for them to be interpreted by the Linux kernel properly. As with Windows EXEs, there’s a structure to the header that defines the overall layout of the binary.
readelf -a elf_file
# -h --file-header Display the ELF file header
# -l --program-headers Display the program headers
# -S --section-headers Display the sections' header
# -s --syms Display the symbol table
# --dyn-syms Display the dynamic symbol table
| 工具 | 命令 | 说明 |
|---|---|---|
hexdump | hexdump -C execfile | 查看文件的十六进制编码 |
objdump -d execfile | ||
readelf | readelf -aW file | 查看ELF二进制文件结构 |
strip execfile |
stripreads a binary file, and removes a lot of the extra debug and compiler info that isn’t needed.
动态链接库
查看可执行程序的动态链接库依赖信息
ldd -v /usr/bin/bash # -v 递归显示依赖关系(默认列出所有直接和简介依赖项)
ldd /usr/bin/bash | awk '{print $1}' # 提取输出信息中的依赖项信息
Windows配置管理
安装
磁盘初始化,如果回收磁盘空间重新初始化,则会创建单独的启动分区。
UEFI
以UEFI模式安装系统,启动设备需要使用FAT32文件系统。
问题:无法为安装介质加载驱动程序
切换到USB2.0接口。
管理工具
远程访问
通过会话访问远程主机并执行命令。在目标机器上启用PowerShell远程会话:
Enable-PSRemoting # 以管理员身份运行,网络类型“专用”
由于此计算机上的网络连接类型之一设置为公用,因此 WinRM 防火墙例外将不运行。 将网络连接类型更改为域或专用,然后再次尝试。
$Cred = Get-Credential # 弹出对话框选择账号并输入密码
Enter-PSSession -ComputerName dc01 -Credential $Cred #建立远程登录会话
Exit-PSSession
错误:使用 winrm.cmd 配置
TrustedHosts。
Invoke-Command -ComputerName dc01, sql02, web01 {Get-Service -Name W32time} -Credential $Cred
$Session = New-PSSession -ComputerName dc01, sql02, web01 -Credential $Cred
Invoke-Command -Session $Session {(Get-Service -Name W32time).start()}
Invoke-Command -Session $Session {Get-Service -Name W32time}
Get-PSSession | Remove-PSSession # close established sessions
硬件
主板
wmic baseboard get Manufacturer,Model,Name,PartNumber,serialnumber
CPU
wmic cpu
GPU
dxdiag
nvidia-smi
BIOS
wmic BIOS get name,version,serialnumber
Get-WmiObject -Class Win32_Bios | Format-List -Property *
serialnumber为主机序列号。
内存
wmic MemoryChip get BankLabel,Capacity,MemoryType,TypeDetail,Speed,Tag
虚拟内存配置:如果系统物理内存足够大,可选择关闭系统分页文件:pagefile.sys,swapfile.sys以节省磁盘空间。
磁盘
列出物理磁盘信息:
wmic diskdrive list brief # DeviceID as disks path
wmic diskdrive get Name,Model,InterfaceType,MediaType,SerialNumber,Size,Status
wmic PARTITION
wmic VOLUME
可查看型号(
Model)、序列号(SerialNumber)。
diskpart # 启动磁盘管理交互环境
在交互环境中可执行的命令(通过help查看):
| 命令 | 说明 |
|---|---|
| `list disk | partition |
| `select disk | parition |
rescan | 重新扫描计算机,查找磁盘和卷 |
clean | 从磁盘清除配置信息或所有信息。 |
compact | 尝试减少文件的物理大小。 |
convert | 在不同的磁盘格式之间转换。 |
create | 创建卷、分区或虚拟磁盘。 |
format | 格式化卷或分区 |
shrink | 减小选定卷。 |
remove | 删除驱动器号或装载点分配。 |
delete | 删除对象。 |
exit | 退出diskpart。 |
磁盘分区类型
如果在MBR分区类型的磁盘上安装了
mbr2gpt可将MBR分区类型的磁盘转换为GPT分区类型,而无需移动磁盘上的数据。
mbr2gpt /validate # 验证选定磁盘可进行转换操作(未指定磁盘则使用安装系统的磁盘)
/convert /disk:N # 验证并执行转换操作
/allowFullOS # 使该命令可用于完整Windows环境(默认仅用于PE环境,推荐)
打开高级启动模式:“设置->更新和安全->恢复->高级启动->立即重新启动”(或按住Shift键点击重启按钮);在启动选项中选择:疑难解答->高级选项->命令行,然后重新启动电脑,执行上述命令。
电源管理
powercfg /a # 睡眠状态
powercfg -H OFF # 关闭休眠模式(删除系统磁盘下的hyberfi.sys文件)
# /LIST、/L 列出所有电源方案。
网络接口
wmic nic get AdapterType,Name,MACAddress,Speed,NetConnectionStatus
系统管理
系统信息
systeminfo # 输出系统信息[CLI]
msinfo32 # 系统信息[GUI]
ver # [cmd]查看系统版本
winver # [GUI]查看系统版本对话框
wmic COMPUTERSYSTEM
wmic OS
Get-ComputerInfo -Property "*version"
Get-WmiObject -Class Win32_ClassName | Format-List -Property '*'
Computer System Hardware Classes - Win32 apps | Microsoft Docs
Operating System Classes (Windows) | Microsoft Docs
Collecting Information About Computers - PowerShell | Microsoft Docs
系统启动信息
启动配置数据存储编辑器:
bcdedit /delete {uuid}
单独运行 "
bcdedit" 等同于运行 "bcdedit /enum ACTIVE"(列出激活的启动项)。
注册表
Working with Registry Entries - PowerShell | Microsoft Docs
Working with Registry Keys - PowerShell | Microsoft Docs
文件管理
Set-Location [-Path] path # >> cd, chdir
切换当前目录。
读取目录
Get-ChildItem -Recursive -Path *.txt # >> dir
创建文件
New-Item -ItemType "file" -Path . -Name "testfile1.txt" -Value "This is a text string."
New-Item -ItemType "directory" -Path "c:\" -Name "logfiles" # -> mkdir
链接文件
硬链接(Hard link)==只能用于文件==,且不能跨磁盘使用。多个硬链接可以指向同一个文件,并且删除一个硬链接或原始文件,其他硬链接仍然可以访问。删除软链接(Symbolic link)不会影响原始文件,但删除原始文件会使软链接失效。
权限:创建符号链接需要有“
SeCreateSymbolicLinkPrivilege”用户权利,administrators 组成员默认具有此权利。 这个权利可以在“本地安全策略(secpol.msc)\本地策略\用户权利分配”中设置。
New-Item -ItemType SymbolicLink -Path "Link" -Target "Target"
-ItemType SymbolicLink|Junction|HardLink:
-Path:符号链接文件的路径;
-Target:符号链接的目标路径;
-Force:覆盖已有文件。
cmd:
mklink {/D|/H|/J} Link Target
/D:创建目录符号链接(symbolic link),默认为文件符号链接。/H:创建硬链接(hard link)而非符号链接,目标文件必须位于同一磁盘分区(卷)。/J:创建目录联接(junction),目录必须位于本地。Link指定新的符号链接名称,Target指定新链接引用的路径 (相对或绝对)。Adobe Reader保存文件时,可能会先删除原有文件,再创建新文件,由此使得指向原文件的硬链接与新文件不同。
查看文件链接
dir path -recurse -force | ?{$_.LinkType} | select FullName,LinkType,Target
dir->Get-ChildItem
复制移动文件
del filename % 删除文件。
dir
rmdir
move
Move-Item -Path C:\test.txt -Destination E:\Temp\tst.txt # move file
Move-Item -Path C:\Temp -Destination C:\Logs # move folder
Move-Item -Path .\*.txt -Destination C:\Logs # wildcard
查找
查找可执行程序
Get-Command dotnet # [gcm] -> "where" in cmd
#CommandType Name Version Source
#----------- ---- ------- ------
#Application dotnet.exe 5.0.152... C:\Program Files\dotnet\dotnet.exe
应用管理
https://dev.to/bowmanjd/chocolatey-vs-scoop-package-managers-for-windows-2kik
Working with Software Installations - PowerShell | Microsoft Docs
Get-CimInstance -Class Win32_Product | Select-Object -Property Name,Vendor,Version
离线安装
appx包
获取appx包
包括AppxBundle和appx包,其中AppxBundle是多个appx包的合集。
- 软件发布者在GitHub等网站提供
appx包的下载(某些可能为将依赖项打包); - 从应用商店获取应用的分享链接,然后在Microsoft Store - Generation Project查找并下载应用的
appx包及其依赖包。
安装
以管理员身份使用PowerShell命令提供安装选项:
Add-AppxPackage FILENAME.appx
双击软件包即也可执行安装。但离线安装程序无法启动,提示找不到启动文件:可能是由于安装位置
C:\Program Files\WindowsApps没有访问权限。由于以上两种文件格式都是以zip格式封装,因此可以提取其中的appx包内容并手动安装到用户提供目录下。安装如果出现证书无法被信任的问题,需要将
appx包所带证书(通过“属性/数字签名”查看)安装到本机的证书目录下(选择“受信任的xxx”)。
winget
winget list [-q QUERY] # 显示已安装软件列表(包括非winget安装)
--id ID
--name NAME
--source SOURCE # -s 使用指定的源查找程序包
--count # -n 显示不超过指定数量的结果
--exact # -e 使用精确匹配
winget list > winget.installed.txt # 在cmd中执行避免乱码
即使非
winget安装,如果在相应软件源发现匹配软件,仍会显示相应的源(msstore/winget)。
winget search PACKAGE --source SOURCE
winget show PACKAGE --source SOURCE # 显示软件的详细信息
winget search > winget.repo.txt # 在cmd中执行避免乱码
当
show发现多个匹配时,会提示用户提供更精确的包名或限定源。
winget install <package> --source msstore
upgrade
uninstall
winget export --output FILE --source SOURCE
import --import-file FILE
winget source list \ # 列出源的名称和URL
--name winget # 列出指定源的详细信息
winget settings # 打开设置文件进行编辑
Chocolatey
配置
choco source [list] # 列出软件源
choco source add -n=REPONAME -s=url
choco source enable/disable/remove -n=REPONAME
choco config [list] # 列出配置信息
choco config get [--name] CONFIG_NAME
choco config set [--name] CONFIG_NAME --value VALUE
搜索软件
choco list/find/search openjdk[--exact --verbose]
choco list/find/search <appname> --local-only # 查找已安装应用
choco info pkgname
更新
choco upgrade <appname>|all --except="appname,..." # 升级应用
choco outdated # 列出可更新软件 upgrade all --noop
choco pin <package_name> # 固定软件版本
安装卸载
choco install <appname>
choco uninstall <appname>
搭建本地软件仓库
使用Nexus代理
仅代理Chocolaty安装脚本信息(nuget),软件的安装文件仍然需要访问官方资源。因此该代理只是提高对软件仓库的查询速度,而不能离线部署。
Name=chocolatey
Format=nuget
URL=http://172.28.76.100:8081/repository/chocolatey/
Protocl="NuGet V2"
Remote=https://chocolatey.org/api/v2/
Chocolatey Software Docs | Host packages internally
Scoop
如果没有管理员权限,则采用Scoop更加合适。
# Enable execution of PowerShell scripts
Set-ExecutionPolicy AllSigned
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
Invoke-Expression (
New-Object System.Net.WebClient).DownloadString('https://get.scoop.sh')
# or shorter: iwr -useb get.scoop.sh | iex
scoop search [<app>] # 省略app名称将列出仓库中所有可用软件
scoop info <app> # 显示软件信息(含必要配置说明)
scoop install|uninstall <app>
scoop list
scoop status # 检查软件是否有新版本
scoop hold|unhold <app> # 停用/启用更新
scoop update [<app>] # 更新scoop或指定软件
scoop cleanup * # 清理所有旧版软件, 清理指定软件, 清理过期的安装包
scoop cleanup <app>
安装的软件在
~\scoop\apps目录下。
软件源
Scoop buckets by number of apps | scoop-directory (rasa.github.io)
scoop bucket add|list|known|rm <bucket>
下载
利用aria2加速下载:
scoop install aria2
scoop config aria2-enabled true # default: true
scoop config aria2-retry-wait 8 # default: 2
scoop config aria2-split 8 # default: 5
scoop config aria2-max-connection-per-server 8 # default: 5
scoop config aria2-min-split-size 2M # default: 5M
添加库 versions, 可以安装其他(落后的)版本:
scoop bucket add versions
scoop install python@3.7.7
MSYS2
Software Distribution and Building Platform for Windows.
Terminal:
mintty、bash;CLI tools:
git、tar、awk;Develop tools:GCC, mingw-w64, CPython, CMake, Meson, OpenSSL, FFmpeg, Rust, Ruby。
package management:
Pacman(Arch Linux)
winget install msys2.msys2
用法: pacman <操作> [...]
操作:
pacman {-h --help}
pacman {-V --version}
pacman {-D --database} <选项> <软件包>
pacman {-F --files} [选项] [文件]
pacman {-Q --query} [选项] [软件包]
pacman {-R --remove} [选项] <软件包>
pacman {-S --sync} [选项] [软件包]
pacman {-T --deptest} [选项] [软件包]
pacman {-U --upgrade} [选项] <文件>
MSYS2提供模拟文件系统,其物理位置为MSYS2安装目录(可直接从物理系统访问其中内容)。
df -hT /home/gary/
# 文件系统 类型 容量 已用 可用 已用% 挂载点
# C:/msys64 ntfs 931G 221G 711G 24% /
Office
安装office部署工具(Office Deployment Tool)。
配置文件(configuration.xml)
<Configuration>
<Add OfficeClientEdition="64" Channel="Monthly"> <!--PerpetualVL2019-->
<Product ID="HomeStudent2019Retail">
<!-- ProPlus2019Volume|VisioPro2019Volume... -->
<Language ID="zh-cn" />
</Product>
</Add>
<!-- <RemoveMSI All="True" /> -->
<!-- <Display Level="None" AcceptEULA="TRUE" /> -->
<!-- <Property Name="AUTOACTIVATE" Value="1" /> -->
</Configuration>
下载安装文件:
setup /download configuration.xml # run in cmd
安装应用:
setup /configure configuration.xml # run in cmd
https://docs.microsoft.com/en-us/deployoffice/office2019/deploy.
激活Office
# 查看激活状态
cscript "C:\Program Files\Microsoft Office\Office16\OSPP.VBS" /dstatus
# 移除key
cscript "C:\Program Files\Microsoft Office\Office16\OSPP.VBS" /unpkey:F6YYT
RDP
RDPWrap
https://raw.githubusercontent.com/sebaxakerhtc/rdpwrap.ini/master/rdpwrap.ini
VMWare Workstation
VM16 Pro:ZF3R0-FHED2-M80TY-8QYGC-NPKYF
进程管理
查看进程信息:
tasklist /V /FI "ImageName eq winlogon.exe"
/V:显示更多信息
/FI:设置过滤条件(不区分大小写)。筛选器包括:Status(运行状态)、ImageName(程序名称)、Pid(进程号)等等(查看tasklist /?)。
wmic process
wmic可以获得包括命令行信息在内的详细信息。
Get-Process [-Name] [firefox, powershell] # alias as ps
Get-Process DataExchangeHost -Module # need admin privilage
Get-Process WindowsTerminal -FileVersionInfo
Managing Processes with Process Cmdlets - PowerShell | Microsoft Docs
获取当前进程信息?
创建进程
直接在当前终端中运行可执行程序,程序将在前台运行。
新进程与终端分离
Start-Process在新的进程中运行可执行文件(类似Linux exec)。
-
如果指定
-NoNewWindow,则直接在当前Shell中创建新进程,并与当前Shell分离(输入输出默认仍在当前终端,除非添加重定向选项)。 -
反之,首先新建一个Shell进程(桌面环境弹出控制台界面),并在新的Shell环境中运行可执行程序。可执行程序同样与Shell环境分离,因此新的Shell环境在执行启动命令后即退出。
-
在脚本中调用
Start-Process和上述情况一致,执行脚本仅在当前Shell进程中创建一个子Shell环境。 -
如果出现新终端窗口不退出的情况(后台任务未成功与终端分离,使用Terminal作为默认终端时可能出现),可添加
-WindowStyle Hidden(不能与-NoNewWindow同时使用)手动隐藏终端。如果直接从图形界面启动脚本,并使用
-NoNewWindow,导致后台进程无法启动。因为系统分配的终端没有被阻塞执行完脚本内容后直接退出。使用-NoNewWindow会使在当前Shell环境的后台进程也退出。
非Windows平台上子进程总是连接到父进程终端,可以使用
Start-Process nohup命令脱离父终端。
Start-Process -FilePath command \ # -> start*
-ArgumentList ('-jar',"$jEdit", '-settings="$JEditSettings"')\
-WorkingDirectory path \
-RedirectStandardInput "source_file"
-RedirectStandardOutput "$JEditLogs\console.out" \
-RedirectStandardError "$JEditLogs\console.err" \
-PassThru # 返回进程对象
-Verb [RunAs|Print|Open] #
$processOptions = @{...}
Start-Process $processOptions
*:start是Start-Process的别名,与cmd命令用法有区别。start "" "Notepad.exe" # [cmd] 脱离终端,start命令处理引号中的参数
进程启动方式
通过-Verb选项指定-FilePath传递的进程或文件的启动方式(如以管理员运行),通过以下命令查看可执行程序(如PowerShell.exe)可用的启动方式:
startExe = New-Object System.Diagnostics.ProcessStartInfo -Args PowerShell.exe
startExe.verbs # -> open/runas/runasuser
从图形界面启动新进程
对于从图形界面点击脚本,其打开方式默认为终端,因此系统会首先为其创建一个Shell环境再执行程序,类似于调用Start-Process powershell.exe -ArgumentList ('xxx.ps1'),因此还是会弹出临时终端。
对于从图形界面点击.exe程序,则系统直接新建进程(中间不涉及创建Shell环境)。
启动PowerShell任务
Start-Job用于运行PowerShell脚本(-FilePath/-LiteralPath)或命令(-ScriptBlock)。
$job=Start-Job -Name PShellJob -ScriptBlock { Get-Process -Name pwsh } `
-InitializationScript {Import-Module MapFunctions} `
-InputObject "C:\Servers.txt" ` # $input
-ArgumentList powershell, pwsh, notepad ` # 逗号分隔参数列表或数组对象$args
-WorkingDirectory C:\Test\Scripts # PS7 $PWD
Get-Process -Name pwsh &
Receive-Job -Id $job.Id # -Keep保留已获取的输出结果。
Get-Job # 获取当前会话启动的后台任务,可查看任务状态。
Stop-Job/Remove-Job
PowerShell Core 6.0+支持使用
&使启动的进程与当前终端脱离(Start-Job的语法糖)。
任务类型:
RemoteJob:运行在远程会话中的任务;BackgroundJob:运行在独立进程中的任务;PSTaskJob或ThreadJob运行在当前进程的独立线程中的任务。
Invoke-Command支持在本机或远程执行任务。
$s = New-PSSession -ComputerName Server02 -Credential Domain01\User01
Invoke-Command -ComputerName HostName
-FilePath ScriptPath
-ScriptBlock $command
-PSSession $s # 在指定的PS会话中执行命令
-InDisconnectedSession
-AsJob # 运行为后台任务(->Start-Job)
Invoke-Command (Microsoft.PowerShell.Core) - PowerShell | Microsoft Learn
服务管理
Managing Services - PowerShell | Microsoft Docs
网络管理
Performing Networking Tasks - PowerShell | Microsoft Docs
网络连接信息
显示网络信息:
netstat
连接信息:
-a:显示所有连接(包括地址0.0.0.0)和侦听端口。
-b:显示进程对应的可执行程序。
-n:以数字形式显示地址和端口号。
-p PROTOCOL:显示指定协议的连接,包括:TCP、UDP、TCPv6和UDPv6。
路由信息:
-r:路由信息;
统计信息:
-s:显示 IP、IPv6、ICMP、ICMPv6、TCP、TCPv6、UDP 和 UDPv6 的统计信息;
-e:显示以太网统计信息。
arp
arp -agv
ip
ipconfig
ping
tracert
网络配置
netsh.exe COMMAND # netstat help
netsh.exe -f ScriptFile
# COMMAND
# interface - 更改网络接口配置。
# lan/wlan/bridge - 更改有线/无线局域网/网桥配置
# firewall/advfirewall - 更改防火墙(高级)配置
# winsock - 更改套接字配置。
# dhcpclient/dnsclient - 更改DHCP/DNS客户端配置。
# ipsec/http/winhttp/rpc - 更改IPSec/http/RPC配置。
# dump - 显示一个配置脚本。
# exec - 运行一个脚本文件。
# set - 更新配置设置。
# show - 显示信息。
# delete - 在项目列表上删除一个配置项目。
远程管理选项:
[-r RemoteMachine] [-u [DomainName\]UserName] [-p Password | *]。
netsh interface portproxy show [all|v4tov4|v4tov6|v6tov4|v6tov6]
网络共享
权限
网络访问问题
网络连接
问题:Windows网络连接显无法连接网络,实际可以上网?
原因:DNS服务器导致系统的网络探测服务无法正常工作,修改DNS服务器。
网络发现问题
问题:在网络中无法查看开启共享的机器。
原因:目标机器相关服务可能未运行(Function Discovery Provider Host和Function Discovery Resource Publication服务)。
共享权限
访问共享目录的用户(例如everyone)需要同时有本地文件系统的访问权限和共享目录的访问权限。
共享安全问题
Windows 10:0x80070035 找不到网络路径。
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters]
"AllowInsecureGuestAuth"=dword:00000001
windows 10 0x80070035 找不到网络路径_SOESC.COM-CSDN博客_0x80070035
UWP应用的网络代理
UWP应用(包括Microsoft Store)运行在沙箱环境中,其网络访问与物理机隔离(总是通过本地环回地址转发给物理机),因此无法使用物理机配置的网络代理。
解除应用的本地环回限制
以应用商店程序为例:
-
基于UWP应用可执行文件的所在路径(通过任务管理器找到可执行文件,查看其属性可找到其位置),确定UWP应用包名
Microsoft.WindowsStore_22207.1401.9.0_x64__8wekyb3d8bbwe。 -
通过UWP包名中的App名称
WindowsStore,在注册表中查找应用对应的安全标识符SID(Mappings条目下的名称)或系列名称(Moniker)[HKEY_CURRENT_USER\SOFTWARE\Classes\Local Settings\Software\Microsoft\Windows\CurrentVersion\AppContainer\Mappings\S-1-15-2-1609473798-1231923017-684268153-4268514328-882773646-2760585773-1760938157] "DisplayName"="Microsoft Store" "Moniker"="microsoft.windowsstore_8wekyb3d8bbwe" -
使用
CheckNetisolation程序,传入SID或系列名称解除本地环回限制。CheckNetIsolation.exe loopbackexempt -a/-d -p=$SID -n=$Moniker # 添加/移除例外项 CheckNetIsolation.exe LoopbackExempt -s # 列出已解除的列表
修改系统WinHttp代理规则
netsh winhttp import proxy source=ie # 使用系统设置中配置的代理服务器
netsh winhttp show proxy # 查看当前配置
Windows HTTP Services - Win32 apps | Microsoft Learn
虚拟网络
VMWare虚拟网络
WSL虚拟网络
-
在Windows主机上通过
localhost可访问WSL开放的服务;使用
127.0.0.1不能访问WSL的服务。 -
WSL和Windows主机连接到内置的Hyper-V虚拟网络,因此可使用同一网段的IP地址互相访问;
通过Windows主机的网络管理可以找到Windows主机在虚拟网络中的地址;WSL中
/etc/resolv.conf记载了Windows主机的IP地址(作为WSL的域名服务);WSL的
/etc/hosts也记录了Windows中手动配置的域名。 -
局域网访问WSL服务:WSL服务需要绑定到虚拟网卡IP地址而非本地环回地址,WSL中开放的端口会通过Windows主机的
wslhost.exe进行端口转发(默认仅监听WSL2的localhost,需要使用以下脚本添加监听地址,或使用WSL Host Patcher自动监听并转发WSL2中打开的端口)。同时,确保Windows防火墙策略允许外部IP访问wslhost.exe应用。# 1. Get IP Address of WSL 2 machine # 2. Remove previous port forwarding rules netsh interface portproxy delete v4tov4 listenport=$host_port listenaddress=$host_addr ... # 3. Add port Forwarding rules netsh interface portproxy add v4tov4 listenport=$host_port listenaddress=$host_addr # (0.0.0.0) connectport=$wsl_port connectaddress=$wsl_addr
Docker on WSL2
通过VMWare NAT网络连接的VM->本地Docker服务:VM需要使用本地主机的物理地址(而非主机在虚拟机子网中的地址)访问Docker服务。虽然Docker已经将Docker服务端口映射到物理端口,但其绑定的IP地址实际不包含虚拟网卡地址(如VMWare虚拟网卡)。因此,VM中发起的请求必须经过源NAT,以访问主机物理地址上的服务。
用户管理
whoami /UPN # User Principal Name (域用户)
/FQDN # Fully Qualified Differentiable Name (域用户)
/LOGONID # 当前用户的登录ID (S-1-5-5-0-28587288)
whoami /USER # 显示用户名与安全标识符 (SID)
/GROUPS # 用户所属组名称、类型、SID 和属性。
/CLAIMS # 当前用户的声明
/PRIV # 当前用户的安全特权
/ALL
[/FO format] # format=TABL(default)|LIST|CSV
[/NH] #
安全
证书管理
通过Windows“运行”对话框(Win+R启动)打开证书管理工具:
certmgr.msc:当前用户证书管理;certlm.msc:本地计算机证书管理(需要管理员权限);
安装证书
点击证书文件进行安装,可选择存储位置为当前用户或本地计算机(需要管理员权限)。
再证书管理工具中,可通过拖拽更改证书所属路径。
证书类型
| 类型 | 标识符 |
|---|---|
| 个人 | My |
| ==中间证书颁发机构== | CA |
| ==第三方根证书颁发机构== | AuthRoot |
| ==受信任的根证书颁发机构== | Root |
| 企业信任 | Trust |
| 受信任的发布者 | TrustedPublisher |
| 受信任的封装应用安装颁发机构 | TrustedAppRoot+ |
| 受信任的设备 | TrustedDevices*+ |
| 受信任人 | TrustedPeople* |
| 其他人 | ADDRESSBOOK |
| 智能卡受信任的根 | SmartCardRoot* |
| 客户端身份验证颁发者 | ClientAuthIssuer* |
| Active Directory 用户对象 | UserDS* |
| - | AAD Token Issuer*+ |
| 证书注册申请 | REQUEST* |
| 不信任的证书 | Disallowed* |
| 测试版根目录 | TestSignRoot+ |
| 预览版根 | FlightRoot+ |
| 远程桌面 | Remote Desktop+ |
| - | WindowsServerUpdateServices*+ |
| - | eSIM Certification Authorities+ |
| - | Windows Live ID Token Issuer+ |
| - | Homegroup Machine Certificates*+ |
| - | Local NonRemovable Certificates* |
| - | MSIEHistoryJournal* |
*通常为空目录。
+本地计算机目录下才有的类型。
Windows配置管理
安装
磁盘初始化,如果回收磁盘空间重新初始化,则会创建单独的启动分区。
UEFI
以UEFI模式安装系统,启动设备需要使用FAT32文件系统。
问题:无法为安装介质加载驱动程序
切换到USB2.0接口。
管理工具
远程访问
通过会话访问远程主机并执行命令。在目标机器上启用PowerShell远程会话:
Enable-PSRemoting # 以管理员身份运行,网络类型“专用”
由于此计算机上的网络连接类型之一设置为公用,因此 WinRM 防火墙例外将不运行。 将网络连接类型更改为域或专用,然后再次尝试。
$Cred = Get-Credential # 弹出对话框选择账号并输入密码
Enter-PSSession -ComputerName dc01 -Credential $Cred #建立远程登录会话
Exit-PSSession
错误:使用 winrm.cmd 配置
TrustedHosts。
Invoke-Command -ComputerName dc01, sql02, web01 {Get-Service -Name W32time} -Credential $Cred
$Session = New-PSSession -ComputerName dc01, sql02, web01 -Credential $Cred
Invoke-Command -Session $Session {(Get-Service -Name W32time).start()}
Invoke-Command -Session $Session {Get-Service -Name W32time}
Get-PSSession | Remove-PSSession # close established sessions
硬件
主板
wmic baseboard get Manufacturer,Model,Name,PartNumber,serialnumber
CPU
wmic cpu
GPU
dxdiag
nvidia-smi
BIOS
wmic BIOS get name,version,serialnumber
Get-WmiObject -Class Win32_Bios | Format-List -Property *
serialnumber为主机序列号。
内存
wmic MemoryChip get BankLabel,Capacity,MemoryType,TypeDetail,Speed,Tag
虚拟内存配置:如果系统物理内存足够大,可选择关闭系统分页文件:pagefile.sys,swapfile.sys以节省磁盘空间。
磁盘
列出物理磁盘信息:
wmic diskdrive list brief # DeviceID as disks path
wmic diskdrive get Name,Model,InterfaceType,MediaType,SerialNumber,Size,Status
wmic PARTITION
wmic VOLUME
可查看型号(
Model)、序列号(SerialNumber)。
diskpart # 启动磁盘管理交互环境
在交互环境中可执行的命令(通过help查看):
| 命令 | 说明 |
|---|---|
| `list disk | partition |
| `select disk | parition |
rescan | 重新扫描计算机,查找磁盘和卷 |
clean | 从磁盘清除配置信息或所有信息。 |
compact | 尝试减少文件的物理大小。 |
convert | 在不同的磁盘格式之间转换。 |
create | 创建卷、分区或虚拟磁盘。 |
format | 格式化卷或分区 |
shrink | 减小选定卷。 |
remove | 删除驱动器号或装载点分配。 |
delete | 删除对象。 |
exit | 退出diskpart。 |
磁盘分区类型
如果在MBR分区类型的磁盘上安装了
mbr2gpt可将MBR分区类型的磁盘转换为GPT分区类型,而无需移动磁盘上的数据。
mbr2gpt /validate # 验证选定磁盘可进行转换操作(未指定磁盘则使用安装系统的磁盘)
/convert /disk:N # 验证并执行转换操作
/allowFullOS # 使该命令可用于完整Windows环境(默认仅用于PE环境,推荐)
打开高级启动模式:“设置->更新和安全->恢复->高级启动->立即重新启动”(或按住Shift键点击重启按钮);在启动选项中选择:疑难解答->高级选项->命令行,然后重新启动电脑,执行上述命令。
电源管理
powercfg /a # 睡眠状态
powercfg -H OFF # 关闭休眠模式(删除系统磁盘下的hyberfi.sys文件)
# /LIST、/L 列出所有电源方案。
网络接口
wmic nic get AdapterType,Name,MACAddress,Speed,NetConnectionStatus
系统管理
系统信息
systeminfo # 输出系统信息[CLI]
msinfo32 # 系统信息[GUI]
ver # [cmd]查看系统版本
winver # [GUI]查看系统版本对话框
wmic COMPUTERSYSTEM
wmic OS
Get-ComputerInfo -Property "*version"
Get-WmiObject -Class Win32_ClassName | Format-List -Property '*'
Computer System Hardware Classes - Win32 apps | Microsoft Docs
Operating System Classes (Windows) | Microsoft Docs
Collecting Information About Computers - PowerShell | Microsoft Docs
系统启动信息
启动配置数据存储编辑器:
bcdedit /delete {uuid}
单独运行 "
bcdedit" 等同于运行 "bcdedit /enum ACTIVE"(列出激活的启动项)。
注册表
Working with Registry Entries - PowerShell | Microsoft Docs
Working with Registry Keys - PowerShell | Microsoft Docs
文件管理
Set-Location [-Path] path # >> cd, chdir
切换当前目录。
读取目录
Get-ChildItem -Recursive -Path *.txt # >> dir
创建文件
New-Item -ItemType "file" -Path . -Name "testfile1.txt" -Value "This is a text string."
New-Item -ItemType "directory" -Path "c:\" -Name "logfiles" # -> mkdir
链接文件
硬链接(Hard link)==只能用于文件==,且不能跨磁盘使用。多个硬链接可以指向同一个文件,并且删除一个硬链接或原始文件,其他硬链接仍然可以访问。删除软链接(Symbolic link)不会影响原始文件,但删除原始文件会使软链接失效。
权限:创建符号链接需要有“
SeCreateSymbolicLinkPrivilege”用户权利,administrators 组成员默认具有此权利。 这个权利可以在“本地安全策略(secpol.msc)\本地策略\用户权利分配”中设置。
New-Item -ItemType SymbolicLink -Path "Link" -Target "Target"
-ItemType SymbolicLink|Junction|HardLink:
-Path:符号链接文件的路径;
-Target:符号链接的目标路径;
-Force:覆盖已有文件。
cmd:
mklink {/D|/H|/J} Link Target
/D:创建目录符号链接(symbolic link),默认为文件符号链接。/H:创建硬链接(hard link)而非符号链接,目标文件必须位于同一磁盘分区(卷)。/J:创建目录联接(junction),目录必须位于本地。Link指定新的符号链接名称,Target指定新链接引用的路径 (相对或绝对)。Adobe Reader保存文件时,可能会先删除原有文件,再创建新文件,由此使得指向原文件的硬链接与新文件不同。
查看文件链接
dir path -recurse -force | ?{$_.LinkType} | select FullName,LinkType,Target
dir->Get-ChildItem
复制移动文件
del filename % 删除文件。
dir
rmdir
move
Move-Item -Path C:\test.txt -Destination E:\Temp\tst.txt # move file
Move-Item -Path C:\Temp -Destination C:\Logs # move folder
Move-Item -Path .\*.txt -Destination C:\Logs # wildcard
查找
查找可执行程序
Get-Command dotnet # [gcm] -> "where" in cmd
#CommandType Name Version Source
#----------- ---- ------- ------
#Application dotnet.exe 5.0.152... C:\Program Files\dotnet\dotnet.exe
应用管理
https://dev.to/bowmanjd/chocolatey-vs-scoop-package-managers-for-windows-2kik
Working with Software Installations - PowerShell | Microsoft Docs
Get-CimInstance -Class Win32_Product | Select-Object -Property Name,Vendor,Version
离线安装
appx包
获取appx包
包括AppxBundle和appx包,其中AppxBundle是多个appx包的合集。
- 软件发布者在GitHub等网站提供
appx包的下载(某些可能为将依赖项打包); - 从应用商店获取应用的分享链接,然后在Microsoft Store - Generation Project查找并下载应用的
appx包及其依赖包。
安装
以管理员身份使用PowerShell命令提供安装选项:
Add-AppxPackage FILENAME.appx
双击软件包即也可执行安装。但离线安装程序无法启动,提示找不到启动文件:可能是由于安装位置
C:\Program Files\WindowsApps没有访问权限。由于以上两种文件格式都是以zip格式封装,因此可以提取其中的appx包内容并手动安装到用户提供目录下。安装如果出现证书无法被信任的问题,需要将
appx包所带证书(通过“属性/数字签名”查看)安装到本机的证书目录下(选择“受信任的xxx”)。
winget
winget list [-q QUERY] # 显示已安装软件列表(包括非winget安装)
--id ID
--name NAME
--source SOURCE # -s 使用指定的源查找程序包
--count # -n 显示不超过指定数量的结果
--exact # -e 使用精确匹配
winget list > winget.installed.txt # 在cmd中执行避免乱码
即使非
winget安装,如果在相应软件源发现匹配软件,仍会显示相应的源(msstore/winget)。
winget search PACKAGE --source SOURCE
winget show PACKAGE --source SOURCE # 显示软件的详细信息
winget search > winget.repo.txt # 在cmd中执行避免乱码
当
show发现多个匹配时,会提示用户提供更精确的包名或限定源。
winget install <package> --source msstore
upgrade
uninstall
winget export --output FILE --source SOURCE
import --import-file FILE
winget source list \ # 列出源的名称和URL
--name winget # 列出指定源的详细信息
winget settings # 打开设置文件进行编辑
Chocolatey
配置
choco source [list] # 列出软件源
choco source add -n=REPONAME -s=url
choco source enable/disable/remove -n=REPONAME
choco config [list] # 列出配置信息
choco config get [--name] CONFIG_NAME
choco config set [--name] CONFIG_NAME --value VALUE
搜索软件
choco list/find/search openjdk[--exact --verbose]
choco list/find/search <appname> --local-only # 查找已安装应用
choco info pkgname
更新
choco upgrade <appname>|all --except="appname,..." # 升级应用
choco outdated # 列出可更新软件 upgrade all --noop
choco pin <package_name> # 固定软件版本
安装卸载
choco install <appname>
choco uninstall <appname>
搭建本地软件仓库
使用Nexus代理
仅代理Chocolaty安装脚本信息(nuget),软件的安装文件仍然需要访问官方资源。因此该代理只是提高对软件仓库的查询速度,而不能离线部署。
Name=chocolatey
Format=nuget
URL=http://172.28.76.100:8081/repository/chocolatey/
Protocl="NuGet V2"
Remote=https://chocolatey.org/api/v2/
Chocolatey Software Docs | Host packages internally
Scoop
如果没有管理员权限,则采用Scoop更加合适。
# Enable execution of PowerShell scripts
Set-ExecutionPolicy AllSigned
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
Invoke-Expression (
New-Object System.Net.WebClient).DownloadString('https://get.scoop.sh')
# or shorter: iwr -useb get.scoop.sh | iex
scoop search [<app>] # 省略app名称将列出仓库中所有可用软件
scoop info <app> # 显示软件信息(含必要配置说明)
scoop install|uninstall <app>
scoop list
scoop status # 检查软件是否有新版本
scoop hold|unhold <app> # 停用/启用更新
scoop update [<app>] # 更新scoop或指定软件
scoop cleanup * # 清理所有旧版软件, 清理指定软件, 清理过期的安装包
scoop cleanup <app>
安装的软件在
~\scoop\apps目录下。
软件源
Scoop buckets by number of apps | scoop-directory (rasa.github.io)
scoop bucket add|list|known|rm <bucket>
下载
利用aria2加速下载:
scoop install aria2
scoop config aria2-enabled true # default: true
scoop config aria2-retry-wait 8 # default: 2
scoop config aria2-split 8 # default: 5
scoop config aria2-max-connection-per-server 8 # default: 5
scoop config aria2-min-split-size 2M # default: 5M
添加库 versions, 可以安装其他(落后的)版本:
scoop bucket add versions
scoop install python@3.7.7
MSYS2
Software Distribution and Building Platform for Windows.
Terminal:
mintty、bash;CLI tools:
git、tar、awk;Develop tools:GCC, mingw-w64, CPython, CMake, Meson, OpenSSL, FFmpeg, Rust, Ruby。
package management:
Pacman(Arch Linux)
winget install msys2.msys2
用法: pacman <操作> [...]
操作:
pacman {-h --help}
pacman {-V --version}
pacman {-D --database} <选项> <软件包>
pacman {-F --files} [选项] [文件]
pacman {-Q --query} [选项] [软件包]
pacman {-R --remove} [选项] <软件包>
pacman {-S --sync} [选项] [软件包]
pacman {-T --deptest} [选项] [软件包]
pacman {-U --upgrade} [选项] <文件>
MSYS2提供模拟文件系统,其物理位置为MSYS2安装目录(可直接从物理系统访问其中内容)。
df -hT /home/gary/
# 文件系统 类型 容量 已用 可用 已用% 挂载点
# C:/msys64 ntfs 931G 221G 711G 24% /
Office
安装office部署工具(Office Deployment Tool)。
配置文件(configuration.xml)
<Configuration>
<Add OfficeClientEdition="64" Channel="Monthly"> <!--PerpetualVL2019-->
<Product ID="HomeStudent2019Retail">
<!-- ProPlus2019Volume|VisioPro2019Volume... -->
<Language ID="zh-cn" />
</Product>
</Add>
<!-- <RemoveMSI All="True" /> -->
<!-- <Display Level="None" AcceptEULA="TRUE" /> -->
<!-- <Property Name="AUTOACTIVATE" Value="1" /> -->
</Configuration>
下载安装文件:
setup /download configuration.xml # run in cmd
安装应用:
setup /configure configuration.xml # run in cmd
https://docs.microsoft.com/en-us/deployoffice/office2019/deploy.
激活Office
# 查看激活状态
cscript "C:\Program Files\Microsoft Office\Office16\OSPP.VBS" /dstatus
# 移除key
cscript "C:\Program Files\Microsoft Office\Office16\OSPP.VBS" /unpkey:F6YYT
RDP
RDPWrap
https://raw.githubusercontent.com/sebaxakerhtc/rdpwrap.ini/master/rdpwrap.ini
VMWare Workstation
VM16 Pro:ZF3R0-FHED2-M80TY-8QYGC-NPKYF
进程管理
查看进程信息:
tasklist /V /FI "ImageName eq winlogon.exe"
/V:显示更多信息
/FI:设置过滤条件(不区分大小写)。筛选器包括:Status(运行状态)、ImageName(程序名称)、Pid(进程号)等等(查看tasklist /?)。
wmic process
wmic可以获得包括命令行信息在内的详细信息。
Get-Process [-Name] [firefox, powershell] # alias as ps
Get-Process DataExchangeHost -Module # need admin privilage
Get-Process WindowsTerminal -FileVersionInfo
Managing Processes with Process Cmdlets - PowerShell | Microsoft Docs
获取当前进程信息?
创建进程
直接在当前终端中运行可执行程序,程序将在前台运行。
新进程与终端分离
Start-Process在新的进程中运行可执行文件(类似Linux exec)。
-
如果指定
-NoNewWindow,则直接在当前Shell中创建新进程,并与当前Shell分离(输入输出默认仍在当前终端,除非添加重定向选项)。 -
反之,首先新建一个Shell进程(桌面环境弹出控制台界面),并在新的Shell环境中运行可执行程序。可执行程序同样与Shell环境分离,因此新的Shell环境在执行启动命令后即退出。
-
在脚本中调用
Start-Process和上述情况一致,执行脚本仅在当前Shell进程中创建一个子Shell环境。 -
如果出现新终端窗口不退出的情况(后台任务未成功与终端分离,使用Terminal作为默认终端时可能出现),可添加
-WindowStyle Hidden(不能与-NoNewWindow同时使用)手动隐藏终端。如果直接从图形界面启动脚本,并使用
-NoNewWindow,导致后台进程无法启动。因为系统分配的终端没有被阻塞执行完脚本内容后直接退出。使用-NoNewWindow会使在当前Shell环境的后台进程也退出。
非Windows平台上子进程总是连接到父进程终端,可以使用
Start-Process nohup命令脱离父终端。
Start-Process -FilePath command \ # -> start*
-ArgumentList ('-jar',"$jEdit", '-settings="$JEditSettings"')\
-WorkingDirectory path \
-RedirectStandardInput "source_file"
-RedirectStandardOutput "$JEditLogs\console.out" \
-RedirectStandardError "$JEditLogs\console.err" \
-PassThru # 返回进程对象
-Verb [RunAs|Print|Open] #
$processOptions = @{...}
Start-Process $processOptions
*:start是Start-Process的别名,与cmd命令用法有区别。start "" "Notepad.exe" # [cmd] 脱离终端,start命令处理引号中的参数
进程启动方式
通过-Verb选项指定-FilePath传递的进程或文件的启动方式(如以管理员运行),通过以下命令查看可执行程序(如PowerShell.exe)可用的启动方式:
startExe = New-Object System.Diagnostics.ProcessStartInfo -Args PowerShell.exe
startExe.verbs # -> open/runas/runasuser
从图形界面启动新进程
对于从图形界面点击脚本,其打开方式默认为终端,因此系统会首先为其创建一个Shell环境再执行程序,类似于调用Start-Process powershell.exe -ArgumentList ('xxx.ps1'),因此还是会弹出临时终端。
对于从图形界面点击.exe程序,则系统直接新建进程(中间不涉及创建Shell环境)。
启动PowerShell任务
Start-Job用于运行PowerShell脚本(-FilePath/-LiteralPath)或命令(-ScriptBlock)。
$job=Start-Job -Name PShellJob -ScriptBlock { Get-Process -Name pwsh } `
-InitializationScript {Import-Module MapFunctions} `
-InputObject "C:\Servers.txt" ` # $input
-ArgumentList powershell, pwsh, notepad ` # 逗号分隔参数列表或数组对象$args
-WorkingDirectory C:\Test\Scripts # PS7 $PWD
Get-Process -Name pwsh &
Receive-Job -Id $job.Id # -Keep保留已获取的输出结果。
Get-Job # 获取当前会话启动的后台任务,可查看任务状态。
Stop-Job/Remove-Job
PowerShell Core 6.0+支持使用
&使启动的进程与当前终端脱离(Start-Job的语法糖)。
任务类型:
RemoteJob:运行在远程会话中的任务;BackgroundJob:运行在独立进程中的任务;PSTaskJob或ThreadJob运行在当前进程的独立线程中的任务。
Invoke-Command支持在本机或远程执行任务。
$s = New-PSSession -ComputerName Server02 -Credential Domain01\User01
Invoke-Command -ComputerName HostName
-FilePath ScriptPath
-ScriptBlock $command
-PSSession $s # 在指定的PS会话中执行命令
-InDisconnectedSession
-AsJob # 运行为后台任务(->Start-Job)
Invoke-Command (Microsoft.PowerShell.Core) - PowerShell | Microsoft Learn
服务管理
Managing Services - PowerShell | Microsoft Docs
网络管理
Performing Networking Tasks - PowerShell | Microsoft Docs
网络连接信息
显示网络信息:
netstat
连接信息:
-a:显示所有连接(包括地址0.0.0.0)和侦听端口。
-b:显示进程对应的可执行程序。
-n:以数字形式显示地址和端口号。
-p PROTOCOL:显示指定协议的连接,包括:TCP、UDP、TCPv6和UDPv6。
路由信息:
-r:路由信息;
统计信息:
-s:显示 IP、IPv6、ICMP、ICMPv6、TCP、TCPv6、UDP 和 UDPv6 的统计信息;
-e:显示以太网统计信息。
arp
arp -agv
ip
ipconfig
ping
tracert
网络配置
netsh.exe COMMAND # netstat help
netsh.exe -f ScriptFile
# COMMAND
# interface - 更改网络接口配置。
# lan/wlan/bridge - 更改有线/无线局域网/网桥配置
# firewall/advfirewall - 更改防火墙(高级)配置
# winsock - 更改套接字配置。
# dhcpclient/dnsclient - 更改DHCP/DNS客户端配置。
# ipsec/http/winhttp/rpc - 更改IPSec/http/RPC配置。
# dump - 显示一个配置脚本。
# exec - 运行一个脚本文件。
# set - 更新配置设置。
# show - 显示信息。
# delete - 在项目列表上删除一个配置项目。
远程管理选项:
[-r RemoteMachine] [-u [DomainName\]UserName] [-p Password | *]。
netsh interface portproxy show [all|v4tov4|v4tov6|v6tov4|v6tov6]
网络共享
权限
网络访问问题
网络连接
问题:Windows网络连接显无法连接网络,实际可以上网?
原因:DNS服务器导致系统的网络探测服务无法正常工作,修改DNS服务器。
网络发现问题
问题:在网络中无法查看开启共享的机器。
原因:目标机器相关服务可能未运行(Function Discovery Provider Host和Function Discovery Resource Publication服务)。
共享权限
访问共享目录的用户(例如everyone)需要同时有本地文件系统的访问权限和共享目录的访问权限。
共享安全问题
Windows 10:0x80070035 找不到网络路径。
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters]
"AllowInsecureGuestAuth"=dword:00000001
windows 10 0x80070035 找不到网络路径_SOESC.COM-CSDN博客_0x80070035
UWP应用的网络代理
UWP应用(包括Microsoft Store)运行在沙箱环境中,其网络访问与物理机隔离(总是通过本地环回地址转发给物理机),因此无法使用物理机配置的网络代理。
解除应用的本地环回限制
以应用商店程序为例:
-
基于UWP应用可执行文件的所在路径(通过任务管理器找到可执行文件,查看其属性可找到其位置),确定UWP应用包名
Microsoft.WindowsStore_22207.1401.9.0_x64__8wekyb3d8bbwe。 -
通过UWP包名中的App名称
WindowsStore,在注册表中查找应用对应的安全标识符SID(Mappings条目下的名称)或系列名称(Moniker)[HKEY_CURRENT_USER\SOFTWARE\Classes\Local Settings\Software\Microsoft\Windows\CurrentVersion\AppContainer\Mappings\S-1-15-2-1609473798-1231923017-684268153-4268514328-882773646-2760585773-1760938157] "DisplayName"="Microsoft Store" "Moniker"="microsoft.windowsstore_8wekyb3d8bbwe" -
使用
CheckNetisolation程序,传入SID或系列名称解除本地环回限制。CheckNetIsolation.exe loopbackexempt -a/-d -p=$SID -n=$Moniker # 添加/移除例外项 CheckNetIsolation.exe LoopbackExempt -s # 列出已解除的列表
修改系统WinHttp代理规则
netsh winhttp import proxy source=ie # 使用系统设置中配置的代理服务器
netsh winhttp show proxy # 查看当前配置
Windows HTTP Services - Win32 apps | Microsoft Learn
虚拟网络
VMWare虚拟网络
WSL虚拟网络
-
在Windows主机上通过
localhost可访问WSL开放的服务;使用
127.0.0.1不能访问WSL的服务。 -
WSL和Windows主机连接到内置的Hyper-V虚拟网络,因此可使用同一网段的IP地址互相访问;
通过Windows主机的网络管理可以找到Windows主机在虚拟网络中的地址;WSL中
/etc/resolv.conf记载了Windows主机的IP地址(作为WSL的域名服务);WSL的
/etc/hosts也记录了Windows中手动配置的域名。 -
局域网访问WSL服务:WSL服务需要绑定到虚拟网卡IP地址而非本地环回地址,WSL中开放的端口会通过Windows主机的
wslhost.exe进行端口转发(默认仅监听WSL2的localhost,需要使用以下脚本添加监听地址,或使用WSL Host Patcher自动监听并转发WSL2中打开的端口)。同时,确保Windows防火墙策略允许外部IP访问wslhost.exe应用。# 1. Get IP Address of WSL 2 machine # 2. Remove previous port forwarding rules netsh interface portproxy delete v4tov4 listenport=$host_port listenaddress=$host_addr ... # 3. Add port Forwarding rules netsh interface portproxy add v4tov4 listenport=$host_port listenaddress=$host_addr # (0.0.0.0) connectport=$wsl_port connectaddress=$wsl_addr
Docker on WSL2
通过VMWare NAT网络连接的VM->本地Docker服务:VM需要使用本地主机的物理地址(而非主机在虚拟机子网中的地址)访问Docker服务。虽然Docker已经将Docker服务端口映射到物理端口,但其绑定的IP地址实际不包含虚拟网卡地址(如VMWare虚拟网卡)。因此,VM中发起的请求必须经过源NAT,以访问主机物理地址上的服务。
用户管理
whoami /UPN # User Principal Name (域用户)
/FQDN # Fully Qualified Differentiable Name (域用户)
/LOGONID # 当前用户的登录ID (S-1-5-5-0-28587288)
whoami /USER # 显示用户名与安全标识符 (SID)
/GROUPS # 用户所属组名称、类型、SID 和属性。
/CLAIMS # 当前用户的声明
/PRIV # 当前用户的安全特权
/ALL
[/FO format] # format=TABL(default)|LIST|CSV
[/NH] #
安全
证书管理
通过Windows“运行”对话框(Win+R启动)打开证书管理工具:
certmgr.msc:当前用户证书管理;certlm.msc:本地计算机证书管理(需要管理员权限);
安装证书
点击证书文件进行安装,可选择存储位置为当前用户或本地计算机(需要管理员权限)。
再证书管理工具中,可通过拖拽更改证书所属路径。
证书类型
| 类型 | 标识符 |
|---|---|
| 个人 | My |
| ==中间证书颁发机构== | CA |
| ==第三方根证书颁发机构== | AuthRoot |
| ==受信任的根证书颁发机构== | Root |
| 企业信任 | Trust |
| 受信任的发布者 | TrustedPublisher |
| 受信任的封装应用安装颁发机构 | TrustedAppRoot+ |
| 受信任的设备 | TrustedDevices*+ |
| 受信任人 | TrustedPeople* |
| 其他人 | ADDRESSBOOK |
| 智能卡受信任的根 | SmartCardRoot* |
| 客户端身份验证颁发者 | ClientAuthIssuer* |
| Active Directory 用户对象 | UserDS* |
| - | AAD Token Issuer*+ |
| 证书注册申请 | REQUEST* |
| 不信任的证书 | Disallowed* |
| 测试版根目录 | TestSignRoot+ |
| 预览版根 | FlightRoot+ |
| 远程桌面 | Remote Desktop+ |
| - | WindowsServerUpdateServices*+ |
| - | eSIM Certification Authorities+ |
| - | Windows Live ID Token Issuer+ |
| - | Homegroup Machine Certificates*+ |
| - | Local NonRemovable Certificates* |
| - | MSIEHistoryJournal* |
*通常为空目录。
+本地计算机目录下才有的类型。
Windows PowerShell
PowerShell is built on .NET:
- Windows PowerShell 5.1 is built on top of the .NET Framework v4.5.
- PowerShell is an open source project built on .NET Core.
安装
Windows
以下为安装PowerShell 7.x的方法(Windows内置PowerShell 5.1,PowerShell 7.x可与之并存)。
-
msi安装,下载安装包点击执行或运行以下命令:msiexec.exe /package PowerShell-7.2.4-win-x64.msi /quiet \ USE_MU=1 ENABLE_MU=1 # 通过Windows Update自动更新PowerShell -
winget安装:winget install Microsoft.PowerShell -
安装为
.NET全局工具:dotnet tool install|update --global PowerShell # [Admin] 安装PowerShell 7.x -
通过应用商店安装(有运行权限限制)。
Linux
-
从软件源安装
sudo apt install -y wget apt-transport-https software-properties-common wget -q "https://packages.microsoft.com/config/ubuntu/$(lsb_release -rs)/packages-microsoft-prod.deb" sudo dpkg -i packages-microsoft-prod.deb # Register the repository GPG keys sudo apt update && sudo apt install -y powershell -
直接从发布页面下载软件包安装。
安装相关路径:
$PSHOME=/opt/microsoft/powershell/7/;- 用户配置文件:
~/.config/powershell/profile.ps1; - 用户模块目录:
~/.local/share/powershell/Modules;
PowerShell命令
PowerShell命令命名规则为Verb-Noun(动词-名词)形式。
探索PowerShell命令
-
Get-Verb:获取命令库中多数命令的开头动词(有助于用户使用命令); -
Get-Command:返回所有已安装的命令。也可以添加参数以过滤列举内容(参数支持通配符*):Get-Command -Name|Verb|Noun <cmdlet> \ # 按名称/动词/名词匹配 -CommandType Cmdlet, Function, Alias # 按命令类型匹配 -Module <module> # 按模块匹配 -ParameterType Process # 根据命令接受的主要参数的类型筛选 Get-Command Get-Process -Syntax # 获取命令语法 -
Get-Alias:获取命令别名的信息。Get-Alias -Definition Get-Command,Get-Member # 获取别名 Get-Alias ls,dir # 获取全名在脚本中尽量使用全名而非别名,以增强可读性。
-
Get-Member:对输出对象进行操作,并返回对象的属性和方法(可根据参数过滤)。$s = Get-Service -Name w32time $s | Get-Member # 返回对象的类型,及其包含属性的方法的名称、类型和定义 -
Get-Help <cmdlet-name>:获取命令的文档信息。
模块管理
包管理模块
PowerShellGet用于查找、安装、更新和发布模块、脚本等内容。
错误:A parameter cannot be found that matches parameter name
AllowPrerelease.:检查是否安装/导入PowershellGet模块。
安装/更新PowerShellGet的两种方法:
-
安装
Nuget将自动安装PowerShellGet;Install-PackageProvider -Name NuGet -Force # with Admin -
直接安装
PowerShellGet;Install-Module -Name PowerShellGet -AllowClobber -Force
安装模块
Install-Module [-Name] <ModuleName*>
-Scope CurrentUser|AllUsers # AllUsers needs Admin previllege
-AllowPrerelease
-WhatIf
-MinimumVersion 2.0.1 # -RequiredVersion -MaximumVersion
-Force # 安装同名不同版本模块
-AllowClobber # 覆盖同名模块
Update-Module # 参数与Instal-Module相似
Uninstall-Module [-Name] <ModuleName>
安装模块前可以先进行搜索。首先查找本地是否已安装相应模块:
Get-Module -ListAvailable [-Name <ModuleName>] # 从当前当前会话查找模块
-ListAvailable:列出指定模块的所有本地安装版本(可能包含系统内置版本和用户安装版本)。
如果本地不存在指定模块,可查找Nuget仓库(可使用Nexus搭建镜像仓库)。
Find-Module -Name <ModuleName> # -> PSRepositoryItemInfo
如果本地存在指定模块,找到的模块会被加载到当前会话。
Find-Command -Name <CmdName> -ModuleName <ModName> # -> PSGetCommandInfo
-AllowPrerelease
-RequiredVersion # -MinimumVersion -MaximumVersion
Find-Module,Find-Command的返回的结果可以传递给Install-Module执行安装。
导入模块
位于$env:PSModulePath路径下加模块会自动被加载。其他模块,在命令行或脚本中执行导入:
Import-Module [-Name] <ModuleName>
$m = Get-Module -ListAvailable PowershellGet, Dism
Import-Module -ModuleInfo $m
Import-Module -Name c:\ps-test\modules\test -Verbose
离线手工安装模块
可以从PowerShell Gallery下载模块的nupkg包。.nupkg以zip格式封装了模块数据以及NuGet相关的描述数据(非模块本身的数据)。NuGet相关数据包括:
_rels/:包含模块的依赖声明(.rels文件);package/:NuGet相关数据;[Content_Types].xml:描述扩展模块如何与NuGet共同使用;<name>.nuspec:包的元数据。
手工安装:将.nupkg中非NuGet相关数据解压到$env:PSModulePath中的一个路径下,并仅以包名命名该模块的文件夹1。
文档
PowerShell文档介绍了PowerShell的cmdlet、函数、脚本及模块,并解释了PowerShell 语言的元素等概念。在命令行中使用Get-Help cmdlet来显示帮助主题。
Get-Help cmdname -examples|detailed|full|online
help cmdname # => Get-Help cmdname | more
help Get-Command -Full | Out-GridView # 在独立的文档查看器中查看帮助文档
如果本地没有帮助文件,
Get-Help会显示自动生成的有关 cmdlet、函数及脚本的帮助。
help不是Get-Help的别名:每次仅显示一页内容,需要手动翻页。
Get-Help会搜索与cmdname匹配的相关命令(类似于Get-Command),cmdname可包含通配符(==如果前后未添加*,则在名称中间添加*是无效的通配符==)。因此,当查找结果多于一条,将显示结果列表;反之显示查找结果的详细信息。
获取命令的参数信息:
help cmdname -Parameter <ParameterName>
获取本地文档
PowerShell 中默认不包含帮助文件,但可以联机查看帮助主题,或使用 Update-Help cmdlet将帮助文件下载到本地或在网站发布更新的时候更新本地文档。
Update-Help (Microsoft.PowerShell.Core) - PowerShell | Microsoft Docs。
Update-Help \
[-UICulture en-US,zh-CN] # 指定文档语言
[-Module Microsoft.PowerShell*] # 更新指定模块的文档(默认更新所有已安装的模块)
-SourcePath path # Save-Help
开发环境
Debugging with Visual Studio Code
变量
PowerShell accepts and returns .NET objects, rather than text.
设置变量:
$JAVA_HOME="C:\tools\java"
Set-Variable -Name 'JAVA_HOME' -Value 'C:\tools\java' # -> set*
*:set是Set-Variable的别名,与cmd的变量设置命令set无关。
==变量名不区分大小写==。
输出变量:
$JAVA_HOME # => echo $JAVA_HOME
$JAVA_HOME.ToUpper() # 调用变量对象的属性或方法
$v=Get-Variable -Name 'JAVA_HOME' # get (Name,Value) object
$v.Value
数据类型
空值
Everything you wanted to know about $null - PowerShell | Microsoft Docs
字符串
字符串需要使用''或""进行表示,否则相应内容将被视为shell命令。==字符串使用+拼接==。
Everything you wanted to know about variable substitution in strings - PowerShell | Microsoft Docs
裁剪字符串
str.Trim() # TrimEnd/TrimStart
str.Trim("a", " ") # 可指定多个裁剪模式(单个字符)
返回新的对象。
分割字符串
$array="abcdefghi".split("de") # -> -split运算符
数组
许多命令(如Get-Process)的返回值都是一个数组。手动构造数组方法:
$data=@('Zero','One','Two','Three') # 空数组 $data = @()
$data=('Zero','One','Two','Three') # => $data = 'Zero','One','Two','Three'
数组元素可换行声明,此时两行间的元素不需要通过
,分隔。
通过迭代构造数组:
$array = 1..5 | ForEach-Object { "ATX-SQL-$PSItem" }
$array = foreach ( $node in (1..5)){ "ATX-SQL-$node" }
数组默认类型为[PSObject[]],即其元素都继承自PSObject。在创建数组时可指定严格的类型限制:
[int[]] $numbers = 1,2,3
预分配内存的数组:
$data = [Object[]]::new(4)
嵌套数组:
$data = @(
@(1,2,3), # 嵌套数组元素换行时仍需","分隔
@(4,5,6),
@(7,8,9)
)
$data[1][2] # -> 6
多维数组:
[string[,]]$rank2 = [string[,]]::New(3,2)
数组属性
Write-Output -NoEnumerate $data | Get-Member # 获取数组的属性和方法
$data | Get-Member # 获取数组元素的属性和方法
$data.Count # 数组元素数量 => $data.Length
$data.Rank # 数组维数
不仅数组可以获取长度,标量对象也可(返回1),空数组长度为0(特别地
$null.count->0,注意区别)。
访问元素
$data[i] # 0-based index
$data[0,2,3] # 获取子数组(可添加重复编号以生成重复元素)
$data[1..3] # 切片(区间可反向,即"3..1:")
$data[-1] # 负索引
$data[i,-j] # => [i,i-1,...0,-1,...-j] (与Python负索引语义不同)
访问不在数组长度范围内元素将返回
$null而非产生异常。
i..j将自动生成一个整数数组。
访问数组元素属性(链式调用):
$data[0].PropName
$data.PropName # 返回所有元素的PropName返回值组成的新数组
更新数组
$data[2] = 'dos' # 索引编号超过数组长度将产生异常
$data.Clear() # 重置数组元素的值为默认值
迭代数组
$data.foreach({"Item [$PSItem]"}) # => $data.foreach{"Item [$PSItem]"}
$data | ForEach-Object {"Item: [$PSItem]"} # $PSItem => $_
foreach ( $node in $data ){ "Item: [$node]" }
for ( $index = 0; $index -lt $data.count; $index++){
"Item: [{0}]" -f $data[$index]
}
switch( $data ) {...} # 对数组每个元素执行分支判断
当数组元素类型为值类型时,使用for语句块可在迭代数组时对其进行更新。反之,如果为引用类型,则其他迭代语句也可对数组元素的属性进行更改。
ForEach-Object -Parallel[7.x]:管道并行。
数组对象运算
数组对象运算都将产生新的数组对象。
-
字符串拼接:使用连接符将数组内容拼接为一个字符串对象。
$data -join '-' -
替换:
$data -replace 'ATX','LAX' # 对数组每个元素执行替换 -
查找:返回
True|False。-contains, -notcontains,-in, -notin$data -contains 'green' # => 'green' -in $data -
比较或匹配过滤(
-eq,-ne,-match):数组与对象比较返回匹配对象(或子数组):$data -eq 'green' $servers -match 'SQL' # => $servers | Select-String SQL判断数组对象是否为
$null,应该使用$null -eq $array避免上述语法对数组的$null值的筛选。 -
追加:
$data = $data + 'four' # $data += 'four' -
拼接:
$array=$array1+$array2 $array = $array * 3 # 复制并拼接(使用这种方法可构造初始值为固定值的数组)
数组过滤
基于数组元素或元素属性的值过滤元素。如果数组元素本身就是字符串对象,则直接在迭代语句中使用$_。
$data | Where-Object {$_.Name -eq w32time}
$data.Where({$_.FirstName -eq 'Kevin'}) # 使用成员函数
$data | Select-Object -First 3
分组统计
$data | Group-Object -Property ModuleName |
Sort-Object -Property Count -Descending
字典(hashtable)
$hashtable = @{}
$hashtable['key'] = $value
字典可传递给命令,以代替逐个传递命令行参数,方便动态构造传入参数。
Everything you wanted to know about hashtables - PowerShell | Microsoft Docs
运算符
具有相同优先级的运算符从左到右依次计算。例外:赋值运算符、类型转换运算符、和取反运算符(!,-not,-bnot)从有至左计算。
可以使用()来显式限定优先计算的部分表达式。
运算符优先级从高到低2:
-
$(), @(), (), @{} -
. ?.(member access) -
::(static) -
[0] ?[0](index operator) -
[int](cast operators)[datetime]$birthday = "1/10/66" # 将birthday转换为datetime类型 -
-split(unary) -
-join(unary) -
,(comma operator) -
++ --:自增运算符,支持前置或后置。 -
! -not:逻辑取反运算。 -
..(range operator) -
-f(format operator)"{0:N2} - {1}" -f 10 1.5 -
-(unary/negative) -
* / % -
+ - -
以下命令具有同等优先级:
-
-split -join(binary):分割字符串(合并见数组运算)。$array="abcdefghi" -split "de" # -> $array="abcdefghi".split("de") -
-is -isnot:判断是否为.Net Framework类型。42 –is [int] -
-as:类型转换。$a = 42 –as [String] -
-eq -ne -gt -ge -lt -le:比较运算符。涉及字符串比较的运算符默认为大小写不敏感的,带前缀c的运算符(-ceq)为大小写敏感的(具有同等优先级)。不支持
==,!=,>,<=,<,<=。 -
-match -notmatch:正则表达式匹配,返回是否匹配; -
-like -notlike:通配符匹配; -
-in -notIn,-contains -notContains -
-replace:字符串替换。"abcde" -replace "bc", "TEST" # replace bc with TEST # aTESTde
-
-
-band -bnot -bor -bxor -shr -shl:位运算,-shl, -shr(移位)。 -
-and -or -xor:逻辑运算。 -
以下命令非真正的运算符而是PowerShell命令语法的一部分,在命令解释执行过程中具有最低优先级。
-
.(dot-source) -
&(call) -
? <if-true> : <if-false>(Ternary operator) -
??(null-coalese operator) -
|(pipeline operator) -
> >> 2> 2>> 2>&1 -
&& ||(pipeline chain operators) -
= += -= *= /= %= ??=:赋值运算符。$result=$a*$b
-
容器类型
数组定义后无法增加元素,PowerShell可调用多种.NET容器类型以解决此问题。
ArrayList
$myarray = [System.Collections.ArrayList]::new()
[void]$myArray.Add('Value') # [void] to suppress return value.
List
ArrayList不支持泛型,因此类似于数组默认存储PSObject元素。List类型支持泛型(类似于数组声明时限定类型):
$mylist = [System.Collections.Generic.List[int]]::new()
$mylist = [System.Collections.Generic.List[int]]@(1,2,3) # 将数组转换为List
对于类型元素多样的情况,也可使用
PSObject作为类型参数。
List和ArrayList都支持元素的的增加和删除。
[void]$myList.Remove("Two") # -> True|False: if element is found
[void]$drives.Remove($drives[2]) # remove reference type
StringBuilder
https://powershellexplained.com/2017-11-20-Powershell-StringBuilder/
其他容器类型
时间日期
date=Get-Date \
-Format "dddd MM/dd/yyyy HH:mm K" \ # 返回个格式化字符串。
-UFormat "%A %m/%d/%Y %R %Z" \
-DisplayHint Date \ # 仅显示日期
-Year 2020 -Month 12 -Day 31 \ # 用户初始化
| Specifier | Definition |
| --- | --- |
| `dddd` | Day of the week - full name |
| `MM` | Month number |
| `dd` | Day of the month - 2 digits |
| `yyyy` | Year in 4-digit format |
| `HH:mm` | Time in 24-hour format -no seconds |
| `K` | Time zone offset from Universal Time Coordinate (UTC) |
| Specifier | Definition |
| --- | --- |
| `%A` | Day of the week - full name |
| `%m` | Month number |
| `%d` | Day of the month - 2 digits |
| `%Y` | Year in 4-digit format |
| `%R` | Time in 24-hour format -no seconds |
| `%Z` | Time zone offset from Universal Time Coordinate (UTC) |
.NET format specifiers (/dotnet/standard/ba se-types/custom-date-and-time-format-strings?view=netframework-4.8)
date.DayOfYear
$timelabel = Get-Date -Format 'yyyy-MM-ddTHHmmss'
New-Item -Path C:\Test\$timelabel -Type Directory
内置变量
$PSVersionTable # Powershell版本信息
$PROFILE # Powershell配置文件路径
对象
使用Get-Noun方法获取对象,其中None代表对象类型。
对象成员
获取对象类型,及其成员属性/方法信息。
$Obj | Get-Member
$Obj | Get-Member -MemberType {Method|Property...} -Name name
Get-Member仅显示默认显示的成员。如果要显示所有成员,可使用Select-Object筛选对象属性值,返回仅包含指定属性(模式)的对象。
$Obj | Select-Object -Property {*|FriendlyName,Issuer}
-ExpandProperty SerialNumber # 将返回值转换为字符串而非对象
*获取对象所有属性,反之给出要获取的属性名列表(可包含通配符)。如果管道输入一个序列,则返回每个对象的属性值。
对象方法
对象方法通常用于修改对象。
访问对象属性
$x=$myObject.PropertyName
动态访问对象的属性:
$PROP = 'Name'
$myObject.$PROP # $myObject."Name" => $myObject.Name
Providers
提供访问数据的统一接口,数据以类似文件系统的树形结构组织。
Get-PSProvider列出所有支持的数据接口类型,包括文件系统、证书目录、注册表等。特别地,==PowerShell的函数、环境变量==等也支持该接口。
Get-PSProvider
# Name Capabilities Drives
# ---- ------------ ------
# Registry ShouldProcess, Transactions {HKLM, HKCU}
# Alias ShouldProcess {Alias}
# Environment ShouldProcess {Env}
# FileSystem Filter, ShouldProcess, Credentials {C, D, E, F}
# Function ShouldProcess {Function}
# Variable ShouldProcess {Variable}
# Certificate ShouldProcess {Cert}
# WSMan Credentials {WSMan}
Get-PSDrive获取所有支持类型的数据源实例信息。
Get-PSDrive
# Name Used (GB) Free (GB) Provider Root
# ---- --------- --------- -------- ----
# Alias Alias
# Cert Certificate \
# C 256.94 674.00 FileSystem C:\
# D 310.46 1552.56 FileSystem D:\
# E 920.11 6531.80 FileSystem E:\
# F FileSystem F:\
# Env Environment
# Function Function
# HKCU Registry HKEY_CURRENT_USER
# HKLM Registry HKEY_LOCAL_MACHINE
# Variable Variable
# WSMan WSMan
省略了
CurrentLocation属性,调整了显示顺序。
使用Get-ChildItem读取数据源路径下的数据。
Get-ChildItem -Path Cert:\LocalMachine\CA
Get-ChildItem -Path Function:
路径的根为
Name:,其中Name为数据源实例名称,如C:、Cert:等。
Services
Get-Service <Name>
调用服务的方法:
$service=$(Get-Service -Name w32time)
$service.Stop()
成员方法可用于修改获取的对象,而通常没有相关
cmdlet直接修改对象。
自定义对象类型
$obj = [pscustomobject]@{
FirstName='Kevin';
LastName='Marquette'
}
添加和删除属性
$myObject | Add-Member -MemberType NoteProperty -Name 'ID' -Value 'KevinMarquette'
$myObject.psobject.properties.remove('ID')
添加方法
$scriptBlock = {...} # 使用this引用目标对象
Add-Member -MemberType ScriptMethod -InputObject $myObject -Name 'ToHashtable' -Value $scriptBlock
语法
语句
使用;在一行书写多条语句;
换行
,,{},[],(),;,=,',"可以支持命令跨行书写。
ps_cmd (expr) # "(...)" 优先计算子表达式并返回值
如果命令中包含需要首先展开的参数,则使用&对参数进行展开,然后执行展开后的命令语句。
& $str_cmd $str_opts # 执行字符串参数所表示的命令
==在行末使用`强制命令换行以增强可读性==,换行命令间可包含多行注释内容<#...#>。
引号
In PowerShell, you should always use single quotes instead of double quotes unless the contents of the quoted string contains a variable that needs to be expanded to its actual value. By using single quotes, PowerShell doesn't have to parse the contents contained within the quotes so your code runs a little faster.
注释
单行注释:#后续内容为注释;
多行注释:<# comment #>。
管道
通过管道传递对象(变量、数组)将多个命令连接起来。
dir | Sort-Object -Descending | Select-Object -First 1
使用管道操作符连接的命令可在操作符后换行,以方便阅读。
命令必须产生输出才能传递给管道,使用-PassThru参数强制命令输出内容。通过帮助文档可查看命令的输入和输出要求(INPUT,OUTPUT),查看参数帮助文档以确定参数值是否接受管道输入以及接受输入的类型(Accept pipeline input? True (ByValue, ByPropertyName))。
Get-Command -ParameterType ServiceController
帮助文档中可能会给出命令的输入输出说明(是否接受管道输入)。
非PowerShell命令输出的文本行会被自动转换为字符串对象,因此后续命令可基于字符串对象进行计算(如过滤)。
左侧过滤优先
优先使用命令参数过滤返回结果(除非过滤条件没有对应参数支持);对返回结果进行过滤(Where-Object)可能产生较大开销。
右侧格式化优先
尽可能最后对数据执行格式化输出(如Format-Table)。
流程控制
分支
if (<result1-to-be-matched> -eq (<test-expression>)) {<action>}
Everything you wanted to know about the if statement - PowerShell | Microsoft Docs
switch [-regex| -wildcard| -exact] [-casesensitive](<test-expression>)
{
<result1-to-be-matched> {<action>}
<result2-to-be-matched> {<action>}
default { <action-scriptblock> }
}
默认为精确比较(
-exact)。如果输入对象为数组,则对每个元素进行计算。
Everything you ever wanted to know about the switch statement - PowerShell | Microsoft Docs
循环
for ($i = 1; $i -lt 5; $i++) {
Write-Output "Sleeping for $i seconds"
Start-Sleep -Seconds $i
}
do{ statements } until (cond_expr)
do{ statements } while (cond_expr)
while (cond_expr) { statements }
跳转
使用break,continue,return控制循环执行(loop, switch)。
labeled continue
用于连续中断多层循环。
:labelA for ($i = 1; $i -le 10; $i++) {
:labelB for ($j = 1; $j -le 10; $j++) {
:labelC for ($k = 1; $k -le 10; $k++) {
if ($conditionA) {
continue labelA # 连续中断
else if ($conditionB) {
continue labelB # 等效于brek
} else {
$condition = Update-Condition
}
}
}
}
异常处理
try { CmdName -ErrorAction Stop } catch {...}
Only terminating errors are caught.
Everything you wanted to know about exceptions - PowerShell | Microsoft Docs
函数
函数命名遵循Verb-Noun原则(通过Get-Verb查看常用动词)。
function Get-Version {
[CmdletBinding()] # << turns into an advanced function
param (
[Parameter(Mandatory)] # 必须提供的参数
[String[]]$ComputerName, # 声明类型以在运行时自动执行参数类型校验
[ValidateNotNullOrEmpty()] # 可选参数
[string[]]$ComputerName = $some_value, # 可选参数的默认值
[Parameter(Mandatory,ValueFromPipeline)] # 接受管道传递参数(by value
[String[]]$ComputerName, # ValueFromPipelineByPropertyName(by name)
)
dynamicparam {<statement list>}
begin { begin_statements }
process { process_statements }
end { end_statements }
}
function Get-Version([type1]$param1[,[type2]$param2]) {}
通过param声明输入参数,参数命名尽量与内置标准命令方式一致,多个参数以,分隔;对于较为简单的参数声明,也可以直接在函数名后声明。
输入参数
参数类型
- 命名参数:通过
param()语句声明的参数,可以指定默认值,为指定默认值的参数在运行时必须提供参数值,否则函数报错。 - 位置参数:非命名参数,通过
$args[i]数组访问。可通过@args将所有参数传递给其他函数或命令。 - 开关参数:通过
param()声明类型为[switch]的参数。不需要为该参数提供值,当该参数选项出现在命令时,参数的的值为True。 - 动态参数:
从管道读取参数
begin、process和end语句块用于处理管道输入。begin和end会在函数开始和结束时分别被执行一次,而process语句块则对每一个管道输入对象$_执行一次。
如果声明了以上语句块,则函数的所有语句都必须位于语句块中。未声明语句块的情况,所有语句相当于位于end语句块中。
过滤器
过滤器(Filters)可被看作只有process代码块的函数。
返回值
函数的返回值可以在终端显示、赋值给变量或转递给其他函数/命令。函数中可通过调用的命令返回数据,或通过调用return返回数据对象。return语句会立即令函数返回。
高级函数
高级函数具有自动添加的公共参数,例如Debug和Verbose。
Everything you wanted to know about ShouldProcess - PowerShell | Microsoft Docs
cmdlets
注释文档
函数注释文档可位于:函数体开头(位于{之后的行);函数体结束前(位于}之前),或==函数定义关键字前function的行(不可有空行隔开)==。
脚本注释文档位于脚本开始或结束。
脚本模块注释文档.psm1与函数注释文档语法一致。
<#
.SYNOPSIS
函数用途简要说明。
.DESCRIPTION
函数功能的详细描述。
.PARAMETER ComputerName
参数说明
.EXAMPLE
使用示例。
.INPUTS
输入类型
.OUTPUTS
输出类型
.NOTES
Author: Mike F Robbins
Website: http://mikefrobbins.com
Twitter: @mikefrobbins
#>
PARAMETER和EXAMPLE可声明多次。
命名空间
在脚本开始位置引入命名空间,方便引用其中的类型和方法。
using namespace System.Collections.Generic
$myList = [List[int]]@(1,2,3)
作用域
about Scopes - PowerShell | Microsoft Learn
输入输出
Get-Content [-Path] filepath # -> cat, type
Write-Output 'message' > filename # -> echo
'message' > filename
'message' | Out-File -FilePath filename
不同级别的输出函数:
Write-Verbose -Message "message" # 仅在开启Verbose选项时输出
Write-Debug
Write-Information
Write-Warning
Write-Error
重定向
输出重定向
n>, n>>:输出流n=:* All output;1 Success output;2 Errors;3 Warning messages;4 Verbose output;5 Debug messages。
吸收输出
expr | Out-Null,expr > $null;[void] expr;$null=expr;
格式输出
当输出为多个对象组成的列表格式(即key:value形式),可通过Format-Table将其转换为表格形式:
$obj | Select-Object -Property Name,Type,Status | Format-Table
反之,可以将表格输出转换为列表输出。
Format-List
Format-*命令会将输出对象封装为Foramt对象,因此可能不再能传递给其他命令。
文本模式输出
将对象转换为文本输出(可用于传统基于文本的命令进行后续处理):
Find-Module *cim* | Out-String -Stream | grep CimSession
-Stream将输出按行分解便于后续处理。
-Width设置输出宽度,避免换行或截断。
网络应用
The
Invoke-WebRequestcmdlet sends HTTP and HTTPS requests to a web page or web service. It parses the response and returns collections of links, images, and other significant HTML elements.
Invoke-WebRequest # alias => curl,wget
-Uri <uri>
-Headers <dict> # http header
-Body <obj> # http body
-InFile <file> # read request from file
-OutFile <filename> # 未指定则输出到管道
-Method <m> # http method: get/put/post...
脚本
脚本文件类型.ps1。
在当前Shell环境执行脚本。
. 'c:\scripts\sample.ps1'
脚本文件编码
PowerShell 5.x默认使用的是本地化编码方案(如GBK/936),因此如果包含非ASCII码文字的脚本应该使用对应区域的本地化编码方案保存。(例外:VS Code中的集成终端代码页为936,但能正确读取UTF-8编码)
PowerShell 7.x默认使用UTF-8/65001编码。
PowerShell解释器会首先读入整个脚本文件内容,并检查语法错误。如果出现编码问题导致语法错误,则会直接抛出语法错误而不执行文件。
通过启动配置$Profile修改终端的默认编码(由于.NET缓存机制的原因,在启动后的PowerShell终端中调用chcp命令无效,chcp在cmd中是有效的):
$OutputEncoding = [console]::InputEncoding `
= [console]::OutputEncoding `
= New-Object System.Text.UTF8Encoding
作用域
全局作用域
位于脚本中的函数的作用域为脚本(Script scope),当脚本被加载或执行完后,脚本作用域中的函数不再可见。使用.命令加载脚本中的函数到全局作用域(Global scope)。
. .\My-Script.ps1
脚本模块
以.psm1保存的脚本。如果脚本模块保存在PoweShell模块搜索路径下,则会被自动加载;反之,需要手动导入。
Export-ModuleMember -Function Get-PublicFunction # 在模块中导出定义公开函数
为模块创建元数据(元数据存储路径通常和模块位于同一路径下):
New-ModuleManifest -Path $ModulePath\MyScriptModule\MyScriptModule.psd1
-RootModule MyScriptModule # 必须指定
-Author 'Mike F Robbins'
-Description 'MyScriptModule'
-CompanyName 'mikefrobbins.com'
Update-ModuleManifest # 更新元数据,重复调用New-ModuleManifest会导致GUID变化
导出的公开函数也可在元数据文件中指定:
FunctionsToExport = 'Get-PublicFunction'
运行环境
环境变量
读取环境变量
Get-ChildItem env: # 注意结尾的“:”
Get-ChildItem Env:JAVA_HOME # => Get-ChildItem Env:\JAVA_HOME
echo $Env:JAVA_HOME # echo ${Env:JAVA_HOME} => echo ${Env:\JAVA_HOME}
Get-ChildItem Env: | Format-Table -Wrap -AutoSize
设置环境变量
$Env:JAVA_HOME='C:\tools\jdk' # 仅当前会话有效
$Env:Path='C:\tools\jdk;'+$Env:Path
路径搜索优先级:从左至右搜索,将新路径置于左侧将覆盖已有配置。
脚本输入参数
脚本的输入参数格式与函数输入参数语法格式一致。
param (
[string]$Target = '.\src',
[string]$Source = '.\target'
)
定义的参数可在命令行中获得自动补全功能。
语句的退出状态码
$? # return 'True'/'False' for success/error
$LastExistCode # Return 0 for success
执行策略
PowerShell 执行策略是一项安全功能,用于控制 PowerShell 加载配置文件和运行脚本的条件。 此功能有助于防止恶意脚本的执行。可以为本地计算机、当前用户或特定会话设置执行策略。 你还可以使用组策略设置为计算机和用户设置执行策略。本地计算机和当前用户的执行策略存储在注册表中。 不需要在 PowerShell 配置文件中设置执行策略。 特定会话的执行策略仅存储在内存中,并在会话关闭时丢失。
执行策略不是限制用户操作的安全系统。 例如,当用户无法运行脚本时,可以通过在命令行中键入脚本内容来轻松地绕过策略。 相反,执行策略可帮助用户设置基本规则并防止无意中违反它们。
| 策略 | 详情 |
|---|---|
| AllSigned | 脚本必须由信任发布方签名;在未确认的脚本运行前提示用户;==可能面临运行已签名的恶意脚本的风险==。 |
| Bypass | 不会阻止且不会产生警告或信息; |
| Default | 默认策略:Restricted for Windows clients.RemoteSigned for Windows servers. |
| RemoteSigned | 来自互联网的脚本需要来自信任发布方的数字签名;本地脚本允许执行。 |
| Restricted | ==允许单独执行命令,但不允许运行脚本==; |
| Undefined | If the policy in all scopes is Undefined, use Default. |
| Unrestricted | 非Windows主机的默认策略;未签名脚本可以运行,非本地脚本运行前警告用户。 |
设置策略
Set-ExecutionPolicy <policy>
标准库
WMI和CIM
Windows Management Instrumentation (WMI)模块:弃用。
Common Information Model (CIM)模块:跨平台,通过CIM可访问WMI。
Get-Command -Module CimCmdlets
Get-CimInstance -Query 'Select * from Win32_BIOS' # WMI Query Language (WQL)
Get-CimInstance -ClassName Win32_BIOS
远程管理(指定ComputerName参数):以域管理员启动PowerShell并执行
Get-CimInstance -ComputerName dc01 -ClassName Win32_BIOS
或者首先提供凭据(密码)并创建CIM会话:
$CimSession = New-CimSession -ComputerName dc01 -Credential (Get-Credential)
Get-CimInstance -CimSession $CimSession -ClassName Win32_BIOS
远程登录
从Windows可选功能中安装OpenSSH Server。
Installation of OpenSSH For Windows Server 2019 and Windows 10
远程登录后默认的Shell是cmd.exe,如果要启用PowerShell,可在命令窗口中运行powershell,或者直接在远程登录命令中运行该命令。
ssh user@host "chcp65001 && powershell"
直接进入Powershell会导致中文乱码,需要先切换编码到
UTF-8。
PowerShell Remoting Over SSH - PowerShell | Microsoft Docs
附录
cmd
注释语句:
REM comment something
使用^对单条命令进行换行,^后不可包含任何符号。
变量
变量名不区分大小写。查看变量:
set [ | more]
set var # print: key=value
echo %variable% # 使用`%%`读取变量的值,未定义的变量将打印变量名
定义console环境变量
set variable=value # 必须设用set,不支持VAR=VALUE
PATH既是环境变量,也是一个命令(单独使用PATH可显示PATH变量的值,也可使用PATH=value为PATH变量赋值,普通变量必须使用set命令)。
参数变量:
%1 %2 %3 %4 %5 %6 %7 %8 %9
%~dp0
获取当前执行文件所在目录。
字符串
字符串不需要使用引号表示,单双引号均为普通字符。将两个字符串连接即视为字符串拼接。
环境变量
echo %USERPROFILE% # 用户目录
echo %PROGRAMDATA% # 应用程序配置文件路径
chcp 65001 # 支持PowerShell
Windows Code page 936, is Microsoft's character encoding for simplified Chinese, one of the four DBCSs for East Asian languages. Originally, Windows-936 covered GB 2312 (in its EUC-CN form), but it was expanded to cover most of GBK with the release of Windows 95.
https://en.wikipedia.org/wiki/UTF-8#Official_name_and_variants.
Windows Code Page: 936/1386 (GBK), 950/1370 (Big5), 1200 (UTF-16LE), 1201 (UTF-16BE), 54936 (GB18030), 65001 (UTF-8).
环境变量作用域
setlocal # 执行之后所做的环境改动只限于批处理文件直到endlocal。
endlocal # 脚本结束前隐式执行
语句
dir & echo foo
dir && echo foo # execute only if the first exited successfully
batch file - How do I run two commands in one line in Windows CMD? - Stack Overflow
常用命令
help [cmd] # cmd /?
call jobname.bat
调用脚本。
pause
暂停。
exit
退出。
cd [/D] path
切换当前目录。
type file
输出文件内容。
流程控制
if [not] ERRORLEVEL <number> <command> [else <expression>]
if [not] <string1> == <string2> <command> [else <expression>]
if [not] exist <filename> <command> [else <expression>]
errorlevel:上一条命令的执行状态。
for {%% | %}<variable> in (<set>) do <command> [<commandlineoptions>]
# for %f in (*.doc *.txt) do type %f
控制台输入输出
echo on|off # 控制是否回显命令行提示符
echo some string
字符串不需要使用引号表示,单双引号均为普通字符。
参考资料
Windows PowerShell Language Specification 3.0 6: Reference - Microsoft.PowerShell.Core 2: about Operator Precedence - PowerShell | Microsoft Docs
Windows应用软件
视频编辑
字幕
字幕格式
srt
1
00:00:01,000 --> 00:00:04,000
<font color=red>{\fn黑体\fs27}这是一条字幕</font>
2
00:00:04,100 --> 00:00:06,000
<i>在经历了一场人生巨变之后</i>
<b>When I was lying there in the VA hospital ...</b>
字幕包含序号,以空行分隔。可以添加HTML格式标记。
SRT字幕格式 - Tocy - 博客园 (cnblogs.com)
字幕编辑软件
视频编码
格式工厂
- 问题1:添加字幕和倍速播放不能同时进行;
浏览器
防止浏览器自动使用到HTTPS协议:访问chrome://net-internals/#hsts。在Delete domain中输入要访问的域名,并点击删除(但无法删除系统内置规则的域名)。
程序开发软件
编辑器
Vim
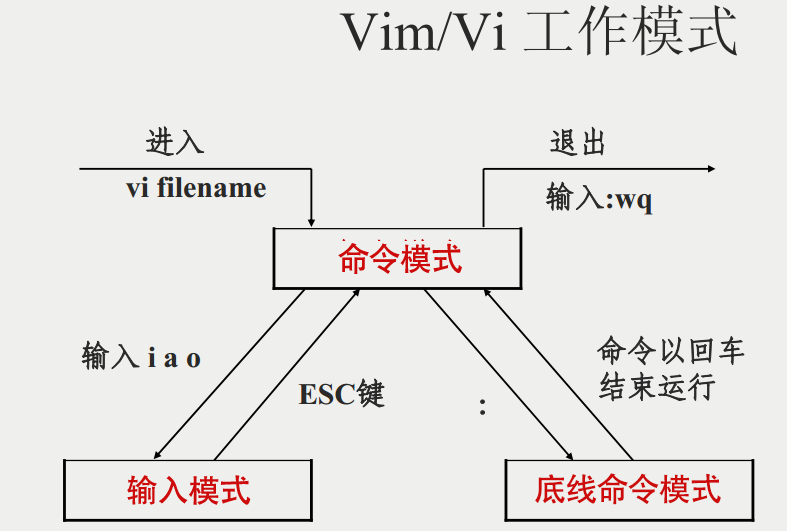
https://www.runoob.com/linux/linux-vim.html
配置
在命令模式下输入set命令修改当前配置,或在配置文件/etc/vim/vimrc中配置相应命令以永久修改。
缩进
# edit
set tabstop=4
set softtabstop=0 # 不要将空格和tab混合输入
set shiftwidth=4 # 默认用4个空格
set autoindent # 自动缩进
set expandtab # tab转换为空格
# 对于下列文件类型,4个空格太宽了,可以换成2个空格。
autocmd FileType html,css,xml,yaml,json,sh set sw=2 ts=2
https://www.kawabangga.com/posts/2817
显示行号
set [no]number # => set [no]nu
set [no]relativenumber # => set [no]rnu *
set numberwidth=2
*:相对行号和绝对行号可同时存在。
常用命令
查找
/<search-pattern> # forward
?<search-pattern> # backward
回到命令模式后,输入n查找下一个,输入N查找上一个。
替换
使用sed替换语法:
:n,[m]$s/<origin>/<replace>/g #替换第n行(到m行,默认到最后)中origin为replace
转义字符"/" $\rightarrow$ "\/"。
复制粘贴
yy # 复制一行,
V #选择连续多行,
v # 移动方向键任意选择,Ctrl+v 选择光标开始的矩形区域
y # 复制所选内容
d # 剪切
p # 粘贴所选内容,如果选择整行,则粘贴到所在行的后一行;否则粘贴到光标所在位置
删除
# 普通命令模式
gg # 返回文件开始
dG # 删除至文件末尾的所有行
# 底线命令模式
:1,$d # 删除第1行至最后一行$的所有内容
:%d # %代表所有行
撤销|重做
u,:u,:undo # 撤销单步
4u # 撤销多步
Ctrl+r # 重做
保存
:w !sudo tee % # 以管理员权限保存只读文件
If
Ctrl+Sfreezes your terminal, typeCtrl+Qto get it going again.
Visual Studio Code
开发环境
VSCode+MSYS2
安装MSYS2后,在MSYS2终端中安装开发工具链,以C++/mingw64开发为例,
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
将$MSYS2_ROOT/mingw64/bin加入Windows路径,可在Windows下使用MSYS2的开发工具链。
Get Started with C++ and Mingw-w64 in Visual Studio Code
资源管理器
排除要显示的文件
设置的文件模式将不会在资源管理器中显示,如果直接在用户主目录下工作,通常需要将系统或程序产生的隐藏目录排除。
"files.exclude": {
".*hst": true,
".*rc": true,
".bash*": true,
".pki": true,
".vscode-server": true
}
离线安装VSCode远程服务
在联网状态下,VSCode远程服务会在建立远程连接后自动安装。在离线状态下,自动安装会失败,但可以从日志中得到要安装的远程服务软件包的地址。
https://update.code.visualstudio.com/commit:dfd34e8260c270da74b5c2d86d61aee4b6d56977/server-linux-x64/stable
利用此地址,可以从联网计算机上下载安装包,并解压到目标机器的~/.vscode-server/bin/目录下,并将解压内容根目录以上述URL中的commit ID命名。
Code-Server
安装
Install - code-server docs (coder.com)
Usage - code-server docs (coder.com)
安装插件
Code-Server从Open VSX Registry下载安装插件。如果存在网络问题,可离线安装:
code-server --install-extension ext_name.vsix # --list-extensions
反向代理
目前不支持为Web服务设置根路径,因此需要使用独立的服务站点(独立端口)来代理。
server {
listen 80;
listen [::]:80;
server_name mydomain.com;
location / {
proxy_pass http://localhost:8080/;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
proxy_set_header Accept-Encoding gzip;
}
}
多用户使用

可以为每个系统用户启用一个服务:
systemctl enable --now code-server@USER
# ExecStart=/usr/local/code-server
服务将从用户目录下读取配置文件~/.config/code-server/config.yaml(配置项对应命令行参数名),其中包含服务的监听地址端口和身份认证配置。
bind-addr: 0.0.0.0:8081
auth: password
password: xxxxyyyy
#cert: /PATH/CERTFILE
#cert-key: /PATH/CERT_KEY
disable-telemetry: true
disable-update-check: true
user-data-dir: /PATH
extensions-dir: /PATH
建议使用普通用户建立Code-Server服务,防止用户越权修改服务器后台文件。
Coder
安装
预装环境
如果需要在本地使用docker部署工作空间,则需要首先安装docker。
如果未预先安装docker,会出现以下错误:
...Got permission denied while trying to connect to the Docker daemon socket。此时,需要将用户coder加入docker组中。sudo usermod -aG docker coder systemctl restart coder.service
在线安装
curl -fsSL https://coder.com/install.sh | sh
离线安装
使用发行版软件包.deb、.rpm、.apk安装。
Docker-compose安装
Kubernetes+Helm
Helm 是 Kubernetes 的包管理器。
配置和启动服务
服务的访问地址CODER_ACCESS_URL,可通过/etc/coder.d/coder.env配置。
coder server
-a,--address $CODER_ADDRESS # 127.0.0.1:3000
--access-url $CODER_ACCESS_URL # http://localhost:3000
--postgres-url $CODER_PG_CONNECTION_URL # 数据库地址*
--global-config $CODER_CONFIG_DIR # 配置数据目录**
sudo systemctl enable --now coder # 作为服务启动
*:如果未指定,则Coder将自动下载PostgreSQL数据库,并将数据存储在配置目录下。使用coder server postgres-builtin-url可查看内置数据库的访问地址。
**:默认配置数据目录位于/root/.config/coderv2。
网络代理:为了保证Coder服务访问registry.terraform.io以及github.com等网站下载资源,可能需要配置代理(通过/etc/coder.d/coder.env配置)。
身份认证
通过终端登录并配置第一个管理员用户。Coder默认使用用户名和密码认证。
coder login http://localhost:3000 # 配置用户名、邮箱和密码
coder login -u USER http://localhost:3000 # 在终端登录
管理用户身份:
| Functions | User Admin | Template Admin | Owner |
|---|---|---|---|
| Add and remove Users | ✅ | ✅ | |
| Change User roles | ✅ | ||
| Manage Templates | ✅ | ✅ | |
| View, update and delete ALL Workspaces | ✅ | ✅ | |
| Execute and use ALL Workspaces | ✅ |
所有用户隐含Member身份,可创建工作空间。
工作空间配置
工作空间模板配置
在终端中登录用户并执行:
coder templates init [directory] -v # 选择模板类型并初始化。
cd directory && vim main.tf # 修改模板描述文件
coder templates create/push --parameter-file params.yaml # 创建/更新模板
directory是模板名称和模板文件所在目录名。
创建工作空间
命令行基于模板创建工作空间,也可登录Web界面选择模板创建。
coder create --template="yourTemplate" <workspace-name>
coder show <workspace-name>
问题:==访问https://registry.terraform.io/.well-known/terraform.json失败,网络连接问题。==
编写模板
Templates - Coder OSS main docs
安装IDE
resource "coder_agent" "main" {
arch = "amd64"
os = "linux"
startup_script = <<EOF
#!/bin/sh
# install and start code-server
curl -fsSL https://code-server.dev/install.sh | sh
code-server --auth none --port 13337
EOF
}
Configuring Web IDEs - Coder OSS main docs
安装JetBrains Projector
安装JupyterLab
安装airflow
终端
Windows Terminal
离线安装
从Github下载最新的发布版本,如果离线安装需要使用带依赖库的Win10版本包。
Add-AppxPackage FILENAME.msixbundle
安装时如果出现VC运行时版本错误,则首先安装附带的依赖库(
Microsoft.VCLibs.x64.*.appx);如果手动安装,可能需要安装VC_redist.x64.exe。
配置
Windows Terminal Tips and Tricks | Windows Command Line
配置文件为settings.json,其中终端配置项位于$.profiles.list[*],基本配置项如下:
{
"name": "Windows PowerShell",
"commandline": "powershell.exe",
"startingDirectory": "%HOMEPATH%",
"startingDirectory": "//wsl$/Ubuntu/home/gary", // 代替默认的"~",避免找不到目录
}
字体

{
"fontFace": "Cascadia Code PL",
"fontSize": 12
}
颜色和背景
终端的颜色配置项包括:
{
"colorScheme": "One Half Dark",
"useAcrylic": true,
"opacity": 70
}
内置颜色方案位于配置文件的
$.schemes[*],可自定义颜色方案。

背景
{
"backgroundImage": "C:\Users\admin\background.png",
"backgroundImageAlignment" : "bottomRight",
"backgroundImageStretchMode" : "uniform",
"backgroundImageOpacity" : 0.3,
}
除上述基础配置外,可使用Oh-My-Posh等工具对终端进行个性化定制。
集成终端工具
MSYS2
C:\msys64\msys2_shell.cmd -mingw64 -defterm -no-start
启动的终端环境包括mingw64、clang64、msys、ucrt64等。
Anaconda
%windir%\System32\WindowsPowerShell\v1.0\powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'C:\Users\gary\miniconda3\shell\condabin\conda-hook.ps1' ; conda activate 'C:\Users\gary\miniconda3' "
Nushell
Nushell is both a programming language and a shell.
安装
winget install nushell # [Windows]--> choco/scoop
brew install nushell # [Linux/Mac]
设置登录终端
Linux:将nu加入/etc/shells白名单中,然后使用chsh命令切换Shell程序。
Windows:安装完成后将自动为Windows Terminal生成Nushell配置,初次启动会进行初始化。
配置
config nu
常用命令
Nushell命令输出内容为对象(类似于Powershell,包括表格、字典和字符串等)并以表格形式显示,方便后续命令操作数据。
命令支持Tab补全,并同时提供命令候选与帮助信息。
ps:显示进程信息。
date:显示日期信息。
date now | date to-table
sys:显示系统硬件信息。返回对象不是简单表格,而是键值组成的字典(以表格列的形式分别显示键和值),每个值是嵌套的字典或表格。
sys | get host # 返回嵌套字典
sys | get cpu # 返回嵌套表格
sys | get host.sessions.name
文件操作
ls:显示目录内容。
ls | sort-by size | reverse # 排序
ls | where size > 1kb # 筛选
ls *.md # 匹配 (**/*.md:匹配所有子目录)
cd,mv,cp,rm,mkdir(跨平台)。
读取数据
open package.json # 将数据加载为记录对象。
open pokemon.csv # 将数据加载为表格对象。
open Cargo.lock | from toml # 将未识别格式数据按指定格式处理
open Cargo.toml --raw # 按原始文本输出
Nushell当前支持加载以下格式的数据:csv,ini,json,nuon,SQLite,toml,url,xlsx/xls,xml,yaml/yml……对于不支持的文件格式,Nushell将尝试直接输出文件内容。
Nushell Object Notation (NUON) 是JSON的一个超集,支持注释(
#开头)。
读取SQLite
open foo.db | query db "select * from some_table"
读取URL指定的文件
fetch https://blog.rust-lang.org/feed.xml
帮助信息
除通过Tab补全时提供的提示信息外,通过help命令可查看Nushell命令的使用方法。
输出设置
使用ansi命令,设置输出文字颜色(ansi reset回复之前的设置)。
$'(ansi purple_bold)This text is a bold purple!(ansi reset)'
语法
Web终端
tsl0922/ttyd: Share your terminal over the web (github.com)
WebSSH
通过浏览器访问远程的SSH连接终端,其工作模式
+---------+ http +--------+ ssh +-----------+
| browser | <==========> | webssh | <=======> | ssh server|
+---------+ websocket +--------+ ssh +-----------+
webssh是一个Python模块,可通过pip或Conda安装。启动服务:
wssh --address=0.0.0.0 --port=8080 \ # 服务器地址端口
--ssladdress=0.0.0.0 --sslport=8088 \ # HTTPS地址端口
--certfile="path_to_certfile.crt" \
--keyfile="path_to_keyfile.key" \ # 证书密钥文件
--fbidhttp=True \ # 禁用外部HTTP请求(只允许localhost访问)
--maxconn=20 \ # 最大连接数
--debug --origin='*' #
> /tmp/wssh/wssh.log 2> /tmp/wssh/wss.error.log & # 日志输出,脱离终端
避免证书/密钥文件询问密码。
Cross origin operation is not allowed:设置
--debug --orgin='*'。
butterfly
Butterfly is an xterm-compatible web terminal based on websocket and tornado.
butterfly.server.py --host=soc3.113.cn --port=57575 --unsecure
使用SSL加密通信
butterfly.server.py --generate-certs --host=soc3.113.cn
butterfly.server.py --generate-user-pkcs=root
butterfly.server.py --host=soc3.113.cn --port=57575
SSL Error on 8 ('172.28.76.6', 65440): [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: EE certificate key too weak (_ssl.c:997).
终端复用
Tmux
Tmux可以将终端窗口与会话解绑:
- 从而使任务可以进入后台运行,
- 同时也能在同一终端访问多个已存在的会话;
- 且支持将终端窗口进行拆分,从而同时访问多个会话。
在终端中执行tmux进入Tmux环境,输入exit退出。
快捷键
使用Ctrl+b进入快捷键模式,输入命令对应的快捷键。
| 快捷键 | 命令 | 说明 |
|---|---|---|
? | 显示帮助信息 | |
d | attach | 分离当前会话 |
$ | rename | 重命名会话 |
% | split-window -h | 左右拆分窗格 |
" | split-window | 上下差分窗格 |
$\uparrow\downarrow$-><- | `select-pane -U | D |
x | exit | 退出当前窗格 |
Ctrl+$\uparrow\downarrow$-><- | 按箭头方向调整窗格大小 | |
q | 显示窗格编号 | |
c | new-window | 新建窗口(状态栏显示窗口信息) |
| `p | n | |
w | select-window | 从列表中选择窗口 |
, | rename-window | 窗口重命名 |
会话管理
新建窗格(子窗口)时创建会话,并自动编号(0,1,...);或者手动创建会话并命名,方便后续访问该会话。
tmux new -s <session-name>
tmux detach # 将当前会话与终端脱离
tmux ls # 列出所有Tmux会话
tmux attach|switch -t <session-id>|<session-name> # 重新接入或切换会话
tmux kill-session -t ......
tmux rename-session -t 0 <new-name>
划分窗格
tmux split-window [-h] # -h => 拆分为左右两个窗口
tmux swap-pane -U|D # 移动当前窗口位置(上移|下移)
窗口管理
除了将一个窗口划分成多个窗格,Tmux 也允许新建多个窗口并在多个窗口间切换(命令类型与窗格管理)。
tmux new-window -n <window-name> # 默认自动编号
tmux select-window -t <window-number>|<window-name> # 切换窗口
终端主题化工具
oh-my-posh
使用“Oh my Posh 3”来为PowerShell/Bash等终端提供主题功能。
安装
winget install|upgrade oh-my-posh # JanDeDobbeleer.OhMyPosh
安装内容:
oh-my-posh.exe- Windows executable, added to your $PATH;oh-my-posh-wsl- Linux executable, added to your $PATH for use in the ==WSL==;themes- The latest Oh My Posh themes (~\AppData\Local\Programs\oh-my-posh\themes\)。
安装Linux版本
使用linuxbrew安装/升级。
brew install oh-my-posh # jandedobbeleer/oh-my-posh/oh-my-posh
brew update && brew upgrade oh-my-posh # 新版本的路径可能发生变化,需要重新开启Shell
安装内容位于$(brew --prefix oh-my-posh),包括可执行文件和主题。
应用样式
在Powshell中执行Get-PoshThemes预览样式。
在PowerShell初始化配置文件($PROFILE)中设置命令:
# code $PROFILE
oh-my-posh init pwsh --config $env:POSH_THEMES_PATH/paradox.omp.json | Invoke-Expression
Windows内置的PowerShell 5和独立安装的PowerShell 7使用的shell配置都为
pwsh;
Linux版本命令
预览主题:
THEME_PATH="$(brew --prefix oh-my-posh)/themes"
for file in $THEME_PATH/*.omp.json; do
eval "$(oh-my-posh init bash --config $file)" #**无法预览主题**
echo "$file"
done
设置主题(~/.bashrc):
eval "$(oh-my-posh init bash --config $THEME_PATH/agnoster.omp.json)"
离线安装
从Github Release直接下载发布的可执行文件以及主题文件,将可执行文件路径添加到系统路径中,配置方法与自动安装一致。
图标
下载带图标的字体(nerdfont)。优先使用Windows Compatible的Code字体(Mono字体不支持连字)。

在PowerShell中安装并设置图标模块:
Install-Module -Name Terminal-Icons -Repository PSGallery -Scope CurrentUser
Import-Module -Name Terminal-Icons # code $PROFILE
git插件
Install-Module posh-git -Scope CurrentUser
Posh-Git将Git状态信息添加到提示,并为Git命令、参数、远程和分支名称添加
Tab自动补全。
Import-Module posh-git
powerline-go
A beautiful and useful low-latency prompt for your shell, written in go.
sudo apt install golang-go
export GOPROXY=https://goproxy.io
export GO111MODULE=on
go get -u github.com/justjanne/powerline-go
编辑shell配置文件(.bashrc)
GOPATH=$HOME/go
function _update_ps1() {
PS1="$($GOPATH/bin/powerline-go -error $?)"
}
if [ "$TERM" != "linux" ] && [ -f "$GOPATH/bin/powerline-go" ]; then
PROMPT_COMMAND="_update_ps1; $PROMPT_COMMAND"
fi
服务器管理软件
网络管理工具
IP工具包
ip -Version # => ip utility, iproute2-ss200127
ip -batch filename
选项:-b,-batch:从文件中读取命令执行。
ip [OPTIONS] OBJECT COMMAND
默认命令为show(即列出指定对象的信息)或help(对应object的帮助信息)。
信息选项
-h,-human,-human-readable:以更易阅读的方式输出统计信息。-s,-stats,—statistics:输出更多信息,如果该选项出现多次,则输出更多信息。-d,-details:输出更多详细信息。-o,-online:每行输出一条记录,使用\替换原纪录中的换行。-r,-resolve:使用DNS解析。-c,-color=always|auto|never:设定彩色输出模式。-t,-timestamp:输出当前时间;-ts, -tshort:使用短时间格式。-br, -brief:以列表形式显示简要信息,目前仅适用于ip addr show和ip link show。-j, -json:以JSON格式输出信息;-p, -pretty增强JSON输出的可读性。
协议族选项
-
-f, -family <FAMILY>:选择协议族,包括:
inet, inet6, link-4:等效于-family inet;-6:等效于-family inet6;-B:等效于-family bridge;-M:等效于-family mpls;-0:等效于-family link;
网络命名空间选项
-n, -netns <NETNS>:切换网络命名空间到NETS以执行命令;该选项等效于ip netns exec NETNS...
命令对象(object)
IP地址
ip address show [up] # address <-> addr
ip address show [up] dev eth0
ip address add|delete 2001:0db8:85a3::0370:7334/64 dev eth1 # add/delete address
ip address flush dev eth4 scope global # remove global address
网络设备
ip link set x up|down
虚拟设备
tuntap:manage TUN/TAP devices.
路由表项
route:;
其他
-
neighbour,neigh:管理ARP或NDISC缓存项; -
addrlabel:地址标签; -
maddress:多播地址; -
rule:路由策略数据库中的规则; -
mroute:多播路由缓存项; -
mrule:多播路由策略数据库中的规则; -
ntable:管理邻居缓存空间; -
l2tp: -
tunnel:IP承载的隧道; -
xfrm: - 管理IPSec策略。 -
monitor: -
netns:管理网络命名空间; -
tcp_metrics/tcpmetrics:管理TCP 度量; -
token:manage tokenized interface identifiers.
系统监控软件
cockpit
yum install cockpit
systemctl enable --now cockpit.socket
firewall-cmd --permanent --zone=public --add-service=cockpit
firewall-cmd --reload
glances
安装
可通过Python虚拟环境安装:
conda create -n glances -c conda-forge glances \
bottle # for web server mode
zeroconf # for autodiscover mode
docker-py # docker monitor
netifaces # IP
py3nvml # GPU
py-cpuinfo # quicklook cpuinfo
elasticsearch # es export
kafka-python # kafka export
conda activate glances & pip install \
hddtemp # Linux HDD temerature monitoring
pymdstat # Linux RAID
pySMART.smartx # Linux HDD SMART
# pip install glances[browser,cpuinfo,docker,export,gpu,ip,raid,web]'
或通过Linux发行版软件仓库安装(如果提供):
sudo apt install glances
Debian/Ubuntu发行版中可能不包含Web预编译文件,导致Web服务模式无法正常工作。
CentOS 7软件仓库不包含
glances。
运行
标准模式:直接运行glances,根据终端窗口尺寸自动布局监控指标。
输出模式:
glances --stdout cpu.user,mem.used,load # 显示指定度量
glances --stdout-csv cpu.user,mem.used,load # 以CSV格式显示
Web服务模式:glances -w,在浏览器中显示监控数据(终端风格)。
客户服务器模式:客户端可访问并显示服务端的监控数据。
glances -s -B ip_addr -p PORT # server side (默认0.0.0.0:61209)
glances -c <addr> -p PORT # client side
显示网络上所有的Glances服务(自动发现或根据配置文件定义)。
glances --browser
--disable-autodiscover # 禁用自动发现
扫描配置文件:
[serverlist]
server_1_name=xps
server_1_alias=xps
server_1_port=61209
tiptop
tiptop的终端显示更加整齐美观,但与glances相比没有服务模式和Web访问模式。
conda create -n tiptop -c conda-forge tiptop
# pip install tiptop
网络访问软件
SSH
SSH可以通过终端或Web终端远程访问Linux服务器,也可以使用X Window访问服务器的图形界面应用。使用SSH访问服务器需要在服务器上安装openssh-server。
ssh -p SSH_PORT [user@]host
-4/6 # ipv4/ipv6 only
-b ip_addr
通过中间节点登录远程主机:
ssh -J [user@]host[:port] user@host # connect via a jump host
中间节点需要与目的节点建立连接,因此如果目的节点使用主机名,则需要在中间节点上配置目的节点的“主机名
<->IP地址”映射。
SSH客户端配置文件
配置文件用于保存固定的SSH连接配置,以简化命令行输入参数。
HOST dev # 远程地址匹配模式*
HostName dev.example.com
User gary
当SSH的目标非user@host形式,则客户端逐次匹配HOST指定的模式,并将匹配模式下的SSH连接配置应用于当前连接请求。如果有多个模式匹配成功,==重复出现的配置项被忽略==(先出现的配置项优先级高)。
*:可使用通配符*和?,可对模式添加前缀!表示反向匹配;
服务器身份记录
当客户端尝试SSH连接远程服务器时,服务器会提供一个身份识别信息(ECDSA key指纹)让客户端确认。当客户端确认后,该服务器地址和对应的身份信息被保存到.ssh/known_hosts中。如果服务器发生变更导致其提供的身份识别信息发生变化,则会产生*Host key verification failed*错误。要解决此问题,只需从.ssh/known_hosts中删除对应服务器的记录(错误信息提示该记录所在的行号)。
SSH配置问题
-
root账户无法通过SSH登录,其他账户可以。原因:SSH配置不允许root登录,修改配置(/etc/ssh/sshd_config):#PermitRootLogin prohibit-password #PubkeyAuthentication yes PermitRootLogin yes #**:允许root远程登录存在较大安全隐患,使用密码登录风险更大(已知密码可在任意可访问服务器的机器上登录)。将该选项设置为prohibit-password并设置使用公钥验证,则只有预先在远程机器上配置了客户端的公钥,才能在相应客户端上登录root账户。 -
由于SELinux的安全策略,Fedora/CentOS非root账户仍无法自动登录,需要修改目标主机下的目录
.ssh及文件.ssh/authorized_keys的权限。chmod 0700 ~/.ssh # rwx------ chmod 0600 ~/.ssh/authorized_keys # rw------- -
无法使用密码进行远程登录(出现
publickey错误)。原因:sshd的配置未开启密码验证(各发行版的默认配置可能不同,此问题出现在WSL上)。PasswordAuthentication yes ChallengeResponseAuthentication no UsePAM yes # 利用PAM管理使用者认证有很多好处,可以记录与管理。 # 所以这里我们建议你使用 UsePAM 且 ChallengeResponseAuthentication 设定为 no -
无法从Linux主机免密登录Windows主机:Windows 10 v1809之后的OpenSSH服务器定义了以下配置,用于管理员用户登录。
# sshd_config Match Group administrators AuthorizedKeysFile __PROGRAMDATA__/ssh/administrators_authorized_keys解决方法:
- 使用非管理员用户登录;
- 注释上述配置项,恢复默认在用户目录下读取用户的公钥(推荐);
- 将管理员用户的公钥添加到
%PROGRAMDATA%\ssh\administrators_authorized_keys文件中。
-
client_loop: send disconnect: Connection reset,Windows终端长时间未操作自动断开与服务器的连接,修改终端配置。ClientAliveInterval 60 ClientAliveCountMax 5如果错误信息为
Connection reset by peer,则可尝试修改服务端的对应配置:ServerAliveInterval 60 ServerAliveCountMax 5
免密码登录
在远程主机保存登录用户的公钥。
ssh-keygen # 在本地生成SSH的登录密钥
for node in '[user@]node1' 'node2' ...; do
ssh-copy-id -i ~/.ssh/id_rsa.pub $node
done
ssh-keygen选项
-t rsa | dsa | ecdsa | ed25519:指定创建的密钥类型;
-b bits:密钥的长度。RSA密钥最小长度为1024,默认为2048;DSA密钥长度为1024;ECDSA密钥长度为256、384或521(椭圆曲线);Ed25519密钥长度为定值,该选项无效。
-C comment:添加注释。
-f filename:指定密钥文件(默认位于~/.ssh目录下)
-h:创建主机凭证而非用户凭证;
-e:读取一个OpenSSH公钥文件并以指定格式输出(-m RFC4756|PKCS8|PEM,默认格式为RFC4716)。
-F hostname:在known_hosts文件中搜索指定主机并列举。
-l:输出公钥文件的指纹,使用-E md5|sha256指定文件hash算法。
-R hostname:移除known_hosts中所有属于hostname的密钥。
从Windows主机免密登录Linux主机:
# Powershell at user home of Windows host
cat ~/.ssh/id_rsa.pub | ssh user@HOST 'mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys'
SSH远程执行命令
ssh user@remote_server "command1; command2; ./script"
ssh user@remote_server "command1;" "command2;" "./script"
可以提供多条命令,分隔的命令会在远端重组。
提升远端管理员权限
适用于Ubuntu等未开启root账号的系统,从远程执行管理命名需要提升管理员权限。此时需要使用-t选项使终端支持输入远程主机的密码。
ssh -t adminuser@host "sudo command"
远程执行命令时远程主机默认只提供基本环境变量(non-interactive,不会自动加载~/.bashrc文件)。为了自动加载~/.bashrc中的环境变量(不是.bash_profile或.profile文件),在SSH配置文件/etc/ssh/sshd_config中启用:
sed -Ei 's/#(PermitUserEnvironment\s+)(no)/\1yes/' /etc/ssh/sshd_config
再次启动SSH会话后,新添加环境变量生效。
在Ubuntu(20.04)的
.bashrc的开头有判断,如果是非交互式shell的语句(例如通过ssh远程执行的命令),则直接跳过后续初始化,因此需要把需要暴露给远端用户的变量置于该判断条件之前。if [[ ! $PATH = *java* ]]; then export PATH=$PATH:$JAVA_HOME/bin fi
允许root远程登录
# vi /etc/ssh/sshd_config
PermitRootLogin yes
# service sshd restart
通过SSH进行安全端口转发
本地通过SSH客户端与远程服务端口建立安全连接,利用SSH端口转发功能,用户只需访问本地SSH开放的端口即可访问远程服务。(使用前提是服务器开启SSH服务,且网络策略允许通过SSH访问服务器)
使用SSH建立隧道代理远端服务
ssh会在本地建立一个监听套接字local_addr:local_port以转发其接收的请求到远端的服务端口r_addr:r_port。
ssh -N -L [local_addr]:local_port:r_addr:r_port USER@HOST
# -N disables executing a remote shell
将远端访问请求转发至本地服务端口
ssh -N -R [r_addr:]r_port:local_addr:local_port USER@HOST
r_addr:远端地址,默认为环回地址,如果为空或*则表示所有地址。
ssh会在远端建立一个监听套接字以转发其接收的请求到本地。
常见问题
-
SSH登录等待时间太长。
原因:可能是SSH服务所在主机配置了DNS服务器地址,但对应的服务器不可用,导致DNS解析等待。
解决方法:查看
/etc/resolve.conf查看是否存在不可用的DNS服务器地址。如果有,修改网络接口的DNS配置并重启网络服务。
wget
HTTP, HTTPS, FTP和FTPS下载。
wget [option]... [URL]...
选项:
-c, --continue # Continue getting a partially-downloaded file.
--limit-rate=amount # Limit download speed
--user=user, --password=password # user/password if necessary
--ask-password
-P prefix, --directory-prefix=prefix # base directory
-O --output-document=FILE # save download as FILE
如果所在网络的Web流量是经本地网络的代理转发的,需要为wget配置本地代理(系统/etc/wgetrc或用户~/.wgetrc)。
https_proxy = http://USERNAME:PASSWORD@proxy.server.net:port/
http_proxy = http://proxy.server.net:port/
ftp_proxy = http://proxy.server.net:port/
或者通过环境变量配置代理。
curl
curl [optiosn] url
| 选项 | 说明 |
|---|---|
-H HEADER | 为请求添加头部信息 |
-d, --data <data> | 上传数据体 JSON数据需要指定: Content-Type: application/json |
-k,--insecure | 允许非安全SSL |
-I,--head | 仅返回响应头部 |
-L,--location | 跟踪重定向 |
-o,--output file | 输出内容到文件 |
-x,--proxy addr | 使用代理[protocol://]host[:port] |
-0,--http1.0 | HTTP 1.0,`http1.1 |
-1,--tlsv1 | 使用TLS,`tlsv1.0 |
| `--ssl,-2 | 3` |
-u,--user user:password | 提供服务器用户名和密码 |
-E,--cert CERT | CERT=certificate[:password] |
-#,--progress-bar | 传输进度显示为进度条 |
-Z,--parallel | 并发传输 |
| `-4 | 6,--ipv4 |
信息展示
-v,--verbose:显示curl的处理过程;
-s,--silent: ==不输出传输过程的状态信息(仅输出响应数据)==;
-S,--show-error:在安静模式下仍能输出错误信息;
--trace dumpfile:将传输过程中输出的信息和接收的数据(十六进制编码)输出到文件中,使用-代替文件名以输出到标准输出。
--trace-ascii dumpfile:将数据以ASCII码方式存储;
--trace-time:在输出信息/数据前显示时间hours:minutes:seconds.microseconds。
-w,--write-out MSG:在传输完成后输出信息,信息可以是简单字符串,文件内容@filename(标准输入@-),或是从接受数据中提取的字段%{variable_name}。
下载
上传
HTTP
HTTP with curl - Everything curl
HTTP方法
默认为GET,添加-d,-F选项则默认为POST,-T则默认为HEAD,-T默认为PUT。
-X,--request COMMAND:COMMAND=GET|POST|...。
netcat
选项:
-s 10.1.2.3 # 指定源端IP
-p 31337 # 指定源端本地端口
-w 5 # 连接超时(秒)
-u # 建立UDP连接
basic client-server model
nc -l [server_addr] port # server
nc server_addr port # client
建立连接后可双向通信(通过标准输入输出进行通信)。
远程Shell访问服务
rm -f /tmp/f; mkfifo /tmp/f # remove the FIFO file when finished
cat /tmp/f | /bin/sh -i 2>&1 | nc -l 127.0.0.1 1234 > /tmp/f
nc从远程接收的数据被定向到管道;管道中的数据被cat读取作为sh的输入命令;执行命令的输出作为nc的输入由其转发给远端。(==该操作可让远端执行任何命令==)
数据传输
nc -l 1234 > filename.out
nc -N host.example.com 1234 < filename.in
访问基于文本协议的服务
printf "GET / HTTP/1.1\r\n\r\n" | nc www.baidu.com 80
端口扫描
nc -zv host.example.com 20-30 http
通过代理连接
nc -x10.2.3.4:8080 -Xconnect [-P<username>] host.example.com 42
代理
v2ray
Qv2ray
在==分组==中编辑订阅信息:
在分组的订阅设置中输入订阅地址并选择订阅类型。
clash
初始化配置
wget -O ~/.config/clash/config.yaml $SUBSCRIBE_URL
COUNTRY_DB_URL=https://www.sub-speeder.com/client-download/Country.mmdb
wget -O ~/.config/clash/Country.mmdb $COUNTRY_DB_URL
配置前端web界面
git clone https://github.com/Dreamacro/clash-dashboard.git
cd clash-dashboard
git checkout -b gh-pages origin/gh-pages
编辑clash配置文件,设置界面的登录密码和网页资源地址。
secret: gang2019
external-ui: /home/gary/downloads/clash-dashboard
Clash的Web访问地址为:http://127.0.0.1:9090/ui/。
启动服务
clash -d /home/gary/.config/clash/
设置为系统服务:
[Unit]
Description=Clash - a rule-based tunnel in Go.
Documentation=https://github.com/Dreamacro/clash
After=network.target network-online.target
[Service]
Type=simple
User=clash
Group=clash
WorkingDirectory=/home/clash
ExecStart=/usr/local/clash/clash -d /usr/local/clash/config
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=clash
ProtectSystem=true
[Install]
WantedBy=multi-user.target
设置Crontab规则以周期更新配置文件中的订阅信息。
sudo crontab -e # 进入编辑模式
m h dom mon dow command
30 4 1,15 * * bash /home/gary/bin/clash.sh init $URL
软路由
主机具有多个网络接口,其中一个连接WAN(假设为eth0),其他作为LAN接口(eth1, eth2, ...,使用ifconfig查看网络接口信息)1。
场景1:与可联网主机
host1在同一网络的另一台设备host2无法认证上网。
-
编辑网络接口配置
根据网络状况分别设置WAN口的IP地址获取方式(手动配置或DHCP),LAN口设置固定IP地址。
-
如果需要为LAN中的机器分配IP地址,则为LAN口配置DHCP服务器
sudo apt install isc-dhcp-server sudo nano /etc/default/isc-dhcp-server # configure interfaces for DHCP server # INTERFACESv4="eth1" # support multi-interfaces, "eth0 eth1". sudo nano /etc/dhcp/dhcpd.conf # configure DHCP server... # after editing, start DHCP server sudo systemctl restart isc-dhcp-server sudo systemctl enable isc-dhcp-server # check the status of DHCP server sudo systemctl status isc-dhcp-server编辑DHCP服务器的配置文件(
dhcpd.conf)option domain-name "whatever.you.want"; option domain-name-servers 223.5.5.5, 223.6.6.6; default-lease-time 600; max-lease-time 7200; ddns-update-style none; authoritative; log-facility local7; subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.101 192.168.1.200; option subnet-mask 255.255.255.0; option routers 192.168.1.1; option broadcast-address 192.168.1.255; }如果配置正确,则最后查看DHCP服务器状态,可以看到一行显示
active。 -
==启用防火墙==并配置转发规则。
sudo ufw enable sudo vi /etc/rc.local sudo chmod 755 /etc/rc.local # make it executable, executed at boot time在
rc.local中配置防火墙的转发规则。#!/bin/bash LAN=eth1 WAN=eth0 # Default policy to drop all incoming packets. iptables -P INPUT DROP iptables -P FORWARD DROP # Accept incoming packets from localhost and the LAN interface. iptables -A INPUT -i lo -j ACCEPT iptables -A INPUT -i $LAN -j ACCEPT # Accept incoming packets from the WAN if the router initiated the connection. iptables -A INPUT -i $WAN -m conntrack \ --ctstate ESTABLISHED,RELATED -j ACCEPT # Forward LAN packets to the WAN. iptables -A FORWARD -i $LAN -o $WAN -j ACCEPT # Forward WAN packets to the LAN if the LAN initiated the connection. iptables -A FORWARD -i $WAN -o $LAN -m conntrack \ --ctstate ESTABLISHED,RELATED -j ACCEPT # NAT traffic going out the WAN interface. iptables -t nat -A POSTROUTING -o $WAN -j MASQUERADE exit 0 # rc.local needs to exit with 0
虚拟机解决方案
如果物理主机仅有单个网络接口,可使用虚拟机进行软件路由,可为虚拟机配置两个接口,一个用于连接宿主机NAT网络访问WAN,另一个用于桥接物理网络(转发其他机器的流量)。
- 为虚拟机
vm-router设置两张网卡:eth0使用NAT连接至主机host1;eth1使用网桥连接至主机host1(与物理网络其他主机连通);- 按上述方法配置软件路由;
- 将
host2的默认网关设置为eth1的IP地址;- 将
eth1的默认网关设置为自己的IP地址(如果设置为物理网络的网关会导致eth1向host2发送网关重定向)。
虚拟机的路由表内容如下:
# vm router的路由表
Destination Gateway Genmask ... Metric Iface
0.0.0.0 192.168.178.2 0.0.0.0 0 eth0 # 默认路由网关
172.28.76.0 0.0.0.0 255.255.255.0 0 eth1 # PHY net
192.168.178.0 0.0.0.0 255.255.255.0 0 eth0 # NAT net
路由失效解决方案
- 主机无法访问通过软路由访问其他虚拟主机:可能是主机网络问题,重启虚拟机和主机。
参考资料
How To: Build a Simple Router with Ubuntu Server 18.04.1 LTS (Bionic Beaver) - Ascinc.com 2: Using curl - Everything curl
网络服务软件
Apache2
安装
sudo apt install apache2
安装完成后,服务器在后台运行,即可通过IP地址访问服务器。
服务器以管理员身份运行。
服务器运行管理
sudo service apache2 start
sudo /etc/init.d/apache2
apache2ctl start|stop|restart|....
创建网站
默认站点
内容位于/var/www/html(可通过配置文件/etc/apache2/sites-enabled/000-default.conf修改站点的根目录等信息)。
创建站点
Apache通过编辑虚拟主机(Virtual Host)文件来管理多个站点。可以通过复制默认站点文件来创建新的站点的配置文件。
cd /etc/apache2/sites-available
sudo cp 000-default.conf server.conf
000-default.conf对应的是HTTP服务的默认站点,default-ssl.conf对应的是HTTPS服务的默认站点。
虚拟站点
然后编辑站点的配置文件*,其中
[Listen [ip_addr:][port]]
<VirtualHost [ip_addr][:port]>
ServerAdmin yourname@example.com # 管理员邮箱
DocumentRoot /var/www/server/ # 站点根目录
ServerName www.server.net # 站点域名(默认文件中没有此项)
</VirtualHost>
IP地址可以为通配符(
*);一个配置文件可包含多个
VirtualHost,默认站点不需要添加域名,其他站点需要设置唯一的ServerName。也可以将不同的VirtualHost放到单独的配置文件中。
在/var/www/(或其他目录)下创建站点对应的文件夹。
sudo mkdir /var/www/server
完成上述配置后,需要运行以下命令以启用站点。
sudo a2ensite server.conf # enable an apache2 site(virtual host)
使用
a2dissite停用站点。
完成后重启Apache,
service apache2 reload # or
systemctl reload apache2
启用安全服务(HTTPS)
启用ssl模块和安全站点的配置文件。
sudo a2enmod ssl
systemctl restart apache2 # 重启Apache服务器
服务器管理
配置文件
配置文件位于:/etc/apache2/。
/etc/apache2/
|-- apache2.conf
|---- ports.conf
|-- mods-enabled
|---- *.load
|---- *.conf
|-- conf-enabled
|---- *.conf
|-- sites-enabled
|---- *.conf
apache2.conf是主要配置文件。
ports.conf
httpd
默认欢迎页面配置:/etc/httpd/conf.d/welcome.conf,移除该文件以禁用默认配置。
支持在服务目录下访问符号链接的权限:
-
服务目录配置支持跟踪符号链接;
<Directory "/var/www/html"> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory> -
http服务的运行用户(
apache)具有访问(execute)目标目录(及其父目录)的权限;httpdSymbolic link not allowed or link target not accessible -
可能需要关闭SELinux,以允许http服务访问服务目录外的位置。
You don't have permission to access
/directoryon this server
Nginx
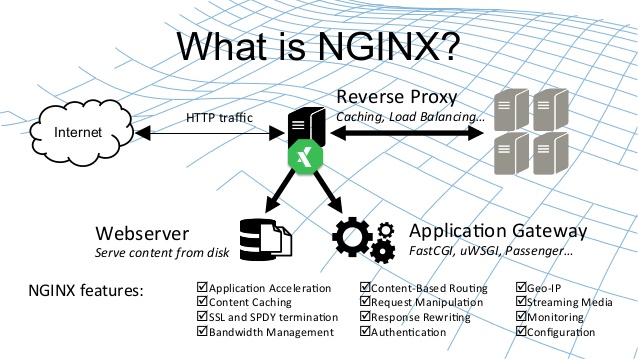
CentOS安装:Nginx位于EPEL软件源中;Ubuntu软件源中已包含Nginx。
Nginx服务通常通过systemd管理(start|stop|restart|reload)。
服务器配置
配置文件
/etc/nginx/
-- /etc/nginx/nginx.conf # top-level configuration file
-- /etc/nginx/conf.d/ # HTTP server sites
-- /etc/nginx/conf.d/default.conf # configuration template
-- /etc/nginx/sites-available # apache-style config dir
-- /etc/nginx/sites-enable
nginx.conf是Nginx的主要配置文件,其中可以使用include指令将其他服务配置文件加入。如果某个配置项有错误,该配置项以及之后的配置项都不会被加载。在运行Nginx之前可先测试配置是否存在问题:
nginx -t -c /PATH/nginx.conf # 使用绝对路径,否则nginx会从默认配置目录读取
配置语法
设置变量:set $variable value;,值如果包含空格等特殊字符,需要使用""。
基本配置
access_log /var/nginx/logs/access.log;
error_log /var/nginx/logs/error.log; # 错误日志
error_log /var/nginx/logs/info.log info; # 将指定级别日志输出到指定文件
pid /var/nginx/logs/nginx.pid; # Nginx主进程ID
日志格式
log_format main '$remote_addr - $remote_user [$time_local] $server_name ...'
日志中NGINX提供的内置变量,以记录请求服务信息。
$server_name/server_addr/server_port:接受该请求的服务器名称(域名/IP地址)、地址、端口;$request_uri/$uri|$document_uri:原始请求URI(包含参数)、规范化URI;$query_string|$args:请求URI的查询参数;$scheme/$server_protocol/$request_method:请求使用http/https、HTTP协议版本、HTTP方法;$https:是否开启HTTPS、$request_length/$request:请求数据长度(包括请求行、头部以及请求体)、请求行;$remote_addr/$remote_port/$remote_user/:客户端地址、端口和用户名(基本认证机制);$content_type/$cookie_name:请求头部信息;$time_local:服务器当前时间;status:响应状态;
HTTP静态站点
通过server块定义虚拟HTTP服务站点。其中listen和server用于定义虚拟服务的映射条件1:
listen:映射目标IP和端口,多个虚拟服务可共用相同的地址和端口,通过域名进行区分;如果省略IP地址,则监听服务器的所有地址;如果省略端口,则默认监听端口为80或8000。server_name:客户端请求域名,多个域名以空格分隔,支持通配符以及正则表达式匹配2。如果未匹配到任何域名,则将请求转发至listen字段包括default_server的服务站点。
http {
server {
listen 80 default_server; # 监听[ip_addr:]port
server_name www.example.com example.com;
root /var/www; # 默认根目录(仅能访问根目录下的内容)
location / { # 根目录配置
index index.html index.htm; # 默认主页,设置在根目录的配置下
root /usr/share/nginx/html; # 根目录对应的物理目录[路径重定向]
}
}
server { # 使用相同地址服务不同域名的HTTP服务
listen 80;
server_name test.example.com;
root /var/test;
}
}
default_server:未匹配到域名时的默认服务。
Nginx默认的服务进程用户为nobody/nginx,因此服务目录下文件应该对所有用户有读权限,所有目录对所有用户有访问权限,否则会产生403 Forbidden错误。
文件服务器
http {
server {
autoindex on; # 显示目录
autoindex_exact_size on; # 显示文件大小
autoindex_localtime on; # 显示文件时间
# ...
root /share/fs;
}
}
反向代理转发
location ^~ /test/ {
proxy_pass http://host_addr:8080;
}
location ^~ /test/1 {
proxy_pass http://127.0.0.1:8080;
}
location = /test/prefix/ {
proxy_pass http://127.0.0.1:8080;
}
location ~ ^/debug(.*)/log(.*)/ {
proxy_pass http://host_addr:8080/debug_log/$1/$2/; #*
}
location / {
proxy_pass http://127.0.0.1:8080;
}
*:如果匹配规则为正则表达式,转发地址中可包含正则表达式的捕获参数。
URL位置匹配规则(匹配优先级从高到低)3:
-
前缀匹配:以
=、^~修饰或无修饰符的匹配规则,按书写顺序检查。location = URI:精确匹配,匹配后立即响应请求。通常写在规则列表前面,用于匹配最常访问的URL如location = /。location ^~ URI:优先最长匹配,如果请求路径包含指定前缀,在匹配所有前缀匹配规则后,返回带^~的最长匹配;通常用于匹配服务器上的资源目录。location URI:最长匹配,记录下最长匹配记录,==但不做处理==(==优先级最低==,但搜索先于正则匹配;可能是为了一同调用前缀匹配模块)。
以
/test/1合上述规则为例,匹配顺序为:priority prefix match for location: /test/ priority prefix match for location: /test/1 # Final Match prefix match for location: / -
正则表达式匹配:
location ~ URI(~*大小写敏感)按顺序查找,匹配到后立即响应请求;通常用于根据规则匹配URL,并在后续对URL进行修改。 -
最长前缀匹配:使用前缀匹配过程中记录到的最长匹配响应请求;通常会设置
location /作为默认规则,因此,请求最后总能被一条规则所处。Nginx location block section:https://stackoverflow.com/a/59846239/6571140
编写匹配规则时,应该将较为精确的匹配项放在靠前的位置,否则更加模糊匹配项会覆盖精确匹配项,导致与期望的转发行为不一致。当出现转发失败或未按期望转发时,可对比Nginx的日志文件access.log和error.log(其中包含了用户的请求URL与Nginx的响应URL),排查错误原因。
资源路径重定向
rewrite将指定路径并替换为新的路径,root重新指定资源的根目录。
location [modifier] [URI] {
rewrite /path/($REGEX)/subpath/ replace_path break;
root base_path; # 实际访问 base_path/replace_path
}
$REGEX表达式可使用正则表达式,replace_path和base_path可使用rewrite表达式的捕获组($1,$2,...)。
HTTPS配置
Docker Containers - Rocket.Chat Docs
server {
ssl_certificate /etc/nginx/certificate.crt;
ssl_certificate_key /etc/nginx/certificate.key;
ssl_dhparam /etc/nginx/dhparams.pem;
}
"ngx_master_****" was not signaled for 5s:在Windows下,由于SSL密钥需要输入密码导致Nginx服务启动超时。可将证书密码保存在文本文件中(放在安全位置),并在Nginx配置文件中添加ssl_password_file pass.txt或者将密钥的密码验证移除:
openssl rsa -in server.key -out serverunsecure.key
负载均衡
http {
upstream load_balance_server {
least_conn; # 负载均衡策略(默认为轮询)
server 192.168.1.11:80 weight=5; #*
server 192.168.1.12:80 weight=1;
server 192.168.1.13:80 weight=6;
}
server {
location / {
proxy_pass http://load_balance_server;
}
}
}
负载均衡策略:
- (加权)轮询:
weigth参数表示权值,权值越高被分配到的几率越大。; - (加权)最少连接:
least_conn; - IP映射:
ip_hash; - URL映射:
hash $request_uri;
Nginx常见错误
-
unknown directive "ssl" nginx:Nginx未安装SSL模块。 -
403 Forbidden (nginx: Permission denied):1)文件及其上级目录权限配置不正确,Nginx工作进程所属用户无访问权限;SELinux开启阻止Nginx访问文件(特殊情况下,仅某个特殊文件无法被访问)。Modifying SELinux Settings for Full NGINX and NGINX Plus Functionality
-
502 Bad Gateway (nginx: (13: Permission denied) while connecting to upstream):系统开启SELinux,默认不允许HTTP服务软件连接系统的其他服务(进行代理转发)。可选择:1)关闭SELinux;2)修改SELinux策略;setsebool -P httpd_can_network_connect on # [on/1] -P for persistent -
CORS(cross-origin resource sharing,跨源资源共享)错误:客户端请求缺少CORS标准相关的HTTP头部字段,浏览器不允许上述跨域访问行为。在不修改客户端(HTML或JS代码等)的情况下,可通过NGINX代理修改HTTP请求头部实现跨域资源共享。
add_header 'Access-Control-Allow-Origin' '*'; #* add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; #** add_header 'Access-Control-Allow-Headers' '*'; #*** add_header 'Access-Control-Allow-Credentials' 'true'; #**** if ($request_method = 'OPTIONS') { return 204; }*:该头部选项允许通配符以允许匹配的请求源站点。**:允许跨域访问的HTTP方法,支持通配符。***:如果出现Request header field xxx is not allowed by Access-Control-Allow-Headers in preflight response.,添加该头部,支持通配符。****:如果响应内容未携带该头部,浏览器将不会把响应内容返回给请求发送者。在响应附带身份凭证的请求时,不能将上述头部的值设置为通配符。 -
修改配置重新加载不生效(例如日志配置无效不输出日志):
可能原因:Nginx后台进程未正常关闭(Windows),导致新启动的Nginx实例无法正常初始化。
解决方法:手动结束所有Nginx进程后,重新启动Nginx。
Caddy
Fast and extensible multi-platform HTTP/3 web server with automatic HTTPS.
安装
choco install caddy
运行Caddy服务
$env:XDG_DATA_HOME='path/'
caddy run --config caddy.json/Caddyfile --watch #*
caddy start|stop|reload # 后台服务管理
caddy.json或Caddyfile是配置文件,如果未提供配置文件,则服务器只有管理接口可访问。
*:--watch将监视配置文件更改并自动重新加载。
管理接口
http://localhost:2019/config/
Caddy模块
Caddy预装了标准模块,如匹配器、处理器、反向代理、TLS和日志等。
.\caddy.exe list-modules
配置Caddy
可使用JSON或Caddyfile对Caddy服务进行配置。JSON格式信息完整,对计算机解析更加友好;Caddyfile相对更加简洁,适合人工配置。
JSON配置
{
"apps": {
"http": {
"servers": {
"<server-name>": {
"listen": [
"[host]:port"
],
"routes": [
{
"match": [
{"host": ["domain.name"]}
],
"handle": [
{
"handler": "file_server",
"root": "/path/to/html"
}
]
}
]
}
}
}
},
"admin": {/*...*/},
"logging": {/*...*/},
"storage": {/*...*/}
}
JSON Config Structure - Caddy Documentation (caddyserver.com)
routes
定义了请求的匹配规则及其处理路径。match用于定义匹配规则,handle定义请求的处理方法。
handler
static_response:直接通过配置文件设置响应内容(body);file_server:响应服务器上的静态文件资源(root)。reverse_proxy:反向代理。
Caddyfile配置
Caddyfile包含全局选项(可选)、配置片段(可选)、一个或多个站点配置块以及注释(#开头后续内容)。如果配置文件只包含一个站点,其配置块的{}可省略。

匹配器必须在站点内部定义,不存在跨站点的全局匹配器。
站点地址格式:
localhost、localhost:8080、127.0.0.1:监听指定IP地址/主机名和端口的请求;example.com、http://example.com:监听指定端口上的域名请求;:443、[::1]:2015、http://:监听所有地址的指定端口;*.example.com:监听所有匹配域名的请求。
在Caddyfile中可引用Shell环境变量,{$SITE_ADDRESS}。
静态资源服务
文件服务
example.com { # 站点域名(IP地址端口)
root * /home/me/mysite
try_files {path} /index.html # 如果指定URL不存在, 则回落到index.html
templates # 支持模板
encode zstd gzip # 开启内容压缩
file_server browse #*
}
*:browse选项为没有index.html的目录提供自动文件索引,否则访问对应目录的URL将返回404。
提供文件服务的快捷方式:
caddy file-server --listen :2015 --browse --root ~/mysite --domain my.domain
静态响应
localhost {
respond "hello world!"
}
反向代理
example.com {
reverse_proxy "/api/*" localhost:5000
# handle /api/* {
# reverse_proxy backend:8000
# }
}
反向代理可与静态站点结合使用:反向代理仅转发API请求,通过/api/*过滤后的静态文件则直接通过文件服务器响应。==具有匹配规则的处理方法将被优先检查==。
反向代理服务快捷方式:
caddy reverse-proxy --from :2080 --to :9000
省略
--form,则默认监听localhost:443的请求(或在.localhost中定义的域名)。--to默认转发至协议为http,如果后端使用https,则在转发地址中显式指定https://。
HTTPS
By default, Caddy serves all sites over HTTPS.
local_certs:(全局选项)所有证书采用通过本地签发,不通过公开的证书签发机构(用于开发环境)。
本地HTTPS
To serve non-public sites over HTTPS, Caddy generates its own certificate authority (CA) and uses it to sign certificates. The trust chain consists of a root and intermediate certificate. Leaf certificates are signed by the intermediate. They are stored in Caddy's data directory at
pki/authorities/local.
Pelican
Pelican is a static site generator
- Write your content directly with your editor of choice in reStructuredText or Markdown formats
- Includes a simple CLI tool to (re)generate your site
http://docs.getpelican.com/en/3.6.3/index.html
http://docs.getpelican.com/en/3.6.3/publish.html#deployment
Gunicorn
Gunicorn, 'Green Unicorn' is a Python WSGI HTTP Server for UNIX.
It is best to use Gunicorn behind an HTTP proxy server. We strongly advise you to use nginx.
Squid代理服务
web proxy cache server:提供HTTP、FTP等协议的代理和缓存服务,支持全面、细粒度的访问控制机制。
安装:
sudo apt install squid
sudo systemctl start/stop/reload squid #* 非root用户需要使用sudo, 否则可能导致缓存目录创建失败
配置
/etc/squid/squid.conf
服务端口
http_port 3128
服务地址:http://proxy-server:http_port。
磁盘缓存
默认缓存在内存中(重启服务丢失),可指定多行以使用不同的磁盘分区。
cache_dir ufs/aufs/diskd Directory-Name Mbytes L1 L2 [options]
cache_dir rock Directory-Name Mbytes [options]
-
缓存数据格式,包括
ufs(默认包含)、aufs、diskd、rock。不同系统中的分发版可能不包含所有格式,通过修改配置文件并尝试启动服务确定相应格式是否可用。 -
Mbytes:缓存容量限制(默认100MB); -
L1:缓存目录下一级子目录数量,默认为16,Squid将请求URL通过Hash计算确定缓存内容的目录;这些子目录不是动态生成的,因此在服务运行时删除缓存目录下生成的子目录,会导致后续缓存内容无法保存(从而无法响应客户端)。
-
L2:缓存一级子目录下二级子目录数量限制,默认为256;
访问控制
限定访问代理服务的用户IP、访问时间。
acl src_rule src ip_addr/mask
acl time_rule time M T W T F 9:00-17:00 # 工作日工作时段
http_access allow src_rule time_rule # 满足所有规则才可使用代理
Nexus代理服务
安装
主机安装
下载Linux版本的二进制档案文件,并解压到安装路径(例如/opt/sonatype),将nexus-ver重命名为nexus。档案的基本结构如右图所示。
创建运行nexus服务的用户,并将nexus的安装目录所有权限更改为该用户。
useradd --system --no-create-home nexus
chown -R nexus:nexus /opt/sonatype
# edit: nexus/bin/nexus.rc
run_as_user="nexus"
设置数据和日志目录(nexus/bin/nexus.vmoptions)。如果默认位置的存储空间不够或读写速率较低,则可以修改以下配置项。
-XX:LogFile=../sonatype-work/nexus3/log/jvm.log
-Dkaraf.data=../sonatype-work/nexus3
-Dkaraf.log=../sonatype-work/nexus3/log # 日志文件目录
-Djava.io.tmpdir=../sonatype-work/nexus3/tmp
Nexus主要配置位于安装目录etc/目录下,其中nexus-default.properties为HTTP连接和网络应用默认配置。用户可在数据目录下的$data_dir/etc/nexus.properties修改相应属性(首次运行前该目录和文件不存在)4。
application-port=9081 # 网络连接 nexus-context-path=/nexus/ # Base URL
base URL也可以在运行后,通过System/Capabilities/Base URL来设置。
更新Java运行环境():
export JAVA_HOME=/usr/local/openjdk8 # 或 JDK_HOME,INSTALL4j_JAVA_HOME
INSTALL4J_JAVA_HOME_OVERRIDE=/usr/local/openjdk8 # edit: nexus/bin/nexus
修改打开文件限制(如果使用systemd启动则在服务配置文件中设置相应选项):
# edit: /etc/security/limits.conf
#<domain> <type> <item> <value>
nexus - nofile 65536
配置为系统服务、加载服务配置并启用该服务。
[Unit]
Description=Nexus Service
After=syslog.target network.target
[Service]
Type=forking
LimitNOFILE=65536
Environment=JAVA_HOME=/usr/local/openjdk8
ExecStart=/opt/sonatype/nexus/bin/nexus start
ExecStop=/opt/sonatype/nexus/bin/nexus stop
User=nexus
Group=nexus
Restart=on-failure
[Install]
WantedBy=multi-user.target
注意启动命令不要使用符号链接,因为
nexus启动时会根据可执行文件所在目录的相对路径来寻找数据目录sonatype-work,而符号链接会导致相对路径位置不正确。
首次登录管理员:初始密码随机生成,存储在/nexus-data/admin.password。
Windows下的服务管理,
./nexus.exe /install/uninstall # 安装卸载服务 ./nexus.exe /start/status/stop # 启停服务,查看状态 ./nexus.exe /run # 直接运行服务
Installing Sonatype Nexus Repository OSS on CentOS 7 | FOSS Linux
存储配置
仓库清理策略:通过Repository/Cleanup Policies添加清理策略,可按包的发布时间或最后下载时间设置清理策略。
HTTP网络代理配置
System/HTTP/{HTTP proxy|HTTPS proxy}(例外项可使用http.nonProxyHosts通配符)。
docker
docker run -d -p 8081:8081 --name nexus-porxy \
-v nexus-data:/nexus-data sonatype/nexus3
配置软件源代理
主要配置访问地址(仓库名称)、仓库的远程仓库地址和本地存储设置。

Blocked:阻止从远程仓库获取内容,适用于服务无法访问网络的情况以避免产生无效的网络请求。

pypi代理
Name="pypi-proxy"
Remote="https://pypi.doubanio.com" # 远端镜像去掉/simple后缀
URL="http://localhost:8081/repository/pypi-proxy/simple"
/simple是仓库下的索引目录,Nexus会为远端地址自动添加该后缀。
conda代理
Name="conda-pkgs"
Remote="https://mirror.sjtu.edu.cn/anaconda/pkgs"
URL="http://localhost:8081/repository/conda-pkgs[/main]" # 使用时去掉main后缀
Name="conda-cloud"
Remote="https://mirror.sjtu.edu.cn/anaconda/cloud"
URL="http://localhost:8081/repository/conda-cloud[/main]" # 使用时去掉main后缀
如果远程仓库中包含多个通道(如conda-forge和pytorch),则可将多个通道配置为一个代理仓库。配置condarc文件时,custom_channels对应的URL均为上述代理访问URL。
maven代理
Name="maven-central"
Remote="https://maven.aliyun.com/repository/central"
URL="http://localhost:8081/repository/maven-central/"
apt代理
需要为不同版本设置不同的代理仓库(在配置中要填写版本名称,如focal,jammy),不支持多个仓库合并为组。
Name="ubuntu-focal"
Remote="https://mirrors.tuna.tsinghua.edu.cn/ubuntu/"
URL="http://localhost:8081/repository/ubuntu-focal/"
Name="ubuntu-jammy"
Remote="https://mirrors.tuna.tsinghua.edu.cn/ubuntu/"
URL="http://localhost:8081/repository/ubuntu-jammy/"
yum代理
Name="yum-centos"
Remote="http://mirrors.aliyun.com/centos/"
# https://mirrors.tuna.tsinghua.edu.cn/{fedora|centos}
URL="http://localhost:8081/repository/yum-centos/"
配置合并镜像源(group)
可从同一个地址获取多个仓库的内容(按顺序依次请求)。
Web服务目录与反向代理
设置Web服务目录:1) ==修改配置文件==。2)通过Web管理界面“System/Capabilities/Create capabilities”添加“Base URL”(http://addr_or_name:8081/prefix)。
client_max_body_size 1G; # allow large uploads of files
proxy_max_temp_file_size 2G; # optimize downloading files larger than 1G
location /nexus {
# Use IPv4 address to avoid IPv6 DNS lookup
proxy_pass http://127.0.0.1:8081/nexus;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto "https"; # If https terminated at nginx proxy
}
参考资料
Configuring the Runtime Environment (sonatype.com) 1: How nginx processes a request 2: Server names (nginx.org)
文档生成工具
Sphinx
Sphinx最初用于生成Python代码文档,支持多种语言软件项目的文档生成。支持:输出HTML、LaTeX、ePub、manual页面等、自动交叉引用以及代码高亮等。Sphinx使用reStructuredText作为标记语言(类似于Markdown,标记语法更多)1。
Sphinx uses reStructuredText as its markup language, and many of its strengths come from the power and straightforwardness of reStructuredText and its parsing and translating suite, the Docutils2.
安装
独立安装
apt install python3-sphinx # yum install python-sphinx, choco install sphinx
如果系统不存在Python环境,将自动安装Python环境;
虚拟环境安装
使用virtualenv或conda虚拟环境。如果用于生成代码文档,应该安装在代码开发所在虚拟环境中,因为在导入代码模块时会导入其中的依赖项。因此,独立的虚拟环境无法满足依赖。
conda activate env_dev && conda install sphinx -c conda-forge
Getting Started with Sphinx — Read the Docs 5.21.0 documentation
Sphinx tutorial — Sphinx documentation (sphinx-doc.org)
配置和编译
sphinx-quickstart # 自动生成配置文件和编译脚本(make.bat)
sphinx-build -b html sourcedir builddir # => make html
sourcedir:Sphinx项目使用的所有源文件所在目录(子目录)
语言:默认为英语en,可选择设置中文zh_CN。
Configuration — Sphinx documentation (sphinx-doc.org)
首页配置文件
定制文档首页以及目录。
.. toctree::
:maxdepth: 2
usage/installation 添加要转换的文件:省略扩展名,使用`/`作为路径分隔符
usage/quickstart
...
被添加文件所引用的文件也会被解析。
文件路径
编译配置文件
主题:
conda install -c conda-forge sphinx_rtd_theme
html_theme = 'sphinx_rtd_theme' # in conf.py
extensions = [ 'sphinx_rtd_theme' ]
Sphinx Themes Gallery (sphinx-themes.org)
解析和转换Python代码
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.napoleon' # 使用Numpy/Google风格代码注释
]
NumPy风格代码注释:可在VS Code中使用
autoDocstring自动生成模板并修改内容。注释章节标题:
Parameters|Arguments|Args/Keyword Args|Keyword Arguments:参数说明;Return|Returns:返回值说明;Raise|Raises:抛出异常说明;Example|Examples:示例;References/See Also:参考文献或跳转链接;Tip/Note/Warns|Warn/Todo:额外的提示信息。
自动导入模块内容:
.. automodule:: my.module
:members: 自动导入所有内容并生成文档
.. autoclass:: my.module.class
:members: open, close 导入指定内容并生成文档
sphinx.ext.autodoc – Include documentation from docstrings — Sphinx documentation (sphinx-doc.org)
使用sphinx-apidoc可自动扫描指定模块中的内容,并生成对应的.rst文件。
sphinx-apidoc [OPTIONS] -o <OUTPUT_PATH> <MODULE_PATH> [EXCLUDE_PATTERN, ...]
#-f,--force
#-e, --separate put documentation for each module on its own page
#-M, --module-first put module documentation before submodule documentation
包含
__init__.py的目录才会被识别为子模块。
解析和转换Markdown文件3
安装插件:
conda install myst-parser -c conda-forge
更新Sphinx配置文件:配置处理的文件格式扩展名,以及支持的Markdown扩展。
extensions = ['myst_parser']
source_suffix = {
'.rst': 'restructuredtext',
'.txt': 'restructuredtext',
'.md': 'markdown',
}
myst_enable_extensions = [...] # optional depends: linkify-it-py
myst-parser不能转换代码中Markdown格式的注释文档。
d2lbook
安装
conda create -n d2lbook -c conda-forge python=3.8 sphinx pandoc librsvg
conda activate d2lbook
git clone https://github.com/d2l-ai/d2l-book.git
pip install ./d2l-book
如果需要编译为PDF需要安装一个LaTeX发行版(如TexLive或MikTeX),librsvg用于将SVG转换为PDF文件。
编写编译配置文件
[build]
index = index # 默认首页index.md
notebooks = *.md source/*.md # 需要将markdown文件放在notebooks类别才会输出内容
exclusions = source/get_started.md # 排除文件
non-notebooks =
eval_notebook = False # 是否执行代码块中的代码
tabs = mxnet, pytorch, tensorflow # 多标签内容
编写文档
和Sphinx的首页文件类似,在首页文件(index.md)中添加目录:
````toc
source/get_started
source/reference
````
编写正文:
使用:begin_tab:和:end_tab:来标记标签页,以生成多标签页面。
:begin_tab:`mxnet`
接下来,我们实例化`mxnet`类并访问其模型参数。
:end_tab:
在代码块中,使用#@tab tabname来标记相应标签(默认为配置文件中声明的第一个标签)。
```python
#@tab pytorch
import torch
from torch import nn
import torch.nn.functional as F
```
编译
生成HTML文件:
d2lbook build --tab all html # 需要执行两次,否则可能出现错误(找不到index.rst)
编译前可能需要执行
d2lbook clear(rm -rf _build),否则更改内容可能不会被重新编译。
修改主题资源
在线资源处理:主题中的部分字体图片资源需要在线下载,如果网络不佳或离线使用会使页面等待加载。因此,可以将这些资源预先下载到本地,并修改资源文件使用本地资源路径(文件或本地http URL)替换相应资源URL。
-
字体:将
_build/html/_static/font.css(来自安装的mxtheme主题)中以//fonts.gstatic.com开头的字体URL添加协议https:,使之能被正常访问;其次,将其中的字体URL提取出来并批量下载到本地,然后将font.css中的URL替换为本地路径。 -
图片:修改
d2l-book的sphinx_template模块引用的在线资源文件为本地文件加快访问速度。https://raw.githubusercontent.com/choldgraf/sphinx-copybutton/master/sphinx_copybutton/_static/copy-button.svg -> PREFIX/_static/copy-button.svg -
服务:注释
d2l-book.sphinx中生成的访问google-analytics的JavaScript代码;
2. User Guide — D2L-Book: A Toolkit for Hands-on Books 0.1.17 documentation
doxygen
Doxyfile
DOXYFILE_ENCODING = UTF-8
PROJECT_NAME = "Triangle Library"
PROJECT_NUMBER = 1.1
PROJECT_BRIEF = "Triangle Library for C++ Documentation Tutorial"
OUTPUT_DIRECTORY = "build"
FULL_PATH_NAMES = NO
INPUT = "source/path"
RECURSIVE = YES
GENERATE_XML = NO
GENERATE_LATEX = NO
GENERATE_RTF = NO
GENERATE_MAN = NO
mdBook
安装
下载mdbook。
创建工作目录并初始化项目(作者、项目标题,信息位于工作目录下的book.toml文件中)。
mdbook init book_path
--theme # 将主题文件复制到工作目录下以便修改默认配置(./theme/)
--title TITLE # 未指定改选项则提示用户输入标题
--ignore # 生成默认的.gitignore文件(其中包含book目录)
项目的Markdown文档内容位于src/目录下(Markdown文件内不能超链接该目录外的文件,可通过符号链接将外部文档置于src/下),src/SUMMARY.md是所有文档的入口。
修改
./theme/css/general.css以自定以标题和正文以及代码块的字体字号。
安装插件
从插件仓库下载发行版本,并释放到mdbook同一目录下(将该目录加入路径变量)。
-
slowsage/mdbook-pagetoc: Adds sidebar table of contents. (github.com)
下载安装侧边栏目录插件:
[preprocessor.pagetoc] [output.html] additional-css = ["theme/pagetoc.css"] additional-js = ["theme/pagetoc.js", "theme/MathJax.js"] no-section-label = true
项目配置
预处理器
渲染器
mdBook内置HTML渲染器和Markdown渲染器(调试用途),第三方渲染器包括pdf、epub和man等。
[output.html]
theme = "mytheme"
mathjax-support = true # 暂不支持$$标记的数学公式
# [output.pdf]
# mdbook-pdf 利用chrome提供的PDF生成功能生成PDF文件,无法控制文档格式。
文档结构
# Summary
[prefix_chapter](./prefix.md)
# Part Title
- [chapter name](./chapter_name.md)
- [sub_chapter_name](./some_path/sub_chapter_name.md)
--- <!-- separater line -->
[suffix_chapter](./suffix.md)
以
-开头的声明为编号章节,通过缩进区分大纲级别,可在编号章节前后添加无编号的序言/附录等内容(不可出现在编号章节之间,不可缩进嵌套)。如果章节声明的超链接为空,则在目录中该章节无法点击。
使用
---以在目录中添加分割线。
渲染文档
使用mdBook内置服务
mdbook serve --open # 在工作目录下执行
项目目录下的源文件修改后,mdBook将会重新编译内容并刷新浏览页面。
编译发布
mdbook build
--dest-dir [book_path] # 生成HTML文件,输出到指定目录(默认为./book/)
--open # 打开编译结果
编译过程会将源文件目录下的除
.md外的所有文件复制到输出目录下。
编译输出内容可通过HTTP服务进行发布。
MkDocs
安装MkDocs
conda create -n mkdocs mkdocs
安装插件
pip install mkdocs-section-index mkdocs-exclud
创建项目
mkdocs new [dir-name] # Create a new project.
编译配置
theme:
docs_dir: docs
site_dir: site
include_sidebar: true
use_directory_urls: false #*
*:问题:附件相对路径多了一层当前文档名,如./docs/docs.assets/xyz.png,正确形式应该为./docs.assets/xyz.png。
构建项目
mkdocs serve # Start the live-reloading docs server.
mkdocs build # Build the documentation site.
gitbook
https://app.gitbook.com/
插入文档作为子页面
与git仓库(GitHub或GitLab)同步
参考资料
A ReStructuredText Primer (sourceforge.io) 2:Overview — Sphinx documentation (sphinx-doc.org) 3:Getting Started with Sphinx — using-markdown-with-sphinx
文件处理工具
切割和拼接
将一个文件分割为多块:
split [OPTION]... FILE PREFIX
PREFIX:输出文件名前缀,输出文件名自动添加后缀编号,形如:PREFIXaa、PREFIXab、...。
FILE:输入文件名,如果未提供或为-则从标准输入读取(管道)。
选项:
-a:后缀长度;
-d:使用数字编号,--numeric-suffixes[=FROM]允许指定起始编号;
-x:使用十六进制编号,--hex-suffix[=FROM];
-b,--bytes=SIZE:每个输出文件的长度(字节),K,M,G,T,P,E,Z,Y (1024)或KB,MB,... (1000);
-l,--lines=NUMBER:每个输出文件的行数;
-n,--number=CHUNKS:指定输出文件的个数,l/N不在行内分割;K/N仅输出第K个分块到标准输出(l/K/N);==r/N将文本文件内容按行轮流输出到N个分块中==。
合并文件
cat [OPTION] ... FILE ...
将文件拼接并输出到标准输出,或使用输出重定向将内容输出到新文件。如果FILE未提供或为-则从标准输入读取(管道)。
diff and patch
用法
diff [options] origin_filename changed_file
diff [options] origin_dir/ updated_dir/ # 对比文件夹下的对应文件变更
diff文件模式:默认模式仅记录改动的位置信息和改动内容;
-
-c:copied context(补丁内容附带修改部分的前后内容,从而不仅依赖行号定位改动位置);-C N:指定上下文行数; -
-u:unified context(修改内容直接对比,更加紧凑,GNU diff and patch)。 -
-y:side-by-side(输出两列对比)。colordiff不支持此模式的高亮。
空白对比处理:
-b,--ignore-space-change-w, --ignore-all-space-B, --ignore-blank-lines
升级补丁(patch)
diff输出内容可保存为补丁文件,利用patch程序可基于旧版本和补丁文件重建新文件。
patch originalfile -i patchfile.patch -o updatedfile #*
patch -p 0 -i patchfile.patch # -p N 仅处理<=第N层子文件夹
*:yum install patch;
对于已分发文文件v1.file,如果要进行更新可选择生成补丁(diff v1.file v2.file > v12.patch),从而减小传输带宽;在远程机器上将补丁应用于修改后的文件(patch v1.file -i v12.patch -o v2.file)。对于被修改过的远程文件v1r.file,则这种更新方式会失败,因为补丁信息与基础文件不能匹配,因此需要人工将v1.file->v1r.file中的修改内容合并到v2.file中。
Comparing and Merging Files (gnu.org)
高亮比较结果
diff origin changed | colordiff # => colordiff origin changed *
diff origin changed | vim -R - # 在Vim中显示diff结果
vim -d origin changed # => vimdiff 在Vim中显示对比结果,显著高亮行内不同部分。
git diff --no-index --word-diff=color origin changed # **
*:yum install colordiff:高亮比较结果。
**:--no-index比较的文件不在git仓库中时使用。
归档
tar -[cruxt][z][v] -f path/archive.tar.gz \
-C /file/path \ # 更改操作目录
file1 file2 ...
操作模式
-c,--create:从选定的文件创建新的档案(覆盖已有同名档案);
当不声明压缩格式选项
-z时(且文件扩展名为.tar或添加--no-auto-compress选项),只进行归档而不执行压缩。
-r,--append:将选定文件追加文件至档案末尾(不会覆盖同名文件);
-u,--update:追加文件至档案,覆盖档案中较旧的文件;
-t,--list:列出档案内容;
-x,--extract:提取档案中的文件(到当前目录),使用-C指定提取文件的存储目录;
-A :追加tar文件合并至档案末尾(--catenate, --concatenate);
--delete:从档案中删除文件;
tar -f archive.tar --delete test2.txt
文件
-f,--file=ARCHIVE:选择操作的目标档案文件;-T,--files-from=FILE:从文件读取进行操作的文件列表。
-C,--directory=DIR:更改操作目录。对于归档操作,该选项影响后续源文件的根目录;对于提取操作,该选项影响提取内容的存储目录。
-h,--dereference:压缩时读取符号链接指向的目标文件内容==替换符号链接==;如果压缩时未指定-h,则保留符号链接信息,解压缩时还原为符号链接。(相应地,--hard-dereference对于hardlink文件似乎没用)。
--strip-components=1:移除档案中的目录层级(==为了修改根目录名而自行创建根目录==);
--add-file=FILENAME:添加包含特殊字符的文件。
--exclude=PATTERN:排除文件的模式;-X,--exclude-from=FILE:从文件中读取排除文件的多个模式;
--exclude="*.pyc" --exclude="*tmp/*" --exclude="*model/*" --exclude="*output/*"
-N, --newer=DATE-OR-FILE, --after-date=DATE-OR-FILE:仅存储比所给日期或文件更新的文件(包括所给定日期的文件)。
-p,--preserve-permissions:保留文件访问权限。
压缩
-z:等效于对归档后的文件/文件夹,使用gzip压缩或解压文件,输出文件扩展名为.tar.gz。
tar -cvf archive.tar FILES ...
gzip --keep archive.tar # >> archive.tar.gz
信息
-v:列出所处理的文件。
文件覆盖
-k, --keep-old-files:不覆盖文件,提示错误(默认为覆盖),--skip-old-files直接跳过,不产生错误。
--keep-newer-files :不覆盖本地更新的文件(本地存在相同时间或更新时间的同名文件时输出提示)。
--overwrite:提取时覆盖已有文件。
--remove-files:归档后删除原文件。
https://www.rootusers.com/23-tar-command-examples-for-linux/
压缩/解压
gzip
gzip filename # 压缩*
-c,--stdout # 输出到标准输出, 保留源文件
-k,--keep # 保留输入文件
-f,--force # 强制覆盖输出文件
-r,--recursive # 递归遍历文件,并分别执行压缩**
-1,--fast
-9,--best
gzip -l,--list filename # 列出压缩内容的信息
如果未指定文件名,或文件名为
-,从标准输入读取数据。
*:gzip默认进行压缩操作,指定-d,--decompress执行解压任务(等效于调用gunzip)。
**:gzip只支持压缩文件,不支持文件夹;使用-r选项会对文件下的文件分别进行压缩;使用tar对文件夹归档后再进行压缩。
zip
# sudo apt install zip unzip
zip [options] archive[.zip] INPATH1 INPATH2 ...
# -可替代使用标准输入/输出分别代替输入(文件名)/输出(压缩内容),
# 使用-代替输入会将输出定位到标准输出; -@则仍将压缩内容输出至文件;
-r,--recurse-paths # 默认至包括给定的目录/文件,不包含子目录内容
-x,--exclude file_pattern # 排除文件 -x@exclude.lst
-i,--incldue # 指定输入
-y,--symlinks # 存储符号链接而非其指向的文件
--out,--output-file # 不更新已有zip文件而是输出到新文件
-FS,--filesync # 源和zip文件同步模式
-P,--password password
-du,--display-usize # Display the uncompressed size of each entry.
-z,--archive-comment # 从标准输入/文件(<conmment_file)读取注释
-Z,--compression-method=store|deflate|bzip2 # 压缩方法
-N # N=0-9 0表示不压缩(-Z store)
zip add|update|freshen|delete|copy ...
# "update" (-u,--update)
# "freshen" (-f,--freshen) only update existed files, not add new files.
# "delete" (-d,--delete)
# "copy" (-U,--copy-entries) 从zip文件中选取文件并输出到新的zip文件(--out)
unzip -O GB2312 file.zip -d dir
-l FILE # 仅列出包含的文件的信息
-z FILE # 仅列出压缩包的注释信息
-P password
如果出现文件名乱码:
-O指定Windows压缩文件使用的编码方案;-I指定UNIX或其他系统下的编码方案。
zip在操作时会先创建一个临时文件,仅当
zip可对压缩文件进行分片,从而方便大文件的传输。unzip无法直接对分片的压缩文件进行解压,可首先将其拼接(cat)为一个文件再执行解压。
A split archive is a standard zip archive split over multiple files. (Note that split archives are not just archives split in to pieces, as the offsets of entries are now based on the start of each split. Concatenating the pieces together will invalidate these offsets, but unzip can usually deal with it. zip will usually refuse to process such a spliced archive unless the -FF fix option is used to fix the offsets.
When changing an existing zip archive, zip will write a temporary file with the new contents, and only replace the old one when the process of creating the new version has been completed without error.
zip -s 700m ARCHIVE.zip --out ARCHIVE-SPLIT.zip # 将字zip文件分片(-s,--split-size)
# ARCHIVE-SPLIT.z01, ARCHIVE-SPLIT.z02, ..., ARCHIVE-SPLIT.zip.
# k (kB), m (MB), g (GB), or t (TB) (the default is m)
zip -s 0 input-split.zip --out input-unsplit.zip # 将分片文件合并
还支持将一种分片容量的输入改变为另一种分片容量进行输出(中间过程可能需要恢复为完整文件)。
主机之间复制文件
scp
scp命令(secure copy)用于Linux之间复制文件和目录,是linux系统下基于ssh登录进行安全的远程文件拷贝命令。scp是加密的,scp是 rcp (不加密的)加强版。
scp [options] file user@dest_host:file # local to remote
scp [options] user@src_host:file file # remote to local
-P:指定远程服务器端口号。注意:使用
scp命令要确保使用的用户具有可读取远程服务器相应文件的权限,否则scp命令是无法起作用的。
scp可以在源与目的主机以外的第三台主机执行,只需保证源与目的主机间有相应地读写权限。
rsync
rsync常用于文件备份和镜像,支持本地和远程目标之间的文件传输。对于目标路径已有的文件,仅传输源和目标文件的差异部分;并且支持只更新较新的文件。rsync默认检测文件的修改时间和大小,如果未发生变化,则仅修改目标文件的相关属性信息。rsync会对传输文件按文件名排序。
==目标目录如果不存在==,rsync会自动创建。
rsync支持两种模式:远程shell(如ssh,目标形如user@host:path);rsync daemon(目标形如user@host::path或rsync://)。rsync==必须安装在收发两台机器==。启动
rsync daemon:man rsyncd.conf。
rsync -rua srcfiles ... user@host:path # files支持通配符
rsync -ua --delete source/ target # source->target同步
文件路径格式
- ==如果源路径为目录且以
/结尾则只拷贝目录下的内容到目标目录;反之,将该目录拷贝到目目录下(目标目录后是否有/无影响)==; - 如果源路径为文件,目标路径为目录,则将该文件保存到目标目录下;如果目标路径为文件,则保存为目标文件。
文件传输控制
-a,--archive:归档模式,保证文件属性保留,等效于-rlptgoD。
-r:递归复制子目录内容,若未指定该选项,将跳过提供的文件夹;-d,--dirs只拷贝==当前目录==,不包含目录内容(除非目录名为.或以/结尾);如果同时出现,-r优先级高于-d。-l,--links符号链接不转换为实际文件;-L,--copy-links将符号链接转换为实际文件。-t,--times:保留文件的时间信息。-g,--group;-o,--owner:保留文件的用户信息。-D,--devices --specials:传输字符或块设备文件和特殊文件(如明明套接字和FIFIO)。
-v,--verbose:打印传输过程信息,可叠加最多两个-v以增加输出信息量。
--progress:显示传输进度信息。
-R,--relative:保留源文件参数给出的路径并拼接到目标路径下。
-c,--checksum:使用文件大小和校验和(MD5)而非修改时间检查文件是否更改。由于收发两端都需要读取文件计算校验和,因此处理速度较慢。
-z,--compress:压缩传输内容;--compress-level=NUM。
-b,--backup:目标位置已存在的文件和目录将被重命名;--backup-dir=DIR,--suffix=SUFFIX
-n,--dry-run:与-v或-i结合使用。如果未指定目标路径,则列出源文件(类似于
ls -l,源也可以是远程)。如果源和目的都为本地路径,则在本地路径间进行复制。
目标文件权限控制
-p,--perms:目标文件的权限信息与源文件保持一致。如果未指定该选项:已有文件再更新时权限信息不变;新文件的普通权限标志位与源文件一致,其他的继承自接收目录的默认权限。-E,--executability:在未启用--perms时,为普通文件添加可执行权限(启用时忽略该选项)。--chmod=u=rw,go=r,D+x:该选项修改来自源文件的权限信息(而非已保存在本地的文件权限),因此未启用--perms,则对已有文件无影响。除chmod的权限声明方式外(也支持数字模式--chomd=F644,D755),可添加额外的前缀:D表示仅应用于目录,F表示仅应用于普通文件。
同步条件选项
-u,--update:跳过目标路径下修改时间比源文件新的文件。
--delete:删除目标路径下,不存在于发送方的内容,与发送方保持一致(镜像)。
--existing, --ignore-non-existing:只同步目标已存在的内容;
--ignore-existing:只同步目标不存在的内容。
--exclude=PATTERN:排除无需同步的文件(收发双方同时忽略),可多次使用该选项;--exclude-from=FILE从文件指定多个模式;文件中的空行、以’;’或’#’开头的行被忽略。
foo # 包含foo的路径
/foo # 匹配传输目录下以foo开头的文件路径
foo/ # 仅匹配目录
* # 匹配任何内容直到"/"
** # 匹配任何内容
? # 匹配除了"/"以外的字符
[] # 定义匹配字符集合
--include=PATTERN和--include-from=FILE:指定要包括的文件,优先级高于--exclude。
--files-from=FILE:确切指定要传输的文件。
增量备份
第一次同步是全量备份,所有文件在基准目录里面同步一份。其后每次使用最近的备份目录作为基准目录,只同步源目录与基准目录之间有变动的部分并将其保存到新的目标目录;没有变动的文件都是指向基准目录文件的==硬链接==(不能生成软链接,否则后期对比时与源文件不同)。
rsync -a --delete --link-dest=COMPARE_DIR /source/path /target/path
--copy-dest=DIR:直接从基准目录DIR复制未发生变化的文件(而非创建链接),减少网络传输量。通过复制而非创建硬链接保证对基准目录的修改不会影响目标目录内容。--compare-dest=DIR:仅复制与基准目录DIR相比发生变化的文件,并删除目标目录下已存在于DIR中未发生变化的文件。==利用该选项可以找出两个版本之间的差异文件(相当于文件级别的diff)==。rsync -a --delete --compare-dest=LastVersion LastestVersion AddedFiles rsync -a --delete --compare-dest=LastestVersion LastVersion RemovedFiles
rsync 用法教程 - 阮一峰的网络日志 (ruanyifeng.com)
cwrsync
cwrsync是基于cgywin开发的rsync软件。cwrsync 5.5 包含rsync 3.1.2(与CentOS7.x rsync版本兼容),cwrsync 6.2.4包含rsync 3.2.3。
配置cwrsync执行脚本
SET CWRSYNCHOME=C:\apps\cwRsync_5.5.0_x86_Free
SET PATH=%CWRSYNCHOME%\bin;%PATH%
如果系统中未安装其他SSH客户端,可将
%CWRSYNCHOME%\bin配置到用户路径中。
配置免密码远程访问
如果系统已经使用Open-SSH客户端,并生成密钥且已配置远程SSH免密码访问。则将~/.ssh/目录下的id_rsa复制到%CWRSYNCHOME%/home/%USERNAME%/.ssh目录下,并将其访问权限设置为仅限当前用户。
如果系统未使用Open-SSH客户端,则使用cwrsync自带SSH客户端程序ssh-keygen生成密钥并分发给远程机器。
文件访问权限配置
由于Windows与Linux的文件访问权限设置方式不一致,容易导致向Linux系统同步时目标系统文件权限不正确。因此执行rsync命令时配置以下选项(关闭保持权限的选项,并显式设置目标系统的访问权限):
rsync -urltDv --delete --chown USER:GROUP --chmod a+rX,u+w,go-w SOURCE TARGET
协作办公软件
Rocket.Chat
安装
可手动、使用容器或使用snap安装。推荐使用snap安装,可避免多数配置。
sudo snap install rocketchat-server # 安装后自动启动运行
可使用浏览器或下载客户端访问http://<host_addr>:3000并进行初始设置(默认仅支持localhost或IP地址访问,主机名或域名访问需要配置Caddy或其他代理服务)。使用snap可查看服务状态。
离线安装snap版本
在未安装过snap软件的机器上需要下载和安装core18和snapd依赖。
配置
获取rocketchat-server当前的配置:
snap get rocketchat-server
# Key Value
# backup-on-refresh disable
# ignore-errors false
# mongo-oplog-url mongodb://localhost:27017/local
# mongo-url mongodb://localhost:27017/parties
# port 3000
# siteurl http://localhost:3000
如果
siteurl与实际访问URL不匹配,客户端会提示URL跳转。
启动服务
snap start rocketchat-server # 将启动server以及数据库(和可选的caddy服务)
snap start rocketchat-server.rocketchat-server # 单独启动server服务
问题:
- 服务无限重启,日志(
snap logs -f rocketchat-server.rocketchat-server查看服务日志)出现Segmentation fault未知错误:尝试重启服务器然后启动rocketchat-server服务。- 重启
rocketchat-server服务后,无法正常访问:需要重启机器(可能是因为之前的服务占用某些资源未释放)。
设置端口
sudo snap set rocketchat-server port=8080 # 默认端口3000
sudo snap restart rocketchat-server.rocketchat-server # 重启服务生效
将配置项置空将恢复默认配置。
注意:如果设置的服务端口或以下代理端口无法连接,检查是否开启防火墙及相关策略。如果客户端配置了代理将无法正常访问,需要将域名或地址排除到代理范围外。
设置数据库服务配置
Mongdb数据库服务的配置文件位于/var/snap/rocketchat-server/current/mongod.conf。
问题:
Failed to set up listener: SocketException: No such file or directory:无法(在默认位置/tmp)创建UNIX域套接字,修改配置文件,显式设置UNIX域套接字所在目录:net: unixDomainSocket: enabled: true pathPrefix: /var/snap/rocketchat-server/common # 使用数据目录
配置访问代理
RocketChat服务本身可作为独立的HTTP服务。如果需要配置外部使用HTTPS请求,可使用内置caddy作为反向代理(如果要使用其他代理(例如NGINX),则无需以下配置)。
sudo snap set rocketchat-server https=enable
sudo snap set rocketchat-server caddy=enable
sudo snap set rocketchat-server caddy-url=https://<domain-name>[:<port>]
sudo snap run rocketchat-server.initcaddy # 生成Caddyfile*
*:如果提示找不到initcaddy命令,可直接编辑配置目录下的Caddyfile文件。
https://example-domain.com { # *
tls self_signed # **
proxy / localhost:3000 {
websocket
transparent
}
}
*:同一服务器上代理与rocketchat服务不要使用同一端口。
**:测试或内部使用可使用Caddy自签名证书,仅需在Caddyfile中声明tls self_signed|internal。如果具有公开可访问的域名,Caddy可自动使用Let's Encrypt生成SSL证书。
配置完成后,启动caddy服务并重启server服务。
sudo snap start rocketchat-server.rocketchat-caddy
升级迁移
进行升级迁移前首先对数据进行备份,以防过程中出现错误。snap支持对应用数据生成快照,但快照通常仅能用于同一版本的数据恢复(通常用于使用过程中的备份)。升级迁移情况下,需要使用RocketChat内部的数据备份恢复机制。
数据备份和恢复
备份或恢复操作时应先停止server服务,保留数据库服务。
sudo rocketchat-server.backupdb # 然后,将备份文件保存到其他地方
sudo cp /var/snap/rocketchat-server/common/rocketchat_backup.tar.gz ~/backup
恢复(必须将备份文件存放到/var/snap/rocketchat-server/common/)
sudo rocketchat-server.restoredb rocketchat_backup.tgz
文件服务
filebrowser
安装
filebrowser仅包含单独的可执行文件,将档案文件释放到创建的指定目录即可。
tar -xzf linux-amd64-filebrowser.tar.gz -C /opt/filebrowser
/opt/filebrowser/filebrowser -r /content/root/ # 指定文件服务的根目录
默认用户名和密码为
admin:admin,可在启动服务后通过Web界面或命令行修改。
filebrowser的运行数据保存在工作目录下的数据库文件database.db(Bolt DB)中,不依赖于外部数据库服务。
配置
配置项可通过配置文件、环境变量、命令行选项提供,配置项的优先级高于数据库中存储的配置项。优先级从高到低:
- 选项:
-a,--address:监听地址;-p,--port:监听端口;-b,--baseurl:Web服务URL的根路径;-c,--config:配置文件路径;-d,--databse:数据库文件路径;
- 环境变量命名规则:
FB_OPTION_NAME。 - 配置文件
.filebrowser.{json|toml|yaml|yml},搜索路径包括:./、$HOME/、/etc/filebrowser/。 - 数据库配置:通过Web界面或命令行
filebrowser config等修改的信息将更新到数据库中。 - 默认值。
服务配置
[Unit]
Description=filebrowser - Web File Explorer
Documentation=https://filebrowser.org/
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
WorkingDirectory=/opt/filebrowser/
ExecStart=/opt/filebrowser/filebrowser -c config.json -r /content/root/
ExecStop=/bin/kill -s TERM $MAINPID
KillSignal=SIGTERM
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=filebrowser
[Install]
WantedBy=multi-user.target
Syncthing
配置
配置文件
配置文件路径:
$HOME/.config/syncthing # Linux
%LOCALAPPDATA%\Syncthing # Windows
--config CONFIG_PATH覆盖默认路径。
配置文件路径下可能包含的内容:
config.xml
cert.pem # ECDSA public/private key
key.pem
https-cert.pem # for HTTPS GUI
https-key.pem
csrftokens.txt # A list of recently issued CSRF tokens
数据库路径(优先级从高到低):
/path/to/exist_db # 指定的路径???
$XDG_DATA_HOME/syncthing
~/.local/share/syncthing # Windows:$HOME\AppData\Local\Syncthing
$HOME/.config/syncthing
--data DB_PATH覆盖默认配置。
配置文件格式
<configuration version="35">
<folder></folder>
<device></device>
<gui></gui>
<ldap></ldap>
<options></options>
<remoteIgnoredDevice></remoteIgnoredDevice>
<defaults></defaults>
</configuration>
通信方式与监听地址配置
-
TCP:
tcp[4]://0.0.0.0:22000,tcp[4|6]://:22000,tcp6://[::]:22000;tcp协议监听IPv4/v6地址。 -
QUIC:
quic://[0.0.0.0]:22000,类似于TCP,可指定quic4和quic6。如果上述端口被占用,则
syncthing会自动切换为选择随机端口(如57350)。 -
发现服务:
https://discover_server:8443?; -
中继
- 动态中继:
dynamic+https://relays.syncthing.net/endpoint; - 动态中继池:
dynamic+https://192.0.2.42/relays; - 静态中继:
relay://192.0.2.42:22067?id=abcd123...;
- 动态中继:
-
默认(
default):tcp://0.0.0.0:22000,quic://0.0.0.0:22000和dynamic+https://relays.syncthing.net/endpoint.
Syncthing Configuration — Syncthing v1.20.2 documentation
命令行
服务启动选项:
--home=<dir> # 配置文件和数据库路径
# --config=<dir>, --data=<dir>
--gui-address=0.0.0.0:8384 # or '/var/run/st.sock'
--logfile=<filename> # '-' for stdout
--log-max-old-files=<num>
--log-max-size=<num>
--no-browser # 不启动浏览器(适用于服务器)
--no-console # 隐藏终端窗口(Windows)
syncthing --device-id # Print device ID
syncthing --paths # 打印配置相关路径
--version
syncthing --generate=<dir> # 生成配置文件和密钥文件
syncthing generate \ # 指定新的用户名和密码
--gui-user=<username>
--gui-password=<password> # or '-' 从命令行读取,覆盖配置文件(Hash)
命令行扩展工具
tenox7/stc: Syncthing CLI Tool (github.com)
自启动配置
Starting Syncthing Automatically — Syncthing documentation
常见问题
inotify limit
echo "fs.inotify.max_user_watches=204800" | sudo tee -a /etc/sysctl.conf
Linux只读目录的同步
syncthing不推荐使用root账户运行,但syncthing会在目录下创建.stfolder目录以存放同步信息,只读目录下无法自动创建。可用root账户手动创建该目录并将其所有者修改为syncthing服务的执行用户。
Web用户界面简介
文件夹视图
屏幕左侧显示所有已配置文件夹的 ID 和当前状态。单击文件夹名称可使该部分展开以显示更详细的文件夹信息,以及用于暂停文件夹、强制重新扫描或编辑配置的按钮。
文件夹可以处于以下任一状态:
- 未知:在加载 GUI 时,
- 未共享:当您尚未共享此文件夹时,
- 暂停:当文件夹的活动被搁置时,
- 停止:当文件夹遇到错误时,
- 最新的:当文件夹与其他设备同步时,
- 等待扫描:在扫描文件夹之前等待其他文件夹空闲时,
- 扫描:当Syncthing在文件夹中查找本地更改时,
- 等待同步:在同步文件夹之前等待其他文件夹空闲时,
- 准备同步:当 Syncthing 收集要同步的文件更改时,
- 同步:当此设备从网络下载更改时,
- 等待清洁:在清理版本之前等待文件夹空闲时,
- 清洁版本:同时从
.stversions文件夹中删除过时的文件。
在文件夹详细信息中,您可以看到当前的“全局状态”和“本地状态”摘要,以及如果文件夹状态不是最新的,则“不同步”的数据量。
- 全局状态:指示完全最新的文件夹包含的数据量,这基本上是所有连接设备中所有文件的最新版本的总和。这是计算机上与远程设备完全同步时文件夹的大小。
- 本地状态:显示文件夹现在实际包含的数据量。如果文件夹当前正在与其他设备同步,则此值可能大于或小于全局状态。
- 不同步:显示需要从其他设备同步的数据量。请注意,这是所有不同步文件的总和 - 如果您已经拥有此类文件的一部分或该文件的旧版本,则需要通过网络传输的数据少于此值。
- 错误:介绍了文件夹处于“已停止”状态时出现的问题。一种可能的消息是“缺少文件夹标记”。这意味着此文件夹的根目录不包含名为 (marker) 的文件或目录。当此标记丢失时,同步将停止,以防止数据丢失,例如,当文件夹路径被卸载时。如果标记被意外删除,只需重新创建它,然后按 UI 中的重新扫描按钮即可。
创建新的同步文件夹
使用同步 Web 界面。单击“添加文件夹”按钮,该按钮将显示具有以下选项的对话框:
- 文件夹标签:应设置为描述性内容。此标签最初将与远程设备共享,但可以根据需要在每个设备上进行更改。
- 文件夹标识:所有设备都必须相同,因为它是文件夹的唯一标识符。最佳做法是保留自动生成的 ID,以避免与其他设备上的同名文件夹发生冲突。
- 文件夹路径:指定文件夹的物理路径,即硬盘驱动器上的物理路径。
接下来,选择要与哪些设备共享文件夹,然后按添加,这将添加文件夹并开始同步。
设备视图
屏幕右侧显示所有已配置设备的整体状态。本地设备始终位于顶部,远程设备按字母顺序排列。对于每个设备,您都会看到其当前状态,并在展开时看到更详细的信息。所有传输速率(“下载速率”和“上传速率”)都是从本地设备的角度出发的,即使是针对远程设备显示的传输速率。本地设备的速率是远程设备的速率之和。对于每个速率,您可以看到当前的传输速度,然后是到目前为止传输的数据总量。您可以单击当前传输速度以在字节和位之间切换单位。
桌面软件
Martchus/syncthingtray: Tray application and Dolphin/Plasma integration for Syncthing (github.com)
Syncthing Discovery Server
如果需要同步的设备不在同一网络中,则需要配置发现服务。syncthing默认使用联网的发现服务器(default)。如果在离线环境部署syncthing,则需要自行部署发现服务。
stdiscosrv
-cert=./cert.pem -key=./key.pem
-db-dir=./discovery.db
-debug
-http # Listen on HTTP (使用HTTPS反向代理)
-listen=':8443'
-metrics-listen=<address> # default disabled
-replicate=<peers>
-replication-listen=':19200'
syncthing配置选项:
https://discover_server:8443:使用CA签发证书。https://discover_server:8443?id=<server_id>:使用自签名证书,使用发现服务ID验证证书。http://discover_server:8443?insecure:取消证书验证。
如果需要要从互联网访问发现服务,可能需要动态DNS服务。
负载均衡
Syncthing Discovery Server — Replication
反向代理
Syncthing Discovery Server — Reverse Proxy Setup
自定义升级服务器
Custom Upgrade Server — Syncthing documentation
HedgeDoc
安装
安装依赖组件:
-
Node.js 16(包含NPM);
-
数据库(PostgreSQL, MySQL, MariaDB, SQLite),数据库应使用UTF-8编码(PostgreSQL和SQLite默认)。为数据库创建库实例和用户,并分配访问权限。
createdb hedgedoc createuser -h localhost hedgedoc -PGRANT ALL ON DATABASE hedgedoc TO hedgedoc;
安装配置HedgeDoc:
-
在软件根目录下执行:
bin/setup在线下载依赖项和生成配置文件; -
如果需要对前端进行定制修改(例如markdown的展示样式),可在修改后重新编译前端内容。
yarn install --frozen-lockfile && yarn build -
修改配置文件(
./config.json):{ "production": { "domain": "10.131.5.6", "port": 4000, "urlAddPort": true, "db": { "dialect": "postgres", "username": "USERNAME", "password": "PASSWORD", "database": "hedgedoc", "host": "10.131.5.11", "port": "5432" } } } -
手动启动服务,检查是否产生错误:
NODE_ENV=production yarn start -
创建用户。
useradd -m hedgedoc mkdir -p /home/hedgedoc/public/uploads /home/hedgedoc/db -
配置系统服务
hedgedoc.service。基于文档提供模板根据实际安装情况进行修改。Environment=PATH=/node/path:/system/path Environment=NODE_ENV=production ExecStart=/path/to/yarn start --production WorkingDirectory=/path/to/hedgedoc ReadWritePaths=/home/hedgedoc/public/uploads /home/degedoc/db -
将服务文件安装到系统服务目录,启用并运行服务,查看服务运行状态。
cp hedgedoc.service /lib/systemd/system/ systemctl daemon-reload && systemctl enable --now hedgedoc journalctl -xe -f -u hedgedoc
反向代理配置
如果需要通过反向代理访问HedegDoc服务,则服务的某些配置与直接访问的方式不同。具体包括:
domain:配置为反向代理的域名或IP,这将使响应内容中URL的主机地址为代理服务器,而非HedgeDoc服务所在主机。同时,也避免浏览器的跨站访问检测策略阻止访问HedgeDoc服务(CSP和CORS策略)。protocolUseSSL:如果浏览器是通过HTTPS访问服务,则应该设置为true;这将保证响应内容中的URL统一使用https,从而能正确被反向代理响应。该选项只影响URL的协议,而不影响实际使用HTTP或HTTPS。urlAddPort:由于反向代理具有统一的访问端口,通常为80或443,因此响应内容中的URL应该不添加HedgeDoc服务所使用的端口。urlPath:如果反向代理处需要通过URL路径区分服务,则需要为HedgeDoc设置根路径而不是使用默认的/。
Nginx配置中添加HedgeDoc服务(HTTP)的转发规则。
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
server {
server_name hedgedoc.example.com;
location / {
proxy_pass http://hedgedoc-server:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
location /socket.io/ { # WebSocket
proxy_pass http://hedgedoc-server:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
}
}
如果设置了urlPath='hedgedoc',则上述转发规则做相应修改:
location /hedgedoc {
proxy_pass http://hedgedoc-server:3000/;
}
location /hedgedoc/socket.io/ { # WebSocket
proxy_pass http://hedgedoc-server:3000/socket.io/;
}
远程桌面
VNC
安装TigerVNC服务
Gnome(Fedora)自带远程桌面服务无法连接,在配置以下服务前首先关闭系统自带的远程桌面服务。
sudo dnf -y install tigervnc-server
sudo firewall-cmd --add-service=vnc-server --permanent
sudo firewall-cmd --reload
vncpasswd
编辑~/.vnc/config修改显示分辨率geometry=1920x1080。
编辑/etc/tigervnc/vncserver.users添加用户映射::2=gary。
启动服务:systemctl enable --now vncserver@:2.service
注意:
:1显示可能无法正常工作,因此从:2开始配置。如果服务无法启动,尝试禁用并重启服务。
连接安全性
VNC传输未加密。为保证通信安全,应该在受信任的网络中使用,或首先从建立一条安全的隧道:
ssh -v -C -L 590N:localhost:590M vncserver.host # local_590N -> remote_590M
VNC客户端
常用包括:UtralVNC、TigerVNC Viewer、TightVNC等。
MobaXTerm连接质量较低(切换屏幕会导致VNC服务终止);
VNC客户端连接黑屏:登录界面显示服务不兼容,修改/etc/gdm/custom.conf。
# Uncomment the line below to force the login screen to use Xorg
WaylandEnable=false
RDP
How to Install Xrdp Server (Remote Desktop) on Ubuntu 20.04 | Linuxize。
*
XRDP*在Elementary OS上无法正常使用。
文档处理
Visio
为形状添加连接点

更改连接线跨越风格
“设计/版式/连接线”:取消“显示跨线”,则交叉点处不会拐弯。
参考资料
syncthing - Open Source Continuous File Synchronization. 2: Syncthing Configuration — Syncthing v1.20.2 documentation. 3: Understanding Synchronization — Syncthing documentation
知识管理软件
Obsidian
callout
> [!INFO]
> Here's a callout block.
> It supports **markdown**, [[Internal link|wikilinks]], and [[Embed files|embeds]]!
> ![[og-image.png]]
多媒体编辑软件
图形编辑软件
GIMP
GNU Image Manipulation Program1。
winget install GIMP.GIMP
Inkscape
winget install Inkscape.Inkscape
ImageMagick
create, edit, compose, or convert digital images2:
- *resize, flip, mirror, rotate, distort, shear and transform images, *
- *adjust image colors, *
- *apply various special effects, *
- draw text, lines, polygons, ellipses and Bézier curves.
ImageMagick适用于后台处理图像。
- https://imagemagick.org/archive/binaries/ImageMagick-7.1.0-51-Q16-HDRI-x64-dll.exe
- ImageMagick – Download
安装:
apt install imagemagick # ImageMagick 6.9.11-60 Q16 x86_64
winget install ImageMagick.ImageMagick # ImageMagick 7.1.0-51 Q16-HDRI x64
A
Q16version permits you to read or write 16-bit images without losing precision but requires twice as much resources as theQ8version.
magick -version
magick -help
用法
在Linux下ImageMagick提供的命令行工具是独立的,如convert、identify、display……;在Windows下,相应地工具则统一通过magick子命令调用(Linux下也支持此方式)。
command { [settings] [operation] }... "implict_write"
命令执行模式,每个命令由一个或多个operation和一个输出操作组成。每个operation定义包含读取/创建图像以及对图像的处理选项,处理后的图像缓存在图像序列中,由最后定义的输出操作统一处理。
工具集简介
magick:作为所有命令行的调用入口;未提供子命令时,默认调用convert命令。identify:输出一个或多个图像文件的格式和特征信息,如分辨率、大小、尺寸、色彩空间等。convert:创建、编辑图像,转换图像格式,以及调整图像大小、模糊、裁切、除去杂点、抖动 ( dither )、绘图、翻转、合并、重新采样等。mogrify:与convert功能一样,直接修改原始图像文件。composite:将一个图片或多个图片组合成新图片。montage:组合多个独立的图像来创建合成图像。每个图像都可以用边框,透明度等特性进行装饰。compare:从数学和视觉角度比较源图像与重建图像之间的差异。stream:将图像或部分图像的一个或多个像素组件流式传输到存储设备。在处理大图像或原始像素组件时很有用。conjure:解释并执行 MSL ( Magick Scripting Language ) 写的脚本。
✨Basic Usage -- ImageMagick Examples
[ImageMagick – Command-line Tools](file:///C:/Program Files/ImageMagick-7.1.0-Q16-HDRI/www/command-line-tools.html)
JELLY | 图像处理 - ImageMagick 简单介绍与案例 (jd.com)
convert
magick input.jpg \
-resize 50% \
output.png
参考资料
机器学习实践
搭建开发环境
Python环境
数据处理和算法库:
numpy、pandas;scipy、sklearn (scikit-learn)tensorflow、keras(tensorflow已将keras作为内置模块,但使用需要单独安装);pytorch;
安装Tensorflow
tensorflow 1.x分为CPU和GPU版本,且1.x和2.x版本不兼容,因此需要在单独的虚拟环境中分别安装:
conda create -n tf2 [tensorflow-gpu] tensorflow=<ver> cudnn cudatoolkit=11.2 keras
conda create -n tfgpu tensorflow-gpu=<ver> ... # 1.x GPU版本
2.x版本的包名不区分GPU/CPU版本,根据是否安装GPU工具包(
cudnn和cudatoolkit)决定是否能使用GPU计算。tensorflow-gpu声明了对GPU库的依赖保证安装支持GPU的版本。使用
pip安装:pip install tensorflow # CPU 版本
GPU支持
在系统中安装NVIDIA® GPU 驱动程序(CUDA 11.2需要450.80.02或更高版本)。==使用Conda安装tensorflow-gpu将自动为虚拟环境安装兼容版本的CUDA Toolkit和cuDNN==。官方提供CUDA Toolkit包含了进行CUDA相关程序开发的编译、调试等过程相关的所有组件。而Conda虚拟环境提供的CUDA Toolkit仅包含运行时库。以下为可选安装内容:
-
CUDA® 工具包(CUDA Toolkit):TensorFlow 支持 CUDA 11.2(TensorFlow 2.5.0及更高版本)。
-
cuDNN SDK(8.1.0)
-
CUDA 工具包附带的 CUPTI。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64 -
TensorRT 6.0,可缩短用某些模型进行推断的延迟时间并提高吞吐量。
TensorFlow容器
docker run -it -p 8888:8888 tensorflow/tensorflow:latest-jupyter
验证安装
import tensorflow as tf
print(tf.version.VERSION)
tf.config.list_physical_devices()
Tensorflow with DirectML on WSL
安装PyTorch
使用Conda安装pytorch:相关包可使用pytorch通道下载(注意选择操作系统和计算平台,以下仅为示例)。
conda create -n pytorch[-gpu] python=3.8 # python>=3.6
conda install pytorch torchvision torchaudio cpuonly -c pytorch
conda install pytorch="1.10.*"="*cuda*" torchvision torchaudio cudatoolkit=11.3 -c pytorch
2022/01/21:
conda-forge: cudatoolkit<=11.2;pytorch: cudatoolkit<=11.3。当Pytorch和TensorFlow共同安装时,可能导致依赖解析问题无法安装Pytorch的GPU版本,此时可指定安装pytorch-gpu(Linux下才有此包)。使用pip安装
pytorch:pip install torch torchvision torchaudio # CPU version pip3 install torch==1.10.1+cu113 \ torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 \ -f https://download.pytorch.org/whl/cu113/torch_stable.html # GPU version验证安装:
import torch x = torch.rand(5, 3); print(x) torch.cuda.is_available()
Enable PyTorch with DirectML on WSL 2
图神经网络库
DGL
conda create -n dgl -c pytorch pytorch=1.12 cudatoolkit=11.6 cudnn
conda activate dgl
conda install -c dglteam dgl-cuda11.6
dglteam仓库仅在Anaconda官方源中可用,如果使用Nexus代理,增加以下仓库代理。
Name=anaconda-cloud
Remote=https://conda.anaconda.org/
URL=http://192.168.178.52:8081/repository/anaconda-cloud
也可使用DGL提供的pip仓库安装dgl库。
pip install dgl-cu116 dglgo -f https://data.dgl.ai/wheels/repo.html
通过配置文件~/.dgl/config.json 或环境变量指定使用的深度学习框架后端。
{
"backend": "pytorch"
}
export DGLBACKEND=pytorch # pytorch, mxnet, tensorflow
PyTorch Geometric
PyG (PyTorch Geometric) is a library built upon PyTorch to easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data.
conda create -n pyg -c pytorch pytorch=1.12 cudatoolkit=11.6 cudnn
conda activate pyg
conda install pyg -c pyg
使用pip安装:
CUDA={cpu|cu102|cu113|cu116}
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.12.0+${CUDA}.html
pip install torch-sparse -f https://data.pyg.org/whl/torch-1.12.0+${CUDA}.html
pip install torch-geometric
cpu | cu102 | cu113 | cu116 | |
|---|---|---|---|---|
| Linux | ✅ | ✅ | ✅ | ✅ |
| Windows | ✅ | ✅ | ✅ | |
| macOS | ✅ |
pyg-team/pytorch_geometric: Graph Neural Network Library for PyTorch (github.com)
GPU计算库
NVIDIA CUDA
安装:./cuda-xxx.run --no-opengl-libs;
如果机器已经安装驱动程序,则安装过程中可跳过驱动程序安装;
修改环境变量使CUDA全局可用;
CUDA on WSL 2
系统版本需要为Windows 10 21H2或更高,WSL发行版使用Ubuntu或Debian(Linux 5.10.43.3+)。
-
在Windows中安装支持WSL的NVIDIA CUDA驱动程序。
-
[可选] 在WSL中安装专用CUDA工具包(注意使用
run文件不要安装显卡驱动);如果需要编译CUDA程序,则需要安装CUDA Toolkit。 -
使用CUDA自带样例验证安装是否正确;
-
安装完成后,即可和普通Linux一样使用PyTorch、TensorFlow或NVIDIA Docker。
# 验证 nvidia-smi -q chmod -R a+w /usr/local/cuda-11.4/samples cd /usr/local/cuda-11.4/samples/4_Finance/BlackScholes make BlackScholes && ./BlackScholes
NVIDIA Docker
Note that NVIDIA Container Toolkit has not yet been validated with Docker Desktop WSL 2 backend(实测可以运行).
NVIDIA/nvidia-docker: Build and run Docker containers leveraging NVIDIA GPUs (github.com)
安装NVIDIA Docker工具包:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update && sudo apt install -y nvidia-docker2
需要重启docker服务以完成安装。
容器示例:
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
docker run -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
docker run --gpus all -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/tensorflow:20.03-tf2-py3 # Unknown runtime specified nvidia.
Java环境
数据准备
尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见。
- 向量:$\mathbf{y}, \boldsymbol{y}$
- 矩阵:$\mathbf{A}, \boldsymbol{A}$
- 张量:$\mathsf{X}$
数据类型
数据集划分
将数据集按比例随机抽样划分为训练集、开发集(交叉验证集)和测试集。
能在开发集上运行性能良好,却在测试集上效果不佳的系统。如果此时开发集和测试集的分布相同,那么你就能清楚地明白问题所在:算法在开发集上过拟合了(overfit)。解决方案显然就是去获取更多的开发集数据。
但是如果开发集和测试集服从不同的分布,解决方案就不那么明确了。此时可能存在以下一种或者多种情况:
- 算法在开发集上过拟合了。
- 测试集比开发集更难进行预测,尽管算法做得足够好了,却很难有进一步的提升空间。
- 测试集不一定更难预测,但它与开发集性质并不相同(分布不同)。因此在开发集上表现良好的算法不一定在测试集上也能够取得出色表现。如果是这种情况,大量针对开发集性能的改进工作将会是徒劳的。
真实数据集
-
keras.datasets提供在线获取(缓存在本地
~/.keras/datasets/)和加载示例数据集的接口。数据集包括:mnist、boston_house、cifar、imdb、reuters等。
数据预处理
- 清理:错误、丢失信息;
- 使用统计方法理解数据;
- 可视化数据,发现有用特征;
- 构造新特征;
- 反复迭代;
数值化(Numeralization)
类别数据(Categorical Variables)
- 无序数据(nominal),例如:
{male, female};不应该被编码为数值,类别之间无大小关系; - 有序数据(ordinal),例如
{low, medium, high};可以编码成任意具有大小关系的数值,不能准确表示原始数据的意图。
One-hot Encoding Scheme
pd_dummy= pd.get_dummies(drop_first=True)
默认仅对object类型的列进行编码。
Dummy Variable Trap
Multicollinearity: Variance Inflation Factor.
https://towardsdatascience.com/one-hot-encoding-multicollinearity-and-the-dummy-variable-trap-b5840be3c41a
Dummy Coding Scheme
Effect Coding Scheme
Bin-counting Scheme
Feature Hashing Scheme
- UNDERSTANDING FEATURE ENGINEERING (PART 2), Categorical Data, Strategies for working with discrete, categorical data, https://towardsdatascience.com/understanding-feature-engineering-part-2-categorical-data-f54324193e63.
- scikit-learn 0.22.1, Preprocessing data, Discretization, https://scikit-learn.org/stable/modules/preprocessing.html#discretization.
Word2vec
利用One-hot Encoding表示单词,使用降维方法减小向量空间。
通俗理解word2vec - 简书 (jianshu.com)
word2vec 中的数学原理详解 - peghoty - 博客园 (cnblogs.com)
标签编码
标签编码,将文本数据转换为整数。
标签二值化,将样本的负/正标签值转换为(0,1)二值。如果标签值类别超过两类,则分别对每类值(视为正样本,映射为1)执行二值化(非正样本映射为0)。
多标签二元化,样本的每个标签对应的编码位置为1。
标准化(Normalization)
Change the values of numeric columns in the dataset to a common scale, without distorting differences in the ranges of values.
每个特征具有的物理意义不同,其具体数值在特征之间通常不具有可比性(更换数据的单位其数值就相应地缩放,但是物理意义没有变化);将数据特征的区间缩放到一个常见的范围,提升算法稳定性。
对于基于距离的算法,则需要考虑:1)原始数据的取值范围(单位)是否影响算法;2)标准化是否破坏了原始的距离信息;
如果一列数据为常量,缩放方法无效;同时,该列数据在学习任务中通常没有作用。
线性缩放
线性缩放处理特征之间数据范围不一致的情形。
标准缩放(StandardScaler)
移除样本的统计均值并将统计方差缩放为1: $$ z = (x-\mu)/\sigma \notag $$
Min-Max缩放
将特征区间缩放到$[0,1]$区间。 $$ \hat{x}=\frac{x-\min{x}}{\max{x}-\min{x}}\notag $$
非线性缩放
对数缩放(LogScaler)*
样本特征分布范围很大(长尾分布),根据特征的属性,如果在特征取值较大,而其变化对目标任务影响较小时(例如收入、数据下载量、音量等),可以采用对数缩放,从而保留更多特征信息。
对数缩放可能使得异常点不显著。
$$ \hat{x}=\log_{10}{(1+x)}\notag $$
可以与线性缩放结合使用。
归一化(Unit Vector Normalization)
针对每个样本而不是每个特征进行处理。
将向量(样本特征向量)长度缩放为1,即将所有样本缩放到一个单位超球面上。需要注意,==如果原始数据本身具有不同的向量长度,且算法对数据的向量长度敏感==(基于距离的算法),则此类标准化方法不适用。此方法常用于文本分类或聚类。 $$ \hat{\boldsymbol{x}}=\frac{\boldsymbol{x}}{|\boldsymbol{x}|}\notag $$
Compare the effect of different scalers on data with outliers。
特征生成
多项式特征生成
基于已有特征生成高阶非线性特征,如:$x^2, x^3, xy, \cdots$。
处理流程
Pipeline
将数据预处理、学习算法等流程串联起来(最后一个流程必须执行预测)。
性能评估
评估方法:
-
学习方法(estimator)的
score方法 -
sklearn.metrics提供的评估预测误差的方法,包括分类误差计算方法:accuracy_score、f1_score、precision_score、recall_score,回归误差计算方法r2_score。 -
交叉验证的评分策略,通过
scoring参数选择评分方法。评分器(scorer)约定越高评分代表越好的性能。预定义的scoring参数对应了metrics中的评估方法。make_scorer自定义打分方法:
def scoring_func(estimator, X, y): # do scoring return score # higher is better.
多分类或多标签分类的评分方法。
当你需要在多个分类器之间进行选择时,使用单值评估指标将帮助你更快速地作出决定。它能给出一个清晰明了的分类器性能排名,从而帮助团队明确后续的改进方向。
交叉验证
Cross Validation (CV) provides the ability to estimate model performance on unseen data not used while training.
- test on unseen data
- avoid overfitting
K折交叉验证
步骤:splitting the data into subsets (called folds, K-fold) and rotating the training and validation among them.
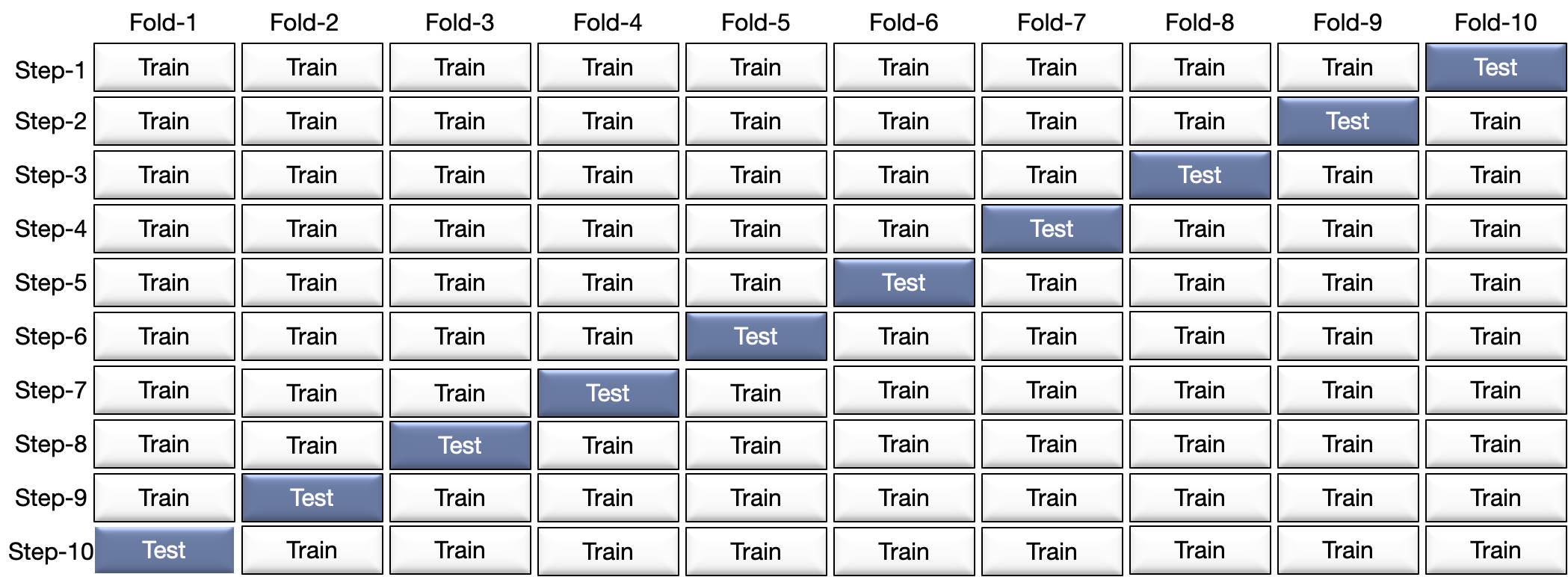
https://towardsdatascience.com/what-is-cross-validation-60c01f9d9e75
Metrics and scoring: quantifying the quality of predictions
参数搜索
获取非训练过程调整的你参数。
网格搜索交叉验证
在各个超参数的取值范围内穷举参数组合,分别应用于模型进行训练和预测,根据预测性能获得最佳的超参数组合。为了计算应用超参数组合的模型的性能,需要结合(K折)交叉验证,即将数据集划分为==训练集和验证集==。
Random Search Cross Validation
从参数空间中随机采样。
深度学习算法
AutoEncoder
Building Autoencoders in Keras, 2016
End-to-End ML Lifecycle Management
MLflow
- MLflow Tracking: 记录实验结果,比较参数和结果;
- MLflow Projects:将ML代码打包未可重用可复现的形式(用于共享或生产部署);
- MLflow Models:支持多种机器学习库模型在多种平台上的管理和部署;
- MLflow Registry:提供模型管理协作中心。
Concepts — MLflow 1.24.0 documentation
Tutorials and Examples — MLflow 1.24.0 documentation
Orchestrating Multistep Workflows
conda create -n mlflow -c conda-forge mlflow
pip install mlflow
pip install mlflow[pipelines] # + experimental MLflow Pipelines
pip install mlflow[extras] # + extra ML libraries and 3rd-party tools
pip install mlflow-skinny # + lightweight version of MLflow
MLflow requires
condato be on thePATHfor the projects feature.
MLflow Tracking
MLflow Tracking — MLflow 1.24.0 documentation
Tracking API
from mlflow import log_metric, log_param
mlflow.set_tracking_uri("http://YOUR-SERVER:4040") # 默认为本地文件存储
mlflow.set_experiment("my-experiment") # 实验名,默认为Default
log_param("param1", randint(0, 100)) # 记录输入的参数
log_metric("foo", random() + 2) # 记录输出的指标
为不同的实验设置不相同的实验名称,从而方便对比实验参数和输出指标。
默认将运行记录写入本地./mlruns目录,可在当前目录下运行mlfllow ui查看其中的运行记录。每个运行记录由唯一的Run ID。
Artifacts包含模型代码、运行环境声明等信息。
MLflow Projects
mlflow run --no-conda project_path -P param1=value1
如果指定--no-conda,则MLflow不会自动创建虚拟环境并安装依赖(MLflow内部会维护虚拟环境列表而不会重复创建),而是使用系统已有环境。
项目声明文件:
name: tutorial # 项目名称
conda_env: conda.yaml # 项目使用的虚拟环境配置
entry_points: # 代码入口信息
main: # 可定义多个入口,按顺序指定(构成处理流程)
parameters: # 代码接收的参数
alpha: {type: float, default: 0.5}
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}" # 执行代码的命令
虚拟环境配置文件:
name: tutorial # 虚拟环境名称(MLflow内部使用,映射conda虚拟环境名称)
channels: # 使用的软件源通道
- conda-forge
dependencies: # 依赖库声明
- python=3.7
- pip
- pip: # 需要使用pip安装的依赖库
- scikit-learn==0.23.2
- mlflow>=1.0
- pandas
sklearn
pandas, numpy, and sklearn
MLflow Models
保存模型
mlflow.log_artifacts("output_path") # 将本地目录中的内容作为模型内容保存
mlflow.sklearn.log_model(lr, "model") # 将模型对象保存到本地
运行模型
mlflow models serve -m runs:/<RUN_ID>/model --port 5001
根据模型自带的环境声明自动创建Conda虚拟环境并运行模型。模型启动后可以通过REST接口向其发送数据。模型将执行预测并输出结果。
运行模型使用的Python版本必须与创建模型时使用的版本一致(否则pickle无法正常工作)。
运行时检测依赖库
specifying pip requirements using pip_requirements and extra_pip_requirements
Ray
安装
机器学习运行环境架构

-
Ray Train: Scalable Model Training
-
Tune: Scalable Hyperparameter Tuning
-
Serve: Scalable and Programmable Serving
-
RLlib: Industry-Grade Reinforcement Learning
Ray Datasets is designed to load and preprocess data for distributed ML training pipelines.

安装机器学习运行环境
conda create -n ray-ml python=3.10
pip install 'ray[air]' # 包含机器学习运行环境的所有模块
pip install tqdm # tqdm用于显示数据处理进度
pip install fastapi # 用于模型部署提供API
pip install xgboost xgboost_ray torch tensorflow
Ray集成的机器学习框架以及其他工具需要独立安装。
数据预处理
加载并拆分数据集,构造训练、验证和测试集。
dataset = ray.data.read_csv("s3://anonymous@air-example-data/breast_cancer.csv")
train_dataset, valid_dataset = dataset.train_test_split(test_size=0.3)
test_dataset = valid_dataset.drop_columns(cols=["target"])
Ray会自动在本地创建一个集群,可通过仪表板查看(
http://127.0.0.1:8265)。
构造预处理器,如标准化等;
from ray.data.preprocessors import StandardScaler
preprocessor = StandardScaler(columns=["mean radius", "mean texture"])
预处理器
预处理处理标准的数据集对象DataSet。预处理器在训练阶段进行拟合(fit_transform)并应用于训练和服务阶段(transform)。
自定义预处理器:
import ray
from pandas import DataFrame
from ray.data.preprocessor import Preprocessor
from ray.data import Dataset
from ray.data.aggregate import Max
class CustomPreprocessor(Preprocessor):
def _fit(self, dataset: Dataset) -> Preprocessor:
self.stats_ = dataset.aggregate(Max("value"))
def _transform_pandas(self, df: DataFrame) -> DataFrame:
return df * self.stats_["max(value)"]
使用BatchMapper构造无需拟合的预处理
preprocessor = BatchMapper(lambda df: df * 2)
训练模型
选择常用机器学习框架训练模型。此阶段通常需要输入训练和验证数据集以优化模型,防止过拟合。
from ray.air.config import ScalingConfig
from ray.train.xgboost import XGBoostTrainer
trainer = XGBoostTrainer(...)
result = trainer.fit()
print(result.metrics)
超参数调优
from ray import tune
param_space = {"params": {"max_depth": tune.randint(1, 9)}}
metric = "train-logloss"
from ray.tune.tuner import Tuner, TuneConfig
from ray.air.config import RunConfig
tuner = Tuner(trainer,param_space=param_space,tune_config=TuneConfig(**kwargs))
result_grid = tuner.fit()
# Fetch the best result.
best_result = result_grid.get_best_result()
print("Best Result:", best_result)
使用模型进行预测
Checkpoints
Checkpoint对象由训练器、调优器以及预训练模型生成,用于构建模型对象。
批量预测
from ray.train.batch_predictor import BatchPredictor
from ray.train.xgboost import XGBoostPredictor
# You can also create a checkpoint from a trained model using
# `XGBoostCheckpoint.from_model`.
checkpoint = best_result.checkpoint
batch_predictor = BatchPredictor.from_checkpoint(checkpoint, XGBoostPredictor)
predicted_probabilities = batch_predictor.predict(test_dataset)
predicted_probabilities.show()
模型部署
from ray import serve
from fastapi import Request
from ray.serve import PredictorDeployment
from ray.serve.http_adapters import json_request
async def adapter(request: Request):
content = await request.json()
print(content)
return pd.DataFrame.from_dict(content)
serve.start(detached=True)
deployment = PredictorDeployment.options(name="XGBoostService")
deployment.deploy(
XGBoostPredictor, result.checkpoint, batching_params=False, http_adapter=adapter
)
print(deployment.url)
import requests
sample_input = test_dataset.take(1)
sample_input = dict(sample_input[0])
output = requests.post(deployment.url, json=[sample_input]).json()
print(output)
参考文献
- Nyandwi/machine_learning_complete: A comprehensive machine learning repository containing 30+ notebooks on different concepts, algorithms and techniques. (github.com)
- 规模驱动机器学习发展 (deeplearning-ai.github.io)
- deeplearning-ai/machine-learning-yearning-cn: Machine Learning Yearning 中文版 - 《机器学习训练秘籍》 - Andrew Ng 著 (github.com)
Scikit Learn
数据准备
数据集划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df_data, # 支持DataFrame输出DataFrame, 可省略.to_numpy()
df_target, # support 1d array/series
test_size=0.25, random_state=1
)
数据预处理
数值化
特征编码
One-Hot Encoder
OneHotEncoder可以利用数据训练得到数据的取值集合,随后用于新数据的编码(fit、transform);而pd.get_dummies仅能对当前数据进行编码(fit_transform)。
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categories='auto', drop=None, sparse=True,
dtype=np.float64, handle_unknown='error')
categories:指定离散数据的类型。默认为'auto',编码器从数据中推导每个特征包含的类别(fit());反之,可以为每一列指定离散值(list_of_list,每个特征对应的类别数量可能不同,不适合使用矩阵表示),==每一列的值不应该混合字符串和数值;如果为数值类型,则应该有序==。
drop:默认保留编码后的所有列,first:丢弃第一列,去除冗余;if_binary:仅对有两类的列丢弃第一列。
sparse:如果设置为True,则在执行transform时,要求数据也是稀疏类型的。
enc.categories_:拟合后得到的类别数据取值集合(enc.categories为初始化的集合)。
enc.get_feature_names(col_names):根据原数据列名(col_names为序列类型),生成编码后数据列名;==需要首先执行fit()操作==,fit()返回的是编码后的数值矩阵,可结合生成的列名构建编码后的表格(pd.DataFrame)。
标签编码
LabelEncoder
-
fit:统计标签类别; -
transform:将标签根据已知类别进行数字编码。fit_transform:在相同数据上进行类别学习和编码。
LabelBinarizer
fit(y)/transform(y)/fit_transform(y):从y(序列类型)中统计标签的类别,标签按数值/字符串大小排序。
fit决定拟合的类别数量n_classes;transform根据输入决定标签类型:y_type=multiclass/binary/...'
-
普通情况:拟合数据包含两类(==从小到大==分别为
neg_label,pos_label),变换数据包含相同的一类/两类;则对变换数据根据y中二值对应进行编码;由于负标签和正标签总是按拟合数据的大小顺序确定的,因此如果与认为规定的正负标签不一致,可对变换后的编码求反:y=1-y。 -
标签正交二值化(
'multiclass'):如果fit或transform的数据y至少包含两类,且总类别数超过两类;则将拟合数据y中的每类数值单独进行二值编码,不同类别的标签变换后的编码相互正交。lb.fit(['a', 'b', 'c']) lb.transform(['c','b','a','d']) # input l_a l_b l_c # fit -> a b c # c 0 0 1 # 对应类型标签列的值为1,其余为0 # b 0 1 0 # a 1 0 0 # d 0 0 0 # 不属于任何一类 -
如果拟合数据只有一类(通常不应该出现),如果变换数据包含除拟合类别外的数值,则将拟合类别视为正类别;如果变换数据也只包含拟合类别,视拟合类别为负类别(即该列为常量,应该剔除)。
lb.fit(['b', 'a']) # 记录拟合的标签 ['a','b']
lb.classes_ # 按大小顺序,与出现顺序无关
y = lb.transform(['a', 'b', 'b','a']) # ->[0, 1, 1, 0]
y = lb.transform(['a', 'b', 'c','a']) # ->[[1,0], [0,1], [0,0], [1,0]]
标签二值编码的计算实现:
y = column_or_1d(y) # pick out the known labels from y y_in_classes = np.in1d(y, classes) # Test whether each element of a 1-D array is also # present in a second array. y_seen = y[y_in_classes] indices = np.searchsorted(sorted_class, y_seen) # Find indices where elements should be # inserted to maintain order. # 此处等效查找y的分类序号 indptr = np.hstack((0, np.cumsum(y_in_classes))) # if y_in_classes, then it has 1 # corresp. index. data = np.empty_like(indices) data.fill(pos_label) Y = sp.csr_matrix((data, indices, indptr), # 每一行只有一个非零元素(只属于一类) shape=(n_samples, n_classes)) # 因此适用于csr_matrix
MultiLabelBinarizer
与LabelBinarizer存在超过两类的情况不同在于,==每个样本可以拥有多个标签,样本标签可以有交集,因此样本二值编码后并不一定相互正交==。如果每个样本仅包含一个标签,则等价于LabelBinarizer。
mlb.fit_transform([{'sci-fi', 'thriller'}, {'comedy'}])
# array([[0, 1, 1],
# [1, 0, 0]])
mlb.classes_
# array(['comedy', 'sci-fi', 'thriller'], dtype=object)
每个样本的多个标签应该用列表,元组或集合表示。
上述示例中,总共包括三类标签,记录的类别按标签字典序排序。所以第一个标签样本编码后为
011,第二个标签样本编码为100。
特征生成
多项式特征生成
from sklearn.preprocessing import PolynomialFeatures
pf = PolynomialFeatures(degree=2)
X_train = pf.fit_transform(X_train) # 生成所有特征的所有二阶及以下多项式组合特征
特征尺度变换
StandardScaler
MinMaxScaler
Normalizer(norm='l2', copy=True)
机器学习流程
steps = [
('proc_name', estimator),
...
]
workflow = Pipeline(steps)
pred = workflow.fit(x) # fit transform/predict
pipe.score(x,y)
pipe['proc_name'].func_name()
流程的参数可以通过Pipeline.set_params进行修改,也可以对每个流程的对象单独修改。
为了与Pipeline保持兼容,相应处理流程需要提供三个参数(self,x,y=None),对于预处理流程第三个参数不起作用。
机器学习算法模型
模型参数
estimator.get_params()
Pipeline工作流
FeatureUnion
多个转换流程并行处理所有数据,并将转换结果合并。
ColumnTransformer
对数据特征执行并行处理,并将结果合并。
colunm_trans = ColumnTransformer[
[('proc_name', proc, idx), ...]
]
proc:可以是具体的对象,或是'passthrough'、'drop'。
Ignored. This parameter exists only for compatibility with sklearn.pipeline.Pipeline.
性能评估
交叉验证
from sklearn.model_selection import KFold
kf = KFold(n_split=5)
X_train = [None]*5 # X_test = X_train.copy() ...
# 通过迭代依次交换训练/测试集
for train_index, test_index in kf.split(X):
X_train[i], X_test[i] = X[train_index], X[test_index]
y_train[i], y_test[i] = y[train_index], y[test_index]
参数搜索
网格搜索交叉验证
from sklearn.model_selection import GridSearchCV
cv = GridSearchCV(estimator, param_grid, scoring=None,jobs=None,cv=None)
cv.fit(data, label)
参数网格定义:可定义一个或多个参数组合。
# 使用字典代表参数网格
param_grid = {'kernel': ('linear', 'rbf'), 'C': [1, 10]}
# 使用字典的列表代表多个参数网格
param_grid = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4], 'C': [1, 10, 100]},
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
交叉验证参数cv:
None:默认使用5折交叉验证;N:N折交叉验证;CV splitter:- 一个返回
(train,test)数据的迭代器。
计算结果包括:
-
cv_results_:各个参数组合及其评估性能结果; -
best_estimator_:通过搜索得到的性能最好的模型实例; -
best_score_ -
best_params_ -
best_index_:最佳结果在cv_results_中的索引;
随机搜索交叉验证
RandomizedSearchCV
TensorFlow
数据结构
Tensor
操作间传递的数据的数据结构都是Tensor,内部可以看作储存了一个N维的数组(类似于Numpy.ndarray)。 Rank, Shape, 和 Type.
x.name # 'input:0'
x.valaue_index # 0
x.op.name # 'input'
创建变量
当训练模型时,用变量来存储和更新参数。变量的初始值可以为Numpy数组或tensorflow提供的初始化方法(tf.zeros、tf.random_normal等)生成。
state = tf.Variable(0, name="counter")
biases = tf.Variable(tf.zeros([200]), name="biases", dtype=tf.int32)
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
tf.Variable操作储存初始值以及相关信息(例如name)。变量类型至关重要,不同类型的变量无法进行运算。
常量
one = tf.constant(1)
计算图
TensorFlow将耗时计算任务完全运行在Python外部,通过计算图来描述各计算任务(Operation)间的交互。因此Python代码的目的是用来构建这个可以在外部运行的计算图,以及安排计算图的哪一部分应该被运行。
变量的初始化必须在模型的其它操作运行之前先明确地完成。
# 在计算图启动之后,变量必须先经过`初始化` 操作初始化
# 事先定义初始化操作:
init_op = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_op) # Run the init operation.
# Use the model
tf.initialize_all_variables()函数便捷地添加一个操作来初始化模型的所有变量。你也可以给它传入一组变量进行初始化。(事实上是一个tf.assign操作)
有时候会需要用另一个变量的初始化值给当前变量初始化,而tf.initialize_all_variables()是并行地初始化所有变量,所以在有这种需求的情况下需要小心。用其它变量的值初始化一个新的变量时,使用其它变量的initialized_value()属性。
激活函数
内置激活函数定义在tensorflow.keras.activations模块中,可使用激活函数的函数名或函数对象作为activation参数的值。函数名会由tensorflow.keras.activations.deserialize()方法(或get())转换为函数对象。
Session
Tensorflow依赖于一个高效的C++后端来进行计算。与后端的这个连接叫做session。一般而言,使用TensorFlow程序的流程是先创建一个图,然后在session中启动它。
import tensorflow as tf
sess = tf.Session()
result = sess.run(graph)
sess.close()
with tf.Session() as sess:
[with tf.device("/gpu:1"):]
result = sess.run(result)
管理多个图
取回结果
可以在使用Session对象的run()调用 执行图时, 传入一些 tensor, 这些 tensor 会帮助你取回结果。
Feed
input1 = tf.placeholder(tf.types.float32)
input2 = tf.placeholder(tf.types.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
InteractiveSession
InteractiveSession让你在运行图的时候,插入一些计算图,这些计算图是由某些操作(operations)构成的。
如果你没有使用InteractiveSession,那么你需要在启动session之前构建整个计算图,然后启动该计算图。
import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.Variable([1.0, 2.0])
a = tf.constant([3.0, 3.0])
x.initializer.run()
sub = tf.sub(x, a)
使用GPU计算
devs = tf.config.list_physical_devices() # 列出计算设备,包括CPU、GPU
with tf.device(devs[0].name.replace('physical_device:','')):
# 构建计算图
设备名称形如'/physical_device:CPU:0',而tf.device只需要'/CPU:0' 。
构建模型
权重初始化
Weight initialization is a procedure to set the weights of a neural network to small random values that define the starting point for the optimization (learning or training) of the neural network model.
We cannot initialize all weights to the value 0.0 as the optimization algorithm results in some asymmetry in the error gradient to begin searching effectively.
Weight Initialization for Deep Learning Neural Networks (machinelearningmastery.com)
训练
We run a machine learning “algorithm” on a dataset to get a machine learning “model.”
- Algorithm: Procedure run on data that results in a model (e.g. training or learning).
- Model: Data structure and coefficients used to make predictions on data.
Stochastic machine learning algorithms use randomness during learning, ensuring a different model is trained each run.
- Initialization, such as weights.
- Regularization, such as dropout.
- Layers, such as word embedding.
- Optimization, such as stochastic optimization.
Why Do I Get Different Results Each Time in Machine Learning? (machinelearningmastery.com)
The random initialization allows the network to learn a good approximation for the function being learned. Nevertheless, there are times when you need the exact same result every time the same network is trained on the same data. Such as for a tutorial, or perhaps operationally.
Seed the Random Number Generator
Random number generators require a seed to kick off the process, and it is common to use the current time in milliseconds as the default in most implementations.
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)
This is a best practice because it is possible that some randomness is used when various Keras or Theano (or other) libraries are imported as part of their initialization, even before they are directly used.
Keras
Keras库结构:
-
models:包括神经网络模型的定义,例如
Sequential。from keras.models import Sequential -
layers:神经网络各层的模型定义,例如
Dense。from keras.layers import Dense model.layers # 获取模型中各层对象。
模型类
Sequential
层类
输入
Input类:限定模型的输入维度。
input=Input(shape=, batch_shape=, name=, dtype=, sparse=, tensor=)
当模型仅包含输入层时,模型不包含任何可训练参数(权重矩阵和偏置);训练参数位于两层之间。使用model.summary()可查看层定义、输出维数以及参数数量,使用model.inputs, model.outputs查看整个模型的输入输出维数。
预处理
Working with preprocessing layers | TensorFlow Core
Normalization
Dense
layer = Dense(
units, # 计算单元数量(输出数量)
activation=None, # 激活函数,不指定则直接输出
use_bias=True, # 是否添加偏置
bias_initializer="zeros", # 偏置向量初始化函数
kernel_initializer="glorot_uniform", # 权重矩阵初始化方法
**kwargs
)
其他参数kernel_regularizer, bias_regularizer, activity_regularizer, kernel_constraint, bias_constraint。
模型参数数量:(num_input+1)*units,每个计算单元对应一组权重和一个偏置:$\mathbf{y}=\mathbf{Wx}+\mathbf{b}$;
Conv2D
2D卷积层:创建卷积核与输入数据进行运算($\mathbf{y}=\mathbf{wx}+b$)。
layer = Conv2D(
filters, # 每个输入通道的卷积核数量(对应输出图像的数量)
kernel_size, # 卷积核大小
strides=(1, 1), # 卷积滑动的步长
padding='valid', # 边缘填充,"valid"不填充,"same"填充0
data_format="channels_last",
input_shape=(28,28,3), # 28*28 RGB image
activation=None, use_bias=True, bias_initializer='zeros',
kernel_initializer='glorot_uniform', # 卷积核(权重矩阵)初始化函数
**kwargs) -> None
data_format:输入数据格式,数据中RGB通道的表示方式:channels_last->(batch_size, height, width, channels);channels_first->(batch_size, channels, height, width);
input_shape:当作为输入层时,使用此参数指定输入数据样本的维数(对应data_format去掉batch_size)。
其他参数:
dilation_rate, groups,
输出维数:
channels_last->(batch_size, new_rows, new_cols, filters);channels_first->(batch_size, filters, new_rows, new_cols);
MaxPooling2D
UpSampling2D
构建编译模型
构建模型
顺序式构建:创建Sequential对象,并使用model.add(layer)方法逐次添加层。
from tf.keras import Input,Model
from tf.keras.layers import Dense
model = tf.keras.Sequential()
model.add(Dense(8, input_shape=(16,)))
model.add(Dense(4)) # automatic shape inference
input_shape参数用于限定模型的输入数据维数,等效于首先添加Input(shape=(16,));如果未指定输入维数,则会在训练时根据输入维数确定输入层到第一层的权重矩阵维数。
函数式API:将每层对象视为函数,将前一层的输出作为该层的输入;最后使用输入和最后的输出构建模型,通过输入输出关系构建整个网络。
inputs = Input(shape=(3,))
x = Dense(4, activation=tf.nn.relu)(inputs)
outputs = Dense(5, activation=tf.nn.softmax)(x)
model = Model(inputs=inputs, outputs=outputs)
配置Keras模型
model.compile(
optimizer="rmsprop", # 优化算法
loss=None, # 损失函数
metrics=None, # 性能度量函数,如accuracy,mse
loss_weights=None,
weighted_metrics=None,
**kwargs
)
损失函数;
训练模型
fit()
ModelCheckpointcallback is used in conjunction with training usingmodel.fit()to save a model or weights (in a checkpoint file) at some interval, so the model or weights can be loaded later to continue the training from the state saved.
自定义模型组件
自定义模型
class CustomModel(keras.Model):
def get_config(self):
return {"hidden_units": self.hidden_units}
@classmethod
def from_config(cls, config):
return cls(**config)
自定义模型的导入导出:需要定义get_config()方法用于导出自定义类型的参数,from_config用于正确初始化模型和层对象。
自定义层
class CustomLayer(keras.Layer):
pass
Making new Layers and Models via subclassing | TensorFlow Core
常见问题
序列化数据和模型
保存TensorFlow模型
Protocol Buffers
保存和加载计算图
The GraphDef class is an object created by the ProtoBuf library. After you've created a TensorFlow Graph object, you can save it out by calling as_graph_def(), which returns a GraphDef object.
保存GraphDef。
tf.io.write_graph(
graph_or_graph_def, # A Graph or a GraphDef protocol buffer.
logdir, # Directory where to write the graph
name, # file name
as_text=True # By default, writes as an ASCII proto
)
Text and Binary Formats
Text Format is a human-readable form, which makes it nice for debugging and editing, but can get large when there's numerical data like weights stored in it.
Binary format files are a lot smaller than their text equivalents, even though they're not as readable.
f.write(graph_def.SerializeToString()) # save as binary
graph_def.ParseFromString(f.read()) # read from binary
保存和加载变量
保存变量
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
# Do some work with the model.
# Save the variables to disk.
save_path = saver.save(sess, "/tmp/model.ckpt")
print("Model saved in path: %s" % save_path)
默认保存全部变量。在创建Saver对象时指定要保存的变量,可以创建多个Saver对象以保存不同分组的变量。
# Add ops to save and restore only `v2` using the name "v2"
saver = tf.train.Saver({"v2": v2})
恢复变量
恢复变量时无需执行初始化操作。如果只是恢复部分变量,那么需要在会话开始前初始化其他变量。
saver = tf.train.Saver()
# Later, launch the model
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, "/tmp/model.ckpt")
# do some work with the model
保存和加载模型
simple_save:模型(*.pb)和变量(/variables)分别输出(等效于使用Saver.save+tf.io.write)。
tf.saved_model.simple_save(
session,
export_dir,
inputs, // providing names for model's inputs
outputs, // providing names for model's outputs
legacy_init_op=None
)
检查保存后的模型:
saved_model_cli show --dir {export_path} --all
Serve your model with TensorFlow Serving
https://www.tensorflow.org/tfx/tutorials/serving/rest_simple#serve_your_model_with_tensorflow_serving
SavedModel
builder = tf.saved_model.builder.SavedModelBuilder(export_dir)
builder.add_meta_graph_and_variables
builder.add_meta_graph
A MetaGraph is a dataflow graph, plus its associated variables, assets, and signatures.
A MetaGraphDef is the protocol buffer representation of a MetaGraph.
A signature is the set of inputs to and outputs from a graph.
tf.saved_model.loader.load
Estimators自动保存和恢复变量。
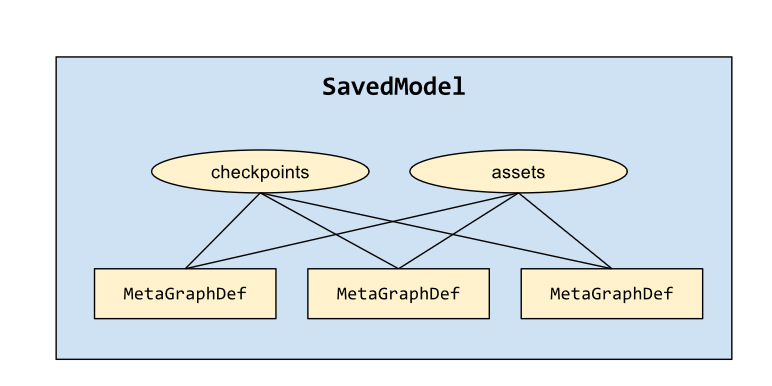
Export
Freezing
The weights usually aren't stored inside the file format during training. Instead, they're held in separate checkpoint files, and there are Variable ops in the graph that load the latest values when they're initialized.
==there's the freeze_graph.py script that takes a graph definition and a set of checkpoints and freezes them together into a single file.==
tensorflow.python.tools.freeze_graph.freeze_graph(...)
freeze_graph调用以下方法将图中的变量(权重)转换为常量:
tf.graph_util.convert_variables_to_constants(
sess, # Active TensorFlow session
input_graph_def, # GraphDef object holding the network
output_node_names, # List of node names for the result graph.
variable_names_whitelist=None,
variable_names_blacklist=None
)# Warning: deprecated
将图中的变量全部替换为常量,使得图能够以单一
GraphDef对象被导出保存,同时也移除了关于加载和保存变量的操作。 默认转换所有变量(variable_names_whitelist=None)。 返回:GraphDef对象。
导入导出Keras模型
Keras模型包括:
- 架构,即该模型所包含的层及其连接关系配置;
- 权重值集合,即模型的状态;
- 优化器(通过编译模型定义);
- 损失度量指标(通过编译模型、调用
add_loss()或add_metric()定义)。
Keras支持将上述所有信息一次性保存(SaveModel或H5格式),或选择其中部分保存(如使用JSON格式保存架构)。
导入导出完整模型数据
from tensorflow import keras
model.save(filepath,overwrite=True,include_optimizer=True,
save_format=None, # 'tf'(tf2.x) or 'h5'(tf1.x)
) # signatures=None, options=None, save_traces=True,
keras.models.save_model(model,...) # --> Model.save()
SaveModel导出数据为一个文件夹,其中模型架构、训练配置(包括优化器、损失和度量指标)保存在saved_model.pb中,训练权重保存在variabes/目录下。相比之下,H5格式为单个HDF5文件,且不包含外部添加(add_loss()或add_metric())的损失和度量指标(需要在加载模型时重新添加),不包含自定义类的计算图(需要在加载时通过这些对象的代码重构模型)。
如果某种序列化方式不能存储自定义模型或层的Python字节码,则加载时需要通过custom_objects参数来指定这些对象类型的名称和类名映射。如果目标平台无法导入自定义代码,则可以使用pickle等方法导入导出自定义类型的代码数据(不安全且存在兼容性问题)。
save_traces=True[tf2.4]:在没有自定义类型的定义代码情况下也能加载模型;否则,自定义对象必须定义get_config/from_config方法,并在加载时通过custom_objects传递的类型定义进行初始化。
加载模型:
keras.models.load_model(filepath, custom_objects=None) # compile=True, options=None
导入导出模型结构和权重
将模型架构导出为Python字典或JSON文本,其中包含了各层的类型、参数定义与连接关系。
config:dict = model.get_config() # the configuration of the model.
Sequential.from_config(config) # Model.from_config(config)
config:str = model.to_json() # not include the weights, only the architecture.
model = keras.models.model_from_json() # recover the model
等效API:
tf.keras.models.model_to_json()。YAML格式:
model.to_yaml()和keras.models.model_from_yaml()。
导入导出模型权重参数:
model.get_weights() # A list of all weight tensors in the model, as Numpy arrays.
model.save_weights() # saves the weights of the model as a HDF5 file.
model.load_weights() # the architecture is expected to be unchanged.
model.set_weights() # same shape as get_weights()
此外,还可以调用层对象的方法获取层的权重值,适用于迁移学习中权重系数迁移。
加载完模型架构和参数后,需要调用model.compile()重新编译模型(和最初构建时的编译配置相同)。
Saving & loading only the model's weights values
应用示例
SoftMAX模型
数据集介绍
MINST(Modified National Institute of Standards and Technology)数据集。
训练数据集mnist.train.images
mnist.train.images是一个形状为[60000, 784]的张量

每一张图片包含$28\times28$像素。
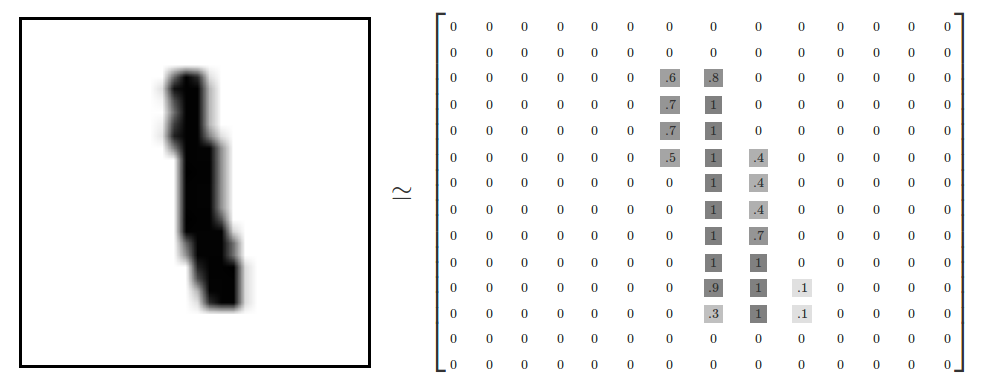
训练数据集标签mnist.train.labels是一个 [60000, 10] 的数字矩阵。

Softmax Regression
给定图片代表每个数字的概率。
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值低,相反如果这个像素拥有有利的证据支持这张图片属于这个类,对应权值高。
我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。
对于给定的输入图片$\boldsymbol{x}$,它代表数字$i$的证据可以表示为
$$ e_i=\sum_{j}{W_{i,j}x_j+b_i} $$
其中$\boldsymbol{W}_i$ 代表权重,$\boldsymbol{b}i$代表数字$i$类的偏置量,$j$代表给定图片$\boldsymbol{x}$的第$j$个像素。 $$ y=\mathrm{softmax}(e_i) $$ 这里的$\mathrm{softmax}$可以看成是一个激励函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。 $$ \begin{align} y & = \mathrm{softmax}(\boldsymbol{e})=\mathrm{normalize}(\mathrm{exp}(\boldsymbol{e})) \Rightarrow\ y_i&= \mathrm{softmax}(e_i)=\frac{\mathrm{exp}(e_i)}{\sum{j}\mathrm{exp}(e_j)}\Rightarrow\ y&=\mathrm{softmax}(\boldsymbol{W}_i\boldsymbol{x}+\boldsymbol{b}) \end{align} $$ 这个幂运算表示,更大的证据对应假设模型里面更大的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。将上述过程表示为图的形式:
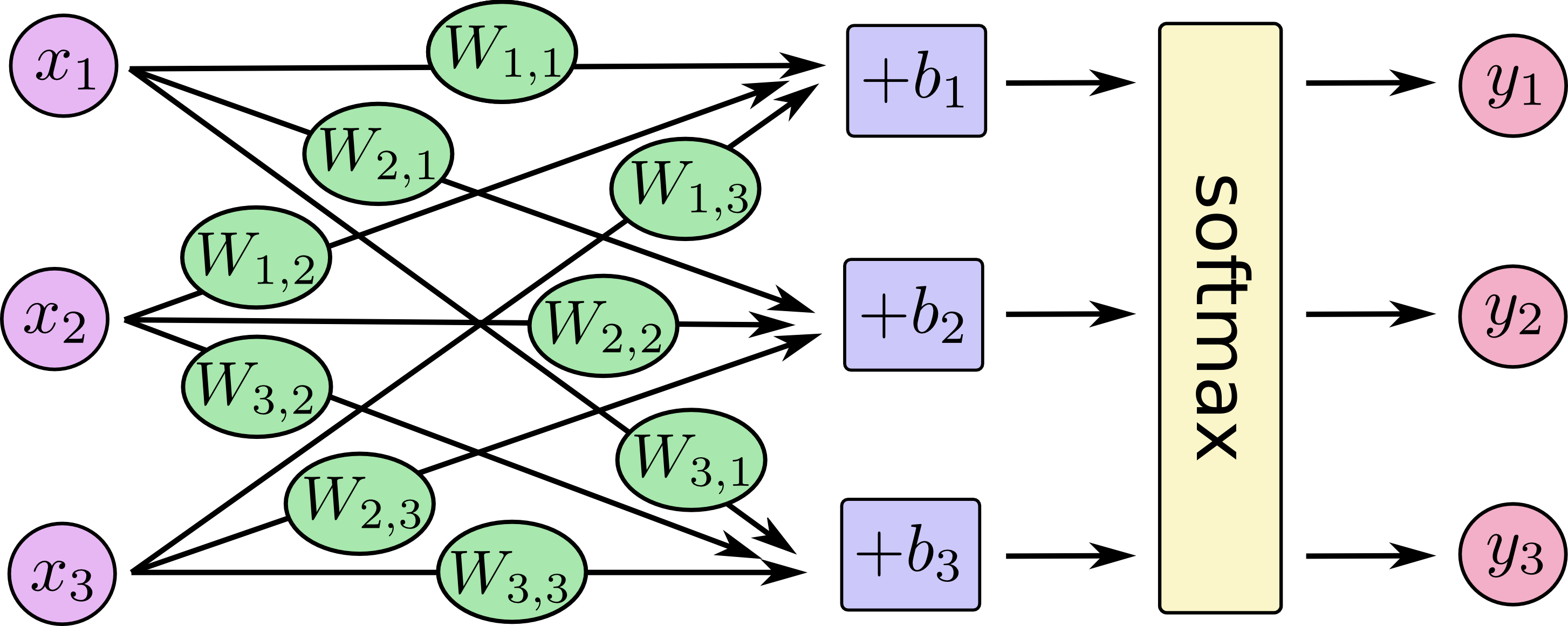
TensorFlow实现
-
为输入图像和目标输出类别创建节点,来开始构建计算图。
x = tf.placeholder("float", shape=[None, 784]) y_ = tf.placeholder("float", shape=[None, 10]) -
为模型定义权重$W$和偏置$b$。
W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) -
初始化变量
sess.run(tf.initialize_all_variables()) -
回归模型计算图
计算每个分类的softmax概率值:
y = tf.nn.softmax(tf.matmul(x,W) + b)为训练过程指定最小化误差用的损失函数(目标类别和预测类别之间的交叉熵):
cross_entropy = -tf.reduce_sum(y_*tf.log(y)) -
训练模型
因为TensorFlow知道整个计算图,它可以使用自动微分法找到对于各个变量的损失的梯度值。TensorFlow有大量内置的优化算法。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)往计算图上添加一个新操作,其中包括计算梯度,计算每个参数的步长变化,并且计算出新的参数值。
整个模型的训练可以通过反复地运行train_step来完成。
for i in range(1000): batch = mnist.train.next_batch(50) train_step.run(feed_dict={x: batch[0], y_: batch[1]})每一步迭代,我们都会加载50个训练样本,然后执行一次train_step,并通过
feed_dict将x和y_张量占位符用训练训练数据替代。 -
评估模型
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
多层卷积网络
深入MNIST
权重初始化:加入少量的噪声来打破对称性以及避免0梯度。
偏置初始化:由于我们使用的是ReLU神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
Pytorch
PyTorch张量
PyTorch张量torch.Tensor表示高维数组结构,方法参考numpy.ndarray,张量运算方法可以通过torch模块和/或张量对象访问。
x = torch.tensor([1,2,3],dtype=torch.float32)
x = torch.arange(0,12).reshape(3,4)
x.numel() # => np.size
张量对象变换:
torch.concat(X,Y,dim=0) # <=> torch.cat() => np.concatenate()
张量与ndarray相互转换(.numpy和.from_numpy方法共享底层内存)。
A=X.numpy() # X=torch.Tensor(A)
对于大小为1的张量,可通过Python内置函数转换为标量。
运算
矩阵向量乘积(matrix-vector product):y=torch.mv(A,x);
矩阵乘法(matrix-matrix multiplication):C=torch.mm(A,B);
范数
x=torch.norm(u,p='fro') # (L2) norm
x=torch.abs(u).sum() # => L1 norm
x=torch.frobenius_norm(A) # matrix L2 norm
梯度
创建张量时可同时分配存储梯度的空间,用于后续反向求导时更新梯度值。PyTorch提供自动计算梯度的功能。
x=torch.arange(4.0,requires_grad=True) # x.requires_grad_(True)
y.backward() # 方向传导自动计算梯度
x.grad # 梯度值(未计算前为None)
x.grad.zero_()# 重新计算梯度前需要清除先前的结果,默认会累积梯度
u=y.detach() # 将u视为常量,不再反向传播
DGL
Deep Graph Library基于深度学习框架(PyTorch, MXNet and TensorFlow),用于快速实现图神经网络模型。
节点分类
semi-supervised node classification with GNN[@kipf2016semi]
参考资料
机器学习与数据挖掘
(Machine Learning and Data Mining)
概念
| Machine Learning | Statistics |
|---|---|
| 网络、图 | 模型 |
| 权重 | 参数 |
| 学习 | 拟合 |
| 监督学习 | 回归/分类 |
| 无监督学习 | 密度估计、聚类 |
parametric model: fixed number of parameters.
nonparametric model: the number of parameters grow with the amount of training data.
监督学习
分类
$$ \newcommand{\bm}[1]{\boldsymbol{#1}} \newcommand{\b}[1]{\bold{#1}} \newcommand{\t}[1]{{#1}^{\top}} \newcommand{\l}{\left} \newcommand{\r}{\right} \bm{x}\rightarrow y\in{1,\cdots,C} $$
$C=2$:二分类(binary classification);
$C>2$:多分类(multi-class classification with a single output);
多重二元分类(multi-label classification):标签不互斥。
Function Approximation
未知分类函数(hypothesis):$y=h(\bm{x})$。
目标:根据训练集估计分类函数$\hat{y}=\hat{h}(\bm{x})$。
预测:使用估计函数计算新数据的分类。
经验风险最小化
Empirical risk minimization
损失函数(loss function)
$$ l(\hat{y},y)=l(h(x),y) $$
L2范数是常用于损失函数,即:$l(\hat{y},y)=|h(x)-y|^2$
期望风险
$$
R(h)=\b{E}\left[l(h(x),y\right]=\begin{cases}
\int\limits_{x\in\mathcal{D}}{l(h(x),y)\mathrm{d}P(x,y)}(连续变量)\
\sum\limits_{x\in\mathcal{D}}{l(h(x),y)P(x,y)}(离散变量)
\end{cases}
$$
目标:求最优预测模型(函数$h^$),使得期望风险最小: $$ h^=\mathop{\mathrm{argmax}}_{h\in\mathcal{H}}{R(h)} $$
由于联合分布$P(x,y)$通常未知使得$R(h)$无法计算,因此使用训练集上的经验风险作为近似: $$ R_{\mathrm{emp}}(h)=\frac{1}{n}\sum_{i=1}^n{l(h(x_i),y_i)} $$ 即优化目标为最小化经验风险 $$ \hat{h}=\mathop{\mathrm{argmin}}{h\in\mathcal{H}}{R{\mathrm{emp}}(h)} $$
概率预测(Probabilistic Predictions)
使用概率作为估计分类函数的输出,以应对模糊的情况。
给定训练集$\mathcal{D}$和输入数据$\bm{x}$,可以表示关于各个分类标签的条件概率$p(y|\bm{x},\mathcal{D})$(使用的预测模型$M$也是条件之一,没有对比模型的情况下省略)。
分类函数:MAP (maximum a posteriori,最大后验概率) 估计,选择最大可能的类别。 $$ \hat{y}=\hat{h}(\boldsymbol{x})=\mathop{\mathrm{argmax}}_{c=1}^C{p(y=c|\boldsymbol{x},\mathcal{D})} $$
无监督学习
发现数据中结构(知识发现)。
目标:估计数据的概率密度分布$p(\bm{x}_i|\bm{\theta})$,其中$\bm{x}_i$ 为数据特征组成的向量,$\bm{\theta}$为数据采样空间的参数,因此这是一个多维概率模型。
半监督学习(Semi-supervised Learning)
强化学习
迁移学习
领域(domain)
$$ \mathcal{D}={\mathcal{X},P(\boldsymbol{x})},~\boldsymbol{x}\in\mathcal{X} $$ $\mathcal{X}$为特征空间,$P(\bm{x})$为边缘概率分布。领域不同$\mathcal{D}_s\ne \mathcal{D}_t$意味着特征空间不同$\mathcal{X}_s\ne \mathcal{X}_t$或边缘分布不同$P_s(x)\ne P_t(x)$。
任务(Task)
$$ \mathcal{T}={\mathcal{Y},P(y|\boldsymbol{x})} $$ $\mathcal{Y}$为类别空间,$P(y|\bm{x})$为预测模型(条件概率分布)。任务不同$\mathcal{T}_s\ne \mathcal{T}_t$意味着类别空间不同$\mathcal{Y}_s\ne \mathcal{Y}_t$或预测模型不同$P_s(Y|X)\ne P_t(Y|X)$。
给定辅助领域的标注数据$\mathcal{D}_s$和学习任务$\mathcal{T}_s$,目标领域的无标数据$\mathcal{D}_t$和学习任务$\mathcal{T}_t$,迁移学习是在$\mathcal{D}_s\ne \mathcal{D}_t$或$\mathcal{T}_s\ne \mathcal{T}_t$的情况下,==降低预测模型$P_t(y|\bm{x})$的误差==。
分类
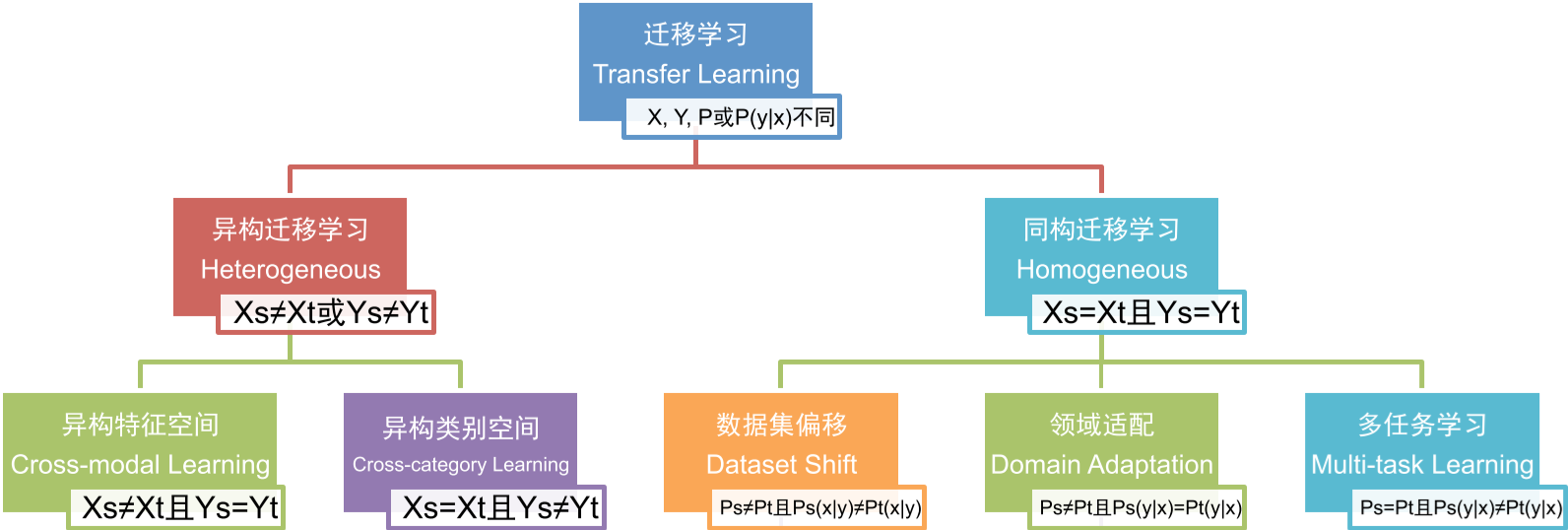
在异构特征空间进行迁移学习,通常==必须依赖领域特定的先验知识==,包括特征空间之间的关联关系(如双语词典)、多模数据每个视图之间的对应关系(如网页中的文本和图像)或社交关联关系。
无监督迁移学习:目标领域没有标注数据的迁移学习任务。
-
异构特征空间迁移学习:特征空间不同,类别空间相同。
- 将辅助领域映射(翻译)到目标领域,转换为同构迁移学习问题;
- 跨语言文本分类:给定标签时词翻译条件概率由双语字典、辅助领域数据、目标领域数据的期望最大化算法协同学习得到。
Shi L, Mihalcea R, Tian M. Cross language text classification by model translation and Semi-Supervised learning. Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010.
- 跨语言文本分类:给定标签时词翻译条件概率由双语字典、辅助领域数据、目标领域数据的期望最大化算法协同学习得到。
- 将辅助领域和目标领域映射到同一个抽象空间;
- 翻译学习:
- 文本到图像间的知识迁移方法
Zhu Y, Chen Y, Lu Z, et al. Heterogeneous Transfer Learning for Image Classification. Proceedings of the 25th AAAI Conference on Artificial Intelligence, 2011.
- **异构领域适配:基于特征对齐、 扩充和支持向量机的通用异构迁移学习方法
Li W, Duan L, Xu D, et al. Learning with Augmented Features for Supervised and Semi-supervised Heterogeneous Domain Adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 99(PrePrints).
- 将辅助领域映射(翻译)到目标领域,转换为同构迁移学习问题;
-
异构类别空间迁移学习:
-
同构迁移学习:特征空间和类别空间相同。
-
数据集偏移:边缘概率分布和条件概率分布不同
-
实例权重法:对辅助领域中的实例进行权重调整、提升位 于目标领域高密度区域的辅助领域实例权重,从而更好地与目标领域数据分布匹配。
Bickel S, Bruckner M, Scheffer T. Discriminative learning for differing training and test distributions. Proceedings of the 24th international conference on Machine learning, 2007.
-
特征表示法:找到原始数据的新特征表示,使得辅助领域和目标领域的数 据分布更加相似、或使得领域相关的具体特征可以被领域无关的抽象特征所表示。
Zhong E, Fan W, Peng J, et al. Cross Domain Distribution Adaptation via Kernel Mapping. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2009.
- 隐含表征学习法通过分析辅助领域和目标领域的大量无标样例来构建抽象特征表 示,从而隐式地缩小领域间的分布差异
- 结构对应学习
- 概率分布适配法通过惩罚或移除在领域间统计可变的特征、或通过学习子空间嵌入表示来最小化特定距离函数,从而显式地提升辅助领域和目标领域的样本分布相似度。
- 隐含表征学习法通过分析辅助领域和目标领域的大量无标样例来构建抽象特征表 示,从而隐式地缩小领域间的分布差异
要求目标领域存在少量标注数据。
-
-
领域适配
-
多任务学习
-
性能度量(Performance Metrics)
准确率(Accuracy)
$$ \mathrm{Accuracy}=\frac{\mathrm{True Predict}}{\mathrm{Total}}=\frac{TP+TN}{TP+TN+FP+FN}\notag $$
检出率(Recall)
Detection Rate:正确预测正例与真实正例数量之比(反映漏报与正确预报之比): $$ \mathrm{Recall}=\frac{\mathrm{True Positive}}{\mathrm{TotalActualPositive}}=\frac{TP}{TP+FN}=\frac{1}{1+\frac{FN}{FP}}\notag $$
精度(Precision)
正确预测正例与所有预测正例数量之比(反映误报与正确预报之比): $$ \mathrm{Precision}=\frac{\mathrm{True Positive}}{\mathrm{TotalPredictPositive}}=\frac{TP}{TP+FP}=\frac{1}{1+\frac{FP}{TP}}\notag $$
当正样本数非常少时,召回率和精度可以更加准确反映模型的有效性。
F1
$$ \begin{align} \mathrm{F1}&=2\times\frac{\mathrm{Precision}\times\mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}\notag\ \mathrm{F_{\beta}}&=(1+{\beta}^2)\times\frac{\mathrm{Precision}\times\mathrm{Recall}}{({\beta}^2\mathrm{Precision})+\mathrm{Recall}}\notag \end{align} $$
ROC curve and AUC: Area Under the ROC Curve
可解释性
z-score:数据标准化,检查特征偏离中心的程度。
概率模型
对于观测的随机变量$X$而言,
-
先验(prior)概率:$p(X)$,未知其他信息的情况下的概率信息;
-
后验(posterior)概率:$p(X|Y=y)$,已知额外信息的情况下的概条件率信息
-
似然(likelihood)函数:$X=x$发生在条件$Y$下的可能性$p(Y|X=x)$,对应后验概率。
贝叶斯定理: $$ p(X|Y)=\frac{p(X,Y)}{p(Y)}=\frac{p(Y|X)p(X)}{p(Y)}\propto p(Y|X)p(X) $$
参数估计
最大似然
maximum likelihood estimation (MLE):使事件$X=x$(样本)的似然函数最大的参数估计: $$ \hat{\boldsymbol{\theta}}=\mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}{p(X=x|\boldsymbol{\theta})} $$
最小二乘
最小化观测值与模型预测值的残差。
当模型是高斯分布时,最大似然估计和最小二乘估计是等价的。
$$ \begin{align*} \min {|A\bm{x}-\bm{b}|^2} & \Longrightarrow f(\bm{x})=\bm{x}^\top A^\top A\bm{x}-2\bm{b}^\top A\bm{x} + \bm{b}^\top\bm{b} \Longrightarrow \frac{\mathrm{d}f}{\mathrm{d}\bm{x}}=2A^\top A\bm{x}- 2A^\top\bm{b}=0\ &\Longrightarrow \bm{x}^{\ast}=(A^\top A)^{-1}A^\top\bm{b} \end{align*} $$
通常$A$的行数远大于列数,$A^\top A$为可逆矩阵。
线性回归
对于线性模型拟合:$y=\bm{w}^\top \bm{x} + b$,有 $$ \begin{align*} l(\bm{w},b)&=|\bm{x}_i^\top\bm{w}+b-\bm{y}_i|^2 \ &\Longrightarrow \bm{x}_i^\top\bm{w}+b-\bm{y}_i= [\bm{x}_i^\top,1]\left[\begin{array}{c} \bm{w}\b \end{array}\right]-y_i \end{align*} $$ 考虑所有样本可得:$l(\bm{w},b)=|\hat{X}\hat{\bm{w}}-\bm{y}|^2$,其中$\hat{X}=(X^\top,\b{1}),~\hat{\bm{w}}=(\bm{w}^\top,b)^\top,$
最小均方误差
贝叶斯推理(Bayesian Inference)
最大后验概率
$$ \begin{align} \hat{\boldsymbol{\theta}}&=\mathop{\mathrm{argmax}}{\boldsymbol{\theta}}{p(\boldsymbol{\theta}|X=x)}\notag\ &=\mathop{\mathrm{argmax}}{\boldsymbol{\theta}}{p(X=x|\boldsymbol{\theta})p(\boldsymbol{\theta})}\notag\ &=\mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}{\left{\log{p(X=x|\boldsymbol{\theta})}+\log{p(\boldsymbol{\theta})}\right}} \end{align} $$
设$h$为假设采样空间,$\mathcal{D}$为样本集合: $$ \begin{align} \hat{h}^{MAP}&=\mathop{\mathrm{argmax}}_h{p(\mathcal{D|h})p(h)}\notag\ &=\mathop{\mathrm{argmax}}_h{\log{p(\mathcal{D|h})}+\log{p(h)}} \end{align} $$ {eq_bayes_map}
For example, if we assume the prior distribution to be Gaussian, MAP is equal to MLE with L2 regularization; if we assume the prior distribution to be Laplace, MAP is equal to MLE with L1 regularization.
当样本点足够多时,数据提供的信息将淹没先验信息(data overwhelms the prior),MAP收敛为最大似然估计(maximum likelihood estimate)。 $$ \hat{h}^{MLE}=\mathop{\mathrm{argmax}}_h{p(\mathcal{D|h})} $$
几何模型
K-Nearest Neighbors
距离度量:$D(x,y)={|x-y|_p}$
多数表决:每个邻居节点的权重可以相同,也可以与距离相关(例如$\frac{1}{d}$)。
比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出了。
- 分类:训练集里和预测的样本特征最近的$K$个样本,选取样本中的主要类别作为预测。
- 回归:平均法,即最近的$K$个样本的样本输出的平均值作为回归预测值。
参数选择
对于$k$值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的$k$值。
距离计算
暴力搜索
计算预测样本与训练集所有样本的距离,找出$k$邻近样本,进行多数表决确定预测样本的类型。
KD树(K-Dimensional Tree)
在训练阶段建立KD树(模型)。
- 计算样本集合各个特征的取值的方差,用方差最大的第$n$维特征$f_n$来作为根节点的划分标准(方差越大,则数据在该维度上更加分散)。
- 将样本按$f_n$划分为两个子集,作为根节点的左右子节点的输入。
- 对于左右子节点,重复上述操作。
搜索临近节点:
球树
参考资料
K-means
对于给定的样本集,按照样本之间的距离大小,将样本集划分为$K$个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。 $$ \begin{align*} E &= \sum_{i=1}^k\sum_{x \in C_i} {|x-\mu_i|}2^2\ \mu_i &= \frac{1}{|C_i|}\sum\limits{x \in C_i}x \end{align*} $$ $k$值的选择:根据对数据的先验经验选择一个合适的$k$值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的$k$值。
选择$k$个初始化的质心:$k$个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的$k$个质心,最好这些质心不能太近。
优化
K-Means++
优化初始质心的选择。
Mini Batch K-Means
参考资料
谱聚类(Spectral Clustering)
算法
聚类问题:不同分组间的边(相似度)权重较低,而相同分组内节点间的边权重较高。
主要思想:==将数据点映射到相似矩阵的特征向量。==
割图(Graph Cut)
点的聚类近似对应了最小割(min-cut):即割集(割间的边)的权重之和最小,且割内边权重之和尽可能大。由此得到两种优化目标,即RatioCut和Ncut。
$$ \begin{align*} \mathrm{cut}(A,B)&=\sum_{i\in A,j\in B}{w_{ij}}\ \mathrm{cut}(A_1,A_2,\cdots,A_k)&=\sum_{i=1}^k{\mathrm{cut}(A_i,\bar{A}_i)}\notag \end{align*} $$
平衡性:
RatioCut:使用子集的节点数调整子集的权重。
$$
\mathrm{RatioCut}(A_1,\cdots,A_k) = \sum_1^k{\frac{\mathrm{Cut}(A_i,\hat{A})}{|A_i|}}
$$
对应非规范化的拉普拉斯矩阵$L$。
Ncut:使用子集的边权重调整子集的权重。
$$
\mathrm{Ncut}(A_1,\cdots,A_k) = \sum_1^k{\frac{\mathrm{Cut}(A_i,\hat{A})}{\mathrm{vol}(A_i)}}
$$
对应规范化的拉普拉斯矩阵$L_{\mathrm{rw}}$或$L_{\mathrm{sym}}$。
Logistic Regression
学习框架
AdaBoost
调整训练实例的权重已提升弱学习器的准确率。
应用
分类
Document classification
bag of words: a binary document × word co-occurrence matrix
Image Classification
Object (Face) detection and recognition
回归
Predict tomorrow's stock market price
Predict the location in 3D space of a robot arm end effector
Predict the temperature at any location
聚类(Clustering)
- estimate the distribution over the number of clusters, $p(K|D)$
- estimate which cluster each point belongs to, $z^{*}_i = \mathop{\mathrm{argmax}}_k{p(z_i=k|\bm{x}_i,\mathcal{D})}$, where $z_i$ is hidden or latent variable.
model based clustering: fit a probabilistic model to the data.
Discovering latent factors
Discovering graph structure
measure a set of correlated variables; discover which ones are most correlated with which others. $$ \hat{G}=\mathop{\mathrm{argmax}}{p(G|\mathcal{D})} $$
Matrix Completion
Collaborative filtering
recommendation system
特征选择(Feature Selection)
方法
Naive Bayes(朴素贝叶斯)
基于概率预测实际需要建立$p(y|\bm{x},\mathcal{D})$的模型,根据贝叶斯定理可得, $$ \begin{align} p(y|\boldsymbol{x})&=\frac{p(\boldsymbol{x},y)}{p(\boldsymbol{x})}\notag\ &=\frac{p(\boldsymbol{x}|y)p(y)}{\sum_i{p(\boldsymbol{x}|y=c_i)p(y=c_i)}} \notag\ &\propto p(\boldsymbol{x}|y)p(y) \end{align} $$
分母与$y$无关。
因此需要求出联合概率分布或间接求出类别的先验概率$p(y)$和样本关于类别的条件概率。
朴素贝叶斯方法假设数据服从某种类型的分布,利用样本估计该分布的参数。当获得估计参数后,利用概率模型以及贝叶斯公式即可计算出分类的概率。首先,每个类别的对应参数$\bm{\theta}^c,c=1,...,C$可能不同;其次,给定类别中数据的每个维度对应一组参数$\bm{\theta}^c_{!j}, j=1,...,F$,各组参数可能并非相对独立。为了简化计算,假设数据的各个维度的特征(feature)的条件分布独立(因此参数估计是相互独立的,实际情况并不一定成立,因此朴素)。
设样本点维度为$F$,类别总数为$C$。
单个样本点发生的概率(似然函数): $$ \begin{align} p(\boldsymbol{x}i,y_i|\boldsymbol{\theta})&=p(\boldsymbol{x}i|y_i,\boldsymbol{\theta})p(y_i|\boldsymbol{\theta})\notag\ &=p(y_i|\boldsymbol{\theta})\prod{c=1}^{C}{p(\boldsymbol{x}i|y_i,\boldsymbol{\theta})^{\mathbb{I}(c=y_i)}}\ &=p(y_i|\boldsymbol{\theta})p(\boldsymbol{x}i|c,\boldsymbol{\theta}^c)|{c=y_i}\ &=p(y_i|\boldsymbol{\pi})p(\boldsymbol{x}i|\boldsymbol{\theta}^c)|{c=y_i}\ &=p(y_i|\boldsymbol{\pi})\prod{j=1}^{F}{p(x{ij}|\boldsymbol{\theta}^c_{!j})|_{c=y_i}} \end{align} $$
其中$\bm{\pi}=(\pi_c)|_{c=1,...,C}$为标签$y$的概率分布。由于样本点已知其分类,因此仅考虑其对应分类的概率$p(\bm{x}_i|y_i=c,\bm{\theta})\ne0$。由于参数独立,因此在计算条件概率时,条件只包含样本点所属类别对应特征维度的参数。
样本集合发生的概率为各个样本点发生的联合概率(认为各个点相互独立) $$ \begin{align} p(\mathcal{D}|\boldsymbol{\theta})&=\prod_{i=1}^D{\left{p(y_i|\boldsymbol{\pi})\prod_{j=1}^F{p(\boldsymbol{x}{ij}|\boldsymbol{\theta}{!j}^c)|{c=y_j}}\right}}\notag\ &=\prod{i=1}^D{p(y_i|\boldsymbol{\pi})}\prod_{i=1}^D{\prod_{j=1}^F{p(\boldsymbol{x}{ij}|\boldsymbol{\theta}{!j}^c)|{c=y_j}}}\ \log{p(\mathcal{D}|\boldsymbol{\theta})}&=\sum{i=1}^{D}{\log{p(y_i|\boldsymbol{\pi})}}+\sum_{i=1}^D{\sum_{j=1}^F{\log{p(\boldsymbol{x}{ij}|\boldsymbol{\theta^c{!j}})|{c=y_i}}}}\notag\ &=\sum{i=1}^C{N_c\log{\pi_c}}+\sum_{i=1}^D{\sum_{j=1}^F{\log{p(\boldsymbol{x}{ij}|\boldsymbol{\theta^c{!j}})|_{c=y_i}}}} \end{align} $$
其中$\N_c$表示所有$D$个样本点中类别为$c$的数量(对应的概率为$\pi_c$)。
采用最大似然估计,则是要使(对数)似然函数在考察参数条件下最大化, $$ \begin{align} \mathop{\mathrm{argmax}}\boldsymbol{\theta}~&{\log{p(\mathcal{D}|\boldsymbol{\theta})}},\ \mathrm{s.t.~~~} &\sum{c=1}^C{\pi_c}=1. \notag \end{align} $$
Gaussian Naive Bayes
连续数据,假设数据的每一个特征服从一个正态分布,
$$ p(\boldsymbol{x}|y=c,\boldsymbol{\theta})=\prod_{j=1}^D\mathcal{N}(x_j|\mu_{!j}^c,{{\sigma}_{!j}^c}^2) $$
估计分布的期望和方差。
Bernoulli Naive Bayes
特征的值由两个取值(0和1),采用伯努利分布$p(\bm{x}|y=c,\bm{\theta})=\prod_{j=1}^D\mathrm{Ber}(x_j|{\mu}_{!j}^c)$,估计每个特征的分布的期望${\mu}_j^c$(即$x=1$的概率)。
Multinomial Naive Bayes
特征可以取多个离散值,在二值基础上推广。
模型拟合
神经网络
A neural network is a very powerful machine learning mechanism which basically mimics how a human brain learns. The brain receives the stimulus from the outside world, does the processing on the input, and then generates the output.
激活函数(Activation Function)
单个神经元:输入$\bm{x}=(x_i){i=1,\cdots,n}$,神经元输入权重$W_i=(w_i){i=1,\cdots,n}$, $$ \begin{align*} y_j&=f(b+\sum_{i=1}^{n}{x_iw_i})=f(W_i\bm{x}+b),\ z_j&= b_j+W_i\bm{x} \Longrightarrow y_j=f(z_j) \end{align*} $$
A neural network without an activation function is essentially just a linear regression model.
单层网络:第$k$层神经元序列$\bm{q}^{(k)}=(q_j^{(k)}=(f_j^{(k)},b_j^{(k)})){j=1,\cdots,m}$,$\bm{f}^{(k)}=(f_j^{(k)}){j=1,\cdots,m}, \bm{b}^{(k)}=(b_j^{(k)})_{j=1,\cdots,m}$。每个神经元的激活函数分别处理一个线性组合输入$z_j$。
可以将各层网络的处理写作迭代的形式: $$ \begin{align*} \bm{q}^{(k+1)}(\bm{x}^{(k)})&=\begin{cases} \bm{z}^{(k+1)}=\bm{b}^{(k+1)}+\bm{W}^{(k+1)}\bm{x}^{(k)} \ \bm{x}^{(k+1)}=\bm{f}^{(k)}(\bm{z}^{(k+1)}) \end{cases},~~k=1,2,\cdots\ x^{(k+1)}_j&=f_j^{(k)}(z^{(k+1)}_j) \end{align*} $$
通常每一层使用相同类型的神经元,即激活函数相同$f_j^{(k)}=f^{(k)}$。
Sigmoid
$$ f(x)=\frac{1}{1+e^{-x}} $$
This means that in this range small changes in x would also bring about large changes in the value of Y. So the function essentially tries to push the Y values towards the extremes. This is a very desirable quality when we are trying to classify the values to a particular class.
Problem:
- when $x$ is large, the gradient is approaching to zero and the network is not really learning.
Tanh - Scaled Sigmoid
$$ \begin{align} \mathrm{tanh}(x)&=2\mathrm{sigmoid}(2x)-1 \notag\ & =\frac{2}{1+e^{-2x}} -1 \end{align} $$
it ranges from -1 to 1.
ReLU
$$ f(x)=\mathrm{max}(0,x) $$
The main advantage of using the ReLU function over other activation functions is that it does not activate all the neurons at the same time.
Problems: gradients moving towards zero.
Solution:
- Leaky ReLU.
$$ f(x)=\begin{cases} ax, & x< 0 \ x, & x \ge 0 \end{cases} ~~(a\rightarrow0^+) $$
- Parameterized ReLU function
Softmax
$$ \boldsymbol{\sigma}(\boldsymbol{z})j=\frac{e^{z_j}}{\sum{k=1}^{K}{e^{z_k}}},~\forall j=1,\cdots,K. $$
==Multi-class problem==: the softmax function would squeeze the outputs for each class between 0 and 1 and would also divide by the sum of the outputs. This essentially gives the probability of the input being in a particular class.
- Sigmoid functions and their combinations generally work better in the case of classifiers
- Sigmoids and tanh functions are sometimes avoided due to the vanishing gradient problem
- ReLU function is a general activation function and is used in most cases these days
- If we encounter a case of dead neurons in our networks the leaky ReLU function is the best choice
- Always keep in mind that ReLU function should only be used in the hidden layers ???
- As a rule of thumb, you can begin with using ReLU function and then move over to other activation functions in case ReLU doesn’t provide with optimum results
https://www.analyticsvidhya.com/blog/2017/10/fundamentals-deep-learning-activation-functions-when-to-use-them/
The Neural Network Zoo - The Asimov Institute
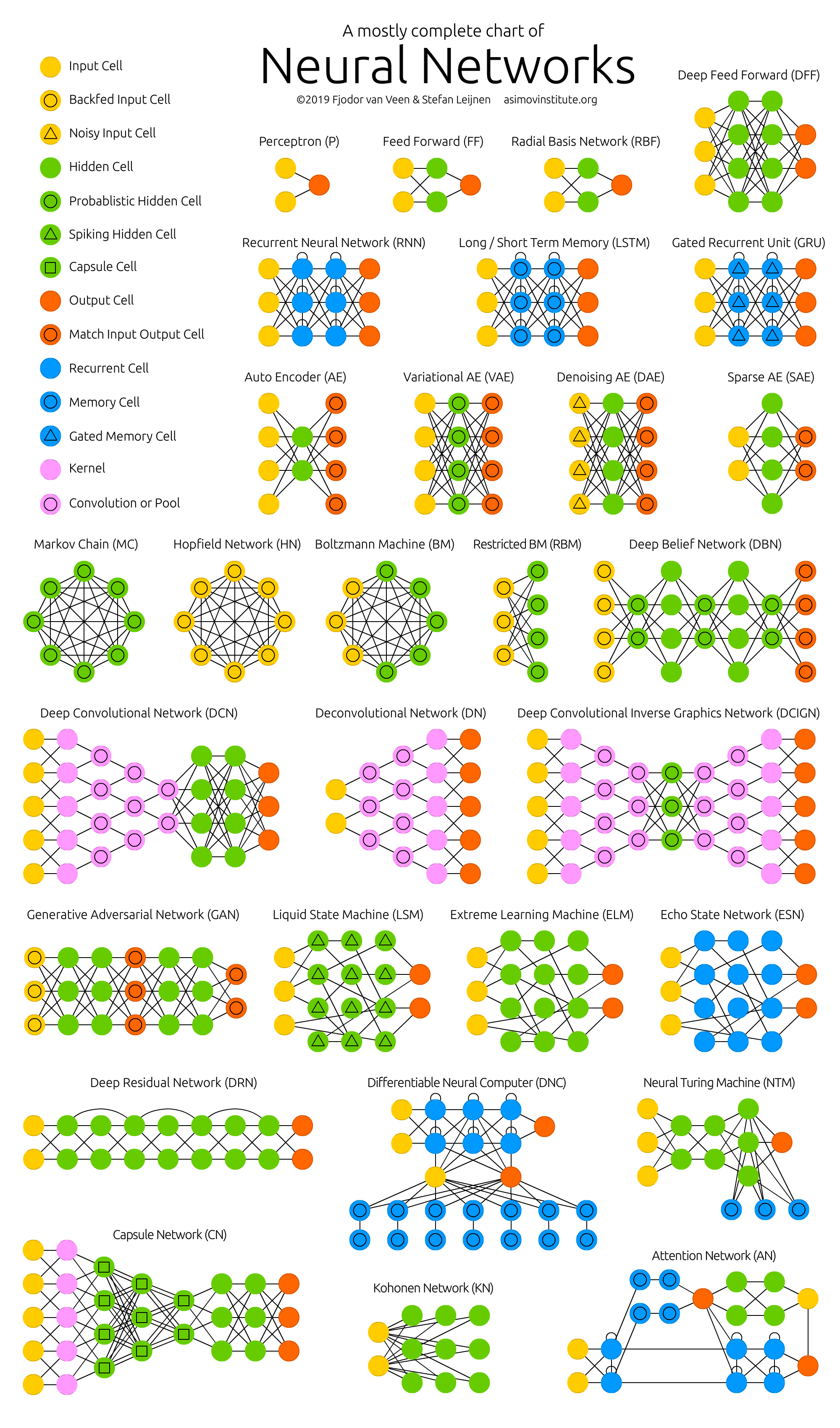
Feed-forward Neural Network
感知器(Perceptron)
单层感知器仅能学习线性可分模式。
https://www.simplilearn.com/what-is-perceptron-tutorial
Multi-Layer Perceptrons (MLPs)
线性神经网络
感知器传输函数是一个二值阈值元件,而线性神经网络的传输函数是线性的。这就决定了感知器只能做简单的分类,而线性神经网络还可以实现==线性==拟合或逼近。
非线性神经网络
要形成非线性分界面,网状结构和非线性激活函数缺一不可。如果缺乏网状结构(逻辑回归),$\bm{x}$经过投影其信息只在 $W$方向上有变化。若缺乏非线性激活函数,则无论有多少层,网络仍然是一个线性回归。
优化神经网络:调整网络中的参数$W,b$,以最小化损失函数。
参考文献
- https://www.learnopencv.com/understanding-feedforward-neural-networks/
- https://www.analyticsvidhya.com/blog/2018/07/using-power-deep-learning-cyber-security/
卷积神经网络CNN
CNNs specifically are inspired by the biological visual cortex1.
In this experiment, the researchers showed that some individual neurons in the brain activated or fired only in the presence of edges of a particular orientation like vertical or horizontal edges. Hubel and Wiesel found that all of these neurons were well ordered in a columnar fashion and that together they were able to produce visual perception.
层间特征的映射关系不是通过全连接,而是局部卷积构造。
preprocessing: 降采样
convolution
提取局部特征(模式)。
卷积核模式匹配无法区分以下模式:设计不同的卷积核可区分以上两种模式,从而避免额外的归一化操作。
每一个kernel在一张图上通过卷积运算生成一个feature map(每个卷积核代表了一种图像模式),输入图像本身也相当于一个kernel map(对于RGB图像,每个图像对应三个输入通道,相当于有三个kernel map)。每个输入图像使用同一组卷积核分别进行计算,因此输出feature map数量:n_input_map*n_kenerls_per_map;
输出数据的形状:n_input_map*n_kernels_per_map*(n_rows*n_cols);
因此每层参数数量:(n_input_map*kernel_size+1)*n_kernels_per_map,每个卷积核对应一个权重系数矩阵和一个bias参数($y_{ij}=\boldsymbol{wx}_{ij}+b$)。对于输入层,num_input_map=1(对于RGB图像,num_input_map=3,因此输入层需要三个二维卷积核分别对三个通道进行卷积并将结果求和(Keras的Conv2D)。
bias:单个输入图上的卷积核使用独立的bias,但这些bias跨feature map是共享的参数,因此偏置参数的个数为
n_kenerls_per_map。(==同一层卷积核在不同feature map是独立的,但偏置是共享的?==)
==卷积计算实际是权重与数据的内积。卷积核的移动过程类比于数字信号处理中的卷积运算过程==。卷积计算可在feature_map内部(复制image数据)以及feature_map之间并行。
dot product between their weights (kernel) and a small receptive field to which they are connected to in the input volume.
subsampling: 降低分辨率
有助于==减小过拟合==。
-
max-pooling: takes the largest value from the window of the image currently covered by the kernel of the pooling layer.
卷积运算的值越大,意味着对应位置的模式与卷积核越匹配。因此,通过
max-pooling运算后,卷积运算提取的模式信息仍能在feature_map中得到保留。池化层窗口移动步长为窗口宽度。
-
full connected layers: 类似传统神经网络的部分
全连接层
将feature maps转换为1维向量,从而可用于输出层的softmax分类器或sigmoid进行预测。
损失函数
损失函数以神经网络的输出作为自变量,以训练数据集的标签作为参数。
binary_crossentropy
AutoEncoder
深度学习
- https://www.analyticsvidhya.com/blog/2016/03/introduction-deep-learning-fundamentals-neural-networks/
- https://www.analyticsvidhya.com/blog/2018/05/essentials-of-deep-learning-trudging-into-unsupervised-deep-learning/
Time Series forecasting & modeling
Methods
-
Moving Average
-
Linear Regression
-
k-Nearest Neighbors
-
Auto ARIMA
-
Prophet
-
Long Short Term Memory (LSTM)
-
https://www.analyticsvidhya.com/blog/2018/10/predicting-stock-price-machine-learningnd-deep-learning-techniques-python/
-
https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/?utm_source=blog&utm_medium=stockmarketpredictionarticle
GAN
https://www.analyticsvidhya.com/blog/2019/04/top-5-interesting-applications-gans-deep-learning/
训练
Model Selection
数据集
training set
validation set
We fit all the models on the training set, and evaluate their performance on the validation set, and pick the best.
cross validation: split the training data into $K$ folds; train on all the folds but the $k$’th, and test on the $k$’th, in a round-robin fashion.
test set
优化理论
梯度搜索算法
Stochastic Gradient Descent
learning of linear classifiers under convex loss functions such as (linear) Support Vector Machines and Logistic Regression.
SGD has been successfully applied to large-scale and sparse machine learning problems often encountered in text classification and natural language processing.
Stochastic Gradient Descent:根据一个样本计算梯度;
Batch Gradient Descent:根据所有样本计算平均梯度(计算所有样本的平均误差,以2范数构造损失函数即为均方误差(MSE));
mini-batch SGD:计算一批样本的平均梯度(兼顾计算效率与收敛速率)。
参考文献
- https://scikit-learn.org/stable/modules/sgd.html#sgd
- https://adventuresinmachinelearning.com/stochastic-gradient-descent/
ADAM
Back-Propagation

利用链式规则对$W_{ij}^{(k)}$反向逐级求导: $$ \newcommand{\d}[2]{\frac{\partial#1}{\partial#2}} \begin{align*} \d{l}{f_1^{(3)}}&=\dot{l}(u),~~u=f_1^{(3)}-y_1\
\d{l}{w_{11}^{(2)}}&=\d{l}{f_1^{(3)}}\d{f_1^{(3)}}{z_1^{(3)}}\d{z_1^{(3)}}{w_{11}^{(2)}}=\d{l}{f_1^{(3)}}\cdot\dot{f}_1^{(3)}\cdot f_1^{(2)} \end{align*} $$ 其中,通过正向传播并利用初始化的权重系数$W$,可获得各级神经元输入值$z$、激活函数的函数值$f$和导数值$\dot{f}$。
Without the differentiable non linear function, this would not be possible.
类似地对$b_i^{(k)}$求导可得: $$ \d{l}{b_1^{(2)}}=\d{l}{f_1^{(3)}}\d{f_1^{(3)}}{z_1^{(3)}}\d{z_1^{(3)}}{b_1^{(2)}}=\d{l}{f_1^{(3)}}\cdot\dot{f}_1^{(3)}, ~~\left(\d{z_1^{(3)}}{b_1^{(2)}}=1\right)\notag $$
利用后一级已有导数信息,可迅速计算当前层级的导数: $$ \begin{align*} \d{l}{f_{1}^{(2)}}&=\d{l}{f_1^{(3)}}\d{f_1^{(3)}}{z_1^{(3)}}\d{z_1^{(3)}}{f_{1}^{(2)}}=\d{l}{f_1^{(3)}}\cdot\dot{f}1^{(3)}\cdot w{11}^{(2)}\
\d{l}{w_{11}^{(1)}}&=\d{l}{f_1^{(2)}}\d{f_1^{(2)}}{z_1^{(2)}}\d{z_1^{(2)}}{w_{11}^{(1)}}=\d{l}{f_{1}^{(2)}}\cdot\dot{f}1^{(2)}\cdot f{1}^{(1)} \end{align*} $$
$z_1^{(3)}=w_{11}^{(2)}f_1^{(2)}+b_1^{(2)}$,因此对$w_{11}^{(2)}$求导仅与$f_1^{(2)}$相关。
如果存在多个输出,或者较浅的层级在求导时,其前置神经元存在多条路径: $$ \begin{align*} \d{l}{f_{1}^{(1)}}&=\sum_{i=1}^{n_2}\left{\d{l}{f_i^{(2)}}\d{f_i^{(2)}}{z_i^{(2)}}\d{z_i^{(2)}}{f_1^{(1)}}\right}=\sum_{i=1}^{n_2}\left{\d{l}{f_{i}^{(2)}}\cdot\dot{f}i^{(2)}\cdot w{i1}^{(1)}\right}\
\d{l}{w_{12}^{(0)}}&=\d{l}{f_1^{(1)}}\d{f_1^{(1)}}{z_1^{(1)}}\d{z_1^{(1)}}{w_{12}^{(0)}}=\d{l}{f_1^{(1)}}\dot{f}_1^{(1)}\cdot f_2^{(0)} \end{align*} $$
向量化
将各级的函数值、导数值信息表示为向量,并根据各级的维度关系,可以得到各级梯度的向量化表示。 $$ \begin{align*} \bm{d}^{(k)}&=\left(\d{l}{f_{i}^{(2)}}\cdot\dot{f}i^{(k)}\right){i=1,\cdots,n_k},& \bm{f}^{(k)}&=\left(f_i^{(k)}\right)_{i=1,\cdots,n_k},\ \frac{\mathrm{d}l}{\mathrm{d}\bm{f}^{(k)}}&={W^{(k)}}^{\top}\cdot\bm{d}^{(k+1)},& \frac{\mathrm{d}l}{\mathrm{d}\bm{W}^{(k)}}&=\bm{d}^{(k+1)}\cdot{\bm{f}^{(k)}}^{\top}. \end{align*} $$ 基于梯度信息,我们可以利用梯度下降算法进行迭代从而优化神经网络的参数,以最小化训练数据集的损失。
参考文献
- https://towardsdatascience.com/applied-deep-learning-part-1-artificial-neural-networks-d7834f67a4f6
- https://adventuresinmachinelearning.com/neural-networks-tutorial/
开源项目
Generative Models in TensorFlow 2
This repository contains TF implementations of multiple generative models, including:
- Generative Adversarial Networks (GANs)
- Autoencoder
- Variational Autoencoder (VAE)
- VAE-GAN, among others.
STUMPY – Time Series Data Mining
Below are a few time series data mining tasks this matrix profile helps us perform:
- Anomaly discovery
- Semantic segmentation
- Density estimation
- Time series chains (temporally ordered set of subsequence patterns)
- Pattern/motif (approximately repeated subsequences within a longer time series) discovery
Awesome Decision Tree Research Papers
The repository also contains the implementation of each paper.
框架
PyTorch
PyTorch is a Python based scientific computing package that is similar to NumPy, but with the added power of GPUs. It is also a deep learning framework that provides maximum flexibility and speed during implementing and building deep neural network architectures.
- https://www.analyticsvidhya.com/blog/2019/01/guide-pytorch-neural-networks-case-studies/
- Use Case 1: Handwritten Digits Classification (Numerical Data, MLP)
- Use Case 2: Objects Image Classification (Image Data, CNN)
- Use Case 3: Sentiment Text Classification (Text Data, RNN)
- Use Case 4: Image Style Transfer (Transfer Learning)
统计学习算法
线性回归
最小二乘回归:
from scipy import stats
m, b, r, p, se = stats.linregress(x, y)
def f(x): # linear model
m = 6.3134
b = -17.9164
return m*x + b
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # fit/predict
基于局部距离信息的算法
KNN
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(k_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None, ...)
weights:权重函数。
uniform:邻居节点权重相同;distance:另据节点权重与距离成反比;[callable]:用户自定义权重函数。
algorithm:计算邻居节点算法。
ball_treekd_treebruteauto:根据传递给fit方法的数据决定选择的算法。
Kmeans
The k-means problem is solved using either Lloyd's or Elkan's algorithm.
from sklearn.cluster import KMeans
KMeans(n_clusters=8, init='k-means++', n_init=10, random_state=None)
init:初始化方法,包括k-means++,random(随机选择n_cluster个点作为初始中心点),ndarray(给定初始点),callable(自定义生成初始点的方法);
n_init:k-means算法使用不同中心点运行的次数,最终输出最好的结果。
random_state:随机数状态,初始化为整数使得结果确定。
方法
kmeans = Kmeans().fit(X)
labels = kmeans.labels_ # predicted labels
labels = KMeans().fit_predict(X) # predict labels
x_new = KMeans().fit_transform(X) # to point-centroid distance
基于分布的算法
Naive Bayes
from sklearn.naive_bayes import GaussianNB
决策树
Decision Tree
from sklearn.tree import DecisionTreeClassifier
Random Forest
from sklearn.ensemble import RandomForestClassifier
SQL语法
词法
SQL输入由一系列命令(command)组成;一个命令由多个由空白(空白、制表符、换行符)分隔的符号(token)组成,并以;结束(换行不代表命令结束)。符号可能是关键字(keyword)、标识符(identifier)、引用标识符(quoted identifier)、字面值(literal)或特殊字符(special character symbol)。
关键字和标识符
SQL关键字和标识符以字符或下划线开头,其他字符还可以是数字或$。根据SQL标准,
- 标识符不允许使用
$, - 关键字不包含数字或以下划线开头或结尾。
关键字与非引用标识符是==大小写不敏感==的,惯例是关键字使用大写字母,标识符使用小写字母,==解释器会统一转换为小写字母==。
在SQL语句中引用数据库名、表名、列名等标识符,如果标识符的定义包含大写字母、特殊字符或关键字,应该使用引用标识符(使用引号转义),==解释器将保留标识符的输入格式,不做转换==。
PostgreSQL使用""表示引用标识符;MySQL使用`表示。
select "Column A" from "Users";
在PostgreSQL数据库中,模式名称和表名称需要分开使用引用标识符,否则会将其视为单个引用标识符。
select * from "public"."Users";
--或/**/:注释。
字面值
字符串
字符串常量使用''(引用标识符使用"")。可使用C语言风格转义和Unicode转义。
'This is a string'
E'This is\ta string\\' -- "This is a string\"
U&'\0441\043B\043E\043D'
PostgresSQL的原始字符串:
$$Dianne's horse$$ --非转义字符串
$TAG$Dianne's horse$TAG$ --添加TAG保证字符串中不出现引用标识
Binary String
B'1010:比特序列;
X'1FF':半字节序列;
数值常量
运算符
+ - * / < > = ~ ! @ # % ^ & | ` ?
下标运算符:[]
字段选择:xxx.fieldname
变量
DECLARE variable_name datatype(size) DEFAULT default_value;
[数据库定义](SQL DDL.md)
[数据操作](SQL DML.md)
流程控制
SELECT IF(var<1000, "YES", "NO");
BEGIN
declare stu_grade float;
select grade into stu_grade from grade where student_no=stu_no;
IF stu_grade > 90 THEN
statement_list;
ELSEIF stu_grade > 80 THEN
statement_list;
ELSE
statement_list;
END IF;
END
MySQL存储过程循环 - MySQL教程™ (yiibai.com)
存储过程是存储在数据库目录中的一段声明性SQL语句。
MySQL游标 - 使用MySQL游标来遍历SELECT语句返回的结果集。
CREATE PROCEDURE
MySQL存储函数 - 使用CREATE FUNCTION语句创建存储的函数。
数据库定义语言
Data Definition Languages.
数据库
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[[DEFAULT] CHARACTER SET [=] charset_name ]
[[DEFAULT] COLLATE [=] collation_name ];
可选项为数据库使用的字符集和校对规则,不声明则使用默认值。 创建数据库前应该指定所使用的字符集,否则数据表中容易出现乱码。
在MySQL中:
SCHEMA和DATABASE是同义词。在PostgreSQL中,SCHEMA是命名空间,将一个数据库划分为逻辑空间。
修改数据库
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET [=] charset_name ]
[[DEFAULT] COLLATE [=] collation_name ];
主要是修改数据的字符集和校对方法。如果db_name没有指定,则是对默认的数据库进行修改。
删除数据库
DROP DATABASE [IF EXISTS] database_name;
表
创建表格
CREATE TABLE [IF NOT EXISTS] table_name (
column_name data_type [column_contraint], ...
)
#[table_options]
#[partition_options]
#[IGNORE | REPLACE];
column_definition表示表的列的声明,每个声明包含:
col_name data_type[(params)]
[NOT NULL | NULL]
[DEFAULT value]
[AUTO_INCREMENT] [UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
column_constraint表示对数值的一个或多个约束,例如NOT NULL、UNIQUE、PRIMARY KEY、AUTO_INCREMENT、比较规则(COLLATE)等;
table_options表示设置表的一些属性,例如:引擎(ENGINE)、字符集(CHARACTER SET)、全局比较规则(COLLATE)等,以及约束条件等。
MySQL :: MySQL 8.0 Reference Manual :: 13.1.20 CREATE TABLE Statement
PostgreSQL: Documentation: 12: CREATE TABLE
注释
COMMENT ON TABLE "employees" IS '雇员信息';
COMMENT ON COLUMN "employees"."department" IS '部门名称';
根据其他表格创建
基于源表的数据类型重新创建数据表并插入数据(WITH NO DATA不插入数据)。
CREATE TABLE dup_table AS (SELECT * FROM table_name);
CREATE TABLE dup_table AS (SELECT * FROM table_name) WITH NO DATA;
上述方法不会保留源数据表字段的属性。可以使用以下方法复制源表的属性,然后再从源表复制数据。
CREATE TABLE dup_table (LIKE table_name INCLUDING ALL);
查看表的定义
查询数据表的属性:
SELECT table_catalog as db,
TABLE_SCHEMA as schema,
TABLE_NAME, TABLE_TYPE, [VERSION, ]
TABLE_ROWS as num_rows,
CREATE_TIME
FROM information_schema.tables where table_name='table_name';
table_schema:MySQL为数据库名,PostgreSQL为模式名(table_catalog为数据库名);
索引
PRIMARY KEY:
Foreign Keys:所定义列取值范围由所引用的外部数据表列确定。
column_name data_type references another_table(col_name)
创建索引
CREATE [UNIQUE] INDEX [[IF NOT EXISTS] index_name] ON table_name [USING method]
( {column_name | (expression) }[ASC|DESC][, ...] ) -- index columns
[ TABLESPACE tablespace_name ]
[ WHERE predicate ] -- partial index
USING method: PostgreSQL provides the index methods btree (default), hash, gist, spgist, gin, and brin.
{column_name|(expression): Multiple fields can be specified if the index method supports multicolumn indexes. An index field can be an expression computed from the values of one or more columns of the table row. This feature can be used to obtain fast access to data based on some transformation of the basic data. For example, an index computed on upper(col) would allow the clause WHERE upper(col) = 'JIM' to use an index.
UNIQUE: 索引列数据有重复值将产生错误。
删除表
DROP TABLE table_name;
修改表
修改表的字段类型
ALTER TABLE table_name MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]
默认不改变列的位置。
修改表的字段名称和类型
ALTER TABLE table_name CHANGE [COLUMN]
old_col_name new_col_name column_definition
[FIRST|AFTER col_name]
只修改名称则列的定义应该保持不变,只修改列的定义则old_col_name和 new_col_name应该相同。可以选择更改列的位置。
增加表的字段
ALTER TABLE table_name ADD [COLUMN] col_name column_definition [FIRST|AFTER col_name]
FIRST:表示作为表的首个字段; AFTER col_name:表示位于col_name字段之后; 默认:增加字段位于表的末端
删除表的字段
ALTER TABLE table_name DROP [COLUMN] col_name
更改表名
ALTER TABLE table_name RENAME [TO] new_tbl_name
注意:CHANGE/FIRST/AFTER/COLUMN这些关键字是MySQL在标准SQL上的扩展,在其他数据库上不一定适用。
https://www.yiibai.com/sql/sql-create-table.html
Partitioning
Bucketing
CLUSTERED BY声明分组。
CREATE TABLE table_name (column1 data_type, column2 data_type, …) PARTITIONED BY (partition1 data_type, partition2 data_type,….) CLUSTERED BY (clus_col1) SORTED BY (sort_col2) INTO n BUCKETS;
分组被存储为文件。
数据操作语言
Data Manipulation Languages.
修改数据表
插入数据记录
INSERT INTO table_name [(col_name,...)]
VALUES (col_value,...),(...),...
WHERE conditions;
MySQL可省略INTO关键字。如果未指定列名,则需按列定义顺序给出所有列的值;反之,只需给出指定的列名对应的值(未指定的列的值为
NULL)。非数值类型:使用单引号包含起来,以免发生错误。
批量插入记录
从表格复制
INSERT INTO target_table (SELECT * from source_table);
替换数据记录
REPLACE works exactly like INSERT, except that if an old row in the table has the same value as a new row for a PRIMARY KEY or a UNIQUE index, the old row is deleted before the new row is inserted.
REPLACE INTO table_name [(col_name,...)]
VALUES (col_value,...),(...),...;
INSERT IGNORE table_name ...;
忽略导致错误的行,并将其余行插入到表中。
更新记录字段
将满足条件的表项的字段值更新为设定值。
UPDATE table_name
SET col_name1=value1[, col_name2=expr1] ...
[WHERE where_condition]
删除数据记录
删除单表记录
DELETE FROM tbl_name [WHERE where_condition];
清空表内容
TRUNCATE TABLE tbl_name -- 类似于使用`DELETE`删除所有记录。
如果该表有外键约束,则可临时禁用外键约束再清空表内容(可能破坏关联表的数据完整性,需要同时处理相关表)。
SET FOREIGN_KEY_CHECKS = 0; -- 当前会话禁用约束检查
删除多表的记录
DELETE tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition];
示例:
DELETE t1,t2 FROM store_info t1,store_geo t2 where t1.store_name='Boston' AND t2.store_name='Boston';
注意多表时,FROM后面如果使用了表的别名,则DELETE之后也要使用表的别名,否则会出现错误。
无论是单表还是多表,如果不加WHERE作为条件限制将会导致表的记录全部被删除,因此要小心。
查询数据
查询使用SELECT命令。一般语法:https://dev.mysql.com/doc/refman/8.0/en/select.html。
SELECT [DISTINCT] field1, field2 AS Name, FUNC(field3), ...
FROM table_reference
[WHERE condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[LIMIT [offset], num_rows];
使用*代替字段名称,用于查询所有列,AS为返回结果的变量设置列名。查询语句中不仅可以直接使用变量,也可以将函数应用于查询字段或条件中的字段。
SELECT DISTINCT关键字用于查询不重复的记录。
条件过滤
通常基于字段的值构造逻辑表达式,表达式返回结果长度与表格行数一致(返回结果也可以是标量)。
SELECT * FROM store_info WHERE sales<1000;
SELECT * FROM Customers WHERE Country='Germany' AND (City='Berlin' OR City='München');
条件表达式可以使用比较运算符:“=”(等于)、“>”、“<”、“>=”、“<=”、“!=”/“<>”(不等于)。
不支持“
==”。
空值判断运算符:IS NULL和IS NOT NULL ,空值不支持比较运算符。
时间日期字段可以和字面值进行比较:start_time>='2021-11-01'。
注意:条件过滤的执行先于SELECT,因此在SELECT语句中声明的查询结果别名无法在WHERE语句中使用。如果查询条件需要用到SELECT计算出的列,可先执行[子查询](# 查询表引用子查询结果),再从子查询结果中指定过滤条件再次查询。
复合条件
多个表达式之间还可以使用 AND、OR和NOT等逻辑运算符进行多条件联合查询。
模糊查询
SELECT * FROM table_name WHERE columnN LIKE pattern;
pattern支持通配符:
%:零个或多个字符;_:一个字符;[]:任何一个在括号中的字符,[^abc]任何不在括号中的字符,[a-z]指定字符区间。
Hive:
LIKE支持函数式调用LIKE(A,B)。
正则表达式
MySQL需要8.0版本支持。
正则表达式函数
REGEXP_LIKE(expr, pat[, match_type]):匹配返回1,否则返回0;若参数为NULL,则返回NULL;REGEXP和RLIKE是作为运算符的同义词,即
key REGEXP pattern
expr NOT_REGEXP pattern, NOT (expr REGEXP pattern)
Hive:
REGEXP,RLIKE返回true|false|null,同时也支持函数式调用。
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
pos:匹配起始位置,默认为1;occurrence:表示返回匹配的序号,默认0表示返回全部匹配;Hive语法为:
REGEXP_EXTRACT(colname, 'pattern', index),其中index为0表示返回匹配结果,index>0表示返回对应的捕获组。
select REGEXP_SUBSTR(store_name, '10\.12.*') from test_type
where store_name REGEXP '10\.12.*';
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
排序和限制
SELECT * FROM table_name
ORDER BY field1 [DESC|ASC],field2 [DESC|ASC]...
LIMIT [offset_start,] row_count ;
根据给出字段,对选出的查询记录进行排序,可以指定升序或降序。如果排序后只希望显示结果的一部分,则可以使用limit关键字来实现。
记录的索引是从0开始的,如果没有声明offset_start,则默认从第0条显示。
limit经常和order by一起使用,用于分页显示。
运算
算术运算
SELECT 1*2*3 as a, 1+2+3 as b;
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
字符串运算
大小写转换
SELECT UPPER(Name) FROM Customers where UPPER(Name)='GARY'; -- LOWER
JSON函数和运算符
The main difference of json and jsonb data type is json will store the data into the plain text format while jsonb data type will store the data in binary format.
PostgreSQL
SELECT json_field::json->0 as f FROM table; # 获取JSON数组的元素
SELECT json_field::json->'key' as f FROM table; # 获取JSON对象的值
SELECT json_field::json#>'{key_idx,subkey_idx,...}' as f FROM table; # 查询嵌套对象的元素
另外,运算符->>,#>>将返回值转换为文本类型。
jsonb类型支持比较运算符而json类型不支持,此外jsonb还支持以下特殊比较运算。
json_a::jsonb @> json_b::jsonb # A是否包含B,"<@" 反之
json_a::jsonb ? 'key' # A的顶层键名/元素是否包含'key'
json_a::jsonb ?| array['key1', 'key2'] # 是否包含任意键名/元素,"?&"包含所有键名/元素
连接
当需要同时显示多个表中的字段时,就可以使用连接来实现。 连接可分为内连接和外连接。它们之间最主要的区别在于内连接只选出表中互相匹配的记录,而外连接会选出其他不匹配的记录。
内连接
SELECT * | T1.cm [AS A1],T2.cn [AS A2][,...]
FROM table_1 [AS] T1,table_2 [AS] T2
WHERE T1.cx=T2.cy;
SELECT * FROM weather
[INNER] JOIN cities
ON (weather.city = cities.name);
当两个表存在相同列名时,需要使用表名(或别名)来区分引用同名列。
在使用内连接时,必须注意
WHERE语句的条件一定要是两个表的匹配条件,如果该条件是错误的(不匹配),则会产生笛卡尔连接,导致产生巨大的查询结果。
外连接
外连接又分为:
- 全连接:包含所有
- 左连接:包含所有左边表中的记录,右表没有的记录填充
NULL; - 右连接:包含右边表中的所有记录,左表没有的记录填充
NULL;
外连接语法:
SELECT * FROM table_1 [[AS] T1]
[LEFT|RIGHT|FULL] OUTER JOIN table_2 [[AS] T2]
ON (T1.cx=T2.cy);
交换FROM后表的顺序,则左连接和右连接可以相互转换。
子查询
查询语句中引用的数据,例如表或查询条件的值,可以是其他查询的返回值。
查询表引用子查询结果
SELECT * FROM ( SELECT sql_func(col) AS F FROM table) AS T where F = 'some_value';
查询条件引用子查询结果
SELECT * FROM table_name WHERE field_n OPERATOR (sub_select)
SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
视图
将查询语句保存为视图。相比于子查询,方便后续重复引用。
CREATE VIEW myview AS
SELECT col_names FROM weather, cities WHERE city = name;
SELECT * from myview;
聚合与分组
SELECT [field,...] agg_func(field_i) FROM table_name
[GROUP BY field1,field2,...,fieldn [WITH ROLLUP]]
[HAVING where_condition]
agg_func:表示聚合函数,即对表的某一列进行的统计运算。常用的有sum、count(计数)、max(最大值)、min(最小值)。
GROUP BY:对查询的表首先根据字段进行分组 ,然后对每个子类进行运算统计(聚合)。WITH ROLLUP(汇总):表示将分组统计结果作为一个整体,再次进行聚合运算,并将结果附加到分组计算结果之后。
HAVING:类似于WHERE,只是HAVING是在聚合之后对结果进行过滤,而WHERE是在聚合之前对原表进行过滤。
Window Functions
进行分组并调用聚合函数,但聚合结果将关联到对应组的所有行,而非聚合为单条记录。
SELECT depname, salary, avg(salary) OVER (PARTITION BY depname)
FROM empsalary;
事务(Transactions)
将多个操作步骤组合到一起形成原子操作,保证该组操作仅处于完全完成或未执行的状态。
A transactional database guarantees that all the updates made by a transaction are logged in permanent storage (i.e., on disk) before the transaction is reported complete.
BEGIN;
-- SQL statements
ROLLBACK; -- cancel the transaction
COMMIT; -- complete the transaction
SQL数据类型
MySQL
数值类型
| 类型 | 说明 |
|---|---|
BIT(size) | size=[1,64](1) |
TINYINT(size) | 8-bit int |
SMALLINT(size) | 16bit int |
MEDIUMINT(size) | 24bit int |
INT(size) | 32bit int, as INTEGER(size) |
BIGINT(size) | 64bit int |
FLOAT(p) | $p\le 24$ as FLOAT()$25\le p\le53$ as DOUBLE() |
DOUBLE(size, d) | size: number of total digitsd: 小数点后位数 |
DECIMAL(size, d) | as DEC(size, d) |
BOOL | as BOOLEAN, zero (false) or nonzero (true) |
DOUBLE PRECISION(size, d)
可选属性
UNSIGNED
ZEROFILL:用于显示格式,告知MySQL用0将数值的空格补齐,而不是空着。ZEROFILL也会自动添加UNSIGNED属性。整形数据后面括号中的数表示数据的显示宽度。当数据的宽度小于显示宽度的时候将会使用空格补齐,如果声明了ZEROFILL,则以0填充;如果数据的宽度大于显示宽度,则按数据的实际宽度显示。
AUTO_INCREMENT:用于类型为整数的列,且一个表中只能有一列可以有该属性,当插入的行的该列的值为NULL,该列的值会被自动设置成该列的最大值加1。对于要使用AUTO_INCREMENT属性的列,应该定义为NOT_NULL,并定义为PRIMARY KEY或定义为UNIQUE。可按下列方式定义AUTO_INCREMENT列:
CREATE TABLE table_name(id INT AUTO_INCREMENT NOT NULL PRIMARY KEY);
CREATE TABLE table_name(id INT AUTO_INCREMENT NOT NULL, PRIMARY KEY(id));
CREATE TABLE table_name(id INT AUTO_INCREMENT NOT NULL, UNIQUE(id));
字符串数据
| 类型 | 说明 | |
|---|---|---|
CHAR(size) | size=[0,255](1) | 固定长度,填充空白(读取时移除填充) |
VARCHAR(size) | size=[0,65535] | 储存长度和值,最大长度还受限于行记录最大长度65535以及使用的编码方法。 |
TINYTEXT | [0,255] | |
TEXT(size) | size=[0,65535] | |
MEDIUMTEXT | [0,16777215] | 16MB |
LONGTEXT | [0,4294967295] | 4GB,字符数限制与编码方法相关。 |
SET(val1, ...) | 枚举字符串(最多64个) | |
ENUM(val1, ...) | 枚举字符串(最多65535个) |
字符串类型列声明时可指定字符集的属性(覆盖数据库默认属性):
CREATE TABLE t
(
c1 VARCHAR(20) CHARACTER SET utf8mb4,
c2 TEXT CHARACTER SET latin1 COLLATE latin1_general_cs
);
JSON数据类型
使用JSON数据类型相比于字符串类型有以下优点:
- 自动校验;
- 优化存储格式,支持快速访问(直接通过建或索引访问子对象,无需读取整个JSON文档)。
JSON类型的存储空间需求与LONGTEXT相似。
CREATE TABLE t1 (jdoc JSON);
INSERT INTO t1 VALUES('{"key1": "value1", "key2": "value2"}');
JSON_ARRAY():构造JSON数组。
JSON_OBJECT():构造JSON对象。
The
UPDATEstatement uses any of the three functionsJSON_SET(),JSON_REPLACE(), orJSON_REMOVE()to update the column.The input column and the target column must be the same column; a statement such as
UPDATE mytable SET jcol1 = JSON_SET(jcol2, '$.a', 100)cannot be performed as a partial update.
MySQL :: MySQL 8.0 Reference Manual :: 11.5 The JSON Data Type
Binary类型
与相应的字符串类型类似,但存储字节串。
| 类型 | 说明 |
|---|---|
BINARY(size) | |
VARBINARY(size) | |
TINYBLOB | |
BLOB(size) | |
MEDIUMBLOB | |
LONGBLOB |
日期时间类型:
| 类型 | 说明 | |
|---|---|---|
DATE | YYYY-MM-DD | |
DATETIME(fsp) | YYYY-MM-DD hh:mm:ss | |
TIMESTAMP(fsp) | ||
TIME(fsp) | hh:mm:ss | |
YEAR | 1901-2155, 0000 |
PostgreSQL
SQL Server
字符类型
| Data type | Description | Max size | Storage |
|---|---|---|---|
char(n) | 定长字符序列 | 8000 chars | n chars |
varchar(n) | 变长字符序列 | 8000 chars | 2+n chars |
varchar(max) | 变长字符序列 | 1073741824 chars | 2+n chars |
text | 变长字符序列 | 2GB of text data | 4+n chars |
ncharnvarchar | 定长Unicode字符串 | 4000 chars | 2n bytes |
nvarchar(max) | 变长Unicode字符串 | 536870912 chars | |
ntext | 变长Unicode字符串 | 2GB of text data |
Binary类型:
| Data type | Description | Max size | Storage |
|---|---|---|---|
binary(n) | 定长字节序列 | 8,000 bytes | |
varbinary | 变长字节序列 | 8,000 bytes | |
varbinary(max) | 变长字节序列 | 2GB | |
image | 变长字节序列 | 2GB |
数值类型:
| Data type | Description | Storage |
|---|---|---|
bit | 0, 1, or NULL | |
tinyint | 8-bit int 0 to 255 | 1 byte |
smallint | 16-bit int, -32,768 and 32,767 | 2 bytes |
int | 32-bit int | 4 bytes |
bigint | 64-bit int | 8 bytes |
decimal(p,s) | 5-17 bytes | |
numeric(p,s) | 5-17 bytes | |
smallmoney | Monetary data | 4 bytes |
money | Monetary data | 8 bytes |
float(n) | 4 or 8 bytes | |
real | 4 bytes |
日期时间类型:
| Data type | Description | Storage |
|---|---|---|
datetime | 1753/1/1-9999/12/31 , 3.33 milliseconds | 8 bytes |
datetime2 | 0001/1/1-9999/12/31, accuracy of 100 nanoseconds | 6-8 bytes |
smalldatetime | 1900/1/1-2079/6/6, accuracy of 1 minute | 4 bytes |
date | 0001/1/1-9999/12/31 , date only | 3 bytes |
time | time only, accuracy of 100 nanoseconds | 3-5 bytes |
datetimeoffset | as datetime2 ,with time zone offset | 8-10 bytes |
timestamp |
MySQL
MariaDB vs MySQL, a Database Technologies Rundown (kinsta.com)
安装运行
本机安装运行
sudo apt install mysql-server mysql-client # 可选
图形界面:
MySQL Workbench。
使用Yum源安装MySQL
自动添加源信息:下载RPM包,使用安装包自动添加源信息。
sudo yum localinstall mysql80-community-release-fc34-1.noarch.rpm
yum repolist enabled | grep "mysql.*-community.*"
软件源提供多个版本的源信息,但安装官方未提供支持的版本可能出现问题。
MySQL 5.7 does not support Fedora; support was removed in MySQL 5.7.30.
手动添加源信息:/etc/yum.rpo.d/mysql-community.repo
sudo dnf remove @mysql
sudo dnf module reset mysql && sudo dnf module disable mysql
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/7/$basearch/
enabled=1
gpgcheck=0
[mysql-connectors-community]
name=MySQL Connectors Community
baseurl=http://repo.mysql.com/yum/mysql-connectors-community/el/7/$basearch/
enabled=1
gpgcheck=0
[mysql-tools-community]
name=MySQL Tools Community
baseurl=http://repo.mysql.com/yum/mysql-tools-community/el/7/$basearch/
enabled=1
gpgcheck=0
执行安装:
sudo dnf config-manager --disable mysql80-community
sudo dnf config-manager --enable mysql57-community
sudo dnf install mysql-community-server
sudo systemctl enable --now mysqld
如果系统中由
maria-db相关库,可能导致依赖检查失败,需要首先手动卸载maria-db相关库。
修改管理员登录密码:
# [CentOS] 获取临时密码,Ubuntu下初始密码为空
# sudo grep 'A temporary password' /var/log/mysqld.log |tail -1
sudo mysql_secure_installation
# 或使用 mysql -u root -p <<< <temp_passwd>
# 然后修改密码:ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass4!';
The default password policy implemented by
validate_passwordrequires that passwords contain at least one uppercase letter, one lowercase letter, one digit, and one special character, and that the total password length is at least 8 characters.
使用Docker容器
使用docker-compose运行配置文件:
version: "3.1"
services:
db:
image: mysql:5.7
container_name: mysql57
environment:
- "MYSQL_ROOT_PASSWORD=gang2019" # 设置管理员密码
- "MYSQL_DATABASE=exchange" # 设置默认数据库
- "MYSQL_USER=gary" # 添加数据库用户(授权访问上述数据库)
- "MYSQL_PASSWORD=gang2019" # 设置用户密码(测试)
command: --default-authentication-plugin=mysql_native_password
volumes:
- mysql:/var/lib/mysql # 数据库文件的存储位置
- mysqlinit:/docker-entrypoint-initdb.d # 初始化脚本目录(可选)
- mysqlconf:/etc/mysql/conf.d # 自定义配置目录(可选)
ports:
- 3306:3306 # host -> docker
restart: always
adminer: # 管理服务
image: adminer
restart: always
ports:
- 18080:8080
volumes:
mysql:
driver: local
......
目录
mysql和mysql-init不要嵌套。环境变量
MYSQL_ROOT_PASSWORD_FILE=/run/secrets/mysql-root设置从本地文件读取密码,类似地还有MYSQL_PASSWORD等。
或使用脚本运行:
#!/bin/bash
docker run -d \
--name mysql57 \
-v /home/gary/mysql:/var/lib/mysql \
-v /home/gary/mysql-init:/docker-entrypoint-initdb.d \
-v /my/custom:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=gang2019 \
-e MYSQL_USER=gary \
-e MYSQL_PASSWORD=gang2019 \
-e MYSQL_DATABASE=exchange \
mysql:5.7 \
--default-authentication-plugin=mysql_native_password
运行环境和配置
配置
配置文件路径:
Ubuntu:/etc/mysql/mysql.cond.d/mysqld.conf ;
CentOS:/etc/my.cnf;
数据存储路径
datadir=/var/lib/mysql
如果系统启用了SELinux或appamor,则直接修改路径配置将导致服务无法启动。在保证相应目录的文件权限设置正确的情况下,需要检查SELinux的策略配置。
MySQL :: MySQL 8.0 Reference Manual :: 6.7.4 SELinux File Context
版本信息
mysql --version # mysql客户端版本信息
mysql # 登录后客户端显示服务器版本信息
SHOW VARIABLES LIKE 'version';
SELECT VERSION() as version;
STATUS; # 包括服务器版本信息
目录信息
/etc/mysql/mysql.conf.d/mysqld.cnf # mysql-server配置文件
How To Move a MySQL Data Directory to a New Location on Ubuntu 18.04 | DigitalOcean
插件管理
SHOW PLUGINS;
查看MySQL服务状态
sudo netstat -nlp
使用系统服务管理程序(systemctl、service等)管理MySQL服务。
访问MySQL
命令行工具
登录
mysql -u <username> -p [<database>];
mysql -u root -p # 使用root用户登录数据库的root账号
username表示要登录的用户的用户名,-p表示如果用户设置了密码,则在登录时要输入密码。
以下问题可能发生:
-
Shell登录用户密码验证失败:未创建本地访问账户(
user@localhost)或本地账户与远程账户密码不一致。 -
不允许主机访问:未对相应的主机/域名上的用户进行授权,需要在本机创建对应的用户账号。
-
root无法通过密码登录:为管理员账号设置密码(Generic Instructions)。Ubuntu系统下,MySQL 默认以安装软件的用户(通常为
root)为数据的内置账户,通过系统中的用户身份进行登录验证(auth_socket),无需MySQL用户密码。因此,首先尝试使用sudo mysql [-u root]命令进行登录(sudo命令表示以root用户登录数据库,其后的用户参数不一定要使用root,仅使用该用户的信息进行验证);如果失败或者是需要从远程登录,则需要修改MySQL对用户的认证方式。在安全模式下启动MySQL:
systemctl stop mysql # => service mysql stop sudo mkdir -p /var/run/mysqld && chown mysql:mysql /var/run/mysqld sudo mysqld_safe --skip-grant-tables & mysql -u root # login without password service mysql restart==如果未取消==
skip-grant-tables,则无法使用网络连接访问(为了安全起见,服务器未开启网络监听端口)。修改数据库中
root用户的==认证方式==和修改密码:USE mysql; UPDATE user SET plugin="mysql_native_password" WHERE User='root'; ALTER USER root@localhost IDENTIFIED BY 'NewPassword'; flush privileges;终止服务进程并重启服务再尝试登录。
-
warning: cannot change directory to /nonexistent: No such file or directory:https://stackoverflow.com/a/63040661/6571140。该问题导致用户登录无法认证。
sudo usermod -d /var/lib/mysql/ mysql sudo systemctl start mysql.service # service mysql start -
使用
init的系统(例如WSL2)无法正常停止MySQL:为debian-sys-maint配置数据库账户。CREATE USER 'debian-sys-maint'@localhost identified by 'password' GRANT ALL PRIVILEGES ON *.* TO 'debian-sys-maint'@localhost -
Host xxx is blocked:使用mysqladmin -h MYSQL_HOST flush_hosts刷新客户端主机地址缓存。
远程访问
MySQL 8.0默认开放UNIX套接字/var/run/mysqld/mysqld.sock和本地TCP/IP套接字访问localhost/127.0.0.1;因此无法从远程机器连接到数据库(Connection refused error)。
修改MySQL Server配置文件,令bind-address=0.0.0.0,以允许本地回环地址以外的主机访问数据库。
注意:如果错误地将bind-address绑定到非本机IP将导致无法创建TCP套接字。
测试网络访问:
sudo mysqladmin version
mysqladmin \ # no address option for local connect with root
-h $(hostname)|<host_ip> [--port=3306] \ # TCP/IP with user@hostname
--protocol=SOCKET --socket=/var/run/mysqld/mysqld.sock \ # UNIX SOCKET
-u mysqluser \
-p \ # specify user and password
version
--protocol=tcp,socket,pipe,memory
账户管理
创建删除角色
CREATE ROLE [IF NOT EXISTS] role [, role ...]
DROP ROLE [IF EXISTs] role
给定IF NOT EXISTS或IF EXISTS,则在不满足条件时产生警告而非错误。
示例:
CREATE ROLE 'administrator', 'developer';
CREATE ROLE 'webapp'@'localhost';
创建用户
CREATE [OR REPLACE] USER [IF NOT EXISTS] user_name
[IDENTIFIED BY {'password' | PASSWORD 'password_hash'}] # 使用默认认证方法
|[IDENTIFIED WITH auth_plugin ] # 显式指定认证方法(后续再设置密码)
|[IDENTIFIED WITH auth_plugin BY PASSWORD('password')] # mariadb使用USING->BY
DEFAULT ROLE role; # Only MySQL
RENAME USER old_user TO new_user;
SET DEFAULT ROLE
{NONE | ALL | role [, role ...]}
TO user[, user ...]
SET ROLE {
DEFAULT | NONE | ALL [except role[,...]] | role[, role ...]}
username用户名和域名组成'<username>'@'domain'(默认省略域名,等效于以%表示)中如果有特殊字符(例如-)则需要使用引号,密码必须置于引号中。
MySQL/Mariadb 5.x不支持同时设置密码和验证方法,可先创建用户并设定验证方法,随后设置密码。
SET ROLE设置当前用户当前会话的有效角色。
查看用户信息:
SELECT Host, User FROM mysql.user;
删除用户
DROP USER 'bloguser'@'localhost';
修改密码
ALTER USER '<username>'@'domain' IDENTIFIED
[WITH mysql_native_password]
BY '<password>';
SET PASSWORD FOR <user> = PASSWORD('pass_word') # 设置密码Hash值
权限管理
授权给用户或角色
GRANT priv_type ON priv_level TO user_or_role;
priv_level: { * | *.* | db_name.*
| db_name.tbl_name | tbl_name | db_name.routine_name };
GRANT role TO user_or_role;
priv_type表示对数据库的各类操作类型。
示例:
GRANT ALL [PRIVILEGES] ON *.* TO 'garywang';
GRANT ALL ON db1.* TO jeffrey@localhost;
GRANT SELECT, INSERT ON world.* TO 'role3';
GRANT 'role1', 'role2' TO user1, user2;
授权的对象必须存在,否则出错。
ERROR 1410 (42000): You are not allowed to create a user with GRANT.
SHOW GRANTS FOR 'bloguser'@'localhost';
撤销权限
REVOKE ALL PRIVILEGES, GRANT OPTION FROM '<username>';
REVOKE INSERT ON *.* FROM jeffrey@localhost; # revoke insert privilage
REVOKE 'role1', 'role2' FROM user1, user2;
REVOKE SELECT ON world.* FROM role3;
mysql> FLUSH PRIVILEGES;
https://dev.mysql.com/doc/refman/8.0/en/grant.html
退出客户端:
exit;
SQL脚本
在MySQL命令行执行SQL脚本:
source path/to/mysql.sql
在终端执行MySQL命令或SQLSQL脚本:
mysql -u USER -p -e "sql_command"
mysql -u USER -p DATABASE < msyql.sql
SQL命令
- 每条命令以“
;”或“\g”结束; - 命令的关键字和标识符默认不区分大小写;
- 命令行输入可以使用“tab键”自动补全;
- 通过上下键可以查询输入历史;
- SQL 语法表述中“
[]”中包含的内容是可选的,如果没有指明,则表示使用默认的命令;
在交互式命令行通过help命令,查看SQL命令文档。
help CREATE TABLE;
help SELECT;
数据库管理
SHOW DATABASES;
USE database_name;
SHOW TABLES; -- 查看数据库的表
DESC table_name; -- => describe 显示表的字段定义
SHOW COLLATION; -- 显示内置的比较规则
使用SHOW CREATE TABLE查看创建分区的语句;
查看对象的定义
通过输出的语句,可重新创建相同定义的对象。
SHOW CREATE DATABASE db_name \G; # 显示数据库定义
SHOW CREATE TABLE tb_name \G; # 显示表的定义
SHOW CREATE PROCEDURE sp_name \G; # 显示过程定义
SHOW CREATE FUNCTION sp_name \G;
分区
every unique key on the table must use every column in the table's partitioning expression.
当声明unique key(primary key)时,其组成部分必须包含分区的列。
UNIQUE KEY (col1, col2) -- col2 used for partitioning
Range Partition
CREATE TABLE table_name (column_name type contraints,...)
PARTITION BY RANGE (column_name_x) (
PARTITION part_name_a VALUES LESS THAN (n0), # () 是必要的
...
PARTITION part_name_x VALUES LESS THAN MAXVALUE # 不需要括号
)
可以在创建表后(即使已经添加数据)再修改表的定义添加分区定义:
ALTER TABLE table_name PARTITION BY RANGE (column_name_x) (...)
也可以为表格添加一个或多个新的分区:
ALTER TABLE table_name ADD PARTITION (...)
划分已有分区(不会丢失数据):
ALTER TABLE table_name REORGANIZE PARTITION exist_part INTO (
PARTITION s0 VALUES LESS THAN (n00),
PARTITION s1 VALUES LESS THAN (n01)
);
调整分区定义(只能调整连续分区):
ALTER TABLE table_name REORGANIZE PARTITION p0,p1,... INTO (
PARTITION p0 VALUES LESS THAN (n01)
);
ALTER TABLE tbl_name REORGANIZE PARTITION partition_list
INTO (partition_definitions);
List Partition
Hash Partition
Key Partition
分区信息
SELECT TABLE_SCHEMA,TABLE_NAME,PARTITION_NAME,
PARTITION_ORDINAL_POSITION as part_idx,
PARTITION_METHOD as method,
PARTITION_EXPRESSION as part_expr,
PARTITION_DESCRIPTION as part_desc,
TABLE_ROWS as num_rows,
CREATE_TIME
FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'table_name';
分区筛选
支持分区筛选的命令包括:SELECT、DELETE、INSERT、REPLACE、UPDATE、LOAD DATA、LOAD XML。
SELECT * FROM table_name partition (p1,p2,...) WHERE ...
变量
用户变量
set @var_name = EXPRESSION,...; -- => SELECT @test;
一条语句可设置多个变量。
参数和局部变量
CREATE PROCEDURE p(increment INT)
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < 10 DO
-- ... do work ...
SET counter = counter + increment;
END WHILE;
END//
系统变量
系统变量影响数据库行为,其中,全局变量影响当前会话以及其后建立的会话,会话变量仅影响当前会话。要设置永久性的系统变量,应该在选项文件中配置。
全局系统变量
SET GLOBAL max_connections = 1000; -- => SET @@GLOBAL.max_connections = 1000;
要设置的系统变量必须是系统已经定义的,不能通过
SET创建全局变量。
会话系统变量
SET SESSION sql_mode = 'TRADITIONAL';
-- => SET @@SESSION.sql_mode = 'TRADITIONAL';
SET LOCAL sql_mode = 'TRADITIONAL';
-- => SET @@LOCAL.sql_mode = 'TRADITIONAL';
SET sql_mode = 'TRADITIONAL';
-- => SET @@sql_mode = 'TRADITIONAL';
SET max_join_size = DEFAULT;
-- => SET max_join_size = @@GLOBAL.max_join_size;
显示系统变量
SELECT @@GLOBAL.sql_mode; -- => 'TRADITIONAL';
SELECT @@sql_mode -- 局部变量
SHOW VARIABLES -- 显示所有系统变量的名称和值
过程
创建过程的语法如下:
-- CREATE ROUTINE privilege of DEFINER
delimiter // --*
CREATE [DEFINER = user] PROCEDURE [IF NOT EXISTS]
routine_name ([proc_parameter[,...]])
[characteristic ...]
routine_body
CREATE [DEFINER = user] FUNCTION [IF NOT EXISTS]
routine_body_name ([func_parameter[,...]]) RETURNS type
[characteristic ...]
routine_body
delimiter ; --*
过程默认保存在当前使用的数据库,可显式指定关联数据库db_name.routine_name。
routine_body过程内容:可以为单条SQL语句,或由BEGIN...END语句块包含多条SQL语句。
*:过程中==包含多条SQL语句==时,过程本身的结束标识和过程内容routine_body中的语句结束标识不能一致,因此修改当前环境的结束标识为//。
PROCEDURE参数列表:[IN|OUT|INOUT] param_name type,默认为IN(输入参数),OUT(输出参数,初始值为NULL)可将值返回给调用者。
FUNCTION参数列表:param_name type,函数形式通过RETURN语句返回结果,RETURNS语句声明返回结果的类型。
调用过程
call db_name.routine_name(proc_parameter,...)
数据导入导出
SQL脚本
MySQL中如果表和表之间建立的外键约束,则无法删除表及修改表结构。解决方法是在Mysql中取消外键约束:
SET FOREIGN_KEY_CHECKS=0;然后将原来表的数据导出到sql语句,重新创建此表后,再把数据使用sql导入,然后再设置外键约束:SET FOREIGN_KEY_CHECKS=1;
命令行导入导出工具
mysqldump生成SQL语句以重新申城原数据库对象的定义以及数据表的数据,用于备份数据库或传输到其他SQL服务器,mysqldump命令还可以输出CSV、其他分隔符文件或XML文件。
mysqldump -u root -p DATABASE_NAME [TABLE_NAME...] \
--result-file=database_name.db # 导出一个库的某些表
--databases db_name ... # 导出指定的库
--all-databases # 导出所有库
-d, --no-data # 不导出数据仅导出定义
mysqldump [options] --tab=dirname \ # 仅用于服务器所在机器,因为服务器要在指定目录创建文件
--fields-terminated-by=... --fields-enclosed-by=... --fields-escaped-by=... \
--lines-terminated-by=... # mysqldump独立生成数据表创建文件和MYSQL服务导出数据文件
mysqldump使用和mysql相同参数连接数据库服务。
mysqldump可以方便查看和编辑导出的数据,适用于测试开发目的;但并不是一种快速或可扩展的备份大量数据的方法,因为恢复数据时执行SQL语句将产生大量插入、创建索引等磁盘I/O,导致恢复过程及其缓慢。对于大数据备份和恢复,可直接复制数据库文件目录。
问题
-
'Access denied; you need (at least one of) the PROCESS privilege(s) for this operation' when trying to dump tablespaces:指定
--no-tablespaces选项。 -
error: 1227: Access denied; you need (at least one of) the FILE privilege(s) for this operation when executing 'SELECT INTO OUTFILE':指定全局文件权限
GRANT FILE ON *.* TO user; -
error: 1290: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement when executing 'SELECT INTO OUTFILE':当指定
--tab选项时,仅能从secure-file-priv指定的目录读写数据或在配置文件中将指定路径清空。SHOW VARIABLES LIKE "secure_file_priv"[mysqld] secure-file-priv = ""
mysql -u USER -p DB_NAME < database_name.db
mysql db_name < backup-file.sql
mysql -e "source /path-to-backup/backup-file.sql" db_name
导入文本数据(CSV)
mysqlimport [options] db_name textfile1 [textfile2 ...]
LOAD DATA [LOCAL] INFILE 'path/to/file.csv' INTO TABLE table_name
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS; -- 忽略表头
如果使用--tab导出的数据,可分别导入.sql文件和文本文件。
MySQL命令行导入导出工具
MySQL连接器
Java
使用包管理器(rpm或deb)安装连接器的库还需要顺带安装依赖包。
========================================================================
Package Arch Version Size
========================================================================
Installing:
mysql-connector-java noarch 1:8.0.26-1.el7 2.7 M
Installing for dependencies:
avahi-libs x86_64 0.6.31-20.el7 62 k
copy-jdk-configs noarch 3.3-10.el7_5 21 k
cups-libs x86_64 1:1.6.3-51.el7 359 k
java-1.8.0-openjdk-headless x86_64 1:1.8.0.302.b08-0.el7_9 33 M
javapackages-tools noarch 3.4.1-11.el7 73 k
libjpeg-turbo x86_64 1.2.90-8.el7 135 k
libxslt x86_64 1.1.28-6.el7 242 k
lksctp-tools x86_64 1.0.17-2.el7 88 k
pcsc-lite-libs x86_64 1.8.8-8.el7 34 k
python-javapackages noarch 3.4.1-11.el7 31 k
python-lxml x86_64 3.2.1-4.el7 758 k
tzdata-java noarch 2021a-1.el7 191 k
如果只需要连接器的库,可下载平台无关的档案文件。
常见问题
ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes:将键对应的列的数据类型长度减小。MySQL 经典案例分析:Specified key was too long - 云+社区 - 腾讯云 (tencent.com)。
PostgreSQL
安装
Ubuntu
sudo apt install postgresql postgresql-client
CentOS
wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y ./pgdg-redhat-repo-latest.noarch.rpm
yum install -y postgresql12-server # or postgresql-server
docker
version: "3.1"
services:
db_postgres:
image: postgres:12
container_name: postgresql-server
environment:
- "POSTGRES_PASSWORD=gang2019"
# POSTGRES_PASSWORD_FILE=/run/secrets/postgres-passwd
volumes:
- pgdata:/var/lib/postgresql/data
- pginit:/docker-entrypoint-initdb.d # contains init-user-db.sh
ports:
- 5432:5432
volumes:
pgdata:
driver: local
pginit:
driver: local
可以和
adminer部署在同一集群,从而方便数据库管理。
配置
远程访问
设置访问地址和端口(默认监听localhost):
# edit: /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*' # listen to all address
port = 5432
网络访问规则
用户访问时规则从上到下匹配,匹配到规则后按相应规则校验是否能访问数据库,不再使用后续规则。因此,匹配范围大的规则通常放在靠后位置。
# edit: /var/lib/pgsql/12/data/pg_hba.conf
# IPv4 local connections:
# TYPE DATABASE USER ADDRESS METHOD
host all gary 0.0.0.0/0 md5 #*
host all all 127.0.0.1/32 ident
*:密码认证方法,可使用md5或scram-sha-256(推荐)。对于已有用户切换密码验证方法,参考:PostgreSQL中使用scram-sha-256认证 - 墨天轮 (modb.pro)。
设置防火墙规则:
sudo firewall-cmd --add-service=postgresql --permanent
数据存储位置
新的数据存储位置的所有者需要是数据库服务进程的用户(postgres),同时访问权限应该为700/750(即不能包含others访问权限)。如果已经经过初始化,则需要将原数据存储目录下的内容复制到新目录下(cp -ra)。
启动服务
==初始化数据库==(CentOS):
sudo /usr/pgsql-12/bin/postgresql-12-setup initdb # or postgresql-setup initdb
启动数据库:
sudo service postgresql start # => WSL2
sudo systemctl enable --now postgresql-12
服务的日志数据位于:/var/lib/pgsql/data/log/。
命令行工具
访问数据库
安装完毕后,会在系统中创建一个超级用户postgres(密码为空)。使用该用户管理据库。
sudo -i -u postgres
psql \
-h,--host=PGHOST \ # 服务器地址或UNIX套接字地址:/var/run/postgresql*
-p,--port=PGPORT \ # 端口:5432
-U,--username=NAME \ # 用户名:postgres,使用相应地系统账号登录
-w,--no-password \ # 不提供密码
-W,--password \ # 输入密码提示
[dbname] # 默认:与用户名同名的数据库
*:如果未指定主机IP地址,则默认连接本地套接字地址。
查看数据库服务版本:
SELECT version();
使用\q退出数据库终端。
Peer authentication and password authentication.
本地账号默认使用peer方式登录,即使用当前系统用户的身份凭据作为数据库的身份凭据。如果要在当前系统用户登录其他账户,应该采用密码认证模式,将认证方式从peer改为md5。针对默认账户postgres,首先使用peer模式登录系统后为其设置密码\password postgres。
# edit: /etc/postgresql/12/main/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
local all postgres md5
local代表UNIX域套接字。
导入导出数据
pg_dump -h src_host -U src_user src_db > table-to-copy.sql
-f,--filename=FILENAME # 代替重定向命令输出
-a,--data-only # 仅导出数据(不包含模式)
-s,--schema-only # 仅导出表结构定义
-C,--create # 包含创建数据库的命令
-n,--schema=SCHEMA # 只导出指定名称的模式
-N,--exclude-schema=SCHEMA # 不导出指定名称的模式
-t,--table=TABLE # 仅导出指定名称的表
psql -h dst_host -U dst_user -d dst_db -f table-to-copy.sql
可多次使用
-t选项一次性导出多个表。
用户管理
命令行模式:
createuser -h localhost USERNAME -P # 最后需要输入postgres的密码*
*:如果使用密码登录,则需在数据库访问规则中添加密码访问规则(md5)。
显示用户信息:
\du -- lists all user
授权
使用管理员账户登录为用户授权。
授权数据库访问权限:
GRANT CREATE ON DATABASE database_name TO [GROUP] role_name;
权限声明包括:CREATE,CONNECT,TEMPORARY,TEMP或全部权限ALL [PRIVILEGES]。
授权表的访问权限:
\c DB_NAME # use ngsoc
GRANT SELECT ON TABLE table_name TO [GROUP] role_name;
GRANT ... ON ALL TABLES IN SCHEMA schema_name TO [GROUP] role_name;
权限声明包括一个或多个:SELECT,INSERT,UPDATE,DELETE,TRUNCATE,REFERENCES,TRIGGER或使用ALL表示所有权限。
PostgreSQL: Documentation: 9.0: GRANT
执行SQL脚本
psql obejctrocket [options] -d db_name -f test.sql
在交互式环境下执行SQL脚本:
\c db_name
\i /path/TO/file_name.sql
数据库管理命令
Database管理
\l -- list databases
\c db_name -- use database
select * from pg_catalog.pg_collation; -- show collation
Basically, information schema is a set of views of pg_catalog.
PostgreSQL supports the standard SQL types int, smallint, real, double precision, char(N), varchar(N), date, time, timestamp, and interval, as well as other types of general utility and a rich set of geometric types. PostgreSQL can be customized with an arbitrary number of user-defined data types.
Constants that are not simple numeric values usually must be surrounded by single quotes (').
创建database
使用SQL语句创建数据库。或使用数据库命令行工具,创建:
createdb mydb # <-> CREATE DATABASE mydb
删除database
dropdb mydb # DROP DATABASE mydb
Schema管理
获取命名空间信息
命名空间(schema)是一个数据库所包含数据表的逻辑分组。
SELECT catalog_name,schema_name,schema_owner
FROM information_schema.schemata;
SELECT nspname,nsponwer,nspacl FROM pg_catalog.pg_namespace;
schema_name和nspname是一一对应的。
创建Schema
CREATE SCHEMA [IF NOT EXISTS] schema_name [AUTHORIZATION user_name]
[schema_element [...]];
DROP SCHEMA schema_name;
schema_name:defaults to user_name.
user_name:the new schema's owner, defaults to the current user.
schema_element:Schema中需要创建的内容(包括TABLE, VIEW, INDEX, GRANT等),也可在创建Schema之后创建内容。
切换Schema
set search_path to schema_name;
Table管理
获取数据表
pgsql命令:
\d[+] -- show tables [and schema]
-- Schema | Name | Type | Owner
-- -------+----------------+-------------------+----------
-- public | pokemon | partitioned table | postgres
-- public | pokemon_gen_01 | table | postgres
\dn -- show user created schema
SQL语句:
SELECT schemaname,tablename,tableowner,*
FROM pg_catalog.pg_tables
WHERE schemaname != 'pg_catalog'
AND schemaname != 'information_schema';
SELECT table_schema,table_name
FROM information_schema.tables
WHERE table_schema = 'public';
获取数据表详细信息
pgsql命令:
\d[+] table_name -- -> DESC table: '+'显示更多列和分区定义
SQL语句:
SELECT column_name,data_type
FROM information_schema.columns
WHERE table_schema = 'table_name';
创建数据表
If a schema name is given (for example, CREATE TABLE myschema.mytable ...) then the table is created in the specified schema. Otherwise it is created in the current schema. Temporary tables exist in a special schema, so a schema name cannot be given when creating a temporary table. The name of the table must be distinct from the name of any other table, sequence, index, view, or foreign table in the same schema.
复制数据表
跨数据库复制数据表
不支持直接跨数据库复制表格,需要首先将数据从一个数据库导出,再导入另一个数据库。
修改表格
ALTER TABLE [IF EXISTS] name RENAME TO new_name
ALTER TABLE [IF EXISTS] name SET SCHEMA new_schema
ALTER TABLE [IF EXISTS] name RENAME [COLUMN] column_name TO new_column_name
数据表分区
The partitioned table itself is a “virtual” table having no storage of its own. Instead, the storage belongs to partitions, which are otherwise-ordinary tables associated with the partitioned table. Each partition stores a subset of the data as defined by its partition bounds. All rows inserted into a partitioned table will be routed to the appropriate one of the partitions based on the values of the partition key column(s). Updating the partition key of a row will cause it to be moved into a different partition if it no longer satisfies the partition bounds of its original partition.
分区引用的列使用PARTITION BY声明。
CREATE TABLE table_name (column1 data_type, column2 data_type, …)
PARTITION BY RANGE(col_name1,...);
CREATE TABLE table_part_xx PARTITION OF table_name
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
每个分区被存储为一个目录。
INSERT INTO TABLE table_name
PARTITION (partition1='partition1_val', partition2='partition2_val', ...)
VALUES (col1_val, col2_val, …, partition1_val, partition2_val, …);
必须在创建时定义分区,创建分区表后,仅能添加或移除分区。
ALTER TABLE [ IF EXISTS ] name
ATTACH PARTITION partition_name { FOR VALUES partition_bound_spec | DEFAULT }
ALTER TABLE [IF EXISTS] name DETACH PARTITION partition_name
不支持分区和分解和合并,可以将相关分区先移出父表,再修改分区定义,并将移出的子表格数据写回父表。
数据类型
PostgreSQL 数据类型 | 菜鸟教程 (runoob.com)
继承
CREATE TABLE cities (
name text,
population real,
elevation int -- (in ft)
);
CREATE TABLE capitals (
state char(2) UNIQUE NOT NULL
) INHERITS (cities); -- 继承表的定义并进行扩展
ONLY
Hive SQL
Hive是基于Hadoop的数据库,底层数据存储采用HDFS,提供HQL(Hive SQL)查询功能。
Hive将SQL语句转换为MapReduce任务运行。
Hive用于做海量离线数据统计分析:
- 不支持记录级别的增删改操作,可以将查询结果导出到文件
- 查询延时很严重,因为 MapReduce任务的启动过程消耗很长时间,所以不能用在交互查询系统中。
- 不支持事务,因为没有增删改操作,所以主要用来做 OLAP(联机分析处理),而不是 OLTP(联机事务处理)。
配置
Hive命令行回显结果不显示表名:
hive> set hive.resultset.use.unique.column.names=false;
定义数据库
CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name
[COMMENT 'database comment']
[WITH DBPROPERTIES (property_name=property_value, ...)];
DROP DATABASE|SCHEMA [IF EXISTS] database_name [RESTRICT|CASCADE];
CASCADE删除数据库前先删除表格,默认情况RESTRICT如果数据库非空则删除操作失败。
定义数据表
CREATE TABLE tablename (
col_name DATA_TYPE [constraints] [COMMENT col_comment], ...)
[COMMENT 'table comment'] -- 表格说明
[PARTITIONED BY (col_name data_type,...)] -- 分片: 必须声明为(col type)格式
ROW FORMAT DELIMITED -- 分隔符文件
FIELDS TERMINATED BY '\t' -- 分隔符
-- LINES TERMINATED BY '\n'
STORED AS TEXTFILE -- 存储格式:默认TEXTFILE,其他PARQUET、AVRO、ORC、JSONFILE等
TBLPROPERTIES("skip.header.line.count" = "1",...);
DROP TABLE tablename [purge];
==分片的列单独声明==,不应在列定义中重复声明;STORED AS TEXTFILE应该放在其他格式声明之后。
数据表属性声明:
skip.header.line.count=1:使用Hive查询时,跳过数据文件中的首行(包含表头的情况,列名不要包含特殊字符,如#,空格等)。
对于具有表头的原始数据,可以去除表头后再导入HDFS(从而与Spark读取处理方式兼容)。
tail -n +2 data.csv > data_nohead.csv
hdfs dfs -put data_nohead.csv /datasets/data.csv
对于较大数据量,使用
tail处理时间较长(需要复制数据)。
查看表的定义
DESC table_name; -- DESCRIBE
SHOW CREATE TABLE table_name;
# STORED AS TEXTFILE <=> STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
# OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
# LOCATION 'hdfs://CLUSTER_ADDR/hive/warehouse/DBNAME.db/TABLE_FILE'
从定义中可看到表的底层数据在HDFS上的存储位置。
自动获取数源的定义
使用Pandas可加载数据文件并自动推导数据类型定义,然后生成数据表的定义。
table_schema = pd.io.sql.get_schema(df.drop(columns=parition_cols), 'table_name')\
.replace('"', '`')\
.replace('TEXT', 'STRING')\
.replace('INTEGER', 'INT')
# print(table_schema)
# CREATE TABLE `table_name` (
# `field1` STRING,
# `field2` INT
# )
转换后的SQL语句语法不完全与HQL兼容,例如需要将标识符范围限定符"(PosgreSQL)替换为ˋ(MySQL);某些类型关键字转换(如TEXT转换为STRING)。此外,为了支持设置分片列声明,可提前将分片列从源数据中分离出来并单独生成类型声明。
part_schema = pd.io.sql.get_schema(df[parition_cols], 'part_name')\
.replace('"', '`')\
.replace('TEXT', 'STRING')
part_schema = ''.join(part_schema.split('\n')[1:-1])
基于上述结果,可继续添加Hive表格属性限定声明(如分片、分隔符、存储格式等),从而生成Hive表格定义。
table_schema = '\n'.join(table_schema, f"PARTITIONED BY ({part_schema})",
"ROW FORMAT DELIMITED", "STORED AS TEXTFILE", ...)
如果使用Spark加载数据文件为表格,类似地,能基于自动推导生成表格定义(需要自行生成SQL语句)。
def spark_get_schema(df, tablename):
ts = []
ts.append(f'CREATE TABLE `{tablename}` (')
tts = []
for x in df.schema:
tts.append('`{0}` {1}'.format(x.name, x.dataType.typeName()))
ts.append(',\n'.join(tts))
ts.append(')')
table_schema = '\n'.join(ts)
return table_schema
修改表定义
ALTER TABLE table_name RENAME TO new_table_name; # 修改表名
ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, ...);
修改表的Schema,不在参数声明中的列将被丢弃。
修改表属性
ALTER TABLE pokemon SET TBLPROPERTIES ("skip.header.line.count"="1");
数据类型
基本类型
| 分类 | 数据类型 |
|---|---|
| 逻辑类型 | BOOLEAN |
| 整数 | TINYINT,SMALLINT,INT,BIGINT |
| 浮点数 | FLOAT,DOUBLE |
| 高精度浮点数 | DECIMAL,DECIMAL(precision, scale) |
| 字符文本 | STRING,VARCHAR,CHAR |
| 时间日期 | TIMESTAMP,DATE |
| 原始数据 | BINARY |
导入数据
将本地文件导入Hive数据仓库:
LOAD DATA [LOCAL] INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
LOAD DATA [LOCAL] INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
LOCAL:从本地文件系统上传(省略则从HDFS中查找文件并移动到hive目录下);OVERWRITE覆盖当前已有数据(省略则==追加==到当前数据);如果是已定义分区的数据表,则必须指定PARTITION指定要写入数据的分区(分区字段将被写入设置的值,而非源数据中的值)。
不会验证数据的
schema;
读取数据
使用SQLSELECT语句进行查询,结果将输出至标准输出。
查询的列名可使用正则表达式模糊匹配。
保存数据
使用HiveINSERT命令将查询结果写入Hive表、HDFS或本地存储。
INSERT OVERWRITE [LOCAL] DIRECTORY 'directory1'
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...;
-- row_format
:DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
INSERT OVERWRITE DIRECTORY '/tmp/hdfs' SQL_STATEMENT; -- to HDFS
INSERT OVERWRITE TABLE events; -- to hive table
INSERT OVERWRITE LOCAL DIRECTORY '/tmp' SQL_STATEMENT; -- to local storage
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
基于分区的查询
计算
在查询语句使用TRANSFORM和USING,可以调用外部程序(例如使用Python脚本)处理数据。
import sys
import datetime
for line in sys.stdin: # 从标准输入读取一行数据
line = line.strip()
userid, movieid, rating, unixtime = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([userid, movieid, rating, str(weekday)]) # 输出结果到标准输出
add FILE weekday_mapper.py;
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (userid, movieid, rating, unixtime)
USING 'python weekday_mapper.py' -- 运行Python程序处理每一行记录
AS (userid, movieid, rating, weekday)
FROM u_data;
GettingStarted - Apache Hive - Apache Software Foundation
Tutorial - Apache Hive - Apache Software Foundation
LanguageManual DDL - Apache Hive - Apache Software Foundation
LanguageManual DML - Apache Hive - Apache Software Foundation
Elasticsearch
准备工作
安装Elasticsearch
Ubuntu
apt
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo apt-get install apt-transport-https
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
sudo apt-get update && sudo apt-get install elasticsearch logstash filebeat
程序的安装位置为
/usr/share。
deb
CentOS
软件仓库安装
rpm包安装
wget https://artifacts.elastic.co/.../elasticsearch-7.14.1-x86_64.rpm
wget https://artifacts.elastic.co/.../elasticsearch-7.14.1-x86_64.rpm.sha512
shasum -a 512 -c elasticsearch-7.14.1-x86_64.rpm.sha512
sudo rpm --install elasticsearch-7.14.1-x86_64.rpm
Docker
安装最新版ElasticSearch必须带具体标签(latest标签未绑定至最新版本)。
Development Mode (Single Node)
docker network create elastic
docker run -d --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:tag
Note: Pulling an images requires using a specific version number tag. The
latesttag is not supported.
Production Mode
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/docker.html
The vm.max_map_count kernel setting must be set to at least 262144 for production use.
Error:
> ERROR: for kib01 Container "7d61ad9aeddd" is unhealthy. > bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
vi /etc/sysctl.conf
vm.max_map_count=262144 # permanent settings for Linux
sudo sysctl -w vm.max_map_count=262144 # enable now for WSL (/etc/rc.local => u+x)
kibana
kibana用于Elasticsearch数据的可视化分析,可以与Elasticsearch安装在同一集群。
https://www.elastic.co/guide/en/kibana/current/docker.html
services:
kibana:
image: kibana:7.9.2
container_name: kibana7
environment:
ELASTICSEARCH_HOSTS: http://es_node:9200
ports:
- "5601:5601"
默认的Elasticsearch集群主节点名为elasticsearch,如果不是,通过环境变量ELASTICSEARCH_HOSTS设置,否则无法与集群建立连接。
启用安全配置
启用HTTPS/TLS:https://www.elastic.co/guide/en/elastic-stack-get-started/7.12/get-started-docker.html。启用HTTP后,访问elasticsearch/kibana都需要用户名和密码进行验证。
# 重启集群应用密码
docker-compose -f elastic-docker-tls.yml stop
docker-compose -f elastic-docker-tls.yml up -d
# 清理环境
docker-compose -f elastic-docker-tls.yml down -v
WSL中的证书文件:\\wsl$\docker-desktop-data\version-pack-data\community\docker\volumes\es_certs\_data(安装证书到系统)
问题
-
*WSL2文件系统访问权限问题
"Causedby:java.nio.file.NoSuchFileException:/usr/share/elasticsearch/data/nodes/0/node.lock"
原因:可能是镜像对挂载的数据卷(位于docker的卷目录下,在WSL中实际映射到Windows的文件系统中)没有正确的读写权限。==该问题在Linux虚拟机中不曾出现,且在删除出错的服务和数据卷后重新创建服务后该问题没有复现==。
-
问题:Exception in thread "main" java.nio.file.FileSystemException: /tmp/elasticsearch-15594239510299122966: No space left on device。
原因:宿主机存储空间不足,无法创建数据卷。清理磁盘或增加磁盘容量。
配置
系统配置(/etc/default/elasticsearch[Ubuntu]或/etc/sysconfig/elasticsearch[CentOS]):包括ES运行相关的系统环境变量。
ES_PATH_CONF=/etc/elasticsearch # default
ES_JAVA_HOME=/usr/share/elasticsearch/jdk/bin/java
MAX_OPEN_FILES=65535
配置文件位于/etc/elasticsearch/elasticsearch.yml。重要配置项:
ES_TMPDIR: /data/tmp/es # 不使用默认临时文件目录防止被以外删除
node.name: es_005_data # 默认为$(hostname)
path:
data: /path/to/data # Multiple data paths deprecated in 7.13
logs: /path/to/logs
path.plugins: /path/to/plugins
network.host: 0.0.0.0 # 默认仅监听loopback
action.auto_create_index: *
ElasticSearch自带Java运行环境。ElasticSearch默认监听端口9200,如果被占用,将自动向后查询可用端口。
集群环境配置:
cluster.name: es_cluster # 集群名相同的节点才能加入集群
discovery.seed_hosts: # 发现集群节点,默认会扫描同一机器上的实例(9300 to 9305)
- node-1
- 192.168.1.11:9300
- seeds.mydomain.com
cluster.initial_master_nodes:
- node-1 # => node.name
- node-2
# at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master节点,并加入集群。
集群恢复:在集群重启的时候避免过多的分片交换。这可能会让数据恢复从数个小时缩短为几秒钟。
# gateway.recover_after_nodes: 3 # 集群至少有3个节点可用才开始恢复数据
gateway.recover_after_master_nodes: 1
gateway.recover_after_data_nodes: 3
# gateway.expected_nodes # 等待达到4个节点或持续5min钟后开始恢复
gateway.expected_data_nodes: 3
gateway.expected_master_nodes: 1
gateway.recover_after_time: 5m
配置插件
elasticsearch-plugin install [plugin_name] # curl host:9200/_cat/plugins
配置logstash
插件管理
Logstash包含了常用插件。
bin/logstash-plugin list --verbose
--group output|input|filter|codec
在线安装插件
从RubyGems.org获取插件:
logstash-plugin install|remove logstash-input-github
logstash-plugin install /path/to/logstash-output-kafka-1.0.0.gem # 安装本地插件
logstash-plugin update [logstash-input-github] # 默认更新所有插件
离线安装和更新插件:
logstash-plugin prepare-offline-pack --output OUTPUT.zip --overwrite [PLUGINS]
logstash-plugin install|update file:///path/to/logstash-offline-plugins.zip
PLUGINS表示要打包的插件(可使用通配符*)。
logstash执行环境
node.name: ${HOSTNAME}
path.data: LOGSTASH_HOME/data
timzzone?
pipelines.yml:
logstash管道配置
/etc/logstash/conf.d
The default Logstash installation includes the Beats input plugin. The Beats input plugin enables Logstash to receive events from the Elastic Beats framework, which means that any Beat written to work with the Beats framework, such as Packetbeat and Metricbeat, can also send event data to Logstash.]
可定义多个输入数据源和输出目标。
input {
beats {
port => "5044"
}
file {
path => "/var/log/messages"
type => "syslog"
}
kafka{
bootstrap_servers=>"192.168.13.10:9092"
topics=>["kafka_es_test"]
group_id=>"logstash_kafka_test"
}
}
filter {
grok {
# parse apache web logs
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => [ "localhost:9200" ]
index => "logstash_kafka_test"
}
}
测试
"@timestamp"日志收集时间,非日志中表示时间的字段。
bin/logstash -f first-pipeline.conf --config.test_and_exit # 测试配置文件
bin/logstash -f first-pipeline.conf --config.reload.automatic # 启用管道
启用服务
sudo systemctl daemon-reload
sudo systemctl enable --now elasticsearch.service # sudo is required
sudo systemctl start logstash.service
查看状态
查看集群状态
http://hostip:9200/ # 访问elasticsearch
http://hostip:5601/ # 访问kibana
GET /_cat/health?v
GET _cluster/health
The cluster status will remain yellow if you are only running a single instance of Elasticsearch.
查看日志
sudo journalctl --unit elasticsearch \
--since "2016-10-30 18:17:16"
API
使用REST接口访问Elasticsearch以查询或写入数据。使用curl提交数据访问请求:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB:GET, POST, PUT, HEAD, or DELETE.
PROTOCOL:http or https
PATH:数据路径。
BODY:JSON请求体。
示例:
curl -XGET http://localhost:9200/_index/_doc/_id
查看可用管理接口
_/cat # 列出可用接口
列出的接口通常有两种调用方式:
_cat/ACTION?v # 返回简要信息(表格,v显示表头)
_ACTION # 返回详细信息(JSON)
/_cat/snapshots对应的API是/_snapshot[/{repo_name}]
常用接口:
GET /_cat/indices/{index}?v # 查看(指定索引模式)索引列表
GET /_cat/templates/?v # 查看索引模板
# health status index uuid pri rep docs.count ... store.size ...
GET /_cat/tasks?v # 查看正在运行的任务
# action task_id ... type start_time ... running_time ip node
GET /_cat/health?v # 查看集群状态
GET /_cat/master?v # 查看主节点信息
GET /_cat/nodes?v # 查看主节点信息
GET /_cat/plugins?v # 查看各节点安装的插件信息
GET /_cat/repositories # 查看快照仓库列表
GET /_cat/count/{index}?v # 查看(指定索引模式)文档数量
查看索引定义
GET /<index>
GET /<index>/{_mapping|_mappings}
GET /<index>/_mapping/field/fieldname //显式定义的映射才有返回结果
GET /<index>/_settings
GET /<index>/{_alias|_aliases}
GET _data_stream
GET _data_stream/{data_stream_name}
index可以包含通配符,_all代表所有索引(等效于*或省略索引)。
索引生命周期管理
将旧数据移动到较为便宜的存储设备中,从而提高性能并减小开销。
data tiers
| tiers | necessity | description |
|---|---|---|
| hot warm | required optional | 高性能节点 快速索引和搜索最近数据 |
| content | required | 非时序数据 |
| cold frozen | optional | 慢速便宜节点 |
在节点的配置文件中声明节点对应的tier。一个节点可以对应一个或多个tier。
node.roles: [ data_content, data_hot, data_warm ]
Searchable Snapshot
使用可搜索快照以减小本地存储开销。
Hadoop HDFS Repository Plugin | Elasticsearch Plugins and Integrations 7.14 | Elastic。
// PUT _snapshot/my_hdfs_repository
{
"type": "hdfs",
"settings": {
"uri": "hdfs://namenode:8020/",
"path": "elasticsearch/repositories/my_hdfs_repository",
"conf.dfs.client.read.shortcircuit": "true"
}
}
生命周期策略
内置生命周期策略:logs,metrics,synthetics。
GET _ilm/policy
GET _ilm/policy/logs
PUT _ilm/policy/my-lifecycle-policy
{...}
写入数据
将JSON文档存入Elasticsearch索引。
- 按需创建索引:添加数据时创建对应的索引,使用动态映射;
- 手动创建索引:
- 使用显式映射;
- 使用动态映射;
- 基于模板自动创建索引:添加映射模板和设置模板(生命周期管理);
术语
索引
索引名称:在API中索引名称可使用日期函数动态生成查询索引名。表达式:
<static_name{now/d{yyyy.MM.dd-HH:mm:ss|+08:00}}>
索引名称中的包含的特殊字符必须使用URL编码:
from urllib.parse import quote
index = quote_plus(index_expr) # quote_plus对"/"也进行编码,以与路径分隔符区分开
浏览器等Web客户端通常会自动编码,而使用API时需要手动进行上述编码转换。
 文档
文档
JSON对象。
文档类型
type,即一个索引可声明一个或多个映射类型,在提交或查询数据时指定type,则按指定类型映射进行处理。如果一个索引的多个映射类型包含同一字段,但其数据类型不同,则在索引或查询数据时会产生冲突。5.6版本设置
index.mapping.single_type: true使索引仅支持单个映射类型;6.x版本仅支持定义单个type(可以是任意合法标识),且为了与7.x版本兼容,最好声明为_doc;7.x版本将弃用type声明(在API请求中声明参数include_type_name=true将产生启用警告),8.x版本将不再支持声明type。在新版本中索引的API中,
type=_doc且不再表示文档类型,仅作为API路径(类似于_mappings和_settings_):PUT {index}/_doc/{id} POST {index}/_doc
Runtime fields:查询时进行计算的字段。
索引文档
创建索引
如果没有配置自动创建索引,那么在索引文档前,需要首先创建索引。
// PUT /my-index-000001
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
},
"mappings": {
"properties": {
"field1": { "type": "text" }
}
}
}
创建索引时,可选择指定索引的配置、映射等信息。如果未指定映射,则索引将使用默认的自动映射规则。创建完成后返回执行状态。
{'acknowledge': True, 'shards_acknowledged': True}
删除索引
DELETE /<index_name>
不支持通配符批量删除。
索引的数据类型映射
将文档中的数据字段转换为ES存储的目标数据类型,在创建索引时为索引指定映射设置。
显式类型映射
映射定义了文档字段的数据类型、格式等。查看映射的定义。
//PUT /my-index-000001
{
"mappings": {
"<doc_type>":{ // *
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
} } } }
*:doc_type已弃用(7.x)无须声明,直接将properties声明在mappings中。5.x需要声明。
更新映射:添加一个字段。注意,通常无法修改已经定义的字段,否则会与已有数据冲突。
//PUT /my-index-000001/_mapping # =>
{
"properties": {
"city": {
"type": "text",
"fields": { // 该字段的属性
"name": {
"type": "keyword"
}
}
}
}
动态类型映射
ES自动解析数据并设定对应的字段的类型。
Dynamic field mapping | Elasticsearch Guide 7.14 | Elastic
-
自动类型映射:修改自动映射配置(如果索引不存在将自动创建索引):
//PUT my-index-000001 { "mappings": { "<doc_type>": { // * "dynamic": true, "date_detection": true, // 转换日期类型 "dynamic_date_formats": ["MM/dd/yyyy"], // 日期转换格式 "numeric_detection": true } } }*:doc_type已弃用(7.x)无须声明,直接将properties声明在mappings中。5.x需要声明。 -
基于规则的动态类型映射:基于规则进行类型映射。
{
"mappings":{
"dynamic_templates":[ // 可定义多个动态映射模板
{
"as_integer":{ // 模板名称
"match_mapping_type": "long", // 匹配检测到的数据类型*
"norms": false, // 不存储index-time scoring factor
"mapping":{
"type": "integer",
"index": false // 不索引该字段**
}
}
},
{
"as_date":{
"match_pattern": "regex",
"match": "_time$", // 匹配字段名
"unmatch": "^collect",
"mapping":{ }
}
},
{
"as_keyword":{
"path_match": "name.*", // 匹配路径名
"path_unmatch": "*.middle",
"mapping": {},
"runtime": {}, // 查询时将字符串转换为keyword
}
]
}
}
*:匹配条件:如果未指定match_mapping_type,match,path_match中的任意一个,则该动态模板不会匹配任何字段。
查询时映射
- 通过脚本生成运行时的字段。
- 在执行搜索时定义运行时字段。
索引模板
如果索引名不存在且匹配该模板,则ES将根据该模板创建索引。
创建模板组件
索引模板组件通常由映射(mappings)和索引设置(index settings)模板组成。模板组件从模板定义中被抽离出来从而可以被==复用==(索引生命周期策略配置同理)。
映射模板
// PUT _component_template/my-mappings # => Create a mappings template
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date", // 数据类型
"format": "date_optional_time||epoch_millis" // 格式
},
"message": {
"type": "wildcard"
}
}}},
"_meta": {
"description": "Mappings for @timestamp and message fields",
"my-custom-meta-field": "自定义元数据"
}}
索引设置模板
索引设置定义了索引的生命周期策略。
//PUT _component_template/my-settings # Create a index settings template
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy" // 索引生命周期策略
}},
"_meta": {
"description": "Settings for ILM",
"my-custom-meta-field": "自定义元数据"
}}
创建索引模板
//PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"], // 匹配索引/数据流的名称
"data_stream": { }, // data stream enabled
"composed_of": [ "my-mappings", "my-settings" ], // 模板组件
"priority": 500, // 优先级>=200,避免与内置索引模板冲突
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}}
创建文档
使用PUT/POST提交文档
将JSON文档存储为ES索引对象。API接口格式:
// PUT /<index>/_doc/<_id> # 创建或更新指定id文档 *
// POST /<index>/_doc/ # 创建文档并自动创建id **
// PUT /<index>/_create/<_id> # 显式创建指定id的文档
// POST /<index>/_create/<_id> # 显式创建指定id的文档
{
"fristName": "sunke",
"lastName" : "Lee" ,
"tags" : ["guitar","ball"]
}
// POST /users/_doc/1 => index/type_id
index:索引或数据流名称。如果目标不存在,则自动创建。
*:5.x:API第二级为<doc_type>,后续版本弃用doc_type,使用_doc/_create代替。
**:要自动创建ID,需要使用POST方法,op_type设置为create。
API查询参数:
version:显式指定文档的版本号(整数);op_type:create如果文档存在则返回创建失败,默认index为创建或更新已有文档。等效于在API后添加/_create。timeout:等待主分片可用的超时时长,默认为1m(1分)。
批量提交文档索引操作
将文档索引操作数据放在HTTP请求主体中。每条操作数据需要包含操作说明和可选的文档数据,并以换行结束。
// PUT logs-my_app-default/_bulk?_source=false
{ "create": { } } // action and meta data => [PUT]
{ "@timestamp": "2099-05-07T16:24:32.000Z", "event": { "original": "192.0.2.242 - - [07/May/2020:16:24:32 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0" } } // data
{ "index": { "_id":"1", "_type": "_doc"} } // => {POST}
{ "@timestamp": "2099-05-08T16:25:42.000Z", "event": { "original": "192.0.2.255 - - [08/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" } }
// new line
操作方式包括:create, index,update,delete(无数据行)。由于数据以\n区分记录,因此要确保JSON文件不能格式化换行缩进。如果数据量较大,也可指定传输的文件。
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@accounts.json"
如果未指定目标索引,则需要在action数据中指定"_index"参数:
// PUT _bulk
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
请求参数
_source是否返回提交的数据,或要返回的数据字段。
参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/getting-started-index.html。
数据流
数据流适用于日志、事件、指标等自动生成数据。一个数据流由一个或多个后台索引组成。
数据流需要一个匹配的索引模板。
Every document indexed to a data stream must contain a
@timestampfield, mapped as adateordate_nanosfield type.
Filebeat
/var/lib/filebeat/registry存储了文件读取记录,进行重复测试时需要删除该目录。
filebeat.inputs:
- type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: ["localhost:5044"]
Kafka
The Logstash Kafka consumer handles group management and uses the default offset management strategy using Kafka topics.
Logstash instances by default form a single logical group to subscribe to Kafka topics Each Logstash Kafka consumer can run multiple threads to increase read throughput.
当Elasticsearch遇见Kafka--Logstash kafka input插件 - 云+社区 - 腾讯云 (tencent.com)
input {
kafka {
bootstrap_servers=>"kafka_server:9092"
topics=>["kafka_es_test"]
group_id=>"logstash"
client_id=>"logstash"
auto_offset_resetedit=>"latest"
consumer_threads=>N_PARTITIONS
decorate_events=>"basic"|"extended" // 添加Kafka元数据 =>@metadata
security_protocol=>"PLAINTEXT"
topics_pattern=>"kafka*"
add_field=>{ }
codec=>"plain"
enable_metric=>true // 记录插件的性能日志
id=>"plugin_id" // 插件ID
tags=>["TAG_a", "TAG_b"]
type=>"log_type"
}
}
filter {
mutate {
add_field => { "[@metadata][target_index]" => "prod-%{+YYYY.MM.dd}" }
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "logstash_kafka_test"
index => "%{[some_field][sub_field]}-%{+YYYY.MM.dd}" // 动态生成索引名
index => "%{[@metadata][target_index]}" // 使用添加的元数据作为索引名
id=>"plugin_id"
enable_metric=>true // 记录插件的性能日志
}
elasticsearch { // 数据流
hosts => [ "localhost:9200" ]
data_stream => "true"
data_stream_type => "metrics"
data_stream_dataset => "foo"
data_stream_namespace => "bar"
ilm_rollover_alias => "custom"
ilm_pattern => "000001"
ilm_policy => "custom_policy"
}
}
元数据:
[@metadata][kafka][topic][@metadata][kafka][offset][@metadata][kafka][timestamp]
查询文档数据
Query DSL
POST http://hostip:9200/index_name[/<doc_type>]/_search # *
POST http://hostip:9200/index1,index2,.../_search # "," => "%2C"
*:由于doc_type属性已弃用(7.x),查询时可不用指定。
index:索引名支持通配符*,使用*或_all查询所有索引。
查询参数
结构简单的查询参数可通过URL参数设置,所有参数均可通过HTTP请求体字段设置,URL参数优先级高于请求体字段。请求体使用JSON对象可表示复杂的序列或字典对象参数。
// POST http://hostname:9200/index_name/_search
{
"query": {<query_specifications>},
"sort": sort_specs,
"from": 10, // default=0
"size": 10, // default=10
"_source": ["account_number", "firstname"]
}
query:DSL查询语句声明,包括[单项查询]( #Term-level queries)、[复合查询]( #Compound queries)等。allow_no_indices=true:如果为false,目标索引==存在任何==缺失或关闭则返回错误;_source/_source_include/_source_exclude:是否要在返回结果中包含文档的字段数据,以及需要包含/排除的字段(支持字段名模糊匹配)。size=10:返回文档数量。from:指定返回记录偏移;Avoid using from and size to page too deeply or request too many results at once. By default, you cannot usefromandsizeto page through more than 10,000 hits. ==from+size<=10000==:search requests take heap memory and time proportional tofrom + size.timeout:等待每个分片响应的超时时长。version=false:返回文档的版本信息。
生成字段
通过脚本计算生成新的字段(也可使用查询时映射计算新的字段);
"script_fields": {
"field_name": {
"script": {
"lang": "painless", // the script language, default to "painless"
"source": "field1 * field2"
}}}
字符串拼接脚本:默认禁用文本字段计算,可使用
keyword运算。doc['firstname.keyword'].value + ' ' + doc['lastname.keyword'].value使用
keyword得到的结果带“[]”,使用.value获取其字符串值。
查询视图
搜索请求默认获取当前可用的最新数据,使用查询视图可保证每次查询访问一致的数据。
分页视图
-
scroll=1m:分页搜索上下文的保存时长。由于后续请求会刷新上下文的保存时长,因此该值的设置只要大于一批数据处理的时长即可。查询结果返回
_scroll_id(每次查询后返回的值可能会发生变化,应使用最新值),后续查询使用_scroll_id继续获取数据。每次调用
scrollAPI返回下一批数据直到获取所有查询结果(即返回查询结果为空);如果查询语句包含聚合查询,仅第一次响应包含聚合查询结果。// GET /my-index-000001/_search -> _scroll_id { "scroll": "1m" } // POST /_search/scroll { "scroll" : "1m", // 后续请求将更新分页上下文的保存时长* "scroll_id": _scroll_id }*:如果后续请求未指定scroll参数,后台将删除该搜索上下文。也可通过DELETE /_search/scroll接口删除搜索上下文以释放资源。分页搜索的结果在首次请求搜索时已经确定,后续分页返回结果不受文档更新的影响。
We no longer recommend using the scroll API for deep pagination. If you need to preserve the index state while paging through more than 10,000 hits, use the search_after parameter with a point in time (PIT).
排序视图
-
sort:排序字段,命令行参数格式为field1:asc,field:desc,...;使用sort语句后,返回的结果包含sort字段,表示当前文档的排序字段的值。{ "sort": [ "_doc", // simplest with default order { "account_number": "asc" }, //simple: asc|desc { "post_date" : {"order" : "asc", "format": "yyyy-mm-dd"}}, //complex ], "from": 0 // 设置为0或-1 } -
search_after:分页返回排序查询结果。包含sort声明的查询返回文档hits每条记录中包含额外的sort字段,将该字段值设置为search_after参数的值以返回排序结果的下一页。
PIT
Point in time接口生成查询发起时的轻量级数据视图,从而保证在一段时间内使用查询接口可获取一致的数据而不受数据更新的影响。[7.10+]
// POST /my-index-000001/_pit?keep_alive=1m // create pit view -> pit_id
// POST /_search // pit search not specify index name
{
"query": {},
"pit": { "id": "<pit_id>", "keep_alive": "1m" }
}
// DELETE /_pit
{ "id" : pit_id } // 完成搜索任务后删除视图释放资源
分片查询
当查询大量文档时,可将其分片,并分别请求每个分片的查询结果。
// GET /_search
{
"slice": {
"id": 0, // 当前分片
"max": 2 // 分片最大数量
},
"query": {},
"pit": { "id": "<pit_id>" }
}
分页返回排序结果
如果查询语句包含排序参数声明,则返回结果包含更新的pit ID,同时返回的最后一条数据包含搜索分界编号:
{
"pit_id" : "<updated_pit_id>",
"hits" : {
"hits" : [
//... hitted documents
{
"sort" : [ "2021-05-20T05:30:04.832Z", 4294967298 ]
}
]
}
}
基于上述返回信息,可查询排序结果的下一页数据(类似于排序视图):
// GET /_search
{
// query 和 sort 声明需要保持不变
"pit": { "id": "<updated_pit_id>", "keep_alive": "1m" },
"search_after": [ "2021-05-20T05:30:04.832Z", 4294967298 ],
"track_total_hits": false // speed up pagination.
}
参数值的单位约定
| 纯量 | 字节 | 长度 | 时间 |
|---|---|---|---|
b: bytes | nanos | ||
k: kilo | kb | nmi | micros |
m: mega | mb | mm | ms |
g: giga | gb | cm | s: seconds |
t: tera | tb | m: meters | m: minutes |
p: peta | pb | km | h: hours |
d: days |
Term-level queries
You can use term-level queries to find documents based on precise values in structured data. Examples of structured data include date ranges, IP addresses, prices, or product IDs.
查询文档属性
type query
Returns documents of the specified type.
ids query
Returns documents based on their document IDs.
查询文档字段
exists
返回索引中包含指定字段的文档。文档不含某个字段的原因包括:
- JSON文档字段的值为
null或[]; - 在映射模板中,该字段设置了
"index": false、该字段长度超过ignore_above或触发ignore_malformed(字段值格式不正确);
"exists": {
"field": "user"
}
term
term query:Returns documents that contain an exact term in a provided field.
"term" : { "tags" : "production" }
terms query: Returns documents that contain one or more exact terms in a provided field.
"terms" : { "tags" : ["production", "price"] }
range
range query:返回给定区间的记录,区间可以为数值或时间。
"range": {
"query_field": {
"gte": 10, "lte": 20,
"format": "yyyy-MM-dd"
}
}
IP地址类型匹配方式:支持
term或range匹配方式:"term" : { "ip_addr" : "172.28.76.0/24" } // "/24"用于匹配子网 "range": { "ipaddr": { "gt": "10.0.1.3", "lt": "10.0.1.14"} // 用于匹配非完整子网 }
关键字匹配
prefix 前缀:匹配一个字段的前缀。
wildcard通配符:*匹配零或多个字符,?恰匹配一个字符。
regexp正则表达式。模式必须与字段的值完整匹配(即默认包含起始和结束锚点^...$)。
"regexp": { "collect_time_hour": "[0-9]{8}(18|19|20|21|22)"} // 简写,仅提供字段与模式
"regexp": { // 完整语法,提供额外选项
"collect_time_hour": {
"value": "[0-9]{8}(18|19|20|21|22)",
"flags": "ALL", // enables all optional regexp syntax.
"case_insensitve": false // 7.10.0起支持
}
}
Elasticsearch未使用Perl兼容正则表达式,非捕获组(
?:)不能正常使用。
flags为正则表达式语法可选项标识,用|连接一个或多个标识。其中包括:
INTERVAL:<001-200>用于匹配一个区间的数字(字符串);INTERSECTION:启用&运算符(交集),即一个字符串同时满足两个匹配模式;COMPLEMENT:启用~运算符(补集);
使用wildcard或regexp时,应该避免起始位置为通配符或正则表达式的匹配模式,应该使用一个确定前缀以提高匹配效率。字段类型为keyword类型;如果字段为text类型,上述匹配方式无效,需要使用match查询。
全文查询
match:在文档所有内容中匹配一个或多个单词,计算匹配分数。
{
"match_all": {}, // 特殊匹配:匹配所有内容
"match": {
"message": {
"query": "this is a test",
"operator": "AND", // AND | OR 匹配所有/任意单词
"minimum_should_match": 1
}
},
"match": { "message": "this is a test" }
}
math_phrase:匹配整个词组,语法类似match。
match_phrase_prefix:模式中的最后一个单词可以仅前缀匹配。
fuzzy query:Returns documents that contain terms similar to the search term. Elasticsearch measures similarity, or fuzziness, using a Levenshtein edit distance.
Compound queries
Compound queries wrap other compound or leaf queries, either to combine their results and scores, to change their behaviour, or to switch from query to filter context.
constant_score query
A query which wraps a filter query, executing it in filter context. All matching documents are given the same “constant” _score.
"query": {
"constant_score": {
"filter": { // 仅能包含一个条件
"term": { "user.id": "kimchy" }
}}}
filter查询仅可包含一个查询条件,如果需要提供多个查询条件,则使用bool查询封装查询条件。
bool query
The default query for combining multiple leaf or compound query clauses, as must, should, must_not, or filter clauses. T==he must and should clauses have their scores combined== — the more matching clauses, the better — while the must_not and filter clauses are executed in filter context.
"query": {
"bool" : {
"filter": { // 多个条件则为字典构成的序列
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : { "age" : { "gte" : 10, "lte" : 20 } }
},
"must" : {
"term" : { "user.id" : "kimchy" }
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}}
minimum_should_match:指定should语句必须匹配的数量或百分比(而非仅依据相似性得分)。如果bool查询仅包含should,那么默认值为1,反之,默认值为0(可选条件)。
should为空时,minimum_should_match应该设置为0,否则无返回结果。
boosting query
Return documents which match a positive query, but reduce the score of documents which also match a negative query.
dis_max query
A query which accepts multiple queries, and returns any documents which match any of the query clauses. ==While the bool query combines the scores from all matching queries, the dis_max query uses the score of the single best-matching query clause==.
function_score query
Modify the scores returned by the main query with functions to take into account factors like popularity, recency, distance, or custom algorithms implemented with scripting.
EQL
Event Query Language (EQL) is a query language for event-based, time series data, such as logs.
We designed EQL for security use cases.
GET /my-index-000001/_eql/search
{
"query": """
sequence by process.pid with maxspan=1h
[ process where process.name == "regsvr32.exe" ]
[ file where stringContains(file.name, "scrobj.dll") ]
"""
}
SQL
Elasticsearch SQL allows SQL-like queries to be executed in real-time against Elasticsearch. One can think of Elasticsearch SQL as a translator, one that understands both SQL and Elasticsearch and makes it easy to read and process data in real-time, at scale by leveraging Elasticsearch capabilities.
//POST /_sql?format=txt csv,json,yaml,...
{
"query": "SELECT * FROM library WHERE release_date < '2000-01-01'",
"fetch_size": 5, // 分页查询
"columnar": false // 按列返回数据
}
[Mapping concepts across SQL and Elasticsearch | Elasticsearch Guide 7.14] | Elastic
[Response Data Formats | Elasticsearch Guide 7.14] | Elastic
SQL CLI
./bin/elasticsearch-sql-cli http[s]://some.server:9200
聚合查询
根据文档查询结果进行聚合。聚合查询DSL基本语法:
{
"query": {},
"aggregations" : { // => "aggs"
"<aggregation_name>" : {
"<aggregation_type>" : {
// <aggregation_body>
},
// [,"meta" : { [<meta_data_body>] } ]?
// [,"aggregations" : { [<sub_aggregation>]+ } ]?
},
"<aggregation_name_2>" : { }
}
}
aggregation_name也作为返回结果的key。aggs是aggregations的别名。
聚合分为四类:Metric、Bucketing、Matrix、[Pipeline](Pipeline Aggregations)。
统计聚合
Metric Aggregation:字段的统计特征计算。查询返回结果为字典,通常其中value字段为查询结果。
Average/Max/Min/Sum Metrics
"avg": {"field": "grade" , "missing": 10 } # aggregation_body
missing: 填充缺失值。
Weighted Average
"weighted_avg": {
"value" : {"field": "grade", "missing": 10},
"weight": {"field": "weight", "missing": 1}
} # aggregation_body
Percentile
"percentiles": {
"field": "load_time",
"percents": [ 95, 99, 99.9 ],
"keyed": true
}
默认区间为
[ 1, 5, 25, 50, 75, 95, 99],使用percent指定区间。
keyed:默认将百分比设置为返回值的键名,设为false则返回key和value分别表示百分比和对应的值。
Boxplot (quantile)
"boxplot": { "field": "load_time" }
返回结果包括:min、q1、q2、q3、max。
Median
"median_absolute_deviation": {"field": "rating"} # 近似计算
Stats
"stats": { "field": "grade" }
"extended_stats": { "field": "grade" } # more statistic details
stats返回结果包括:min、max、sum、count和avg等多个字段(不包括value字段)。
String Stats
"string_stats": { "field": "message.keyword" }
计数
"cardinality" : {"field": "type"} # 近似计算不重复值的数量
"value_count" : { "field" : "type" } # 不去除重复
value_countif a field has duplicates each value will be counted individually.
Geo Bounds/Centroid
计算坐标边界和中心。
T-Test
检查一个字段是否符合学生t分布。
Top-Metrics
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"},
"size": 3
} # 返回按sort字段排序后位于顶部的记录的指定字段的值
metrics可用数组指定返回多个字段。
Top Hits Aggregation
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-top-hits-aggregation.html
分组聚合
Buckets Aggregation:根据指定标准(criterion)对记录进行分组(bucket),并返回每一组包含的记录数(doc_count)。==Bucket聚合可以包含针对每个分组记录的子聚合==。
"aggs":{
"bucket_agg_name":{
"bucket_agg_type":{"param": "value"},
"aggs":{ // 子聚合查询
"sub_agg_name":{"sub_agg_type":{"param": "value"} },
}}}
==嵌套的聚合sub_agg_type可以是针对每个bucket的统计聚合、分组聚合、或者针对整个聚合结果的[Parent管道聚合](#Parent Aggregation)==。
Range
按给定区间分组;
Date Range
按给定的日期区间分组(from/to);
Terms
"terms": {
"field": "genre[.keyword]",
"size": 1000,
"show_term_doc_count_error": true,
"order": { "_count": "asc" },
"order": { "playback_stats.max": "desc" },
"include": ".*sport.*",
"include": [ "mazda", "honda" ],
"exclude": "water_.*",
"exclude": [ "rover", "jensen" ],
}
size指定返回分组的数量(默认为10)。
order='_count'|'_key'|...,可以==使用子统计聚合返回的结果==进行排序。
首先计算include,再计算exclude,表达式可以是精确匹配或正则表达式。
terms仅支持根据单个字段进行分组,[Composite Aggregation](#Composite Aggregation)可使用多个字段进行分组,并支持分页返回结果。
返回结果中的计数是近似值。
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
响应内容:
doc_count_error_upper_bound:计数误差上界;
sum_other_doc_count:响应结果中未包含的匹配内容计数;
直方图(Histogram)
按给定字段的值所在区间$[nT,(n+1)T)$对记录进行分组,聚合后的bucket_key的计算方式为bucket_key = Math.floor((value-offset)/interval)*interval+offset(offset为区间边界偏移量)。
"histogram": { "field": "price", "interval": 50 }
For range values,其覆盖区间上的所有分组都计算在内。
对分组结果再进行[求和](#Average/Max/Min/Sum Metrics)等聚合运算,可以得到统计直方图。
Date Histogram
"date_histogram": {
"field": "date",
"calendar_interval": "month",
"format": "yyyy-MM-dd",
"time_zone": "+08:00"
}
支持的日历周期(calendar_interval)包括:minute,1m、hour,1h、day,1d、week,1w、month,1M、quarter,1q和year,1y。不支持支持区间取值为多个单位周期。
支持的固定周期(fixed_interval)包括:ms、s、m、h、d,最为单位与数字组合使用。
Filters Aggregation
过滤聚合内容(也可在查询语句使用filter设定,此处可作为聚合的补充过滤条件,可用于match等方法过滤内容),返回一个分组:
"filter": { "term": { "type": "t-shirt" } },
添加多个过滤条件,每个条件对应一个分组;如果other_bucket=true,则未被任何过滤条件匹配的记录将被分到一个额外分组中:
"filters":{
"filters": {
"error": {"term": { "body": "error" }},
"warning": {"term": {"body": "warning"}}
},
"other_bucket": true,
"other_bucket_key": "other_messages"
}
复合分组聚合
多个层级的聚合。聚合语句内容:
"genre_group":{ // genre + state
"terms": {
"field": "genre[.keyword]" // ,...
},
"aggs": { // 针对genre_group得到的分组分别根据state进行再一次分组
"state_group":{
"terms": {
"field": "state[.keyword]",
} } } }
The composite aggregation is expensive.
composite使用多个字段组合进行分组;支持分页返回分组结果(类似查询记录时的scroll)
"composite_group":{ // genre + state
"composite": { // R6.1
"sources": [
{ "state": {
"terms": { "field": "state.keyword", "order": 'asc' }
}},
{ "gender": { "terms": { "field": "gender.keyword" } } }
],
"after": {},
"size": 10
}}
返回结果中包含after_key字段,并在后续查询中指定为after的值,可从上次返回结果后查询剩余内容(如果记录数多于size给定的值,则后续返回内容非空)。
composite仅支持根据分组字段进行排序,如果需要根据分组的计算结果(例如记录计数),则需要使用管道聚合([bucket_sort](#Bucket Sort))。如果指定的字段值为序列,则序列每个元素会和其他分组字段进行组合,形成多个分组。
multi_terms类似于composite,但不支持分页,可使用order定义排序。
"multi_group":{ // genre + state
"multi_terms": { // R7.12
"terms": [
{ "field": "state" },
{ "field": "gender"}
],
"size": 10 // 返回分组数量
}}
Pipeline Aggregations
管道聚合对其他聚合的输出进行统计运算。
bucket_path语法:指定输入分组。
PATH = [AGG_NAME>]SUB_AGG_NAME[.METRIC];
"_count"是一个特殊的路径,用于表示记录计数。
Sibling
Sibling:使用一个聚合的输出计算,并在生成一个新的聚合结果。==与分组聚合子聚合的区别==:与相关聚合在同一层级,而非在其内部。
使用相对路径:
"aggs": {
"agg_name": { "agg_type":{"param": "value"} },
"sibling_agg_name": {
"sibling_pipe_agg_type": {
"buckets_path": "AGG_NAME[>SUB_AGG_NAME]"
}}}
Avg/Max/Min/Sum
"max_bucket": {"buckets_path": "aggs_name>sub_agg_name"}
与统计聚合的对应类型区别,Pipeline聚合的类型名称带后缀
_bucket。
Percentile Bucket
"percentiles_bucket": {
"buckets_path": path, "percents": [], "keyed": true
}
查看Percentile。
Parent Aggregation
Parent:位于父聚合(例如Buckets聚合)内部,根据父聚合的输出字段进行计算,并将结果添加到父聚合生成的buckets中或影响父聚合的返回结果(如bucket_sort)。
"aggs": {
"agg_name": {
"agg_type": { "param": "value" },
"sub_agg_name": {
"parent_pipe_agg_type": {
"buckets_path": "the_sum" ,
"param": "value"
}}}
Sibling和Parent聚合类型的用法和使用位置:Sibling聚合类型应用于所有Buckets中的某个统计量,需要在一个聚合计算完成后才能使用其结果进行计算,因此需要置于Buckets聚合的同层级。==Parent管道聚合的计算结果是作用于父聚合的,因此位于父聚合内部,由父聚合调用执行==。
Sibling置于Buckets聚合内部出错:The first aggregation in buckets_path must be a multi-bucket aggregation for aggregation.
Parent置于Buckets聚合的同级出错:XXX aggregation [xxx] must have a histogram, date_histogram or auto_date_histogram as parent but doesn't have a parent。
Moving Avg
"moving_avg": {
"buckets_path": "the_sum",
"model": "holt",
"window": 5,
"gap_policy": "insert_zeros",
"settings": {"alpha": 0.8}
}
差分(Derivative)
"derivative": { "buckets_path": "the_sum" }
CumSum/CumCardinality
"cumulative_sum": {"buckets_path": "the_sum"}
"cumulative_cardinality": {"buckets_path": "my_cardinality_agg"}
Bucket Sort
使用父聚合的结果中的字段进行排序:
"bucket_sort_name":{
"bucket_sort": {
"sort": [
{ "sort_field_1": { "order": "asc" } },
{ "sort_field_2": { "order": "desc" } },
"sort_field_3"
],
"from": 1,
"size": 3
}}
bucket_sort仅对当前返回页排序,如果bucket结果分页,则每一页单独排序。
备份和恢复
快照
创建快照仓库
curl -XPOST http://hostname:9200/_snapshot/hdfs_backup -d \
{
"type": "hdfs",
"settings": {
"uri": "hdfs://namenode:9000/",
"path": "backup/path" // 使用相对目录,在ES用户主目录下
}
}
curl http://hostname:9200/_snapshot/hdfs_backup # get repo info
curl -XDELETE /_snapshot/hdfs_backup # 删除快照仓库
快照仓库名支持通配符
*;如果仓库名未_all或未提供,则会返回所有快照仓库的信息。
使用HDFS作为快照仓库
安装插件repository-hdfs。
验证仓库配置
如果创建备份仓库时未指定?verify=false参数,可以单独执行验证:
curl http://hostname:9200/_snapshot/hdfs_backup/_verify # verifying
创建快照
curl -XPUT /_snapshot/hdfs_backup/snapshot_1?wait_for_completion=true -d
{
"indices": "index_1,index_2"
} # 指定索引名称过滤快照内容,支持通配符
快照是增量创建的,对比仓库中已有的索引文件,仅加入新建或修改过的文件到快照中。
集群同一时间只能运行一个快照进程。
获取快照信息
curl /_snapshot/hdfs_backup/snapshot_1
curl /_snapshot/hdfs_backup/snapshot_*,some_other_snapshot
curl /_snapshot/hdfs_backup/_all
curl /_snapshot/hdfs_backup/_current # 正在执行的快照
curl /_snapshot/_status
curl /_snapshot/hdfs_backup/_status
curl /_snapshot/hdfs_backup/snapshot_1/_status
删除快照
curl -XDELETE /_snapshot/hdfs_backup/snapshot_1
删除快照将删除快照中未被其他快照引用的文件。删除正在执行的快照终止快照过程。
恢复
curl -XPOST /_snapshot/hdfs_backup/snapshot_1/_restore -d \
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": true,
}
恢复时可指定索引设置覆盖快照中的设置。
恢复到其他集群
快照数据未绑定到特定集群或集群名,因此可以恢复到其他集群(无须具有相同集群大小和拓扑)。
5.x=>6.x,5.x/=>7.x
问题
HDFS访问权限:java.security.AccessControlException: access denied ("javax.security.auth.PrivateCredentialPermission" "org.apache.hadoop.security.Credentials" "read")。
修改插件的Java安全选项
$PLUGIN_PATH/repository-hdfs/plugin-security.policy:grant { permission javax.security.auth.PrivateCredentialPermission "org.apache.hadoop.security.Credentials * \"*\"", "read"; }
在ES启动脚本ES_HOME/bin/elasticsearch中,为启动命令添加以下Java选项,并重启集群。
-Djava.security.policy=ES_HOME/plugins/repository-hdfs/plugin-security.policy
复制数据
elasticsearch-dump \
--input=http://source.es.com:9200/my_index \ # 源索引支持通配符
--output=http://target.es.com:9200/my_index \
--type=data \
--limit 100 \ # 根据集群配置将单批读取数据量上调可加快读取速度
elasticsearch-dump: Import and export tools for elasticsearch (github.com)
Python客户端
底层接口elasticsearch:封装了Elasticsearch REST API,通过Helper类简化API调用2。
HTTP传输:客户端每个配置或探测到的节点建立一个持久连接(
ConnectionPool),并追踪每个节点的状态。如果节点变为无响应,则其对应的连接将被设置一个超时区间,直到超时区间结束才重新检测该节点是否可用。默认,连接池中的节点随机排列,并通过轮询方式调用以实现负载均衡。
高层接口elasticsearch-dsl:以Python风格提供搜索接口。
使用Elasticsearch主版本号相同的Python客户端版本:
elasticsearch5、elasticsearch6……elasticsearch总是与当前Elasticsearch最新稳定版本一致。
Python REST API
创建客户端连接实例
import elasticsearch5 as es
es_cli = es.Elaticsearch(
hosts=[
{'host': 'hostname'},
{'host': 'ip_addr', 'port': 9200},
'[http://user:secret@]host_addr:9200/path'
]
# Transports参数[elasticsearch.transport.Transport]
sniff_on_start=True, # 自动探测集群节点
sniff_on_connection_fail=True,
sniffer_timeout=60, # 自动探测的时间间隔*
retry_on_timeout=False, # 超时触发使用不同节点重试
# Connection参数[Urllib3HttpConnection]**
timeout=10, # 全局HTTP/TCP超时限制
maxisize=10, # 限制客户端与每个ES节点建立连接数(多线程并发查询)
#
)
es_cli.info() # 获取当前集群的基本信息
es_cli.ping() # 探测集群是否可用
*:另一个参数sniff_timeout表示一次探测请求的超时时限(通常设置较小以尽可能快地探测集群所有节点)。
**:HTTPS连接的相关参数:use_ssl=False, verify_certs=True, ca_certs=None, client_cert=None, client_key=None。
ES客户端内置属性
提供访问ES集群以及各类对象的代理,查看集群和数据的相关状态。
cat、cluster、indices、ingest、nodes、snapshot、tasks。
API全局参数(8.x版本弃用)
ignore=[400,404]:出错时默认会抛出异常,如TransportError,通过该参数忽略某些错误。
request_timeout=1:API请求超时限制(秒)。
某些API包含的
timeout参数限制其内部操作的超时时间,不能保证请求在指定时间后返回。
文档操作接口
读取信息
es_cli.exists(index, doc_type, id) # 查看文档是否存在*
es_cli.count(index,doc_type,body)
*:要查看索引是否存在,调用cli.indices.exists()方法。
读取文档
es_cli.get(index, id, doc_type,...) # 返回指定id的JSON文档
es_cli.mget(ids, index, doc_type,...) # 返回指定id的多个JSON文档
es_cli.get_source(index, id, doc_type,...) # 返回指定索引文档的源文档
搜索文档内容
es_cli.search(index,
doc_type=None,
body=dsl, # JSON文本或字典对象
_source, # 是否返回_source字段
_source_{include|exclude}, # 返回数据要包含/排除的文档字段
from_=0,
scroll='1000s', # 启用分页并指定分页存活时长
size=10, # 返回的数据量
allow_no_indices=False, # 允许通配符匹配不到任何索引
ignore_unavailable=True, # 忽略
version=False, # 是否返回文档的版本信息
)
_source:True/False指定是否返回JSON文档的字段;也可指定字段列表返回指定的字段(等效于指定_source=True,_source_include=fields);default_operator:AND/OR(default),查询文本的默认连接运算符。expand_wildcards:通配符的匹配范围,默认为open,其他包括:closed、none、all。
分页搜索:
es_cli.scroll(scroll_id, body=dsl, scroll='1000s')
es_cli.clear_scroll()
迭代读取:
from elasticsearch import helpers
helpers.scan(es_cli, query,scroll,preserve_order=False,clear_scroll=True)
搜索模板:
es_cli.search_template(...) es_cli.get_template(id) es_cli.put_template(id) es_cli.delete_template(id) es_cli.exist_template(name)
id:搜索模板ID。
聚合搜索
在查询结构的查询语句body中,声明aggregations/aggs语句。
创建文档接口
必须指定文档IDid(可以是整数或字符串形式,最终存储为文本),如果文档已存在,且未指定不同的version,会抛出ConflictError。
es_cli.create(index, doc_type, body, id=None, timeout,version...) # -> 文档的基本信息
创建的文档会经过一定的延迟才可被搜索。
doc_type:文档类型。5.x必须指定文档类型,7.x为可选参数。body:文档数据;id:文档编号。如果未指定,则由ES自动生成。timestamp:文档显式指定时间戳;ttl:文档失效时间;version:显式指定文档版本号。
更新文档:==不会覆盖原有文档,而是创建一个新的版本并更新版本号==。
es_cli.update(...,_source,_source_include,_source_exclude,fields)
创建或更新文档:
es_cli.index(index, doc_type, body, id, op_type='index',...) # -> 文档的基本信息
op_type:'index'表示创建或更新,create仅在文档不存在的情况下创建文档。
批量写入操作
底层的bulk()API需要传递批量的文档文本,不方便进行数据处理。es.helpers提供封装直接处理包含文档对象的序列。
es_cli.bulk(
body, # action-data pair, separated by newline.
index, doc_type
)
helpers.bulk(es_cli,actions,stats_only=False,raise_on_error=True) #-> (...)*
helpers.streaming_bulk(es_cli, actions,...) # bulk()封装streaming_bulk()
helpers.parallel_bulk(...)
*:stats_only=True:除返回写入成功的数量外,仅返回错误的统计数量;反之,返回错误的详细信息构成的列表。为了避免批量插入中途出现错误而终端批量操作,可令raise_on_error=False。
批量对象序列的元素结构通常与search()的返回结构一致:
{
'_index': 'index-name',
'_type': 'doc',
'_id': 42,
'_source': {...}
}
如果输入数据字段中不包含source,则helpers.bulk()将从输入对象的字段中首先提取元数据字段,将剩余数据作为文档数据。可通过元数据_op_type指定操作类型,包括index(默认)、create、delete和update。
删除文档
es_cli.delete(index, doc_type, id, timeout)
删除查询匹配的结果:
es_cli.delete_by_query(...) # 接受search接口的参数
索引管理接口
通过ES客户端实例提供的索引的客户端代理IndicesClient提供的接口来管理索引。
查看索引接口
索引汇总信息:
es_cli.cat.indices(index, format='json|yaml', health=None,s=None,v=False)
health:'green'|'yellow'|'red',按节点状态筛选;
索引详细信息:
es_cli.indices.exists(index, ignore_unavailable) # 索引是否存在
es_cli.indices.get(index) # 获取索引信息(alises,settings,mappings)
index:支持通配符。
创建索引接口
es_cli.indices.create(index, body,...) # -> 返回执行状态
body:dict:索引的配置,包括设置(settings)和映射(mappings)的JSON对象。
获取已有索引的这些配置:
es_cli.indices.get_mapping(fileds, index, doc_type,...) # 获取索引的映射
es_cli.indices.get_settings(fileds, index, doc_type,...) # 获取索引的配置
es_cli.indices.get_field_mapping(fileds, index, doc_type,...)
返回JSON对象以索引名为根节点。
开启或关闭索引接口
es_cli.indices.open(index, ingore_unavailable,...)
es_cli.indices.close(index, ingore_unavailable,...)
删除索引接口
es_cli.indices.delete(index)
es_cli.indices.delete_alias(index, name)
索引数据迁移
es_clit.reindex(body=dsl, ) # reindex all docs from one index to another
helpers.reindex(es_cli, src_index, tgt_index,...)
模板管理接口
es_cli.cat.templates(
name=pattern, #*
format='json', # 以JSON/YAML格式输出,默认以纯文本表格输出
h='name,template', # 要输出的列
s='name,template', # 对输出按列排序
v=True # 显示表头
) # 返回匹配的模板名称
es_cli.indices.exists_template(name='xxx') -> bool
es_cli.indices.get_template(name='xxx') -> Dict[str,dict]
es_cli.indices.put_template(name='xxx', body, create=False) #**
es_cli.indices.delete_template(name='xxx')
*:name参数支持通配符。
**:create=False支持替换已有模板。
OpenSearch
OpenSearch is a community-driven, open source fork of Elasticsearch and Kibana.
OpenSearch is a community-driven, Apache 2.0-licensed open source search and analytics suite that makes it easy to ingest, search, visualize, and analyze data. Developers build with OpenSearch for use cases such as application search, log analytics, data observability, data ingestion, and more.
OpenSearch consists of a data store and search engine (OpenSearch), and a visualization and user interface (OpenSearch Dashboards). Users can extend the functionality of OpenSearch with a selection of plugins that enhance search, security, performance analysis, machine learning, and more.
Get started - OpenSearch documentation
参考文献
Log Consolidation with ELK Stack — Log Consolidation with ELK Stack 1.2 documentation (elastic-stack.readthedocs.io) 1: Search APIs | Elasticsearch Guide 8.2 | Elastic 2:Python Elasticsearch Client — Elasticsearch 5.5.1 documentation (elasticsearch-py.readthedocs.io)
Elastic Datasource
数据源
Beats
Filebeat
Metricbeat
Metricbeat is a lightweight way to send system and service statistics:
- system-level CPU usage, memory, file system, disk IO, and network IO statistics, as well as top-like statistics for every process running on your systems.
- collect metrics from services like Apache, Jolokia, NGINX, MongoDB, MySQL, PostgreSQL, Prometheus, and more.
Packetbeat

Winlogbeat
数据处理
Logstash
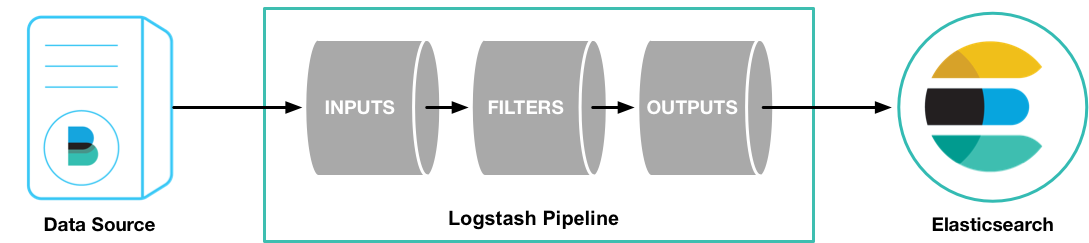
Event ordering:https://www.elastic.co/guide/en/logstash/current/processing.html#event-ordering
插件介绍
Inputs
file:reads from a file on the filesystem, much like the UNIX command tail -0F
syslog:listens on the well-known port 514 for syslog messages and parses according to the RFC3164 format;
Filters
-
grok:parse and structure arbitrary text.
-
mutate:rename, remove, replace, and modify fields in your events.
-
geoip
-
date:==parses out a timestamp and uses it as the timestamp for the event (regardless of when you’re ingesting the log data).==
Accessing event data and fields in the configuration | Logstash Reference [7.15] | Elastic
Logstash configuration examples | Logstash Reference [7.15] | Elastic
Outputs
- elasticsearch
- file
- ……
采集器管理
Fleet provides a web-based UI in Kibana to add and manage integrations for popular services and platforms, as well as manage a fleet of Elastic Agents.
Install Elastic Agent (Fleet)
设置Fleet
修改Elasticsearch和Kibana集群的URL。
使用集中管理需要创建一个具有创建API keys并写入logs-*和metrics-*索引权限的用户(使用超级用户登录Kibana后可自动创建)。
Fleet作为服务运行于一个或多个Elast Agent上。
下载安装
Ubuntu
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-<version>-amd64.deb
sudo dpkg -i elastic-agent-<version>-amd64.deb
sudo elastic-agent enroll -i <kibana_url> <enrollment_token> # 1,3
sudo systemctl enable elastic-agent
sudo systemctl start elastic-agent # 2
没有
systemd的系统(如WSL),使用service启动服务:service elastic-agent start由于登记为服务,因此代理会在系统重启时启动启动。
kibana_url和enrollment_token可在代理添加页面找到。安装目录位于
/opt/Elastic/Agent。
Windows
从解压目录执行安装命令:
.\elastic-agent.exe install -i -f \
--kibana-url=<kibana_url> \
--enrollment-token=<token>
Download the Elastic Agent Windows zip file from the downloads page.
安装目录位于:
C:\Program Files\Elastic\Agent。
代理管理
需要将集群使用的证书(Kibana)添加到代理所在系统(生成证书时要在配置文件中添加集群所使用的域名)。
Windows需要将证书添加到
LocalMachine目录下。
从Fleet管理界面修改代理配置策略以及解除代理注册。
使用elastic-agent enroll命令重新注册到Fleet。
Install Elastic Agent (Manually)
配置文件
使用Fleet生成配置文件elastic-agent.yml,手动修改配置。
outputs:
default:
type: elasticsearch
hosts:
- 'http://localhost:9200'
username: ES_USERNAME
password: ES_PASSWORD
创建代理用户
POST /_security/role/standalone_agent
{
"cluster": ["monitor"],
"indices": [
{
"names": ["logs-*", "metrics-*", "events-*", ".ds-logs-*", ".ds-metrics-*", ".ds-events-*"],
"privileges": ["write", "create_index", "indices:admin/auto_create"]
}
]
}
安装
无需提供参数,安装程序将使用本地配置文件进行初始化。
Upgrade Elastic Agent
sudo elastic-agent upgrade <version-number>
卸载
cd C:\Program Files\Elastic\Agent
.\elastic-agent.exe uninstall
数据源
Elastic Endpoint Security
卸载
以管理员运行:
cd C:\Program Files\Elastic\Endpoint
.\elastic-endpoint.exe uninstall
Mongodb
安装
单机配置
storage:
dbPath: /var/lib/mongo
net:
port: 27017
bindIp: 0.0.0.0
replication:
replSetName: rs # 定义副本集的名称
启动服务:
systemctl enable --now mongod
默认服务端口为:TCP/27017和UNIX/tmp/mongodb-27017.sock。默认监听地址为127.0..0.1,可改为0.0.0.0以监听所有地址。
MongoDB Shell
mongosh:a fully functional JavaScript and Node.js 14.x REPL environment.
关键字为小写(大小写敏感)。
SQL to MongoDB Mapping Chart — MongoDB Manual
用户管理
use admin
db.createUser({ // => 创建用户
user: 'root',
pwd: '123456',
roles:[{ role: 'root', db: 'admin' }]
})
db.getUser("root")
db是关键字,表示当前数据库;
常用命令
db.auth("root","123456") // 如果启用授权验证,则在进入shell后需要提供用户凭据
db.stats()
db.adminCommand({getParameter:"*"})
db._adminCommand({getCmdLineOpts: 1})
集群配置
在集群每个节点安装Mongodb服务。
replica set
replica set包含一组维护相同数据集的mongod实例,提供冗余和高可靠性,提高读取速率。

一个集群仅包含一个主节点。数据需要从主节点写入,次级节点根据主节点的操作记录修改本地数据以与主节点保持一致。节点之间通过发送心跳信息检测可用性。当主节点失效,次级节点将发起竞选以产生新的主节点。
副本集配置
启动Mongo Shell,执行以下命令==将当前节点设置为主节点==。如果返回结果显示ok=1,则集群配置成功。
rs.initiate({
"_id": "rs",
"members": [
{ "_id": 1, "host": "172.17.218.11:27017" },
{ "_id": 2, "host": "172.17.218.12:27017" },
{ "_id": 3, "host": "172.17.218.13:27017" }
]
})
当节点配置使用replica set后,启动shell时会自动创建replica set管理对象
rs,用于执行replica set得初始化和管理。
MongoDB Replica Set副本集配置 - 掘金 (juejin.cn)
验证集群
rs.status() // 查看当前复制集的状态
// { "set": "rs", "members": [...], "ok": 1 }
rs.isMaster() // 返回当前节点是否为集群主节点得相关信息
在线集群配置
conf = rs.conf()
// 修改conf的属性
rs.reconfig(conf)
Sharded Cluster
docker配置
replica set
MongoDB Replica Set / docker-compose / mongoose transaction with persistent volume (github.com)
存储引擎
Storage Engines — MongoDB Manual
写入数据
数据模型
同一个集合中的文档不需要具有相同的字段和数据类型;可以灵活更新文档的字段以及数据类型;
可以在创建文档集合时声明JSON Schema以限制数据操作。
db.createCollection("students", {
validator: {
$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "address" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
description: "must be an integer in [ 2017, 3017 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
//...
}
}
}
}
文档结构
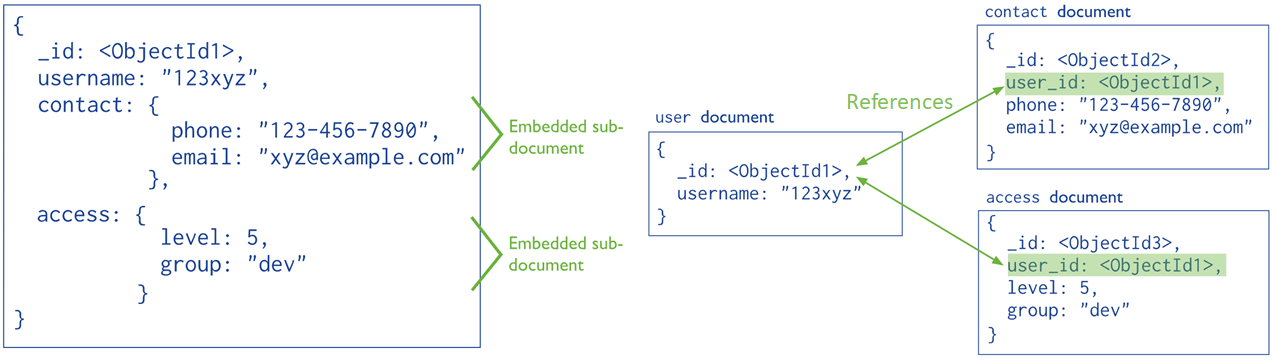
Data Modeling Introduction — MongoDB Manual
写入操作
插入单个文档
db.collection.insertOne(
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
)
插入多个文档
db.collection.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], size: { h:14, w:21, uom:"cm" } },
{ item: "mat", qty: 85, tags: ["gray"], size: { h:27.9, w:35.5, uom:"cm" } },
{ item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h:19, w:22.85, uom:"cm" } }
])
如果文档不包含_id字段(主键),则自动为文档添加_id字段:{"_id": ObjectId("value")}。如果指定了_id,则需要保证_id唯一,否则会产生异常。
如果文档集合collection不存在,则自动创建集合;
Insert Methods — MongoDB Manual
更新文档
db.inventory.updateOne( // updateMany(), replaceOne()
{ item: "paper" },
{
$set: { "size.uom": "cm", status: "P" },
$currentDate: { lastModified: true }
}
)
删除文档
db.collection.deleteMany(conditions)
db.collection.deleteOne( conditions )
conditions为空字典,则删除集合的所有文档。
批量写操作
一次执行多个写操作。
Bulk Write Operations — MongoDB Manual
查询
show dbs
use <db_name>
show collections
show users // users of current database
等式查询
db.inventory.find( {item:"canvas"} ) # => SELECT * FROM db.inventory WHERE item='canvas'
find()的参数为查询条件构成的文档;如果字段为空,则返回所有文档。
字段值可以是嵌套的子文档值;或者指定子文档字段:field.nestfield。
数组字段查询:指定数组所有元素;$all运算符不限定数组元素顺序,指定单个元素查询数组字段是否包含该元素。
指定查询条件
{ <field1>: { <operator1>: <value1> }, ... }
比较运算符:$in,$nin,$lt,$gt,$gte,$lte,$eq,$ne;
逻辑运算符:默认情况下,查询条件文档字段之间为AND连接;使用$or构造OR连接
db.inventory.find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
})
逻辑运算符可以嵌套使用,构造复杂查询条件。
正则表达式运算符:$regex(MongDB使用PCRE)
{ <field>: { $regex: 'pattern', $options: '<options>' } }
{ <field>: /pattern/<options> }
限定返回字段
db.collection.find(condition, projection)
projection指定返回的字段(为指定该参数返回所有字段),要返回字段名对应的值为1;默认返回_id字段。如果仅包含值为0的字段声明,则返回除声明字段外的字段。
{ "field1": 1, "field2": 1, ..., "_id": 0}
Python API
Python API语法pymongo基本和Mongo Shell一致。
连接
from pymongo import MongoClient
client = MongoClient("mongodb://root:passwd@server_name/db", authSource="admin")
数据库信息
db = client.get_database(name=None) # => client['db_name'] => client.db_name
db.list_collections() # -> Iterator[collection]
db.list_collection_names() # -> List[str]
c = db.get_collection('collection') # => db['collection'] => db.collection
写入
db.collection.insert(dict_item)
db.collection.insert_many([dict_item,...])
查询
db.collection.find({...}) # -> Iterator(dict)
db.collection.find_one({...}) # -> dict
图数据分析
-
图计算引擎:Apache Spark是一个横向扩展和以节点为中心的图计算引擎。
GraphFrames是 Spark 的一个图处理库,于 2016 年替代 GraphX,但是它与核心Spark是分离的。
Spark Graph项目是在Spark 3.0 版本中增加对DataFrame、Cypher 和基于DataFrame的算法的支持。
-
图数据库:Neo4j图平台是图数据库和算法中心式处理紧密集成的典范,针对图进行了优化。
-
兼用Spark和Neo4j进行图处理:将Spark用于大规模数据集的高层筛选与预处理以及数据集成,将Neo4j用于特定处理并且与基于图的应用集成。
Spark Graph
dgraph
安装
当前稳定版本为21.03。
export DGRAPH_HOME=/opt/dgraph-21.03
export DGRAPH_DATA=$DGRAPH_HOME/data
export PATH=$DGRAPH_HOME/bin:$PATH
.
├── bin
│ ├── badger
│ └── dgraph
└── data
系统架构
运行Dgraph需至少包含以下类型节点:
-
Alpha:数据库节点,包括数据存储、访问、管理和节点管理功能。
-
Zero:管理节点,管理集群中的节点,自动在数据库节点间进行数据移动。
-
Ratel:UI服务,支持DQL。Releases · dgraph-io/ratel (github.com)。
对于高可用集群,每类节点至少运行三个实例。
配置
Configuration - Deploy (dgraph.io)
运行
dgraph zero --my=IPADDR:5080
# Setting up grpc listener at: 0.0.0.0:5080
# Setting up http listener at: 0.0.0.0:6080
for ((i=0; i<N; ++i)); do
dgraph alpha --my=IPADDR:7080 --zero=ZERO_IPADDR:5080 -o $i
done
# Sending member request to Zero: addr:"192.168.0.200:7080"
# Worker listening at address: [::]:7080
# Bringing up GraphQL HTTP admin API at 0.0.0.0:8080/admin
# gRPC server started. Listening on port 9080
# CONN: Connecting to 192.168.0.200:5080
# Connected to group zero. Assigned group: 1
# Raft Id after connection to Zero: 0x1
# Node ID: 0x1 with GroupID: 1
# RaftContext: id:1 group:1 addr:"192.168.0.200:7080"
ratel -addr "http://192.168.0.200:8080"
# Listening on :8000...
GraphQL
GraphQL API接口
-
查询接口:
http://alpha-server:8080/graphql(启动服务时日志输出该地址);curl -XPOST alpha-server:8080/graphql \ --header='Content-Type: application/graphql' --data '...' --data-binary '@file-path.graphql' curl -XGET alpha-server:8080/graphql?query={...}&variables={...}&operation=...POST请求的数据格式支持graphql或json,JSON格式的请求数据支持添加变量等(也可通过客户端分别添加查询语句和变量)。curl -XPOST alpha-server:8080/graphql \ --header='Content-Type: application/json' --data-binary '@file-path.json'{ "oeprationName": "query_name", "query": "query query_name(......", "variable": { "filter": { ... } } } -
管理接口:
http://alpha-server:8080/admin(启动服务时日志输出该地址);curl -XPOST alpha-server:8080/admin/schema \ --header='Content-Type: application/graphql' --data '...' --data-binary '@schema.graphql'
返回信息:
{"data":{"code":"Success","message":"Done"}}管理接口授权:
"resolving updateGQLSchema failed because unauthorized ip address。
响应数据:总是以JSON格式返回,成功返回data和extensions字段,错误返回errors字段。
客户端
schema
schema定义了实体类型及其包含的属性。
type Product {
productID: ID!
name: String @search(by: [term])
reviews: [Review] @hasInverse(field: about)
}
type Customer {
username: String! @id @search(by: [hash, regexp])
reviews: [Review] @hasInverse(field: by)
}
type Review@withSubscription { //*
id: ID!
about: Product!
by: Customer!
comment: String @search(by: [fulltext])
rating: Int @search
}
*:@withSubscription:启用订阅,当数据更新时,自动向订阅者发送查询结果。
String! @id:使用该字段作为ID;ID!自动生成ID。
Dgraph将根据定义的schema自动生成访问数据的API,包括:
getType(postID: ID!): Type
queryType(filter: TypeFilter, order: TypeOrder, first: Int, offset: Int): [Type]
aggregateType(filter: PostFilter): TypeAggregateResult
注释:
"""xxx"""内容在生成API时会被自动处理为文档。#...会被自动忽略。
修改Schema
通过API提交schema数据可更新schema。
数据类型
-
Int、Float、String、Boolean、Int64、DateTime(RFC3389)。 -
序列类似于无序集合不会存储重复值:
[Type]。 -
ID:不能声明ID类型的序列,每个模式只能有一个ID类型字段。 -
枚举
enum Tag { GraphQL Database Question } type Post { tags: [Tag!]! } -
自定义模式也可作为其他模式的类型声明。
接口
interface Post {
id: ID!
text: String
datePublished: DateTime
}
type Question implements Post {
title: String!
}
type Comment implements Post {
commentsOn: Post!
}
在类型中重复声明接口中已有字段不会产生重复字段,必须具有相同类型及是否为空的条件,其他属性则继承接口声明。
联合
union HomeMember = Dog | Parrot | Human
搜索和过滤
@search命令控制如何构建索引以及搜索类型,基于字段的搜索类型决定在查询时如何设置过滤表达式。
数值类型搜索
Int、Float和DateTime类型,DateTime类型支持设置时间查询单位(包括year、month、data、hour)。过滤条件支持的运算符包括lt、le、eq、in、between、ge、gt。
numLikes: Int @search
querySomeType(filter: { numLikes: { gt: 50 }})
datePublished: DateTime @search(by: [day])
Boolean类型搜索
isPublished: Boolean @search // schema
filter: { isPublished: true } // filter
字符串类型搜索
搜索类型及其对应的过滤运算符:
-
hash:eq、in。 -
exact:过滤运算符与数值类型相同。 -
regexp:regexp。正则表达式必须置于/.../之间(类似于sed语法)。filter: { name: { regexp: "/.*iggy.*/" } } -
term:allofterms、anyofterms。 -
fulltext:alloftext、anyoftext。
支持为字符串类型字段设置多个搜索类型。
枚举类型搜索
搜索类型及其对应的过滤运算符:
- 未指定/
hash:eq、in。 exact:过滤运算符与数值类型相同。regexp:regexp。
地理位置
mutation
mutation {
addProduct(input: [ // add an object of Product*
{ name: "GraphQL on Dgraph"},
{ name: "Dgraph: The GraphQL Database"}
]) {
product {
productID
name
}
}
addCustomer(input: [{ username: "Michael"}]) {
customer {
username
}
}
}
*操作名称基于对象类型和操作类型自动识别。
curl -XPOST localhost:8080/graphql \
--header "Content-Type: application/graphql" \
--data-binary '@add-data.graphql'
query
query [query_name($variable: Type)]{
queryType(filter: { comment: {alloftext: "easy to install"}}) {
// 指定查询字段及其引用对象的字段
comment
by {
username
}
about {
name
}
posts(filter: {title: {allofterms: "GraphQL"}}) {
title
text
datePublished
}
}
}
序列字段也可指定过滤表达式。
查询操作可选择设置名称和传入的变量,如果仅包含一个查询操作,也可省略外侧query关键字。
一个查询语句块中,可包含多个查询命令,返回结果将包含每个查询命令的返回数据。
可以在查询请求中声明多个查询操作,但一次请求只能指定一个操作(通过operationName指定)。
Search and Filtering - GraphQL (dgraph.io)
GraphQL订阅
GraphQL Subscriptions - GraphQL (dgraph.io)
DQL
GraphQL couldn’t support many of the features required from a language meant to interact with Graph data, and we felt some of the features were unnecessary and complicated. So, we’ve created a simplified and feature rich version of GraphQL.
修改schema
curl -XPOST "localhost:8080/alter" --silent --data-binary @alter_schema.dql
RDF文件中的数据字段名称最好添加前缀,避免与数据库中已有字段发生冲突。
schema的定义语法与GraphQL一致。
可通过Ratel UI修改Schema。
mutate
curl -XPOST "localhost:8080/mutate?commitNow=true" --silent \
--header "Content-Type: application/rdf" \
--data-binary "@starwars.rdf"
# --data 'rdf_data'
使用
--data-binary将保留数据中的换行,因此数据中的注释内容能得到正确处理。
查询
curl -XPOST "localhost:8080/query" --silent \
--header "Content-Type: application/dql" \
--data $'{ me(func: has(starring)){ name }}'
查询语法
{
me(func: allofterms(name, "Star Wars"), orderasc: release_date)
@filter(ge(release_date, "1980")) {
name
release_date
revenue
running_time
director {
name
}
starring (orderasc: name) {
name
}
}
}
返回数据为JSON(与GraphQL一致),data字段为图数据对象(与查询语句中命令对象me一致)。图数据包含节点(JSON对象)序列,==每个节点可嵌套JSON对象数组以表示与其他节点的关系==。
Python - Clients (dgraph.io):Official Dgraph client implementation for Python (Python>=v2.7 and >=v3.5), using gRPC.
Dgraph Query Language - Query language (dgraph.io)
图数据
链路
在类型声明中包含指向另一类型的成员(标量或向量),则在实际声明数据时即创建了链路。
type Author {
posts: [Post] @hasInverse(field: author)
}
type Post {
author: Author
}
双向链路
为了保证数据实例A->B有反向链路B->A,需要在A的外链成员声明后添加hasInverse属性。该属性保证在添加节点时自动更新其外链节点的属性。
Neo4j
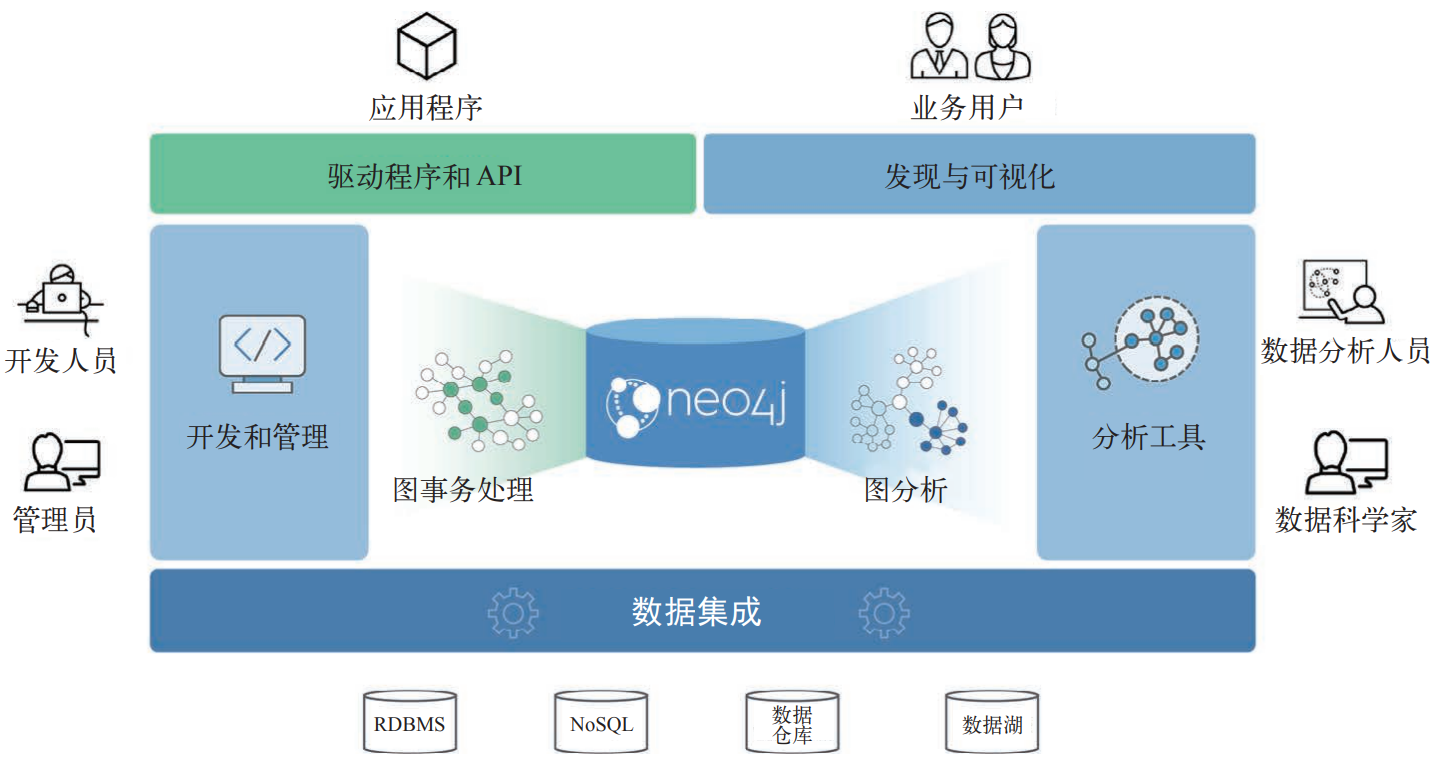
Neo4j Desktop User Interface Guide - Developer Guides
Awesome Procedures On Cypher (APOC) - Neo4j Labs
Graph Applications Overview - Developer Guides (neo4j.com)

Neo4j Graph Data Science - Developer Guides
安装运行
安装
yum
rpm --import https://debian.neo4j.com/neotechnology.gpg.key
cat <<EOF> /etc/yum.repos.d/neo4j.repo
[neo4j]
name=Neo4j Yum Repo
baseurl=http://yum.neo4j.com/stable
enabled=1
gpgcheck=1
EOF
sudo yum install neo4j # 社区版
apt
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.com stable 4.0' | sudo tee /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
手动安装
tar -xf neo4j-community-4.4.11-unix.tar.gz -C /opt
ln -sf /opt/neo4j-community-4.4.11 /usr/local/neo4j
export NEO4J_HOME=/usr/local/neo4j
Neo4j图算法库
Neo4j图算法库(Graph Data Science)以插件形式与数据库一起安装,提供了一个可通过Cypher查询语言执行的用户自定义程序集。提供了支持图分析和机器学习工作流程的并行算法。这些算法在基于任务的并行计算框架上执行,并针对 Neo4j平台进行了优化。
APOC库
APOC(Awesome Procedures on Cypher)库用于辅助完成数据集成、数据转换和模型重构等常规任务。
Cypher Shell
配置
Java版本:
Please use Oracle(R) Java(TM) 11, OpenJDK(TM) 11 to run Neo4j.
# Paths of directories in the installation.
dbms.default_database=neo4j
dbms.default_listen_addres=0.0.0.0 # 默认监听localhost
dbms.directories.data=/home/neo4j/data #*
dbms.directories.logs=/home/neo4j/logs
dbms.directories.run=/home/neo4j/run
dbms.directories.transaction.logs.root=/home/neo4j/data/transactions
dbms.directories.import=/home/neo4j/import # CSV文件加载源目录,注释取消限制
*:如果运行Neo4j的用户没有Neo4j安装目录的写权限,应该修改输出目录,或修改默认目录的写权限。
NEO4J_ULIMIT_NOFILE=60000
# edit: /etc/security/limits.conf
neo4j soft nofile 40000
neo4j hard nofile 40000
运行
docker
docker run \
--publish=7474:7474 --publish=7687:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j:4.3.5-community
命令行
将neo4j添加到PATH。
neo4j console
neo4j start # background
以systemd服务启动。
[Unit]
After=network.target
[Service]
Environment=PATH=/usr/local/openjdk11jre/bin:/usr/local/sbin:/usr/local/bin:/usr/bin:/usr/bin
Environment=NEO4J_ULIMIT_NOFILE=60000
Type=forking
ExecStart=/usr/local/neo4j/bin/neo4j start
PIDFile=/home/neo4j/run/neo4j.pid
User=neo4j
Group=neo4j
[Install]
WantedBy=multi-user.target
交互命令
访问数据库界面:http://localhost:7474,默认用户名和密码为neo4j:neo4j,首次登录需要修改密码。
API端口:
7687。
数据库和服务器信息:
:server user list/add # 列出/添加用户
:server disconnect
:dbs # 列出服务器中的数据库
:sysinfo # 列出数据存储信息
选择数据库
:use graph_db_name # ":"是命令的一部分
查询语言
变量赋值表达式
WITH "URL" AS base
WITH base + "transport-nodes.csv" AS uri
多条命令使用;分隔。
数据库管理
SHOW DATABASES;
SHOW DATABASE name;
企业版支持数据库创建和修改。
CREATE DATABASE name [IF NOT EXISTS];
ALTER DATABASE name [IF EXISTS] SET ACCESS {READ ONLY | READ WRITE};
START/STOP DATABASE name;
DROP DATABASE name [IF EXISTS] [{DUMP|DESTROY} [DATA]];
定义数据
Neo4j的底层数据类型为Directed Multi-Graph,节点间可存在多条边(多种连接关系)。通过节点/边的标签或者其包含的属性,可获取其中的一个或多个子图用于分析。
添加节点
节点类似于关系型数据库表的一条记录,但没有严格的Schema约束,即每个节点可任意添加属性。具有相同标签的节点通常具有相同的属性。
CREATE (n:NodeLabel {name:'John'}) RETURN n;
CREATE (:NodeLabel {name:'John'});
CREATE ({name:'John'});
创建节点的可选参数(可在后续通过查询节点并补充设置相应参数):
-
n为当前创建节点的引用标识,用于当前语句后续命令引用(例如RETURN n)。 -
NodeLabel:标签/类型(可选,后续可设置),如果省略了节点标识,则需要保留:NodeLabel; -
属性列表:字典类型
{...}(可选,后续可设置)。CREATE()如果不接受任何属性,则会创建一个空节点。
注意:添加节点时无法检查是否有重复节点,用户需要首先根据属性查询是否有匹配节点再决定是否创建新节点。
添加或更新节点
MERGE (n:Person {name: $value}) // 节点属性用于匹配已有节点
ON CREATE SET n.created = timestamp() // 根据匹配结果:创建或更新节点属性
ON MATCH SET
n.counter = coalesce(n.counter, 0) + 1,
n.accessTime = timestamp()
在节点间添加关系
仅在已有节点间添加关系,需要注意设置过滤条件,否则匹配的点对可能非常多。
MATCH (a:Person {name:'Liz'}), (b:Person {name:'Mike'})
MERGE (a)-[r:EdgeType {since:2001}]->(b);
MATCH (a:Person {name:'Liz'})
MERGE (a)-[r:EdgeType {since:2001}]->(b:Person {name:'Mike'}); //*
*:匹配一个节点,新增一个节点。
(a)-[r]->(b)表示点之间的关系(边):类似于节点表示,边也可以指定标签Relation和属性{...}(如果没有标签和属性,可完全省略[r])。Neo4j仅支持创建有向边,即表达式中必须使用-->或<--,不支持--或<-->。
自动创建节点和边。由于不会检测已存在节点或边,通常不使用这种方式添加关系,无法对已有数据进行修改,应该使用
MATCH语句首先获取已有数据。CREATE (a:Person {name:'Todd'})-[r:Friends]->(b:Person {name:'Carlos'}); CREATE (a)-[r:Relation {name: value}]->(b); //*
*:由于未指定节点属性,因此将在所有已存在节点对之间添加边(不推荐)。
查询数据
查询满足条件的节点
MATCH (a:Label {prop...}) RETURN a LIMIT 10;
MATCH (a:Label) WHERE a.prop=value RETURN a.prop AS prop LIMIT 10;
节点/链路的标签和属性用于限定查询范围,可省略。
AS用于定义返回值的别名。
查询关系中的节点
与一类节点有关系的节点,关系描述表达式可使用-->和<--来表示单向边,--或<-->表示具有任意方向的边(这种方式会遍历a->b和b->a返回重复数据,不推荐)。
MATCH (a:LabelA{prop})-[r:LinkLabel{prop}]->(b:LabelB{prop}) RETURN b; //
MATCH (a)-->(b) RETURN b; // 所有对外有关系的节点
查询关系
MATCH (a:Person)-[r:BornIn]->(b:Location {city:'Boston'}) RETURN a,b //查询满足条件的节点
返回数据为表格结构,每一列对应一个返回参数。节点对(a,b),以及对应的关系r可用于可视化。
通过查询也可以直接获取节点或关系的属性并返回,例如:
MATCH (a)-[r]->(b) RETURN a.name, b.name, type(r) //字段不存在返回null
修改属性
MATCH (a:Person {name:'Liz'}) SET a.age=34, a.title='',...
SET a += {...}
SET a = {...};
MATCH (a:Person {name:'Liz'}) SET a:Student; // 添加(不是替换)标签
MATCH (a:Person {name:'Liz'}) SET a = {}; // 清空属性
MATCH (a:Person {name:'Mike'}) REMOVE a.test; // 移除属性
MATCH (a:Person {name:'Mike'}) REMOVE a:Student; // 移除标签
删除数据
删除边:
MATCH ()-[r]->() WHERE r.id = 123 DELETE r;
删除节点及其关联边:
MATCH (n) DETACH DELETE n // 删除所有节点
MATCH (n)-[r]-() WHERE r.id = 123 AND n.id = 'abc' DELETE n, r //*
MATCH (a:Location {city:'Portland'}) DELETE a
*:如果节点还关联其他边,将无法删除(抛出错误)。
导入数据
导入节点数据
LOAD CSV WITH HEADERS FROM uri AS row // 支持通过HTTP/HTTPS/FTP读取数据
MERGE (place:Place {id:row.id}) // 将CSV节点数据合并到图中
SET place.latitude = toFloat(row.latitude),
place.longitude = toFloat(row.latitude),
place.population = toInteger(row.population)
本地数据通过 file:///导入,仅能导入Neo4j数据库设置的导入目录中的数据。
dbms.security.allow_csv_import_from_file_urls=True dbms.directories.import=import
导入链路数据
LOAD CSV WITH HEADERS FROM "file:///transport-relationships.csv" AS row
MATCH (origin:Place {id: row.src})
MATCH (destination:Place {id: row.dst})
MERGE (origin)-[:EROAD {distance: toInteger(row.cost)}]->(destination)
Python API
Python Driver
连接数据库:
from neo4j import GraphDatabase
uri = "neo4j://example.com:7687"
def write_func(tx, *args, **kwargs):
tx.run(query, **kwargs) # 查询语句中使用占位符`$var`代替要传入的关键字参数
def read_func(tx, *args, **kwargs):
result = tx.run(query, **kwargs)
# 每条record对应查询语句返回的所有参数组成的一行记录。
return [record for record in result]
with GraphDatabase.driver(uri, auth=("neo4j", "password")) as driver:
with driver.session() as s:
# Auto-commit Transactions,
# support only one statement per transaction
# and are not automatically retried on failure.
s.run()
# Explicit Transactions
with session.begin_transaction() as tx:
pass
# Managed Transactions
s.write_transaction(write_func, *args, *kwargs)
result = s.read_transaction(read_func, *args, *kwargs)
result.data() # 将返回数据转换为字典。
# use the driver
使用上下文管理器代替相应的
close()方法。
Py2neo Client
使用
conda安装py2neo可能缺失以下依赖项,需要指定。conda install py2neo monotonic pansi
查询节点
使用NodeMatcher封装获取节点的Cypher查询语句。
from py2neo import Graph
from py2neo.matching import *
g = Graph(uri, auth)
nodes = NodeMatcher(g)
nodes[identity] # [raise KeyError] identity是由图数据库自动生成的*
nodes.get(identity) # return None if not exist.
nodes是所有节点的集合,可进行迭代或获取节点总数(len(nodes))。通常会设置条件过滤后再获取节点。
matches:NodeMatch = nodes.match(*labels, **properties)\
.where('key=value',..., key=value,...)\
.limit(count)\
.skip(count)\
.order_by(*fields)
# MATCH (n:labels {properties}) RETURN n;
# 返回可迭代的节点集合
matches.exists() # 判断匹配是否为空
matches.first()
matches.all()
matches.count()
for node in matches:
print(node)
节点对象
节点对象可在本地创建,或通过查询语句返回(与数据库绑定)。
a = Node('Person', name='Alice')
a.graph # 节点绑定的远端图数据库
a.identity # 节点标识号
a.add_label('Employee') # -> a.labels, a.has_label, a.clear_label
a.update_labels(lables)
如果节点与远端数据库绑定,则节点相等关系取决于数据库分配的ID(与属性或标签无关);反之,节点仅与其自身相等。
节点数据的访问方式类似于字典对象。节点数据也可转换为字典对象。
a[prop] = value
a.get(prop, default=None)
del a[prop]
a.clear() # 清除所有属性
dict[a] # 节点的所有属性组成的字典
a.items(), a.keys(), a.values(), a.update(**kwargs)
条件表达式
除字符串形式的WHERE表达式外,可通过API构造表达式。
from py2neo import AND, OR
nodes.match("Person", born=ALL(GE(1964), LE(1966)))
运算符类型:
null检查:IS_NULL、IS_NOT_NULL;- 值比较:
EQ、NE、LT、LE、GT、GE; - 字符串比较:
STARTS_WITH、ENDS_WITH、CONTAINS、LIKE(正则表达式); - 集合比较:
IN; - 逻辑连接:
AND、OR、XOR。
查询关系
类似于节点查询接口。
links = RelationshipMatcher(g)
matches:RelationshipMatch = links.match(
nodes:List[Node]=None, r_type=None, **properties)
nodes指定匹配关系的节点范围(None不限定节点);r_type为关系类型。
关系对象
KNOWS = Relationship.type("Knows")
ab = KNOWS(a,b)
ab.nodes # -> (a,b)
ab.start_node, ab.end_node
关系对象也可像节点对象一样设置和访问属性。
路径对象
路径对象可通过查询或本地构造获取。Path构造方法的参数由节点对象和关系(关系对象或字符串)交替组成,路径遍历不固定方向,但关系对象的起点或终点必须是上一个节点参数。
alice, bob, carol = Node(name="Alice"), Node(name="Bob"), Node(name="Carol")
abc = Path(alice, "KNOWS", bob, Relationship(carol, "KNOWS", bob), carol)
子图对象
子图Subgraph是任意节点和关系的集合,也是Node、Relationship和Path的基类(子图可以和这些对象运算)。使用子图,可以在本地构造图对象,并与远端的图数据进行运算(创建、合并)。
subgraph | other |... # 合并图(自动去重)
subgraph & other &... # 图交集
subgraph - other -... # 差集
subgraph ^ other ^... # 对称差集(不在其中一个子图中对象)
subgraph.keys() # 所有对象使用过的属性名
subgraph.labels() # 所有节点使用过的标签名
subgraph.types() # 所有关系使用过的标签名
subgraph.nodes, subgraph.relationships
修改图数据库
修改图数据库可直接通过图数据库对象Graph,或通过图数据库对象创建的事务Transaction进行。
with g.begin(readonly=False) as tx:
tx.exists(subgraph)
tx.match(nodes=None, r_type=None, limit=None)
tx.match_one(nodes=None, r_type=None)
tx.create(subgraph)
tx.merge(subgraph, label=None, *property_keys)
tx.delete(subgraph)
tx.delete_all()
tx.suparate(subgraph) # 删除数据库中的关系(保留节点)
当修改数据库查询返回对象并需要与数据库同步时,可通过pull和push方法。
with g.begin(readonly=False) as tx:
tx.push(subgraph) # 将本地修改回写到远端
tx.pull(subgraph) # 从远端获取最新数据
执行Cypher原生查询
类似于
neo4j-python-driver的查询接口。
from py2neo import Cursor
g = Graph(uri, auth)
cs:Cursor = db.run('MATCH (a)-[r:Friends]->(b) RETURN a,b,r')
cs.stats # 命令执行状态
cs.to_supgraph()
Cursor是查询结果Record(一行记录)的迭代器,可使用for语句或调用forward()/current()或next()方法遍历查询记录。使用任何读取方法,都只能从迭代器获取一次数据。
访问记录
通过编号或返回参数名访问Record(访问方法类似于Cursor,区别在于只包含一条记录)。
原始数据批量处理
py2neo.bulk – Bulk data operations — py2neo 2021.1
导出原生查询结果。
graph_data= cs.data(*keys)
# 返回查询结果的字典序列,`keys`为`RETURN`语句指定的返回参数名(`cs.keys()`)。
graph_df = cs.to_data_frame(index=None, columns=None)
图对象映射OGM
py2neo.ogm – Object-Graph Mapping — py2neo 2021.1
图分析算法
配置算法参数:
:param limit => (null);
:param config => ({
relationshipWeightProperty: null
});
:param startNode => ('Amsterdam');
:param endNode => ('London');
:param graphConfig => ({
nodeProjection: 'Place',
relationshipProjection: {
relType: {
type: 'EROAD',
orientation: 'UNDIRECTED',
properties: {}
}
}
});
:param communityNodeLimit => ( 10);
:param generatedName => ('in-memory-graph-1662349638926');
创建和删除内存图实例:
CALL gds.graph.project($generatedName, $graphConfig.nodeProjection, $graphConfig.relationshipProjection, {})
运行图算法:
CALL db.propertyKeys() YIELD propertyKey MATCH (start) WHERE start[propertyKey] contains $startNode
WITH start
LIMIT 1
CALL db.propertyKeys() YIELD propertyKey MATCH (end) WHERE end[propertyKey] contains $endNode
WITH start, end
LIMIT 1
WITH $config AS config, start, end
WITH config { .*, sourceNode: id(start), targetNode: id(end)} as config
CALL gds.shortestPath.dijkstra.stream($generatedName, config)
YIELD nodeIds, costs
UNWIND range(0, size(nodeIds)-1) AS index
RETURN gds.util.asNode(nodeIds[index]) AS node, costs[index] AS cost
删除内存图实例:
CALL gds.graph.drop($generatedName)
NebulaGraph
NebulaGraph Database 手册 (nebula-graph.com.cn)
Apache TinkerPop
Apache TinkerPop™ is a graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP).
分布式大数据处理
MapReduce
Map操作将运算依次作用到序列的每个元素,并把运算结果作为新的序列返回。
Reduce操作把运算依次作用在序列元素上进行聚合运算。
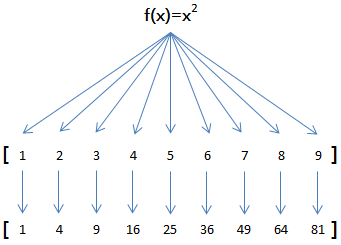
Python内建了map()、filter()和reduce()函数。
maped_set = map(fcn, dataset) # 等价于 list=[fcn(x) for x in dataset]
tf = filter(lambda x: cond(x), list) # tf=[cond(x) for x in list]
list = list(tf) # list=[x for x in list if cond(x)]
from functools import reduce
result = reduce(lambda x,y: x+y, dataset)
Hadoop Framework
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
Hadoop包括分布式文件系统HDFS和计算框架Hadoop Yarn。
Hadoop的部署模式为主从模式,包括:
-
Master Node of HDFS:
- NameNode manages the distributed file system and knows where are stored data blocks.
-
Master Node of Yarn:
- 资源管理器(ResourceManager) manages the YARN jobs and takes care of scheduling and executing processes on worker nodes. 调度器(Scheduler)是资源管理器的组成部分,allocating resources to applications based on the resource requirements of applications, subject to constraints of capacities, queues etc.
-
Worker Nodes: store the actual data and provide processing power to run the jobs.
- DataNode manages the physical data stored on the node;
- NodeManager:负责工作节点上运行任务(Container)的资源管理,并与ResourceManager交互。
- Container: the abstract notion of resources, including memory, CPU, disk, network etc.
App Mstr:ApplicationMaster,即应用主节点,是应用运行的主要容器,负责管理同一应用的其他容器并与调度器交互。Yarn的部署方式也是主从方式,但无需与HDFS的主从节点重合。
HDFS daemons are NameNode, SecondaryNameNode, and DataNode. YARN daemons are ResourceManager, NodeManager, and WebAppProxy.
部署
下载安装
从镜像站点下载hadoop-x.y.z.tar.gz并解压缩到目标文件夹。
版本:CDH 6 Version, Packaging, and Download Information | 6.x | Cloudera Documentation。
设置运行环境
如果同时使用Hive则需要使用Java 8。
Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only). Apache Hadoop from 3.0.x to 3.2.x now supports only Java 8. Apache Hadoop from 2.7.x to 2.10.x support both Java 7 and 8.
用户环境变量
# edit /home/<user>/.bashrc
# JAVA_HOME set to the root of your Java installation:
# update-alternatives --display java
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
通过Hadoop环境配置文件etc/hadoop/hadoop-env.sh设置JAVA_HOME,不影响全局Java环境配置。
Single Node
Pseudo-Distributed Operation
-
配置
etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml(参考集群配置)。 -
设置本地SSH免密登录
ssh-copy-id -i ~/.ssh/id_rsa.pub $hostname -
格式化HDFS文件系统,由
dfs.namenode.name.dir指定,默认位置root=/tmp/hadoop-gary/dfs/name:hdfs namenode -format不同版本的HDFS文件系统不兼容。
-
启动Name Node和Data Node守护进程:
start-dfs.sh(关闭stop-dfs.sh) -
执行MapReduce任务
YARN on a Single Node
- 在上述步骤基础上,配置
etc/hadoop/mapred-site.xml和etc/hadoop/yarn-site.xml(参考Cluster配置)。 - 启动守护进程:
start-yarn.sh(停止:stop-yarn.sh)
Cluster
Typically one machine in the cluster is designated as the NameNode and another machine as the ResourceManager, exclusively.
The rest of the machines (workers) in the cluster act as both DataNode and NodeManager.
If MapReduce is to be used, then the MapReduce Job History Server will also be running.
For large installations, these are generally running on separate hosts.
如果使用虚拟机进行实验,可先将多数内容在单节点上创建完成,然后复制虚拟机。
-
编辑
/etc/hosts,配置集群所有节点的域名映射。 -
配置主节点(Name Node和Resource Manager)到从节点的SSH连接,实现[免密登录](../Linux and UNIX/Linux配置和管理#通过SSH访问服务器),从而从主节点完成所有节点的配置(设置SSH服务的
PermitUserEnvironment从而保证远程连接能够使用环境变量)。 -
配置
etc/hadoop/core-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/mapred-site.xml和etc/hadoop/yarn-site.xml(包括Yarn的资源分配)。如没有配置
hadoop.tmp.dir参数,系统使用默认的临时目录:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。 -
创建文件读写目录。配置文件中设置的相关目录,需要运行
hadoop的用户或其所属组具有写权限(使用chmod或chown修改相应权限);否则应将相关目录设置到有权限的目录下。hadoop-master: ERROR: Cannot set priority of secondarynamenode process 3001.
-
编辑
etc/hadoop/workers(Hadoop2.x为slave),配置工作节点(主机名); -
配置内存分配规则(小内存节点需要);
-
将配置文件分发到各个节点:
for node in nodes; do scp -r etc/hadoop/* $node:hadoop_home/etc/hadoop/; done注意将配置文件的权限应该包括
scp用户的可写权限。 -
在NameNode节点上执行格式化HDFS文件系统
完成格式化后显示
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.3.110。输出日志中记载了文件系统的配置信息(包括磁盘路径)。 -
在
NameNode上启动HDFS:start-dfs.sh(停止:stop-dfs.sh) -
在作为
ResourceManager上启动Yarn:start-yarn.sh(停止:stop-yarn.sh)在非
ResourceManager的节点上(根据配置文件声明)启动Yarn会导致ResourceManager启动失败并触发BindException。因为启动脚本会监听域名/主机名对应的IP和端口,其并非当前主机的IP地址,所以导致上述异常。 -
执行MapReduce任务。
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/RackAwareness.html
网络拓扑
Hadoop可根据集群的网络拓扑优化数据读写。
在core-site.xml中指定拓扑声明文件:
net.topology.node.switch.mapping.impl=org.apache.hadoop.net.TableMapping
net.topology.table.file.name=$FILEPATH/network.mapping
拓扑声明文件可手动编写或通过脚本生成:
172.28.76.111 /rack-001
172.28.76.112 /rack-002
172.28.76.113 /rack-003
可能的问题
pdsh导致无法远程配置节点,卸载pdsh。- DataNode的路径配置不正确,导致节点不能启动,检查
hdfs-site.xml配置文件。
Hadoop命令行
shellcommand [SHELL_OPTIONS] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
shellcommand:例如hadoop, hdfs, yarn,...,
COMMAND是子命令,
GENERIC_OPTIONS是多类命令通用的选项,
-libjars xxx.jar,yyy.jar,...:提交任务时在CLASSPATH中添加额外jar包。
Apache Hadoop 3.3.1 – Hadoop Commands Guide
Hadoop命令
hadoop classpath [--glob | --jar <path> ]
hadoop jar <jar> [mainClass] args... # 使用yarn jar启动YARN applications.
HDFS命令
HDFS命令用于管理HDFS数据。HDFS默认目录为/user。
hdfs dfs -cmd [options] args # 等效命令:hadoop fs
hdfs dfs -help/-usage [cmd ...] # 查看命令的帮助信息/使用语法
多数命令cmd与Linux命令相同,包括ls、mkdir、rm等。
文件系统信息
hdfs fsck PATH # 检查文件系统状态
hdfs dfs -df -h [PATH ...] # 查看指定路径所在文件系统的名称、容量、使用量、可用量、使用比例
-du -s -h PATH ... # 查看指定类路径下个目录的使用容量
hdfs dfs -count -h PATH # 统计指定路径下目录、文件数量和数据量
格式化输出文件/目录的统计信息,格式化字符串中可包含普通字符和%替换指令:
hdfs dfs -stat FORMAT PATH # %n(name) %F(type) %u(user) %g(group) %b(filesize) %o(blocksize)
# %y(datetime) %Y(timestamp-ms) %r(replication)
设置文件的副本数量:
hadoop fs -setrep [-w] [-R] <numReplicas> <path> # => hdfs dfs
hadoop fs –setrep -w 3 hdfs:///some/path/spark-libs.jar
-w:等待操作完成。-R选项用于向后兼容,如果找不到命令可添加该选项。
文件管理
使用get命令导出数据到本地磁盘,使用put命令将本地磁盘的数据存入HDFS文件系统。
hdfs dfs -copyFromLocal|copyToLocal SRC DEST # 本地系统与DHFS间文件复制 => -get/-put
-moveFromLocal/moveToLocal SRC DEST
-appendToFile SRC ... DEST
hdfs dfs -cp/-mv -f SRC DEST # HDFS文件复制/移动
hdfs dfs -ls -h -R PATH
hdfs dfs -find PATH ... EXPRESSION ... # => linux find
hdfs dfs -rm -skipTrash FILE
hdfs dfs -mkdir/-rmdir /user/gary/packages # 创建/移除目录
hdfs dfs -test -[defsrwz] PATH_URL # 测试文件/目录信息(d:目录,e:存在,f:文件,s:非空,z:空文件)
hdfs dfs -touchz PATH # 创建空文件
权限管理
hdfs dfs -chgrp|chown|chmod -R ... PATH
文件输入输出
hdfs dfs -cat SRC ..
hdfs dfs -tail -f FILE # Show the last 1KB of the file.
hdfs dfs -truncate [-w] LENGTH PATH
HDFS URL
hdfs:/hostname[:port]/path/file # 使用域名或IP,端口可省略
hdfs:///path/file # 省略主机采用Hadoop集群配置
/path/file # 省略协议
错误:Operation category READ is not supported in state Standby:集群使用了高可用配置,而HDFS地址指向了备份节点。解决方法:使用集群名称
HACluster或省略主机名。
Apache Hadoop 3.3.0 – HDFS Commands Guide
提交MapReduce任务
Yarn命令
Apache Hadoop 3.3.1 – YARN Commands
权限
如果HDFS开启权限管控,则只有文件或目录授权的用户才能对相应目录进行操作(主机的root用户如果不在superuser组中也也无法操作)。
sudo -u hdfs hadoop fs -mkdir /user/root # /user目录的所有者为hdfs:superuser
sudo -u hdfs hadoop fs -chown root /user/root
如果没有操作权限,则可能会出现以下错误:Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x。
Resource Allocation on Yarn
内存分配
yarn.scheduler.minimum-allocation-mb 256
yarn.scheduler.maximum-allocation-mb 1024
yarn.nodemanager.resource.memory-mb 2048
虚拟内存分配配置:
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value> <!--如果因为VMEM不足导致容器被终止,可适当将该值调大-->
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Fair Scheduler
为应用程序设置优先级(权重);建立多个队列,并未每个队列设置优先级;系统根据队列优先级按比例为各队列分配资源(同时考虑最小和最大资源约束)。
It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness.
队列中应用程序根据优先级按比例分配队列可用资源(只有1个应用时,该应用可占用所有资源)。
每个队列可设置最大可运行的App数量。由于App按比例分配队列中的资源,当运行的App过多时,每个App可用的资源减少,新提交的App可能由于资源不足而挂起;已有App也可能因为抢占而被提前终止。
Capacity Scheduler
The CapacityScheduler is designed to allow sharing a large cluster while giving each organization capacity guarantees.
- Hierarchical Queues
- Capacity Guarantees
- Elasticity
- Multi-tenancy
- Resource-based Scheduling
- Priority Scheduling
Using GPU on Yarn
Apache Hadoop 3.1.0 – Using GPU On YARN
分布式数据仓库Hive
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
Hive提供类SQL查询语言HiveQL(Hive query Language)以读取数据,并在内部将HiveQL转换为MapReduce任务并在Hadoop集群上执行。
安装
从镜像站点下载apache-hive-3.1.2-bin.tar.gz。
Hive目前还不支持Java 11,Hive使用Hadoop指定的Java版本。
Hive环境配置
export HIVE_HOME=/usr/local/hive
export PATH=${PATH}:${HIVE_HOME}/bin
Hive的数据存储于HDFS中,因此首先在HDFS中创建Hive数据存储路径(hive.metastore.warehouse.dir)并设置读写权限:
hdfs dfs -mkdir -p /tmp /user/hive/warehouse # 这是默认的数据仓库位置
# drwxr-xr-x - gary supergroup 0 2021-05-30 22:34 /hive/warehouse
hdfs dfs -chmod g+w /tmp /user/hive/warehouse
Hive配置文件:conf/hive-site.xml(默认值hive-site.xml.template)。
初始化元数据库
Hive应用在访问Hive数据前需要首先获取Hive的元数据库(metastore)信息,因此需要配置对metastore的访问路径和方法等(具体配置参考相应的访问方式)。
javax.jdo.option.ConnectionURL=jdbc:<db_scheme>
javax.jdo.option.ConnectionDriverName=<driver_name>
javax.jdo.option.ConnectionUserName=hiveuser
javax.jdo.option.ConnectionPassword=hivepass
用户名(
ConnectionUserName)和密码用于初始化数据库,且不能改作其他名称,否则会产生错误:Schema 'UNSERNAME' does not exist。
使用数据库前执行初始化,在执行初始化的位置生成metastore_db。根据元数据的存储方式设置dbType,默认存储在磁盘上使用derby。如果使用数据库,则选择相应的数据库类型,如mysql。初始化数据库前需要设置好配置文件,需要读取其中的访问方式以及用户凭据,==并且==在存储metastore的数据源==设置hive访问权限==。
schematool -dbType <db_type> \ # 必须指定数据库类型e.g., derby, mysql
-initSchema # 初始化metastore
-upgradeSchema
-validate # 验证
初始化错误:NoSuchMethodError: .......Preconditions.checkArgument(......。Hive与Hadoop中的Java包版本不兼容:guava-xxx.jar,使用Hadoop提供的包替换hive提供的包。
hadoop/share/hadoop/common/lib/guava-27.0-jre.jar
hive/lib/guava-19.0.jar
并发访问Hive
要实现并发访问Hive,必须实现对元数据metastore的并发访问(Derby服务和数据库服务),或提供可并发的Hive数据读写服务(Hiveserver2、metastore服务)。Hive CLI、Beeline/Hiveserver2等应用利用内置Derby驱动、Derby服务或数据库服务读写metastore数据,提供查询Hive数据的应用和服务。metastore服务基于metastore数据提供Thrift接口(默认端口tcp/9083)以支持第三方应用分布式访问Hive数据。
使用Derby网络服务或数据库服务读取metastore,从而允许多类客户端对metastore的并发访问。
metastore
本地metastore存储
在未配置ConnectionURL的情况下,应用将尝试寻找是否存在metastore数据(默认当前工作目录下),并使用内置的derby driver访问本地metastore数据文件。其metastore的配置如下:
driver_name=org.apache.derby.jdbc.EmbeddedDriver
db_scheme=derby:/local/path/metastore_db;create=true
嵌入模式下不支持使用URL作为数据库的源,derby.jdbc.EmbeddedDriver claims to not accept jdbcUrl。
db_scheme可额外指定一个参数databaseName=metastore_db,该参数将添加到路径后面。路径可为绝对或相对路径,如果留空,则表示读取该配置文件的程序的当前工作目录。
该驱动方法将占用本地磁盘上的metastore文件,导致其他应用无法访问元数据(数据库文件目录下由db.lck和dbex.lck两个文件,防止其他客户端并发访问),从而无法并发访Hive数据。
通过Derby服务访问metastore
为了支持并发访问数据库,可使用独立的Derby Network Server(tcp/1527,需要单独下载并首先启用该服务)。在该模式下,Derby服务也将占用metastore_db,但Derby网络服务可支持并发连接。通过配置URL使用该服务,访问Hive的程序与Derby服务可以位于不同主机上。
driver_name=org.apache.derby.jdbc.ClientDriver
db_scheme=derby://hadoop-master:1527//.../metastore_db;create=true
路径中在“
protocol://domain:port”后使用//表示绝对路径。
数据库存储metastore
由于数据库提供服务支持并发访问,因此也可以使用数据库(如mysql-server 8.0、postgresql 12.6等)来存储metastore数据。
driver_name=com.mysql.cj.jdbc.Driver
db_scheme=jdbc:mysql://hadoop-namenode:3306/hive?createDatabaseIfNotExist=true
如果使用数据库,则需要相应的数据库驱动包(例如MySQL需要在官网下载
MySQL Connector/J安装包,驱动包安装在/usr/share/java/mysql-connector-java-8.0.25.jar)。
需要在数据库中首先创建账户并配置访问权限。
CREATE USER hiveuser@'%' IDENTIFIED BY 'PassWord';
GRANT ALL ON hive_metastore.* TO hiveuser@'%';
Metastore Thrift服务
hive --service metastore > /tmp/metastore.log 2>&1 &
此时需要访问Hive的应用(应用所在目录的hive配置)无需配置ConnectionURL和ConnectionDriverName,而是配置hive.metastore.uris。
hive.metastore.uris=thrift://hadoop-namenode:9083
运行metastore服务的节点上
hive-site.xml需配置jdbc的方式以使该服务访问metastore数据。需要访问Thrift服务的其他应用程序(同一节点或远程节点)应在自身的hive-site.xml文件(设置HIVE_CONF_DIR指定配置文件所在目录)中设置hive.metastore.uris。
数据访问
从命令行访问Hive
Hive提供Hive CLI(已弃用)和Beeline/Hiveserver2访问Hive数据,提供HQL数据查询功能。
hive --silent # --verbose for information
Beeline (Hiveserver2 CLI )
Beeline/Hiveserver2将数据查询的前后端分离,Hiveserver2作为服务在后台运行,提供访问Hive数据的jdbc接口(jdbc:hive2://hadoop-master:10000),因此支持多个Beeline客户端(或其他应用)接入服务,并由Hiveserver2统一调度Hive数据查询。除直接访问metastore数据的方式外,Hiveserver2也支持[读取Thrift接口访问metastore](#metastore service)。
使用
org.apache.hive.jdbc.HiveDriver访问Hiveserver2的接口。启动Hiveserver2服务
hiveserver2 > /tmp/hive/hiveserver2.log 2>&1 &Hiveserver2的接口包括
binary(默认,使用10000端口)和http(使用10001端口)两种模式。如果使用http模式,则接口格式为:jdbc:hive2://hadoop-master:10001/;transportMode=http;httpPath=cliserviceURL需要以
/;结尾以与后面的参数分隔。http模式的配置项:hive.server2.transport.mode=http hive.server2.thrift.http.port=10001
默认不需要提供用户名和密码,以匿名用户登录(user=anonymous),不具有对HDFS的写入权限。指定用户名登录:注意此处的用户名应该是能够写HDFS中Hive数据仓库的用户,而非Hive配置文件中的用户。
beeline -u jdbc:hive2://localhost:10000/default -n gary
#> beeline
#beeline> !connect jdbc:hive2://localhost:10000/default
AccessControlException Permission denied: user=hiveuser, access=WRITE, inode="/user/hive/warehouse":gary:supergroup:drwxrwxr-x。
退出Beeline:
#0: jdbc:hive2://hadoop-master:10000>!q # exit CLI => !quit
读写数据
在命令行中,可通过SQL语句执行数据库/表格的创建以及数据读写;
问题诊断
查看/tmp/<user>/hive.log查看完整日志,启动服务时设置以下选项输出更多调试信息。
--hiveconf hive.root.logger=DEBUG,console
Hive CLI无法初始化会话
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
Hiveserver2未监听10000端口,但未产生错误提示
metastore版本问题:上述两个问题可能是由于metastore的版本检查出错。可以通过配置hive-site.xml禁用版本检查(hive.metastore.schema.verification=false),或修改metastore_db数据库中的版本信息。不推荐上述修改方式,忽略版本兼容性或修改版本信息可能导致无法正确读取数据,应该使对应版本的库读取数据。
上述问题也有可能是由于接管metastore的服务异常退出,导致metastore_db/*.lck未被删除(直接访问metastore数据的配置下),从而无法再次启用相应的服务。Hiveserver2会不断尝试连接服务,并不会给出错误提示,需要==查看日志==。
Hive用户登录问题
User not allowed to impersonate User:设置hive查询用户
<property> <!--hive-site.xml-->
<!--true: 使用提交查询的用户(beeline登录用户);
----false: 使用hiveserver2进程所属用户 -->
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
Hive以上述两种用户身份登录,还需要设置Hadoop的代理用户(Proxy user - Superusers Acting On Behalf Of Other Users)。
没有读写权限
Permission denied: user=anonymous, access=WRITE, inode="/user/hive/warehouse":gary:supergroup:drwxrwxr-x
连接hive时需要指定用户名,否则以匿名用户登录,没有写入权限。
参考文献
HBase
Java版本:JDK8。
vi hbase-env.sh
export JAVA_HOME=/usr/jdk64/jdk1.8.0_112
安装部署
测试
单机运行
伪分布式运行
分布式部署
Apache HBase ™ Reference Guide
Apache HBase ™ Reference Guide -- ZooKeeper
Spark
Apache Spark™ is a unified analytics engine for large-scale data processing.
框架概览
Spark程序是运行在一个集群上的相互独立的程序集(independent sets of processes),由用户主程序(driver program)中的SparkContext 对象进行协调。SparkContext可以连接至多种集群管理器(cluster managers),例如Spark的独立集群管理器、Apache Mesos、Hadoop YARN以及Kubernetes。建立连接后,Spark与集群节点上的执行器(executors)进行通信。
集群管理器负责应用程序间的资源分配。
执行器(Executor)是运行执行运算并储存结果的进程,每个应用程序有独立的执行器进程,并以多线程的方式运行计算任务(Tasks)。
然后集群管理器将应用程序代码(传递给SparkContext的JAR或Python文件)发送给执行器。最后SparkContext 将计算任务发送给执行器从而运行计算。
应用部署模式
cluster模式:driver程序在集群分配的主节点(如Hadoop集群的[ApplicationMaster](#Hadoop Framework))中运行,客户端完应用提交后即退出。适用于提交位置与工作节点距离较远(当前独立模式不支持cluster模式下的Python应用提交)。
client模式:提交的应用(driver程序)在客户端上运行,集群上的主节点仅用于向集群请求资源。适用于提交应用位置与工作节点接近(例如在同一网络中,shell属于client模式)。
模块
安装
选择稳定版的下载链接,下载至本地并解压。Spark需要Java语言运行时。
Spark 3.0已支持Java 11。
在Windows上运行Spark需要添加Hadoop工具包模拟Hadoop集群,并配置环境变量。
$env:HADOOP_HOME=$WIN_UTILS_HOME/hadoop-VER在Windows上运行Spark任务时,在任务结束后会出现异常
Exception while deleting Spark temp dir...。这是由于Windows不允许删除正在被使用的文件。因此,只能在Spark程序推出后再进行清理。
==PySpark安装配置==
如果需要通过Python运行Spark程序,需要使用PySpark库。Spark发行版本自带Python库(模块位于$SPARK_HOME/python、命令行工具pyspark位于$SPARK_HOME/bin)。如果仅需要Python环境,可不安装Spark发行包,而是从Python源安装PySpark库(同样包括上述内容,并安装Java模块运行所需的jar包),并单独指定Spark配置目录等相关环境变量。
如果是通过Python环境启动Spark,需要提前配置
SPARK_HOME环境变量,否则启动脚本以其所在位置(Python环境的Scripts或bin目录)为SPARK_HOME,从而找不到Spark的库。export SPARK_HOME=$PYTHON_HOME/lib/python3.10/site-packages/pyspark$env:SPARK_HOME=$PYTHON_HOME/lib/python3.10/site-packages/pyspark
运行Spark集群的所有节点都需要安装Python环境(客户端通过配置spark.pyspark.python或PYSPARK_PYTHON指定使用的Python环境路径),根据节点是否安装Spark发行包决定是采用Spark内置Pyspark发行包或在Python环境中安装PySpark。
export PYSPARK_PYTHON=/usr/local/miniconda3/envs/dataproc/python
export PYSPARK_DRIVER_PYTHON=/opt/apps/miniconda3/envs/process/bin/python
问题:
Exception: Python in worker has different version 2.7 than that in driver 3.7, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.。客户端程序和集群需要使用相同的Python版本。
如果要使用Spark发行包自带的PySpark库,则在Python搜索路径中添加库文件所在路径:
export PYTHONPATH="${SPARK_HOME}/python/:$PYTHONPATH"
export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.6-src.zip:$PYTHONPATH"
问题:
java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST,安装的py4j版本和Spark支持的版本不一致。创建Python环境时,需要使用与Spark分发版内置Python库相同的版本,通过设置PYTHONPATH指定(参考bin/pyspark脚本)。# Name Version Build Channel py4j 0.10.9 pyh9f0ad1d_0 conda-forge pyspark 3.1.2 pyh6c4a22f_0 conda-forge
单机测试
测试Java/Scala环境:
./bin/run-example SparkPi 10
未识别Hadoop的安装目录,因此上述计算直接采用内置的java模块执行计算:NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable。
测试PySpark环境:
./bin/spark-submit examples/src/main/python/pi.py 10
配置Spark运行环境
配置系统环境变量,以方便调用Spark命令。
export SPARK_HOME=/home/gary/apps/spark
export PATH=$PATH:${SPARK_HOME}/bin
export SPARK_CONF_DIR=${SPARK_HOME}/conf # conf/spark-env.sh中的默认值
Spark的运行参数配置主要包括三个部分:
-
Spark属性:用于运行Spark应用程序的参数(
conf/spark-default.conf); -
Spark环境变量:继承系统环境变量,主要设置Spark集群相关环境变量(
conf/spark-env.sh),在提交任务前加载;Spark on YARN in
clustermode: environment variables need to be set using thespark.yarn.appMasterEnv.[EnvironmentVariableName]property. Environment variables that are set inspark-env.shwill not be reflected in the YARN Application Master process inclustermode. -
conf/log4j.properties:控制日志。log4j.rootCategory=WARN, console # 后台日志 WARN ==> INFO log4j.logger.org.apache.spark.repl.Main=WARN # spark shell 日志级别还可指定其他文件作为任务运行时的日志配置文件:
spark-submit --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties"
Spark属性:可通过配置文件、命令行参数、程序中通过SparkConf设置。在提交应用程序时,后者具有更高优先级。
在Client模式下,关于Client资源分配的属性无法通过程序设置,例如“
spark.driver.memory”。这些属性在Client启动时已经确定,无法动态更改,因此需要由配置文件或命令行参数提供。
--conf spark.prop=value:从命令行参数设置配置文件中的配置项;--properties-file:指定配置文件(默认为conf/spark-default.conf);
任务执行模式
spark.master(--master):集群地址;
spark.submit.deployMode(--deploy-mode):任务提交模式cluster或client;
执行器环境变量
spark.executorEnv.[EnvironmentVariableName]:当系统自动设置的环境变量不正确时,可设置此类环境变量。
spark.executorEnv.PYTHONPATH:执行节点的Python附加库搜索路径。
Spark任务路径和文件
spark.{driver|executor}.extraClassPath (--driver-class-path,执行器无对应选项):Extra classpath entries to ==prepend== to the classpath of the driver.
spark.jars(--jars):从给定源读取并复制到每个SparkContext的工作目录下(Yarn模式支持自动清理,独立模式可配置spark.worker.cleanup.appDataTtl清理),文件的URL格式(==使用逗号分隔多个文件==,不支持路径展开,重复提供该选项不会叠加而是覆盖):
-
file:/path/to/file:集群节点从主程序(driver)内置的HTTP文件服务拉去拉取文件(即Driver所在节点的文件,==绝对路径标识==);file://path/to/file不是合法的路径标识,应该为file:/或file:///。 -
{hdfs|http|https|ftp}://server:port/path:集群节点从相应的URI获取文件(如果在Spark-on-Yarn模式下,HDFS可省略server:port,使用部署配置中的HDFS集群); -
local:/path:集群工作节点上的文件(存在于每个集群节点)。
spark.jars.packages(--packages):driver和executor需要使用的位于Maven仓库的jar包(逗号分隔列表),包名的格式为groupId:artifactId:version(可从中央仓库查找)。
spark.pyspark.python:driver和executor使用的Python解释器(PYSPARK_PYTHON)。
spark.pyspark.driver.python:Driver单独使用的Python解释器(PYSPARK_DRIVER_PYTHON)。
spark.submit.pyFiles (--py-files):上传.zip, .egg, or .py 并添加到PYTHONPATH。
spark.files (--files):list of files to be placed in the working directory of each executor.
spark.archives (--archives):将指定文件解压到每个执行器SparkContext工作目录下,支持格式包括.jar, .tar.gz, .tgz 和 .zip(使用file.zip#directory [3.1.0]指定档释放后存放的目录)。
spark.{driver|executor|yarn.am}.extraLibraryPath:JVM加载的附加库目录,指定为执行节点上的本地路径(如hadoop/lib/native),--driver-library-path为驱动程序等效的命令行选项(执行器无对应选项);
网络配置
spark.driver.bindAddress:Hostname or IP address where to bind listening sockets. (SPARK_LOCAL_IP)
spark.driver.host:Hostname or IP address for the driver. This is used for communicating with the executors and ==the standalone Master==.
应用配置
spark.app.name=none (--name)
spark.driver.maxResultSize=1g:序列化结果的大小限制(0为无限制),受限于spark.driver.memory,同时需要考虑对象的内存占用量。
spark.driver.supervise:If true, restarts the driver automatically if it fails with a non-zero exit status on Spark standalone mode or Mesos cluster deploy mode.
spark.python.worker.reuse:use a fixed number of Python workers, does not need to fork() a Python process for every task.
spark.local.dir:including map output files and RDDs that get stored on disk. on a fast, local disk in your system.
spark.driver.resource.{resourceName}.xxx
spark.executor.resource.{resourceName}.xxx
https://mapr.com/blog/resource-allocation-configuration-spark-yarn/
Spark SQL:
Spark Streaming:
Configuration - Spark 3.1.2 Documentation (apache.org)
集群部署
Spark支持的部署模式及其主节点地址。
| Master URL | 说明 |
|---|---|
local[K] | 本地使用k个工作线程运行spark,local等效于local[1];local[*]使用与机器逻辑处理相同数量的工作线程。 |
spark://HOST:PORT | 连接至spark独立集群主节点(默认端口为7077)。 |
mesos://HOST:PORT | |
yarn | 主节点(Resource Manger)地址在yarn-site.xml中给出。 |
k8s://HOST:PORT | 连接至Kubernetes集群。 |
默认主节点在spark-default.conf文件中给出。
spark.master yarn
Spark on Yarn
配置运行环境
在hadoop yarn集群上运行Spark需要读取集群的配置文件,包括core-site.xml,hdfs-site.xml,yarn-site.xml和hive-site.xml等,因此需要在conf/spark-env.sh中配置这些配置文件的所在目录。
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
通过conf/spark-env.sh配置运行应用实例的默认参数,这些参数也可以通过conf/spark-default.conf来设定。
Spark context stopped while waiting for backend:可能是虚拟内存分配问题。
在没有设置spark.yarn.jars和spark.yarn.archive时,提交Spark应用时将给出提示并将从本地spark/jars目录搜索应用依赖的jar包并打包上传至yarn集群上的应用工作目录。为了避免应用多次运行造成重复上传,可以将上述目录中的所有文件上传至HDFS上,并通过spark.yarn.jars引用。此外,spark.yarn.archive设置时将覆盖spark.yarn.jars的设置,所有jar包应该在档案文件的根目录。
# spark-default.conf
spark.yarn.jars hdfs:///share/jars/spark/*.jar
spark.yarn.archive hdfs:///share/jars/spark-libs.jar
spark.yarn.jars接受的参数格式与spark.jars要求格式相同,并支持路径展开(参考CDH配置)。
HDFS:可手动设置依赖包副本数量设置为与HDFS数据节点数相同,保证Spark任务无需从其他节点读取依赖包数据。设置该选项后,必须保证HDFS的相应路径下有运行Spark程序所需的包,否则程序无法启动。
spark.yarn.jars不会应用到client部署模式下的客户端。因此,如果客户端有特殊需求的包(如数据库驱动mysql-connector.jar)可以放在客户端侧,或者通过spark.jars选项分发给客户端。设置
spark.yarn.jars后,该选项的值在配置中可能显示为空字符串,但实际已传递给集群(可查看Yarn应用的日志看到应用的依赖库已经链接到HDFS上的文件。
问题
1. 远程启动Spark-Shell后出现超时或以客户端模式提交任务后无法执行。
可能出现的错误信息:
YarnScheduler: Initial job has not accepted any resources
RpcTimeoutException: Cannot receive any reply from HOSTNAME:PORT in 120 seconds.
RpcTimeoutException: Futures timed out after [120 seconds]
出现此错误是由于集群向客户端请求建立连接未完成。集群端正常情况下应该有以下日志:
:Registering the ApplicationMaster
:Successfully created connection to CLIENTHOST/IP_ADDRESS:PORT after xx ms
在提交计算任务后,客户端会选择空闲端口(可配置)启动名为NettyBlockTransferService的服务(可通过客户端日志查看并通过telnet或netstat查看相应的IP地址和端口是否启动监听),当Spark集群为计算任务分配好资源后(AM Container和Executor),会向客户端的该服务发送确认信息。造成服务器与客户端连接不成功的原因可能是:
-
客户端有多个网络接口(IP地址),而上述服务仅监听了其中一个地址。Spark使用的域名映射地址与监听地址不一致,故无法建立通信。因此修改Spark配置文件:
spark.driver.bindAddress 192.168.137.1 # 防止绑定到loopback地址 spark.driver.host ws-gary # 指定域名或主机名 spark.driver.port (random) -
如果将
spark.driver.host设置为域名/主机名,则Hadoop集群在响应该客户端时必须能够解析该域名/主机名(修改集群每个节点的hosts文件,否则报未知主机异常,UnknownHostException: hostname);也可将该配置项设置成客户端的IP地址,无需再设置bindAddress。 -
如果在WSL2中启动Spark客户端访问物理机局域网中的Yarn集群时,客户端默认绑定WSL的虚拟网卡IP地址;该地址与集群不在同一网络,因此Yarn调度器无法与客户端直接通信。因此需要在配置文件中指定客户端使用物理机的==域名/主机名==并配置物理机的端口转发规则(WSL2需要配置端口转发)。如果客户端配置域名/主机名与集群通信,则集群所有节点应配置该域名/主机名的解析地址。
spark.driver.bindAddress 0.0.0.0 spark.driver.host ws-gary -
防火墙策略阻止了连接,修改防火墙策略以允许外部连接访问应用(
java)或端口。在Windows上根据网络接口的网络类型(公用或专用)设置策略。
2. 未配置hadoop共享库的位置,Unable to load native-hadoop library for your platform
在conf/spark-env.sh中配置:
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${HADOOP_HOME}/lib/native
3. 从HDFS读文件时找不到Hadoop依赖库
出现*Compression codec com.hadoop.compression.lzo.LzoCodec not found.*:Hadoop使用的压缩库不在搜索路径中。需要将相应的库hadoop-lzo-xxx.jar从HADOOP/share/hadoop/common/lib==复制到spark的jar目录(和HDFS集群spark.yarn.jars目录==)。
参考文献
Install, Configure, and Run Spark on Top of a Hadoop YARN Cluster
独立Spark集群
建立主节点
./sbin/start-master.sh [-h,--host host] [-p port] [--webui-port PORT]
Spark默认使用主节点的主机名作为Spark服务的URL。这导致其他工作节点主机无法通过主机名或IP地址访问主节点。
WARN Utils: Your hostname, ubuntu-vm resolves to a loopback address: 127.0.1.1; using 192.168.192.128 instead (on interface ens33)
Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp6 0 0 ubuntu-vm:7077 [::]:* LISTEN解决办法:
执行命令时,指定主节点所使用的IP地址
./sbin/start-master.sh --host IP_ADDR删除
/etc/hosts文件中的主机名映射,再启动服务修改Spark配置文件
conf/spark-env.sh关于节点IP的设置(以上两种方式似乎会导致工作节点仍然访问hostname)export SPARK_MASTER_HOST=IP_ADDR export SPARK_LOCAL_IP=192.168.137.99注意:当主机IP发生变化时要及时更新此处设置的IP地址,否则服务无法正常开启。
“
Service 'sparkDriver' could not bind on a random free port.”
建立工作节点
./sbin/start-slave.sh <master-spark-URL>
Spark Standalone Mode - Spark 3.3.0 Documentation (apache.org)
资源分配
在spark-default.conf中配置资源分配。
在
conf/spark-defaul.conf中配置的选项也可在spark-env.sh中配置:export SPARK_WORKER_OPTS=\ "-Dspark.executor.cores=2 \ -Dspark.executor.memory=512m" #内存分配可直接配置为环境变量 export SPARK_EXECUTOR_MEMORY=512M export SPARK_DRIVER_MEMORY=512M
节点资源
Yarn资源分配和调度:Spark任务包括执行计算的执行器和执行调度的Application Master。在cluster模式下,Application Master也是Client程序的容器。由于计算任务由Executor执行,而Executor映射到Yarn的容器,因此Executor的内存分配受到Yarn的容器内存分配规则(最大/最小分配量)限制。
Executor的内存分配与MapReduce任务内存分配无关。
https://mapr.com/blog/resource-allocation-configuration-spark-yarn/
spark.python.worker.memory:memory to use per python worker process during aggregation. above this amount, spill the data into disks.
任务资源
任务资源需求
spark.executor.instances(--num-executors,启动的执行器数量):根据对执行器核心数的配置以及工作节点的计算资源总量,可创建多个执行器;
spark.cores.max :设置任务在集群中可使用的计算单元数上限;未设置时,独立集群将其设置为defaultCores;而Mesos集群则默认是无穷(集群所有计算单元)。
spark.deploy.defaultCores=10
CPU
spark.executor.cores :每个执行器所需计算核心数。默认情况:在独立模式或Mesos粗粒度模式下,执行器将占用工作节点的的所有核心;==在Yarn模式下占用1个核心==。
spark.yarn.am.cores :Yarn-Client模式下主程序CPU资源;
spark.driver.cores :Cluster模式下Client程序的CPU资源(--driver-cores);
内存
driver内存总量计算方式:driver.memory+driver.memoryOverhead,上限不超过底层容器的最大内存容量。memoryOverhead为虚拟机开销等其他本地开销(driverMemory*0.1, ==最小384MB==,在YARN, Mesos and Kubernetes上支持该选项)。
驱动程序内存开销和JVM的额外开销(VM overheads, interned strings, other native overheads......This option is currently supported on YARN, Mesos and Kubernetes.);
spark.yarn.am.{memory|memoryOverhead}:Yarn-Client模式下主程序内存资源开销;spark.driver.{memory|memoryOverhead}:Cluster模式下Client程序(包括Application Master)的内存资源开销(--driver-memory);
executor的内存总量为(YARN and Kubernetes上支持memoryOverhead):memoryOverhead+memory+offHeap.size+pyspark.memory。
spark.executor.{memory|memoryOverhead}:(--executor-memory)spark.executor.pyspark.memory*(2.4.0):
内存分配不足:System memory XXX must be at least 471859200. Please increase heap size using the
--driver-memoryoption orspark.driver.memoryin Spark configuration. 根据提示至少应该提供需要450MB内存,但实际设置这么多仍然不够,可根据提示的可用数量反推比例并给出满足需求的最小内存。
任务调度
spark.scheduler.mode=FIFO|FAIR
spark.task.cpus
spark.cores.max:
spark.yarn.queue (--queue)
设置任务提交到Yarn的队列中:(spark.yarn.queue或--queue QUEUE_NAME,默认为default)。
应用程序内部任务调度
每个应用可包含多个任务。https://spark.apache.org/docs/latest/job-scheduling.html
FIFO
spark.scheduler.mode FIFO # FAIR
spark.task.cpus 1
fair sharing: Spark assigns tasks between jobs in a “round robin” fashion.
Fair Scheduler Pools: grouping jobs into pools with different weights
调度策略
https://spark.apache.org/docs/latest/job-scheduling.html
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
动态资源分配
多个应用可共享集群资源,按需申请资源。在粗粒度集群管理器中可用,包括standalone、Mesos,yarn。
spark.dynamicAllocation.enabled false
运行Spark应用程序
提交应用程序
提交程序:./bin/spark-submit脚本用于向集群提交并启动应用程序,并动态配置应用程序参数。默认的应用部署模式可在spark-default.conf中给出。
./bin/spark-submit \ # from spark root folder
--master <master-url> \
--deploy-mode <deploy-mode> \ # client | cluster
--name AppName # 应用程序名称
--class <main-class> \ # entry point: full java class name
--conf "<key>=<value>" \ # spark.yarn.queue=root.share
#...other options
<application-jar>|app.py \ # application and dependencies
[application-arguments]
该脚本程序实际上是封装了Spark的启动器org.apache.spark.launcher.Main,用于处理输入参数(利用SparkSubmitCommandBuilder生成)和设置运行环境:
java -Xmx128m -cp "jars/*" org.apache.spark.launcher.Main "$@"
命令行配置
spark-shell和spark-submit支持命令行参数作为选项,或通过--conf选项按配置文件中的格式设置。可以通过spark-submit --help获取可配置选项。
--class:仅在程序包含多个默认入口主函数,且在项目文件未指明入口函数时使用;
打包依赖项
Java:将依赖项打包在应用程序的jar文件中,或者使用--jars JARS选项(以逗号分隔)将已封装好的jar包传输至集群(自动添加到应用程序环境的CLASSPATH中)。
Python:使用--py-files PY_FILES参数添加.py,.zip,.egg类型的文件。集群模式下主程序运行于集群节点上,其依赖的Python文件上传需要上传至集群节点。
Standalone集群不支持Python应用以cluster部署模式提交。
sc.addPyFiles(path_url):在会话中添加Python依赖文件,之后执行的所有任务均可使用。
本地文件将上传到集群各节点的工作目录。
使用交互环境
交互环境本身即是一个Spark应用程序,包括Java/Scala交互环境、Python交互环境等。交互环境的启动命令支持与spark-submit相同的选项。
-
Java/Scala交互环境
./bin/spark-shell [--master MASTER_URL] #>:q # execute CLI将
spark/bin加入$PATH后,可以从任意位置执行命令。 -
Python交互环境
./bin/pyspark --master spark://IP:PORT # => bin/spark-submit pyspark-shell-main --name PySparkShell "$@"pyspark交互环境会将Spark分发的Python包加入搜索路径(优先搜索);
编写应用程序
可以使用Maven编译Java应用(jar)。将Master URL传递给SparkContext构造对象。
Java代码
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkExample");
SparkContext = new SparkContext(conf);
或者
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
public class SimpleApp {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("App").getOrCreate();
// do your querying
spark.stop(); //spark.close()
}
}
使用Maven为项目添加spark-sql依赖:
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.5</version>
<scope>provided</scope>
</dependency>
Python代码
通过构建[SparkContext](Spark Python API.md#底层API)或[SparkSession](Spark Python API.md#Spark会话)开始编写Spark程序。Python代码提交:
spark-submit --deploy-mode cluster \
--conf spark.pyspark.python=.../envs/data/bin/python \
pyspark_sql.py
除了标准的提交方式(spark-submit),可直接用Python解释器执行程序(默认Client模式)。
与ZooKeeper集成
高可用性
Standby Masters with ZooKeeper
Single-Node Recovery with Local File System
管理控制
监控程序
hdfs dfsadmin -report
yarn node -list
yarn application -list
yarn application -status app_id
jps | grep -v JPS # 查看节点上运行的相关进程 JDK required
Hadoop端口信息
| 服务 | 默认端口 | 说明 |
|---|---|---|
| HDFS NameNode | 9000 | fs.defaultFS |
| 9870 | HDFSWeb服务端口* | |
| 50090 | SecondaryNameNode | |
| Yarn | 8030 | 资源调度器 |
| 8031 | 资源追踪器resource-tracker | |
| 8032 | 资源管理 | |
| 8033 | ||
| 8088 | Web服务端口 | |
| 19888 | 任务历史Web应用mapreduce.jobhistory.webapp.address | |
| 10020 | 任务历史mapreduce.jobhistory.address | |
| Hive | 9083 | Metastore |
| 10000 | jdbc接口 | |
| 10002 | Web管理服务端口 |
*:2.x版本为50070。
集群的网页
可查看Hadoop集群应用的配置信息。
http://hadoop-namenode:9870 # dfs.namenode.http-address [50070-2.x]
http://resource-manager:8088 # yarn cluster
http://hadoop-namenode:10002 # hive web
Spark状态监控
http://driver-node:4040:通过web访问运行任务的信息。通过Environment选项卡可查看应用的配置信息(仅展示通过上述方式设置过的参数)。
http://master-node:8080:访问主节点的运行信息。
http://worker-node:8081:访问工作节点的运行信息。
http://history-server:18080 :
任务管理
结束正在运行的任务:
yarn application -kill application_1450259063324_0001
数据处理
Hive数据
Hive数据查询模式:
- Hive(
Hiveserver2):使用自身的SQL引擎,MapReduce作为计算引擎; - SparkSQL with Hive:SparkSQL使用Spark提供的SQL引擎,并使用Spark作为计算引擎。由于Spark的计算在内存中进行,因此相比MapReduce,可以显著提升计算效率。Spark读取的数据在内存中以RDD/DataSet的形式加载;
- Spark JDBC server:基于SparkSQL with Hive运行的服务;客户端通过
jdbc:hive2接口提交查询和计算并获取输出数据;
- Spark JDBC server:基于SparkSQL with Hive运行的服务;客户端通过
- Hive on Spark:使用Hive SQL引擎,Spark作为计算引擎。
Hive,Hive on Spark和SparkSQL区别 - 李晓春 - 博客园 (cnblogs.com)
SparkSQL with Hive
Spark要访问Hive的数据,需要获取metastore数据库的访问方式。Spark不需要与Hive部署在同一主机上,仅需要配置Hive信息以及数据库驱动程序。Spark-shell使用上述配置方式中暴露的网络接口访问Hive。当Spark未与任何数据仓库连接,会在本地当前工作目录创建一个数据仓库。
通过conf/spark-default.conf配置连接属性。以metastore使用MySQL为例:
-
将
$HIVE_HOME/conf/hive-site.xml、core-site.xml(安全配置)和hdfs-site.xml(HDFS配置)复制或链接到$SPARK_HOME/conf下;编写程序时,也可以通过以下方法在代码中设定访问Hive的方式。var spark = SparkSession .builder() .config("hive.metastore.uris", "thrift://hadoop-master:9083") .enableHiveSupport() .getOrCreate()Hive配置名可以为:
[spark.[hadoop.]]hive.metastore.uris。缺少spark开头的配置项会生成警告Ignoring non-Spark config property(仍有效)。 -
配置访问Hive元数据的JDBC驱动(Spark的库中不包含)。需要将驱动包部署到
jar目录下(可使用符号链接),或在spark-default.conf配置以下两个参数添加jar包到搜索路径(==不能使用HDFS路径==)。spark.executor.extraClassPath /path/mysql-connector-xxx.jar spark.driver.extraClassPath /path/mysql-connector-xxx.jar或者直接引用相应版本的Hive依赖库目录(在其中添加JDBC驱动包)并配置。
spark.sql.hive.metastore.jars /path/hive-VERSION/*Spark已经内置derby驱动包,如果使用derby作为metastore服务,如果驱动不兼容则添加:
spark.executor.extraClassPath /.../derby/lib/derbyclient.jar spark.driver.extraClassPath /.../derby/lib/derbyclient.jar注意不要将整个
hive/lib加入Spark的额外搜索路径,其中某些包与Spark不兼容。 -
在完成相关设置后,
spark-shell等内置应用能自动启用Hive读写。在bin/beeline可用于在命令行访问Hive数据(使用Hive配置)。
访问非默认版本Hive:Spark发行版自带的hive库仅可访问指定版本的hive(Hive Schema可能不兼容,例如Spark 3.2使用的Hive Schema为2.3),需要将目标系统上对应的Hive依赖库复制到Spark客户端,并在spark-default.conf中指定:
spark.sql.hive.metastore.version 1.2.0
spark.sql.hive.metastore.jars /usr/local/spark3/jars/hive-1.2.0/*
Thrift JDBC/ODBC server
Spark-Shell默认支持访问metastore数据库服务(JDBC)的方式访问hive数据,或通过thrift服务访问hive数据库。要使用jdbc:hive2:的访问方式,需要配置连接JDBC服务。
import java.sql.*;
Connection con = DriverManager.getConnection(
"jdbc:hive2://localhost:10000/default", "hiveuser", ""); // 连接HiveServer(on Spark)
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
String sql = "SHOW TABLES 'testHiveDriverTable'";
ResultSet res = stmt.executeQuery(sql);
HiveServer on Spark:对应Hive内置的Hiveserver2服务(Thrift JDBC/ODBC server) ,但运行在Spark集群上,使用Spark任务代替MapReduce任务。
Hive目录的权限问题:root scratch dir on HDFS should be writable. Current permissions are: rwx------。在HDFS上为Hive创建的临时目录的权限不正确,手动删除该目录再尝试提交任务。
0643-Spark SQL Thrift简介 - 云+社区 - 腾讯云 (tencent.com)
Distributed SQL Engine - Spark 3.1.2 Documentation (apache.org)
Hive on Spark
Hive on Spark: Getting Started - Apache Hive - Apache Software Foundation
Elasticsearch for Spark
Apache Spark support 7.14 | Elastic
Elasticsearch for Apache Hadoop 7.14 | Elastic
配置
Configuration | Elasticsearch for Apache Hadoop 5.1
版本兼容性:注意选择与Spark内置Scala版本一致的elasticsearch-spark库。
- Spark 3.x内置Scala 2.12,Elasticsearch从7.12版本支持Scala 2.12;
- Spark 2.x内置Scala 2.10/2.11,选择对应版本的库(可通过
spark-shell查看内置Scala版本);
读取数据
es_options = {
"nodes": "es_ndoe1,es_ndoe2,es_ndoe3",
"port": 9200,
"pushdown": true # translate Spark SQL into Query DSL
}
df = spark.read.format("org.elasticsearch.spark.sql")\
.options(**es_options)\
.option("es.read.field.as.array.include","domain_id,domain_name")\
.load("index_path") # => es.resource
无法表示为
options关键字参数的选项名,可通过option方法单独指定。
必要选项:
-
es.resource/es.resource.read/es.resource.write:数据索引,读取可指定多个索引(使用,分隔)或使用通配符;写入可使用基于数据字段生成的动态索引,例如:my-index/{media_type} my-collection/{@timestamp|yyyy.MM.dd} # 格式化时间字段 -
es.nodes,es.port:集群地址,节点可单独指定端口;无需指定集群的所有节点,由es库自动发现。
读取选项:
-
es.read.field.include/exclude:包括或排除读取的字段名列表(使用,分隔); -
es.read.source.filter:[5.4]新增,选取数据字段; -
es.read.field.as.array.include/exclude:显式指定/排除一个或多个字段为序列类型,防止字段只有一个值而被推测为标量类型;可指定多维数field_name:3;如果存在嵌套数组,应该单独声明。 -
es.query:查询语句,支持DSL语句(JSON文本,需要将Python字典转换为字符串类型);{ "query" : { "term" : { "user" : "costinl" } } }
写入选项:
es.write.operation=index|create|update|upsert;index为默认值;es.mapping
错误
-
scala.MatchError: 2887535652 (of class java.lang.Long):数据中包含IP字段(该字段实际为整数
2887535652->172.28.76.112)(==未复现==);解决方法:丢弃IP字段。
val df_valid = df.drop("collect_ip", "dev_ip") val df_valid = df.select("user_name", "user_id", ...) -
scala.MatchError: Buffer(default)...WARNING: Field "xxx" is backed by an array but the associated Spark Schema does not reflect this;(use es.read.field.as.array.include/exclude):数据字段包含嵌套的序列对象,但未从数据自动解析为序列类型(由于数据为空或只有单个值);解决方法:1)设置指定列转换序列对象;2)丢弃可能为序列的无用列。
es.read.field.as.array.include author,client,project # spark-default.conf可在运行时配置该选项。
Kafka Streaming
安装Kafka集成模块
Kafka流处理模块作为Spark的可选插件需要单独安装:下载spark-streaming-kafka-0-8-assembly.jar到Spark的依赖库目录(如果使用Yarn模式,同步到HDFS)。该依赖库中已包含kafka-client等依赖库的字节码,因此不需要添加额外的依赖库引用。
如果通过
spark-submit提交任务且可连接Maven仓库,可以通过--packages org.apache.spark:spark-streaming-kafka-0-8:2.4.6选项从仓库下载依赖项。
Spark Streaming + Kafka Integration Guide
Spark和Kafka版本选择
spark-streaming-kafka-0-8从2.3版本开始被弃用,推荐使用spark-streaming-kafka-0-10(不提供Python API)。如果需要使用Python编写Kafka流处理程序,应该使用Spark 2.x+spark-streaming-kafka-0-8。此外,Spark 3.x支持结构化流处理,可以切换使用spark-sql-kafka库以接入Kafka数据源。
如果尝试PySpark 3.2+版本中引入Kafka库,会出现错误:
ModuleNotFoundError: No module named 'pyspark.streaming.kafka'。
Spark和Kafka依赖冲突
问题:java.lang.NoSuchMethodError: net.jpountz.lz4.LZ4BlockInputStream.<init>(Ljava/io/InputStream;Z)V。Sparkspark-core和Kafkaspark-streaming-kafka同时依赖net.jpountz.lz4包,但两者分别打包了不同版本的依赖包,即Spark依赖库目录下的lz4-java-1.4.0.jar和spark-streaming-kafka包中的net/jpountz/lz4,后者版本较低且包含上述方法定义,因此导致上述错误(由于依赖库加载顺序不确定,部分时候也能够引用正确Spark下的正确版本)。
解决方法:删除spark-streaming-kafka包中的net/jpountz/lz4字节码目录,并修改META-INF目录下spark-streaming-kafka-0-8_2.11/spark-streaming-kafka-0-8-assembly关于net.jpountz.lz4的依赖声明:
<dependency>
<groupId>net.jpountz.lz4</groupId>
<artifactId>lz4-java</artifactId>
<version>1.4.0</version>
</dependency>
Kafka Structured Streaming模块
需要安装spark-sql-kafka及其附加依赖项:
spark-sql-kafka-0-10_SCALA_VERSION-SPARK_VERSION.jar;commons-pool2-2.8.0.jar;kafka-clients-2.0.1.jar;spark-token-provider-kafka-0-10_SCALA_VERSION-SPARK_VERSION[3.0+].jar[optional]。
spark-sql-kafka库和spark-streaming-kafka库存在冲突,不要放在同一搜索路径下。
Kubernetes
https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
Mesos
Dask
Comparison to Spark — Dask documentation
conda install dask
pip install "dask[complete]" # Install everything
Scheduling — Dask documentation
Dask-ML — dask-ml 0.1 documentation
运行环境
代码传播:修改依赖库的代码后,需要同步到所有节点(重启工作进程);非依赖库代码在程序运行时同步到各工作进程。
调度器设置
单机调度器
无需设置,直接使用,Dask会在开始计算时启动本地进程/线程池。
import dask.dataframe as dd # 本地单机执行
df = dd.read_csv(...)
df.x.sum().compute(scheduler="threads"|"processes"|"single-threaded")
-
本地线程池(
concurrent.futures.ThreadPoolExecutor)dask.array,dask.dataframe, anddask.delayed的默认模式。由于在同一个进程中,任务间没有数据传输开销。但由于GIL的存在,只能提供non-Python代码的并行。import dask dask.config.set(scheduler='threads') # overwrite global setting -
本地进程池(
concurrent.futures.ProcessPoolExecutor)dask.bag的默认模式。任务及其依赖的数据传输到本地进程执行,再将结果返回主进程。即使纯Python代码(处理字符串、字典、列表等)也不受GIL限制。但是进程间来回传输数据代价增大,因此任务间数据交互少的情况下性能更好。import dask.multiprocessing dask.config.set(scheduler='processes') -
单线程:用于调试(
scheduler='synchronous')。
设置调度模式
全局配置:
必须放置在主模块
__main__中,否则出现错误:RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase.
使用上下文管理器:
with dask.config.set(scheduler='threads'):
x.compute()
即时调用:
x.compute(scheduler='threads')
单机分布式调度器
对于复杂工作负载,其中会产生大量中间结果,则推荐使用分布式调度器dask.distributed。分布式调度器可以在单机或集群运行。
分布式调度器包含更多特性,即使是单机运行也更偏向使用分布式模式。
- 提供异步API,例如
Futures; - 提供诊断仪表板,查看性能和进度信息;
- 更加灵活有效地处理数据位置问题。
分布式环境配置:https://docs.dask.org/en/latest/setup.html。
预先配置计算资源池
dask-scheduler --host $(hostname) --port 8786 \
--dashboard-address "localhost:8787" --dashboard-prefix='/dask' \
--pid-file dask-local-scheduler.pid \
--scheduler-file dask-local-scheduler.info \
> /tmp/dask/local-scheduler.log \
2> /tmp/dask/local-scheduler.error.log &
# kill -SIGKILL $(cat dask-local-scheduler.pid) # 停止集群
dask-worker [tcp://]$(scheduler):8786 \
--nthreads 4 --nprocs 10 --memory-limit 2GiB \
--name dask-worker \
--pid-file dask-worker.pid \
--local-directory /var/local/dask \
> dask-local-worker.log &
dask-scheduler日志量过大:切分清理日志。
按需创建计算资源池
使用Client或LocalCluster在程序中按需创建本机集群。
from dask.distributed import Client,LocalCluster,Worker
if __name__ == "__main__":
client = Client(**kwrags) # 自动创建本地集群
cluster = LocalCluster(...) # 手动创建本地集群
client = Client(cluster)
df.x.sum().compute() # 在本地集群上执行计算
LocalCluster:在本地机器上创建调度器(Scheduler)和工作节点(Worker)。
LocalCluster(n_workers=None,
threads_per_worker=None,
processes=True,
host='localhost', # scheduler listen address
scheduler_port=0, # 8786 as default, 0 for random
dashboard_address=':8787', # set to None to disable
worker_dashboard_address='localhost:8787', # disabled by default
service_kwargs=None,
**worker_kwargs)
n_workers:工作节点数量;process:是否使用进程构造工作节点;threads_per_worker:每个工作节点启动的线程数量;host:调取器监听地址;dashboard_address:仪表板地址;scheduler_kwargs:worker_kwargs:其余参数将传递给工作节点。
Worker:工作节点告知调度器其拥有的数据,并从调度器获取其他节点上的数据信息。
Worker(nthreads=None, memory_limit='auto', **kwargs)
nthreads:工作进程的线程数量。memory_limit='2GB'|2e9|auto:计算节点内存限定。auto按工作进程数分配系统内存作为可用内存上限。对于单机集群模式,当数据量很大时,工作节点占用内存将达到系统内存上限。但是由于系统中其他进程还要占据一定内存,由此导致工作节点无法分配足够内存而重启。解决方法是为工作节点设置固定内存上限,当内存达到与上限相关的门限时,会触发将不适用的数据写回磁盘,从而避免耗尽系统内存。
分布式调度器
Dask with SSH
使用SSH自动创建集群。
dask-ssh [OPTIONS] \
--scheduler <scheduler> \ # Defaults to first host.
--scheduler-port <scheduler_port>
--nthreads <nthreads> --nprocs <nprocs> --memory-limit <memory_limit>
--ssh-username <ssh_username> --ssh-port <ssh_port>
--log-directory <log_directory>
--local-directory <local_directory>
--remote-python <remote_python> # Python环境路径
[HOSTNAMES]...
Dask on yarn
Dask-Yarn — Dask Yarn documentation
Managing Python Environments
Managing Python Environments — Dask Yarn documentation
访问集群
Client:Client将用户连接至Dask集群。Client初始化后接管程序中所有的dask.compute 、dask.persist等计算任务。
Client(address=None)
cli.close() # 关闭连接
cli.shutdown() # 关闭集群
address:调度器地址和端口,例如'127.0.0.1:8786',或集群对象,例如LocalCluster()(本地集群环境,当不提供集群地址时,将自动创建一个LocalCluster)。
集群信息
client.dashboard_link:
client.get_scheduler_logs(n=N)
client.has_what()
client.status
client.id
client.scheduler
client.scheduler_info()
client.ncores
client.nthreads
vaex
https://vaex.readthedocs.io/en/latest/index.html
pip install --upgrade vaex
conda install -c conda-forge vaex
ray
概念
基础架构
Ray Core provides a small number of core primitives (i.e., tasks, actors, objects) for building and scaling distributed applications.
Ray Cluster
to run Ray applications on multiple nodes you must first deploy a Ray cluster.

数据处理模式
支持的数据格式
CSV、JSON、Parquet、Numpy、Text、Spark/Dask/Python DataFrame、Python object、ndarray……;


安装
conda create -n ray -c conda-forge ray-all # 安装所有模块
pip install ray # with minimal dependencies
pip install "ray[default]" # + the dashboard + cluster launcher
pip install "ray[air]" # + dependencies for Ray AI Runtime
pip install "ray[data]" #
pip install "ray[serve]" # model-serving library
Ray on Windows is currently in beta.
Python 3.10 support is currently experimental.
Ray conda packages are maintained by the community, not the Ray team. While using a conda environment, it is recommended to install Ray from PyPi using
pip install rayin the newly created environment.
Launching an On-Premise Cluster — Ray 2.0.0
- It also assumes that Ray is installed on each machine.
Deploying on YARN — Ray 2.0.0(In progress)
Spark on Ray
Using Spark on Ray (RayDP) — Ray 2.0.0
Dask on Ray
参考文献:
CDH6大数据集群离线安装
前言
为什么要用离线的方式安装CDH6大数据集群
CDH,全称Cloudera’s Distribution, including Apache Hadoop。是Hadoop众多分支中对应中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建,提供了Hadoop的核心(可扩展存储、分布式计算),最为重要的是提供基于web的用户界面。
CDH的优点:版本划分清晰,更新速度快,支持Kerberos安全认证,支持多种安装方式(如Yum、rpm等)。
Cloudera公司最近在官网宣布:
从2021年1月31日开始,所有Cloudera软件都需要有效的订阅,并且只能通过付费墙进行访问。
也就是说CDH各版本都不能免费获取了。很多以前的文章、书籍中提到CDH大数据平台,都是会引用Cloudera官网下载地址,例如:https://archive.cloudera.com/cm6/6.2.0/redhat7/yum/RPMS/x86_64/
现在开始要输入账号密码认证了。用Cloudera的账号密码的话,会得到如下失败信息:
403 Forbidden (varnish) the provided credentials were incorrect
说明没有权限获取CDH了。在Cloudera官网社区里有很多讨论。
解决办法如下:
-
使用开源的Hadoop、Spark、Hive等分别安装;
-
使用自己或别人以前下载过的CDH安装包,共享使用,官网说的是CDH6.6以后收费,以前的还是可以使用。
链接: https://pan.baidu.com/s/1ION1DoWnqpfVO_sBx0GpeA 提取码: rqyi
下载安装包
CDH分为Cloudera Manager管理平台和CDH parcel(parcel包含各种组件的安装包)。
从共享的百度网盘链接将CDH安装包下载到本地工作机,如下所示:
~/workspace$
tree CDH
CDH
├── CDH
│ ├── CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
│ ├── CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha1
│ ├── CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha256
│ └── manifest.json
├── ClouderaManager
├── cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
├── cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
├── cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm
├── cloudera-manager-server-db-2-6.3.1-1466458.el7.x86_64.rpm
├── enterprise-debuginfo-6.3.1-1466458.el7.x86_64.rpm
└── oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm
编辑映射文件
root@cdh001:~# vim /etc/hosts
在该文件中添加如下内容:
172.18.48.175 cdh001.gary.com cdh001
172.18.48.176 cdh002.gary.com cdh002
172.18.48.177 cdh003.gary.com cdh003
配置SSH免密登录
1.执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa
2.将公钥拷贝到要免密登录的目标机器上
将公钥拷贝到本机
for node in cdh001 cdh002 ...; do
ssh-copy-id -i ~/.ssh/id_rsa.pub $node
done
编写集群分发脚本
1.需求:循环复制文件到所有节点的相同目录下 2.需求分析: (a)期望脚本使用方法:
xsync <要同步的文件路径>
3.脚本实现 (a)在/root目录下创建bin目录,并在bin目录下xsync创建文件,操作如下:在该文件中编写如下代码
#!/bin/bash
#1获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2获取文件路径
p1=$1
fname=`basename $p1`
echo fname=$fname
#3获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1);pwd
echo pdir=$pdir
#4获取当前用户名称
user=`whoami`
#5循环
for((num=2;num<4;num++));do
host=$(printf "%03d" "$num")
echo -------------------cdh$host--------------
rsync -rvl $pdir/$fname $user@cdh$host:$pdir
done
(b)修改脚本xsync具有执行权限
chmod u+x xsync
(c)调用脚本形式:
xsync <文件路径>
(d)分发集群分发脚本
xsync /usr/local/bin/xsync
(e)分发映射文件
xsync /etc/hosts
安装MySQL(主节点)
下载并安装mysql
下载并安装
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
启动服务
systemctl start mysqld
查看状态
systemctl status mysqld
查看mysql临时密码
grep "password" /var/log/mysqld.log
# 2021-04-15T07:31:51.264538Z 1 [Note] A temporary password is generated for root@localhost: LeuhBAe2ai,u
登录后修改密码
尽量复杂一点,太简单了验证不通过,也可以查看如何关闭mysql校验规则
[root@cdh001 ~]# mysql -u root -p
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_length=4;
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Mysql@gang2019';
Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
重启服务并设置开机启动
systemctl enable mysqld && systemctl restart mysqld
下载并安装JDBC 驱动
要求使用5.1.26以上版本的jdbc驱动,可点击这里直接下载mysql-connector-java-5.1.47.tar.gz
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
tar -xzf mysql-connector-java-5.1.47.tar.gz
mkdir -p /usr/share/java
ln -s /usr/share/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar /usr/share/java/mysql-connector-java.jar
创建CDH所需要的数据库
根据所需要安装的服务参照下表创建对应的数据库以及数据库用户,数据库必须使用utf8编码,创建数据库时要记录好用户名及对应密码:
| 服务名 | 数据库名 | 用户名 | 密码 |
|---|---|---|---|
| Cloudera Manager Server | scm | scm | CDH@gang2019 |
| Activity Monitor | amon | amon | CDH@gang2019 |
| Reports Manager | rman | rman | CDH@gang2019 |
| Hue | hue | hue | CDH@gang2019 |
| Hive Metastore Server | metastore | hive | CDH@gang2019 |
| Sentry Server | sentry | sentry | CDH@gang2019 |
| Cloudera Navigator Audit Server | nav | nav | CDH@gang2019 |
| Cloudera Navigator Metadata Server | navms | navms | CDH@gang2019 |
| Oozie | oozie | oozie | CDH@gang2019 |
创建sql脚步文件
vim cdhinit.sql
添加内容如下:
# scm
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'CDH@gang2019';
# amon
CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY 'CDH@gang2019';
# rman
CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY 'CDH@gang2019';
# hue
CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY 'CDH@gang2019';
# hive
CREATE DATABASE metastore DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON metastore.* TO 'hive'@'%' IDENTIFIED BY 'CDH@gang2019';
# sentry
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY 'CDH@gang2019';
# nav
CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY 'CDH@gang2019';
# navms
CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY 'CDH@gang2019';
# oozie
CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY 'CDH@gang2019';
# flush
FLUSH PRIVILEGES;
SHOW DATABASES;
修改mysql密码校验策略
[root@cdh001 ~]# mysql -u root -p
mysql> set global validate_password_policy=LOW;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_length=6;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| validate_password_check_user_name | OFF |
| validate_password_dictionary_file | |
| validate_password_length | 6 |
| validate_password_mixed_case_count | 1 |
| validate_password_number_count | 1 |
| validate_password_policy | LOW |
| validate_password_special_char_count | 1 |
+--------------------------------------+-------+
7 rows in set (0.00 sec)
运行脚本
mysql> source /root/cdhinit.sql
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
.....
13 rows in set (0.00 sec)
配置Cloudera Manager yum库(主节点)
首先安装httpd和createrepo:
yum -y install httpd createrepo
启动httpd服务并设置开机自启动:
systemctl enable --now httpd
将上传的CDH安装包移到httpd的html目录下:
mv CDH/ /var/www/html/
生成RPM元数据:
cd /var/www/html/CDH/ClouderaManager/
createrepo .
接着再创建ClouderaManager的repo文件
vim /etc/yum.repos.d/cloudera-manager.repo
添加如下内容:
[cloudera-manager]
name=Cloudera Manager 6
baseurl=http://cdh001/CDH/ClouderaManager/
gpgcheck=0
enabled=1
分发
xsync /etc/yum.repos.d/cloudera-manager.repo
修改/etc/httpd/conf/httpd.conf配置文件:
把第284行的
AddType application/x-gzip .gz .tgz修改为AddType application/x-gzip .gz .tgz .parcel。
重启httpd服务
systemctl restart httpd
安装JDK(所有节点)
yum install oracle-j2sdk1.8
设置环境变量
vim /etc/profile.d/cdh.sh
添加如下内容:
#java
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
环境变量生效
source /etc/profile.d/cdh.sh
java -version
分发配置文件
xsync /etc/profile
安装Cloudera Manager
安装Cloudera Manager Server (主节点)
yum install cloudera-manager-server
安装Cloudera Manager Agent(所有节点)
./sync_cluster.sh cmd "yum install cloudera-manager-daemons cloudera-manager-agent -y"
修改agent配置,指向Server节点cdh001 (所有节点)
sed -i "s/server_host=localhost/server_host=cdh01/g" /etc/cloudera-scm-agent/config.ini
xsync /etc/cloudera-scm-agent/config.ini
启动 agent 服务(所有节点)
systemctl start cloudera-scm-agent
初始化scm数据库
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm 'CDH@gang2019'
启动Cloudera Manager Server(主节点)
systemctl start cloudera-scm-server
systemctl status cloudera-scm-server
查看启动日志
tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log
看到下面的信息,说明启动完成
2021-04-15 16:11:08,771 INFO WebServerImpl:com.cloudera.server.cmf.WebServerImpl: Started Jetty server.
安装CDH集群
通过浏览器访问Cloudera Manager WEB界面
打开浏览器,访问地址:http://<server_host>:7180,默认账号和密码都为admin:
欢迎页面
首先是Cloudera Manager的欢迎页面,点击页面右下角的【继续】按钮进行下一步:
接受条款
勾选接受条款,点击【继续】进行下一步:
版本选择
这里选择免费版:

第二个欢迎界面
选择版本以后会出现第二个欢迎界面,不过这个是安装集群的欢迎页:
设置群集名称
选择主机
这一步是要选择用于安装CDH集群的主机:
选择存储库
CDH and other software
点击更多选项添加远程Parcel存储库:http://39.108.122.82/CDH/CDH/
Fix: 在阿里云服务器上url应该改为http://cdh001/CDH/CDH/,采用公网ip会限速
返回后会加载出CDH版本,确认无误后点击【继续】:

Install Parcels
主机检查
等待检查完成即可:
选择服务类型
这里我选择Data Engineering Process, develop, and serve predictive models. 服务: HDFS、YARN(含 MapReduce 2)、ZooKeeper、Oozie、Hive、Hue 和 Spark

角色分配
CDH会自动给出一个角色分配,如果觉得不合理,我们可以手动调整一下,注意角色分配均衡:
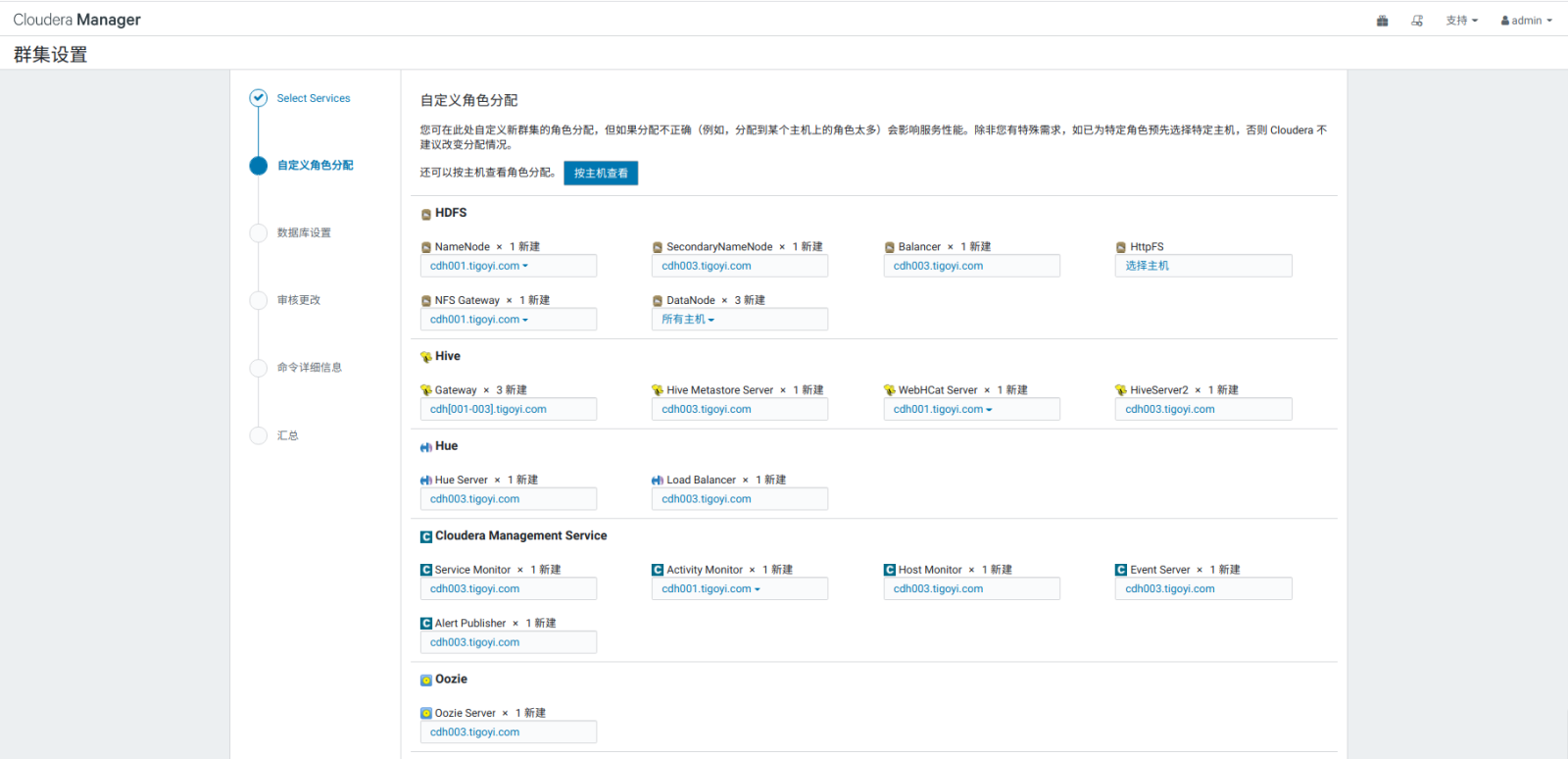
Gateway Roles https://docs.cloudera.com/documentation/enterprise/5-9-x/topics/cm_mc_managing_roles.html#managing_roles__section_scv_ywt_cn
数据库设置

审核更改
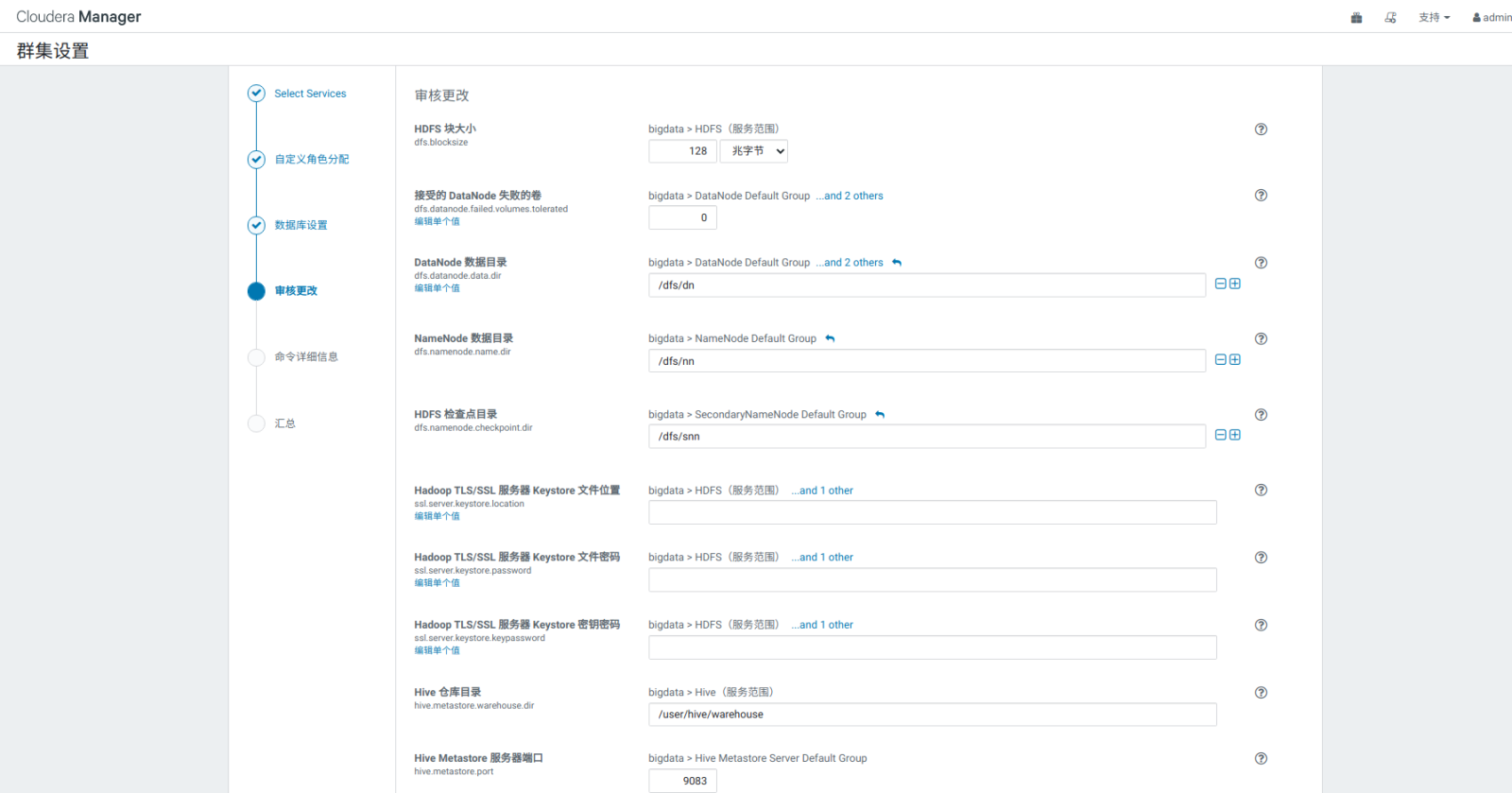
等待命令执行完成
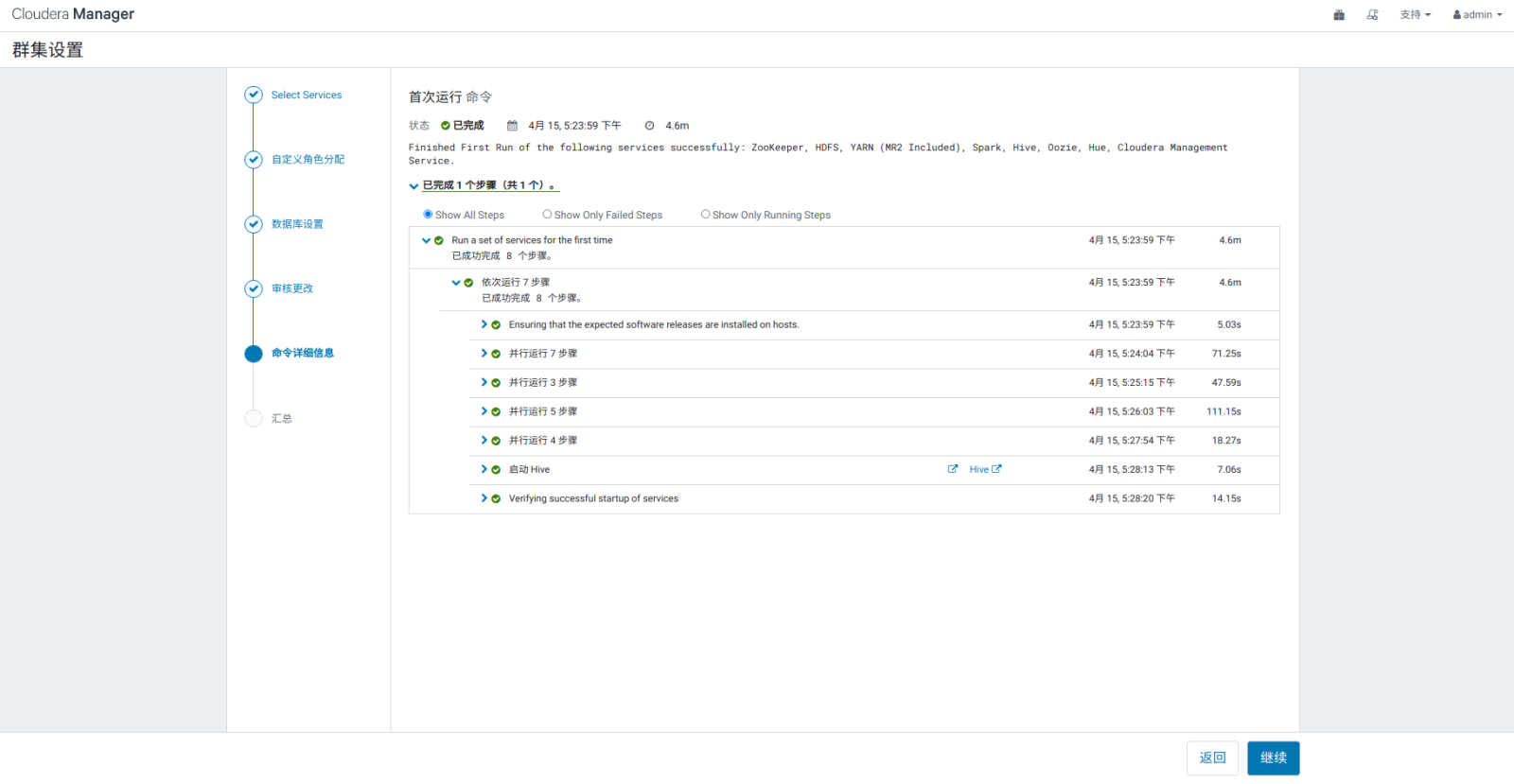
安装完成
进入监控界面

组件配置
Spark
安装目录:
SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark
配置目录:
/etc/spark/conf # CDH分发配置目录
$SPARK_HOME/../../etc/spark/conf # 内置默认配置目录
Web配置
输入spark-conf过滤设置项,在展示的相应设置项中配置spark-env.sh和spark-defaults.conf中的选项。客户端配置在Gateway Default Group中。
export PYSPARK_PYTHON=/opt/miniconda3/envs/dataproc/bin/python
export PYSPARK_DRIVER_PYTHON=/opt/miniconda3/envs/dataproc/bin/python
注意在最后一行添加换行,防止生成的配置文件格式不正确。export语句在一行,且worker上未生效。
如果界面配置环境变量不生效,在代码中加入:
import os
os.environ["PYSPARK_PYTHON"]='/opt/miniconda3/envs/dataproc/bin/python'
Kafka集成
spark-streaming-kafka:离线环境默认缺少spark-streaming-kafka-0-8-assembly包,手动添加到SPARK_HOME并在集群中同步。
spark-sql-kafka:
Spark Python API
基础类型
数据类型
DataType是具体数据类型的基类。
| 类型 | Python类型 | 说明 |
|---|---|---|
BooleanType | bool | |
ByteType | ||
IntegerType | int | ShortType/LongType |
DoubleType/FloatType | float | |
DecimalType() | precision,scale参数控制精度; | |
StringType | str | |
DateType | dt.date | |
TimestampType | dt.datetime | |
NullType | None | |
BinaryType | ||
ArrayType(EType) | List[Type] | nullable=True |
MapType(KType,VType) | dict | 必须声明确定的key和value类型(命名元组)。nullable=True |
StructType([fields]) | dict | StructType包含固定字段;而MapType可以有任意数量的key-value。 |
StructField(name,DType) | nullable=True |
Data Types - Spark 3.2.0 Documentation (apache.org)
数据结构
底层API
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("AppName").setMaster(master).set(...)
sc = SparkContext(conf=conf)
master表示集群的URL,或者local[k]。
交互式环境(PySparkShell)中有一个默认的
SparkContext对象sc。
输入
文件
lines = sc.textFile("examples/src/main/resources/people.txt")
默认文件传输协议为
file://;使用Spark-on-Yarn时,默认的文件传输协议为hdfs://,即文件应该存储在HDFS集群上。如果要在Client模式下使用主程序所在节点的文件,显式指定协议为file://。省略文件传输协议,且路径非
/开头,则表示使用相对路径。
local:/不是有效的文件传输协议(仅适用于Spark集群自身分发依赖库)。
变换
map()
输出
first()
Spark SQL
Spark会话
from pyspark.sql import SparkSession
spark=SparkSession\
.builder\
.master("yarn")
.appName("PythonApp")\
.config("hive.metastore.uris", "thrift://hadoop-master:9083")\
.enableHiveSupport()\
.getOrCreate()
# 如果能定位SPARK_HOME下的配置文件,则可获得相应配置,否则需要通过代码指定
spark.sparkContext.setLogLevel('WARN') # set log level to WARN after then
数据类型
输入数据以pyspark.sql.DataFrame表示。DataFrame相当于是基于Row组织的RDD,可与RDD相互转换。
Spark DataFrame
spark.createDataFrame(data[,schema][,samplingRatio],verifySchema=True)
基于Row序列(本地或分布式RDD类型)创建,
data = [Row(a=1, b=2., c='string1', d=date(2000, 1, 1)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1))]
# data = spark.sparkContext.parallelize(data) -> RDD
df = spark.createDataFrame(data) # 自动推测数据类型
基于Python序列(本地或分布式RDD类型)创建,由于序列没有列名信息,需要指定schema。
data = [(1, 2., 'string1', date(2000, 1, 1)),
(2, 3., 'string2', date(2000, 2, 1)),
(4, 5., 'string3', date(2000, 3, 1))]
# data = spark.sparkContext.parallelize(data) -> RDD
df = spark.createDataFrame(data, schema='a long, b double, c string, d date')
Spark Row类型
Row表示Spark DataFrame中的一行数据,可以使用字典、元组的方式访问其元素,也可以将元素名称作为成员名来访问该元素(类似于命名空间成员的访问方式)。
from pyspark.sql import Row
row = Row(name="Alice", age=11)
'name' in row
row.age, row['name'], row[1]
Person = Row("name", "age")
Person("Alice", 11) # Row(name='Alice', age=11)
数据格式声明
schema可以以字符串形式简单描述(类型可省略,根据数值采样自动推测)或使用StructType完整描述。
schema = StructType([StructField("a", StringType(), True),
StructField("b", DoubleType(), False),
StructField("c", StringType(), True),
StructField("d", DateType(), False)])
还可以基于pandas.DataFrame创建。由于pandas.DataFrame已知数据类型,无需指定Schema。
pd.DataFrame(pandas_df)
读取文件
reader:DataFrameReader = spark.read:获取读取接口,可通过以下方式对该接口进行配置:reader.format(<FORMAT>) ->reader.<FORMAT>:支持的文件格式包括Text、CSV、Parquet、OCR、JSON等。
df = spark.read.json(FILE_PATH)
df = spark.read.format("JSON").load(FILE_PATH)
reader.option(key, value)/options(**options):设置输入选项;
csv读取参数
-
schema:StructType或文本col0 INT, col1 DOUBLE;header=False;inferSchema=False:推断数据格式,需要读取两次数据;samplingRatio=1.0:推断数据格式所需读取的记录比例;enforceSchema=True:默认强制应用指定的或推断的数据格式被数据源所有文件,CSV文件中的头部被忽略;反之,仅验证CSV文件的头部字段(推荐禁用该选项以避免意外错误)。maxColumns=20480:限制读取的列数;multiLine=False:数据记录跨行;
csv不支持仅读取部分数据,可在读取后执行limit()方法返回部分数据 -
文本编码:
encoding='UTF-8'; -
特殊字符:
sep=',';quote='"':用于包含分隔符的字段;escape='\':用于转义已经使用引号的字段中的引号,即\";charToEscapeQuoteEscape='\';用于转义引号字段中的转义字符,即\\;comment=None(数据中的注释行开头字符);ignoreLeadingWhiteSpace/ignoreTrailingWhiteSpace=False:忽略空白;
-
特殊值:
nullValue='':文件中的缺失值形式;emptyValue='""':文件中空字符串的形式;nanValue='NaN':文件中无效数值的表示形式;positiveInf/negativeInf='Inf':文件中无穷大的表示形式;
-
数值格式:
dateFormat='yyyy-MM-dd':文件中日期表示形式;timestampFormat="yyyy-MM-dd'T'HH:mm:ss.SSSXXX":文件中时间表示形式;maxCharsPerColumn=-1:限制每个字段读取字符数量(默认无限制);
-
错误处理:
mode='PERMISSIVE':发现坏记录将其存储在名为columnNameOfCorruptRecord的列(需要用户在数据格式中设置该列,否则丢弃该列),并将其他列设置为null;当记录字段比数据格式的列少,则缺少的列设置为null;反之,丢弃多余的列。DROPMALFORMED忽略整条坏记录。FAILFAST直接抛出异常。columnNameOfCorruptRecord=spark.sql.columnNameOfCorruptRecord:
Hive
df = spark.sql("select * from pokes limit 10")
Hive数据源格式
CSV文件:为了保证Spark能正确推测Hive数据的数据类型,Hive数据源的文件存储中不要包含表头(Spark不识别Hive的表格选项skip.header.line.count),否则Spark将表头视为数据,由于表头为字符串类型,导致自动推导数据类型失败。对于具有表头的数据文件,可直接存储在HDFS上,并通过Spark提供的CSV文件读取接口读取数据。
数据表视图
df.createOrReplaceTempView("people") # createTempView(name)
df = spark.sql("SELECT * FROM people")
df.createGlobalTempView("people") # createOrReplaceGlobalTempView()
df = spark.sql("SELECT * FROM global_temp.people")
df = spark.table('global_temp.people')
DataFrame API
df.cache():持久化数据(MEMORY_AND_DISK);df.persist([storageLevel])设置持久化存储等级;
df.unpersist([blocking]):释放持久化存储资源;
df.coalesce(numPartitions):重新分片;
df.withColumnRenamed(existing, new):重命名列;对于为暂未计算的抽象列Column调用其alias方法修改随后返回的数据的列名。
df.columns:返回列名组成的列表。
df.dtypes->List[(name,type)]
df.schema->StructType
df.isStreaming:该数据集是否是流数据;
df.rdd->RDD(List[Row])
df.toJSON(use_unicode=True)->RDD(List[str])
变换
-
df.select(col:Column,...):从DataFrame选择列并执行变换,select执行的操作类似于map。可以提供序列类型或可变长参数列表作为参数。Column类用于表示==基于列的变换过程的声明式对象==,包括以下声明方式:-
'col_name'|col/column(col_name)|df['col_name']|df.col_name:使用列名读取该列不做其他变换;仅提供列名默认引用当前查询的数据集的列;from pyspark.sql.functions import col,column # col<->column可使用
df.columns[i:j]选择数据的一个分片。对于结构数据字段可通过路径对象来返回嵌套字段值:
df.select("name.firstname","name.lastname").show(truncate=False) -
df.col_name+1:基于列的数值运算、逻辑运算(+,-,*,/...)等;参与运算的数值不能是
numpy类型的数值,否则会出错:'numpy.int32' object has no attribute '_get_object_id';应该将此类型转换为兼容的Python内置类型。 -
df.col_name.func(),df['col_name'].func()或col('col_name').func():使用列名调用内置的变换方法; -
sqlfunc(col('col_name'))或sqlfunc(df['col_name']):使用SQL函数库或或自定义变换函数。SQL函数可能不接受字符串列名。from pyspark.sql.functions import sqlfunc; # 从内置SQL函数库导入变换方法 pysaprk.sql.functions import udf; # 通过udf,用户可自定义变换函数 -
expr("EXPR"):由于表达式文本在运行时构造,这种方式==可动态生成查询语句==;from pyspark.sql.functions import expr df.select(expr('a*2+1'))
-
-
df.selectExpr(*expr):使用表达式代文本替df.select()的列声明(df.select('col_name')的扩展,等效于df.select(expr("EXPR"))),这种方式无法通过列声明对象调用内置方法(如列重命名)。df.selectExpr("age * 2", "abs(age)") -
SQL查询语句:通过构造数据表视图并利用
spark.sql(...)方法传入包含SQL变换方法的原生SQL查询语句进行数据变换。df.createOrReplaceTempView('data') spark.sql('SELECT a, FUNC(a) FROM data').show() -
df.transform(func):func可包含一系列select变换; -
条件变换:
when相当于是一个条件选择函数的简化形式。from pysaprk.sql.functions import when df.select(when(df.col==1,df.col+1).otherwise(0).alias("result"))
通过列声明调用变换方法
Column.cast/astype(TYPE):列数据类型变换,TYPE可以是文本类型描述或DataType的子类对象。
Column.alias/name:修改列名,默认列名为该列的变换表达式;
Column.asc/asc_nulls_first/asc_nulls_last/desc/desc_nulls_first/desc_nulls_last(col):参考对应的SQL函数;
Column.bitwiseAND/bitwiseOR/bitwiseXOR
Column.between(lower,upper):判断列值是否在上下界之间;
Column.startswith/endswith(other)
Column.contains(other)
Column.isin(*cols):当前列的值是否在其他列中;
Column.dropFields(*fields)/getField(name)/withField(name,value):提取/丢弃/修改StructType字段;
Column.getItem(idx_or_key):从序列或字典中提取元素或字段;
Column.eqNullSafe(other):NaN = NaN returns true.
Column.isNull/isNotNull()
Column.like/rlike(other):模糊匹配/正则匹配;
Column.substr(startPos,length):获取子串(functions.substring);
SQL变换函数
Sspark定义了大量内置的变换函数以及自定变换函数的接口。
import pyspark.sql.functions as sqlfunc
自定义变换函数
from pyspark.sql.functions import udf
@udf(returnType=ArrayType(StringType()))
def str_2_array(x: str):
if x is None: return []
elif x.startswith('[') and x.endswith(']'): return eval(x)
else: return [x]
df.select(str_2_array(df.a)).show()
Pandas变换函数
from pyspark.sql.functions import pandas_udf
@pandas_udf(returnType='long', functionType=None)
def pandas_plus_one(series: pd.Series) -> pd.Series:
return series+1
df.select(pandas_plus_one(df.a)).show()
def filter_func(iterator):
for pdf in iterator: # iterator over pandas DataFrames
yield pdf[pdf.id == 1] # return iterator of pandas DataFrames
df.mapInPandas(filter_func, df.schema).show() # [3.0]
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.applyInPandas(plus_mean, schema=df.schema).show()
SparkML变换方法
SparkML提供了基于数值特征的变换方法fit/transoform(),==支持拟合变换过程中的参数;相比之下,基于select()和SQL变换函数,需要自己实现参数拟合的方法==。此外,SparkML提供的变换类,支持同时处理多个列;SQL变换函数的输入为一列,需要自己实现多列处理逻辑并记录对应参数。
SparkML的变换方法的输入要求==将每一行数据参与变换的特征列拼接为向量Vector==(SQL函数库中的array函数实现的拼接与变换方法的输入类型不一致),可以使用VectorAssembler实现此变换。
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=["x", "y", "z"], outputCol="features")
x = assembler.transform(x)
some_transformer = SomeTransformer(*,inputCol='features',outputCol='_features')
model = some_transformer.fit(x) # -> SomeTransformerModel
x = model.transform(x).drop('features').withColumnRenamed('_features', 'features')
变换后的数据包含原有数据列,以及变换后新增的features列(DenseVector)。为了方便后续分别处理各特征列的数据,需要将features[拆分为多列](# 将字典或序列转换为多列)。
@udf(returnType=ArrayType(DoubleType())) # from pyspark.sql.functions import udf
def vector_2_array(x: DenseVector):
return [ float(i) for i in x ]
y:SparkColumn = vector_2_array(x['features']).alias('features')
y = {col: y.getItem(i).alias(col) for i, col in enumerate(_columns)}
x = x.select(*x.columns, *y.columns) # 此处需要处理变换后的重名列(drop or rename)
Spark 3.0
pyspark.ml模块自带vector_to_array()方法。
列变换
内置变换方法来自pyspark.sql.functions(SQL函数)和pyspark.ml.feature(变换类)等模块。
broadcast(df)
bucket(numBuckets, col)
coalesce(*cols):返回第一个不为null的列;
生成列
input_file_name():获取当前任务的文件名;
current_date/current_timestamp():返回当前日期,同一个查询中的调用返回相同值。
lit(VALUE):创建常量列;
monotonically_increasing_id():
rand(seed=None)/randn([seed]):生成[0,1)区间均匀分布/标准正态分布随机数;
sequence(col_start,col_stop[,col_step]):生成等差数列数组,输入参数为列名或常量列(lit);
spark_partition_id():
无效值处理
isnan/isnull(col):判断值是否为NaN/null;
nanvl(col1, col2):如果col1!=NaN,返回col1;否则返回col2;
df.fillna(value[,subset])
数值计算函数
abs/exp/expm1/sqrt/cbrt/log/log10/log1p/log2(col)/pow(x,y):cbrt三次方根,expm1->$e^x-1$;
greatest/least(*cols):返回多个列元素中的最大/小值;
factorial(col):阶乘;
ceil/floor/rint(col):近似;
round/bround(col[,scale]):HALF_UP/HALF_EVEN rounding mode,整数scale控制近似精度,负数表示整数部分精度。
degrees/radians(col):弧度和角度转换;
cos/sin/tan/acos/asin/atan(col)/atan2(y,x):三角/反三角函数;
sinh/cosh/tanh/acosh/asinh/atanh:双曲/反双曲函数;
bitwise_not(col):
shiftleft/shiftright/shiftrightunsigned(col,numBits)
exists(col,f):返回指定判断函数的真值;
hypot(x,y):sqrt(a^2+b^2)
数值特征处理
MinMaxScaler:$(0,1)$规范化;
字符串计算函数
length(col):字符串或字节序列的长度;
levenshtein(left, right):两个字符串的Levenshtein距离;
sentences(string,language=None,country=None):将字符串拆分为语句数组,语句拆分为单词数组。
字符串变换
initcap/lower/upper(col):
translate(srcCol,matching,replace):对srcCol出现在matching中的字符替换为replace相应位置上的字符,例如matching='123',replace='ZYX',则替换规则为1->Z,2->Y,3->X;
ascii(col):计算字符串的首字符ASCII码数值;
lpad/rpad(col,len,pad)
trim/ltrim/rtrim(col)
repeat(col, n):复制字符串n次构成新值;
reverse(col):反转字符串(或数组);
split(str,pattern,limit[3.0]):按指定模式(Java正则表达式)拆分字符串;
查找替换
instr(col,substr)/locate(substr,col,pos=0):查找子串;
substring(col,pos,len):获取子串;substring_index(str,delim,count)查找分隔符出现count次之前的子串(如果count为负数则反向查找)。
overlay(src,replace,pos,len=-1):从src的指定位置pos(位置从1开始),用replace的内容替换src内容,最大替换长度为len;
regexp_extract(str, pattern, idx):抽取idx指定的捕获组,如果模式未匹配或指定捕获组未匹配,返回空字符串。
regexp_replace(str, pattern, replacement)
编码
base64/unbase64(col):BASE64编码/解码;
crc32(col):计算二进制序列的CRC32校验值返回bigint;
hash/xxhash64(*col):计算输入列元素的HASH整数值/长整数值;
md5/sha1(col)/sha2(col,numBits):返回输入列的MD5/SHA-1/SHA-2xx十六进制编码字符串;
bin(col):二进制数据的字符串表示;
hex/unhex(col):字符串/整数的十六进制字符串表示(字符串每个字符的ASCII码值映射为十六进制);
conv(col,fromBase,toBase):字符串表示的数值进行进制转换;
decode/encode(col,charset)使用指定编码方法将字节序列解码为字符串(将字符串编码为字节序列);
concat(*cols)/concat_ws(sep,*cols):将多个列字符串/字节序列拼接为新数据;
format_string(format, *cols):printf模式输出新列;
日期计算函数
year/quarter/month/hour/minute/second(col)
add_months(start,months)/date_add/date_sub(start,days)
next_day(date, dayOfWeek):返回下一个是指定DayOfWeek的日期(“Mon”, “Tue”, “Wed”, “Thu”, “Fri”, “Sat”, “Sun”)
trunc(col_date,format)/date_trunc(format,col_timestamp):按给定格式舍弃末尾的时间值;timestamp_seconds(col):[3.1]截取时间字段到秒;
datediff(end,start):返回两个日期间相差的天数;months_between(date1,date2[,roundOff])计算两个日期间相差的月数(如果为月中同一天或最后一天返回整数,否则返回浮点数);
dayofmonth/dayofweek/dayofyear/weekofyear/last_day(col):last_day表示日期所在月的最后一天;
date_format/to_date(col,format):将date/timestamp/string类型的日期按给定格式(形如yyyy-mm-dd)转换为字符串。to_date->col.cast("date")。
from_unixtime/to_timestamp/unix_timestamp(col,format=None):将时间戳(秒)转换为时间文本(to_timestamp->col.cast("timestamp"),unix_timestamp输入列如果为指定则返回当前时间);
from_utc_timestamp/to_utc_timestamp(timestamp, tz):可指定时区。
排序
asc/asc_nulls_first/asc_nulls_last/desc/desc_nulls_first/desc_nulls_last(col):返回排序表达式。
df.orderBy(*cols)/df.sort(*cols,ascending=True):使用上述UDF声明排序表达式。
df.sortWithinPartitions(*cols,ascending=True)
集合类型处理函数
数组计算
array(*cols)/array_repeat(col,count):将一个或多个列拼接成数组、将一列重复构成数组;
array_join(col,delimiter[,null_replacement]):将数组拼接为字符串;
zip_with(left,right,f(l,r)):合并两个序列,合并值基于两个序列相应元素通过f计算;
flatten(col):拼接嵌套数组(指拼接第一层嵌套);
array_contains(col, value)
forall(col,f):判断数组元素是否都满足判断条件f;
transform(col,f):[3.1]对数组每个元素进行f变换,返回变换后的数组;
element_at(col,idx):从数值提取指定索引的元素;
slice(x,start,length):返回子数组;
array_max/array_min(col)/array_position(col,value):查找元素;
array_sort(col)/sort_array(col,asc=True):(升序)排序;
array_remove(col,element)/array_distinct(col):移除指定元素;去除重复元素;
array_except/array_intersect/array_union(col1,col2):集合操作(差集/交集/并集);
arrays_overlap(a1,a2):判断两个数组是否存在公共元素(如果无公共元素且都包含null返回null)。
shuffle(col):随机置换序列元素。
字典计算
create_map(*cols):使用输入列构建字典,输入列分别轮流作为字典的key和value值;
map_concat(*cols):将多个输入的字典拼接为一个字典;
map_from_arrays(col1, col2):将两列数据分别转换为字典的key和value,如果输入数据为数组,则返回的字典包含多个字段;
map_zip_with(col1,col2,f(key,v1,v2)):[3.1]合并两列字典,使用指定函数合并相同key对应的value;
map_entries[3.0]/map_keys/map_values(col)<->map_from_entries(col):将字典的key和value转换为一条记录Row(key=,value=),并将所有记录拼接为数组返回(后续可通过explode将数组中的记录展开为数据表中的记录)。
transform_keys/transform_values(col,f):对字段的key/value执行f变换、返回变换后的字典;
map_filter(col, f(k,v)):[3.1]过滤字典中不满足条件的字段;
结构体计算
struct(*cols):基于列名和列类型生成StructType;
结构化数据处理
CSV文本处理[3.0]
from_csv(col,schema[,options]):将CSV字符串转换为一行记录;
to_csv(col[, options]):将StructType转换为CSV字符串;
schema_of_csv(col,options=None):从CSV字符串推测Schema;
JSON文本处理
from_json(col,schema,options=None):将JSON文本转换为Row/StructType对象(可再从结构体扩展为多列);使用schema_of_json(json:str,options[3.0])从==JSON文本==推测Schema并传递给from_json;
get_json_object(col,path):使用JSON Path从==JSON文本==提取字段,例如"$.field";
json_tuple(col,*fields):从==JSON文本==的根节点提取一个或多个字段fields;==由于get_json_object和json_tuple没有指定Schema,返回数据转换为字符串(默认类型)==。
to_json(col,options=None)将StructType、ArrayType或MapType转换为JSON文本;
按元素变换
df.replace(to_replace[, value, subset])
过滤
行过滤
filter(col,f):行过滤;
df.filter/where(col_expr):数据集过滤;df.toDF(*cols)基于列名过滤;
df.limit(num)->DataFrame:保留num行数据;
df.sample([withReplacement, …])
df.dropna(how='any',thresh=None,subset=None):how=any|all,thresh指定null的比例,subset指定检查的列;
df.distinct()/df.drop_duplicates([subset]):保留唯一行。
列过滤
df.select(*cols)或df.select(df.columns[i:j]):按列名或列编号选择列;
df.drop(*cols)或df.drop(df.columns[i:j]):按列名或列编号丢弃列;
df.colRegex(colNamePattern)->Column:选择列名与模式匹配的列;
插入和扩展
插入新列
df.withColumn(colName, col):添加或替换一列数据;添加的数据列仅能为常量或基于当前DataFrame声明的列变换(从而保存分布式数据结构计算的兼容性)。
将集合类型扩展为多列
将字典或序列转换为多列
使用列的getItem()函数可按位置或键名获取集合类型的元素,从而实现一列到多列的变换。由于字典或序列长度可能不统一,导致无法合并并行处理结果,必须预先给定固定数量的列或列名。
col_names = ['a', 'b', 'c']
cols = [df['map_col'].getItem(col).alias(col) for col in col_names]
cols = [df['list_col'].getItem(i).alias(str(i)) for i,_ in enumerate(col_names)]
df_new = df.select(*cols)
如果实际已知MapType具有固定数量且相同的字段,则可以:
col_names = list(df.first().asDict()[col_name].keys())
将结构体转换为多列
由于结构体具有固定字段,所以能够并行处理:
df.select("struct_col.*")
df.select([df['struct_col'].getField(f) for in fields])
将集合类型扩展为多行
explode/explode_outer/posexplode/posexplode_outer():将输入列(序列/字典)扩展为多行记录;其中字典的key和value分别映射为两列(后者保留null元素)。pos-函数为返回值增加位置编号字段(表示其在源数据中的顺序,默认为pos)。
数据集运算
df.join(other[, on, how])
df.crossJoin(other)
df.exceptAll(other):数据集列差集,返回在当前数据集但不在另一个数据集的列;
df.intersect/intersectAll(other):返回两个数据集都存在的行(intersectAll保留重复);
df.subtract(other):返回在此数据集但不在另一个数据集的行。
df.union/unionAll(other):==纵向拼接==(不去重,使用df.distinct()去重);
df.unionByName(other, allowMissingColumns=False):根据列名对应拼接;
聚合
聚合内置函数:aggregate(col, initialValue, merge[, finish])
df.agg(count_distinct(df.age, df.name).alias('c'))
分组聚合:df.groupBy(col:Column,...).agg_func()
agg(*expr)
apply(udf)
applyInPandas(func, schema)
# avg/count/max/min/mean/sum... => 存在等效的UDF
时间窗口聚合:
w = df.groupBy(window("date", "5 seconds")).agg(sum("val").alias("sum"))
col.over(window)
统计量
avg/count/max/min/mean/sum(col):
stddev/stddev_samp/stddev_pop(col):样本/总体标准差(stddev->stddev_samp);
variance/var_samp/var_pop(col):样本/总体方差=>df.cov(col1,col2);
corr/covar_pop/covar_samp(col1,col2):计算两列的相关系数/总体协方差/样本协方差;=>df.corr(col1,col2[,method])
approx_count_distinct(col[, rsd]):近似统计列的不同值数量。
count_distinct/sum_distinct(*cols):统计不相同元素的数量/求和;
累积数值运算
product(col):累计运算;
合并拼接
collect_list/collect_set(col):将列数据合并为序列或集合;
采样
first/last(col[,ignorenulls]):获取分组的第一个元素;
窗口操作
lag/lead(col[,offset,default]):返回当前行的前/后第offset行的值;
nth_value(col, offset[, ignoreNulls]):返回当前窗口中第offset行(从1开始)的值;
输出
在Driver侧输出DataFrame的数据信息:
df.printSchema()
df.explain() # Prints the (logical and physical) plans
df.count()
df.show(vertical=False)
在Driver侧收集DataFrame数据:
df.collect() # -> List[Row]
df.take(num) # -> List[Row]
df.head/tail(n=NUM) # -> List[Row]
df.first() # -> Row <=> df.head()
df.toPandas() # -> pandas.DataFrame
df.to_pandas_on_spark([index_col])
注意,上述方法与
df.limit()不同,后者输出未SparkDataFrame。
df.foreach(f(Row))
df.foreachPartition(f(List[Row]))
df.toLocalIterator(prefetchPartitions=False):将每个分区逐次取到本地进行处理;
for part in df.toLocalIterator(prefetchPartitions=False):
# do processing in client
# part is a Local DataFrame
存储方法
writer=df.write->DataFrameWriter:
writer.format(<source>):输出格式包括:csv,json,jdbc,parquet,...,等效调用writer.<source>;
df.writeStream
CSV存储参数
- 存储方法
- 模式
mode='append'|'overwrite'|'ignore'|'error'; - 压缩
compression=None|'bzip2'|'gzip'|'lz4'|'snappy'|'deflate':CSV读取不止解压缩方法,因此如果还要将存储数据读出来则选择不压缩输出。
- 模式
- 数据格式:
header=False:将数据的字段名写入文件的首行;
- 特殊字符,参考CSV读取参数;
escapeQuotes=True:默认将包含引号的字段使用引号包围并对其中的引号转义;quoteAll=False:将所有字段使用引号包含;
- 数值格式,参考CSV读取参数;
分区
df.repartition(numPartitions, *cols)
writer.partitionedBy(days("ts"))
分区方法
years/months/days/hours(col):按天分区;
Spark SQL Guide: Getting Started - Spark 3.2.0 Documentation (apache.org)
Spark SQL API Reference — PySpark 3.2.0 documentation (apache.org)
用于从Hive读取数据生成DataFrame或DataSet。
Spark Pandas API
Pandas DataFrame [3.2]
Spark SQL and DataFrames - Spark 3.2.0 Documentation (apache.org)
Quickstart: Pandas API on Spark — PySpark 3.2.0 documentation (apache.org)
Pandas API on Spark User Guide — PySpark 3.2.0 documentation (apache.org)
Pandas API on Spark Reference — PySpark 3.2.0 documentation (apache.org)
Spark Streaming
可扩展、高吞吐、可容错的实时数据流处理。

内部数据流
将数据流拆分为小批次(discretized stream or DStream,a sequence of RDDs)。每一次处理程序调用时,接收到的数据在Spark上生成一个RDD对象。
数据源:kafka、TCP socket、……
算法API:map、reduce、join、window;可将机器学习算法和图处理算法应用于数据流;
输出:文件、数据库、仪表板
流处理程序框架
以Kafka作为数据源的流处理程序框架:
sc = SparkContext(conf=conf) # 创建Spark连接上下文
stream_context = StreamingContext(sc, batchDuration=5) # 创建Kafka流处理上下文
# 设置Kafka消费者订阅参数
zookeeper = 'node1:2181,node2:2181,node3:2181'
group_id = 'spark-streaming-consumer'
topics = {'noah.unix': 1}
# 创建Kafka数据流: 需要根据数据源的编码格式指定对应的解码方法
kafkaStream = KafkaUtils.createStream(
stream_context, zookeeper, group_id, topics,valueDecoder=msgpack.loads)
# 流处理过程:KafkaDStream/TransformedDStream变换方法
results = kafkaStream.map(func1).reduce(func2)...
# 输出过程
kafkaStream.foreachRDD(proc_rdd) # 定义每一批数据的处理函数
stream_context.start() # 启动流处理任务
stream_context.awaitTermination() # 等待流处理结束或中断,防止程序提前退出
在上述框架中添加的普通Python程序(例如打印语句)仅会被执行一次,只有流处理相关代码才会在流数据处理每次触发执行时被执行。当流处理启动后,不能再修改处理过程。程序同一时间仅能有一个有效的
StreamingContext,一个StreamingContext可以创建多个数据流。
数据源
stream_context.socketTextStream("localhost", 9999) # TCP socket数据源
stream_context.textFileStream(dataDirectory) # python仅支持文本文件(HDFS)
Kafka连接模式
Reciever模式
上述框架采用Reciever模式。Receiver接收的数据储存在Spark执行器中,Spark流处理任务处理接收的数据。如果任务出错可能导致数据丢失,需要启用Write Ahead Logs将接收数据写到分布式存储以在必要时恢复。
Receiver要占用Spark应用的一个任务线程,因此分配给执行器的
cores总数要大于1。
直连模式
kafkaStream = KafkaUtils.createDirectStream(
kafka_context, list(topics.keys()),
{"metadata.broker.list": "node1:9092,node2:9092,node3:9092"},
valueDecoder=msgpack.loads
)
流处理过程
处理过程以RDD作为处理对象,针对当前批次数据RDD执行map、reduce等分布式变换处理操作,返回TransformedDStream处理结果。
流处理过程是在执行器上分布式执行的,因此在Driver侧无法查看这些处理过程中的输出。
map(func):对当前批次数据的每一条记录执行运算并返回结果;传递给func的数据为RDD中每一条记录(普通Python对象)。
mapPartitions(func):对当前批次数据的每个分片执行map操作,传递给func的数据是一个分片。该变换的效果和map相同,返回结果都是包含每条记录的RDD。使用该方法代替map()的场景为减少变换方法需要反复执行的初始化操作。
因为无法通过数据序列化将特殊对象从Driver传递给执行器(例如数据库连接),因此需要在变换方法中反复调用初始化方法,造成较大开销。利用
mapPartitions仅需为每个分片在对应的执行器上执行一次初始化。
def func_partition_map(data:Iterable):
for data in Iterable:
yield func_map(data)
flatMap(split_func):一对多映射,将一条记录拆分为序列,并将其转换为多条记录。
transform(trans_func):将一批数据RDD整体进行变换,可定义任意针对RDD的变换方法。可以在trans_func中将RDD转换为DataFrame。
filter(func):仅返回func值为true的记录。
统计聚合
count()->TransformedDStream:返回当前批次数据的数量(标量RDD)。
countByValue():统计不同记录的数量(groupby-count),返回包含(record, num)的数据流。
reduce(redfunc):对当前批次数据执行reduce运算,并返回标量RDD。redfunc应该满足结合律和交换律从而支持并行计算。
reduceByKey(func, numPartitions=None):(groupby-aggregate)对于数据结构为(key,value)的数据流,按key分组,并对value进行聚合。numPartitions指定分组任务的并行数量(即RDD的分片数量,集群模式默认值为spark.default.parallelism)。
updateStateByKey(func_update_state):数据记录内部状态维护。对于数据(key,value),针对每个key维护一个状态变量(可定义任意数据类型)。当处理一批数据时,会将每个key对应的值构成序列传递给状态更新函数,基于该值序列可计算更新状态。
def func_update_state(values, state):
if state is None:
# init_state
# state_update <- values
# state <- state + state_update
return state
时间窗操作
窗口操作时间参数:1)windowDuration:时间窗长度;2)slideDuration:滑动时长;均为处理周期的整数倍。
window(...) :获取时间窗口中的所有数据。
countByWindow(...):获取时间窗口中的所有数据的计数。
reduceByKeyAndWindow(func,[invFunc],...,numPartitions=None,filterFunc=None):记录滑动窗口中每个批次数据的聚合结果reduceByKey,通过func将新加入窗口的批量数据的聚合结果合并到窗口聚合结果中,利用invFunc从窗口聚合结果中移除离开活动窗口的批量数据的聚合结果。如果未提供invFunc(某些合并结果可能也不支持反向移除),那么每次要对聚合窗口中的每个批次的聚合结果做合并,因此效率较低。filterFunc基于数据(key,value)进行过滤,仅对满足条件的数据聚合。
countByValueAndWindow()基于countByValue结果;reduceByWindow()基于reduce结果。
内部变换
repartition(numPartitions):将RDD重新分片。
多数据流处理
union(otherStream):和其他数据流合并。
join(otherStream,numPartitions=None):合并数据流,(K,V)+(K,W)->(K,(V,W));还可以指定合并方式:leftOuterJoin,rightOuterJoin,fullOuterJoin。
cogroup(otherStream,numPartitions=None):合并数据流,将每个数据流相同键值的数据聚合为一个序列再进行拼接,(K,V1)+(K,V2)...+(K,W1)+(K,W2)+...->(K,(V1,V2,...),(W1,W2,...))。
输出过程
针对当前批次数据执行输出操作(标准输出、文件、数据库、流引擎……),无返回数据。==流处理流程需要以输出过程来触发处理过程执行,否则系统会直接丢弃数据而不会执行变换处理操作==。
pprint: (num=10):输出当前批次数据RDD中前num条记录;如果RDD为序列类型则输出为序列,如果为标量,则输出标量。
saveAsTextFiles(prefix, [suffix]):输出文件名称格式prefix-TIME_IN_MS[.suffix](PythonAPI仅支持文本文件)。
foreachRDD(proc_rdd):对当前批次数据进行自定义处理。可在处理逻辑中添加输出方法。proc_rdd是==运行在Driver侧==的方法(不要将连接对象传递给执行器),因此可以将数据输出到终端、保存到Driver节点的文件系统、输出到数据库或HDFS。也可将RDD转换为DataFrame再执行输出处理。
def proc_rdd(data: RDD):
data = rdd.map(...).reduce(...) # 进一步分布式操作
print(data) # 输出到driver终端
pd.DataFrame.from_records(data).to_parquet(FILEPATH) # 输出到文件
Checkpointing容错机制
How to configure Checkpointing
性能优化
Structured Streaming
结构化流处理是基于Spark SQL引擎的可扩展、高容错流处理引擎。可以使用Dataset/DataFrame API来描述数据处理过程。
容错机制:checkpointing and Write-Ahead Logs。
处理模式:
- micro-batch processing:最少延迟100ms(默认);
- continuous processing:最少1ms延迟(Spark 2.3+)。
流处理程序框架
stream_df = spark\
.readStream\
.format("kafka")\
.trigger(processingTime=None,...)\ # 流处理周期
.option("kafka.bootstrap.servers", "node1:9092,node2:9092,node3:9092")\
.option("subscribe", "tpoics")\
.load()
# "topic1,topic2" | "topic.*"
query = stream_df.select(...)\
.writeStream.foreachBatch(batch_func)\
.start()
query.awaitTermination()
流处理程序必须以流式DataFrame进程传递,最后调用writeStream进行输出。
变换过程必须返回流式
DataFrame,否则产生*Queries with streaming sources must be executed with writeStream.start();*
流处理周期
可设置一项触发选项,指定处理周期。
reader.trigger(processingTime='5 seconds',once=None,continuous='1 minute')
Structured Streaming Programming Guide - Spark 3.2.0 Documentation (apache.org)
Structured Streaming API Reference — PySpark 3.2.0 documentation (apache.org)
输入
可使用与批量处理相同的接口读取文件,此外还可指定流数据源(如Kafka)。
Kafka输入流数据可能是以字节序列存储,需要在接收数据后自行进行反序列化(解码)。
变换处理
由于数据流以结构化的流式DataFrame组织,因此Spark SQL的DataFrame API都适用于流数据的处理。
Kafka数据流除了数据字段
value,还包含元数据字段,包括key,topic,partition,offset,timestamp,timestampType,headers。实际处理开始前,需要首先从value字段(例如JSON文本)中将数据字段提取出来并结构化为新的DataFrame。
输出
writer.outputMode('append|complete|update'):
writer.queryName('streaming_query'):指定处理流程的名称(query.name);
外部存储
参考批量处理的输出方式,仅支持append模式。
输出至Kafka
自定义处理
foreach
def proc_row(row):
# ......
class ForeachWriter:
def open(self, partition_id, epoch_id): # 创建到目标的writer连接
def process(self, row): # 处理和写入数据
def close(self, error): # 关闭writer连接
df_stream = writeStream.foreach(proc_row).start() # Append,Update,Complete
foreachBatch
def batch_print(df: DataFrame, epoch_id: int):
print(f"_________________ {epoch_id} ____________________")
df.persist() # 防止重复计算
df.printSchema()
df.show()
df_stream = writeStream.foreachBatch(batch_func).start() # Append,Update,Complete
不支持连续模式,使用
foreach。
调试输出
console
writeStream.format('console')\
.option('numRows', 20)\
.option('truncate', True)\
.start() # Append,Update,Complete
memory
writeStream.format("memory").queryName("tableName").start() # Append,Complete
图分析算法
GraphFrame
GraphFrame库用于在Spark上基于DataFrame表示图数据,并封装了图分析算法。
conda create -n graph -c conda-forge pyspark graphframes
在代码中引用GraphFrame库:
from graphframes import *
spark = SparkSession.builder\
.appName('Spark Graph')\
.config('spark.jars.packages', 'graphframes:graphframes:0.8.1-spark3.0-s_2.12')\
.getOrCreate()
或通过命令行(spark-submit或pyspark)参数添加引用:
pyspark --packages graphframes:graphframes:0.7.0-spark2.4-s_2.11 #*
*:根据实际安装的Spark版本,从Maven仓库选择对应版本的库。
通过分别表示图的节点和边的DataFrame构造图对象,通过edges和vertices访问图的边和节点。
g = GraphFrame(v, e)
g.vertices
.filter("population > 100000 and population < 300000")
.sort("population")
图分析算法
from_expr = "id='Den Haag'"
to_expr = "population > 100000 and population < 300000 and id <> 'Den Haag'"
result = g.bfs(from_expr, to_expr)
GraphX
MLlib
MLlib: Main Guide - Spark 3.2.0 Documentation (apache.org)
MLlib (DataFrame-based) API Reference — PySpark 3.2.0 documentation (apache.org)
Breeze, which depends on netlib-java
native BLAS such as Intel MKL, OpenBLAS, can use multiple threads in a single operation, which can conflict with Spark’s execution model.
流式大数据处理
Kafka
event streaming
Kafka is a distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol.
- Server
- Broker
- Kafka Connect
- Client
Concepts
Event
Publisher
Consumer
Topic: event organized as topics. Topics in Kafka are always multi-producer and multi-subscriber.
Events in a topic can be ==read as often as needed==—unlike traditional messaging systems, events are ==not deleted after consumption==.
Instead, you define for how long Kafka should retain your events through a per-topic configuration setting, after which old events will be discarded.
Kafka's performance is effectively constant with respect to data size, so ==storing data for a long time is perfectly fine==.
Topics are partitioned, for scalability.
To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters
安装运行
Linux
启动服务
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
可将
bin目录加入路径,后续直接引用命令脚本。
docker
创建集群:
version: "2.2"
services:
zookeeper:
image: bitnami/zookeeper:3.7
ports:
- 2181:2181
volumes:
- zookeeper_data:/bitnami
networks:
- kafka
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
node-01:
image: bitnami/kafka:2
volumes:
- data01:/bitnami
- ./server01.properties:/bitnami/kafka/config/server.properties
networks:
- kafka
ports:
- 9092:9092
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_BROKER_ID=0
- KAFKA_CFG_LISTENERS=PLAINTEXT://node-01:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://node-01:9092
depends_on:
- zookeeper
node-02:
environment:
- KAFKA_CFG_BROKER_ID=1
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://node-02:9093
ports:
- 9093:9093
volumes:
zookeeper_data:
driver: local
data01:
driver: local
......
networks:
kafka:
driver: bridge
由于外部需要访问所有节点,因此需要将每个服务的端口映射到宿主机的不同端口。外部访问时,仅指定其中一台节点。
额外配置项:指定容器名和容器主机名。
container_name: kafka-zookeeper hostname: zookeeper
bitnami/bitnami-docker-kafka: Bitnami Docker Image for Kafka (github.com)
管理
CLI
主题管理
创建主题:
kafka-topics.sh --create --topic topic-name \
--zookeeper HOST1:2181,HOST2:PORT2,...\
--bootstrap-server HOST1:9092,...\ # [3.x]
--partitions 1 \
--replication-factor 2
对于2.x版本,必须指定
zookeeper选项,不支持bootstrap-server选项;对于3.x版本可仅指定bootstrap-server。Bootstrap server vs zookeeper in kafka? - Stack Overflow
状态监控:
kafka-topics.sh ... --list all # 列出所有主题名称
kafka-topics.sh ... --describe [--topic topic] # 输出主题信息--desc
# Topic: first-topic TopicId: CjMZOiXeSXOaaXBlfZx_fQ PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
# Topic: first-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
写入数据(生产者)
启动生产者以写入数据(通过Ctrl+C终止)。
kafka-console-producer.sh --topic topic-name \
--zookeeper node1:2181,node2:2181,... \
--bootstrap-server node1:9092,...
对于2.x版本,必须指定
zookeeper选项,bootstrap-server为可选项;对于3.x版本可仅指定bootstrap-server(消费者参数同理)。
读取数据(消费者)
kafka-console-consumer.sh --topic topic-name \
--from-beginning \
--bootstrap-server ... --zookeeper ...
--from-beginning:从kafka缓存的数据开始处开始读取(默认从当前时间点读取)。
API
There are multiple Python libraries available for usage:
- Kafka-Python — An open-source community-based library.
- PyKafka — This library is maintained by Parsly and it’s claimed to be a Pythonic API. Unlike Kafka-Python you can’t create dynamic topics.
- Confluent Python Kafka:- It is offered by Confluent as a thin wrapper around librdkafka, hence it’s performance is better than the two.
Kafka-Python
Admin
Producer
Consumer
Getting started with Apache Kafka in Python | by Adnan Siddiqi | Towards Data Science
import json
from time import sleep
from kafka import KafkaConsumer
import msgpack
if __name__ == '__main__':
parsed_topic_name = 'parsed_recipes'
# Notify if a recipe has more than 200 calories
calories_threshold = 200
consumer = KafkaConsumer(
parsed_topic_name,
auto_offset_reset='earliest',
bootstrap_servers=['localhost:9092'],
api_version=(0, 10),
consumer_timeout_ms=1000,
value_deserializer=msgpack.loads # 解码:可能采用其他解码方法
)
for msg in consumer:
record = json.loads(msg.value)
calories = int(record['calories'])
title = record['title']
if calories > calories_threshold:
print('Alert: {} calories count is {}'.format(title, calories))
sleep(3)
if consumer is not None:
consumer.close()
解码方法
根据Kafka的数据序列化方法,可能需要选择合适的解码方法:
- 纯文本,无需解码;
msgpack:使用msgpack.loads解码;如果kafka记录的value字段为JSON对象文本,则会自动将其转换为字典。
Kafka Stream:处理数据
Kafka Connect:导入导出数据(事件流)
message queue
对接Elasticsearch
当Elasticsearch遇见Kafka--Kafka Connect - 云+社区 - 腾讯云 (tencent.com)
当Elasticsearch遇见Kafka--Logstash kafka input插件 - 云+社区 - 腾讯云 (tencent.com)
对接Spark
spark-streaming-kafka:Spark流处理对接Kafka数据源;spark-sql-kafka:Spark结构化流处理对接Kafka数据源;
容器编排
容器技术
Namespace
Namesapce:资源隔离和虚拟化。
- UTS
- IPC
- PID
- Network
- Mount
- User
Cgroup
文件系统
网络
Docker
docker LXC, namespace, cgroups, 资源隔离与安全保障
docker client/server: REST API
docker组件:
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)

https://www.backblaze.com/blog/vm-vs-containers/
https://docs.docker.com/get-started/overview/
容器的优点
面向产品:简化交付
面向开发:简化环境配置
面向测试:多版本测试
面向运维:环境一致性(一次构建、代码与配置分离)
面向架构:自动化扩容(微服务)
不可变基础设施:用替换代替变更
安装Docker Engine
Ubuntu
# install necessray tools
sudo apt-get install apt-transport-https ca-certificates \
curl gnupg-agent software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo apt-key fingerprint 0EBFCD88
# Add repository
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# install docker
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose
https://learnku.com/articles/34941
Fedora/CentOS
目前支持Fedora ==34/35/36==版本和CentOS ==7/8/9==(centos-extras仓库需要启用)1。
yum install -y yum-utils # dnf -y install dnf-plugins-core
yum-config-manager --add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# dnf config-manager --add-repo
# https://mirrors.aliyun.com/docker-ce/linux/fedora/docker-ce.repo
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
systemctl enable --now docker # start and enable
移除旧版本docker
yum remove docker docker-latest \
docker-client docker-client-latest \
docker-common \
docker-logrotate docker-latest-logrotate \
docker-engine
位于
/var/lib/docker的镜像、容器、卷和网络等数据不会被移除。
Windows
安装Doker Desktop,需要启用Hyper-V/WSL2支持。
管理镜像
docker pull centos[:tag] # get docker iamge from DockerHub
docker images # show local images
docker save -o centos.tar centos # save image as archive
docker load --input centos.tar # load image from archive
docker rmi [ID|tag] # remove image
docker rmi $(docker images -q) # remove all iamges
Ubuntu(不包括WSL发行版)不支持
root账号,因此需要使用sudo运行命令。
运行容器
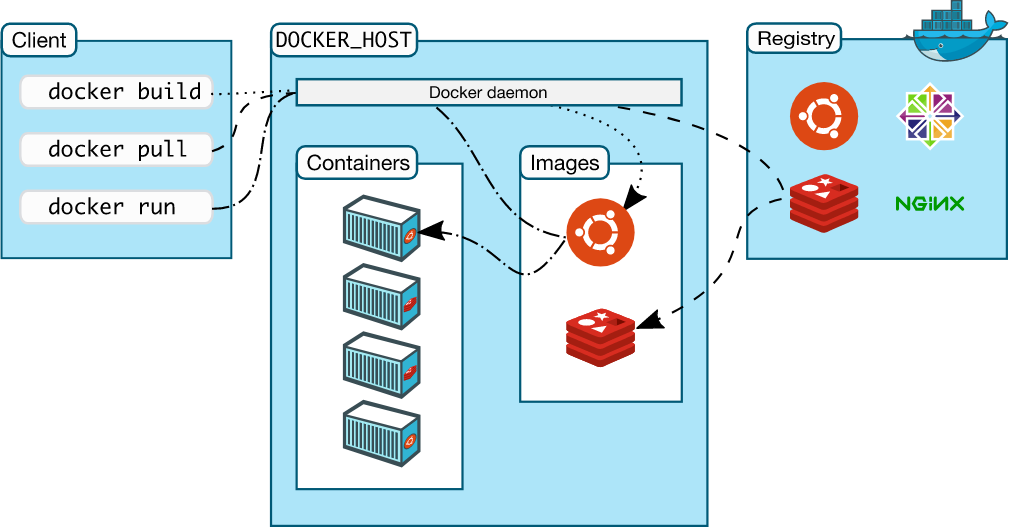
docker run [--name NAME] centos[:latest] echo "Hello World"
docker run --name mydocker -d -t -i centos /bin/bash
# [start,stop]
docker start mydocker # start an existing iamge
docker ps [-a] # show docker instance (and history process)
-d,--detach:Run container in background and print container ID.--network <net>:Connect a container to a network.--name <name>:Assign a name to the container.-e, --env <vars>:设置环境变量;-i, --interactive:Keep STDIN open even if not attached--ip string:IPv4 address (e.g., 172.30.100.104)-t, --tty:Allocate a pseudo-TTY-h, --hostname string:Container host name
查看容器的输出信息:
docker logs [OPTIONS] CONTAINER
进入容器
attach
连接到docker的进程。
docker attach mydocker
在我们使用
attach进入容器的时候,如果同时有多个窗口attach到同一个容器的时候,所有窗口都会同步显示。某个窗口因命令阻塞时,其他窗口也无法执行操作。一个窗口执行exit,则容器就推出运行。
nsenter
PID=$(docker inspect --format "{{ .State.Pid }}" mydocker)
nsenter --target $PID --mount --uts --ipc --net --pid
exec
通过docker让容器执行命令。
docker exec mydocker ln -sf target destfile
容器中执行命令的返回值将通过上述命令返回。
进入容器:
docker exec -it mydocker /bin/bash
此时重新在容器中启动了一个shell。
删除容器
docker rm [id|name]
docker run --rm centos /bin/echo "One" # remove after stop
# 执行完命令后退出
docker kill $(docker ps -a -q) # kill all containers
docker rm $(docker ps -a -q) # remove all stopped containers
数据管理
docker volume create <vol_name> -d,--driver <driver>
docker [ps|rm|prune]
driver:默认为local,卷的物理位置。
prune:删除所有未被任何容器所使用的数据卷。
创建的数据卷位于/var/lib/docker/volumes目录下。在WSL2中,数据卷的物理映射路径(/var/lib/docker/volumes)不变但无法访问。其实际位置在Windows的文件系统上(通过网络访问:\\wsl$\docker-desktop-data\version-pack-data\community\docker\volumes)。
查看容器挂载的WSL卷时,发现其不是指定的目录,这里应该是做了某种映射(新版本已经做了更改)。
当停止并删除容器后,容器曾挂载过的卷仍被docker所占用,因此无法删除,需要首先退出Docker Desktop。
在Windows虚拟机(WSL2,VMware等)中挂载Windows目录时需要注意,容器挂载路径不要映射到Windows卷。由于Windows和Linux的读写权限配置不同,容器在Windows卷下读写文件可能会失败;因此目前最好使用WSL或虚拟机内部存储映射到容器路径。
VMware可以为虚拟机添加额外的虚拟磁盘或物理磁盘/分区供虚拟机独占使用。
挂载数据
使用-v、--volume或--mount挂载目录或文件。
-v /root/mediawiki:/usr/local/mediawiki
-v /root/mediawiki/logo.png:/var/www/html/resources/assets/wiki.png
如果目标不存在,则-v、--volume将自动创建目标,而--mount会产生错误。
网络管理
docker network create <netname> \
-d,--driver <driver> \
--gateway strings --ip-range strings --subnet strings
docker network connect|disconnect
docker network ls|rm|prune
docker network inspect <net> # show detail of network
driver:指定网络类型(管理网络的驱动:bridge/host/null)。系统中分别存在以每个类型名命名的默认网络实例。
地址端口映射
将主机物理端口绑定到容器端口。
-p <host_addr>:<host_port>:<container_port>/protocol
protocol=tcp|udp.
容器域名映射
hosts文件属于镜像的只读层,重启容器后对该文件的修改丢失。在构建容器阶段替换hosts文件或者在启动容器时在hosts文件中添加额外内容。
--add-host wiki.ica.caep.cn:127.0.0.1
容器主机名(ID)映射将由docker在最后添加:
172.18.0.3 d6e8e32ea99b。
位于同一网络中的容器(通常使用docker-compose等工具构建)可通过容器名互相访问(由dockerd提供映射查询)。
Docker Desktop网络
Docker Desktop使用vpnkit管理外发流量(TCP/IP协议栈代理,非NAT),同时使用vpnkit处理DNS查询和HTTP(S)代理2。
HTTP(S)代理可在Docker Desktop配置界面中设置。
对于未配置DNS服务器的容器,其域名请求将由
vpnkit转发至Docker Desktop内部的DNS服务(包括dockerd和CoreDNS服务)。通过CoreDNS服务,容器中的域名解析依赖主机的域名服务配置,因此容器内部服务也能够与外部主机正常通信。
Docker Desktop通过com.docker.backend将Docker端口映射到主机端口0.0.0.0:port,从而对外提供服务。外部机器可直接通过主机地址访问相应端口(到com.docker.backend.exe的防火墙访问策略通过询问用户打开)。
类似于
wslhost.exe,但不同于wslhost.exe默认仅限于localhost访问。
docker-compose
除了直接通过docker命令接收参数的形式配置容器,也可以通过docker-compose输入配置文件的形式配置容器参数并构建容器(两者参数对应)。
services:
<service_name>: # service_name作为主机名
image: <image_name>[:version]
container_name: <name> # --name <name> 容器名
environment: # 容器中的环境变量 (array)
# docker属性
- node.name=<hostname> # -h, --hostname <hostname>
# 环境变量 # -e,--env <vars>
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- DEBUG # 传递shell环境变量
volumes:
- data01:/usr/share/elasticsearch/data # 卷->容器路径
networks: # --network <net>
- net
ports:
- 9200:9200 # host -> docker, expose is only informative
depends_on:
db:
condition: service_healthy
<service_name>:
build: path_to_dockerfile
environment: # 容器中的环境变量 (dict)
key1: value1
key2: value2
depends_on: # 依赖服务
- <service_name>
restart: always # no, always, on-failure, unless-stopped
dns:
- 8.8.8.8
- 9.9.9.9
domainname: app.net
hostname: node-1 # 主机名
ports:
target: 80
host_ip: 127.0.0.1
published: 8080
protocol: tcp
mode: host
networks:
net:
aliases: # 网络上的主机别名
- node-alias_name1
- node-alias-name2
ipv4_address: 172.16.238.10 # 需要在网络声明中配置子网
ipv6_address: 2001:3984:3989::10
extra_hosts:
- "somehost:162.242.195.82"
- "otherhost:50.31.209.229"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost"]
interval: 1m30s
timeout: 10s
retries: 3
start_period: 40s
volumes:
data01:
driver: local # docker volumn create data01 --driver local
networks:
net:
driver: bridge # docker network create --driver local
net2: # 配置子网,如果需要为容器设置IP,则需设置子网
ipam:
driver: default
config:
- subnet: "172.16.238.0/24"
- subnet: "2001:3984:3989::/64"
环境变量
在docker-compose.yml文件中,通过${VAR}引用环境变量。环境变量包含:
-
.env文件:声明编排过程中的环境变量,默认位于项目文件夹下或使用--env-file指定环境变量定义文件;项目文件夹即docker-compose.yml文件所在目录根据--file或COMPOSE_FILE环境变量确定,默认为docker-compose启动目录;COMPOSE_PROJECT_NAME=elastic VERSION=7.14.1 -
Shell环境变量,优先级高于
.env文件(可以在执行docker-compose命令前声明); -
project-name由环境变量COMPOSE_PROJECT_NAME指定(默认为docker-compose.yaml文件所在目录名)。由docker-compose创建的对象(服务、卷、网络等)名称将自动添加project-name作为前缀。
网络配置
根据networks声明自动创建网络;如果没有声明网络,则会自动创建默认的网络(<project-name>_default)。
数据卷配置
自动创建卷位于/var/lib/docker/volumes/,卷名为<project-name>_<volume-name>。
启动顺序
Control startup and shutdown order in Compose | Docker Documentation
管理
# [up,create,start,restart]
docker-compose up -d # Create and start containers (as daemon)
# [start,pause,unpause,stop,restart]
docker-compose kill #
docker-compose rm # 删除停止服务(镜像)
docker-compose down -v # 删除容器以及相关网络、数据卷等
docker-compose ps # at dir with docker-compose.yaml
状态检查
Compose file version 3 reference | Docker Documentation
构建镜像
手动
手动向容器添加内容,并将该容器保存为镜像。
docker commit -m "message" container_id image_name:tag
Dockerfile
Dockerfile:构建容器镜像的声明文件。
# This docker file uses the centos image
# VERSION 1
# Author: Jason Zhao
# Base image
FROM centos
# Maintainer
MAINTAINER shundong.zhao zhaoshundong@gmail.com
#Commands to update the image
# LABEL url=""
ENV DEBIAN_FRONTEND noninteractive # 环境变量
RUN rpm -ivh http://mirrors.aliyun.com/epel/epel-release-latest-7.noarch.rpm
RUN yum install -y nginx --enablerepo=epel # 在容器中运行命令
# VOLUME
WORKDIR /your/path # 切换工作目录
ADD index.html /usr/share/nginx/html/index.html
COPY host/src container/target # 拷贝文件
RUN echo "daemon off;" >> /etc/nginx/nginx.conf
EXPOSE 80 # 暴露容器端口
CMD ["python3", "-m", "pelican.server", "80"] # 运行命令,可添加多个参数
USER xxx #
COPY命令似乎不支持符号链接拷贝。
ARG存在于docker build命令执行期间。默认值写在 Dockerfile里。如果需要修改,可以通过docker build命令里的--build-arg参数来指定。
ENV存在于docker run命令执行期间。默认值写在Dockerfile里。如果要修改,可以通过docker run命令的--env参数来指定。
ARGENV:如果要把ARG的值保存到container运行起来之后仍然可以可用。
RUN
在镜像容器中执行命令。
构建命令
docker build -t img_name:img_tag -f app.dockerfile PATH
-f指定Dockerfile的路径,默认为PATH/Dockerfile;PATH参数不可省略(当前路径使用".")
镜像分层设计:
- 操作系统
- 运行环境
- 应用
SSH
Supervisor
Docker仓库
设置镜像源
创建或修改/etc/docker/daemon.json文件,修改为如下形式:
{ "registry-mirrors" : [
"https://famqhaa8.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com",
"https://registry.docker-cn.com"
]}
重启docker服务使配置生效。
systemctl daemon-reload
systemctl restart docker
Docker Registry
Harbor
Nexus
docker login reg.example.com
docker push
容器编排
https://mp.weixin.qq.com/s/spNSMozSrCO7AgqyRVfwug
常见的容器编排引擎包括:Kubernetes、Docker Swarm、Apache Mesos等。
With that said, if you’re just looking to get up and running and test out using an orchestration engine, then Docker Swarm is probably a good choice. When you’re ready to delve further into the subject, or possibly deploy something leaning toward industrial grade, look to Kubernetes. If flexibility and massive scale are your goals, then consider Apache Mesos. https://www.sumologic.com/insight/kubernetes-vs-mesos-vs-swarm/
Kubernetes架构
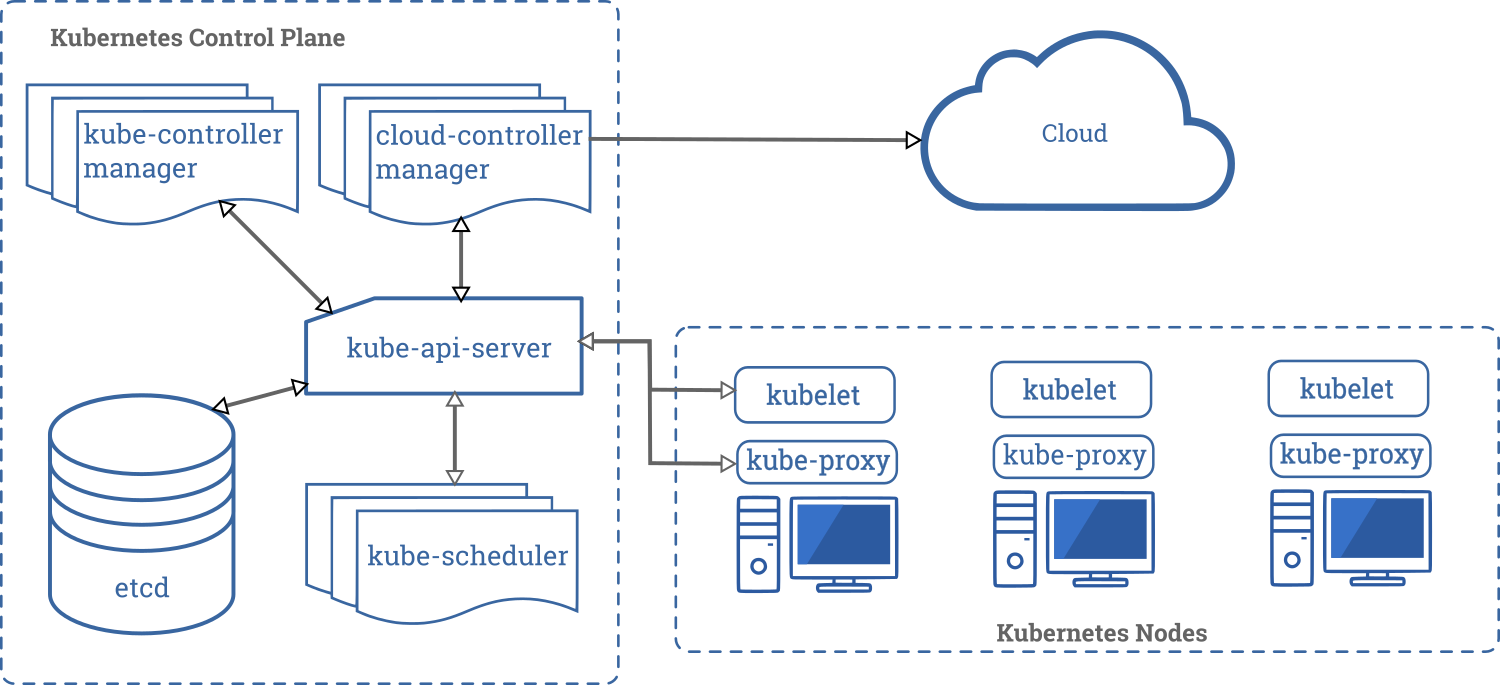
https://kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/
物理节点
Master
- API Server:提供Kubernetes API接口,主要处理 Rest操作以及更新Etcd中的对象。是所有资源增删改查的唯一入口。
- Scheduler:绑定Pod到Node上,主要做资源调度。
- Controller Manager:所有其他群集级别的功能,目前由控制器Manager执行。资源对象的自动化控制中心,Kubernetes集群有很多控制器。
- Etcd:所有持久化的状态信息存储在Etcd中,这个是Kubernetes集群的数据库。
Node
从节点上运行kubelet、kube-proxy分别作为计算节点的代理和网络代理。
节点上运行容器引擎(例如Docker),负责容器创建等具体工作。
虚拟节点
Pod
封装一个或多个容器(通常为1个)。Pod中封装的容器由容器引擎创建。
Service Cluster
运行同一服务的所有Pod组成的集合。
Kubernetis网络
A visual guide to Kubernetes networking fundamentals | Opensource.com
intra-pod and inter-pod
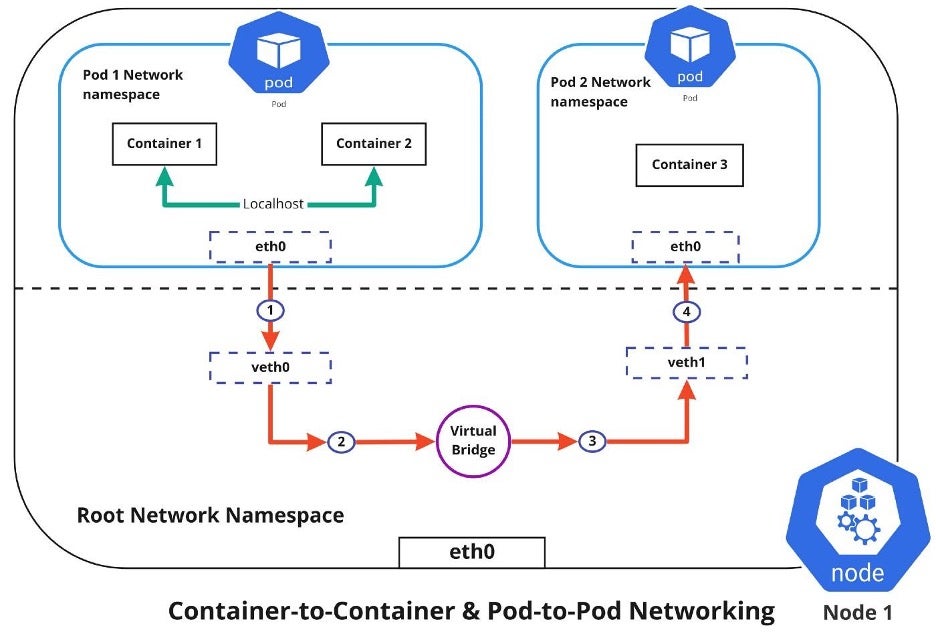
pod/internet-to-service
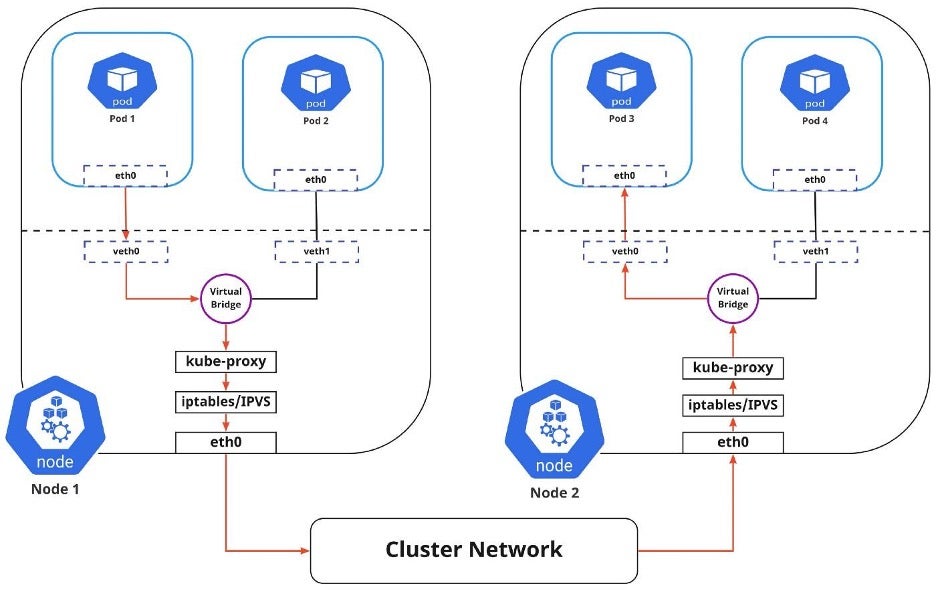
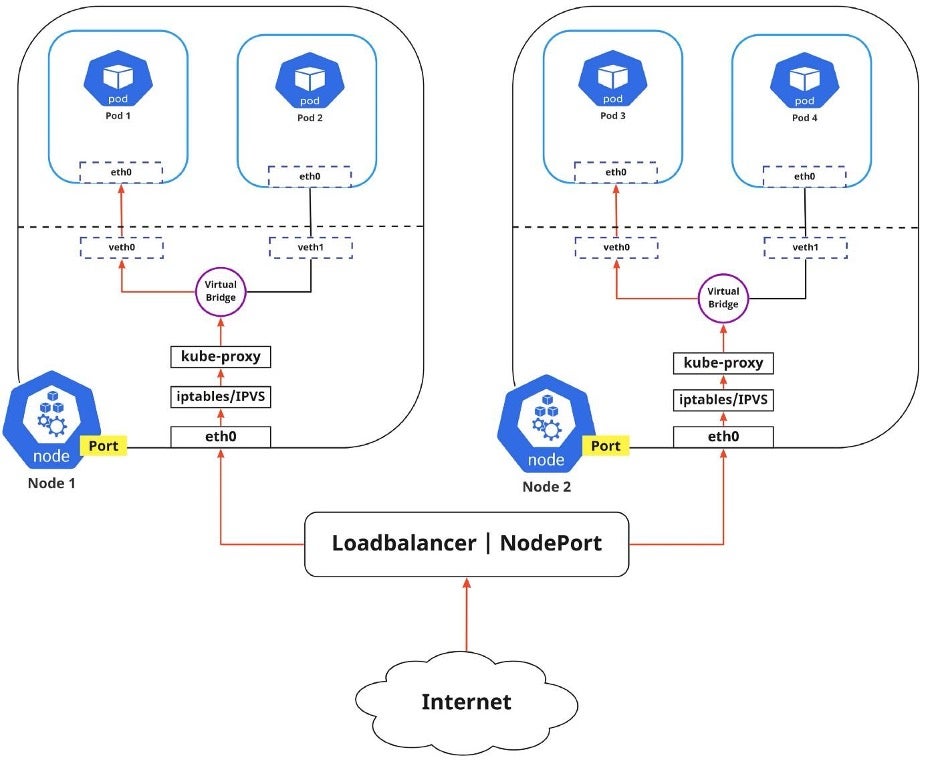
安装配置Kubernetes集群
管理集群
常用管理命令
创建资源
将集群中的资源进行抽象封装,由Kubernetes进行管理。
kubectl create -f res-manifest.yaml # create resources
kubectl apply -f res-manifest.yaml # apply changes to created resources
kubectl delete <type> <resource> # delete resources
Kubernetes管理的资源类型包括计算资源(Pod)、网络资源(Service)、存储资源(Volumn)等类型。
kubectl api-resources # list type of kubernetes resources
某些资源名称可使用缩写代替,
all可以代表所有资源类型
资源信息
kubectl get <type> [<resource>] # list specified (type of) resource
kubectl get <type> -l app=nginx
-o wide:默认按列表形式显示,该选项可显示更多列内容;-o yaml:输出资源对应的配置;-l expr:通过标签筛选;
kubectl describe <type> [<resource>] # get details of specified (type of) resources
虚拟资源可按命名空间分组。
kubectl create ns <namedspace>
kubectl <command> -n nginx # 在指定命名空间进行操作
计算资源
Node
添加标签。标签可用于创建资源时对节点进行筛选。
kubectl label node <host> <label=value>
kubectl get node --show-labels
Pod
# pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: pod-nginx # lable and values can be customized
spec:
containers:
- name: nginx
image: nginx:1.13.12
ports:
- containerPort: 80
将Pod运行在指定的Node上。
# deploy.yaml
spec:
template:
spec:
nodeSelector:
disktype: ssd
控制器
通过控制器实现容器应用的自动化管理。
ReplicationController (RC)
确保应用运行的Pod的数量。与手动创建的 pod 不同,如果有 pod 失败、被删除或被终止,ReplicationController 会自动维护并替代这些 pod 。
ReplicaSet (RS)
ReplicaSet支持标签选择器,而ReplicationController仅支持基于等级的选择器。
Deployment
封装了Pod的副本管理、部署更新、回滚、扩容、缩容等功能。
Deployment封装了ReplicaSet。
# deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: nginx
name: nginx-deployment # must be lowercase alphabet, '.', or '-'
labels:
app: deploy-nginx
spec:
replicas: 3 # number of pod instance
selector:
matchLabels: # ?
app: nginx
template:
metadata:
labels: # pod label
app: pod-nginx
spec:
containers:
- name: nginx
image: nginx:1.13.12
ports:
- containerPort: 80
更新和回滚:
kubectl set image deployment/nginx-deployment nginx=nginx:1.14.2 --record # update and record history version
kubectl rollout history deployment/nginx-deployment # output history
kubectl rollout history deployment/nginx-deployment --revision=1
kubectl rollout undo deployment/nginx-deployment
Scale-in/out:设置应用运行的pod实例数量。
kubectl scale deployment nginx-deployment --replicas <n>
DaemonSet
DaemonSet+nodeSelector:使容器仅运行在通过标签筛选的节点上,且每个节点上只运行一个Pod实例。
StatefulSet
有状态的应用,为 Pod 提供唯一的标识,它可以保证部署和 scale 的顺序。
Job
使用Kubernetes运行单一任务。
CronJob
使用Kubernetes运行定时任务。
网络资源
Node网络指的是Kubernetes Node节点本地的网络,所有的Node和Master在该网段都可以正常通信。
每一个Pod都会有一个IP地址(Pod内的容器/进程共享一个IP地址),这个IP地址网络段被称之为Pod网络。
Service是为Pod提供访问和负载均衡的网络地址段。
服务
由于Pod的生命周期是短暂的,而且每次重启Pod的IP地址都会发生变化。Kubernetes使用Service来实现Pod的访问,而且Service有一个Cluster IP,通常也称之为VIP,是固定不变的。
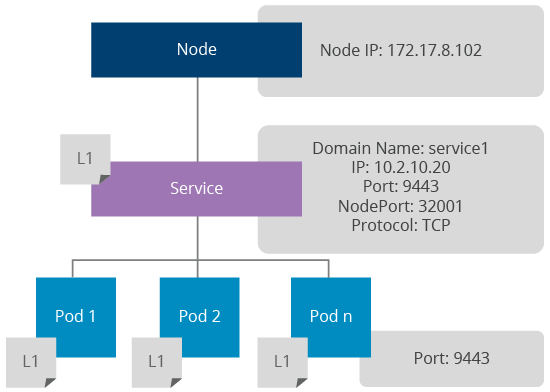
每个Service实例存在一个对应的Endpoint实例,记录了该Service中的Pod实例信息。
Serivce类型:
-
ClusterIP:使用Serivce的IP访问服务,只能在集群内部使用;
-
NodePort:使用边缘节点的IP和端口映射到Service的VIP和端口(传输层负载均衡);
# service.yaml kind: Service apiVersion: v1 metadata: namespace: nginx name: svc-nginx-nodeport spec: type: NodePort selector: app: pod-nginx # match pod's label ports: - protocol: TCP port: 80 # sevice port targetPort: 80 # pod port nodePort: 32222 # mapping service port to edge node port
负载均衡
应用层负载均衡:根据URL进行转发。
LVS
ipvs
http://www.linuxvirtualserver.org/zh/lvs1.html
Ingress Controller
Ingress Controller目前有两大开源项目,一个是Nginx Controller,一个是目前比较流行的Traefik。
创建ingress实例
设置ingress规则
从Service处获取Endpoint信息,从而直接转发到Pod。
# ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
namespace: nginx
name: ingress-webserver
spec:
rules:
- host: nginx.example.com
http:
paths:
- path: /
backend:
serviceName: nginx-web-server # service name (not deploy)
servicePort: 80
存储
Volume:需要在Pod中进行定义,生命周期和Pod一样;
- emptyDir卷
- HostPath卷
PersistentVolume(PV):集群中的存储资源。
访问模式:
- ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
- ReadOnlyMany——该卷可以被多个节点以只读模式挂载
- ReadWriteMany——该卷可以被多个节点以读/写模式挂载
回收策略:
- Retain(保留)——手动回收
- Recycle(回收)——基本擦除(
rm -rf /thevolume/*) - Delete(删除)——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)将被删除
storageClassName
PersistentVolumeClaim (PVC):请求并关联PV资源。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)。
StorageClass
NFS
salt-ssh '*' -r 'yum install -y nfs-utils rpcbind'
echo "/data/k8s-nfs *(rw,sync,no_root_squash)" >> /etc/exports
systemctl enable --now rpcbind
showmount -e <host> # show mounted NFS
创建PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-demo
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /data/k8s-nfs/pv-demo
server: 192.168.56.11
创建PVC
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: nginx
name: pvc0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs
PVC的使用在应用部署声明中给出:
# deployment.yaml
template:
spec:
containers:
- name: nginx
volumnMounts:
- mountPath: "/usr/share/nginx/html"
name: pvc0
volumes:
- name: pvc0
persistentVolumeClaim:
claimName: pvc0
persistentvolume-controller Volume recycled
部署应用
# create a name space
kubectl create ns <namedspace>
kubectl label ns nginx name="NginxWebServer"
# creat a deployment (computing)
# specify name space in <yaml> file or by "-n <namespace>"
kubectl apply -f nginx-deployment-web.yaml
# creat a service (networking)
# creat a NodePort mapping
kubectl create -f nginx-service-web.yaml
# set an ingress rule for "nginx.example.com"
kubectl create -f nginx-ingress-web.yaml
# mount data volumn (storage)
kubectl apply -f nginx-deployment-pvc-web.yaml
应用
使用Docker
Mediawiki
https://hub.docker.com/_/mediawiki
Mediawiki使用MySQL存储数据,首先在数据库中为Mediawiki创建用户并分配权限。
docker run -d \
--net=xwiki-nw \
--name mysql-xwiki \
-v /home/gary/mysql:/var/lib/mysql \
-v /home/gary/mysql-init:/docker-entrypoint-initdb.d \
-e MYSQL_ROOT_PASSWORD=xwiki \
-e MYSQL_USER=xwiki \
-e MYSQL_PASSWORD=xwiki \
-e MYSQL_DATABASE=xwiki \
mysql \
--character-set-server=utf8mb4 \
--collation-server=utf8mb4_bin \
--explicit-defaults-for-timestamp=1 \
--default-authentication-plugin=mysql_native_password # mysql 8.0
CREATE USER mediawiki IDENTIFIED BY 'mediawiki'; % 创建额外用户
grant all privileges on *.* to xwiki@'%', mediawiki@'%';
sudo docker run -d \
--name my-mediawiki \
--net xwiki-nw \
-p 10080:80 \
-v /home/gary/mediawiki:/usr/local/mediawiki \
-v
mediawiki
可能需要配置数据库权限
生成的
LocalSettings.php文件放到/var/www/html目录下(与index.php同级)。可以在其中添加并修改includes/DefaultSettings.php中的配置项。可以将该文件所在的外部目录挂载到容器中,并链接到http服务主目录下。
xwiki
https://github.com/xwiki-contrib/docker-xwiki/blob/master/README.md
docker network create -d bridge xwiki-nw
首先创建数据库。
docker run -d \
--net=xwiki-nw \
--name xwiki \
-p 8080:8080 \
-v /my/path/xwiki:/usr/local/xwiki \
-e DB_USER=xwiki \
-e DB_PASSWORD=xwiki \
-e DB_DATABASE=xwiki \
-e DB_HOST=mysql-xwiki \
xwiki:lts-mysql-tomcat
Mysql>=5.7。
参考资料
虚拟化
VMWare
网络配置
虚拟网络
VMware虚拟网桥
vmnet0:与主机网络连接复用物理接口。
虚拟网桥的物理主机是透明的。在Windows中,无需通过网络管理配置接口的桥接。
==配置自动桥接的主机网络适配器==:可选列表中可能包含了Hyper-V的虚拟适配器,应该取消选择,否则其IP地址与物理网卡地址可能不在同一网段。
vmnet1:Host-Only网络模式,类似于vmnet0但无法访问物理网络。
VMware NAT
vmnet8:宿主机地址为:192.168.xxx.1,虚拟网关/DNS服务器地址为:192.168.xxx.2(见配置文件%PROGRAMDATA%/VMWare/vmnetnat.conf);
NAT设备:通过网络地址转换为物理机IP地址,由物理网络接口收发数据。
通过vmnetnat.conf可配置入网流量的NAT端口地址映射。
[incomingtcp]
# Use these with care - anyone can enter into your virtual machine through these...
#
# WEB (make sure that if you are using named webhosting, names point to
# your host, not to guest... And if you are forwarding port other
# than 80 make sure that your server copes with mismatched port
# number in Host: header)
# lynx http://localhost:8888
#8888 = 192.168.27.128:80
[incomingudp]
# UDP port forwarding example
#6000 = 192.168.27.128:6001
完成后重启VMWare NAT服务。在宿主机或其他主机上,可通过宿主机的IP地址和映射后的端口访问虚拟机中开放的服务。==如果防火墙开启,则需要设置一条防火墙入站规则,允许访问主机的目标端口。==
https://www.vmware.com/support/ws3/doc/ws32_network21.html
共享
宿主磁盘文件共享
安装vmware-tools
vmware-tools需要Linux虚拟机安装perl解释器。
在Linux虚拟机中安装vmware-tools时找不到gcc、kernel-headers,需要安装编译工具和依赖库。
yum install gcc binutils make kernel-devel -y
无法在虚拟机中访问已共享的宿主机文件夹。
sudo vi /etc/fstab
# append following content
# .host:/ /mnt/hgfs fuse.vmhgfs-fuse allow_other 0 0
显示
虚拟机屏幕尺寸
问题:虚拟机不能自适应屏幕尺寸。
The issue is that
libresolutionKMS.sois not loaded into the Wayland session on Fedora. It works as expected in Ubuntu 20.10 with either Wayland or Xorg.
cp /etc/vmware-tools/tools.conf.example /etc/vmware-tools/tools.conf
nano /etc/vmware-tools/tools.conf
Remove the # from this block:
[resolutionKMS]
enable=true
systemctl restart vmtoolsd.service
移动和复制虚拟机
当移动或复制虚拟机后,VMWare会提示用户查虚拟机磁盘文件(对应虚拟机配置文件中的scsi0:0.fileName),并在虚拟机配置文件.vmx中增加一个搜索路径fileSearchPath;当再次复制或移动上述虚拟机,如果仍在本机上,由于fileSearchPath存在,将直接访问该路径下的虚拟磁盘文件,而非复制到当前虚拟机目录下的虚拟磁盘文件。因此需要修改或删除该搜索路径。
虚拟机快照
删除快照:每个快照会在磁盘上额外生成一个较小的虚拟磁盘文件;删除快照将删除该文件。可删除某些不再使用的快照以节约存储空间。
Window Sub-system of Linux (WSL)
安装
自动安装
自动安装WSL需要的系统组件、Linux内核并安装默认的Linux发行版(默认为Ubuntu)1。
版本要求:Windows 10 2004+(Build 19041+) or Windows 11。
wsl --set-default-version 2 # 安装保证WSL2已经启用
wsl --install # 安装默认发行版
wsl --update # 升级至应用商店版本(或通过应用商店升级)
wsl --version # 商店版本可用
手动安装
启用WSL2:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
# Restart before updating to WSL 2
- 下载Linux内核更新包:WSL2 Linux kernel update package for x64 machines。
设置WSL2,WSL2需要开启Hyper-V。
wsl --set-default-version 2 # 更改默认安装的版本 (WSL2)
wsl --set-version <dist-name> 2 # 转换已安装的版本 (WSL2)
安装管理发行版
从应用商店查找安装Linux发行版。发行版管理:
wsl --set-default <dist-name> # 设置默认发行版
wsl --install -d <DistroName> # 安装一个发行版
wsl --list [--all|--running] [--quiet|--verbose] # 列出系统中的发行版
离线安装
如果联网安装下载发行版很慢,或者机器离线,则在开启系统的WSL组件后可以离线下载并手动安装WSL发行版。如果应用商店不可用,则从appx文件(zip)中提取安装内容(解压其中的Ubuntu_2004_*.appx到安装位置,同级目录下还包含不同缩放比例下的图标资源文件,解压到安装目录下的Assets目录中),并手动执行安装(运行ubuntu.exe)。
配置WindowsTerminal:由于是手动安装,需要修改启动目录(否则找不到路径无法启动,可设置为WSL用户主目录\\wsl$\Ubuntu\home\gary)和资源图标文件(任意图片文件,可使用安装自带的图标$INSTALLPATH\Assets\StoreLogo.scale-100.png)。
开启systemd
编辑/etc/wsl.conf,重启WSL。(需要WSL版本为0.67.6及以上)
[boot]
systemd=true
WSL系统配置
忘记密码
# windows CLI
ubuntu config --default-user root
# login WSL with root
passwd <username>
# windows terminal
ubuntu config --default-user <username>
其他发行版,将
ubunut替换为其他发行版名称。
网络配置
WSL端口转发
Advanced settings configuration in WSL | Microsoft Docs。
使用WSL
启动和停止WSL
wsl --user root # 以指定用户身份运行
wsl --exec cmd # 不启动shell运行命令
wsl --distribution,-d <distname> # 运行指定发行版
wsl --shutdown # 终止所有正在运行WSL2实例
wsl --terminate <dist-name> # -t, 终止指定发行版
Windows下执行WSL命令
不启动WSL终端,直接运行命令:
wsl [wsl_opts] -- [linux_args]
# wsl -- ip a '|' grep -E 'inet.*eth0'
文件共享
本地磁盘位于/mnt目录下,例如C盘位于/mnt/c。
文件权限:WSL挂载的Windows目录权限均为777(WSL也不能改动该目录中的内容的权限),代表WSL未对该目录做任何权限控制,其实际权限由Windows文件系统决定。
某些应用要令其某些文件的权限为特定值,如果设置失败会产生异常。
开发环境
Visual Studio Code server:在WSL中运行code便可以从Windows中启动VS Code Remote Extension连接至WSL。
QEMU
QEMU目前支持模拟的架构包括ARM、CRIS、i386、M68k (ColdFire)、MicroBlaze、MIPS、PowerPC、SH4、SPARC和x86-64。
In system emulation mode QEMU emulates a full system, including a processor and various peripherals.
In user mode, QEMU can launch Linux processes compiled for one CPU on another CPU.
安装
Linux/apt
QEMU包含多个架构的模拟功能,而用户通常不会使用到所有架构,因此只需要安装对应架构的包qemu-system-ARCH。如果要使用用户模式模拟,则安装qemu-user或qemu-user-static。
sudo apt install qemu-system # full installation
sudo apt install qemu-system-arm # only specific architecture
sudo apt install qemu-system-gui qemu-utils ipxe-qemu \
qemu-efi-aarch64 qemu-efi-arm
qemu-system包含以下架构的包:arm, mips, ppc, sparc, x86, s390x, misc。
qemu-system-arm支持aarch64(64位)和arm(32位)架构。
qemu-system-x86支持x86_64(64位)和i386(32位)架构。
qemu-kvm在(x86机器)KVM模式下运行qemu-system-x86(后向兼容);qemu-system-x86-microvm裁剪了大量功能提供轻量容器用于KVM隔离(常规用途使用qemu-system-x86);qemu-system-x86-xen:run Xen in HVM mode.
qemu-system-gui提供(GTK)图形界面。
qemu-utils提供虚拟磁盘镜像工具、网络磁盘访问等工具。
qemu-efi-aarch64提供BIOS固件,支持包含安全启动的UEFI。
安装管理工具
sudo apt install libvirt-daemon-system libvirt-clients bridge-utils
sudo apt install virt-manager
Libvirt is a C toolkit to interact with the virtualization capabilities of recent versions of Linux (and other OSes). The library aims at providing a long term stable C API for different virtualization mechanisms. It currently supports QEMU, KVM, XEN, OpenVZ, LXC, and VirtualBox.
libvirt-daemon-systemcontains the configuration files to run thelibvirtdaemon as a system service.libvirt-clientscontains the libvirt shellvirshand other client binaries.bridge-utilscontains utilities for configuring the Linux Ethernet bridge in Linux.
virt-managerpresents a summary view of running domains and their live performance & resource utilization statistics. A detailed view presents graphs showing performance & utilization over time. Ultimately it will allow creation of new domains, and configuration & adjustment of a domain's resource allocation & virtual hardware. Finally an embedded VNC client viewer presents a full graphical console to the guest domain.
创建虚拟机
创建磁盘镜像:
qemu-img create --format "raw|qcow2" arm64linux.img 40G
创建虚拟机:
qemu-system-aarch64.exe \
-M virt \
-bios QEMU_EFI.fd \
-cpu cortex-a72 -smp 4,cores=4,threads=1,sockets=1 \
-m 8192 \
-netdev tap,id=mynet0,ifname=tap1 \
-device e1000,netdev=mynet0,mac=52:55:00:d1:55:01 \
-device nec-usb-xhci \
-device usb-kbd \
-device usb-mouse \
-device VGA \
-device virtio-scsi-device \
-device virtio-blk-device,drive=hd0 \
-drive if=none,file=arm64linux.img,id=hd0 \
-device scsi-cd,drive=cdrom \
-drive if=none,file=Kylin-Server-10-SP1-Release-Build04-20200711-arm64.iso,id=cdrom,media=cdrom
启动虚拟机时,无需再指定CD驱动器设备;可重新指定虚拟网卡(tap)。
虚拟机网络配置
需要为虚拟机添加虚拟网络设备,否则虚拟机启动后无法与宿主机进行通信,仅能通过QEMU提供的终端操作虚拟机。创建虚拟机时指定以下选项以创建虚拟网络设备:
-netdev tap,id=mynet0,ifname=tap1 # 指定虚拟网络设备类型、名称和ID
-device e1000,netdev=mynet0 # 指定虚拟机网络设备对应的虚拟网络设备
-device还可添加附加参数:mac=52:55:00:d1:55:01。
创建Windows Tap网络接口
- 在Windows主机上安装TAP网卡驱动:可下载openvpn客户端软件,只安装其中的TAP驱动;在网络连接中,会看到一个新的虚拟网卡,属性类似于
TAP-Windows Adapter V9,将其名称修改为tap0。 - 将虚拟网卡和Windows上真实网卡桥接:选中这两块网卡并桥接生成网桥。==生成的网桥将使用所选的第一个设备的物理信息作为外部接口信息==。
创建Linux虚拟网桥和Tap网络接口
以管理员身份运行以下命令,创建虚拟网桥和Tap接口。
ip link add br0 type bridge # 创建虚拟网桥 => brctl addbr br0
ip addr delete IP/MASK dev eth0 # 删除主机连接的IP => ip addr flush dev eth0
ip link set dev eth0 master br0 # 将主机连接绑定到网桥 => brctl addif br0 eth0
ip addr add IP/MASK dev br0 # 为网桥添加IP地址,或自动分配 dhclient -v br0
ip link set br0 up # 启用网桥 => ifconfig br0/tap1/eth0 up
ip route add default via IP dev br0 # 主机通过网桥访问网络
ip tuntap add dev tap1 mode tap # 创建tap接口
ip link set dev tap0 master br0 # 将tap接口绑定到网桥 => brctl addif br0 tap1
ifconfig,tunctlandbrctlare mostly considered deprecated nowadays.
查看网桥和接口信息:
brctl show # show bridge information
ip link show qemu_bridge # show link information of bridge
ip link show qemu_tap1 # show link information of tap interface
虚拟网桥通过数据链路层协议(Ethernet)连接物理接口和虚拟接口构成虚拟网络,同时网桥也承载主机的IP协议栈以代替主机原有的网络连接(eth0)提供主机的网络服务。
Tap网络接口则通过虚拟网桥复用物理接口:网桥从主机的上层协议接收的数据以及其他Tap接口接收到的外发数据将转发给物理接口,物理接口执行外发操作;对于接收数据,物理接口将数据转发给网桥,网桥根据MAC地址按端口进行转发。(通常,一个物理网卡应该只与一个虚拟网桥连接)
参考文献
Install WSL | Microsoft Docs. 2: Manual installation steps for older versions of WSL | Microsoft Docs.
Airflow
Airflow is a platform to programmatically author, schedule and monitor workflows.
Use Airflow to author workflows as Directed Acyclic Graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies.
Airflow is used to process data, but has the opinion that tasks should ideally be idempotent (i.e. results of the task will be the same, and will not create duplicated data in a destination system), and should not pass large quantities of data from one task to the next (though tasks can pass metadata using Airflow's Xcom feature).
Airflow is not a streaming solution, but it is often used to process real-time data, pulling data off streams in batches.
安装
单机试用
试用环境配置:使用SQLite+SequentialExecutor1。
airflow standalone
# airflow db init
# airflow users create \
# --username admin \
# --firstname Peter \
# --lastname Parker \
# --role Admin \
# --email spiderman@superhero.org
# airflow webserver --port 8080
# airflow scheduler
部署Airflow
使用Docker部署
从官方获取示例docker-compose.yaml文件2,并根据生产环境进行定制。
VERSION="2.2.5"
curl -LfO "https://airflow.apache.org/docs/apache-airflow/$VERSION/docker-compose.yaml"
airflow-scheduler- The scheduler monitors all tasks and DAGs, then triggers the task instances once their dependencies are complete.airflow-webserver- The webserver is available athttp://localhost:8080.airflow-worker- The worker that executes the tasks given by the scheduler.airflow-init- The initialization service(执行后正常退出).flower- The flower app for monitoring the environment. It is available athttp://localhost:5555.postgres- The database.redis- The redis - broker that forwards messages from scheduler to worker.
在.env文件设置要使用的Airflow版本(默认为docker-compose.yaml文件中指定的默认版本)以及用户名和密码。
COMPOSE_PROJECT_NAME=airflow2
# AIRFLOW_IMAGE_NAME="apache/airflow:2.2.5"
_AIRFLOW_WWW_USER_USERNAME="gary"
_AIRFLOW_WWW_USER_PASSWORD="gang2019"
AIRFLOW_UID=50000 # run service as the user with UID inside the containers
如果需要映射主机目录到容器,则设置
AIRFLOW_UID=$(id -u),防止在相关数据目录下以root账户创建文件。如果使用数据卷则使用默认值即可。
此外,配置额外插件及插件的配置参数,插件将在初始化阶段安装。不推荐在生产环境中使用这种方式安装插件,而是应该构建自定义Docker镜像。
_PIP_ADDITIONAL_REQUIREMENTS="airflow-code-editor black"
AIRFLOW__CODE_EDITOR__ROOT_DIRECTORY="/opt/airflow/dags"
AIRFLOW__CODE_EDITOR__LINE_LENGTH=90
AIRFLOW__CODE_EDITOR__STRING_NORMALIZATION=False
AIRFLOW__CODE_EDITOR__GIT_ENABLED=False
执行数据库初始化并创建首个用户(初始化成功返回状态为0)。
docker-compose up airflow-init
docker-compose down --volumes --remove-orphans # 如果出现错误,清理环境,检查配置文件重新执行初始化
启动Airflow服务集群(docker-compose up -d)并检查服务状态(docker-compose ps)。
数据存储
在上述集群配置文件中,所有相关服务共享同一个Airflow的工作目录(包括dags,logs和plugins)。
自定义镜像
https://airflow.apache.org/docs/docker-stack/build.html
安装插件
插件以Python模块的形式提供。
- Docker:在
_PIP_ADDITIONAL_REQUIREMENTS中指定附加插件,或构建自定义镜像时安装插件。
安装Providers
http://airflow.apache.org/docs/apache-airflow-providers/index.html
eco-system
Elyra Documentation — Elyra 3.2.2 documentation
Airflow: Creating a DAG in airflow via UI - Stack Overflow
配置
export AIRFLOW_HOME=/opt/airflow/ # 默认工作目录: 包含dags,logs等子目录
$AIRFLOW_HOME/airflow.cfg:配置文件。
概念
DAG
作业设计说明(有向无环图)。有一个或多个任务构成。
airflow dags list
airflow dags list-jobs # 列出作业
airflow dags list-runs
airflow dags test dag_id run_date
默认路径位于
$AIRFLOW_HOME/dags,在该目录下创建的作业会被airflow扫描并自动加载(有一定的时延)。
task
[Tasks — Airflow Documentation (apache.org)](https://airflow.apache.org/docs/apache-airflow/stable/concepts/tasks.html?highlight=create task)
任务。
airflow run dag_id task_id date
jobs
正在运行的作业。
airflow jobs check
使用Airflow
CLI
进入任意服务节点的终端,执行airflow info可查看Airflow的配置以及系统环境信息。
airflow [-h] GROUP_OR_COMMAND ...
positional arguments:
GROUP_OR_COMMAND
Groups:
celery Celery components
config View configuration
connections Manage connections
dags Manage DAGs
db Database operations
jobs Manage jobs
kubernetes Tools to help run the KubernetesExecutor
pools Manage pools
providers Display providers
roles Manage roles
tasks Manage tasks
users Manage users
variables Manage variables
Commands:
cheat-sheet Display cheat sheet
info Show information about current Airflow and environment
kerberos Start a kerberos ticket renewer
plugins Dump information about loaded plugins
rotate-fernet-key
Rotate encrypted connection credentials and variables
scheduler Start a scheduler instance
standalone Run an all-in-one copy of Airflow
sync-perm Update permissions for existing roles and optionally DAGs
triggerer Start a triggerer instance
version Show the version
webserver Start a Airflow webserver instance
usage: airflow dags [-h] COMMAND ...
Manage DAGs
positional arguments:
COMMAND
backfill Run subsections of a DAG for a specified date range
delete Delete all DB records related to the specified DAG
list List all the DAGs
list-jobs List the jobs
list-runs List DAG runs given a DAG id
next-execution
Get the next execution datetimes of a DAG
pause Pause a DAG
report Show DagBag loading report
show Displays DAG's tasks with their dependencies
state Get the status of a dag run
test Execute one single DagRun
trigger Trigger a DAG run
unpause Resume a paused DAG
dags
tasks
airflow tasks test $DAG_ID $TASK_ID $DATE # 执行任务
使用Web界面
访问airflow-web服务开启的HTTP端口(默认为http://localhost:8080,默认用户名和密码为预先使用环境变量配置的)。
使用REST接口
使用REST API访问Web服务。
ENDPOINT_URL="http://localhost:8080/"
curl -X GET --user "USER:PASSWD" "${ENDPOINT_URL}/api/v1/pools"
Airflow提供了封装的Python API客户端访问Web服务(apache/airflow-client-python: Apache Airflow - OpenApi Client for Python (github.com))
任务编排
为任务添加标签方便查询相关任务。
with DAG(dag_id="first_airflow_dag",
schedule_interval='* * * * *', # crontab语法或@once/hourly/daily/weekly/monthly/yearly
start_date=datetime(year=2022, month=2, day=1),
tags = ["team1", "sql"]) as dag:
task_get_datetime = BashOperator(
task_id='get_datetime',
bash_command='date'
)
task_get_datetime >> task_process_datetime >> task_save_datetime
任务保存在工作目录的dags/目录下,可从Web界面访问并执行/暂停任务(可在DAG列表或DAG页面执行)。

任务执行的返回值由Airflow内部保存,可通过xcoms接口获取。
使用>>或set_downstream()连接任务,保证任务按正确顺序执行。


Airflow将动态检测任务编排文件,并应用最新的任务调度配置。
Tutorial — Airflow Documentation (apache.org)
Best Practices — Airflow Documentation (apache.org)
内置任务模块
BashOperator(task_id, bash_command)
PythonOperator(task_id, python_callable=pyfunc)
系统内置变量
访问Airflow网页,进入Admin-Variables创建变量(Key-Value-Description)。变量可在任务编排代码中引用。
var_name = Variable.get('var_name')
问题
Airflow not loading dags in /usr/local/airflow/dags - Stack Overflow
python - DAG not visible in Web-UI - Stack Overflow
任务编排工具对比
最好的任务编排工具:Airflow vs Luigi vs Argo vs MLFlow - 数据黑客的文章 - 知乎 https://zhuanlan.zhihu.com/p/321231718
Getting Started — Luigi 2.8.13 documentation
参考文献
Installation — Airflow Documentation (apache.org) 1: Running Airflow locally — Airflow Documentation (apache.org) 2: Running Airflow in Docker — Airflow Documentation (apache.org)
数据序列化语言
JSON
JSON(JavaScript Object Notation)是存储和交换文本信息的语法,类似 XML,JSON 比 XML 更小、更快,更易解析。JSON 使用 JavaScript 语法来描述数据对象,但是 JSON 仍然独立于语言和平台。
{
"employees": [
{ "firstName":"Bill" , "lastName":"Gates" },
{ "firstName":"George" , "lastName":"Bush" },
{ "firstName":"Thomas" , "lastName":"Carter" }
]
}
JSON 语法规则
JSON语法是JavaScript对象表示法语法的子集,使用简单标记储存文本数据类型。
-
JSON定义的数据类型包括:
- 数字(整数或浮点数)
- 字符串(在双引号中)
- 逻辑值(true 或 false)
null- 数组(在方括号中):数组元素是JSON类型;
- 对象(在花括号中):对象封装了字典,每个成员及其值构成字典的键值对,值是JSON类型。
数组元素和对象的成员的值可以嵌套JSON对象。
-
同一级数据由逗号分隔
-
花括号定义对象
-
方括号定义数组
JSON不支持添加注释。注释内容可以作为数据的一个字段(例如_comment)
https://raw.githubusercontent.com/microsoft/winget-cli/master/schemas/JSON/settings/settings.schema.0.2.json
JSONPath查询语言
JSONPath Syntax | AlertSite Documentation (smartbear.com)
访问路径
$表示对象或数组的根,以绝对路径访问元素。省略$则直接以当前节点的键名访问数据。
直接子节点内容
选择元素可使用.KEY或['KEY']运算符,获取当前节点的子元素。(中括号表达可处理特殊标识符,如包含括号)
$.store.book[0].title # dot notation
$['store']['book'][0]['title'] # bracket notation
任意层级节点内容
X..KEY:递归获取键名为KEY的值。
数组内容
下标访问
$.store.book[0,1,3,...] # 获取固定顺序位置的值
$.store.book[0:10:2] # 获取数组切片的值
$.store.book[5:] # 省略切片区间结束位置
$.store.book[:10] # 省略
$.store.book[-1:-5] # 反向迭代
使用表达式确定下标:
# $.store.book[(expression)]
$.store.book[(@.length-1)] # $.store.book[-1]
条件过滤
获取满足条件的所有数组元素构成的列表。
# $.store.book[?(expression)]
$.store.book[?(@.price)] # 存在price字段
$.store.book[?(@.price < 10)] # book.price < 10
@用于引用当前节点名。
返回当前对象或数组的所有元素:*可以匹配任意键名或数组下标。
$.store.book[*]
获取数据元素字段
$.store.book[*].title # 所有数组元素的title字段的值组成的序列
YAML
YAML is primarily a data serialization language. XML was designed to be backwards compatible with the Standard Generalized Markup Language (SGML), which was designed to support structured documentation. XML therefore had many design constraints placed on it that YAML does not share. XML is a pioneer in many domains, YAML is the result of lessons learned from XML and other technologies.
语法
YAML可视为JSON的超集(YAML不支持重复的key,JSON允许出现重复key)1。
基本元素类型
序列
- Mark McGwire
- Sammy Sosa
- Ken Griffey
字典
hr: 65 # Home runs
avg: 0.278 # Batting average
rbi: 147 # Runs Batted In
字符串
YAML支持无引号、双引号和单引号表示字符串。字符串支持换行(换行符被替换),其中双引号可包含转义序列。
unicode: "Sosa did fine.\u263A"
control: "\b1998\t1999\t2000\n"
hex esc: "\x0d\x0a is \r\n"
single: '"Howdy!" he cried.'
quoted: ' # Not a ''comment''.'
tie-fighter: '|\-*-/|'
文本块
使用|或>声明文本块。
text_block: | # 保留换行
Mark McGwire's
year was crippled
by a knee injury.
text_block2: > # 将换行替换为空格,单独空行与额外缩进内容的换行将得到保留
Sammy Sosa completed another
fine season with great stats.
63 Home Runs
0.288 Batting Average
What a year!
注释
#及其后内容为注释内容。
复合类型
序列类型和字典类型可以相互嵌套。
值为序列的字典
american:
- Boston Red Sox
- Detroit Tigers
- New York Yankees
national: [New York Mets, Chicago Cubs, Atlanta Braves]
元素为字典的序列
-
name: Mark McGwire
hr: 65
avg: 0.278
- item : Super Hoop # 紧凑写法
quantity: 1
- {name: Sammy Sosa, hr: 63, avg: 0.288} # 以{}确定范围,可以换行,无需对齐缩进
复杂映射类型
使用?可定义除字符串外复杂的映射键类型(如序列和字典):
? - Detroit Tigers
- Chicago cubs
:
- 2001-07-23
? [ New York Yankees, Atlanta Braves ]
: [ 2001-07-02, 2001-08-12, 2001-08-14 ]
类型标记
整数字面值
canonical: 12345
decimal: +12345
octal: 0o14
hexadecimal: 0xC
浮点数字面值
canonical: 1.23015e+3
exponential: 12.3015e+02
fixed: 1230.15
negative infinity: -.inf
not a number: .NaN
时间日期字面值
canonical: 2001-12-15T02:59:43.1Z
iso8601: 2001-12-14t21:59:43.10-05:00
spaced: 2001-12-14 21:59:43.10 -5
date: 2002-12-14
其他类型
null: # 空值
booleans: [ true, false ]
string: '012345' # 默认字面值类型都为字符串文本
显式类型声明
not-date: !!str 2002-04-28 # 表示字符串而非日期
picture: !!binary | # 二进制编码序列
R0lGODlhDAAMAIQAAP//9/X
17unp5WZmZgAAAOfn515eXv
Pz7Y6OjuDg4J+fn5OTk6enp
56enmleECcgggoBADs=
--- !!set # Sets are special Mapping where key is mapped to null value
? Mark McGwire
? Sammy Sosa
? Ken Griff
--- !!omap # Ordered maps
- Mark McGwire: 65
- Sammy Sosa: 63
- Ken Griffy: 58
自定义类型声明
结构
一个yaml文件可包含多个YAML文档,每个文档以---行开始。...用于显式声明一个文档的结束,后续直到发现---才开始新的文档(通常用于流式传输)。
锚点与引用
在需要引用的对象前添加&id_obj,在其他位置引用该对象使用*id_obj。
bill-to: &id001
given : Chris
family : Dumars
address:
lines: |
458 Walkman Dr.
Suite #292
city : Royal Oak
state : MI
postal : 48046
ship-to: *id001 # refer to the above address information block
参考文献
Oren Ben-Kiki, Clark Evans, Ingy döt Net, YAML Ain’t Markup Language (YAML™) Version 1.2, 3rd Edition, Revision 1.2.2 (2021-10-01), YAML Language Development Team.
XML
简介
XML与HTML
- XML被设计用来传输和存储数据,HTML被设计用来显示数据。
- XML标签没有被预定义,需要自行定义标签,XML 被设计为具有自我描述性; HTML中使用的标签(以及 HTML的结构)是预定义的,HTML文档只使用在HTML标准中定义过的标签(比如
<p>、<h1>等等)。
结构
命名空间
XML 命名空间提供避免元素命名冲突的方法。(使用前缀来避免命名冲突)
xmlns:namespace-prefix=\"namespaceURI\"
用于标示命名空间的地址不会被解析器用于查找信息。其惟一的作用是赋予命名空间一个惟一的名称。不过,很多公司常常会作为指针来使用命名空间指向实际存在的网页,这个网页包含关于命名空间的信息。
默认的命名空间(Default Namespaces):为元素定义默认的命名空间可以让我们省去在所有的子元素中使用前缀的工作。
xmlns =\"namespaceURI\"
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。
<bookstore>
<book category="CHILDREN">
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title>Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
元素(Element):从(且包括)开始标签直到(且包括)结束标签的部分。 父元素,子元素;
XML 文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
标签(Tag):XML 元素使用 XML 标签进行定义。XML 标签对大小写敏感。所有元素都必须有结束标签(声明不属于XML本身的组成部分。它不是XML 元素,也不需要关闭标签。)
属性(Attribute):键值对,值必须加引号(单引号和双引号均可使用,如果属性值本身包含双引号,那么有必要使用单引号包围它)。
\<note date=\"08/08/2008\"\>
因使用属性而引起的一些问题:
- 属性无法包含多重的值(元素可以)
- 属性无法描述树结构(元素可以)
- 属性不易扩展(为未来的变化)
- 属性难以阅读和维护
在 XML 中,您应该尽量避免使用属性。元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
特殊字符
| 命令 | 特殊字符 | 意义 |
|---|---|---|
< | < | 小于 |
> | > | 大于 |
& | & | 和号 |
' | ' | 单引号 |
" | " | 引号 |
空格
文档中的空格不会被缩减。
注释
\<!\-- This is a comment \--\>
XML验证
XML DTD
XML Schema:An XML schema language is used to describe the structure and content of an XML document. The one that currently rules the roost is the W3C XML Schema Definition Language typically abbreviated as XSD.
如果 XML 文档存在错误,那么程序就不应当继续处理这个文档。
显示
CSS
XSLT 是首选的 XML 样式表语言。
XML解析
解析方法
- DOM XML DOM (XML Document Object Model) 定义了访问和操作 XML文档的标准方法。 DOM 把 XML 文档作为树结构来查看。能够通过 DOM树来访问所有元素。可以修改或删除它们的内容,并创建新的元素。元素,它们的文本,以及它们的属性,都被认为是节点。
- SAX
XML解析器
Tree Model-based APIs:把 XML 转换为 DOM对象。
Cursor-based APIs
Streaming APIs
.NET Framework实现
-
XmlReader, XmlWriter
-
System.Xml.XPath
快速查询定位XML元素。
System.Xml.Xsl
System.Xml.Schema
System.Xml.Linq
System.Xml.XmlDocument/XmlNode
-
Properties
-
Attributes
-
DocumentElement:获取根元素。
-
DocumentType:DOCTYPE
-
ChildNodes
-
FirstChild
-
LastChild
-
ParentNode
-
Item[String]:获取为指定名称的第一个子节点。
-
Name
-
LocalName
If the node does not have a prefix, LocalName is the same as Name.
-
Value
-
-
Methods
- AppendChild
XPathNavigator
Namespace: System.Xml.XPath
- Assembly: System.Xml (in System.Xml.dll)
Provides a cursor model for navigating and editing XML data.
- System.Xml.XmlReader
Represents a reader that provides fast, noncached, forward-only access to XML data.
Java实现
Python实现
Python有三种方法解析XML,SAX,DOM,以及ElementTree。ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
**注:**因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
XPath查询语言
XPath 是用于XML文档的查询语言,可以查询XML元素节点并计算相应的值。
简写语法(Abbreviated syntax)
使用节点名,按XML树结构逐级限定查询节点位置。
- 绝对路径
/tag1/tag2/.../tagn
/tag1/tag2/.../@prop
xxx//tag/...
xxx/tag/*
//查询指定范围内所有层级的节点。
*查询指定层级的所有节点。
- 相对路径
childname/...
./childname
../tag
使用节点名,根据当前节点位置指定查询节点。
多个路径可以由|运算符连接,从而同时选择多个路径。
限定声明(Predicates)
每一层级声明可以附加限定声明。
| 限定表达式 | 结果 |
|---|---|
name[1] | 选取满足表达式条件的第一个元素。 |
name[last()] | 选取满足表达式条件的最后一个元素。 |
name[last()-n] | |
name[position()<n] | |
name[@lang] | 选取满足表达式且具有lang属性的元素。 |
name[@lang='en'] | 选取满足表达式且lang='en'的元素 |
name[@*] | 选取具有属性的节点。 |
name[price>100] | 选取满足表达式且其子元素price>100的节点。 |
完整语法(Full Syntax)
使用路径表达式(Location Path)扩展简写语法:
/step1/step2/step3...
step1/step2/...
每一级step由三部分组成(可省略):
axis::test[predicates]
-
轴(
axis): 指定基于当前节点的查询范围,简写语法中的轴总是child(省略)。 -
节点测试(
test): 测试满足条件的节点,简写语法中总是节点名。text():获取节点的文本内容comment():获取节点内的注释内容node():获取节点。 -
限定声明(
predicates):与简写语法一致。
| 完整语法 | 简写语法 | Notes |
|---|---|---|
ancestor | 选取当前节点的所有先辈(父、祖父等)。 | |
ancestor-or-self | 选取当前节点及其所有先辈(父、祖父等)。 | |
attribute | @ | @abc is short for attribute::abc |
child | xyz is short for child::xyz | |
descendant | 选取当前节点的所有后代元素(子、孙等)。 | |
descendant-or-self | // | // is short for /descendant-or-self::node()/ |
following | 选取文档中当前节点的结束标签之后的所有节点。 | |
following-sibling | 选取当前节点之后的所有同级节点。 | |
namespace | 选取当前节点的所有命名空间节点。 | |
parent | .. | .. is short for parent::node() |
preceding | 选取文档中当前节点的开始标签之前的所有节点。 | |
preceding-sibling | 选取当前节点之前的所有同级节点。 | |
self | . | . is short for self::node() |
//div[@class='tab-content-item'] # 查询所有指定类型的div节点
div[@class='p-name p-name-type-2']/a/em//text() # 查询指定范围内所有层级的文本
div[@class='p-operate']/a[1]/attribute::data-sku[1] # 查询指定节点的指定属性
XSLT
XQuery
XML Query
Xlink和XPointer
SVG
使用SVG构造网站图标
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 100 100">
<text y="0.9em" font-size="90">🍦</text>
</svg>
HTML
语法
术语
HTML元素

-
元素(Element)
-
标签(Tag)
-
内容(Content)

- 属性(Attribute)
嵌套元素
<p>My cat is <strong>very</strong> grumpy.</p>
空元素
<img src="images/firefox-icon.png" alt="My test image">
CSS
Cascading Style Sheets are used to selectively style HTML elements.
- 选择器(Selector):匹配HTML元素。
- 声明(Declaration):包含要一个或多个元素属性;
布局

CSS layout is mostly based on the box model, where properties
padding,borderandmarginare involved. Besides, the size (width, height) of the element itself also affects the final layout.
HTML结构
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My test page</title>
<link rel="icon" href="favicon.ico" type="image/x-icon">
<link rel="stylesheet" href="styles/style.css"> <!--CSS-->
<script src="my-js-file.js" defer></script> <!--load JavaScript*-->
</head>
<!-- 注释 -->
<body>
<img src="images/firefox-icon.png" alt="My test image">
</body>
</html>
*:defer表示在HTML加载完后再加载JavaScript程序文件,以避免程序访问还未解析的HTML元素。
元数据
<meta charset="utf-8">
<meta name="author" content="Chris Mills">
<meta name="description" content="The MDN Web Docs."> <!--*->
*:描述信息用于搜索引擎搜索结果展示。
What's in the head? Metadata in HTML - Learn web development | MDN (mozilla.org)
标题
标签标题:<title>位于<head>,显示在浏览器标签上。
章节标题:HTML contains 6 heading levels, <h1>-<h6>。<h1>作为正文的文章标题。
<h1>My main title</h1>
段落
<p>This is a single paragraph</p>
列表
无编号列表<ul>和编号列表<ol>。列表可嵌套在段落中,或独立成为段落。
<ul>
<li>technologists</li>
<li>thinkers</li>
<li>builders</li>
</ul>
文字风格
强调:
<em>,<strong>;斜体:
<i>粗体:
<b>下划线:
<u>。斜体、粗体、下划线等文字风格是元素的呈现形式而非元素,因此不推荐使用这种形式。考虑使用
<span>等元素代替。
图像
alt属性:图像的描述性文本;
表格
✨HTML table basics - Learn web development | MDN (mozilla.org)
链接
<a href="https://www.mozilla.org/en-US/about/manifesto/">Mozilla Manifesto</a>
链接不仅可用于文本,也可用于整个元素,例如图像(<img>):
<a href="https://www.mozilla.org/en-US/">
<img src="mozilla-image.png" alt="logo of the Mozilla homepage">
</a>
链接支持使用相对路径,即相对当前文档访问链接目标的路径。
使用文档片段指向目标文档中id属性对应的元素,从而直接跳转到该元素位置而非文档顶部。
<a href="contacts.html#Mailing_address">mailing address</a>
下载链接,download属性提供文件默认保存名称:
<a href="https://download.mozilla.org/"
download="firefox-latest-64bit-installer.exe">
Download Latest Firefox for Windows (64-bit) (English, US)
</a>
CSS
CSS使HTML所呈现的内容与格式分离。
✨Learn to style HTML using CSS - Learn web development | MDN (mozilla.org)
选择器
==元素选择器==
选择多个元素
p, li, h1 {
color: red;
}
标识选择器
#my-id {} /* -> <p id="my-id"> */
On a given HTML page, each id value should be unique.
==类选择器==
选择所有属于该类的元素。
.my-class {} /* -> <p class="my-class"> */
伪类选择器
选择处于某一状态的所有元素。
a:hover {}
属性选择器
选择包含指定属性的所有元素。
img[src] {} /* -> <img src="myimage.png"> not <img> */
更多选择器:https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Selectors。
Getting started with CSS - Combining selectors and combinators。
边距与填充声明语法
p {
margin: all
margin: tb lr;
margin: t r b [l];
}
距离声明:
-
12px:固定值(像素),0表示0px。 -
auto:与其他元素共同分配剩余空间。
Inline Styles
<head>
<style>
h1 {}
p {}
</style>
</head>
格式
以下使用css来书写HTML元素属性,相应的属性可直接用于HTML元素。
布局
body {
width: 600px;
margin: 0 auto;
padding: 0 20px 20px 20px;
border: 5px solid black;
}
字体
html {
font-size: 10px;
font-family: "Open Sans", sans-serif;
font-weight: bold;
}
颜色
html {
color: #00539F;
background-color: #FF9500;
}
颜色表示法:
- 十六进制RGB:
#00539F; - RGBA:
rgba(0,0,200,0.3) - 颜色名称:
red,blue,green,……
阴影
p {
text-shadow: 3px 3px 1px black;
box-shadow: 1px 1px 2px rgba(0,0,200,0.4);
}
段落格式
间距
p,li {
line-height: 2;
letter-spacing: 1px;
}
对齐
p,li {
text-align: center;
}
编号1
h1 {
counter-reset: h2counter;
}
h2::before {
counter-increment: h2counter;
content: "Section " counter(h2counter) ": "; /*显示在对应内容前, 由指定内容拼接成 */
}
交互格式
p {
cursor: pointer;
}
网页结构
✨Document and website structure - Learn web development | MDN (mozilla.org)
表单
✨Web forms — Working with user data - Learn web development | MDN (mozilla.org)
多媒体嵌入
✨Multimedia and embedding - Learn web development | MDN (mozilla.org)
参考资料
HTTP
通信流程
HTTP使用TCP协议在客户端和服务器间传输数据,从而保证传输的可靠性,使得HTTP应用无需关注传输细节。
HTTP程序从URL获取服务器域名和端口号,并通过DNS得到服务器的IP地址。
DNS查询
- 查询浏览器DNS缓存
- 查询本机
hosts文件 - 查询DNS服务器
HTTP报文
HTTP报文由起始行、头部和主体组成。
行终止符:CRLF(0x0D0A);标准要求行终止符为两个字符,但应用程序也应该接受单个字符作为行终止符。
起始行
请求报文的起始行由方法、URL(路径)和HTTP版本组成:
GET /index.html http/1.1
响应报文的起始行由HTTP版本、状态码和状态信息组成:
http/1.1 200 OK
状态码
所有处理过程都使用响应码而非其文本描述。
1xx信息提示
2XX成功
200:returns with a response body
201:Created
204:no content
3XX重定向
301 Moved Permanently:请求资源已经被永久移动,返回资源的新地址;
302 Found:请求资源被暂时修改,客户端随后应该使用该URI请求更新内容;
304 Not Modified:请求的资源未被修改过,客户端可使用已缓存内容;
4XX客户端错误
400 Bad Request:服务器无法解析请求数据;
401 Unauthorized:需要输入用户名和密码;
403 Forbidden:拒绝访问;
404 Not Found:no item matches the requested URL
5XX服务器错误
5xx:Unhandled exceptions
头部字段
User-Agent
让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号。
User-Agent: Mozilla/<version> (<system-information>) <platform> (<platform-details>) <extensions>
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36 OPR/38.0.2220.41
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0)
User-Agent: Googlebot/2.1 (+http://www.google.com/bot.html)
Content-Type
用于指示资源的MIME类型。
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
boundary由1~70个字符组成(known to be very robust through email gateways),用于封装消息的多个部分的边界,对于多部分实体(multipart entities,具有一组而不是单个内容体)是必需的。通常头部边界前缀添加--,尾部边界后缀添加--。
Content-Disposition
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition
Content-Disposition: inline
Content-Disposition: attachment
Content-Disposition: attachment; filename="filename.jpg"
Content-Disposition: form-data
Content-Disposition: form-data; name="fieldName"
Content-Disposition: form-data; name="field2"; filename="example.txt"
Content-Encoding
媒体数据的压缩编码。通常尽可能压缩数据,但对于已经压缩过的类型(如jpeg)则不必要。
Content-Encoding: gzip
Content-Encoding: compress
Content-Encoding: deflate
Content-Encoding: br
Content-Encoding: deflate, gzip
Content-Language
用于设定内容的目标观众所适用的语言。
Content-Language: en-US
Content-Language: de-DE, en-CA
Set-Cookie
服务器向客户代理发送cookie,从而客户代理随后能将其返回给服务器。要设置多个cookies,则设置多个该字段。
Set-Cookie: <cookie-name>=<cookie-value>
Set-Cookie: <cookie-name>=<cookie-value>; Expires=<date>
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>
Set-Cookie: <cookie-name>=<cookie-value>; Path=<path-value>
// Multiple attributes are also possible, for example:
Set-Cookie: <cookie-name>=<cookie-value>; Secure; HttpOnly; SameSite=Strict
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Set-Cookie
Web资源
URI
URI(Uniform Resource Identifier)分为URL(Uniform Resource Locator)和URN(Uniform Resource Name)
URL
URL描述一台特定服务器上特定资源的位置及其访问方式。
The components of a URL - IBM Documentation
Uniform Resource Identifier - Wikipedia
URL格式
URL通常由协议、服务器地址和路径(服务器上资源的位置)组成。
scheme://user:password@host:port/path;params?query#frag
query:key1=value1&key2=value2&...
frag(片段)并不会发送给服务器,服务器将资源返回后,客户端通过片段决定显示的资源内容。
相对URL
相对于当前文档路径的URL。
URL编码
URN
URN作为特定内容的全局唯一标识,与资源位置无关(例如DOI)。
资源类型
MIME (Multipurpose Internet Mail Extension)类型最初用于电子邮件系统,在HTTP中用于标识媒体资源类型(Content-Type)。
Web服务架构
代理
缓存
网关
隧道
HTTP/SSL
代理
代表用户发起HTTP请求的程序(客户端),例如浏览器、爬虫。
HTTP方法
GET
获取记录。
GET https://localhost:5001/api/TodoItems
User-Agent: PostmanRuntime/7.26.8
Accept: */*
Postman-Token: 4241178d-38d3-4b68-a7e1-6d2540938bdb
Host: localhost:5001
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
-------------------------------------
HTTP/1.1 200 OK
Date: Fri, 08 Jan 2021 13:05:35 GMT
Content-Type: application/json; charset=utf-8
Server: Kestrel
Transfer-Encoding: chunked
[{"id":1,"name":"walk dog","isComplete":true}]
POST
添加记录。
POST https://localhost:5001/api/TodoItems
Content-Type: application/json5
# User-Agent/Accept/Postman-Token/Host/Accept-Encoding/Connection
Content-Length: 47
{"name":"walk dog","isComplete":true}
---------------------------------------
HTTP/1.1 201
Date: Fri, 08 Jan 2021 13:05:22 GMT
Content-Type: application/json; charset=utf-8
Server: Kestrel
Transfer-Encoding: chunked
Location: https://localhost:5001/api/TodoItems/1
{"id":1,"name":"walk dog","isComplete":true}
PUT
更新记录
PUT https://localhost:5001/api/TodoItems/1
Content-Type/User-Agent/Accept/Postman-Token/Host/Accept-Encoding/Connection/Content-Length
{"id":1,"name":"walk cat","isComplete":true}
--------------------------------------------
HTTP/1.1 204
Date: Fri, 08 Jan 2021 13:53:03 GMT
Server: Kestrel
在URL和请求数据中都需要包含
id。
DELETE
DELETE https://localhost:5001/api/TodoItems/1
---------------------------------------------
HTTP/1.1 204
Date: Fri, 08 Jan 2021 14:00:06 GMT
Server: Kestrel
HTTP cookies
附录
HTTP版本
HTTP/0.9:只支持GET方法,不支持MIME类型、HTTP首部和版本号。
HTTP/1.0:添加了版本号,HTTP首部和多媒体对象处理。
HTTP/1.0+:很多特性被加入,包括:keep-alive连接、虚拟主机、代理连接。
HTTP/1.1:校正设计中的结构性缺陷,明确语义,引入重要的性能优化措施,并删除一些不好的特性。
HTTP/2.0:性能优化,服务逻辑远程执行框架。
HTTP: Why a new protocol? (w3.org)
Web Architecture from 50,000 feet (w3.org)
Domain Name Service
传输协议
DNS主要使用UDP 53端口服务请求。
DNS queries consist of a single UDP request from the client followed by a single UDP reply from the server.
当响应长度大于512字节且客户端和服务器都支持EDNS,则使用长UDP分组;否则使用TCP重新发起查询。某些解析器全部采用TCP进行查询。
https://en.wikipedia.org/wiki/Domain_Name_System
端口分配
Well-known ports
| Ports | Description | ||
|---|---|---|---|
| 1 | Yes | Assigned | TCP Port Service Multiplexer (TCPMUX). Historic. Both TCP and UDP have been assigned to TCPMUX by IANA,[1] but by design only TCP is specified.[6] |
| 5 | Assigned | Assigned | Remote Job Entry[7] was historically using socket 5 in its old socket form, while MIB PIM has identified it as TCP/5[8] and IANA has assigned both TCP and UDP 5 to it. |
| 7 | Yes | Yes | Echo Protocol[9][10] |
| 9 | Yes | Yes | Discard Protocol[11] |
| No | Yes | Unofficial | |
| 11 | Yes | Yes | Active Users (systat service)[14][15] |
| 13 | Yes | Yes | Daytime Protocol[16] |
| 15 | Yes | No | Previously netstat service[1][14] |
| 17 | Yes | Yes | Quote of the Day (QOTD)[17] |
| 18 | Yes | Yes | Message Send Protocol[18][19] |
| 19 | Yes | Yes | Character Generator Protocol (CHARGEN)[20] |
| 20 | Yes | Assigned | File Transfer Protocol (FTP) data transfer[10] |
| 21 | Yes | Assigned | File Transfer Protocol (FTP) control (command)[10][12][21][22] |
| 22 | Yes | Assigned | Secure Shell (SSH),[10] secure logins, file transfers (scp, sftp) and port forwarding |
| 23 | Yes | Assigned | Telnet protocol—unencrypted text communications[10][23] |
| 25 | Yes | Assigned | Simple Mail Transfer Protocol (SMTP),[10][24] used for email routing between mail servers |
| 28 | Yes | Palo Alto Networks' Panorama High Availability (HA) sync encrypted port.[25] | |
| 37 | Yes | Yes | Time Protocol[26] |
| 42 | Assigned | Yes | Host Name Server Protocol[27] |
| 43 | Yes | Assigned | WHOIS protocol[28][29][30] |
| 47 | Reserved | Reserved | |
| 49 | Yes | Yes | TACACS Login Host protocol.[31] TACACS+, still in draft which is an improved but distinct version of TACACS, only uses TCP 49.[32] |
| 51 | Reserved | Reserved | Historically used for Interface Message Processor logical address management,[33] entry has been removed by IANA on 2013-05-25 |
| 52 | Assigned | Assigned | Xerox Network Systems (XNS) Time Protocol. Despite this port being assigned by IANA, the service is meant to work on SPP (ancestor of IPX/SPX), instead of TCP/IP.[34] |
| 53 | Yes | Yes | Domain Name System (DNS)[35][10] |
| 54 | Assigned | Assigned | Xerox Network Systems (XNS) Clearinghouse (Name Server). Despite this port being assigned by IANA, the service is meant to work on SPP (ancestor of IPX/SPX), instead of TCP/IP.[34] |
| 56 | Assigned | Assigned | Xerox Network Systems (XNS) Authentication Protocol. Despite this port being assigned by IANA, the service is meant to work on SPP (ancestor of IPX/SPX), instead of TCP/IP.[34] |
| 58 | Assigned | Assigned | Xerox Network Systems (XNS) Mail. Despite this port being assigned by IANA, the service is meant to work on SPP (ancestor of IPX/SPX), instead of TCP/IP.[34] |
| 61 | Reserved | Reserved | Historically assigned to the NIFTP-Based Mail protocol,[36] but was never documented in the related IEN.[37] The port number entry was removed from IANA's registry on 2017-05-18.[1] |
| 67 | Assigned | Yes | Bootstrap Protocol (BOOTP) server;[10] also used by Dynamic Host Configuration Protocol (DHCP) |
| 68 | Assigned | Yes | Bootstrap Protocol (BOOTP) client;[10] also used by Dynamic Host Configuration Protocol (DHCP) |
| 69 | Assigned | Yes | Trivial File Transfer Protocol (TFTP)[10][38][39][40] |
| 70 | Yes | Assigned | Gopher protocol[41] |
| 71–74 | Yes | Yes | NETRJS protocol[42][43][44] |
| 79 | Yes | Assigned | Finger protocol[10][45][46] |
| 80 | Yes | Yes | Hypertext Transfer Protocol (HTTP)[47][48] uses TCP in versions 1.x and 2. HTTP/3 uses QUIC,[49] a transport protocol on top of UDP. |
| 81 | Yes | TorPark onion routing[verification needed] | |
| 82 | Yes | TorPark control[verification needed] | |
| 83 | Yes | Assigned | MIT ML Device, networking file system [50] |
| 88 | Yes | Assigned | Kerberos[10][51][52] authentication system |
| 90 | Yes | Yes | PointCast (dotcom)[1][third-party source needed] |
| 95 | Yes | Assigned | SUPDUP, terminal-independent remote login [53] |
| 101 | Yes | Assigned | NIC host name[54] |
| 102 | Yes | Assigned | ISO Transport Service Access Point (TSAP) Class 0 protocol;[55][56] |
| 104 | Yes | Yes | Digital Imaging and Communications in Medicine (DICOM; also port 11112) |
| 105 | Yes | Yes | CCSO Nameserver[57] |
| 107 | Yes | Yes | Remote User Telnet Service (RTelnet)[58] |
| 108 | Yes | Yes | IBM Systems Network Architecture (SNA) gateway access server |
| 109 | Yes | Assigned | Post Office Protocol, version 2 (POP2)[59] |
| 110 | Yes | Assigned | Post Office Protocol, version 3 (POP3)[10][60][61] |
| 111 | Yes | Yes | Open Network Computing Remote Procedure Call (ONC RPC, sometimes referred to as Sun RPC) |
| 113 | Yes | No | Ident, authentication service/identification protocol,[10][62] used by IRC servers to identify users |
| Yes | Assigned | Official | |
| 115 | Yes | Assigned | Simple File Transfer Protocol[10][64] |
| 117 | Yes | Yes | UUCP Mapping Project (path service)[citation needed] |
| 118 | Yes | Yes | Structured Query Language (SQL) Services[jargon] |
| 119 | Yes | Assigned | Network News Transfer Protocol (NNTP),[10] retrieval of newsgroup messages[65][66] |
| 123 | Assigned | Yes | Network Time Protocol (NTP), used for time synchronization[10] |
| 126 | Yes | Yes | Formerly Unisys Unitary Login, renamed by Unisys to NXEdit. Used by Unisys Programmer's Workbench for Clearpath MCP, an IDE for Unisys MCP software development |
| 135 | Yes | Yes | DCE endpoint resolution |
| Yes | Yes | Official | |
| 137 | Yes | Yes | NetBIOS Name Service, used for name registration and resolution[68][69] |
| 138 | Assigned | Yes | NetBIOS Datagram Service[10][68][69] |
| 139 | Yes | Assigned | NetBIOS Session Service[68][69] |
| 143 | Yes | Assigned | Internet Message Access Protocol (IMAP),[10] management of electronic mail messages on a server[70] |
| 152 | Yes | Yes | Background File Transfer Program (BFTP)[71][importance?] |
| 153 | Yes | Yes | Simple Gateway Monitoring Protocol (SGMP), a protocol for remote inspection and alteration of gateway management information[72] |
| 156 | Yes | Yes | Structured Query Language (SQL) Service[jargon] |
| 158 | Yes | Yes | Distributed Mail System Protocol (DMSP, sometimes referred to as Pcmail)[73][importance?] |
| 161 | Assigned | Yes | Simple Network Management Protocol (SNMP)[74][citation needed][10] |
| 162 | Yes | Yes | Simple Network Management Protocol Trap (SNMPTRAP)[74][75][citation needed] |
| 170 | Yes | Yes | Network PostScript print server |
| 177 | Yes | Yes | X Display Manager Control Protocol (XDMCP), used for remote logins to an X Display Manager server[76][self-published source] |
| 179 | Yes | Assigned | Border Gateway Protocol (BGP),[77] used to exchange routing and reachability information among autonomous systems (AS) on the Internet |
| 194 | Yes | Yes | Internet Relay Chat (IRC)[78] |
| 199 | Yes | Yes | SNMP Unix Multiplexer (SMUX)[79] |
| 201 | Yes | Yes | AppleTalk Routing Maintenance |
| 209 | Yes | Assigned | Quick Mail Transfer Protocol[80][self-published source] |
| 210 | Yes | Yes | ANSI Z39.50 |
| 213 | Yes | Yes | Internetwork Packet Exchange (IPX) |
| 218 | Yes | Yes | Message posting protocol (MPP) |
| 220 | Yes | Yes | Internet Message Access Protocol (IMAP), version 3 |
| 225–241 | Reserved | Reserved | |
| 249–255 | Reserved | Reserved | |
| 259 | Yes | Yes | Efficient Short Remote Operations (ESRO) |
| 262 | Yes | Yes | Arcisdms |
| 264 | Yes | Yes | Border Gateway Multicast Protocol (BGMP) |
| 280 | Yes | Yes | http-mgmt |
| 300 | Yes | ThinLinc Web Access | |
| 308 | Yes | Novastor Online Backup | |
| 311 | Yes | Assigned | Mac OS X Server Admin[10] (officially AppleShare IP Web administration[1]) |
| 318 | Yes | Yes | PKIX Time Stamp Protocol (TSP) |
| 319 | Yes | Precision Time Protocol (PTP) event messages | |
| 320 | Yes | Precision Time Protocol (PTP) general messages | |
| 350 | Yes | Yes | Mapping of Airline Traffic over Internet Protocol (MATIP) type A |
| 351 | Yes | Yes | MATIP type B |
| 356 | Yes | Yes | cloanto-net-1 (used by Cloanto Amiga Explorer and VMs) |
| 366 | Yes | Yes | On-Demand Mail Relay (ODMR) |
| 369 | Yes | Yes | Rpc2portmap |
| 370 | Yes | Yes | codaauth2, Coda authentication server |
| Yes | Official | ||
| 371 | Yes | Yes | ClearCase albd |
| 376 | Yes | Yes | Amiga Envoy Network Inquiry Protocol |
| 383 | Yes | Yes | HP data alarm manager |
| 384 | Yes | Yes | A Remote Network Server System |
| 387 | Yes | Yes | AURP (AppleTalk Update-based Routing Protocol)[82] |
| 388 | Yes | Assigned | Unidata LDM near real-time data distribution protocol[83][self-published source][84][self-published source] |
| 389 | Yes | Assigned | Lightweight Directory Access Protocol (LDAP)[10] |
| 399 | Yes | Yes | Digital Equipment Corporation DECnet+ (Phase V) over TCP/IP (RFC1859) |
| 401 | Yes | Yes | Uninterruptible power supply (UPS) |
| 427 | Yes | Yes | Service Location Protocol (SLP)[10] |
| 433 | Yes | Yes | NNSP, part of Network News Transfer Protocol |
| 434 | Yes | Yes | Mobile IP Agent (RFC 5944) |
| 443 | Yes | Yes | Hypertext Transfer Protocol (HTTP)[47][48] uses TCP in versions 1.x and 2. HTTP/3 uses QUIC,[49] a transport protocol on top of UDP. |
| 444 | Yes | Yes | Simple Network Paging Protocol (SNPP), RFC 1568 |
| 445 | Yes | Yes | Microsoft-DS (Directory Services) Active Directory,[85] Windows shares |
| Yes | Assigned | Official | |
| 464 | Yes | Yes | Kerberos Change/Set password |
| 465 | Yes | No | URL Rendezvous Directory for SSM (Cisco protocol)[importance?] |
| Yes | No | Official | |
| 475 | Yes | Yes | tcpnethaspsrv, Aladdin Knowledge Systems Hasp services |
| 491 | Yes | GO-Global remote access and application publishing software | |
| 497 | Yes | Yes | Retrospect |
| 500 | Assigned | Yes | Internet Security Association and Key Management Protocol (ISAKMP) / Internet Key Exchange (IKE)[10] |
| 502 | Yes | Yes | Modbus Protocol |
| 504 | Yes | Yes | Citadel, multiservice protocol for dedicated clients for the Citadel groupware system |
| 510 | Yes | Yes | FirstClass Protocol (FCP), used by FirstClass client/server groupware system |
| 512 | Yes | Rexec, Remote Process Execution | |
| Yes | Official | ||
| 513 | Yes | rlogin | |
| Yes | Official | ||
| 514 | Yes | Remote Shell, used to execute non-interactive commands on a remote system (Remote Shell, rsh, remsh) | |
| No | Yes | Official | |
| 515 | Yes | Assigned | Line Printer Daemon (LPD),[10] print service |
| 517 | Yes | Talk | |
| 518 | Yes | NTalk | |
| 520 | Yes | efs, extended file name server | |
| Yes | Official | ||
| 521 | Yes | Routing Information Protocol Next Generation (RIPng) | |
| 524 | Yes | Yes | NetWare Core Protocol (NCP) is used for a variety things such as access to primary NetWare server resources, Time Synchronization, etc. |
| 525 | Yes | Timed, Timeserver | |
| 530 | Yes | Yes | Remote procedure call (RPC) |
| 532 | Yes | Assigned | netnews[10] |
| 533 | Yes | netwall, For Emergency Broadcasts | |
| 540 | Yes | Unix-to-Unix Copy Protocol (UUCP) | |
| 542 | Yes | Yes | commerce (Commerce Applications) |
| 543 | Yes | klogin, Kerberos login | |
| 544 | Yes | kshell, Kerberos Remote shell | |
| 546 | Yes | Yes | DHCPv6 client |
| 547 | Yes | Yes | DHCPv6 server |
| 548 | Yes | Assigned | Apple Filing Protocol (AFP) over TCP[10] |
| 550 | Yes | Yes | new-rwho, new-who[87] |
| 554 | Yes | Yes | Real Time Streaming Protocol (RTSP)[10] |
| 556 | Yes | Remotefs, RFS, rfs_server | |
| 560 | Yes | rmonitor, Remote Monitor | |
| 561 | Yes | monitor | |
| 563 | Yes | Yes | NNTP over TLS/SSL (NNTPS) |
| 564 | Yes | 9P (Plan 9) | |
| 585 | Port 993 | ? | Legacy use of Internet Message Access Protocol over TLS/SSL (IMAPS), now in use at port 993.[88] |
| 587 | Yes | Assigned | email message submission[10][89] (SMTP) |
| 591 | Yes | FileMaker 6.0 (and later) Web Sharing (HTTP Alternate, also see port 80) | |
| 593 | Yes | Yes | HTTP RPC Ep Map, Remote procedure call over Hypertext Transfer Protocol, often used by Distributed Component Object Model services and Microsoft Exchange Server |
| 601 | Yes | Reliable Syslog Service — used for system logging | |
| 604 | Yes | TUNNEL profile,[90] a protocol for BEEP peers to form an application layer tunnel | |
| 623 | Yes | ASF Remote Management and Control Protocol (ASF-RMCP) & IPMI Remote Management Protocol | |
| 625 | Yes | No | Open Directory Proxy (ODProxy)[10] |
| 631 | Yes | Yes | Internet Printing Protocol (IPP)[10] |
| Yes | Yes | Unofficial | |
| 635 | Yes | Yes | RLZ DBase |
| 636 | Yes | Assigned | Lightweight Directory Access Protocol over TLS/SSL (LDAPS)[10] |
| 639 | Yes | Yes | MSDP, Multicast Source Discovery Protocol |
| 641 | Yes | Yes | SupportSoft Nexus Remote Command (control/listening), a proxy gateway connecting remote control traffic |
| 643 | Yes | Yes | SANity |
| 646 | Yes | Yes | Label Distribution Protocol (LDP), a routing protocol used in MPLS networks |
| 647 | Yes | DHCP Failover protocol[91] | |
| 648 | Yes | Registry Registrar Protocol (RRP)[92] | |
| 651 | Yes | Yes | IEEE-MMS |
| 653 | Yes | Yes | SupportSoft Nexus Remote Command (data), a proxy gateway connecting remote control traffic |
| 654 | Yes | Media Management System (MMS) Media Management Protocol (MMP)[93] | |
| 655 | Yes | Yes | Tinc VPN daemon |
| 657 | Yes | Yes | IBM RMC (Remote monitoring and Control) protocol, used by System p5 AIX Integrated Virtualization Manager (IVM)[94] and Hardware Management Console to connect managed logical partitions (LPAR) to enable dynamic partition reconfiguration |
| 660 | Yes | Assigned | Mac OS X Server administration,[1] version 10.4 and earlier[10] |
| 666 | Yes | Yes | Doom, first online first-person shooter |
| Yes | Unofficial | ||
| 674 | Yes | Application Configuration Access Protocol (ACAP) | |
| 688 | Yes | Yes | REALM-RUSD (ApplianceWare Server Appliance Management Protocol) |
| 690 | Yes | Yes | Velneo Application Transfer Protocol (VATP) |
| 691 | Yes | MS Exchange Routing | |
| 694 | Yes | Yes | Linux-HA high-availability heartbeat |
| 695 | Yes | IEEE Media Management System over SSL (IEEE-MMS-SSL)[95] | |
| 698 | Yes | Optimized Link State Routing (OLSR) | |
| 700 | Yes | Extensible Provisioning Protocol (EPP), a protocol for communication between domain name registries and registrars (RFC 5734) | |
| 701 | Yes | Link Management Protocol (LMP),[96] a protocol that runs between a pair of nodes and is used to manage traffic engineering (TE) links | |
| 702 | Yes | IRIS[97][98] (Internet Registry Information Service) over BEEP (Blocks Extensible Exchange Protocol)[99] (RFC 3983) | |
| 706 | Yes | Secure Internet Live Conferencing (SILC) | |
| 711 | Yes | Cisco Tag Distribution Protocol[100][101][102]—being replaced by the MPLS Label Distribution Protocol[103] | |
| 712 | Yes | Topology Broadcast based on Reverse-Path Forwarding routing protocol (TBRPF; RFC 3684) | |
| 749 | Yes | Yes | Kerberos (protocol) administration[10] |
| 750 | Yes | kerberos-iv, Kerberos version IV | |
| 751 | Yes | Yes | kerberos_master, Kerberos authentication |
| 752 | Yes | passwd_server, Kerberos password (kpasswd) server | |
| 753 | Yes | Yes | Reverse Routing Header (RRH)[104] |
| Yes | Unofficial | ||
| 754 | Yes | Yes | tell send |
| Yes | Unofficial | ||
| 760 | Yes | Yes | krbupdate [kreg], Kerberos registration |
| 782 | Yes | Conserver serial-console management server | |
| 783 | Yes | SpamAssassin spamd daemon | |
| 800 | Yes | Yes | mdbs-daemon |
| 802 | Yes | Yes | MODBUS/TCP Security[105] |
| 808 | Yes | Microsoft Net.TCP Port Sharing Service | |
| 829 | Yes | Assigned | Certificate Management Protocol[106] |
| 830 | Yes | Yes | NETCONF over SSH |
| 831 | Yes | Yes | NETCONF over BEEP |
| 832 | Yes | Yes | NETCONF for SOAP over HTTPS |
| 833 | Yes | Yes | NETCONF for SOAP over BEEP |
| 843 | Yes | Adobe Flash[107] | |
| 847 | Yes | DHCP Failover protocol | |
| 848 | Yes | Yes | Group Domain Of Interpretation (GDOI) protocol |
| 853 | Yes | Yes | DNS over TLS (RFC 7858) |
| 860 | Yes | iSCSI (RFC 3720) | |
| 861 | Yes | Yes | OWAMP control (RFC 4656) |
| 862 | Yes | Yes | TWAMP control (RFC 5357) |
| 873 | Yes | rsync file synchronization protocol | |
| 888 | Yes | cddbp, CD DataBase (CDDB) protocol (CDDBP) | |
| Yes | Unofficial | ||
| 897 | Yes | Yes | Brocade SMI-S RPC |
| 898 | Yes | Yes | Brocade SMI-S RPC SSL |
| 902 | Yes | Yes | VMware ESXi[108][109] |
| 903 | Yes | VMware ESXi[108][109] | |
| 953 | Yes | Reserved | BIND remote name daemon control (RNDC)[110][111] |
| 981 | Yes | Remote HTTPS management for firewall devices running embedded Check Point VPN-1 software[112] | |
| 987 | Yes | Microsoft Remote Web Workplace, a feature of Windows Small Business Server[113] | |
| 989 | Yes | Yes | FTPS Protocol (data), FTP over TLS/SSL |
| 990 | Yes | Yes | FTPS Protocol (control), FTP over TLS/SSL |
| 991 | Yes | Yes | Netnews Administration System (NAS)[114] |
| 992 | Yes | Yes | Telnet protocol over TLS/SSL |
| 993 | Yes | Assigned | Internet Message Access Protocol over TLS/SSL (IMAPS)[10] |
| 994 | Reserved | Reserved | |
| Maybe | Maybe | Unofficial | |
| 995 | Yes | Yes | Post Office Protocol 3 over TLS/SSL (POP3S)[10] |
| 1010 | Yes | ThinLinc web-based administration interface[115][self-published source?] | |
| 1011–1020 | Reserved | Reserved | |
| 1023 | Reserved | Reserved | [1] |
| Yes | Yes | Unofficial |
Registered ports
| 1024 | Reserved | Reserved | Reserved | Official |
|---|---|---|---|---|
| 1027 | Reserved | Reserved | Official | |
| Yes | Native IPv6 behind IPv4-to-IPv4 NAT Customer Premises Equipment (6a44)[117] | Official | ||
| 1028 | Deprecated | Official | ||
| 1029 | Microsoft DCOM services | Unofficial | ||
| 1058 | Yes | Yes | nim, IBM AIX Network Installation Manager (NIM) | Official |
| 1059 | Yes | Yes | nimreg, IBM AIX Network Installation Manager (NIM) | Official |
| 1080 | Yes | Yes | SOCKS proxy | Official |
| 1085 | Yes | Yes | WebObjects[10] | Official |
| 1098 | Yes | Yes | rmiactivation, Java remote method invocation (RMI) activation | Official |
| 1099 | Yes | Assigned | rmiregistry, Java remote method invocation (RMI) registry | Official |
| 1109 | Reserved – IANA | Official | ||
| Yes | Kerberos Post Office Protocol (KPOP)[citation needed] | Unofficial | ||
| 1113 | Assigned[note 1][118] | Yes[119] | Licklider Transmission Protocol (LTP) delay tolerant networking protocol | Official |
| 1119 | Yes | Yes | Battle.net chat/game protocol, used by Blizzard's games[120] | Official |
| 1167 | Yes, and SCTP | Yes | Cisco IP SLA (Service Assurance Agent) | Official |
| 1194 | Yes | Yes | OpenVPN | Official |
| 1198 | Yes | Yes | The cajo project Free dynamic transparent distributed computing in Java | Official |
| 1214 | Yes | Yes | Kazaa | Official |
| 1218 | Yes | No | William POWER | Official |
| 1220 | Yes | Assigned | QuickTime Streaming Server administration[10] | Official |
| 1234 | Yes | Yes | Infoseek search agent | Official |
| Yes | VLC media player default port for UDP/RTP stream | Unofficial | ||
| 1241 | Yes | Yes | Nessus Security Scanner | Official |
| 1270 | Yes | Yes | Microsoft System Center Operations Manager (SCOM) (formerly Microsoft Operations Manager (MOM)) agent | Official |
| 1293 | Yes | Yes | Internet Protocol Security (IPSec) | Official |
| 1311 | Yes | Yes | Windows RxMon.exe | Official |
| Yes | Dell OpenManage HTTPS[121] | Unofficial | ||
| 1314 | ? | ? | Festival Speech Synthesis System server[122][self-published source?] | Unofficial |
| 1337 | Yes | neo4j-shell[citation needed] | Unofficial | |
| Yes | Strapi[123] | Unofficial | ||
| Yes | ? | Sails.js default port[124] | Unofficial | |
| Yes | WASTE Encrypted File Sharing Program[citation needed] | Unofficial | ||
| 1341 | Yes | Yes | Qubes (Manufacturing Execution System) | Official |
| 1344 | Yes | Yes | Internet Content Adaptation Protocol | Official |
| 1352 | Yes | Yes | IBM Lotus Notes/Domino (RPC) protocol | Official |
| 1360 | Yes | Yes | Mimer SQL | Official |
| 1414 | Yes | Yes | IBM WebSphere MQ (formerly known as MQSeries) | Official |
| 1417 | Yes | Yes | Timbuktu Service 1 Port | Official |
| 1418 | Yes | Yes | Timbuktu Service 2 Port | Official |
| 1419 | Yes | Yes | Timbuktu Service 3 Port | Official |
| 1420 | Yes | Yes | Timbuktu Service 4 Port | Official |
| 1431 | Yes | Reverse Gossip Transport Protocol (RGTP), used to access a General-purpose Reverse-Ordered Gossip Gathering System (GROGGS) bulletin board, such as that implemented on the Cambridge University's Phoenix system | Official | |
| 1433 | Yes | Yes | Microsoft SQL Server database management system (MSSQL) server | Official |
| 1434 | Yes | Yes | Microsoft SQL Server database management system (MSSQL) monitor | Official |
| 1481 | Yes | Yes | AIRS data interchange. | Official |
| 1492 | Yes | Sid Meier's CivNet, a multiplayer remake of the original Sid Meier's Civilization game[citation needed] | Unofficial | |
| 1494 | Yes | Yes | Citrix Independent Computing Architecture (ICA)[125] | Unofficial |
| 1500 | Yes | IBM Tivoli Storage Manager server[126] | Unofficial | |
| 1501 | Yes | IBM Tivoli Storage Manager client scheduler[126] | Unofficial | |
| 1503 | Yes | Yes | Windows Live Messenger (Whiteboard and Application Sharing)[127] | Unofficial |
| 1512 | Yes | Yes | Microsoft's Windows Internet Name Service (WINS) | Official |
| 1513 | Yes | Yes | Garena game client[citation needed] | Unofficial |
| 1521 | Yes | Yes | nCUBE License Manager | Official |
| Yes | Oracle database default listener, in future releases[when?][128] official port 2483 (TCP/IP) and 2484 (TCP/IP with SSL) | Unofficial | ||
| 1524 | Yes | Yes | ingreslock, ingres | Official |
| 1527 | Yes | Yes | Oracle Net Services, formerly known as SQL*Net[129] | Official |
| Yes | Apache Derby Network Server[130] | Unofficial | ||
| 1533 | Yes | Yes | IBM Sametime Virtual Places Chat | Official |
| 1534 | No | Yes | Eclipse Target Communication Framework [131] | Unofficial |
| 1540 | Yes | Yes | 1C:Enterprise server agent (ragent)[132][133][self-published source] | Unofficial |
| 1541 | Yes | Yes | 1C:Enterprise master cluster manager (rmngr)[132] | Unofficial |
| 1542 | Yes | Yes | 1C:Enterprise configuration repository server[132] | Unofficial |
| 1545 | Yes | Yes | 1C:Enterprise cluster administration server (RAS)[132] | Unofficial |
| 1547 | Yes | Yes | Laplink | Official |
| 1550 | Yes | Yes | 1C:Enterprise debug server[132] | Unofficial |
| Yes | Gadu-Gadu (direct client-to-client)[citation needed] | Unofficial | ||
| 1560–1590 | Yes | Yes | 1C:Enterprise cluster working processes[132] | Unofficial |
| 1581 | Yes | Yes | MIL STD 2045-47001 VMF | Official |
| Yes | IBM Tivoli Storage Manager web client[126] | Unofficial | ||
| 1582–1583 | Yes | IBM Tivoli Storage Manager server web interface[126] | Unofficial | |
| 1583 | ? | ? | Pervasive PSQL[134] | Unofficial |
| 1589 | Yes | Yes | Cisco VLAN Query Protocol (VQP) | Official |
| 1604 | Yes | Yes | DarkComet remote administration tool (RAT)[citation needed] | Unofficial |
| 1626 | Yes | ? | iSketch[135] | Unofficial |
| 1627 | Yes | ? | iSketch[135] | Unofficial |
| 1628 | Yes | Yes | LonTalk normal | Official |
| 1629 | Yes | Yes | LonTalk urgent | Official |
| 1645 | Yes | Early deployment of RADIUS before RFC standardization was done using UDP port number 1645. Enabled for compatibility reasons by default on Cisco[citation needed] and Juniper Networks RADIUS servers.[136] Official port is 1812. TCP port 1645 MUST NOT be used.[137] | Unofficial | |
| 1646 | Yes | Old radacct port,[when?] RADIUS accounting protocol. Enabled for compatibility reasons by default on Cisco[citation needed] and Juniper Networks RADIUS servers.[136] Official port is 1813. TCP port 1646 MUST NOT be used.[137] | Unofficial | |
| 1666 | Yes | Perforce[138] | Unofficial | |
| 1677 | Yes | Yes | Novell GroupWise clients in client/server access mode | Official |
| 1688 | Yes | Microsoft Key Management Service (KMS) for Windows Activation[139] | Unofficial | |
| 1701 | Yes | Yes | Layer 2 Forwarding Protocol (L2F) | Official |
| Assigned | Yes | Layer 2 Tunneling Protocol (L2TP)[10] | Official | |
| 1707 | Yes | Yes | Windward Studios games (vdmplay) | Official |
| Yes | L2TP/IPsec, for establish an initial connection[140] | Unofficial | ||
| 1716 | Yes | America's Army, a massively multiplayer online game (MMO)[141] | Unofficial | |
| 1719 | Yes | Yes | H.323 registration and alternate communication | Official |
| 1720 | Yes | Yes | H.323 call signaling | Official |
| 1723 | Yes | Assigned | Point-to-Point Tunneling Protocol (PPTP)[10] | Official |
| 1755 | Yes | Yes | Microsoft Media Services (MMS, ms-streaming) | Official |
| 1761 | Yes | Yes | Novell ZENworks[142][143] | Unofficial |
| 1783 | Decomissioned [sic] Port 04/14/00, ms | Official | ||
| 1801 | Yes | Yes | Microsoft Message Queuing | Official |
| 1812 | Yes | Yes | RADIUS authentication protocol, radius | Official |
| 1813 | Yes | Yes | RADIUS accounting protocol, radius-acct | Official |
| 1863 | Yes | Yes | Microsoft Notification Protocol (MSNP), used by the Microsoft Messenger service and a number of instant messaging Messenger clients | Official |
| 1880 | ? | ? | Node-RED[144] | Unofficial |
| 1883 | Yes | Yes | MQTT (formerly MQ Telemetry Transport) | Official |
| 1900 | Assigned | Yes | Simple Service Discovery Protocol (SSDP),[10] discovery of UPnP devices | Official |
| 1935 | Yes | Yes | Macromedia Flash Communications Server MX, the precursor to Adobe Flash Media Server before Macromedia's acquisition by Adobe on December 3, 2005 | Official |
| Yes | Yes | Real Time Messaging Protocol (RTMP)[citation needed], primarily used in Adobe Flash[145] | Unofficial | |
| 1965 | Yes | No | Gemini protocol, a lightweight, collaboratively designed protocol, striving to fill the gap between Gopher and HTTP[146] | Unofficial |
| 1967 | Yes | Cisco IOS IP Service Level Agreements (IP SLAs) Control Protocol[citation needed] | Unofficial | |
| 1970 | Yes | Yes | Netop Remote Control | Official |
| 1972 | Yes | Yes | InterSystems Caché | Official |
| 1984 | Yes | Yes | Big Brother | Official |
| 1985 | Assigned | Yes | Cisco Hot Standby Router Protocol (HSRP)[147][self-published source] | Official |
| 1998 | Yes | Yes | Cisco X.25 over TCP (XOT) service | Official |
| 2000 | Yes | Yes | Cisco Skinny Client Control Protocol (SCCP) | Official |
| 2010 | ? | ? | Artemis: Spaceship Bridge Simulator[148][self-published source?] | Unofficial |
| 2033 | Yes | Yes | Civilization IV multiplayer[149] | Unofficial |
| 2049 | Yes, and SCTP | Yes | Network File System (NFS)[10] | Official |
| 2056 | Yes | Yes | Civilization IV multiplayer[149] | Unofficial |
| 2080 | Yes | Yes | Autodesk NLM (FLEXlm) | Official |
| 2082 | Yes | cPanel default[150] | Unofficial | |
| 2083 | Yes | Yes | Secure RADIUS Service (radsec) | Official |
| Yes | cPanel default SSL[150] | Unofficial | ||
| 2086 | Yes | Yes | GNUnet | Official |
| Yes | WebHost Manager default[150] | Unofficial | ||
| 2087 | Yes | WebHost Manager default SSL[150] | Unofficial | |
| 2095 | Yes | cPanel default web mail[150] | Official | |
| 2096 | Yes | cPanel default SSL web mail[150] | Unofficial | |
| 2100 | Yes | Warzone 2100 multiplayer[citation needed] | Unofficial | |
| 2101 | Yes | Networked Transport of RTCM via Internet Protocol (NTRIP)[citation needed] | Unofficial | |
| 2102 | Yes | Yes | Zephyr Notification Service server | Official |
| 2103 | Yes | Yes | Zephyr Notification Service serv-hm connection | Official |
| 2104 | Yes | Yes | Zephyr Notification Service hostmanager | Official |
| 2123 | Yes | Yes | GTP control messages (GTP-C) | Official |
| 2142 | Yes | Yes | TDMoIP (TDM over IP) | Official |
| 2152 | Yes | Yes | GTP user data messages (GTP-U) | Official |
| 2159 | Yes | Yes | GDB remote debug port | Official |
| 2181 | Yes | Yes | EForward-document transport system | Official |
| Yes | Apache ZooKeeper default client port[citation needed] | Unofficial | ||
| 2195 | Yes | Apple Push Notification Service[10][151] | Unofficial | |
| 2196 | Yes | Apple Push Notification Service, feedback service[10][151] | Unofficial | |
| 2210 | Yes | Yes | NOAAPORT Broadcast Network | Official |
| 2211 | Yes | Yes | EMWIN | Official |
| 2221 | Yes | ESET anti-virus updates[152] | Unofficial | |
| 2222 | Yes | Yes | EtherNet/IP implicit messaging for IO data | Official |
| ? | ? | DirectAdmin Access[153] | Unofficial | |
| 2222–2226 | Yes | ESET Remote administrator[152] | Official | |
| 2240 | Yes | Yes | General Dynamics Remote Encryptor Configuration Information Protocol (RECIPe) | Official |
| 2261 | Yes | Yes | CoMotion master | Official |
| 2262 | Yes | Yes | CoMotion backup | Official |
| 2302 | Yes | ArmA multiplayer[citation needed] | Unofficial | |
| Yes | Halo: Combat Evolved multiplayer host[154] | Unofficial | ||
| 2303 | Yes | ArmA multiplayer (default port for game +1)[citation needed] | Unofficial | |
| Yes | Halo: Combat Evolved multiplayer listener[154] | Unofficial | ||
| 2305 | Yes | ArmA multiplayer (default port for game +3)[citation needed] | Unofficial | |
| 2351 | Yes | AIM game LAN network port[citation needed] | Unofficial | |
| 2368 | Yes | Ghost (blogging platform)[155] | Unofficial | |
| 2369 | Yes | Default for BMC Control-M/Server Configuration Agent | Unofficial | |
| 2370 | Yes | Default for BMC Control-M/Server, to allow the Control-M/Enterprise Manager to connect to the Control-M/Server | Unofficial | |
| 2372 | Yes | Default for K9 Web Protection/parental controls, content filtering agent[citation needed] | Unofficial | |
| 2375 | Yes | Reserved | Docker REST API (plain) | Official |
| 2376 | Yes | Reserved | Docker REST API (SSL) | Official |
| 2377 | Yes | Reserved | Docker Swarm cluster management communications[156][self-published source] | Official |
| 2379 | Yes | Reserved | CoreOS etcd client communication | Official |
| Yes | KGS Go Server[157] | Unofficial | ||
| 2380 | Yes | Reserved | CoreOS etcd server communication | Official |
| 2389 | Assigned | Assigned | OpenView Session Mgr | Official |
| 2399 | Yes | Yes | FileMaker Data Access Layer (ODBC/JDBC) | Official |
| 2401 | Yes | Yes | CVS version control system password-based server | Official |
| 2404 | Yes | Yes | IEC 60870-5-104, used to send electric power telecontrol messages between two systems via directly connected data circuits | Official |
| 2424 | Yes | OrientDB database listening for binary client connections[158] | Unofficial | |
| 2427 | Yes | Yes | Media Gateway Control Protocol (MGCP) media gateway | Official |
| 2447 | Yes | Yes | ovwdb—OpenView Network Node Manager (NNM) daemon | Official |
| 2459 | Yes | Yes | XRPL | Official |
| 2480 | Yes | OrientDB database listening for HTTP client connections[158] | Unofficial | |
| 2483 | Yes | Yes | Oracle database listening for insecure client connections to the listener, replaces port 1521[when?] | Official |
| 2484 | Yes | Yes | Oracle database listening for SSL client connections to the listener | Official |
| 2500 | Yes | Yes | NetFS communication[159] | Unofficial |
| 2501 | Yes | NetFS probe | Unofficial | |
| 2535 | Yes | Yes | Multicast Address Dynamic Client Allocation Protocol (MADCAP).[160] All standard messages are UDP datagrams.[161] | Official |
| 2541 | Yes | Yes | LonTalk/IP | Official |
| 2546–2548 | Yes | Yes | EVault data protection services | Official |
| 2593 | Yes | Yes | Ultima Online servers[citation needed] | Unofficial |
| 2598 | Yes | Citrix Independent Computing Architecture (ICA) with Session Reliability; port 1494 without session reliability[125] | Unofficial | |
| 2599 | Yes | Yes | Ultima Online servers[citation needed] | Unofficial |
| 2628 | Yes | Yes | DICT [162] | Official |
| 2638 | Yes | Yes | SQL Anywhere database server[163][164] | Official |
| 2710 | Yes | Yes | XBT Tracker.[165] UDP tracker extension is considered experimental.[166] | Unofficial |
| 2727 | Yes | Yes | Media Gateway Control Protocol (MGCP) media gateway controller (call agent) | Official |
| 2775 | Yes | Yes | Short Message Peer-to-Peer (SMPP)[citation needed] | Official |
| 2809 | Yes | Yes | corbaloc:iiop URL, per the CORBA 3.0.3 specification | Official |
| 2811 | Yes | Yes | gsi ftp, per the GridFTP specification | Official |
| 2827 | Yes | I2P BOB Bridge[167] | Unofficial | |
| 2944 | Yes | Yes | Megaco text H.248 | Official |
| 2945 | Yes | Yes | Megaco binary (ASN.1) H.248 | Official |
| 2947 | Yes | Yes | gpsd, GPS daemon | Official |
| 2948 | Yes | Yes | WAP push Multimedia Messaging Service (MMS) | Official |
| 2949 | Yes | Yes | WAP push secure (MMS) | Official |
| 2967 | Yes | Yes | Symantec System Center agent (SSC-AGENT) | Official |
| 3000 | Yes | Cloud9 IDE server[citation needed] | Unofficial | |
| Yes | Ruby on Rails development default[168] | Unofficial | ||
| Yes | Meteor development default[169][failed verification] | Unofficial | ||
| Yes | Yes | Resilio Sync,[170] spun from BitTorrent Sync. | Unofficial | |
| Yes | Distributed Interactive Simulation (DIS)[citation needed] | Unofficial | ||
| 3004 | Yes | iSync[10] | Unofficial | |
| 3020 | Yes | Yes | Common Internet File System (CIFS). See also port 445 for Server Message Block (SMB), a dialect of CIFS. | Official |
| 3050 | Yes | Yes | gds-db (Interbase/Firebird databases) | Official |
| 3052 | Yes | Yes | APC PowerChute Network | Official |
| 3074 | Yes | Yes | Xbox LIVE and Games for Windows – Live | Official |
| 3101 | Yes | BlackBerry Enterprise Server communication protocol[171] | Unofficial | |
| 3128 | Yes | ? | Squid caching web proxy[172] | Unofficial |
| 3225 | Yes | Yes | Fibre Channel over IP (FCIP) | Official |
| 3233 | Yes | Yes | WhiskerControl research control protocol | Official |
| 3260 | Yes | Yes | iSCSI | Official |
| 3268 | Yes | Yes | msft-gc, Microsoft Global Catalog (LDAP service which contains data from Active Directory forests) | Official |
| 3269 | Yes | Yes | msft-gc-ssl, Microsoft Global Catalog over SSL (similar to port 3268, LDAP over SSL) | Official |
| 3283 | Yes | Yes | Net Assistant,[10] a predecessor to Apple Remote Desktop | Official |
| Yes | Yes | Apple Remote Desktop 2.0 or later[10] | Unofficial | |
| 3290 | Yes | Virtual Air Traffic Simulation (VATSIM) network voice communication[citation needed] | Unofficial | |
| 3305 | Yes | Yes | Odette File Transfer Protocol (OFTP) | Official |
| 3306 | Yes | Assigned | MySQL database system[10] | Official |
| 3323 | Yes | Yes | DECE GEODI Server | Unofficial |
| 3332 | Yes | Thundercloud DataPath Overlay Control | Unofficial | |
| 3333 | Yes | Eggdrop, an IRC bot default port[173] | Unofficial | |
| Yes | Network Caller ID server | Unofficial | ||
| Yes | CruiseControl.rb[174] | Unofficial | ||
| 3351 | ? | ? | Pervasive PSQL[134] | Unofficial |
| 3386 | Yes | Yes | GTP' 3GPP GSM/UMTS CDR logging protocol | Official |
| 3389 | Yes | Yes | Microsoft Terminal Server (RDP) officially registered as Windows Based Terminal (WBT)[175] | Official |
| 3396 | Yes | Yes | Novell NDPS Printer Agent | Official |
| 3412 | Yes | Yes | xmlBlaster | Official |
| 3423 | Yes | Xware xTrm Communication Protocol | Official | |
| 3424 | Yes | Xware xTrm Communication Protocol over SSL | Official | |
| 3455 | Yes | Yes | Resource Reservation Protocol (RSVP) | Official |
| 3478 | Yes | Yes | STUN, a protocol for NAT traversal[176] | Official |
| Yes | Yes | TURN, a protocol for NAT traversal[177] (extension to STUN) | Official | |
| Yes | Yes | STUN Behavior Discovery.[178] See also port 5349. | Official | |
| 3479 | Yes | Yes | PlayStation Network[179] | Unofficial |
| 3480 | Yes | Yes | PlayStation Network[179] | Unofficial |
| 3483 | Yes | Slim Devices discovery protocol | Official | |
| Yes | Slim Devices SlimProto protocol | Official | ||
| 3493 | Yes | Yes | Network UPS Tools (NUT) | Official |
| 3516 | Yes | Yes | Smartcard Port | Official |
| 3527 | Yes | Microsoft Message Queuing | Official | |
| 3535 | Yes | SMTP alternate[180] | Unofficial | |
| 3544 | Yes | Teredo tunneling | Official | |
| 3632 | Yes | Assigned | Distcc, distributed compiler[10] | Official |
| 3645 | Yes | Yes | Cyc | Official |
| 3659 | Yes | Yes | Apple SASL, used by Mac OS X Server Password Server[10] | Official |
| Yes | Battlefield 4 | Unofficial | ||
| 3667 | Yes | Yes | Information Exchange | Official |
| 3689 | Yes | Assigned | Digital Audio Access Protocol (DAAP), used by Apple's iTunes and AirPlay[10] | Official |
| 3690 | Yes | Yes | Subversion (SVN)[10] version control system | Official |
| 3702 | Yes | Yes | Web Services Dynamic Discovery (WS-Discovery), used by various components of Windows Vista and later | Official |
| 3724 | Yes | Yes | Some Blizzard games[120] | Official |
| Yes | Club Penguin Disney online game for kids | Unofficial | ||
| 3725 | Yes | Yes | Netia NA-ER Port | Official |
| 3749 | Yes | Yes | CimTrak registered port | Official |
| 3768 | Yes | Yes | RBLcheckd server daemon | Official |
| 3784 | Yes | Bidirectional Forwarding Detection (BFD)for IPv4 and IPv6 (Single Hop) (RFC 5881) | Official | |
| 3785 | Yes | VoIP program used by Ventrilo | Unofficial | |
| 3799 | Yes | RADIUS change of authorization | Official | |
| 3804 | Yes | Yes | Harman Professional HiQnet protocol | Official |
| 3825 | Yes | RedSeal Networks client/server connection[citation needed] | Unofficial | |
| 3826 | Yes | Yes | WarMUX game server | Official |
| Yes | RedSeal Networks client/server connection[citation needed] | Unofficial | ||
| 3835 | Yes | RedSeal Networks client/server connection[citation needed] | Unofficial | |
| 3830 | Yes | Yes | System Management Agent, developed and used by Cerner to monitor and manage solutions | Official |
| 3856 | Yes | Yes | ERP Server Application used by F10 Software | Unofficial |
| 3880 | Yes | Yes | IGRS | Official |
| 3868 | Yes, and SCTP | Diameter base protocol (RFC 3588) | Official | |
| 3872 | Yes | Oracle Enterprise Manager Remote Agent | Official | |
| 3900 | Yes | udt_os, IBM UniData UDT OS[181] | Official | |
| 3960 | Yes | Warframe online interaction[citation needed] | Unofficial | |
| 3962 | Yes | Warframe online interaction[citation needed] | Unofficial | |
| 3978 | Yes | Yes | OpenTTD game (masterserver and content service) | Unofficial |
| 3978 | Yes | Palo Alto Networks' Panorama management of firewalls and log collectors & pre-PAN-OS 8.0 Panorama-to-managed devices software updates.[182] | Unofficial | |
| 3979 | Yes | Yes | OpenTTD game | Unofficial |
| 3999 | Yes | Yes | Norman distributed scanning service | Official |
| 4000 | Yes | Yes | Diablo II game | Unofficial |
| 4001 | Yes | Microsoft Ants game | Unofficial | |
| Yes | CoreOS etcd client communication | Unofficial | ||
| 4018 | Yes | Yes | Protocol information and warnings[clarification needed] | Official |
| 4035 | Yes | IBM Rational Developer for System z Remote System Explorer Daemon | Unofficial | |
| 4045 | Yes | Yes | Solaris lockd NFS lock daemon/manager | Unofficial |
| 4050 | Yes | Mud Master Chat protocol (MMCP) - Peer-to-peer communications between MUD clients.[183] | Unofficial | |
| 4069 | Yes | Minger Email Address Verification Protocol[184] | Official | |
| 4070 | Yes | Yes | Amazon Echo Dot (Amazon Alexa) streaming connection with Spotify[185] | Unofficial |
| 4089 | Yes | Yes | OpenCORE Remote Control Service | Official |
| 4090 | Yes | Yes | Kerio | Official |
| 4093 | Yes | Yes | PxPlus Client server interface ProvideX | Official |
| 4096 | Yes | Yes | Ascom Timeplex Bridge Relay Element (BRE) | Official |
| 4105 | Yes | Yes | Shofar (ShofarNexus) | Official |
| 4111 | Yes | Assigned | Xgrid[10] | Official |
| 4116 | Yes | Yes | Smartcard-TLS | Official |
| 4125 | Yes | Microsoft Remote Web Workplace administration | Unofficial | |
| 4172 | Yes | Yes | Teradici PCoIP | Official |
| 4190 | Yes | ManageSieve[186] | Official | |
| 4198 | Yes | Yes | Couch Potato Android app[187] | Unofficial |
| 4201 | Yes | TinyMUD and various derivatives | Unofficial | |
| 4222 | Yes | NATS server default port[188] | Unofficial | |
| 4226 | Yes | Yes | Aleph One, a computer game | Unofficial |
| 4242 | Yes | Orthanc – DICOM server[189] | Unofficial | |
| Yes | Quassel distributed IRC client | Unofficial | ||
| 4243 | Yes | Docker implementations, redistributions, and setups default[190][needs update?] | Unofficial | |
| Yes | CrashPlan | Unofficial | ||
| 4244 | Yes | Yes | Viber[191] | Unofficial |
| 4303 | Yes | Yes | Simple Railroad Command Protocol (SRCP) | Official |
| 4307 | Yes | TrueConf Client - TrueConf Server media data exchange[192] | Official | |
| 4321 | Yes | Referral Whois (RWhois) Protocol[193] | Official | |
| 4444 | Yes | Yes | Oracle WebCenter Content: Content Server—Intradoc Socket port. (formerly known as Oracle Universal Content Management). | Unofficial |
| ? | ? | Metasploit's default listener port[194] | Unofficial | |
| Yes | Yes | Xvfb X server virtual frame buffer service | Unofficial | |
| 4444–4445 | Yes | I2P HTTP/S proxy | Unofficial | |
| 4486 | Yes | Yes | Integrated Client Message Service (ICMS) | Official |
| 4488 | Yes | Assigned | Apple Wide Area Connectivity Service, used by Back to My Mac[10] | Official |
| 4500 | Assigned | Yes | IPSec NAT Traversal[10] (RFC 3947, RFC 4306) | Official |
| 4502–4534 | Yes | Microsoft Silverlight connectable ports under non-elevated trust | Official | |
| 4505–4506 | Yes | Salt master | Unofficial | |
| 4534 | Yes | Armagetron Advanced server default | Unofficial | |
| 4560 | Yes | default Log4j socketappender port | Unofficial | |
| 4567 | Yes | Sinatra default server port in development mode (HTTP) | Unofficial | |
| 4569 | Yes | Inter-Asterisk eXchange (IAX2) | Official | |
| 4604 | Yes | Identity Registration Protocol | Official | |
| 4605 | Yes | Direct End to End Secure Chat Protocol | Official | |
| 4610–4640 | Yes | QualiSystems TestShell Suite Services | Unofficial | |
| 4662 | Yes | Yes | OrbitNet Message Service | Official |
| Yes | Default for older versions of eMule[195] | Unofficial | ||
| 4664 | Yes | Google Desktop Search | Unofficial | |
| 4672 | Yes | Default for older versions of eMule[195] | Unofficial | |
| 4711 | Yes | eMule optional web interface[195] | Unofficial | |
| 4713 | Yes | PulseAudio sound server | Unofficial | |
| 4728 | Yes | Computer Associates Desktop and Server Management (DMP)/Port Multiplexer[196] | Official | |
| 4730 | Yes | Yes | Gearman's job server | Official |
| 4739 | Yes | Yes | IP Flow Information Export | Official |
| 4747 | Yes | Apprentice | Unofficial | |
| 4753 | Yes | Yes | SIMON (service and discovery) | Official |
| 4789 | Yes | Virtual eXtensible Local Area Network (VXLAN) | Official | |
| 4791 | Yes | IP Routable RocE (RoCEv2) | Official | |
| 4840 | Yes | Yes | OPC UA Connection Protocol (TCP) and OPC UA Multicast Datagram Protocol (UDP) for OPC Unified Architecture from OPC Foundation | Official |
| 4843 | Yes | Yes | OPC UA TCP Protocol over TLS/SSL for OPC Unified Architecture from OPC Foundation | Official |
| 4847 | Yes | Yes | Web Fresh Communication, Quadrion Software & Odorless Entertainment | Official |
| 4848 | Yes | Java, Glassfish Application Server administration default | Unofficial | |
| 4894 | Yes | Yes | LysKOM Protocol A | Official |
| 4944 | No | Yes | DrayTek DSL Status Monitoring[197][self-published source] | Unofficial |
| 4949 | Yes | Munin Resource Monitoring Tool | Official | |
| 4950 | Yes | Yes | Cylon Controls UC32 Communications Port | Official |
| 5000 | Yes | UPnP—Windows network device interoperability | Unofficial | |
| Yes | Yes | VTun, VPN Software | Unofficial | |
| Yes | ASP.NET Core — Development Webserver | Unofficial | ||
| Yes | FlightGear multiplayer[198] | Unofficial | ||
| Yes | Synology Inc. Management Console, File Station, Audio Station | Unofficial | ||
| Yes | Flask Development Webserver | Unofficial | ||
| Yes | Heroku console access | Unofficial | ||
| ? | ? | Docker Registry[199][self-published source] | Unofficial | |
| Yes | AT&T U-verse public, educational, and government access (PEG) streaming over HTTP[200][self-published source?] | Unofficial | ||
| ? | ? | High-Speed SECS Message Services[citation needed] | Unofficial | |
| Yes | 3CX Phone System Legacy Management Console | Unofficial | ||
| 5000–5500 | No | Yes | League of Legends, a multiplayer online battle arena video game[201] | Unofficial |
| 5001 | Yes | Slingbox and Slingplayer | Unofficial | |
| Yes | Yes | Iperf (Tool for measuring TCP and UDP bandwidth performance) | Unofficial | |
| Yes | Synology Inc. Secured Management Console, File Station, Audio Station | Unofficial | ||
| Yes | 3CX Phone System Secured Management Console, Secure API | Unofficial | ||
| 5002 | Yes | ASSA ARX access control system[202] | Unofficial | |
| 5003 | Yes | Assigned | FileMaker – name binding and transport[10] | Official |
| 5004 | Yes, and DCCP | Yes | Real-time Transport Protocol media data (RTP) (RFC 3551, RFC 4571) | Official |
| 5005 | Yes, and DCCP | Yes | Real-time Transport Protocol control protocol (RTCP) (RFC 3551, RFC 4571) | Official |
| 5007 | Yes | Palo Alto Networks - User-ID agent | Unofficial | |
| 5010 | Yes | Yes | Registered to: TelePath (the IBM FlowMark workflow-management system messaging platform)[203] The TCP port is now used for: IBM WebSphere MQ Workflow | Official |
| 5011 | Yes | Yes | TelePath (the IBM FlowMark workflow-management system messaging platform)[203] | Official |
| 5025 | Yes | Yes | scpi-raw Standard Commands for Programmable Instruments | Official |
| 5029 | Yes | Sonic Robo Blast 2 and Sonic Robo Blast 2 Kart servers | Unofficial | |
| 5031 | Yes | Yes | AVM CAPI-over-TCP (ISDN over Ethernet tunneling)[citation needed] | Unofficial |
| 5037 | Yes | Android ADB server | Unofficial | |
| 5044 | Yes | Standard port in Filebeats/Logstash implementation of Lumberjack protocol. | Official | |
| 5048 | Yes | Texai Message Service | Official | |
| 5050 | Yes | Yahoo! Messenger | Unofficial | |
| 5051 | Yes | ita-agent Symantec Intruder Alert[204] | Official | |
| 5060 | Yes | Yes | Session Initiation Protocol (SIP)[10] | Official |
| 5061 | Yes | Session Initiation Protocol (SIP) over TLS | Official | |
| 5062 | Yes | Yes | Localisation access | Official |
| 5064 | Yes | Yes | EPICS Channel Access server[205] | Official |
| 5065 | Assigned | Yes | EPICS Channel Access repeater beacon[205] | Official |
| 5070 | Yes | No | Binary Floor Control Protocol (BFCP)[206] | Unofficial |
| 5084 | Yes | Yes | EPCglobal Low Level Reader Protocol (LLRP) | Official |
| 5085 | Yes | Yes | EPCglobal Low Level Reader Protocol (LLRP) over TLS | Official |
| 5090 | Yes | Yes | 3CX Phone System 3CX Tunnel Protocol, 3CX App API, 3CX Session Border Controller | Unofficial |
| 5093 | Yes | SafeNet, Inc Sentinel LM, Sentinel RMS, License Manager, client-to-server | Official | |
| 5099 | Yes | Yes | SafeNet, Inc Sentinel LM, Sentinel RMS, License Manager, server-to-server | Official |
| 5104 | Yes | IBM Tivoli Framework NetCOOL/Impact[207] HTTP Service | Unofficial | |
| 5121 | Yes | Neverwinter Nights | Unofficial | |
| 5124 | Yes | Yes | TorgaNET (Micronational Darknet) | Unofficial |
| 5125 | Yes | Yes | TorgaNET (Micronational Intelligence Darknet) | Unofficial |
| 5150 | Yes | Yes | ATMP Ascend Tunnel Management Protocol[208] | Official |
| 5151 | Yes | ESRI SDE Instance | Official | |
| Yes | ESRI SDE Remote Start | Official | ||
| 5154 | Yes | Yes | BZFlag | Official |
| 5172 | Yes | PC over IP Endpoint Management[209] | Official | |
| 5190 | Yes | Yes | AOL Instant Messenger protocol.[10] The chat app is defunct as of 15 December 2017.[210] | Official |
| 5198 | Yes | EchoLink VoIP Amateur Radio Software (Voice) | Unofficial | |
| 5199 | Yes | EchoLink VoIP Amateur Radio Software (Voice) | Unofficial | |
| 5200 | Yes | EchoLink VoIP Amateur Radio Software (Information) | Unofficial | |
| 5201 | Yes | Yes | Iperf3 (Tool for measuring TCP and UDP bandwidth performance) | Unofficial |
| 5222 | Yes | Reserved | Extensible Messaging and Presence Protocol (XMPP) client connection[10][211][212] | Official |
| 5223 | Yes | Apple Push Notification Service[10][151] | Unofficial | |
| Yes | Extensible Messaging and Presence Protocol (XMPP) client connection over SSL | Unofficial | ||
| 5228 | Yes | HP Virtual Room Service | Official | |
| Yes | Google Play, Android Cloud to Device Messaging Service, Google Cloud Messaging | Unofficial | ||
| 5242 | Yes | Yes | Viber[191] | Unofficial |
| 5243 | Yes | Yes | Viber[191] | Unofficial |
| 5246 | Yes | Control And Provisioning of Wireless Access Points (CAPWAP) CAPWAP control[213] | Official | |
| 5247 | Yes | Control And Provisioning of Wireless Access Points (CAPWAP) CAPWAP data[213] | Official | |
| 5269 | Yes | Extensible Messaging and Presence Protocol (XMPP) server-to-server connection[10][211][212] | Official | |
| 5280 | Yes | Extensible Messaging and Presence Protocol (XMPP)[214] | Official | |
| 5281 | Yes | Extensible Messaging and Presence Protocol (XMPP)[215] | Unofficial | |
| 5298 | Yes | Yes | Extensible Messaging and Presence Protocol (XMPP)[216] | Official |
| 5310 | Assigned | Yes | Outlaws, a 1997 first-person shooter video game[citation needed] | Official |
| 5318 | Yes | Reserved | Certificate Management over CMS[217] | Official |
| 5349 | Yes/No | Yes/No | STUN over TLS/DTLS, a protocol for NAT traversal[176] | Official |
| Yes/No | Yes/No | TURN over TLS/DTLS, a protocol for NAT traversal[177] | Official | |
| Yes | Reserved | STUN Behavior Discovery over TLS.[178] See also port 3478. | Official | |
| 5351 | Reserved | Yes | NAT Port Mapping Protocol and Port Control Protocol—client-requested configuration for connections through network address translators and firewalls | Official |
| 5353 | Assigned | Yes | Multicast DNS (mDNS)[10] | Official |
| 5355 | Yes | Yes | Link-Local Multicast Name Resolution (LLMNR), allows hosts to perform name resolution for hosts on the same local link (only provided by Windows Vista and Server 2008) | Official |
| 5357 | Yes | Yes | Web Services for Devices (WSDAPI) (only provided by Windows Vista, Windows 7 and Server 2008) | Unofficial |
| 5358 | Yes | Yes | WSDAPI Applications to Use a Secure Channel (only provided by Windows Vista, Windows 7 and Server 2008) | Unofficial |
| 5394 | Yes | Kega Fusion, a Sega multi-console emulator[218][219] | Unofficial | |
| 5402 | Yes | Yes | Multicast File Transfer Protocol (MFTP)[220][importance?] | Official |
| 5405 | Yes | Yes | NetSupport Manager | Official |
| 5412 | Yes | Yes | IBM Rational Synergy (Telelogic Synergy) (Continuus CM) Message Router | Official |
| 5413 | Yes | Yes | Wonderware SuiteLink service | Official |
| 5417 | Yes | Yes | SNS Agent | Official |
| 5421 | Yes | Yes | NetSupport Manager | Official |
| 5432 | Yes | Assigned | PostgreSQL[10] database system | Official |
| 5433 | Yes | Bouwsoft file/webserver[221] | Unofficial | |
| 5445 | Yes | Cisco Unified Video Advantage[citation needed] | Unofficial | |
| 5480 | Yes | VMware VAMI (Virtual Appliance Management Infrastructure)—used for initial setup of various administration settings on Virtual Appliances designed using the VAMI architecture. | Unofficial | |
| 5481 | Yes | Schneider Electric's ClearSCADA (SCADA implementation for Windows) — used for client-to-server communication.[222] | Unofficial | |
| 5495 | Yes | IBM Cognos TM1 Admin server | Unofficial | |
| 5498 | Yes | Hotline tracker server connection | Unofficial | |
| 5499 | Yes | Hotline tracker server discovery | Unofficial | |
| 5500 | Yes | Hotline control connection | Unofficial | |
| Yes | VNC Remote Frame Buffer RFB protocol—for incoming listening viewer | Unofficial | ||
| 5501 | Yes | Hotline file transfer connection | Unofficial | |
| 5517 | Yes | Setiqueue Proxy server client for SETI@Home project | Unofficial | |
| 5550 | Yes | Hewlett-Packard Data Protector[citation needed] | Unofficial | |
| 5554 | Yes | Yes | Fastboot default wireless port | Unofficial |
| 5555 | Yes | Yes | Oracle WebCenter Content: Inbound Refinery—Intradoc Socket port. (formerly known as Oracle Universal Content Management). Port though often changed during installation | Unofficial |
| Yes | Freeciv versions up to 2.0, Hewlett-Packard Data Protector, McAfee EndPoint Encryption Database Server, SAP, Default for Microsoft Dynamics CRM 4.0, Softether VPN default port | Unofficial | ||
| 5556 | Yes | Yes | Freeciv, Oracle WebLogic Server Node Manager[223] | Official |
| 5568 | Yes | Yes | Session Data Transport (SDT), a part of Architecture for Control Networks (ACN)[224][full citation needed] | Official |
| 5601 | Yes | Kibana[citation needed] | Unofficial | |
| 5631 | Yes | pcANYWHEREdata, Symantec pcAnywhere (version 7.52 and later[225])[226] data | Official | |
| 5632 | Yes | pcANYWHEREstat, Symantec pcAnywhere (version 7.52 and later) status | Official | |
| 5656 | Yes | IBM Lotus Sametime p2p file transfer | Unofficial | |
| 5666 | Yes | NRPE (Nagios) | Unofficial | |
| 5667 | Yes | NSCA (Nagios) | Unofficial | |
| 5670 | Yes | FILEMQ ZeroMQ File Message Queuing Protocol | Official | |
| Yes | ZRE-DISC ZeroMQ Realtime Exchange Protocol (Discovery) | Official | ||
| 5671 | Yes | Assigned | Advanced Message Queuing Protocol (AMQP)[227] over TLS | Official |
| 5672 | Yes, and SCTP | Assigned | Advanced Message Queuing Protocol (AMQP)[227] | Official |
| 5683 | Yes | Yes | Constrained Application Protocol (CoAP) | Official |
| 5684 | Yes/No | Yes | Constrained Application Protocol Secure (CoAPs) | Official |
| 5693 | Yes | Nagios Cross Platform Agent (NCPA)[228] | Unofficial | |
| 5701 | Yes | Hazelcast default communication port[229] | Unofficial | |
| 5722 | Yes | Yes | Microsoft RPC, DFSR (SYSVOL) Replication Service[citation needed] | Official |
| 5718 | Yes | Microsoft DPM Data Channel (with the agent coordinator) | Unofficial | |
| 5719 | Yes | Microsoft DPM Data Channel (with the protection agent) | Unofficial | |
| 5723 | Yes | System Center Operations Manager[230] | Unofficial | |
| 5724 | Yes | Operations Manager Console | Unofficial | |
| 5741 | Yes | Yes | IDA Discover Port 1 | Official |
| 5742 | Yes | Yes | IDA Discover Port 2 | Official |
| 5800 | Yes | VNC Remote Frame Buffer RFB protocol over HTTP | Unofficial | |
| Yes | ProjectWise Server[231] | Unofficial | ||
| 5900 | Yes | Yes | Remote Frame Buffer protocol (RFB) | Official |
| Yes | Virtual Network Computing (VNC) Remote Frame Buffer RFB protocol[10][232] | Unofficial | ||
| 5931 | Yes | Yes | AMMYY admin Remote Control | Official |
| 5938 | Yes | Yes | TeamViewer remote desktop protocol[233] | Unofficial |
| 5984 | Yes | Yes | CouchDB database server | Official |
| 5985 | Yes | Windows PowerShell Default psSession Port[234] Windows Remote Management Service (WinRM-HTTP)[235] | Official | |
| 5986 | Yes | Windows PowerShell Default psSession Port[234] Windows Remote Management Service (WinRM-HTTPS)[235] | Official | |
| 5988–5989 | Yes | CIM-XML (DMTF Protocol)[236] | Official | |
| 6000–6063 | Yes | Yes | X11—used between an X client and server over the network | Official |
| 6005 | Yes | Default for BMC Software Control-M/Server—Socket used for communication between Control-M processes—though often changed during installation | Unofficial | |
| Yes | Default for Camfrog chat & cam client | Unofficial | ||
| 6009 | Yes | JD Edwards EnterpriseOne ERP system JDENet messaging client listener | Unofficial | |
| 6050 | Yes | Arcserve backup | Unofficial | |
| 6051 | Yes | Arcserve backup | Unofficial | |
| 6086 | Yes | Peer Distributed Transfer Protocol (PDTP), FTP like file server in a P2P network | Official | |
| 6100 | Yes | Vizrt System | Unofficial | |
| Yes | Ventrilo authentication for version 3 | Unofficial | ||
| 6101 | Yes | Backup Exec Agent Browser[citation needed] | Unofficial | |
| 6110 | Yes | Yes | softcm, HP Softbench CM | Official |
| 6111 | Yes | Yes | spc, HP Softbench Sub-Process Control | Official |
| 6112 | Yes | Yes | dtspcd, execute commands and launch applications remotely | Official |
| Yes | Yes | Blizzard's Battle.net gaming service and some games,[120] ArenaNet gaming service, Relic gaming service | Unofficial | |
| Yes | Club Penguin Disney online game for kids | Unofficial | ||
| 6113 | Yes | Club Penguin Disney online game for kids, Used by some Blizzard games[120] | Unofficial | |
| 6136 | Yes | ObjectDB database server[237][self-published source] | Unofficial | |
| 6159 | Yes | ARINC 840 EFB Application Control Interface | Official | |
| 6200 | Yes | Oracle WebCenter Content Portable: Content Server (With Native UI) and Inbound Refinery | Unofficial | |
| 6201 | Yes | Oracle WebCenter Content Portable: Admin | Unofficial | |
| 6225 | Yes | Oracle WebCenter Content Portable: Content Server Web UI | Unofficial | |
| 6227 | Yes | Oracle WebCenter Content Portable: JavaDB | Unofficial | |
| 6240 | Yes | Oracle WebCenter Content Portable: Capture | Unofficial | |
| 6244 | Yes | Yes | Oracle WebCenter Content Portable: Content Server—Intradoc Socket port | Unofficial |
| 6255 | Yes | Yes | Oracle WebCenter Content Portable: Inbound Refinery—Intradoc Socket port | Unofficial |
| 6257 | Yes | WinMX (see also 6699) | Unofficial | |
| 6260 | Yes | Yes | planet M.U.L.E. | Unofficial |
| 6262 | Yes | Sybase Advantage Database Server | Unofficial | |
| 6343 | Yes | SFlow, sFlow traffic monitoring | Official | |
| 6346 | Yes | Yes | gnutella-svc, gnutella (FrostWire, Limewire, Shareaza, etc.) | Official |
| 6347 | Yes | Yes | gnutella-rtr, Gnutella alternate | Official |
| 6350 | Yes | Yes | App Discovery and Access Protocol | Official |
| 6379 | Yes | Redis key-value data store | Official | |
| 6389 | Yes | EMC CLARiiON | Unofficial | |
| 6432 | Yes | PgBouncer—A connection pooler for PostgreSQL | Official | |
| 6436 | Yes | Leap Motion Websocket Server TLS | Unofficial | |
| 6437 | Yes | Leap Motion Websocket Server | Unofficial | |
| 6444 | Yes | Yes | Sun Grid Engine Qmaster Service | Official |
| 6445 | Yes | Yes | Sun Grid Engine Execution Service | Official |
| 6463–6472 | Yes | Discord RPC[238] | Unofficial | |
| 6464 | Yes | Yes | Port assignment for medical device communication in accordance to IEEE 11073-20701 | Official |
| 6502 | Yes | Yes | Netop Remote Control | Unofficial |
| 6513 | Yes | NETCONF over TLS | Official | |
| 6514 | Yes | Syslog over TLS[239] | Official | |
| 6515 | Yes | Yes | Elipse RPC Protocol (REC) | Official |
| 6516 | Windows Admin Center | Unofficial | ||
| 6543 | Yes | Pylons project#Pyramid Default Pylons Pyramid web service port | Unofficial | |
| 6556 | Yes | Check MK Agent | Unofficial | |
| 6566 | Yes | SANE (Scanner Access Now Easy)—SANE network scanner daemon[240] | Official | |
| 6560–6561 | Yes | Speech-Dispatcher daemon[citation needed] | Unofficial | |
| 6571 | Windows Live FolderShare client | Unofficial | ||
| 6600 | Yes | Microsoft Hyper-V Live | Official | |
| Yes | Music Player Daemon (MPD) | Unofficial | ||
| 6601 | Yes | Microsoft Forefront Threat Management Gateway | Official | |
| 6602 | Yes | Microsoft Windows WSS Communication | Official | |
| 6619 | Yes | Yes | odette-ftps, Odette File Transfer Protocol (OFTP) over TLS/SSL | Official |
| 6622 | Yes | Yes | Multicast FTP | Official |
| 6653 | Yes | Assigned | OpenFlow[citation needed] | Official |
| 6660–6664 | Yes | Internet Relay Chat (IRC) | Unofficial | |
| 6665–6669 | Yes | Internet Relay Chat (IRC) | Official | |
| 6679 | Yes | Yes | Osorno Automation Protocol (OSAUT) | Official |
| Yes | IRC SSL (Secure Internet Relay Chat)—often used | Unofficial | ||
| 6690 | Yes | Synology Cloud station | Unofficial | |
| 6697 | Yes | IRC SSL (Secure Internet Relay Chat)—often used | Official | |
| 6699 | Yes | WinMX (see also 6257) | Unofficial | |
| 6715 | Yes | AberMUD and derivatives default port | Unofficial | |
| 6771 | Yes | BitTorrent Local Peer Discovery | Unofficial | |
| 6783–6785 | Yes | Splashtop Remote server broadcast | Unofficial | |
| 6881–6887 | Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial |
| 6888 | Yes | Yes | MUSE | Official |
| Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial | |
| 6889–6890 | Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial |
| 6891–6900 | Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial |
| 6891–6900 | Yes | Yes | Windows Live Messenger (File transfer) | Unofficial |
| 6901 | Yes | Yes | Windows Live Messenger (Voice) | Unofficial |
| Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial | |
| 6902–6968 | Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial |
| 6969 | Yes | Yes | acmsoda | Official |
| Yes | BitTorrent tracker | Unofficial | ||
| 6970–6999 | Yes | Yes | BitTorrent part of full range of ports used most often | Unofficial |
| Yes | QuickTime Streaming Server[10] | Unofficial | ||
| 7000 | Yes | Default for Vuze's built-in HTTPS Bittorrent Tracker | Unofficial | |
| Yes | Avira Server Management Console | Unofficial | ||
| 7001 | Yes | Avira Server Management Console | Unofficial | |
| Yes | Default for BEA WebLogic Server's HTTP server, though often changed during installation | Unofficial | ||
| 7002 | Yes | Default for BEA WebLogic Server's HTTPS server, though often changed during installation | Unofficial | |
| 7005 | Yes | Default for BMC Software Control-M/Server and Control-M/Agent for Agent-to-Server, though often changed during installation | Unofficial | |
| 7006 | Yes | Default for BMC Software Control-M/Server and Control-M/Agent for Server-to-Agent, though often changed during installation | Unofficial | |
| 7010 | Yes | Default for Cisco AON AMC (AON Management Console)[241] | Unofficial | |
| 7022 | Yes | Database mirroring endpoints[242] | Unofficial | |
| 7023 | Yes | Bryan Wilcutt T2-NMCS Protocol for SatCom Modems | Official | |
| 7025 | Yes | Zimbra LMTP [mailbox]—local mail delivery | Unofficial | |
| 7047 | Yes | Zimbra conversion server | Unofficial | |
| 7070 | Yes | Yes/No | Real Time Streaming Protocol (RTSP), used by QuickTime Streaming Server. TCP is used by default, UDP is used as an alternate.[10] | Unofficial |
| 7133 | Yes | Enemy Territory: Quake Wars | Unofficial | |
| 7144 | Yes | Peercast[citation needed] | Unofficial | |
| 7145 | Yes | Peercast[citation needed] | Unofficial | |
| 7171 | Yes | Tibia | Unofficial | |
| 7262 | Yes | Yes | CNAP (Calypso Network Access Protocol) | Official |
| 7272 | Yes | Yes | WatchMe - WatchMe Monitoring | Official |
| 7306 | Yes | Zimbra mysql [mailbox][citation needed] | Unofficial | |
| 7307 | Yes | Zimbra mysql [logger][citation needed] | Unofficial | |
| 7312 | Yes | Sibelius License Server | Unofficial | |
| 7396 | Yes | Web control interface for Folding@home v7.3.6 and later[243] | Unofficial | |
| 7400 | Yes | Yes | RTPS (Real Time Publish Subscribe) DDS Discovery | Official |
| 7401 | Yes | Yes | RTPS (Real Time Publish Subscribe) DDS User-Traffic | Official |
| 7402 | Yes | Yes | RTPS (Real Time Publish Subscribe) DDS Meta-Traffic | Official |
| 7471 | Yes | Stateless Transport Tunneling (STT) | Unofficial | |
| 7473 | Yes | Rise: The Vieneo Province | Official | |
| 7474 | Yes | Neo4J Server webadmin[244] | Official | |
| 7478 | Yes | Default port used by Open iT Server.[245] | Official | |
| 7542 | Yes | Yes | Saratoga file transfer protocol[246][247] | Official |
| 7547 | Yes | Yes | CPE WAN Management Protocol (CWMP) Technical Report 069 | Official |
| 7575 | Yes | Populous: The Beginning server | Unofficial | |
| 7624 | Yes | Yes | Instrument Neutral Distributed Interface | Official |
| 7631 | Yes | ERLPhase | Official | |
| 7634 | Yes | hddtemp—Utility to monitor hard drive temperature | Unofficial | |
| 7652–7654 | Yes | I2P anonymizing overlay network | Unofficial | |
| 7655 | Yes | I2P SAM Bridge Socket API | Unofficial | |
| 7656–7660 | Yes | I2P anonymizing overlay network | Unofficial | |
| 7670 | Yes | BrettspielWelt BSW Boardgame Portal | Unofficial | |
| 7680 | Yes | Delivery Optimization for Windows 10[248] | Unofficial | |
| 7687 | Yes | Bolt database connection | Official | |
| 7707–7708 | Yes | Killing Floor | Unofficial | |
| 7717 | Yes | Killing Floor | Unofficial | |
| 7777 | Yes | iChat server file transfer proxy[10] | Unofficial | |
| Yes | Oracle Cluster File System 2[citation needed] | Unofficial | ||
| Yes | Windows backdoor program tini.exe default[citation needed] | Unofficial | ||
| Yes | Just Cause 2: Multiplayer Mod Server[citation needed] | Unofficial | ||
| Yes | Terraria default server | Unofficial | ||
| Yes | San Andreas Multiplayer (SA-MP) default port server | Unofficial | ||
| Yes | SCP: Secret Laboratory Multiplayer Server | Unofficial | ||
| 7777–7788 | Yes | Yes | Unreal Tournament series default server[citation needed] | Unofficial |
| 7831 | Yes | Default used by Smartlaunch Internet Cafe Administration[249] software | Unofficial | |
| 7880 | Yes | Yes | PowerSchool Gradebook Server[citation needed] | Unofficial |
| 7890 | Yes | Default that will be used by the iControl Internet Cafe Suite Administration software | Unofficial | |
| 7915 | Yes | Default for YSFlight server[250] | Unofficial | |
| 7935 | Yes | Fixed port used for Adobe Flash Debug Player to communicate with a debugger (Flash IDE, Flex Builder or fdb).[251] | Unofficial | |
| 7946 | Yes | Yes | Docker Swarm communication among nodes[156] | Unofficial |
| 7990 | Yes | Atlassian Bitbucket (default port)[citation needed] | Unofficial | |
| 8000 | Yes | Commonly used for Internet radio streams such as SHOUTcast[citation needed], Icecast[citation needed] and iTunes Radio[10] | Unofficial | |
| ? | ? | DynamoDB Local[252][self-published source?] | Unofficial | |
| ? | ? | Django Development Webserver[253][self-published source?] | Unofficial | |
| 8005 | Yes | Tomcat remote shutdown[10] | Unofficial | |
| 8006 | Yes | Quest AppAssure 5 API[254] | Unofficial | |
| Yes | No | Proxmox Virtual Environment admin web interface[255] | Unofficial | |
| 8007 | Yes | Quest AppAssure 5 Engine[254] | Unofficial | |
| 8008 | Yes | Yes | Alternative port for HTTP. See also ports 80 and 8080. | Official |
| Yes | IBM HTTP Server administration default[importance?] | Unofficial | ||
| Yes | iCal, a calendar application by Apple[10] | Unofficial | ||
| Yes | ? | Matrix homeserver federation over HTTP[256][self-published source?] | Unofficial | |
| 8009 | Yes | Apache JServ Protocol (ajp13)[citation needed] | Unofficial | |
| 8010 | Yes | ? | Buildbot Web status page[citation needed] | Unofficial |
| 8042 | ? | ? | Orthanc – REST API over HTTP[189][self-published source?] | Unofficial |
| 8069 | Yes | OpenERP 5.0 XML-RPC protocol[257][self-published source?] | Unofficial | |
| 8070 | Yes | OpenERP 5.0 NET-RPC protocol[257] | Unofficial | |
| 8074 | Yes | Yes | Gadu-Gadu | Official |
| 8075 | Yes | Killing Floor web administration interface[citation needed] | Unofficial | |
| 8080 | Yes | Yes | Alternative port for HTTP. See also ports 80 and 8008. | Official |
| Yes | Apache Tomcat[258] | Unofficial | ||
| Yes | Atlassian JIRA applications[259][self-published source?] | Unofficial | ||
| 8088 | Yes | Asterisk management access via HTTP[citation needed] | Unofficial | |
| 8089 | Yes | No | Splunk daemon management[260][self-published source] | Unofficial |
| Yes | Fritz!Box automatic TR-069 configuration[261] | Unofficial | ||
| 8090 | ? | ? | Atlassian Confluence[262][self-published source?] | Unofficial |
| Yes | Coral Content Distribution Network (legacy; 80 and 8080 now supported)[263] | Unofficial | ||
| ? | ? | Matrix identity server[citation needed] | Unofficial | |
| 8091 | ? | ? | CouchBase web administration[264] | Unofficial |
| 8092 | ? | ? | CouchBase API[264] | Unofficial |
| 8111 | Yes | JOSM Remote Control | Unofficial | |
| 8112 | Yes | PAC Pacifica Coin | Unofficial | |
| 8116 | Yes | Check Point Cluster Control Protocol | Unofficial | |
| 8118 | Yes | Privoxy—advertisement-filtering Web proxy | Official | |
| 8123 | Yes | Polipo Web proxy | Official | |
| Yes | BURST Reference Software P2P | Unofficial | ||
| 8124 | Yes | Standard BURST Mining Pool Software Port | Unofficial | |
| 8125 | Yes | BURST Reference Software Web Interface | Unofficial | |
| 8139 | Yes | Puppet (software) Client agent | Unofficial | |
| 8140 | Yes | Puppet (software) Master server | Official | |
| 8172 | Yes | Microsoft Remote Administration for IIS Manager[265] | Unofficial | |
| 8184 | Yes | NCSA Brown Dog Data Access Proxy | Unofficial | |
| 8194–8195 | ? | ? | Bloomberg Terminal[266] | Official |
| 8200 | Yes | GoToMyPC | Unofficial | |
| Yes | MiniDLNA media server Web Interface | Unofficial | ||
| 8222 | ? | ? | VMware VI Web Access via HTTP[267] | Unofficial |
| 8243 | Yes | Yes | HTTPS listener for Apache Synapse[268] | Official |
| 8245 | Yes | Dynamic DNS for at least No-IP and DyDNS[269] | Unofficial | |
| 8280 | Yes | Yes | HTTP listener for Apache Synapse[268] | Official |
| 8281 | Yes | HTTP Listener for Gatecraft Plugin | Unofficial | |
| 8291 | Yes | Winbox—Default on a MikroTik RouterOS for a Windows application used to administer MikroTik RouterOS[270] | Unofficial | |
| 8303 | Yes | Teeworlds Server | Unofficial | |
| 8332 | Yes | Bitcoin JSON-RPC server[271] | Unofficial | |
| 8333 | Yes | Bitcoin[272] | Unofficial | |
| ? | ? | VMware VI Web Access via HTTPS[267] | Unofficial | |
| 8337 | Yes | VisualSVN Distributed File System Service (VDFS)[273] | Unofficial | |
| 8384 | Yes | Syncthing web GUI | Unofficial | |
| 8388 | Yes | Shadowsocks proxy server[citation needed] | Unofficial | |
| 8443 | Yes | SW Soft Plesk Control Panel | Unofficial | |
| Yes | Apache Tomcat SSL | Unofficial | ||
| Yes | Promise WebPAM SSL | Unofficial | ||
| Yes | iCal over SSL[10] | Unofficial | ||
| Yes | MineOs WebUi | Unofficial | ||
| 8444 | Yes | Bitmessage | Unofficial | |
| 8448 | Yes | ? | Matrix homeserver federation over HTTPS[256] | Unofficial |
| 8484 | Yes | MapleStory Login Server | Unofficial | |
| 8500 | Yes | Adobe ColdFusion built-in web server[274][self-published source?] | Unofficial | |
| 8530 | ? | ? | Windows Server Update Services over HTTP, when using the default role installation settings in Windows Server 2012 and later versions.[275][276] | Unofficial |
| 8531 | ? | ? | Windows Server Update Services over HTTPS, when using the default role installation settings in Windows Server 2012 and later versions.[275][276] | Unofficial |
| 8580 | ? | ? | Freegate, an Internet anonymizer and proxy tool[277] | Unofficial |
| 8629 | Yes | Tibero database[citation needed] | Unofficial | |
| 8642 | Yes | Lotus Notes Traveler auto synchronization for Windows Mobile and Nokia devices[278] | Unofficial | |
| 8691 | Yes | Ultra Fractal, a fractal generation and rendering software application – distributed calculations over networked computers[279][280][self-published source?] | Unofficial | |
| 8765 | Yes | ? | Default port of a local GUN relay peer that the Internet Archive[281][self-published source] and others use as a decentralized mirror for censorship resistance.[282][self-published source] | Unofficial |
| 8767 | Yes | Voice channel of TeamSpeak 2,[283] a proprietary Voice over IP protocol targeted at gamers[citation needed] | Unofficial | |
| 8834 | ? | ? | Nessus, a vulnerability scanner – remote XML-RPC web server[284][third-party source needed] | Unofficial |
| 8840 | ? | ? | Opera Unite, an extensible framework for web applications[285][286] | Unofficial |
| 8880 | Yes | Alternate port of CDDB (Compact Disc Database) protocol, used to look up audio CD (compact disc) information over the Internet.[287] See also port 888. | Official | |
| ? | ? | IBM WebSphere Application Server SOAP connector[288][jargon] | Unofficial | |
| 8883 | Yes | Yes | Secure MQTT (MQTT over TLS)[289][290] | Official |
| 8887 | ? | ? | HyperVM over HTTP[citation needed] | Unofficial |
| 8888 | ? | ? | HyperVM over HTTPS[citation needed] | Unofficial |
| ? | Yes | Freenet web UI (localhost only)[citation needed] | Unofficial | |
| ? | ? | Default for IPython[291][self-published source?] / Jupyter[292][self-published source?] notebook dashboards | Unofficial | |
| ? | ? | MAMP[293] | Unofficial | |
| 8889 | ? | ? | MAMP[293] | Unofficial |
| 8983 | ? | ? | Apache Solr[294] | Unofficial |
| 8997 | ? | ? | Alternate port for I2P Monotone Proxy[167][jargon] | Unofficial |
| 8998 | ? | ? | I2P Monotone Proxy[167][jargon] | Unofficial |
| 8999 | ? | ? | Alternate port for I2P Monotone Proxy[167][jargon] | Unofficial |
| 9000 | Yes | SonarQube Web Server[295] | Unofficial | |
| Yes | DBGp | Unofficial | ||
| Yes | SqueezeCenter web server & streaming | Unofficial | ||
| Yes | UDPCast | Unofficial | ||
| Yes | Play! Framework web server[296] | Unofficial | ||
| Yes | Hadoop NameNode default port | Unofficial | ||
| Yes | PHP-FPM default port | Unofficial | ||
| Yes | QBittorrent's embedded torrent tracker default port[297] | Unofficial | ||
| 9001 | Yes | Yes | ETL Service Manager[298] | Official |
| Microsoft SharePoint authoring environment | Unofficial | |||
| cisco-xremote router configuration[citation needed] | Unofficial | |||
| Tor network default | Unofficial | |||
| Yes | DBGp Proxy | Unofficial | ||
| Yes | HSQLDB default port | Unofficial | ||
| 9002 | Newforma Server comms | Unofficial | ||
| 9006 | De-Commissioned Port | Official | ||
| Yes | Tomcat in standalone mode[10] | Unofficial | ||
| 9030 | Yes | Tor often used | Unofficial | |
| 9042 | Yes | Apache Cassandra native protocol clients | Unofficial | |
| 9043 | Yes | WebSphere Application Server Administration Console secure | Unofficial | |
| 9050–9051 | Yes | Tor (SOCKS-5 proxy client) | Unofficial | |
| 9060 | Yes | WebSphere Application Server Administration Console | Unofficial | |
| 9080 | Yes | Yes | glrpc, Groove Collaboration software GLRPC | Official |
| Yes | WebSphere Application Server HTTP Transport (port 1) default | Unofficial | ||
| Yes | Remote Potato by FatAttitude, Windows Media Center addon | Unofficial | ||
| Yes | ServerWMC, Windows Media Center addon | Unofficial | ||
| 9090 | Yes | Prometheus metrics server | Unofficial | |
| Yes | Openfire Administration Console | Unofficial | ||
| Yes | SqueezeCenter control (CLI) | Unofficial | ||
| Yes | Cherokee Admin Panel | Unofficial | ||
| 9091 | Yes | Openfire Administration Console (SSL Secured) | Unofficial | |
| Yes | Transmission (BitTorrent client) Web Interface | Unofficial | ||
| 9092 | Yes | H2 (DBMS) Database Server | Unofficial | |
| Yes | Apache Kafka A Distributed Streaming Platform[299] | Unofficial | ||
| 9100 | Yes | Assigned | PDL Data Stream, used for printing to certain network printers[10] | Official |
| 9101 | Yes | Yes | Bacula Director | Official |
| 9102 | Yes | Yes | Bacula File Daemon | Official |
| 9103 | Yes | Yes | Bacula Storage Daemon | Official |
| 9119 | Yes | Yes | MXit Instant Messenger | Official |
| 9150 | Yes | Tor Browser | Unofficial | |
| 9191 | Yes | Sierra Wireless Airlink | Unofficial | |
| 9199 | Yes | Avtex LLC—qStats | Unofficial | |
| 9200 | Yes | Elasticsearch[300]—default Elasticsearch port | Unofficial | |
| 9217 | Yes | iPass Platform Service | Unofficial | |
| 9293 | Yes | Sony PlayStation RemotePlay[301] | Unofficial | |
| 9300 | Yes | IBM Cognos BI[citation needed] | Unofficial | |
| 9303 | Yes | D-Link Shareport Share storage and MFP printers[citation needed] | Unofficial | |
| 9306 | Yes | Sphinx Native API | Official | |
| 9309 | Yes | Yes | Sony PlayStation Vita Host Collaboration WiFi Data Transfer[302] | Unofficial |
| 9312 | Yes | Sphinx SphinxQL | Official | |
| 9332 | Yes | Litecoin JSON-RPC server | Unofficial | |
| 9333 | Yes | Litecoin | Unofficial | |
| 9339 | Yes | Used by all Supercell games such as Brawl Stars and Clash of Clans, mobile freemium strategy video games | Unofficial | |
| 9389 | Yes | Yes | adws, Microsoft AD DS Web Services, Powershell uses this port | Official |
| 9392 | Yes | ? | OpenVAS Greenbone Security Assistant web interface | Unofficial |
| 9418 | Yes | Yes | git, Git pack transfer service | Official |
| 9419 | Yes | MooseFS distributed file system – master control port[303][self-published source] | Unofficial | |
| 9420 | Yes | MooseFS distributed file system – master command port[303] | Unofficial | |
| 9421 | Yes | MooseFS distributed file system – master client port[303] | Unofficial | |
| 9422 | Yes | MooseFS distributed file system – Chunkservers[303] | Unofficial | |
| 9425 | Yes | MooseFS distributed file system – CGI server[303] | Unofficial | |
| 9443 | Yes | VMware Websense Triton console (HTTPS port used for accessing and administrating a vCenter Server via the Web Management Interface) | Unofficial | |
| Yes | NCSA Brown Dog Data Tilling Service | Unofficial | ||
| 9535 | Yes | Yes | mngsuite, LANDesk Management Suite Remote Control | Official |
| 9536 | Yes | Yes | laes-bf, IP Fabrics Surveillance buffering function | Official |
| 9600 | No | Yes | Factory Interface Network Service (FINS), a network protocol used by Omron programmable logic controllers[citation needed] | Unofficial |
| 9669 | Yes | No | VGG Image Search Engine VISE | Unofficial |
| 9675 | Yes | Yes | Spiceworks Desktop, IT Helpdesk Software | Unofficial |
| 9676 | Yes | Yes | Spiceworks Desktop, IT Helpdesk Software | Unofficial |
| 9695 | ? | ? | Content centric networking (CCN, CCNx)[citation needed] | Official |
| 9785 | Yes | Yes | Viber[191] | Unofficial |
| 9800 | Yes | Yes | WebDAV Source | Official |
| WebCT e-learning portal | Unofficial | |||
| 9875 | Yes | Club Penguin Disney online game for kids | Unofficial | |
| 9898 | Yes | Tripwire—File Integrity Monitoring Software[304] | Unofficial | |
| 9899 | Yes | SCTP tunneling (port number used in SCTP packets encapsulated in UDP, RFC 6951) | Official | |
| 9901 | Yes | Banana for Apache Solr | Unofficial | |
| 9981 | Yes | Tvheadend HTTP server (web interface)[305] | Unofficial | |
| 9982 | Yes | Tvheadend HTSP server (Streaming protocol)[305] | Unofficial | |
| 9987 | Yes | TeamSpeak 3 server default (voice) port (for the conflicting service see the IANA list) | Unofficial | |
| 9993 | Yes | ZeroTier Default port for ZeroTier | Unofficial | |
| 9997 | Yes | Splunk port for communication between the forwarders and indexers | Unofficial | |
| 9999 | Urchin Web Analytics[citation needed] | Unofficial | ||
| 10000 | Yes | Yes | Network Data Management Protocol | Official |
| BackupExec | Unofficial | |||
| Webmin, Web-based Unix/Linux system administration tool (default port) | Unofficial | |||
| 10000–20000 | No | Yes | Used on VoIP networks for receiving and transmitting voice telephony traffic which includes Google Voice via the OBiTalk ATA devices as well as on the MagicJack and Vonage ATA network devices.[306] | Unofficial |
| 10001 | Yes | Ubiquiti UniFi access points broadcast to 255.255.255.255:10001 (UDP) to locate the controller(s) | Unofficial | |
| 10009 | Yes | Yes | CrossFire, a multiplayer online First Person Shooter[citation needed] | Unofficial |
| 10011 | ? | ? | Teamspeak3 Chat Server[307] | Unofficial |
| 10024 | Yes | Zimbra smtp [mta]—to amavis from postfix[citation needed] | Unofficial | |
| 10025 | Yes | Zimbra smtp [mta]—back to postfix from amavis[citation needed] | Unofficial | |
| 10042 | Yes | Mathoid server[citation needed] | Unofficial | |
| 10050 | Yes | Yes | Zabbix agent | Official |
| 10051 | Yes | Yes | Zabbix trapper | Official |
| 10110 | Yes | Yes | NMEA 0183 Navigational Data. Transport of NMEA 0183 sentences over TCP or UDP | Official |
| 10172 | Yes | Intuit Quickbooks client | Unofficial | |
| 10200 | Yes | FRISK Software International's fpscand virus scanning daemon for Unix platforms[308] | Unofficial | |
| Yes | FRISK Software International's f-protd virus scanning daemon for Unix platforms[309] | Unofficial | ||
| 10201–10204 | Yes | FRISK Software International's f-protd virus scanning daemon for Unix platforms[309] | Unofficial | |
| 10212 | Yes | GE Intelligent Platforms Proficy HMI/SCADA – CIMPLICITY WebView[310] | Official | |
| 10308 | ? | ? | Lock On: Modern Air Combat[citation needed] | Unofficial |
| 10480 | ? | ? | SWAT 4 Dedicated Server[citation needed] | Unofficial |
| 10505 | Yes | BlueStacks (android simulator) broadcast[311] | Unofficial | |
| 10514 | Yes | Yes | TLS-enabled Rsyslog (default by convention) | Unofficial |
| 10800 | Yes | Touhou fight games (Immaterial and Missing Power, Scarlet Weather Rhapsody, Hisoutensoku, Hopeless Masquerade and Urban Legend in Limbo) | Unofficial | |
| 10823 | Yes | Farming Simulator 2011[citation needed] | Unofficial | |
| 10891 | Yes | Jungle Disk (this port is opened by the Jungle Disk Monitor service on the localhost)[citation needed] | Unofficial | |
| 10933 | Yes | No | Octopus Deploy Tentacle deployment agent[312] | Official |
| 11001 | Yes | Yes | metasys ( Johnson Controls Metasys java AC control environment ) | Official |
| 11100 | No | Yes | Risk of Rain multiplayer server | Unofficial |
| 11111 | Yes | RiCcI, Remote Configuration Interface (Redhat Linux) | Unofficial | |
| 11112 | Yes | Yes | ACR/NEMA Digital Imaging and Communications in Medicine (DICOM) | Official |
| 11211 | Yes | Yes | memcached[10] | Unofficial |
| 11214 | Yes | Yes | memcached incoming SSL proxy | Unofficial |
| 11215 | Yes | Yes | memcached internal outgoing SSL proxy | Unofficial |
| 11235 | Savage: Battle for Newerth[citation needed] | Unofficial | ||
| 11311 | Yes | Yes | Robot Operating System master | Unofficial |
| 11371 | Yes | Yes | OpenPGP HTTP key server | Official |
| 11753 | Yes | OpenRCT2 multiplayer[313][self-published source] | Unofficial | |
| 12000 | Yes | Yes | CubeForm, Multiplayer SandBox Game | Unofficial |
| 12012 | Yes | Audition Online Dance Battle, Korea Server—Status/Version Check | Unofficial | |
| 12013 | Yes | Yes | Audition Online Dance Battle, Korea Server | Unofficial |
| 12035 | Yes | Second Life, used for server UDP in-bound[314] | Unofficial | |
| 12043 | Yes | Second Life, used for LSL HTTPS in-bound[315] | Unofficial | |
| 12046 | Yes | Second Life, used for LSL HTTP in-bound[315] | Unofficial | |
| 12201 | Yes | Yes | Graylog Extended Log Format (GELF)[316][importance?] | Unofficial |
| 12222 | Yes | Light Weight Access Point Protocol (LWAPP) LWAPP data (RFC 5412) | Official | |
| 12223 | Yes | Light Weight Access Point Protocol (LWAPP) LWAPP control (RFC 5412) | Official | |
| 12307 | Yes | Makerbot UDP Broadcast (client to printer) (JSON-RPC)[317] | Unofficial | |
| 12308 | Yes | Makerbot UDP Broadcast (printer to client) (JSON-RPC)[317] | Unofficial | |
| 12345 | Yes | Yes | Cube World[318] | Unofficial |
| Yes | Little Fighter 2 | Unofficial | ||
| NetBus remote administration tool (often Trojan horse). | Unofficial | |||
| 12443 | Yes | IBM HMC web browser management access over HTTPS instead of default port 443[319] | Unofficial | |
| 12489 | Yes | NSClient/NSClient++/NC_Net (Nagios) | Unofficial | |
| 12975 | Yes | LogMeIn Hamachi (VPN tunnel software; also port 32976)—used to connect to Mediation Server (bibi.hamachi.cc); will attempt to use SSL (TCP port 443) if both 12975 & 32976 fail to connect | Unofficial | |
| 13000–13050 | Yes | Second Life, used for server UDP in-bound[320] | Unofficial | |
| 13008 | Yes | Yes | CrossFire, a multiplayer online First Person Shooter[citation needed] | Unofficial |
| 13075 | Yes | Default[321] for BMC Software Control-M/Enterprise Manager Corba communication, though often changed during installation | Official | |
| 13400 | Yes | Yes | ISO 13400 Road vehicles — Diagnostic communication over Internet Protocol(DoIP) | Official |
| 13720 | Yes | Yes | Symantec NetBackup—bprd (formerly VERITAS) | Official |
| 13721 | Yes | Yes | Symantec NetBackup—bpdbm (formerly VERITAS) | Official |
| 13724 | Yes | Yes | Symantec Network Utility—vnetd (formerly VERITAS) | Official |
| 13782 | Yes | Yes | Symantec NetBackup—bpcd (formerly VERITAS) | Official |
| 13783 | Yes | Yes | Symantec VOPIED protocol (formerly VERITAS) | Official |
| 13785 | Yes | Yes | Symantec NetBackup Database—nbdb (formerly VERITAS) | Official |
| 13786 | Yes | Yes | Symantec nomdb (formerly VERITAS) | Official |
| 14550 | Yes | MAVLink Ground Station Port | Unofficial | |
| 14567 | Yes | Battlefield 1942 and mods | Unofficial | |
| 14800 | Yes | Age of Wonders III p2p port[322] | Unofficial | |
| 15000 | Yes | psyBNC | Unofficial | |
| Yes | Wesnoth | Unofficial | ||
| Yes | Kaspersky Network Agent[citation needed] | Unofficial | ||
| Yes | Teltonika networks remote management system (RMS) | Unofficial | ||
| 15009 | Yes | Yes | Teltonika networks remote management system (RMS) | Unofficial |
| 15010 | Yes | Yes | Teltonika networks remote management system (RMS) | Unofficial |
| 15441 | ? | ? | ZeroNet fileserver[citation needed] | Unofficial |
| 15567 | Yes | Battlefield Vietnam and mods | Unofficial | |
| 15345 | Yes | Yes | XPilot Contact | Official |
| 15672 | Yes | No | RabbitMQ management plugin[323][self-published source] | Unofficial |
| 16000 | Yes | Oracle WebCenter Content: Imaging (formerly known as Oracle Universal Content Management). Port though often changed during installation | Unofficial | |
| Yes | shroudBNC | Unofficial | ||
| 16080 | Yes | Mac OS X Server Web (HTTP) service with performance cache[324] | Unofficial | |
| 16200 | Yes | Oracle WebCenter Content: Content Server (formerly known as Oracle Universal Content Management). Port though often changed during installation | Unofficial | |
| 16225 | Yes | Oracle WebCenter Content: Content Server Web UI. Port though often changed during installation | Unofficial | |
| 16250 | Yes | Oracle WebCenter Content: Inbound Refinery (formerly known as Oracle Universal Content Management). Port though often changed during installation | Unofficial | |
| 16261 | Yes | Yes | Project Zomboid multiplayer. Additional sequential ports used for each player connecting to server.[citation needed] | Unofficial |
| 16300 | Yes | Oracle WebCenter Content: Records Management (formerly known as Oracle Universal Records Management). Port though often changed during installation | Unofficial | |
| 16384 | Yes | CISCO Default RTP MIN | Unofficial | |
| 16384-16403 | Yes | Real-time Transport Protocol (RTP), RTP Control Protocol (RTCP), used by Apple's iChat for audio and video[10] | Unofficial | |
| 16384-16387 | Yes | Real-time Transport Protocol (RTP), RTP Control Protocol (RTCP), used by Apple's FaceTime and Game Center[10] | Unofficial | |
| 16393-16402 | Yes | Real-time Transport Protocol (RTP), RTP Control Protocol (RTCP), used by Apple's FaceTime and Game Center[10] | Unofficial | |
| 16403-16472 | Yes | Real-time Transport Protocol (RTP), RTP Control Protocol (RTCP), used by Apple's Game Center[10] | Unofficial | |
| 16400 | Yes | Oracle WebCenter Content: Capture (formerly known as Oracle Document Capture). Port though often changed during installation | Unofficial | |
| 16482 | CISCO Default RTP MAX | Official | ||
| 16567 | Yes | Battlefield 2 and mods | Unofficial | |
| 17011 | Yes | Worms multiplayer | Unofficial | |
| 17224 | Yes | Yes | Train Realtime Data Protocol (TRDP) Process Data, network protocol used in train communication.[1][325] | Official |
| 17225 | Yes | Yes | Train Realtime Data Protocol (TRDP) Message Data, network protocol used in train communication.[1][326] | Official |
| 17333 | Yes | CS Server (CSMS), default binary protocol port | Unofficial | |
| 17475 | Yes | DMXControl 3 Network Broker | Unofficial | |
| 17500 | Yes | Yes | Dropbox LanSync Protocol (db-lsp); used to synchronize file catalogs between Dropbox clients on a local network. | Official |
| 18080 | Yes | No | Monero P2P network communications[citation needed] | Unofficial |
| 18081 | Yes | No | Monero incoming RPC calls[citation needed] | Unofficial |
| 18091 | Yes | Yes | memcached Internal REST HTTPS for SSL | Unofficial |
| 18092 | Yes | Yes | memcached Internal CAPI HTTPS for SSL | Unofficial |
| 18104 | Yes | RAD PDF Service | Official | |
| 18200 | Yes | Yes | Audition Online Dance Battle, AsiaSoft Thailand Server status/version check | Unofficial |
| 18201 | Yes | Yes | Audition Online Dance Battle, AsiaSoft Thailand Server | Unofficial |
| 18206 | Yes | Yes | Audition Online Dance Battle, AsiaSoft Thailand Server FAM database | Unofficial |
| 18300 | Yes | Yes | Audition Online Dance Battle, AsiaSoft SEA Server status/version check | Unofficial |
| 18301 | Yes | Yes | Audition Online Dance Battle, AsiaSoft SEA Server | Unofficial |
| 18306 | Yes | Yes | Audition Online Dance Battle, AsiaSoft SEA Server FAM database | Unofficial |
| 18333 | Yes | Bitcoin testnet[272] | Unofficial | |
| 18400 | Yes | Yes | Audition Online Dance Battle, KAIZEN Brazil Server status/version check | Unofficial |
| 18401 | Yes | Yes | Audition Online Dance Battle, KAIZEN Brazil Server | Unofficial |
| 18505 | Yes | Yes | Audition Online Dance Battle R4p3 Server, Nexon Server status/version check | Unofficial |
| 18506 | Yes | Yes | Audition Online Dance Battle, Nexon Server | Unofficial |
| 18605 | Yes | Yes | X-BEAT status/version check | Unofficial |
| 18606 | Yes | Yes | X-BEAT | Unofficial |
| 18676 | Yes | Yes | YouView | Unofficial |
| 19000 | Yes | Yes | Audition Online Dance Battle, G10/alaplaya Server status/version check | Unofficial |
| Yes | JACK sound server | Unofficial | ||
| 19001 | Yes | Yes | Audition Online Dance Battle, G10/alaplaya Server | Unofficial |
| 19132 | Yes | Minecraft: Bedrock Edition multiplayer server[327] | Unofficial | |
| 19133 | Yes | Minecraft: Bedrock Edition IPv6 multiplayer server[327] | Unofficial | |
| 19150 | Yes | Yes | Gkrellm Server | Unofficial |
| 19226 | Yes | Panda Software AdminSecure Communication Agent | Unofficial | |
| 19294 | Yes | Google Talk Voice and Video connections[328] | Unofficial | |
| 19295 | Yes | Google Talk Voice and Video connections[328] | Unofficial | |
| 19302 | Yes | Google Talk Voice and Video connections[328] | Unofficial | |
| 19531 | Yes | No | systemd-journal-gatewayd[329] | Unofficial |
| 19532 | Yes | No | systemd-journal-remote[330] | Unofficial |
| 19812 | Yes | No | 4D database SQL Communication[331] | Official |
| 19813 | Yes | Yes | 4D database Client Server Communication[331] | Official |
| 19814 | Yes | 4D database DB4D Communication[331] | Official | |
| 19999 | Distributed Network Protocol—Secure (DNP—Secure), a secure version of the protocol used in SCADA systems between communicating RTU's and IED's | Official | ||
| 20000 | Distributed Network Protocol (DNP), a protocol used in SCADA systems between communicating RTU's and IED's | Official | ||
| Usermin, Web-based Unix/Linux user administration tool (default port) | Unofficial | |||
| Yes | Used on VoIP networks for receiving and transmitting voice telephony traffic which includes Google Voice via the OBiTalk ATA devices as well as on the MagicJack and Vonage ATA network devices.[306] | Unofficial | ||
| 20560 | Yes | Yes | Killing Floor | Unofficial |
| 20582 | Yes | HW Development IoT comms | Unofficial | |
| 20583 | Yes | HW Development IoT comms | Unofficial | |
| 20595 | Yes | 0 A.D. Empires Ascendant | Unofficial | |
| 20808 | Yes | Ableton Link | Unofficial | |
| 21025 | Yes | Starbound Server (default), Starbound | Unofficial | |
| 22000 | Yes | Syncthing (default) | Unofficial | |
| 22136 | Yes | FLIR Systems Camera Resource Protocol | Unofficial | |
| 22222 | Yes | Davis Instruments, WeatherLink IP | Unofficial | |
| 23073 | Soldat Dedicated Server | Unofficial | ||
| 23399 | Skype default protocol | Unofficial | ||
| 23513 | ? | ? | Duke Nukem 3D source ports | Unofficial |
| 24441 | Yes | Yes | Pyzor spam detection network | Unofficial |
| 24444 | NetBeans integrated development environment | Unofficial | ||
| 24465 | Yes | Yes | Tonido Directory Server for Tonido which is a Personal Web App and P2P platform | Official |
| 24554 | Yes | Yes | BINKP, Fidonet mail transfers over TCP/IP | Official |
| 24800 | Synergy: keyboard/mouse sharing software | Unofficial | ||
| 24842 | StepMania: Online: Dance Dance Revolution Simulator | Unofficial | ||
| 25565 | Yes | Minecraft (Java Edition) multiplayer server[332][333] | Unofficial | |
| Yes | Minecraft (Java Edition) multiplayer server query[334] | Unofficial | ||
| 25575 | Yes | Minecraft (Java Edition) multiplayer server RCON[335] | Unofficial | |
| 25826 | Yes | collectd default port[336] | Unofficial | |
| 26000 | Yes | Yes | id Software's Quake server | Official |
| Yes | EVE Online | Unofficial | ||
| Yes | Xonotic, an open-source arena shooter | Unofficial | ||
| 26900–26901 | Yes | EVE Online | Unofficial | |
| 26909-26911 | Yes | Action Tanks Online | Unofficial | |
| 27000 | Yes | PowerBuilder SySAM license server | Unofficial | |
| 27000–27006 | Yes | id Software's QuakeWorld master server | Unofficial | |
| 27000–27009 | Yes | Yes | FlexNet Publisher's License server (from the range of default ports) | Official |
| 27000–27015 | No | Yes | Steam (game client traffic)[337][self-published source] | Unofficial |
| 27015 | No | Yes | GoldSrc and Source engine dedicated server port[337] | Unofficial |
| 27015-27018 | Yes | Unturned, a survival game | Unofficial | |
| 27015–27030 | No | Yes | Steam (matchmaking and HLTV)[337] | Unofficial |
| Yes | Yes | Steam (downloads)[337] | Unofficial | |
| 27016 | Magicka server port | Unofficial | ||
| 27017 | Yes | No | MongoDB daemon process (mongod) and routing service (mongos)[338] | Unofficial |
| 27031 | Ports 27036 & 27037 | Yes | Steam (In-Home Streaming)[337] | Unofficial |
| 27036 | Yes | Yes | Steam (In-Home Streaming)[337] | Unofficial |
| 27037 | Yes | Ports 27031 & 27036 | Steam (In-Home Streaming)[337] | Unofficial |
| 27374 | Sub7 default. | Unofficial | ||
| 27500–27900 | Yes | id Software's QuakeWorld | Unofficial | |
| 27888 | Yes | Kaillera server | Unofficial | |
| 27901–27910 | Yes | id Software's Quake II master server | Unofficial | |
| 27950 | Yes | OpenArena outgoing | Unofficial | |
| 27960–27969 | Yes | Activision's Enemy Territory and id Software's Quake III Arena, Quake III and Quake Live and some ioquake3 derived games, such as Urban Terror (OpenArena incoming) | Unofficial | |
| 28001 | Starsiege: Tribes[citation needed] | Unofficial | ||
| 28015 | Yes | Rust (video game)[339] | Unofficial | |
| 28016 | Yes | Rust RCON (video game)[340] | Unofficial | |
| 28260 | Yes | Palo Alto Networks' Panorama HA-1 backup unencrypted sync port.[25] | Unofficial | |
| 28443 | Yes | Palo Alto Networks' Panorama-to-managed devices software updates, PAN-OS 8.0 and later.[182] | Unofficial | |
| 28769 | Yes | Palo Alto Networks' Panorama HA unencrypted sync port.[25] | Unofficial | |
| 28770 | Yes | Palo Alto Networks' Panorama HA-1 backup sync port.[25] | Unofficial | |
| 28770–28771 | Yes | AssaultCube Reloaded, a video game based upon a modification of AssaultCube[citation needed] | Unofficial | |
| 28785–28786 | Yes | Cube 2: Sauerbraten[341][self-published source?] | Unofficial | |
| 28852 | Yes | Yes | Killing Floor[citation needed] | Unofficial |
| 28910 | Yes | Yes | Nintendo Wi-Fi Connection[342] | Unofficial |
| 28960 | Yes | Yes | Call of Duty; Call of Duty: United Offensive; Call of Duty 2; Call of Duty 4: Modern Warfare;[citation needed] Call of Duty: World at War (PC platform)[343] | Unofficial |
| 29000 | ? | ? | Perfect World, an adventure and fantasy MMORPG[citation needed] | Unofficial |
| 29070 | Yes | Yes | Jedi Knight: Jedi Academy by Ravensoft[citation needed] | Unofficial |
| 29900–29901 | Yes | Yes | Nintendo Wi-Fi Connection[342] | Unofficial |
| 29920 | Yes | Yes | Nintendo Wi-Fi Connection[342] | Unofficial |
| 30000 | Yes | XLink Kai P2P | Unofficial | |
| 30033 | ? | ? | Teamspeak3 Chat Server[307] | Unofficial |
| 30564 | Yes | Multiplicity: keyboard/mouse/clipboard sharing software[citation needed] | Unofficial | |
| 31337 | Yes | Back Orifice and Back Orifice 2000 remote administration tools[344][345] | Unofficial | |
| 31416 | ? | ? | BOINC RPC[346] | Unofficial |
| 31438 | Yes | Rocket U2[347][self-published source?] | Unofficial | |
| 31457 | Yes | TetriNET | Official | |
| 32137 | Yes | Yes | Immunet Protect (UDP in version 2.0,[348] TCP since version 3.0[349]) | Unofficial |
| 32400 | Yes | Plex Media Server[350] | Official | |
| 32764 | Yes | A backdoor found on certain Linksys, Netgear and other wireless DSL modems/combination routers[351] | Unofficial | |
| 32887 | Yes | Ace of Spades, a multiplayer FPS video game[citation needed] | Unofficial | |
| 32976 | Yes | LogMeIn Hamachi, a VPN application; also TCP port 12975 and SSL (TCP 443).[352] | Unofficial | |
| 33434 | Yes | Yes | traceroute | Official |
| 33848 | Yes | Jenkins, a continuous integration (CI) tool[353][354] | Unofficial | |
| 34000 | Yes | Infestation: Survivor Stories (formerly known as The War Z), a multiplayer zombie video game[verification needed] | Unofficial | |
| 34197 | No | Yes | Factorio, a multiplayer survival and factory-building game[355] | Unofficial |
| 35357 | Yes | OpenStack Identity (Keystone) administration[356][self-published source?] | Official | |
| 36330 | Yes | Folding@home Control Port | Unofficial | |
| 37008 | Yes | TZSP intrusion detection[citation needed] | Unofficial | |
| 40000 | Yes | Yes | SafetyNET p – a real-time Industrial Ethernet protocol | Official |
| 41121 | Yes | Yes | Tentacle Server[357] - Pandora FMS | Official |
| 41794 | Yes | Yes | Crestron Control Port[358] - Crestron Electronics | Official |
| 41795 | Yes | Yes | Crestron Terminal Port[359] - Crestron Electronics | Official |
| 41796 | Yes | No | Crestron Secure Control Port[360] - Crestron Electronics | Official |
| 41797 | Yes | No | Crestron Secure Terminal Port[361] - Crestron Electronics | Official |
| 43110 | Yes | ZeroNet web UI default port[citation needed] | Unofficial | |
| 43594–43595 | ? | ? | RuneScape[362] | Unofficial |
| 44405 | Yes | Mu Online Connect Server[citation needed] | Unofficial | |
| 44818 | Yes | Yes | EtherNet/IP explicit messaging | Official |
| 47808–47823 | Yes | Yes | BACnet Building Automation and Control Networks (4780810 = BAC016 to 4782310 = BACF16) | Official |
| 49151 | Reserved | Reserved | Reserved[1] | Official |
| 49160 | Yes | Palo Alto Networks' Panorama.[182] | Unofficial | |
| 49190 | Yes | Palo Alto Networks' Panorama.[182] | Unofficial |
Dynamic, private or ephemeral ports
List of IP protocol numbers
| Hex | Protocol Number | Keyword | Protocol | References/RFC |
|---|---|---|---|---|
| 0x00 | 0 | HOPOPT | IPv6 Hop-by-Hop Option | RFC 8200 |
| 0x01 | 1 | ICMP | Internet Control Message Protocol | RFC 792 |
| 0x02 | 2 | IGMP | Internet Group Management Protocol | RFC 1112 |
| 0x03 | 3 | GGP | Gateway-to-Gateway Protocol | RFC 823 |
| 0x04 | 4 | IP-in-IP | IP in IP (encapsulation) | RFC 2003 |
| 0x05 | 5 | ST | Internet Stream Protocol | RFC 1190, RFC 1819 |
| 0x06 | 6 | TCP | Transmission Control Protocol | RFC 793 |
| 0x07 | 7 | CBT | Core-based trees | RFC 2189 |
| 0x08 | 8 | EGP | Exterior Gateway Protocol | RFC 888 |
| 0x09 | 9 | IGP | Interior Gateway Protocol | |
| 0x0A | 10 | BBN-RCC-MON | BBN RCC Monitoring | |
| 0x0B | 11 | NVP-II | Network Voice Protocol | RFC 741 |
| 0x0C | 12 | PUP | Xerox PUP | |
| 0x0D | 13 | ARGUS | ARGUS | |
| 0x0E | 14 | EMCON | EMCON | |
| 0x0F | 15 | XNET | Cross Net Debugger | IEN 158[2] |
| 0x10 | 16 | CHAOS | Chaos | |
| 0x11 | 17 | UDP | User Datagram Protocol | RFC 768 |
| 0x12 | 18 | MUX | Multiplexing | IEN 90[3] |
| 0x13 | 19 | DCN-MEAS | DCN Measurement Subsystems | |
| 0x14 | 20 | HMP | Host Monitoring Protocol | RFC 869 |
| 0x15 | 21 | PRM | Packet Radio Measurement | |
| 0x16 | 22 | XNS-IDP | XEROX NS IDP | |
| 0x17 | 23 | TRUNK-1 | Trunk-1 | |
| 0x18 | 24 | TRUNK-2 | Trunk-2 | |
| 0x19 | 25 | LEAF-1 | Leaf-1 | |
| 0x1A | 26 | LEAF-2 | Leaf-2 | |
| 0x1B | 27 | RDP | Reliable Data Protocol | RFC 908 |
| 0x1C | 28 | IRTP | Internet Reliable Transaction Protocol | RFC 938 |
| 0x1D | 29 | ISO-TP4 | ISO Transport Protocol Class 4 | RFC 905 |
| 0x1E | 30 | NETBLT | Bulk Data Transfer Protocol | RFC 998 |
| 0x1F | 31 | MFE-NSP | MFE Network Services Protocol | |
| 0x20 | 32 | MERIT-INP | MERIT Internodal Protocol | |
| 0x21 | 33 | DCCP | Datagram Congestion Control Protocol | RFC 4340 |
| 0x22 | 34 | 3PC | Third Party Connect Protocol | |
| 0x23 | 35 | IDPR | Inter-Domain Policy Routing Protocol | RFC 1479 |
| 0x24 | 36 | XTP | Xpress Transport Protocol | |
| 0x25 | 37 | DDP | Datagram Delivery Protocol | |
| 0x26 | 38 | IDPR-CMTP | IDPR Control Message Transport Protocol | |
| 0x27 | 39 | TP++ | TP++ Transport Protocol | |
| 0x28 | 40 | IL | IL Transport Protocol | |
| 0x29 | 41 | IPv6 | IPv6 Encapsulation | RFC 2473 |
| 0x2A | 42 | SDRP | Source Demand Routing Protocol | RFC 1940 |
| 0x2B | 43 | IPv6-Route | Routing Header for IPv6 | RFC 8200 |
| 0x2C | 44 | IPv6-Frag | Fragment Header for IPv6 | RFC 8200 |
| 0x2D | 45 | IDRP | Inter-Domain Routing Protocol | |
| 0x2E | 46 | RSVP | Resource Reservation Protocol | RFC 2205 |
| 0x2F | 47 | GREs | Generic Routing Encapsulation | RFC 2784, RFC 2890 |
| 0x30 | 48 | DSR | Dynamic Source Routing Protocol | RFC 4728 |
| 0x31 | 49 | BNA | Burroughs Network Architecture | |
| 0x32 | 50 | ESP | Encapsulating Security Payload | RFC 4303 |
| 0x33 | 51 | AH | Authentication Header | RFC 4302 |
| 0x34 | 52 | I-NLSP | Integrated Net Layer Security Protocol | TUBA |
| 0x35 | 53 | SwIPe | SwIPe | RFC 5237 |
| 0x36 | 54 | NARP | NBMA Address Resolution Protocol | RFC 1735 |
| 0x37 | 55 | MOBILE | IP Mobility (Min Encap) | RFC 2004 |
| 0x38 | 56 | TLSP | Transport Layer Security Protocol (using Kryptonet key management) | |
| 0x39 | 57 | SKIP | Simple Key-Management for Internet Protocol | RFC 2356 |
| 0x3A | 58 | IPv6-ICMP | ICMP for IPv6 | RFC 4443, RFC 4884 |
| 0x3B | 59 | IPv6-NoNxt | No Next Header for IPv6 | RFC 8200 |
| 0x3C | 60 | IPv6-Opts | Destination Options for IPv6 | RFC 8200 |
| 0x3D | 61 | Any host internal protocol | ||
| 0x3E | 62 | CFTP | CFTP | |
| 0x3F | 63 | Any local network | ||
| 0x40 | 64 | SAT-EXPAK | SATNET and Backroom EXPAK | |
| 0x41 | 65 | KRYPTOLAN | Kryptolan | |
| 0x42 | 66 | RVD | MIT Remote Virtual Disk Protocol | |
| 0x43 | 67 | IPPC | Internet Pluribus Packet Core | |
| 0x44 | 68 | Any distributed file system | ||
| 0x45 | 69 | SAT-MON | SATNET Monitoring | |
| 0x46 | 70 | VISA | VISA Protocol | |
| 0x47 | 71 | IPCU | Internet Packet Core Utility | |
| 0x48 | 72 | CPNX | Computer Protocol Network Executive | |
| 0x49 | 73 | CPHB | Computer Protocol Heart Beat | |
| 0x4A | 74 | WSN | Wang Span Network | |
| 0x4B | 75 | PVP | Packet Video Protocol | |
| 0x4C | 76 | BR-SAT-MON | Backroom SATNET Monitoring | |
| 0x4D | 77 | SUN-ND | SUN ND PROTOCOL-Temporary | |
| 0x4E | 78 | WB-MON | WIDEBAND Monitoring | |
| 0x4F | 79 | WB-EXPAK | WIDEBAND EXPAK | |
| 0x50 | 80 | ISO-IP | International Organization for Standardization Internet Protocol | |
| 0x51 | 81 | VMTP | Versatile Message Transaction Protocol | RFC 1045 |
| 0x52 | 82 | SECURE-VMTP | Secure Versatile Message Transaction Protocol | RFC 1045 |
| 0x53 | 83 | VINES | VINES | |
| 0x54 | 84 | TTP | TTP | |
| 0x54 | 84 | IPTM | Internet Protocol Traffic Manager | |
| 0x55 | 85 | NSFNET-IGP | NSFNET-IGP | |
| 0x56 | 86 | DGP | Dissimilar Gateway Protocol | |
| 0x57 | 87 | TCF | TCF | |
| 0x58 | 88 | EIGRP | EIGRP | Informational RFC 7868 |
| 0x59 | 89 | OSPF | Open Shortest Path First | RFC 2328 |
| 0x5A | 90 | Sprite-RPC | Sprite RPC Protocol | |
| 0x5B | 91 | LARP | Locus Address Resolution Protocol | |
| 0x5C | 92 | MTP | Multicast Transport Protocol | |
| 0x5D | 93 | AX.25 | AX.25 | |
| 0x5E | 94 | OS | KA9Q NOS compatible IP over IP tunneling | |
| 0x5F | 95 | MICP | Mobile Internetworking Control Protocol | |
| 0x60 | 96 | SCC-SP | Semaphore Communications Sec. Pro | |
| 0x61 | 97 | ETHERIP | Ethernet-within-IP Encapsulation | RFC 3378 |
| 0x62 | 98 | ENCAP | Encapsulation Header | RFC 1241 |
| 0x63 | 99 | Any private encryption scheme | ||
| 0x64 | 100 | GMTP | GMTP | |
| 0x65 | 101 | IFMP | Ipsilon Flow Management Protocol | |
| 0x66 | 102 | PNNI | PNNI over IP | |
| 0x67 | 103 | PIM | Protocol Independent Multicast | |
| 0x68 | 104 | ARIS | IBM's ARIS (Aggregate Route IP Switching) Protocol | |
| 0x69 | 105 | SCPS | SCPS (Space Communications Protocol Standards) | SCPS-TP[4] |
| 0x6A | 106 | QNX | QNX | |
| 0x6B | 107 | A/N | Active Networks | |
| 0x6C | 108 | IPComp | IP Payload Compression Protocol | RFC 3173 |
| 0x6D | 109 | SNP | Sitara Networks Protocol | |
| 0x6E | 110 | Compaq-Peer | Compaq Peer Protocol | |
| 0x6F | 111 | IPX-in-IP | IPX in IP | |
| 0x70 | 112 | VRRP | Virtual Router Redundancy Protocol, Common Address Redundancy Protocol (not IANA assigned) | VRRP:RFC 3768 |
| 0x71 | 113 | PGM | PGM Reliable Transport Protocol | RFC 3208 |
| 0x72 | 114 | Any 0-hop protocol | ||
| 0x73 | 115 | L2TP | Layer Two Tunneling Protocol Version 3 | RFC 3931 |
| 0x74 | 116 | DDX | D-II Data Exchange (DDX) | |
| 0x75 | 117 | IATP | Interactive Agent Transfer Protocol | |
| 0x76 | 118 | STP | Schedule Transfer Protocol | |
| 0x77 | 119 | SRP | SpectraLink Radio Protocol | |
| 0x78 | 120 | UTI | Universal Transport Interface Protocol | |
| 0x79 | 121 | SMP | Simple Message Protocol | |
| 0x7A | 122 | SM | Simple Multicast Protocol | draft-perlman-simple-multicast-03 |
| 0x7B | 123 | PTP | Performance Transparency Protocol | |
| 0x7C | 124 | IS-IS over IPv4 | Intermediate System to Intermediate System (IS-IS) Protocol over IPv4 | RFC 1142 and RFC 1195 |
| 0x7D | 125 | FIRE | Flexible Intra-AS Routing Environment | |
| 0x7E | 126 | CRTP | Combat Radio Transport Protocol | |
| 0x7F | 127 | CRUDP | Combat Radio User Datagram | |
| 0x80 | 128 | SSCOPMCE | Service-Specific Connection-Oriented Protocol in a Multilink and Connectionless Environment | ITU-T Q.2111 (1999) |
| 0x81 | 129 | IPLT | ||
| 0x82 | 130 | SPS | Secure Packet Shield | |
| 0x83 | 131 | PIPE | Private IP Encapsulation within IP | Expired I-D draft-petri-mobileip-pipe-00.txt |
| 0x84 | 132 | SCTP | Stream Control Transmission Protocol | RFC 4960 |
| 0x85 | 133 | FC | Fibre Channel | |
| 0x86 | 134 | RSVP-E2E-IGNORE | Reservation Protocol (RSVP) End-to-End Ignore | RFC 3175 |
| 0x87 | 135 | Mobility Header | Mobility Extension Header for IPv6 | RFC 6275 |
| 0x88 | 136 | UDPLite | Lightweight User Datagram Protocol | RFC 3828 |
| 0x89 | 137 | MPLS-in-IP | Multiprotocol Label Switching Encapsulated in IP | RFC 4023, RFC 5332 |
| 0x8A | 138 | manet | MANET Protocols | RFC 5498 |
| 0x8B | 139 | HIP | Host Identity Protocol | RFC 5201 |
| 0x8C | 140 | Shim6 | Site Multihoming by IPv6 Intermediation | RFC 5533 |
| 0x8D | 141 | WESP | Wrapped Encapsulating Security Payload | RFC 5840 |
| 0x8E | 142 | ROHC | Robust Header Compression | RFC 5856 |
| 0x8F | 143 | Ethernet | IPv6 Segment Routing (TEMPORARY - registered 2020-01-31, expires 2021-01-31) | |
| 0x90-0xFC | 144-252 | Unassigned | ||
| 0xFD-0xFE | 253-254 | Use for experimentation and testing | RFC 3692 | |
| 0xFF | 255 | Reserved |
IGP: any private interior gateway (used by Cisco for their IGRP)
RPC
MSRPC
ports:TCP/135, UDP/135, SMB(TCP/139, TCP/445), web sevice (TCP/593)

https://book.hacktricks.xyz/pentesting/135-penstesting-msrpc