Linux Shell
Shell
Shell包括命令行Shell和图形Shell,Linux中使用的命令行Shell包括:
- Bourne Shell(
/usr/bin/sh或/bin/sh) - Bourne Again Shell(
/bin/bash,常用) - C Shell(
/usr/bin/csh) - K Shell(
/usr/bin/ksh) - Shell for Root(
/sbin/sh) - ……
如今Debian和Ubuntu中,
/bin/sh默认已经指向dash,这是一个不同于bash的shell,它主要是为了==执行脚本==而出现,而不是交互环境,它速度更快,但功能相比bash要少很多,语法严格遵守POSIX标准。
chsh -s /usr/bin/bash # 切换用户默认的登录环境
Shell将用户输入的命令进行解释并提交系统执行,从而实现用户与系统间的交互。为了避免不必要的用户操作,Shell支持从文件自动读取命令并执行,即执行Shell Script/Shell Program。
A shell is a command language interpreter which provide an interface to user to use operating system services.
Shell脚本文件
注释:“#”用于注释。第一行#!/bin/bash声明执行这个脚本所使用的shell程序的名称。在较为特殊的程序代码部分,务必要加上批注说明。
保持良好的编程风格,应该在每个脚本文件的头部记录文件相关信息:功能、版本信息、作者与联络方式、版权宣告方式、
主要代码部分:如果读到一个换行符号(CR),就尝试开始执行该行(或该串)指令。指令、选项与参数之间的多个空白(空格、制表符、空白行)会被忽略掉。如果一行内容太多,可使用“\”来延伸至下一行(\之后不==能有包括空白在内的任何内容==);
Windows换行规则
CR LF不能被正确识别。
语句块:使用花括号“{}”可以将多条语句放在一起,一个语句块相当于一条语句。
变量
变量名大小写敏感,有效字符包括字母、下划线和数字,但首字母不能是数字。变量的值为字符串。
变量属性
declare [option] [name=[value]]
-i:使变量具有整数性质,对变量赋值时将评估赋值表达式的数值结果;
-a/-A:将一个变量声明为数组/字典;
-l/-u:将赋给变量的值自动转换为小写/大写;
-r:使变量只读;
-x:使变量成为环境变量(export);
使用
+关闭相应的属性;
输出控制:
-
-p:显示==变量的值和属性==;如果未指定名称,则显示所有变量的信息;declare -p # 输出所有变量的信息 y=0; declare -p y # 输出: declare -- y="0" declare -p array # 输出: declare -a array='([0]="1" [1]="2" [2]="3")' -
-f/-F:仅显示函数,-F仅显示函数名和属性;
赋值
未赋值的变量也可以使用,其值为空字符串。==字符串可以跨行表示,两行内容之间会添加空白分隔(使用“\”连接两行消除换行符)==。
var_name="value"
readonly var_name # 将变量设置为只读。
等号两边不能有空格。
当value中包含空白字符时,需要使用引号'或"将其包围起来,否则只能识别空白之前的内容。引号内容可以换行(两行间的空白内容以及换行符被自动替换为一个空格)。两个相邻字符串(无空分隔)视为一个字符串。
-
==变量如果不带引号,则能触发通配符
*和?匹配文件名;会消耗转移字符,\a实际内容为a。== -
单引号中的内容不做额外解释,即双引号
"、取值运算符$、历史记录运算符!、以及转义字符\等都视为普通字符。 -
双引号中可使用特殊字符,并使用
\$、\"和\\分别来取消$、"和\的特殊含义,单引号视为普通字符。双引号中非转义字符前出现的
\无特殊作用,例如\a,不会消耗转义字符,内容为"\a"。
读取
获取变量的值,使用大括号用于帮助解释器识别变量名的边界。
$var_name
${var_name}abc
echo "$str_name"
获取变量的值时,一定要带上
$,否则只是使用变量名字符串。
输出当前Shell环境中的所有变量和函数:
set/declare
命令行展开
Shell解释器执行语句时,会首先对语句中的变量$var进行值替换,然后对其中的特殊字符(如*,~)进行替换,最后根据空白将语句内容解析为命令和参数序列。
-
避免特殊字符展开:将特殊字符或包含特殊字符的变量置于引号中
"$var",其中的所有字符都被视为普通字符(除转义序列外); -
避免包含空白的变量被展开为多个参数:同样将该变量的引用置于
""中。如"hello world"或"$var_with_spaces"; -
如果变量的内容已经显示指定了参数边界,如
'arg 1' 'arg2',则命令行不要为其添加""(否则仅相当于一个参数);但如果该变量受上述两项限制需要"",则使用eval对命令行内容执行两遍解释,从而对该变量进行两次解释(第一次执行变量替换,第二次执行参数解析)。消除参数中成对的双引号(字符),并将引号之间的内容作为一个参数。
eval echo '"abc' 'def"' 'ghi' # => echo "abc def" ghi => abc def ghi变量值中自带的引号只是普通字符(区别与命令行或脚本上书写的引号边界),其不能避免变量在空白处被展开。带空格的变量与其他变量拼接后再作为参数传递给其他脚本,则无法避免该变量在空格处被展开。应该单独将该变量置于引号中传递给脚本,或者使用
eval命令对参数中包含的引号做第二次解释。x="x 'y z'" y="\"a b c\"" z="$y $x" # => z = ["a b c" x 'y z'] ./script.sh $z # ./script.sh '"a' 'b' 'c"' 'x' 'y' 'z' eval./script.sh $z # ./script.sh 'a b c' 'x' 'y z' ./script.sh "$y" "$x" # ./script.sh '"a b c"' 'x 'y z'
删除变量
unset TEST_VAR # clear a shell/env variable
数据结构
数组
序列由()包含多个元素
array=('abc' 123 4.56 ...) # declare -a array=(1 2 3)
名为
@的数组:脚本的所有输入参数组成的特殊的数组。
使用从0开始的下标访问数组元素:
ai="${array[i]}" # ${array}=>${array[0]}
数组与字符串转换
使用“@”或“*”获取数组所有元素,其返回结果为字符串。
x="${array[@]}" # 所有元素拼接成的字符串*
cmd "${array[@]}" # 将数组展开到命令行,每个元素成为单独参数**
*:表达式添加""后,数组元素中可以包含空白,解释器视整个数组元素内容为一个参数(类似于命令行输入'abc d');
**:用于命令行时(如作为for循环的迭代序列或命令参数序列),Shell会首先对"${array[@]}"进行解释展开为多个参数,而赋值时则不会(否则如x=1 2 3这样的语句会报错);
将字符串转换为数组:根据展开表达式中的空格分隔数组元素
array=($cat_array)
eval array=("$cat_array") #*
*:如果字符串中人为定义了元素边界'',则使用eval对字符串内容再解释一次。
数组元素迭代
for a in "${array[@]}"; do #*
echo $a
done
# => 也可根据子串长度,按编号顺序迭代
for ((i=0;i<${#array[@]};i++)); do echo ${array[$i]}; done
查找序列中的元素:
function arrayfind(){
local value=$1; shift; local array=("$@"); #*
local index=-1
for (( i=0; i<${#array[@]}; i++ )); do
if [[ "$value" == ${array[$i]} ]]; then
index=$i
break
fi
done
echo $index
}
*:函数无法接受数组对象作为参数,传入数组首先被扩展为多个参数,再在函数中重新拼装为数组。
子数组
获取子数组,第二个参数省略则获取到结束。
sub_array=(${array[@]:i[:j]})
如果数组元素包含空格,则应该使用"${array[@]:i[:j]}"防止数组元素边界丢失,否则上述表达式将按空格为边界重新构造数组。
序列长度:
${#array[@]} # <=> ${#array[*]}
注意:
${#array}返回数组第一个元素(字符串)的长度。
扩展序列,序列元素可动态增加,跳过赋值的序列元素为空。
a+=(1 2) # 不支持 (1 2)+(3 4)
array[5]=v2 # echo $array[4] ==> 输出为空
字典
declare -A dict # decalre dict as a dictonary
dict[x]=1
declare -A dict=([x]=1 [y]=2 ...)
echo dict[x]
运行
脚本文件如果具有可读可执行权限 (rx),可将其视为命令在Shell中执行:
/home/gary/work.sh # 绝对路径
./work.sh # 相对路径(不能省略./)
work.sh # 文件位于系统路径PATH
对于不具有执行权限的脚本文件,则可由解释器(bash)读取执行:
bash /path/to/file.sh arg1, arg2,...
可以为运行脚本提供多个参数。通过以上各方法执行Shell脚本将会创建一个新Shell实例(进程),脚本将由新的Shell实例解释执行。==环境变量将由原有的Shell实例传递给新的Shell实例,而普通变量将不会传递==。在脚本执行过程中,新Shell中任何变量的修改都不会传递回原有的Shell。
利用 source 来执行脚本:在当前Shell进程中执行脚本中的语句,而不创建新的Shell进程。如果提供额外参数,则脚本的运行的参数变量会被更新,脚本执行完后恢复原有的参数变量。==脚本执行过程中对原Shell中的变量更新有效==。
source script [args] # . script
source ~/.bashrc # Ubuntu必须在交互式Shell中运行=> bash -i script.sh
Ubuntu环境下运行
.bashrc必须在交互式Shell中进行(运行的Shell脚本非交互环境),否则脚本直接返回。如果不屏蔽.bashrc中判断交互式逻辑,可将初始化内容移至其他脚本文件中并在用户脚本中使用source调用。注意:
.bashrc中如果有输出语句(例如echo),可能导致从远端执行scp无法正常工作(启动SSH会话会自动加载.bashrc,输出语句可能中断后续传输命令)。
执行符号链接的脚本时,当前工作目录为符号链接所在目录。
运行环境
Shell配置文件通常定义了环境变量以及初始化脚本。配置文件根据作用范围分为系统配置文件和用户配置文件。
系统配置脚本
/etc/profile为系统默认配置,在系统启动时加载。不推荐用户修改此文件,以免系统升级时造成配置丢失,应该在/etc/profile.d目录下创建appxxx.sh定义环境变量。
系统环境变量
/etc/environment保存了系统环境变量(如PATH)的赋值表达式,在==用户登录==时读取。
用户配置文件
用户登录时,Shell会自动按序尝试加载~/.bash_profile、~/.bash_login和~/.profile(如果发现一个文件则不再加载后续文件)。系统默认创建的~/.bash_profile还会加载~/.bashrc,而~/.bashrc则会加载/etc/bashrc1。如果希望配置仅对当前用户有效,应修改用户目录下的上述配置文件。
当使用SSH远程登录时,上述与Shell相关配置文件不会被加载,而是直接加载~/.bashrc(Ubuntu中会在~/.bashrc中判断Shell是否为交互式,如果非交互式跳过后续配置加载)。
设置运行时选项
set命令可以对Shell进行设置。
set -x # [-o xtrace] 按执行内容回显命令
set -e # [-o errexit] 命令返回非0时退出程序
set -u # [-o nonset] 引用未设置的变量产生错误
set -v # [-o verbose] 按输入内容回显命令
set -n cmdline # [-o noexec] 读取命令输入但不执行
set -o posix # config to print variables only
set -o history # enable command history
使用
set +opt关闭选项。
环境变量
Environmental Variable:可以被子进程或Shell继承的变量。
| 变量 | 描述 |
|---|---|
$PATH | 可执行文件的搜索路径 |
$LANG | 操作系统的语言和编码方案(例如en_US.UTF-8) |
$LD_LIBRARY_PATH | 非标准共享库的搜索路径 |
$HOME | 用户家目录 |
共享库的寻找和加载是由
/lib/ld.so实现的。ld.so在标准路经(/lib,/usr/lib) 中寻找共享库。Linux通用的做法是将非标准路径加入/etc/ld.so.conf,然后运行ldconfig生成/etc/ld.so.cache。
Shell Variable:独立为每个Shell定义的变量。
| 变量 | 描述 |
|---|---|
$$ | 当前进程的进程号,通常用它来生成唯一的临时文件。 |
$! | 最后运行的==后台==进程的进程标识(pid)。 |
$? | 上个命令的退出状态,或函数的返回值(可获取ssh远程执行命令的返回值)。 |
$LINENO | 当前的行号(sh中无效,使用bash) |
$- | ==启用的Shell环境选项==。 |
env NAME=VALUE
[-u,--unset=NAME]
修改(删除)环境变量。
查看环境变量:
env
printenv [ | grep PATH]
printenv NAME
转换普通变量为环境变量:
export [-n] SHELL_VAR # turn into env-variable / turn normal
export var=value # define a new env-variable
set -a # [-o allexport] export all defined variables
参数变量
执行程序(脚本、二进制文件)时,可以传入多个参数。
./shfile.sh [arg1 arg2 ...]
传入程序的参数变量为字符串值而非脚本中书写的字面值,变量中的转义字符不会被再被解释。
在脚本文件内部,按以下方式获取参数信息:
| 变量 | 描述 |
|---|---|
$0, $1,$2,... | 按序号访问传入参数($0为脚本名) |
$*、$@ | 输入参数(不包含$0)组成的序列,使用""避免参数展开。 |
"$*" | 结果为一个字符串'arg 1 arg 2 arg 3' |
"$@" | 保留原参数结构'arg 1' 'arg 2' 'arg 3' |
${@:m:n} | 获取输入参数序列部分内容,使用""避免原参数展开。==使用 ()使返回结果仍以数组存储,否则结果会转换为字符串==。 |
$# | 传递给脚本的参数个数,不包括脚本名称($0) |
命令行参数展开测试:
for arg in "$@" ; do # <-> $* "$*" echo $arg done
shift n:移动输入参数起始下标,向右移动$i和$@等参数读取位置(默认n=1,不影响$0)。
设置参数:更新当前Shell环境得输入参数(覆盖调用时传入值):
set -- args...
eval set -- "arg1 'arg 2' 'arg 3'" #*
set - # -x and -v options are off **
*:如果参数通过字符串提供且其中带字符串边界('),则需使用eval避免错误空白位置参数展开。
**:如果未提供参数,则将当前状态下的"$@"(如经过shift移位后)设置为输入参数。
隔离运行
使用chroot命令切换待执行程序的根目录,运行的程序不能访问指定根目录以外的文件,适用于做为测试环境。要在指定根目录下和真正根目录下一样运行相应的程序,需要:
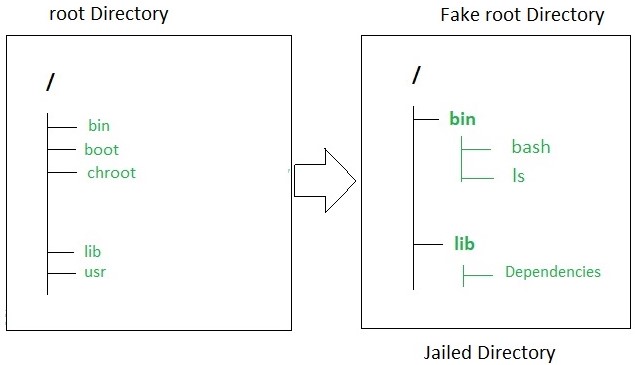
- 在该根目录下安装对应的程序,该方法将自动安装程序及其依赖包。
- 手动复制系统根目录下已可执行文件及其依赖项,需要自行确定依赖项。
chroot --userspec=USER:GROUP --groups=G_LIST NEWROOT [COMMAND [ARG]...]
如果未指定命令,则默认运行:'${SHELL} -i'。
历史记录
ctrl + r # 在终端反向搜索历史命令
!! # 执行上一条命令
!* # 上一条命令的所有参数 (!:1-$)
!$ # 上一条命令的最后一个参数 (!:N,第N个参数; !-n:$, last-but-n)
历史记录中最常用的命令:
history | awk 'BEGIN {FS="[ \t]+|\\|"} {print $3}' | \
sort | uniq -c | sort -nr | head -n N
清空屏幕:ctrl+l。
复制/粘贴:ctrl+shift+c/v。
运算
字符串操作
${#str} # 字符串的长度,注意数组长度${#array[@]}
查找
使用grep和正则表达式可以自定义查找方式,包括startswith,endswith等,在程序中可根据返回值判断是否成功匹配。
grep 'hive' <<< 'apache-hive-3.1.2-bin'
#> apache-hive-3.1.2-bin
grep -Po '^(\w)+' <<< 'spark-3.0.1-bin-hadoop3.2.tgz' # startswith
#> spark
grep -Eo '(tar.gz|tgz)$' <<< 'hadoop-3.2.1.tar.gz' # endswith
#> tar.gz
在条件表达式中,通过字符串比较测试也可进行查找匹配,但仅能判断是否匹配,而不能获取匹配结果;另一方面,grep的返回值可用于条件表达式判断是否成功匹配。
替换
${param:-DEFAULT} # 如果param为空,则返回为默认值
${param-DEFAULT} # 如果param未定义,则返回为默认值
${param:=DEFAULT} # 如果param为空,则把它设置为默认值,并返回param的值
${param=DEFAULT} # 如果param未定义,则把它设置为默认值,并返回param的值
# ":"限定判断条件变量为空,"=/-"决定是否为变量赋值
${param%PATERRN} # 从param尾部删除与PATERRN最小匹配
${param%%PATERRN} # 从param尾部删除与PATERRN最长匹配
${param#PATERRN} # 从param头部删除与PATERRN最小匹配
${param##PATERRN} # 从param头部删除与PATERRN最长匹配
shell 编程:冒号 后面跟 等号,加号,减号,问号的意义 - 笨鸟教程的博客 | BY BenderFly (handerfly.github.io)
使用sed和正则表达式可以很容易实现字符串内容的修改:
sed -n 's/ /\*/p' <<< 'hello world' # 替换匹配内容
#> hello*world
sed -E 's/.(tar.gz|tgz)$//' <<< 'hadoop-3.2.1.tar.gz' # 删除后缀
#> hadoop-3.2.1
拼接
str3=$str1$str2
拼接变量的值,由于变量的值为字符串,因此实际等效于字符串拼接。
拼接文件内容:
STR=''
for line in $(cat filename); do
line=$(sed -E 's/#.*//' <<< $line) # edit the line
STR="$STR $line"
done
获取子串
按索引(0-based index)获取:
sub_str=${str:START:LENGTH} # ${string:start=0:length=${#str}}
使用正则表达式(捕获组)获取匹配子串:
ps -ef | sed -nE '100s/^[a-zA-Z0-9\+]+ +([0-9]+).*/\1/p' # 获取pid
#> 184289
使用分隔符拆分字符串并获取子串:
read -a cmd_args <<< "sudo apt update" # 将拆分结果存入数组(分隔符$IFS,默认为空白)
仅获取拆分后的某个子串:
ps -ef | sed -n '10p' | awk '{print $2}' # use awk
cut -d ";" -f 1 <<< "bla@some.com;john@home.com" # use cut
awk将连续多个分隔符视为一个分隔符;cut将连续分隔符之间视为空字符串。
xargs将管道或标准输入(stdin)数据转换成命令行参数。
xargs # https://www.runoob.com/linux/linux-comm-xargs.html
local_home=${local_home%'/'} # trim the trailing '/'
整数运算
declare
declare -i n
n=7/3 # echo $n => 2 : 非四舍五入(舍去小数)
n=n+1 # 计算表达式中无须使用$对变量求值
expr
expr将参数解释为表达式并进行评估,输出计算结果。表达式中操作符和操作数需要使用空白分开,可以包含简单四则==整数==运算(+、-、*、/)、求余(%)、逻辑运算(|、&、=、>、>=、<、<=、!=)。乘号(*)前边必须加反斜杠(\)避免通配符展开。
R=$(expr $a + $b – 20 \* $c / $d + $e % 10)
==let==
let表达式中不能包含空格,且变量名无需添加$,let会对表达式进行解释和计算。
let z=5
let z=z+1 # <=> let z=$z+1
bash算术运算
((a = $b + 10)) # 对空格没有要求
日期和时间
date命令可以对表示时间的变量进行增加(+)/减少(-)操作。
iter_date=$(date +%Y%m%d -d "$iter_date + 1 year")
输入
$iter_date为空时,默认为当前日期时间
计算时间差
利用时间戳计算时间差。
let DIFF=($(date +%s -d 20210131)-$(date +%s -d 20210101)) # diff of seconds
let t_minutes=t_elapse/60
let t_seconds=t_elapse%60
条件表达式
语法:使用[ expr ]定义条件表达式。表达式返回值0表示true,1表示false。
注意在中括号内的变量,最好都以双引号括号起来(避免空字符串以及带空白的字符串展开造成语法错误);常数也最好都以单或双引号括号起来。
[是条件表达式的命令名,其后的内容作为其参数展开,因此[]、运算符、变量之间必须以空格分隔,而展开后带空格的变量也需要使用引号保证参数的完整性。<、>、&&、||、()等特殊字符作为Shell的命令,是不能作为参数的,因此不能直接出现在条件表达式中(使用转义字符\)。
表达式中仅允许使用以下定义的运算符对变量进行测试,而使用其他命令将会出错。
数值比较
-eq(==)、-ne(!=)、-gt(>)、-lt(<)、-ge(>=)、-le(<=),只支持数值比较。
[ $a -eq $b ]
由于
>、<为特殊字符不能作为关系运算符,使用命令选项表示关系运算符。
逻辑运算
[ ! expr1 ] # logical not
[ $a -o $b ] # logical or
[ $a -a $b ] # logical and
[ -r $1 ] && [ -s $1 ]
字符串比较
字符串运算符:=、!=;
[ $str1 != $str2 ] # 字符串比较
[ -z "$str" ] # true(0) if str is zero-length
[ -n "$str" ] # true(0) if str is non-zero-length
-n参数需要使用""括起来,否则对空字符串的计算结果不正确。
文件测试
[ -dfrwxse file ]
-e:文件是否存在;-d:目录;-f:普通文件;-r:读权限;-w:写权限;-x:访问/执行权限;-s:文件是否为空。
Robust Condition Expression
相比于[],[[]]提高了条件语句的健壮性和可用性,具体地,[[]]可以==处理空字符串以及带空格的字符串==,因此不用对变量取值($var)增加额外的引号。
需要在
bash环境中使用[[]]。
-
使用
&&、||作为逻辑运算符[[ expr1 && expr2 ]] # logical and [[ expr1 || expr2 ]] # logical or -
支持使用
<,>,==,>,<,!=做字符串比较; -
=~运算符,用于正则表达式匹配(==正则表达式模式不能加引号==);[[ $answer =~ ^y(es)?$ ]]; echo $? #* -
通配符
*、?匹配(模式表达式不能带引号,否则视为普通字符串);[[ $ANSWER = y* ]]; echo $? # start with
优先级
在[[]]表达式中,使用()保证优先级。
流程控制
不存在块作用域:语句块中定义的变量在语句块结束后仍有效(因为不存在变量声明语句)。
==流程控制语句块可以嵌套==。
==语句块内容不能为空,否则有语法错误==。
函数
在脚本中可将一组常用操作定义为函数。函数的定义必须出现在调用之前,不存在前向声明。
function fun_name(){ # function keyword is optional
statements;
return n; # optional
}
函数输入参数
函数没有显式定义参数,参数传入规则与脚本一致,即在函数内部参数变量$1,...将被更新未调用函数时传递的参数,其中$0==仍为调用脚本名==。函数执行完返回调用程序后,参数变量将恢复到调用程序之前的状态。
函数返回值
返回值代表函数的执行状态,不表示函数的输出内容。因此,使用 return返回整数值(通常<128);如果不加return语句,将以最后一条命令的返回值作为函数的返回值。
函数输出
函数应该向标准输出发送输出数据(如echo "output"),从而使调用程序可通过$(func args)捕获到输出内容。同时,应该向标准错误输出(command >&2)发送预计行为外的输出(如错误信息、日志信息等),以保证调用程序获得预期的输出内容(或在出现异常的情况下获得空内容)。调用程序如果未捕获输出结果且未做重定向,则标准输出和标准错误输出通常都会打印到控制台。
函数内的变量作用域
函数中的变量作用域与source script.sh(当前Shell执行)相似:
-
==函数可以访问被执行脚本所在Shell环境中的变量==。
-
==函数中声明的变量默认为
global作用域,即在函数调用返回后仍然有效==。- ==如果函数调用是在
$(...)中而非当前Shell,则函数中定义的变量离开$(...)语句后无效==。
- ==如果函数调用是在
-
使用
local关键字在函数内部声明局部变量。如果局部变量与全局变量名字相同,则在局部变量的作用域内,局部变量将覆盖全局变量。==局部变量仅具有函数范围生命周期==。
语句连接和语句块
&&:如果第一条命令执行成功(返回0)则执行&&后续命令;
;:用于连接两条命令,无论第一条是否执行成功,都继续执行后续命令。在交互环境下执行命令时,前一条命令中的==赋值语句==设置的变量仅限当前命令使用,当前命令执行完后恢复设置前的值;在脚本中编写同样的命令则不会被重置。这个特性方便临时设置分隔符等变量。
IFS=:; read host path <<< 'user@host:downloads/'; echo IFS=$IFS;
上述命令在交互终端中运行时,打印
IFS为空;在脚本中执行(bash -c)则打印:。仅对赋值语句有效,通过read赋值的变量的值在下一语句执行后仍然保留。
条件
if cond_expr1 ; then
statements
elif cond_expr2 ; then # elif 可选
statements
else # else 可选
statements
fi
cond_expr1为条件表达式。then可以和condition置于一行,但需要在condition和then之间添加“;”。
case $variable in # swith-case
pattern1 [|pattern11...] )
statements
;;
pattern2 [|pattern22...] )
statements
;;
......
*)
;;
esac
pattern表示匹配模式字符串,不需要添加引号。多种模式可以使用“|”合并为一类。使用“)”表示模式说明的结束,使用“;;(双分号)”表示一个模式行的结束。
只执行一个匹配行,即使其后有更精确的匹配。
模式语句支持正则表达式。
模式可使用通配符,因此可以使用“*”作为默认模式。当所有的匹配都不成功时,才执行“*”对应的命令。通配符扩展在引号中不起作用。
循环
迭代
基于数值的迭代:
for ((i=0;i<len;i++)); do # 控制语句不需要使用$i和$len, 但过程语句需要$i
echo $i
done
遍历基于空格分割的字符串序列:
for v in v1 v2 v3 ...; do
statements
done
==v1 v2 v3...是由空格分隔的字符串==。
序列展开迭代
可由序列转换v in ${array[@]}得到迭代元素。如果序列元素本身包含空白,则要使用v in "${array[@]}",防止元素被分割。
命令行参数展开(*),将被替换为所有匹配文件名构成的可迭代对象。
for s in ./*.sh; do echo $s; done # 文件名包含空格不会被中断
条件循环
while condition ; do
statements
done
until condition ; do
statements
done
其他
break:跳出循环(case语句使用;;终止分支,不需要使用break);
continue:跳过本次循环的剩余内容;
return:用于函数的返回(或使用source/shell调用的脚本的返回),并提供返回值。
exit:用于脚本提前退出并提供返回值。
输入输出
标准输入输出
输出
echo -n -e $var
echo `expr`
echo $var1 $var2
-n:不输出换行;-e:确保输出内容启用==转义字符==(例如\n, \t);
C语言风格输出函数:
printf "%10s %08d %-10.2f\n" hello 8 9.9
printf '%s\n' A-{1..5} # 自动展开并迭代1到5的序列
printf -v outstr FORMAT ARGS # 将格式化输出存储到变量中。
获取命令的==标准输出==(非返回值,返回值为$?)。错误输出不会被$()捕获,仍正常输出(到终端)。
result=$(cmd.sh args) # assign the output string to result
result=`cmd.sh args`
输入
read从标准输入==读取一行==内容。可将文件或标准输出重定向至read。
read -a array -d delim prompt -r ... [vars ...]
如果提供了一个或多个位置参数变量,则==使用分隔符$IFS分割读取内容==,并将分隔后的内容依次存入位置参数;如果没有位置参数变量,则将读取内容存入$REPLY中。
read如何从子shell中返回变量到父进程?
参数:
-a array:将分割后的内容按顺序存入数组;
-d delim:将行结束符设置为delim的第一个字符(后续字符无效)而不是以换行结束;将行结束符置空将读取整个文件的内容。
-e:使用readline读取一行内容(可自动补全文件名等);
-n nchars:读取最多nchars个字符后结束(不用等到换行),仍支持分隔符;-N忽略分隔符;
-p prompt:输入内容前的提示信息;
-r:忽略字符串中的转义字符(\);
-s:不在终端上显示输入内容(用于==输入密码==);Enter结束输入但不会产生换行作用;需要在程序中执行换行。
-t timeout:设置读取超时时间(用于交互式界面);
从标准输入读取多行内容:直到输入一行内容为"EOF"终止,也可以使用ctrl+D结束输入标准输入流。
text=$(cat << EOF)
重定向
Linux程序通常使用标准输入/输出与用户或系统交互。
- 编写程序时,默认仅需要处理标准输入输出,在不必要的情况下不额外打开文件,以简化程序逻辑。
- 调用程序时,通过重定向命令使用文件数据流代替标准输入输出;
重定向语法
| 语法 | 说明 |
|---|---|
command < filename | 使用文件代替标准输入。 |
command >&2 | 将命令的输出定向到错误输出。 |
command <<[-] end_word | 从标准输入读取内容,直到一行仅包含end_word;-去除内容开始前的tab制表符。 |
command <<< args | 使用命令行参数代替标准输入。 |
command > filename | 使用文件代替标准输出(>>追加模式)。 |
command 2> filename | 使用文件代替标准错误输出(2>>追加模式)。 |
command > filename 2>&1command 2> filename 1>&2 | 将标准输出和标准错误输出都定向到指定文件。 ( >>或2>>追加模式) |
2>&1表示将标准错误输出再定向到标准输出。
https://www.gnu.org/software/bash/manual/html_node/Redirections.html
示例:
command > /dev/null 2>&1 # 将标准输出和错误输出丢弃
清空文件
> FILENAME # => > FILENAME => true > FILENAME
cat /dev/null > FILENAME # => cp /dev/null FILENAME
truncate -s 0 FILENAME
不要尝试将一个文件读出的同时再写回当前文件(cat file > file),因为此命令在执行前会为输出流清空当前文件。
管道
管道用于连接两个命令,将上一个命令的标准输出作为下一个命令的标准输入。示例如下:
ps -ef | grep 'apache' | grep -v grep
将错误输出流传入管道:
command | 2>&1 grep 'something'
文件输入输出
text=$(cat txtfile)
除了使用文件名读取文件内容外,使用重定向语法也可以使程序读取文件内容代替默认的标准输入。
head/tail用于过滤部分数据:
head -n,--lines=[-]N FILE # 输出前N行内容,-表示除去最后N行的内容
tail -f,--follow FILE
-n,--lines=[+]N # 输出文件最后N行,+表示从第N行开始输出
--pid=PID # with -f, terminate after process PID dies
more:键入用〈space〉键显示后续内容,显示当前查看的百分比。
pg:分屏显示文件的内容,按<enter>键显示下一屏的内容。
按行读写和处理文件
使用循环读取文件中每一行的内容:将while语句块视为一条语句,可使用“|”接收前置命令的输出或使用“<,>”等 来重定向标准输入/输出输入到文件,那么while语句块中的所有命令将使用重定向后的输入输出。
# read name=value pairs from file
lines=()
while IFS='=' read name ...; do # 如果读整行则指定一个变量(IFS='')
echo $name $value;
# process line
lines+=($name) # 将文件内容保存到数组
done < src_file # default: from stand input
IFS=默认以空白为分隔符(将自动截断输入的前后空白内容)。需要注意,如果使用文件重定向,但循环过程中存在交互输入,则交互输入内容也会从文件中获取,这可能是不希望的行为。因此需要首先==将文件内容读取序列==中,然后再使用
for循环迭代并获取用户的输入。如果需要对读入的每一行分别进行处理输出(如替换修改等,可使用
grep/sed/awk等工具)。当如果需要处理的内容与上下文相关,则需要自定义处理逻辑。
将文件内容构造为序列
mapfile和readarray可简化上述读取操作。
mapfile -t lines < file.txt # ==> readarray
# 默认分隔符为所有空白,这里将分隔符设置为换行,因此按行拆分为序列
IFS=$'\r\n' GLOBIGNORE='*' command eval 'XYZ=($(cat /etc/passwd))'
IFS=$'\n' read -d '' -r -a lines < /etc/passwd
如果使用
for语句读取文件输入(使用cat, sed等),需要注意==文件内容将会被拼接为一个整体,并按空格分离进行迭代==。for pkg in $(sed -E 's/#.*//' all_conda.pkgs); do echo $pkg; done
将序列内容写入文件
将整个命令的标准输出定向到文件,避免重复打开文件。
for line in "${text_array[@]}"; do
echo $line
done > text.txt
for ((i=0;i<${#text_array[@]};i++)); do
echo "$i: ${text_array[i]}"
done > text.txt
进程
创建进程
Shell执行命令时创建子进程(子Shell,进程号$!),并等待子进程结束。如果要立即返回则使用&使子进程与Shell分离。
./script.sh args > tmp.log 2>&1 &
子进程分离后,其标准输入输出仍然绑定在原Shell,因此需要进行重定向。也可以使用nohup自动进行重定向,输出内容到nohup.out中。
nohup ./script.sh args &
信号处理
通常,当子进程在执行时,bash会忽略所有信号。
#!/bin/bash
term_handler() {
echo "Caught SIGTERM signal!"
kill -TERM "$child" 2>/dev/null
}
trap term_handler SIGTERM
echo "Doing some initial work...";
/bin/start/main/server --nodaemon &
child=$! # get Process ID
wait "$child" # wait child to end or any signals
term_handler='-'默认处理方式;term_handler=''忽略信号。
调度
休眠
sleep 100 # seconds
调试程序
Fix bugs in Bash scripts by printing a stack trace | Opensource.com
set -E # the error trap is inherited throughout the script
trap 'ERRO_LINENO=$LINENO' ERR # traps commands that exit with a non-zero code
trap '_failure' EXIT
_failure() {
ERR_CODE=$? # capture last command exit code
set +xv # turns off debug logging, just in case
if [[ $- =~ e && ${ERR_CODE} != 0 ]]
then
# only log stack trace if requested (set -e)
# and last command failed
echo
echo "========= CATASTROPHIC COMMAND FAIL ========="
echo
echo "SCRIPT EXITED ON ERROR CODE: ${ERR_CODE}"
echo
LEN=${#BASH_LINENO[@]}
for (( INDEX=0; INDEX<$LEN-1; INDEX++ ))
do
echo '---'
echo "FILE: $(basename ${BASH_SOURCE[${INDEX}+1]})"
echo " FUNCTION: ${FUNCNAME[${INDEX}+1]}"
if [[ ${INDEX} > 0 ]]
then
# commands in stack trace
echo " COMMAND: ${FUNCNAME[${INDEX}]}"
echo " LINE: ${BASH_LINENO[${INDEX}]}"
else
# command that failed
echo " COMMAND: ${BASH_COMMAND}"
echo " LINE: ${ERRO_LINENO}"
fi
done
echo
echo "======= END CATASTROPHIC COMMAND FAIL ======="
echo
fi
}
The following built-in shell values are used to build the stack trace:
BASH_SOURCE: Array of filenames where each command was called back to the main script.FUNCNAME: Array of function names matching each file inBASH_SOURCE.BASH_LINENO: Array of line numbers per file matchingBASH_SOURCE.BASH_COMMAND: Last command executed with flags and arguments.
应用
选项参数设置
选项参数解析:getopt是标准的参数处理程序,可以处理长、短选项参数以及位置参数。将arguments中的选项参数和位置参数使用"--"分离开,任意位置的非选项参数全部移至"--"之后。
getopt --longoptions longopts \ # 长选项
--options shortopts \ # 短选项
--name progname \ # 解析参数出错时显示的程序名(通常为当前脚本名"$0")
arguments... # 带解析的参数列表(通常为$@)
OPTIONS和LONGOPTS不能包含空格。==如果某类选项为空,仍需要传递空字符串""作为相应的参数==,否则解析选项参数不正确。
参数处理程序
将命令行输入参数中的选项参数与位置参数分离并处理,提供给后续程序使用。
SHORT=dfo:v
LONGS=debug,force,output:,verbose
! PARSED=$(getopt --options=$SHORT --longoptions=$LONGS --name "$0" -- "$@") #*
if [ ${PIPESTATUS[0]} -ne 0 ]; then # [ $? -ne 0 ]
exit 2
fi
eval set -- "$PARSED" #**
while true; do
case "$1" in
-d|--debug)
OPT_DEBUG='--debug'
;;
-o|--output)
OUTPUT=$2
shift
;;
--)
shift
break # break the while loop
;;
*)
echo "Programming error"
exit 3
;;
esac
shift
done
*:"$@"防止包含空格的原有参数被展开为多个参数,!忽略命令执行错误并继续执行(如果未设置set -o errexit则无需添加,直接检查$0而非$PIPESTATUS)。
**:正确处理解析后带空格的参数,如-d --source 'test 1' -- 'test 2'。其中的'是字符串中的普通字符而非参数边界,如果直接书写$PARSED,则会导致命令行按其值的空白展开得到'test,1'这样的参数,破坏原有参数结构。通过添加""以及使用eval可将解析后的参数中的'重新解释为参数边界。
执行脚本:如果选项的值带有空格,可使用引号将选项括起来,防止空格后内容被展开解释为独立参数。
./script.sh --option="sip REGEXP 10.12.20.4[5-9]"
如果脚本还具有子命令,则在调用上述处理参数前首先处理并消耗固定的子命令参数。
if [[ $1 == "command" ]]; then
shift
set - #*
sub_process "$@" #**
fi
*:消耗子命令参数后,重设参数变量。
**:可以将该子命令的参数处理程序及功能代码写在当前if语句块中,或者将其封装为单独函数(函数支持参数传递)。
固定参数检测逻辑
以下命令不做替换,仅检测参数是否为空已决定程序是否继续执行,适用于处理固定参数。
param=${param:?MESSAGE}
如果param为空,则向标准错误输出信息,并退出脚本。
文本处理
文本处理工具grep,sed,awk对比:
- 三者均可以通过正则表达式对输入行进行筛选;
grep仅用于查找匹配模式,并返回匹配行(或匹配模式部分);sed还可以对匹配行进行编辑(替换),并进行上下文相关的修改,==通过替换操作可提取文本中的正则表达式捕获内容==;awk更适合格式化文本,对文本进行较复杂格式处理(如分割字段并格式化)。
grep
从文件读取行并执行正则表达式匹配。返回值:0匹配到模式;1未匹配到模式。
grep [option] PATTERN [file1 file2 …]
-作为文件名代表标准输入;使用管道输入则无需提供文件输入参数。
正则表达式类型:-G,--basic-regexp,-E,--extended-regexp ,-P,--perl-regexp。-P支持\d,\w等字符集合;此外,grep支持预定义的命名字符集合(这些与实现相关,仅在grep中可用)。
匹配模式(pattern)
| 选项 | 说明 |
|---|---|
-e,--regexp=PATTERN | 使用PATTERN进行匹配。由于 PATTERN直接提供在命令行,该选项可以省略。该选项可以用于提供多个匹配模式,而命令行中只能提供一个。 |
-f,--file=FILE | 从文件FILE中读取PATTERN。 |
-i,--ignore-case | 忽略大小写 |
-w,--word-regexp | 匹配整个单词 |
-x,--line-regexp | 匹配整行 |
执行控制
| 选项 | 说明 |
|---|---|
-m,--max-count=NUM | 在NUM次匹配之后停止 |
--binary-files=TYPE | 文件类型:binary,text或without-match |
-a, --text--binary-file=text | |
-I--binary-file=without-match | 表示不查找二进制文件。 |
-d,--directories=ACTION | 如何处理文件夹:read,recurse,skip |
-r, --recursive | --directories=recurse |
-R | 递归,但不追踪符号链接。 |
-D,-devices=ACTION | 如何处devices,FIFOs和socket:read,skip |
--include=FILE_PATTERN | 搜索文件的文件名需要匹配FILE_PATTERN,FILE_PATTERN可以包括通配符“*”“?”。 |
--exclude=FILE_PATTERN | 排除文件名与FILE_PATTERN匹配的文件。 |
--exclude-from=FILE | 跳过与FILE中的模式匹配的文件 |
--exclude-dir=PATTERN | 跳过与PATTERN匹配的文件夹 |
-v, --inver-match | 选择没有匹配的行 |
输出控制
| 选项 | 说明 |
|---|---|
-b,--byte-offset | 在输出的匹配行前添加匹配行相对文件起始位置的字节数。 |
-n,--line-number | 在输出的匹配行前添加行号 |
-H,--with-filename -h,--no-filename | 在输出的匹配行前添加文件名 (从起始位置开始的相对路径,默认)。 -h不输出文件名。 |
-o, --only-matching | ==只输出匹配部分== |
-q, --quiet, --silent | 不输出普通消息 |
-s, --no-message | 不输出错误消息(要输出其他消息) |
-L,--files-without-match | 仅输出没有发生匹配的文件的文件名。 |
-l,--files-with-matches | 仅输出发生匹配的文件的文件名 (从起始位置开始的相对路径)。 |
-c, --count | 仅输出一个文件中匹配的行数。 |
-B, --before-context=N | 输出匹配行及其之前的N行内容 |
-A, --after-context=N | 输出匹配行及其之后的N行内容 |
-C, --context=<NUM>-<NUM> | 输出匹配行及其前后的NUM行内容 |
--color[=WHEN] --colour[=WHEN] | 使用颜色高亮匹配内容,WHEN='always','never', 'auto'。 |
sed
stream editor for filtering and transforming text. (
info sed)
sed一次处理一行内容,把当前行存储在称为“模式空间”(pattern space)临时缓冲区中,接着用sed命令处理模式空间中的内容;处理完成后将结果发送到输出流并清空模式空间,再继续处理下一行内容直到文件输入结束。保持空间(hold space)用于保存一些内容,在整个循环执行过程中不会被自动清空。
sed [options] [script] input-files
-E,-r,--regexp-extended:在脚本中==使用扩展的正则表达式==(ERE)而非基本正则表达式(BRE),由于/在sed表达式中用于脚本命令的分隔符,因此是特殊字符,对于普通的/字符需要添加转义\,或使用\%REGEXP%设置分隔符(%可以为任意字符)。
不支持字符集合
\d、\w等。
脚本script:处理一行内容sed脚本语句。如果没有指定-e,-f选项,则sed使用第一个非选项参数作为脚本,其他参数作为输入文件;-e,-f选项可组合使用也可出现多次,最终的命令脚本是所有选项提供的脚本的组合;
-e,--expression=script:要执行的命令;-f,--file=script-file:从文件中读取命令;
script参数中使用;分隔多个命令;文件中的命令使用换行分隔;
输入输出:如果未指定输入文件,或输入文件为-,则sed使用标准输入流作为输入,也可以接收管道作为输入;sed使用标准输出流输出,可将输出重定向到文件(注意不要将输出重定向到输入文件,这样会先清空输入文件内容,应该使用--in-place[=BACKUP_SUFFIX]选项更新源文件)。
sed 's/hello/world/' input.txt > output.txt
cat input.txt | sed 's/hello/world' - > output.txt
sed默认输出所有输入内容(除了被d命令删除的内容)。使用-n抑制输出后,仅输出命令指定的内容(例如使用p命令输出指定的行)。
ps -ef | sed -n '1p;10p;$p' file.txt # 仅输出第1、10行和最后一行
-s,--separate:将多个文件视为独立的流,而非一个单独的长输入流;
-i,--inplace[=SUFFIX]:修改原始文件(inplace);具体操作是先将输出保存到一个临时文件,结束处理时用临时替换原始文件。如果提供SUFFIX则将原始文件重命名为以SUFFIX结尾的备份文件。如果SUFFIX包含*,则将*替换为原始文件名,从而实现添加前缀(或路径名)。==由于-i是对原文修改,因此慎用-n选项,否则导致原文内容被误删除==;
--follow-symlinks:仅在-i指定时有效,修改符号链接最终指向的文件;
-n,--silent,--quiet:抑制自动输出;
-l,--line-length=N:指定输出自动换行的长度,默认值为70;
返回值:0成功;1无效命令;2某个文件无法打开;4输入输出错误;使用命令q或Q自定义返回值Q42。
sed脚本语句
sed脚本语句的语法:[addr]{X[/options/];Y[/opts/];...}。
X,Y,...代表单字符的sed命令;addr为行地址;options为某些命令的选项。
一条语句中包含一个行地址,但可包含多条命令构成命令组。如果只有一条命令则可以省略{}。
如果没有使用
{},则;后的命令属于下一条语句(没有行地址,默认匹配全部文本)。
行地址
使用数值表示单独的行(从1开始,$表示最后一行),使用N1,N2指定连续的行区间;使用start~step来指定每隔若干行取一行执行;==未指定行地址则默认对所有行执行命令==;可以使用正则表达式/pattern/来匹配目标行:
ps -ef | sed -n '2,$/p' # 跳过第一行
sed '/apple/s/hello/world/' input > output # edit on line contain 'apple'
无论是数字或正则表达式表示的行地址,取补集即:
'/REGEXP/!cmd'。
| 命令 | 说明 |
|---|---|
aTEXT, a TEXT | 在一行后插入文本 |
cTEXT, c TEXT | 替换文本 |
iTEXT, i TEXT | 在一行前插入文本 |
p,P,l | 打印模式空间(一行),-P打印到出现换行符; |
d | 删除模式空间,进入下一次循环;-D删除换行符之前内容,并重新开始当前循环(没有换行符则进入下一循环); |
n | 非安静模式下,输出当前模式空间内容, 在任何情况下,用下一行内容替换当前模式空间内容 (下一行内容被消耗不会再被下一个循环读取) |
z | 清空模式空间(空字符串,仍占一行) |
F | 将前行所属的文件名作为一行插入当前行之前 |
g,G | 用保持空间的内容替换模式空间的内容;G为追加模式 |
h,H | 使用模式空间内容替换保持空间的内容;H为追加模式 |
x | 交换模式空间和保持空间的内容 |
s/REGEXP/REPLACE/[FLAGS] | ==替换匹配行的匹配内容== |
y/src/dst/ | 将模式空间中属于src集合中的字符用dst集合中的相应字符代替 |
'a', 'c', 'i'命令之后内容为插入的文本,因此不能在其后使用;连接其他命令。这些命令只能放在脚本最后或使用换行符分隔其他命令(命令行输入一条命令后换行继续输入另一条命令)。$ seq 2 | sed '1a Hello > 2d'替换模式:使用源空间内容替换目标空间内容;
追加模式:在目标空间的内容基础上拼接一个换行符(
newline)以及源空间的内容;
-n命令常用于处理每隔N行执行的操作;
seq 6 | sed '0~3s/./x/' # 等效于 sed 'n;n;s/./x'
s命令(substitute)
s命令可添加的选项(FLAG):
g:==替换所有匹配,而不仅是首个匹配==;
p:如果发生替换,则输出替换后的模式空间;未发生替换则不输出内容;未添加该选项时,根据-n选项(抑制自动输出)确定是否输出当前行(可能发生替换)的内容。
w FILENAME:如果发生替换,则将结果输出到文件,使用/dev/stderr和/dev/stdout表示标准输出流;
i,I:大小写不敏感的匹配;
当使用==扩展正则表达式==(-E)时,REPLACE中的特殊字符需要添加\转义为普通字符。
\、&、空格和换行(换行为\n)。对于非转义字符,使用\c等效于直接使用该字符。
使用\N(N=1~9)表示第N个捕获(位于正则表达式中(和)之间的内容),用&表示整个匹配(即实现在原文内容前后插入内容);
\L:将替换内容变换为小写字母直到\U或\E;\l将后续第一个字符变为小写;
\U:将替换内容变换为大写字母直到\L或\E;\u将后续第一个字符变为大写;
大小写替换范围作用在一个匹配结果之内,每个匹配结果独立执行大小写替换;
awk/gawk
gawk - pattern scanning and processing language.
基本用法
awk '{[pattern] action}' {filenames}
awk的命令语句只能用单引号'',避免shell展开其中的参数(例如$1)。
输出:
awk '{print $1,$4}' <<< 'this is a string' # 每行按空格或TAB分割,输出文本中的1、4项
awk '{printf "%-8s %-10s\n",$1,$4}' <<< 'this is a string' # 格式化输出
printf的格式声明和参数之间使用,分隔(可包含空格)。
设置分隔符:
awk -F, '{print $1,$2}' log.txt # 使用","分割
awk 'BEGIN{FS=","} {print $1,$2}' log.txt
# 使用多个分隔符:先使用空格分割,然后对分割结果再使用","分割,[]不是分隔符的一部分
awk -F '[ ,]' '{print $1,$2,$5}' log.txt
设置变量:
awk -va=1 '{print $1,$1+a}' log.txt # set a=1
调用脚本:
awk [options] -f program-file [--] file ...
awk [options] [--] program-text file ...
运算符
内置变量
$NF:字符串的最后一列;
https://www.runoob.com/linux/linux-comm-awk.html
过滤
过滤:
awk '$1>2' log.txt
awk '$1==2 {print $1,$3}' log.txt
awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt
可使用正则表达式过滤行。对整行进行过滤,/REGEXP/是模式。
awk '/re/ ' log.txt # 输出包含 "re" 的行 ==> grep 're' < log.txt
awk '!/th/ {print $2,$4}' log.txt # 取反匹配
awk 'BEGIN{IGNORECASE=1} /this/' log.txt # 忽略大小写
或根据分割后的字段进行过滤,~表示模式开始:
awk '$2 ~ /th/ {print $2,$4}' log.txt # 第二列包含 "th"
awk '$2 !~ /th/ {print $2,$4}' log.txt # 取反匹配
awk脚本
#!/bin/awk -f
BEGIN{} #运行前
{} #运行中:处理每一行
END{} #运行后
awk参考资料
全文处理
按行排序
sort [OPTIONS] FILES...
sort << EOF # 对键入内容按行进行排序
cmd_output | sort # 对命令输出内容按行排序 <==
-b, --ignore-leading-blanks:忽略起始空白;-f, --ignore-case:忽略大小写;-r, --reverse:反向排序;-o, --output=FILE:输出文件。
去重
检测连续的重复记录(可能需要先进行排序),默认输出去除重复记录的结果。
uniq INPUT
cmd_output | unique
以标准输入或文件作为输入,并输出到标准输出或文件。选项:
-c, --count:在每一行前添加出现次数;-d, --repeated:仅打印重复行(只保留一条记录);-u, --unique:仅打印不重复的行;
参考文献
Math in Shell Scripts, http://faculty.salina.k-state.edu/tim/unix_sg/bash/math.html